企业里最容易被低估的工程,往往是"登录"。
大多数人觉得登录就是输账号密码,或者接个 OAuth,两天搞定。直到真正要在一套系统里同时支持飞书、钉钉、内部账号,还要让 token、中间件、目录同步全部跟着走------才会意识到,认证体系是整个平台的地基,动一块,全身抖。
这几天最大的一块工作,就是把钉钉认证接进来,同时把原来单渠道的登录逻辑彻底重构成多渠道 provider 架构。
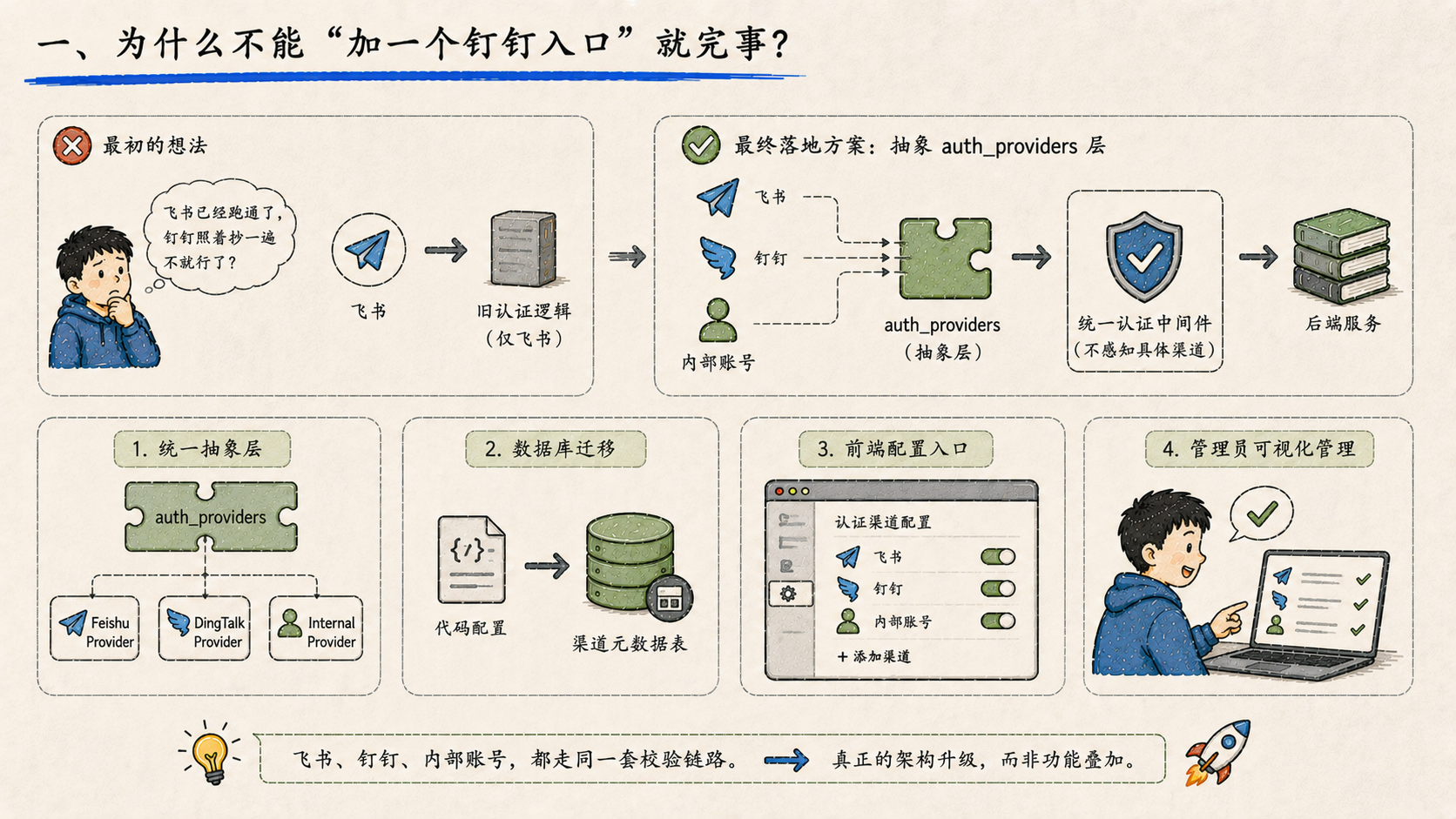
一、为什么不能"加一个钉钉入口"就完事?
最初的想法确实是这样:飞书已经跑通了,钉钉照着抄一遍不就行了?
但真正动手才发现,原来的认证逻辑是"为飞书量身定制"的,token 管理、中间件校验、目录同步,每一层都隐含着"只有一个渠道"的假设。加第二个渠道,不是加一个 if,是要把整个认证层的概念模型换掉。
最终落地的方式是:抽象出 auth_providers 层,每个渠道作为独立 provider 注册进来,中间件不再感知具体渠道,只认 provider 接口。飞书、钉钉、内部账号,都走同一套校验链路。数据库也跟着加了一张迁移,把渠道元数据从代码里剥离出来落进库里。前端登录页和设置页也补了对应的配置入口,管理员可以在界面上直接管理各渠道的认证配置,不用改代码。
这是一次真正意义上的架构升级,不是功能叠加。
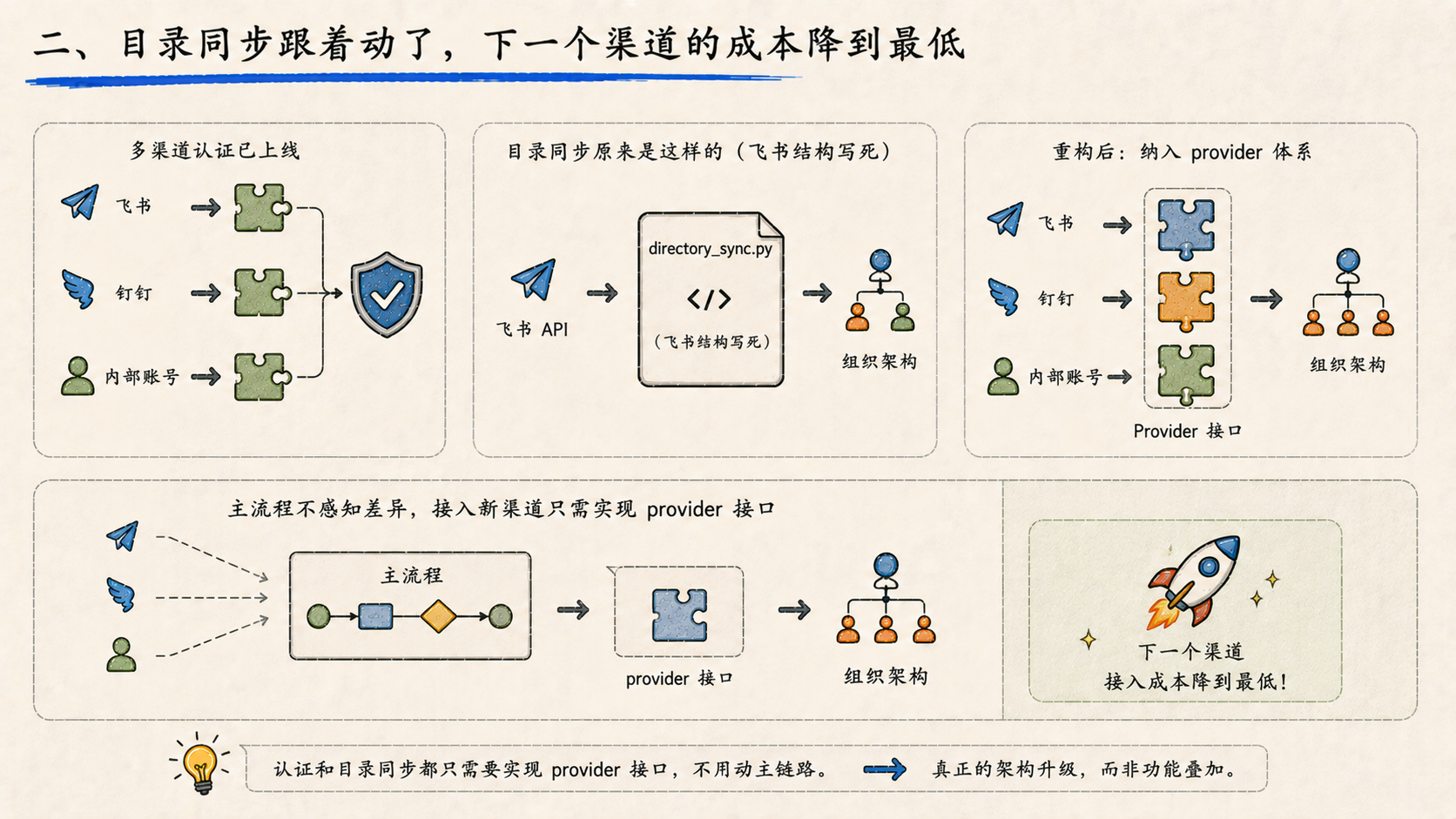
二、目录同步跟着动了,下一个渠道的成本降到最低
多渠道认证上线之后,随之而来的问题是:用户目录怎么同步?
钉钉和飞书的组织架构 API 完全不同,原来的 directory_sync.py 是按飞书结构写死的。这次重构把目录同步也纳入了 provider 体系,每个渠道自己实现同步逻辑,主流程不感知差异。
这意味着以后再接第三个渠道,认证和目录同步都只需要实现 provider 接口,不用动主链路。这次重构真正的价值在于:下一个渠道的接入成本降到了最低。
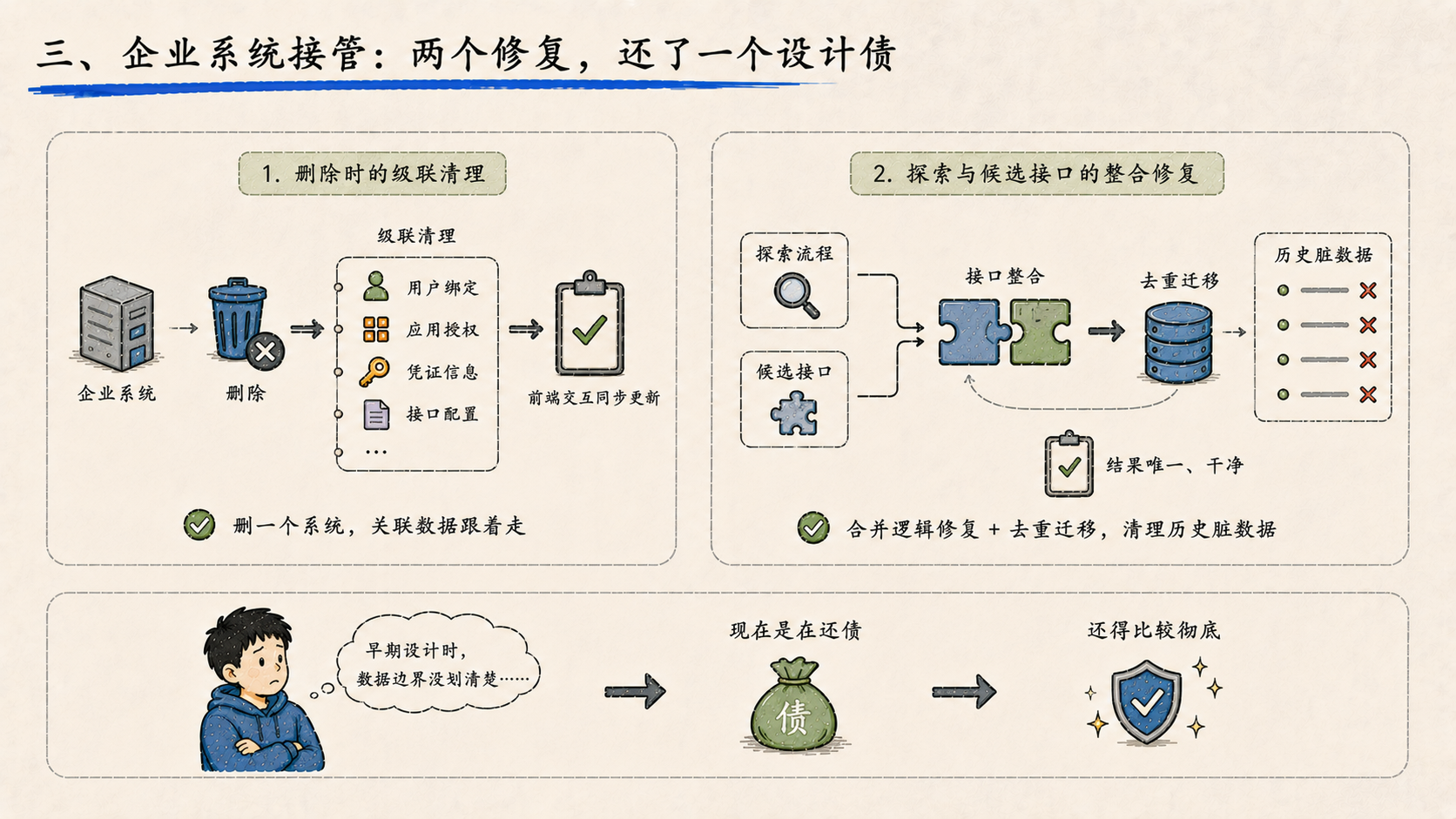
三、企业系统接管:两个修复,还了一个设计债
企业系统接管模块这几天做了两件事,看起来是修复,实际上是在补一个更早的设计欠账。
第一件:删除时的级联清理。 之前删除企业系统,只删主记录,关联资源留在库里,时间一长积累大量孤儿数据。这次加了级联清理逻辑,删一个系统,关联数据跟着走,前端交互也同步更新。
第二件:探索与候选接口的整合修复。 探索流程和候选接口的结果之前分开存储,合并逻辑有问题,还有重复数据。这次做了接口整合,同时加了去重迁移,把历史脏数据清理干净。
这两个修复说明同一件事:企业系统接管模块在早期设计时数据边界没有划清楚。现在是在还债,但还得比较彻底。
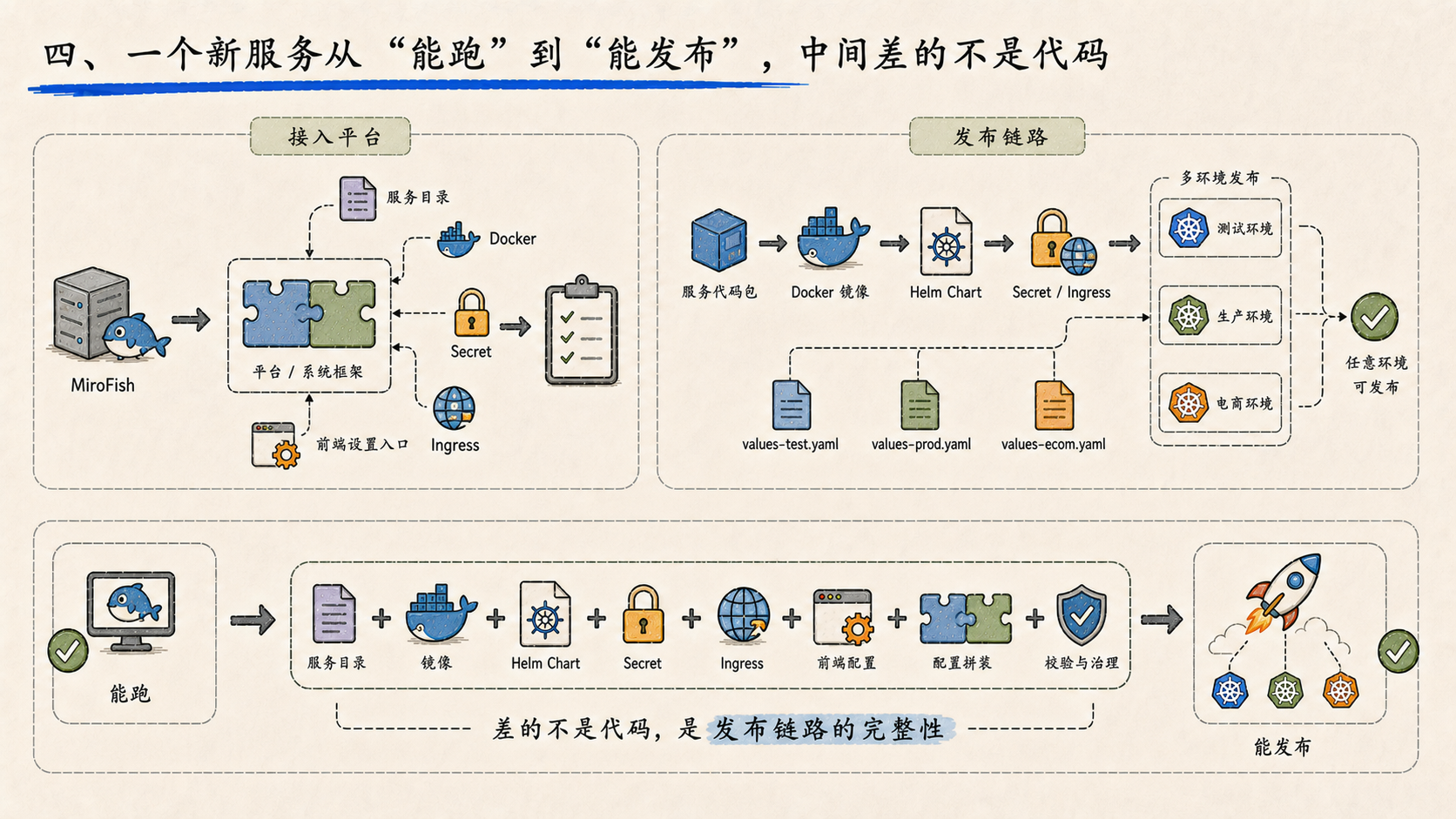
四、一个新服务从"能跑"到"能发布",中间差的不是代码
另一件事是把 MiroFish 服务集成进平台,并且纳入 Helm 发布链路。
不是写个文档说"支持 MiroFish",而是真的把服务目录、Docker 配置、Secret、Ingress、各环境 values 全部补齐,前端设置页也加了管理入口。测试、生产、电商三套 values 分开维护。
一个新服务从"能跑"到"能发布到任意环境",中间差的不是代码,是发布链路的完整性。这次算是把这条链路走完了。
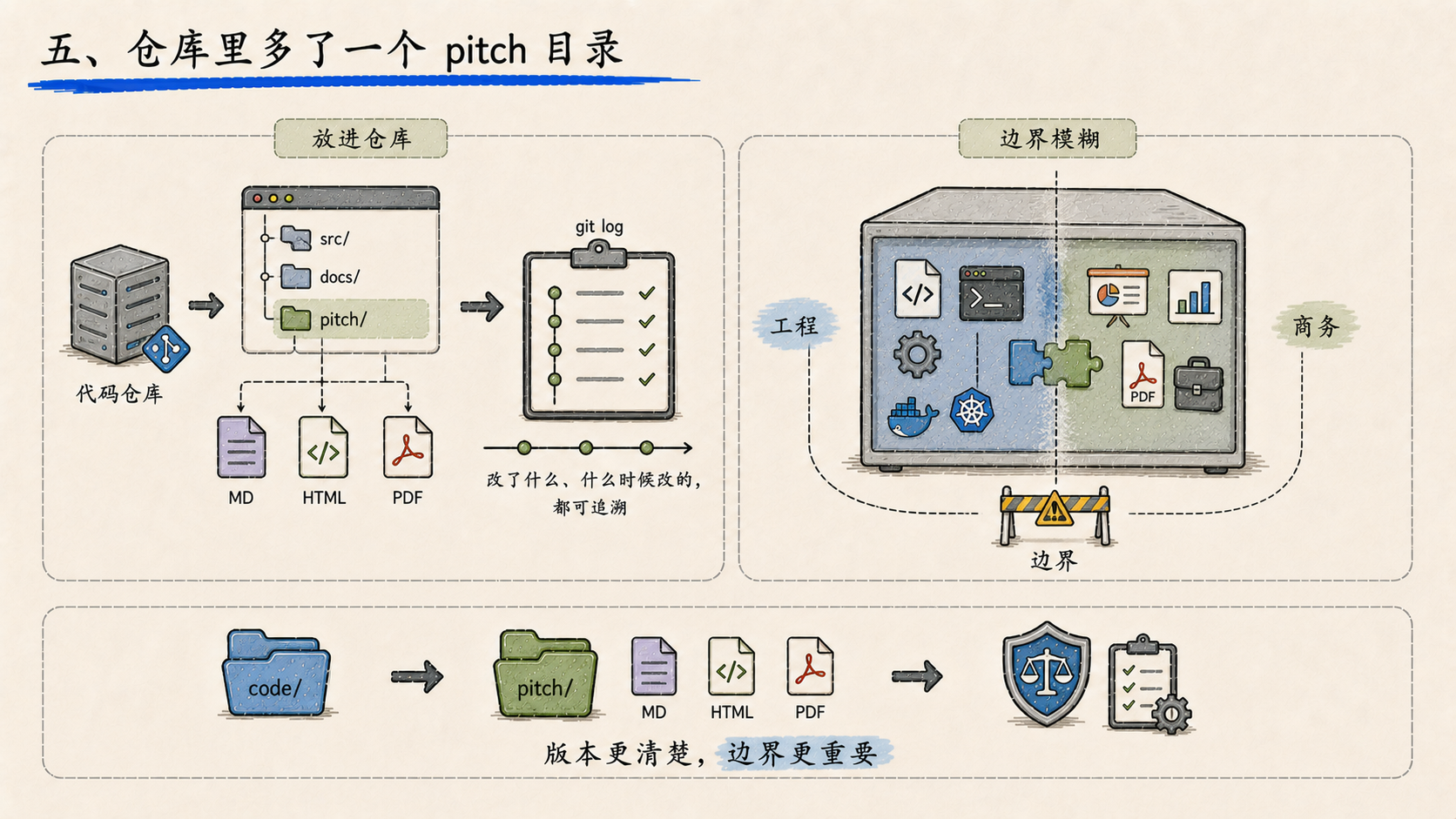
五、仓库里多了一个 pitch 目录
还有一件事,不是产品功能,但值得记一笔。
仓库里新增了 pitch/ 目录,放的是对外演示用的商业介绍材料,包括 Markdown、HTML 和 PDF 版本。
把 pitch 材料放进代码仓库,好处是版本可追溯,改了什么、什么时候改的,git log 一查就清楚。但这也意味着仓库的边界开始模糊------这里既是工程代码,也是商务资产。这个边界以后会越来越重要。
从第20天到现在,平台经历了从"能跑"到"可信",从单渠道到多渠道,从手动发布到 Helm 链路。每一期写的时候都觉得"这次改动不算大",但回头看,每一期都在往同一个方向走:让这套系统能真正交给别人用,而不只是自己能跑起来。
这,是第三十二天。
**《从0到1:企业级AI项目迭代日记》**记录一个企业级 AI 项目从创意、架构到落地的真实过程。不讲神话,只记录进化。
如果你也在做企业 AI 落地,欢迎留言来聊。或者,把这篇转发给一个正在踩同样坑的朋友。