
🔥个人主页:爱和冰阔乐
📚专栏传送门:《数据结构与算法》 、【C++】 、【Linux】
🐶学习方向:C++方向学习爱好者
⭐人生格言:得知坦然 ,失之淡然

🏠博主简介

文章目录
- 前言
- [一、进程优先级状态 PRI](#一、进程优先级状态 PRI)
-
- [1.1 优先级的基本概念](#1.1 优先级的基本概念)
- [1.2 查看与计算优先级](#1.2 查看与计算优先级)
- [1.3 动态调整优先级与 Nice 值的极值](#1.3 动态调整优先级与 Nice 值的极值)
- [1.4 竞争、独立、并行与并发](#1.4 竞争、独立、并行与并发)
- 二、进程切换与上下文管理
-
- 2.1.死循环程序为什么不会让系统卡死?
- [2.2 CPU 寄存器与硬件上下文](#2.2 CPU 寄存器与硬件上下文)
- [2.3 进程切换的详细步骤](#2.3 进程切换的详细步骤)
- [三、 Linux 2.6 内核 O(1) 调度算法](#三、 Linux 2.6 内核 O(1) 调度算法)
-
- [3.1 核心数据结构拆解](#3.1 核心数据结构拆解)
- [3.2 解决进程饥饿:双阵列滚动切换机制](#3.2 解决进程饥饿:双阵列滚动切换机制)
- 总结
前言
在前文中,我们深入探究了 Linux 进程的静态结构与纷繁复杂的进程状态切换。然而,操作系统在微观上面临着一个更具挑战性的动态问题:系统中可能同时存在数百个处于 R 状态的进程,而物理 CPU 的核心数量通常只有寥寥几个。
进程之间是如何为了争夺 CPU 资源展开竞争的?当一个进程的时间片耗尽时,它的状态数据是如何在转瞬之间被封存并切换的?Linux 2.6 内核引入的顶级 O(1) 调度算法,又是如何完成常数级别查找效率的?本文将为你全景解密。
一、进程优先级状态 PRI
1.1 优先级的基本概念
在多进程并发的环境中,理解优先级的本质是理解资源分配的核心。
-
本质原因:资源的稀缺性。由于物理 CPU 核心资源远远无法满足同时运行所有就绪进程的需求,进程之间必然存在竞争属性。为了保障系统的高效运转以及核心任务的顺畅推进,必须引入排队机制。
-
权限与优先级的区别:权限决定了你"能不能"获取某种目标资源;而优先级建立在"能获取"的前提下,决定了你获取资源的"先后顺序"。
1.2 查看与计算优先级
在 Linux 终端中,我们可以通过 ps -al 命令查看当前终端下的进程优先级信息:
bash
ps -al | head -1 && ps -al | grep mycode执行后,终端会输出多列属性。其中有三个至关重要的指标需要我们深度剖析:
-
UID(User ID):代表执行者的身份。在 Linux 系统内部,识别用户权限并非通过字符串形式的用户名,而是通过一串被称为 UID 的数字。任何资源的访问本质上都是由进程发起的,进程克隆了用户的 UID,从而决定了其所代表的用户的访问权限。
-
PRI(Priority):代表进程当前可被 CPU 执行的优先级。在操作系统设计中,该值越小,代表其优先级越高。普通进程的默认基准值为 80。
-
NI(Nice):代表进程优先级的动态修正数据,常被称为 "Nice 值"。
🔢 优先级计算公式
进程最终真实优先级 (PRI) = 默认优先级 (80) + Nice值 (NI) \text{进程最终真实优先级 (PRI)} = \text{默认优先级 (80)} + \text{Nice值 (NI)} 进程最终真实优先级 (PRI)=默认优先级 (80)+Nice值 (NI)
-
当 Nice 值为负数时,进程的 PRI 减小,意味着其优先级得到提升(更加积极地抢占资源)。
-
当 Nice 值为正数时,进程的 PRI 增大,意味着其优先级被降低(更加"高风亮节"地让出资源)。
1.3 动态调整优先级与 Nice 值的极值
⚠️ 优先级重置特性
在 Linux 中,用户可以通过 top 命令动态微调进程的 Nice 值(进入 top 后,按下 r 键,输入目标进程的 PID,再输入需要修改的 Nice 修正值,如 10 或 -10)。
这里存在一个极其重要的重置特性:假设某进程默认 PRI = 80, NI = 0。
- 我们首先将其 Nice 值调整为 10,此时通过 ps 查看,它的 PRI 变成了 90( 80 + 10 80 + 10 80+10),NI 变成了 10。
- 随后,我们再次修改该进程的 Nice 值为 -10。此时,最终的 PRI 不是从 90 减去 10 变为 80,而是变成了 70( 80 + ( − 10 ) = 70 80 + (-10) = 70 80+(−10)=70)。
📌 核心逻辑:每一次调整 Nice 值,操作系统底层都是基于最初始的默认基准 PRI = 80 进行累加计算的,而非在上一次修改后的基础之上递增。这种"无记忆性"的设计极大地避免了因连续微调而导致优先级雪崩或失控的复杂度。
🔒 为什么 Nice 值被严格限制在 -20, 19 之间?
经测试,若向系统给进程设置 Nice 值为 -100 或 +100,系统会自动将其截断为极值 -20 或 19。因此,Linux 普通进程的优先级被牢牢锚定在 60, 99 这 40 个级别内。
- 设计目的:基于时间片轮转的分时操作系统必须考虑调度的绝对公平性与确定性。如果允许用户无限制地拉高或降低优先级,普通用户可能会将某些无关紧要的娱乐程序优先级设得极端高,导致关系到系统稳定的内核基础进程、网络守护进程长时间无法获得 CPU 时间片,从而引发系统崩溃或严重的"进程饥饿(Starvation)"。
1.4 竞争、独立、并行与并发
为了更准确地描述多进程运动,我们必须明晰以下四个核心概念:
-
竞争性:系统进程数目众多,而 CPU 资源少量。进程为了高效完成任务,彼此间通过优先级确定先后顺序,合理竞争。
-
独立性:多进程运行需要独享各种资源。通过进程地址空间等机制,多进程在运行期间数据互不干扰,一个进程崩溃绝不会导致另一个进程瘫痪。
-
并行(Parallelism):在多个 CPU 核心的计算机结构下,多个进程在不同的核心上同时、物理上独立地进行运行。
-
并发(Concurrency):在单个 CPU 核心的限制下,系统采用进程切换的方式,让多个进程轮流占有 CPU 推进各自的代码。在微观上它们交替运行,在宏观的"一段时间之内",多个进程都得以向前推进。
二、进程切换与上下文管理
2.1.死循环程序为什么不会让系统卡死?
我们在写代码时如果写出了死循环(如 while(1);),会发现该程序会独占一个 CPU 核心导致发热,但系统依然可以操作,并不会直接死机。
- 时间片机制:当代的 Linux 操作系统都是基于时间片的分时操作系统。一个进程占有 CPU 后,绝不会允许它一直跑到完工(除非代码极端简短)。OS 为每个进程分配了毫秒级的时间片,一旦时间片消耗殆尽,无论代码是否执行完,调度器会强行将其从 CPU 上剥离下来,换上下一个进程。
2.2 CPU 寄存器与硬件上下文
在 CPU 内部,存在着一套极其珍贵的、用于存储临时数据的高速硬件空间------寄存器(Registers)。它们分工明确:
-
通用寄存器(如 eax, ebx, ecx 等):用于存放算术运算的临时操作数和结果。
-
程序计数器(PC / eip):存放下一条即将执行的机器指令的内存虚拟地址。
-
栈指针寄存器(esp / ebp):指向当前进程的用户态或内核态运行时栈顶和栈底。
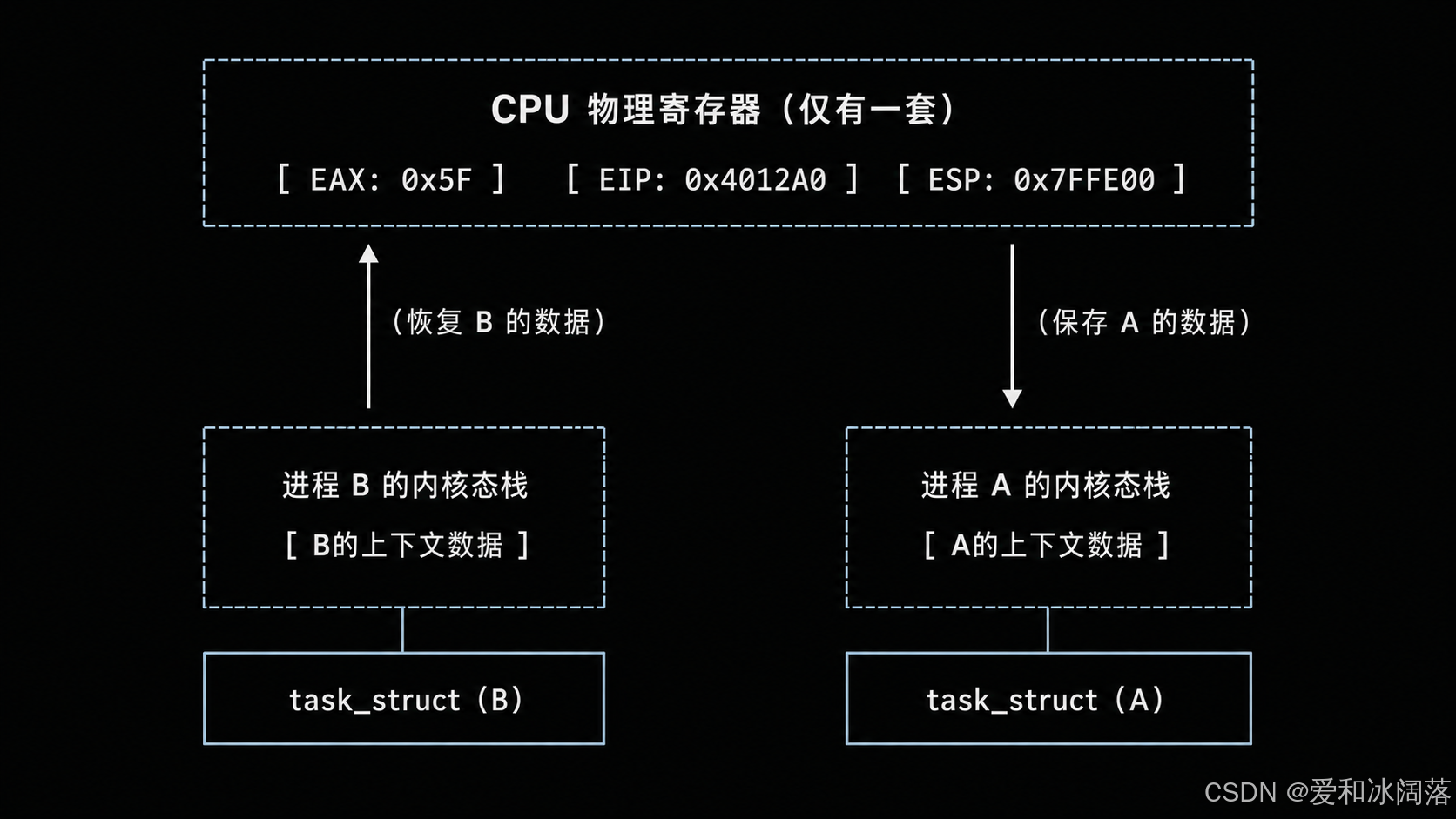
⚠️ 高频误区:寄存器本身 ≠ \neq = 寄存器里的数据。在物理层面上,一个物理核心内部的寄存器只有一套,它是所有进程公用的硬件空间。但是,寄存器内部流动的数据,是当前正在运行进程的临时计算结果、跳转指针和状态信息,这被称为该进程的硬件上下文(Hardware Context)。硬件上下文是属于各个进程独占的,内存中有多少个进程,就有多少套上下文。
2.3 进程切换的详细步骤
当进程 A 的时间片耗尽,需要切换到进程 B 执行时,调度器会协调 CPU 完成以下核心步骤:
1. 触发中断与模式切换
硬件时钟中断(Timer Interrupt)到来,CPU 强行暂停当前正在执行的用户态进程 A,压入寄存器状态,并自动跳转到操作系统的时钟中断处理程序,此时 CPU 从用户态(User Mode)切换到内核态(Kernel Mode)。
2. 保存硬件上下文(Save Context)
内核调度函数 schedule() 被激活。它会将此时 CPU 寄存器中所有属于进程 A 的残留数据(包括 eax, eip, esp 等)依次剥离,并转储到进程 A 自身的内核栈以及 task_struct 关联的特定的内核数据结构(如 Linux 的 tss_struct 任务状态段)中。
此时,进程 A 的最新生命体征被完美"封存"在内存中。
3. 运行调度算法(Pick Task)
调度器执行调度算法(即下文要讲的 O(1) 算法),从就绪队列中挑选出下一个最渴望获得 CPU 的进程 B,并获取进程 B 之前保存的上下文数据指针。
4. 切换页表与虚拟地址空间
内核修改 CPU 的控制寄存器(如 x86 架构下的 CR3 寄存器),将页表基地址切换为进程 B 的页表。至此,整个虚拟内存空间无缝切换到了进程 B 的世界。
5. 恢复硬件上下文(Restore Context)
内核将进程 B 之前封存的上下文数据从其内核栈中依次弹出,重新强行填入 CPU 的物理寄存器中。特别是当把进程 B 曾经保存的 eip 数据填入 CPU 的程序计数器,把当时的栈指针填入 esp 后,CPU 的指针立刻指向了进程 B 曾经被切走时的那一行代码的下一条指令。
6. 返回用户态
CPU 执行中断返回指令,从内核态切回用户态,进程 B 毫无察觉地在它当年停下的地方继续狂奔。
📌 全新进程的特例:对于一个全新创建(如刚通过 fork 出来)从未被调度过的进程,其 PCB 内存在特定的初始化标记位。调度器识别后,由于其没有"过去的历史上下文",无需执行复杂的恢复流程,而是直接跳转到特定的统一内核入口(如 ret_from_fork),完成初始化后直接执行用户代码。
三、 Linux 2.6 内核 O(1) 调度算法
在早期的 Linux 内核(如 2.4 版本)中,调度器维护着一个简单的就绪进程链表。当需要挑选下一个进程时,调度器必须遍历整个链表,对每个进程的优先级和剩余时间片进行计算打分。
- 传统算法的死穴:其查找的时间复杂度是 O ( N ) O(N) O(N)。这意味着,如果系统中有 10 个进程,速度很快;但如果是高并发的服务器,运行着 10000 个进程,每一次切换都要强制遍历 10000 次。CPU 将耗费海量的算力在"寻找进程"本身上,引发系统级性能瘫痪。
为了攻克这一瓶颈,Linux 2.6 内核引入了划时代的 O(1) 调度算法,使得无论就绪队列里有 10 个进程还是 10 万个进程,调度器选出下一个目标的时间耗时都是绝对恒定的常数级别。
3.1 核心数据结构拆解
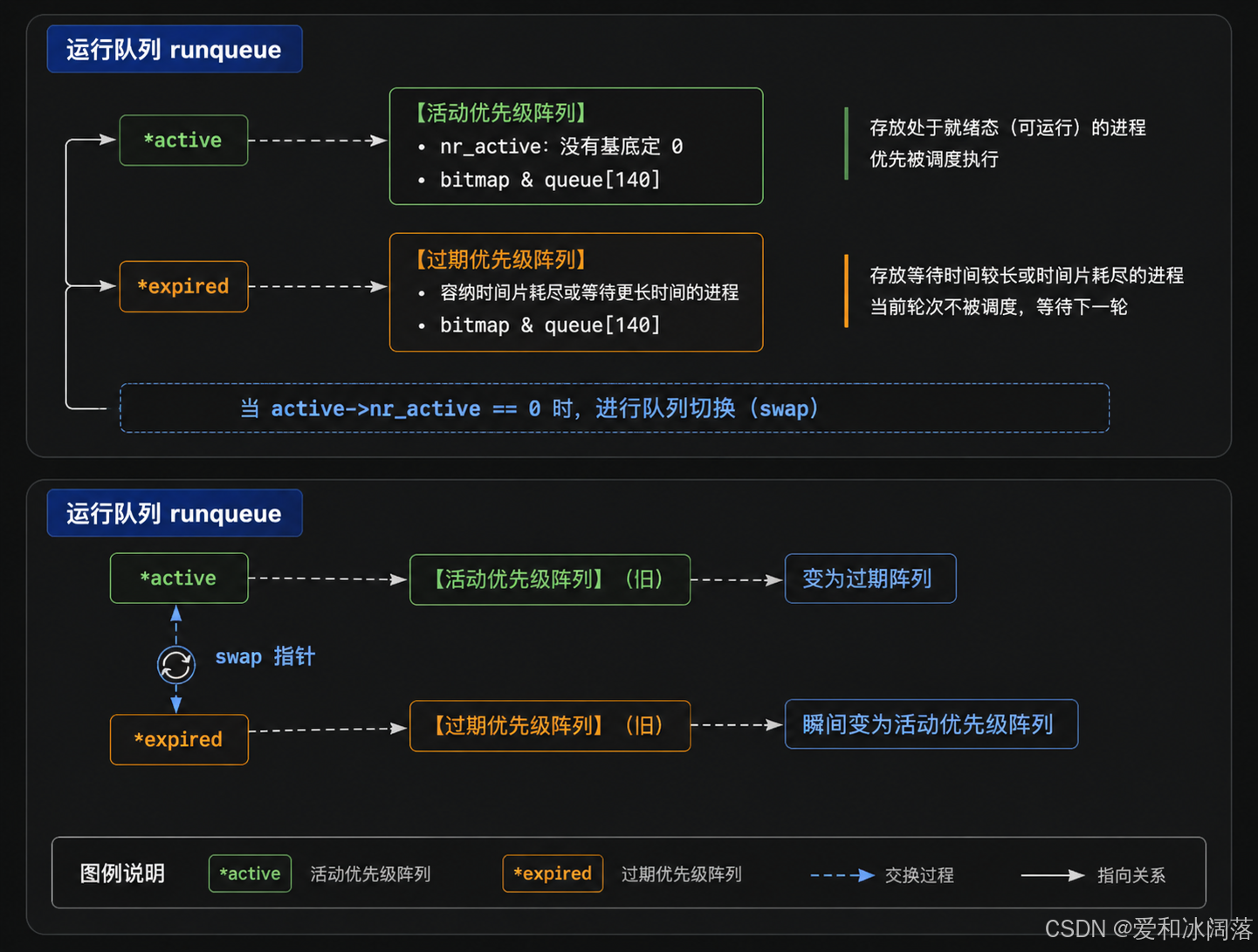
在 Linux 2.6 中,每一个 CPU 核心都拥有自己独立管理的一个运行队列(runqueue)。这种设计消除了多核锁竞争。
在 runqueue 中,包含两个重要的结构体数组阵列指针:active 指向活动队列阵列,expired 指向过期队列阵列。
而在每个阵列结构(struct prio_array)内部,设计了以下三个极为精妙的核心成员:
c
struct prio_array
{
int nr_active; // 当前队列阵列中就绪的进程总数
unsigned long bitmap[5]; // 核心加速神器:优先级位图
struct list_head queue[140]; // 优先级队列指针数组
};1. 优先级阵列:queue140
Linux 内部将进程的优先级划分为了 140 个级别:
-
0, 99:属于实时优先级。供实时进程(如高精工业控制、车载刹车系统等需要绝对硬实时响应的进程)使用。它们遵循高优先级直接强占,不采用普通的分时时间片策略。
-
100, 139:这 40 个位置正好对应我们前面所讲的普通进程经 Nice 值动态转化后的动态优先级范围(60, 99)。
内核通过一个简单的数学映射公式:
数组下标 = 动态PRI − 60 + 100 \text{数组下标} = \text{动态PRI} - 60 + 100 数组下标=动态PRI−60+100
所有相同优先级的进程,会直接挂载到对应的 queuei 链表头上。在同一个链表内部,多进程遵循朴素的先进先出(FIFO)或时间片轮转。
加速神器:bitmap5 位图
如果某一时刻系统负载很低,140 个就绪队列中只有 queue112 和 queue130 挂载了进程,其余 138 个指针全部为 NULL。调度器如果去逐个遍历指针判断其是否为空,依然存在空遍历的性能损耗。
Linux 巧妙地在阵列内嵌了位图加速器。在 32 位操作系统中,一个 unsigned long 占用 32 个比特位(Bit),5 个这样的变量拼接成的数组 bitmap5 一共拥有 5 × 32 = 160 5 \times 32 = 160 5×32=160 个比特位,足以精准覆盖 140 个优先级对应的数组下标。
-
位图映射机制:如果 queuek 下标处存在就绪进程,内核就会将位图中第 k 个 Bit 位强行设置为 1,否则保持为 0。
-
O ( 1 ) O(1) O(1) 的真谛:当调度器挑选进程时,它不再遍历 queue 数组,而是直接对这 5 个内置的 unsigned long 变量进行位图位流运算。在硬件级别,现代 CPU 提供了极为高效的内联汇编指令(如 x86 的 bsfl,意为 Bit Scan Forward,寻找最低的置 1 比特位)。调度器只需检查 bitmap0 是否为 0,若为 0 证明前 32 个队列皆空,直接跳到 bitmap1。只要找到一个不为 0 的变量,一条 CPU 指令就能瞬间定位到那一位是 1。
📌 结论:通过位图定位优先级最高的非空链表,仅需常数次(最多 5 次)逻辑判断与一条硬件汇编指令。这种查找时间与系统中就绪进程的多寡彻底脱钩,达成了无上的 O ( 1 ) O(1) O(1) 查找效率。
3.2 解决进程饥饿:双阵列滚动切换机制
如果系统中不断有新的、优先级极高的进程涌入 active 活动队列,那些处于 queue139 的低优先级普通进程是否会陷入无限期的等待,进而发生严重的进程饥饿?
Linux 2.6 调度器通过 active 与 expired 双阵列滚动机制,用纯数学的指针切换完美破解了这一难题:
-
活动队列(Active Queue):当前 CPU 调度器唯一认可并从中挑选进程的阵列。
-
过期队列(Expired Queue):当活动队列中的某个进程消耗光了它本次分配的所有时间片后,调度器会重新计算其时间片,但不允许将它放回活动队列,而是将其强制链入过期队列中。同样的,在系统运行期间新创建的子进程,也会一律先投入过期队列。
-
动态指针交换:随着时间的推移,活动队列中的进程由于时间片用光会变得越来越少(nr_active 逐渐递减至 0);而过期队列中的进程越来越多。当活动队列彻底变空的一瞬间,调度器会执行一个极为高效的指针置换操作:
c
// 仅需交换两个结构体指针,耗时为 O(1)
struct prio_array *tmp = rq->active;
rq->active = rq->expired;
rq->expired = tmp;交换之后,原本已经处于饥饿边缘、在过期队列中排队等待的低优先级进程所在的阵列,在一瞬间变成了全新的活动队列,重新接受 CPU 的轮流调度。
通过这种双阵列交替滚动的精妙设计,Linux 2.6 内核既将进程寻找和切换的效率推向了 O ( 1 ) O(1) O(1) 的工程极致,又从底层机制上彻底根除了进程饥饿问题,保障了多任务分时环境下的绝对公平。
总结
通过本篇对 Linux 动态进程运行机理的剖析,我们层层剥离了系统高并发运转的核心幕后黑手:
- 优先级(PRI/NI):建立了多进程健康竞争、防范饥饿的资源分配机制。
- 硬件上下文切换:通过寄存器数据的封存与恢复,在微观上完成了多任务"花开两朵,各表一枝"的独立并发推进。
- O(1) 调度算法:摒弃了传统的 O ( N ) O(N) O(N) 暴力遍历,利用 160位级别位图加速器 与 Active/Expired 双阵列滚动切换机制,将系统的检索与防饥饿成本压缩到了恒定的常数级别。
进程的管理与调度,是整个内核大厦最基础也最精妙的引擎。唯有将静态的数据结构(如侵入式链表)与动态的算法演进(如位图与双阵列)融会贯通,我们才能在面对大规模高并发的复杂底层场景时,做到真正的心中有数、游刃有余。
资源分享
《 从OS通用理论到Linux内核源码:全景拆解 task_struct 状态流转与内核双链表设计精髓 》
【硬核Linux】打通OS任督二脉:从冯诺依曼到进程Fork,看完直呼过瘾!
【Linux工具链】从代码托管到精准追踪Bug:Git常用指令+GDB临时变量与调用栈剖析