
1. 项目定位与愿景
1.1 项目概述
Apache Gravitino 是一个高性能、地理分布式、联邦式元数据湖(Metadata Lake)项目,于2024年进入 Apache 孵化器,由 Datastrato 公司(现为 TabbyML 旗下)发起并捐赠。Gravitino 的核心目标是成为组织内所有数据与 AI 资产的唯一真实来源(Single Source of Truth, SSOT),通过统一的元数据层连接异构数据源,提供集中化的元数据管理、安全管控和联邦访问能力。
与传统元数据管理系统(如 Apache Atlas、DataHub、Amundsen)不同,Gravitino 并非"元数据采集系统",而是"元数据管理系统"------它通过连接器直接连接底层数据源,实现对元数据的直接读写管理,而非被动采集与同步。
1.2 核心愿景
Gravitino 的愿景可以概括为四个关键词:
| 愿景维度 | 描述 |
|---|---|
| 统一 | 统一管理 Data + AI 资产,涵盖关系型数据、文件集、消息队列、AI模型等 |
| 集中 | 集中安全管控,跨数据源的统一权限策略 |
| 联邦 | 地理分布式元数据联邦,支持多区域数据的统一视图 |
| 管理 | 不仅"看到"元数据,更要"管理"元数据------支持统一 DDL 操作直接作用于底层 |
1.3 解决的核心问题
传统元数据管理痛点
- 多源异构
Hive/MySQL/PG/Kafka/Iceberg... 各自管理
→ 用户需在不同系统间切换,数据发现困难
2. 被动采集
定时拉取元数据,时效性差
→ 元数据变更延迟分钟~小时级,影响数据可靠性
3. 权限分散
每个数据源独立权限体系
→ 管理员在多个系统中分别配置权限,效率低易遗漏
4. 引擎锁定
计算引擎与特定元数据服务绑定
→ Spark绑定Hive Metastore,Trino绑定自己的Catalog
5. AI资产缺失
模型、特征等AI资产无元数据管理
→ AI与数据资产割裂,缺乏统一管理
1.4 与同类项目的定位差异
| 维度 | Gravitino | Apache Atlas | DataHub | Amundsen | OpenMetadata |
|---|---|---|---|---|---|
| 核心模式 | 直接管理 | 被动采集 | 被动采集 | 被动采集 | 被动采集+部分管理 |
| 元数据同步 | 实时双向 | 定时拉取 | 定时拉取 | 定时拉取 | 定时拉取+事件 |
| 元数据操作 | 统一CRUD+DDL | 只读浏览 | 只读浏览 | 只读浏览 | 部分CRUD |
| 统一命名空间 | Metalake四级 | 无 | 无 | 无 | 无 |
| AI资产管理 | Model元数据 | 无 | 无 | 无 | 无 |
| 授权下推 | 支持(Ranger) | 有限 | 无 | 无 | 有限 |
| 引擎联邦 | Spark/Trino/Flink | 无 | 无 | 无 | 无 |
关键判断:Gravitino 的定位是"元数据湖"(Metadata Lake),而非传统"数据目录"(Data Catalog)。它更接近于 Hive Metastore 的升级替代品,同时具备数据目录的发现能力。
2. 核心架构
2.1 四层架构总览
Gravitino 采用经典的分层架构设计,从上到下分为四层:
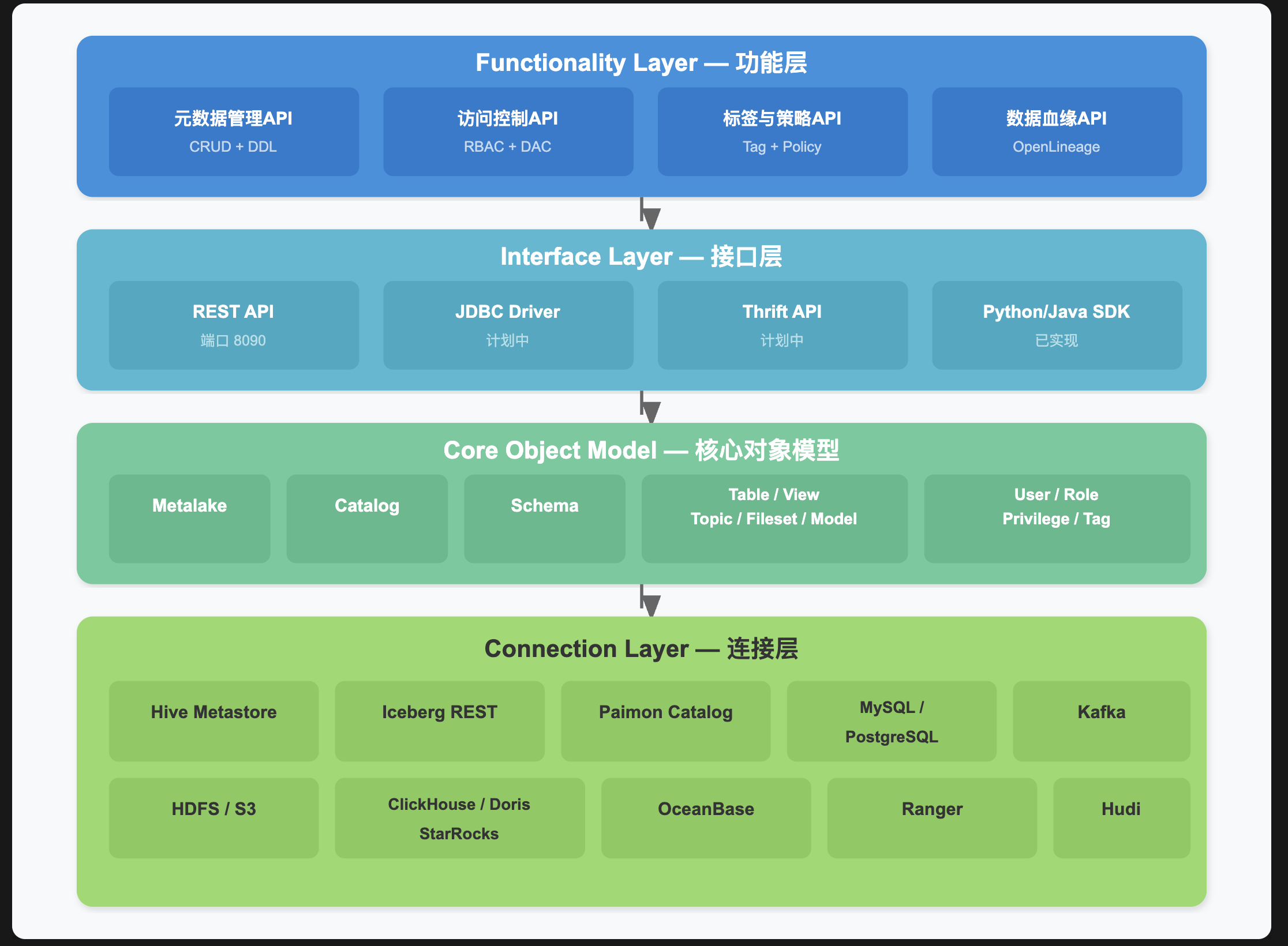
各层职责:
| 层次 | 职责 | 关键特性 |
|---|---|---|
| Functionality Layer | 提供元数据管理、访问控制、标签策略、血缘等业务功能API | 面向上层应用,功能语义清晰 |
| Interface Layer | 定义统一的访问接口协议 | REST API为主,JDBC/Thrift计划中 |
| Core Object Model | 统一元数据对象模型,屏蔽底层数据源差异 | Metalake→Catalog→Schema→资源对象的四级模型 |
| Connection Layer | 连接不同元数据源的适配器层 | 可插拔连接器,支持13种Provider |
2.2 架构设计特点
2.2.1 直连管理模式
Gravitino 最大的架构特点是采用"直连管理"模式,而非传统的"采集同步"模式:
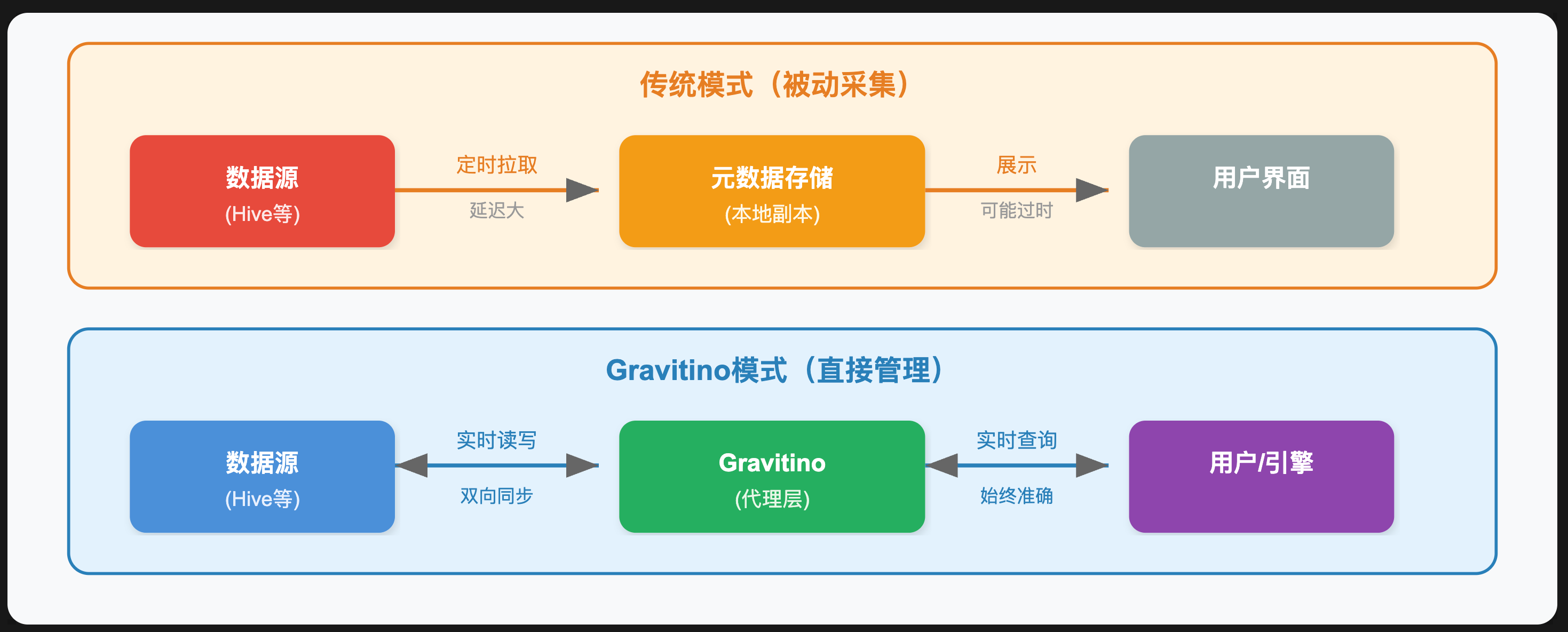
直连管理的优势:
- 元数据始终与底层保持一致,无同步延迟
- 支持通过统一入口执行DDL操作(CREATE TABLE等),直接作用于底层
- 权限变更可实时下推到数据源
直连管理的要求:
- Gravitino需要具有底层系统的访问凭证
- 底层系统不可用时,Gravitino也无法提供该源的元数据
- 网络连通性是前提条件
2.2.2 统一对象模型
Gravitino 定义了一套统一的元数据对象模型,无论底层是Hive、MySQL还是Kafka,上层都看到相同的模型结构。连接器负责将底层元数据映射到统一模型。
2.2.3 可插拔连接器
Connection Layer 采用可插拔设计,每种数据源对应一个Catalog Provider。新增数据源支持只需开发新的连接器,不影响核心模型和API。
2.3 组件交互架构
数据源
存储后端
Gravitino Server
客户端
连接器
连接器
连接器
Iceberg REST
连接器
连接器
连接器
连接器
连接器
Spark
Trino
Flink
Web UI
CLI/SDK
Gravitino Server
:8090
Iceberg REST
Catalog Service
:9001
PostgreSQL
元数据存储
HDFS/S3
文件存储
Hive
Metastore
MySQL
PostgreSQL
Kafka
Iceberg
3. 元数据模型
3.1 四级命名空间
Gravitino 采用 Metalake → Catalog → Schema → 资源对象 的四级命名空间模型:
Metalake
元数据湖/租户
Catalog: hive_prod
类型: relational
Provider: hive
Catalog: iceberg_dw
类型: relational
Provider: lakehouse-iceberg
Catalog: kafka_stream
类型: messaging
Provider: kafka
Catalog: s3_files
类型: fileset
Provider: hdfs
Schema: default
Schema: analytics
Schema: dw
Schema: staging
Schema: events
Schema: datasets
Table: orders
Table: users
View: v_order_summary
Table: fact_sales
Table: dim_product
Topic: order_events
Topic: user_actions
Fileset: raw_logs
Fileset: ml_features
3.2 各层级对象详解
3.2.1 Metalake(元数据湖)
Metalake 是 Gravitino 中最顶级的元数据容器,类似于"租户"或"虚拟数据湖"的概念。
| 属性 | 说明 |
|---|---|
| 标识符 | 全局唯一名称 |
| 职责 | 包含一组相关的Catalog,形成逻辑上的数据湖 |
| 隔离 | 不同Metalake之间的元数据完全隔离 |
| 典型用法 | 按组织/业务域划分Metalake,如company_data_lake、ai_platform |
Metalake 管理API示例:
bash
# 创建Metalake
curl -X POST http://localhost:8090/api/metalakes \
-H "Content-Type: application/json" \
-d '{
"name": "company_data_lake",
"comment": "公司级统一元数据湖",
"properties": {
"location": "s3://data-lake/metalake"
}
}'
# 列出所有Metalake
curl http://localhost:8090/api/metalakes
# 获取Metalake详情
curl http://localhost:8090/api/metalakes/company_data_lake3.2.2 Catalog(目录)
Catalog 代表来自特定元数据源的元数据集合,是连接器的实例化配置。
| 属性 | 说明 |
|---|---|
| 类型(Type) | relational(关系型)、fileset(文件集)、messaging(消息)、model(模型) |
| Provider | 具体的连接器实现,如hive、lakehouse-iceberg、kafka |
| 职责 | 绑定到具体数据源,提供该源的元数据读写能力 |
| 典型用法 | 一个Catalog对应一个数据源实例,如hive_prod → 生产Hive集群 |
Catalog 创建示例:
bash
# 创建Hive Catalog
curl -X POST http://localhost:8090/api/metalakes/company_data_lake/catalogs \
-H "Content-Type: application/json" \
-d '{
"name": "hive_prod",
"type": "relational",
"provider": "hive",
"comment": "生产Hive集群",
"properties": {
"metastore.uris": "thrift://hive-metastore:9083",
"warehouse": "hdfs://namenode:8020/user/hive/warehouse"
}
}'
# 创建Iceberg Catalog
curl -X POST http://localhost:8090/api/metalakes/company_data_lake/catalogs \
-H "Content-Type: application/json" \
-d '{
"name": "iceberg_dw",
"type": "relational",
"provider": "lakehouse-iceberg",
"comment": "Iceberg数据仓库",
"properties": {
"uri": "http://gravitino:9001/iceberg",
"warehouse": "s3://iceberg-warehouse/dw",
"catalog-backend": "jdbc"
}
}'3.2.3 Schema(模式)
Schema 是第二级命名空间,对应关系型数据库中的"数据库"或"模式"概念。
| 属性 | 说明 |
|---|---|
| 归属 | 属于某个Catalog |
| 职责 | 组织Table/View/Topic/Fileset等资源对象 |
| 映射 | Hive中的Database、MySQL/PG中的Schema/Database、Kafka中的Namespace |
3.2.4 资源对象
Schema 下支持六种资源对象类型:
| 对象类型 | 对应Catalog类型 | 说明 | 典型场景 |
|---|---|---|---|
| Table | relational | 关系型数据表,包含列定义、分区、排序等 | Hive表、Iceberg表、MySQL表 |
| View | relational | 虚拟视图,基于SQL查询定义 | 数据聚合视图、权限过滤视图 |
| Topic | messaging | 消息主题 | Kafka Topic元数据管理 |
| Fileset | fileset | 文件集,映射到HDFS/S3上的文件目录 | 日志文件、ML训练数据集 |
| Model | model | AI模型元数据 | 模型版本管理、模型注册 |
Table 对象属性详解:
json
{
"name": "orders",
"comment": "订单明细表",
"columns": [
{"name": "order_id", "type": "long", "nullable": false, "comment": "订单ID"},
{"name": "user_id", "type": "long", "nullable": false, "comment": "用户ID"},
{"name": "amount", "type": "decimal(10,2)", "nullable": true, "comment": "订单金额"},
{"name": "created_at", "type": "timestamp", "nullable": false, "comment": "创建时间"}
],
"properties": {
"format": "ORC",
"location": "s3://warehouse/hive_prod/orders"
},
"partitioning": [
{"strategy": "identity", "fieldName": ["created_at"]}
],
"distribution": {
"strategy": "hash",
"number": 16,
"funcArgs": [{"fieldName": ["order_id"]}]
}
}3.3 标签与策略模型
除层级命名空间外,Gravitino 还提供标签(Tag)和策略(Policy)两种横切关注点模型:
标签(Tag):
- 可附加到任意元数据对象(Table、Column等)
- 支持标签的增删改查和批量操作
- 典型用途:数据分类(
pii、sensitive)、业务标签(core_data、reporting)
策略(Policy):
- 基于条件的规则引擎
- 可绑定到Metalake/Catalog/Schema等层级
- 典型用途:数据保留策略、脱敏规则、访问策略
bash
# 创建标签
curl -X POST http://localhost:8090/api/metalakes/company_data_lake/tags \
-H "Content-Type: application/json" \
-d '{"name": "pii", "comment": "个人身份信息"}'
# 给表添加标签
curl -X POST http://localhost:8090/api/metalakes/company_data_lake/catalogs/hive_prod/schemas/default/tables/users/tags \
-H "Content-Type: application/json" \
-d '{"tagsToAdd": ["pii", "sensitive"], "tagsToRemove": []}'4. Catalog系统
4.1 Catalog Provider 总览
Gravitino 目前支持 13 种 Catalog Provider,覆盖关系型数据库、Lakehouse格式、消息队列、文件系统和AI模型:
特殊服务
Iceberg REST Catalog
Lance REST
MCP Server
文件系统
HDFS / S3
fileset
消息队列
Kafka
Lakehouse格式
Iceberg
lakehouse-iceberg
Hudi
lakehouse-hudi
Paimon
lakehouse-paimon
关系型数据库
Hive Metastore
MySQL
PostgreSQL
ClickHouse
Doris
StarRocks
OceanBase
4.2 各Provider详细介绍
4.2.1 Hive Metastore(Provider: hive)
| 维度 | 详情 |
|---|---|
| Catalog类型 | relational |
| 连接方式 | Thrift协议连接Hive Metastore |
| 支持操作 | 完整CRUD(Database/Table/Partition) |
| 特性 | 支持表分区、桶、存储格式等Hive特有属性 |
| 关键配置 | metastore.uris(Thrift URI)、warehouse(仓库路径) |
配置示例:
json
{
"provider": "hive",
"properties": {
"metastore.uris": "thrift://hive-metastore:9083",
"warehouse": "hdfs://namenode:8020/user/hive/warehouse",
"impersonation-enable": "true",
"client.pool-size": "10"
}
}注意事项:
- Hive Catalog 是最成熟的Provider,支持最完整
- 支持Kerberos认证
- 支持代理用户(impersonation)
4.2.2 Iceberg(Provider: lakehouse-iceberg)
| 维度 | 详情 |
|---|---|
| Catalog类型 | relational |
| 后端模式 | JDBC Catalog、Hive Catalog、REST Catalog |
| 支持操作 | 完整CRUD + Iceberg特有操作(快照管理、分支等) |
| 特殊能力 | Gravitino自身可作为Iceberg REST Catalog服务 |
| 关键配置 | uri、warehouse、catalog-backend |
配置示例:
json
{
"provider": "lakehouse-iceberg",
"properties": {
"uri": "jdbc:postgresql://pg-host:5432/iceberg_db",
"warehouse": "s3://iceberg-warehouse",
"catalog-backend": "jdbc",
"jdbc.user": "iceberg",
"jdbc.password": "***",
"io-impl": "org.apache.iceberg.aws.s3.S3FileIO"
}
}Iceberg REST Catalog 服务:
Gravitino 可以作为 Iceberg REST Catalog 协议的服务端,让 Spark/Flink 等引擎直接通过 REST 协议访问:
bash
# 启动Iceberg REST Catalog服务(Gravitino内置)
# 默认端口:9001
# Spark配置:
spark.sql.catalog.iceberg = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.iceberg.catalog-impl = org.apache.iceberg.rest.RESTCatalog
spark.sql.catalog.iceberg.uri = http://gravitino:9001/iceberg4.2.3 Paimon(Provider: lakehouse-paimon)
| 维度 | 详情 |
|---|---|
| Catalog类型 | relational |
| 后端模式 | 文件系统Catalog、Hive Catalog |
| 支持操作 | 完整CRUD |
| 关键配置 | uri、warehouse、catalog-backend |
配置示例:
json
{
"provider": "lakehouse-paimon",
"properties": {
"uri": "thrift://hive-metastore:9083",
"warehouse": "s3://paimon-warehouse",
"catalog-backend": "hive"
}
}4.2.4 Hudi(Provider: lakehouse-hudi)
| 维度 | 详情 |
|---|---|
| Catalog类型 | relational |
| 支持操作 | 读取为主,写入能力逐步完善 |
| 关键配置 | uri、warehouse |
4.2.5 MySQL / PostgreSQL(Provider: jdbc-mysql / jdbc-postgresql)
| 维度 | 详情 |
|---|---|
| Catalog类型 | relational |
| 连接方式 | JDBC |
| 支持操作 | Schema/Table/View的读取和有限写入 |
| 关键配置 | jdbc-url、jdbc-user、jdbc-password、jdbc-driver |
MySQL配置示例:
json
{
"provider": "jdbc-mysql",
"properties": {
"jdbc-url": "jdbc:mysql://mysql-host:3306/?useSSL=false",
"jdbc-user": "gravitino",
"jdbc-password": "***",
"jdbc-driver": "com.mysql.cj.jdbc.Driver"
}
}注意事项:
- JDBC Catalog的写入能力受限于底层数据库的DDL支持
- 支持授权下推(将权限变更同步到MySQL/PG的GRANT/REVOKE)
4.2.6 ClickHouse / Doris / StarRocks / OceanBase
| Provider | 标识符 | 连接方式 | 特殊说明 |
|---|---|---|---|
| ClickHouse | jdbc-clickhouse |
JDBC | 支持ClickHouse特有类型映射 |
| Doris | jdbc-doris |
JDBC | 与StarRocks共享大部分实现 |
| StarRocks | jdbc-starrocks |
JDBC | 支持物化视图元数据读取 |
| OceanBase | jdbc-oceanbase |
JDBC | MySQL兼容模式 |
4.2.7 Kafka(Provider: kafka)
| 维度 | 详情 |
|---|---|
| Catalog类型 | messaging |
| 连接方式 | Kafka Admin Client |
| 支持操作 | Topic元数据CRUD |
| 关键配置 | bootstrap.servers |
配置示例:
json
{
"provider": "kafka",
"properties": {
"bootstrap.servers": "kafka-broker1:9092,kafka-broker2:9092",
"schema.name": "default"
}
}4.2.8 Fileset(Provider: hdfs)
| 维度 | 详情 |
|---|---|
| Catalog类型 | fileset |
| 支持操作 | 文件集元数据管理,映射到HDFS/S3目录 |
| 关键配置 | location(根路径) |
4.3 Catalog Provider 成熟度评估
| Provider | 元数据读取 | 元数据写入 | 授权下推 | 引擎集成 | 综合成熟度 |
|---|---|---|---|---|---|
| Hive | ★★★★★ | ★★★★★ | ★★★★ | ★★★★★ | ★★★★★ |
| Iceberg | ★★★★★ | ★★★★★ | ★★★ | ★★★★★ | ★★★★★ |
| Paimon | ★★★★ | ★★★★ | ★★★ | ★★★★ | ★★★★ |
| MySQL | ★★★★ | ★★★ | ★★★★ | ★★★ | ★★★★ |
| PostgreSQL | ★★★★ | ★★★ | ★★★★ | ★★★ | ★★★★ |
| Kafka | ★★★★ | ★★★★ | ★★ | ★★ | ★★★ |
| Hudi | ★★★ | ★★ | ★★ | ★★★ | ★★★ |
| ClickHouse | ★★★ | ★★ | ★★ | ★★ | ★★★ |
| Doris | ★★★ | ★★ | ★★ | ★★ | ★★★ |
| StarRocks | ★★★ | ★★ | ★★ | ★★ | ★★★ |
| OceanBase | ★★ | ★★ | ★ | ★ | ★★ |
| Fileset | ★★★★ | ★★★★ | ★★ | ★★ | ★★★ |
| Model | ★★★ | ★★★ | ★ | ★ | ★★ |
5. 统一API
5.1 API体系总览
Gravitino 提供统一的API接口层,当前以REST API为主,JDBC和Thrift接口在路线图中:
上层应用
计划中
当前可用
REST API
端口: 8090
Java SDK
Python SDK
JDBC Driver
Thrift API
GraphQL API
Web UI
CLI工具
计算引擎连接器
第三方集成
5.2 REST API
Gravitino 的 REST API 是主要的交互接口,遵循标准的 RESTful 设计原则。
5.2.1 API端点结构
| 资源 | 端点模式 | 示例 |
|---|---|---|
| Metalake | /api/metalakes |
GET /api/metalakes |
| Catalog | /api/metalakes/{ml}/catalogs |
GET /api/metalakes/prod/catalogs |
| Schema | /api/metalakes/{ml}/catalogs/{cat}/schemas |
GET /api/metalakes/prod/catalogs/hive/schemas |
| Table | /api/metalakes/{ml}/catalogs/{cat}/schemas/{sch}/tables |
GET /api/metalakes/prod/catalogs/hive/schemas/default/tables |
| View | .../views |
同上模式 |
| Topic | .../topics |
同上模式 |
| Fileset | .../filesets |
同上模式 |
| Model | .../models |
同上模式 |
| Tag | /api/metalakes/{ml}/tags |
GET /api/metalakes/prod/tags |
| User/Role | /api/metalakes/{ml}/users, /api/metalakes/{ml}/roles |
用户和角色管理 |
| Permission | /api/metalakes/{ml}/permissions/{role}/{privilege} |
权限授予/撤销 |
5.2.2 常用API操作示例
创建表:
bash
curl -X POST \
http://localhost:8090/api/metalakes/prod/catalogs/hive/schemas/default/tables \
-H "Content-Type: application/json" \
-d '{
"name": "orders",
"comment": "订单表",
"columns": [
{"name": "id", "type": "long", "nullable": false},
{"name": "amount", "type": "decimal(10,2)", "nullable": true},
{"name": "created_at", "type": "timestamp", "nullable": false}
],
"properties": {
"format": "ORC"
},
"partitioning": [
{"strategy": "identity", "fieldName": ["created_at"]}
]
}'查询表:
bash
curl http://localhost:8090/api/metalakes/prod/catalogs/hive/schemas/default/tables/orders授予权限:
bash
curl -X PUT \
http://localhost:8090/api/metalakes/prod/permissions/analyst/privileges \
-H "Content-Type: application/json" \
-d '{
"privileges": [
{
"name": "SELECT_TABLE",
"condition": "true",
"authorize": "ALLOW",
"metadataObject": {
"type": "TABLE",
"fullName": "hive.default.orders"
}
}
]
}'5.2.3 REST API特性
| 特性 | 说明 |
|---|---|
| 认证 | OAuth 2.0 / Basic Auth(可配置) |
| 版本 | URL中包含版本号/api/v1/...(当前默认v1) |
| 分页 | 列表接口支持分页参数 |
| 错误码 | 标准HTTP状态码 + Gravitino自定义错误码 |
| 并发控制 | 基于ETag的乐观并发控制 |
5.3 Iceberg REST Catalog API
Gravitino 独立提供 Iceberg REST Catalog 服务(端口9001),完全兼容 Iceberg REST Catalog 协议:
bash
# Iceberg REST API端点
# 命名空间操作
GET /iceberg/v1/{prefix}/namespaces
POST /iceberg/v1/{prefix}/namespaces
# 表操作
GET /iceberg/v1/{prefix}/namespaces/{ns}/tables
POST /iceberg/v1/{prefix}/namespaces/{ns}/tables
# 快照操作
GET /iceberg/v1/{prefix}/namespaces/{ns}/tables/{table}/snapshots5.4 SDK
Java SDK:
xml
<dependency>
<groupId>org.apache.gravitino</groupId>
<artifactId>gravitino-client-java</artifactId>
<version>1.2.1</version>
</dependency>
java
// Java SDK使用示例
GravitinoClient client = GravitinoClient.builder("http://localhost:8090")
.withMetalake("prod")
.build();
// 获取Catalog
Catalog hiveCatalog = client.loadCatalog("hive");
// 列出所有Schema
String[] schemas = hiveCatalog.asSchemas().listSchemas();
// 获取表
Table orders = hiveCatalog.asTableCatalog().loadTable(NameIdentifier.of("default", "orders"));Python SDK:
python
from gravitino import GravitinoClient
client = GravitinoClient(uri="http://localhost:8090", metalake_name="prod")
# 获取Catalog
catalog = client.load_catalog("hive")
# 列出Schema
schemas = catalog.as_schemas().list_schemas()
# 获取表
table = catalog.as_table_catalog().load_table(("default", "orders"))5.5 计划中的接口
| 接口 | 状态 | 预期用途 |
|---|---|---|
| JDBC Driver | 开发中 | 让BI工具和JDBC客户端直接连接Gravitino查询元数据 |
| Thrift API | 规划中 | 提供更高效的二进制协议,适合引擎内部调用 |
| GraphQL API | 社区讨论中 | 支持灵活的元数据查询和关联查询 |
6. 权限与安全
6.1 安全体系总览
Gravitino 构建了完善的安全体系,涵盖认证、授权、审计三个层面:
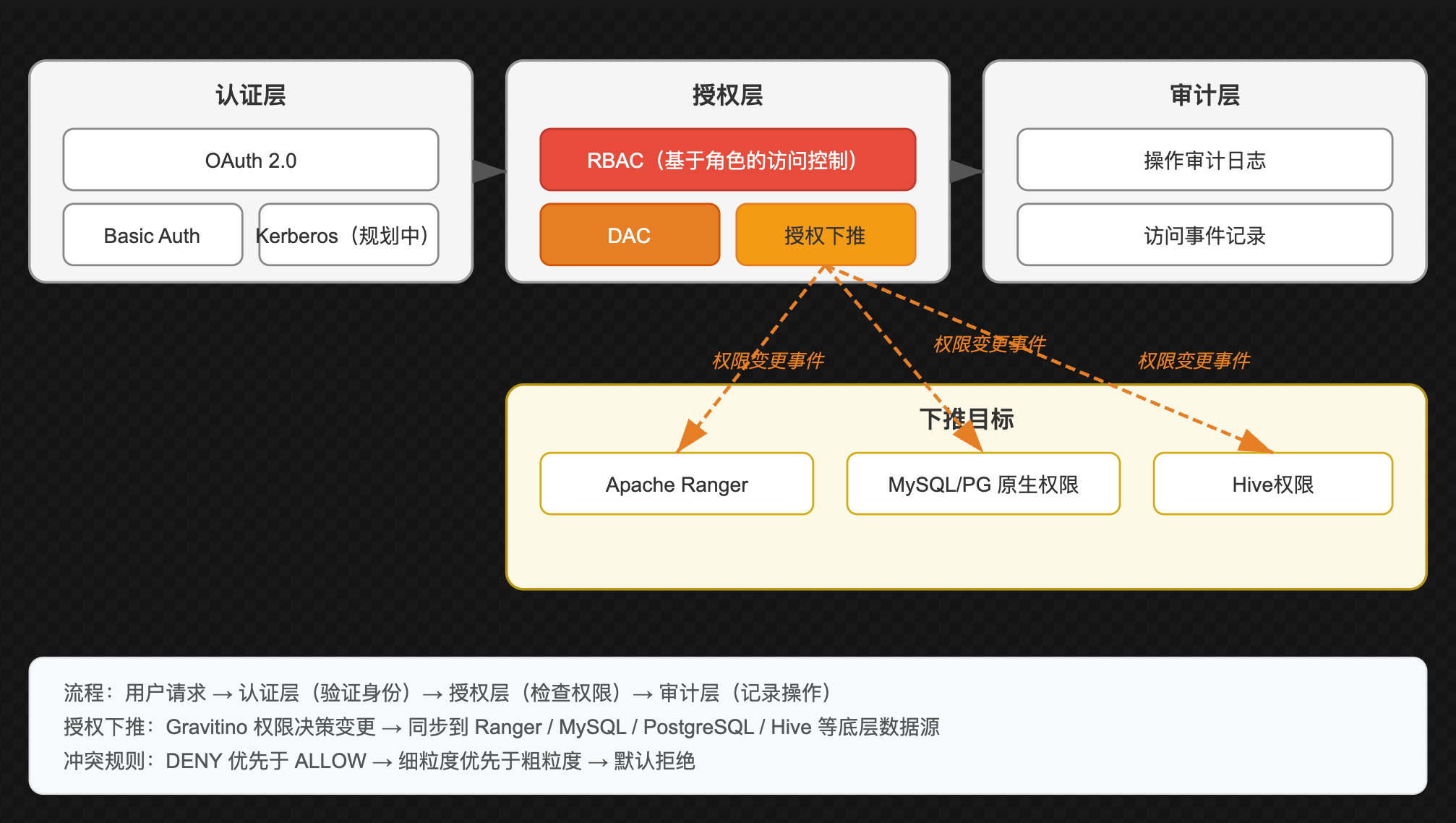
6.2 RBAC(基于角色的访问控制)
Gravitino 的 RBAC 模型遵循标准的三层结构:用户/组 → 角色 → 权限。
6.2.1 核心概念
| 概念 | 说明 |
|---|---|
| User | 具名用户,对应实际操作者 |
| Group | 用户组,用于批量授权 |
| Role | 角色是权限的集合,可分配给用户或组 |
| Privilege | 具体权限,定义对特定资源的操作许可 |
| SecurableObject | 受保护对象,权限绑定的目标资源 |
6.2.2 权限类型
Gravitino 定义了丰富的权限类型,覆盖所有资源对象:
| 资源类型 | 权限列表 |
|---|---|
| Metalake | CREATE_CATALOG, USE_CATALOG, CREATE_SCHEMA, USE_SCHEMA |
| Catalog | CREATE_SCHEMA, USE_SCHEMA |
| Schema | CREATE_TABLE, CREATE_TOPIC, CREATE_FILESET, CREATE_MODEL |
| Table | SELECT_TABLE, MODIFY_TABLE, CREATE_TABLE |
| Topic | PRODUCE_TOPIC, CONSUME_TOPIC |
| Fileset | READ_FILESET, WRITE_FILESET |
| Model | USE_MODEL, CREATE_MODEL_VERSION, READ_MODEL_VERSION |
6.2.3 权限层级继承
权限沿层级向下继承:
继承到
继承到
继承到
Metalake权限
Catalog
Schema
Table
示例:如果在Metalake级别授予 USE_CATALOG 权限,则用户可以访问该Metalake下所有Catalog。
6.2.4 权限冲突解决
当多个角色授予冲突权限时,遵循以下规则:
- DENY 优先于 ALLOW:显式拒绝优先于显式允许
- 细粒度优先于粗粒度:表级权限优先于Schema级权限
- 默认拒绝:无任何权限授予时,默认拒绝访问
6.3 DAC(自主访问控制)
DAC 模型基于对象所有权(Ownership):
| 规则 | 说明 |
|---|---|
| 所有权 | 每个元数据对象有且仅有一个Owner(当前仅支持用户Owner,不支持组Owner) |
| Owner权限 | Owner自动拥有该对象的所有操作权限 |
| 授权能力 | Owner可以将权限授予其他用户 |
| 转让 | Owner可以转让所有权 |
6.4 授权下推(Privilege Delegation)
授权下推是 Gravitino 安全体系的关键差异化能力,可将Gravitino中的权限决策同步到底层数据源:
下推目标
Gravitino
权限变更事件
权限变更事件
权限变更事件
权限变更事件
Gravitino
权限决策中心
Apache Ranger
Hadoop生态统一授权
MySQL
GRANT/REVOKE
PostgreSQL
GRANT/REVOKE
Hive
SQL授权
下推模式:
| 模式 | 配置 | 说明 |
|---|---|---|
| 内置授权 | gravitino.authorization.enable = true |
Gravitino自身执行权限检查,适用于通过Gravitino API/引擎连接器访问的场景 |
| Ranger下推 | Catalog级别配置Ranger连接 | 权限变更同步到Ranger,由Ranger在数据访问时执行检查 |
| 数据源原生下推 | JDBC Catalog自动支持 | 权限变更通过GRANT/REVOKE语句同步到MySQL/PG等 |
Ranger下推配置示例:
json
{
"provider": "hive",
"properties": {
"metastore.uris": "thrift://hive-metastore:9083",
"authorization.enable": "true",
"authorization.provider": "ranger",
"ranger.admin.url": "http://ranger-admin:6080",
"ranger.auth.type": "simple",
"ranger.username": "admin",
"ranger.password": "***"
}
}6.5 认证配置
OAuth 2.0认证:
properties
# gravitino.conf
gravitino.authenticator = oauth
gravitino.auth.oauth.serverUri = https://auth.company.com/oauth2
gravitino.auth.oauth.tokenPath = /token
gravitino.auth.oauth.clientId = gravitino-server
gravitino.auth.oauth.clientSecret = ***Basic认证:
properties
gravitino.authenticator = simple
# 用户凭证存储在后端数据库中6.6 安全最佳实践
| 维度 | 建议 |
|---|---|
| 传输安全 | 启用HTTPS,配置TLS证书 |
| 认证 | 生产环境使用OAuth 2.0,避免Basic Auth |
| 授权 | 启用内置授权 + 授权下推,双保险 |
| 凭证管理 | Catalog连接凭证使用加密存储,避免明文 |
| 审计 | 开启操作审计日志,定期审查 |
| 最小权限 | 按最小权限原则分配角色,避免过度授权 |
| 定期轮换 | 定期轮换服务账号密码和OAuth密钥 |
7. 部署与运维
7.1 部署架构
7.1.1 单节点部署
最简部署模式,适用于开发测试和小规模生产:
单节点
连接器
连接器
连接器
Gravitino Server
:8090 REST API
:9001 Iceberg REST
PostgreSQL
元数据存储
Hive Metastore
MySQL
Kafka
7.1.2 高可用部署
Gravitino 支持基于数据库的高可用部署:
Gravitino集群
负载均衡器
HAProxy/Nginx
Gravitino Server 1
Gravitino Server 2
Gravitino Server 3
PostgreSQL
主从复制
S3/HDFS
共享存储
HA注意事项:
- Gravitino 本身是无状态的,状态存储在PostgreSQL中
- 多节点同时运行时,通过数据库锁保证一致性
- 当前不支持自动Leader选举,所有节点均可服务
- Iceberg REST Catalog服务需独立考虑HA
7.2 系统要求
| 组件 | 最低要求 | 推荐配置 |
|---|---|---|
| 操作系统 | Linux (CentOS 7+/Ubuntu 18.04+) | CentOS 8+ / Ubuntu 20.04+ |
| Java | JDK 11 | JDK 17 |
| CPU | 2核 | 8核+ |
| 内存 | 4GB | 16GB+ |
| 磁盘 | 20GB | 100GB+(SSD) |
| PostgreSQL | 12+ | 15+ |
| 网络 | 1Gbps | 10Gbps |
注意:Gravitino 当前不支持 Windows 操作系统。
7.3 部署方式
7.3.1 二进制部署
bash
# 下载发行版
wget https://downloads.apache.org/gravitino/1.2.1/apache-gravitino-1.2.1-bin.tar.gz
# 解压
tar -xzf apache-gravitino-1.2.1-bin.tar.gz
cd apache-gravitino-1.2.1
# 配置
cp conf/gravitino.conf.template conf/gravitino.conf
# 编辑配置文件...
# 启动
bin/gravitino.sh start
# 验证
curl http://localhost:8090/api/metalakes7.3.2 Docker部署
bash
# 拉取镜像
docker pull apache/gravitino:1.2.1
# 运行
docker run -d \
--name gravitino \
-p 8090:8090 \
-p 9001:9001 \
-e GRAVITINO_URI=http://localhost:8090 \
-v /path/to/gravitino.conf:/opt/gravitino/conf/gravitino.conf \
apache/gravitino:1.2.17.3.3 Kubernetes部署
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: gravitino
spec:
replicas: 3
selector:
matchLabels:
app: gravitino
template:
metadata:
labels:
app: gravitino
spec:
containers:
- name: gravitino
image: apache/gravitino:1.2.1
ports:
- containerPort: 8090
- containerPort: 9001
env:
- name: GRAVITINO_HOME
value: /opt/gravitino
volumeMounts:
- name: config
mountPath: /opt/gravitino/conf
volumes:
- name: config
configMap:
name: gravitino-config7.4 配置速查
7.4.1 核心配置项
properties
# ============ 服务器基础配置 ============
# 监听地址
gravitino.host = 0.0.0.0
# REST API端口
gravitino.httpPort = 8090
# Iceberg REST Catalog端口
gravitino.icebergRest.port = 9001
# ============ 后端存储配置 ============
# 存储后端类型(h2/postgresql)
gravitino.entity.store = relational
# JDBC连接URL
gravitino.entity.store.relational.jdbcUrl = jdbc:postgresql://pg-host:5432/gravitino
gravitino.entity.store.relational.jdbcDriver = org.postgresql.Driver
gravitino.entity.store.relational.jdbcUser = gravitino
gravitino.entity.store.relational.jdbcPassword = ***
# ============ 认证配置 ============
# 认证方式(simple/oauth/kerberos)
gravitino.authenticator = simple
# OAuth配置(当authenticator=oauth时)
gravitino.auth.oauth.serverUri = https://auth.company.com/oauth2
gravitino.auth.oauth.tokenPath = /token
# ============ 授权配置 ============
# 启用授权
gravitino.authorization.enable = true
# 超级用户
gravitino.authorization.superUsers = admin
# ============ 目录缓存配置 ============
# Catalog元数据缓存TTL(毫秒)
gravitino.catalog.cache.evictionIntervalMs = 3600000
# Catalog连接池大小
gravitino.catalog.connection.pool.size = 10
# ============ 审计日志 ============
# 启用审计日志
gravitino.audit.enabled = true
# 审计日志存储
gravitino.audit.store = file
gravitino.audit.file.path = /var/log/gravitino/audit.log7.4.2 Catalog连接器配置模板
properties
# ---- Hive Catalog ----
gravitino.catalog.hive.type = hive
gravitino.catalog.hive.metastore.uris = thrift://hive-metastore:9083
gravitino.catalog.hive.warehouse = hdfs://namenode:8020/user/hive/warehouse
# ---- Iceberg Catalog ----
gravitino.catalog.iceberg.type = lakehouse-iceberg
gravitino.catalog.iceberg.uri = jdbc:postgresql://pg-host:5432/iceberg
gravitino.catalog.iceberg.warehouse = s3://iceberg-warehouse
gravitino.catalog.iceberg.catalog-backend = jdbc
# ---- MySQL Catalog ----
gravitino.catalog.mysql.type = jdbc-mysql
gravitino.catalog.mysql.jdbc-url = jdbc:mysql://mysql-host:3306/
gravitino.catalog.mysql.jdbc-user = gravitino
gravitino.catalog.mysql.jdbc-password = ***
# ---- Kafka Catalog ----
gravitino.catalog.kafka.type = kafka
gravitino.catalog.kafka.bootstrap.servers = kafka-host:90927.5 监控与告警
7.5.1 监控指标
Gravitino 通过Metrics暴露关键运行指标:
| 指标类别 | 关键指标 |
|---|---|
| 请求指标 | 请求总量、请求延迟(P50/P95/P99)、错误率 |
| 连接池指标 | 活跃连接数、等待连接数、连接超时次数 |
| 缓存指标 | 缓存命中率、缓存淘汰率 |
| Catalog指标 | 各Catalog连接状态、操作延迟 |
7.5.2 Prometheus集成
yaml
# prometheus.yml
scrape_configs:
- job_name: 'gravitino'
metrics_path: '/metrics'
static_configs:
- targets: ['gravitino:8090']7.5.3 健康检查
bash
# 健康检查端点
curl http://localhost:8090/api/metalakes
# 详细健康状态
curl http://localhost:8090/health7.6 备份与恢复
bash
# 备份元数据
pg_dump -h pg-host -U gravitino -d gravitino > gravitino_backup_$(date +%Y%m%d).sql
# 恢复元数据
psql -h pg-host -U gravitino -d gravitino < gravitino_backup_20260525.sql7.7 常见运维操作
| 操作 | 命令/方法 |
|---|---|
| 启动服务 | bin/gravitino.sh start |
| 停止服务 | bin/gravitino.sh stop |
| 重启服务 | bin/gravitino.sh restart |
| 查看状态 | bin/gravitino.sh status |
| 查看日志 | tail -f logs/gravitino-server.log |
| 配置重载 | 需重启服务(部分配置支持热加载) |
| 版本升级 | 停止 → 备份 → 替换二进制 → 执行升级脚本 → 启动 |
7.8 运维注意事项
- HA局限性:当前多节点HA模式下,所有节点均可写入,极端并发场景下可能存在性能瓶颈
- GC调优:建议配置G1GC,堆内存建议8GB+
- 连接池管理:每个Catalog连接器维护独立的连接池,Catalog数量较多时需注意连接池总数
- 缓存一致性:多节点部署时,缓存通过数据库事件通知机制保持最终一致
- 版本升级:升级前务必阅读Release Notes中的Breaking Changes
8. 生态集成
8.1 计算引擎连接器
Gravitino 通过原生连接器实现与主流计算引擎的集成,让引擎通过Gravitino统一访问所有数据源。
数据源
Gravitino
计算引擎
Spark连接器
Trino连接器
Flink连接器
Daft连接器
Apache Spark
3.3/3.4/3.5
Trino
Java 17+
Apache Flink
Daft
Rust DataFrame
Gravitino Server
REST API: 8090
Iceberg REST: 9001
Hive
Iceberg
Paimon
MySQL/PG
8.2 Spark集成
8.2.1 支持矩阵
| Spark版本 | 支持的Catalog | 血缘采集 | 安装方式 |
|---|---|---|---|
| Spark 3.3 | Hive, Iceberg, Paimon, JDBC | OpenLineage | spark-submit --jars |
| Spark 3.4 | Hive, Iceberg, Paimon, JDBC | OpenLineage | spark-submit --jars |
| Spark 3.5 | Hive, Iceberg, Paimon, JDBC | OpenLineage | spark-submit --jars |
8.2.2 Spark配置示例
bash
# Spark提交配置
spark-submit \
--jars gravitino-spark-connector-runtime_2.12-1.2.1.jar \
--conf spark.sql.catalog.hive=org.apache.gravitino.spark.connector.connector.SparkCatalog \
--conf spark.sql.catalog.hive.gravitino.uri=http://gravitino:8090 \
--conf spark.sql.catalog.hive.gravitino.metalake=prod \
--conf spark.sql.catalog.hive.gravitino.catalog=hive \
--conf spark.sql.gravitino.enableIcebergSupport=true \
-f your_spark_job.py通过Gravitino访问Hive表:
sql
-- 在Spark SQL中通过Gravitino访问Hive数据
SELECT * FROM hive.default.orders WHERE amount > 100;
-- 跨Catalog联邦查询
SELECT h.order_id, i.product_name
FROM hive.default.orders h
JOIN iceberg.dw.dim_product i
ON h.product_id = i.id;8.2.3 Spark血缘采集
Gravitino Spark连接器内置OpenLineage集成,自动采集表级和列级血缘:
bash
# 启用血缘采集
spark-submit \
--conf spark.gravitino.lineage.enable=true \
--conf spark.openlineage.transport.type=http \
--conf spark.openlineage.transport.url=http://lineage-api:8080 \
...血缘能力矩阵:
| 血缘类型 | 支持情况 | 说明 |
|---|---|---|
| 表级血缘 | ✅ 完整支持 | 自动跟踪表到表的数据流转 |
| 列级血缘 | ✅ 完整支持 | 跟踪字段到字段的转换关系 |
| 跨Catalog血缘 | ✅ 支持 | 跟踪跨数据源的数据流转 |
| Flink血缘 | ❌ 计划中 | 社区路线图中 |
| Trino血缘 | ❌ 计划中 | 社区路线图中 |
8.3 Trino集成
8.3.1 配置示例
properties
# etc/catalog/gravitino.properties (Trino配置)
connector.name=gravitino
gravitino.uri=http://gravitino:8090
gravitino.metalake=prod8.3.2 Trino集成特点
| 特点 | 说明 |
|---|---|
| 动态Catalog | Trino通过Gravitino自动发现和加载Catalog,无需手动配置 |
| 全Catalog支持 | 支持Gravitino管理的所有relational类型Catalog |
| 权限透传 | Trino查询时的权限检查可由Gravitino统一控制 |
| 血缘 | 暂不支持(Trino血缘路线图中) |
8.4 Flink集成
8.4.1 配置示例
yaml
# Flink SQL Gateway配置
catalog:
- name: gravitino
type: gravitino
gravitino.uri: http://gravitino:8090
gravitino.metalake: prod8.4.2 Flink集成成熟度
| 能力 | 支持情况 | 说明 |
|---|---|---|
| Catalog发现 | ✅ | 通过Gravitino发现数据源 |
| Hive表读写 | ✅ | 成熟度较高 |
| Iceberg表读写 | ✅ | 成熟度中等 |
| Paimon表读写 | ✅ | 成熟度中等 |
| JDBC表读写 | ✅ | 基础支持 |
| 血缘采集 | ❌ | 计划中 |
8.5 OpenLineage血缘集成
Gravitino 基于OpenLineage标准实现数据血缘采集,形成统一的血缘事件流:
OpenLineage事件
血缘数据
统一血缘视图
计划中
计划中
Spark任务
OpenLineage
Backend
Gravitino
Lineage Service
Web UI / API
Flink任务
Trino查询
血缘标识符映射:
Gravitino统一标识符:
metalake.catalog.schema.table
OpenLineage标识符映射:
namespace: metalake.catalog
name: schema.table8.6 AI生态集成
Gravitino 提供了多项面向AI场景的集成能力:
| 集成 | 说明 | 成熟度 |
|---|---|---|
| Model Catalog | AI模型元数据注册和版本管理 | ★★★ |
| Lance REST | Lance格式的模型/数据服务 | ★★★ |
| MCP Server | Model Context Protocol服务,支持AI工具直接查询元数据 | ★★ |
| Daft连接器 | Rust DataFrame库的Gravitino连接器 | ★★ |
MCP Server使用示例:
bash
# 启动Gravitino MCP Server
# 配置AI工具(如Claude Desktop)连接Gravitino MCP Server
# AI助手可直接查询元数据,回答数据相关问题8.7 生态集成成熟度总评
| 集成维度 | 成熟度 | 评价 |
|---|---|---|
| Spark + Hive | ★★★★★ | 生产可用,最成熟的集成路径 |
| Spark + Iceberg | ★★★★★ | 生产可用,REST Catalog模式特别优秀 |
| Spark + Paimon | ★★★★ | 可用于生产,部分高级特性待完善 |
| Trino联邦查询 | ★★★★ | 可用于生产,动态Catalog是亮点 |
| Flink集成 | ★★★ | 可用于测试和小规模生产,需持续关注 |
| OpenLineage血缘 | ★★★★ | Spark血缘成熟,其他引擎待扩展 |
| AI资产管理 | ★★ | 基础能力可用,生产实践较少 |
| MCP Server | ★★ | 概念验证阶段,潜力大 |
9. 社区活跃度与成熟度评估
9.1 社区数据
基于 GitHub 仓库 apache/gravitino 的统计数据(截至2026年5月):
| 指标 | 数值 |
|---|---|
| 贡献者 | 303+ |
| Star数 | 1200+ |
| Fork数 | 380+ |
| Open Issues | 715+ |
| 最近6个月PR | 活跃 |
| 最新版本 | v1.2.1 |
| 首次发布 | 0.1.0 (2023年) |
| 进入孵化器 | 2024年 |
9.2 各版本关键特性
| 版本 | 时间 | 关键特性 |
|---|---|---|
| v0.6.0 | 2024 Q3 | 进入Apache孵化器,基础元数据管理 |
| v0.7.0 | 2024 Q4 | 权限下推到Ranger,Hudi Catalog |
| v0.8.0 | 2025 Q1 | 标签系统、Policy管理、Web UI增强 |
| v1.0.0 | 2025 Q2 | 生产就绪版本,性能优化,稳定性提升 |
| v1.1.0 | 2025 Q3 | Flink连接器、Model元数据、Lance REST |
| v1.2.0 | 2025 Q4 | HA改进、ClickHouse/Doris/StarRocks Catalog |
| v1.2.1 | 2026 Q1 | Bug修复、稳定性提升、安全增强 |
9.3 成熟度评估
| 评估维度 | 成熟度 | 说明 |
|---|---|---|
| 核心元数据管理 | ★★★★ | 基础功能完善,生产可用 |
| Spark集成 | ★★★★ | 最成熟的引擎集成,生产验证充分 |
| Trino集成 | ★★★★ | 动态Catalog是亮点,生产可用 |
| Flink集成 | ★★★ | 基础能力可用,高级特性待完善 |
| 访问控制 | ★★★★ | RBAC+DAC+授权下推,体系完善 |
| 数据血缘 | ★★★ | 仅覆盖Spark,其他引擎路线图中 |
| 地理分布式 | ★★ | 核心能力WIP,尚未生产就绪 |
| AI资产管理 | ★★ | 基础Model Catalog可用,生态不成熟 |
| 多节点HA | ★★★ | 基于数据库的HA可用,但无自动故障转移 |
| Web UI | ★★★ | 管理功能完善,业务发现能力待增强 |
| 文档质量 | ★★★★ | 官方文档详尽,API文档完整 |
9.4 社区路线图(2026年展望)
| 方向 | 预期进展 |
|---|---|
| JDBC Driver | 计划发布,支持BI工具直连 |
| Thrift API | 规划中,提升引擎集成性能 |
| Flink血缘 | 计划支持,扩展血缘覆盖 |
| 地理分布式 | 持续迭代,目标多区域元数据联邦 |
| 更多Catalog | 持续扩展数据源支持 |
| 性能优化 | 大规模元数据场景的性能提升 |
| 毕业评估 | 向Apache顶级项目毕业迈进 |
9.5 风险评估
| 风险维度 | 风险等级 | 说明 |
|---|---|---|
| 项目持续性 | 低 | 背后有Datastrato/TabbyML商业支持,社区活跃 |
| API兼容性 | 中 | 从0.x到1.x有过Breaking Changes,1.x后承诺向后兼容 |
| 生产稳定性 | 中 | v1.0.0后显著改善,但大规模生产案例仍有限 |
| 社区多样性 | 中 | 核心贡献者仍以Datastrato员工为主,社区多样性待提升 |
| 版本升级 | 中 | 升级可能涉及数据库Schema变更,需仔细阅读Release Notes |
| Bug修复速度 | 中低 | 社区响应积极,关键Bug修复较快 |
10. 总结与建议
10.1 核心发现
10.1.1 Gravitino的核心价值
- 元数据湖而非数据目录:Gravitino的定位是"元数据湖"(Metadata Lake),它从根本上区别于传统的"元数据采集系统"。通过直连管理模式,Gravitino实现了元数据的实时双向同步,消除了传统采集模式的时效性问题和一致性问题。
- 统一命名空间:Metalake → Catalog → Schema → 资源对象的四级命名空间,为多源异构数据提供了统一的组织模型和访问入口。
- 统一安全管控:RBAC + DAC + 授权下推的三层安全体系,真正实现了跨数据源的统一权限管理,这是传统数据目录产品所不具备的。
- 引擎联邦访问:通过Spark/Trino/Flink连接器,让计算引擎通过统一入口访问所有数据源,是实现"湖仓一体"架构的关键基础设施。
- AI资产统一管理:Model元数据和MCP Server的引入,使Gravitino成为连接数据资产和AI资产的桥梁。
10.1.2 Gravitino的局限
- 非传统数据目录:Gravitino不具备数据质量、资产运营、语义搜索等传统数据目录的核心能力,它更像是元数据基础设施而非完整的治理平台。
- 血缘覆盖有限:目前仅覆盖Spark引擎的OpenLineage血缘,Flink/Trino血缘尚未支持。
- HA方案不完善:多节点部署的HA依赖数据库,无自动故障转移机制。
- AI生态不成熟:Model Catalog、MCP Server等AI能力处于早期阶段,生产实践不足。
- Windows不支持:当前不支持Windows操作系统部署。
- 社区多样性:核心贡献者仍以发起公司员工为主,社区多样性有待提升。
10.2 适用场景分析
10.2.1 强烈推荐引入的场景
| 场景 | 理由 |
|---|---|
| 多数据源统一管理 | 核心价值所在,直连管理模式优势明显 |
| Iceberg REST Catalog服务 | Gravitino作为Iceberg REST Catalog服务是最成熟的用法之一 |
| 跨数据源统一权限管控 | RBAC+授权下推的组合是独特能力 |
| Spark/Trino联邦查询 | 计算引擎通过Gravitino统一访问多数据源 |
| Lakehouse架构演进 | 原生支持Iceberg/Paimon/Hudi,是Lakehouse架构的自然选择 |
10.2.2 需要审慎评估的场景
| 场景 | 风险点 |
|---|---|
| 替代完整数据目录 | Gravitino不具备数据质量、资产运营等能力 |
| 多引擎血缘采集 | 仅覆盖Spark血缘,其他引擎需自建 |
| 地理分布式部署 | 该能力WIP,尚未生产就绪 |
| 大规模AI资产管理 | Model Catalog基础能力可用,生态不成熟 |
10.2.3 不建议引入的场景
| 场景 | 理由 |
|---|---|
| 仅需元数据浏览 | 如果只需要只读浏览,DataHub/OpenMetadata更成熟 |
| Windows环境部署 | 当前不支持 |
| 要求5个9高可用 | HA方案尚不完善 |
| 已有完善的Hive Metastore体系且无扩展需求 | 引入成本高于收益 |
10.3 与现有数据治理平台的集成建议
基于对现有数据治理平台的能力梳理,提出以下集成建议:
10.3.1 定位关系
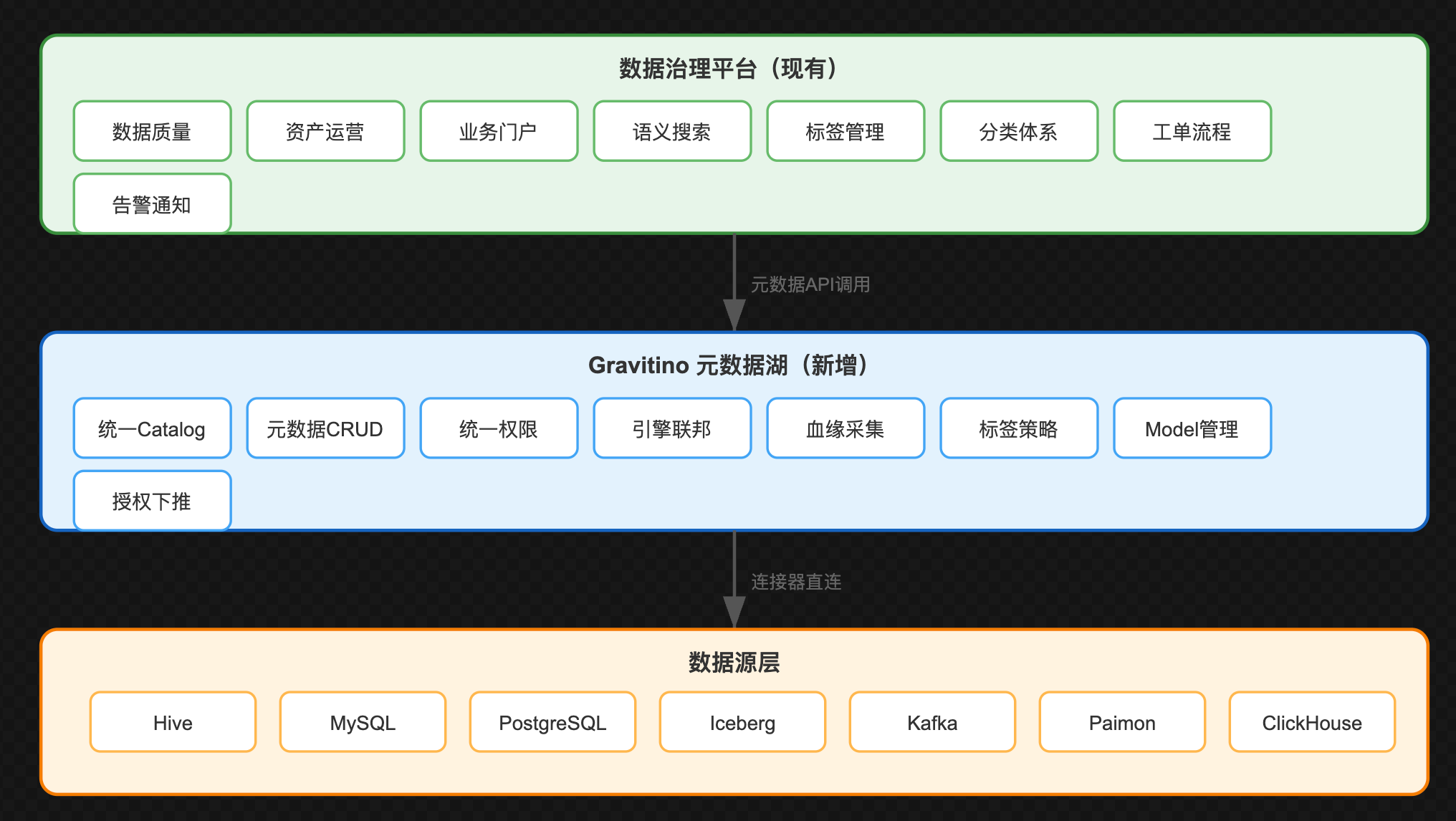
关键原则:
- Gravitino作为元数据基础设施:负责元数据的读写管理和统一访问
- 现有平台作为业务治理层:负责质量、运营、门户等业务化能力
- 互补而非替代:各取所长,避免重复建设
10.3.2 集成优先级
| 优先级 | 集成方向 | 预估工期 | 价值 |
|---|---|---|---|
| P0 | 统一Catalog管理 + Iceberg REST Catalog | 1-2个月 | 核心价值验证 |
| P1 | 统一权限管控 + Spark血缘集成 | 2-3个月 | 安全与血缘增强 |
| P2 | 元数据采集层替代 + 引擎联邦访问 + 质量联动 | 3-4个月 | 深度整合 |
| P3 | 标签策略整合 + AI资产管理 | 4-6个月 | 拓展创新 |
10.3.3 关键决策点
- 元数据权威源:建议Phase 1-2采用双写模式,Phase 3逐步切换到Gravitino为权威源
- 权限体系演进:建议采用灰度切换策略,新数据源使用Gravitino权限,存量数据源逐步迁移
- 现有采集层去留:Phase 1-2并存互验,Phase 3后期当覆盖率达90%+时退役
10.4 最终建议
推荐引入Apache Gravitino作为统一元数据基础设施,与现有数据治理平台互补集成。
理由:
- 架构先进性:Gravitino的"直连管理"模式是对传统"被动采集"模式的代际升级,从根本上解决了元数据时效性和一致性问题
- 能力互补性:Gravitino在元数据管理、统一Catalog、权限管控方面具有独特优势,而现有平台在数据质量、资产运营方面是核心价值------两者互补大于替代
- 生态前瞻性:Gravitino在AI资产管理(Model Catalog、MCP Server)方面的布局,使其成为连接数据和AI资产的桥梁,符合行业发展趋势
- 社区活跃度:303+贡献者、活跃的版本迭代、清晰的路标规划,项目发展势头良好
- 风险可控:建议从P0优先级(统一Catalog + Iceberg REST Catalog)开始灰度验证,逐步扩展,风险可控
引入前提条件:
- 确保有专职团队(建议2-3人)负责Gravitino的部署、运维和集成开发
- 预留充分的概念验证(PoC)时间,验证核心场景可行性
- 建立与Gravitino社区的沟通渠道,及时获取技术支持和版本信息
- 制定详细的回滚方案,确保出现问题时可快速降级
附录
A. 术语表
| 术语 | 英文 | 说明 |
|---|---|---|
| 元数据湖 | Metadata Lake | Gravitino的核心定位,统一管理所有元数据的容器 |
| Metalake | Metalake | Gravitino中最顶级的元数据容器,类似租户 |
| Catalog | Catalog | 绑定到具体数据源的元数据集合,是连接器的实例 |
| Schema | Schema | 第二级命名空间,对应数据库/模式 |
| Provider | Provider | 连接器实现标识,如hive、jdbc-mysql |
| 授权下推 | Privilege Delegation | 将Gravitino的权限决策同步到底层数据源 |
| SSOT | Single Source of Truth | 唯一真实来源 |
| RBAC | Role-Based Access Control | 基于角色的访问控制 |
| DAC | Discretionary Access Control | 自主访问控制(基于所有权) |
| Lakehouse | Lakehouse | 湖仓一体架构,结合数据湖和数据仓库的优势 |
B. 参考资源
| 资源 | 链接 |
|---|---|
| 官方文档 | https://gravitino.apache.org/docs |
| GitHub仓库 | https://github.com/apache/gravitino |
| REST API文档 | https://gravitino.apache.org/docs/latest/api/rest |
| Iceberg REST Catalog | https://gravitino.apache.org/docs/latest/iceberg-rest-catalog |
| Spark连接器 | https://gravitino.apache.org/docs/latest/spark-connector |
| Trino连接器 | https://gravitino.apache.org/docs/latest/trino-connector |
| 访问控制文档 | https://gravitino.apache.org/docs/latest/security |
| 社区邮件列表 | dev@gravitino.apache.org |