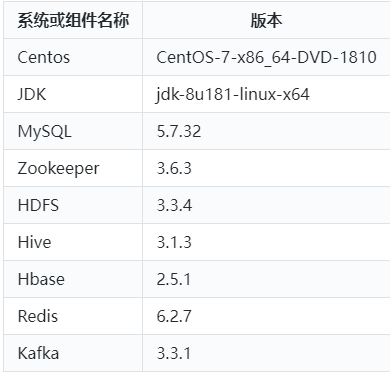
Flink可以运行在所有类unix环境中,例如:Linux,Mac OS 和Windows,一般企业中使用Flink基于的都是Linux环境,后期我们进行Flink搭建和其他框架整合也是基于linux环境,使用的是Centos7.6版本,JDK使用JDK8版本(Hive版本不支持JDK11,所以这里选择JDK8),本小节主要针对Flink集群使用到的基础环境进行配置,不再从零搭建Centos系统,另外对后续整合使用到的技术框架也一并进行搭建,如果你目前已经有对应的基础环境,可以忽略本小节,Linux及各个搭建组件使用版本如下表所示。
Centos7节点配置
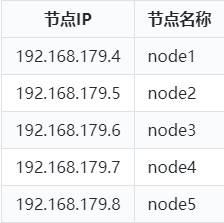
这里准备5台Linux节点,节点名称和ip信息如下,我们可以从头搭建各个Linux节点也可以基于已有快照创建各个Linux节点。
这里默认已经创建好以上各个节点,并且每个节点分配资源为4核2G,下面进行节点的其他配置。
配置各个节点的Ip
启动每台节点,在对应的节点路径"/etc/sysconfig/network-scripts"下配置ifg-ens33文件配置IP(注意,不同机器可能此文件名称不同,一般以ifcfg-xxx命名),以配置ip 192.168.179.4为例,ifcfg-ens33配置内容如下:
TYPE=Ethernet
BOOTPROTO=static #使用static配置
DEFROUTE=yes
PEERDNS=yes
PEERROUTES=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_PEERDNS=yes
IPV6_PEERROUTES=yes
IPV6_FAILURE_FATAL=no
ONBOOT=yes #开机启用本配置
IPADDR=192.168.179.4 #静态IP
GATEWAY=192.168.179.2 #默认网关
NETMASK=255.255.255.0 #子网掩码
DNS1=192.168.179.2 #DNS配置 可以与默认网关相同

配置主机名
在每台节点上修改/etc/hostname,配置对应的主机名称,参照节点IP与节点名称对照表分别为:node1、node2、node3、node4、node5。配置完成后 需要重启 各个节点,才能正常显示各个主机名。
关闭防火墙

关闭SELinux
SELinux就是Security-Enhanced Linux的简称,安全加强的linux。传统的linux权限是对文件和目录的owner, group和other的rwx进行控制,而SELinux采用的是委任式访问控制,也就是控制一个进程对具体文件系统上面的文件和目录的访问,SELinux规定了很多的规则,来决定哪个进程可以访问哪些文件和目录。虽然SELinux很好用,但是在多数情况我们还是将其关闭,因为在不了解其机制的情况下使用SELinux会导致软件安装或者应用部署失败。
在每台节点/etc/selinux/config中将SELINUX=enforcing改成SELINUX=disabled即可。
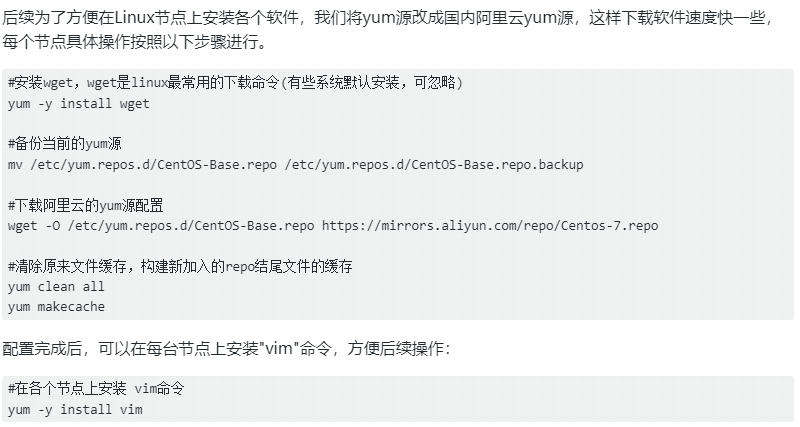
配置阿里云yum源
设置Linux 系统显示中文/英文

设置自动更新时间

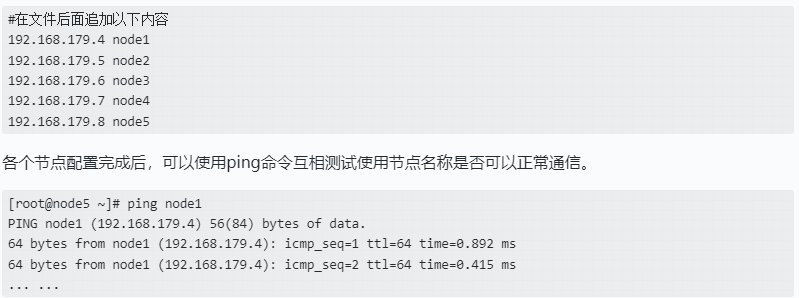
设置各个节点之间的ip映射
每个节点都有自己的IP和主机名,各个节点默认进行文件传递或通信时需要使用对应的ip进行通信,后续为了方便各个节点之间的通信和文件传递,可以配置各个节点名称与ip之间的映射,节点之间通信时可以直接写对应的主机名称,不必写复杂的ip。每台节点具体操作按照以下操作进行。
进入每台节点的/etc/hosts下,修改hosts文件,vim /etc/hosts:
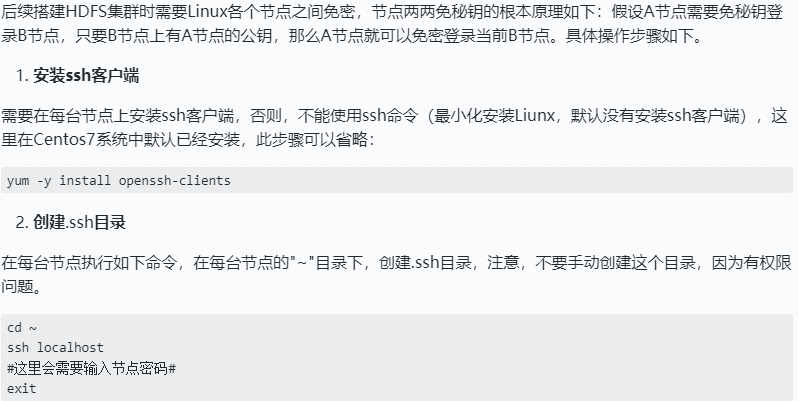
配置节点之间免密访问

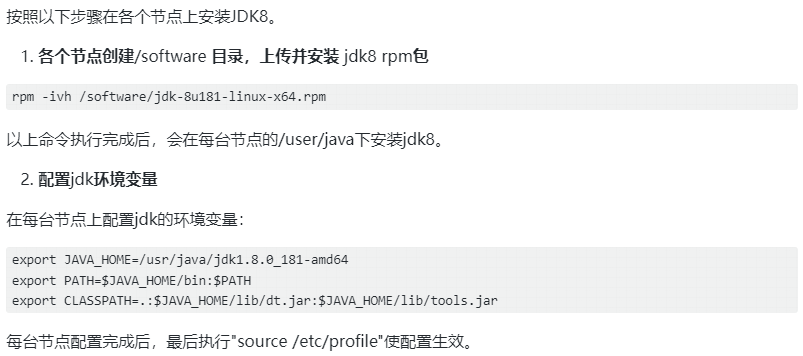
安装JDK
安装MySQL
节点划分

安装MySQL

配置MySQL
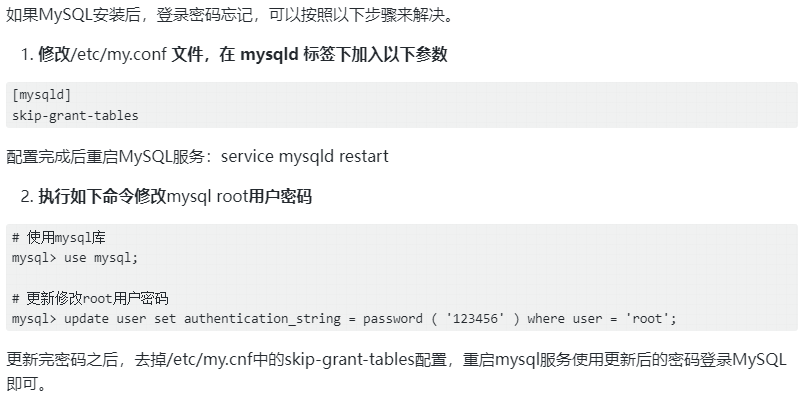
 Mysql密码忘记处理
Mysql密码忘记处理
安装Zookeeper
节点划分

安装Zookeeper


安装HDFS
节点划分
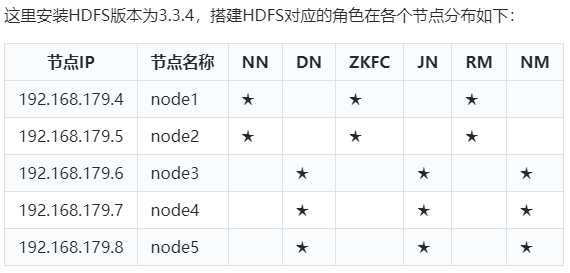
安装配置HDFS

html
<configuration>
<property>
<!--这里配置逻辑名称,可以随意写 -->
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<!-- 禁用权限 -->
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<!-- 配置namenode 的名称,多个用逗号分割 -->
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<!-- dfs.namenode.rpc-address.[nameservice ID].[name node ID] namenode 所在服务器名称和RPC监听端口号 -->
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node1:8020</value>
</property>
<property>
<!-- dfs.namenode.rpc-address.[nameservice ID].[name node ID] namenode 所在服务器名称和RPC监听端口号 -->
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node2:8020</value>
</property>
<property>
<!-- dfs.namenode.http-address.[nameservice ID].[name node ID] namenode 监听的HTTP协议端口 -->
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node1:50070</value>
</property>
<property>
<!-- dfs.namenode.http-address.[nameservice ID].[name node ID] namenode 监听的HTTP协议端口 -->
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node2:50070</value>
</property>
<property>
<!-- namenode 共享的编辑目录, journalnode 所在服务器名称和监听的端口 -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node3:8485;node4:8485;node5:8485/mycluster</value>
</property>
<property>
<!-- namenode高可用代理类 -->
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!-- 使用ssh 免密码自动登录 -->
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<!-- journalnode 存储数据的地方 -->
<name>dfs.journalnode.edits.dir</name>
<value>/opt/data/journal/node/local/data</value>
</property>
<property>
<!-- 配置namenode自动切换 -->
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
配置$HADOOP_HOME/etc/hadoop/yarn-site.xml
html
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<!-- 配置yarn为高可用 -->
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<!-- 集群的唯一标识 -->
<name>yarn.resourcemanager.cluster-id</name>
<value>mycluster</value>
</property>
<property>
<!-- ResourceManager ID -->
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<!-- 指定ResourceManager 所在的节点 -->
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node1</value>
</property>
<property>
<!-- 指定ResourceManager 所在的节点 -->
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node2</value>
</property>
<property>
<!-- 指定ResourceManager Http监听的节点 -->
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node1:8088</value>
</property>
<property>
<!-- 指定ResourceManager Http监听的节点 -->
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node2:8088</value>
</property>
<property>
<!-- 指定zookeeper所在的节点 -->
<name>yarn.resourcemanager.zk-address</name>
<value>node3:2181,node4:2181,node5:2181</value>
</property>
<property>
<!-- 关闭虚拟内存检查 -->
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 启用节点的内容和CPU自动检测,最小内存为1G -->
<!--<property>
<name>yarn.nodemanager.resource.detect-hardware-capabilities</name>
<value>true</value>
</property>-->
</configuration>
初始化HDFS
bash
#在node3,node4,node5节点上启动zookeeper
zkServer.sh start
#在node1上格式化zookeeper
[root@node1 ~]# hdfs zkfc -formatZK
#在每台journalnode中启动所有的journalnode,这里就是node3,node4,node5节点上启动
hdfs --daemon start journalnode
#在node1中格式化namenode
[root@node1 ~]# hdfs namenode -format
#在node1中启动namenode,以便同步其他namenode
[root@node1 ~]# hdfs --daemon start namenode
#高可用模式配置namenode,使用下列命令来同步namenode(在需要同步的namenode中执行,这里就是在node2上执行):
[root@node2 software]# hdfs namenode -bootstrapStandby启动及停止
#node1上启动HDFS,启动Yarn
root@node1 sbin# start-dfs.sh
root@node1 sbin# start-yarn.sh
注意以上也可以使用start-all.sh命令启动Hadoop集群。
#停止集群
root@node1 \~# stop-dfs.sh
root@node1 \~# stop-yarn.sh
注意:以上也可以使用 stop-all.sh 停止集群。
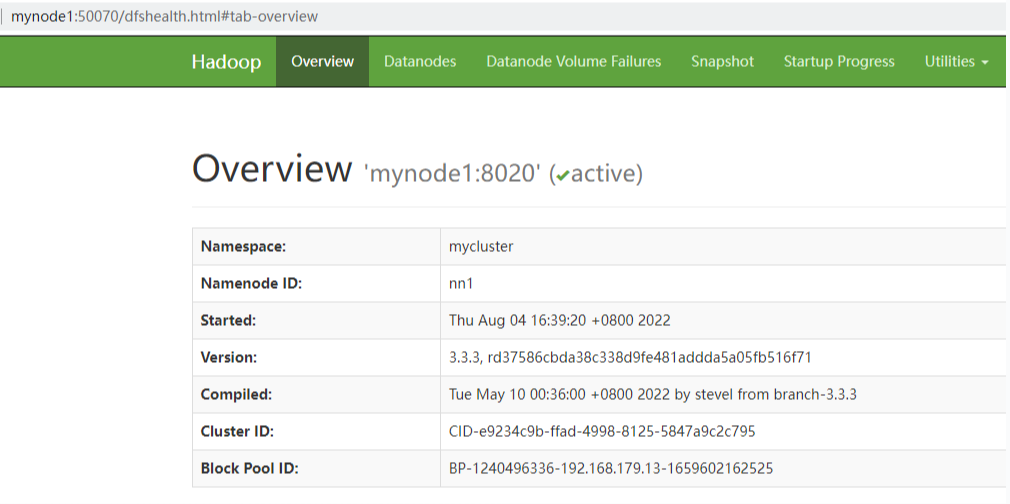
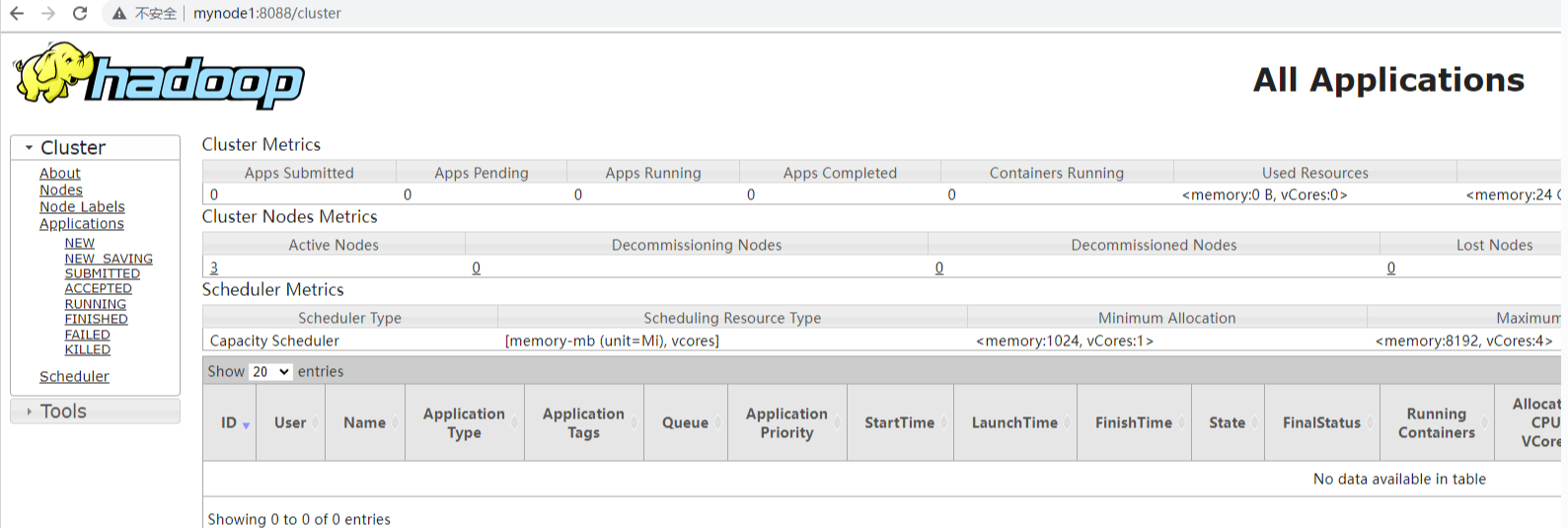
访问WebUI