面向指令式视频编辑的区域约束上下文生成
paper title:Region-Constraint In-Context Generation for Instructional Video Editing
paper是USTC发表在ICML 2026的工作
Code:链接

图 1. 我们的 ReCo 支持仅基于文本指令的视频编辑,实现精准且高保真的视频内容修改。
ReCo 能够熟练处理多样且具有挑战性的视频编辑任务,包括局部对象编辑和全局风格迁移。
摘要
上下文生成范式近期在指令式图像编辑中展现了强大的能力,兼具数据效率和合成质量。然而,将这种上下文学习方式应用于基于指令的视频编辑并非易事。在不指定编辑区域的情况下,结果可能面临编辑区域不准确以及去噪过程中编辑区域与非编辑区域之间的token干扰问题。为此,我们提出ReCo,一种新颖的指令式视频编辑范式,创新性地在上下文生成过程中对编辑区域与非编辑区域之间的约束进行建模。技术上,ReCo将源视频和目标视频沿宽度方向拼接进行联合去噪。为校准视频扩散学习,ReCo利用两个正则化项------即潜在空间正则化和注意力正则化------分别作用于单步反向去噪潜变量和注意力图。前者增大源视频与目标视频编辑区域的潜在差异,同时减小非编辑区域的差异,强调对编辑区域的修改并缓解编辑区域外的意外内容生成。后者抑制编辑区域中token对源视频对应区域token的注意力,从而减轻目标视频中新对象生成时的token干扰。此外,我们构建了一个大规模、高质量的视频编辑数据集ReCo-Data,包含50万条指令-视频对,以促进模型训练。在四种主要指令式视频编辑任务上的大量实验验证了本方法的优越性。
1. 引言
随着扩散模型的快速发展,基于指令的图像和视频视觉编辑受到了广泛关注。近期基于指令的图像编辑模型能够仅基于自然语言指令编辑输入图像,无需额外条件。然而,将图像编辑领域取得的成功复制到基于指令的视频编辑领域并非易事。一些有前景的视频编辑方案通常需要输入mask来定位编辑区域,或需要特定任务的配置,限制了其在实际场景中的实用性。仅基于文本指令来引导视频编辑仍是文献中尚未充分探索的问题。
受上下文生成范式在图像编辑中兼具数据效率和生成质量的成功启发,我们构建了一个联合源-目标视频扩散框架用于基于指令的视频编辑。由于视频固有的时间复杂性,在塑造视频生成的上下文学习时面临两个主要挑战:1)当仅有文本指令时,如何准确定位编辑区域?2)如何进一步减少源视频编辑区域对目标视频中新对象生成的内容干扰?遵循视觉处理中区域约束建模的思路,我们通过在视频潜变量和注意力图上建模区域关系来解决这两个问题。我们通过增大源视频与目标视频编辑区域的潜在差异、减小非编辑区域的差异来缓解第一个问题,这强制了编辑区域的内容再生成以及背景的一致性。为缓解第二个问题,我们抑制编辑区域中token对源视频同一区域token的注意力,减轻来自原始内容的token干扰。这一项也鼓励新对象生成从目标视频自身背景中的token获取更多信息,实现更好的背景一致性。
通过整合区域约束上下文生成的思想,我们提出了一个名为ReCo的新框架用于基于指令的视频编辑。技术上,ReCo首先将源视频和目标视频沿左右面板拼接,并进行联合视频去噪以实现编辑生成。在每个训练步骤中,配对视频潜变量首先通过单步反向扩散过程估计。然后,ReCo计算源视频和目标视频潜变量之间的潜在差异,并进一步施加逐对约束以增大编辑区域的潜在差异、减小非编辑区域的差异。类似的正则化项也作用于DiT块的注意力图,以抑制编辑区域中token对源视频同一区域token的集中度。此外,编辑区域中token对目标视频自身背景的注意力被增强,以实现新对象与背景之间的和谐组合。整个框架通过流匹配扩散损失和两个区域约束正则化项联合优化。
本工作的主要贡献是面向基于指令的视频编辑的新型区域约束上下文生成范式。除架构设计外,我们精心构建了一个大规模、高质量的视频编辑数据集ReCo-Data,包含50万条指令-视频对,涵盖广泛的编辑任务,以促进指令式视频编辑的社区研究。大量实验进一步验证了ReCo在编辑准确性和质量方面的有效性。
2. 相关工作
基于指令的图像编辑。文本到图像生成取得的显著进展推动了指令引导图像编辑的发展。InstructPix2Pix作为该领域的代表性工作,建立了高效的图像编辑数据构建流程并取得了良好的编辑效果。后续工作以此数据流程为原型,进一步提供更多数据来训练强大的基于指令的编辑器。基于此,多模态模型如Emu Edit、OmniGen、ICEdit、HiDream-E1、Flux-Kontext、Qwen-Image和Nano-Banana进一步解锁了复杂能力,如局部编辑和场景变换,甚至无需特定微调。然而,将图像编辑的成功复制到指令式视频编辑领域并非易事。视频编辑的挑战不仅在于数据稀缺,还在于需要同时处理空间和时间token之间的复杂依赖关系。本工作通过上下文生成范式结合区域约束建模来解决这些挑战,并以我们新构建的ReCo-Data作为支撑。
基于指令的视频编辑。早期基于指令的视频编辑尝试通常利用无训练推理范式,将预训练的文本到图像扩散模型适配为逐帧视频编辑。例如,FateZero通过DDIM反演编辑视频帧。然而,缺乏时间建模导致时间不一致问题。为此,后续工作如TokenFlow、VidToMe、FLATTEN和RAVE采用token合并或相似性约束来增强时间一致性。也有一些方法(如FlowEdit和FlowDirector)利用先进的文本到视频扩散模型实现更准确的扩散反演。尽管无训练范式具有灵活性,但视频质量和模型泛化能力仍存在固有局限。
基于训练的视频编辑发展的主要障碍是大规模、高质量配对训练数据的严重匮乏。早期方法通过单样本微调技术(如Tune-A-Video和Video-P2P)克服这一困难,但仍难以达到理想的编辑效果。另一方向上,多项工作在数据集构建和框架设计方面推动了视频编辑的边界。例如,GenProp和Senorita将编辑表述为图像传播机制,先编辑首帧再将内容修改传播到其他帧。最近,Lucy-Edit和Ditto提出直接在源-目标视频和文本指令上训练视频编辑模型。Lucy-Edit将源视频潜变量与去噪视频潜变量拼接作为条件,而Ditto通过ControlNet方式学习条件。同时,上下文学习已在图像编辑中被验证兼具数据效率和生成质量。本工作利用这一思路,并进一步深入研究区域约束的表述以促进准确的视频编辑。
总之,本工作设计了一种新颖的区域约束上下文生成范式用于指令式视频编辑。ReCo不仅研究如何准确定位编辑区域,还研究如何进一步减少编辑区域与非编辑区域之间的token干扰,以实现连贯的视觉修改。
3. 方法
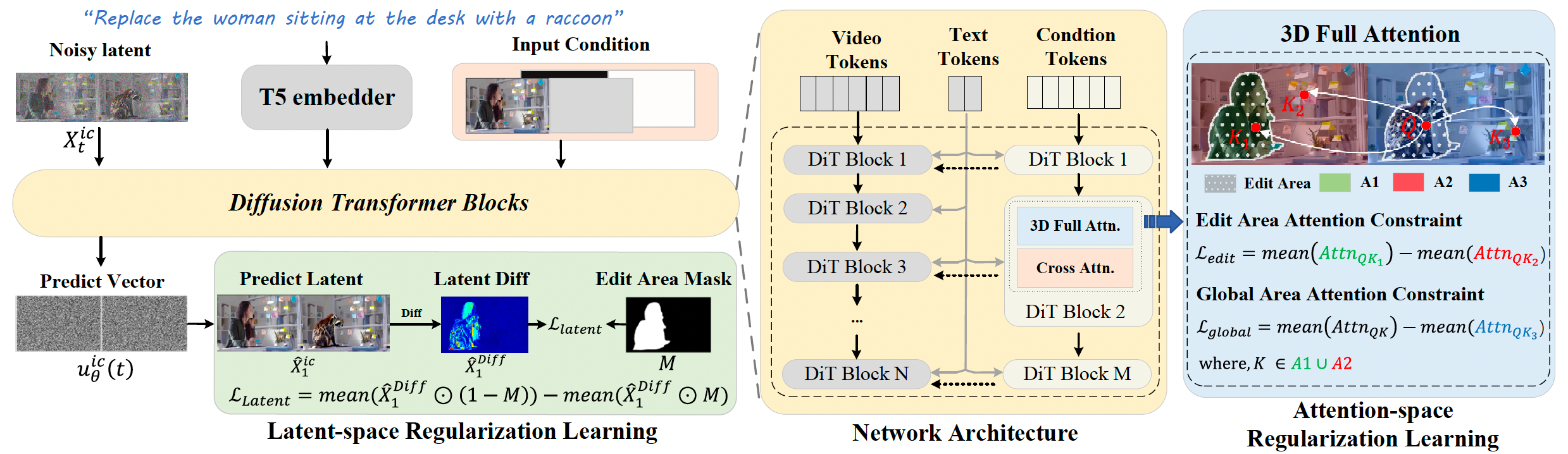
图 2. 我们的 ReCo 框架概览。我们将指令式视频编辑任务重新表述为一种上下文生成范式,并由源视频和指令提示共同引导。源视频通过输入到一个辅助视频条件分支中,被视为一种显式条件。为了突出编辑修改并缓解编辑区域与非编辑区域之间的 token 干扰,ReCo 引入了两种基于区域的约束:(1)潜空间正则化,它增大源视频与目标视频之间编辑区域的潜表示差异,同时减小非编辑区域的潜表示差异。(2)注意力空间正则化,它抑制目标编辑区域对源视频中对应区域的注意力,从而缓解固有的 token 干扰,同时增强其对自身生成内容的注意力。
这里我们介绍ReCo,一种新颖的区域约束上下文视频生成框架用于指令式视频编辑。整体架构如图2所示。给定一对源视频和目标视频,ReCo将生成过程重新表述为上下文学习范式,通过沿宽度方向拼接两个视频进行联合去噪。同时,为确保源视频信息的忠实保留,我们引入一个额外的视频条件分支来探索源视频上的条件学习。在训练阶段,我们引入两个正则化项------即潜在空间正则化和注意力正则化------以在无需预先指定编辑区域的情况下促进准确的视频编辑学习。潜在空间正则化学习作用于单步反向去噪潜变量,以放大区域级修改并保持背景一致性。同时,注意力正则化项抑制目标视频编辑区域中新生成对象对源视频编辑区域的注意力,从而减少来自原始视觉内容的token干扰。
3.1 预备知识:视频DiT训练
为利用预训练视频生成模型的先验知识,我们采用先进的视频扩散Transformer------Wan-T2V-1.3B作为ReCo的骨干架构。为便于理解,我们首先回顾视频DiT的训练过程。通常,大多数视频DiT模型基于Rectified Flow的流匹配理论,该理论为学习连续时间生成过程提供了严格的理论框架。其目标是学习一个向量场,将样本从简单先验分布 P 0 P_0 P0(如高斯分布 N ( 0 , 1 ) \mathcal{N}(0,1) N(0,1))平滑传输到目标数据分布 P 1 P_1 P1。
给定视频潜变量 x 1 x_1 x1,在训练中从logit-normal分布采样随机噪声 x 0 ∼ N ( 0 , 1 ) x_0 \sim \mathcal{N}(0,1) x0∼N(0,1) 和时间步 t ∈ 0 , 1 t \in 0,1 t∈0,1。然后, x 0 x_0 x0 与 x 1 x_1 x1 通过Rectified Flow的前向扩散过程结合得到中间加噪潜变量 x t x_t xt:
x t = t x 1 + ( 1 − t ) x 0 . ( 1 ) x_t = tx_1 + (1-t)x_0. \quad (1) xt=tx1+(1−t)x0.(1)
则真实速度向量计算为:
v t = d x t d t = x 1 − x 0 . ( 2 ) v_t = \frac{dx_t}{dt} = x_1 - x_0. \quad (2) vt=dtdxt=x1−x0.(2)
视频DiT模型通过以下方式学习估计该向量:
u θ ( t ) = u ( x t , c , t ; θ ) , ( 3 ) u_\theta(t) = u(x_t, c, t; \theta), \quad (3) uθ(t)=u(xt,c,t;θ),(3)
其中 x t x_t xt 是加噪潜变量, θ \theta θ 表示模型参数, c c c 是输入条件集合。对于指令式视频编辑任务, c c c 包含文本指令和源视频。因此,训练目标 L \mathcal{L} L 定义为模型输出与真实速度 v t v_t vt 之间的均方误差(MSE):
L = E x 0 , x 1 , c , t ∥ u ( x t , c , t ; θ ) − v t ∥ 2 . ( 4 ) \mathcal{L} = \mathbb{E}_{x_0, x_1, c, t} \left\| u(x_t, c, t; \theta) - v_t \right\|^2. \quad (4) L=Ex0,x1,c,t∥u(xt,c,t;θ)−vt∥2.(4)
该目标表明,在任意给定时间步 t t t,瞬时速度简单表述为 x 1 − x 0 x_1 - x_0 x1−x0。该目标异常清晰和稳定,使神经网络易于学习,从而产生高质量的视频生成。
3.2 用于视频编辑的上下文生成
上下文生成范式近期在图像编辑中展现了显著优势,尤其在数据效率和生成质量方面。受此启发,我们将视频编辑过程重新表述为上下文生成。技术上,给定视频潜变量对(即源视频 x 1 s r c x_1^{src} x1src 和目标视频 x 1 t a r x_1^{tar} x1tar),我们将它们沿宽度方向拼接形成单个上下文视频潜变量 x 1 i c x_1^{ic} x1ic:
x 1 i c = x 1 s r c , x 1 t a r . ( 5 ) x_1^{ic} = x_1\^{src}, x_1\^{tar}. \quad (5) x1ic=x1src,x1tar.(5)
在模型训练中,从高斯分布采样噪声潜变量 x 0 i c x_0^{ic} x0ic,然后加到 x 1 i c x_1^{ic} x1ic 上以生成加噪潜变量 x t i c x_t^{ic} xtic,送入视频DiT进行联合源视频和目标视频去噪:
x t i c = t x 1 i c + ( 1 − t ) x 0 i c . ( 6 ) x_t^{ic} = tx_1^{ic} + (1-t)x_0^{ic}. \quad (6) xtic=tx1ic+(1−t)x0ic.(6)
真实速度向量重新表述为:
v t i c = d x t i c d t = x 1 i c − x 0 i c . ( 7 ) v_t^{ic} = \frac{dx_t^{ic}}{dt} = x_1^{ic} - x_0^{ic}. \quad (7) vtic=dtdxtic=x1ic−x0ic.(7)
相应地,我们将训练目标公式(4)适配为上下文生成范式,形成 L i c \mathcal{L}_{ic} Lic:
u θ i c ( t ) = u ( x t i c , c , t ; θ ) , ( 8 ) u_\theta^{ic}(t) = u(x_t^{ic}, c, t; \theta), \quad (8) uθic(t)=u(xtic,c,t;θ),(8)
L i c = E x 0 i c , x 1 i c , c , t ∥ u ( x t i c , c , t ; θ ) − v t i c ∥ 2 . ( 9 ) \mathcal{L}{ic} = \mathbb{E}{x_0^{ic}, x_1^{ic}, c, t} \left\| u(x_t^{ic}, c, t; \theta) - v_t^{ic} \right\|^2. \quad (9) Lic=Ex0ic,x1ic,c,t u(xtic,c,t;θ)−vtic 2.(9)
在我们的上下文生成场景中,预测向量 u θ i c ( t ) u_\theta^{ic}(t) uθic(t) 需要联合学习源视频的重建和编辑视频的生成。由于源视频与目标视频在编辑中的高度相关性,这种联合学习促进了强token交互,带来更优的视频编辑性能。同时,我们引入一个视频条件分支(如图2所示),以确保视频条件被全面学习以校准视频去噪。此外,我们利用低秩适配(LoRA)技术实现高效稳定的视频DiT微调。
3.3 潜在空间中的区域约束
上下文生成有利于源视频和目标视频之间的token交互,从而改善指令式视频编辑。然而,与需要预先指定编辑区域的先前方法相比,仅依赖文本指令仍可能导致编辑区域不准确的问题。为缓解这一局限,我们在潜在空间中引入区域约束。该机制旨在增大源视频与目标视频编辑区域的潜在差异,同时减小非编辑区域的差异,分别放大编辑区域的修改并缓解编辑区域外的意外内容生成。
给定视频DiT在时间步 t t t 估计的速度向量 u θ i c ( t ) u_\theta^{ic}(t) uθic(t),我们首先基于Rectified Flow定义推导单步反向去噪潜变量 x ^ 1 i c \hat{x}_1^{ic} x^1ic:
x ^ 1 i c = x t i c + ( 1 − t ) u θ i c ( t ) . ( 10 ) \hat{x}1^{ic} = x_t^{ic} + (1-t)u\theta^{ic}(t). \quad (10) x^1ic=xtic+(1−t)uθic(t).(10)
获得的去噪视频潜变量 x ^ 1 i c \hat{x}_1^{ic} x^1ic 然后沿宽度维度分割得到源和目标部分:
x \^ 1 s r c , x \^ 1 t a r = x ^ 1 i c . ( 11 ) \\hat{x}_1\^{src}, \\hat{x}_1\^{tar} = \hat{x}_1^{ic}. \quad (11) x\^1src,x\^1tar=x^1ic.(11)
接下来,我们计算 x ^ 1 s r c \hat{x}_1^{src} x^1src 和 x ^ 1 t a r \hat{x}_1^{tar} x^1tar 之间的潜在差异向量 X ^ 1 D i f f \hat{X}_1^{Diff} X^1Diff:
X ^ 1 D i f f = ∣ x ^ 1 t a r − x ^ 1 s r c ∣ . ( 12 ) \hat{X}_1^{Diff} = |\hat{x}_1^{tar} - \hat{x}_1^{src}|. \quad (12) X^1Diff=∣x^1tar−x^1src∣.(12)
对于成功的编辑,我们假设源视频与目标视频编辑区域之间的潜在差异应该较大,而非编辑区域应保持不变。为此,我们引入潜在空间区域约束 L l a t e n t \mathcal{L}{latent} Llatent 来规范DiT训练。设 M M M 为指示编辑区域的二值潜在mask( M = 1 M=1 M=1 表示应被编辑的区域)。 L l a t e n t \mathcal{L}{latent} Llatent 旨在最小化非编辑区域的均值差异,同时最大化编辑区域内的差异,计算如下:
L l a t e n t = mean ( X ^ 1 D i f f ⊙ ( 1 − M ) ) − mean ( X ^ 1 D i f f ⊙ M ) . ( 13 ) \mathcal{L}_{latent} = \text{mean}\left(\hat{X}_1^{Diff} \odot (1-M)\right) - \text{mean}\left(\hat{X}_1^{Diff} \odot M\right). \quad (13) Llatent=mean(X^1Diff⊙(1−M))−mean(X^1Diff⊙M).(13)
3.4 注意力空间中的区域约束
除了潜在空间上的区域约束外,上下文生成的鲁棒学习还需要缓解编辑区域与非编辑区域之间固有的token干扰。例如,编辑区域中的内容对源视频编辑区域的原始内容应减少关注,而对自身生成的背景应增加关注以获得更好的一致性。为表述注意力上的这些相对关系,我们从两个角度提出注意力图学习的正则化:即编辑区域内的相对关系和整个视频区域内的相对关系。
如图2右侧所示,我们首先将源-目标视频对的整个区域划分为三个关键区域:源视频的编辑区域(A1)、源视频的非编辑区域(A2)和整个目标视频区域(A3)。为表述编辑区域内注意力学习的相对关系,目标编辑区域的token(查询 Q Q Q)应减少对源编辑区域对应token(键 K 1 K_1 K1)的注意力。我们将此定义为编辑注意力损失 L e d i t \mathcal{L}_{edit} Ledit:
L e d i t = mean ( A t t n Q K 1 ) − mean ( A t t n Q K 3 ) , ( 14 ) \mathcal{L}{edit} = \text{mean}(Attn{QK_1}) - \text{mean}(Attn_{QK_3}), \quad (14) Ledit=mean(AttnQK1)−mean(AttnQK3),(14)
其中 A t t n Q K Attn_{QK} AttnQK 是查询 Q Q Q 与键 K K K 之间的相似度分数。此外,为保证生成内容与背景的一致整合,查询 Q Q Q 应减少对整个源视频的依赖(如A1∪A2中的键 K K K),同时更多关注目标视频区域中上下文相关的区域(如A3中的键 K 3 K_3 K3)。因此,这种约束表述为全局注意力损失 L g l o b a l \mathcal{L}_{global} Lglobal:
L g l o b a l = mean ( A t t n Q K ) − mean ( A t t n Q K 3 ) , ( 15 ) \mathcal{L}{global} = \text{mean}(Attn{QK}) - \text{mean}(Attn_{QK_3}), \quad (15) Lglobal=mean(AttnQK)−mean(AttnQK3),(15)
注意力空间区域约束因此定义为两个分量之和:
L a t t n = L e d i t + L g l o b a l . ( 16 ) \mathcal{L}{attn} = \mathcal{L}{edit} + \mathcal{L}_{global}. \quad (16) Lattn=Ledit+Lglobal.(16)
最终,ReCo的整体训练目标表述为多任务损失,整合基本的上下文流匹配损失 L i c \mathcal{L}{ic} Lic 和两个区域约束------潜在空间 L l a t e n t \mathcal{L}{latent} Llatent 和注意力空间 L a t t n \mathcal{L}_{attn} Lattn:
L = L i c + λ 1 L l a t e n t + λ 2 L a t t n , ( 17 ) \mathcal{L} = \mathcal{L}{ic} + \lambda_1 \mathcal{L}{latent} + \lambda_2 \mathcal{L}_{attn}, \quad (17) L=Lic+λ1Llatent+λ2Lattn,(17)
其中 λ 1 \lambda_1 λ1 和 λ 2 \lambda_2 λ2 是权衡参数。这两个约束强调更准确的编辑区域定位和正确token关系的学习,缓解token干扰以实现更自然的视频内容生成。
4. 实验
4.1 实验设置
数据集。尽管指令式视频编辑近期取得了巨大进展,缺乏大规模、高质量训练数据集仍是一个显著瓶颈。为应对这一挑战,我们提出ReCo-Data,精心策划以支持四种主要视频编辑任务:实例级对象添加、移除、替换和全局视频风格化。我们的数据构建流程包含六个主要阶段:(1) 原始数据预处理;(2) 对象分割;(3) 使用VLLM(即Gemini-2.5-Flash-Thinking)生成指令;(4) 条件对构建;(5) 使用VACE进行视频合成;(6) 使用VLLM进行视频过滤和重新描述。最终,我们构建了包含50万条高质量指令-视频对的ReCo-Data。每个视频片段包含81帧,分辨率为 480 × 832 480 \times 832 480×832,视频时长为5.0秒。
我们将ReCo-Data与现有视频编辑数据集在高质量样本比例方面进行比较,这反映了数据集的可用性和整体质量。具体而言,我们从每个编辑任务的所有数据集中随机采样200个视频编辑对,并邀请10位评估者定性评估视频编辑质量。如图3所示,现有数据集(即InsV2V、InsVIE和Senorita)中高质量样本的比例通常较低(17.9%~29.2%)。这表明这些数据集未经过严格的数据清洗,大量低质量样本使其不适合训练高性能指令式视频编辑模型。此外,数据重新清洗的成本极高,而由于低帧率、低分辨率和先前数据集合成质量差,潜在收益有限。相比之下,我们的ReCo-Data具有非常高的高质量样本比例(91.6%)和跨不同任务的均衡数据分布,可直接用于模型训练而无需任何数据预处理。
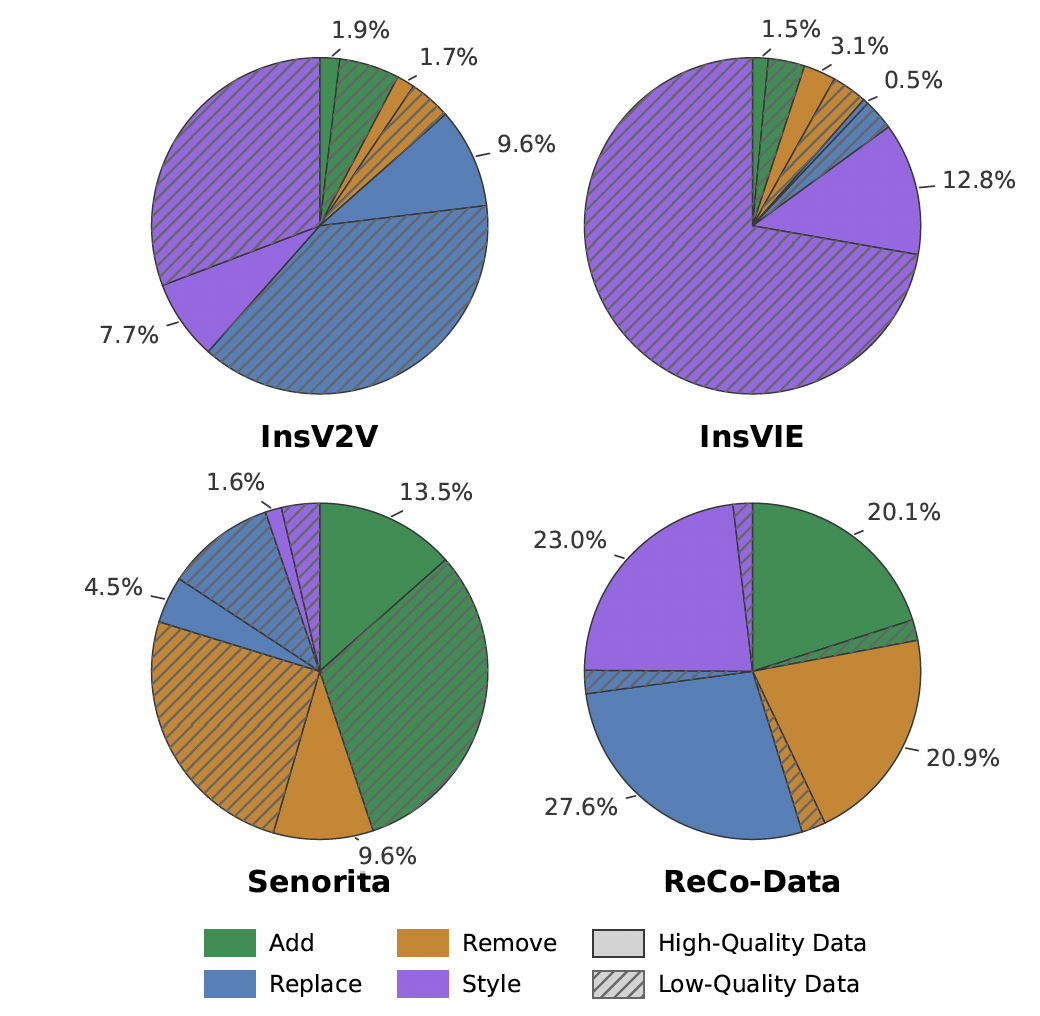
图 3. 现有视频编辑数据集与我们的 ReCo-Data 的对比。我们的数据集具有最均衡的数据分布,并且高质量样本占比更高。
基准测试。我们构建了一个视频编辑评估基准,包含480个视频-指令对,四种视频编辑任务各120对。由于传统指标通常难以准确全面地评估跨多维度的视频编辑,我们遵循图像编辑评估的进展,采用VLLM作为评估裁判。考虑到视频数据固有的复杂性,我们扩展了图像编辑指标,构建了专为视频编辑定制的多样化评估维度。我们从三个主要方面衡量视频编辑:(1) 编辑准确性,包含语义准确性(SA)、范围精确性(SP)和内容保留(CP)子维度;(2) 视频自然度,包含外观自然度(AN)、尺度自然度(SN)和运动自然度(MN);(3) 视频质量,包含视觉保真度(VF)、时间稳定性(TS)和编辑稳定性(ES)维度。
VLLM对每个子维度评分范围为0到10。然后,我们通过计算各主要视角下子维度的几何均值得到各类别分数(即 S E A S_{EA} SEA、 S V N S_{VN} SVN、 S V Q S_{VQ} SVQ):
S E A = S A ⋅ S P ⋅ C P 3 , ( 18 ) S_{EA} = \sqrt3{SA \cdot SP \cdot CP}, \quad (18) SEA=3SA⋅SP⋅CP ,(18)
S V N = A N ⋅ S N ⋅ M N 3 , ( 19 ) S_{VN} = \sqrt3{AN \cdot SN \cdot MN}, \quad (19) SVN=3AN⋅SN⋅MN ,(19)
S V Q = V F ⋅ T S ⋅ E S 3 . ( 20 ) S_{VQ} = \sqrt3{VF \cdot TS \cdot ES}. \quad (20) SVQ=3VF⋅TS⋅ES .(20)
最终,总分 S S S 计算为三个类别分数的算术均值:
S = 1 3 ( S E A + S V N + S V Q ) . ( 21 ) S = \frac{1}{3}(S_{EA} + S_{VN} + S_{VQ}). \quad (21) S=31(SEA+SVN+SVQ).(21)
实现细节。在ReCo中,我们采用Wan-T2V-1.3B作为基础架构。每个训练样本为81帧视频片段,帧率16fps,分辨率 480 × 832 480 \times 832 480×832。为使mask生成与视频潜变量分辨率对齐,我们首先通过VAE编码编辑mask,然后应用 k k k-means聚类进行二值化。LoRA秩设为128。ReCo使用AdamW优化器训练,采用两阶段学习率策略:模型首先以 1 × 10 − 4 1 \times 10^{-4} 1×10−4 的学习率训练以实现稳定收敛,随后以 2 × 10 − 5 2 \times 10^{-5} 2×10−5 的较低学习率进行微调阶段以进一步精炼。所有实验在24块NVIDIA A800 GPU上进行,mini-batch大小为24。
4.2 与最先进方法的比较
我们在基于VLLM的基准上将ReCo与多种最先进的指令式视频编辑方法进行比较,包括InsViE、Ditto、Lucy-Edit和VACE。表1总结了四种视频编辑任务的性能比较。总体而言,ReCo在所有任务的总分 S S S 上一致优于现有基线。特别是在局部视频编辑方面,ReCo在Add任务上取得8.23的总分 S S S,在Replace任务上取得8.74,分别超越强竞争对手Ditto(7.56)和Lucy-Edit(6.72)0.67和2.02。在编辑准确性方面(即 S E A S_{EA} SEA)也可观察到显著的性能趋势。结果表明,我们的ReCo不仅准确遵循指令正确定位编辑区域,还保留了非编辑区域的内容。在视频自然度方面(即 S V N S_{VN} SVN),我们模型取得的更好性能验证了自然整合编辑对象到源视频中的效果。尽管Ditto在Add任务上的 S V N S_{VN} SVN 略高于ReCo,但我们的方法能更好地保持原始视频内容,而Ditto倾向于将整个视频重新渲染为不同的色彩风格(如图4所示)。这一现象也由Ditto较低的 S E A S_{EA} SEA 分数(6.70)所证实。此外,最佳的视频质量表现( S V Q S_{VQ} SVQ)进一步表明ReCo生成的视频具有最少的视觉伪影或退化。即使在多任务训练设置下(即统一局部编辑和全局风格化,这可能在模型优化中带来一些冲突),ReCo在视频风格迁移方面仍展现出强大能力,总分 S S S 达到9.17。所有这些结果基本验证了在指令式视频编辑的上下文生成中执行区域约束建模的价值。
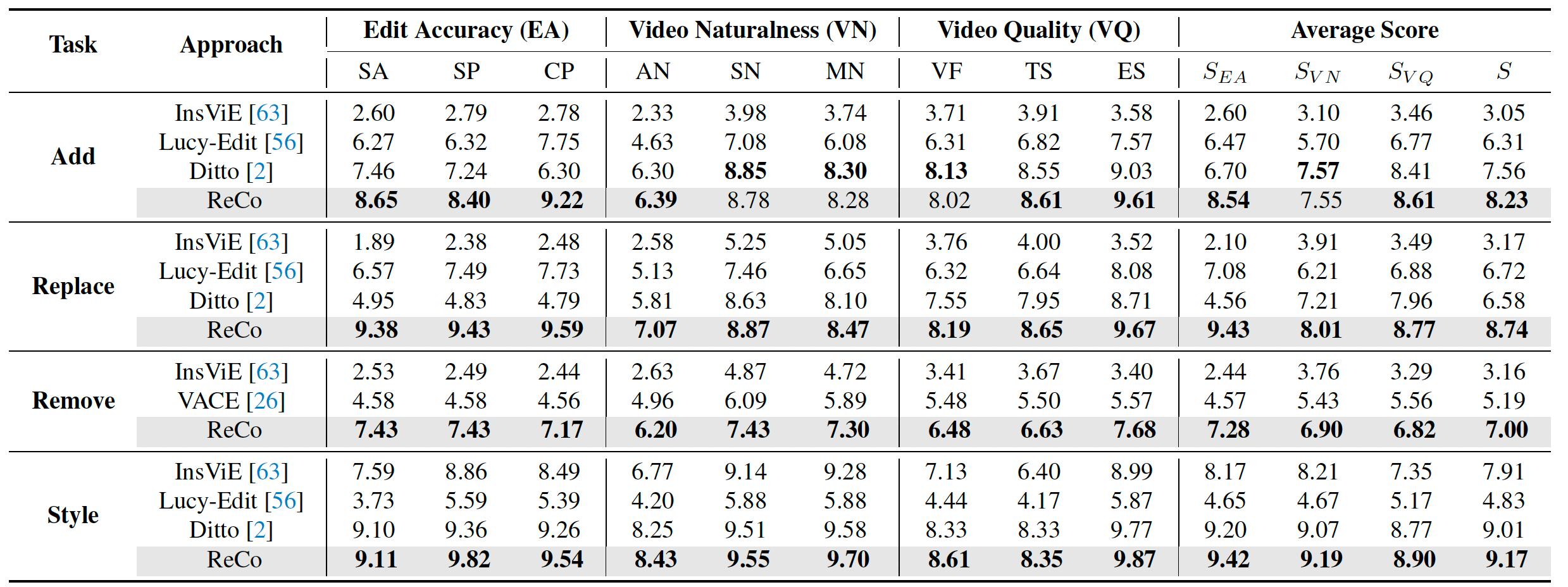
表 1. 四个视频编辑任务(即添加对象、替换对象、移除对象和风格迁移)的性能比较。我们通过将源视频和目标视频对输入到 Gemini-2.5-Flash-Thinking 1 中,并要求 VLLM 从三个主要角度给出评分来评估视频编辑质量:(1)编辑准确性包括语义准确性(SA)、范围精确性(SP)和内容保持性(CP)三个子维度;(2)视频自然性包含外观自然性(VN)、尺度自然性(SN)和运动自然性(MN);(3)视频质量包括视觉保真度(VF)、时间稳定性(TS)和编辑稳定性(ES)。每个评估子维度的分数范围为 0 到 10(分数越高越好)。我们还通过计算每个主要角度下所有子维度分数的几何平均值,报告各类别得分(即 S E A S_{EA} SEA、 S V N S_{VN} SVN、 S V Q S_{VQ} SVQ)以及总体平均得分 S S S。
图4和图5进一步展示了四种任务的视频编辑结果。总体而言,与其他基线相比,ReCo编辑的视频具有更好的指令遵循、更高的视频质量和更好的背景一致性。例如,InsViE倾向于产生带有伪影的视频,且经常出现编辑失败。近期的Lucy-Edit表现出较差的指令遵循能力,无法准确渲染指定属性(如穿连帽衫的棕色黑猩猩)。尽管Ditto在Add任务中能生成自然外观的对象,但它难以保持非编辑区域的背景一致性并准确定位编辑区域(如将皇冠添加到海豹背部)。同时,Ditto的指令遵循能力不如我们的方法,错误地在人旁边合成了一只新猴子而非替换他。我们推测Ditto的这些问题是由于在使用文本指令直接微调VACE进行上下文生成时缺乏区域相关性建模所致。相比之下,我们的ReCo通过区域约束来规范上下文生成学习,以强调编辑区域定位并同时缓解跨区域token干扰。因此,ReCo修改的视频既反映了准确的编辑结果,又实现了新对象与原始视频背景的自然整合。

图 4. 不同方法在视频编辑任务(即添加对象、替换对象和风格迁移)上的结果示例。

图 5. 对象移除任务的视觉对比。
4.3 区域约束消融研究
我们研究了ReCo中两个区域约束如何影响最终的指令式视频编辑。表2总结了ReCo不同变体的视频编辑性能。涉及两个额外的实验组:即 ReCo L C − \text{ReCo}{LC-} ReCoLC− 和 ReCo A C − \text{ReCo}{AC-} ReCoAC−,分别移除了ReCo中的潜在空间区域约束和注意力区域约束。具体而言,当丢弃潜在空间中的区域约束时, S E A S_{EA} SEA 出现显著性能下降,表明编辑准确性严重衰退。 S V N S_{VN} SVN 和 S V Q S_{VQ} SVQ 的分数也略有下降但仍具可比性。结果突显了潜在空间区域约束学习在放大编辑区域准确定位方面的有效性。图6上部进一步可视化了 ReCo L C − \text{ReCo}{LC-} ReCoLC− 和ReCo之间的一个视频编辑案例。给定"将沙发上的小男孩替换为扎辫子的小女孩"的指令, ReCo L C − \text{ReCo}{LC-} ReCoLC− 能够替换男孩,但错误地移除了旁边的狗。
当移除注意力空间中的正则化项时, ReCo A C − \text{ReCo}{AC-} ReCoAC− 在视频自然度方面(即 S V N S{VN} SVN)表现更差,如表2所示。我们也在图6下部展示了一个编辑示例。如图所示, ReCo A C − \text{ReCo}_{AC-} ReCoAC− 生成了一只相对于环境尺寸不自然的大鹦鹉。通过配备注意力正则化------减少编辑区域的token干扰并增强新对象生成中与背景的交互------ReCo合成了自然尺寸且一致性更好的鹦鹉。

表 2. ReCo 不同变体在四个视频编辑任务上的性能比较。

图 6. ReCo 不同变体在替换任务上的编辑结果。
- 结论
我们提出了ReCo,一种塑造上下文生成用于基于指令的视频编辑的方法。特别地,我们研究了将编辑区域与非编辑区域之间的区域约束建模整合到扩散训练中的问题。为实现我们的想法,ReCo基于自然语言指令联合去噪沿宽度拼接的源-目标视频对,并在单步反向去噪潜变量和注意力图上施加两个正则化项以强调区域关系。为缓解非编辑区域中的意外内容生成,潜在空间中的正则化项试图减小源视频与目标视频非编辑区域的潜在差异,同时增大编辑区域的差异。同时,ReCo抑制编辑区域中token对源视频同一部分token的注意力,缓解原始编辑区域token对新对象生成的干扰。此外,我们精心构建了一个高质量视频编辑数据集ReCo-Data,包含50万条指令-视频对,涵盖广泛的编辑任务。在四种编辑任务上的大量实验验证了ReCo优于最先进方法的优越性。