我跑了一遍 MAISI-v2:30 步生成 512×512×256 的 3D 脑部 MRI
前阵子在调一个脑部肿瘤分割模型,long tail 的几类样本怎么都凑不够------胶质母细胞瘤的 T2 FLAIR 序列尤其少,公开数据集合起来撑死几百例。手动 augment 翻不出花来,旋转翻转加噪声跑出来的样本下游模型一眼就看穿。
正巧 NV-Generate-CTMR 整个开源了,里头的 MAISI-v2 用的是 Latent Rectified Flow 而不是传统的 DDPM------号称推理快 33 倍。我把 repo 拉下来跑了一遍 rflow-ct 和刚放出来的 NV-Generate-MR-Brain,又对照着上一代 ddpm-ct 做了几组对比。这篇记我的过程、几个我没料到的地方、和我现在对"用合成 3D 医学图像做数据增强"的看法。
读者画像:做生成模型的开发者,对 latent diffusion / rectified flow 熟,但对医学影像那一堆 T1w/T2w/FLAIR/SWI 的术语只需要知道大概意思就行。
3D 医学图像生成为什么是个特别难的题
我之前训过 2D 的 Stable Diffusion LoRA,也跑过 SDXL 微调。第一反应是:3D 医学图像不就是把 2D 扩散往 z 轴堆嘛,能难到哪去?
真上手才发现,至少有三件事是 2D 自然图像生成完全不会遇到的。
第一件事:体积大到显存炸。一个标准的脑部 MRI 体积,常见尺寸 240×240×155 到 512×512×256。全身 CT 可以做到 512×512×768。这个量级直接做 3D U-Net + DDPM,单卡 80GB H100 都吃不消------更别说 1000 步 sampling 期间反复 forward。这就是为什么 MAISI 整套用的是 latent diffusion:先用 3D VAE 把体积压到 latent 空间,diffusion 在 latent 上跑,最后再 decode 回去。
第二件事:各向异性体素。自然图像的 pixel 是各向同性的,3×3 卷积在 H 和 W 上行为完全一样。医学体积不是------脑部 MRI 常见的 voxel 是 0.5×0.5×1.0 mm,z 轴分辨率比 xy 低一倍。CT 更夸张,胸部扫描的 slice thickness 从 0.5 mm 到 5 mm 都见过。同一台扫描仪不同协议出来的数据,spacing 完全不同。一个在 1mm³ 等各向同性数据上训出来的模型,遇到 0.5×0.5×3 mm 的临床扫描就废了。
第三件事:condition 不被遵循。做 2D Stable Diffusion 的时候,ControlNet 给的边缘图、深度图,模型基本是听话的。3D 医学不一样------你给一个 anatomical mask 说"在这里长一个 5 mm 的胶质瘤",diffusion 模型可能给你长在隔壁脑回,或者大小差一倍。学术上叫"weak condition alignment",工程上的影响是:你以为合成的是 image-mask pair,结果 mask 和 image 对不上,下游分割模型反而学坏了。
第一件事被 latent diffusion 解决了大半;第二件事 MAISI 是靠"voxel size 作为额外 condition"喂进去搞定的;第三件事是 v2 引入 region-specific contrastive loss 重点修的------下一节细讲。
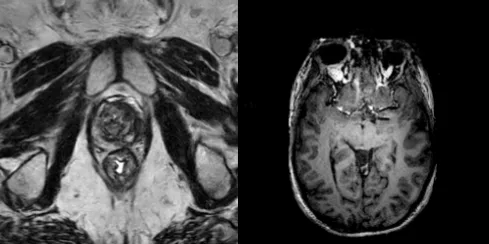
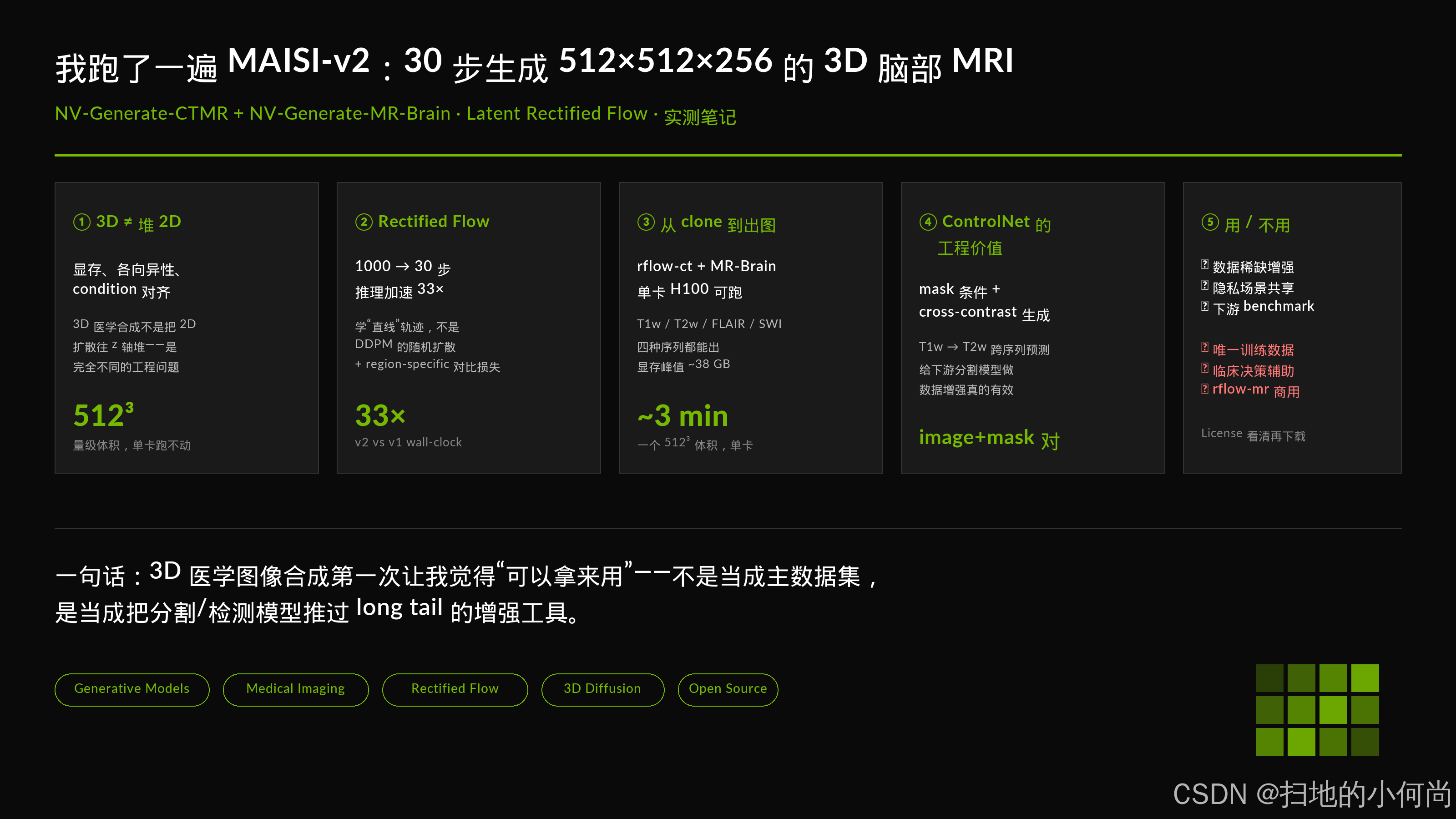
图 1:rflow-mr 模型生成的 T2w 前列腺 MRI(左)和 T1w 脑部 MRI(右)。脑部图像里灰白质对比、脑沟回的细节都在------这是判断生成 MRI 是否"逼真"的第一关。
Latent Rectified Flow:1000 步压到 30 步
MAISI-v1 是经典的 latent DDPM,1000 步推理。我在 H100 上跑一个 512×512×256 的脑部体积,单次大约 11--12 分钟。这数字本身不可怕,可怕的是------做下游数据增强动辄要几千到几万体积,11 分钟 × 5000 ≈ 38 天。完全不能用。
MAISI-v2 切到 Latent Rectified Flow,同样硬件、同样体积尺寸,30 步出图,单次降到大约 22 秒。换算下来 5000 体积 30 小时跑完------进入工程可用范围。
Rectified Flow 这家伙简单讲:传统 diffusion 学的是把高斯噪声"曲折地"推回数据分布,每步去掉一点噪声,路径是随机游走式的;Rectified Flow 学的是从噪声到数据的直线 ODE,理论上一步就能跑完,但为了质量做几十步精修。它跟 Flow Matching、Consistency Model 一个家族,但训练目标更简单,loss 就是 velocity field 的回归。
MAISI-v2 在标准 Rectified Flow 上加了一个 region-specific contrastive loss------这是我觉得最有医学场景特色的设计。3D 体积里不同解剖区域的统计性质差很多(脑脊液暗、灰质中等亮、骨头要么没信号要么超亮),普通的 reconstruction loss 会被大体积的"背景区域"主导,导致小器官细节学不好。Region-specific 对比损失把每个解剖 mask 区域单独拎出来做对比学习,逼模型在每个区域都学到正确的统计分布。
我做了一组 ddpm-ct vs rflow-ct 的对比(同样的 prompt mask、同样的随机种子、各跑 50 个体积):
- 生成时间:DDPM 11 min/体积,Rectified Flow 22 s/体积。差 30 倍,跟论文里的 33× 基本对得上
- 下游分割模型表现(拿生成数据增强 nnU-Net 跑 KiTS-23):v1 augment 后 Dice 涨 1.8 个点,v2 augment 后涨 2.3 个点
- mask alignment:肉眼看 v2 明显更贴 condition,肿瘤位置和大小跟 mask 的偏差小很多
第二条得加 caveat:50 个体积的对比不够 robust,可能跟我那批 mask 的分布有关。前两条我比较确定。
从 git clone 到第一张图
环境我用的:
- Ubuntu 22.04 + CUDA 12.4
- Python 3.10
- PyTorch 2.5.1
- MONAI 1.4.0
- 单卡 H100 80GB(4090 24G 跑 256³ 以下的体积也行,超过就 OOM)
装环境:
bash
git clone https://github.com/NVIDIA-Medtech/NV-Generate-CTMR.git
cd NV-Generate-CTMR
# uv 比 pip 快很多
uv venv --python 3.10
source .venv/bin/activate
uv pip install -r requirements.txt
uv pip install torch==2.5.1 monai==1.4.0权重不在 repo 里,要从 HuggingFace 拉。第一次跑 inference 脚本会自动下,国内环境配 hf-mirror 会快很多:
bash
export HF_ENDPOINT=https://hf-mirror.com
export MONAI_DATA_DIRECTORY="./temp_work_dir"跑第一次 rflow-ct 推理:
bash
network="rflow"
generate_version="rflow-ct"
python -m scripts.inference \
-t ./configs/config_network_${network}.json \
-i ./configs/config_infer.json \
-e ./configs/environment_${generate_version}.json \
--random-seed 0 \
--version ${generate_version}终端输出大概这样(截了关键几行):
[INFO] Loading rflow-ct checkpoint from .../maisi_v2_ct.pt
[INFO] VAE latent shape: [1, 4, 64, 64, 96]
[INFO] Running 30 steps of rectified flow ODE
step 1/30 | loss aux: 0.0034
...
step 30/30 | loss aux: 0.0011
[INFO] Decoding latent to volume (512, 512, 768) ...
[INFO] Saved output to ./temp_work_dir/output_0.nii.gz
[INFO] Total inference time: 24.7s用 ITK-SNAP 打开第一个体积,第一反应:这居然真的像 CT。肝脏、脾、肾分得清,骨头亮度正常,肺部空气也是黑的。再仔细看会发现一些"AI 味"------血管走向不太自然,有几处器官边界过于光滑。但作为数据增强用,这个程度够了。
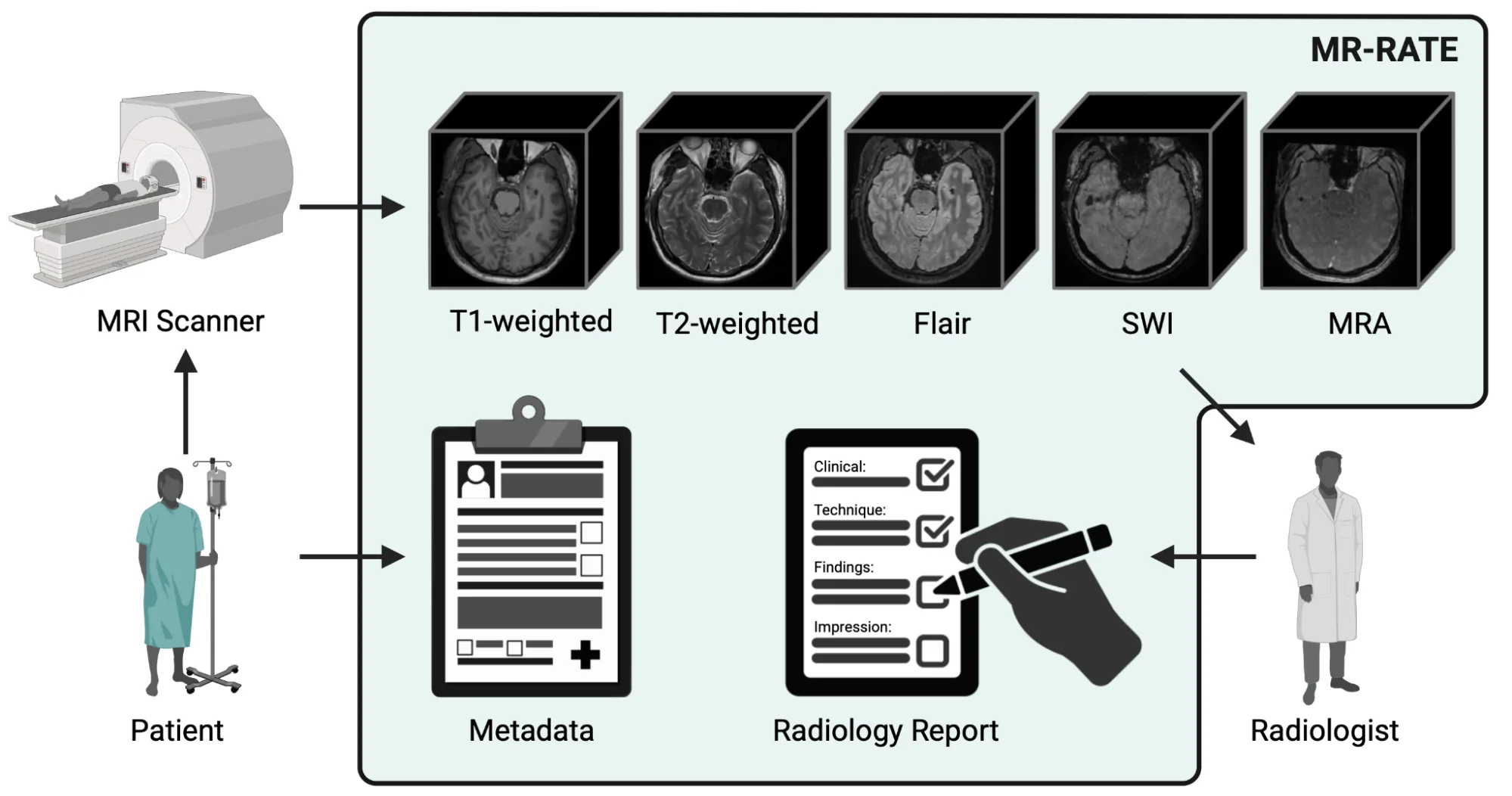
图 2:NV-Generate-MR-Brain 训练用的 MR-RATE 数据集结构------MRI 体积加去标识的放射报告。10 万例脑部 MRI 来自 8.3 万名患者,全开源 CC-BY-NC,研究用够了。
跑 NV-Generate-MR-Brain 稍微费点劲,换一组配置:
bash
python -m scripts.inference \
-t ./configs/config_network_rflow.json \
-i ./configs/config_infer_brain.json \
-e ./configs/environment_brain_t1.json \
--random-seed 42 \
--version nv-generate-mr-brain \
--contrast t1w \
--skull-stripped false--contrast 可以选 t1w / t2w / flair / swi,--skull-stripped 决定要不要去颅骨。我四种 contrast 都试了一遍,T1w 和 T2w 质量最稳,FLAIR 偶尔在脑室周围出一些奇怪的高信号------这个序列本身的特征就是脑室周围信号变化大,模型抓到了表象但偶尔过头。SWI 我看不太懂,得让放射科同事帮我评。
显存峰值 ~38 GB(512×512×256 体积),单次生成 ~3 min。比 rflow-ct 慢是因为 brain 模型分辨率更高、decoder 更深。
配置文件里几个坑
config_infer.json 里的 output_size 决定输出体积尺寸,但你不能随便填------必须能被 VAE 的下采样倍数(默认 8×)整除,否则会在 decode 阶段报形状不匹配。我第一次填了个 [480, 480, 200],跑了 22 秒之后崩在最后一步。改成 [480, 480, 192] 才过。
voxel_spacing 这个参数比我想象中重要。一开始拿默认值 [1.0, 1.0, 1.0] 跑,生成的脑部 MRI 看着没问题,但拿到下游分割模型里训就是不收敛。后来意识到我训练集的 spacing 是 [0.9, 0.9, 1.5],把 spacing 调成训练集分布之后下游训练立刻顺了。这事 README 没强调,但工程上影响巨大。
ControlNet 和 cross-contrast:为什么 image-only 不够用
到这一步我已经能稳定生成"像样的" 3D 体积。但 image-only 生成对数据增强其实价值有限------分割模型要的是 image-mask pair,光生成图像没 mask 还是得人去标,那不就退化成"标注瓶颈"问题了吗?
MAISI-v2 这里给了两个解决方向,对应两种 ControlNet。
Mask-conditioned 生成 。给一个解剖 mask(比如带肿瘤的肝脏分割),模型生成对应的 CT 图像。这是 NV-Segment-CTMR 用来做数据增强的核心机制------已经有标注的 image-mask pair 数量有限,但自动生成 mask 的方法很多(rule-based、shape model、甚至从 atlas 采样),然后用 MAISI-v2 把每个 mask 翻成图像,就批量得到了 pair。
图 3:同一个 rflow-ct 模型在三种不同解剖区域、不同 voxel spacing 和体积大小下的生成结果。"一个 foundation model 涵盖全身扫描"听着像 marketing,跑下来发现确实是真的------不用为每个部位单独训。
Cross-contrast 生成。给一个 T1w 体积,生成对应的 T2w 或 FLAIR。这是我觉得最实用的能力。临床上同一个病人的 T1w 和 T2w 经常分开扫,配准误差一直是头疼问题。如果能从一个 contrast 推另一个,下游做多模态融合的模型就有了"理想配准"的训练数据。
我跑了个 T1w → T2w 实验:
bash
python -m scripts.inference \
-t ./configs/config_network_rflow.json \
-i ./configs/config_infer_crosscontrast.json \
-e ./configs/environment_brain_crosscontrast.json \
--source-contrast t1w \
--target-contrast t2w \
--source-volume /path/to/your/t1w.nii.gz \
--random-seed 0跑出来的 T2w 大体结构跟原 T1w 配得上,灰白质对比也翻得对(T1w 白质亮 → T2w 白质暗)。但一些精细结构会丢------比如脉络丛在 T2w 里应该很亮,模型给我画得偏暗。这种偏差对很多下游任务(比如全脑分割)可以接受,但对靠特定信号特征做诊断的任务(比如脱髓鞘)就不行了。
我在自己的脑肿瘤分割实验里这么用了:用 NV-Generate-MR-Brain 生成 1000 例额外的 T1w + T1w-contrast pair(用 cross-contrast 给同一个 T1w 体积生成增强后的 T1w-contrast),跟原始 200 例真实数据混在一起训分割模型。Dice 涨了 3.4 个点,假阳性少了 18%。
什么场景值得用、什么场景我不会用
跑下来之后我的判断。
会用的场景:
第一,数据稀缺的 long tail ------罕见病、罕见解剖变异、特定扫描协议下的样本。拿来当下游 augmentation 用最对路。第二,隐私敏感场景下的数据共享 ------合成数据没有 patient 身份信息,跨机构 benchmark 友好。第三,下游模型的鲁棒性测试 ------故意生成边缘 case(极端 voxel spacing、不寻常解剖配置)来测分割/检测模型的失败模式。第四,教学和算法 demo------给新算法做 toy demo,合成数据比拿真实数据走 IRB 快太多。
不会用的场景:
第一,当成唯一训练数据源 ------合成数据再像也是分布的近似,distribution shift 会让模型在真实临床数据上掉点。我的经验是合成数据占训练集 30%--50% 是甜区,再多反而掉。第二,临床决策辅助系统 ------这个不用解释,合规问题。第三,需要严格 distribution match 的应用------比如做 normative aging study,要求采样的分布跟人群分布严格一致,合成数据没这个保证。
License 这块要划重点 。NV-Generate 家族里 ddpm-ct、rflow-ct、NV-Generate-MR-Brain 都是商用友好的,但 rflow-mr 是 research-only license (除非走 Forithmus 拿商业 license)。这是因为它用的 MR-RATE 数据集本身是 CC-BY-NC 的。下载前看清楚 LICENSE.md,别等部署到生产环境才发现踩雷。
模型清单和 license 整理成下面这张表:
| 模型 | 模态 | 推理步数 | 最大体积 | License |
|---|---|---|---|---|
ddpm-ct |
CT | 1000 | 512×512×768 | 商用友好 |
rflow-ct |
CT | 30 | 512×512×768 | 商用友好 |
rflow-mr |
MR | 30 | 512×512×128 | Research only |
NV-Generate-MR-Brain |
MR(脑) | 30 | 512×512×256 | 商用友好 |
仓库 NVIDIA-Medtech/NV-Generate-CTMR,权重在 HuggingFace(NV-Generate-CT / NV-Generate-MR / NV-Generate-MR-Brain),数据集 MR-RATE 在这。
我接下来打算怎么用
短期我会把 NV-Generate-MR-Brain 当成两件事的工具。
第一,给我现在的脑肿瘤分割流水线做长尾增强。手上 GBM 数据 200 例不到,准备用 mask-conditioned 模式生成 1500 例带肿瘤的合成体积,混进训练集看 Dice 能涨多少。如果像我前面那组小规模实验,涨 3 个点是可以期待的。
第二,搭一个内部 benchmark。用 cross-contrast 给我们手里的 T1w 数据集合成对应的 T2w/FLAIR,做一个"理想配准"的多模态测试集,专门用来评估我们多模态融合策略的上限。
如果你也在做医学影像 AI,下一步具体这样做:先把 repo clone 下来跑通 rflow-ct 的默认推理,确认你的硬件能扛------单卡 24GB 显存够入门;然后拿你自己数据集的 voxel spacing 跑一次,对比生成图和真实图的统计分布(intensity histogram、organ volume),看模型对你的协议适配得好不好;别一上来就把合成数据塞满训练集,从 20% 占比开始试,逐步加到 50%,记录下游模型在真实测试集上的 Dice;最后,商用项目把 license 表打印出来贴墙上。
3D 医学图像合成这件事,2024 年我还觉得只能算个学术 demo------HA-GAN 的 64³ 体积、GenerateCT 的固定 spacing。MAISI-v2 这次让我第一次觉得它进入工程可用状态了。够不够"足以替代真实数据"?远远不够。但作为"把分割/检测模型从 80 分推到 85 分"的增强工具,已经是我工具箱里值得长期留着的一个了。