补充知识点
1. 权限字符串
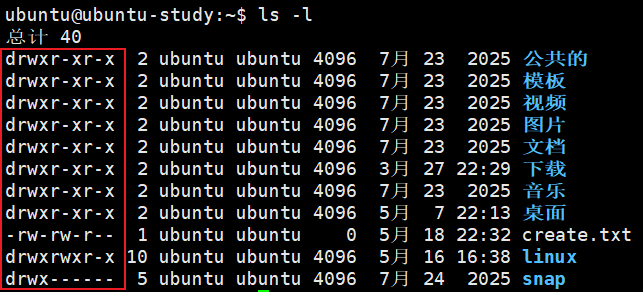
比如第一行的 drwxr-xr-x,一共 10 个字符,分 4 部分理解:
(1) 第 1 个字符:文件类型
| 字符 | 含义 |
|---|---|
- |
普通文件(比如 .txt、.cpp) |
d |
目录(文件夹) |
l |
软链接(快捷方式) |
b/c |
设备文件(块设备 / 字符设备) |
(2) 第 2-4 个字符:文件所有者(用户)权限
对应 rwx 三个权限:
r:读权限(read)w:写权限(write)x:执行权限(execute,对目录来说是进入目录的权限)-:没有对应权限
(3) 第 5-7 个字符:所属用户组权限
- 同样是
rwx,代表同组用户的权限。 - 比如
drwxr-xr-x的第 5-7 位是r-x→ 同组用户有读、进入权限,没有写权限。
(4) 第 8-10 个字符:其他用户权限
- 代表系统里所有其他用户的权限。
- 比如
drwxr-xr-x的第 8-10 位是r-x→ 其他用户有读、进入权限,没有写权限。
2. 权限字符串的本质
权限字符串的终极本质是二进制位(Bit)。
在 Linux 内核和文件系统的底层(比如 inode 结构体中),权限是用一个普通的整数(通常是 16 位的二进制数)来存储的。
其中,低 9 位专门用来表示 rwx 权限:
| 拥有者 (User) | 所属组 (Group) | 其他人 (Others) |
|---|---|---|
| r w x | r w x | r w x |
| 1 1 1 | 1 0 1 | 1 0 1 |
注:1 表示启用,0 表示关闭(计算机眼中的 1 和 0)
为什么我们在代码(如 mode 参数)或 chmod 命令中总用八进制,而不是十进制或十六进制呢?
如果用十进制:上面的二进制 111101101 转换为十进制是 493。这个数字和权限完全对不上,人类根本看不懂。
如果用八进制:因为 23=82^3 = 823=8,1 位八进制数刚好可以完美代表 3 位二进制数。而 Linux 的权限恰好就是 3 位一组(rwx)。所以:111 刚好是八进制的 7,101 刚好是八进制的 5 拼起来就是 0755。所以,八进制是程序员和编译器之间的一种默契。当你写下 0755 时,编译器会把它秒变二进制存入系统的 mode 变量中。
底层的二进制 (0/1)⟶{代码/命令里用 八进制 (方便输入)终端屏幕上用 权限字符串 (方便阅读) \text{底层的二进制 (0/1)} \longrightarrow \begin{cases} \text{代码/命令里用 \textbf{八进制} (方便输入)} \\ \text{终端屏幕上用 \textbf{权限字符串} (方便阅读)} \end{cases} 底层的二进制 (0/1)⟶{代码/命令里用 八进制 (方便输入)终端屏幕上用 权限字符串 (方便阅读)
3. stat 命令(Linux 系统)
- 全称:status,状态。
- 功能 :获取文件或目录的详细状态信息(元数据)。
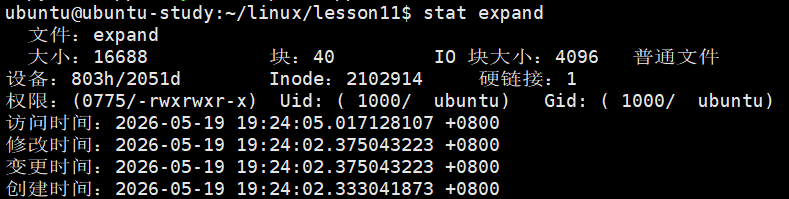
4. Linux 系统文件的底层存储架构
在 Linux 文件系统中,一个文件并不是作为一个整体连续存放在磁盘上的,而是被拆分为以下三个核心部分:
Inode(索引节点,Index Node)
- 本质:文件的元数据面板。
- 包含内容 :文件大小、访问权限(rwx)、所有者(UID)、所属组(GID)、时间戳,以及指向实际数据块的指针。
- 唯一标识 :每个 Inode 在所属的文件系统内都有一个唯一的、非负整数编号,称为 Inode ID。内核访问文件时,实际上是通过 Inode 号来识别的,而非文件名。
Data Block(数据块)
- 本质:磁盘上实际存放文件内容的物理区域(如代码、文本、图片等)。
Directory Entry(目录项,简称 dentries)
- 本质 :Linux 中"一切皆文件",目录也是一个文件。目录的数据块中存放的是一张映射表,记录了该目录下的
| 文件名 | Inode 编号 |的对应关系。 - 结论:文件名并不存储在文件本身的元数据中,而是存储在其父目录的映射表里。
5. ln 命令 (硬链接与软链接)
ln 命令(全称 link,链接)用于在文件之间建立链接。链接分为硬链接(Hard Link)和符号链接(Symbolic Link,俗称软链接)。
1.硬链接
-
创建命令 :
ln 源文件 硬链接名(不加任何参数) -
底层原理 :在父目录的映射表中,新增一行映射关系,让一个新的文件名指向同一个已存在的 Inode 编号。
-
特点:
- 共享 Inode:源文件和硬链接文件的 Inode 号完全相同,它们在物理磁盘上指向同一份数据块。
- 计数机制 :Inode 内部有一个
st_nlink(硬链接计数器)。每增加一个硬链接,计数 +1 ;删除一个文件名,计数 -1。只有当计数归零时,磁盘上的物理数据才会被真正释放。
-
局限性:
- 不能跨文件系统/分区(不同分区的 Inode 编号独立,会产生冲突)。
- 不允许对目录创建硬链接(为了防止文件系统拓扑结构中出现环路,导致遍历死循环)。
2.符号链接 (软链接)
- 创建命令 :
ln -s 源文件 软链接名(-s 代表 symbolic ,符号的) - 底层原理 :符号链接是一个完全独立的特殊文件 。它拥有自己独立的 Inode 号和独立的数据块,其数据块内部存储的内容是目标源文件的绝对或相对路径字符串。
- 特点 :
- 独立性:软链接与源文件的 Inode 号不同。
- 依赖性:由于它只记录路径,一旦源文件被移动或删除,该软链接将变为死链接 / 断链(Dangling Link),再次访问会报 No such file or directory 错误。
- 灵活性 :
- 可以跨文件系统/分区创建。
- 完美支持目录。在日常部署中,常用于为深层目录或版本迭代的软件目录创建快捷访问入口。
样例 :
(1) 创建 a.txt 文件内容 :
(2) 建立软链接:
bash
ln -s a.txt b.txt(3) 查看两文件的详细信息
查看 b.txt 文件内容 :
这里发现和 a.txt 内容一样,但这并不代表软链接的内容和源文件一样。
详细查看两文件详细信息:
bash
stat a.txt
stat b.txt
ll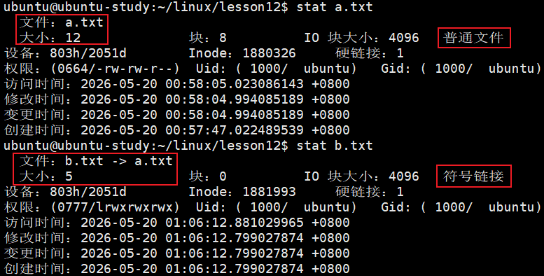
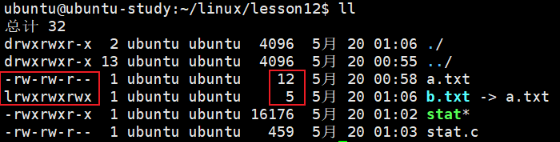
这里可以看到 b.txt 的文件大小只有 5 ,这是因为软链接数据块内部存储的内容是目标源文件的绝对或相对路径字符串,也就是 "a.txt" ,刚好 5 个字节。
6. getpwuid 函数
头文件:
c
#include <sys/types.h>
#include <pwd.h>函数定义:
c
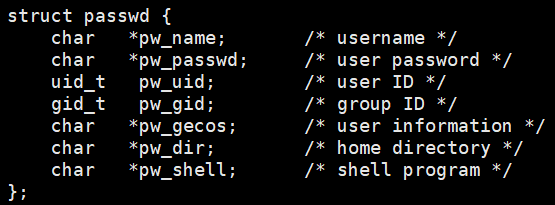
struct passwd *getpwuid(uid_t uid);- 参数 :这里的
uid,其实可以将stat结构体中的st_uid(用户 id ) 直接传入。 - 返回值:passwd 结构体。
作用 :getpwuid() 函数返回一个指向结构体的指针,该结构体包含密码数据库中与用户 ID uid 匹配的记录的各个拆分字段。
7. getgrgid 函数
头文件:
c
#include <sys/types.h>
#include <grp.h>函数定义:
c
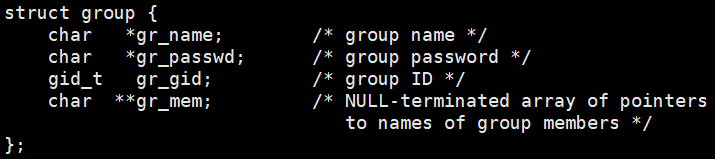
struct group *getgrgid(gid_t gid);- 参数 :这里的
gid,其实可以将stat结构体中的st_gid(组 id ) 直接传入。 - 返回值:group 结构体。
作用 :getgrgid() 函数返回一个指针,该指针指向一个结构体,该结构体包含组数据库中与组 ID gid 匹配的记录的分解字段。
8. ctime 函数
头文件:
c
#include <time.h>函数定义:
c
char *ctime(const time_t *timep);- 参数 :这里的
timep是一个指向time_t类型(时间戳)的指针。其实可以将 stat 结构体中的 st_mtime(最后修改时间)时间的地址直接传入。 - 返回值:指向一个静态分配的字符串指针,该字符串包含了可读的日期和时间信息。
作用 :ctime() 函数将参数 timep 指向的时间戳(自 1970-01-01 00:00:00 UTC 以来的秒数)转换为本地时间,并格式化为一个以换行符 \n 和空字符 \0 结尾的字符串。
perror 函数
1. 头文件
c
#include <stdio.h>2. 函数定义
作用:打印 errno 对应的错误描述
c
void perror(const char *s);参数 s :用户任意描述,比如 hello,最终输出的内容是 hello:xxx(实际的错误描述),但是官方推荐这里用对应的函数名
open 函数
1. 头文件
c
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>你可能会好奇为什么一个函数需要三个头文件,这里来解释下:
(1) <sys/types.h>:基础类型定义
它是 Linux 系统编程的 "基础工具箱",定义了各种系统级别的数据类型,比如:
size_t、ssize_toff_t(文件偏移量类型)pid_t(进程 ID 类型)- 还有
open会用到的mode_t(文件权限类型)
很多系统调用的参数 / 返回值类型,都在这里定义,所以写 Linux 程序时,几乎都会默认包含它。
(2) <sys/stat.h>:文件状态与权限
这个头文件主要和文件的元数据、权限相关,和 open 相关的作用是:
- 定义了文件权限相关的宏(比如
0644里的S_IRUSR、S_IWUSR等) - 补充定义了
mode_t类型的相关细节 - 还有
stat()函数相关的结构体定义(open里的mode参数,需要它来支撑)
简单说:当你用 open(path, O_CREAT, 0644) 创建文件时,第三个权限参数 mode_t 的相关定义,就靠它了。
(3) <fcntl.h>:文件控制与 open 核心定义
这才是 open 真正的主头文件,它直接包含了:
open()函数的原型声明- 所有
open用的标志位宏:O_RDONLY、O_WRONLY、O_RDWR、O_CREAT、O_TRUNC等 - 还有
fcntl()系列文件控制函数的定义
没有这个头文件,编译器会直接报错:O_RDONLY 未定义,open 未声明。
2. 函数定义
(1) 打开一个已经存在的文件
c
int open(const char *pathname, int flags);参数:
pathname:要打开的文件路径。flags:对文件的操作权限设置还有其他的设置,O_RDONLY(只读),O_WRONLY(只写),O_RDWR(可读可写) 这三个设置是互斥的。
返回值:返回一个新的文件描述符,如果调用失败,返回 -1 。
样例
在 /linux/lesson09/ 下创建 t.cpp :
cpp
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
int main()
{
int fd = open("a.txt", O_RDONLY);
if(fd == -1)
{
perror("open");
}
close(fd);
return 0;
}编译成可执行程序 t :
bash
g++ t.cpp -o t执行可执行程序 t :
bash
./t运行效果:

(2) 创建一个新的文件
c
int open(const char *pathname, int flags, mode_t mode);参数:
mode:表示文件权限。
样例 :
创建一个 create.cpp 文件:
c
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
int main()
{
int fd = open("a.txt", O_RDONLY | O_CREAT, 0777);
if(fd == -1)
{
perror("open");
}
close(fd);
return 0;
}将 create.cpp 文件编译成可执行程序 create:
bash
g++ create.cpp -o create运行可执行程序 create :
bash
./create可以发现成功生成了 a.txt 文件:

这里注意一下!!!
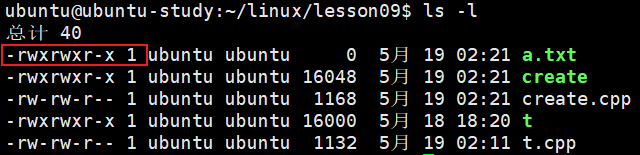
终端显示 a.txt 的权限是 -rwxrwx-x ,但是 create.cpp 文件中设置的文件权限是 0777 。

可以看到 umask 的默认值为 0002 ,因此 ~mask 等于 0775 ,mode & ~mask 就等于
plaintext
mode: 0 111 111 111
按位与 (&) ~umask: 0 111 111 101
------------------------------------------
= 0 111 111 101 --> -rwx rwx r-x这里的 umask 用于抹去文件创建时的某些权限,使文件默认权限更合理、安全。
(3) 函数定义解析
Linux 操作系统以及像 glibc 这样的核心 C 库,绝大部分都是用 C 语言写的,只有极少部分涉及底层硬件初始化、上下文切换和性能绝杀的部分,才会使用汇编语言。
因此关于 open 函数的两种使用形式并不是 C++ 的函数重载原理,而是 C 语言的另一机制------可变参数 !
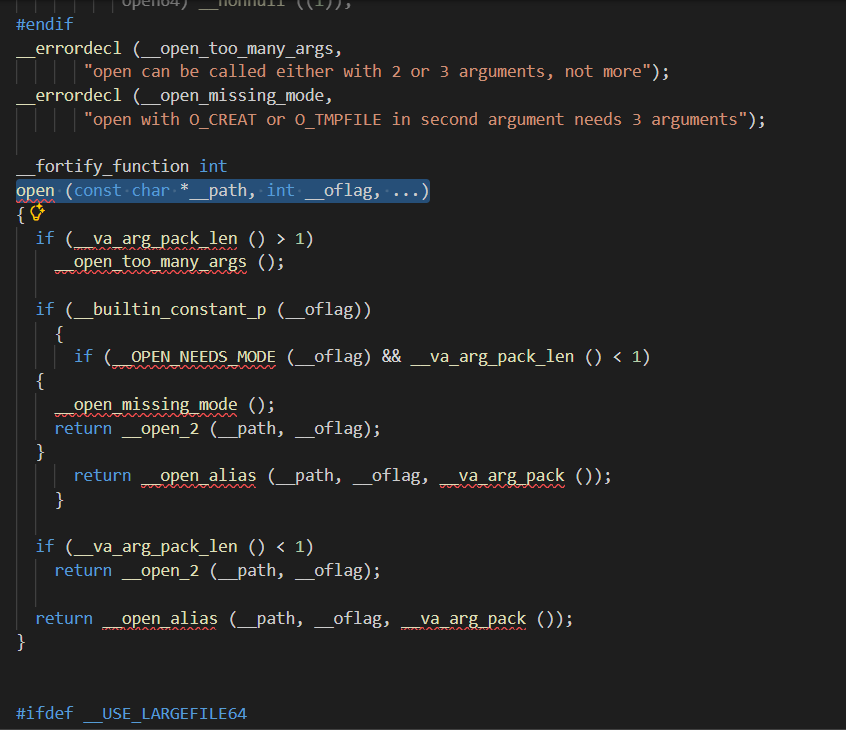
查看源码验证了猜想:
c
int open(const char *_file, int _oflag, ...)C 语言的变长参数机制(...)是非常盲目的,系统在编译时根本不知道你传的是什么类型,也不知道你传了几个参数,这使得程序可能会因为乱传变量崩溃,官方对于这里 ... 的处理是:
- 只要
flags传入了0_CREATE(新建文件) 或者0_TMPFILE(创建匿名临时文件),第三个参数就按mode_t解析(在大部分 Linux 系统上就是 unsigned int 或 mode_t 对应的整型),它不会去猜别的类型。并且此时必须要求提供第三个参数mode,如果不提供系统会将栈内的随机字节赋值给mode。 - 在原生的、最传统的 C 语言中,如果你多传了参数,系统会完全无视它们。因为 C 语言的函数调用约定(通常是 cdecl 或 System V AMD64 ABI)规定:调用者负责把所有参数依次压入栈(Stack)或者特定的寄存器中。open 函数内部的底层实现,只会去拿前 3 个参数(文件名、标志位、权限)。至于你后面多传的参数,它们虽然也被老老实实地放进了内存或寄存器里,但 open 内部的代码压根不去看它们。函数执行完后,这些多余的参数就会被自动清理掉,什么都不会发生。
3. 参数详解
(1) flags 参数详解
- 必选项:访问模式,三选一,互斥。
O_RDONLY:只读模式O_WRONLY:只写模式O_RDWR:读写模式
- 可选项:可通过按位或
|组合多个标志位。O_APPEND:追加模式,每次写操作前将文件偏移量定位到文件末尾O_CREAT:如果文件不存在则创建新文件O_ASYNC:启用信号驱动 I/OO_CLOEXEC:设置 close-on-exec 标志(执行 exec 时自动关闭文件描述符)O_DIRECTORY:如果路径不是目录则失败O_EXCL:与O_CREAT一起使用,确保调用者创建文件(文件已存在则报错)O_NOCTTY:不将终端分配为控制终端O_NOFOLLOW:不跟随符号链接O_TMPFILE:创建未命名临时文件O_TRUNC:如果文件存在且可写,则将其长度截断为 0
为什么通过按位或 | 来实现组合多个标志位?
在 C 语言中,一个 int 类型的 flags 变量有 32 个二进制位(Bit)。为了方便程序员记忆,系统给这些特殊的二进制位起了名字(也就是宏定义),每个二进制位分别对应不同的宏,通过按位或可以实现组合,例如:
plaintext
100 (读)
按位或 (|) 010 (写)
---------------------------------
= 110 (读写,八进制的 6)(2) mode 参数详解
- 参数类型 :
mode_t类型,表示文件权限 - 数值格式 :必须使用八进制数表示 (刚好对应权限字符串)。
每一个八进制位刚好可以转化为 3 个二进制位,对应r(读)、w(写)、x(执行),如 0775:- 7 → 二进制 111 →
rwx(读、写、执行) - 6 → 二进制 110 →
rw-(读、写) - 5 → 二进制 101 →
r-x(读、执行)
- 7 → 二进制 111 →
- 权限位说明 :
- 每个八进制位对应 3 个权限位(
rwx) - 第一位:文件所属用户(所有者)权限
- 第二位:同用户组(group)权限
- 第三位:其他用户(other)权限
- 每个八进制位对应 3 个权限位(
- 权限计算 :
- 最终权限:mode & ~umask
- 例如: 0777&~0002 = 0775
(3) umask 作用说明
- 用于抹去文件创建时的某些权限,使文件默认权限更合理、安全
- 普通用户默认
umask为0002(默认抹掉其他用户的写权限) - root 用户默认
umask为0022(默认抹掉同组和其他用户的写权限) - 可通过
umask()系统调用在程序中临时修改进程的权限掩码
close 函数
1. 头文件
c
#include <unistd.h>unistd 的全称是 Unix Standard(Unix 标准)。
它是 Linux/Unix 系统编程中最核心、最基础的头文件之一。
2. 函数定义
c
int close(int fd);参数:fd ,文件描述符。
返回值:
-
成功:返回 0 ,表示文件描述符已被成功关闭。
-
失败:返回 -1,并且会自动设置全局变量 errno (全局错误码) ,通过它来告诉你究竟为什么失败(例如 EBADF 代表你传入了一个无效的 fd)。
调用 close(fd)⟶{成功 (0)⟶引用计数减 1⟶计数 == 0: 释放内核资源失败 (-1)⟶fd 本身不变⟶通过全局变量 errno 查错 \text{调用 close(fd)} \longrightarrow \begin{cases} \text{成功 (0)} \longrightarrow \text{引用计数减 1} \longrightarrow \\text{计数 == 0: 释放内核资源} \\ \text{失败 (-1)} \longrightarrow \text{fd 本身不变} \longrightarrow \text{通过全局变量 errno 查错} \end{cases} 调用 close(fd)⟶{成功 (0)⟶引用计数减 1⟶计数 == 0: 释放内核资源失败 (-1)⟶fd 本身不变⟶通过全局变量 errno 查错
作用 :
Linux 管理文件采用引用计数机制。调用 close(fd) 时,内核的真实动作取决于该文件的引用计数(是否被 dup() 复制或 fork() 继承):
-
情况 A:引用计数 > 1(只断开连接)
还有其他 fd 指向该文件。调用 close() 只会让引用计数减 1,用于追踪读写位置的内核内存资源不会被释放。
-
情况 B:引用计数 == 1(彻底释放)
这是全系统最后一个指向该文件的 fd。调用 close() 让计数归零,内核才会彻底回收该文件的打开文件表项内存。
read 函数
1. 头文件
c
#include <unistd.h>2. 函数定义
c
ssize_t read(int fd, void *buf, size_t count);参数:
fd:文件描述符,通过open函数获得,用于标识和操作特定的文件。buf(传出参数):指向内存缓冲区的指针,读取的数据将存储在此缓冲区中,通常使用数组地址作为参数。count:指定缓冲区的大小,决定每次读取的最大字节数。
返回值:
- 成功:
- 大于 0 :返回实际读取的字节数
- 等于 0 :表示已到达文件末尾
- 失败:
- 返回 -1 ,同时设置 errno 以指示具体错误
- 特殊情况:
- 返回值可能小于请求的字节数,这种情况不视为错误,可能原因包括接近文件末尾,从管道读取或读取被信号中断。
作用:从⽂件中读取数据到内存缓冲区。
write 函数
1. 头文件
c
#include <unistd.h>2. 函数定义
c
ssize_t write(int fd, const void *buf, size_t count);参数:
fd:文件描述符,通过open函数获得,用来标识你想把数据写到哪一个具体的文件、屏幕或网络 Socket 中。buf(传入参数):指向你要写入的数据源内存首地址。因为是 void * 类型,所以你可以传入任何类型的数据(如数组、结构体、字符串)。函数只会从这个地址读取数据,带有 const 保护,其内容在调用过程中不会被修改。count:指定要写入的实际数据大小,当数组装满数据时,可以只写入部分数据。
返回值:
- 成功:
- 返回实际写入的字节数
- 返回 0 表示没有写入任何内容
- 返回值可能小于请求写入的字节数 (如磁盘空间不足时)
- 失败:
- 返回 -1 ,同时设置 errno 以指示具体错误
- 特殊情况:
- 当 count 为 0 且 fd 指向普通文件时,可能返回失败状态
- 如果未检测到错误,则返回 0 且不产生其他影响
作用:把用户内存的数据拷贝到指定 fd 对应的内核缓冲区中。
样例:read 与 write 的使用
这里来利用这两个函数实现文件内容拷贝:
1.先创建一个文本文件 english.txt
bash
touch english.txt2.创建一个 C++ 程序实现文件拷贝
cpp
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
int main()
{
// 1.通过open打开english.txt文件
int srcfd = open("english.txt", O_RDONLY);
if(srcfd == -1)
{
perror("open");
return -1;
}
// 2.创建一个新的文件(拷贝文件)
int desfd = open("cpy.txt", O_WRONLY | O_CREAT, 0664); // -r-xr-x-w-
if(desfd == -1)
{
perror("open");
return -1;
}
// 3.频繁的读写操作
char buf[1024] = {0};
int len = 0;
while((len = read(srcfd, buf, sizeof(buf))) > 0)
{
write(desfd, buf, len);
}
// 4.关闭文件
close(srcfd);
close(desfd);
return 0;
}3.将 copyfile.cpp 编译成可执行程序 copyfile
bash
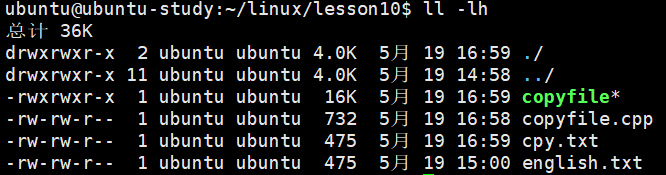
g++ copyfile.cpp -o copyfile4.运行程序并比对前后文件内存大小
bash
./copyfile
ls -lh可以看到内存大小一样,成功拷贝了文件。
lseek 函数
1. 头文件
c
#include <sys/types.h> // 包含 off_t 类型定义
#include <unistd.h> // 包含函数声明2. 函数定义
c
off_t lseek(int fd, off_t offset, int whence);参数:
fd:文件描述符,用于标识和操作特定文件。offset:指定偏移量大小。whence:决定偏移量的计算基准位置。SEEK_SET:- 含义:设置文件指针的绝对偏移量。
- 计算方式:从文件开头 偏移 offset 字节,新位置 = 0+offset0 + \text{offset}0+offset。
SEEK_CUR:- 含义:设置相对当前位置的偏移量。
- 计算方式:当前位置 加上 offset 字节,新位置 = current_pos+offset\text{current\_pos} + \text{offset}current_pos+offset(offset 可正可负)。
SEEK_END:- 含义:设置相对于文件末尾的偏移量。
- 计算方式:文件大小 加上 offset 字节,,新位置 = file_size+offset\text{file\_size} + \text{offset}file_size+offset(offset 可正可负)。
SEEK_DATA:- 含义:将偏移量移动到大于或等于当前位置的第一个包含数据的区域。
SEEK_HOLE:- 含义:将偏移量移动到大于或等于当前位置的第一个空洞区域。
- 特殊说明:
- 可以设置偏移量超过文件末尾 (不会改变文件大小)。
- 在空洞处读取会返回空字节 ('\0') ,直到实际写入数据。
返回值:
- 成功:返回以文件起始位置为基准,计算得出的偏移位置量 (字节数)。
- 失败:返回 -1 。
作用:
- 移动文件指针到文件头
c
lseek(fd, 0, SEEK_SET);- 获取当前文件指针的位置
c
lseek(fd, 0, SEEK_CUR);- 获取文件长度
c
lseek(fd, 0, SEEK_END);- 拓展文件的长度,当前文件 10b -> 110b ,增加了 100 个字节
c
lseek(fd, 100, SEEK_END);
lseek只是一个纯粹的内存状态操作,它仅仅修改了内核中文件描述符的偏移量(f_pos),并不会改变文件的逻辑大小或触发磁盘物理空间的分配。只有当程序在超出文件末尾的偏移量处执行实际的write系统调用时,内核才会正式修改文件的 inode 元数据以更新文件大小,并触发文件系统的块分配器为新写入的数据分配磁盘物理块。
- 瞬间跳到下一个数据块的起点
c
lseek(fd, start, SEEK_DATA);- 从数据起点开始,瞬间找到它在哪里结束(即下一个空洞的起点)
c
lseek(src_fd, data_pos, SEEK_HOLE);3. 样例
(1) 拓展文件的长度 (SEEK_END)
1. 创建一个文本文件 test.txt ,并向里面输入数据 "hello,world"
bash
echo "hello,world" > test.txt2. 查看文件目前大小
bash
ls -lh
3. 将 test.txt 文件大小拓展到112字节
创建 expand.cpp :
cpp
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
int main()
{
int srcfd = open("test.txt", O_RDWR);
if(srcfd == -1)
{
perror("open");
return -1;
}
int offset = lseek(srcfd, 100, SEEK_END);
close(srcfd);
return 0;
}编译并运行 expand 可执行文件:
bash
touch expand.cpp
g++ expand.cpp -o expand
./expand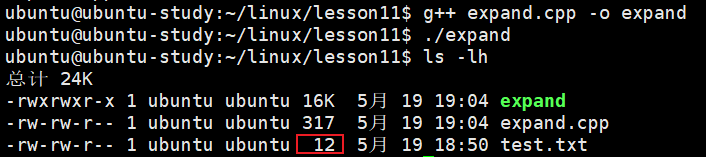
通过终端看到,test.txt 文件的大小并未增长,只是由于 lseek 函数只负责将读写指针偏移,并不为文件分配磁盘空间。
在 test.cpp 中加上 write 函数的调用然后再重新编译和运行:
cpp
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#include <iostream>
int main()
{
// 打开test.txt文件
int srcfd = open("test.txt", O_RDWR);
if(srcfd == -1)
{
perror("open");
return -1;
}
// 修改文件长度
int offset = lseek(srcfd, 100, SEEK_END);
std::cout << offset << std::endl;
write(srcfd, " ", 1);
// 关闭文件
close(srcfd);
return 0;
}可能会有好奇这里 write 函数的调用:
c
write(srcfd, " ", 1);注意看这里的参数 buf (要写入的数据源内存首地址),在 C++ 中,双引号 " " 包裹的是一个字符串常量。
" " 里面有一个空格,它在内存中其实占 2 个字节:' '(空格,ASCII 码 32)和 \0(字符串结束符,ASCII 码 0)。
无论字符串里写什么,双引号在 C++ 表达式中传递的永远是这个字符串在内存中的首地址 (即一个 const char* 指针)
因此这里的含义是从空字符串的地址获取1个字节的数据,然后写入与srcfd对应的数据源
运行可执行程序,可以看到文件大小发生变化:

(2) 拷贝文件内容 (SEEK_DATA 和 SEEK_HOLE)
cpp
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
int main()
{
// 1.通过open打开test.txt文件
int srcfd = open("test.txt", O_RDONLY);
if(srcfd == -1)
{
perror("open");
return -1;
}
int start = 0;
while(1)
{
// 2.定义源文件中有数据的起点
off_t data_pos = lseek(srcfd, start, SEEK_DATA);
if(data_pos == -1)
break;
// 3.定位这段数据的结束点 (即下一个空洞的起点)
off_t hole_pos = lseek(srcfd, data_pos, SEEK_HOLE);
// 4.进行拷贝 (这里不进行演示)
// [data_pos, hole_pos) 是文件中一段连续的数据内容
// 5.更新数据段起点
start = hole_pos;
}
// 关闭文件
close(srcfd);
return 0;
}stat 结构体

st_mode 变量
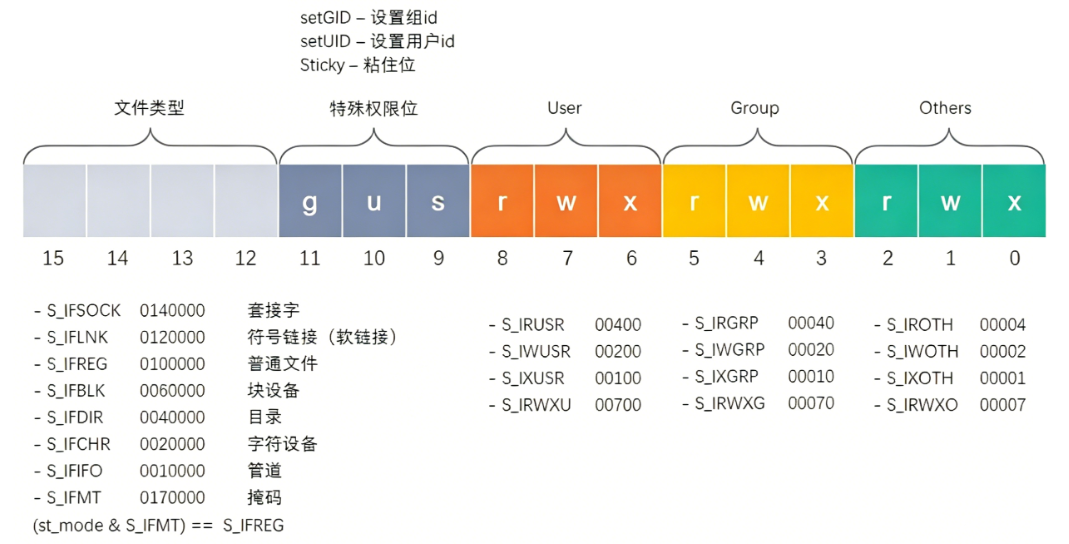
注意:
- 对于
st_mode变量的低 9 位的判断方式可以用:待判断权限 & 猜测权限 == 猜测权限 ,这是因为低 9 位的每个标准位都对应一个唯一的权限。
- 比如:如果待判断权限 & S_IROTH == S_IROTH,则说明待判断权限就是 S_IROTH
- 但是对于
st_mode的高四位,也就是文件类型这样判断就行不通了,拿 块设备 (S_IFBLK) 举例,其八进制值为 0060000 ,对应的二进制为 0110 000 000 000 000 ,可以看到文件类型是由一个或两个标准位组合表示出来的。
- 如果草率的用上面的方法,当待测权限是 块设备 ,猜测权限是 字符设备 时,S_IFBLK & S_IFCHR == S_IFCHR ,会错误判断为字符设备。
- 注意观察,掩码 (S_IFMT) 的八进制为 0170000 ,对应的二进制为 1111 000 000 000 000 ,因此可以通过待判断权限 & 掩码来判断文件类型的具体权限。
stat 函数
1. 头文件
c
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>2. 函数定义
c
int stat(const char *pathname, struct stat *statbuf);参数:
pathname:需要获取信息的⽂件路径(字符串形式)statbuf:传出参数,⽤于保存获取到的⽂件信息(struct stat类型结构体)
返回值:
- 成功返回 0 。
- 失败返回 -1 ,并设置 errno 。
作用:⽤于获取⽂件的状态信息,包括⽂件类型、权限、⼤⼩等属性。
3. 样例
编写一个 C 程序如下:
c
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
int main()
{
struct stat statbuf;
int ret = stat("./a.txt", &statbuf);
if(ret == -1)
{
perror("stat");
return -1;
}
printf("st_size: %ld\n", statbuf.st_size);
return 0;
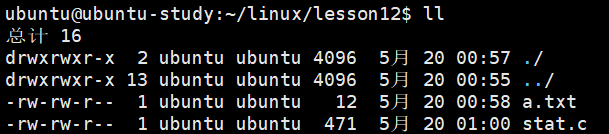
}通过 ll 查看 a.txt 的文件大小:
编译并运行程序:

可以看到终端确实输出 a.txt 的文件大小为 12 字节。
lstat 函数
1. 头文件
c
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>2. 函数定义
c
int lstat(const char *pathname, struct stat *statbuf);参数:
pathname:需要获取信息的⽂件路径(字符串形式)statbuf:传出参数,⽤于保存获取到的⽂件信息(struct stat类型结构体)
返回值:
- 成功返回 0 。
- 失败返回 -1 ,并设置 errno 。
作用:
- 如果传入的路径
pathname不是软链接,而是一个普通文件或目录,lstat的行为与stat完全一致。 - 但是当传入路径为符号链接 (软链接) 时,
lstat专注于获取链接文件本身的元数据,而不会像stat那样顺着链接去追踪目标文件。
3. 样例
创建一个 C 程序如下:
c
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
int main()
{
struct stat statbufa; // 存储a.txt的stat结构体
struct stat statbufb; // 存储b.txt的stat结构体
int reta = lstat("./a.txt", &statbufa);
if(reta == -1)
{
perror("lstat");
return -1;
}
int retb = lstat("./b.txt", &statbufb);
if(retb == -1)
{
perror("lstat");
return -1;
}
printf("a.txt的st_size: %ld\n", statbufa.st_size);
printf("b.txt的st_size: %ld\n", statbufb.st_size);
return 0;
}编译并运行程序:

可以看到 a.txt 和 b.txt 的文件大小不同,b.txt 为软链接名,其数据块内部存储的内容是目标源文件的绝对或相对路径字符串,也就是 "a.txt" 这 5 个字符对应的 5 个字节。
样例:ls -l 的复刻
c
#define _GNU_SOURCE
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <pwd.h>
#include <grp.h>
#include <time.h>
#include <string.h>
int main(int argc, char* argv[])
{
if(argc < 2)
{
printf("%s filename\n", argv[0]);
return -1;
}
// -rw-rw-r-- 1 ubuntu ubuntu 12 5月 20 00:58 a.txt
struct stat st;
int ret = stat(argv[1], &st);
if(ret == -1)
{
perror("stat");
return -1;
}
// 打印文件类型和权限
char perms[11] = {0}; // 用于保存文件类型和文件权限的字符串
switch(st.st_mode & S_IFMT)
{
case S_IFSOCK:
perms[0] = 's';
break;
case S_IFLNK:
perms[0] = 'l';
break;
case S_IFREG:
perms[0] = '-';
break;
case S_IFBLK:
perms[0] = 'b';
break;
case S_IFDIR:
perms[0] = 'd';
break;
case S_IFCHR:
perms[0] = 'c';
break;
case S_IFIFO:
perms[0] = 'p';
break;
default:
perms[0] = '?';
break;
}
// 判断文件的访问权限
// 文件所有者
perms[1] = (st.st_mode & S_IRUSR) ? 'r' : '-';
perms[2] = (st.st_mode & S_IWUSR) ? 'w' : '-';
perms[3] = (st.st_mode & S_IXUSR) ? 'x' : '-';
// 文件所在组
perms[4] = (st.st_mode & S_IRGRP) ? 'r' : '-';
perms[5] = (st.st_mode & S_IWGRP) ? 'w' : '-';
perms[6] = (st.st_mode & S_IXGRP) ? 'x' : '-';
// 其他人
perms[7] = (st.st_mode & S_IROTH) ? 'r' : '-';
perms[8] = (st.st_mode & S_IWOTH) ? 'w' : '-';
perms[9] = (st.st_mode & S_IXOTH) ? 'x' : '-';
// ---------------------------------------------
// 硬链接数
int linkNum = st.st_nlink;
// ---------------------------------------------
// 文件所有者
char *fileUser = getpwuid(st.st_uid)->pw_name;
// ---------------------------------------------
// 文件所在组
char *fileGrp = getgrgid(st.st_gid)->gr_name;
// ---------------------------------------------
// 文件大小
long int fileSize = st.st_size;
// ---------------------------------------------
// 修改时间
char *time = ctime(&st.st_mtime);
// 去掉ctime自带的换行符
char mtime[512];
strncpy(mtime, time, strlen(time)-1);
mtime[strlen(time) - 1] = '\0';
// ---------------------------------------------
// 输出结果
char buf[1024];
sprintf(buf, "%s %d %s %s %ld %s %s", perms, linkNum, fileUser, fileGrp, fileSize, mtime, argv[1]);
printf("%s\n", buf);
return 0;
}系统命令 :

最终效果 :

access 函数
1. 头文件
c
#include <unistd.h>2. 函数定义
c
int access(const char *pathname, int mode);参数:
pathname:要判断的文件路径。mode:R_OK:判断是否有读权限W_OK:判断是否有写权限X_OK:判断是否有执行权限F_OK:判断文件是否存在
返回值:
- 成功返回 0 (所有请求权限被授予,或 mode 是 F_OK 且⽂件存在)
- 失败返回 -1 ,并设置 errno (⾄少⼀个权限被拒绝,或 mode 是 F_OK 且⽂件不存在,或其他错误)
作用:判断某个文件是否有某个权限,或者判断文件是否存在。
3. 样例
创建一个文本文件 a.txt :
bash
touch a.txt创建 access.c 文件 (查看目标文件是否有读写权限):
c
#include <unistd.h>
#include <stdio.h>
int main()
{
int ret = access("a.txt", F_OK | R_OK | W_OK);
if(ret == -1)
{
perror("access");
return -1;
}
printf("文件存在!!!\n");
return 0;
}
可以看到,运行成功,下面用 stat 命令查看下 a.txt 的权限:
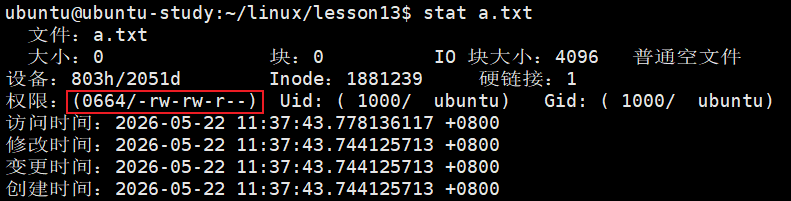
当前是 a.txt 文件的所有者,所以只需要看第一个 rw- ,确实有读写权限。
如果在源码中再加上 X_OK ,就会显示权限被拒绝:

chmod 函数
1. 头文件
c
#include <sys/stat.h>2. 函数定义
c
int chmod(const char *pathname, mode_t mode);参数:
pathname:指定需要修改的文件目录,如果是符号链接,将影响其目标文件。mode:设置新的文件权限值 。
可以通过 宏定义组合 或者 直接使用八进制数表示 。
常见宏定义:S_IRUSR(00400):所有者读权限S_IWUSR(00200):所有者写权限S_IXUSR(00100):所有者执⾏权限S_IRGRP(00040):组⽤户读权限S_IWGRP(00020):组⽤户写权限S_IXGRP(00010):组⽤户执⾏权限
返回值:
- 成功返回 0 。
- 失败返回 -1 ,并设置 errno 。
作用:⽤于修改⽂件权限的系统调⽤函数。
3. 样例
创建 chmod.c 文件:
c
#include <sys/stat.h>
#include <stdio.h>
int main()
{
int ret = chmod("a.txt", 0777);
if(ret == -1)
{
perror("chmod");
return -1;
}
return 0;
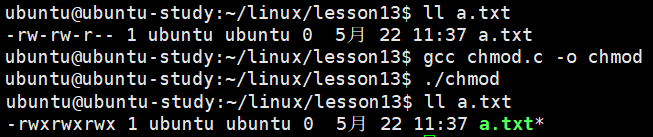
}可以看到 a.txt 的权限从 -rw-rw-r-- 变成了 -rwxrwxrwx:
chown 函数
1. 头文件
c
#include <unistd.h>2. 函数定义
c
int chown(const char *pathname, uid_t owner, gid_t group);参数:
pathname:要修改的文件路径名owner:目标用户ID (UID) ,表示要将文件修改为哪个用户所有
⽤户ID查看:- 查看
/etc/passwd⽂件 - 格式:⽤户名: x :⽤户ID:组ID:描述信息:家⽬录:登录shell
- 示例:nowcoder: x :1000:1000:nowcoder,:/home/nowcoder:/bin/bash
- 查看
group:目标组 (GID) ,表示要将文件修改为哪个组所有
组ID查看:- 查看
/etc/group⽂件 - 格式:组名: x :组ID:组成员
- 示例:nowcoder: x :1000:
- 查看
返回值:
- 成功返回 0 。
- 失败返回 -1 ,并设置 errno 。
作用:⽤于修改⽂件的所有者和所属组。
truncate 函数
1. 头文件
c
#include <unistd.h>
#include <sys/types.h>2. 函数定义
c
int truncate(const char *path, off_t length);参数:
path:需要修改的⽂件的路径length:⽂件最终需要变成的⼤⼩(单位:字节)- 当 length > 原⽂件⼤⼩时:扩展⽂件,新增部分⽤空字符填充
- 当 length < 原⽂件⼤⼩时:截断⽂件,保留前 length 字节内容
返回值:
- 成功返回 0 。
- 失败返回 -1 ,并设置 errno 。
作用 :⽤于缩减或扩展⽂件的尺⼨⾄指定⼤⼩。(使用 truncate 文件必须是可写的)
3. 样例
创建 truncate.c 文件:
c
#include <unistd.h>
#include <sys/types.h>
#include <stdio.h>
int main()
{
int ret = truncate("a.txt", 20);
if(ret == -1)
{
perror("truncate");
return -1;
}
return 0;
}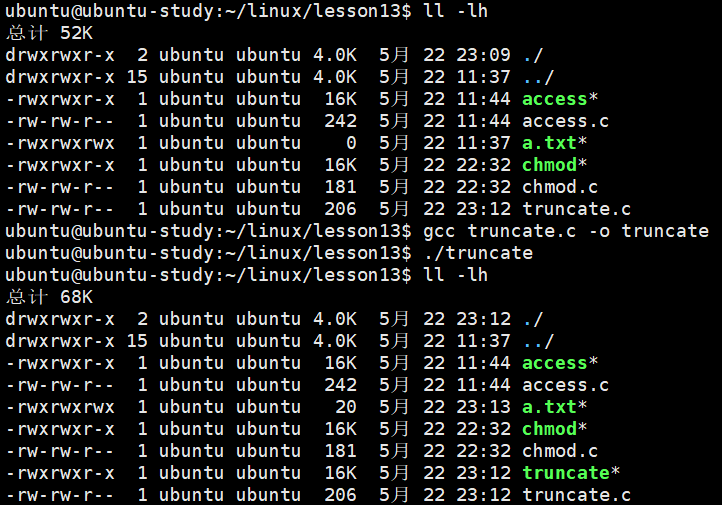

可以看到 a.txt 文件的大小从 0 拓展到了 20 ,并且是 20 个空字符。
mkdir 函数
1. 头文件
c
#include <sys/stat.h>
#include <sys/types.h>2. 函数定义
c
int mkdir(const char *pathname, mode_t mode);参数:
pathname:要创建的目录路径mode:目录权限,使用八进制表示
实际生效值 :(mode & ~umask & 0777)
返回值:
- 成功返回 0 。
- 失败返回 -1 ,并设置 errno 。
作用:创建一个自命名的目录。
3. 样例
创建一个 mkdir.c 程序:
c
#include <stdio.h>
#include <sys/stat.h>
#include <sys/types.h>
int main()
{
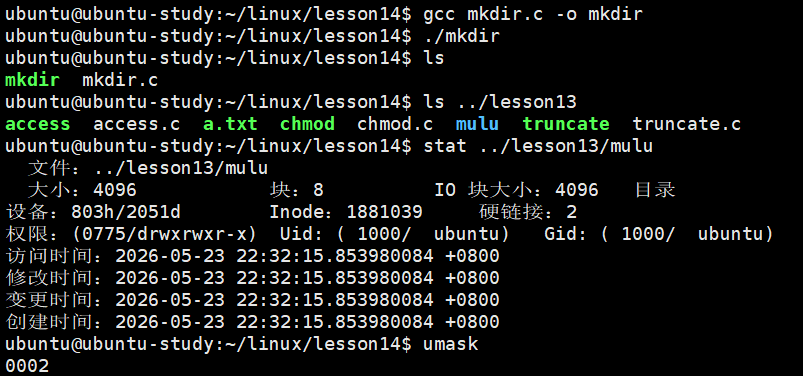
int ret = mkdir("../lesson13/mulu", 0777);
if(ret == -1)
{
perror("mkdir");
return -1;
}
return 0;
}可以看到创建的目录确实不是 mode 指定的八进制数 0777 。
rmdir 函数
1. 头文件
c
#include <unistd.h>2. 函数定义
c
int rmdir(const char *pathname);参数:
pathname:要删除的目录路径。
返回值:
- 成功返回 0 。
- 失败返回 -1 ,并设置 errno 。
作用 :删除一个目录,但此目录必须为空,否则必须先清空内容才能删除成功。
3. 样例
创建一个 rmdir.c 程序:
c
#include <stdio.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
int ret = rmdir("../lesson13/mulu");
if(ret == -1)
{
perror("rmdir");
return -1;
}
return 0;
}可以看到空目录 mulu 已经成功被删除:

rename 函数
1. 头文件
c
#include <stdio.h>2. 函数定义
c
int rename(const char *oldpath, const char *newpath);参数:
oldpath:原文件/目录路径newpath:新文件/目录路径
返回值:
- 成功返回 0 。
- 失败返回 -1 ,并设置 errno 。
作用:⽤于⽂件和⽬录的重命名,但需要确保对原路径有写权限。
3. 样例
先在 lesson13 目录下创建 mulu 目录:

编译 rename.c 程序,并查看目录:
c
#include <stdio.h>
int main()
{
int ret = rename("../lesson13/mulu", "./newmulu");
if(ret == -1)
{
perror("rename");
return -1;
}
return 0;
}
chdir 函数
1. 头文件
c
#include <unistd.h>2. 函数定义
c
int chdir(const char *path);参数:
path:需要修改的目标工作目录路径。
返回值:
- 成功返回 0 。
- 失败返回 -1 ,并设置 errno 。
作用:修改进程的工作目录。
- 进程是正在运行的程序,系统为其分配资源。
- 工作目录是程序运行时默认操作文件的路径。
- 例如在 /home/ubuntu 目录下启动 a.out 程序,该进程的工作路径就是 /home/ubuntu
注意:
- 修改后所有相对路径操作都会基于新工作目录。
- 工作目录修改只影响当前进程及其子进程。
getcwd 函数
1. 头文件
c
#include <unistd.h>2. 函数定义
c
char *getcwd(char *buf, size_t size);参数:
buf:存储当前工作目录路径的字符数组 (传出参数)。size:数组的大小,防止缓冲区溢出。
返回值:
- 成功返回指向当前工作目录的指针。
- 失败返回 NULL ,并设置 errno 值,此时 buf 所指向数组的内容是未定义的。
作用:获取当前工作目录。
样例:chdir 和 getcwd 的使用
创建一个 test.c 程序
c
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
int main()
{
// 打印当前工作目录
char buf1[128];
getcwd(buf1, sizeof(buf1));
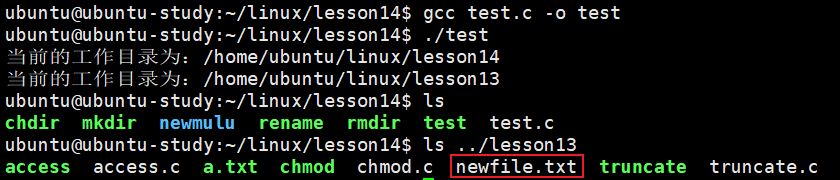
printf("当前的工作目录为:%s\n", buf1);
// 修改工作目录
int ret = chdir("../lesson13/");
if(ret == -1)
{
perror("chdir");
return -1;
}
// 创建新文件
int fd = open("newfile.txt", O_CREAT | O_RDWR, 0664);
if(fd == -1)
{
perror("open");
return -1;
}
close(fd);
// 获取当前工作目录
char buf2[128];
getcwd(buf2, sizeof(buf2));
printf("当前的工作目录为:%s\n", buf2);
return 0;
}可以看到终端打印的工作目录已经改变,创建的文件也是在当前的工作路径。
dirent 结构体和 d_type

opendir 函数
1. 头文件
c
#include <sys/types.h>
#include <dirent.h>2. 函数定义
c
DIR *opendir(const char *name);参数:
name:需要打开的目录名称。
返回值:
- 成功返回 DIR* 类型的指针,指向目录流信息
- 失败返回 NULL 。
作用:打开指定名称的目录,返回指向目录流的指针。
流位置:目录流初始位置指向目录的第一个条目
readdir 函数
1. 头文件
c
#include <dirent.h>2. 函数定义
c
struct dirent *readdir(DIR *dirp);参数:
dirp:指向目录流信息的DIR*指针 (由opendir返回的目录流指针)。
返回值:
- 成功则返回一个
dirent结构体指针 (这个结构体指针可能是静态分配,因此不用企图释放它)。 - 到达流末尾或出错时返回
NULL,如果出错就会设置对应的errno。
为了区分到达流末尾还是出错,可以在调用 readir 函数前设置 errno 为 0 ,当返回 NULL 时检查 errno 的值
作用:读取目录流中的下一个条目。
流位置:每次调用后,流位置都会自动后移。
closedir 函数
1. 头文件
c
#include <sys/types.h>
#include <dirent.h>2. 函数定义
c
int closedir(DIR *dirp);参数:
dirp:指向目录流信息的DIR*指针 (由opendir返回的目录流指针)。
返回值:
- 成功返回 0 。
- 失败返回 -1 ,并设置 errno 。
作用 :关闭与 dirp 关联的目录流 ,成功调用 closedir 函数还会关闭与 dirp 关联的底层文件描述符。调用此函数后目录流描述符 dirp 将不可用。
样例:opendir 函数 、readdir 函数和 closedir 函数的使用
创建一个 readFileNum.c 程序:
c
#define _DEFAULT_SOURCE
#include <sys/types.h>
#include <dirent.h>
#include <stdio.h>
#include <errno.h>
#include <string.h>
int getFileNum(const char *path);
// 记录某个目录下所有普通文件的个数
int main(int argc, char *argv[])
{
if(argc < 2)
{
printf("%s path\n", argv[0]);
return -1;
}
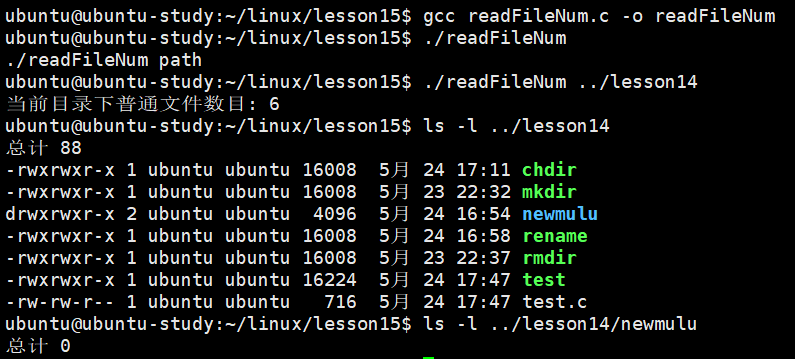
int fileNum = getFileNum(argv[1]);
printf("当前目录下普通文件数目: %d\n", fileNum);
return 0;
}
// 用于读取目录下所有普通文件的个数
int getFileNum(const char *path)
{
int fileNum = 0; // 该目录下普通文件个数
// 1.打开目录
DIR* dir = opendir(path);
if(dir == NULL)
{
perror("opendir");
return -1;
}
// 2.循环读取目录
errno = 0;
struct dirent* ptr;
while((ptr = readdir(dir)) != NULL)
{
// 获取名称和类型
char* dname = ptr->d_name;
unsigned char dtype = ptr->d_type;
// 忽略掉 . 和 ..
if(strcmp(dname, ".")==0 || strcmp(dname, "..")==0)
{
continue;
}
if(dtype == DT_DIR) // 目录
{
// 对新目录进行递归调用
char newpath[256];
sprintf(newpath, "%s/%s", path, dname);
fileNum += getFileNum(newpath);
}
if(dtype == DT_REG) // 普通文件计数+1
{
fileNum++;
}
}
// 区分 readdir 发生错误和到达文件流末尾
if(errno != 0)
{
perror("readdir");
return -1;
}
// 关闭目录流
closedir(dir);
return fileNum;
}可以看到正常读取了指定目录下的普=普通文件个数:
dup 函数
1. 头文件
c
#include <unistd.h>2. 函数定义
c
int dup(int oldfd);参数:
oldfd:被复制的文件描述符。
返回值:
- 成功返回新复制的文件描述符。
- 失败返回 -1 ,并设置 errno 。
作用 :创建文件描述符 oldfd 的副本,使用最小可用编号作为新描述符 (与 dup2 的区别)。新旧文件描述符共享文件偏移量和文件状态标志,但是不共享文件描述符标志 (如 close-on-exec 标志)。
3. 样例
创建一个 dup.c 程序:
c
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <string.h>
int main()
{
int fd = open("a.txt", O_CREAT | O_RDWR, 0664);
int cpyfd = dup(fd); // 复制文件描述符
if(cpyfd == -1)
{
perror("dup");
return -1;
}
printf("fd: %d, cpyfd: %d\n", fd, cpyfd);
close(fd);
char * str = "hello, linux";
write(cpyfd, str, strlen(str)); // 更改文件
close(cpyfd);
return 0;
}由于文件描述符表前三个分别是标准输入,标注输出以及标准错误,因此这里分配的文件描述符从 3 开始,通过复制的文件描述符 4 更改了 a.txt 的内容:
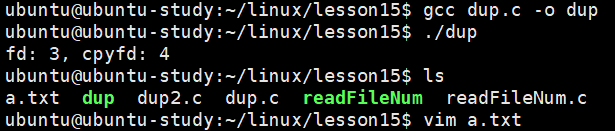
dup2 函数
1. 头文件
c
#include <unistd.h>2. 函数定义
c
int dup2(int oldfd, int newfd);参数:
oldfd:被复制的文件描述符。newfd:指定的文件描述符编号。
返回值:
- 成功返回新复制的文件描述符。
- 失败返回 -1 ,并设置 errno 。
作用 :创建文件描述符 oldfd 的副本,使用指定参数 newfd 作为复制后的文件描述符 (与 dup 的区别)。如果文件描述符 newfd 处于打开状态,系统在重新使用指定的 newfd 前会先将其关闭。
比如 oldfd 指向 a.txt ,newfd 指向 b.txt ,调用 dup2 函数会先把 newfd 对应的文件表项引用计数 -1 ,把 newfd 与 b.txt 解除关联 (自动 close),再将 newfd 指向 a.txt。
原子操作特性 :关闭和重新使用文件描述符 newfd 的步骤是具有原子性的 。相对于 close() + dup 组合,dup2 能避免竞态条件。
在计算机里,原子操作就是:一个操作,对外看起来只有两种结果:要么完全成功,要么完全失败,不存在中间状态。
3. 样例
创建一个 dup2.c 程序:
c
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <string.h>
int main()
{
int fd1 = open("1.txt", O_CREAT | O_RDWR, 0664);
int fd2 = open("2.txt", O_CREAT | O_RDWR, 0664);
printf("执行dup2前 fd1: %d, fd2: %d\n", fd1, fd2);
int cpyfd = dup2(fd1, fd2);
if(cpyfd == -1)
{
perror("cpyfd");
return -1;
}
printf("执行dup2后 fd1: %d, fd2: %d, cpyfd: %d\n", fd1, fd2, cpyfd);
char * str = "hello";
int ret = write(fd2, str, strlen(str));
if(ret == -1)
{
perror("write");
return -1;
}
close(fd1);
close(fd2);
return 0;
}通过终端输出证明了如果调用 dup2 时,newfd 已经打开了,会先把 newfd 对应的文件表项引用计数 -1 ,断开 newfd 和文件的绑定,然后再重新绑定 oldfd 指向的文件,整个过程原子完成。
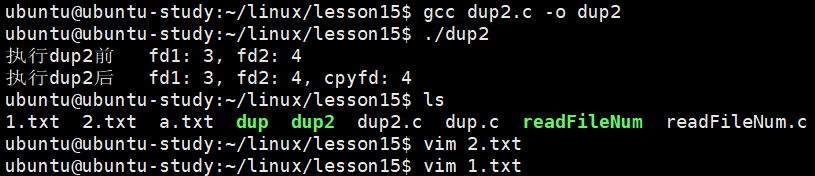
fcntl 函数
1. 头文件
c
#include <unistd.h>
#include <fcntl.h>2. 函数定义
c
int fcntl(int fd, int cmd, ... /* arg */ );参数:
fd:文件描述符参数,表示要操作的目标文件。cmd:命令参数,决定fcntl执行的操作类型,由预定义的宏制定。...:可变参数,根据cmd的不同可能有 0 个或多个参数。
返回值:根据具体操作类型而论。
作用 :对打开的文件描述符 fd 执行特定操作,操作类型由 cmd 参数决定。
- 复制文件描述符:使用
F_DUPFD
复制的是第一个参数fd,得到一个新的文件描述符,int ret = fcntl(fd, F_DUPFD);- 复制机制: 使用大于等于
arg的最小可用文件描述符编号。 - 返回值:成功时返回新的文件描述符。
- 复制机制: 使用大于等于
- 获取指定的文件描述符文件状态
flags:使用F_GETFL
获取的flags和我们通过open函数传递的flags是一个东西。- 返回(作为函数结果)文件访问模式和文件状态标志;参数
arg被忽略。
- 返回(作为函数结果)文件访问模式和文件状态标志;参数
- 设置文件描述符文件状态
flags:使用F_SETFL- 必选项:
O_RDONLY,O_WRONLY,O_RDWR不可以被修改 - 可选项:
O_APPEND(追加数据) ,O_NONBLOCK(设置成非阻塞)
- 必选项:
3. 样例
创建一个 fcntl.c 程序:
c
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
#include <string.h>
int main()
{
int fd = open("a.txt", O_RDWR);
if(fd == -1)
{
perror("open");
return -1;
}
// 1.复制文件描述符
int cpyfd = fcntl(fd, F_DUPFD);
printf("fd: %d, cpyfd: %d\n", fd, cpyfd);
// 2.修改或获取文件的状态flag
// 获取文件状态
int flags = fcntl(cpyfd, F_GETFL);
// 修改文件描述符状态的flag (追加数据状态)
flags = flags | O_APPEND;
fcntl(cpyfd, F_SETFL, flags);
char * str = "你好,Linux!";
int ret = write(cpyfd, str, strlen(str));
if(ret == -1)
{
perror("write");
return -1;
}
close(fd);
return 0;
}
可以看到连续向 a.txt 文件中追加两次数据成功:

看到这里,关于 Linux 的基础编程也结束啦,敬请期待多进程!!!