一、引言
在传统批处理中,对数据执行GROUP BY聚合后可以得到一个最终结果;但在流处理中,数据是无界的,聚合结果会随着新数据到来而持续变化。例如实时统计每个用户的订单总金额,当新订单到来时,某个用户的total_amount需要更新。如果下游是一个数据库,我们可以用UPSERT覆盖旧值;但如果下游是另一个 Flink 算子(如再次聚合),它如何知道之前发出的值已经"过期"了?
为了解决持续查询中结果更新的问题,Flink 引入了动态表(Dynamic Table)和 变更日志流(Changelog Stream) ,其中回撤流(Retract Stream)就是向外部系统或下游算子表达"更新/删除"语义的核心手段。
二、核心概念
1.动态表(Dynamic Table)
Flink SQL 将流抽象为动态表------一张内容持续变化的表,对动态表的持续查询(Continuous Query)产生的结果也是一张动态表。
2.变更日志流(Changelog Stream)
动态表的每一次变更都可以编码为一条 changelog 消息,Flink 内部使用RowKind枚举来标识消息类型。
| RowKind | 符号标记 | 含义 |
|---|---|---|
| INSERT | +I | 插入一条新记录 |
| UPDATE_BEFORE | -U | 更新前的旧值(回撤) |
| UPDATE_AFTER | +U | 更新后的新值 |
| DELETE | -D | 删除一条记录 |
3.回撤流(Retract Stream)
回撤流是动态表转化为数据流的一种模式,它将所有动态表变更编码为两种消息:
- Accumulate 消息(累加消息,标记为
true/+):表示新增一行 - Retract 消息(回撤消息,标记为
false/-):表示撤回之前发出的一行
| 动态表变更类型 | 回撤流编码 |
|---|---|
| INSERT | 发送 (true, newRow) |
| DELETE | 发送 (false, oldRow) |
| UPDATE | 发送 (false, oldRow) + (true, newRow) |
回撤流的工作流程以SELECT city, COUNT(*) FROM orders GROUP BY city为例:
yaml
输入流 (orders):
+I (order1, Beijing)
+I (order2, Shanghai)
+I (order3, Beijing)
+I (order4, Beijing)
═══════════════════════════════════════════════════════════
处理过程与回撤流输出:
Step 1: 收到 (order1, Beijing)
State: {Beijing: 1}
输出: +(Beijing, 1) -- 新增
Step 2: 收到 (order2, Shanghai)
State: {Beijing: 1, Shanghai: 1}
输出: +(Shanghai, 1) -- 新增
Step 3: 收到 (order3, Beijing)
State: {Beijing: 2, Shanghai: 1}
输出: -(Beijing, 1), +(Beijing, 2) -- 撤回旧值,发送新值
Step 4: 收到 (order4, Beijing)
State: {Beijing: 3, Shanghai: 1}
输出: -(Beijing, 2), +(Beijing, 3) -- 撤回旧值,发送新值
═══════════════════════════════════════════════════════════
下游算子收到的完整消息序列:
+(Beijing, 1)
+(Shanghai, 1)
-(Beijing, 1) ← 撤回
+(Beijing, 2)
-(Beijing, 2) ← 撤回
+(Beijing, 3)
如果下游再做 SUM 聚合,效果等价于:
1 + 1 - 1 + 2 - 2 + 3 = 4 ✓ (正确的全局总数)4.不同流模式对比
Flink 内部将动态表转化为实际的数据流(Table-to-Stream Conversion),除了回撤流,还可以转换为追加流与更新流。Changelog 是灵魂,Append、Retract、Upsert 是它的三种肉体呈现形式,三种流模式对比总览如下:
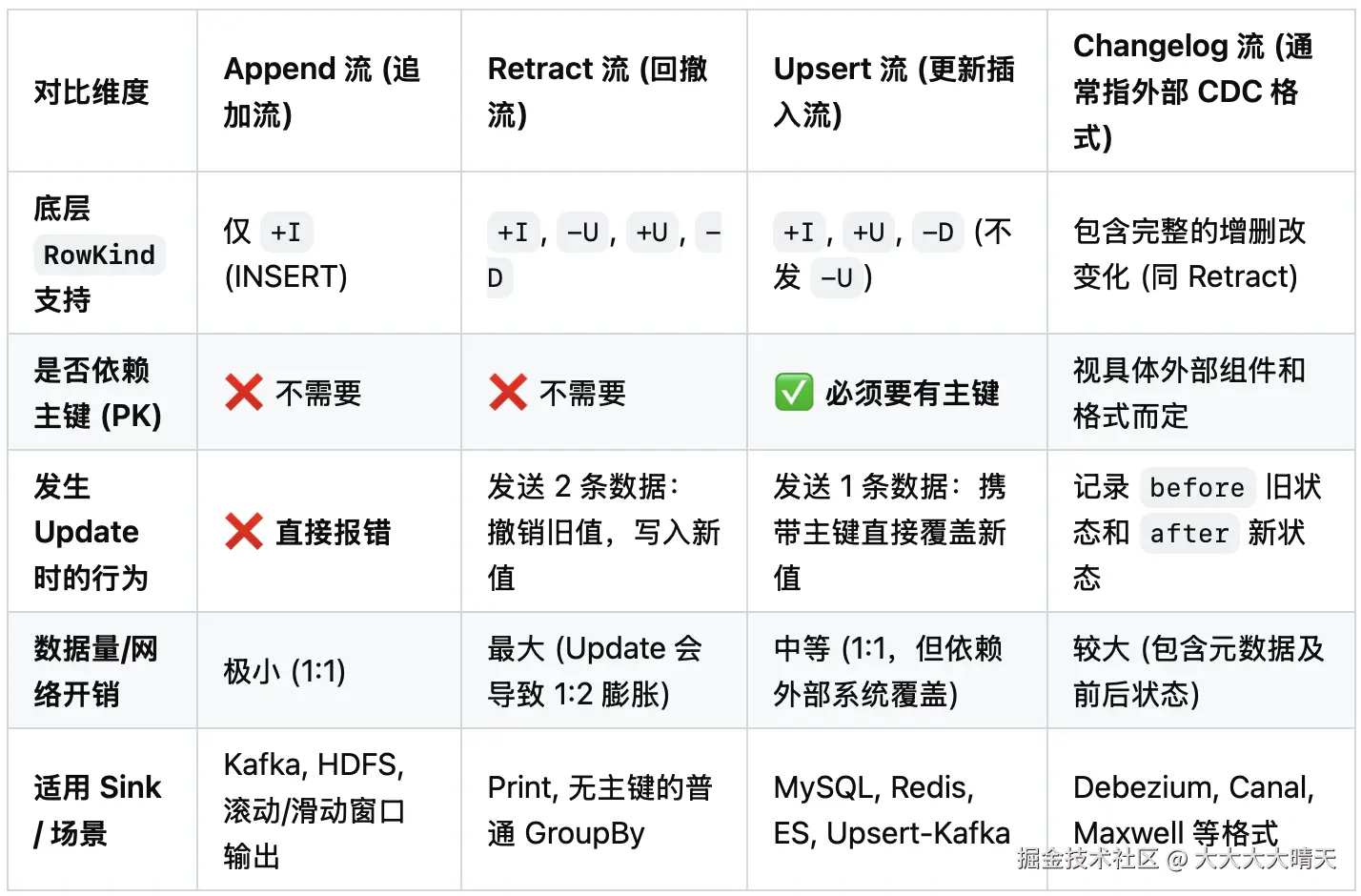
三、回撤流代码示例
1.Table API(旧版toRetractStream)
sql
// Flink 1.13 及之前版本
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
Table result = tEnv.sqlQuery(
"SELECT city, COUNT(*) AS cnt FROM orders GROUP BY city"
);
// 转换为回撤流:DataStream<Tuple2<Boolean, Row>>
DataStream<Tuple2<Boolean, Row>> retractStream = tEnv.toRetractStream(result, Row.class);
retractStream.print();
// 输出示例:
// (true, Beijing, 1)
// (true, Shanghai, 1)
// (false, Beijing, 1) ← retract
// (true, Beijing, 2) ← accumulate2.Table API(新版toChangelogStream)
typescript
// Flink 1.14+ 推荐方式
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
Table result = tEnv.sqlQuery(
"SELECT city, COUNT(*) AS cnt FROM orders GROUP BY city"
);
// 转换为 changelog 流,行带有 RowKind 标记
DataStream<Row> changelogStream = tEnv.toChangelogStream(result);
changelogStream.process(new ProcessFunction<Row, String>() {
@Override
public void processElement(Row row, Context ctx, Collector<String> out) {
switch (row.getKind()) {
case INSERT: // +I
case UPDATE_AFTER: // +U
out.collect("ACC: " + row);
break;
case UPDATE_BEFORE: // -U
case DELETE: // -D
out.collect("RET: " + row);
break;
}
}
});四、典型场景与最佳实践
| 场景 | 说明 | 推荐模式 |
|---|---|---|
| 非窗口聚合 → 再聚合 | SELECT SUM(cnt) FROM (SELECT city, COUNT(*) AS cnt ...) | Retract |
| 无主键的复杂 Join | 多表 Join 后无法确定唯一键 | Retract |
| Regular Join(双流Join) | 两侧都可能更新 | Retract |
| DISTINCT 聚合 | COUNT(DISTINCT user_id) | Retract |
| 写入 Kafka 中间 Topic | Kafka 本身不支持按 key 更新消息体 | Retract(需编码) |
| 写入 MySQL/HBase 等 | 支持 UPSERT 的存储 | Upsert 优先 |
在日常Flink回撤流使用过程中,配置实践参考如下:
- 【开启 Mini-Batch】高频更新场景下必开,显著减少消息量
- 【合理设置 State TTL】TTL过大则状态存储增长,过小会导致回撤丢失,需在存储成本和数据正确性之间权衡
- 【优先使用窗口聚合】如果业务允许延迟,用 tumble/hop 窗口替代 unbounded 聚合
- 【开启Local/Global 两阶段聚合】第一阶段本地预聚合(无回撤),第二阶段全局聚合(回撤减少)
- 【善用 Upsert Sink】写入 MySQL/Redis 等支持覆盖的存储,避免将回撤传播到外部
- 【避免不必要的多级回撤传播】尽量在靠近 Source 端完成聚合
- 【避免在回撤流上做 Append-only Sink】如 CSV 文件,会写入 retract 消息
- 【避免超高基数 Key 的无界聚合】数百万级 Key 的 GROUP BY 会导致状态爆炸
- 【避免忽略回撤消息】下游消费时必须正确处理 retract,否则结果错误
- 【监控状态大小】通过 Flink Web UI 和 Metrics 监控 State 增长趋势