概念:
把杂乱数据整理、计算、找规律、出结论,就是数据分析,主要分为4个核心步骤:
-
数据收集:获取业务数据(如CSV文件、数据库记录、日志信息等),作为分析的原始素材。
-
数据清洗处理:对脏数据进行预处理,包括去重、处理缺失值、格式修正等,确保数据的准确性与可用性。
-
数据分析:基于清洗后的数据,进行筛选、分组、聚合计算,挖掘数据中的规律与业务洞察。
-
数据可视化:将分析结果通过图表直观呈现,便于理解结论、辅助决策。
pandas:
网站地址:
What's new in 2.3.3 (September 29, 2025) --- pandas 3.0.3 documentation
安装命令:这里我选取的版本是2.3.3,可根据自己的需求选择
bash
pip install pandas==2.3.3终端执行:
DataFrame:
构造方式:
一、从字典创建(最常用)
字典的键作为列名,值作为对应列的数据列表,是最直观、最符合业务场景的构建方式。
python
import pandas as pd
# 构建字典:键=列名,值=列数据列表
data = {
"姓名": ["张三", "李四", "王五"],
"年龄": [22, 24, 23],
"城市": ["北京", "上海", "广州"]
}
# 转为 DataFrame
df = pd.DataFrame(data)
print(df)二、从二维列表创建
用嵌套列表表示"行数据",再通过 columns 参数指定列名,适合快速录入行数据。
python
# 二维列表:每个子列表代表一行数据
data = [
["张三", 22, "北京"],
["李四", 24, "上海"],
["王五", 23, "广州"]
]
# 指定列名,转为 DataFrame
df = pd.DataFrame(data, columns=["姓名", "年龄", "城市"])
print(df)三、从 NumPy 数组创建
如果数据是纯数值型,可直接用 NumPy 数组构建 DataFrame,适合科学计算场景。
python
import numpy as np
# 创建 3x2 的 NumPy 数组
arr = np.array([[1, 100], [2, 200], [3, 300]])
# 转为 DataFrame,指定列名和索引
df = pd.DataFrame(arr, columns=["序号", "数值"], index=["A", "B", "C"])
print(df)四、从文件读取(实战首选)
真实项目中,绝大多数 DataFrame 都是从外部文件读取的,最常用的是 CSV 和 Excel 文件。
python
# 读取 CSV 文件
df_csv = pd.read_csv("data.csv", encoding="utf-8")
# 读取 Excel 文件(需安装 openpyxl 库)
df_excel = pd.read_excel("data.xlsx", sheet_name="Sheet1")五、单行/单列快速构建
适合临时创建单条或单个字段的数据,用于测试或数据补充。
python
# 1. 单行数据
single_row = pd.DataFrame([["赵六", 25, "深圳"]], columns=["姓名", "年龄", "城市"])
# 2. 单列数据
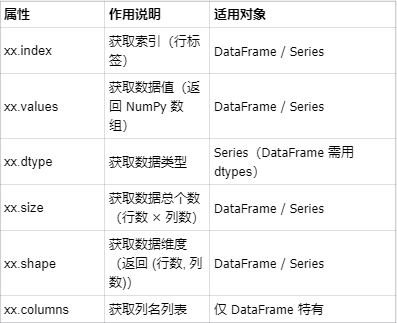
single_col = pd.DataFrame({"姓名": ["张三", "李四", "王五"]})Pandas DataFrame / Series 常见属性和方法:
读出与写入:
python
import pandas as pd
# 读取 CSV 文件
df = pd.read_csv("data.csv", encoding="utf-8")
# 读取 Excel 文件
df = pd.read_excel("data.xlsx", sheet_name="Sheet1")
python
# 写入 CSV 文件
df.to_csv("output.csv", index=False, encoding="utf-8-sig")
# 写入 Excel 文件
df.to_excel("output.xlsx", index=False, sheet_name="结果数据")查询与选择:
python
# 显示数据前10行(快速查看数据长什么样)
df.head(10)
# 显示数据最后10行
df.tail(10)
# 显示数据的统计信息(均值、最大值、最小值、标准差等)
df.describe()
# 查看数据的基本信息(列名、数据类型、是否有缺失值)
df.info
# ------------------- 列选择 -------------------
# 一个中括号取 单个列,返回一维数据结构 Series
df['产品名称']
# 两个中括号取 多个列,传入的是一个列表,返回二维表格 DataFrame
df[['产品名称','单价']]
# ------------------- 行选择 -------------------
# 选择行:iloc 和 loc
# 示例:从第0行到第99行,每隔2行取一行(筛选偶数行)
df.iloc[0:100:2]
# 注意:loc 必须用真实的索引值,不能乱写,在读取csv文件时,需要用到"index_col='指定列名称'"来指定需要的索引列
df.loc[6805677496:5852807025:2]数据过滤:
python
# 获取产品类别是食品或服装的
df[df['产品类别'].isin(['食品','服装'])]
# 获取销售数量大于10的且单价大于400的
df[(df['销售数量'] >= 10) & (df['单价'] >= 400)]数据清洗:
python
# 数据清洗
# 2.1 删除缺失值
# 查看缺失值
df.isnull()
# 删除缺失值所在行
# axis=0 删除行 axis=1 删除列,默认axis=0删除行
df.dropna()
# 删除缺失值所在列
df.dropna(axis=1)
# 2.2 填充缺失值
df.fillna('--null--')
# 按照上一行内容填充
df.ffill()
# 按照下一行内容填充
df.bfill()
# 2.3 查看重复数据
# df.duplicated()
df.duplicated(subset=['订单号'])
# 删除重复值
df.drop_duplicates(subset=['订单号'])
# 异常值处理
# 1. 异常值查看
df[df['单价'] < 0]
# 异常值删除
df.drop(df[df['单价'] < 0].index)
# 修复异常值
df['单价'] = df['单价'].abs()
# 数据格式转换
df['订单日期'] = df['订单日期'].str.replace('-', '/')
df数据排序:
python
# 数据排序, 默认升序,ascending=True表示升序,False表示降序
df.sort_values('单价',ascending=True)
df.sort_values(['单价','销售数量'],ascending=[True,False])数据分组:
python
df['销售金额'] = df['单价'] * df['销售数量']
# 分组
# 3.1 根据 产品类别 分组,统计各个类别的 订单数量
df.groupby('产品类别')['订单号'].count()
# 3.2 根据 产品类别 分组,统计各个类别的 销售数量 之和
df.groupby('产品类别')['销售数量'].sum()
# 3.3 根据 产品类别 分组,统计各个类别的 销售金额 之和
df.groupby('产品类别')['销售金额'].sum()
# 3.4 根据 产品类别 分组,统计各个类别的最低商品 单价
df.groupby('产品类别')['单价'].min()
# 3.5 根据 产品类别 分组,统计各个类别的最高商品 单价
df.groupby('产品类别')['单价'].max()
# 3.6 根据 产品类别 分组,统计各个类别的平均商品 单价
df.groupby('产品类别')['单价'].mean()
# 3.7 根据 产品类别 分组,统计各个类别的 平均单价、最高单价、最低单价
df.groupby('产品类别')['单价'].agg(['mean','max','min'])
# 3.8 根据 产品类别 分组,统计各个类别的:销售数量之和、销售金额之和、平均单价
df.groupby('产品类别').agg({'销售数量':'sum','销售金额':'sum','单价':'mean'})