"The Bitter Lesson"(苦涩的教训) 是由强化学习先驱理查德·萨顿(Rich Sutton)于2019年撰写的一篇标志性文章。
核心内容
一个贯穿人工智能 70 年历史的残酷客观规律:
-
人类知识派(Domain-specific Insights):试图人类对特定领域的理解(如规则、知识、经验)精心编码到AI系统中,这种方法:
- 短期内通常有效并带来成就感;
- 从长期看,人为注入知识的方法往往很快触及瓶颈,甚至成为进一步突破的阻碍。
-
通用计算派(General-purpose Methods):利用持续增长的算力,通过搜索和学习等通用方法,让AI自己从海量数据中发现规律和策略。
许多人毕生致力于用人类智慧构建精巧的系统,但历史一次次证明,那些看似"笨拙"、依赖暴力计算的通用方法,最终反而以压倒性优势胜出。
经典案例
支撑这一论点的经典案例广泛分布于AI的各个分支领域。
- 1997年卡斯帕罗夫的"深蓝"依靠的是大规模深度搜索击败国际象棋世界冠军,而非人类棋理知识。
- 围棋领域,AlphaGo/AlphaZero通过自我对弈和海量算力碾压了所有基于人类知识的系统。
- 语音识别和计算机视觉:卷积神经网络等通用学习方法自动习得的视觉模式全面超越了手工设计的特征工程(程序员精心编写边缘检测、形状识别等算法)。
启示
综合论述、近年来的学术争论以及AI产业的实践经验:
- 理解算力与算法设计的正确关系。研究者应当设计那些"能随算力增长而持续受益"的通用算法结构------构建一个能容纳海量计算和数据的"容器",让AI自己去发现知识。
- 警惕知识的"短期主义陷阱"。人类知识在短期内几乎总能带来性能提升,这很容易让研究者产生路径依赖和心理承诺,进而在错误的方向上越走越远。
- 下一代AI的突破点可能在于经验学习而非数据模仿。真正的智能究竟是来自对既有知识的统计建模,还是来自与世界的持续交互?
- 保持知性谦逊。不要高估人类既有知识的长期价值,低估通用计算规模化的颠覆性力量。"
在 AI 中体现
这一思想为大语言模型(LLM)革命提供了核心的理论支撑。GPT-3及其后继者正是其直接的实践产物:它们采用通用架构,在海量数据上以巨大算力训练而成,性能提升与规模扩展之间的相关性远强于与架构精巧度之间的关系。
Transformer 一统天下与 Scaling Law 的确立:当前大语言模型(LLM)的绝对统治地位,正是这一理论的工业级投射。OpenAI 坚定不移推进的 Scaling Law(缩放定律)------即模型性能随着计算量、数据集大小和参数量的指数级增长而线性提升------本质上就是"Bitter Lesson"的量化版。
- 抛弃语言学结构:过去自然语言处理(NLP)依赖的句法分析、词性标注等人类知识被全部废弃,取而代之的是最纯粹的 Next-token 预测。
"合成数据"与"强化学习"的自我演进:随着人类高质量文本数据即将耗尽,AI 界开始全面转向使用大算力在虚拟/模拟环境中进行自我博弈或强化学习(如 OpenAI o1/o3 的推理模型、DeepSeek-R1)。
- o1 / R1 模型的本质:通过在推理阶段(Inference-time)投入数倍的算力进行搜索(Search)与自我纠错(Learning),AI 表现出了超越人类专家预设模板的思考能力。
具身智能与计算机视觉的范式转移:在计算机视觉(CV)和机器人领域,过去依赖于人工定义的几何特征(如 SIFT 特征、逆运动学精确数学建模)。而现在的趋势是 End-to-End(端到端)大模型,直接给足算力和视频数据,让模型自己去理解物理世界的规律。
但,LLM的训练数据全部来自人类生成且数量有限------数据是"AI的化石燃料"。当前已经接近"数据峰值";而且,LLM缺乏通过环境反馈持续优化行为的能力,它们学习的是"某个人会说什么",而非"世界会发生什么"。
工程中的权衡
不要试图用人类当前的傲慢与微观经验,去对抗摩尔定律和数学统计的宏大尺度。 优秀的系统软件和架构,往往不是那些最复杂的,而是那些最简单的、能够最完美地将硬件算力转化为智能输出的系统。
架构设计原则:拥抱"通用性",警惕"过度工程"
- 反面模式(Anti-Pattern):在系统底层硬编码过多的业务逻辑、先验假设或严格的基于规则的过滤器。这些设计在初期能解决80%的问题,但在面对复杂长尾场景时会成为限制系统演进的"技术债"。
- 健壮方案:设计精简、高度并行化、能够吞噬算力的通用架构。将系统设计为"计算的容器",而不是"知识的容器"。让数据和优化器去决定系统行为,而不是由架构师的直觉决定。
系统优化重心:向"数据流"与"计算吞吐"倾斜
既然算法趋于简单通用(例如由堆叠的 Attention 块组成的模型),系统软件工程师的战场就从"算法优化"变成了"极致的系统工程优化":
- 数据流水线(Data Pipeline):如何以微秒级的延迟源源不断地为计算单元喂入高密度、洗净的数据。
- 扩展性(Scalability):设计无状态、高并发、支持万卡乃至百万卡级别片上超高速互联(如 NVLink、Ultra Ethernet)的分布式计算系统。降低通信开销,确保计算效率不随算力规模扩大而发生灾难性衰减。
防御性工程思维:兼顾"暴力美学"与"确定性边界"
- 虽然"Bitter Lesson"在长期看是正确的,但在工业落地和商业交付中,纯粹的概率性模型(Non-probabilistic elements)存在不可控性(幻觉、边界对齐问题)。
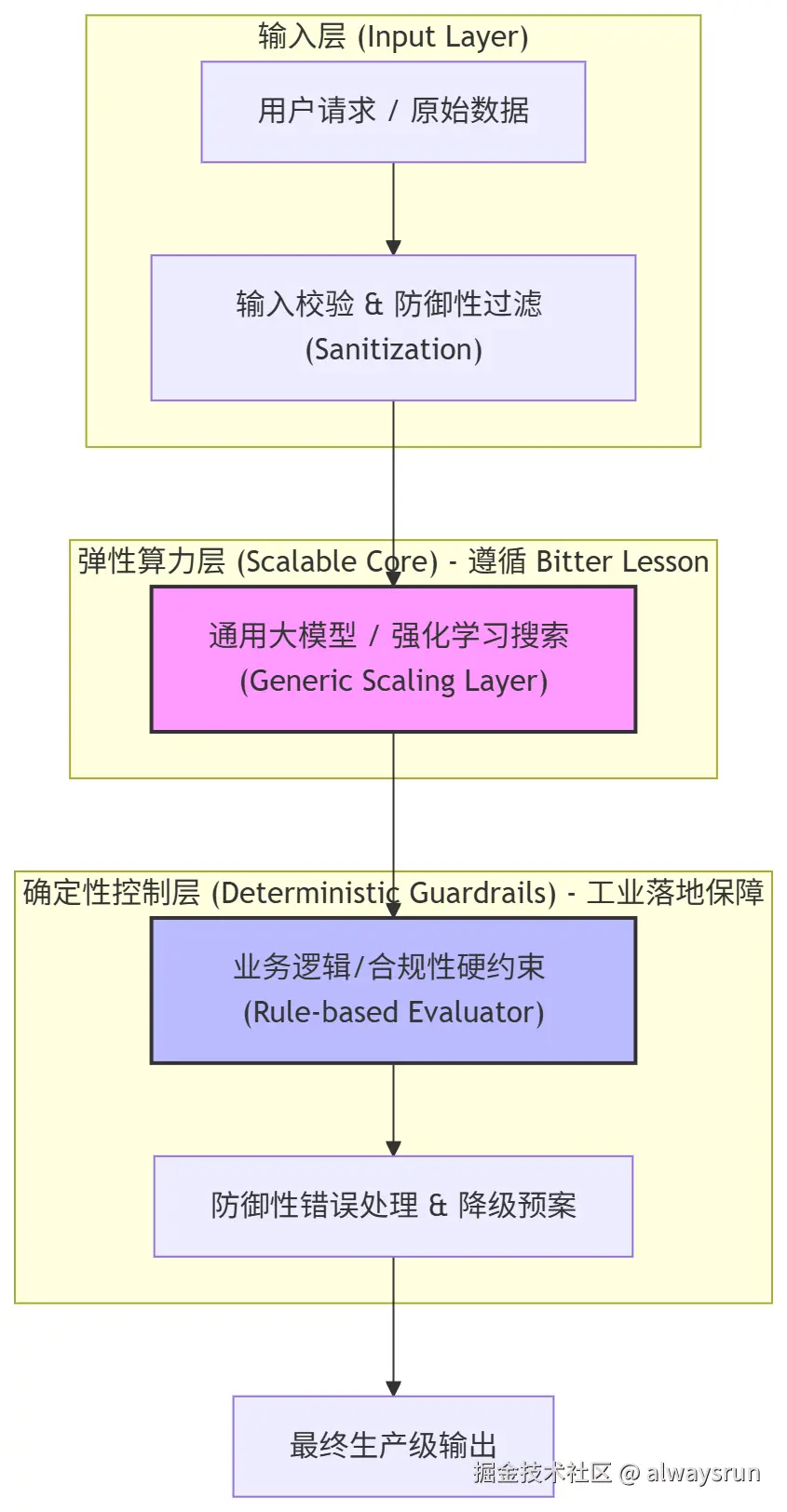
核心权衡:把核心理解与生成能力交给的通用大模型,而把安全合规、财务结算、硬性业务约束交给基于经典软件工程的确定性控制层,绝不让系统静默失败。
本文使用 markdown.com.cn 排版