
Lance 是 ByteDance Intelligent Creation Lab 推出的原生统一多模态模型,以 3B 激活参数和多任务协同训练,在单一原生统一框架中支持图像/视频理解、生成与编辑,兼顾资源效率、能力广度与跨任务泛化。
基于 3B 激活参数量(总参数 6B),以及最大 128-GPU 训练预算下,Lance 在多个统一多模态基准上取得强性能:VBench 85.11、MVBench 62.0、GenEval 0.90、GEdit-Bench 7.30。相关主页、论文、代码与模型资源已发布,欢迎社区关注与体验。
Homepage:
lance-project.github.ioarXiv:
arxiv.org/abs/2605.18...Code (GitHub):
github.com/bytedance/L...Code (HuggingFace):
huggingface.co/bytedance-r...
多模态理解和生成能力的统一,一直是业界关注的重点方向。然而,当前主流的学术研究模型仍面临两方面不足:
- 模型规模与成本较高。 许多统一模型依赖更高参数量来兼顾理解、生成与编辑,训练和部署成本较高。
- 任务覆盖有限。 多数工作仍集中在文本-图像任务或部分能力组合上,对视频统一模型领域探索不足。
此外,对现有多模态统一模型的统计结果显示,任务覆盖更完整的统一模型更有可能表现出 emergent generalization(涌现泛化)能力。这意味着,多任务协同并非简单的能力堆叠,而可能是激发统一模型进一步潜能的重要机制。
基于这一观察,Lance 将 X2T、X2I、X2V 任务放入同一原生模型中进行联合训练,覆盖图像理解、视频理解、文本到图像/视频生成、图像/视频编辑、主体驱动图像/视频生成等多重任务。Table 1 对比了代表性统一多模态模型的任务覆盖范围,Lance 在图像/视频理解、图像/视频生成、编辑、主体驱动生成以及 emergent generalization 等维度上提供了更完整的显式支持。
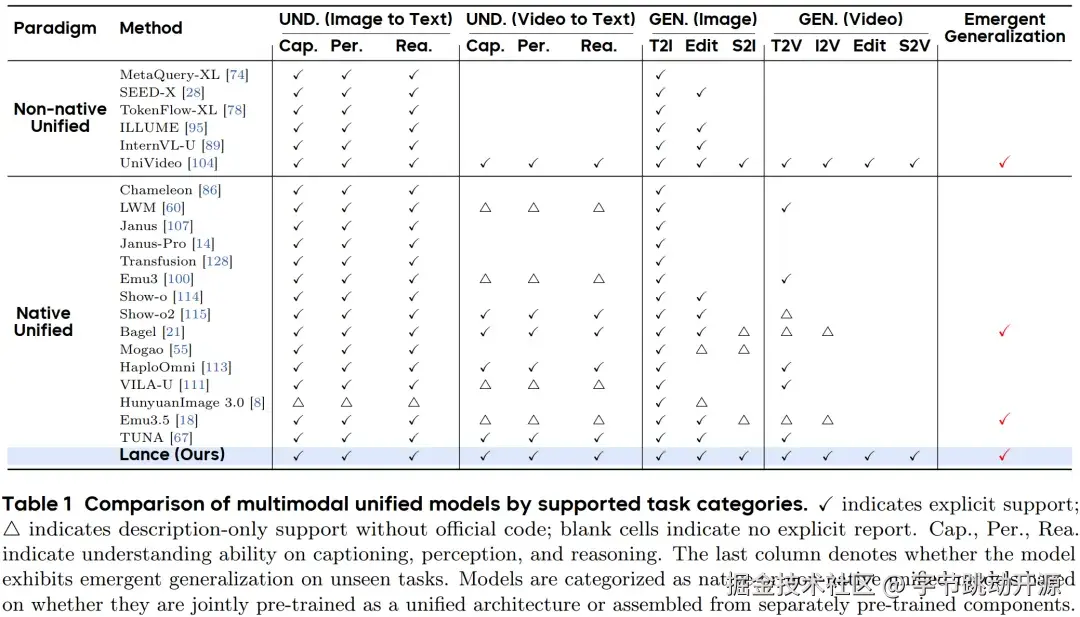
统一多模态模型任务覆盖范围对比
团队开源了 Lance,同 AI 社区分享团队在这一领域的研究探索。
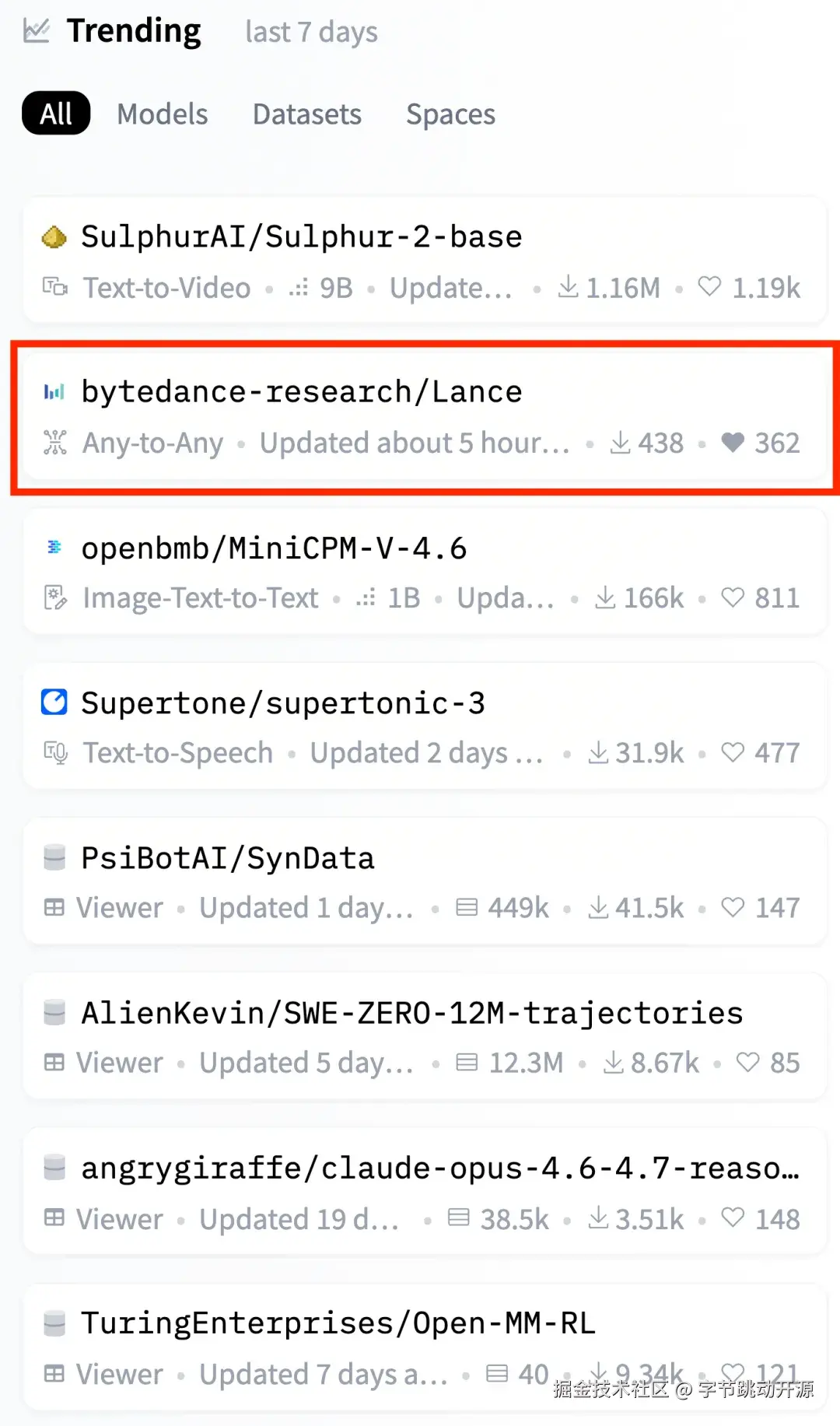
Lance 位列 Hugging Face Trending 前三
1. Lance 能力展示:面向视频与图像的多任务统一支持
Lance 的核心优势之一,是在 3B 模型规模下提供更完整的多任务支持。它不是将若干模块简单拼接,而是在统一上下文空间中联合建模不同模态与任务,使理解、生成和编辑能力能够相互促进。
视频生成
Lance 在视频生成中能够准确遵循复杂文本指令,生成具备自然运动、稳定时序一致性、清晰视觉细节和较强语义表达的视频内容。




视频生成:复杂文本指令下的视频生成示例
视频编辑
Lance 在视频编辑中能够根据文本指令实现对象替换、背景变化、风格迁移与细粒度属性修改,同时保持主体身份、画面结构和运动过程的时序一致性,并支持多轮一致性编辑。

source video

replace short straight hair with French curly hair

add a floral headband with red and white flowers to her hair

change the background to a fairytale castle by a lake
视频编辑:多轮一致性编辑示例
视频理解
Lance 在视频理解中能够准确识别动态场景中的人物、物体、动作与时序变化,并结合视觉细节、OCR 信息和上下文语义生成细致可靠的描述与问答结果。

视频理解:视频问答与细粒度时序理解示例
图像生成
Lance 可根据复杂文本指令生成较高质量、视觉自然的图像内容,并在数量关系、属性绑定、空间布局和风格控制等方面展现出较强的组合生成能力。

图像生成:复杂文本指令下的图像生成示例
图像编辑
Lance 可基于自然语言指令完成图像中的主体增删、局部替换、风格迁移、动作调整和自由形式编辑,并在修改过程中较好地保持主体身份、画面结构和视觉一致性。
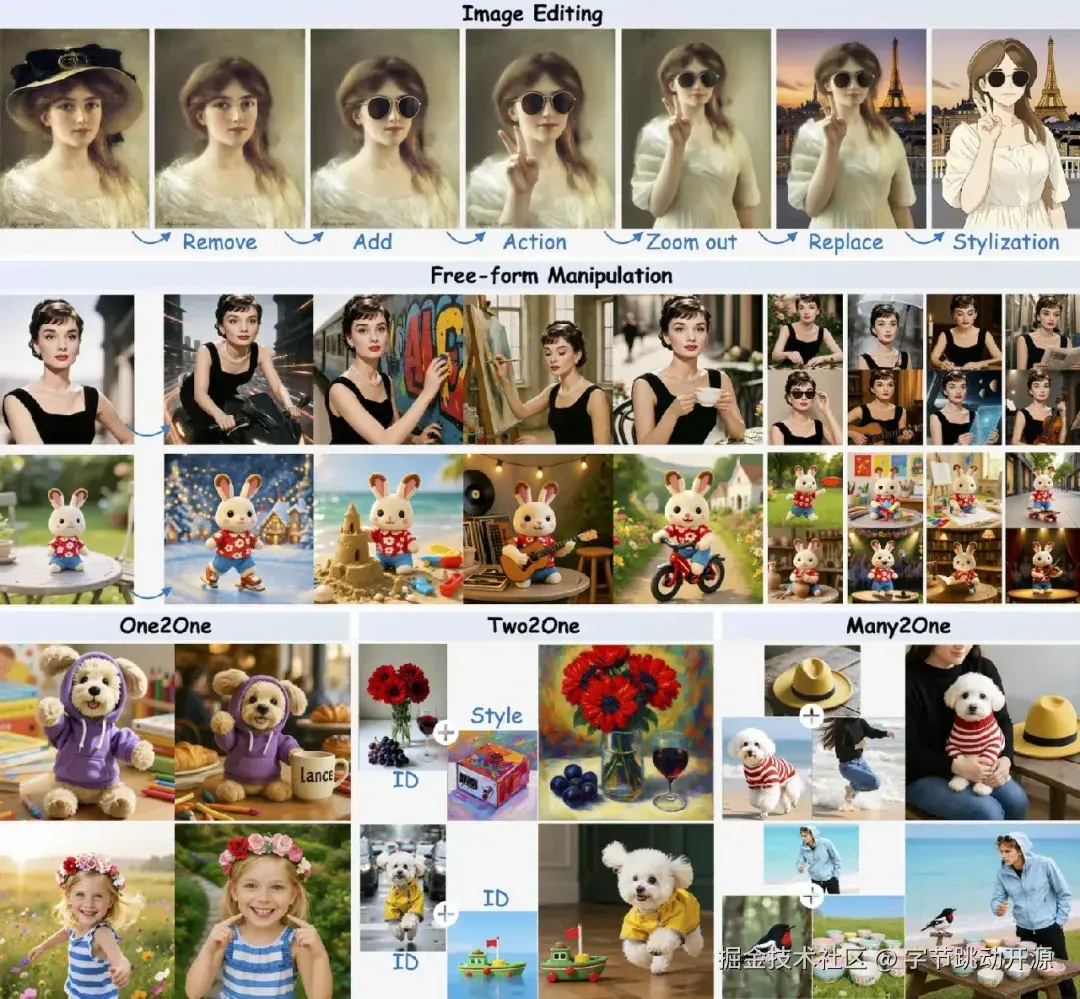
图像编辑:多类型图像编辑与主体一致性生成示例
图像理解
Lance 具备较强的图像理解能力,可准确识别图像中的物体、人物、场景、文字信息和空间关系,并结合视觉细节完成内容描述、OCR 理解和问答推理。

图像理解:OCR、知识问答与多图理解示例
2. 方法核心:统一上下文建模 + 解耦能力路径
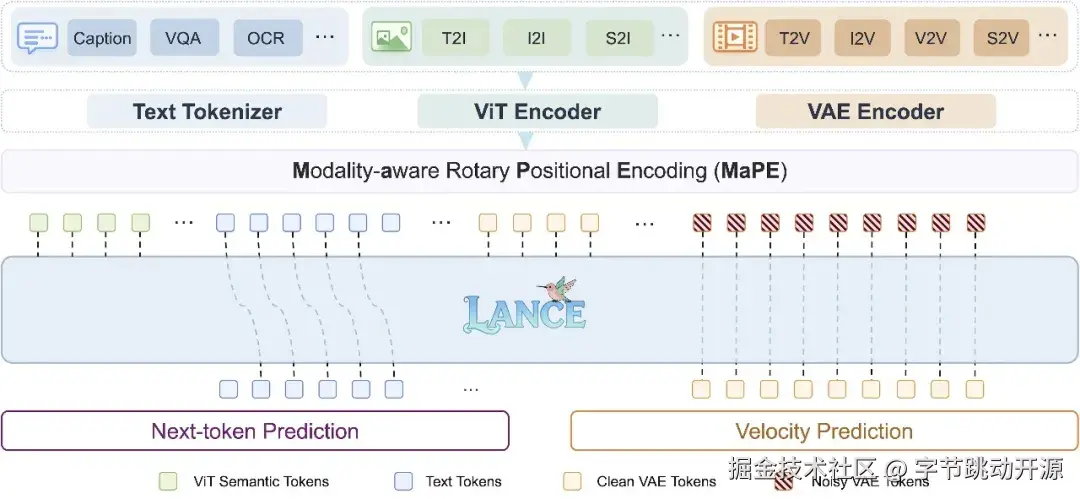
Lance 整体架构示意图
Lance 的核心设计围绕两个原则展开:一方面,通过统一上下文建模,将文本、图像和视频组织为共享的交错多模态序列,使不同任务能够在同一上下文空间中进行信息交互;另一方面,通过解耦能力路径,为理解和生成分别分配专门化的表征与模型容量,避免异质任务在优化目标和视觉表示上相互干扰。
具体来看,Lance 采用 dual-stream mixture-of-experts 架构:理解路径主要处理文本 token 与语义视觉 token,用于图像/视频理解、问答和推理;生成路径主要处理 VAE latent token,用于图像/视频生成与编辑。两条路径共享统一的交错多模态上下文,但在能力建模上保持解耦,从而兼顾跨任务交互与任务专门化。
此外,为了更好地协调统一序列中的异构视觉 token,Lance 引入了 Modality-Aware Rotary Positional Encoding(MaPE) 。在统一多模态训练中,同一序列中可能同时包含用于理解的语义 ViT token、用于生成条件的 clean VAE token,以及作为生成目标的 noisy VAE token。它们来源不同、功能不同,如果仅使用标准位置编码,容易造成位置空间中的角色混淆。
MaPE 通过在位置编码的时间维度中加入模态/功能组信息,使得模型在不破坏图像的空间结构和视频的时序关系的同时,能够显式区分不同视觉 token 的作用。整体而言,MaPE 有助于缓解多任务联合优化过程中的异构视觉 token 之间的位置干扰,并提升跨任务上下文对齐能力。
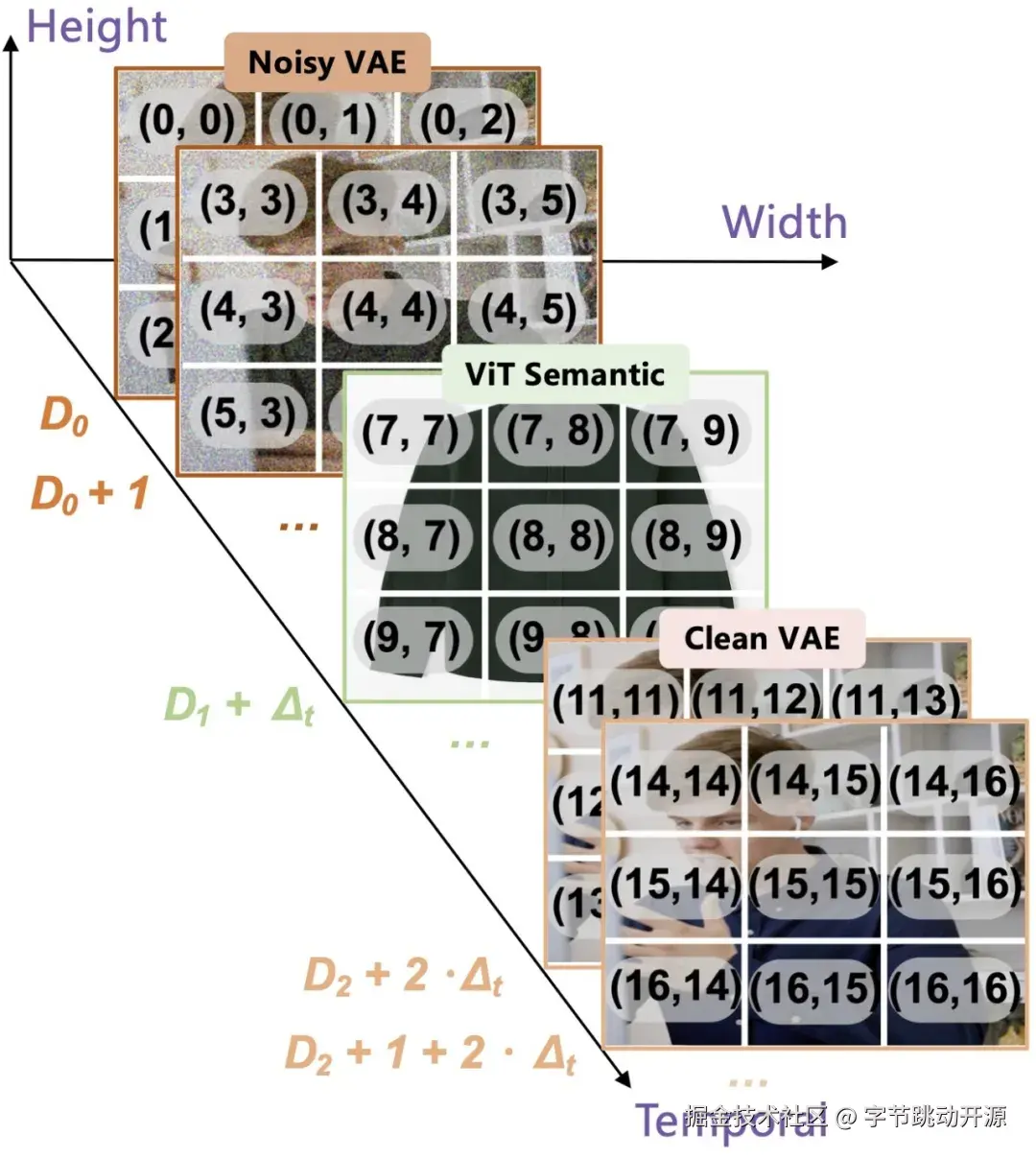 MaPE 通过显式区分异构视觉 token 的功能角色,提升统一上下文中的跨任务对齐能力
MaPE 通过显式区分异构视觉 token 的功能角色,提升统一上下文中的跨任务对齐能力
3. 多任务协同训练:激发统一模型的进一步潜能
训练方面,Lance 采用分阶段多任务训练范式,将不同任务统一到 X2T、X2I、X2V 的任务形式中,并通过能力导向目标与自适应数据调度逐步增强模型能力。
整体训练流程包括预训练、持续训练、监督微调和强化学习阶段。预训练建立基础图像/视频理解与生成能力;持续训练扩展到更多交错多任务数据,促进跨任务迁移;监督微调用高质量数据强化指令跟随、视觉保真、编辑准确性和身份一致性;强化学习进一步优化图像生成中的细粒度文本约束、图文一致性和组合遵循能力。
为了进一步分析模型能力随训练推进的变化,Lance 对不同训练 token 预算下的模型版本进行了动态评估。结果显示,图像生成和视频生成能力随着训练 token 增加呈现出较一致的 scaling trend:在早期预训练阶段,模型快速获得基础生成能力;随着持续训练和监督微调推进,模型进一步提升复杂 prompt 对齐、视觉保真度以及视频时序一致性。
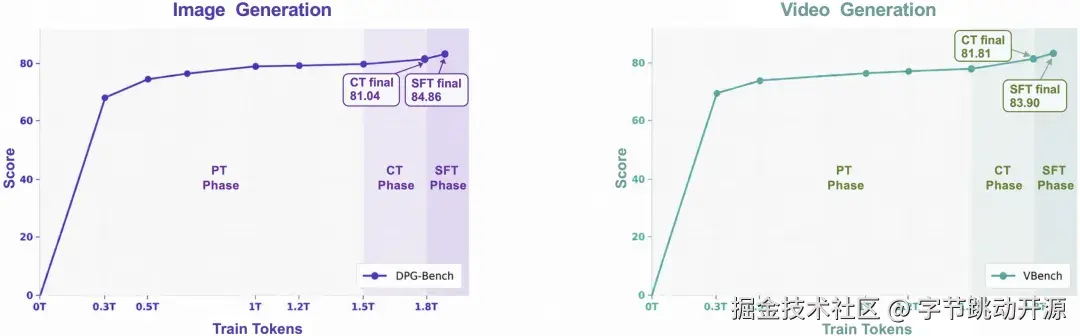
Lance 图像与视频生成能力随训练 token 增加持续提升,CT阶段的增长体现出多任务协同训练对统一模型能力演化的促进作用
值得注意的是,持续训练阶段在不引入额外的基础生成类数据,仅引入更多图像/视频编辑、主体驱动生成等多任务数据的情况下,模型的基础生成能力仍然继续提升。这说明多任务数据并未削弱基础生成能力,反而通过更丰富的任务监督促进了视觉组合、语义对齐和跨任务泛化能力的发展。
消融实验也进一步表明,多任务生成数据都能为生成能力和理解能力均带来增益。结合 Table 1 中关于 emergent generalization 的观察,Lance 的结果进一步支持这一观点:多任务协同不是能力的线性叠加,而是帮助统一模型在跨模态、跨任务边界上形成迁移与泛化的重要路径。
4. 性能评估
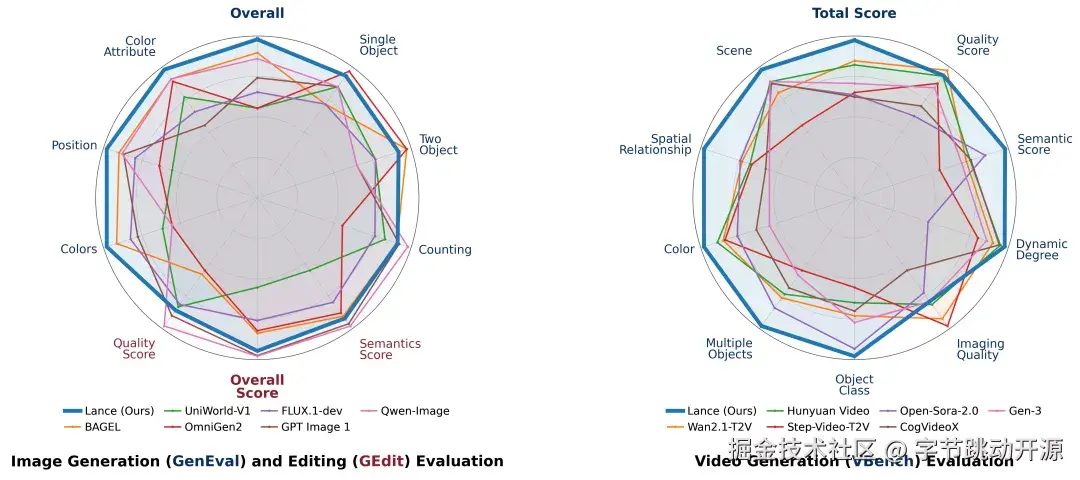
在图像生成方面,Lance 在 GenEval 上达到 0.90,与统一模型中的最佳总体分数持平,并在计数、颜色、空间位置等组合生成维度表现突出。在 DPG-Bench 上,Lance 在复杂 prompt 下展现出较好的关系建模能力。
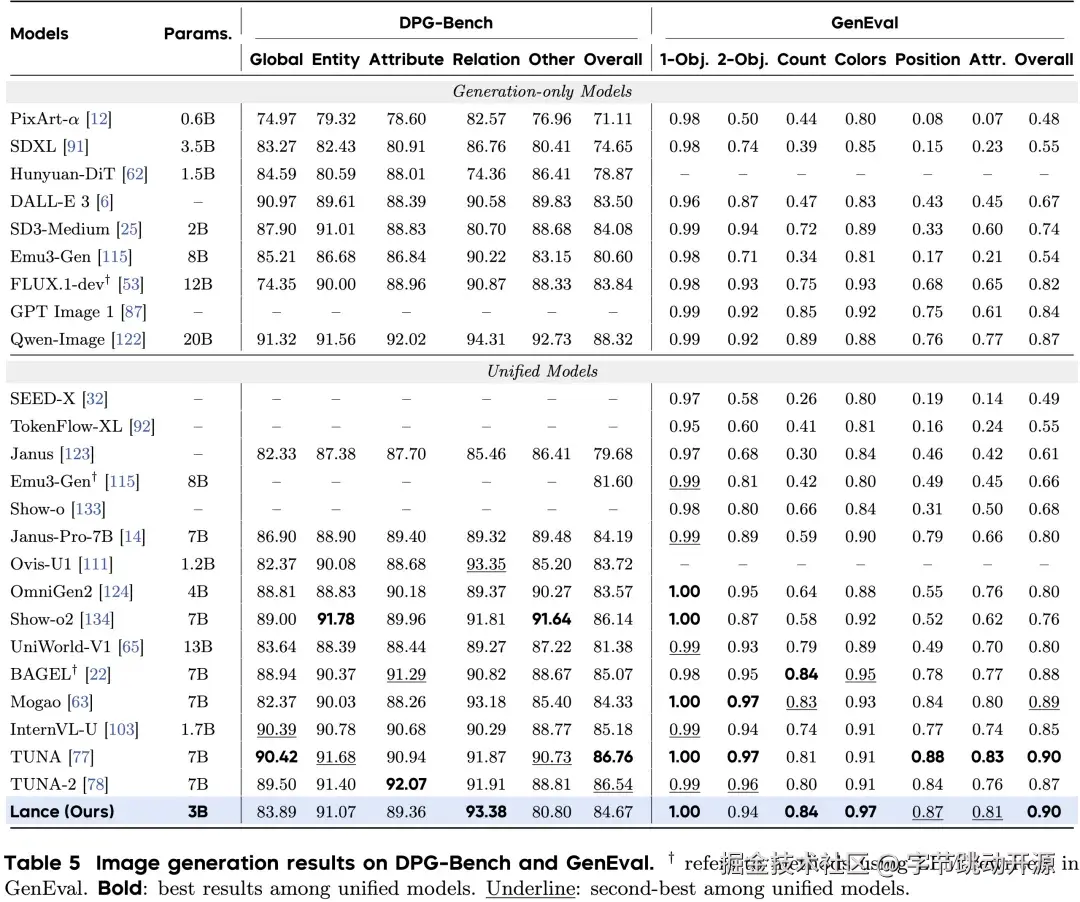
图像生成:GenEval 与 DPG-Bench 指标对比
在视频生成方面,Lance 在 VBench 上取得 85.11 的总体分数,在统一模型中表现领先,并在视觉质量、对象语义对齐、颜色一致性、空间关系、场景理解、时序风格等维度展现出稳定性能。这说明 Lance 的统一框架不仅适用于图像生成,也能够扩展到更具时序建模难度的视频生成任务。
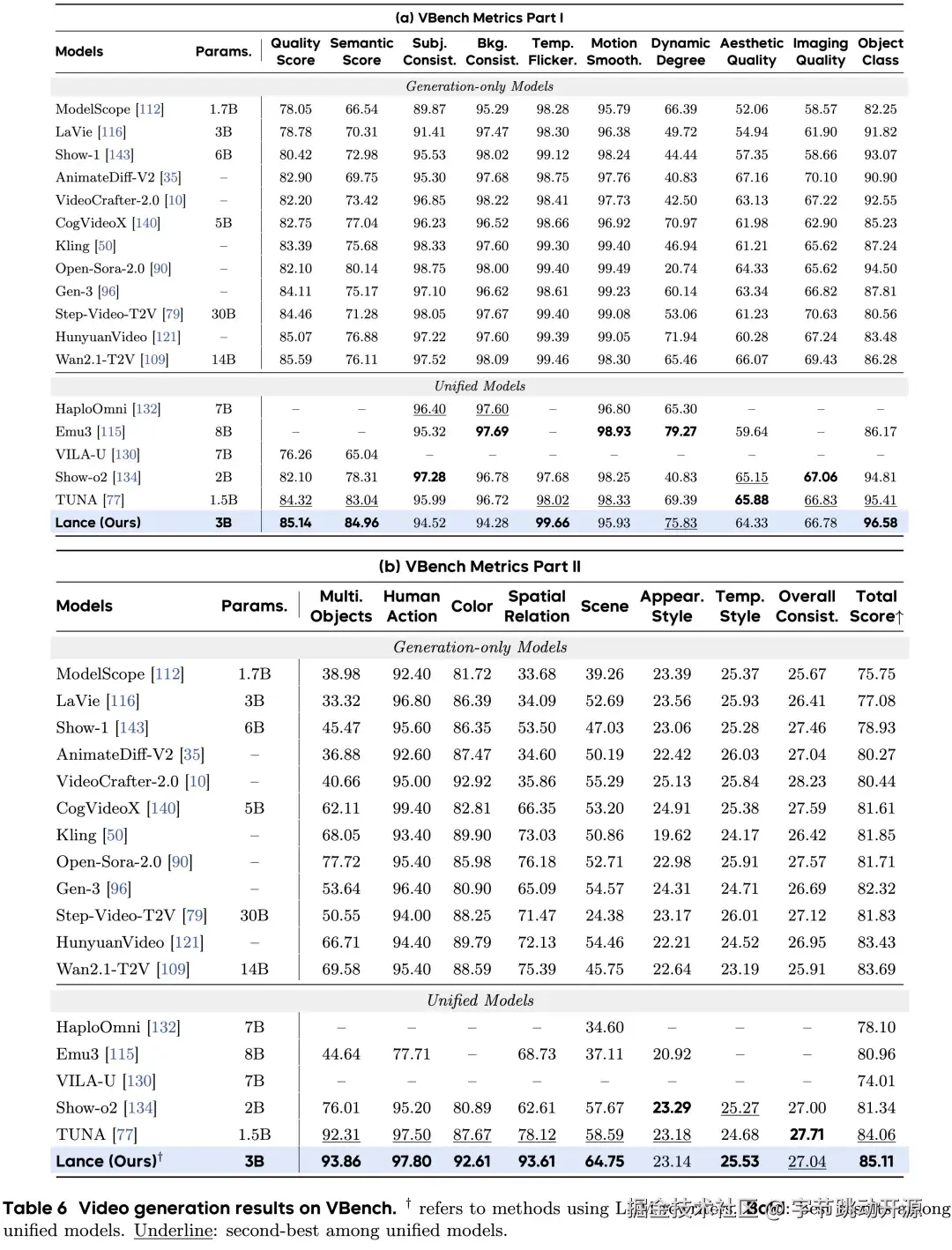
视频生成:VBench 指标对比
在多模态编辑方面,Lance 在图像编辑基准 GEdit-Bench 上取得 7.30 Avg/G_O,在统一模型中取得最佳平均表现,覆盖背景改变、材质修改、动作改变、人像美化、主体移除、替换和色调迁移等多类编辑任务。
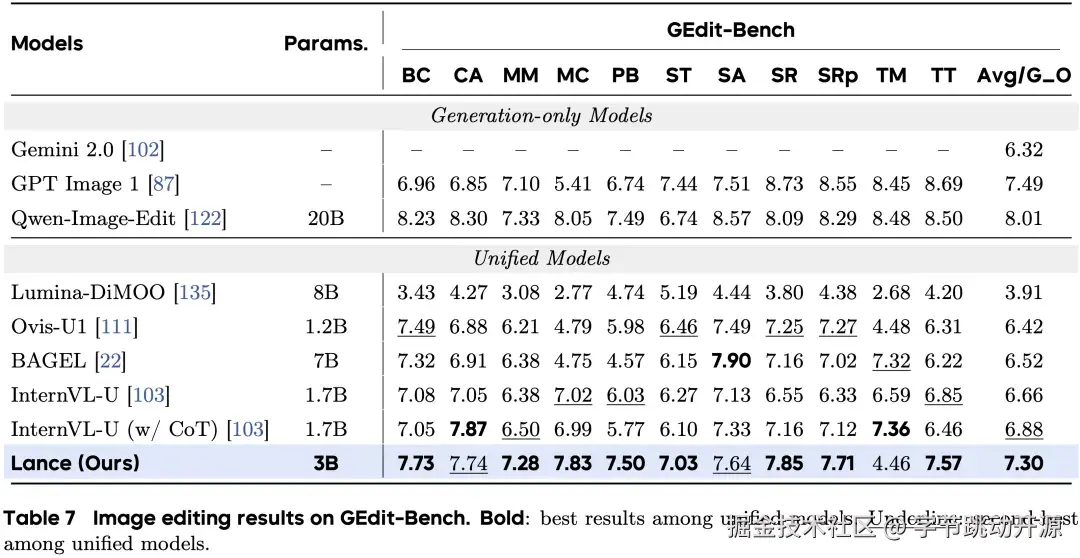
图像编辑:GEdit-Bench 指标对比
在多模态理解方面,Lance 在视频理解基准 MVBench 上达到 62.0,在已有统一多模态模型中取得最佳总体分数,相比第二名 Show-o2 7B 约有 11.3% 的相对提升,同时保持生成和编辑能力。这表明多任务统一训练可以在引入视频生成和编辑能力的同时,保留较强的视频语义理解与时序推理能力。
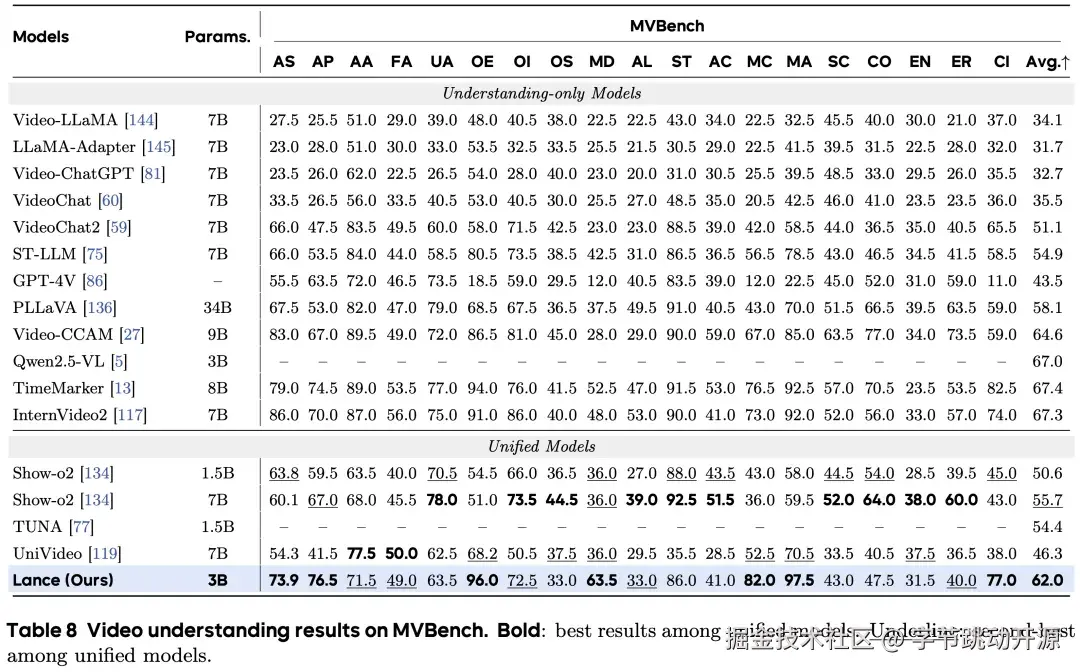
视频理解:MVBench 指标对比
目前,ByteDance 团队已开放 Lance 的模型权重和代码,欢迎大家体验和反馈。
Lance 以 3B 激活参数量统一支持图像/视频理解、生成与编辑,可作为多模态理解、多模态生成及理解-生成统一建模研究的轻量级 backbone。其参数规模也更适合实验室规模的 SFT、RL 等 post-training 探索,欢迎社区基于 Lance 开展更多高效统一多模态模型研究。