本体系整合所有Spring基础、进阶、源码、实战、微服务、面试、避坑知识点,补齐全网大部分教程遗漏盲区,是一套从零入门→企业开发→源码深耕→架构落地的完整学习路线,无知识点遗漏、无逻辑断层、适配企业主流技术栈。
知识图谱:
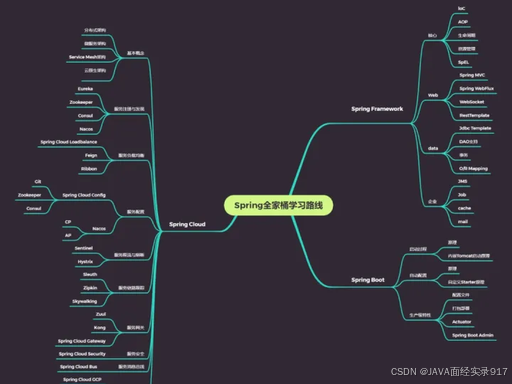
第一阶段:前置必备基础(Spring学习核心基石,不学直接看不懂源码)
1. Java 核心基础(Spring原理专属强化版)
以下所有知识点直接支撑Spring底层核心原理,是破解「会用不懂原理」的关键,摒弃冗余Java语法,只保留Spring高频依赖的核心能力,每一项均标注对应Spring应用场景:
(1)面向对象与类加载机制(Bean底层基础)
-
核心知识点:封装、继承、多态、重写与重载、抽象类&接口、SPI服务发现机制、双亲委派模型、类的初始化时机
-
Spring关联:Bean的多态注入、接口编程、Spring SPI扩展、自动配置类加载、FactoryBean机制全部依赖此基础
(2)集合与泛型(容器数据存储核心)
-
核心知识点:HashMap/ConcurrentHashMap底层、List/Set特性、泛型擦除、通配符、集合遍历、快速失败机制(fail-fast)
-
Spring关联:Spring容器底层大量用Map存储Bean定义、单例池、三级缓存;泛型适配统一参数绑定、集合依赖注入
(3)异常体系(Spring事务、异常处理核心)
-
核心知识点:受检异常、非受检异常、自定义异常、异常捕获与抛出、异常传播机制
-
Spring关联:@Transactional默认只回滚RuntimeException、事务失效(异常被try-catch捕获)、全局异常处理器原理
(4)反射机制(Spring IoC核心基石)
-
核心知识点:Class对象获取、构造器/字段/方法反射调用、暴力反射、动态创建对象、获取注解信息
-
Spring关联 :Spring通过反射实例化所有Bean、完成属性注入、调用初始化方法,无反射则无IoC容器
(5)注解与元注解(Spring配置核心)
-
核心知识点:四大元注解(@Target/@Retention/@Documented/@Inherited)、自定义注解、注解解析、注解属性获取
-
Spring关联:Spring所有核心注解(@Component/@Autowired/@Transactional)均基于元注解实现,自动配置、Bean扫描全靠注解解析
(6)Java8+高阶特性(Spring Boot标配)
-
核心知识点:Lambda表达式、函数式接口、Stream流、Optional空值处理、方法引用、默认方法
-
Spring关联:SpringBoot自动配置大量使用函数式编程、Bean注册函数式写法、参数空值校验、集合数据处理
(7)多线程与ThreadLocal(Spring事务/上下文核心)
-
核心知识点:线程生命周期、线程池(ThreadPoolExecutor)七大参数、拒绝策略、线程隔离、ThreadLocal原理、内存泄漏问题
-
Spring关联 :Spring事务基于ThreadLocal实现线程隔离、Web请求上下文存储、@Async异步线程池、定时任务线程调度
(8)序列化与IO(数据交互基础)
-
核心知识点:JSON序列化/反序列化、对象序列化、IO资源关闭、资源加载
-
Spring关联:SpringMVC请求体解析、Jackson全局序列化配置、配置文件资源读取、接口数据返回格式化
终极核心重点(进阶必记):反射+注解是Spring IoC/AOP的底层根基,ThreadLocal是Spring事务线程隔离的核心,线程池支撑Spring所有异步、定时任务,这三组知识点是突破「只会用不懂原理」的核心关键。
2. 必备设计模式(Spring底层全覆盖)
Spring 底层90%的功能全部基于设计模式实现,想要吃透Spring源码、弄懂原理,必须掌握以下8种核心设计模式。下面每一种均配套:Spring落地场景 + 完整代码实现,学完可直接对应Spring底层源码。
1. 单例模式(Spring Bean核心)
Spring落地场景:Spring Bean默认单例、单例池(一级缓存)、ApplicationContext容器、工具类组件全部单例。
核心特点:全局唯一实例,Spring通过三级缓存+容器管控实现线程安全单例。
java
// 饿汉式(Spring容器Bean默认思路:容器启动直接创建)
public class SpringSingletonBean {
// 全局唯一实例
private static final SpringSingletonBean INSTANCE = new SpringSingletonBean();
// 私有构造:禁止外部new
private SpringSingletonBean(){}
// 对外统一获取实例
public static SpringSingletonBean getInstance(){
return INSTANCE;
}
}2. 工厂模式(IoC容器核心)
Spring落地场景 :BeanFactory、ApplicationContext、FactoryBean、自动装配Bean创建,IoC本质就是超级工厂模式。
核心作用:统一对象创建,解耦创建与使用,完全契合IoC控制反转思想。
java
// 模拟Spring Bean工厂
// 1. 抽象产品
public interface Bean {}
// 2. 具体产品
class UserBean implements Bean {}
class OrderBean implements Bean {}
// 3. 工厂类(模拟BeanFactory)
class SpringBeanFactory {
public static Bean getBean(String beanName){
switch (beanName){
case "userBean": return new UserBean();
case "orderBean": return new OrderBean();
default: throw new RuntimeException("Bean不存在");
}
}
}
// 测试:使用者无需new,工厂统一创建
class Test {
public static void main(String[] args) {
Bean userBean = SpringBeanFactory.getBean("userBean");
Bean orderBean = SpringBeanFactory.getBean("orderBean");
}
}3. 代理模式(AOP核心底层)
Spring落地场景 :Spring AOP、事务@Transactional、缓存、日志增强、权限拦截,所有横向增强功能全部基于代理模式。
两种实现:JDK动态代理(接口)、CGLIB代理(类)。下面实现JDK动态代理(Spring原生逻辑)。
java
// 目标接口
public interface UserService {
void addUser();
}
// 目标实现类
class UserServiceImpl implements UserService {
@Override
public void addUser() {
System.out.println("执行业务新增用户");
}
}
// 模拟AOP代理增强(日志、事务)
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
class SpringAopProxy implements InvocationHandler {
// 被代理目标对象
private final Object target;
public SpringAopProxy(Object target) {
this.target = target;
}
// 执行增强逻辑
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("前置通知:开启事务/打印日志");
Object result = method.invoke(target, args);
System.out.println("后置通知:提交事务/记录操作日志");
return result;
}
// 获取代理对象
public static Object getProxy(Object target){
return Proxy.newProxyInstance(
target.getClass().getClassLoader(),
target.getClass().getInterfaces(),
new SpringAopProxy(target)
);
}
}
// 测试
class AopTest {
public static void main(String[] args) {
UserService proxy = (UserService) SpringAopProxy.getProxy(new UserServiceImpl());
proxy.addUser();
}
}4. 模板方法模式(Spring事务、JDBC核心)
Spring落地场景:JdbcTemplate、TransactionTemplate、Spring生命周期模板、Bean初始化模板。
核心思想:父类定义固定流程,子类实现可变逻辑,Spring统一管控执行流程。
java
// 模拟Spring Template模板方法
public abstract class SpringTransactionTemplate {
// 固定模板流程(不可修改)
public final void execute(){
beginTransaction();
try {
doBusiness(); // 子类自定义业务
commit();
} catch (Exception e) {
rollback();
}
}
// 固定通用逻辑
private void beginTransaction(){ System.out.println("开启事务"); }
private void commit(){ System.out.println("提交事务"); }
private void rollback(){ System.out.println("回滚事务"); }
// 可变业务:由子类实现
protected abstract void doBusiness();
}
// 自定义业务实现
class UserTransaction extends SpringTransactionTemplate {
@Override
protected void doBusiness() {
System.out.println("执行用户新增业务");
}
}
// 测试
class TemplateTest {
public static void main(String[] args) {
new UserTransaction().execute();
}
}5. 观察者模式(Spring事件机制核心)
Spring落地场景:Spring事件发布监听、容器刷新事件、自定义事件、ApplicationListener。
核心作用:解耦事件发布与事件处理,实现业务解耦、异步通知。
java
import java.util.ArrayList;
import java.util.List;
// 模拟Spring事件发布器
public class SpringEventPublisher {
// 存放所有监听器
private static final List<EventListener> LISTENERS = new ArrayList<>();
// 注册监听器
public static void registerListener(EventListener listener){
LISTENERS.add(listener);
}
// 发布事件,通知所有监听器
public static void publishEvent(String event){
for (EventListener listener : LISTENERS) {
listener.onEvent(event);
}
}
}
// 事件监听接口
interface EventListener {
void onEvent(String event);
}
// 具体监听器
class LogListener implements EventListener {
@Override
public void onEvent(String event) {
System.out.println("日志监听器收到事件:" + event);
}
}
// 测试
class EventTest {
public static void main(String[] args) {
// 注册监听
SpringEventPublisher.registerListener(new LogListener());
// 发布事件(Spring容器刷新/业务事件)
SpringEventPublisher.publishEvent("容器刷新完成");
}
}6. 策略模式(Spring资源解析、条件装配)
Spring落地场景:资源加载策略、类型转换策略、条件注解@Conditional、不同环境配置策略。
核心作用:统一接口,动态切换实现,消除大量if-else。
java
// 策略接口:文件资源解析
public interface ResourceStrategy {
void parseResource();
}
// 具体策略
class YmlResource implements ResourceStrategy{
@Override
public void parseResource() { System.out.println("解析yml配置文件"); }
}
class PropertiesResource implements ResourceStrategy{
@Override
public void parseResource() { System.out.println("解析properties配置文件"); }
}
// 策略上下文(Spring统一调度)
class ResourceContext {
public void parse(String type){
ResourceStrategy strategy = switch (type){
case "yml" -> new YmlResource();
case "properties" -> new PropertiesResource();
default -> throw new RuntimeException("不支持的配置类型");
};
strategy.parseResource();
}
}
// 测试
class StrategyTest {
public static void main(String[] args) {
new ResourceContext().parse("yml");
}
}7. 适配器模式(Spring MVC适配核心)
Spring落地场景:Spring MVC HandlerAdapter、适配不同类型Controller(普通Controller、注解Controller)。
核心作用:统一适配接口,兼容多种不同实现,DispatcherServlet核心依赖此模式。
java
// 适配目标接口
public interface HandlerAdapter {
boolean support(Object handler);
void handle(Object handler);
}
// 普通控制器
class NormalController{
public void doHandle(){ System.out.println("普通控制器处理请求"); }
}
// 适配器实现
class NormalControllerAdapter implements HandlerAdapter{
@Override
public boolean support(Object handler) {
return handler instanceof NormalController;
}
@Override
public void handle(Object handler) {
((NormalController)handler).doHandle();
}
}
// 模拟DispatcherServlet调度
class DispatcherServlet {
public void doDispatch(Object handler){
HandlerAdapter adapter = new NormalControllerAdapter();
if(adapter.support(handler)){
adapter.handle(handler);
}
}
}
// 测试
class AdapterTest {
public static void main(String[] args) {
new DispatcherServlet().doDispatch(new NormalController());
}
}8. 装饰器模式(Spring IoC包装增强)
Spring落地场景:BeanWrapper、IoC容器Bean包装增强、多层Bean后置处理、IO流包装。
核心作用:不修改原类代码,动态叠加功能,Spring多层增强全部依赖此模式。
java
// 基础组件接口
public interface Component {
void service();
}
// 原始基础组件
class BaseComponent implements Component{
@Override
public void service() {
System.out.println("基础Bean业务逻辑");
}
}
// 装饰器包装类
class ComponentDecorator implements Component{
// 持有原始组件
private final Component component;
public ComponentDecorator(Component component){
this.component = component;
}
@Override
public void service() {
// 前置增强
System.out.println("Spring Bean前置增强");
// 执行原逻辑
component.service();
// 后置增强
System.out.println("Spring Bean后置增强");
}
}
// 测试
class DecoratorTest {
public static void main(String[] args) {
// 装饰增强原始Bean
Component bean = new ComponentDecorator(new BaseComponent());
bean.service();
}
}✅ 总结:设计模式与Spring核心对应关系(必背)
-
单例模式:Bean单例池、容器实例
-
工厂模式:IoC Bean工厂、对象创建解耦
-
代理模式:AOP、事务、所有动态增强
-
模板方法:事务模板、JDBC模板、生命周期流程
-
观察者模式:Spring事件发布监听
-
策略模式:配置解析、条件装配、资源加载
-
适配器模式:MVC请求适配、多控制器兼容
-
装饰器模式:Bean多层后置增强、包装扩展
3. 工程与Web基础(Spring运行底层依赖,必会)
本模块是Spring项目打包、运行、Web请求流转的核心基础,90%的Spring环境报错、配置异常、请求异常均源于此基础薄弱。所有知识点精准对接Spring Boot/Spring MVC底层运行逻辑,适配源码学习与企业实战。
一、工程构建基础(Maven核心,Spring项目必备·完整版)
Maven是所有Spring/SpringBoot项目的工程基石,Spring的Starter依赖加载、Bean自动配置、项目打包、多环境部署、热部署、依赖治理全部依托Maven机制。绝大多数新手遇到的Bean找不到、类缺失、版本冲突、启动报错、打包失效,根源都是Maven基础薄弱。以下为Spring专属、企业实战全覆盖的Maven核心知识点:
1. Maven核心核心本质与核心作用
-
核心本质:标准化项目构建、依赖管理、项目生命周期管控的自动化工具,统一所有Java项目工程规范
-
四大核心作用:依赖导入与统一管理、项目编译测试打包、多环境配置切换、插件扩展功能
-
Spring专属价值:SpringBoot Starter体系完全基于Maven依赖机制实现,无需手动导包、无需管理版本,实现「开箱即用」
2. Maven核心坐标与仓库体系
-
GAV坐标(唯一标识依赖):groupId(组织)、artifactId(项目名)、version(版本),Spring所有框架、Starter依赖均通过GAV精准定位
-
仓库层级优先级:本地仓库 > 私服/镜像仓库 > 中央仓库,Spring项目依赖下载遵循该优先级
-
企业配置重点:阿里云镜像加速、私服Nexus配置、本地仓库路径自定义,解决Spring依赖下载慢、下载失败问题
3. 依赖范围(Spring项目高频必考)
决定依赖在「编译、测试、运行、打包」哪个阶段生效,是解决Spring打包后类缺失、依赖冲突的核心:
-
compile(默认):编译+测试+运行+打包全程生效,Spring核心依赖(spring-core、spring-context)均为该范围
-
test:仅测试阶段生效,如junit、spring-test,项目打包不会打入,不影响线上环境
-
provided:编译测试生效,运行打包失效,如servlet-api(SpringBoot内嵌Tomcat已提供,无需打包)
-
runtime:编译不生效、运行打包生效,如mysql驱动
4. 依赖核心高级特性(Spring排障必备)
-
依赖传递:导入SpringBoot Starter会自动传递所有底层依赖(如spring-boot-starter-web自动传递spring-mvc、tomcat、jackson),是Starter简化开发的核心原理
-
依赖冲突(高频报错):多个依赖传递同一Jar不同版本,导致Spring启动报错、类方法不存在、版本不兼容
-
依赖排除exclusions:手动剔除冲突依赖,解决Spring框架版本冲突、第三方Jar冲突问题
-
版本统一管理dependencyManagement:父工程统一管控Spring全家桶版本,避免多模块版本混乱,微服务项目必备
5. Maven完整生命周期(与Spring启动强关联)
Maven生命周期执行顺序固定,Spring项目运行、热部署、打包部署完全遵循该流程:
-
clean:清空target编译目录,解决Spring缓存导致的代码不更新问题
-
validate/compile:校验项目、编译Java源码,Spring项目启动前置步骤
-
test:执行单元测试,SpringTest、Junit5测试依托该阶段
-
package:打包Jar/War,SpringBoot打包插件自动生成可执行Jar包
-
install:安装到本地仓库,多模块Spring项目依赖本地子模块必备
-
deploy:部署到私服,企业微服务版本迭代发布必备
6. 核心插件机制(SpringBoot核心底层)
-
插件作用:扩展Maven功能,SpringBoot所有打包、运行、配置功能全部依托插件实现
-
必备插件:spring-boot-maven-plugin(核心),实现内嵌Tomcat打包、可执行Jar生成、项目启动运行
-
常用扩展插件:热部署插件devtools、代码生成插件、配置加密插件、打包资源过滤插件
7. 多环境配置(企业Spring项目刚需)
-
核心场景:开发dev、测试test、生产prod环境切换,不同环境数据库、端口、配置不同
-
实现方式:Maven环境变量激活 + SpringBoot多配置文件联动
-
核心能力:打包时动态切换环境、过滤配置文件、替换占位符参数,实现一套代码多环境部署
8. 聚合工程与父子模块(微服务必备)
-
父模块:统一版本、统一依赖、统一插件配置,禁止业务代码
-
子模块:继承父模块配置,拆分业务模块(用户、订单、网关)
-
Spring微服务适配:所有SpringCloud Alibaba微服务项目均采用Maven聚合工程架构,实现模块解耦、版本统一管理
9. 高频问题与Spring排障方案
-
依赖缺失:检查仓库下载完整性、依赖范围、传递依赖是否被排除,对应Spring Bean加载失败、类不存在报错
-
版本冲突:通过maven dependency:tree查看依赖树,精准剔除冲突Jar,解决Spring启动异常
-
打包配置失效:检查打包插件、资源过滤规则,解决Spring配置文件打包丢失问题
-
热部署失效:校验devtools插件配置、Maven编译策略,解决Spring项目修改代码不生效问题
✅ 本模块Spring核心关联总结
Maven不是单纯的工具,是SpringBoot Starter机制、依赖自动装配、多环境部署、微服务模块化的底层支撑,弄懂Maven依赖传递、冲突解决、插件机制,能解决Spring开发中80%的环境与配置报错。
总结:
-
核心生命周期:清理→验证→编译→测试→打包→安装→部署,Spring项目启动、热部署、打包部署全依赖该生命周期
-
核心配置:坐标GAV、依赖范围(compile/test/provided/runtime)、依赖排除、版本统一管理
-
企业核心痛点:依赖冲突、Jar包重复、版本冲突、依赖缺失,Spring启动报错(Bean找不到、类不存在)高频诱因
-
高级能力:私服配置、镜像源切换、多环境打包、资源过滤、打包插件配置(SpringBoot打包插件原理)
-
Spring关联:Starter依赖导入、自动配置生效、项目打包部署、外置配置加载全部依托Maven机制
二、HTTP网络基础(Spring MVC请求核心·完整版)
HTTP是Spring MVC所有接口请求、参数解析、响应返回、跨域、请求适配的底层协议规范 。90%的Spring Web报错:405请求方式不允许、415媒体类型不支持、跨域报错、参数接收不到、GET/POST传参差异,根源都是HTTP基础不扎实。以下为Spring专属、原理贴合框架、实战全覆盖的HTTP核心体系:
1. HTTP协议核心本质
-
无状态协议(重中之重) :服务器不记录任何客户端状态,每次请求都是独立无关联。 Spring关联原理:正因HTTP无状态,Spring才需要Session、Cookie、JWT Token、上下文存储,实现用户会话保持。
-
基于请求-响应模型:客户端主动请求、服务器被动响应,Spring DispatcherServlet完全基于该模型设计请求分发流程。
-
应用层协议:基于TCP可靠传输,保证接口数据完整性,支撑Spring所有接口数据交互。
2. HTTP完整报文结构(Spring参数解析底层)
Spring MVC参数绑定、请求头获取、请求体解析,本质就是解析HTTP报文:
-
请求报文:请求行(请求方法+URL+协议版本)、请求头(Header)、空行、请求体(Body)
-
响应报文:响应行(状态码+状态描述)、响应头、空行、响应体(接口返回数据)
Spring精准对应:
-
@RequestParam → 解析请求行URL参数
-
@RequestHeader → 解析请求头参数
-
@RequestBody → 解析请求体JSON数据
-
@CookieValue → 解析请求头Cookie字段
3. 七大请求方法(Spring RESTful接口核心)
Spring MVC RESTful风格完全遵循HTTP方法语义,区分幂等性、传参方式、适用场景(面试高频):
-
GET(查询):幂等、无请求体、参数拼接URL、可缓存、书签收藏。Spring中适配查询接口,@GetMapping。
-
POST(新增):非幂等、支持请求体、无缓存、参数安全。Spring中适配新增、复杂参数提交,@PostMapping。
-
PUT(全量更新):幂等、通过请求体更新全部资源,@PutMapping。
-
DELETE(删除):幂等、用于资源删除,@DeleteMapping。
-
PATCH(局部更新):幂等、仅更新字段差异,企业高频接口优化方案。
-
HEAD/OPTIONS:OPTIONS是Spring跨域预检请求底层依赖方法,HEAD只获取响应头。
Spring高频坑点:GET请求无法接收@RequestBody、POST无法通过URL接收复杂参数,405报错均为请求方法与接口注解不匹配。
4. 幂等性核心概念(Spring接口设计必备)
-
定义:多次请求同一接口,服务器资源状态一致,不会产生重复数据。
-
幂等方法:GET/PUT/DELETE/PATCH/HEAD/OPTIONS
-
非幂等方法:POST
-
Spring实战落地:订单提交、支付接口必须做幂等性防重,解决POST重复提交问题。
5. 常用请求头/响应头(Spring底层适配)
-
Content-Type:告知服务器请求体数据类型,Spring据此选择解析器(Jackson解析JSON、文件解析器解析文件)。 常见值:application/json、multipart/form-data、x-www-form-urlencoded
-
Accept:客户端可接收的响应数据类型,Spring适配数据返回格式。
-
Origin/Referer:浏览器跨域校验核心请求头,Spring CORS跨域配置依赖解析该字段。
-
Cookie/Set-Cookie:会话跟踪核心,Spring Session、Cookie持久化底层依托该头部。
-
Authorization:令牌认证头部,Spring Security JWT登录认证核心解析字段。
6. 高频HTTP状态码(Spring报错快速定位)
-
2xx 成功:200(正常响应)、201(创建成功)、204(无返回内容)
-
3xx 重定向:301永久重定向、302临时重定向(Spring redirect重定向返回状态)
-
4xx 客户端错误(Spring最常见): 400参数异常、404接口不存在、405请求方法不匹配、415媒体类型不支持、403权限拒绝
-
5xx 服务端错误:500代码异常、502网关异常、503服务不可用
7. 两种POST提交方式(Spring参数接收大坑)
新手最容易踩坑:POST并非都能使用@RequestBody,取决于Content-Type:
-
application/x-www-form-urlencoded :表单默认格式,参数放在URL/表单域,Spring只能用@RequestParam接收,不支持@RequestBody
-
application/json :JSON格式请求体,Spring必须用@RequestBody接收,无法用@RequestParam接收
-
multipart/form-data:文件上传专用,Spring文件上传解析器专属适配
8. 跨域CORS完整原理(Spring跨域底层)
-
同源策略:浏览器安全机制,协议、域名、端口任意一个不同即为跨域,服务器无跨域限制。
-
简单请求:GET/POST/HEAD、无自定义请求头、Content-Type为普通表单,直接放行。
-
预检请求OPTIONS:带JSON请求体、自定义Token头部的POST请求,浏览器先发送OPTIONS预检,校验服务器是否允许跨域。
-
Spring关联:Spring MVC全局跨域配置、Gateway网关跨域,本质就是响应OPTIONS预检请求、配置允许的域名、方法、头部。
-
高频坑点:跨域配置只配业务接口、未放行OPTIONS预检请求,导致跨域失效。
9. HTTP缓存机制(Spring接口性能优化)
-
强缓存:Cache-Control、Expires,浏览器直接读取本地缓存,不请求服务器
-
协商缓存:Last-Modified/If-Modified-Since、ETag/If-None-Match,服务端校验资源是否更新
-
Spring实战:静态资源、高频查询接口可开启HTTP缓存,降低服务器压力
✅ 本模块核心总结(会用不懂原理必背)
-
Spring MVC所有参数注解,本质都是解析HTTP报文不同位置的数据
-
HTTP无状态是Spring会话、Token、上下文机制的设计根源
-
请求方法、Content-Type直接决定Spring参数能否正常接收
-
跨域、405、415、参数丢失90%问题,均可通过HTTP原理根治
三、Servlet核心规范(Spring MVC底层根基·完整版)
核心定论:Spring MVC 不是全新技术,是对 Servlet 规范的高阶封装。DispatcherServlet 本质就是原生 Servlet 的子类,所有 Web 请求、拦截、分发、处理流程,底层完全遵循 Servlet 规范。不懂 Servlet,永远只能停留在「调接口、写CRUD」,看不懂 MVC 底层流转、拦截器失效、请求上下文原理。
1. Servlet 核心三大组件(Spring Web 全部依赖)
整套 Web 请求链路由三大组件构成,执行优先级固定:Listener → Filter → Servlet
-
Listener 监听器(全局监听):监听容器启动、销毁、Session创建销毁等全局事件,无请求拦截能力,用于初始化全局资源
-
Filter 过滤器(Servlet 层拦截) :拦截所有 HTTP 请求,在 Servlet 执行前后做预处理/后处理,属于Java Web 原生底层拦截
-
Servlet 处理器(请求核心处理):真正处理业务请求、解析参数、封装响应,Spring MVC 的 DispatcherServlet 就是核心实现类
2. Servlet 完整生命周期(对标 DispatcherServlet 启动流程)
生命周期由 Tomcat 容器管理,而非 Spring 容器,是 Spring Web 启动加载的底层源头:
-
第一步:实例化:Tomcat 启动时扫描 Servlet 配置,通过反射创建 Servlet 实例
-
第二步:初始化 init() :全局只执行一次,加载配置、初始化策略、初始化Spring Web上下文 Spring关联 :DispatcherServlet 在 init 阶段完成SpringMVC九大组件初始化(HandlerMapping、HandlerAdapter等)
-
第三步:服务处理 service() :每次请求都会执行,根据请求方式分发 doGet/doPost Spring关联:DispatcherServlet 重写 service 方法,进入核心 doDispatch 请求分发逻辑
-
第四步:销毁 destroy():项目关闭、Tomcat 销毁时执行,释放资源、关闭连接
3. 四大核心内置对象(Spring Web 上下文底层来源)
Spring MVC 封装的 Request、Response、Session 全部源自 Servlet 原生对象:
-
HttpServletRequest :封装所有请求信息(URL、请求头、请求参数、请求方法、Cookie、输入流),Spring 参数解析、请求绑定全部基于该对象
-
HttpServletResponse :封装所有响应信息(状态码、响应头、响应体、重定向、输出流),Spring 统一结果返回、跨域响应配置依托该对象
-
HttpSession:基于 Cookie 的会话对象,单用户多请求共享数据,Spring Session 机制底层完全复用该规范
-
ServletContext:全局上下文对象,整个 Web 项目唯一,存储全局配置、全局参数、资源路径,Spring 容器与 Tomcat 容器交互的桥梁
4. Filter 过滤器深度详解(Spring 底层预处理核心)
Filter 是Tomcat 层级的拦截,早于 Spring 容器执行,优先级高于所有 Spring 组件
-
核心特性:链式过滤、全局拦截、可拦截静态资源+动态接口、依赖 Servlet 原生 API
-
生命周期:容器启动初始化一次 → 每次请求拦截 → 容器销毁释放
-
Spring 落地场景: 1. 编码过滤器(统一 UTF-8 编码,解决乱码) 2. CORS 跨域过滤器(响应 OPTIONS 预检请求) 3. 权限前置拦截、Token 初步校验 4. 请求参数清洗、请求日志预处理
-
核心短板:无法获取 Spring Bean、无法使用 Spring 上下文、只能做通用预处理,不能操作 Spring 业务组件
5. Listener 监听器企业实战作用
-
ServletContextListener:项目启动预加载资源、初始化字典、初始化线程池、注册全局配置
-
HttpSessionListener:统计在线人数、Session 过期清理、用户下线监听
-
Spring关联:Spring 容器刷新事件、上下文初始化事件,设计思路完全参考 Servlet 监听器机制
6. 面试终极重点:Filter(Servlet层) vs Interceptor(Spring层)
90% 开发者分不清,导致拦截失效、跨域失效、请求拦截异常,核心差异全覆盖:
| 对比维度 | Filter 过滤器 | Interceptor 拦截器 |
|---|---|---|
| 所属层级 | Tomcat/Servlet 原生层级(底层) | Spring MVC 框架层级(上层) |
| 执行顺序 | 更早(请求进入容器先执行Filter) | Filter 放行后、Controller 前执行 |
| 依赖API | 原生 Servlet API | Spring 框架 API |
| 能否获取Spring Bean | 不能(未进入Spring容器) | 可以(完全归Spring管理) |
| 拦截范围 | 所有请求(静态资源+接口) | 仅拦截 Controller 接口请求 |
| 典型用途 | 编码、跨域、限流、全局预处理 | 权限校验、日志记录、Token校验、接口拦截 |
总结:
-
核心三大组件:Servlet(请求处理)、Filter(过滤器)、Listener(监听器)
-
Servlet生命周期:初始化init() → 服务处理service() → 销毁destroy(),对应DispatcherServlet启动流程
-
核心内置对象:HttpServletRequest(请求封装)、HttpServletResponse(响应封装)、HttpSession、ServletContext
-
过滤器Filter:链式过滤、拦截所有请求、优先级机制,Spring跨域、编码过滤、请求预处理底层依托Filter
-
Listener监听器:项目启动/销毁监听、Session监听,Spring容器事件、上下文初始化参考该机制
-
核心区别:Filter(Servlet层)vs Interceptor(Spring层),执行顺序、生效范围、使用场景差异(面试高频)
四、Tomcat容器运行机制(Spring Boot内嵌核心·完整版)
核心定论:Tomcat是Spring Web程序的运行宿主容器 。Spring MVC只是一套Web框架,本身无法独立运行、监听端口、解析HTTP请求,所有Spring Boot Web项目的请求接收、线程调度、Servlet生命周期管理,全部由Tomcat完成。Spring Boot摒弃外置Tomcat,采用内嵌Tomcat,本质是将Tomcat容器集成进Spring容器,统一启动、统一管理。
1. Tomcat核心定位与核心作用
-
核心定位 :轻量级Java Web容器、Servlet规范官方实现,是Java Web程序的运行环境,而非业务框架
-
四大核心作用:端口监听接收HTTP请求、解析HTTP报文、创建线程处理请求、全权管理Servlet/Filter/Listener生命周期
-
Spring强关联:DispatcherServlet交由Tomcat实例化、初始化、调度执行,没有Tomcat,Spring MVC无法接收任何前端请求
2. Tomcat双层核心架构(Connector + Container)
Tomcat采用分层解耦架构,彻底分离「网络通信」和「请求业务处理」,是高并发设计的核心:
-
Connector 连接器(网络层) 核心职责:负责底层TCP网络通信、端口监听、请求报文解析、响应封装、协议适配 核心组件:Endpoint(端口监听)、Processor(报文解析)、Adapter(请求转发) 适配协议:默认HTTP/1.1,支持HTTPS、HTTP2
-
Container 容器(业务处理层) 核心职责:接收Connector转发的请求,匹配项目上下文、执行过滤器链、调度Servlet处理业务 层级结构(由大到小):Engine(引擎,全局容器)> Host(虚拟主机)> Context(项目上下文,Spring项目唯一对应)> Wrapper(包装每一个Servlet)
完整请求流转:浏览器请求 → 端口监听 → Connector解析报文 → Adapter适配转发 → Container匹配上下文 → Filter链式拦截 → DispatcherServlet执行MVC流程 → 响应返回
3. Tomcat核心线程模型(Spring并发底层)
Spring Boot接口并发能力完全取决于Tomcat线程池配置,是线上接口并发、阻塞、超时问题的核心根源:
-
Acceptor线程(接收线程):负责监听端口、接收客户端TCP连接,不处理业务,只负责建立连接,单线程运行
-
Poller线程(轮询线程):基于NIO多路复用,轮询已建立的连接,检测可读可写状态,分发请求任务
-
Worker线程池(业务线程池·核心):真正执行请求处理、过滤器、Servlet、Controller业务逻辑的线程池,Spring所有接口请求均由该线程池处理
4. 内嵌Tomcat核心线程池参数(企业调优必懂)
Spring Boot默认自动配置内嵌Tomcat线程池,线上高并发场景必须手动调优,核心参数全覆盖:
-
核心线程数(core-threads):默认10,长期常驻的工作线程,不会被回收
-
最大线程数(max-threads):默认200,Tomcat最大并发处理能力,超过则请求排队
-
最大连接数(max-connections):默认8192,服务器最大可维持的TCP连接数,超出连接直接拒绝
-
等待队列长度(accept-count):默认100,线程池满负荷后,请求排队的队列容量,队列满则直接返回连接拒绝
-
空闲线程超时:空闲线程超时自动回收,释放服务器资源
实战坑点:接口卡顿、请求排队、503服务不可用,90%是Tomcat线程池耗尽、队列打满导致,而非代码问题
5. 外置Tomcat vs Spring Boot内嵌Tomcat
| 对比维度 | 外置独立Tomcat | Spring Boot内嵌Tomcat |
|---|---|---|
| 部署方式 | 打包War包,部署至Tomcat webapps目录 | 打包可执行Jar包,内置容器,独立运行 |
| 容器归属 | 独立进程,统一管理多个项目 | 绑定当前项目,一个项目一个容器进程 |
| 配置方式 | 修改Tomcat全局配置文件 | Spring配置文件直接配置,灵活独立 |
| 启动方式 | 容器启动,加载所有部署项目 | 项目main方法启动,容器随项目启停 |
| 企业现状 | 老旧项目使用,现已淘汰 | Spring Boot/Cloud项目标配 |
6. 内嵌容器替换机制(高阶拓展)
Spring Boot默认集成Tomcat,支持无缝替换高性能容器,适配不同业务场景:
-
Jetty:轻量、内存占用低,适合小型服务、测试环境
-
Undertow:高性能、支持非阻塞、并发能力强,高并发线上项目首选
替换原理:排除spring-boot-starter-web默认Tomcat依赖,引入对应容器依赖,Spring自动装配生效,无需修改业务代码
7. Tomcat高频报错与Spring排障方案
-
端口占用异常:端口被其他进程占用,导致项目启动失败,可通过Spring配置修改端口、或终止占用进程
-
请求阻塞超时:Tomcat线程池耗尽,接口同步阻塞无释放,需优化线程池参数、减少长同步阻塞逻辑
-
全局乱码问题:Tomcat默认编码问题,Spring可通过内置编码过滤器统一UTF-8编码,彻底根治
-
热部署失效:内嵌Tomcat热加载策略限制,配合devtools插件可实现代码热更新
-
静态资源访问404:Tomcat上下文路径、静态资源拦截规则冲突,Spring可手动配置静态资源放行
8. Tomcat与Spring MVC核心联动链路(必背)
完整启动+请求闭环: 项目启动 → Spring初始化内嵌Tomcat容器 → Tomcat初始化DispatcherServlet → 初始化SpringMVC九大组件 → 监听端口等待请求 → Connector接收HTTP请求 → Filter过滤器预处理 → DispatcherServlet分发请求 → Controller执行业务 → 结果逐层返回 → Tomcat封装响应报文 → 返回浏览器
✅ 本模块核心总结
-
Tomcat是Servlet规范实现容器,是Spring MVC运行的物理载体,无Tomcat则无Web请求处理能力
-
双层架构解耦网络与业务,NIO线程池模型支撑Spring接口高并发处理
-
内嵌Tomcat是Spring Boot工业化开发的核心,支持灵活配置、独立部署、容器调优
-
线上接口并发、阻塞、超时问题,优先排查Tomcat线程池与连接数配置
总结:
-
容器核心作用:解析HTTP请求、创建线程处理请求、管理Servlet生命周期、端口监听
-
核心架构:Connector(连接监听)+ Container(请求处理)
-
线程模型:Tomcat线程池、Acceptor/Worker线程、最大连接数、最大线程数参数意义
-
Spring内嵌Tomcat:SpringBoot取消外置Tomcat、自动内嵌容器、容器参数调优、容器替换(Jetty/Undertow)原理
-
高频问题:端口占用、请求阻塞、并发瓶颈、Tomcat乱码、热部署失效
五、Web核心通用能力(企业项目刚需·完整版)
本模块是所有Spring Web项目必备通用能力 ,不属于框架核心源码,但属于100%企业开发刚需。乱码、跨域、会话失效、转发重定向混用、文件上传报错、前后端参数适配问题,全部集中在本模块。所有知识点均结合Spring底层原理、实战场景、高频报错、解决方案全覆盖。
1. 全局乱码问题(彻底根治·底层+方案)
乱码是Web开发经典问题,核心根源:客户端编码、传输编码、服务器解析编码、响应输出编码不统一,Spring可通过统一配置彻底根治,无需手动逐个接口处理。
(1)乱码核心分类与底层原因
-
GET请求乱码:参数拼接在URL中,由Tomcat解析解码,Tomcat8以下默认ISO-8859-1编码,不兼容中文,导致参数乱码;Tomcat8+默认UTF-8,基本解决GET乱码
-
POST请求乱码:请求体数据传输编码与服务端解析编码不一致,原生Servlet无默认UTF-8配置,不处理必然乱码
-
响应乱码:Spring响应输出默认编码不统一,返回中文前端展示问号/乱码,多出现于自定义响应、静态资源返回场景
(2)Spring Boot统一根治方案
Spring Boot提供CharacterEncodingFilter全局编码过滤器,优先级最高,可统一请求、响应编码为UTF-8,彻底解决所有乱码问题。
-
核心配置:强制请求编码UTF-8、强制响应编码UTF-8、覆盖容器默认编码
-
生效范围:所有接口、静态资源、前后端所有数据交互
-
企业规范:所有项目必须统一配置,杜绝局部乱码修复
(3)高频坑点
-
手动修改单个接口编码无效,底层Tomcat解析优先级高于接口代码
-
未开启强制编码覆盖,导致部分场景默认编码交替生效,乱码偶现
-
升级Tomcat后乱码复发,需重新校验全局编码过滤器配置
2. 跨域CORS完整解决方案(Spring全覆盖)
基于前文HTTP跨域原理,落地Spring全套跨域配置,解决99%跨域失效问题,区分简单请求、预检请求、不同配置层级。
(1)跨域核心本质回顾
跨域是浏览器安全限制,服务器本身无跨域限制;协议、域名、端口任意不同即为跨域,分为简单请求和预检OPTIONS请求。
(2)Spring三种跨域实现方式(企业分级使用)
-
局部跨域(单接口):@CrossOrigin注解,作用于Controller类/方法,适合临时接口、外部对接接口,灵活性高但不适合全局项目
-
全局跨域(推荐):实现WebMvcConfigurer#addCorsMappings,统一配置所有接口跨域规则,支持放行域名、请求方法、请求头、允许证书、预检缓存
-
过滤器跨域(底层兜底):自定义CorsFilter过滤器,优先级高于拦截器,专门解决OPTIONS预检请求拦截失效问题,微服务、网关项目首选
(3)跨域高频失效核心原因(面试+排障重点)
-
只配置业务跨域,未放行OPTIONS预检请求,浏览器预检请求404/403
-
前后端开启Cookie/Token证书传递,后端未配置allowCredentials=true
-
自定义过滤器/拦截器优先级过高,覆盖Spring原生跨域配置
-
多配置冲突:全局跨域+局部注解跨域规则冲突
3. Cookie与Session会话机制(传统会话+无状态改造)
HTTP无状态,Cookie+Session是传统会话保持核心方案,Spring完整兼容Servlet会话规范,同时适配现代JWT无状态改造。
(1)Cookie核心详解
-
核心原理:服务端通过Set-Cookie响应头写入Cookie,浏览器本地存储,后续每次请求自动携带Cookie到服务端
-
核心属性(企业必配): 1. domain:绑定域名,限制Cookie生效域名,防止跨域名泄露 2. path:绑定路径,限制Cookie生效接口路径 3. max-age/expires:过期时间,区分会话Cookie(浏览器关闭失效)、持久Cookie 4. HttpOnly:禁止JS读取Cookie,防止XSS攻击 5. Secure:仅HTTPS请求携带Cookie,提升安全性
-
Spring使用:通过HttpServletResponse写入Cookie、HttpServletRequest获取Cookie、@CookieValue注解直接绑定参数
(2)Session核心详解
-
底层原理:服务端创建Session对象,生成唯一JSESSIONID,通过Cookie返回浏览器,下次请求携带JSESSIONID匹配会话
-
生命周期:首次请求创建 → 持续访问续期 → 超时自动销毁(默认30分钟)→ 手动invalidate销毁
-
核心缺陷 : 1. 服务端存储,集群部署存在Session共享问题 2. 依赖Cookie,移动端、跨端适配差 3. 无法适配分布式、前后端分离项目
(3)企业级改造:Session迁移JWT无状态会话
前后端分离项目彻底摒弃Session,使用JWT令牌替代:客户端存储Token、请求头携带、服务端无状态校验,无需会话共享,适配分布式集群。
4. 转发与重定向(面试高频+业务选型)
是Web页面跳转、接口跳转的核心能力,二者底层原理、请求次数、地址栏、使用场景完全不同,90%开发者混用导致业务bug。
| 对比维度 | 服务器内部转发 forward | 客户端重定向 redirect |
|---|---|---|
| 请求次数 | 1次请求(服务端内部流转) | 2次请求(302响应+客户端二次请求) |
| 地址栏变化 | 地址栏不变,隐藏真实跳转地址 | 地址栏更新为目标地址 |
| 数据共享 | 可共享Request域数据 | 无法共享Request数据 |
| 跳转范围 | 仅可跳转本项目资源 | 可跳转外部域名、任意地址 |
| 底层层级 | Servlet内部跳转,浏览器无感知 | HTTP响应重定向协议机制 |
| 适用场景 | 页面跳转、接口内部流转、参数复用 | 提交后防重复提交、跨域跳转、外部链接跳转 |
高频坑点
-
POST请求转发不会重复提交,POST重定向会丢失请求体、导致参数失效
-
转发无法跳转外部链接,重定向无项目限制
-
视图跳转优先转发,业务提交后置跳转优先重定向(PRG模式)
5. 文件上传下载(Spring企业核心落地)
文件上传是Web高频功能,底层依赖Servlet文件解析规范,Spring做了高阶封装,解决原生IO繁琐、文件超限、大文件卡顿问题。
(1)核心底层原理
-
请求Content-Type必须为multipart/form-data,专属文件上传格式,无法使用JSON格式传文件
-
Spring通过StandardServletMultipartResolver文件解析器解析文件流、参数、文件名、大小
-
核心对象:MultipartFile,封装文件字节流、文件名、文件大小、后缀、保存方法
(2)Spring Boot核心配置(必配)
-
单文件最大大小、单次请求总文件大小(防止超大文件攻击)
-
临时文件存储路径、文件写入阈值(小文件内存存储、大文件磁盘缓存)
-
文件后缀校验、MIME类型校验,防止恶意文件上传
(3)企业级落地规范
-
禁止原文件名存储,防止中文乱码、文件名重复覆盖,采用UUID+时间戳重命名
-
区分本地存储、OSS云存储(阿里云/腾讯云),线上项目统一使用OSS存储
-
大文件分片上传、断点续传,解决超大文件上传超时、失败重传问题
-
文件下载设置响应头,解决中文文件名乱码、浏览器直接打开不下载问题
(4)高频报错与解决方案
-
415媒体类型不支持:未使用form-data格式上传文件
-
文件超限报错:未配置Spring文件大小参数
-
中文文件名乱码:下载响应头未编码处理
-
恶意文件上传漏洞:未校验文件后缀、MIME类型
总结:
-
乱码问题根治:请求乱码、响应乱码、URL乱码底层原因,Spring全局编码配置原理
-
跨域CORS原理:浏览器同源策略、简单请求/预检请求,Spring全局跨域配置、跨域失效场景
-
Cookie&Session:会话机制、Session共享、Cookie域名/路径/过期配置、无状态改造(JWT替代Session)
-
转发与重定向:服务器内部转发(一次请求)、客户端重定向(两次请求)、底层差异、适用场景
-
文件上传下载:Multipart文件解析、Spring文件上传阈值配置、大文件处理原理
六、序列化与数据交互规范(前后端联调刚需·企业统一标准)
序列化是Java对象与网络数据/存储数据互换的核心机制,Spring Web所有前后端数据交互、接口返回、参数接收、缓存存储、远程调用全部依赖序列化实现。90%的前后端联调bug:日期错乱、空值报错、字段大小写异常、循环引用报错、JSON解析失败、数值精度丢失,根源都是序列化规范不统一。本模块全覆盖Spring默认序列化机制、企业统一配置、高频坑点、解决方案、标准化规范。
1. 序列化核心概念与Spring底层机制
(1)核心定义
序列化:将Java复杂对象(Object)转换为可传输、可存储的字符串/字节数据(JSON/字节数组),用于网络传输、文件存储、缓存存储、远程调用。
反序列化:将前端传递的JSON字符串、磁盘字节数据,还原为Java实体对象,供程序业务逻辑使用。
(2)Spring默认序列化选型
-
Spring Boot Web默认集成Jackson作为全局序列化工具,无需手动引入依赖,原生适配@RequestBody、@ResponseBody、全局数据返回
-
替代方案:Fastjson/Fastjson2、Gson,企业项目优先原生Jackson(稳定性高、无安全漏洞、Spring原生适配、无需额外适配)
-
核心生效时机:接口入参JSON解析、接口出参对象转JSON、全局统一结果封装、日志对象打印序列化
(3)核心作用(企业开发必备)
-
统一前后端数据格式,避免字段格式不匹配导致的联调失败
-
解决日期、数值、空值、枚举、自定义对象的格式化问题
-
规避序列化漏洞、循环引用、精度丢失等线上隐患
-
统一项目编码规范,实现多人协作、多模块数据格式统一
2. Jackson全局核心配置(企业强制统一标准)
Spring默认Jackson配置存在大量缺陷,无法适配企业开发,必须手动自定义全局Jackson配置,统一所有接口序列化规则,是项目初始化必配步骤。
(1)基础全局格式化规则
-
日期统一格式化:全局统一 yyyy-MM-dd HH:mm:ss,解决前端时间戳、默认英文日期、时区错乱问题,支持Date、LocalDateTime、LocalDate、LocalTime全类型适配
-
空值统一处理:空对象、空集合、空字符串统一序列化,杜绝null前端展示异常、前端渲染报错
-
数值精度处理:BigDecimal、Long长整型防止前端精度丢失,解决后端19位Long前端失真问题
-
枚举序列化:统一按枚举值/名称序列化,避免默认输出枚举对象地址
(2)企业高阶配置规则
-
字段命名规则:统一驼峰命名,禁止大小写混乱,兼容前端下划线参数
-
未知字段处理:开启忽略未知字段,前端多余传参不报错,避免接口升级兼容问题
-
静态字段忽略:自动忽略static、transient修饰字段,不参与序列化
-
循环引用拦截:自动处理父子对象循环引用,避免栈内存溢出、序列化卡死
-
脱敏规则:支持手机号、身份证、姓名、地址自动脱敏序列化
(3)核心注解精细化控制(局部优先级高于全局)
-
@JsonFormat:局部自定义日期格式、时区,覆盖全局配置
-
@JsonProperty:自定义序列化字段名、设置字段排序、适配前端下划线参数
-
@JsonIgnore:序列化忽略指定字段,适配密码、密钥、敏感字段脱敏
-
@JsonInclude:控制空值是否序列化,按需返回字段
-
@JsonCreator:解决反序列化无参构造、参数绑定失败问题
3. 高频序列化报错与根治方案(线上排障核心)
(1)日期序列化异常(最高频)
-
报错现象:LocalDateTime序列化报错、返回时间戳、英文日期、时区偏移8小时
-
底层原因:Spring默认未适配JDK8+时间类、无全局时区配置、无统一格式化规则
-
根治方案:全局注册JDK8时间序列化器、统一Asia/Shanghai时区、固定日期格式
(2)字段未知异常 Unrecognized field
-
报错现象:前端传递多余字段,后端接口直接400报错
-
底层原因:Jackson默认严格模式,存在未定义字段直接反序列化失败
-
根治方案:全局配置忽略未知字段,兼容前后端版本迭代、字段新增
(3)Long长整型精度丢失
-
报错现象:后端返回19位订单ID、用户ID,前端最后几位数字变为0
-
底层原因:前端JS数值最大精度为16位,超长数字自动失真
-
根治方案:全局将Long类型序列化为字符串,从根源解决精度丢失
(4)循环引用序列化溢出
-
报错现象:一对多、多对一关联对象(用户-订单)序列化栈溢出、接口超时
-
底层原因:父子对象互相引用,Jackson无限递归序列化
-
根治方案:@JsonIgnore忽略关联字段、配置循环引用检测、采用DTO分层返回
(5)空值序列化前端报错
-
报错现象:字段为null时前端获取undefined、渲染空白、表单回显失败
-
底层原因:全局空值规则不统一,部分字段null、部分字段空字符串
-
根治方案:统一空对象返回空Map、空集合返回空数组、字符串空值统一处理
4. 数据交互分层规范(企业架构标准)
杜绝直接返回数据库实体类Entity,是企业项目强制规范,解决字段冗余、敏感数据泄露、序列化不可控问题。
(1)三层数据交互模型
-
PO/Entity(数据库层):仅对应数据库表字段,不参与前后端交互,包含数据库所有字段、主键、创建时间、更新时间、删除标记
-
DTO(数据传输层):前后端交互核心载体,按需定义字段、脱敏字段、格式化字段,适配接口入参和出参
-
VO(视图展示层):专门用于接口返回,过滤敏感字段、格式化数据、适配前端展示逻辑
(2)核心规范
-
禁止Entity直接返回前端,避免数据库冗余字段、敏感字段(密码、删除标记)泄露
-
入参优先使用DTO接收,统一参数校验、参数格式化
-
出参统一返回VO,严格控制序列化字段、数据格式
-
通过工具类实现PO、DTO、VO快速转换,避免手动set赋值冗余代码
5. 各类场景序列化适配方案
(1)普通接口JSON交互
全局Jackson统一格式化,适配99%的CRUD接口,保证所有项目接口数据格式统一、无差异化。
(2)文件/流数据交互
二进制流数据不参与JSON序列化,单独处理文件上传下载、字节流返回,避免流数据序列化异常。
(3)缓存序列化(Redis)
Redis缓存对象必须基于Jackson序列化,统一缓存数据格式,避免JDK原生序列化兼容性差、可读性低、跨服务解析失败问题。
(4)微服务远程调用序列化
OpenFeign远程调用依赖JSON序列化,全局统一格式可解决微服务之间参数解析失败、类型不匹配、日期错乱问题。
6. 序列化避坑终极总结(面试+实战必背)
-
核心底层:Spring Web默认Jackson序列化,所有接口参数、返回值解析全部依托该机制
-
最大坑点:直接返回实体类、无全局格式化、日期/数值未特殊处理、循环引用未规避
-
企业底线规范:全局统一序列化配置 + DTO/VO分层交互 + 敏感字段忽略 + 日期数值统一格式化
-
联调核心:后端所有数据格式统一、稳定、可预期,从根源解决80%前后端联调问题
-
JSON序列化核心:Jackson底层机制、全局日期格式化、空值处理、字段脱敏、序列化忽略规则
-
常见报错:序列化失败、日期转换异常、泛型序列化异常、循环引用序列化问题
-
Spring关联:@ResponseBody、@RequestBody底层依托Jackson实现数据解析与返回
✅ 本模块Spring核心关联总结(必记)
-
Maven:决定Spring项目依赖加载、打包部署、环境适配
-
HTTP:所有Spring接口请求、响应、状态码、跨域的底层规范
-
Servlet:Spring MVC、拦截器、过滤器、请求流转的底层根基
-
Tomcat:Spring项目运行容器、并发处理、线程调度核心
-
序列化:Spring接口数据交互、前后端联调的必备基础
4. 数据库基础(Spring数据层核心前置基石)
数据库是所有业务系统数据存储的核心,Spring JDBC、MyBatis、MyBatis-Plus、Spring事务、分布式数据治理的底层逻辑全部依托数据库规范。本模块摒弃零散SQL语法,只聚焦支撑Spring开发、面试、线上调优的核心知识点,补全CRUD开发者缺失的数据库底层认知,彻底解决Spring事务失效、数据库死锁、索引失效、查询慢、数据一致性等高频问题。
一、MySQL核心基础(企业开发必备)
核心定论:SQL语法只是基础,数据库存储引擎、执行机制、底层原理才是Spring数据层调优的核心,90%的接口查询卡顿、事务异常、数据错乱,根源是MySQL底层认知薄弱。
1. MySQL架构与存储引擎
-
整体架构分层:连接层(权限校验、连接管理)→ 服务层(SQL解析、优化、执行、事务管理)→ 存储引擎层(数据读写、索引维护)→ 磁盘文件层,Spring数据交互全程对接服务层与存储引擎层
-
InnoDB存储引擎(默认必备):支持事务、行级锁、外键、MVCC多版本并发控制、崩溃恢复,是Spring业务项目唯一选型,支撑Spring事务所有特性
-
MyISAM引擎(淘汰):不支持事务、表级锁、无崩溃恢复能力,仅适用于静态数据查询,企业Spring项目彻底摒弃
-
核心差异对标Spring场景:InnoDB的事务特性、行锁机制,是Spring声明式事务、事务隔离级别生效的底层前提
2. 基础SQL规范与企业实战准则
-
DML数据操作语言:SELECT/INSERT/UPDATE/DELETE,Spring业务CRUD核心依托,禁止使用全表DELETE/UPDATE,必须带有效WHERE条件
-
DDL数据定义语言:CREATE/ALTER/DROP,项目初始化、表结构迭代使用,线上生产禁止随意执行DDL,避免锁表阻塞业务
-
DCL数据控制语言:GRANT/REVOKE,权限管控,适配多环境数据库权限配置
-
企业SQL编写规范:禁止SELECT *、字段精准查询、分页必加LIMIT、大字段单独分表、WHERE条件优先索引字段、避免函数嵌套索引字段,适配MyBatis/MyBatis-Plus高效查询
3. 数据库三大范式与表设计
-
三大范式核心:列原子性、主键唯一性、字段无传递依赖,减少数据冗余
-
企业灵活取舍 :互联网项目适当反范式设计,允许少量冗余字段,减少联表查询,提升接口查询性能,适配Spring高并发接口
-
表设计核心原则:主键自增/雪花ID、必备通用字段(create_time/update_time/is_delete)、字段类型适配(VARCHAR长度可控、数值类型精准匹配)、逻辑删除优先物理删除
二、数据库事务核心(Spring事务底层根基)
核心重点:Spring所有事务机制,完全基于MySQL InnoDB事务特性封装,不懂数据库事务ACID、隔离级别、传播底层,永远无法根治Spring事务失效、数据脏读、并发数据错乱问题。
1. 事务四大特性ACID(必背)
-
原子性(Atomicity):事务内所有操作要么全部成功,要么全部回滚,无中间状态,Spring事务回滚的核心底层
-
一致性(Consistency):事务执行前后,数据库数据完整性、约束规则不变,保证数据合法有效
-
隔离性(Isolation):多个并发事务相互隔离、互不干扰,是事务隔离级别、锁机制的设计根源
-
持久性(Durability):事务提交后数据永久落地磁盘,崩溃不丢失,Spring事务提交生效的底层保障
2. 三大并发事务问题(Spring业务高频坑点)
-
脏读 :一个事务读取到另一个事务未提交的脏数据,对方回滚后数据失效,导致业务数据错乱
-
不可重复读:同一事务内,多次读取同一数据,被其他已提交事务修改,前后读取结果不一致
-
幻读:同一事务内,多次范围查询,被其他事务新增/删除数据,导致查询结果数量不一致
3. 四大事务隔离级别(Spring精准适配)
隔离级别逐级升高,并发性能逐级降低,Spring支持通过注解、配置文件全局指定,适配不同业务场景:
-
读未提交(READ UNCOMMITTED):最低级别,允许读取未提交数据,存在脏读、不可重复读、幻读,企业基本不用
-
读已提交(READ COMMITTED):默认级别之一,杜绝脏读,存在不可重复读、幻读,适合绝大多数普通业务,Spring默认适配级别
-
可重复读(REPEATABLE READ):MySQL默认级别,杜绝脏读、不可重复读,存在幻读,依托MVCC实现,适配订单、支付、库存核心业务
-
串行化(SERIALIZABLE):最高级别,完全杜绝所有并发问题,事务串行执行,性能极低,仅适配金融、对账极致一致性场景
4. Spring与数据库事务联动核心
-
Spring @Transactional 隔离级别配置,本质是修改数据库会话事务隔离级别
-
数据库事务是底层实现,Spring事务是上层封装,所有Spring事务失效场景,底层均是破坏了数据库事务执行规则
-
Spring事务传播行为,是在数据库事务基础上,扩展多方法、多类事务嵌套的执行规则
三、MVCC多版本并发控制(InnoDB核心)
MVCC是MySQL实现可重复读隔离级别、无锁并发查询的核心,也是Spring高并发查询接口性能优异的底层保障,彻底区分「快照读」与「当前读」。
1. 核心底层组件
-
隐藏字段:每行数据默认包含DB_TRX_ID(事务ID)、DB_ROLL_PTR(回滚指针)、DB_ROW_ID(隐藏主键)
-
undo log回滚日志:存储数据修改前的历史版本,用于事务回滚、多版本数据读取
-
read view读视图:事务开启时生成,用于校验数据版本可见性,实现隔离效果
2. 快照读与当前读(Spring高频面试+实战)
-
快照读(无锁):普通SELECT查询,读取undo log历史快照数据,无锁、高并发、性能高,Spring普通查询接口默认走快照读
-
当前读(加锁):INSERT/UPDATE/DELETE、SELECT ... FOR UPDATE,读取最新数据、加行锁,Spring事务更新、扣减库存、支付业务必须走当前读
3. MVCC核心作用
实现读写不阻塞、读读不阻塞,极大提升数据库并发能力,支撑Spring Boot高并发接口的读写性能,是互联网项目高性能数据交互的核心底层。
四、MySQL索引体系(接口性能优化核心)
索引是解决Spring接口查询慢、超时、数据库CPU打满的核心手段,90%的线上接口性能问题,均可通过索引优化根治,是Spring调优必备核心知识点。
1. 索引底层原理(B+树核心)
-
选型原因:B+树多路平衡、叶子节点有序串联、非叶子节点只存索引键,IO次数少、查询效率稳定,适配磁盘存储
-
结构特点:所有数据存储在叶子节点、主键索引叶子节点存完整数据、二级索引存主键值
-
回表查询:二级索引查询后,通过主键再次查询完整数据,是索引性能损耗的核心点
-
覆盖索引:查询字段全部包含在索引中,无需回表,Spring高频查询接口优化首选
2. 索引分类与企业使用场景
-
主键索引:唯一非空、自动创建,查询效率最高,所有业务表必须设置主键
-
唯一索引:字段唯一、允许空值,适配手机号、账号、订单号等唯一字段
-
普通索引:常规查询索引,适配高频查询、非唯一字段
-
联合索引(最左匹配原则):多字段组合索引,遵循最左前缀匹配,是企业高频优化手段,Spring多条件查询接口核心优化点
-
全文索引:适配大文本模糊查询,替代低效like %%查询
3. 索引失效大全(Spring排障必背)
-
联合索引不遵循最左匹配原则
-
索引字段使用函数、运算、类型转换
-
like %xxx 左模糊、%%xxx%% 全模糊查询
-
or连接无索引字段、null值判断不当
-
数据库优化器选择全表扫描(数据量少、索引选择性低)
4. 索引企业规范
-
高频查询字段、条件筛选字段优先建索引
-
避免过度索引,索引会降低增删改性能(需维护索引结构)
-
联合索引优先区分度高、高频查询、高频筛选字段在前
-
禁止低区分度字段(性别、状态)建索引,索引失效无意义
五、数据库锁机制(并发数据安全核心)
锁机制是解决Spring并发场景超卖、数据覆盖、并发错乱的底层核心,搭配Spring事务、分布式锁实现数据一致性。
1. 锁粒度分类
-
表级锁(MyISAM):锁定整张表,读写互斥、并发极低,仅静态查询使用
-
行级锁(InnoDB) :锁定单行数据,并发高、精准锁定,Spring并发业务核心依赖,仅通过索引更新数据生效
-
间隙锁+临键锁:可重复读隔离级别下,防止幻读,适配范围更新、分页查询场景
2. 锁类型与实战场景
-
共享锁(S锁):读锁,多事务可共享读取,互斥写锁
-
排他锁(X锁):写锁,独占锁定,其他事务无法读写,更新、扣减库存核心使用
-
乐观锁:无锁、版本号控制,适合读多写少场景,Spring通过版本字段实现乐观锁防并发
-
悲观锁:加锁独占,适合写多场景,通过SELECT ... FOR UPDATE实现,解决高并发数据竞争
3. 死锁成因与解决方案(线上高频)
-
死锁核心条件:互斥持有、请求保持、不可剥夺、循环等待
-
Spring项目死锁场景:多事务交叉更新不同行数据、锁顺序不一致
-
解决方案:统一数据库更新顺序、缩小事务粒度、避免长事务、设置事务超时时间
六、日志机制与数据恢复(底层必备)
1. 三大核心日志
-
redo log(重做日志):保证事务持久性,崩溃恢复、数据落地,Spring事务提交的底层保障
-
undo log(回滚日志):保证事务原子性,事务回滚、MVCC多版本数据依赖
-
binlog(二进制日志):记录所有DDL/DML操作,主从复制、数据同步、数据恢复、审计溯源,Spring微服务数据同步核心依赖
2. 日志联动Spring场景
Spring事务提交、回滚、数据同步、主从架构、读写分离,全部依托MySQL三大日志实现,是分布式数据治理的底层基础。
七、高频优化与坑点总结(对接Spring实战)
本模块聚焦Spring项目与MySQL联动的线上核心问题、性能瓶颈、高频报错、优化方案,摒弃空洞理论,全部为企业实战落地内容,根治Spring数据层开发中事务失效、接口卡顿、并发错乱、死锁、缓存与数据库不一致等核心问题,适配日常开发、线上调优、面试答疑全场景。
1. 线上慢接口终极优化全流程(Spring专属落地版)
Spring项目接口查询超时、响应卡顿、数据库CPU打满是线上最高频问题,标准化优化流程可快速根治80%慢接口问题,流程闭环无遗漏:
-
日志定位问题:开启MySQL慢查询日志,捕获执行超时SQL,同时结合Spring Boot日志、SkyWalking链路追踪,定位超时接口与对应SQL,区分是代码逻辑耗时还是数据库查询耗时。
-
执行计划分析:通过explain解析SQL执行计划,重点关注type(是否全表扫描)、key(是否命中索引)、rows(扫描行数)、Extra(是否Using filesort、Using temporary),精准定位索引失效、排序分页低效等问题。
-
SQL语句优化:摒弃SELECT *、杜绝无索引条件查询、拆分大联表查询、分页必加LIMIT、避免WHERE条件函数运算、优化JOIN和子查询逻辑,适配MyBatis/MyBatis-Plus查询规范。
-
索引精准优化:为高频查询、筛选、排序、分组字段建立联合索引,遵循最左匹配原则,优化覆盖索引杜绝回表查询,删除低效、冗余索引减少索引维护开销。
-
业务架构优化:高频静态查询接口引入Redis缓存、大流量接口做读写分离、超大表实施分表分库、复杂统计接口异步化,从架构层面规避数据库瓶颈。
-
线上压测验证:优化后通过压测工具验证接口QPS、响应耗时,结合Spring监控指标确认性能达标,规避优化后隐性问题。
2. Spring+MySQL高频实战坑点(精准溯源+解决方案)
(1)事务相关坑点(Spring最高频报错)
-
坑点1:事务无故不回滚 根源:Spring @Transactional默认仅回滚RuntimeException,普通Exception、受检异常不会触发回滚;业务代码手动try-catch捕获异常,导致Spring无法感知异常,事务终止回滚逻辑。 解决方案:注解配置rollbackFor = Exception.class,全局捕获异常后手动触发事务回滚(TransactionAspectSupport.currentTransactionStatus().setRollbackOnly())。
-
坑点2:事务失效 根源:非public方法、类内部方法自调用、多线程异步操作、原型Bean、数据库引擎非InnoDB,均会导致Spring事务无法生效。 解决方案:保证事务方法为public,通过Spring代理调用事务方法,异步业务单独管控事务,统一项目存储引擎为InnoDB。
-
坑点3:长事务导致锁等待、超时 根源:Spring业务代码逻辑冗余、外部接口调用、循环查询写入,拉长事务执行时间,长期占用数据库行锁,引发阻塞、死锁。 解决方案:精简事务粒度,仅将数据库增删改操作放入事务,非数据库逻辑抽离事务外,杜绝事务内远程调用、循环IO。
(2)并发数据安全坑点
-
坑点1:库存超卖、数据覆盖 根源:Spring高并发场景下,多线程同时读取同一库存数据,基于旧数据更新,无锁控制;事务隔离级别过低导致脏读、数据不一致。 解决方案:数据库行锁(SELECT ... FOR UPDATE)、乐观锁版本号控制、Redis分布式锁,适配不同并发量级业务。
-
坑点2:幻读导致批量操作数据遗漏 根源:MySQL可重复读隔离级别存在幻读问题,Spring批量新增、批量更新场景,其他事务新增数据导致当前事务操作遗漏。 解决方案:核心业务采用串行化隔离级别,或通过业务唯一索引、分布式锁规避幻读影响。
(3)索引失效性能坑点
-
坑点1:明明建了索引却走全表扫描 根源:索引字段使用函数、运算、类型转换;联合索引不遵循最左匹配;like左模糊查询;数据量过小数据库优化器放弃索引;字段频繁为NULL导致索引选择性低。 解决方案:优化SQL写法,遵循索引规范,优化字段设计,避免索引失效场景。
-
坑点2:过度索引导致增删改卡顿 根源:开发者为所有查询字段建索引,忽略索引需要实时维护,高频写入场景索引过多,大幅降低数据库写入性能,导致Spring新增/更新接口超时。 解决方案:仅为高频查询、筛选、排序字段建索引,定期清理冗余索引、低效索引。
(4)SQL编写与框架适配坑点
-
坑点1:MyBatis动态SQL空判断不当 根源:Spring接口传参空字符串、NULL值未做区分,导致SQL拼接异常、查询条件失效、全表扫描。 解决方案:统一参数校验规范,动态SQL同时判断NULL和空字符串,结合Spring全局参数校验过滤无效参数。
-
坑点2:批量操作性能极低 根源:使用for循环单条插入/更新数据,频繁与数据库建立连接,Spring事务频繁开启提交,极大损耗性能。 解决方案:使用MyBatis批量操作、SQL批量语法,结合Spring事务批量提交,减少数据库交互次数。
-
坑点3:大字段拖慢查询性能 根源:实体类直接关联TEXT、BLOB大字段,普通查询默认加载大字段,增加IO开销,导致接口响应变慢。 解决方案:大字段单独分表,业务查询按需查询大字段,避免全字段查询。
3. 数据库与Spring联动高级优化方案
(1)事务优化核心方案
-
粒度精简:事务只包含数据库操作,剥离日志打印、远程调用、文件操作、循环逻辑,最大化缩短事务执行时长。
-
隔离级别适配:普通业务使用默认可重复读,对账、金融核心业务手动调高隔离级别,查询类业务使用读已提交提升并发性能。
-
超时配置:通过@Transactional(timeout)设置事务超时时间,避免长事务永久占用锁资源,自动释放阻塞事务。
-
只读事务优化:查询接口添加readOnly = true,Spring和数据库均会优化只读事务,提升查询效率、减少锁竞争。
(2)高并发查询优化
-
覆盖索引优先:所有高频单表查询接口,优先设计覆盖索引,杜绝回表查询,大幅提升查询速度。
-
分页深度优化:规避limit 10000,100深度分页,通过主键偏移、延迟关联优化分页SQL,解决深分页接口超时问题。
-
读写分离落地:Spring项目整合读写分离插件,查询路由从读库、写入路由从写库,分担主库压力,适配高并发查询场景。
-
缓存分层:本地缓存+Redis分布式缓存,缓存高频静态数据、字典数据、热门业务数据,彻底避免频繁查询数据库。
(3)并发写入优化
-
批量操作常态化:新增、更新、删除场景优先使用批量SQL,替代循环单条操作,配合Spring事务批量提交。
-
锁粒度最小化:仅锁定业务必要数据行,避免锁表、大范围锁,缩小锁竞争范围,提升并发写入能力。
-
乐观锁适配读多写少场景:商品库存、用户信息等读多写少业务,使用版本号乐观锁,无锁并发提升性能。
-
异步削峰填谷:高并发写入场景,通过RabbitMQ/Kafka消息队列异步写入数据库,避免瞬时流量打满数据库。
4. 线上故障快速排查手册(Spring+MySQL)
-
接口500数据库异常:优先排查SQL语法、字段不匹配、主键重复、外键约束冲突,结合Spring异常日志定位SQL问题。
-
接口响应极慢:优先排查慢查询日志、索引失效、长事务、大事务、深分页SQL,90%为数据库查询瓶颈。
-
数据不一致、脏数据:排查事务回滚机制、异常捕获逻辑、并发锁控制、事务隔离级别问题。
-
数据库死锁报错:查看数据库死锁日志,统一SQL更新顺序、缩小事务粒度、避免交叉更新不同数据表。
-
数据库CPU飙升:排查全表扫描、索引失效、大量慢SQL、高频循环查询,优化SQL与索引结构。
-
数据库连接数打满:排查长事务、SQL超时未释放连接、Spring连接池配置不合理,优化超时时间、连接池参数。
✅ 本模块终极总结(Spring数据层核心命脉)
MySQL是Spring数据层的底层基石,事务ACID、隔离级别、MVCC 支撑Spring所有事务功能,索引体系 决定Spring接口查询性能,锁机制 保障并发业务数据安全,日志机制实现数据持久化与故障恢复。所有Spring数据层框架(MyBatis/MyBatis-Plus/JPA)、事务注解、并发控制,均是对MySQL底层能力的上层封装。掌握本模块优化与避坑方案,可彻底解决Spring项目80%以上的数据层线上问题、性能问题、面试难点。
总结:MySQL基础SQL、事务四大特性、隔离级别、锁机制、索引原理,为Spring事务、数据层框架铺路。
第二阶段:Spring Framework 核心底层(所有框架的根基,重中之重)
Spring Framework是Spring Boot、Cloud的底层核心,底层不牢,上层全废,所有面试核心难点均来自此模块。
1. IoC容器与Bean体系(核心中的核心)
IoC(控制反转)是Spring框架最核心、最底层、最基石 的设计思想,AOP、事务、自动配置、依赖注入所有Spring功能全部基于IoC容器实现。90%的Spring面试核心、源码难点、实战bug(循环依赖、Bean加载失败、注入失效、作用域异常)均出自本模块。本章节全网最全深度拆解,覆盖概念本质、底层源码、生命周期、循环依赖、高级特性、实战坑点、面试原题,彻底吃透Spring根基。
(1)IoC&DI核心本质(告别死记硬背)
1. 传统开发弊端(正向控制)
常规Java开发中,开发者主动通过new创建对象、管理对象依赖、控制对象生命周期,代码高度耦合:上层代码依赖下层实现,修改底层类需改动上层代码,无法实现组件解耦、灵活替换、统一管控,完全不适合大型企业项目迭代。
2. IoC控制反转核心定义
控制反转 = 反转对象控制权 :将开发者手动创建对象、管理依赖、管控生命周期的权利,全部交给Spring IoC容器 统一管理。 核心反转点:谁创建对象、谁管理依赖、谁控制生命周期,从「程序员主动控制」转为「容器被动管控」。
3. DI依赖注入(IoC的实现手段)
IoC是思想,DI是落地实现。容器在创建Bean的同时,自动解析组件之间的依赖关系,自动将依赖对象注入到目标Bean中,无需手动new关联对象。 核心价值 :彻底解耦组件依赖,实现面向接口编程、实现类可动态替换、组件可复用、统一生命周期管控。
4. IoC核心优势(企业实战价值)
-
彻底解耦:业务组件无硬编码依赖,专注自身业务逻辑
-
统一管控:所有Bean统一创建、初始化、销毁、资源回收
-
灵活扩展:配合条件注解、动态注册,实现组件动态替换
-
支撑高阶功能:AOP增强、事务管理、缓存、自动配置全部依托IoC容器
(2)IoC两大核心容器接口(源码顶层设计)
Spring IoC容器采用分层接口设计,底层基础容器+上层高级容器,适配不同场景需求,是源码学习的入口核心。
1. BeanFactory(底层基础IoC容器)
Spring IoC容器最顶层、最基础接口,是所有容器的父接口,定义了Bean容器最核心能力。
-
核心能力:根据Bean名称/类型获取Bean、判断Bean是否存在、获取Bean类型、判断单例/多例
-
核心特性 :延迟加载,仅在调用getBean()时才实例化Bean,节省内存资源
-
缺陷:功能单一,无事件发布、资源加载、国际化、容器刷新等高级能力
-
常用实现:DefaultListableBeanFactory(Spring核心默认工厂)
2. ApplicationContext(高级IoC容器,开发常用)
继承BeanFactory,在基础容器能力之上,扩展企业级高级功能,是Spring Boot/Spring MVC默认使用的容器。
-
核心特性 :立即加载,容器启动时预实例化所有非懒加载单例Bean,启动校验Bean合法性,提前暴露问题
-
四大扩展能力:资源加载、国际化支持、事件发布监听、Web环境适配
-
常用实现类: 1. ClassPathXmlApplicationContext(传统XML配置) 2. AnnotationConfigApplicationContext(注解配置,Spring Boot核心) 3. WebApplicationContext(Web项目专属容器)
3. 两大容器核心区别(面试高频)
-
加载时机:BeanFactory延迟加载、ApplicationContext启动预加载
-
功能范围:BeanFactory仅基础Bean管理、ApplicationContext具备全套企业级能力
-
使用场景:底层源码默认BeanFactory,业务开发统一使用ApplicationContext
(3)Bean全维度核心体系(全网最全精讲)
Bean是Spring IoC容器管理的最小单元,所有被容器接管的组件(Controller、Service、Repository、自定义组件)统称为Bean,本模块全覆盖Bean所有核心特性、底层原理、实战坑点。
1. Bean六大作用域(精准适配业务场景)
作用域决定Bean的实例数量、生命周期、共享范围,是解决Bean状态错乱、数据共享异常的核心。
-
singleton 单例(默认) 核心特性:整个IoC容器全局唯一实例,容器启动初始化(非懒加载)、全局共享、容器销毁时销毁 适用场景:无状态组件(Controller、Service、Dao、工具类,99%业务组件) 实战坑点:单例Bean非线程安全,禁止定义成员变量,避免并发数据覆盖
-
prototype 多例 核心特性:每次调用getBean()/依赖注入都会新建全新实例,容器只创建不销毁,无统一生命周期管理 适用场景:有状态组件、需要独立实例的业务对象 实战坑点:多例Bean无法被AOP完全代理、不参与循环依赖解决、频繁创建消耗性能
-
request 请求域(Web专属) 核心特性:一次HTTP请求对应一个独立Bean,请求结束Bean销毁 适用场景:请求级临时数据存储、参数临时封装
-
session 会话域(Web专属) 核心特性:一个用户Session会话对应一个Bean,会话过期/销毁则Bean销毁 适用场景:用户会话级数据缓存
-
application 全局域(Web专属) 核心特性:整个Web容器全局唯一,与ServletContext生命周期一致 适用场景:全局公共配置、全局静态资源
-
websocket 长连接域 核心特性:单个WebSocket连接独立Bean,连接断开则销毁 适用场景:即时通讯、长连接业务
2. 三大Bean注入方式(官方优选+优劣对比)
(1)构造器注入(Spring 4.3+官方强制推荐)
-
实现方式:通过类构造方法传入依赖,Spring自动解析构造器参数完成注入
-
核心优势 : 1. 保证Bean初始化完成时依赖全部就绪,避免空指针 2. 支持不可变对象(final修饰依赖) 3. 彻底杜绝循环依赖问题(单例Setter注入无法规避的场景除外) 4. 符合单一职责原则,依赖清晰可见
-
适用场景:必须依赖、核心业务组件、框架底层源码
-
底层规则:类只有一个有参构造器时,无需@Autowired自动注入
(2)Setter注入
-
实现方式:通过setXxx()方法注入依赖
-
核心优势 :适合可选依赖、动态修改依赖,Bean创建后可动态替换依赖对象
-
缺陷:Bean初始化完成后可能存在依赖缺失,存在空指针风险
-
适用场景:非必须依赖、运行时动态变更的组件
(3)字段注解注入(@Autowired/@Resource,开发常用)
-
@Autowired(Spring原生) :默认按类型byType注入,可配合@Qualifier按名称精准匹配,支持required属性控制是否必须
-
@Resource(JSR标准) :默认按名称byName注入,名称匹配失败再按类型,无required属性
-
优缺点:代码简洁、开发高效,但隐藏依赖关系,不利于代码可读性,底层本质是反射字段注入
注入方式终极选型规范(企业标准)
核心必须依赖用构造器、可选动态依赖用Setter、简单CRUD快速开发用字段注入
3. Bean完整生命周期(源码级10步拆解,面试必背)
Spring单例Bean从加载到销毁,严格遵循固定生命周期流程,全程由IoC容器管控,每一步对应底层源码逻辑,是理解Bean加载、AOP增强、初始化逻辑的核心。
-
资源加载与解析:容器启动扫描@Component、@Bean等注解,解析Bean定义信息(BeanDefinition),存储到Bean定义注册表,此时未创建实例
-
实例化(无参构造) :容器根据BeanDefinition,通过反射调用无参构造器,创建Bean空实例(此时属性全部为空)
-
属性填充(依赖注入):自动解析依赖Bean,完成@Autowired、构造器、Setter注入,赋值类成员变量
-
前置后置处理(BeanPostProcessor前置):执行Bean后置处理器前置方法,对原始Bean进行预处理
-
初始化前置校验(Aware接口回调):执行系列Aware接口,回调容器资源(BeanNameAware、BeanFactoryAware、ApplicationContextAware),让Bean感知容器信息
-
初始化方法执行: 1. 执行InitializingBean#afterPropertiesSet()内置初始化方法 2. 执行自定义init-method/@PostConstruct初始化方法
-
后置增强处理(BeanPostProcessor后置) :AOP代理核心步骤,对初始化完成的Bean进行动态代理增强,生成代理Bean
-
Bean就绪:完整可用的Bean存入单例池,对外提供服务
-
业务运行:响应业务请求,执行核心逻辑
-
销毁阶段:容器关闭时,执行DisposableBean#destroy()、自定义destroy-method/@PreDestroy销毁方法,释放资源
生命周期核心考点
-
AOP代理时机:初始化完成后、Bean就绪前,是原始Bean转为代理Bean的关键
-
初始化顺序:@PostConstruct > InitializingBean > 自定义init-method
-
销毁触发条件:仅单例Bean容器关闭时触发,多例Bean无销毁回调
4. 特殊Bean体系(面试高频难点)
(1)FactoryBean与BeanFactory核心区别(90%开发者混淆)
-
BeanFactory :IoC容器工厂接口,负责创建所有普通Bean,是容器本身
-
FactoryBean :特殊Bean ,用于自定义复杂对象创建逻辑,专门生产特殊Bean(MyBatis Mapper、第三方组件)
-
核心差异: 1. BeanFactory是容器、FactoryBean是组件 2. FactoryBean可自定义对象创建流程,解决复杂对象无法通过注解快速注册的问题 3. 获取FactoryBean本身需加&前缀,获取生产的Bean直接按名称获取
-
实战场景:MyBatis SqlSessionFactoryBean、Redis连接工厂、自定义复杂组件
(2)父子容器机制
-
核心规则:子容器可访问父容器Bean,父容器不可访问子容器Bean,Bean隔离互不干扰
-
Spring MVC场景:父容器(Spring容器)存放Service/Repository,子容器(SpringMVC容器)存放Controller,实现层级隔离
(3)抽象Bean
abstract修饰的Bean,仅作为父模板提供属性、方法配置,不会被容器实例化,用于统一子类Bean配置,减少冗余代码。
5. Bean高级特性(企业开发必备)
(1)懒加载 @Lazy核心作用 :单例Bean默认启动初始化,添加@Lazy后,首次使用时才实例化适用场景 :启动耗时久、使用率低、非核心业务组件坑点:懒加载Bean初始化异常会延迟到业务运行时抛出,隐藏启动问题
(2)类型转换 ConversionServiceSpring全局统一类型转换组件,支撑配置文件参数绑定、请求参数转换、Bean属性赋值,解决类型不匹配问题。
(3)条件装配 @Conditional系列根据环境、配置、Bean存在与否动态决定是否注册Bean,是Spring Boot自动配置的核心底层,常用注解:
@ConditionalOnClass、@ConditionalOnMissingBean、@ConditionalOnProperty。
6. 循环依赖终极原理(源码级拆解+根治方案)
循环依赖是Spring面试TOP1高频考点,也是实战最常见bug,本章节彻底讲透三级缓存原理、生效范围、无法解决的场景。
(1)循环依赖定义
两个或多个Bean互相依赖(A依赖B、B依赖A),容器加载时出现依赖闭环,若无特殊机制会直接启动报错。
(2)Spring三级缓存核心架构(DefaultSingletonBeanRegistry)
-
一级缓存(singletonObjects):完整初始化完成的单例Bean,对外提供服务,存储成熟Bean
-
二级缓存(earlySingletonObjects) :完成实例化、未完成属性填充和初始化的原始Bean半成品,无代理增强
-
三级缓存(singletonFactories) :存储Bean工厂对象(Lambda表达式),用于延迟获取半成品Bean、生成代理对象,是解决循环依赖的核心关键
(3)循环依赖完整执行流程
-
创建A Bean,实例化后存入三级缓存(工厂对象)
-
A填充属性,发现依赖B,开始创建B
-
B填充属性,发现依赖A,从一/二级缓存未找到,从三级缓存获取A的工厂对象,得到半成品A
-
B完成属性填充、初始化,存入一级缓存
-
A继续完成剩余属性填充、初始化、代理增强,存入一级缓存,清空二三级缓存
(4)生效与失效场景(必背)
-
可解决 :单例Bean、Setter/字段注解注入的循环依赖
-
不可解决 : 1. 构造器注入循环依赖(实例化阶段就需要依赖,无半成品缓存时机) 2. 多例Bean循环依赖(无缓存机制) 3. 内部类、静态变量依赖循环 4. AOP代理+复杂嵌套循环依赖
(5)企业级循环依赖解决方案
-
优先使用构造器注入从根源规避
-
抽取公共依赖,解耦双向依赖
-
使用@Lazy延迟加载打破依赖闭环
-
重构业务逻辑,拆分耦合组件
7. Bean加载失效高频坑点(实战排障必备)
-
Bean无法注入:未添加注册注解(@Component/@Service)、包扫描未覆盖、Bean名称冲突、作用域为多例
-
注入Bean为null:静态变量注入、非Spring管理类调用Bean、构造器注入顺序问题、循环依赖未解决
-
多Bean冲突:同一接口多个实现类,未指定@Qualifier导致byType注入歧义
-
初始化失效:Bean非单例、销毁方法不触发、初始化方法私有
2. AOP面向切面编程(Spring高阶核心、事务/日志/权限底层基石)
AOP(面向切面编程)是Spring横向扩展功能的核心思想 ,可在不修改原有业务代码的前提下,对方法进行前置、后置、异常、环绕增强,实现业务代码与通用横切逻辑解耦。Spring几乎所有高阶功能:声明式事务、日志记录、权限校验、接口限流、缓存增强、监控统计,全部基于AOP底层实现,是从「CRUD开发者」进阶「原理型开发者」的核心分水岭。
核心设计思想 :纵向写业务、横向做增强,剥离通用重复逻辑,统一切面管控,符合开闭原则、单一职责原则。
(1)AOP核心底层原理(动态代理机制)
Spring AOP底层完全基于动态代理实现,运行时动态生成目标类代理对象,通过代理对象拦截目标方法,完成横切增强,不侵入原有业务代码。Spring提供两种代理实现,具备严格的选择规则:
1. JDK动态代理
-
适用条件 :目标类实现了接口
-
核心特点:基于接口生成代理对象,仅能拦截接口中定义的方法,原生JDK自带、无第三方依赖
-
局限性:无法代理普通类、无接口类、类独有方法(非接口定义方法)
2. CGLIB动态代理
-
适用条件 :目标类无接口,默认采用CGLIB代理
-
核心特点:基于ASM字节码技术,继承目标类生成子类代理对象,可代理普通类、所有public方法
-
局限性:无法代理final类、final方法、private方法(无法重写)
3. Spring代理优先级规则(SpringBoot 2.x+新版)
-
SpringBoot 2.x之后默认强制使用CGLIB代理,无论是否实现接口,统一代理规则,规避JDK代理接口限制
-
可通过配置手动切换JDK动态代理,企业开发默认沿用CGLIB
(2)AOP核心专业名词(必背,看懂源码前提)
所有AOP源码、配置、切面逻辑,均围绕以下5大核心组件展开,精准区分概念是杜绝混淆的关键:
-
连接点(JoinPoint) :程序中可被拦截的任意方法(Spring AOP仅支持方法级拦截),是所有可增强的点位
-
切点(Pointcut) :筛选后的连接点,通过表达式匹配需要真正增强的目标方法(精准定位拦截范围)
-
通知/增强(Advice) :拦截方法后执行的具体增强逻辑,分为前置、后置、异常、返回、环绕五大类型
-
切面(Aspect) :切点+通知的集合,封装所有横切逻辑的类,是AOP功能的载体
-
引入(Introduction):动态为目标类新增方法、属性,实现类功能动态扩展(高阶用法)
-
织入(Weaving) :将切面增强逻辑植入目标方法、生成代理对象的过程,Spring为运行时织入
(3)五大通知类型与完整执行顺序(面试高频)
Spring AOP提供五种通知注解,覆盖方法全生命周期增强,不同通知执行顺序固定,适配不同业务场景:
1. 五大通知详解
-
@Before 前置通知 :目标方法执行之前执行,适用于参数校验、权限预检、日志预处理
-
@After 后置通知 :目标方法执行**之后(无论成功/异常)**执行,适用于资源释放、通用收尾
-
@AfterReturning 返回通知 :目标方法正常执行完毕、无异常后执行,可获取方法返回值,适用于结果日志、数据后置处理
-
@AfterThrowing 异常通知 :目标方法抛出异常后执行,可捕获异常信息,适用于异常告警、错误日志、事务回滚辅助
-
@Around 环绕通知 :最强通知,包裹目标方法,可自定义方法执行时机、是否执行、前后逻辑、异常捕获,适配所有复杂增强场景(限流、幂等、耗时统计、事务控制)
2. 单切面完整执行顺序
正常执行:@Around前置逻辑 → @Before → 目标方法执行 → @After → @AfterReturning → @Around后置逻辑
异常执行:@Around前置逻辑 → @Before → 目标方法报错 → @After → @AfterThrowing → 环绕通知异常收尾
3. 多切面执行优先级
-
通过**@Order(num)**指定优先级,数值越小优先级越高
-
执行规则:高优先级切面先进后出(前置先执行、后置后执行)
(4)切点表达式核心写法(企业实战常用)
切点表达式用于精准匹配拦截范围,杜绝全量拦截造成性能损耗,以下为开发高频刚需写法:
-
execution(最常用,方法粒度拦截) 语法:execution(返回值 包名.类名.方法名(参数)) 示例:execution(* com.xxx.service.*.*(..)) 拦截service层所有方法
-
annotation(注解拦截,精准度最高) 示例:@annotation(com.xxx.annotation.Log) 拦截所有标注自定义@Log注解的方法
-
within(类粒度拦截) 示例:within(com.xxx.controller.*) 拦截指定包下所有类的全部方法
-
args(参数匹配拦截):根据方法参数类型、数量匹配拦截
(5)AOP经典实战场景(企业全覆盖)
所有无业务侵入、通用重复的横向逻辑,均可用AOP实现,核心落地场景如下:
-
统一日志处理:接口入参、出参、请求耗时、操作日志自动记录,无需每个方法手写日志
-
权限校验拦截:接口访问权限、角色校验、Token有效性统一拦截,解耦业务代码
-
事务控制:@Transactional基于AOP环绕通知实现事务开启、提交、回滚
-
接口限流防刷:通过环绕通知统计请求频次,拦截高频恶意请求
-
幂等性校验:拦截重复提交请求,基于Token/唯一标识防重
-
性能监控:统计接口、方法执行耗时,快速定位慢接口、慢方法
-
缓存增强:查询方法自动缓存、更新方法自动清空缓存
(6)AOP高频失效场景(面试必考+实战排障核心)
90%的AOP失效问题,均源于违反动态代理执行规则,以下为全网最全失效场景+根治方案:
-
场景1:类内部方法自调用(最高频) 根源:this.方法调用,直接调用原生对象方法,未经过Spring代理对象,切面无法拦截 解决方案:通过Spring上下文获取代理对象调用、开启AOP暴露代理(expose-proxy=true)、AopContext.currentProxy()
-
场景2:非public方法 根源:CGLIB/JDK代理均依赖重写方法,private/protected方法无法被重写,无法织入增强 解决方案:统一将切面拦截方法定义为public
-
场景3:final/static方法 根源:final方法不可重写、static方法属于类而非对象,代理无法覆盖增强 解决方案:业务方法禁止添加final/static修饰
-
场景4:切面类未交给Spring管理 根源:切面类未添加@Aspect+@Component,容器无法识别切面、无法完成织入 解决方案:所有切面必须纳入Spring IoC容器
-
场景5:切点表达式匹配错误 根源:包名、类名、方法参数匹配范围错误,未命中目标方法 解决方案:精准调试切点表达式,缩小拦截范围、精准匹配目标
-
场景6:多线程异步调用 根源:子线程调用目标方法,脱离主线程AOP上下文,拦截失效 解决方案:异步方法单独适配切面,传递线程上下文
(7)AOP底层源码核心流程(精简必背)
-
容器启动扫描所有@Aspect切面类,解析切点、通知信息,封装为切面定义
-
Bean初始化后置阶段(BeanPostProcessor),匹配所有符合切点的目标Bean
-
根据目标类是否存在接口,选择JDK/CGLIB动态代理方式
-
生成代理对象,替换容器中原生Bean存入单例池
-
调用目标方法时,进入代理拦截链,依次执行前置、目标、后置、异常通知
✅ AOP模块终极总结
-
核心本质:动态代理实现方法横向增强,解耦通用横切逻辑
-
代理规则:SpringBoot默认CGLIB代理,适配所有普通类与接口类
-
核心链路:切点匹配→代理生成→方法拦截→通知执行
-
最大坑点:内部自调用、非public、final/static方法导致AOP失效
-
框架支撑:Spring事务、缓存、日志、权限所有高阶功能均依赖AOP实现
3. Spring事务体系(企业核心高频·全网最全完整版)
Spring事务是企业开发最高频、最易踩坑、面试必考 的核心模块,所有支付、订单、对账、库存等核心业务完全依赖事务保障数据一致性。Spring事务基于AOP动态代理+ThreadLocal线程隔离 实现,分为声明式事务(@Transactional) 和编程式事务(TransactionTemplate) 两大实现方式,彻底封装JDBC事务底层,简化事务开发。本模块全覆盖核心原理、七大传播行为、四大隔离级别、高级配置、百分百失效场景、嵌套事务、多线程事务、线上调优,根治99%事务相关bug与面试盲区。
(1)Spring事务核心底层原理
1. 核心实现机制
Spring事务本质是AOP环绕通知+数据库原生事务 :通过动态代理拦截目标方法,在方法执行前开启事务、执行中捕获异常、执行后提交/回滚事务,全程基于ThreadLocal实现单线程事务上下文隔离,多线程之间事务互不干扰。
2. 两大事务实现方式对比
-
声明式事务 @Transactional(99%企业使用) 核心特点:注解驱动、无侵入业务代码、配置简洁、基于AOP代理实现 适用场景:绝大多数业务增删改场景、标准化事务流程 短板:灵活性有限,存在固定失效场景
-
编程式事务 TransactionTemplate 核心特点:代码硬编码、手动控制事务开启/提交/回滚、自由度极高 适用场景:复杂嵌套事务、动态事务逻辑、非常规事务流程 优势:无AOP失效问题,可控性拉满
3. 核心底层依赖
Spring事务不替代数据库事务,而是对MySQL InnoDB事务的高阶封装,事务的ACID特性、锁机制、日志落地完全依赖数据库,Spring仅负责事务的统一管控、线程隔离、切面增强。
(2)七大事务传播行为(面试TOP高频、业务核心)
传播行为定义了当前有事务/无事务时,被调用方法的事务沿用规则,是解决嵌套事务、事务叠加、事务失效的核心关键,7种行为全覆盖场景与坑点:
1. REQUIRED(默认传播行为·最常用)
-
规则 :当前存在事务则加入当前事务 ,无事务则新建事务
-
核心特点:所有嵌套方法共用同一个事务,任意方法异常,整体全部回滚
-
适用场景:绝大多数常规业务,主流程与子流程数据强一致场景
-
实战坑点:子方法异常被捕获,主方法无法感知,导致事务不回滚、数据不一致
2. SUPPORTS(支持事务)
-
规则 :当前有事务则加入事务,无事务则以非事务方式运行
-
适用场景:查询接口、非核心业务、可兼容事务与非事务环境的逻辑
-
坑点:无事务运行时,方法报错不会触发任何回滚
3. MANDATORY(强制事务)
-
规则 :当前必须存在事务,否则直接抛异常
-
适用场景:核心子业务,必须依托主事务执行,禁止独立运行
4. REQUIRES_NEW(新建独立事务·核心重点)
-
规则 :无论当前是否有事务,强制新建独立事务,挂起原有事务
-
核心特性 :新旧事务完全独立、互不影响,子事务回滚不影响主事务,主事务回滚不影响已提交的子事务
-
适用场景:日志记录、操作审计、消息发送、异步兜底(核心业务失败,日志仍需保存)
5. NOT_SUPPORTED(不支持事务)
-
规则 :始终以非事务方式运行,存在当前事务则挂起
-
适用场景:大批量数据查询、非核心统计逻辑、无需事务保障的业务
6. NEVER(强制非事务)
-
规则 :当前存在事务则直接抛异常,必须无事务运行
-
适用场景:绝对禁止事务的特殊业务逻辑
7. NESTED(嵌套事务·高频难点)
-
规则 :有当前事务则嵌套在主事务中运行,无事务则新建事务
-
核心特性 :基于**保存点(SavePoint)**实现,子事务可独立回滚,不影响主事务;但主事务回滚,所有嵌套子事务必须全部回滚
-
与REQUIRES_NEW核心区别:NESTED依赖主事务、主回滚子必回;REQUIRES_NEW完全独立、互不干扰
-
适用场景:主业务整体一致、子业务可单独容错的场景
✅ 传播行为选型终极规范
-
常规业务强一致:默认 REQUIRED
-
查询、兼容场景:SUPPORTS
-
独立日志、兜底逻辑:REQUIRES_NEW
-
嵌套容错、局部回滚:NESTED
-
非事务大批量操作:NOT_SUPPORTED
(3)四大事务隔离级别(并发数据安全核心)
隔离级别用于解决并发事务引发的脏读、不可重复读、幻读问题,Spring完全兼容MySQL事务隔离级别,可通过注解手动指定,适配不同并发业务场景:
1. READ_UNCOMMITTED(读未提交·最低级别)
-
特性 :可读取其他事务未提交数据
-
问题:存在脏读、不可重复读、幻读,数据一致性极差
-
使用场景:几乎不用于企业业务,仅做技术测试
2. READ_COMMITTED(读已提交·Oracle默认)
-
特性 :只能读取其他事务已提交数据
-
解决:脏读问题
-
存在问题:不可重复读、幻读
-
适用场景:高并发查询业务、对一致性要求一般的场景,并发性能高
3. REPEATABLE_READ(可重复读·MySQL默认)
-
特性:同一事务内,多次读取同一数据,结果始终一致(基于MVCC多版本控制)
-
解决:脏读、不可重复读
-
存在问题:幻读
-
适用场景:绝大多数企业核心业务、订单、库存、支付(默认首选)
4. SERIALIZABLE(串行化·最高级别)
-
特性:事务串行执行,完全规避所有并发问题
-
解决:脏读、不可重复读、幻读(全部解决)
-
短板:并发性能极低、极易锁等待、引发死锁
-
适用场景:金融对账、核心交易、数据绝对一致的低并发场景
✅ 隔离级别企业选型原则
常规业务默认 MySQL REPEATABLE_READ;高并发查询业务降级为 READ_COMMITTED;金融核心对账业务升级为 SERIALIZABLE。
(4)@Transactional 高级核心配置(企业优化必备)
默认注解配置无法适配复杂业务,以下高频参数是解决事务异常、性能卡顿、回滚失效的核心:
1. 异常回滚精准配置(根治回滚失效)
-
默认规则 :仅回滚 RuntimeException、Error,普通受检 Exception 不回滚
-
全局通用配置:rollbackFor = Exception.class(所有异常全部回滚,企业标配)
-
排除回滚配置:noRollbackFor = 自定义业务异常(正常业务报错无需回滚)
2. 只读事务优化(性能提升30%+)
-
配置:readOnly = true
-
作用:告知Spring与数据库当前为查询事务,关闭事务写入逻辑、优化锁机制、减少资源占用
-
适用场景:所有查询接口、统计接口,企业性能优化刚需
3. 事务超时配置(解决长事务锁等待)
-
配置:timeout = 秒数
-
作用:事务超时自动强制回滚、释放锁资源,杜绝长事务占用数据库连接与行锁
-
实战配置:常规业务3-5秒,复杂业务10秒,超时直接终止事务
4. 事务隔离级别手动指定
通过isolation属性手动修改单方法隔离级别,覆盖全局默认,适配差异化业务。
(5)Spring事务百分百失效场景(面试必考+实战排障终极版)
所有事务失效问题,全部源于AOP代理规则破坏、事务上下文断裂、数据库不支持事务,全网最全10大失效场景,精准溯源+解决方案:
1. 方法非 public 修饰(最高频)
-
失效根源:Spring AOP动态代理仅拦截public方法,private/protected/default方法无法被代理织入,事务逻辑不生效
-
解决方案:所有事务方法统一定义为public
2. 类内部方法自调用
-
失效根源:this.xxx()调用原生对象方法,未经过Spring代理对象,AOP事务切面无法拦截
-
解决方案:1. 通过AopContext.currentProxy()获取代理对象调用;2. 拆分业务到不同类;3. 开启expose-proxy=true暴露代理
3. 业务代码手动 try-catch 捕获异常
-
失效根源:异常被业务层捕获,Spring事务切面无法感知异常,不会触发回滚逻辑
-
解决方案:catch后手动设置事务回滚:TransactionAspectSupport.currentTransactionStatus().setRollbackOnly()
4. 异常类型不匹配默认回滚规则
-
失效根源:抛出普通受检Exception,默认仅回滚运行时异常
-
解决方案:注解添加 rollbackFor = Exception.class
5. 多线程异步事务(事务上下文断裂)
-
失效根源:Spring事务基于ThreadLocal绑定,子线程无法获取主线程事务上下文,多线程操作属于独立事务
-
解决方案:异步业务单独管控事务,禁止多线程共用主线程事务
6. Bean作用域为原型 prototype
-
失效根源:多例Bean无统一生命周期管控,Spring无法完整代理事务流程
-
解决方案:事务业务组件统一使用单例singleton
7. 数据库引擎非 InnoDB
-
失效根源 :MyISAM引擎不支持事务、锁机制,无论Spring如何配置均无效
-
解决方案:项目所有数据表统一使用InnoDB引擎
8. 事务方法被 final/static 修饰
-
失效根源:final方法不可重写、static方法属于类,CGLIB/JDK代理均无法增强
-
解决方案:业务事务方法禁止添加final、static修饰符
9. 嵌套事务传播行为使用错误
-
失效根源:REQUIRED嵌套场景子异常被捕获,导致整体事务不回滚
-
解决方案:核心嵌套业务改用NESTED或REQUIRES_NEW
10. 只读事务执行写入操作
-
失效根源:readOnly=true的事务禁止写入,执行增删改直接报错
-
解决方案:查询方法开启只读事务,写入方法关闭只读配置
(6)高阶难点:嵌套事务实战坑点与解决方案
嵌套事务是企业开发高频疑难问题,核心区分REQUIRED、NESTED、REQUIRES_NEW三种嵌套场景的容错机制:
-
REQUIRED 嵌套(同事务):父子方法共用一个事务,任意节点异常、整体回滚,无局部容错能力,适合强一致业务
-
REQUIRES_NEW 嵌套(独立事务):子事务完全独立,可单独提交/回滚,主事务失败不影响已提交子事务,适合日志、审计容错
-
NESTED 嵌套(保存点事务):子事务依赖主事务,可局部回滚,主事务失败必整体回滚,适合局部容错、整体一致场景
(7)多数据源事务与分布式事务基础
1. 单服务多数据源事务
普通@Transactional仅支持单数据源事务,跨多个数据库操作时事务失效,需手动配置多数据源事务管理器,通过事务同步机制保障数据一致性。
2. 分布式事务铺垫
微服务跨服务、跨库、跨节点场景,Spring本地事务完全失效,需依赖Seata、RabbitMQ可靠消息、TCC事务实现分布式最终一致性,为后续微服务分布式事务模块做基础铺垫。
(8)Spring事务线上调优与故障排查手册
1. 事务性能优化核心方案
-
缩小事务粒度:仅将数据库增删改逻辑放入事务,剥离日志、远程调用、循环计算、IO操作,杜绝长事务
-
分级隔离级别:查询业务用读已提交、核心交易用可重复读、对账业务用串行化,避免过度锁竞争
-
开启只读事务:所有查询接口启用readOnly,降低数据库事务开销
-
配置事务超时:避免事务永久阻塞、锁资源永久占用
2. 线上高频故障快速排查
-
事务不回滚:优先排查异常捕获、回滚规则、方法权限、内部调用四大问题
-
接口卡顿、锁超时:排查长事务、事务粒度过大、隔离级别过高、锁竞争激烈
-
数据部分成功、部分失败:嵌套事务传播行为错误、多线程事务上下文断裂
-
数据库死锁:事务执行顺序混乱、长事务占用行锁、隔离级别过高
✅ 事务模块终极总结
-
核心本质:AOP代理增强 + ThreadLocal线程隔离 + 数据库原生事务
-
核心重点:七大传播行为区分场景、四大隔离级别适配并发、精准异常回滚配置
-
排障核心:99%事务失效源于代理失效、异常捕获、数据库不支持事务
-
优化核心:精简事务粒度、分级隔离级别、杜绝长事务、查询只读优化
4. ApplicationContext容器高级能力(源码核心+扩展机制+实战落地)
ApplicationContext作为Spring顶级高级容器,除基础Bean管理能力外,具备容器刷新、事件驱动、资源加载、国际化、扩展后置处理、环境配置、层级隔离等企业级高阶能力,是Spring Boot自动配置、Spring MVC运行、组件扩展的核心底层支撑。本模块全覆盖源码级核心流程、高阶扩展用法、实战场景与面试重难点,彻底吃透Spring容器核心内核。
(1)容器核心刷新流程:refresh()十二步源码精讲(Spring最核心源码)
refresh()是Spring容器启动的核心入口,ApplicationContext容器初始化、Bean加载、组件注册、自动配置、上下文初始化全部依托该方法完成,是看懂所有Spring源码的基础,十二步标准执行流程(企业面试必背):
-
准备刷新环境(prepareRefresh):初始化容器启动时间、激活刷新状态、初始化环境变量、校验必填配置、预处理上下文环境,为后续刷新流程做准备。
-
获取Bean工厂(obtainFreshBeanFactory) :刷新并获取底层基础Bean工厂DefaultListableBeanFactory,加载XML/注解配置,解析生成BeanDefinition注册表(仅存定义,未实例化Bean)。
-
预处理Bean工厂(prepareBeanFactory):配置Bean工厂核心参数,设置类加载器、表达式解析器、注册内置环境Bean、忽略依赖注入接口,完成工厂基础初始化。
-
后置处理Bean工厂(postProcessBeanFactory):留给子类扩展的钩子方法,Web容器会在此步注册Web专属上下文、作用域、内置对象,适配Web环境。
-
执行Bean工厂后置处理器(invokeBeanFactoryPostProcessors) :自动配置核心步骤,执行BeanFactoryPostProcessor后置处理器,扫描所有Starter、加载自动配置类、解析条件注解、补充Bean定义,Spring Boot自动配置底层依托此步实现。
-
注册Bean后置处理器(registerBeanPostProcessors):扫描并注册所有BeanPostProcessor后置处理器(AOP、事务、依赖注入的核心处理器),排序后统一注册,为后续Bean增强做准备。
-
初始化消息资源(initMessageSource):初始化国际化i18n资源处理器,加载多语言配置,支撑项目国际化场景。
-
初始化事件广播器(initApplicationEventMulticaster):初始化Spring事件发布与监听核心组件,为后续事件机制提供支撑。
-
注册容器监听器(registerListeners):扫描所有实现ApplicationListener的监听器,注册到事件广播器,提前绑定事件监听关系。
-
实例化所有非懒加载单例Bean(finishBeanFactoryInitialization) :IoC核心步骤,遍历Bean定义注册表,完成单例Bean实例化、属性注入、初始化、AOP代理增强、三级缓存解析,最终存入单例池。
-
完成容器刷新(finishRefresh):发布容器刷新完成事件、初始化生命周期处理器、启动所有生命周期组件、标记容器为就绪状态,容器正式对外提供服务。
-
清理刷新缓存:清空刷新过程临时缓存、释放资源,完成容器完整启动流程。
核心考点总结:Bean定义解析在前、Bean实例化在后;后置处理器先注册、后执行;自动配置、AOP、事务、Bean生命周期全部嵌入refresh()流程中执行。
(2)Spring事件驱动机制(观察者模式落地)
Spring事件机制基于观察者模式实现,依托ApplicationContext事件广播器完成事件发布与监听,实现业务完全解耦,是Spring容器扩展、异步通知、业务解耦的核心能力。
1. 事件机制三大核心组件
-
ApplicationEvent(事件父类):所有自定义事件、内置事件的顶层父类,封装事件源、触发时间等基础信息。
-
ApplicationListener(事件监听器):事件消费接口,监听指定事件并执行处理逻辑,支持泛型精准匹配事件类型。
-
ApplicationEventMulticaster(事件广播器):容器核心调度组件,负责统一发布事件、匹配监听器、分发事件执行。
2. Spring内置核心事件(容器生命周期全程覆盖)
-
ContextRefreshedEvent:容器刷新完成事件(项目启动完成触发,最常用),可用于启动初始化字典、预热缓存、注册定时任务。
-
ContextStartedEvent:容器启动事件,容器主动start()时触发。
-
ContextStoppedEvent:容器停止事件,容器暂停时触发,用于资源临时释放。
-
ContextClosedEvent:容器关闭事件,项目停机时触发,用于资源销毁、连接关闭、数据落地。
-
RequestHandledEvent:Web专属事件,单次请求处理完成后触发,可用于请求日志统计、接口耗时监控。
3. 自定义事件完整落地(企业解耦必备)
适用于订单创建、用户注册、消息推送等解耦场景,替代硬编码调用,实现业务异步解耦。
-
实现步骤:自定义事件类(继承ApplicationEvent)→ 自定义监听器(实现ApplicationListener/注解@EventListener)→ 容器发布事件
-
注解极简用法:通过@EventListener直接监听事件,无需实现接口,支持方法级别精准监听。
-
异步事件:配合@Async实现事件异步监听,不阻塞主业务流程,提升接口响应速度。
4. 事件机制核心坑点
-
默认事件为同步执行,监听器报错会导致主业务报错,需手动捕获异常或开启异步。
-
子容器事件不会向上传递,父子容器事件相互隔离。
-
监听器优先级可通过@Order调整,数值越小执行优先级越高。
(3)统一资源加载机制
ApplicationContext继承ResourceLoader接口,提供统一、跨环境的资源加载能力,兼容本地文件、ClassPath、网络资源、外置配置文件,是Spring配置文件读取、资源加载的底层统一方案。
1. 核心资源路径前缀
-
classpath: 加载项目类路径资源(yml/properties配置、静态资源)。
-
file: 加载服务器本地磁盘外置资源。
-
http: 加载网络远程资源。
-
无前缀:默认优先加载ClassPath资源。
2. 实战场景
-
读取自定义配置文件、模板文件、静态资源。
-
项目打包后读取外置配置、离线资源文件。
-
Spring Boot配置文件优先级、外置配置加载底层依托此机制。
(4)国际化i18n支持(企业多语言必备)
ApplicationContext内置MessageSource国际化组件,支持多语言配置、动态切换语言、统一消息解析,适配跨境项目、多语言后台、接口提示语国际化场景。
-
核心能力:加载多语言配置文件、根据Locale区域信息动态匹配语言、统一管理提示消息、参数占位符替换。
-
实战落地:全局异常提示、接口返回文案、前端弹窗提示统一国际化,无需硬编码文字。
(5)环境与配置绑定能力
ApplicationContext内置Environment环境组件,统一管理系统环境变量、JVM参数、配置文件参数、多环境配置,是Spring Boot配置绑定、动态参数获取的核心底层。
-
核心功能:获取配置参数、区分开发/测试/生产环境、校验配置合法性、动态读取运行时配置。
-
Spring关联:@Value取值、@ConfigurationProperties配置绑定、多环境切换、配置优先级全部依托Environment实现。
-
高阶能力:支持运行时动态刷新配置(适配Nacos配置热更新)、配置占位符解析、参数类型自动转换。
(6)两大核心后置处理器(Spring扩展核心)
后置处理器是Spring开放式扩展核心,允许开发者在容器启动、Bean加载的关键节点自定义逻辑,是框架高扩展性的根本原因,区分两大高频后置处理器:
1. BeanFactoryPostProcessor(工厂后置处理器)
-
执行时机 :Bean定义加载完成、Bean实例化之前
-
核心能力:修改、新增、删除BeanDefinition(Bean定义信息),可动态修改Bean属性、补充配置、注册自定义Bean定义。
-
经典场景:Spring Boot自动配置扫描、MyBatis Mapper接口动态注册、自定义Bean批量注册。
2. BeanPostProcessor(Bean后置处理器)
-
执行时机 :Bean实例化、属性填充完成,初始化前后执行
-
核心能力 :对已创建的Bean进行增强、修改、代理替换,是AOP代理、事务增强、注解解析的核心载体。
-
经典场景:生成AOP代理Bean、处理@Transactional/@Autowired注解、Bean初始化后置增强。
终极区分(面试必考) :BeanFactoryPostProcessor操作Bean定义 (改配置)、BeanPostProcessor操作Bean实例(改对象)。
(7)父子容器层级隔离机制
ApplicationContext支持多层父子容器架构,实现Bean层级隔离、职责拆分、解耦冲突,是Spring MVC经典架构的底层设计。
1. 核心规则
-
子容器可访问父容器所有Bean,继承父容器配置与资源。
-
父容器不可访问子容器Bean,完全隔离子容器业务组件。
-
父子容器Bean名称可重复,互不冲突。
2. Spring MVC经典落地架构
-
父容器(RootApplicationContext):存放底层业务组件(Service、Repository、工具类、事务组件),全局唯一。
-
子容器(WebApplicationContext):存放Web组件(Controller、拦截器、Web配置),可多子容器隔离不同模块。
-
设计价值:业务层与Web层解耦,Web组件销毁不影响底层业务容器,提升框架稳定性。
✅ ApplicationContext高级能力终极总结
-
核心内核:refresh()十二步是容器启动根本,贯穿所有Bean加载、配置、增强流程。
-
扩展核心:两级后置处理器实现框架无限扩展,支撑自动配置、AOP、事务所有高阶功能。
-
解耦能力:事件驱动机制实现业务解耦,支持同步/异步事件,适配复杂业务场景。
-
环境适配:统一资源加载、国际化、多环境配置,适配工业化开发。
-
架构设计:父子容器隔离机制,实现层级解耦、职责拆分,是Spring Web架构的底层基石。
5. Spring MVC 核心全体系(容器落地核心、接口开发基石)
Spring MVC是Spring容器在Web场景的核心落地实现,依托ApplicationContext容器、Servlet规范、DispatcherServlet核心调度,实现HTTP请求全流程处理。承接前文容器高级能力,本模块完整补全MVC核心架构、九大组件、请求流转、参数解析、拦截器、异步开发、全局统一处理,全覆盖企业接口开发、源码原理、高频坑点,彻底打通Spring容器与Web开发的关联闭环。
(1)MVC核心架构与九大核心组件(源码必背)
Spring MVC所有请求处理逻辑,全部依托九大核心组件协同完成,在DispatcherServlet初始化阶段加载注册,是MVC框架运行的底层核心:
-
DispatcherServlet(中央调度器):MVC核心入口,全局请求统一分发、调度所有组件执行,是Servlet的子类,承接Tomcat所有HTTP请求
-
HandlerMapping(处理器映射器):根据请求URL、请求方法,精准匹配对应的Controller处理器,建立请求与业务方法的映射关系
-
HandlerAdapter(处理器适配器):适配不同类型的处理器,统一调用规则,执行目标Controller业务方法,解决不同处理器执行逻辑差异化问题
-
ViewResolver(视图解析器):解析视图名称,匹配物理视图资源,适配前后端不分离页面渲染(前后端分离项目弱化使用)
-
HandlerExceptionResolver(异常解析器):统一捕获请求处理过程中的异常,适配全局异常处理、自定义异常返回
-
LocaleResolver(国际化解析器):解析请求语言环境,适配i18n多语言场景,对接ApplicationContext国际化能力
-
ThemeResolver(主题解析器):解析页面主题样式,适配前端主题切换场景(企业开发极少用)
-
MultipartResolver(文件解析器):解析文件上传请求,封装文件流数据,支撑Spring MVC文件上传功能
-
FlashMapManager(闪存管理器):跨请求临时数据存储,适配重定向场景数据传递,解决重定向参数丢失问题
核心关联:九大组件全部在容器refresh()阶段初始化,由Spring容器统一管理,依托Bean后置处理器完成组件注册与加载。
(2)DispatcherServlet完整请求流转流程(面试TOP高频)
完整梳理从浏览器请求到接口响应的10步闭环流程,吃透MVC底层流转,根治请求参数异常、拦截失效、响应异常等问题:
-
请求接入:浏览器发起HTTP请求,Tomcat端口监听接收请求,解析HTTP报文,封装原生Request/Response对象
-
过滤器链执行:请求进入Tomcat层级Filter,执行编码过滤、跨域过滤、参数预处理,放行后进入DispatcherServlet
-
路由匹配:DispatcherServlet调用HandlerMapping,根据URL精准匹配目标Controller方法,获取处理器执行链(包含拦截器)
-
拦截器前置处理:执行拦截器preHandle方法,权限校验、Token校验、请求拦截,校验失败直接返回响应,终止流程
-
适配器调用 :HandlerAdapter适配目标Controller,完成参数绑定、数据校验、类型转换
-
目标方法执行:调用Controller核心业务方法,执行CRUD、业务逻辑、数据查询与更新
-
拦截器后置处理:方法执行成功后,执行拦截器postHandle方法,可对响应数据二次处理
-
视图渲染/数据封装:前后端分离项目直接封装JSON响应数据;传统项目由ViewResolver解析视图并渲染页面
-
最终拦截处理:执行拦截器afterCompletion方法,完成资源释放、日志记录、请求收尾
-
响应返回:封装统一响应结果,通过Response输出流返回给浏览器,请求结束
(3)RESTful接口规范与核心请求注解
Spring MVC默认适配RESTful接口设计风格,严格遵循HTTP方法语义,是企业接口标准化的核心规范:
1. 五大核心请求注解
-
@GetMapping:适配查询接口,幂等、无请求体、用于数据查询、列表、详情接口
-
@PostMapping:适配新增接口,非幂等、支持JSON请求体、用于数据提交、复杂参数传递
-
@PutMapping:适配全量更新接口,幂等、覆盖式更新所有字段
-
@DeleteMapping:适配删除接口,幂等、用于资源删除、数据移除
-
@PatchMapping:适配局部更新接口,幂等、仅更新变更字段,企业高频优化方案
2. RESTful接口设计规范
-
URL使用名词复数、小写字母、中横线分隔,禁止动词拼接
-
严格区分请求方法语义,查询不用POST、删除不用GET
-
统一接口前缀、版本控制、响应格式,适配前后端协作
(4)全方位参数绑定机制(解决90%参数接收坑点)
Spring MVC参数绑定本质是解析HTTP报文不同位置数据+自动类型转换,不同注解对应不同报文位置,精准规避参数接收失效问题:
-
@RequestParam :解析URL查询参数、表单form参数,适配GET、form-data、x-www-form-urlencoded请求,不支持JSON请求体
-
@RequestBody :解析POST/PUT JSON请求体,自动JSON序列化绑定实体类,不支持GET请求
-
@PathVariable:解析URL路径占位参数,适配RESTful路径传参(如/user/{id})
-
@RequestHeader:解析请求头参数,适配Token、设备信息、版本号等头部参数获取
-
@CookieValue:解析请求头Cookie数据,适配会话、登录状态获取
-
@RequestPart:混合接收文件+普通参数,适配文件上传带表单参数场景
高频坑点总结:GET请求无法使用@RequestBody、JSON请求体必须用@RequestBody、表单参数不可混用注解,否则参数接收为空。
(5)JSR303数据校验(企业参数校验标配)
替代代码硬编码校验,实现参数统一校验、异常统一处理,是企业接口开发标准化刚需:
1. 核心常用校验注解
-
@NotBlank:字符串非空、非空白字符(适配名称、账号等文本参数)
-
@NotNull:对象非空(适配数字、实体、集合,无法校验空字符串)
-
@NotEmpty:集合、字符串非空,校验容器与文本长度
-
@Size:限定字符串、集合长度范围
-
@Min/@Max:限定数字大小范围
-
@Pattern:正则表达式校验(手机号、邮箱、身份证)
2. 实战核心用法
-
实体类字段添加校验注解,自定义异常提示信息
-
接口参数添加**@Valid**触发校验,配合BindingResult捕获校验异常
-
全局异常处理器统一拦截校验异常,返回标准化提示信息
-
支持分组校验、嵌套校验,适配多场景差异化校验规则
(6)拦截器Interceptor深度精讲(Spring层核心拦截)
Interceptor是Spring MVC层级拦截组件,依托容器管理,可获取Spring Bean,是接口权限、日志、Token校验的核心载体,彻底区分Filter与Interceptor:
1. 三大核心拦截方法
-
preHandle(前置拦截):Controller执行前执行,可做权限校验、Token解析、请求拦截,返回false终止请求
-
postHandle(后置拦截):Controller执行完成、视图渲染前执行,可修改响应数据
-
afterCompletion(最终拦截):请求完全结束后执行,用于资源释放、请求日志统计、耗时记录
2. 拦截器配置与放行规则
-
实现HandlerInterceptor接口,注册到WebMvcConfigurer配置类
-
支持拦截指定路径、放行白名单路径(登录、注册、静态资源)
-
多拦截器通过@Order指定优先级,遵循先进后出执行规则
3. 核心适用场景
用户登录校验、Token有效性验证、接口权限拦截、请求日志记录、接口耗时统计、防重复提交校验。
(7)跨域、转发与重定向(Web高频场景)
1. 全局跨域配置
解决浏览器同源策略限制,Spring MVC全局跨域配置优先级高于局部注解,企业统一配置方案:
-
实现WebMvcConfigurer,重写addCorsMappings方法全局放行跨域
-
核心配置:允许域名、允许请求方法、允许请求头、放行OPTIONS预检请求、开启凭证
-
坑点:未放行OPTIONS预检请求、前后端跨域配置重复导致跨域失效
2. 转发与重定向核心区别
-
请求转发(forward):服务器内部跳转、一次请求、地址栏不变、共享Request数据、仅支持内部接口跳转
-
重定向(redirect):客户端二次请求、地址栏变更、不共享数据、支持外部链接跳转
(8)文件上传下载核心实现
依托MultipartResolver文件解析器实现,Spring Boot自动配置封装,适配单文件、多文件上传、大文件分片上传:
-
核心配置:单文件大小限制、单次请求文件总大小、临时文件路径、文件上传超时时间
-
核心API:MultipartFile接收文件、获取文件名、文件流、保存文件到本地/OSS
-
实战优化:文件名重命名防止覆盖、文件类型校验、大文件分片上传、断点续传
(9)Spring MVC异步开发(@Async)
基于Spring线程池实现接口异步处理、任务异步执行,提升接口响应速度,解耦主业务流程:
1. 核心使用规范
-
启动类添加**@EnableAsync**开启异步功能
-
业务方法添加**@Async**,标识为异步任务
-
支持无返回值、Future有返回值异步任务
2. 线程池自定义配置
替换默认线程池,自定义核心线程数、最大线程数、队列容量、拒绝策略、线程名称前缀,适配线上高并发场景。
3. 高频失效场景
-
类内部自调用导致异步失效(未经过代理对象)
-
异步类未交给Spring容器管理
-
未开启@EnableAsync注解
-
主线程提前结束,导致异步任务未执行完成
4. 异步上下文传递
解决异步任务无法获取主线程Request、Token、用户信息问题,通过线程上下文拷贝实现参数透传。
(10)企业级全局统一处理(项目必备)
1. 统一响应结果封装
自定义全局响应实体类,统一成功/失败状态码、提示信息、返回数据格式,适配前后端数据交互规范,杜绝返回格式混乱。
2. 全局异常处理器(@RestControllerAdvice)
全局捕获项目所有异常,分层处理:参数校验异常、业务自定义异常、系统未知异常、空指针异常、SQL异常,统一返回标准化结果,隐藏服务器底层错误信息,提升项目安全性。
3. 统一请求日志打印
通过拦截器统一打印接口请求URL、请求方式、请求参数、响应耗时、客户端IP、响应结果,实现接口日志全链路追溯,方便线上问题排查。
✅ Spring MVC模块终极总结
-
核心本质:基于Servlet规范+Spring IoC容器的Web请求调度框架,所有功能依托容器组件实现
-
核心链路:请求接入→过滤拦截→路由匹配→参数解析→业务执行→响应封装
-
企业核心能力:RESTful接口、参数校验、异步处理、跨域配置、全局统一异常与响应
-
排障核心:参数异常看注解匹配、拦截失效看层级顺序、异步失效看代理调用
-
核心架构:DispatcherServlet中央调度器完整执行流程
-
核心组件:HandlerMapping、HandlerAdapter、Controller、ViewResolver、异常处理器
-
RESTful接口开发:常用请求注解、接口规范
-
参数绑定:路径参数、请求参数、请求体、Header、Cookie参数解析
-
数据校验:JSR303参数校验、全局校验异常处理
-
Web核心功能:拦截器、跨域配置、转发与重定向、文件上传下载
-
异步开发:@Async异步任务、线程池配置、异步上下文传递、异步失效场景
-
统一结果封装、全局异常处理、请求日志统一打印
6. Spring Test 单元测试体系(企业开发必备·全覆盖实战)
单元测试是企业项目迭代、代码重构、Bug规避、版本上线的核心保障,Spring Test 整合 Junit5、Mock机制、事务测试、切面测试、接口测试,提供一站式、标准化、贴近生产的测试方案。本模块摒弃简单Demo,全覆盖企业实战场景、底层原理、高频坑点、测试规范,适配日常开发、代码提测、上线校验全流程,解决「写测试没用、测试不准、测试覆盖率低、测试环境错乱」等核心问题。
(1)核心基础架构与依赖体系
Spring Test 是 Spring 官方提供的测试框架,无缝整合 Spring 容器,支持容器初始化、Bean注入、事务管控、环境模拟,是所有Spring项目测试的底层基石,完全适配Spring Boot自动配置。
1. 核心依赖(Spring Boot项目标配)
spring-boot-starter-test 整合所有测试依赖,无需手动导入,包含:Junit5、Spring Test、MockMvc、Mockito、断言工具、事务测试组件等,是企业唯一标准测试依赖。
-
junit-jupiter:Junit5核心测试引擎,替代老旧Junit4,支持全新注解、拓展机制
-
spring-test:Spring容器测试核心,支持容器加载、Bean注入、上下文模拟
-
mockito:核心Mock框架,模拟依赖Bean、外部接口、复杂依赖,解耦测试
-
hamcrest:流式断言工具,简化测试结果校验,可读性极强
-
json-path:JSON接口响应断言,适配Web接口测试
2. Junit5 核心注解体系(替代Junit4)
Junit5 采用全新注解规范,生命周期更清晰、拓展性更强,是Spring测试的基础语法,高频核心注解全覆盖:
-
@Test:标识测试方法,仅修饰无返回值测试逻辑
-
@DisplayName:自定义测试类/方法名称,提升测试报告可读性,企业规范必备
-
@BeforeEach:每个测试方法执行前执行,用于初始化测试数据、参数重置
-
@AfterEach:每个测试方法执行后执行,用于资源释放、数据清理
-
@BeforeAll:测试类所有方法执行前执行(静态方法),全局初始化
-
@AfterAll:测试类所有方法执行后执行(静态方法),全局资源销毁
-
@Disabled:禁用测试方法/类,临时跳过无效测试
-
@TestFactory:动态测试工厂,适配动态生成测试用例场景
-
@ExtendWith:拓展测试引擎,Spring测试核心拓展注解(SpringBoot已自动整合)
3. Junit5 核心特性(对比Junit4升级点)
-
支持非公有方法测试、默认方法测试,语法更灵活
-
全新断言机制,支持分组断言、批量断言,单个用例多个失败不中断
-
拓展器机制替代老旧Runner,支持多拓展共存,扩展性极强
-
支持Java8+新特性(Lambda、Stream)编写测试逻辑
(2)Spring 容器集成测试(核心重点)
普通Junit测试无法加载Spring容器、无法注入Bean,Spring Test 核心能力就是启动迷你Spring容器、完成Bean初始化、依赖注入、环境绑定,实现贴近生产的单元测试。
1. 两大核心测试注解(企业分级使用)
① @SpringBootTest(全量容器测试·集成测试)
-
核心作用:加载完整Spring Boot容器,初始化所有Bean、自动配置、环境变量、Starter组件,完全模拟生产环境
-
适用场景:业务集成测试、完整流程测试、事务测试、数据库交互测试
-
优点:环境真实、无环境差异、可测试完整业务链路
-
缺点:容器启动慢、测试耗时久,不适合高频轻量单元测试
② @WebMvcTest(轻量化Web测试·接口专项测试)
-
核心作用:仅加载Web层组件(Controller、拦截器、参数解析器),不加载Service、Repository等业务Bean,启动极速
-
适用场景:单独测试Controller接口、参数绑定、请求拦截、响应封装
-
配套注解:配合@MockBean模拟下层Service依赖,解耦测试
2. 核心注入与资源加载
Spring测试环境完全支持容器注入,用法与生产代码一致,支持所有Spring核心特性:
-
@Autowired:正常注入业务Bean、工具类、配置类
-
@Value:读取测试环境配置文件参数
-
@TestPropertySource:自定义测试配置,覆盖全局配置,隔离测试环境与生产环境
-
@Profile:指定测试环境(test),加载专属测试配置
(3)Mockito 模拟测试(解耦测试核心)
单元测试核心原则:只测当前模块,不测依赖模块。针对外部接口、未实现依赖、数据库、第三方服务,通过Mockito模拟Bean与返回结果,实现精准单元测试,杜绝依赖报错。
1. 两大核心注解
-
@MockBean:Spring测试专属,模拟容器中的Bean,替换真实Bean,优先级高于原生Bean
-
@SpyBean:监控真实Bean,默认执行原生方法,可局部模拟指定方法返回值
2. 核心模拟语法(企业高频用法)
-
模拟无参方法返回值:when(bean.method()).thenReturn(结果)
-
模拟带参方法返回值:when(bean.method(参数)).thenReturn(结果)
-
模拟方法抛出异常:when(bean.method()).thenThrow(自定义异常)
-
校验方法执行次数:verify(bean,times(1)).method()(校验是否执行、执行次数)
-
参数任意匹配:any()、anyString()、anyInt(),适配动态参数场景
3. Mock实战场景
-
测试Controller时,Mock Service层依赖,无需启动数据库
-
测试Service时,Mock第三方HTTP接口、OSS、消息队列依赖
-
模拟异常场景、超时场景、空数据场景,覆盖异常分支测试
(4)Web接口专项测试(MockMvc核心)
MockMvc是Spring Test 专为Web接口设计的测试工具,无需启动Tomcat、无需发送真实HTTP请求,直接模拟请求链路,测试接口全流程,速度快、精度高,是接口单元测试标配。
1. 核心使用流程
-
注入MockMvc核心对象
-
构建请求:指定请求方式、URL、请求头、请求参数、JSON请求体
-
执行请求、获取响应结果
-
断言响应状态码、响应数据、返回格式
2. 高频接口测试场景
-
GET接口测试:拼接URL参数、校验查询结果
-
POST JSON接口测试:传递JSON请求体、校验新增逻辑
-
路径参数接口测试:模拟PathVariable参数传递
-
请求头Token测试:手动添加Authorization请求头,测试权限拦截
-
异常接口测试:校验400、405、500异常返回格式
3. 核心断言能力
-
状态码断言:isOk()、isCreated()、isBadRequest()、isForbidden()
-
JSON数据断言:jsonPath精准匹配字段值、数组长度、字段存在性
-
响应头断言:校验跨域头、令牌头、内容类型
(5)事务测试机制(数据库测试核心·杜绝脏数据)
数据库单元测试最大痛点:测试数据写入数据库、产生脏数据、影响后续测试与生产数据。Spring Test 提供专属事务回滚机制,完美解决该问题。
1. 核心注解:@Transactional(测试专属)
-
测试环境特性 :测试方法执行完毕后,自动回滚所有数据库操作,不产生任何脏数据
-
生效范围:加在测试类上,所有测试方法生效;加在方法上,仅当前方法生效
-
手动关闭回滚:@Rollback(value = false),如需持久化测试数据可手动开启
2. 数据库测试最佳实践
-
测试增删改业务时,默认开启事务自动回滚,保证测试环境干净
-
查询业务无需开启事务,提升测试速度
-
复杂流程测试,可通过手动事务控制,分段校验数据状态
(6)分层单元测试规范(企业标准)
遵循分层测试、由浅入深原则,不同层级采用不同测试方案,兼顾测试速度与覆盖率:
1. Dao层测试(数据层)
-
测试Mapper、SQL语句、分页、条件查询、批量操作
-
开启事务自动回滚,仅校验SQL执行结果、数据匹配性
2. Service层测试(业务核心)
-
测试业务逻辑、事务流程、异常分支、参数校验、业务规则
-
Mock第三方依赖、解耦外部服务,专注测试自身业务逻辑
-
覆盖正常场景、异常场景、边界场景(空数据、极值、重复数据)
3. Controller层测试(接口层)
-
测试接口路由、参数绑定、请求拦截、权限校验、响应封装、异常返回
-
使用@WebMvcTest轻量化测试,Mock下层Service,无需数据库
4. 工具类/配置类测试
-
纯逻辑测试,无需容器加载,普通Junit5测试即可
-
全覆盖工具类所有方法、边界参数、异常场景
(7)高阶测试场景(企业进阶必备)
1. AOP切面测试
测试切面日志、权限拦截、事务增强、缓存增强是否生效,通过Mock模拟方法执行,校验切面增强逻辑、执行顺序、拦截效果。
2. 异步方法测试(@Async)
-
开启异步测试支持,校验异步任务执行结果、线程上下文传递
-
解决测试主线程提前结束、异步任务未执行完成问题
3. 定时任务测试
手动触发@Scheduled定时任务方法,校验定时任务执行逻辑、数据处理结果,无需等待Cron表达式触发。
4. 全局异常测试
模拟各类异常(参数异常、业务异常、空指针、SQL异常),校验全局异常处理器返回格式、异常拦截有效性。
(8)高频坑点与排障方案
-
容器启动过慢:优先使用轻量化@WebMvcTest、拆分测试类、按需加载Bean,避免全量容器测试
-
测试数据脏数据:未开启@Transactional事务回滚,数据库测试务必开启自动回滚
-
Mock不生效:混淆@MockBean与@Bean、未正确匹配参数、SpyBean使用场景错误
-
接口参数接收为空:测试请求Content-Type、传参方式与接口注解不匹配(同生产参数坑点)
-
异步测试失效:主线程执行完毕直接退出,未等待异步任务完成,手动阻塞线程等待执行结果
-
测试环境配置错乱:未指定test环境、配置优先级冲突,通过@Profile("test")隔离测试配置
✅ Spring Test 终极总结(企业落地准则)
-
核心本质:依托Spring容器+Junit5+Mockito,实现分层、解耦、无脏数据的标准化单元测试
-
分层策略:Web层轻量化测试、业务层Mock解耦测试、数据层事务回滚测试
-
核心能力:容器模拟、依赖Mock、事务回滚、接口全链路校验、异常场景覆盖
-
落地价值:提前发现代码Bug、保障重构兼容性、标准化业务逻辑、提升项目稳定性、降低线上故障概率
-
避坑核心:区分全量/轻量化测试、严格使用事务回滚、规范Mock使用、隔离测试环境与生产环境
第三阶段:Spring Boot 工业化开发(企业主流开发框架)
Spring Boot 基于Spring Framework封装,简化配置、快速开发,是目前所有Java Web项目的基础,需掌握用法+原理+定制扩展。
1. 核心基础(零基础入门核心,吃透底层核心逻辑,告别只会CRUD)
Spring Boot核心基础是整个工业化开发体系的基石,所有自动配置、Starter机制、项目运行逻辑、配置规则均源于此模块。本部分摒弃网上碎片化浅知识点,结合Spring底层原理、企业实战规范、高频报错坑点,全方位补全核心基础能力,打通「Spring原生框架→Spring Boot框架」的衔接逻辑,彻底理解Spring Boot「简化配置、快速开发」的本质。
(1)核心定位与核心优势(面试必背)
Spring Boot不是替代Spring Framework的全新框架,而是基于Spring Framework的快速开发脚手架,核心目标:简化Spring繁琐的XML配置、统一项目开发规范、自动装配核心组件、快速搭建可上线的企业级项目。
-
核心定位:约定大于配置、零XML配置、快速集成主流技术栈、内嵌运行容器,适配所有Java Web、微服务项目开发
-
五大核心优势: 1. 摒弃XML配置,全程注解+配置文件开发,彻底告别繁琐的Spring手动配置 2. Starter场景启动器,一站式集成技术栈,无需手动管理依赖版本、解决版本冲突 3. 内嵌Tomcat/Jetty/Undertow容器,无需外置容器部署,项目可独立Jar包运行 4. 自动配置机制,根据项目依赖自动装配Bean、环境、插件,开箱即用 5. 内置监控、日志、运维能力,原生适配企业线上运维需求
-
与Spring Framework核心关联:Spring Boot底层完全依赖Spring IoC、AOP、MVC、事务核心能力,仅做上层封装与自动化适配,掌握Spring原生原理是吃透Spring Boot的前提
(2)核心启动注解:@SpringBootApplication(组合注解底层拆解)
@SpringBootApplication是Spring Boot项目唯一核心启动注解,是三合一组合注解,承载项目扫描、自动配置、启动初始化所有核心能力,底层包含三大核心注解,缺一不可:
-
@Configuration:标识当前类为配置类,允许容器注册Bean、读取配置定义,替代传统XML配置文件
-
@EnableAutoConfiguration:核心核心注解,开启Spring Boot自动配置机制,基于SPI机制加载所有场景自动配置类,完成Bean自动装配(自动配置原理核心入口)
-
@ComponentScan :默认扫描当前启动类所在包及子包下所有组件(@Controller/@Service/@Component/@Repository),实现Bean自动扫描注册 高频坑点 :启动类放在根包下,否则会出现Bean扫描不到、注解失效、自动配置不生效问题,需手动指定scanBasePackages扫描路径
拓展:自定义启动注解配置
支持手动排除指定自动配置类,解决版本冲突、功能冗余问题,企业高频用法: @SpringBootApplication(exclude = {DataSourceAutoConfiguration.class}) // 排除数据源自动配置,适配多数据源、自定义数据源场景
(3)Starter场景启动器机制(简化开发的核心本质)
Starter是Spring Boot最核心的设计之一,彻底解决传统Spring项目「依赖繁琐、版本混乱、配置复杂」的痛点,是「开箱即用」的核心支撑。
1. Starter核心本质
Starter是依赖聚合+自动配置类的组合包,一个Starter整合某一场景下所有核心依赖、适配版本、默认配置,开发者只需引入一个依赖,即可拥有完整功能,无需手动导包、配版本、写基础配置。
2. 两大Starter分类
-
官方Starter:spring-boot-starter-xxx,Spring官方封装,适配所有基础场景 核心常用:spring-boot-starter-web(Web核心)、spring-boot-starter-test(单元测试)、spring-boot-starter-data-redis(Redis缓存)、spring-boot-starter-jdbc(数据库基础)、spring-boot-starter-actuator(监控运维)
-
第三方Starter:社区/企业封装,适配主流中间件、第三方服务 核心常用:mybatis-spring-boot-starter、knife4j-spring-boot-starter、alibaba-nacos-discovery(微服务核心)
3. Starter底层执行逻辑
引入Starter依赖 → 依赖传递导入所有底层Jar包 → 项目启动时SPI机制加载对应自动配置类 → 条件注解校验环境是否匹配 → 自动创建Bean、初始化配置、加载默认规则 → 功能直接生效
4. 高频坑点与排障
-
多Starter版本冲突:不同Starter依赖同一底层Jar不同版本,导致类不存在、方法报错,需手动exclusions排除冲突依赖
-
Starter失效:启动类扫描范围不足、自动配置被手动排除、环境条件不匹配导致自动配置失效
(4)约定大于配置核心思想(Spring Boot设计内核)
约定大于配置是Spring Boot的顶层设计思想,框架预设一套通用、标准化的默认配置与文件路径规则,开发者无需手动配置基础内容,仅需修改个性化业务配置,大幅提升开发效率。
1. 核心默认约定(企业必记)
-
配置文件约定:默认读取resources目录下application.yml/application.properties全局配置文件
-
组件扫描约定:默认扫描启动类同级及子包所有注解组件
-
容器约定:默认内嵌Tomcat容器、默认端口8080、默认编码UTF-8
-
日志约定:默认整合SLF4J+Logback,默认日志级别INFO、默认日志输出格式
-
Web约定:默认静态资源路径(resources/static、resources/public)、默认拦截器、参数解析规则
2. 约定与自定义配置关系
框架默认约定为兜底配置,开发者自定义配置可覆盖默认约定,实现个性化适配,兼顾高效性与灵活性。
(5)配置文件体系(yml/properties全覆盖,企业核心刚需)
配置文件是Spring Boot项目参数管理的核心,所有环境参数、组件配置、自定义参数均通过配置文件管控,熟练掌握配置规则、优先级、多环境适配是企业开发基础。
1. 两种配置文件区别与选型
-
properties(传统格式):键值对平铺结构,层级不清晰,适合简单配置,兼容性强 语法示例:server.port=8081
-
yml(主流推荐):缩进层级结构,可读性强、支持对象/集合配置、简洁优雅,企业项目首选 语法规范:严格缩进(2个空格)、大小写敏感、冒号后必须空格,禁止语法错误
2. 完整配置优先级(面试高频,排障核心)
Spring Boot配置加载优先级由高到低,高优先级配置覆盖低优先级配置,彻底解决配置不生效问题:
-
外置命令行参数(启动命令--xxx)
-
外置配置文件(Jar包同级目录config文件夹、同级yml/properties)
-
项目内部配置文件(resources/config目录)
-
项目内部全局配置(resources/application.yml/properties)
-
框架默认自动配置
3. 多环境配置体系(dev/test/prod)
企业项目必备,实现一套代码适配多套环境,避免环境配置混乱:
-
环境文件命名规范:application-{profile}.yml,如application-dev.yml(开发)、application-test.yml(测试)、application-prod.yml(生产)
-
激活方式: 1. 配置文件激活:spring.profiles.active=dev(全局配置) 2. 启动命令激活:java -jar xxx.jar --spring.profiles.active=prod 3. IDEA运行配置激活,适配本地开发
-
核心规则:全局application.yml为公共配置,环境配置为差异化配置,环境配置覆盖公共配置
4. 配置文件参数引用
支持{key}动态引用配置参数,实现配置复用,减少冗余代码: 示例:server.port={custom.port:8080}(支持默认值,参数不存在时使用8080)
(6)配置绑定核心机制(@ConfigurationProperties)
替代传统@Value注解,实现批量、类型安全、结构化配置绑定,是企业自定义配置、组件配置的标准方案,解决@Value零散、无校验、无法批量绑定的痛点。
1. 核心使用步骤
-
- 自定义配置实体类,添加@ConfigurationProperties(prefix = "自定义前缀")
-
- 启动类/配置类添加@EnableConfigurationProperties(配置类.class)开启绑定
-
- 配置文件配置对应前缀的参数,自动绑定到实体类属性
2. @ConfigurationProperties vs @Value 核心区别(面试高频)
-
@Value:单个参数绑定、无类型校验、不支持批量绑定、适合少量简单参数
-
@ConfigurationProperties:批量结构化绑定、自动类型转换、支持参数校验、支持宽松绑定、适合自定义组件、批量配置参数
3. 宽松绑定规则(实战必备)
支持配置文件与实体类属性宽松匹配,适配不同书写规范:下划线、中划线、驼峰命名自动适配,无需严格一致,大幅降低配置报错概率。
✅ Spring Boot核心基础终极总结
-
核心内核:基于Spring原生框架封装,约定大于配置+Starter自动装配是核心灵魂
-
启动核心:@SpringBootApplication三合一注解,管控扫描、配置、自动装配全流程
-
简化本质:Starter聚合依赖、自动配置兜底规则、约定式默认配置,彻底简化开发
-
配置核心:yml为主流配置、多环境隔离、明确配置优先级、结构化配置绑定
-
避坑关键:启动类包扫描范围、配置优先级覆盖、Starter版本冲突、多环境配置隔离
-
核心启动注解:@SpringBootApplication(组合注解原理)
-
Starter机制、自动配置核心思想、约定大于配置
-
配置文件:yml/properties、多环境配置(dev/test/prod)、配置优先级
-
配置绑定:@ConfigurationProperties、自定义配置类
2. 自动配置底层原理(Spring Boot核心灵魂·源码级精讲)
自动配置是Spring Boot「零配置、开箱即用」的核心本质,彻底摆脱Spring原生繁琐的Bean手动注册、组件配置流程。核心底层逻辑:基于SPI机制实现配置类扫描 + 条件注解动态判断环境 + 按需自动装配Bean,全程源码可控、规则可追溯、问题可排障,是面试TOP高频、进阶开发必备的核心体系。本模块全覆盖底层源码流程、核心组件、实战配置、自定义开发与高频坑点。
(1)核心入口注解:@EnableAutoConfiguration 深度拆解
该注解是Spring Boot自动配置的唯一核心入口,也是@SpringBootApplication组合注解的核心能力来源,底层依托SPI机制实现全局自动配置类加载。
1. 注解底层组成
-
@AutoConfigurationPackage:自动配置包扫描注解 核心作用:默认扫描启动类所在包及子包的所有业务组件(@Controller/@Service/@Component),同时将当前包路径注册到Spring容器,作为自动配置的基础包范围。 坑点:启动类未放在根包,会导致业务Bean扫描失效、自动配置适配异常。
-
@Import(AutoConfigurationImportSelector.class) :自动配置核心导入器 核心作用:这是自动配置的核心灵魂,通过该选择器类,加载项目中所有场景的自动配置类,完成批量Bean装配。
2. AutoConfigurationImportSelector 核心能力
该类实现Spring的ImportSelector接口,在容器解析配置类阶段,主动加载外部配置类,核心执行逻辑:
-
读取系统配置与SPI配置文件,筛选所有合法的自动配置类
-
去重、过滤被排除的配置类、校验环境条件
-
将合法的自动配置类注册到Spring容器,完成Bean自动创建
(2)SPI扩展机制(自动配置的底层载体)
Spring Boot完全依托Spring SPI机制实现自动配置类的批量加载,替代传统Java SPI,解决原生SPI加载慢、无法按需筛选、优先级混乱的问题。
1. Spring SPI核心规则
Spring Boot定义固定配置文件路径:META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports
-
文件内批量罗列所有场景自动配置类全限定类名
-
项目启动时,AutoConfigurationImportSelector自动读取该文件
-
批量加载文件中所有配置类,实现无需手动@Import的自动导入
2. 官方核心场景举例
引入spring-boot-starter-web依赖后,SPI文件会自动加载核心Web自动配置类:
-
WebMvcAutoConfiguration:Spring MVC核心自动配置(九大组件、请求解析、视图适配)
-
TomcatAutoConfiguration:内嵌Tomcat容器自动配置
-
HttpEncodingAutoConfiguration:全局请求编码自动配置
同理,Redis、MyBatis、DataSource等所有场景自动配置,均依托SPI文件加载。
(3)条件注解体系(按需装配的核心规则)
SPI加载的配置类不会全部生效,Spring Boot通过**@Conditional系列条件注解**,根据项目依赖、环境配置、Bean存在与否,动态判断是否装配当前组件,实现「按需自动配置」,避免冗余Bean加载。
1. 核心高频条件注解(全覆盖)
-
@ConditionalOnClass:classpath下存在指定类时,配置类生效 场景:引入web依赖才加载WebMvc自动配置,无web依赖自动失效
-
@ConditionalOnMissingBean :容器中不存在指定Bean时,自动创建默认Bean 核心价值:用户自定义Bean优先,框架默认Bean兜底,这是Spring Boot自定义覆盖默认配置的核心原理
-
@ConditionalOnProperty:配置文件存在指定参数且匹配规则,配置生效 场景:通过spring.xxx.enabled=true/false开启/关闭自动配置功能
-
@ConditionalOnWebApplication:仅Web环境生效,非Web项目自动跳过Web相关配置
-
@ConditionalOnResource:classpath下存在指定配置文件时生效
-
@ConditionalOnJava:匹配指定Java版本才生效,适配版本兼容
2. 核心优先级规则
用户自定义Bean > Spring Boot默认自动配置Bean,依托@ConditionalOnMissingBean实现,完美兼顾自动化与自定义扩展性。
(4)自动配置完整源码级加载流程(面试必背10步闭环)
完整梳理项目启动到自动配置生效的全链路,打通底层源码逻辑,彻底解决自动配置失效、Bean冲突、配置不生效等问题:
-
项目启动:执行main方法,触发SpringApplication.run(),初始化Spring容器
-
解析启动注解:识别@SpringBootApplication,加载内部@EnableAutoConfiguration注解
-
导入核心选择器:通过@Import导入AutoConfigurationImportSelector类
-
读取SPI配置:加载META-INF/spring/xxx.imports文件,获取所有自动配置类全量列表
-
过滤筛选配置类:剔除被exclude排除的配置类、无效配置、重复配置
-
条件注解校验:遍历所有配置类,通过@Conditional系列注解校验当前环境是否匹配
-
注册有效配置类:将环境匹配的自动配置类注册到Spring容器,作为配置Bean
-
配置类解析:容器解析配置类中@Bean、@Configuration、@Import等注解
-
自动装配组件Bean:根据配置类逻辑,自动创建Web、数据源、缓存等核心组件Bean
-
用户配置覆盖:用户自定义Bean、配置文件参数,覆盖框架默认自动配置,完成最终初始化
(5)自动配置排除与禁用(企业高频实战)
部分场景需要关闭默认自动配置,解决版本冲突、功能冗余、自定义适配问题,提供两种标准排除方案:
1. 启动注解直接排除(精准排除)
java
// 排除数据源自动配置,适配多数据源、自定义数据源场景
@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}2. 配置文件全局排除(批量排除)
java
spring:
autoconfigure:
exclude:
- org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration
- org.springframework.boot.autoconfigure.web.servlet.WebMvcAutoConfiguration(6)高阶实战:自定义Starter&自定义自动配置(架构师必备)
掌握自动配置原理后,可自定义企业级Starter,封装通用工具、组件、配置,实现项目功能复用,是中高级开发核心能力。
1. 自定义Starter核心结构
-
xxx-spring-boot-autoconfigure:自动配置核心模块,存放配置类、Bean定义、SPI文件
-
xxx-spring-boot-starter:场景启动器模块,仅依赖autoconfigure模块,实现依赖聚合
2. 完整开发步骤
-
创建autoconfigure模块,编写自定义自动配置类(添加@Configuration、@Conditional系列注解)
-
在resources/META-INF/spring/目录下创建AutoConfiguration.imports文件
-
文件中写入自定义配置类全限定类名,完成SPI注册
-
创建starter模块,依赖autoconfigure模块,无任何业务代码
-
项目引入自定义starter依赖,即可实现自动配置、组件开箱即用
3. 核心实战场景
封装统一日志组件、全局异常组件、OSS文件上传、短信发送、权限校验通用组件,实现多项目快速复用。
(7)自动配置高频坑点与排障方案
-
自动配置不生效:① 启动类包扫描范围不足;② SPI文件路径/类名书写错误;③ 条件注解环境不匹配;④ 配置类被手动排除
-
Bean冲突重复创建:未使用@ConditionalOnMissingBean,自定义Bean与默认Bean重复注册,导致容器冲突
-
配置参数不生效:自定义配置未绑定@ConfigurationProperties、配置优先级低于默认配置
-
Starter引入无效果:SPI文件未加载、自动配置类未注册、依赖传递失效
-
版本适配异常:高/低版本Spring Boot的自动配置类路径、条件注解规则变更,导致适配失效
✅ 自动配置原理终极总结(面试+实战必背)
-
核心公式:自动配置 = SPI批量加载 + 条件注解按需筛选 + 默认Bean兜底 + 自定义配置优先
-
核心入口:@EnableAutoConfiguration → AutoConfigurationImportSelector → SPI配置加载
-
核心规则:容器无Bean则创建默认Bean,有自定义Bean则优先使用用户配置
-
核心载体:META-INF/spring/*.imports SPI配置文件,实现无侵入批量配置加载
-
拓展能力:支持配置排除、自定义Starter开发、条件化按需装配
-
排障核心:自动配置失效优先排查SPI文件、条件注解、包扫描范围、配置排除规则
3. Web项目进阶配置(企业工业化Web统一规范·完整版)
本模块为Spring Boot企业级Web项目刚需进阶配置,覆盖统一Web全局规则、容器性能调优、日志规范、接口文档自动化四大核心板块,解决项目编码乱、跨域不统一、容器并发瓶颈、日志排查难、接口文档维护繁琐等线上常见问题,所有配置均为生产落地标准,可直接复用至企业项目。
(1)全局Web统一配置(项目标准化核心)
基于Spring MVC自动配置扩展,统一项目请求、编码、响应、跨域规则,替代零散配置,实现全局Web行为统一管控,适配前后端分离项目。
1. 全局请求编码统一配置
彻底解决GET/POST请求中文乱码、响应乱码问题,Spring Boot高版本已默认UTF-8编码,但企业项目需手动兜底锁定,避免版本升级失效。
-
核心原理:注册CharacterEncodingFilter全局编码过滤器,强制指定请求/响应编码为UTF-8,优先级高于容器默认编码
-
企业配置要点:开启forceEncoding强制编码,忽略客户端默认编码,统一全局标准
-
适配场景:表单提交、JSON请求、文件上传、接口响应所有数据交互场景
2. 全局跨域CORS统一配置
摒弃注解局部跨域(@CrossOrigin),采用全局统一配置,解决多接口跨域配置冗余、OPTIONS预检请求拦截、跨域失效等问题,适配前后端分离、微服务网关场景。
-
核心配置能力:统一放行域名、请求方法、请求头、允许携带Cookie、放行OPTIONS预检请求、设置跨域有效期
-
高频坑点解决:全局配置优先于局部注解、解决过滤器/拦截器层级跨域失效、预检请求403报错
-
企业规范:开发环境全放行,生产环境白名单精准限制域名,杜绝非法跨域访问
3. 全局响应统一格式化配置
统一全局JSON响应规则,解决日期格式化、空值处理、大小写转换、精度丢失问题,适配前后端数据交互规范。
-
核心配置项:全局日期统一格式化(yyyy-MM-dd HH:mm:ss)、空字符串/NULL统一处理、数字精度保留、枚举序列化规则
-
底层原理:自定义Jackson2ObjectMapperBuilder,覆盖Spring默认JSON序列化规则,全局生效
-
实战价值:无需每个接口手动格式化数据,杜绝前后端日期解析失败、数值精度错乱问题
4. 静态资源自定义映射
扩展Spring Boot默认静态资源路径,适配自定义静态资源目录、本地文件访问、资源防盗链场景。
-
默认资源路径:resources/static、resources/public、resources/resources、META-INF/resources
-
自定义配置:支持映射本地绝对路径、自定义项目资源目录、设置资源访问前缀
-
实战场景:项目静态页面、图片资源、临时文件访问、无需放行接口直接访问
5. 拦截器全局注册配置
统一注册自定义拦截器(登录校验、Token拦截、日志拦截),配置拦截路径、放行路径、执行顺序,解决拦截器失效、静态资源被拦截问题。
-
核心规则:优先放行静态资源、放行登录/注册/验证码接口、拦截所有业务接口
-
执行顺序:多拦截器可自定义优先级,保证日志拦截、权限拦截、防刷拦截有序执行
(2)内嵌容器进阶配置与调优(Tomcat/Jetty/Undertow)
Spring Boot默认内嵌Tomcat容器,线上高并发场景需针对性调优,同时支持替换轻量高性能容器,适配不同业务并发场景,是线上接口卡顿、503报错、并发瓶颈的核心优化点。
1. 内嵌Tomcat核心参数调优(生产必备)
Tomcat线程池、连接数、超时时间、队列参数直接决定接口并发能力,默认参数无法支撑线上高并发,企业标准化调优参数如下:
-
核心线程数:默认10,生产根据CPU核心数调整(常规20-50),常驻工作线程,减少线程创建销毁开销
-
最大线程数:默认200,控制单机最大并发量,避免线程过多导致CPU飙升、上下文切换频繁
-
最大连接数:默认8192,限制服务器TCP最大连接数,防止连接耗尽
-
等待队列容量:默认100,线程池满负荷后请求排队数量,队列打满直接返回503服务不可用
-
连接超时时间:自定义请求超时,避免无效长连接占用资源
-
核心坑点:线程池过小导致并发排队、线程过多导致OOM、队列过长导致接口响应超时
2. Tomcat高阶实战配置
-
开启压缩传输:开启Gzip压缩,压缩响应文本、JSON、静态资源,减少网络传输流量,提升接口响应速度
-
请求参数限制:自定义最大请求参数大小、文件上传大小,防止超大请求攻击
-
禁用不安全请求方法:禁用TRACE、OPTIONS多余请求方法,提升项目安全性
-
访问日志自定义:开启Tomcat访问日志,记录请求IP、耗时、状态码、请求路径,用于线上问题溯源
3. 容器替换:Jetty/Undertow选型与配置
针对高并发、长连接、微服务场景,可替换Tomcat为轻量高性能容器,按需选型:
-
Jetty容器:轻量、低内存占用、适配长连接场景,适合网关、微服务客户端项目
-
Undertow容器:非阻塞高性能、并发能力强、无线程池阻塞瓶颈,适合高并发接口、秒杀、流量峰值场景
-
替换方式:排除Tomcat依赖,引入对应容器Starter,零代码配置直接生效
(3)企业级日志体系配置(SLF4J+Logback全覆盖)
Spring Boot默认整合SLF4J+Logback日志体系,摒弃混乱的日志框架混搭,通过标准化配置实现日志分级、归档、脱敏、持久化,满足线上运维、问题排查、日志审计需求。
1. 日志核心架构与统一规范
-
门面+实现架构:SLF4J为日志门面(统一API),Logback为底层实现,杜绝Log4j、JUL日志混乱问题
-
全局规范:所有代码统一使用org.slf4j.Logger打印日志,禁止混用其他日志框架
-
日志级别层级:TRACE(追踪) < DEBUG(调试) < INFO(正常) < WARN(警告) < ERROR(异常)
2. 环境分级日志配置
区分开发、测试、生产环境日志策略,兼顾开发调试效率与生产性能安全:
-
开发环境:开启DEBUG级别、控制台彩色打印、打印SQL语句、完整堆栈异常信息,方便调试
-
测试环境:INFO级别、精简日志输出、保留核心请求与异常日志
-
生产环境:默认INFO级别、关闭DEBUG调试、屏蔽敏感日志、禁止打印完整SQL,提升性能与安全性
3. 日志归档与滚动策略(生产核心)
解决日志文件过大、磁盘占满、日志丢失问题,标准化线上日志滚动规则:
-
按时间滚动:按天拆分日志文件,避免单文件超大
-
按大小滚动:单文件达到指定大小(默认100MB)自动拆分
-
日志保留周期:自动清理7天前历史日志,释放磁盘空间
-
压缩归档:历史日志自动压缩存储,减少磁盘占用
4. 高阶日志实战配置
-
日志脱敏:自动脱敏手机号、身份证、银行卡、密码等敏感信息,满足数据安全规范
-
包级别日志控制:自定义框架日志级别(屏蔽Spring、MyBatis冗余日志)、开启业务模块精准日志
-
异步日志打印:开启Logback异步输出,避免同步日志打印阻塞业务线程,提升接口并发性能
-
日志持久化:本地文件归档+对接日志中心(ELK),实现日志集中收集、检索、告警
5. 高频日志坑点排查
-
日志冲突:多日志框架共存导致打印异常、重复日志,统一排除冗余日志依赖
-
生产日志泄露:未关闭DEBUG级别、敏感数据明文打印,导致安全风险
-
磁盘爆满:未配置日志滚动清理策略,日志无限堆积
-
日志阻塞业务:同步日志打印、大量日志输出导致接口响应变慢
(4)自动化接口文档配置(Knife4j主流方案)
替代老旧Swagger,Knife4j基于OpenAPI3规范,是目前企业主流接口文档方案,实现接口文档自动生成、在线调试、文档实时更新,彻底告别手动维护接口文档的繁琐工作。
1. 核心优势(对比原生Swagger)
-
界面更简洁美观、调试功能更强大、支持全局参数、离线文档导出
-
适配Spring Boot高版本,解决Swagger版本兼容、启动报错问题
-
支持接口排序、分组管理、注解精细化描述,适配大型项目
2. 企业标准化配置
-
文档基础信息:自定义项目名称、版本、作者、描述、接口备注
-
接口分组管理:按业务模块(用户、订单、权限)分组展示接口,结构清晰
-
全局请求参数:统一配置Token、请求头全局参数,无需每个接口单独配置
-
扫描规则配置:精准扫描业务接口,过滤工具类、无效接口
3. 高阶实战功能
-
环境区分:生产环境关闭接口文档,仅开发/测试环境开启,保障项目安全
-
离线文档导出:支持Markdown、HTML、PDF格式文档导出,用于项目交付
-
接口调试:在线模拟请求、参数自动填充、响应实时查看,提升联调效率
-
注解精细化文档:通过@Operation、@Parameter、@Schema注解完善接口、参数、实体注释
4. 高频失效坑点
-
Spring Boot高版本与Knife4j版本不匹配导致启动报错
-
拦截器拦截文档路径,导致接口文档无法访问
-
扫描路径配置错误,接口无法展示
-
生产环境未关闭文档,存在接口信息泄露风险
✅ Web进阶配置终极总结
-
核心价值:统一Web项目工业化规范,解决乱配置、低并发、难排查、文档滞后四大企业痛点
-
全局Web配置:编码统一、跨域全局管控、JSON响应格式化、静态资源映射、拦截器有序注册
-
容器调优:Tomcat线程池/连接数生产调优、Gzip压缩、容器按需替换(Jetty/Undertow)
-
日志体系:SLF4J+Logback架构、多环境分级日志、滚动归档、异步打印、敏感脱敏
-
接口文档:Knife4j自动化文档、分组管理、在线调试、环境隔离、交付导出
-
落地准则:所有配置一次全局生效,杜绝局部零散配置,适配团队统一开发规范
-
全局跨域、请求编码、响应统一配置
-
内嵌容器:Tomcat调优、替换Jetty/Undertow容器
-
日志体系:SLF4J+Logback、日志分级、日志归档、自定义日志配置
-
接口文档:Swagger/Knife4j整合、接口文档自动化生成
4. 监控与运维(企业线上生产必备·完整版)
本模块为Spring Boot项目线上生产运维核心体系,解决项目上线后监控盲区、故障无法溯源、启停异常、配置泄露、部署混乱等生产痛点,全覆盖原生监控、优雅停机、异常告警、多环境打包部署、配置加密、线上排障方案,完全适配企业生产落地规范,是开发转运维、架构进阶的必备能力。
(1)Spring Boot Actuator 原生监控体系(核心基石)
Actuator是Spring Boot官方原生监控组件,无需复杂整合,一键开启项目运行指标、健康状态、运行日志、Bean信息、环境配置监控,是所有线上监控的底层核心,适配单机、微服务全场景监控。
1. 核心依赖与基础配置
-
核心Starter依赖:spring-boot-starter-actuator,专属运维监控场景启动器,无侵入集成监控能力
-
核心作用:暴露项目内置监控端点,采集服务健康状态、JVM指标、请求指标、线程状态、系统配置等核心数据
-
安全规范:生产环境按需开启端点、隐藏敏感配置、限制访问权限,避免信息泄露
2. 高频核心监控端点(生产必开)
-
health(健康检查端点·核心):监控服务整体运行状态、数据库、Redis、消息队列、磁盘、线程池健康度,支持自定义健康指标,是服务存活检测、集群心跳探测的核心依赖
-
info(项目信息端点):展示项目版本、作者、构建时间、环境标识,用于线上版本溯源
-
metrics(性能指标端点):采集接口QPS、响应耗时、错误率、JVM内存、GC次数、线程数、Tomcat连接数等核心性能数据
-
beans(Bean实例端点):查看容器所有注册Bean、Bean数量、自定义Bean加载状态,排查Bean缺失、重复注册问题
-
env(环境配置端点):展示项目所有环境变量、配置参数,排查配置不生效、参数覆盖问题(生产需权限管控)
-
loggers(日志端点):动态修改线上日志级别,无需重启服务,临时开启DEBUG日志排查线上问题
-
threaddump(线程堆栈端点):导出线上线程堆栈信息,快速定位线程死锁、阻塞、CPU飙升问题
-
heapdump(堆转储端点):导出JVM堆内存快照,排查内存泄漏、OOM异常
3. 端点开启与暴露规则
-
默认规则:默认仅开启health、info端点,其余端点默认关闭,保障生产安全
-
开启方式:通过配置文件批量开启/关闭端点,支持通配符统一配置
-
暴露方式:支持HTTP、JMX两种方式暴露,线上优先HTTP接口适配监控平台采集
-
生产规范:关闭heapdump、env等敏感端点,仅开放核心运维端点,配置IP白名单访问
4. 自定义健康指标与监控指标
-
自定义健康检查:实现HealthIndicator接口,自定义第三方服务(OSS、短信、第三方接口)健康检测,补齐原生监控盲区
-
自定义业务指标:通过Micrometer埋点,采集业务QPS、订单量、异常订单数等自定义业务指标,实现业务可视化监控
-
指标聚合:支持指标求和、平均值、峰值统计,适配线上性能分析
(2)可视化监控平台(生产落地)
原生Actuator仅提供原始指标数据,需搭配可视化平台实现数据展示、告警、大盘监控,企业主流两套方案全覆盖:
1. Spring Boot Admin(轻量单机监控)
-
核心定位:轻量级、零复杂配置,适配单体项目、小型微服务集群快速监控
-
核心能力:可视化展示服务状态、日志、线程、JVM指标、端点数据、在线一键查看堆栈、动态调整日志级别
-
部署方式:独立搭建Admin服务,所有业务服务作为客户端接入,自动注册监控
2. Prometheus + Grafana(企业级标准监控)
-
核心定位:工业级时序数据库+可视化大盘,中大型项目、微服务集群标配
-
核心流程:Actuator暴露指标 → Prometheus定时采集存储 → Grafana可视化大盘展示
-
核心能力:性能指标大屏、趋势统计、多维度筛选、阈值告警、历史数据回溯
-
适配场景:线上7*24小时监控、性能瓶颈分析、流量峰值观测、故障溯源
(3)项目优雅启停机制(生产核心刚需)
默认粗暴启停会导致正在执行的业务中断、事务回滚失败、数据脏写、接口报错,优雅启停是生产环境必备规范。
1. 优雅停机核心原理
-
核心机制:收到停机信号后,停止接收新请求,等待正在执行的请求、异步任务、定时任务执行完成后,再销毁容器、释放资源
-
解决问题:避免业务中断、事务异常、数据不一致、客户端请求报错
2. Spring Boot标准化配置
-
开启优雅停机:通过配置文件开启shutdown优雅停机模式
-
等待超时时间:自定义停机等待时长,超时强制停机,避免服务卡死
-
适配组件:支持Tomcat线程池、异步线程、定时任务、消息队列消费者优雅收尾
3. 优雅启动优化
-
启动预热:容器启动完成后初始化缓存、预热Bean、加载字典数据,避免启动初期请求卡顿
-
启动延迟注册:微服务场景下,服务启动完成后再注册到注册中心,避免启动未完成被流量打入
(4)线上异常告警体系(故障早发现)
解决「故障发生后无人知晓、被动排查」问题,实现异常、超时、服务宕机、指标超标主动告警。
1. 核心告警场景
-
服务级告警:服务宕机、健康检查失败、重启频繁
-
性能级告警:接口超时率过高、错误率飙升、QPS异常、GC频繁、内存溢出
-
业务级告警:订单失败、支付异常、核心业务报错
-
资源级告警:服务器CPU、内存、磁盘、线程池耗尽
2. 主流告警渠道
-
钉钉机器人、企业微信机器人、短信、邮件告警,适配企业运维通知规范
-
支持告警分级、告警静默、告警合并,避免轰炸式通知
(5)多环境打包与部署规范(企业标准化)
统一开发、测试、预发、生产环境打包部署流程,杜绝环境混乱、配置错乱、部署失误问题。
1. Maven多环境打包机制
-
打包激活环境:通过Maven打包指令指定环境,自动加载对应配置文件
-
配置过滤替换:打包时动态替换环境变量、数据库地址、密钥、端口等差异化配置
-
资源隔离:不同环境静态资源、配置文件独立隔离,打包自动适配
2. Jar包部署核心规范
-
内外置配置优先级:Jar包同级外置配置优先于内部配置,支持线上动态改配置无需重新打包
-
启动脚本规范:标准化启停脚本,支持后台运行、日志输出、PID管理、优雅停机
-
JVM参数配置:打包部署时指定堆内存、GC算法、堆栈溢出快照输出,适配线上运行
3. 容器化部署基础(Docker)
-
标准化Dockerfile编写、镜像构建、容器启动、端口映射、数据挂载
-
多环境镜像区分、版本标签管理,适配CI/CD持续集成部署
(6)配置加密(生产安全必备)
解决配置文件中数据库密码、密钥、Token秘钥、第三方凭证明文泄露的安全风险,企业生产强制落地。
1. 核心解决方案:Jasypt加密
-
核心能力:对配置文件敏感字段加密,项目启动自动解密,配置文件无明文密码
-
加密范围:数据库账号密码、Redis密码、接口密钥、短信/OSS凭证、JWT秘钥
-
落地规范:加密秘钥通过启动命令传入,不写入配置文件,杜绝秘钥泄露
2. 高级安全方案
-
微服务场景整合Nacos配置中心,敏感配置统一加密存储、权限管控
-
配置脱敏加载,内存中使用、日志不打印明文,全方位保障数据安全
(7)线上高频运维问题排障方案
-
服务启动失败:优先查看启动日志、Bean加载异常、端口占用、配置参数错误、依赖缺失
-
服务频繁重启:排查JVM OOM、线程死锁、接口雪崩、系统资源不足
-
接口响应变慢:通过监控查看GC情况、线程池状态、数据库慢查询、缓存命中率
-
配置不生效:排查配置优先级、外置配置覆盖、环境激活错误、配置缓存问题
-
优雅停机失效:未关闭异步任务、定时任务未停止、消息队列消费者未手动关闭
-
监控无数据:检查Actuator端点开启状态、网络访问权限、监控采集配置
✅ 监控与运维终极总结(企业落地准则)
-
核心底层:Actuator是所有运维监控的基础,提供指标采集、健康检测、端点运维能力
-
可视化体系:小型项目用Spring Boot Admin,中大型微服务用Prometheus+Grafana
-
生产安全:敏感配置加密、端点权限管控、生产关闭冗余监控端点
-
服务稳定:优雅启停杜绝业务中断、预热启动规避初期流量卡顿
-
运维效率:多环境打包部署、动态日志调整、线程/堆快照快速排障、异常主动告警
-
核心价值 :实现项目可监控、可追溯、可告警、可运维、高稳定,满足线上生产交付标准
5. 拓展功能(企业高频刚需拓展组件·完整版)
本模块汇总Spring Boot企业开发高频刚需拓展功能,覆盖定时任务、邮件推送、文件存储、HTTP远程调用、参数校验、国际化、异步处理等通用能力,所有功能均贴合生产场景,补齐项目开发通用组件短板,无需重复造轮子,可直接落地复用。
(1)定时任务体系(@EnableScheduling 完整版)
定时任务是企业项目刚需能力,适配数据同步、定时统计、过期清理、定时推送、订单超时关闭等场景,Spring Boot原生开箱即用,无需第三方框架,同时覆盖基础静态任务与高阶动态任务。
1. 核心开启与基础注解
-
开启入口 :启动类添加 @EnableScheduling 注解,开启Spring定时任务自动装配
-
核心执行注解:@Scheduled,标记方法为定时任务执行方法
2. 四大定时规则(全覆盖)
-
fixedRate:固定频率执行,不受任务执行耗时影响,每隔指定时间执行一次,存在任务叠加风险
-
fixedDelay:固定延迟执行,任务执行完毕后,延迟指定时间再次执行,规避任务叠加问题(企业常用)
-
initialDelay:项目启动延迟指定时间后首次执行,避免启动初期任务抢占资源
-
cron表达式:自定义周期执行,支持秒/分/时/日/月/周/年精准匹配,适配复杂定时场景(面试+实战核心)
3. 高阶动态定时任务(生产必备)
摆脱代码硬编码,实现数据库配置定时规则、后台动态修改cron、启停任务,适配灵活业务场景:
-
核心原理:基于ScheduledTaskRegistrar动态注册、取消定时任务
-
实现方案:数据库存储任务key、cron表达式、任务状态,项目启动加载有效任务,支持运行中动态修改刷新
-
实战场景:动态定时报表、自定义过期清理周期、灵活消息推送
4. 高频坑点与生产优化
-
单线程阻塞问题:Spring定时任务默认单线程池,多任务会互相阻塞,解决方案:自定义Scheduled线程池
-
任务叠加重复执行:fixedRate耗时过长导致任务叠加,优先使用fixedDelay或分布式锁防重
-
集群重复执行:多节点部署任务重复执行,解决方案:结合Redis分布式锁、任务分片、单机调度
-
任务异常终止:单任务异常导致整体任务停止,必须添加try-catch全局异常捕获
(2)邮件发送功能(企业消息推送基础)
Spring Boot原生整合JavaMail,实现验证码推送、消息通知、报表推送、异常告警邮件,适配企业办公通知场景。
1. 核心依赖与基础配置
-
核心Starter:spring-boot-starter-mail
-
基础配置:邮箱主机、端口、发件人账号、授权码、编码格式
2. 四大发送场景全覆盖
-
简单文本邮件:纯文本消息推送,适配简单通知
-
HTML格式邮件:富文本、排版样式、图片内嵌,企业报表、公告推送首选
-
附件邮件:携带Excel、PDF、压缩包文件,适配报表导出推送场景
-
模板邮件:整合Thymeleaf实现动态模板渲染,自定义邮件内容、变量替换,统一邮件样式
3. 生产避坑要点
-
禁止使用账号密码登录,统一使用邮箱授权码配置
-
配置邮件超时时间,避免阻塞业务线程
-
高频发送需做限流、异步发送,防止邮件服务器封禁IP
(3)OSS文件上传与存储(业务核心通用能力)
全覆盖本地文件存储、阿里云OSS、腾讯云COS主流对象存储,适配头像上传、图片回显、文件下载、大文件分片上传、文件删除等高频场景,是所有业务系统必备能力。
1. 本地文件上传(测试/小型项目)
-
核心配置:自定义上传路径、最大文件大小、单次请求文件限制
-
核心能力:文件重命名防覆盖、格式校验、路径映射、静态资源回显
-
适用场景:本地开发测试、小型单机项目
2. 云端OSS存储(生产主流)
-
阿里云OSS:主流企业选型,配置密钥、Bucket存储空间、域名访问
-
核心功能:单文件上传、多文件批量上传、文件删除、URL签名、过期临时链接、文件权限管控
-
高阶能力:大文件分片上传、断点续传、图片压缩、水印添加、文件类型校验
3. 生产规范与坑点
-
禁止存储恶意文件、可执行文件,后端强制校验文件后缀、文件头
-
云端密钥配置加密存储,禁止明文暴露
-
上传文件异步校验、冗余文件定时清理,释放存储空间
-
统一文件访问域名、格式规范,便于后期维护迁移
(4)第三方HTTP远程调用(接口互通核心)
企业项目频繁需要调用第三方接口(支付、短信、地图、第三方平台API),全覆盖Spring主流HTTP调用方案,适配不同场景。
1. 三大主流调用方式对比与选型
-
RestTemplate(原生):Spring原生HTTP工具,简单易用,适配简单单次调用,支持GET/POST、参数绑定、请求头设置
-
WebClient(响应式):Spring5全新非阻塞HTTP客户端,高并发、异步调用首选,适配WebFlux项目、高并发接口调用
-
OpenFeign(声明式):微服务主流,接口注解式调用,无需手动拼接参数,代码简洁、可维护性强,适配多第三方接口统一管理
2. 通用高阶配置
-
连接池配置:避免频繁创建销毁连接,提升调用效率
-
超时时间配置:连接超时、读取超时、写入超时,防止线程阻塞
-
统一请求拦截:请求日志打印、响应异常捕获、Token自动携带
-
重试机制:失败自动重试,规避网络抖动导致的调用失败
(5)全局参数校验(业务容错必备)
摒弃传统代码if判断校验,基于JSR380规范实现注解式参数校验,全局统一异常处理,简化代码、规范校验规则,企业项目强制标配。
1. 核心注解全覆盖
-
非空校验:@NotNull、@NotBlank、@NotEmpty
-
数值校验:@Min、@Max、@Size、@DecimalMin
-
格式校验:@Email、@Pattern、@Phone(自定义)
-
嵌套校验:@Valid 实现实体嵌套参数校验
2. 企业高阶实战
-
自定义校验注解:实现手机号、身份证、银行卡、IP地址自定义校验规则
-
分组校验:新增/修改/查询不同场景差异化校验
-
全局异常统一捕获:绑定校验异常,返回标准化错误信息,前端直接解析
(6)异步任务处理(性能优化核心)
通过Spring异步线程池,将非核心业务异步化,大幅提升接口响应速度,适配日志记录、消息推送、数据统计、文件导出等非实时业务。
1. 核心开启与使用
-
开启注解:启动类添加 @EnableAsync
-
异步标记:方法添加 @Async 注解,自动交由异步线程池执行
2. 生产级线程池配置
-
自定义异步线程池参数(核心线程、最大线程、队列、拒绝策略)
-
线程命名规范,便于线上日志排查
-
异步异常全局捕获,避免任务静默失败
3. 高频坑点
-
同类内异步调用失效(AOP代理失效问题)
-
异步任务无法获取主线程Request上下文
-
线程池耗尽导致异步任务阻塞
(7)国际化i18n(多语言适配)
适配国内外多语言项目,实现中文、英文、繁体动态切换,统一提示信息、接口返回文案,适配跨境项目、多端统一展示场景。
-
核心原理:基于Spring MessageSource实现国际化资源文件加载
-
实战配置:多语言资源文件编写、默认语言配置、请求头语言识别
-
业务落地:全局异常文案、校验提示、接口返回信息动态适配多语言
✅ 拓展功能终极总结(企业落地清单)
-
定时任务:静态cron任务+动态可配置任务,解决集群重复执行、线程阻塞问题
-
邮件推送:文本/HTML/附件/模板邮件,适配告警、通知、报表场景
-
文件存储:本地上传+云端OSS,支持分片上传、权限管控、文件治理
-
HTTP调用:RestTemplate/WebClient/OpenFeign三方案适配所有第三方接口调用
-
参数校验:注解式全局校验+自定义规则,精简代码、统一报错规范
-
异步处理:@EnableAsync异步线程池,业务解耦、提升接口吞吐量
-
国际化:i18n多语言适配,支撑跨境、多语言企业项目
-
Actuator监控端点、健康检查、指标收集
-
项目优雅停机、异常告警、线上问题排查
-
打包部署:多环境打包、外置配置、配置加密
第四阶段:数据层全家桶(业务开发核心)
1. 关系型数据库(MySQL核心+Spring数据层全家桶·企业完整版)
关系型数据库是Java业务系统数据存储核心基石 ,所有Spring项目的业务落地、事务管控、数据持久化均依赖此体系。本模块摒弃零散知识点,从数据库底层原理→Spring框架整合→主流持久层框架实战→高阶企业场景→性能调优→高频坑点全覆盖,完全适配单体、微服务项目生产落地,补齐CRUD开发到高性能数据架构的知识断层。
一、MySQL核心基础(Spring数据层底层根基)
所有持久层框架的性能、事务、锁机制全部依托MySQL底层原理,不懂MySQL底层,无法解决慢查询、事务失效、锁等待、数据不一致等线上核心问题。
1. MySQL核心架构与存储引擎
-
整体架构:连接层→服务层(SQL解析/优化/执行)→存储引擎层→磁盘持久层,Spring数据库连接池、SQL执行流程完全适配该架构
-
InnoDB引擎(企业唯一选型):支持事务、行级锁、MVCC多版本并发控制、外键、崩溃恢复,Spring业务项目默认标配
-
MyISAM引擎(淘汰):不支持事务、表级锁、并发性能差,仅适用于静态数据查询场景,企业开发彻底摒弃
-
核心对比:InnoDB行锁适配高并发读写、事务保障数据一致性,完全匹配Spring事务开发场景
2. 事务核心机制(Spring事务底层依赖)
-
事务四大特性ACID:原子性、一致性、隔离性、持久性,是Spring @Transactional事务生效的底层前提
-
四大隔离级别(面试+实战高频): 读未提交:存在脏读、不可重复读、幻读,生产禁用
-
读已提交(MySQL默认):解决脏读,存在不可重复读、幻读
-
可重复读:解决脏读、不可重复读,存在幻读(InnoDB默认隔离级别)
-
串行化:完全解决并发问题,性能极低,极少使用
事务并发问题:脏读(读取未提交数据)、不可重复读(同一事务多次查询结果不一致)、幻读(范围查询新增数据)
Spring精准关联:Spring事务隔离级别完全对标MySQL原生隔离级别,@Transactional可手动指定适配业务场景
3. MVCC多版本并发控制(InnoDB高并发核心)
-
核心作用:无锁实现读写并发,大幅提升数据库查询性能,是InnoDB高并发能力的核心
-
核心组成:隐藏字段(DB_TRX_ID/DB_ROLL_PTR)、undo log回滚日志、read view读视图
-
执行原理:查询时读取数据历史快照,不加行锁,读写互不阻塞,适配Spring高并发查询接口
-
Spring实战价值:大部分业务查询无需加锁,依托MVCC实现高性能并发查询,避免锁竞争耗时
4. 锁机制(解决并发数据安全问题)
-
锁粒度分类: 表级锁:锁定整张表,并发差,MyISAM使用
-
行级锁:锁定单行数据,并发高,InnoDB核心,精准匹配Spring单行数据操作
-
间隙锁/临键锁:解决可重复读隔离级别下的幻读问题
锁类型分类:共享锁(读锁)、排他锁(写锁),适配读写并发场景
高频坑点:索引失效会导致行锁升级为表锁,造成全表阻塞,是Spring高并发接口卡顿的核心诱因
5. 日志体系(数据持久化与恢复核心)
-
redo log重做日志:保证事务持久性,崩溃重启后恢复已提交事务数据,解决数据丢失问题
-
undo log回滚日志:保证事务原子性,支持事务回滚,同时支撑MVCC数据快照读取
-
binlog二进制日志:记录所有数据变更语句,用于主从复制、数据恢复、增量同步,微服务数据同步核心依赖
6. 索引原理与优化(接口提速核心)
-
索引底层结构:B+树索引特性(矮胖结构、磁盘IO少、有序存储),适配高频查询场景
-
索引分类:主键索引、唯一索引、普通索引、联合索引、覆盖索引、全文索引
-
联合索引最左匹配原则:Spring动态SQL查询高频适配,索引失效核心原因
-
索引失效场景(生产高频):like左模糊、字段类型隐式转换、or无索引、not in/is null、索引列运算
-
慢查询优化准则:避免全表扫描、优先使用覆盖索引、减少索引失效场景、控制返回数据量
二、Spring数据层核心基础(JDBC+连接池)
Spring所有持久层框架均基于JDBC封装,连接池是数据库并发管控的核心,弄懂底层才能解决连接超时、连接耗尽、事务卡死等线上问题。
1. JDBC原生核心流程
-
完整执行流程:加载驱动→获取数据库连接→创建Statement→执行SQL→处理结果集→关闭资源
-
原生痛点:频繁创建销毁连接、代码冗余、资源泄露、无事务统一管控、性能低下
-
Spring优化方案:统一封装JDBC模板、连接池复用、资源自动关闭、事务统一管控
2. Spring JdbcTemplate(原生持久层工具)
-
核心定位:Spring原生JDBC封装框架,无需第三方依赖,轻量高效,适配简单CRUD场景
-
核心优势:自动管理连接、自动关闭资源、简化SQL操作、无ORM映射开销
-
常用实战方法:queryForObject(单条查询)、queryForList(列表查询)、update(增改删)、batchUpdate(批量操作)
-
适用场景:简单业务、批量数据处理、底层数据初始化场景
3. 主流数据库连接池(生产标配)
-
HikariCP(SpringBoot默认):轻量、高性能、低开销、无锁设计,目前企业最优选型,默认适配所有SpringBoot项目
-
Druid(阿里开源):自带监控、防SQL注入、慢查询日志、密码加密,运维能力更强,国内企业高频使用
-
核心配置参数(生产调优必懂):最大连接数、最小空闲连接、连接超时、空闲超时、最大等待时间、SQL超时
-
高频线上问题:连接池耗尽、连接超时、空闲连接失效、长时间SQL占用连接导致接口阻塞
三、MyBatis+MyBatis-Plus(企业主流持久层框架)
目前90%企业Spring项目的首选持久层方案,MyBatis灵活可控、SQL可定制,MyBatis-Plus简化CRUD、补齐通用能力,二者结合适配所有业务场景。
1. MyBatis核心原理与实战(完整版·原理+落地+源码链路)
-
核心定位 :半自动轻量级ORM持久层框架,介于原生JDBC和全自动JPA之间,兼顾SQL灵活可控 与对象自动映射,无冗余封装、性能损耗极低,是国内企业Java持久层技术栈绝对主流,适配所有复杂业务、高并发数据场景。
-
核心底层完整执行链路(源码级) : 配置解析阶段:项目启动加载mybatis全局配置文件、Mapper映射文件,解析环境配置、插件、缓存、类型别名、参数映射、结果映射,封装为全局Configuration配置对象,全局唯一常驻内存。
-
会话工厂构建 :通过SqlSessionFactoryBuilder读取Configuration配置,构建SqlSessionFactory会话工厂,工厂全局单例,负责统一生产数据库会话。
-
创建SqlSession会话:每次数据库操作从工厂获取SqlSession,默认线程不安全、单次请求有效,Spring环境下由容器托管,自动实现线程隔离、事务绑定、资源回收。
-
动态代理生成Mapper:MyBatis通过MapperProxy动态代理机制,无需手动编写Mapper实现类,自动生成接口代理对象,拦截接口方法调用。
-
SQL解析与预编译:拦截方法后匹配对应Mapper SQL,解析动态标签、拼接完整SQL,通过JDBC PreparedStatement完成预编译,杜绝SQL注入。
-
参数绑定:自动解析方法入参,完成Java参数与数据库字段的类型转换、参数填充,支持简单参数、实体参数、Map参数、多参数绑定。
-
执行SQL与结果映射:通过JDBC执行SQL,查询结果自动匹配ResultMap规则,完成数据库字段→Java实体属性的自动映射,支持一对一、一对多关联映射。
-
缓存命中与资源回收:优先查询一级缓存,未命中则执行数据库查询,操作完成后自动关闭Statement、释放连接,事务提交/回滚后清空一级缓存。
-
核心核心组件(必记,对应源码) : Configuration:全局配置核心类,存储所有MyBatis配置、Mapper信息、插件、缓存、类型处理器,框架核心中枢。
-
SqlSessionFactory:会话工厂,全局单例,生产SqlSession,管控整个持久层会话生命周期。
-
SqlSession:数据库会话核心,包含增删改查核心方法,承载一级缓存,Spring环境下与事务绑定。
-
Executor:SQL执行器,核心执行组件,分为简单执行器、可复用执行器、批量执行器,支撑不同业务场景。
-
MappedStatement:封装每一条SQL语句的完整信息(SQL文本、参数类型、返回值类型、缓存规则、超时时间)。
-
TypeHandler:类型处理器,实现Java类型与数据库字段类型的自动转换,解决日期、枚举、特殊字段映射问题。
-
ResultMap:结果映射规则,自定义字段与属性映射关系,解决字段名与属性名不一致、关联查询映射问题。
-
动态SQL全套核心标签(企业高频实战) :彻底解决硬编码SQL冗余、多条件拼接繁琐问题,支持运行时动态生成SQL: if:条件判断,非空、非空字符串、非空集合判断,适配动态可选参数查询。
-
where:自动去除前端多余and/or,无需手动处理拼接空格、逻辑符,杜绝SQL语法错误。
-
choose/when/otherwise:多条件分支选择,类似if-else if-else,适配互斥查询条件。
-
foreach:遍历集合,适配in查询、批量插入、批量更新核心场景。
-
set:动态拼接更新字段,自动去除尾部逗号,解决动态更新字段冗余问题。
-
trim:自定义前缀、后缀、截取字符,灵活适配复杂SQL拼接场景。
-
include:抽取通用SQL片段,复用查询字段、查询条件,精简代码、统一规范。
-
参数绑定核心规则(避坑重点) :单个普通参数:无需注解,直接通过#{参数名}取值,适配简单查询场景。
-
多参数场景:必须添加@Param注解指定参数别名,否则无法绑定参数,启动/运行报错。
-
实体类参数:直接#{属性名}取值,自动映射实体字段,无需逐个传参。
-
Map参数:通过#{key}取值,适配动态不确定参数场景。
-
**#{}与{}核心区别(面试高频)**:#{}为预编译参数占位符,自动防SQL注入、参数转义,安全高效;{}为字符串直接拼接,无预编译、存在注入风险,仅用于动态排序、动态表名、动态字段场景。
-
高级映射实战(复杂业务必备) : 基础映射:自动驼峰命名转换,数据库user_name自动映射实体userName,简化配置。
-
自定义ResultMap:解决字段名与属性名不一致、字段类型不匹配问题,统一全局映射规则。
-
一对一关联映射:association标签,适配用户-用户详情、订单-用户信息关联查询。
-
一对多关联映射:collection标签,适配用户-订单列表、商品-sku列表关联查询,支持嵌套查询、嵌套结果两种实现方式。
-
批量操作实战规范(性能优化核心) : 批量插入:通过foreach拼接values,单次SQL批量插入多条数据,相比循环单条插入,性能提升10倍以上。
-
批量更新:CASE WHEN批量更新,避免循环更新数据库,大幅减少数据库交互次数。
-
批量删除:foreach拼接in条件,批量删除指定数据,适配数据清理、批量作废场景。
-
批量优化要点:控制单次批量操作数据量(500-1000条最佳),避免单次数据过大导致SQL超时、数据包溢出。
Spring整合MyBatis核心机制 :原生MyBatis需要手动创建SqlSession、关闭资源、管理事务,Spring通过MyBatis-Spring适配包实现全自动托管:自动扫描Mapper接口、自动注入SqlSession、自动管理数据库连接、自动绑定Spring事务、自动回收资源,彻底解放手动操作,同时完美兼容Spring事务传播、事务回滚机制,是Spring数据层无缝整合的核心保障。
企业实战适用场景总结:复杂多条件动态查询、批量数据操作、多表关联查询、自定义复杂SQL、高并发数据查询、精细化SQL性能优化场景,均优先使用MyBatis,兼顾灵活性与性能,是企业复杂业务持久层首选方案。
2. MyBatis核心缓存机制(性能优化)
-
一级缓存(默认开启):SqlSession级别缓存,同一会话重复查询直接走缓存,会话关闭缓存清空
-
二级缓存(手动开启):Mapper命名空间级别缓存,跨会话共享,适配高频查询、低频修改场景
-
缓存失效机制:增删改操作自动清空对应缓存,避免数据脏读
-
Spring实战坑点:Spring事务下SqlSession由容器统一管理,一级缓存生效场景受限,优先使用二级缓存+Redis缓存
3. MyBatis-Plus全能增强(生产必备·完整版)
MyBatis-Plus(简称MP)是基于MyBatis的增强工具,只增强、不改变原有MyBatis特性 ,完美兼容原生SQL、动态标签、映射规则,同时补齐MyBatis重复性CRUD代码缺失、通用能力不足的短板,是目前国内企业Spring数据层标配框架。适配单体、微服务、多租户、高并发项目,所有功能均为生产级落地方案,无冗余玩具功能。
一、核心定位与核心优势(选型必懂)
-
核心定位 :轻量级持久层增强框架,弥补MyBatis基础CRUD冗余、通用功能缺失问题,保留SQL自定义灵活性,兼顾开发效率 与性能可控性
-
核心优势:零SQL基础CRUD、条件构造器动态查询、内置分页/乐观锁/逻辑删除、自动填充、多租户隔离、SQL性能监控,开箱即用无需手动封装
-
兼容特性:完全兼容原生MyBatis所有语法、Mapper文件、动态SQL、关联映射,可混合开发,无缝迁移原有MyBatis项目
-
生产价值:减少60%以上重复CRUD代码,统一数据层开发规范,内置企业级通用能力,规避手动封装的Bug与漏洞
二、快速整合与基础配置(SpringBoot标准集成)
1. 核心依赖(SpringBoot2.x/3.x通用)
适配主流SpringBoot版本,无需额外适配,自动完成装配:
XML
<!-- MyBatis-Plus核心依赖 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3.1</version>
</dependency>
<!-- 数据库驱动、连接池依赖沿用SpringBoot标配 -->2. 核心启动注解与配置
启动类添加Mapper扫描注解,自动注册所有Mapper接口,无需手动配置SqlSessionFactory:
java
@SpringBootApplication
// 扫描Mapper接口路径,自动生成代理对象
@MapperScan("com.xxx.project.mapper")
public class SpringApplication {
public static void main(String[] args) {
SpringApplication.run(SpringApplication.class, args);
}
}3. 全局yml生产配置(标准化)
XML
# MyBatis-Plus全局配置
mybatis-plus:
# 映射文件路径
mapper-locations: classpath:mapper/*.xml
# 实体类别名包
type-aliases-package: com.xxx.project.entity
configuration:
# 开启驼峰命名自动转换
map-underscore-to-camel-case: true
# 关闭默认日志,生产按需开启
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
# 开启字段为空不插入、不更新
default-statement-timeout: 3000
global-config:
# 关闭MP默认banner
banner: false
db-config:
# 主键策略、逻辑删除、字段默认值全局配置
id-type: assign_id
logic-delete-field: deleted
logic-delete-value: 1
logic-not-delete-value: 0
update-strategy: not_null三、核心基础能力(CRUD零SQL开发)
1. 双层核心接口体系(Mapper+Service)
MP提供两层通用接口,分层适配数据层与业务层,规范代码结构:
-
BaseMapper(数据层):所有Mapper接口继承,提供单表基础CRUD、批量操作、条件查询,直接操作数据库,无业务逻辑
-
IService+ServiceImpl(业务层):业务层通用接口与实现,封装数据校验、批量操作、事务适配,在BaseMapper基础上增强业务能力
核心区别:简单数据查询用BaseMapper,业务操作、批量处理、事务操作优先用IService
2. 条件构造器(核心精髓)
彻底告别硬编码SQL,通过Java代码动态拼接查询、更新条件,适配多条件模糊查询、动态筛选场景,杜绝SQL语法错误:
-
QueryWrapper(查询构造器):用于列表查询、分页查询、统计查询,支持所有SQL查询条件 精准匹配:eq、ne、in、notIn
-
模糊查询:like、leftLike、rightLike
-
范围查询:gt、lt、ge、le、between
-
排序:orderByAsc、orderByDesc
-
空值判断:isNull、isNotNull
UpdateWrapper(更新构造器):动态更新字段,无需封装实体,精准更新指定字段,减少数据库IO
LambdaQueryWrapper/LambdaUpdateWrapper(企业首选) :基于Lambda表达式,杜绝硬编码字段名,编译期校验字段合法性,避免字段写错导致的线上Bug
实战示例(Lambda无硬编码查询):
java
// 查询正常状态、用户名包含admin的用户列表
LambdaQueryWrapper<User> wrapper = Wrappers.lambdaQuery();
wrapper.eq(User::getStatus, 1)
.like(User::getUsername, "admin")
.orderByDesc(User::getCreateTime);
List<User> userList = userMapper.selectList(wrapper);3. 分页插件(生产必备,杜绝内存分页)
MP内置高性能分页插件,自动适配MySQL、Oracle等多种数据库分页语法,物理分页,避免内存分页数据溢出、数据不准确问题,企业项目必配:
java
// 分页插件配置类
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
// 添加分页插件
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}分页实战用法(自动分页、总条数统计):
java
// pageNum当前页、pageSize每页条数
Page<User> page = new Page<>(1, 10);
LambdaQueryWrapper<User> wrapper = Wrappers.lambdaQuery();
// 执行分页查询,自动统计总条数、总页数
Page<User> userPage = userMapper.selectPage(page, wrapper);四、企业级高阶核心功能(生产刚需)
1. 自动填充(统一字段维护)
自动填充创建时间、修改时间、创建人、修改人,无需手动set字段,统一全局数据规范,杜绝字段遗漏:
-
核心场景:所有业务实体通用基础字段(createTime、updateTime、createUser、updateUser)
-
实现原理:通过MP元对象处理器,在新增/更新时自动拦截填充字段
-
优势:全局统一规则,无需重复编码,避免多模块填充规则不一致
2. 逻辑删除(生产数据规范)
企业项目禁止物理删除数据,全部采用软删除,保留数据溯源、恢复能力,MP全局配置一键生效:
-
核心规则:新增默认未删除(0)、删除修改为已删除(1)
-
自动适配:所有BaseMapper删除方法自动转为更新删除字段,所有查询自动过滤已删除数据
-
注意事项:自定义SQL需要手动添加deleted=0条件,否则会查询到已删除数据
3. 乐观锁(解决并发更新覆盖)
针对商品库存、订单状态、用户信息等并发更新场景,解决多线程同时更新导致的数据覆盖问题,无锁实现并发安全:
-
实现原理:通过version版本号字段,更新时校验版本号,版本一致则更新并自增,不一致则更新失败
-
配置方式:实体类字段添加@Version注解,开启乐观锁插件
-
实战场景:商品扣减库存、订单状态修改、积分变更、并发编辑数据
4. 主键策略(分布式唯一ID)
MP内置多种主键生成策略,适配单机、分布式、微服务场景,杜绝ID重复、自增ID不安全问题:
-
ASSIGN_ID(默认):雪花算法,生成19位Long类型唯一ID,分布式全局唯一,无序号暴露风险
-
AUTO:数据库自增ID,仅适用于单机简单项目
-
INPUT:手动指定ID,适配自定义主键场景
5. 链式查询(极简代码开发)
无需创建构造器对象,一行代码完成查询、更新、删除,精简业务代码:
java
// 链式查询:查询正常状态用户并排序
List<User> userList = UserChainWrappers.queryChain()
.eq(User::getStatus, 1)
.like(User::getUsername, "test")
.list();五、高阶企业特性(中大型项目必备)
1. 多租户隔离(SaaS项目核心)
MP内置多租户插件,实现数据层面租户隔离,无需每条SQL手动拼接租户条件,适配SaaS多租户系统:
-
核心原理:插件拦截所有SQL,自动拼接租户ID查询条件
-
适配场景:多商户、多团队、SaaS平台数据隔离
-
白名单机制:支持指定表、指定SQL不拼接租户条件,适配公共数据查询
2. SQL性能分析(线上调优神器)
内置SQL执行耗时监控,自动打印慢SQL,精准定位性能瓶颈,是数据层调优核心工具:
-
核心能力:统计每条SQL执行耗时、打印完整SQL、参数、执行时长
-
生产配置:设置慢SQL阈值(默认1000ms),超时自动告警打印
-
实战价值:快速排查接口卡顿、数据库慢查询问题
3. 批量操作增强(性能优化)
IService内置高性能批量方法,底层优化JDBC批量提交,相比循环单条操作性能提升10倍以上:
-
saveBatch:批量插入,支持自定义批次大小,避免数据包溢出
-
updateBatchById:批量更新,基于ID批量修改数据
-
适配场景:数据同步、批量导入、批量状态更新
六、生产高频坑点与终极解决方案
-
分页总数为0/分页失效:未注册分页插件、插件优先级过低、自定义SQL未适配分页,解决方案:手动配置MP插件优先级,自定义分页SQL适配count查询
-
逻辑删除查询数据异常:自定义XML SQL不会自动拼接deleted条件,解决方案:统一封装公共SQL片段,全局引入
-
乐观锁更新失效:实体未携带version版本号、版本号字段未自动填充、更新非实体参数,解决方案:更新时必须传递完整实体版本号
-
自动填充不生效:未注册元对象处理器、字段注解缺失、新增/更新策略配置错误
-
批量插入性能差:未开启rewriteBatchedStatements数据库参数,解决方案:连接URL添加批量重写参数,大幅提升批量性能
-
Lambda表达式字段报错:实体字段命名不规范、字段删除未清理代码,编译期可提前拦截,杜绝线上字段错误
七、MP与原生MyBatis混合开发规范
-
简单CRUD:优先使用MP条件构造器、通用方法,零SQL开发
-
复杂多表关联、复杂统计SQL:使用原生MyBatis XML自定义SQL,保证可读性与可维护性
-
批量数据处理:优先使用MP批量方法,结合数据库批量参数优化性能
-
通用数据规范:统一使用MP自动填充、逻辑删除、乐观锁,保证项目规范统一
✅ MyBatis-Plus模块核心总结(生产落地清单)
-
核心定位:增强不侵入,兼容原生MyBatis,兼顾开发效率与性能
-
基础核心:BaseMapper+IService双层CRUD、Lambda条件构造器、物理分页
-
企业标配:自动填充、逻辑删除、乐观锁、雪花主键、SQL性能监控
-
高阶能力:多租户隔离、链式查询、高性能批量操作、动态条件拼接
-
避坑核心:自定义SQL需适配逻辑删除、分页插件必配置、并发更新必开乐观锁
-
技术选型:99%Java企业项目数据层首选,替代原生MyBatis基础CRUD开发
-
核心价值:无SQL实现基础CRUD,大幅减少重复代码,保留MyBatis原生灵活性
-
核心基础能力: 通用CRUD接口:BaseMapper、IService自带全套增删改查
-
条件构造器:QueryWrapper、UpdateWrapper,无SQL动态条件查询
-
分页插件:内置分页功能,自动适配数据库分页语法,杜绝内存分页
-
逻辑删除:全局配置软删除,无需手动修改删除字段
-
自动填充:创建时间、修改时间、创建人、修改人自动填充
-
乐观锁:版本号机制,解决并发更新数据覆盖问题
高阶能力:主键策略、批量操作、链式查询、多租户隔离、SQL性能分析
4. MyBatis高频坑点与生产级排障方案(完整版·底层原因+解决方案)
本节汇总企业开发中MyBatis9大高频致命坑点,全部配套底层原理、报错场景、完整解决方案和避坑规范,解决线上SQL异常、数据错乱、性能卡顿、功能失效等核心问题,适配单体、微服务全场景。
坑点1:#{}与${}混用导致SQL注入&参数失效(面试+生产最高频)
报错场景:用户输入特殊字符(单引号、#、%)导致SQL语法报错、恶意参数篡改数据,动态排序/表名场景参数不生效。
底层原因:#{}是预编译占位符,会自动转义参数、生成PreparedStatement,杜绝注入;${}是字符串直接拼接,无预编译、无参数转义,直接拼接原生字符串,存在严重安全漏洞。
解决方案:
-
常规参数查询、新增、更新统一使用#{},全程杜绝SQL注入;
-
仅动态表名、动态排序、动态字段场景使用${},且必须做参数白名单校验、参数过滤;
-
禁止直接接收前端原生参数用于${}拼接。
反面示例 :${username} 存在注入风险,
正确示例 :#{username} 安全预编译。
坑点2:多参数绑定失效、参数为null报错
报错场景:Mapper接口传入多个普通参数,XML中无法获取参数值,启动/运行报参数未定义异常;部分参数为null时动态SQL判断失效。
底层原因 :MyBatis默认仅能识别单参数、实体参数、Map参数,多个普通参数必须通过@Param注解绑定别名,否则无法完成参数映射;动态SQL空值判断未兼顾null和空字符串。
解决方案:
-
接口多参数强制添加@Param指定别名,统一映射XML参数;
-
动态SQL判断同时校验
null != 参数 and '' != 参数,避免空字符串导致查询异常; -
复杂多参数场景优先封装DTO实体传参,简化参数绑定。
坑点3:动态SQL拼接多余and/or导致SQL语法错误
报错场景:多条件动态查询,前置条件为空、后置条件生效,拼接出多余and/or,数据库抛出SQL语法异常。
底层原因:纯if标签拼接条件时,无法自动剔除头部多余逻辑运算符,原生字符串拼接存在语法漏洞。
解决方案:
-
多条件查询优先使用where标签,自动剔除首部多余and/or;
-
动态更新场景优先使用set标签,自动剔除尾部多余逗号;
-
复杂拼接场景使用trim标签自定义截取规则,兜底兼容特殊场景。
坑点4:分页失效、出现内存分页、总数为0
报错场景:分页查询返回total=0、页码错乱、分页数据不全,实际是查询全部数据后内存分页,而非数据库物理分页。
底层原因:
-
未注册MyBatis分页插件、插件未生效;
-
自定义XML复杂SQL未适配分页count查询;
-
插件优先级过低,被其他插件拦截覆盖。
解决方案:
-
项目全局配置分页插件,指定数据库类型,设置最高执行优先级;
-
自定义复杂SQL手动编写count统计语句,适配分页总数统计;
-
杜绝代码中手动List集合分页,强制使用物理分页。
坑点5:一级缓存导致数据脏读、数据更新不及时
报错场景:同一事务内多次查询同一数据,数据库数据已更新,接口查询依旧返回旧数据,出现数据不一致。
底层原因 :MyBatis一级缓存默认开启,属于SqlSession级别缓存,同一会话内重复查询直接读取缓存,事务未提交、会话未关闭时,不会同步数据库最新数据;Spring事务会复用同一个SqlSession,加剧脏读问题。
解决方案:
-
业务更新后手动清空一级缓存(sqlSession.clearCache());
-
高频更新场景关闭一级缓存,或优先使用二级缓存+Redis分布式缓存;
-
实时性要求极高的接口,强制每次查询走数据库。
坑点6:逻辑删除自定义SQL失效,查询已删除数据
报错场景 :MP全局配置逻辑删除后,Mapper自带CRUD方法自动过滤删除数据,但自定义XML SQL依旧查询出已删除数据。
底层原因 :MP逻辑删除是通过插件拦截通用CRUD方法自动拼接deleted=0条件,不会拦截自定义手写SQL,导致条件缺失。
解决方案:
-
抽取全局通用SQL片段,所有自定义查询统一引入删除条件;
-
自定义SQL手动添加
and deleted = 0过滤条件; -
新项目统一规范:简单查询用MP方法,复杂查询统一封装公共条件。
坑点7:索引失效引发行锁升级为表锁,高并发接口卡顿
报错场景:根据字段更新单条数据,并发场景下出现全表阻塞、接口超时、锁等待严重。
底层原因 :更新条件字段无索引、索引失效、隐式类型转换,导致InnoDB行锁无法生效,自动升级为表级锁,锁定整张表,阻塞所有读写请求。
解决方案:
-
所有更新、删除条件字段必须建立索引;
-
杜绝字符串字段传数字、字段类型不匹配等隐式转换场景;
-
线上慢SQL定期排查,修复索引失效语句。
坑点8:批量操作性能极低、数据包溢出报错
报错场景:循环单条插入/更新数据,批量导入上万条数据耗时极高、接口超时、数据库数据包过大报错。
底层原因:原生循环单条操作会频繁创建数据库连接、频繁提交事务,网络IO开销极大;未开启批量重写参数,MyBatis默认逐条执行SQL。
解决方案:
-
数据库连接URL追加参数:
?rewriteBatchedStatements=true,开启批量SQL重写; -
摒弃循环单条操作,使用foreach批量SQL或MP saveBatch批量方法;
-
控制单次批量数据量(500-1000条),避免数据包溢出、SQL超时。
坑点9:实体字段映射失效、字段值为null
报错场景:数据库有数据,实体对应字段返回null,无报错但数据缺失。
底层原因:
-
未开启驼峰命名转换,数据库下划线字段无法映射实体驼峰字段;
-
自定义ResultMap字段映射关系错误、字段名拼写错误;
-
实体字段权限非private、无get/set方法,无法完成反射赋值;
-
查询字段未包含对应数据库字段,结果集无数据。
解决方案:
-
全局开启驼峰命名自动转换;
-
统一规范ResultMap映射,杜绝手写字段名出错;
-
实体字段私有化,自动生成get/set方法;
-
禁止select *,按需查询所需字段,保证查询字段与实体匹配。
MyBatis排障通用思路(线上快速定位)
-
语法类报错:优先排查动态SQL拼接、and/or冗余、参数绑定、标签闭合问题;
-
数据类报错:优先排查缓存脏读、逻辑删除缺失、字段映射失效、索引失效问题;
-
性能类报错:优先排查批量操作未优化、全表扫描、行锁升级、慢SQL问题;
-
功能类失效:优先排查插件未注册、配置不生效、自定义SQL未适配框架规则问题。
四、Spring Data JPA(企业开发选型·完整版)
Spring Data JPA 是 Spring 生态基于 JPA 规范封装的全自动 ORM 持久层框架 ,主打零SQL、快速迭代、开箱即用,彻底简化数据库CRUD操作。相较于MyBatis手写SQL的模式,JPA通过注解映射实体、方法名自动生成SQL,极大提升开发效率,是中小企业快速开发、后台管理系统、初创项目的主流选型。本模块完整覆盖核心原理、实战用法、高级特性、生产坑点、技术选型对比,适配零基础落地与面试高频考点。
1. 核心定位与底层原理
-
核心定位:Spring Data 子组件,基于 JPA 规范、Hibernate 实现的全自动持久层框架,无需手动编写Mapper接口与XML文件,仅通过接口定义即可完成数据库操作
-
底层依赖 :JPA是Java持久层规范(接口标准),无具体实现;Spring Data JPA 默认依托 Hibernate 作为底层实现,完成SQL生成、实体映射、事务管控
-
核心设计思想:约定大于配置,通过实体注解映射数据库表结构,通过接口方法名语义自动解析、拼接、执行SQL,屏蔽底层JDBC操作细节
-
核心能力:自动建表、全自动CRUD、动态条件查询、分页排序、关联映射、事务自动管控、原生SQL兼容
2. 核心优势与适用场景(选型必懂)
核心优势
-
极致开发效率:零基础CRUD代码,无需手写SQL、Mapper、XML,一行接口方法实现查询、新增、删除、分页
-
跨数据库兼容:依托JPA规范,适配MySQL、Oracle、PostgreSQL等主流数据库,切换数据库几乎无需修改业务代码
-
实体映射简洁:通过注解自动映射表、字段、主键、关联关系,无需手动维护ResultMap映射
-
自动表结构管理:支持项目启动自动建表、更新表结构、新增字段,适配快速迭代开发
-
事务高度集成:无缝适配Spring事务机制,默认支持事务自动提交、回滚,无需手动管控连接
核心短板
-
SQL不可控:自动生成SQL语句晦涩,复杂多表关联、复杂统计查询难以优化,容易出现低效SQL
-
性能损耗:底层Hibernate封装厚重,存在实体托管、缓存开销,高并发场景性能弱于MyBatis
-
调试困难:自动生成SQL报错难以定位,动态查询语法报错不直观,线上排障成本高
-
复杂场景适配差:批量复杂操作、多表嵌套查询、精细化SQL调优场景体验极差
企业适配场景
-
首选场景:后台管理系统、内部工具项目、初创快速迭代项目、业务简单的中小型系统、低并发数据场景
-
禁用场景:高并发互联网项目、复杂业务系统、海量数据场景、需要精细化SQL调优的核心业务
3. SpringBoot标准整合配置
1. 核心依赖
XML
<!-- Spring Data JPA核心依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- 数据库驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>2. 生产级yml配置
XML
# Spring Data JPA全局配置
spring:
jpa:
# 显示SQL语句(开发环境开启,生产关闭)
show-sql: true
# 格式化SQL日志,提升可读性
properties:
hibernate:
format_sql: true
# 自动表结构更新策略
hibernate:
ddl-auto: update
# ddl-auto参数详解:
# create:启动新建表,关闭删除表(测试环境用)
# create-drop:启动建表、销毁删表
# update:增量更新表结构(新增字段、更新字段属性,不删除数据,生产首选)
# validate:仅校验表结构一致性,不修改表(正式环境最安全)
# none:关闭自动建表4. 核心注解体系(实体映射核心)
JPA所有数据库映射均依托注解实现,是框架核心基础,全覆盖企业常用注解:
-
@Entity:标识当前类为数据库实体类,被JPA托管
-
@Table(name = "表名"):绑定实体对应的数据库表,可自定义表名、索引
-
@Id:标识主键字段,每张表必须唯一配置
-
@GeneratedValue:主键生成策略,适配单机/分布式场景 IDENTITY:数据库自增主键(MySQL首选)
-
AUTO:框架自动适配数据库主键策略
-
SEQUENCE:序列主键(Oracle专用)
@Column:字段详细配置,指定字段名、长度、是否可为空、唯一约束、默认值
@Transient:临时字段,不映射数据库表,仅用于业务临时存储
@CreatedDate/@LastModifiedDate:自动填充创建时间、修改时间(需开启审计)
@CreatedBy/@LastModifiedBy:自动填充创建人、修改人
@EnableJpaAuditing:启动类开启JPA审计功能,支持自动字段填充
5. 核心开发模式(零SQL CRUD实战)
1. 基础接口继承体系
Spring Data JPA 提供三层继承接口,分层适配不同业务场景,无需手动实现:
-
Repository(顶层父接口):最基础接口,无内置方法,纯标记接口,自定义简单查询可直接继承
-
CrudRepository:继承Repository,内置完整增删改查方法,适配基础CRUD场景
-
JpaRepository(企业首选) :继承CrudRepository,额外内置分页、排序、批量操作方法,功能最全,项目统一使用
实战接口定义(无需实现类,框架自动生成代理):
java
// 继承JpaRepository<实体类, 主键类型>
public interface UserRepository extends JpaRepository<User, Long> {
// 后续自定义查询方法直接在此定义
}2. 方法名命名查询(核心精髓)
JPA 最核心特性,通过语义化方法名自动解析生成SQL,无需手写语句,适配绝大多数动态查询场景:
-
查询关键字:findBy、getBy、countBy、existsBy、deleteBy
-
条件关键字:Equals、Not、Like、Between、GreaterThan、LessThan、In、IsNull、OrderBy
-
逻辑关键字:And、Or
实战示例:
java
// 根据用户名精准查询
User findByUsername(String username);
// 根据用户名模糊查询+状态筛选+时间排序
List<User> findByUsernameLikeAndStatusOrderByCreateTimeDesc(String username, Integer status);
// 统计指定状态用户数量
long countByStatus(Integer status);
// 判断手机号是否存在
boolean existsByPhone(String phone);
// 根据ID批量删除
void deleteByIdIn(List<Long> ids);3. 分页与排序(企业标配)
框架内置Pageable分页参数、Sort排序工具,一行代码实现物理分页,杜绝内存分页:
java
// 分页查询:pageNum从0开始,pageSize每页条数
Pageable pageable = PageRequest.of(0, 10, Sort.by(Sort.Direction.DESC, "createTime"));
// 条件分页查询
Page<User> userPage = userRepository.findByStatus(1, pageable);
// 获取分页数据、总条数、总页数
List<User> userList = userPage.getContent();
long total = userPage.getTotalElements();6. 自定义SQL查询(弥补自动查询短板)
针对复杂查询、多表关联、统计查询,JPA支持原生SQL与JPQL两种自定义方式,补齐自动查询的不足:
1. JPQL查询(面向对象查询)
基于实体类查询,而非数据库表,无数据库耦合,适配跨数据库场景:
java
@Query("select u from User u where u.status = :status and u.username like :username")
List<User> findUserByCondition(@Param("status") Integer status, @Param("username") String username);2. 原生SQL查询(复杂业务首选)
直接编写原生MySQL语句,适配多表关联、复杂统计、函数查询,灵活性拉满:
java
// nativeQuery=true 开启原生SQL
@Query(value = "select * from sys_user where status = ?1", nativeQuery = true)
List<User> findUserByStatus(Integer status);3. 自定义修改/删除SQL
新增/修改/删除需搭配@Modifying、@Transactional注解,保证事务生效:
java
@Modifying
@Transactional
@Query("update User u set u.status = :status where u.id = :id")
int updateUserStatus(@Param("id") Long id, @Param("status") Integer status);7. 高级核心特性(生产进阶)
1. 实体关联映射(多表关系)
JPA原生支持数据库一对一、一对多、多对多关联关系,自动关联查询,无需手动连表:
-
一对一 @OneToOne:用户-用户详情、订单-订单详情
-
一对多 @OneToMany:用户-订单列表、商品-SKU列表
-
多对多 @ManyToMany:用户-角色、角色-权限
核心优势:自动维护关联关系,无需手动编写连表SQL;短板:关联查询容易触发N+1查询问题,需手动优化抓取策略。
2. 动态条件查询(Specification)
针对多条件动态模糊查询场景,无需定义大量方法,通过Specification动态拼接查询条件,适配复杂筛选场景:
java
// 动态拼接查询条件
Specification<User> spec = (root, query, cb) -> {
List<Predicate> predicates = new ArrayList<>();
// 状态条件
predicates.add(cb.equal(root.get("status"), 1));
// 用户名模糊条件
predicates.add(cb.like(root.get("username"), "%" + "admin" + "%"));
return cb.and(predicates.toArray(new Predicate[0]));
};
// 执行动态查询
List<User> userList = userRepository.findAll(spec);3. 投影查询(按需查询字段)
解决select * 查询冗余字段问题,通过接口投影、类投影实现按需字段查询,减少数据传输开销。
4. 审计自动填充
全局自动填充创建时间、修改时间、创建人、修改人,无需手动set,统一数据规范,适配所有业务实体。
8. 缓存机制(性能优化)
-
一级缓存(默认开启):Session级别缓存,同一会话重复查询直接走缓存,事务提交后清空,减少重复查询
-
二级缓存(手动开启):全局级别缓存,跨会话共享,适配高频查询、低频修改数据,需手动配置缓存策略
-
缓存坑点:自动缓存容易导致数据脏读,数据更新后需手动刷新缓存,生产高实时性场景慎用
9. 生产高频坑点与解决方案(避坑核心)
-
坑点1:N+1查询问题(最高频)现象 :查询主表数据后,循环查询关联表数据,产生大量冗余SQL,接口卡顿 原因 :JPA关联查询默认延迟加载,每次遍历关联数据都会单独查询数据库 解决方案:通过@Fetch注解指定抓取策略、使用JOIN FETCH连表查询、禁止循环遍历关联数据
-
坑点2:自动建表字段错乱、丢失数据现象 :项目重启后字段被删除、字段属性变更导致数据丢失 原因 :ddl-auto配置为create,或update策略适配不精准 解决方案:开发环境用update,测试/生产环境强制用validate,禁止自动修改表结构,手动维护数据库脚本
-
坑点3:事务失效、数据不回滚现象 :方法报错,数据库数据未回滚 原因 :自定义修改SQL未加@Modifying注解、非public方法、异常被try-catch捕获 解决方案:更新删除方法必加@Modifying+@Transactional、保证方法为public、统一异常抛出规则
-
坑点4:查询性能低下、慢SQL过多现象 :自动生成SQL冗余、无索引、全表扫描 原因 :方法名查询生成SQL不优化、关联查询无优化、默认查询所有字段 解决方案:复杂场景手写原生SQL、按需投影查询、核心字段手动建索引、关闭无用关联查询
-
坑点5:懒加载异常(LazyInitializationException)现象 :会话关闭后访问关联属性报错 原因 :关联属性延迟加载,会话结束后无法查询关联数据 解决方案:按需开启立即加载、业务层提前查询关联数据、配置开放会话视图(慎用)
10. MyBatis vs Spring Data JPA 企业选型对比(终极结论)
|--------|----------------|--------------------|
| 对比维度 | MyBatis/MP | Spring Data JPA |
| SQL可控性 | 完全可控,灵活自定义 | 自动生成SQL,可控性弱 |
| 开发效率 | 中等,需手写简单SQL | 极高,零SQL快速开发 |
| 性能表现 | 轻量高效,适配高并发 | 封装厚重,高并发性能一般 |
| 调试排障 | SQL直观,排障简单 | 自动SQL晦涩,排障困难 |
| 复杂业务适配 | 完美适配复杂SQL、多表关联 | 适配性差,复杂场景吃力 |
| 企业主流选型 | 互联网、高并发、复杂业务首选 | 传统企业、后台管理、快速迭代项目首选 |
✅ Spring Data JPA 模块终极总结
-
核心本质 :基于JPA规范、Hibernate实现的全自动ORM框架,以约定大于配置为核心思想
-
核心优势:零SQL CRUD、开发效率高、跨数据库兼容、自动表结构管理
-
核心短板:SQL不可控、性能一般、复杂场景适配差、排障难度高
-
核心能力:方法名查询、JPQL/原生SQL、分页排序、实体关联、动态条件查询、审计填充
-
生产避坑:杜绝生产环境自动建表、解决N+1查询、规范事务使用、规避缓存脏读
-
选型准则:简单快速项目选JPA,高并发、复杂业务、精细化调优项目必选MyBatis+MP
五、企业高阶数据层场景(生产核心)
1. 多数据源动态切换(生产级完整版)
多数据源动态切换是企业项目解耦多库业务、适配异构数据库、隔离数据资源 的核心方案,彻底解决单一项目需操作多个独立数据库的业务痛点,广泛应用于多业务库拆分、第三方数据对接、日志/报表独立库、新旧系统数据兼容等场景。本模块覆盖核心原理、两种主流实现方案、完整可落地源码、配置规范、线程隔离、生产坑点、事务适配,完全适配Spring Boot单体及微服务项目。
一、核心业务场景与适用范围
企业开发中必须使用多数据源的核心场景,精准匹配业务落地:
-
多业务库拆分:核心业务库(用户/订单)、日志库、统计报表库、操作记录库物理隔离,避免非核心业务占用主库资源
-
异构数据库对接:项目同时操作MySQL主库、Oracle业务库、PostgreSQL数据仓库,适配不同第三方系统数据源
-
新旧系统兼容:系统迭代迁移阶段,同时操作旧数据库与新数据库,完成数据平滑迁移
-
读写分离基础:主库写、从库读,基于多数据源切换能力实现读写链路拆分
-
租户隔离场景:独立库多租户SaaS系统,根据租户标识动态切换对应业务数据库
二、核心实现原理(Spring底层机制)
Spring多数据源切换核心依托 AbstractRoutingDataSource 抽象类 + ThreadLocal线程隔离 + AOP动态拦截 实现,全程无侵入业务代码:
-
核心父类:AbstractRoutingDataSource是Spring官方提供的动态数据源路由抽象类,内置多数据源Map缓存,可根据自定义规则动态匹配目标数据源
-
路由核心:重写determineCurrentLookupKey()方法,获取当前线程绑定的数据源标识,匹配对应数据源
-
线程隔离:通过ThreadLocal存储当前数据源Key,每个业务线程数据源独立互不干扰,杜绝并发切换错乱
-
切换时机:AOP切面在业务方法执行前拦截,绑定数据源标识;方法执行后清空标识,避免线程复用导致数据源污染
三、两种主流实现方案(企业选型)
方案一:原生Spring AOP+AbstractRoutingDataSource(零依赖、轻量首选)
无需引入第三方框架,基于Spring原生API实现,无版本冲突、轻量化、可控性强,适合数据源数量固定、简单切换场景,是中小型项目首选方案。
完整落地步骤+源码
- 多数据源yml配置(主库+从库/业务库)
java
# 多数据源配置
spring:
datasource:
# 主库数据源
master:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/db_master?useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT%2B8&allowMultiQueries=true
username: root
password: 123456
# 日志数据源
log:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/db_log?useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT%2B8
username: root
password: 123456
# 报表数据源
report:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/db_report?useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT%2B8
username: root
password: 123456
# 关闭Spring自动数据源配置,避免冲突
autoconfigure:
exclude: org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration- 自定义数据源标识注解(业务无侵入切换)
java
import java.lang.annotation.*;
/**
* 多数据源切换注解
* 作用于类/方法,优先级:方法注解 > 类注解
*/
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface DS {
// 数据源key:对应配置文件中的master/log/report
String value() default "master";
}- 自定义动态数据源路由类(核心路由逻辑)
java
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
/**
* 动态数据源路由核心类
* 重写路由方法,获取当前线程数据源标识
*/
public class DynamicDataSource extends AbstractRoutingDataSource {
// 线程级别的数据源Key存储,线程隔离
private static final ThreadLocal<String> DATA_SOURCE_KEY = new ThreadLocal<>();
/**
* 核心路由方法:决定当前使用哪个数据源
*/
@Override
protected Object determineCurrentLookupKey() {
return DATA_SOURCE_KEY.get();
}
/**
* 设置当前数据源
*/
public static void setDataSource(String key) {
DATA_SOURCE_KEY.set(key);
}
/**
* 清空数据源(防止线程复用污染)
*/
public static void clearDataSource() {
DATA_SOURCE_KEY.remove();
}
}- 多数据源配置类(初始化多数据源、注册Bean)
java
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class DynamicDataSourceConfig {
// 主库数据源
@Bean
@ConfigurationProperties(prefix = "spring.datasource.master")
public DataSource masterDataSource() {
return new DruidDataSource();
}
// 日志库数据源
@Bean
@ConfigurationProperties(prefix = "spring.datasource.log")
public DataSource logDataSource() {
return new DruidDataSource();
}
// 报表库数据源
@Bean
@ConfigurationProperties(prefix = "spring.datasource.report")
public DataSource reportDataSource() {
return new DruidDataSource();
}
/**
* 注册动态数据源Bean(优先使用)
*/
@Primary
@Bean
public DynamicDataSource dynamicDataSource() {
DynamicDataSource dynamicDataSource = new DynamicDataSource();
// 配置多数据源映射关系
Map<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put("master", masterDataSource());
dataSourceMap.put("log", logDataSource());
dataSourceMap.put("report", reportDataSource());
// 设置所有数据源 & 默认数据源(主库)
dynamicDataSource.setTargetDataSources(dataSourceMap);
dynamicDataSource.setDefaultTargetDataSource(masterDataSource());
return dynamicDataSource;
}
}- AOP切面实现动态切换(核心拦截逻辑)
java
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.stereotype.Component;
import java.lang.reflect.Method;
@Aspect
@Component
public class DynamicDataSourceAspect {
// 切点:所有添加@DS注解的方法/类
@Pointcut("@annotation(com.xxx.annotation.DS) || @within(com.xxx.annotation.DS)")
public void dataSourcePointCut(){}
@Around("dataSourcePointCut()")
public Object around(ProceedingJoinPoint point) throws Throwable {
MethodSignature signature = (MethodSignature) point.getSignature();
Method method = signature.getMethod();
// 获取方法上的注解
DS ds = method.getAnnotation(DS.class);
// 方法无注解则获取类上注解
if (ds == null) {
ds = point.getTarget().getClass().getAnnotation(DS.class);
}
// 设置当前线程数据源
if (ds != null) {
DynamicDataSource.setDataSource(ds.value());
}
try {
// 执行目标方法
return point.proceed();
} finally {
// 执行完毕清空数据源,避免线程复用污染
DynamicDataSource.clearDataSource();
}
}
}- 业务使用方式(极简无侵入)
java
@Service
public class LogService {
// 切换日志库执行查询
@DS("log")
public List<Log> getLogList() {
return logMapper.selectList(null);
}
// 默认使用主库
public List<User> getUserList() {
return userMapper.selectList(null);
}
}方案二:dynamic-datasource开源框架(企业微服务首选)
基于Spring生态封装的成熟多数据源框架,零配置冗余、支持动态刷新、读写分离、分布式事务、动态新增数据源,适配微服务、多租户、海量数据源场景,是目前企业主流选型。
- 核心依赖
XML
<!-- 动态数据源框架 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>dynamic-datasource-spring-boot-starter</artifactId>
<version>4.2.0</version>
</dependency>- 极简yml配置(支持分组、读写分离)
XML
spring:
datasource:
dynamic:
# 默认数据源
primary: master
# 严格模式:未匹配数据源直接报错
strict: true
datasource:
# 主库
master:
url: jdbc:mysql://127.0.0.1:3306/db_master?useUnicode=true&characterEncoding=utf-8&serverTimezone=GMT%2B8
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
# 日志库
log:
url: jdbc:mysql://127.0.0.1:3306/db_log
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
# 读写分离分组
order:
master:
url: jdbc:mysql://127.0.0.1:3306/db_order
username: root
password: 123456
slave_1:
url: jdbc:mysql://127.0.0.1:3306/db_order_slave
username: root
password: 123456- 业务使用(和原生注解一致,无缝切换)
java
@Service
public class OrderService {
// 指定写库
@DS("order_master")
public void saveOrder(Order order) {
orderMapper.insert(order);
}
// 指定读库,自动负载均衡
@DS("order_slave")
public List<Order> getOrderList() {
return orderMapper.selectList(null);
}
}四、核心高级特性(生产刚需)
1. 数据源优先级与覆盖规则
-
优先级排序:方法注解 @DS > 类注解 @DS > 全局默认数据源
-
线程隔离:子线程无法继承父线程数据源,异步场景需手动传递数据源标识
-
数据源复用:同一线程连续多个方法执行,未重新指定数据源时,沿用当前数据源
2. 动态数据源事务适配(核心难点)
-
同数据源事务:普通@Transactional完全生效,正常支持回滚、传播机制
-
跨数据源事务 :单一Spring事务无法管控多库事务,会出现部分成功、部分失败的数据不一致问题
-
生产解决方案 :跨多库操作必须使用分布式事务(Seata AT/TCC),禁止原生事务注解跨库使用
3. 异步线程数据源传递方案
Spring异步线程无法继承主线程ThreadLocal数据源,导致切换失效,解决方案:手动捕获主线程数据源Key,传入异步线程:
java
// 主线程获取当前数据源
String currentDs = DynamicDataSource.getDataSource();
// 异步线程手动设置
asyncService.execute(() -> {
DynamicDataSource.setDataSource(currentDs);
try {
// 异步业务逻辑
} finally {
DynamicDataSource.clearDataSource();
}
});五、生产高频坑点与终极解决方案
-
坑点1:线程复用导致数据源错乱 原因 :Tomcat线程池线程复用,上一次线程未清空数据源标识,导致下次业务误用旧数据源 解决方案:AOP切面finally块强制清空ThreadLocal数据源,杜绝残留数据
-
坑点2:跨数据源事务失效、数据不一致 原因 :Spring原生事务基于单数据库连接,无法跨多库回滚 解决方案:多库操作拆分事务,或接入Seata分布式事务,禁止跨库使用本地事务
-
坑点3:异步任务数据源切换失效 原因 :异步线程独立ThreadLocal,无法继承主线程数据源标识 解决方案:手动传递数据源Key,异步方法执行前手动绑定
-
坑点4:未关闭自动数据源配置导致启动冲突 原因 :Spring默认自动加载单数据源配置,与自定义多数据源冲突 解决方案:启动类排除DataSourceAutoConfiguration自动配置类
-
坑点5:动态数据源连接池泄露 原因 :多数据源未配置连接池参数,空闲连接未释放,导致连接耗尽 解决方案:每个数据源独立配置Druid连接池参数,设置空闲超时、最大连接数
六、企业落地规范(统一标准)
-
数据源命名规范:统一使用业务语义命名(master/log/report/order/user),禁止随意命名
-
使用规范:核心业务默认走主库,非核心日志、统计、报表业务拆分独立数据源
-
事务规范:单库操作使用本地事务,多库强制使用分布式事务,禁止跨库本地事务
-
性能规范:每个数据源独立配置连接池,根据业务并发单独调优,避免资源抢占
-
异常规范:开启严格模式,未匹配数据源直接抛出异常,避免业务数据写入错误库
✅ 多数据源动态切换核心总结
-
底层核心:AbstractRoutingDataSource路由 + ThreadLocal线程隔离 + AOP动态拦截
-
选型准则:简单固定数据源场景用原生实现,微服务、动态数据源、读写分离场景用dynamic-datasource框架
-
核心痛点:线程复用污染、异步失效、跨库事务不一致、配置冲突
-
生产价值:实现业务数据隔离、分担主库压力、适配多异构数据库、支撑读写分离与分库架构
-
核心场景:项目需要同时操作多个数据库(主业务库、日志库、报表库、第三方库)
-
主流实现方案:Spring AOP+自定义注解、动态数据源切换框架(dynamic-datasource)
-
核心原理:基于ThreadLocal存储当前数据源标识,AOP切面拦截切换数据源,线程隔离互不干扰
-
生产规范:主从数据源隔离、读写数据源区分、切换优先级管控、异常回滚适配
2. 读写分离架构(企业高并发数据库核心方案)
读写分离是互联网项目解决单库读写瓶颈、提升数据库并发吞吐量 的核心架构,核心设计思想:拆分数据库读写流量,写操作集中走主库,读操作分摊走多从库,彻底解决单库读请求过多导致的数据库卡顿、连接耗尽、查询超时问题,是高并发系统数据库优化的第一阶梯方案,所有读多写少的业务场景必备。
一、核心架构原理与角色分工
基于MySQL主从复制机制实现,搭配Spring动态数据源完成流量拆分,架构分层清晰、职责单一:
-
主库(Master):唯一写节点,负责所有新增、修改、删除业务操作,同时同步数据至所有从库,保证数据写入唯一性,避免多写节点数据冲突
-
从库(Slave):只读节点,不处理任何写请求,专门承接海量查询读请求,可横向扩容多台从库,无限分摊读压力
-
同步机制:依赖MySQL binlog日志,主库数据变更后异步同步至从库,实现主从数据一致性,是读写分离的底层支撑
核心架构优势:读写流量物理隔离、从库可无限横向扩容、不影响主库写入性能、大幅提升系统并发承载能力
二、MySQL主从复制底层机制(读写分离根基)
Spring读写分离只是应用层流量分发,底层数据同步完全依赖MySQL原生主从复制,必须掌握核心原理才能解决主从延迟问题:
1. 核心组件
-
Binlog日志(主库):主库所有数据变更(增删改)的二进制日志记录,是数据同步的数据源
-
IO线程(从库):从库IO线程实时连接主库,拉取主库Binlog日志并写入本地Relay日志
-
SQL线程(从库):读取本地Relay日志,重放执行SQL,同步主库数据变更,完成数据一致
2. 完整同步流程
主库执行业务写操作 → 记录Binlog日志 → 从库IO线程拉取日志 → 写入从库Relay日志 → 从库SQL线程重放SQL → 主从数据同步完成
3. 同步模式分类
-
异步复制(默认):主库写入成功直接返回客户端,无需等待从库同步完成,性能极高,存在短暂主从延迟,企业默认使用
-
半同步复制:主库写入后等待至少一台从库同步完成再返回,牺牲部分性能,保障数据一致性,核心业务场景启用
-
全同步复制:等待所有从库同步完成再返回,数据完全一致,性能极差,几乎不用于生产
三、企业两种落地实现方案(全覆盖)
方案一:代码层读写分离(轻量、灵活、中小项目首选)
基于前文多数据源机制,通过AOP切面+自定义注解,根据业务操作类型手动/自动切换读写数据源,无需中间件,轻量化无侵入。
-
实现逻辑:新增/修改/删除方法强制走主库、查询方法默认走从库、核心查询业务可手动指定主库
-
核心优势:零中间件、部署简单、灵活可控、可精准控制接口读写路由
-
核心短板:需手动规范注解使用,开发有轻微成本,适合从库数量少的场景
核心使用规范:
java
// 写操作:强制主库
@DS("master")
public void saveOrder(Order order){}
// 普通查询:自动走从库(AOP切面拦截查询方法自动路由)
public List<Order> getOrderList(){}
// 核心实时查询:手动指定主库,规避主从延迟
@DS("master")
public Order getRealTimeOrder(Long id){}方案二:框架层读写分离(微服务标配,dynamic-datasource)
基于dynamic-datasource框架实现全自动读写分离,无需手动加注解,框架自动识别读写请求、自动路由主从库,支持从库负载均衡,是目前企业主流方案。
生产级完整配置:
XML
spring:
datasource:
dynamic:
primary: master # 默认主库
strict: true
# 读写分离分组配置
group:
order:
master:
url: jdbc:mysql://127.0.0.1:3306/db_order
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
slave:
# 多从库自动负载均衡
- url: jdbc:mysql://127.0.0.1:3306/db_order_slave1
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
- url: jdbc:mysql://127.0.0.1:3306/db_order_slave2
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver-
自动路由规则:新增/修改/删除→自动路由master、查询→自动轮询路由slave集群
-
负载均衡策略:支持轮询、随机、权重配置,适配多从库流量分摊
-
优势:零代码侵入、全自动路由、从库横向扩容无感知、适配微服务集群
方案三:中间件层读写分离(大型分布式项目)
基于Sharding-JDBC、MyCat等中间件实现,完全屏蔽底层数据源,应用层无需感知主从库,统一由中间件完成读写路由、故障转移、负载均衡,适合海量数据、多从库集群场景。
四、核心痛点:主从延迟解决方案(生产必解)
MySQL异步复制存在毫秒级~秒级数据延迟,会导致「刚新增数据,查询不到」的线上BUG,是读写分离最大核心痛点,全覆盖企业落地解决方案:
1. 延迟产生根源
主库写入成功立即返回,数据异步同步从库,高并发场景Binlog堆积、网络延迟会放大同步时差,导致读从库数据滞后。
2. 五级解决方案(按优先级落地)
-
方案1:核心业务强制读主库(最简有效):支付、订单、用户核心数据等强实时查询,手动指定走主库,彻底规避延迟问题
-
方案2:本地缓存兜底:新增/更新数据后写入本地缓存,优先读取缓存,规避短暂延迟空档期
-
方案3:复制模式升级 :核心业务库开启半同步复制,保证至少一台从库同步完成再返回,牺牲极小性能换数据一致性
-
方案4:延迟阈值路由:监控主从延迟时间,延迟超过阈值自动将读请求切回主库,延迟恢复后自动切回从库
-
方案5:业务层兜底机制:新增数据后短时间内(1-2秒)查询强制走主库,超时后自动走从库
五、从库高可用与故障转移
生产环境从库节点可能宕机、断连,必须配置故障自动转移,避免读服务雪崩:
-
健康检测:框架定时探测从库连接状态,自动剔除故障从库节点
-
故障转移:单从库宕机后,读请求自动分摊至其他正常从库,无感知切换
-
节点恢复:故障从库重启恢复后,自动重新加入集群,承接读流量
六、生产高频坑点与避坑方案
-
坑点1:读从库数据旧、数据不一致 原因:主从异步复制延迟 解决方案:核心实时业务读主库、非实时业务读从库、开启半同步复制
-
坑点2:从库宕机导致查询报错 原因:未配置从库健康检测与故障转移 解决方案:开启框架自动探活、多从库集群部署、故障自动剔除
-
坑点3:主库压力未缓解 原因:大量查询业务未路由到从库、核心接口全部读主库 解决方案:规范读写路由规则、梳理非实时业务全部切从库
-
坑点4:事务内读从库失效 原因:Spring事务基于单数据库连接,事务内所有操作强制走当前连接数据源 解决方案:事务内查询统一读主库,拆分读写事务,避免跨数据源事务
-
坑点5:多从库数据不一致 原因:从库同步进度不一致、部分从库同步延迟更高 解决方案:统一主从配置、优化网络、定时校验从库数据一致性
七、企业落地选型与适配场景
1. 最佳适配场景
-
读多写少业务:商城商品、资讯列表、后台管理查询、用户信息查询
-
海量查询并发场景:秒杀、活动页面、高频列表接口
-
数据实时性要求一般、允许短暂数据延迟的业务
2. 禁止使用场景
-
强实时一致性业务:支付结果查询、订单状态校验、库存扣减查询
-
短时间读写连续操作业务,无延迟容忍度的核心链路
3. 架构迭代选型
-
中小项目:AOP自定义注解读写分离(轻量无依赖)
-
微服务项目:dynamic-datasource全自动读写分离(主流标配)
-
大型分布式项目:Sharding-JDBC/MyCat中间件读写分离+分库分表
✅ 读写分离架构终极总结
-
核心本质:应用层流量路由 + MySQL主从数据同步,实现读写流量物理隔离
-
核心价值:横向扩容读节点、分担主库压力、提升数据库并发承载力、保障高可用
-
核心痛点:异步复制导致的主从数据延迟,所有落地方案均围绕延迟解决
-
落地规范:非实时读从库、核心实时读主库、事务内统一读主库、多从库负载均衡
-
高可用保障:从库集群部署、自动探活、故障转移、延迟阈值路由
-
核心思想:写操作走主库(Master)、读操作走从库(Slave),分担数据库压力,提升并发能力
-
实现方式: 代码层:AOP切面根据操作类型手动切换读写数据源
-
框架层:dynamic-datasource自动适配读写分离,零代码侵入
核心问题解决:主从延迟导致的读不到新增数据问题(核心业务强制读主库)
适配场景:读多写少、高查询并发的业务系统(商城、资讯、后台管理)
3. 分表分库基础(海量数据解决方案·企业完整版)
分表分库是数据库千万级、亿级海量数据场景 的核心优化方案,是读写分离之后的第二阶数据库架构升级。当单表数据量突破1000万、单库数据量突破10G,索引查询、事务执行、数据更新性能会出现断崖式下跌,传统索引优化、SQL调优、读写分离均无法根治性能瓶颈,此时必须通过分表分库实现数据横向拆分、压力分散、性能扩容,是互联网高并发、大数据量项目的必备架构。
一、核心适用场景(精准判断是否需要分片)
杜绝盲目分片,仅以下场景需要落地分表分库,避免过度架构设计:
-
单表数据量超标:常规业务单表数据超1000万、日志/流水表超500万,查询效率持续下降,索引失效、慢SQL频发
-
单库性能瓶颈:单库承载QPS超1000,读写请求拥堵,连接池频繁耗尽,读写分离无法缓解压力
-
数据体量持续增长:业务高速迭代,数据每日增量数万/数十万,短期即将突破单表单库上限
-
业务隔离需求:核心业务数据与非核心数据、高频读写数据与低频归档数据需要物理隔离
黄金阈值(企业通用标准):单表≤500万最优、500万~1000万预警、≥1000万强制分片;单库数据量≤10G最优
二、三大分片架构(核心分类+落地差异)
1. 垂直分库(业务维度拆分)
核心原理 :按照业务模块 拆分数据库,将一个大数据库按业务域拆分为多个独立子库,彻底解耦业务、分散库压力,不拆分表结构、只拆分库。
落地案例:单体大库 → 拆分用户库、订单库、商品库、支付库、日志库、活动库
核心优势:
-
业务完全解耦,各业务库独立运维、独立扩容,互不影响
-
精准隔离核心业务与非核心业务,避免日志、统计等非核心业务占用主库资源
-
适配微服务架构,完美匹配一服务一库的微服务设计思想
核心短板 :无法解决单表海量数据问题,仅解决单库压力过大、业务耦合问题,单表数据超标仍需水平分片
适用场景:业务模块多、库体量庞大、业务耦合严重、微服务架构改造
2. 水平分表(数据维度拆分)
核心原理 :数据库不变,将单张大表 按照固定规则拆分为多张结构完全一致的子表,数据分散存储在同库多表中,库不变、表拆分、结构一致。
落地案例:order订单表(1亿数据)→ 拆分order_0、order_1、order_2...order_15共16张子表
核心优势:
-
单表数据量大幅缩减,索引体积变小,查询、更新、删除性能大幅提升
-
无需拆分数据库,改造难度低、风险小、适配中小型海量数据场景
-
扩容灵活,支持动态新增子表
核心短板 :所有子表仍在同一数据库,无法突破单库连接数、单库IO、单库CPU上限,高并发场景仍有瓶颈
适用场景:单表数据超标、并发适中、无需跨库扩容的业务(日志表、流水表、月度订单表)
3. 水平分库分表(终极海量方案)
核心原理 :结合垂直分库+水平分表,既分库、又分表,将海量数据按照规则分散到多个独立数据库的多张子表中,彻底突破单库单表所有性能上限。
落地案例:海量订单数据 → 分order_db_0~order_db_8共9个库,每个库内分order_0~order_15共16张表
核心优势:无限横向扩容、彻底分散读写压力、支持亿级/十亿级数据存储、高并发承载能力极强
核心短板:架构复杂、改造成本高、需解决跨库查询、分布式事务、主键唯一等分布式问题
适用场景:互联网核心业务、高并发、亿级海量数据、持续高速增长的业务(电商订单、支付流水、用户行为)
三、主流分片策略(企业落地核心规则)
分片策略决定数据分布均匀性,是避免数据倾斜、热点库/热点表的核心,企业主流4种分片规则全覆盖:
1. 哈希分片(最常用、均匀分布)
规则:以核心字段(用户ID、订单ID)做哈希运算,对分片总数取模,路由至对应库表
示例:userId.hashCode() % 16 → 匹配16张子表
优势:数据分布极度均匀,无热点数据,读写压力均衡分散
短板:不支持范围查询(时间段、区间ID查询),扩容需重新分片、数据迁移
适用场景:单点精准查询多、范围查询少的业务(订单查询、用户数据查询)
2. 时间分片(时序数据首选)
规则:按照时间维度(年、月、日)拆分表,如order_202501、order_202502
优势:天然适配时序数据,范围查询友好、归档清理方便、冷热数据分离简单
短板 :容易出现时间热点,当前月份表承载所有新数据,压力集中
适用场景:日志、流水、交易记录、监控数据等时序性极强的业务
3. 范围分片(区间查询首选)
规则:按照ID区间、数值区间拆分,如1~100万数据存表1、100万~200万存表2
优势:范围查询极致友好,无需跨多表关联,扩容简单
短板:极易数据倾斜,业务流量集中在大区间,出现热点表
适用场景:大数据量范围统计、区间查询频繁、流量均匀的业务
4. 地域/维度分片(垂直业务适配)
规则:按照地区、渠道、租户ID等业务维度分片,如北京用户库、上海用户库
优势:业务隔离清晰、精准适配区域化业务、故障影响范围小
短板:流量不均易导致热点,需结合业务流量优化分片规则
适用场景:多租户SaaS、区域型业务、渠道分流业务
四、分片核心配套能力(必须解决的四大问题)
1. 分布式唯一主键
分表分库后,单库自增ID失效,多库会出现ID重复,必须使用全局唯一ID:
-
雪花算法(Snowflake):主流首选,有序、唯一、高性能、适配分布式场景
-
UUID:无序、索引性能差,禁止用于数据库主键
-
数据库号段模式:高性能、无时钟回拨问题,企业批量场景常用
2. 跨库/跨表查询解决方案
-
分片键查询:优先通过分片键精准路由,单表查询,性能最优(业务设计首选)
-
关联查询 :避免跨库关联,通过字段冗余、宽表设计、本地联表替代跨库JOIN
-
聚合查询:分页、统计、排序查询,通过框架聚合结果,或通过ES预聚合兜底
3. 分布式事务适配
跨库分片操作,本地事务失效,必须适配分布式事务:
-
同库多表:原生@Transactional事务完全生效
-
跨库多表:必须使用Seata AT/TCC分布式事务,保证数据一致性
4. 数据扩容与迁移
-
平滑扩容:避免停机迁移,采用双写迁移、增量同步、灰度切换方案
-
冷热分离:历史冷数据归档至归档库,当前热数据留存业务库,减轻主库压力
五、主流落地框架(Spring生态适配)
1. Sharding-JDBC(企业首选)
Spring生态原生适配、无代理、无中间件、轻量嵌入,是目前90%企业的分表分库首选框架,无缝整合Spring Boot、MyBatis、JPA。
核心能力:
-
全自动分库分表、多种分片策略、自适应扩容
-
整合读写分离、分布式主键、分布式事务
-
支持跨分片聚合查询、分页排序、容错降级
-
零侵入业务代码,仅需配置文件开启分片规则
2. MyCat(大型分布式项目)
独立中间件代理层,独立进程运行,统一管理分片规则,适配超大型集群、海量数据场景,适合架构统一管控的分布式项目。
六、生产高频坑点与避坑方案(核心必记)
-
坑点1:数据倾斜、热点库/热点表 原因 :分片规则不合理、头部用户流量集中、时间分片热点 解决方案:优化哈希分片、增加分片维度、冷热数据分离、流量打散
-
坑点2:跨库JOIN查询失效、性能极差 原因 :分库后不同业务数据分散在不同库,无法关联查询 解决方案:业务层关联、字段冗余、宽表设计、禁止跨库JOIN
-
坑点3:分页查询数据错乱、总数不准 原因 :多表分页聚合排序规则不一致、偏移量计算错误 解决方案:框架统一聚合分页、禁止大页码分页、采用游标分页
-
坑点4:扩容重分片数据迁移混乱 原因 :哈希取模分片扩容后,大部分数据需要重新分配 解决方案:采用一致性哈希分片、灰度双写迁移、增量同步
-
坑点5:分布式事务不一致 原因 :跨分片操作使用本地事务,无法回滚多库数据 解决方案:跨分片强制使用Seata分布式事务,拆分非核心事务
-
坑点6:分片键设计不合理导致查询退化 原因 :高频查询字段非分片键,导致全分片扫描,性能倒退 解决方案:优先以高频查询、唯一维度字段作为分片键
七、企业落地优先级与架构迭代规范
数据库架构迭代四阶流程(行业标准):
-
一阶优化:索引优化、SQL调优、连接池调优(零成本优先)
-
二阶优化:读写分离,拆分读写流量,分担主库压力
-
三阶优化:垂直分库,业务解耦,隔离核心与非核心数据
-
四阶优化:水平分库分表,解决海量数据、超高并发瓶颈
✅ 分表分库核心总结
-
核心本质:通过数据物理拆分,突破单库单表数据量、并发、IO、CPU上限,实现数据库无限横向扩容
-
三大架构:垂直分库(解耦业务)、水平分表(拆分数据)、水平分库分表(终极扩容)
-
核心关键:分片键设计决定数据均匀性,是分片架构成败的核心
-
必解问题:分布式主键、跨分片查询、分布式事务、数据倾斜、平滑扩容
-
主流选型:中小海量数据用Sharding-JDBC、大型集群用MyCat
-
落地原则:能不分则不分、能少分则少分,优先简单优化,杜绝过度架构
-
分片场景:单表数据量超千万、查询性能急剧下降,传统索引优化无效时启用
-
分片类型: 水平分表:按规则拆分数据(时间、ID、用户ID哈希)
-
垂直分库:按业务模块拆分数据库(用户库、订单库、商品库)
主流框架:Sharding-JDBC(Spring生态适配、无代理侵入、轻量高效)
核心能力:自动分片、分布式主键、跨分片查询、分布式事务、读写分离整合
4. 批量数据处理优化(生产级大数据量解决方案)
批量数据处理是企业开发高频场景(批量导入、批量更新、数据迁移、定时归档、批量删除),原生循环单条操作会导致数据库IO频繁、连接池耗尽、事务超时、接口卡顿、OOM内存溢出 等线上问题。本模块基于Spring+MyBatis+JDBC底层,全覆盖批量增删改、大数据分页、流式处理、参数调优、坑点避坑、生产规范,全部为可直接落地的生产级方案。
一、核心底层原理(批量优化本质)
-
优化核心思想:减少数据库网络交互次数、合并SQL请求、控制单次处理数据量、避免一次性加载全量数据至内存
-
性能瓶颈根源:单条循环操作,每次都要建立连接、执行SQL、提交事务,网络IO开销远大于SQL执行开销
-
批量处理核心优势:一次网络交互执行多条SQL、单次事务提交批量数据,大幅降低IO损耗,提升10~100倍吞吐量
二、批量插入生产级优化(重点)
1. 常见错误写法(绝对禁止生产使用)
循环调用Mapper.insert(),每次单独提交事务、创建SQL,网络IO爆炸式增长,1万条数据耗时可达数十秒:
java
// 错误写法!循环单条插入,IO频繁、性能极差
for (User user : userList) {
userMapper.insert(user);
}2. MyBatis批量插入(基础落地方案)
通过foreach标签拼接批量INSERT语句,单次SQL提交多条数据,适配中小批量数据(1000条以内):
XML
<!-- 批量插入SQL -->
<insert id="batchInsert">
INSERT INTO user (id, username, phone, create_time)
VALUES
<foreach collection="list" item="item" separator=",">
(#{item.id}, #{item.username}, #{item.phone}, #{item.createTime})
</foreach>
</insert>3. JDBC原生批量插入(高性能首选,大数据量)
基于JDBC Batch机制,关闭自动提交、批量攒批提交,规避MyBatis拼接SQL过长问题,支持上万条大数据量插入,性能最优:
java
@Service
public class BatchDataService {
@Autowired
private DataSource dataSource;
// 批量插入最优实现:JDBC Batch + 手动事务
public void batchInsertUser(List<User> userList) throws SQLException {
// 1. 获取数据库连接,关闭自动提交
Connection connection = dataSource.getConnection();
connection.setAutoCommit(false);
String sql = "INSERT INTO user (id, username, phone, create_time) VALUES (?,?,?,?)";
PreparedStatement statement = connection.prepareStatement(sql);
// 2. 攒批处理,每500条提交一次(生产最优阈值)
int batchSize = 500;
for (int i = 0; i < userList.size(); i++) {
User user = userList.get(i);
statement.setLong(1, user.getId());
statement.setString(2, user.getUsername());
statement.setString(3, user.getPhone());
statement.setDate(4, new Date(user.getCreateTime().getTime()));
// 添加至批处理队列
statement.addBatch();
// 攒批满量,执行提交
if (i > 0 && i % batchSize == 0) {
statement.executeBatch();
statement.clearBatch();
}
}
// 3. 提交剩余数据
statement.executeBatch();
connection.commit();
// 4. 释放资源
statement.close();
connection.close();
}
}4. 批量插入核心配置与阈值规范
-
最优攒批大小:500~1000条/批(适配MySQL数据包上限,避免SQL超长报错)
-
关键配置 :JDBC连接串添加
rewriteBatchedStatements=true,开启MySQL批量重写优化,性能提升3倍+ -
事务规则:批量操作必须关闭自动提交,手动批量commit,杜绝单条事务
-
超时配置:大数据量批量任务,手动延长事务超时时间,避免事务超时回滚
三、批量更新/删除优化(避坑核心)
1. 批量更新最优方案
禁止循环单条update,采用IN批量更新、CASE WHEN批量差异化更新,适配不同业务场景:
XML
<!-- 1. 同字段统一更新(批量修改状态) -->
<update id="batchUpdateStatus">
UPDATE user SET status = 1, update_time = NOW()
WHERE id IN
<foreach collection="idList" item="id" open="(" separator="," close=")">
#{id}
</foreach>
</update>
<!-- 2. 差异化批量更新(不同ID更新不同字段) -->
<update id="batchUpdateUserInfo">
UPDATE user
<set>
<trim prefix="username = CASE" suffix="END,">
<foreach collection="list" item="item">
WHEN id = #{item.id} THEN #{item.username}
</foreach>
</trim>
<trim prefix="phone = CASE" suffix="END,">
<foreach collection="list" item="item">
WHEN id = #{item.id} THEN #{item.phone}
</foreach>
</trim>
update_time = NOW()
</set>
WHERE id IN
<foreach collection="list" item="item" open="(" separator="," close=")">
#{item.id}
</foreach>
</update>2. 批量删除生产规范
-
基础方案:通过ID IN集合批量删除,替代循环删除
-
大数据量删除 :禁止一次性删除上万条,采用分页批量删除,避免锁表、事务过大
-
禁忌操作:禁止不带WHERE条件的批量删除、禁止超大IN集合(超过1000条需拆分)
java
// 分页批量删除(生产安全方案,避免锁表)
public void batchDelete(List<Long> allIdList) {
int pageSize = 500;
int totalPage = (allIdList.size() + pageSize - 1) / pageSize;
for (int i = 0; i < totalPage; i++) {
int start = i * pageSize;
int end = Math.min(start + pageSize, allIdList.size());
List<Long> pageIds = allIdList.subList(start, end);
// 单批删除
userMapper.batchDelete(pageIds);
}
}四、大数据量查询优化(杜绝OOM与接口超时)
千万级数据查询、数据导出、数据迁移场景,传统分页会出现大页码偏移、内存溢出、查询超时问题,采用以下生产级方案:
1. 游标分页(ID偏移分页,最优方案)
放弃limit offset分页,通过自增ID/有序字段偏移查询,无偏移量损耗,支持千万级数据遍历:
java
// 游标分页遍历全表数据(无OOM、高性能)
public void scanAllUserData() {
Long lastId = 0L;
int pageSize = 1000;
while (true) {
// 每次查询大于上一次最大ID的1000条数据
List<User> userList = userMapper.selectPageByCursor(lastId, pageSize);
if (CollectionUtils.isEmpty(userList)) {
break;
}
// 处理当前批次数据
handleBatchData(userList);
// 更新游标ID
lastId = userList.get(userList.size() - 1).getId();
}
}2. MyBatis流式查询(超大文件导出专属)
基于MyBatis ResultHandler流式读取,数据逐条加载,不一次性加载全量数据至内存,彻底解决OOM问题:
java
// 流式查询大数据量
public void streamQueryUser() {
// 流式处理,逐条读取数据
userMapper.streamSelectAllUser(resultContext -> {
// 单条数据处理,内存仅保留单条数据
User user = resultContext.getResultObject();
handleSingleData(user);
});
}3. 禁止大页码分页核心原因
-
性能退化:limit 100000,10 会扫描前10万条数据再丢弃,偏移量越大越慢
-
内存溢出:全表list查询、超大pageSize会一次性加载数万/数十万数据至JVM内存
-
数据库压力大:大分页查询会触发全表扫描、临时表排序,占用大量CPU/IO资源
五、Spring事务批量适配规范
-
小批量数据(1000条内):单事务批量处理,整体成功整体回滚,保证数据一致性
-
大批量数据(1万条+):拆分批次+分段事务,避免单事务过大导致数据库锁超时、事务膨胀
-
超大批量任务 :采用最终一致性,分批提交+失败重试+日志记录,避免整体回滚导致任务重跑
-
异步批量处理:大数据量批量操作禁止同步接口处理,通过@Async异步线程/定时任务执行,避免接口超时
六、生产高频坑点与终极解决方案
-
坑点1:批量SQL过长报错 原因:一次性拼接上万条数据SQL,超出MySQL max_allowed_packet限制 解决方案:固定500~1000条分批提交,优化数据包大小配置
-
坑点2:批量插入重复数据 原因:任务重试、网络重试导致重复插入 解决方案:主键唯一约束、INSERT IGNORE、ON DUPLICATE KEY UPDATE幂等处理
-
坑点3:大批量操作锁表/锁行超时 原因:单事务处理数据量过大,行锁持有时间过长 解决方案:拆分小批次、缩短事务执行时间、避开业务高峰执行批量任务
-
坑点4:内存溢出OOM 原因:一次性查询、加载全量数据至内存 解决方案:游标分页、流式查询、分批处理,杜绝全量List加载
-
坑点5:批量事务超时失效 原因:Spring默认事务超时时间较短,大批量处理耗时过长 解决方案:手动设置事务超时时间,异步任务单独配置事务参数
-
坑点6:IN集合超1000条查询失效 原因:MySQL对超长IN集合优化失效,查询性能暴跌 解决方案:拆分IN集合,分批查询合并结果
七、企业落地统一规范
-
批量插入:1000条以内用MyBatis批量SQL,1000条以上用JDBC Batch攒批提交,开启rewriteBatchedStatements优化
-
批量更新/删除:优先IN批量操作,大数据量必须分页分批执行,禁止超大SQL
-
大数据查询:一律使用游标分页/流式查询,禁止大页码limit分页、禁止全表查询
-
事务规范:小批量单事务、大批量分段事务、超大批量异步重试机制
-
性能阈值:统一500条/批标准攒批大小,所有批量任务限流控批,防止打满数据库连接池
-
幂等规范:所有批量任务必须支持重试幂等,避免重复数据、数据错乱
✅ 批量数据处理核心总结
-
优化核心:减少网络IO、分批攒批提交、控制内存负载、缩短锁持有时间
-
最优方案:中小批量用MyBatis批量SQL、大批量用JDBC Batch、超大查询用流式/游标分页
-
核心避坑:禁止循环单条操作、禁止大页码分页、禁止超大单事务、禁止全量数据加载
-
生产价值:解决批量导入/导出/迁移/归档的性能卡顿、OOM、超时、锁表、数据重复问题
-
批量插入:MyBatis批量foreach、JDBC批量提交、关闭自动提交提升吞吐量
-
批量更新/删除:避免单条循环操作,批量SQL一次性处理,减少数据库交互次数
-
大数据量分页:避免limit大页码分页,采用游标分页、ID偏移分页优化性能
六、数据层事务深度管控(Spring+MySQL联动)
1. Spring事务与MySQL事务联动原理
-
Spring事务是事务管理器的高层封装,底层完全依赖MySQL原生事务实现
-
PlatformTransactionManager事务管理器,统一管控数据库事务的开启、提交、回滚
-
Spring事务传播机制、隔离级别,精准覆盖MySQL事务所有能力并做扩展
2. 数据层高频事务失效场景
-
方法非public、同类内调用导致AOP代理失效,事务不生效
-
异常被try-catch捕获,Spring无法感知异常,不会触发回滚
-
事务传播级别配置错误,导致嵌套事务无法统一回滚
-
数据库引擎非InnoDB,不支持事务
-
多数据源场景未指定事务管理器,事务跨库失效
七、数据层性能调优与线上排障
1. 接口数据查询优化(通用准则)
-
禁止select *,按需查询字段,减少网络传输与内存占用
-
高频查询建立合适索引,杜绝全表扫描
-
大列表分页返回,禁止一次性查询海量数据
-
复杂统计SQL定时预计算,避免实时聚合查询耗时
2. 连接池线上调优方案
-
根据服务器CPU核心数、业务并发量配置连接池参数,避免连接不足或资源浪费
-
开启SQL超时控制,防止慢SQL占用连接池导致服务阻塞
-
定期清理无效连接、监控连接活跃状态,避免连接泄露
3. 高频线上故障排查
-
接口超时:优先排查慢SQL、索引失效、锁等待、连接池耗尽
-
数据不一致:排查事务失效、隔离级别过低、并发更新无锁、主从延迟
-
数据库CPU飙升:全表扫描、大量慢SQL、索引失效、批量操作无优化
-
连接超时异常:连接池参数配置不当、数据库服务卡顿、网络波动
✅ 关系型数据库模块终极总结(学习&落地清单)
-
底层核心:InnoDB引擎、ACID事务、MVCC并发、锁机制、索引原理、日志体系,是所有数据操作的根基
-
基础框架:JDBC+HikariCP/Druid连接池,Spring数据层底层载体
-
主流选型:复杂业务首选MyBatis+MyBatis-Plus,快速开发首选Spring Data JPA
-
企业高阶:多数据源切换、读写分离、分表分库、批量数据优化
-
核心保障:Spring事务+MySQL事务联动,解决数据一致性问题
-
性能核心:索引优化、SQL优化、连接池调优、缓存联动、分页优化
-
排障重点:事务失效、索引失效、连接池耗尽、锁竞争、主从延迟、慢SQL卡顿
2. 缓存体系(企业高并发核心·完整版)
缓存是Java高并发项目的性能核心基石 ,核心作用是降低数据库访问压力、提升接口响应速度、扛住海量并发流量。本模块整合Spring Cache注解缓存、Redis企业实战、缓存经典问题、缓存一致性、分布式锁、接口幂等防重,全覆盖开发落地、线上排障、面试高频考点,完全适配Spring全家桶技术栈。
一、缓存核心基础体系
1. 缓存分层架构(企业标准)
-
一级缓存:本地缓存(JVM级别):基于JVM内存实现,核心框架包含原生Map、Caffeine、Guava。特点是读写速度极快、无网络开销、独立进程隔离,适用于高频不变的静态数据、本地配置缓存,短板是无法跨服务共享、内存受限、集群数据不一致。
-
二级缓存:分布式缓存(Redis):独立中间件服务,跨进程、跨集群共享数据,支持过期淘汰、持久化、高可用,是企业动态业务缓存的核心选型,适配绝大多数高并发接口场景。
-
三级缓存:多级缓存联动:本地缓存+Redis分布式缓存组合,兼顾极速响应与数据共享一致性,是互联网项目标准缓存架构。
2. 缓存核心使用规范
-
缓存适用场景:读多写少、数据更新频率低、允许短暂数据不一致、高频查询的业务(商品信息、字典数据、用户信息、首页列表)。
-
缓存禁用场景:强实时一致性业务、频繁更新数据、海量冷数据、数据量过大的业务,避免缓存冗余、数据错乱、内存溢出。
-
核心设计思想:优先缓存、兜底数据库、异步更新、定时预热、过期淘汰、故障降级。
二、Spring Cache 注解缓存体系(零侵入开发标配)
Spring Cache是Spring生态统一的缓存抽象层,屏蔽底层缓存实现差异,支持无缝切换本地缓存/Redis缓存,基于AOP动态增强,无需手动写缓存读写逻辑,是企业开发标准规范。
1. 核心原理与依赖机制
-
底层原理:基于Spring AOP动态代理,拦截目标方法,自动实现「查询缓存、新增更新缓存、删除清空缓存」逻辑,零业务代码侵入。
-
核心组件:CacheManager缓存管理器、Cache缓存实现类、缓存注解切面、键值生成策略。
-
适配底层:默认支持本地缓存,整合Redis后自动切换为分布式缓存,适配单体/微服务项目。
2. 五大核心注解(生产高频必用)
-
@Cacheable(查询缓存):优先查询缓存,缓存存在直接返回,不存在则执行方法并将结果存入缓存,适配查询接口。支持key自定义、过期时间、条件缓存。
-
@CachePut(更新缓存):强制执行方法,更新数据库数据后同步更新缓存数据,适配新增、修改业务,保证缓存与数据库数据同步。
-
@CacheEvict(删除缓存):方法执行完成后清空指定缓存,适配删除、更新业务,支持精准删除key、批量清空缓存空间。
-
@Caching(组合注解):组合多个缓存操作,适配复杂业务(修改数据后同时更新+清空多组缓存)。
-
@CacheConfig(全局配置):类级别统一配置缓存空间、key前缀,简化重复注解配置。
3. 生产级代码实战
java
@Service
@CacheConfig(cacheNames = "user_cache")
public class UserServiceImpl implements UserService {
// 查询:优先走缓存,未命中查数据库并缓存
@Override
@Cacheable(key = "#userId", unless = "#result == null")
public User getUserById(Long userId) {
// 兜底查询数据库
return userMapper.selectById(userId);
}
// 更新:修改数据同步更新缓存
@Override
@CachePut(key = "#user.id")
public User updateUser(User user) {
userMapper.updateById(user);
return user;
}
// 删除:清空对应缓存
@Override
@CacheEvict(key = "#userId")
public void deleteUser(Long userId) {
userMapper.deleteById(userId);
}
// 批量清空用户缓存
@Override
@CacheEvict(allEntries = true)
public void clearUserCache() {}
}4. Spring Cache 高频坑点避坑
-
缓存失效:同类内方法调用导致AOP代理失效,注解不生效,需通过上下文代理调用或拆分方法。
-
缓存空值问题:默认不缓存null,导致频繁穿透查库,需开启空值缓存、配置unless条件过滤。
-
key重复冲突:多方法共用缓存空间,未自定义key导致数据覆盖,必须规范key命名规则。
-
事务与缓存冲突:事务未提交缓存已更新,导致脏数据,需调整缓存执行顺序。
三、Redis 分布式缓存企业实战(核心主力)
1. SpringBoot 整合Redis生产配置基于Spring Data Redis + Lettuce客户端,适配连接池、序列化优化、超时配置、缓存过期策略,彻底解决默认序列化乱码、连接频繁创建问题。
XML
spring:
redis:
# 基础配置
host: 127.0.0.1
port: 6379
password: 123456
database: 0
# 超时配置
timeout: 3000ms
# Lettuce连接池配置
lettuce:
pool:
max-active: 20
max-idle: 10
min-idle: 5
max-wait: -1ms2. 核心数据结构业务落地场景
String字符串:通用缓存、用户信息、字典、计数器、限流计数、分布式ID。
Hash哈希:对象缓存、用户详情、商品属性,支持单独更新字段,节省内存。
List列表:有序队列、消息队列、日志列表、分页数据缓存。
Set集合:去重场景、点赞、关注、黑名单、交集差集统计。
ZSet有序集合:排行榜、延时队列、权重排序、限流排序。
3. 生产级序列化优化默认JDK序列化存在乱码、体积大、不兼容问题,企业统一使用Jackson2JsonRedisSerializer JSON序列化,实现可读性高、体积小、跨服务兼容。
四、缓存三大经典问题(生产必解+完整解决方案)
缓存穿透、缓存击穿、缓存雪崩是高并发项目最核心的三大缓存故障,90%的缓存线上故障均源于此,以下为企业最优落地解决方案。
1. 缓存穿透(查询不存在数据)
问题本质:查询数据库不存在的数据,缓存无记录,请求直接穿透到数据库,高频恶意请求会打垮数据库。
-
场景:恶意查询不存在的ID、非法参数查询、空数据批量请求。
-
解决方案(优先级从高到低): 1. 缓存空值/默认值:短时间缓存null数据,避免重复查库; 2. 布隆过滤器:前置拦截不存在的key,精准过滤非法请求; 3. 接口参数校验:统一参数合法性校验,拦截无效请求; 4. 限流熔断:对高频异常请求限流拦截。
2. 缓存击穿(热点Key过期)
问题本质:超高并发热点Key过期,瞬间大量请求穿透到数据库,导致数据库压力骤增。
-
场景:秒杀商品、首页热点数据、高频查询单一Key过期瞬间。
-
解决方案(最优落地): 1. 互斥锁(分布式锁):缓存过期时,仅一个请求查库更新缓存,其他请求等待; 2. 热点Key永不过期:核心热点数据取消过期时间,后台异步更新; 3. 定时预热更新:定时任务提前更新热点缓存,避免过期空档。
3. 缓存雪崩(大量Key同时过期)
问题本质:大批量缓存Key同一时间过期,或Redis集群宕机,所有请求全部访问数据库,引发服务雪崩。
-
场景:批量缓存设置相同过期时间、Redis服务宕机断连。
-
解决方案(企业标准): 1. 过期时间随机偏移:统一基础过期时间+随机秒数,打散过期节点; 2. Redis高可用部署:主从+哨兵/集群架构,避免单点宕机; 3. 多级缓存降级:本地缓存兜底,Redis失效直接读取本地缓存; 4. 限流熔断降级:缓存失效时限制数据库请求流量,保护服务。
五、缓存与数据库一致性解决方案(核心难点)
1. 四大更新策略对比
先更新数据库,再更新缓存:适用于更新频繁、查询频繁场景,易产生无效缓存更新,资源浪费。
先更新缓存,再更新数据库 :数据一致性极差,高并发易出现脏数据,生产禁止使用。
先更新数据库,再删除缓存:企业主流方案,适配绝大多数业务,一致性最优。
先删除缓存,再更新数据库:高并发查询易导致旧数据回填,出现数据不一致。
2. 最终一致性落地方案
常规业务:采用「更新数据库+删除缓存」策略,配合缓存过期自动兜底,容忍短暂不一致。
重要业务:更新数据库+删除缓存+异步重试机制,防止缓存删除失败。
强一致业务:放弃缓存,直接查询数据库,杜绝数据偏差。
异步重试兜底:通过消息队列异步重试删除缓存,解决网络波动导致的删除失败问题。
六、分布式锁与接口幂等(缓存配套核心能力)
1. Redis分布式锁实战解决微服务集群并发竞争问题,替代本地锁,适配分布式场景资源抢占。
核心命令:SET key value NX EX timeout(原子加锁)。
解锁规范:Lua脚本原子解锁,避免误删他人锁。
核心问题解决:锁超时释放、锁误删、可重入、锁续命(WatchDog)。
企业最优选型:Redisson框架,封装可重入锁、读写锁、公平锁、红锁,适配所有分布式场景。
2. 接口幂等与防重复提交基于Redis实现接口幂等,解决表单重复提交、网络重试、并发重复请求问题。
实现方案:Token令牌机制、请求唯一ID、幂等Key校验、分布式锁防重。
落地流程:前端获取幂等Token→请求携带Token→后端Redis校验Token→执行业务→删除失效Token。
七、多级缓存架构落地(高并发终极方案)
本地Caffeine缓存 + Redis分布式缓存 双层缓存架构,是互联网高并发项目标准架构,兼顾极致性能与数据一致性。
查询流程:查询本地缓存 → 命中直接返回 → 未命中查询Redis → 命中回填本地缓存 → 未命中查库。
更新流程:更新数据库 → 删除Redis缓存 → 清空本地缓存 → 异步预热。
核心优势:规避Redis网络开销、扛住超高并发、Redis宕机可降级兜底、响应速度极致优化。
适配场景:秒杀、首页、商品列表、高频查询接口、流量入口服务。
八、缓存生产高频坑点终极总结
-
坑点1:缓存数据过期导致业务异常:规范过期时间、热点数据永不过期、定时预热。
-
坑点2:缓存数据与数据库不一致:统一删改策略、异步重试、过期兜底、避免频繁更新缓存。
-
坑点3:缓存内存溢出:限制缓存Key数量、设置过期淘汰、清理无效缓存、本地缓存限流。
-
坑点4:高并发缓存失效风暴:随机过期、分布式锁、多级缓存降级。
-
坑点5:序列化乱码/类型转换异常:统一JSON序列化、规范实体类字段格式。
✅ 缓存体系终极总结
-
核心价值:分担数据库压力、提升接口QPS、降低响应耗时、保障高并发服务稳定性。
-
开发规范:Spring Cache注解快速开发、Redis做分布式核心缓存、多级缓存提升性能。
-
三大核心问题:穿透(空缓存+布隆过滤器)、击穿(分布式锁+永不过期)、雪崩(随机过期+高可用+降级)。
-
一致性核心:优先删缓存、异步重试兜底、冷热数据分层处理。
-
高阶能力:分布式锁、接口幂等、多级缓存架构、限流熔断联动。
-
Spring Cache注解缓存、Redis整合
-
缓存三大问题:穿透、击穿、雪崩解决方案
-
缓存与事务一致性、分布式锁实战
3. 非关系型数据库(NoSQL企业实战体系)
非关系型数据库(NoSQL)是Spring分布式项目高并发、海量数据、非结构化数据、全文检索 的核心解决方案,弥补了MySQL关系型数据库的短板。本模块整合MongoDB文档数据库、Elasticsearch搜索引擎、Redis深度进阶三大主流NoSQL组件,全覆盖Spring生态整合、底层原理、业务落地、数据同步、生产避坑,适配互联网海量数据、检索、时序数据存储场景,和前文关系型数据库、缓存体系形成完整数据层闭环。
一、NoSQL核心分类与选型规范(企业必备)
NoSQL摒弃了关系型数据库的表结构、关联约束,以高并发、高可用、海量存储、灵活拓展为核心优势,不同组件适配专属业务场景,杜绝技术滥用:
-
键值型NoSQL(Redis) :高性能缓存、分布式锁、计数器、限流、会话存储,主打超高读写性能,前文缓存体系已深度讲解,本模块补充高阶整合方案
-
文档型NoSQL(MongoDB) :存储非结构化/半结构化数据、海量日志、用户行为、商品详情、动态表单,主打灵活Schema、海量数据存储
-
搜索引擎NoSQL(Elasticsearch) :全文检索、模糊查询、日志检索、商品搜索、数据聚合统计,主打分词检索、海量数据实时查询
-
时序型NoSQL(InfluxDB) :监控指标、日志时序数据、设备上报数据,主打时序数据高效存储与查询(企业运维监控刚需)
✅ 核心选型原则
-
结构化、强事务、强一致性业务 → 优先MySQL
-
高频读写、热点数据、分布式管控 → 优先Redis
-
非结构化、灵活字段、海量数据存储 → 优先MongoDB
-
全文检索、模糊匹配、聚合统计 → 优先Elasticsearch
二、MongoDB 文档数据库完整版(Spring整合)
MongoDB是企业最主流的文档型数据库,数据以JSON文档形式存储,无固定表结构,支持字段动态拓展,完美适配迭代频繁、字段不固定、海量数据的业务场景,Spring项目通过Spring Data MongoDB无缝整合。
1. 核心基础概念(对标MySQL)
快速对标关系型数据库,零基础快速上手,打通数据层认知:
-
数据库(Database):对标MySQL数据库,独立隔离数据空间
-
集合(Collection):对标MySQL数据表,无需提前定义字段结构
-
文档(Document):对标MySQL数据行,JSON格式存储,字段灵活可变
-
字段(Field):对标MySQL列,支持嵌套对象、数组、多级结构
-
主键_id:全局唯一主键,默认自动生成,替代MySQL自增ID
2. 核心特性与业务落地场景
-
核心特性:无Schema约束、支持嵌套文档/数组、高并发读写、水平分片扩容、自动负载均衡、支持索引与事务
-
适配场景:用户行为日志、商品详情数据、动态表单、评论回复、内容资讯、设备上报数据、海量临时数据存储
-
禁用场景:强事务、多表关联查询、高频更新核心数据(不适合核心交易业务)
3. Spring Boot 生产级整合配置
XML
# MongoDB生产配置
spring:
data:
mongodb:
# 单机连接地址,集群可配置多个节点
uri: mongodb://admin:123456@127.0.0.1:27017/spring_db?authSource=admin
# 连接池配置(优化并发性能)
pool:
max-size: 20 # 最大连接数
min-size: 5 # 最小空闲连接
max-wait: 3000 # 最大等待时间
timeout: 5000 # 读写超时时间4. 核心CRUD实战(Spring Data标准写法)
延续Spring Data统一编程风格,和JPA用法一致,极简开发,支持自定义查询、分页、排序:
java
// 1. 实体类映射(无需建表,自动创建集合)
@Document(collection = "user_behavior")
public class UserBehavior {
@Id
private String id;
private Long userId;
private String behaviorType; // 浏览、点赞、收藏
private String targetId;
private LocalDateTime createTime;
// getter/setter 省略
}
// 2. 持久层接口(继承通用接口,自带CRUD)
public interface UserBehaviorRepository extends MongoRepository<UserBehavior, String> {
// 自定义条件查询(Spring Data自动解析方法名)
Page<UserBehavior> findByUserId(Long userId, Pageable pageable);
}
// 3. 业务层实战
@Service
public class UserBehaviorService {
@Autowired
private UserBehaviorRepository behaviorRepository;
// 新增/更新(save方法幂等,存在则更新,不存在则新增)
public void saveBehavior(UserBehavior behavior) {
behavior.setCreateTime(LocalDateTime.now());
behaviorRepository.save(behavior);
}
// 分页查询用户行为数据
public Page<UserBehavior> getUserBehaviorPage(Long userId, int pageNum, int pageSize) {
Pageable pageable = PageRequest.of(pageNum - 1, pageSize, Sort.by(Sort.Direction.DESC, "createTime"));
return behaviorRepository.findByUserId(userId, pageable);
}
// 删除数据
public void deleteBehavior(String id) {
behaviorRepository.deleteById(id);
}
}5. 核心高阶能力(生产必备)
-
索引优化:支持单字段索引、复合索引、唯一索引、文本索引,解决海量数据查询慢问题,禁止全集合扫描
-
聚合查询:支持分组统计、求和、筛选、排序、联表查询,适配数据报表统计场景
-
事务支持:4.0+版本支持副本集事务,满足单库多文档数据一致性需求
-
分片集群:支持水平分片,解决单集合海量数据瓶颈,适配亿级数据存储
-
冷热数据分离:自动过期删除、归档迁移,节省存储空间
6. 生产高频坑点与避坑方案
-
坑点1:无索引导致全集合扫描:海量数据查询超时、CPU飙升,解决方案:高频查询字段必建索引
-
坑点2:字段随意新增导致数据混乱:Schema灵活导致字段不统一,解决方案:代码层统一实体类规范,禁止随意新增业务字段
-
坑点3:批量写入性能卡顿:单条save写入效率低,解决方案:使用batch批量插入接口,减少网络IO
-
坑点4:事务滥用:分布式跨分片事务不支持,解决方案:仅限单库事务使用,跨分片通过业务兜底
三、Elasticsearch 搜索引擎完整版(全文检索核心)
Elasticsearch(简称ES)是分布式全文检索引擎,基于Lucene底层封装,支持分词检索、模糊匹配、高亮显示、海量数据聚合、实时日志检索,是企业商品搜索、系统检索、日志分析、数据统计的核心组件,Spring生态通过Spring Data Elasticsearch无缝整合。
1. 核心基础概念(对标数据库)
-
索引(Index):对标MySQL数据表,存储一类结构化数据
-
文档(Document):对标MySQL数据行,单条JSON数据
-
字段(Field):对标MySQL列,支持分词、精准匹配、聚合
-
分片&副本:主分片负责读写,副本分片负责高可用、负载均衡
2. 核心优势与落地场景
-
核心优势:全文分词检索、海量数据秒级查询、分布式集群、水平扩容、实时数据聚合、支持模糊/精准/范围多维度查询
-
企业场景:商品全文搜索、文章资讯检索、系统日志检索、用户模糊查询、数据大屏聚合统计、接口模糊匹配
-
核心定位 :不替代MySQL,只做检索增强,核心业务数据存MySQL,检索数据同步至ES
3. Spring Boot 生产级整合配置
XML
# Elasticsearch生产配置(7.x/8.x通用)
spring:
elasticsearch:
uris: http://127.0.0.1:9200
username: elastic
password: 123456
# 连接超时配置
socket-timeout: 10000
connect-timeout: 50004. 核心检索能力实战
支持精准查询、模糊分词、高亮检索、分页排序、聚合统计,覆盖企业99%检索场景:
java
// 实体类索引映射
@Document(indexName = "product_info")
public class ProductDoc {
@Id
private Long id;
@Field(type = FieldType.Text, analyzer = "ik_max_word") // 分词字段
private String productName;
@Field(type = FieldType.Keyword) // 精准匹配字段
private String category;
private Double price;
// getter/setter 省略
}
// 持久层接口
public interface ProductRepository extends ElasticsearchRepository<ProductDoc, Long> {
// 分词模糊查询商品名称
List<ProductDoc> findByProductNameLike(String keyword);
}5. MySQL与ES数据同步方案(生产核心)
解决双库数据一致性问题,企业主流3种落地方案,按业务优先级选型:
-
方案1:代码双写(简单业务首选):新增/修改/删除MySQL数据时,同步调用ES接口更新索引,优点简单易实现,缺点存在代码冗余、同步失败风险
-
方案2:MQ异步同步(主流方案):MySQL操作完成后发送消息至RabbitMQ/Kafka,消费者异步更新ES,解耦业务、削峰容错,支持重试兜底
-
方案3:Canal监听binlog(海量数据首选):监听MySQL二进制日志,自动同步数据至ES,零代码侵入、实时性高,适配大型项目
6. ES生产高频问题与解决方案
-
问题1:分词不准确:默认分词不支持中文,解决方案:安装IK分词器,配置细粒度分词规则
-
问题2:数据同步不一致:双写失败、消息丢失,解决方案:定时任务兜底比对、失败重试机制
-
问题3:深分页性能卡顿:from+size大页码查询性能暴跌,解决方案:游标分页、scroll滚动查询
-
问题4:集群分片异常:分片分配不均、副本缺失,解决方案:合理规划分片数、集群监控告警
四、Redis高阶深化(NoSQL键值型终极落地)
前文缓存体系已讲解基础用法,本模块补充Redis特殊场景、分布式实战、数据持久化、集群架构,完善NoSQL体系闭环:
1. 持久化机制(数据不丢失核心)
-
RDB持久化:定时全量快照,恢复速度快、占用资源低,适合冷数据备份
-
AOF持久化:实时记录操作日志,数据安全性高、几乎无数据丢失,适合核心业务
-
生产组合方案:RDB+AOF混合持久化,兼顾性能与数据安全
2. 集群高可用架构
-
主从架构:主节点读写、从节点备份,解决数据备份问题,无故障转移
-
哨兵架构:监控主从节点,自动故障转移,解决单点故障,适配中小型项目
-
集群架构:分片存储、多主多从、水平扩容,适配海量数据、超高并发大型项目
3. 高阶业务场景补充
-
Geo地理位置:附近的人、门店距离排序、地理位置检索
-
BitMap位图:签到统计、活跃用户标记、状态位存储,极致节省内存
-
HyperLogLog:海量数据去重统计(UV统计),极低内存占用
五、NoSQL整体选型与架构闭环(企业标准)
1. 数据层完整架构组合
MySQL(核心结构化数据)+ Redis(高性能缓存)+ MongoDB(海量非结构化数据)+ ES(全文检索),覆盖企业所有数据存储场景,无技术盲区。
2. 核心落地禁忌
-
禁止用NoSQL替代MySQL做核心交易、强事务业务
-
禁止用ES做数据存储,仅做检索查询,核心数据必须落库MySQL
-
禁止MongoDB存储高频更新、强关联数据,避免数据冗余混乱
✅ 非关系型数据库模块终极总结
-
Redis:键值型,主打高性能缓存、分布式管控、计数器、限流,高并发场景核心
-
MongoDB:文档型,主打灵活Schema、海量非结构化数据存储,适配日志、行为数据、动态表单
-
Elasticsearch:检索型,主打全文分词、模糊查询、聚合统计,解决MySQL检索短板
-
核心架构:MySQL存核心数据,NoSQL做性能、场景补充,各司其职、互补适配
-
核心难点:双库数据同步、一致性保障、索引优化、集群高可用、海量数据性能调优
-
Spring适配:统一Spring Data编程规范,极简整合、零冗余代码,适配单体与微服务项目
第五阶段:安全体系(企业项目必备)
Spring Security 完整体系(企业认证授权·零死角闭环)
Spring Security 是Spring生态官方安全框架 ,适配单体、微服务所有Java项目,核心负责接口认证、权限授权、会话管控、安全防护,替代传统拦截器手写权限逻辑。框架底层基于Spring AOP+Servlet Filter实现,具备零侵入、高拓展、全覆盖、可定制的特点,是企业项目统一安全管控的标准技术栈。本模块全覆盖基础原理、JWT无状态认证、RBAC权限体系、高阶安全防护、微服务安全、生产避坑与源码核心,补齐项目安全体系短板。
一、Spring Security 核心底层原理(必懂根基)
1. 核心定位与核心优势
-
核心定位:Java项目一站式安全解决方案,统一处理「登录认证、权限校验、会话管理、接口防护、攻击拦截」全流程
-
生态优势:Spring原生适配、无缝整合Spring Boot/Spring Cloud、无需冗余原生Filter代码、支持OAuth2.0第三方登录、适配微服务分布式安全
-
企业价值:统一项目安全规范,解决手写权限混乱、防护不全、漏洞频发等问题,适配所有线上项目安全合规要求
2. 核心执行链路(Filter过滤器链)
Spring Security 底层核心是自定义过滤器链 ,依托Servlet Filter机制,优先于Spring MVC拦截器执行,完整请求链路:请求进入 → 多层安全过滤器拦截 → 认证校验 → 权限校验 → 接口放行 → 响应处理
-
核心过滤器层级:跨域过滤器→会话过滤器→登录认证过滤器→权限校验过滤器→异常处理过滤器
-
核心设计思想:责任链模式,每一层过滤器负责单一安全能力,可自定义新增、替换、禁用过滤器,拓展性极强
3. 两大核心核心概念
-
认证(Authentication):验证「你是谁」,校验用户账号密码、Token合法性,区分登录/未登录用户
-
授权(Authorization):验证「你能做什么」,基于用户角色、权限标识,控制接口、资源、按钮的访问权限
4. 核心核心组件(底层支撑)
-
SecurityContext(安全上下文):基于ThreadLocal存储当前登录用户信息,线程隔离,全局可获取登录用户
-
AuthenticationManager(认证管理器):统一认证入口,校验账号密码、Token有效性,认证成功后封装用户权限信息
-
UserDetailsService(用户信息服务):自定义查询数据库用户、角色、权限数据,框架无默认数据源,必须手动实现
-
PasswordEncoder(密码加密器):密码加密、校验工具,企业统一使用BCrypt强哈希加密,杜绝明文存储
-
FilterSecurityInterceptor:核心权限拦截器,所有接口请求最终经过此处完成权限校验
二、基础认证体系(表单登录+会话模式)
传统Session会话登录模式,适配单体传统Web项目,是理解Security认证流程的基础,核心实现账号密码登录、会话维持、退出登录、 RememberMe记住我。
1. 核心登录流程
-
- 客户端提交账号密码,请求登录接口
-
- UsernamePasswordAuthenticationFilter 拦截登录请求,封装认证参数
-
- AuthenticationManager 调用 UserDetailsService 查询数据库用户信息
-
- PasswordEncoder 校验密码是否匹配
-
- 认证成功,生成Session会话,存入SecurityContext,返回登录成功
-
- 后续请求携带SessionId,自动完成身份识别
2. 生产级基础配置代码
java
@Configuration
@EnableWebSecurity
public class SecurityConfig {
// 密码加密器:BCrypt加密(企业标准,自带盐值、不可逆)
@Bean
public PasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
// 安全配置核心规则
@Bean
public SecurityFilterChain securityFilterChain(HttpSecurity http) throws Exception {
http
// 关闭csrf(单体会话模式可开启,前后端分离必须关闭)
.csrf(csrf -> csrf.disable())
// 放行静态资源、登录接口、无需认证的接口
.authorizeHttpRequests(auth -> auth
.requestMatchers("/login", "/register", "/static/**").permitAll()
// 其余所有请求必须认证
.anyRequest().authenticated()
)
// 表单登录配置
.formLogin(form -> form
.loginProcessingUrl("/login") // 登录请求地址
.successHandler(new LoginSuccessHandler()) // 登录成功处理
.failureHandler(new LoginFailHandler()) // 登录失败处理
)
// 退出登录配置
.logout(logout -> logout
.logoutUrl("/logout")
.logoutSuccessHandler(new LogoutSuccessHandler())
.clearAuthentication(true)
.invalidateHttpSession(true)
)
// 记住我功能:有效期7天
.rememberMe(remember -> remember.tokenValiditySeconds(60 * 60 * 24 * 7));
return http.build();
}
}3. 自定义用户认证实现
java
@Service
public class UserDetailsServiceImpl implements UserDetailsService {
@Autowired
private UserMapper userMapper;
@Override
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
// 1. 根据用户名查询数据库用户
User user = userMapper.selectByUsername(username);
if (user == null) {
throw new UsernameNotFoundException("用户名不存在");
}
// 2. 查询用户角色、权限标识
List<GrantedAuthority> authorities = userMapper.selectUserPermissions(user.getId())
.stream()
.map(SimpleGrantedAuthority::new)
.collect(Collectors.toList());
// 3. 封装框架用户对象,返回给认证管理器
return new org.springframework.security.core.userdetails.User(
user.getUsername(),
user.getPassword(),
authorities
);
}
}三、JWT无状态认证体系(前后端分离/微服务标配)
Session会话模式无法适配微服务集群、前后端分离项目,JWT无状态Token认证是目前企业绝对主流方案,无会话存储、跨服务共享、适配分布式集群,彻底解决Session共享、会话过期、集群登录失效问题。
1. JWT核心原理与结构
-
核心结构:Header(头部)+ Payload(载荷,存储用户ID、用户名、权限)+ Signature(签名加密)
-
核心特性:无状态、服务端无需存储、客户端自主携带、防篡改、可设置过期时间
-
登录流程:账号密码登录→认证成功生成JWT→前端存储Token→每次请求携带Token→后端解析校验Token→完成认证授权
2. 生产级JWT工具类(加密/解密/过期校验)
java
public class JwtUtil {
// 自定义密钥(生产配置在配置文件,禁止硬编码)
private static final String SECRET_KEY = "spring-security-jwt-secret-2026";
// Token过期时间:2小时
private static final long EXPIRE_TIME = 2 * 60 * 60 * 1000;
// 生成JWT Token
public static String generateToken(Long userId, String username, List<String> permissions) {
Date now = new Date();
Date expireDate = new Date(now.getTime() + EXPIRE_TIME);
return Jwts.builder()
.setSubject(username)
.setId(userId.toString())
.claim("permissions", permissions)
.setIssuedAt(now)
.setExpiration(expireDate)
.signWith(SignatureAlgorithm.HS256, SECRET_KEY)
.compact();
}
// 解析Token
public static Claims parseToken(String token) {
return Jwts.parser()
.setSigningKey(SECRET_KEY)
.parseClaimsJws(token)
.getBody();
}
// 校验Token是否过期
public static boolean isExpire(String token) {
return parseToken(token).getExpiration().before(new Date());
}
}3. 自定义JWT认证过滤器(核心核心)
替代原生Session登录,拦截所有请求、解析Token、封装登录用户信息,接入Security上下文,实现无状态认证。
java
@Component
public class JwtAuthenticationFilter extends OncePerRequestFilter {
@Autowired
private UserDetailsService userDetailsService;
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException {
// 1. 获取请求头Token
String token = request.getHeader("Authorization");
if (StringUtils.isEmpty(token) || !token.startsWith("Bearer ")) {
filterChain.doFilter(request, response);
return;
}
token = token.substring(7);
try {
// 2. 解析Token、校验有效性
Claims claims = JwtUtil.parseToken(token);
String username = claims.getSubject();
// 3. 查询用户信息,封装认证对象
UserDetails userDetails = userDetailsService.loadUserByUsername(username);
UsernamePasswordAuthenticationToken authentication = new UsernamePasswordAuthenticationToken(
userDetails, null, userDetails.getAuthorities()
);
// 4. 存入安全上下文,完成认证
SecurityContextHolder.getContext().setAuthentication(authentication);
} catch (Exception e) {
// Token失效、篡改,清空上下文
SecurityContextHolder.clearContext();
}
filterChain.doFilter(request, response);
}
}4. JWT完整安全配置(微服务通用)
java
@Configuration
@EnableWebSecurity
@EnableMethodSecurity // 开启方法级权限注解
public class JwtSecurityConfig {
@Autowired
private JwtAuthenticationFilter jwtAuthenticationFilter;
@Bean
public PasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
@Bean
public SecurityFilterChain securityFilterChain(HttpSecurity http) throws Exception {
http
.csrf(csrf -> csrf.disable())
.sessionManagement(session -> session.sessionCreationPolicy(SessionCreationPolicy.STATELESS)) // 无状态,禁用Session
.authorizeHttpRequests(auth -> auth
.requestMatchers("/api/login", "/api/register").permitAll() // 放行登录注册
.anyRequest().authenticated()
)
// 将JWT过滤器加入过滤器链,优先执行
.addFilterBefore(jwtAuthenticationFilter, UsernamePasswordAuthenticationFilter.class);
return http.build();
}
}5. Token刷新与过期解决方案(生产必备)
-
痛点:Token过期直接强制用户重新登录,体验极差
-
企业方案:双Token机制(AccessToken+RefreshToken)
-
实现逻辑:短时AccessToken(2h)用于接口认证、长时RefreshToken(7天)用于刷新令牌,前端检测Access过期,用Refresh无感刷新新Token,无需重新登录
四、RBAC权限体系(企业通用权限模型)
Spring Security 原生适配**RBAC(角色-权限-用户)**权限模型,实现用户、角色、权限标识的分层管控,支持接口级、方法级、按钮级精准权限控制,是所有企业后台的标准权限架构。
1. RBAC核心数据模型
-
用户(User):系统登录用户,关联角色
-
角色(Role):权限集合载体(管理员、普通用户、访客),关联权限标识
-
权限(Permission):最小权限粒度(user:list、user:add、order:update),精准控制接口操作
-
关联关系:用户多对多角色、角色多对多权限
2. 两种核心权限控制方式
1)接口级权限(URL拦截)
基于请求路径匹配,统一拦截接口,适合全局接口权限管控,在Security配置中统一配置规则。
2)方法级权限(注解控制·企业主流)
开启 @EnableMethodSecurity 注解,在业务方法上精准控制权限,粒度更细、灵活度更高,支持角色、权限标识、权限表达式。
java
@RestController
@RequestMapping("/api/user")
public class UserController {
// 必须拥有user:list权限才能访问
@GetMapping("/list")
@PreAuthorize("hasPermission('user:list')")
public Result listUser() {
return Result.success();
}
// 必须是管理员角色才能删除
@DeleteMapping("/delete/{id}")
@PreAuthorize("hasRole('ADMIN')")
public Result deleteUser(@PathVariable Long id) {
return Result.success();
}
// 权限表达式:支持复杂逻辑判断
@PostMapping("/add")
@PreAuthorize("isAuthenticated() && hasPermission('user:add')")
public Result addUser() {
return Result.success();
}
}3. 权限数据持久化与动态加载
-
摒弃框架默认内存权限,实现数据库动态权限
-
启动项目/权限更新时,实时查询数据库用户、角色、权限数据
-
支持后台动态配置权限、无需重启项目生效
五、高阶安全防护能力(生产安全合规)
补齐项目安全短板,拦截常见网络攻击、恶意请求,满足企业安全扫描、等保合规要求。
1. 接口防刷与限流防护
-
基于IP+接口路径限流,限制单IP单位时间请求次数
-
整合Redis实现分布式限流,防止恶意高频请求刷爆接口
-
拦截暴力破解、批量请求攻击,保护登录、支付核心接口
2. 验证码拦截登录
-
自定义登录过滤器,在账号密码认证前校验图片验证码
-
验证码存入Redis,过期失效,防止验证码复用
-
拦截无验证码、验证码错误的登录请求,杜绝暴力破解
3. 常见攻击防护
-
CSRF跨站请求伪造:传统Web项目开启CSRF令牌校验,前后端分离项目基于Token天然防护
-
XSS跨站脚本攻击:配置请求过滤、转义特殊字符、响应头安全策略
-
SQL注入:结合MyBatis参数预编译,Security拦截恶意参数请求
4. 会话安全管控
-
单用户单点登录:禁止同一账号多端同时在线,后登录挤退先登录
-
会话超时自动退出、非法登录拦截、异常登录告警
-
登录日志记录、操作日志留存,满足安全审计要求
六、微服务安全架构(Spring Cloud Alibaba适配)
微服务架构下,统一网关层做全局安全拦截,业务服务只做权限校验,实现安全统一管控。
1. 微服务安全核心架构
-
Gateway网关层:统一拦截所有请求、校验Token有效性、解析用户信息、过滤非法请求、跨域统一处理
-
业务服务层:无需重复校验Token,直接获取网关传递的用户信息,做接口/方法级权限校验
2. 核心落地规范
-
网关统一签发、校验JWT,杜绝各服务重复认证
-
网关解析用户权限,通过请求头传递至下游服务
-
下游服务基于请求头权限数据,完成本地权限校验
-
全局异常统一处理,认证/权限异常统一返回标准错误码
3. 微服务安全核心优势
-
统一安全规范,避免多服务安全逻辑冗余
-
单点管控、全局生效,安全改造无需改动所有业务服务
-
适配灰度发布、动态路由、限流熔断联动安全策略
七、OAuth2.0第三方登录(拓展能力)
适配企业社交登录需求,支持微信、QQ、GitHub、Gitee第三方授权登录,基于Spring Security OAuth2实现标准化授权流程。
-
核心流程:客户端授权→第三方登录→获取授权码→换取令牌→获取用户信息→绑定本地账号→完成登录
-
适用场景:官网、小程序、移动端APP第三方快捷登录
-
核心优势:标准化协议、无需自研授权逻辑、安全合规、拓展性强
八、生产高频坑点与终极解决方案
-
坑点1:权限注解失效 :未开启@EnableMethodSecurity、同类内调用AOP失效、权限标识不匹配 解决方案:开启注解、通过代理调用方法、统一数据库权限标识规范
-
坑点2:JWT Token解析异常、签名失效 :密钥不一致、Token被篡改、过期未刷新 解决方案:统一服务密钥、双Token刷新机制、拦截篡改请求
-
坑点3:认证成功后无法获取登录用户 :未存入Security上下文、线程复用导致上下文残留 解决方案:过滤器正确封装认证信息、请求结束清空上下文
-
坑点4:跨域+安全拦截冲突 :OPTIONS预检请求被拦截、跨域配置失效 解决方案:放行OPTIONS请求、网关统一跨域配置
-
坑点5:密码加密重复加密、校验失败 :自定义登录逻辑未关闭默认密码校验 解决方案:接管认证流程,统一密码加密校验规则
-
坑点6:微服务用户信息丢失 :网关解析用户后未向下游传递、请求头丢失 解决方案:网关透传用户信息、服务拦截器统一获取封装
✅ Spring Security 模块终极总结
-
核心本质 :基于过滤器链的一站式安全框架,核心能力为认证+授权+安全防护
-
技术选型:传统单体用Session会话认证,前后端分离/微服务用JWT无状态认证
-
权限核心:RBAC分层权限模型,方法级注解管控是企业主流规范
-
生产重点:JWT双Token刷新、动态权限、接口防刷、单点登录、微服务统一安全
-
避坑核心:注解开启、上下文管控、跨域放行、Token有效性校验、权限标识统一
-
生态闭环:无缝整合Spring全家桶,适配单体、微服务所有项目,满足企业安全合规、权限管控所有需求
总结:
-
核心流程:认证、授权、会话管理
-
JWT令牌登录、无状态认证、Token刷新与过期处理
-
权限体系:RBAC角色权限、接口级权限控制、权限表达式
-
高级功能:记住我、验证码拦截、接口防刷、请求防篡改、单点登录、会话共享
-
OAuth2.0、第三方登录基础
第六阶段:微服务全家桶(Spring Cloud Alibaba 最新体系)
企业主流微服务技术栈,全覆盖服务治理、通信、容错、配置、分布式问题。
-
服务注册与发现:Nacos、服务健康检测、优雅上下线
-
配置中心:Nacos配置、配置热刷新、多环境配置
-
网关:Spring Cloud Gateway、动态路由、过滤器、灰度发布、权重路由、跨域统一处理
-
服务调用:OpenFeign远程调用、负载均衡算法
-
熔断限流:Sentinel、流量控制、熔断降级、热点参数限流、系统规则
-
分布式事务:Seata、AT/TCC模式、最终一致性方案
-
消息驱动:Spring Cloud Stream、RabbitMQ/Kafka整合、消息可靠投递、死信队列
-
链路追踪:Sleuth+Zipkin、调用链路监控、线上问题溯源
-
分布式核心问题:分布式ID、分布式锁、接口幂等性、防重复提交
第七阶段:响应式编程(高阶进阶·Spring WebFlux 完整版)
响应式编程是Spring生态高阶高并发解决方案 ,区别于传统Servlet阻塞式编程,基于非阻塞、事件驱动、异步响应模型,依托Netty高性能网络框架实现超高吞吐、低延迟接口,是互联网超高并发网关、实时推送、流式接口、秒杀系统的核心技术栈。本模块从零吃透响应式核心思想、Flux/Mono核心API、Spring WebFlux全栈开发、中间件整合、线程模型、生产避坑,补齐传统Spring MVC阻塞编程的性能短板,适配架构师高阶技术能力要求。
一、响应式编程核心基石(必懂原理)
1. 阻塞编程 vs 响应式非阻塞编程
传统Spring MVC基于Servlet阻塞模型,是绝大多数接口性能瓶颈的根源,先搞懂核心差异,才能理解响应式编程的价值:
-
Servlet阻塞模型(MVC):一个请求绑定一个Tomcat工作线程,线程在等待数据库、缓存、网络IO时会阻塞挂起,线程无法复用,高并发下线程池快速耗尽,导致接口卡顿、503服务不可用。线程资源稀缺,吞吐上限完全取决于Tomcat最大线程数。
-
响应式非阻塞模型(WebFlux):基于事件驱动,线程不阻塞等待IO,请求到来后线程仅负责调度任务,IO等待时线程释放复用,海量请求仅需少量线程即可支撑,极大提升服务器吞吐、降低CPU和内存占用,高并发场景性能碾压传统MVC。
2. 核心理论与四大特性
-
异步非阻塞:核心核心,解放线程IO阻塞,最大化利用CPU资源
-
事件驱动:基于数据就绪事件触发执行,而非串行等待执行
-
流式编程:数据以数据流形式持续推送,支持批量、分段、实时处理
-
背压机制(Backpressure):消费者处理速度慢于生产者时,主动限流生产者推送速度,解决数据积压、内存溢出问题,是响应式高可用的核心保障
3. 响应式规范与技术选型
Spring WebFlux 完全遵循 Reactive Streams 响应式规范 ,底层核心实现为 Project Reactor,是Spring官方默认响应式框架,无需引入第三方组件,无缝适配Spring全家桶。
-
规范核心:统一异步数据流处理标准、强制背压机制、标准化订阅与推送流程
-
技术栈定位:Spring MVC(阻塞、业务CRUD首选)、Spring WebFlux(非阻塞、超高并发、实时流式接口首选)
二、Reactor核心API(Flux/Mono零基础精通)
Reactor 是Spring响应式编程的底层核心,所有WebFlux接口、响应式中间件操作均基于 Mono、Flux 两个核心数据流类型,是必须熟练掌握的基础。
1. 两大核心数据流
-
Mono<T> :0/1个元素的异步数据流,适配单条数据查询、单接口响应、新增/修改/删除等单次操作,对应MVC单行数据返回
-
Flux<T> :0/N个元素的异步数据流,适配列表查询、流式推送、批量数据、文件流、实时日志等多数据持续操作,对应MVC集合数据返回
2. 高频创建算子(实战常用)
java
public class ReactorDemo {
// Mono创建:空数据、单数据、延迟数据
public static void monoCreate() {
Mono.empty(); // 空数据流
Mono.just("SpringWebFlux"); // 直接创建固定数据
Mono.delay(Duration.ofSeconds(2)); // 延迟执行,异步任务
}
// Flux创建:数组、集合、区间、流式数据
public static void fluxCreate() {
Flux.just(1,2,3,4,5); // 多元素数据流
Flux.fromIterable(List.of("Java","Spring","WebFlux")); // 集合转换
Flux.range(1,100); // 区间数据流,适配批量处理
}
}3. 核心转换/过滤/聚合算子
替代传统Stream流,支持异步流式处理,适配响应式全链路编程:
-
转换算子:map(单元素转换)、flatMap(异步流式转换,嵌套数据流解耦,生产高频)
-
过滤算子:filter(条件过滤)、distinct(去重)、skip/take(跳过/截取数据)
-
聚合算子:reduce(累加聚合)、collectList(流转集合)、count(统计数量)
-
组合算子:zip(多数据流合并)、merge(数据流合并推送)、concat(串行合并)
4. 异常处理机制(生产必备)
响应式数据流异常不可用传统try-catch,必须使用框架专属异常算子,避免数据流中断:
-
onErrorReturn:异常时返回默认值,兜底返回数据
-
onErrorResume:异常时执行备用数据流,降级兜底接口
-
retry:失败自动重试,适配网络波动、临时超时场景
-
doOnError:异常日志记录、异常告警,不中断数据流
5. 生命周期钩子方法
监听数据流执行全流程,用于日志打印、资源释放、状态监控:
- doOnSubscribe(订阅触发)、doOnNext(每一条数据推送)、doOnComplete(正常结束)、doOnError(异常结束)、doFinally(最终执行,资源释放)
三、Spring WebFlux 核心架构与运行机制
1. 核心定位与底层架构
核心定论 :Spring WebFlux 是 Spring MVC 的非阻塞替代方案 ,不依赖Servlet API、不依赖Tomcat容器,底层默认基于 Netty 异步事件驱动容器,适配高并发、低延迟、流式交互场景。
-
核心容器:Netty(NIO多路复用、事件驱动、轻量高并发)
-
核心入口:DispatcherHandler(替代MVC的DispatcherServlet,无Servlet依赖)
-
核心组件:HandlerMapping(路由匹配)、HandlerAdapter(请求适配执行)、WebExceptionHandler(全局异常处理)
2. WebFlux完整请求流转
客户端请求 → Netty端口监听 → 事件分发 → DispatcherHandler路由匹配 → 执行Controller响应式方法 → 异步数据流处理 → 流式响应返回 → 连接复用
3. 两大开发模式(全覆盖)
(1)注解式开发(兼容MVC习惯,新手首选)
完全沿用Spring MVC注解(@RequestMapping、@GetMapping、@PostMapping),仅返回值替换为Mono/Flux,学习成本极低,快速适配响应式开发。
java
@RestController
@RequestMapping("/api/webflux")
public class WebFluxController {
// 单数据查询:Mono
@GetMapping("/user/{id}")
public Mono<User> getUserById(@PathVariable Long id) {
return userReactiveService.getUserById(id);
}
// 列表查询:Flux
@GetMapping("/user/list")
public Flux<User> listUser() {
return userReactiveService.listUser();
}
}(2)函数式编程开发(高阶首选、性能最优)
摒弃注解,通过路由函数+处理函数定义接口,无反射开销、启动更快、性能更高,是企业高并发核心接口首选方案。
java
@Configuration
public class WebFluxRouteConfig {
@Bean
public RouterFunction<ServerResponse> userRoute(UserHandler userHandler) {
return RouterFunctions.route()
.GET("/api/func/user/{id}", RequestPredicates.path("/api/func/user/{id}"), userHandler::getUserInfo)
.GET("/api/func/user/list", userHandler::listUser)
.build();
}
}
// 自定义处理函数
@Component
class UserHandler {
@Autowired
private UserReactiveService userReactiveService;
public Mono<ServerResponse> getUserInfo(ServerRequest request) {
Long id = Long.parseLong(request.pathVariable("id"));
return userReactiveService.getUserById(id)
.flatMap(user -> ServerResponse.ok().bodyValue(user))
.onErrorResume(e -> ServerResponse.badRequest().bodyValue("查询失败"));
}
public Mono<ServerResponse> listUser(ServerRequest request) {
Flux<User> userFlux = userReactiveService.listUser();
return ServerResponse.ok().body(userFlux, User.class);
}
}四、WebFlux核心实战能力(企业落地必备)
1. 全局异常处理
基于 @ControllerAdvice + @ExceptionHandler 实现响应式全局异常捕获,统一返回标准结果,和MVC异常体系逻辑一致,适配响应式数据流。
2. 拦截器机制(WebFilter)
WebFlux 放弃 Servlet Filter,使用专属 WebFilter 实现请求拦截、Token校验、跨域处理、日志打印,基于响应式非阻塞执行,适配Netty线程模型。
3. 跨域配置
全局配置响应式跨域规则,统一放行预检请求、适配前后端分离,解决WebFlux跨域失效问题。
4. 流式响应(核心特色能力)
WebFlux 核心优势:支持服务端流式推送(SSE),持续向客户端推送数据,适配实时日志、消息推送、大屏实时数据、AI流式问答场景,传统MVC无法高效实现。
java
// 实时流式推送接口
@GetMapping(value = "/stream/data", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> streamData() {
// 每秒推送一条数据,持续推送
return Flux.interval(Duration.ofSeconds(1))
.map(tick -> "实时数据推送:" + LocalDateTime.now());
}五、响应式中间件整合(生产完整链路)
打通全链路响应式,避免「接口非阻塞、IO阻塞」的性能瓶颈,实现真正全链路高并发。
1. 响应式Redis整合(Spring Data Redis Reactive)
使用 ReactiveRedisTemplate 替代传统RedisTemplate,实现Redis异步非阻塞读写,适配高频缓存操作、秒杀限流场景。
2. 响应式MongoDB整合(Spring Data MongoDB Reactive)
MongoDB原生适配响应式编程,通过 ReactiveMongoRepository 实现非阻塞CRUD,适配海量日志、行为数据高并发写入查询。
3. 响应式MySQL整合(R2DBC)
摒弃阻塞的JDBC,使用R2DBC响应式数据库驱动,实现MySQL非阻塞读写,补齐关系型数据库响应式链路,彻底消除IO阻塞。
4. 响应式消息队列整合
Spring Cloud Stream 原生支持响应式编程,实现消息异步非阻塞消费、生产,提升消息处理吞吐。
六、线程模型与性能调优(架构师必懂)
1. 核心线程模型:EventLoopWebFlux 基于 Netty EventLoop 线程模型,核心特点:少量线程、复用无限、无阻塞、高吞吐,默认线程数等于CPU核心数,远超Tomcat线程池吞吐上限。
2. 调度器(Schedulers)
线程切换响应式编程核心线程调度工具,
解决阻塞代码适配、线程隔离问题:
Schedulers.parallel() :并行线程池,适配CPU密集型任务Schedulers.boundedElastic():弹性线程池,适配阻塞IO任务(兼容传统阻塞代码)
Schedulers.single():单线程,适配有序串行任务
3. 生产性能调优
核心禁止在响应式链路中使用阻塞代码(Thread.sleep、同步IO、传统JDBC)合理使用调度器隔离阻塞任务,避免EventLoop线程阻塞配置背压策略,防止海量数据推送导致内存溢出优化Netty参数,调整缓冲区、连接数,适配高并发场景七、WebFlux vs MVC 生产选型规范(避坑核心)
1. 优先使用 Spring MVC 场景
-
普通业务CRUD、低并发接口、内部管理系统
-
强事务、复杂多表关联查询、依赖大量阻塞中间件
-
团队技术栈统一、追求开发效率、无需极致性能
2. 优先使用 Spring WebFlux 场景
-
超高并发、秒杀、流量入口、网关服务(Spring Cloud Gateway底层基于WebFlux)
-
实时流式交互、消息推送、日志监控、AI流式接口
-
长连接、持续数据传输、海量异步IO场景
八、生产高频坑点与解决方案
-
坑点1:混用阻塞代码导致性能失效 :WebFlux链路中使用同步IO、Thread.sleep,阻塞EventLoop线程解决方案:全链路替换响应式组件,阻塞代码通过boundedElastic线程池隔离
-
坑点2:忽略背压导致内存溢出 :生产者推送数据过快,消费者处理不及,数据堆积 解决方案:开启自动背压、限流分批推送、丢弃冗余数据
-
坑点3:异常未捕获导致数据流中断 :未使用响应式异常算子,单条数据异常导致整个接口熔断 解决方案:统一异常兜底、重试机制、默认值返回
-
坑点4:传统拦截器/过滤器失效 :WebFlux不支持Servlet Filter、Interceptor 解决方案:统一使用WebFilter实现拦截逻辑
-
坑点5:MVC与WebFlux混用冲突 :项目同时引入两套依赖,容器启动异常 解决方案:项目技术栈统一,禁止混用两套Web框架
✅ 响应式编程模块终极总结
-
核心本质:非阻塞、事件驱动、背压兜底,以少量线程支撑超高并发,解决Servlet阻塞模型性能瓶颈
-
核心API:Mono(单数据)、Flux(多数据),各类转换、异常、组合算子
-
架构核心:Netty容器+DispatcherHandler,双开发模式(注解+函数式)
-
核心优势场景:网关、高并发接口、实时流式推送、长连接交互
-
生产核心规范:全链路响应式、隔离阻塞代码、重视背压、统一技术选型
-
生态地位:Spring Cloud Gateway、Spring Cloud Stream高阶能力全部基于WebFlux实现,是微服务高并发架构的底层基石
第八阶段:源码深度剖析+性能调优(架构师必备)
1. 核心源码必学(架构师进阶核心,精准拆解重点+流程+考点)
本板块聚焦Spring生态高频面试、底层核心、生产问题根源的源码模块,摒弃冗余边角代码,只学企业架构师、大厂面试必考、解决线上问题必备的核心源码逻辑,每一项均明确:源码核心流程、关键源码类、断点调试位置、底层原理、高频坑点、面试考点。
一、IoC容器核心源码(Spring根基,重中之重)
核心定位:IoC容器是Spring所有功能的基石,Bean生命周期、对象管理、依赖注入、循环依赖全部依托该源码体系,90%的Spring启动报错、Bean异常都源于对该机制不理解。
1. 容器刷新核心 refresh() 完整流程(必通)
核心源码类 :AbstractApplicationContext 核心方法:refresh()(Spring容器启动核心入口,全程12大步骤,无死角闭环)
-
步骤1:prepareRefresh():容器刷新前置准备,设置激活配置、初始化环境变量、加载系统属性、开启刷新状态,解决多环境配置加载底层逻辑。
-
步骤2:obtainFreshBeanFactory() :获取/刷新Bean工厂,初始化DefaultListableBeanFactory,加载XML/注解Bean定义,完成Bean定义资源解析(只解析不实例化)。
-
步骤3:prepareBeanFactory():Bean工厂前置预处理,注册容器内置Bean、后置处理器、解析器,设置Bean工厂类加载器、表达式解析器。
-
步骤4:postProcessBeanFactory():Bean工厂后置扩展,允许子类、自定义后置处理器修改Bean工厂配置,是Spring扩展点核心。
-
步骤5:invokeBeanFactoryPostProcessors() :执行Bean工厂后置处理器,重点:ConfigurationClassPostProcessor,解析@Configuration、@Component、@Bean、@Import等注解,扫描注册所有自定义Bean定义。
-
步骤6:registerBeanPostProcessors():注册Bean后置处理器(如AutowiredAnnotationBeanPostProcessor),为后续Bean属性注入、初始化做准备。
-
步骤7:initMessageSource():初始化国际化资源,适配多语言场景。
-
步骤8:initApplicationEventMulticaster():初始化事件广播器,支撑Spring事件发布、监听机制。
-
步骤9:onRefresh():容器刷新扩展方法,子类实现(如SpringBoot启动内嵌Tomcat、Web容器初始化)。
-
步骤10:registerListeners():注册事件监听器,绑定容器事件、自定义事件监听。
-
步骤11:finishBeanFactoryInitialization() :核心关键步骤 ,实例化所有非懒加载、单例Bean,完成Bean创建、属性注入、初始化、后置处理。
-
步骤12:finishRefresh():容器刷新完成,发布容器刷新完成事件、启动内嵌容器、缓存初始化完成标记。
高频面试考点:refresh()核心步骤、Bean定义加载与实例化时机、扩展点作用、SpringBoot启动联动逻辑。
2. Bean完整生命周期源码(从创建到销毁全流程)
核心源码类 :DefaultListableBeanFactory、AbstractAutowireCapableBeanFactory 核心方法:doCreateBean()(Bean创建核心入口)
完整生命周期流程(源码级闭环):
-
Bean定义解析:容器启动扫描注解/配置,生成BeanDefinition(存储Bean类信息、属性、注解、作用域)
-
实例化(无参构造):通过反射创建Bean空对象(未赋值、未注入依赖)
-
属性填充(依赖注入):AutowiredAnnotationBeanPostProcessor解析@Autowired、@Resource,完成依赖Bean注入
-
初始化前置处理:执行Bean后置处理器前置方法postProcessBeforeInitialization
-
初始化方法执行:依次执行@PostConstruct注解方法 → InitializingBean接口afterPropertiesSet() → 自定义init-method
-
初始化后置处理:执行Bean后置处理器后置方法postProcessAfterInitialization(AOP代理核心生成时机)
-
Bean就绪可用:单例Bean存入一级缓存,全局可获取使用
-
销毁:容器关闭时,执行@PreDestroy注解方法 → DisposableBean销毁方法 → 自定义destroy-method
核心坑点:AOP代理在Bean初始化后置阶段生成、循环依赖依赖三级缓存解决、初始化方法执行顺序不可颠倒。
3. 三级缓存解决循环依赖源码(Spring经典核心)
核心问题 :单例Bean setter注入循环依赖(A依赖B、B依赖A),Spring无需手动处理即可自动解决。 核心缓存结构(DefaultSingletonBeanRegistry):
-
一级缓存(singletonObjects) :存放完全初始化完成的单例Bean,对外提供访问
-
二级缓存(earlySingletonObjects) :存放已实例化、未完成属性注入和初始化的原始Bean对象,避免重复创建原始对象
-
三级缓存(singletonFactories) :存放Bean工厂对象(ObjectFactory),提前暴露Bean引用,核心作用:支持循环依赖下的AOP代理
源码解决流程:
-
创建A Bean,实例化后将A的ObjectFactory存入三级缓存
-
A填充属性,需要注入B,开始创建B
-
B填充属性,需要注入A,从三级缓存获取A的工厂对象,生成A引用(代理/原始对象)
-
B完成创建、初始化,存入一级缓存
-
A完成属性填充、初始化,升级至一级缓存,清空二、三级缓存冗余数据
高频面试终极考点: 1. 为什么需要三级缓存,二级缓存能不能解决循环依赖?(三级缓存适配AOP代理,二级缓存无法实现动态代理提前暴露) 2. 构造器注入循环依赖为什么无法解决?(未实例化就依赖,无缓存可暴露) 3. 原型Bean为什么不支持循环依赖?(无缓存机制,每次新建对象)
二、Spring AOP核心源码(动态代理底层)
核心定位 :AOP是Spring横向扩展的核心,事务、日志、权限、缓存、监控全部基于AOP实现,源码核心为代理创建、拦截链执行。
1. AOP核心源码类与核心流程
核心源码类:AnnotationAwareAspectJAutoProxyCreator(AOP自动代理创建器)、JdkDynamicAopProxy、CglibAopProxy
核心时机:Bean初始化后置阶段(postProcessAfterInitialization)生成代理对象
完整AOP执行链路源码流程:
-
容器扫描切面类、切点表达式,解析所有通知(前置、后置、异常、环绕)
-
Bean初始化完成后,判断当前Bean是否匹配切点规则
-
匹配成功则创建代理对象:有接口用JDK动态代理,无接口用CGLIB代理
-
代理对象替换原始Bean,存入Spring容器
-
调用Bean方法时,进入代理拦截器,执行拦截链链路
2. AOP拦截链执行源码(MethodInvocation)
核心方法:ReflectiveMethodInvocation.proceed()(AOP核心执行入口)
执行顺序源码级规则:环绕前置 → 前置通知 → 目标方法执行 → 环绕后置 → 后置返回 → 异常通知(报错时触发)
核心坑点源码溯源:
-
同类内调用AOP失效:内部调用不走容器代理对象,直接调用原始对象方法,无拦截链执行
-
final/static方法AOP失效:CGLIB无法重写final方法、静态方法无法被代理拦截
-
私有方法AOP失效:代理仅拦截公共方法,私有方法无代理入口
三、Spring事务核心源码(事务失效终极溯源)
核心定位:Spring事务基于AOP动态代理+ThreadLocal实现,所有事务失效、回滚失败、传播机制异常均可通过源码解释。
1. 事务核心源码体系
核心源码类:TransactionInterceptor(事务拦截器)、PlatformTransactionManager(事务管理器)、TransactionSynchronizationManager(事务上下文)
核心底层:AOP代理拦截方法 + ThreadLocal线程隔离事务 + 数据库事务机制
2. 事务完整执行源码流程
-
调用@Transactional方法,进入AOP事务拦截器
-
解析事务注解属性(传播机制、隔离级别、超时时间、回滚规则)
-
根据传播机制判断:新建事务/加入当前事务/挂起事务
-
通过ThreadLocal绑定当前线程事务上下文,开启数据库事务
-
执行目标业务方法
-
异常判断:捕获RuntimeException/Error则回滚,普通受检异常默认不回滚
-
无异常则提交事务,释放连接、清空线程上下文
3. 事务传播机制源码核心(7种机制落地)
源码核心判断逻辑:根据当前线程是否存在事务上下文,适配不同传播规则,重点掌握企业高频5种:
-
REQUIRED(默认):有事务加入,无则新建(最常用)
-
SUPPORTS:有事务加入,无则非事务执行
-
MANDATORY:必须在事务内执行,无事务直接报错
-
REQUIRES_NEW:新建独立事务,挂起当前事务(事务隔离核心)
-
NESTED:嵌套事务,依赖父事务,可单独回滚子事务
4. 事务失效全部源码级原因(生产必背)
-
同类内方法调用,AOP代理失效,未触发事务拦截器
-
方法为private/final/static,无法被AOP代理拦截
-
异常为受检异常(Exception),未配置rollbackFor,默认不回滚
-
业务内try-catch捕获异常,拦截器无法感知异常,默认提交事务
-
传播机制配置不当,导致事务嵌套、事务挂起失效
-
多线程异步执行,ThreadLocal事务上下文无法传递,事务隔离失效
四、Spring Boot自动配置源码(Starter核心原理)
核心定位:SpringBoot零配置、开箱即用的核心,弄懂源码可彻底解决自动配置失效、自定义Starter、配置冲突问题。
1. 核心源码注解与入口
核心启动注解 :@SpringBootApplication 组合注解拆解:
-
@Configuration:标识启动类为配置类
-
@EnableAutoConfiguration:自动配置核心,加载SPI自动配置类
-
@ComponentScan:默认扫描当前包及子包所有组件
2. 自动配置完整源码流程
-
项目启动,触发@EnableAutoConfiguration注解解析
-
通过SPI机制读取META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports文件
-
加载所有场景自动配置类(Web、Redis、MyBatis、Tomcat等)
-
通过条件注解(@ConditionalOnClass、@ConditionalOnMissingBean)判断是否生效
-
满足条件则自动注册Bean、初始化默认配置、加载默认参数
-
支持用户自定义Bean,覆盖默认自动配置(用户Bean优先)
3. 核心条件注解源码逻辑
-
@ConditionalOnClass:类路径存在指定类,配置生效
-
@ConditionalOnMissingBean:容器无对应Bean,才自动创建(用户自定义优先)
-
@ConditionalOnProperty:配置文件存在指定参数,配置生效
4. 自定义Starter实现原理(架构师必备)
基于SPI+条件注解,实现开箱即用的自定义组件,适配企业通用工具封装,核心逻辑与Spring官方Starter完全一致。
五、Spring MVC核心源码(请求全链路闭环)
核心定位:弄懂MVC源码,彻底解决404、405、415、参数绑定失败、拦截失效、异常处理失效等Web问题。
1. 核心入口源码:DispatcherServlet
核心方法:doDispatch()(所有Web请求统一分发入口)
2. 完整请求流转源码流程
-
客户端发起HTTP请求,Tomcat接收并转发至DispatcherServlet
-
获取处理器映射(HandlerMapping):根据URL匹配对应Controller方法
-
获取处理器适配器(HandlerAdapter):适配对应Controller执行方式
-
拦截器前置处理:执行Interceptor preHandle方法
-
参数解析绑定:解析HTTP报文,适配@RequestParam/@RequestBody等注解,封装参数
-
执行目标Controller方法:完成业务逻辑执行
-
结果视图解析/数据返回:统一封装响应结果
-
拦截器后置处理:执行postHandle、afterCompletion方法
3. MVC九大核心组件源码作用(必记)
-
HandlerMapping:URL与Controller方法映射匹配
-
HandlerAdapter:适配执行不同类型处理器方法
-
HandlerExceptionResolver:全局异常解析处理
-
RequestMappingHandlerMapping:注解接口映射核心
-
RequestMappingHandlerAdapter:注解接口执行适配
-
消息转换器:JSON序列化、参数解析、响应格式化
-
视图解析器:视图跳转、页面渲染
-
文件解析器:适配文件上传请求解析
-
跨域处理器:统一处理CORS跨域请求
核心坑点溯源:参数接收失败是消息转换器匹配问题、405是请求方法映射不匹配、415是媒体类型解析器不匹配。
总结:
-
IoC容器refresh()完整源码、三级缓存解决循环依赖源码
-
AOP代理创建流程、拦截链执行源码
-
Spring事务源码、事务失效底层原因
-
Spring Boot自动配置源码、Starter加载机制
-
DispatcherServlet请求分发源码
2. 性能与线上调优(生产全维度落地·架构师核心能力)
-
一、Spring核心组件调优(框架层最优配置)
-
二、Tomcat容器高并发调优(Web服务吞吐核心)
-
三、JVM虚拟机调优(内存、GC、线上稳定性)
-
四、接口性能专项调优(耗时、阻塞、并发优化)
-
五、数据库与事务调优(慢查询、锁、事务失效根治)
-
六、缓存体系调优(Redis缓存穿透、击穿、雪崩、冷热数据)
-
七、线程池专项调优(异步、定时、并发阻塞解决方案)
-
八、线上高频故障排查与兜底方案
-
九、生产监控与持续优化体系
一、Spring核心组件调优(框架层最优配置)
1. Bean生命周期与复用调优
-
核心问题:滥用原型Bean、重复创建对象、初始化耗时过长导致启动慢、并发开销大
-
最优规范 :绝大多数业务Bean统一使用单例模式,利用Spring单例池复用对象,避免频繁反射创建实例
-
原型Bean使用场景:仅多线程可变状态、非线程安全对象使用prototype,禁止全局业务Bean滥用
-
初始化优化 :复杂初始化逻辑使用
@PostConstruct异步执行、项目启动预加载热点数据,避免接口首次访问卡顿 -
Bean懒加载调优:非核心、低频使用Bean配置lazy-init,缩短项目启动时间,减少启动内存占用
2. Spring IoC容器启动调优
-
包扫描优化:精准配置@ComponentScan扫描路径,杜绝全量扫描,减少注解解析、Bean定义加载耗时
-
排除自动配置类 :通过
exclude剔除无用自动配置(如Redis、Mongo、定时任务无效配置),减少容器加载类数量 -
条件注解精准控制:通过@Conditional按需加载组件,避免冗余Bean注册占用内存
3. AOP代理性能调优
-
代理方式优选:无接口业务类统一使用CGLIB代理,避免JDK代理接口限制,同时关闭代理类缓存冗余
-
切点精准匹配:细化AspectJ切点表达式,缩小代理范围,不对工具类、静态方法、私有方法做无效代理
-
减少环绕嵌套通知:过多环绕通知嵌套会增加方法执行链路开销,简化AOP切面逻辑,只保留核心增强
4. 全局异常与参数校验调优
-
统一全局异常捕获,避免频繁抛出未捕获异常导致JVM GC频繁、线程阻塞
-
参数校验前置,拦截无效请求,避免无效业务执行浪费资源
二、Tomcat容器高并发调优(Web服务吞吐核心)
Spring Boot内嵌Tomcat默认配置适配开发环境,线上高并发必须手动调优,解决接口排队、503、请求超时、并发上限低问题。
1. 核心线程池参数生产最优配置
-
核心线程数:CPU核心数*2,常驻线程保障基础吞吐,避免频繁创建销毁线程
-
最大线程数:200~500(高并发接口上调,避免线程池耗尽)
-
最大连接数max-connections:8192,适配海量TCP长连接
-
等待队列accept-count:200,避免队列过小直接拒绝请求、过大导致请求超时
-
空闲线程超时:60s,自动回收闲置线程,释放服务器资源
2. 性能关键优化项
-
开启NIO非阻塞模式:默认启用,摒弃阻塞IO,提升端口监听与请求处理效率
-
禁用Tomcat默认无用过滤器:关闭字符编码、日志冗余过滤器,减少请求链路开销
-
静态资源单独优化:静态资源交由Nginx托管,Tomcat只处理动态接口请求
-
关闭热部署:生产环境禁用devtools,避免内存泄漏、线程残留
3. 线上Tomcat高频问题解决
-
接口卡顿、偶尔超时:线程池满负荷、队列打满,上调最大线程数与队列长度
-
大量CLOSE_WAIT连接:配置连接超时回收、优化请求响应逻辑,避免连接堆积
-
启动端口占用:配置端口重试、优雅停机,释放残留端口进程
三、JVM虚拟机调优(内存、GC、线上稳定性)
JVM调优核心目标:减少Full GC、杜绝OOM内存溢出、低延迟、高吞吐、线程稳定,是线上服务不宕机的核心保障。
1. 内存参数最优配置
-
堆内存配置:Xms与Xmx设置为相同值,避免内存扩容收缩耗时,生产常规配置:4G~8G(根据服务器配置适配)
-
新生代比例:调整新生代占比,提升短期对象回收效率,减少老年代对象堆积
-
元空间配置:MetaspaceSize合理设置,避免类加载过多导致元空间溢出
-
禁用逃逸分析冗余配置:开启JDK默认逃逸分析,优化对象栈上分配,减少堆内存占用
2. GC垃圾回收调优
-
生产首选垃圾收集器:G1收集器(低延迟、适配大内存),高吞吐场景可选ZGC
-
优化Minor GC:提升新生代回收频率、降低单次回收耗时
-
杜绝频繁Full GC:排查大对象创建、内存泄漏、缓存无过期、线程残留问题
-
GC日志开启:生产开启GC日志记录,便于线上卡顿、OOM问题溯源
3. 线上内存泄漏根治方案
-
核心泄漏场景:ThreadLocal未remove、静态集合无限累加、缓存无过期、定时任务线程残留、IO流未关闭
-
排查工具:jmap、jstack、jhat、Arthas,快速定位泄漏对象与阻塞线程
-
解决方案:强制ThreadLocal清空、集合限制最大容量、缓存设置过期时间、try-with-resources自动关闭IO
四、接口性能专项调优(耗时、阻塞、并发优化)
1. 接口通用优化规范
-
杜绝同步阻塞:非核心业务异步化(日志记录、消息推送、数据统计),通过@Async实现异步解耦
-
接口分页强制开启:所有列表接口禁止全量查询,避免大数据量返回导致序列化超时、内存溢出
-
返回字段精简:按需返回字段,杜绝全字段返回,减少JSON序列化开销、网络传输耗时
-
请求参数校验前置:快速拦截非法参数、空参数,避免无效业务执行
2. 异步与并行优化
-
多独立接口查询、多数据聚合场景,使用CompletableFuture并行执行,缩短接口总耗时
-
自定义业务线程池,避免@Async默认线程池混用导致任务阻塞
-
异步任务做好异常兜底、超时控制,杜绝异步任务堆积
3. 序列化性能调优
-
统一使用Jackson全局序列化,关闭冗余格式化、空值序列化优化
-
自定义序列化规则,规避BigDecimal、日期类型序列化耗时问题
-
高频接口启用序列化缓存,减少重复反射序列化开销
五、数据库与事务调优(慢查询、锁、事务失效根治)
1. 慢查询优化核心
-
索引优化:建立联合索引、遵循最左前缀原则,杜绝失效索引、冗余索引
-
SQL精简:禁止select *、禁止复杂子查询、禁止批量in超大集合
-
分页优化:大页码分页使用主键偏移分页,避免limit offset超大偏移量耗时
-
开启慢查询日志:定时采集、分析慢SQL,定期优化迭代
2. 连接池调优(Druid生产最优配置)
-
核心参数:最小空闲连接、最大连接数、最大等待时间、空闲超时时间合理配置
-
解决痛点:连接耗尽、获取连接超时、连接残留、无效连接占用资源
-
监控配置:开启SQL监控、防SQL注入、连接泄漏检测
3. 事务性能调优
-
事务范围最小化:只对增删改业务开启事务,查询业务禁用事务,减少事务锁占用时间
-
传播机制合理选型:非嵌套业务禁止REQUIRES_NEW,避免事务频繁挂起、创建开销
-
杜绝长事务:事务内禁止远程调用、文件操作、循环耗时逻辑,避免锁长时间占用导致并发阻塞
-
隔离级别适配:常规业务使用READ_COMMITTED,杜绝过高隔离级别导致锁竞争加剧
4. 数据库锁优化
-
优先行锁、杜绝表锁,避免无索引更新导致全表锁定
-
热点数据使用乐观锁,减少悲观锁竞争
-
批量操作拆分批次,避免单次批量过大锁表、超时
六、缓存体系调优(Redis缓存穿透、击穿、雪崩、冷热数据)
1. 缓存基础优化
-
热点数据全量缓存,减少数据库查询压力
-
合理设置过期时间,打散过期节点,避免集中过期雪崩
-
缓存Key统一规范,避免Key冗余、重复、无效缓存堆积
2. 三大缓存问题生产解决方案
-
缓存穿透:布隆过滤器、空值缓存、参数前置校验,拦截无效Key查询
-
缓存击穿:热点数据永不过期、互斥锁、分布式锁兜底
-
缓存雪崩:过期时间随机偏移、集群高可用、熔断降级、限流兜底
3. Redis性能调优
-
优先使用String、Hash轻量化数据结构,杜绝大数据量存储
-
批量操作使用pipeline,减少网络IO交互次数
-
开启Redis持久化最优配置,平衡性能与数据安全
-
冷热数据分离,低频数据设置短过期时间,释放内存
七、线程池专项调优(异步、定时、并发阻塞解决方案)
线程池是Spring并发核心,90%的线上并发问题源于线程池配置不合理、任务堆积、线程阻塞。
1. 核心调优规范
禁止使用Executors默认线程池:杜绝无界队列、无限线程导致OOM
自定义线程池隔离:接口业务、异步任务、定时任务、消息消费单独线程池,避免相互影响
参数适配业务:CPU密集型小线程数、IO密集型大线程数
拒绝策略自定义:核心任务降级兜底、非核心任务丢弃告警
2. 线程池线上问题
根治任务堆积:队列过小、线程数不足、任务阻塞,优化线程参数、拆解耗时任务
线程泄漏:任务异常无兜底、阻塞无超时,统一异常捕获、配置任务超时时间
CPU飙高:死循环、频繁GC、线程竞争激烈,通过jstack定位死锁、循环任务八、线上高频故障排查与兜底方案
1. 高频异常故障根治
-
NoSuchBean异常:包扫描未覆盖、注解缺失、依赖冲突、自动配置未生效,精准排查组件注册规则
-
循环依赖报错:构造器注入循环依赖、原型Bean循环依赖,统一改为setter注入、拆分依赖关系
-
AOP/事务失效:内部调用、方法私有/final、异常被捕获、传播机制错误,严格遵循AOP代理规范
-
异步失效:未开启@EnableAsync、同类内调用、线程池耗尽,开启异步注解+线程池隔离
2. 线上稳定性兜底方案
-
超时兜底:所有远程调用、数据库、缓存操作配置超时时间,杜绝无限阻塞
-
熔断降级:整合Sentinel,核心接口熔断、非核心接口降级,避免雪崩效应
-
限流防护:接口限流、IP限流、分布式限流,拦截恶意高频请求
-
重试机制:幂等接口开启重试,解决网络波动、临时超时问题,非幂等接口禁止重试
九、生产监控与持续优化体系
1. 核心监控指标
-
服务指标:接口QPS、响应耗时、错误率、并发数
-
容器指标:Tomcat线程池状态、请求排队数、连接数
-
JVM指标:堆内存使用、GC次数、GC耗时、线程状态、OOM告警
-
中间件指标:数据库连接数、慢查询、缓存命中率、消息堆积量
2. 持续优化闭环
-
日常监控告警、定期性能巡检、慢SQL迭代、接口耗时优化
-
压测验证:上线前全量压测,验证并发上限、瓶颈点,提前优化
-
版本迭代性能回归,避免新功能引入性能退化问题
✅ 性能调优模块终极总结
-
底层核心:框架精简配置、容器高并发适配、JVM内存与GC稳定是服务性能基础
-
业务核心:接口异步化、SQL优化、缓存合理使用、线程池隔离是提速关键
-
稳定核心:超时、重试、熔断、限流、兜底机制杜绝线上雪崩
-
落地核心:先监控定位瓶颈、再针对性调优、最后压测验证,拒绝盲目优化
-
架构价值:从「能用」升级为「高并发、低延迟、高可用、可监控、可迭代」的企业级服务
第九阶段:实战项目+面试闭环(落地变现)
1. 必做实战项目(循序渐进·零基础到微服务落地)
本板块配套整套Spring学习体系,设计三阶递进式实战项目,从基础语法落地、框架熟练运用,到微服务架构搭建、生产问题解决,完全贴合企业开发流程,每个项目均绑定对应阶段知识点,杜绝纸上谈兵,学完即可具备企业初级/中级开发能力。所有项目均适配2026企业主流技术栈,包含完整业务、源码、避坑方案、面试亮点、生产优化。
第一阶:SpringBoot基础Web脚手架项目(入门筑基·零基础必做)
定位:零基础入门项目,打通SpringBoot核心基础,掌握Web项目标准开发规范,解决「会知识点不会写代码」的问题,是所有进阶项目的基石。
核心技术栈:SpringBoot 2.7+/3.x、Spring MVC、MyBatis-Plus、MySQL、Lombok、Validation参数校验
完整落地功能:
-
工程规范搭建:统一项目分层(Controller/Service/Dao/Entity/Util)、全局常量、统一返回结果封装、统一异常处理
-
基础CRUD开发:用户、角色、菜单基础增删改查,适配RESTful接口风格
-
核心功能落地:参数校验(注解+自定义校验)、请求拦截器、跨域配置、日志统一打印、接口防重、分页查询、条件模糊查询
-
事务实战:Spring声明式事务、事务回滚测试、解决事务失效常见问题
-
配置体系实战:多环境配置(dev/test/prod)、自定义配置参数、配置绑定、yml/properties适配
学习收获:
-
熟练掌握SpringBoot项目搭建流程与企业开发规范
-
吃透MVC请求流转、参数解析、拦截器底层落地
-
掌握事务、异常处理、参数校验等核心基础能力
-
具备独立开发小型Web接口项目的能力
面试加分亮点:可熟练阐述Web项目分层思想、全局异常设计思路、RESTful接口规范、事务基础落地场景
第二阶:SpringBoot全功能商城项目(进阶精通·企业CRUD核心)
定位:企业级单体完整业务项目,覆盖SpringBoot高阶特性、缓存、定时任务、文件处理、安全认证,对标中小企业核心业务开发场景,学完可胜任常规CRUD开发工作。
核心技术栈:SpringBoot、MyBatis-Plus、MySQL、Redis、JWT、定时任务、文件上传、SpringAOP、全局日志、Druid连接池
完整落地功能:
-
用户模块:注册、登录、JWT令牌认证、权限拦截、密码加密、登录状态校验、token过期刷新
-
商品模块:商品新增、上下架、分类管理、库存管控、商品详情查询、热门商品缓存
-
订单模块:订单创建、支付模拟、订单状态流转、订单超时取消、订单分页查询、事务保证订单数据一致性
-
缓存模块:Redis实现热点商品缓存、用户信息缓存、防止缓存穿透/击穿简单兜底、缓存过期策略设计
-
工具类模块:阿里云OSS文件上传下载、图片压缩、Excel导入导出
-
运维监控模块:自定义操作日志AOP记录、接口访问统计、定时任务(订单超时清理、数据定时归档)
-
生产优化落地:SQL优化、连接池调优、接口分页、参数脱敏、请求限流简易实现
学习收获:
-
精通SpringBoot高阶功能与AOP、事务、缓存的实战落地
-
掌握JWT认证、权限控制、定时任务、文件操作等企业刚需能力
-
理解业务分层、数据一致性、缓存设计的核心思想
-
具备独立开发完整单体企业项目的能力
面试加分亮点:可阐述缓存三大问题解决方案、订单事务设计、JWT登录认证流程、AOP日志实现原理、定时任务避坑方案
第三阶:SpringCloud Alibaba微服务架构项目(架构进阶·大厂刚需)
定位:高阶架构项目,对标互联网大厂微服务技术栈,实现服务拆分、注册发现、网关路由、容错限流、分布式事务、链路追踪,完整复刻企业微服务生产架构,学完可胜任中高级开发、架构助理岗位。
核心技术栈:SpringCloud Alibaba、Nacos、Gateway、OpenFeign、Sentinel、Seata、SkyWalking、Redis、MQ(RabbitMQ/RocketMQ)、MySQL、Docker部署
微服务模块拆分(企业标准拆分):
-
网关服务(Gateway):统一入口、路由分发、跨域处理、令牌校验、限流拦截、请求日志打印
-
注册配置中心(Nacos):服务注册与发现、动态配置刷新、服务分组、环境隔离
-
用户微服务:用户注册登录、权限管控、会员体系、用户信息维护、分布式session适配
-
商品微服务:商品管理、库存锁定、分类查询、商品缓存、库存防超卖
-
订单微服务:分布式订单创建、跨服务调用、Seata分布式事务、订单超时取消、消息异步通知
-
支付微服务:支付流程模拟、支付状态回调、幂等性设计、支付记录归档
-
消息通知服务:MQ异步消息推送、短信通知、订单状态通知、消息重试与兜底
-
监控运维服务:Sentinel流量限流、熔断降级、SkyWalking链路追踪、服务健康监控、异常告警
核心高阶落地能力(生产必备):
-
微服务治理:服务注册发现、动态路由、负载均衡、灰度发布基础实现
-
容错高可用:Sentinel限流、熔断、降级、热点参数限流,解决服务雪崩问题
-
分布式事务:Seata AT模式实现跨服务事务一致性,解决下单、扣库存、支付数据不一致问题
-
异步解耦:MQ实现业务异步化,解耦订单、通知、库存业务,提升接口吞吐
-
幂等性设计:全局唯一ID、请求幂等Token、防重复提交,解决分布式重复请求问题
-
全链路监控:链路追踪、慢接口定位、服务异常溯源、日志聚合
-
容器化部署:Docker打包、镜像构建、服务器一键部署、多服务集群启动
学习收获:
-
精通SpringCloud Alibaba全套微服务技术栈,理解微服务架构设计思想
-
掌握分布式核心难题:分布式事务、服务容错、异步解耦、幂等性设计
-
具备微服务项目搭建、问题排查、性能优化、架构迭代能力
-
完全匹配大厂微服务面试、实战需求,突破单体项目瓶颈
面试加分亮点:可完整阐述微服务架构优势与痛点、分布式事务解决方案、服务熔断降级机制、网关核心原理、MQ异步解耦场景与坑点
项目学习核心规范(避坑必看)
-
循序渐进:必须按照「基础Web→单体商城→微服务」顺序学习,严禁直接上手微服务,基础不牢极易出现原理盲区
-
学练结合:每个功能先理解底层原理,再手动编码实现,最后复盘坑点与优化方案
-
源码联动:项目开发中关联对应Spring源码(如事务、AOP、自动配置),做到知其然更知其所以然
-
生产思维 :所有项目优先考虑高可用、高性能、可扩展、可监控,杜绝一次性demo代码
-
面试沉淀:每个项目整理核心亮点、技术难点、问题解决方案,直接复用为面试项目经验
2. 高频面试核心题库(全覆盖)
IoC原理、Bean生命周期、循环依赖、AOP原理、事务传播与失效、自动配置原理、微服务容错限流、分布式事务、缓存问题、幂等性设计等所有高频考点。
最终最优学习顺序(避坑版)
前置基础 → Spring Framework(IoC/AOP/事务/MVC)→ Spring Boot → 数据层+缓存 → 安全框架 → 响应式WebFlux → Spring Cloud Alibaba微服务 → 源码剖析 → 性能调优 → 项目实战+面试刷题