同变的归一,异变的拆开。
设计模式和设计原则不用背
学设计模式的时候背了 23 个,用的时候还是 if-else 一把梭。SOLID 原则背得滚瓜烂熟,该耦合的照样耦合。
因为你不需要背。 23 个设计模式和 SOLID 5 条原则,全部能从两个更底层的东西推导出来:
- 实体(节点):持有状态
- 关系(边):连接实体
系统里只有这两种东西。设计的核心决策只有一个:一段逻辑该住在实体内部,还是该住到外面去? 判据是变化速率是否对齐------节奏一样的收进实体,不一样的拆出去。
设计模式:关系外化的标准拓扑
大部分设计模式是关系外化的标准拓扑。当你把一条隐式的关系变成显式的、可独立变化的实体时,就自然推导出了某个设计模式:
| 关系的什么在变 | 拓扑形状 | 自然推导出 |
|---|---|---|
| 谁来做 | 星形(中心委派给可替换的叶节点) | Strategy / State |
| 谁被通知 | 辐射(中心扇出到订阅者) | Observer / Mediator |
| 怎么连 | 插入中间节点做翻译或简化 | Adapter / Bridge / Decorator |
| 按什么顺序 | 链式传递处理 | Chain of Responsibility |
你不需要"选"一个设计模式。你只需要识别出关系的什么在变,拓扑形状自然浮现。不熟悉设计模式也没关系------从最轻量的手段开始选就行。
但不要用大炮打蚊子。 能用配置文件解决的,不写 Strategy。能加一层函数解决的,不建类层次。
SOLID:从两个基元推导
SOLID 的 5 条原则中,4 条直接从变化速率对齐推出,LSP 需要回到两个基元的拓扑层面:
- SRP:类内行为速率对齐 → 速率一致的放一起,自然只有一个变化原因
- OCP:外化不同速率的关系 → 外化点就是扩展点,对扩展开放对修改关闭
- ISP:不同客户端方法速率不对齐 → 接口内部行为速率不一致就该拆开
- DIP:外化时插入抽象层 → 让低频业务和高频实现都依赖抽象,而非互相依赖
前四条都从变化速率推出。LSP 不同------它根本不是一个速率问题,而是两个基元拓扑层面的约束:
- LSP :继承在图拓扑上是子类对父类的"特化复制"------子类复制了父类所有的边(关系)契约。如果子类篡改了这些边的行为,导致契约断裂,拓扑就崩了。LSP 的本质是边契约不可退化 。经典反例 Square/Rectangle:两者变化速率几乎相同(低频),但 Rectangle 有独立的
setWidth/setHeight而 Square 没有------边的契约不一致,继承不成立。这说明 LSP 不是速率判据,而是拓扑判据。
由此也能重新审视"组合优于继承":继承假设节点契约完全等价且生命周期绑定,一旦假设不成立,就该用边(关系)连接而非节点嵌套。但速率对齐且边契约一致时继承更简洁,不对齐时才该用组合------盲目用组合也是过度设计。
一句话
设计模式和设计原则不是需要记忆的规则清单,而是从两个基元可以推导出的定理集。 理解了基元,规则自然浮现。
什么是"变维"
先解释名字。"维"指的是业务中具体的变化维度------支付方式会变、定价规则会变、运费策略会变、风控阈值会变。每个"维"就是系统里一个独立的变化方向。
"变维拆分"做的事情分两步:第一步,变维识别 ------找出系统里有哪些变化维度,各自的变化节奏是什么。第二步,变维拆分------节奏不一致的维度,沿边界拆开。
比如一个电商系统,变维识别发现:支付方式每月在变(高频),订单结构半年不动(低频)。这是两个节奏完全不同的维度。变维拆分的判断是:把它们耦合在同一个类里,每次支付渠道调整都要动订单代码------沿边界拆开,各自独立变化。
这不是什么高深理论,就是一句大白话:同变的归一,异变的拆开。
一、两个基元
不管你用什么语言、什么框架、什么架构,软件系统归根结底只有两种东西:
- 实体(节点):持有状态。可以有简单的自述行为,也可以完全没有行为。
- 关系(边):连接实体。系统的复杂行为,本质上都是关系在运转。
设计的核心决策只有一个:行为的住所------一段逻辑该住在实体内部,还是该住到外面去?
判据是变化速率是否对齐:
- 这段逻辑的变化节奏和实体本身一样吗?→ 内化(收进实体)
- 不一样,甚至经常冲突?→ 外化(拆出去,变成独立实体或外部配置)
举例:
totalPrice = sum(items.price)--- 简单求和,和订单同生共死 → 内化进 Order- 运费计算规则每月调,订单结构半年不动 → 变化节奏不对齐 → 必须外化
就这些。没有第三个基元,没有隐藏维度。两个基元,一个判据,所有设计决策从这出发。
关于"变化速率"的度量------不需要精确到"每月几次"。高/中/低三档在实践中够用:折扣规则天天调(高)、基础定价偶尔改(中)、金额格式化几乎不动(低),三个速率明显不同,边界自然浮现。看准大趋势比纠结精确频率重要得多。
二、三个深度------变维拆分 SKILL
上面的理解被提炼成了一个可给 AI Agent 使用的 SKILL。不是每次都要做完整分析,按场景选深度:
快扫(30 秒):写任何代码之前。问自己:"这里什么会变?" 有答案 → 留口子。没答案 → 直接写。覆盖 80% 的场景。
标准分析(2 分钟):新功能、新模块。找到实体和关系,标注变化热点,在不齐处做隔离。
完整分析(10-15 分钟):新项目启动、重大重构。列出所有实体和关系,标注变化速率和趋势,按一致性分组,每个拆分点从最轻量的手段开始选。
档位之间可以升级。先快扫开始写,发现问题了做标准分析,不够用再上完整分析。
这个 SKILL 写入了 System Prompt,让 AI 在写代码前先做变维分析。下面用实验证明它是否真的有用。
三、实验过程:怎么验证的
光说理论不够。用 Shopizer(310+ Java 文件,1649 行核心类)做对照实验。先看结论:
变维拆分 + Superpowers 组合,用最少代码做到了最彻底的重构:
| 指标 | 无方法论 | 变维拆分 | Superpowers | 变维+Super |
|---|---|---|---|---|
| 累计新增文件 | 4 | 15 | 15 | 8 |
| 累计净增行数 | +391 | +987 | +1071 | +654 |
| 累计测试数 | ~15 | ~18 | ~150 | ~98 |
| PPU 拆分彻底度 | -79.5% | -82.2% | -82.2% | -83.6% |
| 累计工具调用(代价代理) | ~320 | ~500 | ~490 | ~700 |

效率-质量象限:变维+Super 位于最佳平衡点。 Superpowers 提供流程纪律(TDD、Review),变维拆分提供结构判断(拆什么、不拆什么)。两者叠加后比纯 Superpowers 少写 40% 代码、少加一半文件,测试覆盖达到其 65%。比无方法论组多 6 倍测试,拆分更彻底。
最有说服力的一轮:R05 运费规则------变维分析判断出已有架构足够,不需要拆。结果只加了 3 个文件(含测试)。而 Superpowers 自建了一套并行接口(6个文件),变维拆分单独用反而过度设计(5个文件)。
变维分析的核心价值不只是"告诉你怎么拆",也包括"告诉你不需要拆"。
下面是实验细节。
实验设计
四个环境,同一个 AI 模型(GLM-5.1),同样的五轮递进需求。
实验执行方式: 每轮通过 Claude Code 并行启动四个独立子 agent,每个子 agent 只能看到自己环境的 CLAUDE.md(方法论指导)和当前轮的需求文件。子 agent 独立完成分析、编码、编译验证,中间没有任何人工干预。五轮串行推进(每轮内四个子 agent 并行)。
变量控制: 四个环境的执行步骤、编译命令、指标采集脚本、约束条件(不修改 sm-core)完全一致。唯一差异是 CLAUDE.md 中的方法论指导内容。需要说明的是,dims 的 CLAUDE.md 比 dims_superpowers 多了两条设计模式拓扑行和一条禁忌("不要用大炮打蚊子"),这是编写时的疏忽而非有意设计,但 dims_superpowers 在 R05 仍然走了最简路径,说明这个差异对结论影响有限。后续实验会统一所有环境的非方法论内容,避免此类低级失误。
关于变化速率的判断方式: 本实验中,变化速率的标注完全由 AI 自问自答完成,没有任何人为判断参与。这意味着趋势标注(增长/稳定/震荡)可能存在偏差------AI 对业务背景的理解不如真正的开发者深入。理想情况下,变化趋势应由人做价值判断,或从 git 历史中提取客观数据。这是本实验的一个已知局限。
关于 token 消耗: 本实验未采集精确的 token 消耗数据(子 agent 报告的 token 数大多为 0,不可靠)。工具调用次数作为代价代理,间接反映了各环境的计算资源消耗。后续实验会加入精确的 token 计量。
| 环境 | 方法论 |
|---|---|
| Base | 无方法论指导 |
| Dims | 变维拆分 |
| Superpowers | Superpowers 开发流程(Brainstorming→TDD→Review) |
| Dims+Super | 变维拆分 + Superpowers |
Superpowers 代表的是业界共识的软工流程------先想清楚再动手、先写测试再写代码、做完要 Review。这些是对的。但它只管"怎么工作",不管"拆什么"。变维拆分补的正是这一块:结构判断。
五轮需求从支付类型拆解到运费规则,逐步递进复杂度。
简单需求:方法论差异不大
R01 支付分发------所有方法论组都选了 Strategy 模式,base 也能完成任务:
| 指标 | Base | Dims | Super | Dims+Super |
|---|---|---|---|---|
| 耗时 | ~8 min | ~12 min | ~14 min | ~12 min |
| if-else 消除 | 3→2 | 全部→0 | 全部→0 | 全部→0 |
| 测试 | 11 | 14 | 22 | 19 |
R02 微信支付------验证 R01 的外化决策:新增支付方式是否只需加一个实现类?结果是 Dims 和 Dims+Super 的 OrderFacadeImpl 零修改,直接加新的 PaymentProcessor 实现即可。R01 的 Strategy 外化决策经得起后续需求的考验。
复杂需求:方法论拉开差距
R03 定价拆分------ProductPriceUtils(721行)的拆解:
| 指标 | Base | Dims | Super | Dims+Super |
|---|---|---|---|---|
| 耗时 | ~5 min | ~10 min | ~30 min | ~12 min |
| PPU 缩减 | -79.5% | -82.2% | -82.2% | -83.6% |
| 测试 | 0 | 0 | 68 | 42 |
Dims+Super 在质量和效率间找到了最佳平衡------拆分最彻底,测试充足,耗时远低于 Superpowers 单独使用。
R04 风控检查------在购物车转订单流程中插入风控步骤,考察流程变更的影响范围:
| 指标 | Base | Dims | Super | Dims+Super |
|---|---|---|---|---|
| 耗时 | ~40 min | ~20 min | ~23 min | ~56 min |
| 新增文件 | 2 | 3 | 4 | 3 |
| 测试 | 0 | 0 | 22 | 12 |
| 覆盖下单路径 | 只 API | 两条 | 两条 | 两条 |
Base 在这一轮崩了------215 次工具调用,耗时是 Dims 的两倍。没有方法论指导的直觉方案在复杂需求下效率骤降。Dims+Super 虽然耗时最长,但产出了增量变维分析更新、修了预存在问题、测试覆盖了两条下单路径。
耗时趋势------复杂度越高差距越大:
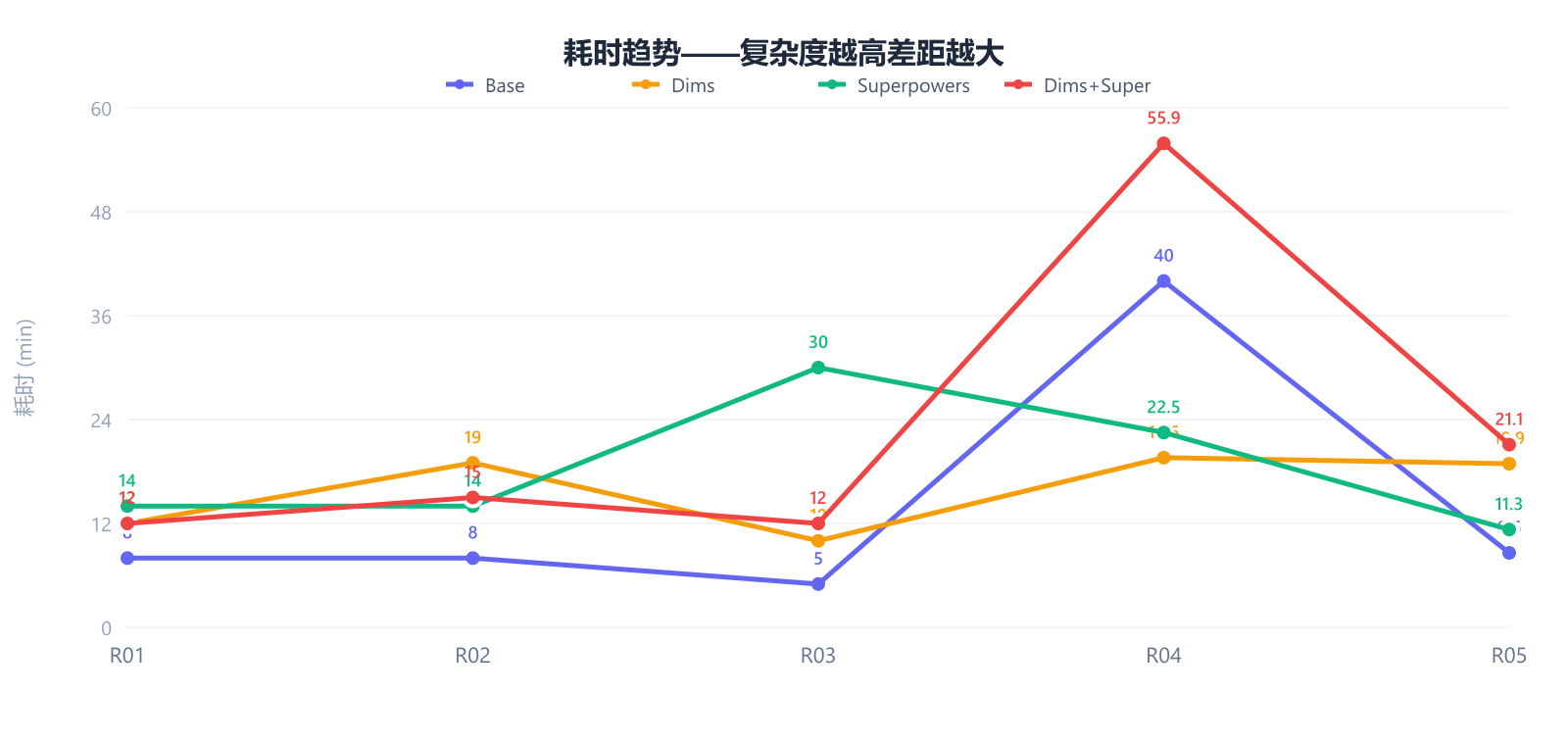
base 在 R04(风控检查)突然飙到 40 分钟(复杂需求走弯路),而方法论组的耗时增长相对平缓。
累计新增文件------Dims+Super 用最少文件做到最彻底拆分:
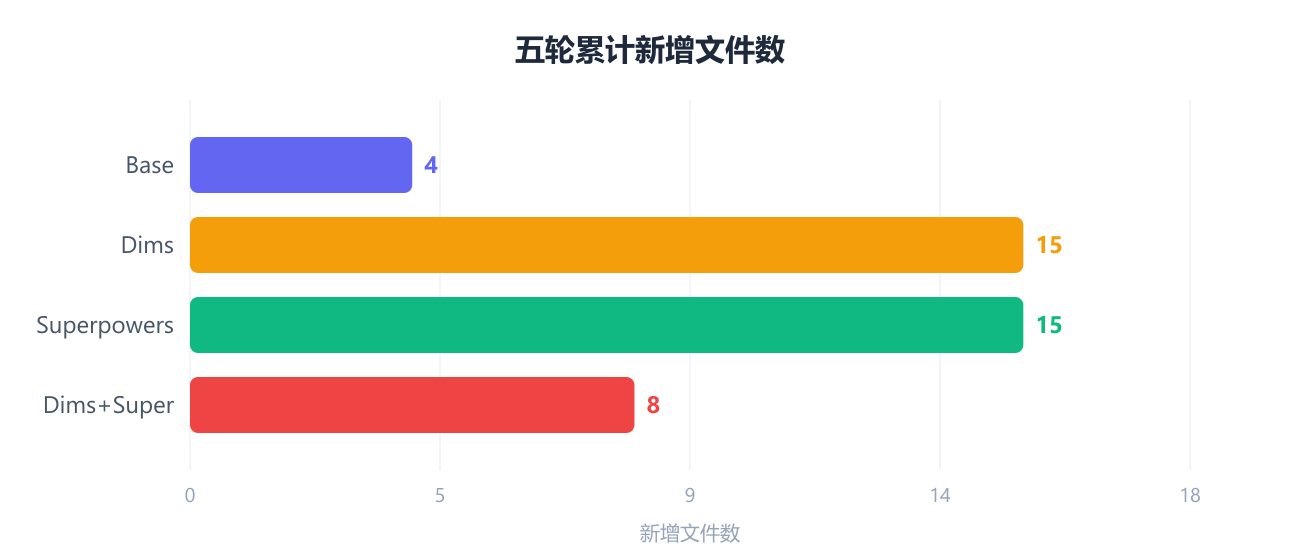
Dims+Super 五轮只新增 8 个文件,Dims 和 Superpowers 各新增 15 个。
累计净增代码行数:
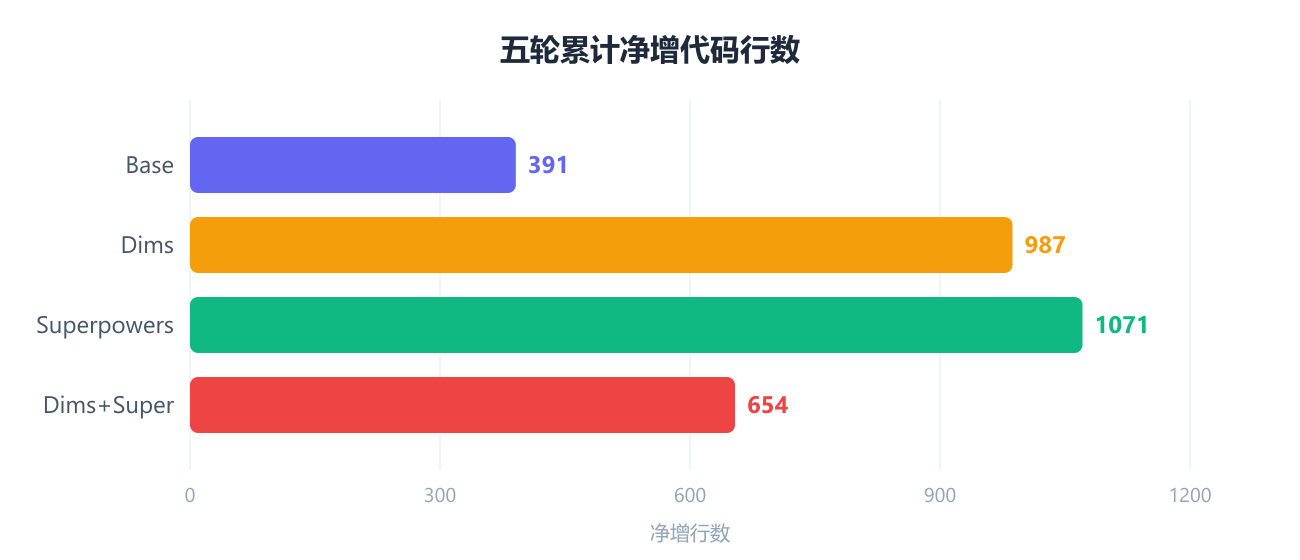
Dims+Super 净增 654 行,不到 Superpowers(1071 行)的 2/3。
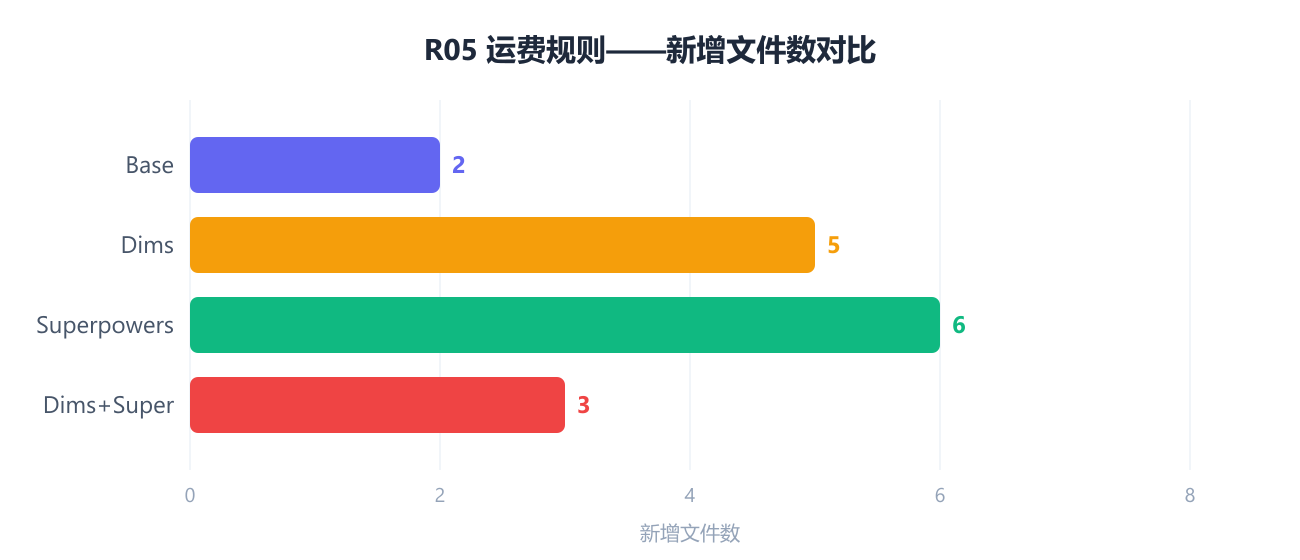
最有说服力的一轮:R05 运费规则
Shopizer 已有 ShippingQuoteModule 接口。需求要求新增运费计算规则。
| 环境 | 方案 | 新文件 | 怎么判断的 |
|---|---|---|---|
| Base | 直接用现有接口 | 2 | 直觉 |
| Dims | 新建策略层 + 适配器桥接 | 5 | 分析了,但过度外化 |
| Superpowers | 自建一套并行接口 | 6 | 没分析,从头设计 |
| Dims+Super | 直接用现有接口 | 3 | 变维分析判断"已有外化足够" |
Dims+Super 的变维分析识别出:运费规则的变化速率已经被现有 ShippingQuoteModule 接口正确外化,不需要新的外化点。
四、变维分析表:跨轮次累积的决策资产
变维拆分有一个独特的产出:变维分析表。每轮分析不是从零开始,而是在已有表格上增量更新。五轮下来,这张表是这样的:
实体识别
| 实体 | 持有的状态 | 变化速率 |
|---|---|---|
| Order | 订单信息(金额、商品、客户) | 低(核心业务对象) |
| Payment | 支付数据(类型、金额、元数据) | 中(随支付方式扩展) |
| PaymentType | 支付类型枚举(9种) | 高(新增支付方式必须扩展) |
| ProductPrice | 商品价格(原价、特价、起止日期) | 低(核心数据模型) |
| FinalPrice | 定价结果(最终价、折扣价、百分比) | 低(核心数据模型) |
| RiskRule | 风控规则(金额阈值、时间窗口) | 高(业务频繁调整) |
| ShippingOption | 运费选项(价格、模块代码) | 低(值对象) |
关系与变化速率
| 关系 | 连接方式 | 速率 | 趋势 | 策略 | 轮次 |
|---|---|---|---|---|---|
| Order→Payment创建 | 按PaymentType分发 | 高 | 增长 | 外化(Strategy) | R01 |
| Order→Payment验证 | 按PaymentType验证 | 高 | 增长 | 外化(Strategy) | R01 |
| Product→定价计算 | 按variant/attribute计算 | 中 | 稳定 | 拆分 | R03 |
| ProductPrice→折扣判断 | 按日期窗口判断 | 高 | 增长 | 拆分 | R03 |
| BigDecimal→金额显示 | 格式化 | 低 | 稳定 | 拆分 | R03 |
| Order→风控检查 | 价格计算后、创建订单前 | 高 | 增长 | 外化(接口+配置) | R04 |
| 商家→运费规则选择 | 按配置查找ShippingQuoteModule | 高 | 增长 | 已有接口 | R05 |
外化决策记录
| 外化点 | 手段 | 创建轮次 | 修改记录 |
|---|---|---|---|
| 支付创建分发 | Strategy(PaymentProcessor + Registry) | R01 | R02 验证:新增微信支付无需修改 |
| 支付验证分发 | Strategy(PaymentProcessor.validate) | R01 | R02 验证:微信支付无特殊验证 |
| 定价计算 | 拆分为 ProductPricer | R03 | --- |
| 折扣判断 | 拆分为 DiscountEvaluator | R03 | --- |
| 金额格式化 | 拆分为 PriceFormatter | R03 | --- |
| 风控检查 | RiskCheckService + 配置化 | R04 | --- |
| 运费计算规则 | 已有 ShippingQuoteModule 接口(无需新增外化) | R05 | --- |
这张表的价值在哪?
- R01 的决策在 R02 被验证:新增微信支付时,变维分析表里 R01 的外化决策"新增支付方式无需修改主流程"得到了验证------OrderFacadeImpl 零修改。
- R03 拆分出三个维度(折扣高/定价中/格式化低),按变化速率不一致的边界拆开,ProductPriceUtils 从 721 行降到 118 行。
- R05 判断"不需要拆" :变维分析表里已有"商家→运费规则"这条关系,发现 sm-core 的
ShippingQuoteModule接口已经正确外化,不需要新的外化点。这是整张表最有价值的一行。
五、和现有理论的关系
"这不就是高内聚低耦合吗?"
一定有人会这么说。对,变维拆分的方向和"高内聚低耦合"一致。但一句"高内聚低耦合"能不能指导 AI 写出符合工程要求的代码?
不能。编程模型在训练时已经被反复灌输这个概念了,生成的代码依然有问题。因为"高内聚低耦合"只给了方向,没给判据------到底要内聚什么?解耦什么?做到什么程度?什么时候该停?这些判断它回答不了。
变维拆分的贡献不在于方向新,而在于把模糊的方向变成了可操作的判据:内聚什么?变化速率对齐的东西。解耦什么?变化速率不对齐的东西。做到什么程度?看趋势,看已有架构是否已覆盖。什么时候停?能不拆就不拆。
当然,这个判据目前主要靠人(或 AI)的主观判断。最理想的方式是从代码仓库的 git 历史中提取客观数据------哪些文件经常一起变(对齐),哪些独立变(不对齐)。这也是后续计划中最优先推进的方向。
和其他理论的关系
变维拆分不取代任何已有方法。它是所有方法的上游分析步骤:
变维拆分(分析实体、关系、变化速率)
↓
决定行为的住所(内化 or 外化)
↓
选择外化手段:
├── 最轻量:配置、回调、数据驱动
├── GoF 设计模式:Strategy、Facade、Composite...
├── DDD 战术:聚合、值对象、领域事件
└── 其他任何合适的手段先分析,再选工具。不预设路线。
和 SOLID 的关系
前面已经展示了 SOLID 全部可以从两个基元推导。这里补充一点:变维拆分不取代 SOLID,而是比 SOLID 多了一个可操作的时间维度。SRP 说"一个类只变一个原因",但没有告诉你怎么判断"原因"的边界。变维拆分用速率对齐做判据,给出了可操作的答案。贡献不算颠覆性,但足以作为独立的方法论增量。
六、给 AI Agent 的指令
如果你用 AI 写代码(Claude、Cursor、Copilot 等),直接把上面的三个深度档位写进 System Prompt。关键原则:
- 大多数时候快扫就够了,不要每次都做完整分析
- 禁忌:能用配置文件解决的,不写 Strategy;能加一层函数解决的,不建类层次
- 禁忌:不要默认使用任何架构框架,不要为假设的未来做设计
局限与边界(诚实的自我审视)
1. 速度判据的主观性
变维拆分用高/中/低三档标注变化速率。在实践中,R03 定价拆分时三档(折扣高/定价中/格式化低)确实帮助区分了边界。但临界情况有挑战:
- 两个维度变化频率相同,但影响范围不同(一个改字段,一个重构整个类)→ 本框架只看速率不看幅度,优先级相同
- 一个维度过去一年没变,但下季度要大改 → 看历史还是看预期?本框架建议看趋势(增长/稳定/震荡),但趋势判断本身有主观性
2. R05 Dims 组翻车了------分析框架的内置约束不够
这是整篇文章最需要诚实面对的一个数据点:R05 中,变维拆分单独使用时过度设计了(5 个文件),而叠加 Superpowers 后反而走了最简路径(3 个文件)。
为什么?拿到"做设计"的指令时,人------包括 AI------天然有倾向去建新类、新接口,觉得这才叫"做了设计"。Dims 组的"寻找变化"雷达过度敏锐,把不该拆的也拆了。
框架的禁忌清单(YAGNI、不要用大炮打蚊子)本应是刹车,但在没有外部 Review 校准的情况下,这些软约束容易被执行者绕过。Superpowers 的 TDD + Review 在这里起到了硬约束的作用------TDD 让你只写满足当前测试的代码,Review 压制过度设计的冲动。
结论:变维拆分给出了正确的分析方向(R01-R04 都验证了),但框架自身的"不拆"约束是软的,需要外部流程提供硬约束。这不是框架的致命缺陷,而是它的适用边界。
3. 简单需求不需要方法论
如果改动不到 3 个文件,直觉够用。方法论在 R01、R05 这类简单需求下的额外开销不划算。
4. 性价比问题------700 次工具调用值不值?
Dims+Super 的累计工具调用约 700 次,是 base(320 次)的 2.2 倍。多花的 380 次调用换来了:多 6.5 倍测试、PPU 拆分多 4.1 个百分点、累计文件少一半。
值不值?取决于场景。生产系统(长期维护、团队协作)值得------测试和精简代码带来的长期收益远超单次开发成本。原型期或一次性脚本不值得,base 的直觉方案就够了。
这也是为什么文章标题说"Vibe Coding + Superpowers 完全不够"------不是说它们没用,而是说在需要高质量交付的场景下,流程纪律和结构判断缺一不可。
总结
变维拆分不是凭空发明的理论。它的思想源头很清楚:单一职责说了"一个类只变一个原因",开闭原则说了"对扩展开放、对修改关闭",领域建模说了"识别实体和关系"。变维拆分做的,是把这些老道理揉成一个可操作的判据------变化速率是否对齐------然后结构化为 SKILL,适配 AI 编程场景,用对照实验验证它是否真的有用。
答案是:有用,但有边界。实验数据支持它在复杂需求下的价值。
但它也有清晰的边界:速度判据有主观性,独立使用时会翻车,需要 Review 流程校准,不取代 SOLID 而是补充它。
一个方法论的价值不在于它无所不能,而在于你清楚知道它不能做什么。
后续计划
本文展示的是第一轮实验结果(GLM-5.1,单一项目)。以下是正在推进的改进方向:
1. 多模型交叉验证
不同模型能力对方法论执行效果的影响是关键变量。计划测试:
- 强模型(Claude Sonnet/Opus):验证方法论在强推理能力下的天花板
- 弱模型(Qwen2.5-Coder-14B,本地 RTX 4080):验证方法论能否弥补模型能力的不足
- 对比假设:模型越弱,方法论的增量价值越大
2. 扩大实验样本
单一项目(Shopizer)不足以覆盖所有场景。计划增加更多中型开源项目,考察不同业务领域(电商、CMS、ERP 等)下方法论的表现差异。
3. Git 历史驱动的变化速率判定
这是最有价值的改进方向。当前"变化速率"靠主观标注(高/中/低),存在 R05 Dims 翻车那种判据偏移问题。
计划开发分析工具,从 git 历史中客观提取:
- 文件级变化频率 :
git log --follow统计每个文件的变更间隔分布 - 模块级聚合:按包/目录聚合,计算模块的平均变更间隔
- 关联分析 :
git log --stat识别哪些文件总是一起变(速率对齐),哪些独立变(速率不对齐)
产出直接喂给变维分析表的"变化速率"列,从主观标注变成数据驱动。这个工具将写入变维拆分的 SKILL 体系。
4. 方法论 Skill 化与能力边界探索
变维拆分不是一篇论文写完就结束的东西。当前已经将它结构化为可给 AI Agent 使用的 SKILL(三个深度档位:快扫/标准/完整),但 Skill 的能力边界还没摸清:
- 方法论对模型能力的依赖:同一个 Skill,给强模型(Claude Sonnet)和弱模型(Qwen2.5-Coder-14B)效果差多少?假设是模型越弱方法论价值越大,但需要实验验证
- 主观偏差的修正:R05 Dims 翻车说明 AI 自问自答的变化速率判断会有偏移,git 历史数据是纠偏手段之一,但不是唯一手段
- 跨领域泛化:Shopizer 是电商领域,换到 CMS、ERP、论坛等不同业务领域,三个深度档位的适用性是否变化
- Skill 迭代循环:实验→发现问题→修正 Skill→再实验。这不是一次性工程,而是持续打磨的过程
后续会持续迭代 SKILL 定义并公开测试结果。