我们于每日同数量众多的数据进行交互之时, count函数属于最为常被运用到的工具里的其中一个。然而, 有许多人仅用它去进行数量的清点, 却遗漏了它背后所潜藏的陷阱与能够优化的空间。不管你是刚开始踏入数据分析师领域的新手, 还是平常常常处理百万级数据的运营工作者, 弄明白count函数的正确运用办法以及提升速度的窍门, 能够使你少踏入许多误区。
count()和count(1)到底哪个快
这个问题于技术社区之中争论了好些年, 从实际执行的角度而言, 在MySQL以及PostgreSQL这类数据库里面, count()与count(1)在大部分场景之下性能几乎不存在差别, 真正对速度产生影响的乃是你所查询的数据量级以及索引设计。
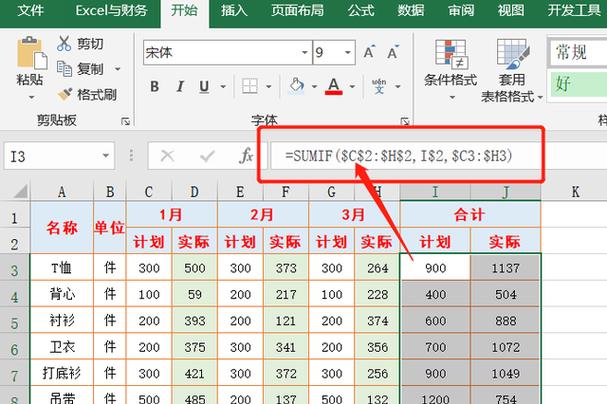
我曾遇见过一位同事 , 在有着500万行记录的订单表当中 , 执行count(id)操作 , 运行了30秒 , 结果却仍未出现。其原因十分简易明了 , id字段尽管存在主键索引 , 然而count(id)却需要逐一判定每一行中的id是否为NULL , 与之不同的是 , count()在MySQL 8.0之中直接采取了聚簇索引的扫描方式 , 最终结果反而更快。若你所使用的是InnoDB引擎, count()会优先去选择占用空间更小, IO开销更低的最小辅助索引来进行计数, 只因辅助索引要比主键索引占用空间小。
在实际开展工作期间, 提议你径直运用count(), 假若是你非得要去纠结性能这一方面的话, 那么能够构建一个仅仅涵盖非空字段的覆盖索引, 就好像索引之中仅仅放置状态字段一样, 凭借如此这般的方式, count()便能够借助这个迷你索引, 进而速度能够得到好几倍的提升。
遇到大表count查询慢应该怎么办
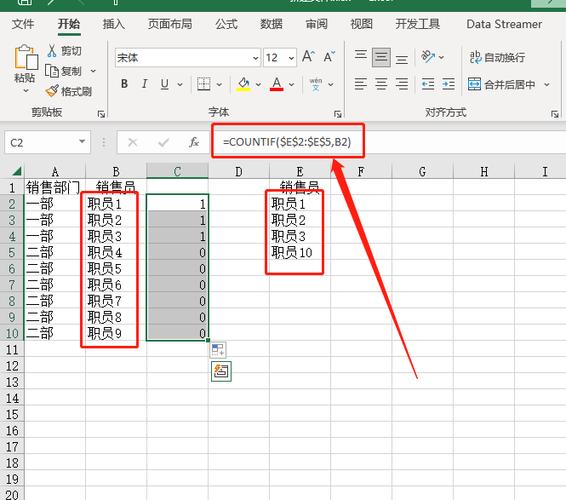
涉及大表去进行绝对精准的计数, 这可是数据库极为让人头疼的繁杂事务之中的一项。我之前所在的上一家公司存在着这样的一个日志表, 每一天都会新增多达200万条的记录, 每一次去制作报表之际都得运行一轮count的操作, 最终呈现出来的结果慢到使得业务人员直接发起投诉。
对于解决办法存在着几个情况 , 第一个情况是进行引擎的更换 , 假定你的业务是允许数据并非实时的 , 那么能够采用MyISAM引擎的表 ,其内部会对表的行数做到缓存 , count(*)几乎是以毫秒级的速度进行返回 , 可是MyISAM并不支持事务 , 要是你需要开展频繁的插入以及更新操作 , 数据的一致性便会存在风险。