数据结构和算法:斐波那契堆
1 惰性策略的极致
在讲解"摊还分析"的文中,我们用摊还分析的三种方法讨论了几个相对简单的例子。这些例子的共同特点是:实际代价的波动幅度并不太大,即便在最坏情形下,单次操作最多也就是线性时间。然而,摊还分析真正的威力,要到那些"单次操作可能极其昂贵,但长期来看代价极小"的数据结构中,才能淋漓尽致地体现出来。斐波那契堆,就是这类数据结构中最具代表性的一例。
回顾一下我们已经熟悉的几种堆结构。二叉堆是最简单的优先队列实现:插入和删除最小元都是 O ( log n ) O(\log n) O(logn),但合并两个堆却需要 O ( n ) O(n) O(n) 时间------必须把两个数组从头拷贝一遍。二项堆在这方面做了改进:它把堆组织成一组"二项树"的集合,合并操作只需归并两个有序的根链表,最坏情形时间降到了 O ( log n ) O(\log n) O(logn)。但是,二项堆仍然存在一个瓶颈:每次插入或合并后,它都立刻整理根链表,使得任意时刻根链表中最多只有一棵给定度数的树。这种"即时整理"保证了结构的规整,却也使得某些本来可以很快的操作背负了不必要的开销。
能不能再往前走一步?能不能让插入和合并在常数时间内完成,而把所有的整理工作推迟到不得不做的时候?
这正是斐波那契堆的核心思想------策略性懒惰。它由 Michael L. Fredman 和 Robert E. Tarjan 于 1984 年提出,1987 年正式发表。它把二项堆的设计哲学推向了一个极端:插入一个新结点?直接把它作为一棵单结点树挂在根链表上,不做任何合并。合并两个堆?把两条根链表首尾相接就行。减小某个结点的键值?把它从原来的位置上剪下来,往根链表上一扔。总之,能不做的整理,一概不做。
这样做的直接后果是:根链表上的树会越来越多、越来越乱。但代价总是要付的------这些被推迟的整理工作,最终在删除最小元(EXTRACT-MIN)操作中一次性完成。摊还分析告诉我们,如果把删除最小元中付出的高昂代价平摊到在此之前的大量插入和合并上去,那么每个操作的摊还代价依然是常数级别的。这正是摊还分析的精妙所在。
2 斐波那契堆的结构
斐波那契堆在结构上与二项堆有不少相似之处,但更加松散。
一个斐波那契堆是由一组满足最小堆性质的有根树构成的集合。所谓"最小堆性质",是指每棵树中,任意结点的关键字都不小于其父结点的关键字,因此整棵树的最小关键字必然位于树根。斐波那契堆中的树并不要求是二项树,它们之间的相对顺序也没有任何规定------根链表中的树是无序的。
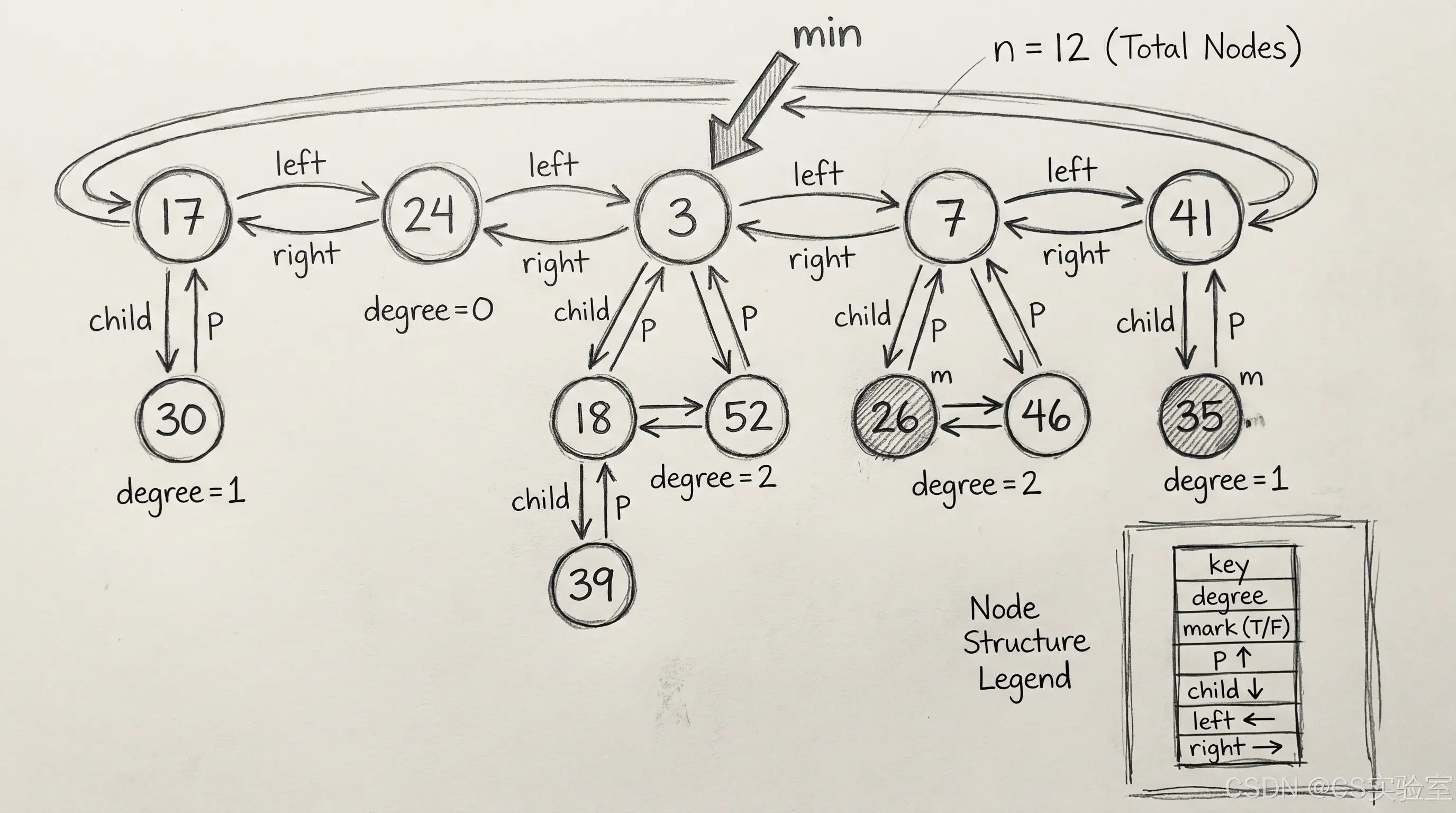
具体而言,斐波那契堆的底层结构依赖双向循环链表 来组织结点。每个结点包含以下字段:指向父结点的指针 p、指向某一个子结点的指针 child(该子结点本身又通过双向链表与其兄弟结点相连,形成"子链表")、左兄弟指针 left 和右兄弟指针 right、记录子结点个数的 degree(度数)、一个布尔型的 mark 标记(用于指示该结点自从上次成为另一个结点的子结点以来,是否已经失去了一个孩子),当然还有关键字 key 本身。
堆本身则维护以下信息:一个指向根链表中最小关键字结点的指针 min,以及堆中当前结点的总数 n。所有树的根结点通过 left 和 right 指针连接成一个环形的双向链表,即根链表。
下图描绘了一个典型的斐波那契堆,其中 min 指针指向关键字为 3 的根结点,根链表包含 5 棵树,标记结点的 mark 位被置为 true。在这种结构下,查找最小值只需直接返回 min 指针,时间为常数。
3 各操作的具体实现
在给出摊还分析之前,我们需要先把每个操作是"怎么做"的讲清楚。以下按照操作的复杂程度,由浅入深逐一介绍。
(1)创建空堆、插入与查找最小值
创建一个空的斐波那契堆是平凡的:将 min 置为 NULL,结点计数置零,时间 O ( 1 ) O(1) O(1)。查找最小值同样平凡------直接返回 min 指针即可。
插入操作则充分体现了"懒惰"二字:为新结点创建一棵单结点树,初始时 degree 为 0,mark 为 false,然后将这棵树直接插入根链表中。如果新结点的关键字比当前 min 的更小,则更新 min 指针。整个过程的实际代价显然为 O ( 1 ) O(1) O(1)。
(2)合并两个堆
合并操作比二项堆中更简单:将两个堆的根链表首尾相接,再比较两个堆的最小关键字,取较小者作为合并后的 min 指针。实际代价 O ( 1 ) O(1) O(1)。不同于二项堆需要做类似"归并"的工作来保持根链表的有序性,斐波那契堆完全不操心这件事------两根链表连在一起就完事了。
(3)删除最小元(EXTRACT-MIN)
这是斐波那契堆中最复杂的一个操作,也是"懒惰"策略的"还债时刻"。它要做以下几件事:
- 第一步,将最小根结点
z = H.min的所有子结点逐一从z的子链表中剥离,插入到根链表中。这些子结点自此成为独立的树根。 - 第二步,从根链表中删除
z,H.min暂时指向z的右兄弟(或其他任意一个根结点)。 - 第三步,也是最关键的一步------Consolidate(合并整理)。此时根链表中可能存在着多棵度数相同的树,我们需要将它们逐一合并,直到根链表中不存在两棵度数相同的树。
Consolidate 的实现通常使用一个辅助数组 A 0.. D ( n ) A0..D(n) A0..D(n),其中 D ( n ) D(n) D(n) 是 n n n 个结点构成的斐波那契堆中任意结点的最大度数上界(可以证明 D ( n ) = O ( log n ) D(n) = O(\log n) D(n)=O(logn))。我们从根链表出发,依次检查每棵树:如果当前树的度数为 d d d,而 A d Ad Ad 为空,就将它填入 A d Ad Ad;如果 A d Ad Ad 已经有一棵树,就将两棵度数相同的树合并成一棵度数 d + 1 d+1 d+1 的新树(将关键字较大者的根结点作为关键字较小者的子结点),然后清空 A d Ad Ad 并继续尝试将新树填入 A d + 1 Ad+1 Ad+1,以此类推。所有可能的合并处理完毕后,扫描整个辅助数组,将其中非空的树重新链接成新的根链表,并确定新的 min 指针。
删除最小元的实际代价取决于需要做的合并次数,而合并次数与根链表中树的棵数和最小根结点的度数有关。可以证明这个实际代价为 O ( D ( n ) + t ( H ) ) O(D(n) + t(H)) O(D(n)+t(H)),其中 t ( H ) t(H) t(H) 是操作前根链表中树的棵数。这里的"账单"后面会有势能来支付。
(4)减小关键字(DECREASE-KEY)与级联剪切
减小关键字操作允许我们将堆中某个结点 x x x 的键值减小为 k k k(要求 k k k 不大于 x x x 当前的关键字)。
- 如果 x x x 在根链表中(即 x x x 是某棵树的根),直接修改其关键字并视情况更新
min指针即可。 - 如果 x x x 不是根结点,且减小后的关键字仍不小于其父结点 y y y 的关键字,也直接修改即可,无需其他动作。
- 真正复杂的情形是: x x x 不是根结点,且减小后的关键字小于 其父结点 y y y 的关键字,从而破坏了最小堆性质。此时的做法是:将 x x x 从其父结点 y y y 的子链表中剪下 ,作为一个新的树根插入根链表,并将 x x x 的
mark重置为false。
但事情还没完。如果 y y y 在此之前已经失去过一个孩子(即 y . m a r k = t r u e y.mark = true y.mark=true),那么 y y y 此时就失去了第二个孩子。按照规则, y y y 自身也必须被剪下、插入根链表, y . m a r k y.mark y.mark 重置为 false;然后继续检查 y y y 的父结点,以此类推。这就是所谓的级联剪切 ------一次键值减小可能会引发一连串的剪切,沿着从 x x x 向上的路径一直传播,直到遇到一个未被标记的祖先结点,或者到达根结点为止。
级联剪切的意义在于:它防止了树变得"过于瘦高",从而将结点的最大度数控制在 O ( log n ) O(\log n) O(logn) 的范围内。没有这条机制,斐波那契堆的结构就会退化,删除最小元的代价也将超出对数级别。事实上,斐波那契堆的分析之所以牵涉斐波那契数,正是因为级联剪切规则保证了"一棵以度数 k k k 的结点为根的子树,其结点总数至少为第 k + 2 k+2 k+2 个斐波那契数",从而导出 D ( n ) = O ( log n ) D(n) = O(\log n) D(n)=O(logn) 这一关键结论。
(5)删除任意结点
删除任意结点 x x x 可以很方便地用已有的操作来实现:先对 x x x 执行 DECREASE-KEY,将其关键字减小到 − ∞ -\infty −∞(即把它变成堆中最小结点),然后执行 EXTRACT-MIN 即可。删除操作的摊还代价因此等于 DECREASE-KEY 与 EXTRACT-MIN 的摊还代价之和,即 O ( log n ) O(\log n) O(logn)。
4 摊还分析
斐波那契堆的摊还分析几乎"标配"了势能方法。原因很简单:斐波那契堆的"混乱程度"可以用一个势函数来量化,而各个操作带来的混乱程度变化(也就是势能变化),恰好可以用来抵消其中高昂的实际代价。
势函数的选取
定义斐波那契堆 H H H 的势函数为
Φ ( H ) = t ( H ) + 2 ⋅ m ( H ) \Phi(H) = t(H) + 2 \cdot m(H) Φ(H)=t(H)+2⋅m(H)
其中 t ( H ) t(H) t(H) 是根链表中树的棵数, m ( H ) m(H) m(H) 是堆中被标记(mark = true)的结点个数。初始状态下空堆的势为 0,且对于任意合法的堆状态,势显然非负,满足势能方法的前提。
为什么是 2 m ( H ) 2m(H) 2m(H) 而不是 m ( H ) m(H) m(H)?这个系数 2 是由级联剪切的特性决定的:一次 DECREASE-KEY 除了可能剪下一个结点(消耗 1 单位势能),还可能触发级联剪切,将一个标记结点变成未标记(消耗 2 单位势能,因为 m ( H ) m(H) m(H) 减小 1 会导致势能减少 2)。系数 2 恰好保证了这个"消耗"足以支付级联剪切的实际代价。这一点在后面会看得更清楚。
各种操作的摊还代价
下面逐一给出各类操作的摊还分析。为方便对比,我们将结果汇总如下:
| 操作 | 实际代价 | 势能变化 Δ Φ \Delta\Phi ΔΦ | 摊还代价 c ^ \hat{c} c^ |
|---|---|---|---|
| MAKE-HEAP | O ( 1 ) O(1) O(1) | 0 | O ( 1 ) O(1) O(1) |
| INSERT | O ( 1 ) O(1) O(1) | +1 | O ( 1 ) O(1) O(1) |
| MINIMUM | O ( 1 ) O(1) O(1) | 0 | O ( 1 ) O(1) O(1) |
| UNION | O ( 1 ) O(1) O(1) | 0 | O ( 1 ) O(1) O(1) |
| EXTRACT-MIN | O ( D ( n ) + t ( H ) ) O(D(n) + t(H)) O(D(n)+t(H)) | ≤ D ( n ) + 1 − t ( H ) \le D(n) + 1 - t(H) ≤D(n)+1−t(H) | O ( D ( n ) ) = O ( log n ) O(D(n)) = O(\log n) O(D(n))=O(logn) |
| DECREASE-KEY | O ( c ) O(c) O(c)( c c c 为剪切次数) | ≤ ( 2 − c ) \le (2 - c) ≤(2−c) | O ( 1 ) O(1) O(1) |
| DELETE | --- | --- | O ( log n ) O(\log n) O(logn) |
下面逐项说明。
-
MAKE-HEAP、MINIMUM、UNION :这些操作不改变堆的势,实际代价均为 O ( 1 ) O(1) O(1),故摊还代价也是 O ( 1 ) O(1) O(1)。
-
INSERT :实际代价 O ( 1 ) O(1) O(1)。插入后根链表增加了一棵树, Δ t = 1 \Delta t = 1 Δt=1,标记结点数不变,故势能增加 1。于是 c ^ = O ( 1 ) + 1 = O ( 1 ) \hat{c} = O(1) + 1 = O(1) c^=O(1)+1=O(1)。
-
EXTRACT-MIN :实际代价约为 O ( D ( n ) + t ( H ) ) O(D(n) + t(H)) O(D(n)+t(H))(将最小结点的 D ( n ) D(n) D(n) 个子结点移入根链表,再完成合并整理)。操作后,根链表中最多剩下 D ( n ) + 1 D(n) + 1 D(n)+1 棵树(因为每棵树的度数互不相同且不超过 D ( n ) D(n) D(n)),而标记结点数不变。因此势能从原来的 t ( H ) + 2 m ( H ) t(H) + 2m(H) t(H)+2m(H) 变为不超过 ( D ( n ) + 1 ) + 2 m ( H ) (D(n) + 1) + 2m(H) (D(n)+1)+2m(H), Δ Φ ≤ D ( n ) + 1 − t ( H ) \Delta\Phi \le D(n) + 1 - t(H) ΔΦ≤D(n)+1−t(H)。于是
c ^ = O ( D ( n ) + t ( H ) ) + ( D ( n ) + 1 − t ( H ) ) = O ( D ( n ) ) \hat{c} = O(D(n) + t(H)) + (D(n) + 1 - t(H)) = O(D(n)) c^=O(D(n)+t(H))+(D(n)+1−t(H))=O(D(n))
由于可以证明 D ( n ) ≤ ⌊ log φ n ⌋ = O ( log n ) D(n) \le \lfloor \log_{\varphi} n \rfloor = O(\log n) D(n)≤⌊logφn⌋=O(logn)(其中 φ = ( 1 + 5 ) / 2 \varphi = (1+\sqrt{5})/2 φ=(1+5 )/2 是黄金比例),因此 EXTRACT-MIN 的摊还代价为 O ( log n ) O(\log n) O(logn)。
-
DECREASE-KEY :这是最需要势能来"买单"的操作。设操作中执行了 c c c 次级联剪切(包括最初的那次剪切)。每次剪切将一个结点从其父结点上剪下、加入根链表,同时将其父结点的
mark重置为false(如果它原本是被标记的话)。分析势能变化:- t ( H ) t(H) t(H) 每剪下一个结点就增加 1(因为被剪的结点成为新树根),共增加 c c c;
- m ( H ) m(H) m(H) 的变化则稍复杂:对于级联剪切路径上的前 c − 1 c-1 c−1 个结点,它们原本被标记、剪切后被取消标记,每个使得 m m m 减少 1;对于路径上的最后一个结点,它可能被标记(如果它原本未标记且不是根),使得 m m m 增加 1。
综合来看, Δ t = c \Delta t = c Δt=c, Δ m ≤ − ( c − 1 ) + 1 = − ( c − 2 ) \Delta m \le -(c-1) + 1 = -(c-2) Δm≤−(c−1)+1=−(c−2)。于是
Δ Φ = Δ t + 2 ⋅ Δ m ≤ c + 2 ⋅ ( − ( c − 2 ) ) = c − 2 c + 4 = 4 − c \Delta\Phi = \Delta t + 2 \cdot \Delta m \le c + 2 \cdot (-(c-2)) = c - 2c + 4 = 4 - c ΔΦ=Δt+2⋅Δm≤c+2⋅(−(c−2))=c−2c+4=4−c
实际代价为 O ( c ) O(c) O(c),因此
c ^ = O ( c ) + ( 4 − c ) = O ( 1 ) − c + 4 \hat{c} = O(c) + (4 - c) = O(1) - c + 4 c^=O(c)+(4−c)=O(1)−c+4
只要选好常数因子, c ^ \hat{c} c^ 就可以被常量上界所控制。这便得出了 DECREASE-KEY 的摊还代价为 O ( 1 ) O(1) O(1) 的结论。
D ( n ) = O ( log n ) D(n) = O(\log n) D(n)=O(logn) 的简要说明
上面的分析依赖于一个关键事实: n n n 个结点的斐波那契堆中,任意结点的最大度数 D ( n ) = O ( log n ) D(n) = O(\log n) D(n)=O(logn)。这个结论的证明恰恰引入了斐波那契数,也是"斐波那契堆"名称的由来。
简要思路如下:设 x x x 是堆中任意一个结点,其度数为 k k k,子女依次为 y 1 , y 2 , ... , y k y_1, y_2, \dots, y_k y1,y2,...,yk(按成为 x x x 子女的时间先后排列)。可以证明, y i y_i yi 的度数至少为 i − 2 i-2 i−2(因为 y i y_i yi 被链接为 x x x 的子女时, x x x 的度数至少为 i − 1 i-1 i−1,而此后 y i y_i yi 最多失去一个孩子------否则它会被级联剪切剪走)。由此可推出,以 x x x 为根的子树至少包含 F k + 2 F_{k+2} Fk+2 个结点,其中 F i F_i Fi 表示第 i i i 个斐波那契数。由于斐波那契数以指数级增长, k k k 必须满足 F k + 2 ≤ n F_{k+2} \le n Fk+2≤n,从而 k = O ( log n ) k = O(\log n) k=O(logn)。
5 实际应用:图算法中的加速
斐波那契堆最重要的实际应用,莫过于在稠密图的单源最短路径和最小生成树算法中替代二叉堆或二项堆,从而从理论上降低算法的时间复杂度。
以 Dijkstra 算法 为例。设图有 ∣ V ∣ |V| ∣V∣ 个顶点和 ∣ E ∣ |E| ∣E∣ 条边。算法在运行过程中需要反复执行三类优先队列操作:
- EXTRACT-MIN:从优先队列中取出当前距离最小的顶点(共执行 ∣ V ∣ |V| ∣V∣ 次);
- DECREASE-KEY:当通过某条边发现到某个顶点的更短路径时,减小该顶点的距离值(最多执行 ∣ E ∣ |E| ∣E∣ 次);
- INSERT:初始化时将顶点插入优先队列。
如果使用二叉堆,所有操作均为 O ( log n ) O(\log n) O(logn),Dijkstra 的总时间复杂度为 O ( ( ∣ V ∣ + ∣ E ∣ ) log ∣ V ∣ ) O((|V| + |E|) \log |V|) O((∣V∣+∣E∣)log∣V∣)。而如果使用斐波那契堆,INSERT 和 DECREASE-KEY 的摊还代价仅为 O ( 1 ) O(1) O(1),EXTRACT-MIN 为 O ( log ∣ V ∣ ) O(\log |V|) O(log∣V∣)。于是总摊还时间为
O ( ∣ V ∣ log ∣ V ∣ + ∣ E ∣ ) O(|V| \log |V| + |E|) O(∣V∣log∣V∣+∣E∣)
将 ∣ E ∣ |E| ∣E∣ 项从"乘以 log ∣ V ∣ \log |V| log∣V∣"降到了"加上"的位置。这在稠密图( ∣ E ∣ ≈ ∣ V ∣ 2 |E| \approx |V|^2 ∣E∣≈∣V∣2)上是一个显著的渐进改进。类似地,Prim 最小生成树算法也能获得同样的优化效果。
不过,必须坦率地指出一个事实:斐波那契堆虽然在理论上极其优美,但它的常数因子相当大。每个结点需要维护多条指针,级联剪切和合并整理的实现细节也比较繁琐。在实际工程中,采用简化实现的配对堆,或者在某些场景下直接用数组实现的二叉堆,往往因为常数小、缓存友好而拥有更好的实测性能。尽管如此,斐波那契堆在理论上证明了"这些操作可以在常数摊还时间内完成"这一上界的存在性,其思想深刻影响了后续数据结构的设计。
6 小结
斐波那契堆将"策略性懒惰"推到了极致:能不现在做的整理工作,就绝对不做,全部扔给删除最小元的时候统一处理。这种设计,使得插入、合并和减小关键字操作都获得了 O ( 1 ) O(1) O(1) 的摊还代价,而仅在删除最小元时付出 O ( log n ) O(\log n) O(logn) 的代价。摊还分析------具体而言是势能方法------在整个论证中扮演了核心角色:势函数 Φ ( H ) = t ( H ) + 2 m ( H ) \Phi(H) = t(H) + 2m(H) Φ(H)=t(H)+2m(H) 精确地量度了堆的"混乱程度",正是这种混乱程度的波动,为那些偶尔昂贵但能显著降低混乱的操作提供了"预算"。