大家好 👋,我是 Moment,目前正在使用 Next.js、NestJS、LangChain 开发 DocFlow。这是一个面向 AI 场景的协同文档平台,集成了基于
Tiptap的富文本编辑、NestJS后端服务、实时协作与智能化工作流等核心模块。在这个项目的持续打磨过程中,我积累了不少实战经验,不只是
Tiptap的深度定制、编辑器性能优化和协同方案设计,也包括前端工程化建设、React 源码理解以及复杂项目架构实践。如果你对 AI 全栈开发、文档编辑器、前端工程化或者 React 源码相关内容感兴趣,欢迎添加我的微信
yunmz777一起交流。觉得项目还不错的话,也欢迎给 DocFlow 点个 star ⭐
很多 Agent 和 RAG 系统一开始跑得很顺,问题往往出现在任务变长之后。历史消息越来越多,检索结果越来越多,工具返回、失败重试、用户偏好、旧版本文档也被不断塞进同一个上下文窗口。模型表面上还在回答当前问题,但判断依据已经慢慢偏了。
比如用户本来问,帮我基于最新合同改一版风险提示。上下文里却同时存在旧合同、旧审批意见、历史聊天、检索结果、风格示例和多个工具返回。模型最后确实写出了一份风险提示,但它可能引用了旧合同条款,语气学了历史示例,风险判断又混进了检索噪声。
这就是语义偏移。它不是简单的 token 太多,而是系统没有管理好上下文边界,把太多目标、历史、文档、工具结果、记忆、示例、约束和无关信息放进同一个窗口,导致模型开始抓错重点。
表面上看,模型还在执行任务,但它的注意力已经从当前目标偏移到了:
- 最近出现的内容
- 更显眼的内容
- 重复次数更多的内容
- 和问题表面词更像的内容
- 历史里已经过期但没有清理的内容
RAG检索里混进来的噪声文档Agent多轮执行过程中残留的中间状态
长上下文不是越长越强,关键是有效上下文
很多人看到模型支持 128K、1M 甚至更长上下文,就会误以为把所有东西都塞进去最稳。但研究和工程经验都指向另一个结论,窗口越大,不代表模型越能稳定利用窗口里的所有信息。
Stanford 等机构的 Lost in the Middle 研究发现,模型在长上下文里并不能稳定使用所有位置的信息,相关信息放在开头或结尾时表现往往更好,放在中间时性能会明显下降。也就是说,长上下文窗口存在,并不等于模型能均匀、可靠地利用里面的所有内容。
NoLiMa 这类更严格的长上下文评测也指出,很多 Needle-in-a-Haystack 测试因为问题和答案之间有明显字面重合,可能高估了模型长上下文能力。当问题和关键证据之间缺少字面匹配、需要关联推理时,随着上下文变长,模型性能会明显下降。
所以工程上的核心判断应该是,不要追求把上下文塞满,而是要让模型在每一步只看到当前决策真正需要的信息。
长上下文能力当然有价值,它适合承载更完整的文档、更复杂的任务轨迹和更丰富的证据集合,但它不应该成为无脑堆上下文的理由。真正影响结果稳定性的,不只是上下文窗口有多大,而是进入窗口的信息是否干净、是否相关、是否有层级、是否被正确排序、是否和当前任务强绑定。
语义偏移通常不是一次发生的,而是逐步积累出来的
在真实 Agent、RAG、AI 编辑器、法律文书生成、代码助手里,语义偏移往往不是某一轮突然坏掉,而是多轮上下文慢慢污染。
一开始,系统只是多保留了一点历史消息。接着,RAG 检索结果追加进来,工具返回追加进来,失败重试的中间信息也追加进来。再往后,示例、规则、用户偏好、历史结论、旧版本文档混在同一个上下文窗口里,模型就很难稳定判断当前任务、历史背景、废弃方案和参考示例之间的边界。
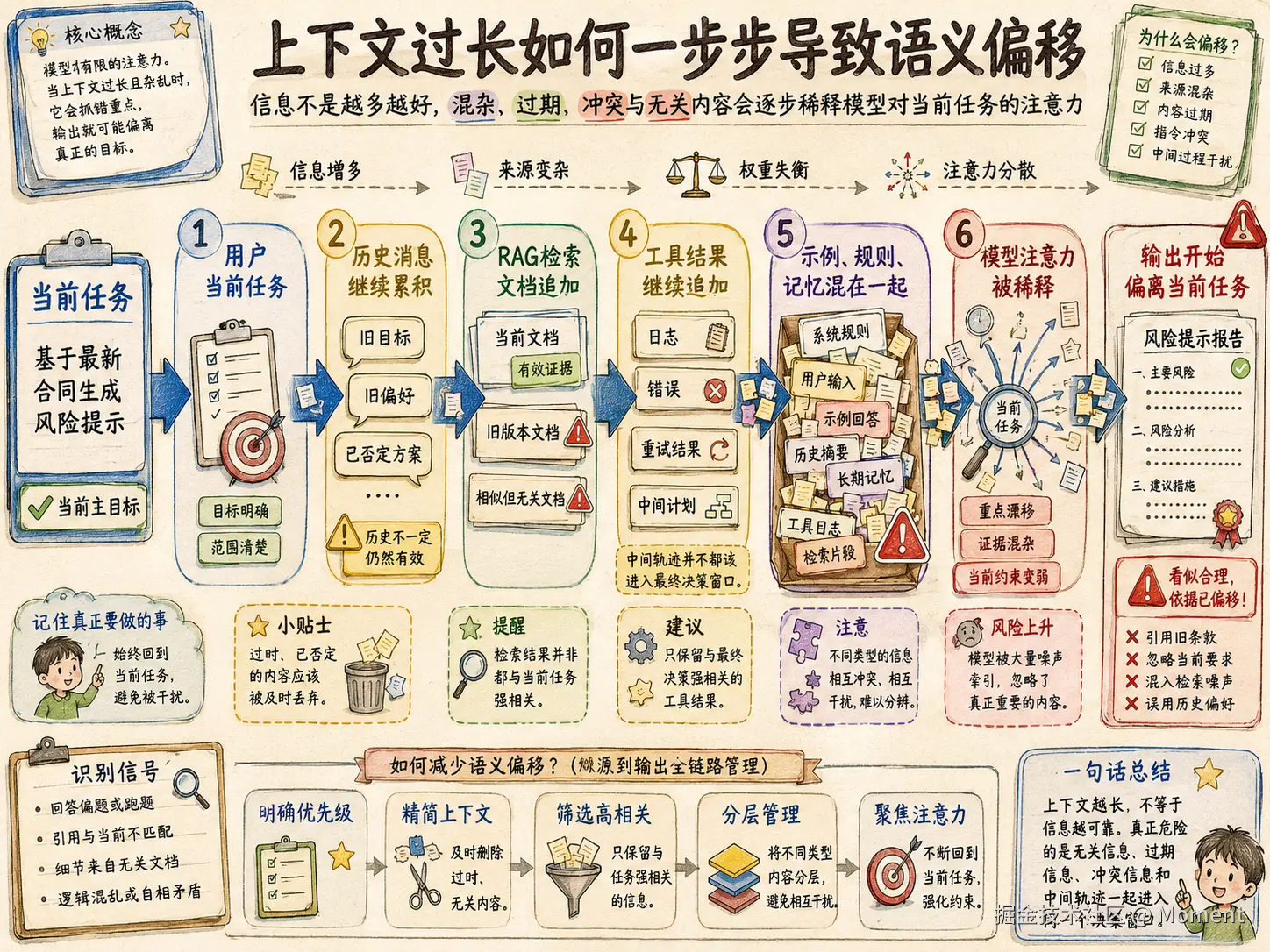
最危险的是,语义偏移通常不是明显报错。模型会给出一段看起来合理、结构完整、语气自信的答案,但答案的依据已经变了。
这也是为什么长上下文治理不能只靠提醒模型不要跑偏。如果输入本身已经混乱,模型只是被要求在混乱里保持稳定,这个稳定性一定是不可靠的。
为什么上下文过长会导致语义偏移
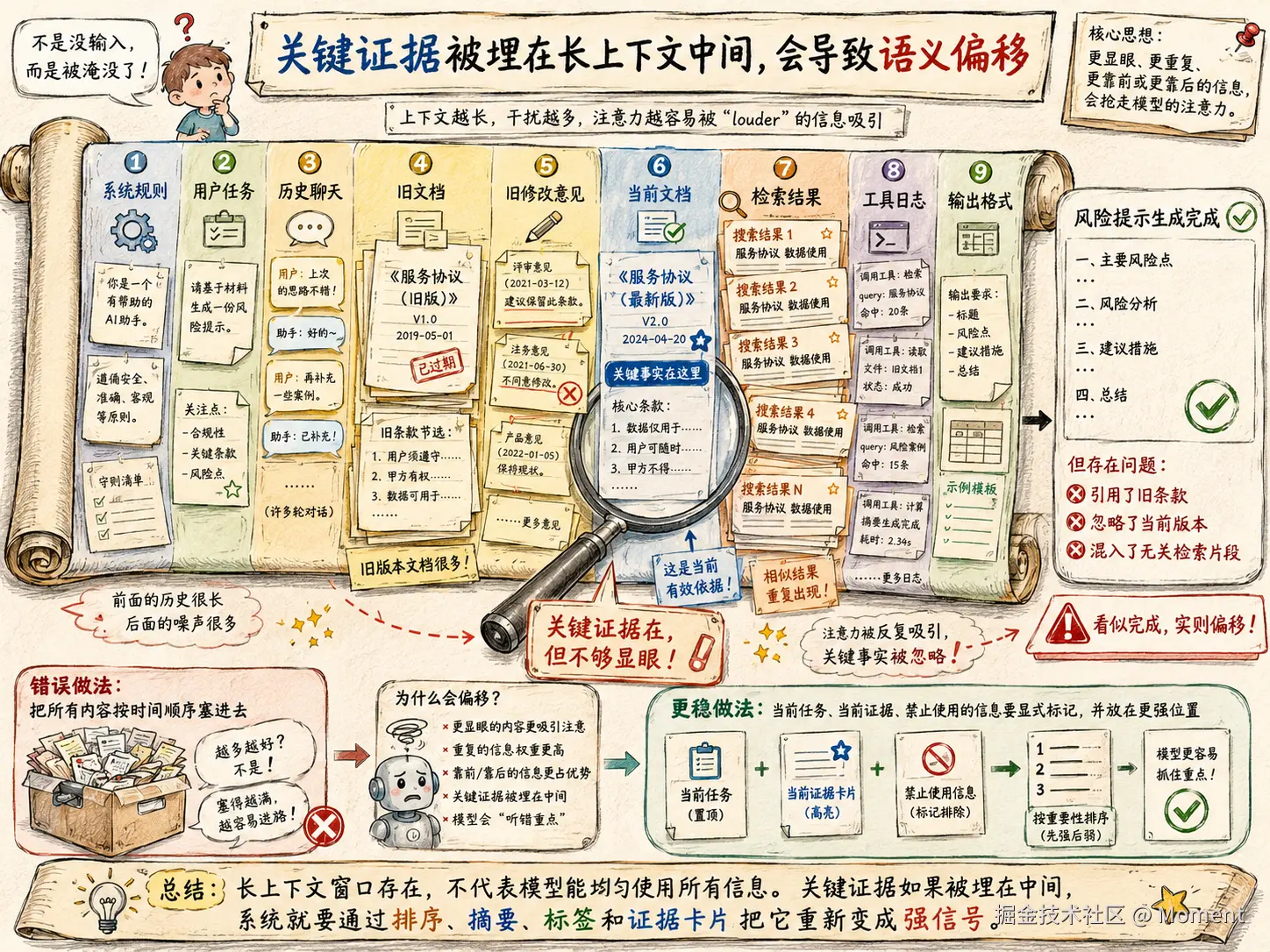
相关信息会被埋在中间
长上下文里,关键事实不一定丢了,但可能被埋了。
比如一个真实任务里,上下文经常会按这种顺序被拼起来:
- 系统规则
- 用户任务
- 历史聊天
- 旧文档
- 旧文档修改意见
- 当前文档
- 检索结果
- 工具日志
- 输出格式要求
如果当前文档被放在中间,而旧文档、检索结果、历史聊天又更长、更重复,模型就可能把旧文档里的强信号当成主要依据。Lost in the Middle 的结论正好解释了这个问题,模型对长上下文不同位置的信息利用并不均匀,中间信息更容易被忽视。
这一点在合同审查、代码仓库问答、长文档问答里特别明显。用户以为自己已经把当前文档放进去了,但模型实际抓到的可能是前面出现过很多次的旧条款、历史接口、旧配置或旧设计方案。
噪声文档会和关键证据竞争注意力
RAG 不是把检索结果拼进去就结束了。检索结果里常见的问题包括:
- 语义相似但任务无关
- 来自旧版本文档
- 和当前问题只共享关键词
- 结论相反但没有标记冲突
- 排序靠前但证据质量不高
U-NIAH 的研究也提到,RAG 能缓解一部分长上下文问题,但检索噪声、chunk 排序等因素会降低效果。也就是说,RAG 的价值不在于塞更多文档,而在于选对、排好、压缩好文档。
很多工程事故不是因为没检索到,而是因为检索到了太多看起来相关的东西。模型面对一堆相似片段时,会倾向于综合它们,甚至把冲突信息强行揉成一个结论。如果系统没有标记文档版本、来源可信度、适用范围和冲突关系,模型就只能靠语义猜。
历史消息会把当前任务带偏
多轮对话里,历史消息经常包含旧目标、旧偏好、旧约束和已经被用户否定的方案。如果系统一直把完整历史塞回模型,模型可能会把早已过期的信息继续当成有效约束。
比如用户前面说过:
- 我想做一个博客系统
后面用户已经改成:
- 我不是做博客,我是做
AI内容生产平台
如果上下文没有显式标记旧目标已废弃,模型可能继续围绕博客系统设计内容。这种偏移在产品文档、PRD、代码生成、合同修改里非常常见。
所以历史消息不能只做保留,还要做状态化。系统不仅要知道用户以前说过什么,也要知道哪些内容仍然有效,哪些内容已经被覆盖,哪些内容只适用于某一次任务。
指令、资料、示例混在一起,模型容易误判优先级
OpenAI 的提示工程建议 里提到,应把指令放在开头,并用清晰分隔符区分指令和上下文。Anthropic 的 Claude 文档 也建议用 XML 标签区分 instructions、context、examples、input 等不同部分,尤其适合复杂长提示。
这背后的工程意义是,模型不是天然知道哪段是规则、哪段是资料、哪段只是示例。你不分层,它就只能靠语义猜。
最容易出问题的上下文通常长这样:
- 先告诉模型你是一个严谨的合同审查助手
- 然后塞入一些资料
- 资料里混着旧合同、用户之前说过的话、示例回答、当前合同
- 最后要求它输出风险提示
看起来信息很多,实际上边界很弱。模型可能把示例回答里的表达当成事实,把旧合同里的条款当成当前条款,把用户之前说的旧偏好当成当前要求。
Agent 多步执行会产生轨迹污染
Agent 场景更容易出现语义偏移,因为它不是一次调用,而是多次 Decide、Act、Observe、Update。
每一步都会产生:
- 中间计划
- 工具调用参数
- 工具返回结果
- 错误信息
- 修复尝试
- 被废弃的方案
- 临时判断
- 人工确认结果
如果这些轨迹不做状态管理,只是全部追加到 messages 里,模型后续决策就会被中间过程污染。
LangChain 的上下文工程文档 把 context engineering 解释为给 LLM 提供正确的信息、工具和格式,让它可靠完成任务。放在 Agent 里,它强调的不是简单堆消息,而是要对上下文进行选择、压缩、隔离和重组。
工程上不要急着修 prompt,要先重构上下文
很多团队遇到语义偏移后,第一反应是加一句:
请严格遵守当前用户问题,不要被无关上下文影响。
这句话有用,但不够。
真正稳定的做法,是把上下文当成一个可管理的数据结构,而不是一大段字符串。
我会把上下文拆成几层:
| 上下文层 | 作用 | 是否应该长期保留 |
|---|---|---|
System Instructions |
系统身份、边界、禁止行为、安全规则 | 长期稳定 |
Task Intent |
当前用户到底要完成什么 | 每轮重建 |
Active Constraints |
当前任务有效约束,比如格式、语言、范围、风险等级 | 每轮重建 |
Evidence |
当前任务需要引用的证据、文档片段、工具结果 | 按需检索 |
Working State |
当前执行进度、已完成步骤、待确认点 | 当前任务内保留 |
Memory |
稳定偏好、长期事实、项目背景 | 检索后少量注入 |
History Summary |
历史摘要,不是完整历史 | 压缩后保留 |
Rejected Context |
已废弃、已过期、已冲突的信息 | 不进入主上下文,只做审计 |
核心原则是:
模型每次调用前,都要重新组装上下文,而不是把历史消息无脑追加。
这里的关键变化是,上下文不再是聊天记录、检索结果和工具日志的拼接物,而是一个经过筛选、排序、压缩和校验的运行时输入。
一个更稳的上下文组装流程
工程上可以设计一个 Context Assembler,专门负责把可能有用的信息变成当前这一步真正该看的上下文。
它要做的不只是检索,而是完整的上下文治理。系统要先理解当前任务,再决定需要哪些信息,然后检索、过滤、重排、压缩、检测冲突,最后组装成模型可以稳定使用的上下文。
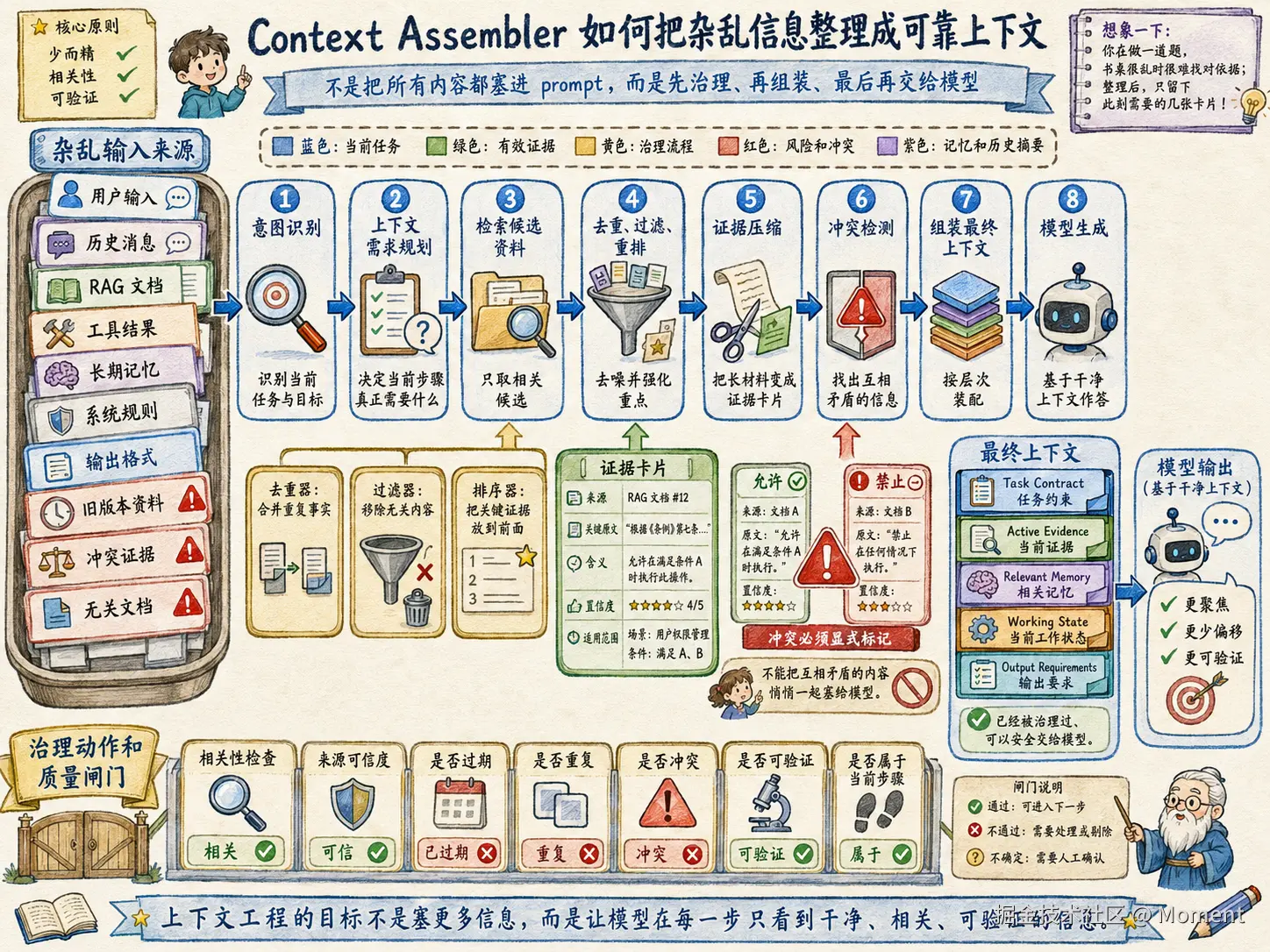
这里最重要的不是检索,而是中间几步:
- 去重:同一事实不要重复出现很多次,重复会放大权重
- 过滤:和当前意图无关的内容不要进入上下文
- 重排:最关键证据放到更显眼的位置
- 压缩:长文档先变成证据卡片,而不是全文塞入
- 冲突检测:旧信息、新信息、用户当前要求之间冲突时,要显式标记
上下文治理要从预算、证据和状态开始
先给上下文设置预算,不要让每一层无限膨胀
上下文窗口再大,也应该有预算。
我一般会按任务类型拆分上下文预算:
- 系统规则:约 5% 到 10%
- 当前任务:约 5% 到 10%
- 核心证据:约 40% 到 60%
- 历史摘要:约 10% 到 15%
- 长期记忆:约 5% 到 10%
- 输出格式和校验规则:约 5% 到 10%
- 预留模型生成空间:至少 20%
这个比例不是死的,但一定要有预算意识。
如果一个任务是合同审查,核心证据应该是当前合同、相关条款、用户指定审查范围,而不是历史聊天。如果一个任务是代码修改,核心证据应该是相关文件、类型定义、调用链、报错栈,而不是整个仓库所有文件。
预算的意义不是省 token,而是防止某一类信息吞掉整个决策空间。历史消息看起来有价值,但它不能挤掉当前证据。长期记忆看起来很智能,但它不能覆盖用户本轮明确要求。检索结果看起来越多越稳,但噪声超过一定比例后,反而会拉低答案可靠性。
把当前任务单独抽成 Task Contract
不要让模型自己从长历史里猜当前任务。每次调用前,先生成一个明确的 Task Contract。
Task Contract 至少应该说明:
- 本轮目标是什么
- 当前使用哪份文档或哪批证据
- 必须使用哪些信息
- 禁止使用哪些信息
- 输出格式是什么
- 证据不足时如何处理
- 当前任务风险等级是多少
比如合同审查任务里,Task Contract 可以表达成这样:
- 目标:基于当前合同生成风险提示
- 当前文档:contract_v5
- 必须使用:当前合同 v5、用户本轮补充要求
- 禁止使用:contract_v1、旧审批意见、历史示例中的虚构条款
- 输出格式:风险点、依据条款、修改建议、风险等级
- 不确定性策略:证据不足时必须标记,不允许编造条款
这个结构的价值很大,它把当前任务是什么、哪些上下文有效、哪些上下文不能用显式写清楚。模型不需要在一堆历史里猜。
Task Contract 也可以作为后续 Verifier 的输入。生成完成后,系统可以检查输出是否违反 must_not_use,是否遗漏 must_use,是否满足 output_format,是否在证据不足时仍然强行编造了结论。
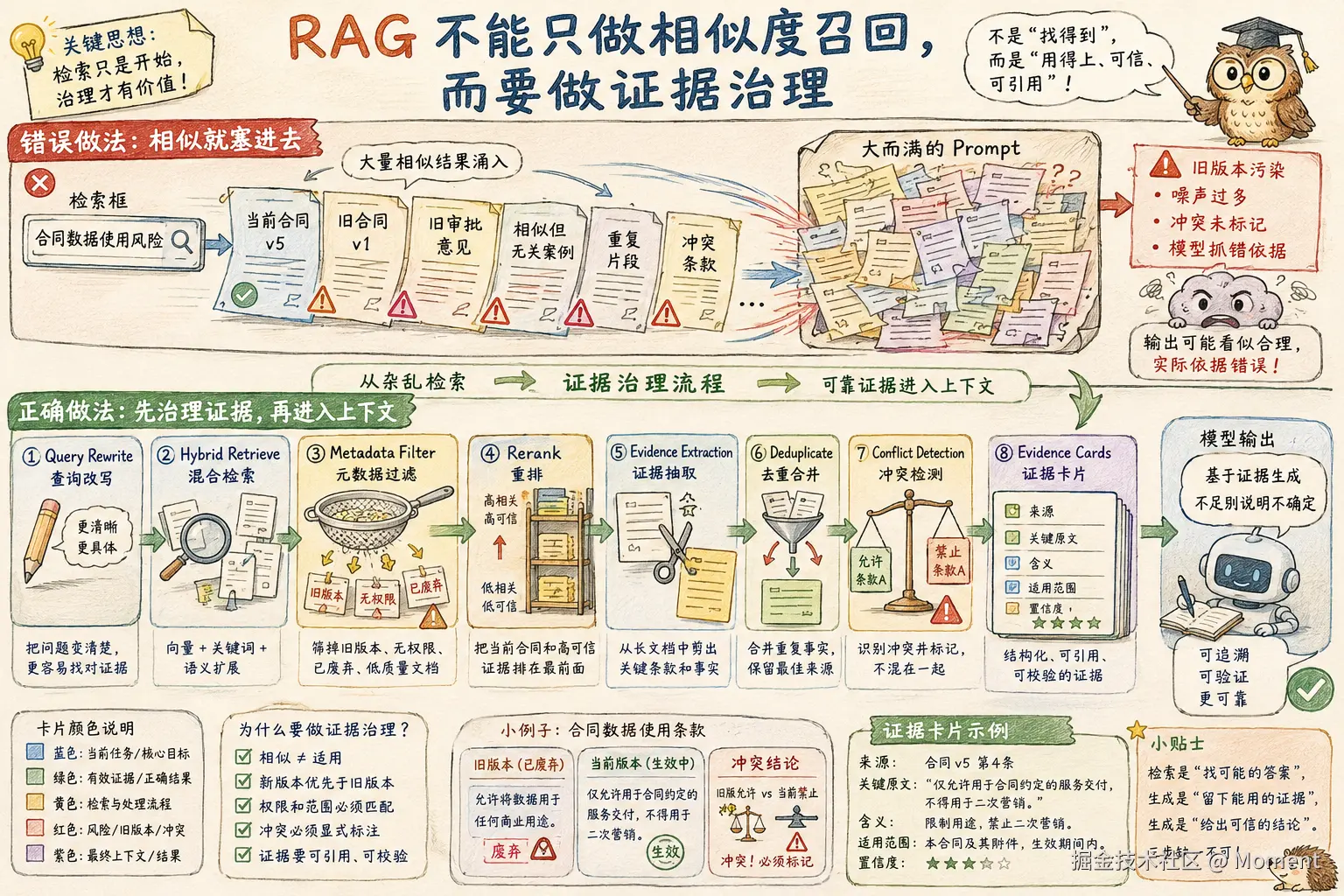
RAG 不要只做相似度召回,要做证据治理
很多语义偏移来自 RAG,因为系统把看起来相关的内容都塞进去了。
更稳的 RAG 不应该停在向量相似度,而要做完整证据治理:
query rewrite:把用户问题改写成更适合检索的查询hybrid retrieve:结合向量检索、关键词检索、元数据过滤metadata filter:按版本、权限、时间、workspace、文档状态过滤rerank:让更关键、更可信、更贴近当前任务的证据排在前面evidence extraction:从文档中抽取可引用证据,而不是整段塞入deduplicate:合并重复事实,避免重复信息放大权重conflict detection:发现相互冲突的证据,并显式标记citeable evidence cards:形成可引用、可校验的证据卡片final context:只把治理后的证据放进最终上下文
其中 metadata filter 很关键。比如法律、合同、项目文档、接口文档里,必须过滤:
- 文档版本
- 所属
workspace - 更新时间
- 适用业务线
- 权限范围
- 是否废弃
- 是否草稿
- 是否用户本轮指定
相似度只能回答像不像,不能回答该不该用。
长文档要先压成证据卡片,而不是直接塞全文
长文档进入模型前,最好先变成结构化证据卡片。
比如合同审查里,一张证据卡片可以包含:
| 字段 | 含义 |
|---|---|
| source | 证据来自哪份文档 |
| section | 证据位于哪个章节或条款 |
| quote | 可引用的原文片段 |
| meaning | 这段内容对当前任务意味着什么 |
| risk | 可能引出的风险 |
| confidence | 当前证据的置信度 |
举个例子:
| 字段 | 内容 |
|---|---|
| source | contract_v5.pdf |
| section | 第 8 条 数据使用 |
| quote | 服务方可在必要范围内处理客户数据 |
| meaning | 条款允许数据处理,但没有明确处理范围、保存期限和删除机制 |
| risk | 数据处理边界不清 |
| confidence | high |
这样比直接塞入一大段合同更稳。模型看到的是已经被筛过的证据,而不是原始噪声。
Anthropic 关于长上下文提示的建议 里也提到,处理长文档任务时,可以先让模型提取相关引用,再执行最终任务。这背后的思路和证据卡片类似,先把长上下文压缩成可定位、可引用、可核验的证据,再让模型基于证据完成写作或判断。
历史消息要摘要化,而且摘要要带状态
不要把完整历史一直塞给模型。更好的做法是维护 running summary,但这个 summary 不能只是普通自然语言摘要,而要带状态。
一个可用的历史摘要应该分成几类:
| 摘要区域 | 作用 |
|---|---|
stable_facts |
仍然稳定有效的事实,比如项目类型、核心技术栈、业务边界 |
current_preferences |
当前仍然有效的表达偏好、格式偏好、工程偏好 |
rejected_or_outdated |
已经被用户否定、覆盖或废弃的信息 |
open_questions |
仍然没有确认、不能擅自假设的问题 |
比如:
stable_facts:用户项目是AI内容生产平台,不是普通博客系统,后端采用NestJS和Fastifycurrent_preferences:中文技术文章要自然、有工程判断、不要模板腔,引用资料要放在正文里,不要文末堆链接rejected_or_outdated:早期讨论过博客形态,但已被用户否定,旧版架构中没有Supervisor,但后续已确定采用Supervisoropen_questions:具体发布端是否包括抖音和头条仍需按任务确认
重点是 rejected_or_outdated。很多系统只总结用户说过什么,却不总结哪些东西已经被否定,这会导致旧信息反复污染新任务。
历史摘要不是为了让模型记住一切,而是为了让模型知道哪些信息仍然有效,哪些信息已经不能再用。
长期记忆必须检索后注入,不能全量注入
长期记忆很有用,但也很危险。
如果每次都把用户所有偏好、项目背景、历史事实塞进去,模型很容易被无关记忆带偏。长期记忆应该像 RAG 一样按当前任务检索,并且经过 relevance gate。
每条记忆最好有这些字段:
| 字段 | 作用 |
|---|---|
memory_id |
记忆唯一标识 |
type |
semantic、episodic、procedural、preference |
scope |
user、workspace、project、document |
content |
记忆内容 |
created_at |
创建时间 |
updated_at |
更新时间 |
confidence |
置信度 |
status |
active、outdated、rejected |
source |
记忆来源 |
注入前要判断:
- 当前任务是否真的需要这条记忆
- 这条记忆是否过期
- 是否和用户本轮输入冲突
- 是否属于当前
workspace - 是否会影响权限或隐私边界
尤其是 Agent 系统,不要把稳定偏好和某一次任务里的临时选择混在一起。一次任务里用户说这次写得夸张一点,不代表长期记忆应该改成用户喜欢标题党。
上下文要按角色隔离,不要混成一段
一个稳定的 prompt 结构应该把不同类型的信息拆开:
| 区域 | 放什么 |
|---|---|
system_rules |
系统身份、权限边界、安全规则、证据规则 |
task_contract |
本轮任务目标、输入范围、输出格式、禁止事项 |
current_user_input |
用户本轮输入 |
active_evidence |
只放和当前任务相关、已过滤、可引用的证据 |
working_state |
当前任务进度、已完成步骤、待确认点 |
relevant_memory |
只放本轮任务需要的少量长期记忆 |
output_requirements |
最终输出格式和校验要求 |
这不是格式洁癖,而是降低模型误解上下文边界的工程手段。
如果所有内容混在一起,模型需要自己判断这段是规则还是资料、这段是示例还是事实、这段是历史要求还是当前要求。上下文越长,这个判断越不稳定。
关键信息不要只出现一次,要做锚点,但不能重复堆噪声
长上下文里,关键任务约束可以在重要位置重复一次,比如在开头的 Task Contract 里声明一次,在结尾的 Output Requirements 里再收束一次。
好的锚点是:
- 目标:只基于
contract_v5生成风险提示 - 禁止:不要引用
contract_v1和旧审批意见 - 证据不足:必须标记不确定,不要补全不存在的条款
坏的重复是:
- 把同一份合同复制很多遍
- 把同一段规则复制很多遍
- 把同一个示例复制很多遍
前者是在强化任务边界,后者是在制造噪声。
生成后必须做验证,不要相信一次输出
上下文过长时,最危险的是模型自信地错。所以工程上要加 Verifier。
Verifier 不一定是另一个大模型,也可以是规则、检索、引用检查、结构校验的组合。
可以检查:
- 输出里的事实是否来自
active_evidence - 是否引用了禁止使用的旧文档
- 是否遗漏用户本轮硬性要求
- 是否出现未提供来源的具体结论
- 是否把历史偏好误当成当前要求
- 是否生成了证据里不存在的条款、接口、字段、金额、日期
- 输出格式是否符合
schema
比如法律文书、合同审查、代码修改、财务分析这类场景,Verifier 是必须的,不应该只靠一次生成。
Context Assembler 要变成可测试的工程模块
下面这个代码不是完整实现,而是用来表达工程边界。上下文组装应该有明确输入、过滤规则、预算控制和输出结构,而不是把字符串一路拼到模型请求里。
ts
type ContextItem = {
id: string;
source:
| "system"
| "current_user_input"
| "history_summary"
| "retrieved_document"
| "tool_result"
| "memory"
| "working_state";
content: string;
relevance: number;
confidence: number;
tokenEstimate: number;
scope?: "user" | "workspace" | "project" | "document";
status?: "active" | "outdated" | "rejected";
};
type TaskContract = {
goal: string;
mustUse: string[];
mustNotUse: string[];
outputFormat: string;
riskLevel: "low" | "medium" | "high";
};
function selectContextItems(items: ContextItem[], maxTokens: number) {
const selected: ContextItem[] = [];
let used = 0;
const candidates = items
.filter((item) => item.status !== "outdated" && item.status !== "rejected")
.filter((item) => item.relevance >= 0.72 && item.confidence >= 0.6)
.sort((a, b) => b.relevance * b.confidence - a.relevance * a.confidence);
for (const item of candidates) {
if (used + item.tokenEstimate > maxTokens) {
continue;
}
selected.push(item);
used += item.tokenEstimate;
}
return selected;
}
function buildPrompt(params: {
task: TaskContract;
systemRules: string;
currentInput: string;
evidence: ContextItem[];
historySummary: ContextItem[];
evidenceBudget: number;
historyBudget: number;
}) {
const evidence = selectContextItems(params.evidence, params.evidenceBudget);
const historySummary = selectContextItems(
params.historySummary,
params.historyBudget,
);
return `
<system_rules>
${params.systemRules}
</system_rules>
<task_contract>
目标:${params.task.goal}
必须使用:${params.task.mustUse.join("、")}
禁止使用:${params.task.mustNotUse.join("、")}
输出格式:${params.task.outputFormat}
风险等级:${params.task.riskLevel}
</task_contract>
<current_user_input>
${params.currentInput}
</current_user_input>
<active_evidence>
${evidence.map((item) => `<item id="${item.id}">${item.content}</item>`).join("\n")}
</active_evidence>
<history_summary>
${historySummary.map((item) => `<summary id="${item.id}">${item.content}</summary>`).join("\n")}
</history_summary>
<output_requirements>
只基于 active_evidence 和 current_user_input 回答。
如果证据不足,明确说明不确定,不要补全不存在的事实。
不要使用 task_contract 中禁止使用的信息。
</output_requirements>
`.trim();
}这个骨架里最关键的不是某个框架写法,而是几个边界:
status可以避免旧信息、废弃信息进入上下文relevance和confidence分开,避免像但不可靠的内容进入上下文scope可以防止跨workspace、跨项目污染evidenceBudget和historyBudget控制每一类上下文的最大占比task_contract明确告诉模型当前目标和禁区active_evidence只放当前任务证据,不放所有检索结果
当上下文组装变成一个可测试、可观测、可回滚的工程模块,系统才有机会定位问题来源。只要复杂任务还停留在把字符串拼起来发给模型的阶段,长上下文、长对话和多工具调用迟早会把系统拖进失控状态。
怎么检测系统已经发生语义偏移
可以从这些信号判断:
| 信号 | 说明 |
|---|---|
| 回答引用了旧版本文档 | 当前任务没有要求旧版本,但模型使用了历史内容 |
| 回答风格突然变了 | 被历史示例或无关记忆影响 |
| 输出看似完整但没有证据 | 模型用上下文噪声补全了空白 |
| 本轮明确要求被忽略 | 当前任务信号被历史信号压过 |
| 模型把示例当事实 | examples 和 evidence 没隔离 |
| 多轮后越来越跑题 | Agent 轨迹和工具结果没有压缩 |
| 同一问题换位置答案不同 | 对上下文位置敏感 |
| 加入更多文档后答案变差 | RAG 噪声超过收益 |
工程上我会专门做一组回归测试,因为这类测试比单纯测能不能在长文本里找到一句话更接近真实系统。
- 关键证据分别放在开头、中间、结尾,比较答案稳定性
- 加入旧版本文档,检查模型是否会误引用过期信息
- 加入语义相似但任务无关的文档,检查模型是否会被噪声带偏
- 加入相互冲突的证据,检查模型是否能显式标记冲突,而不是强行圆回来
- 加入历史偏好或旧要求,检查它们是否会覆盖用户本轮的明确要求
- 把对话拉长到 20 轮甚至更长,检查当前任务是否仍能被正确执行
如果我希望把这组测试可视化,而不是只放一段列表,我会直接换成一张信息密度更高的文生图。这样读者一眼就能看懂,我们测的不是抽象能力,而是真实系统在复杂上下文里的稳定性。
这些测试比单纯测能不能在长文本里找到一句话更接近真实系统。像 LongBench v2 这类评测也在强调,长上下文任务不只是检索,还包括多文档问答、长对话、代码仓库理解、结构化数据理解等更接近真实生产环境的复杂任务。
Agent 系统要把轨迹拆成状态,而不是继续堆消息
到了 Agent 场景,问题会更明显。因为这里不再是一次调用,而是一个持续迭代的过程。模型会不断经历 Decide、Act、Observe、Update,每一步都会生成新的中间产物。如果这些中间状态不加整理地反复堆进上下文,系统就很容易越跑越偏。
所以我不会把所有信息都继续堆在 messages 里,而是先把 Agent 的上下文拆成三块:
messages:只保留最近几轮真正必要的对话state:保存当前任务的结构化运行状态store:保存长期记忆、历史案例、知识资料和可检索文档
这一步的核心不是少放一点,而是按角色隔离。不同类型的信息应该进入不同容器,而不是混成一条无限膨胀的上下文链。
一个更稳的 Agent state 至少应该包含:
taskGoal:当前任务目标currentStep:当前执行到哪一步plan:当前计划completedSteps:已经完成的步骤activeEvidence:当前有效证据pendingQuestions:还需要确认的问题toolResults:结构化后的工具结果rejectedAssumptions:已经被否定的假设riskLevel:当前风险等级finalOutputDraft:最终输出草稿
每一步调用模型前,只取当前 step 需要的部分:
- 意图识别节点,只看用户输入和少量必要历史
- 检索节点,只看任务目标、检索条件和权限范围
- 写作节点,只看当前任务目标、证据卡片和输出要求
- 校验节点,只看输出草稿、证据和规则
- 工具执行节点,只看结构化参数和权限上下文
这样一来,Agent 的每一步都不是在一个巨大的公共上下文池里自由发挥,而是在一个被系统裁剪过的、和当前步骤强相关的小上下文里完成决策。
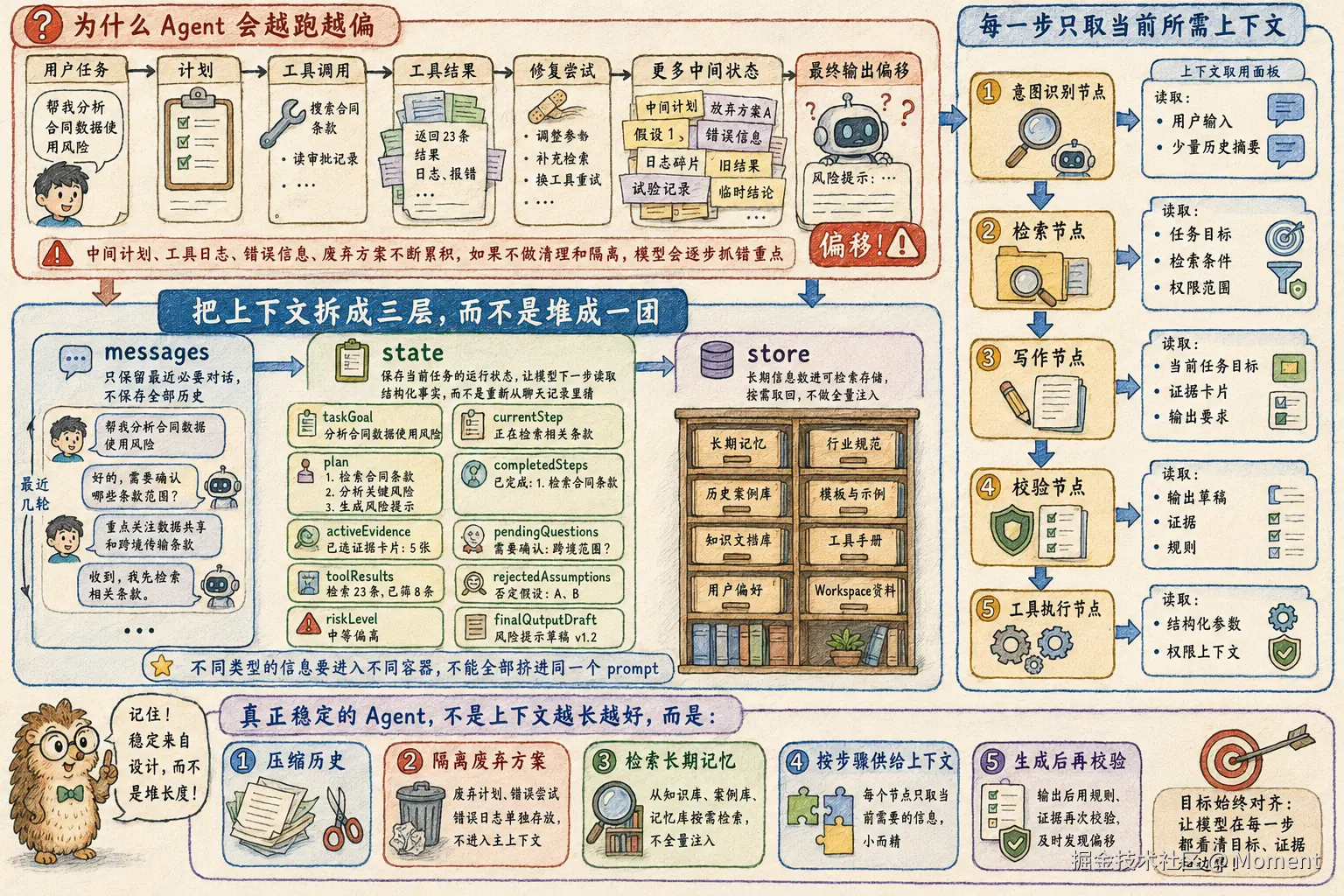
在这个结构里,messages 不再承担保存全部上下文的职责,state 负责保存当前任务真正需要的运行事实,store 负责承载那些应该被检索、而不是被常驻塞入上下文的长期信息。这样做的最大好处,是每个节点都只读取自己需要的那一层内容,系统不会因为中间轨迹无限累积而越来越乱。
这也是为什么我更认同 LangChain 关于 Context Engineering for Agents 的总结 和 LangChain 上下文工程文档 里的思路,上下文治理的重点不是一味加内容,而是持续做选择、压缩、隔离和重组。只有这样,Agent 才不会在长链路执行中越跑越偏。
总结
上下文过长导致语义偏移,本质不是模型记忆力不够,而是系统没有管理好上下文边界。长上下文能力很有价值,但它不应该成为把所有历史、检索结果、记忆和工具日志都塞进窗口里的理由。
真正稳定的工程做法,是把上下文当成运行时数据结构来治理。系统要先限制来源,再用 Task Contract 明确当前目标、必要信息、禁止信息、输出格式和不确定性策略。历史消息不能原样常驻,要被压缩成带有 active、outdated、rejected、open questions 的状态化摘要。RAG 也不能只依赖向量相似度,而要结合 metadata filter 和 rerank 判断版本、权限、时间、workspace 和文档状态,再把原始文档压缩成可引用的 Evidence Card。
模型真正看到的上下文,应该已经经过分层、筛选和排序。系统规则、任务、输入、证据、记忆、历史摘要和输出要求要用清晰分隔符或 XML 标签隔开,每类上下文都要有 token 预算,当前任务、禁止事项和输出要求要放在最显眼的位置。生成之后,还需要 Verifier 检查是否引用旧资料、遗漏当前约束、编造事实或越权使用记忆,并通过长上下文回归测试覆盖位置变化、噪声文档、冲突资料、旧版本资料和多轮对话污染。
这套方法的关键不是多加几个模块,而是把系统从模型自己理解一切,改成系统先治理上下文,模型再基于干净、明确、可验证的上下文完成当前任务。不要让模型在一大堆上下文里自己找重点,重点应该先由系统整理好。