5月25日,面壁智能正式发布并开源了新一代端侧文本基座大模型 MiniCPM5-1B。该模型以 1B 参数规模在 AA-Index 榜单取得 17.9 分,超越 Qwen3.5-2B(16.3 分)等全部 4B 以下开源基座模型,延续了面壁智能提出的"密度定律"------大模型智能密度约每 3.5 个月翻一番。其 Base 版本由面壁自研 AI 训练框架 ForgeTrain 预训练完成,这是全球首个完全由 AI 编写的生产级训练框架。INT4 量化后权重仅 0.5GB,可在手机、浏览器等 90% 以上终端设备运行。官方已原生支持 vLLM、SGLang、llama.cpp 等主流推理框架。
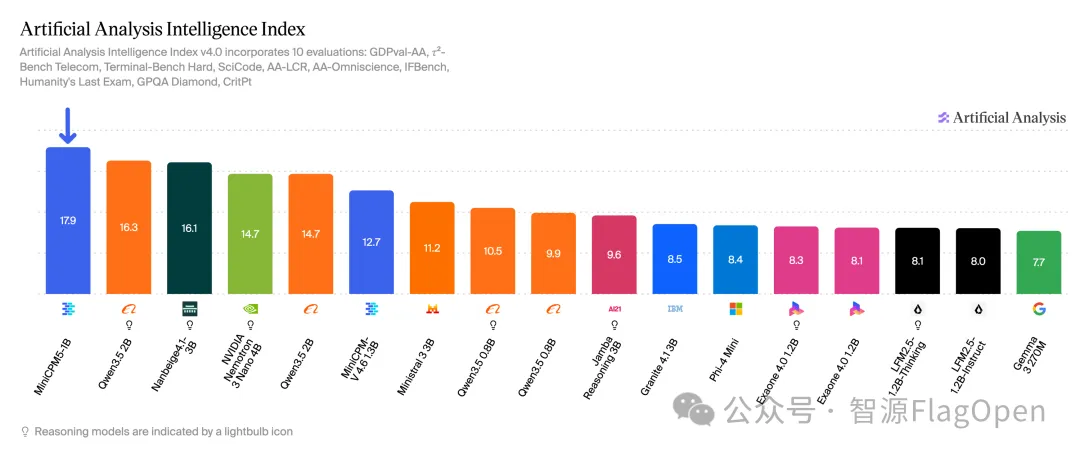
众智 FlagOS 社区基于统一多芯片软件栈,通过 vLLM-plugin-FL 推理插件完成了 MiniCPM5-1B 的跨芯片适配与推理部署 Day-0 发布。此次适配覆盖英伟达、华为昇腾、平头哥、摩尔线程、海光、昆仑芯、沐曦、天数智芯等 8 类数据中心 AI 加速芯片,并针对 MiniCPM5 面向端侧部署的特点,首次将 Day-0 适配延伸至 ARM 端侧平台。FlagOS 支持 MiniCPM5-1B 在 ARM 上以 int8、bf16、fp32 三种精度运行,实现了从数据中心多款AI芯片到端侧 ARM 的"一套代码、跨架构运行"。在性能方面,多款AI芯片的首 token 延迟(TTFT)低于 NVIDIA H20 原生基线,进一步验证了 FlagOS 统一软件栈在跨芯片适配和推理优化上的能力。
一、部分芯片效率追平或略超NVIDIA:
测试条件与基准定义:
所有性能数据基于统一测试环境:单卡、64并发请求、输入长度分别为4k/16k/32k tokens,输出长度为1k tokens,精度统一为bf16。
对比基准定义为 "NV原生" :NVIDIA H20 原生基线指 MiniCPM5-1B 在 NVIDIA H20 上基于原生 vLLM/CUDA 路径运行的结果。在此基础上,我们引入 "NVIDIA H20 + FlagOS" 作为参考,以展示FlagOS优化效果。
其它非英伟达芯片的MiniCPM5-1B 结果是基于FlagOS的运行结果。
多款AI芯片平台在长上下文 TTFT 上达到或优于 NVIDIA H20 原生基线
首Token延迟(TTFT)对比
TTFT(Time To First Token)衡量从接收请求到生成第一个输出token的延迟,数值越低越好。测试结果如下:
-
平头哥真武810E:在所有上下文长度(4k/16k/32k)下TTFT均显著低于NV原生,且随着上下文长度增加优势扩大。
-
摩尔线程、海光、沐曦:在所有测试场景下TTFT同样全面低于NV原生(即首token响应更快)。
-
NVIDIA H20 + FlagOS:由于FlagGems与FlagTree的算子优化,其TTFT在全部上下文长度下均优于NV原生。
需要强调的是,上述"多种AI芯片+FlagOS"与"NV原生"的对比,是芯片+软件栈组合的比较,并非纯硬件能力的直接对等对比。FlagOS在多种AI芯片上的深度适配是取得TTFT优势的关键因素。
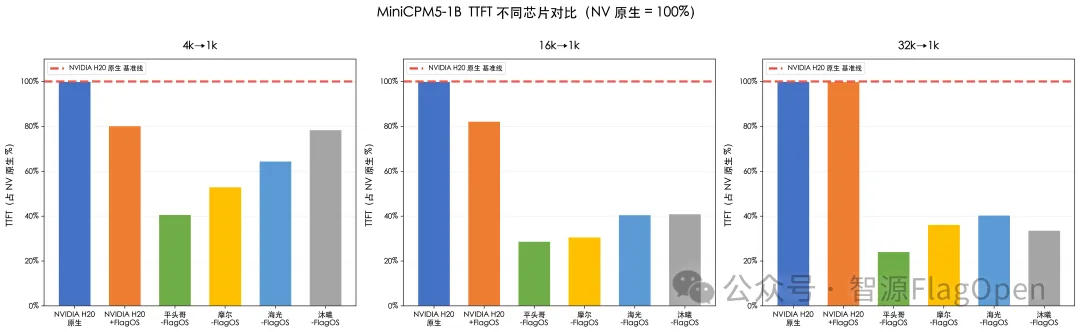
图1. MiniCPM5-1B 在不同AI芯片的首token延迟对比(越低越好)
注:由于各种芯片的硬件算力(TFLOPS)和显存带宽差异较大,所以该数据并不代表芯片的性能对比。
单位算力TTFT效率
考虑到不同芯片的峰值算力和带宽配置差异较大,仅比较绝对 TTFT 难以公平反映算力利用水平。因此,我们进一步计算了按芯片峰值 TFLOPS 归一化后的单位算力TTFT 效率 ------ 1/(TFLOPS * TTFT),用于更公平地衡量各平台在同等单位算力下的首 token 延迟表现。
-
平头哥真武810E:在所有上下文长度下单算力TTFT效率均明显优于NV原生。
-
沐曦、摩尔线程:在16k和32k长上下文场景下单位算力TTFT效率超过NV原生。
-
NVIDIA H20 + FlagOS:在4k和16k场景下优于NV原生,32k场景效率与NV原生持平。
对于其它平台我们将持续优化FlagOS技术栈对其算力效率的提升。
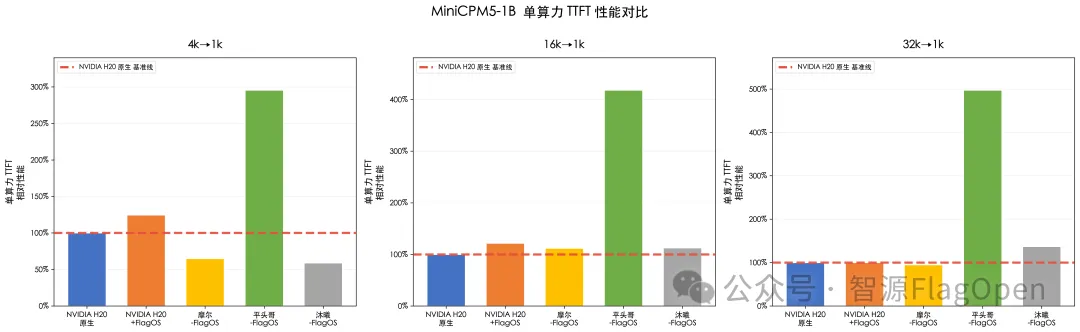
图2. 基于FlagOS的MiniCPM5-1B 在不同AI芯片的单位算力TTFT效率(越高越好)
平头哥的 推理吞吐量 逼近英伟达 同等算力效率:
TTFT主要影响交互体验,而推理吞吐量(total tokens/s)决定系统并发处理能力。两者是不同维度的性能指标。推理总吞吐量通常由芯片计算能力(TFLOPS)、显存带宽等重要因素共同决定。
在吞吐效率方面,在本次适配中,我们在平头哥真武 810E 上采用了 FlagGems + FlagTree + vLLM-plugin-FL 方案。实测结果表明,真武 810E 单卡的 token 总吞吐量超过 2.6 万 tokens/s。
由于MiniCPM 5-1B模型参数规模较小,且长上下文 decode 阶段 KV cache 访问压力显著,整体 workload 更偏 Memory-bound。为公平比较不同算力芯片的效率,在充分考虑真武 810E 与 NVIDIA H20 在计算峰值性能(TFLOPS)与显存带宽差异的前提下,折算至同等有效算力后,真武 810E 在 16K:1K 及 32K:1 等长序列场景下的 token 总吞吐量已逼近 H20 单位算力 token 计算效率,分别为93.3%和95.3%。
二、ARM 端侧支持:将 MiniCPM5-1B 从 GPU 扩展到海量终端设备
ARM 架构广泛存在于手机、AIPC、机器人、车载终端、边缘网关和各类嵌入式设备中,是端侧 AI 部署中数量最大、覆盖最广的计算平台之一。随着 MiniCPM5-1B 这类小尺寸高密度模型的发展,越来越多推理任务有机会从云端 GPU 下沉到端侧设备,以获得更低时延、更低成本、更好的隐私保护和离线可用能力。因此,将模型适配到 ARM 平台,不只是一次硬件迁移验证,更是 FlagOS 面向端侧 AI 和普惠 AI 计算的重要探索。
FlagOS 对 ARM 板端的适配是本次 MiniCPM5-1B 多芯片方案中的差异化能力。过去,高性能大模型推理优化主要集中在 GPU 平台,模型从 GPU 迁移到 ARM 通常需要重新适配推理后端、算子实现和精度路径。FlagOS 通过FlagTree + FlagGems的组合,将 MiniCPM5-1B 的推理能力从 GPU 扩展到 ARM 板端,支持 int8、bf16、fp32 等多种精度路径,探索实现"一套模型、多类架构、统一适配"的端侧部署方式。
-
A RM v9 指令集深度优化:FlagTree 新增 Armv9 CPU 编译目标(FlagTree-CPU),以 Triton-CPU 为底层后端,充分利用 SVE2 / NEON 向量化能力提升通用算子吞吐;通过 i8mm 加速 INT8 GEMM、dotprod 扩展(SDOT / UDOT)优化 INT8 GEMV decode 场景、BF16 指令扩展优化 BF16 matmul。编译链路中开启 +dotprod / +bf16 / +i8mm 等 Arm 目标特性,使 CPU 后端充分匹配 Armv9 硬件能力。
-
FlagGems A RM 后端:围绕矩阵计算、注意力、归一化、动态量化与解码后处理等大模型推理关键模块,提供面向 ARM 的优化算子实现。开发者无需修改模型代码,即可通过 FlagOS 技术栈获得算子层加速。
-
Triton- TLE(Triton Language Extensions) 对ARM指令的 扩展 支持:FlagOS 通过 Triton-TLE(Triton Language Extensions)增强 Triton 在 ARM CPU 后端上的表达和优化能力,基于 NEON / SVE2 等指令能力优化运行时与核心计算路径,并面向注意力 decode、前馈网络融合、归一化、门控状态更新、低精度量化线性计算等大模型推理热路径提供支持。
三、开发者速用指南:MiniCPM5-1B 模型 多芯版本获取与部署
FlagOS技术栈为 MiniCPM5-1B 模型提供了开箱即用的多芯片版本。在FlagOS的vLLM-plugin-FL多芯片推理插件及统一算子库FlagGems、统一编译器FlagTree的支持下,英伟达、华为昇腾、平头哥、摩尔线程等多款芯片已完成 MiniCPM5-1B 的跨芯适配及验证。FlagOS提供了基于vLLM-plugin-FL的统一部署方案。使用源码进行安装部署,可参考以下官方一站式开发者文档,含详细代码示例与操作指引:
-
GitHub:https://github.com/flagos-ai/vllm-plugin-FL/blob/main/README.md
-
GitCode:https://gitcode.com/flagos-ai/vllm-plugin-FL/blob/main/README.md
方式一:FlagOS源码方式
安装部署
python
# 1. 安装 vLLM v0.20.2
pip install vllm==0.20.2
# 2. 安装 vllm-plugin-FL
git clone https://github.com/flagos-ai/vllm-plugin-FL
cd vllm-plugin-FL
pip install --no-build-isolation -e .
# 3. 安装 FlagGems 算子库
git clone https://github.com/flagos-ai/FlagGems
cd FlagGems && git checkout v5.0.0
pip install --no-build-isolation -e .
# 4. (可选) 安装 FlagTree 统一编译器
python3 -m pip uninstall -y triton
python3 -m pip install flagtree===0.5.0 --index-url=https://resource.flagos.net/repository/flagos-pypi-hosted/simple
# 5. (可选) 安装 FlagCX 统一通信库
# 详见 https://github.com/flagos-ai/FlagCX运行推理
python
from vllm import LLM, SamplingParams
prompts = ["你好,请介绍一下你自己。"]
llm = LLM(
model="/path/to/MiniCPM5-1B-FlagOS",
max_num_batched_tokens=16384,
max_num_seqs=2048
)
sampling_params = SamplingParams(max_tokens=512, temperature=0.0)
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
print(f"Prompt: {output.prompt!r}")
print(f"Generated: {output.outputs[0].text!r}")方式二:模型镜像直接下载
用户可以直接拉取在 FlagRelease 上发布的迁移后的模型文件、代码和镜像。以下是迁移适配后的几种 AI 芯片的模型版本,开箱即用、无需迁移。
魔搭平台
| 芯片 | 模型 | 下载链接 |
|---|---|---|
| 英伟达 | MiniCPM5-1B | https://modelscope.cn/models/FlagRelease/MiniCPM5-1B-nvidia-FlagOS |
| 华为昇腾 | MiniCPM5-1B | https://modelscope.cn/models/FlagRelease/MiniCPM5-1B-ascend-FlagOS |
| 平头哥 | MiniCPM5-1B | https://modelscope.cn/models/FlagRelease/MiniCPM5-1B-zhenwu-FlagOS |
| 摩尔线程 | MiniCPM5-1B | https://modelscope.cn/models/FlagRelease/MiniCPM5-1B-mthreads-FlagOS |
| 海光 | MiniCPM5-1B | https://modelscope.cn/models/FlagRelease/MiniCPM5-1B-hygon-FlagOS |
| 昆仑芯 | MiniCPM5-1B | https://modelscope.cn/models/FlagRelease/MiniCPM5-1B-kunlunxin-FlagOS |
| 沐曦 | MiniCPM5-1B | https://modelscope.cn/models/FlagRelease/MiniCPM5-1B-metax-FlagOS |
| 天数智芯 | MiniCPM5-1B | https://modelscope.cn/models/FlagRelease/MiniCPM5-1B-iluvatar-FlagOS |
| ARMv9 | MiniCPM5-1B | https://modelscope.cn/models/FlagRelease/MiniCPM5-1B-Armv9-FlagOS |
HuggingFace 平台
| 芯片 | 模型 | 下载链接 |
|---|---|---|
| 英伟达 | MiniCPM5-1B | https://huggingface.co/FlagRelease/MiniCPM5-1B-nvidia-FlagOS |
| 华为昇腾 | MiniCPM5-1B | https://huggingface.co/FlagRelease/MiniCPM5-1B-ascend-FlagOS |
| 平头哥 | MiniCPM5-1B | https://huggingface.co/FlagRelease/MiniCPM5-1B-zhenwu-FlagOS |
| 摩尔线程 | MiniCPM5-1B | https://huggingface.co/FlagRelease/MiniCPM5-1B-mthreads-FlagOS |
| 海光 | MiniCPM5-1B | https://huggingface.co/FlagRelease/MiniCPM5-1B-hygon-FlagOS |
| 昆仑芯 | MiniCPM5-1B | https://huggingface.co/FlagRelease/MiniCPM5-1B-kunlunxin-FlagOS |
| 沐曦 | MiniCPM5-1B | https://huggingface.co/FlagRelease/MiniCPM5-1B-metax-FlagOS |
| 天数智芯 | MiniCPM5-1B | https://huggingface.co/FlagRelease/MiniCPM5-1B-iluvatar-FlagOS |
| ARMv9 | MiniCPM5-1B | https://huggingface.co/FlagRelease/MiniCPM5-1B-Armv9-FlagOS |
四、开发者极致体验:"发布即多芯" + "零改码"
1、vLLM-plugin-FL:多芯片统一推理的核心路径
本次 MiniCPM5-1B 模型的跨芯适配,核心技术路径是基于 vLLM-plugin-FL 实现多芯片推理部署。vLLM-plugin-FL 是 FlagOS 为 vLLM 推理服务框架打造的专属插件,基于 FlagOS 统一多芯片后端开发,在完全不改变 vLLM 原生接口与用户使用习惯的前提下,将 MiniCPM5-1B 的推理能力扩展到英伟达、华为昇腾、平头哥、摩尔线程、海光等多类 GPU 芯片。
-
兼容 vLLM 原生接口:开发者使用标准的 vLLM API 即可完成模型加载与推理服务部署,无需学习新的部署工具或修改已有代码。
-
多芯片后端自动适配:vLLM-plugin-FL 内置了针对不同芯片的后端适配逻辑,开发者只需指定模型路径,底层的芯片差异由插件自动处理。
2、核心能力与原生版本对齐
经 hellaswag、truthfulqa、winogrande、commonsense_qa 共四项评测集验证,FlagOS 适配后的 MiniCPM5-1B 在大部分芯片和评测集上的推理精度与 NVIDIA H20 原生版本对齐。
|----------------|--------|---------------|--------|--------|--------|--------|--------|--------|--------|----------|----------|
| | NV-原生 | H20-NV-FlagOS | 海光 | 沐曦 | 摩尔 | 昆仑芯 | 华为 | 天数 | 平头哥 | ARM-BF16 | ARM-INT8 |
| hellaswag | 0.4742 | 0.475 | 0.4628 | 0.4438 | 0.475 | 0.4747 | 0.425 | 0.4716 | 0.4752 | 评测中 | 评测中 |
| truthfulqa_mc1 | 0.3293 | 0.3293 | 0.3354 | 0.317 | 0.328 | 0.3317 | 0.3378 | 0.3341 | 0.3305 | 0.2705 | 0.2815 |
| winogrande | 0.5484 | 0.5485 | 0.5406 | 0.5517 | 0.5517 | 0.5525 | 0.5351 | 0.5485 | 0.5391 | 0.5627 | 0.5525 |
| commonsense_qa | 0.3473 | 0.3473 | 0.3522 | 0.3317 | 0.3497 | 0.3473 | 0.3366 | 0.3489 | 0.3432 | 0.4267 | 0.4316 |
3、极简部署:开箱即用
FlagOS将算子库、编译器等组件内置集成,开发者加载模型时底层优化自动生效,无需手动添加FlagOS初始化代码。基于FlagRelease直接提供多芯片版本的 MiniCPM5-1B-FlagOS 模型文件,配合vLLM-plugin-FL启动推理服务,从下载到运行只需几条命令。
五、大模型核心基座:FlagOS 四大技术支撑,实现MiniCPM5-1B极速跨芯适配
包括 MiniCPM5-1B 在内的多款模型跨芯适配,依托的是FlagOS 2.0 统一多芯片系统软件栈的全链路能力。从算子层、编译层、框架层到工具层,全链路为大模型跨芯适配提供技术支撑。
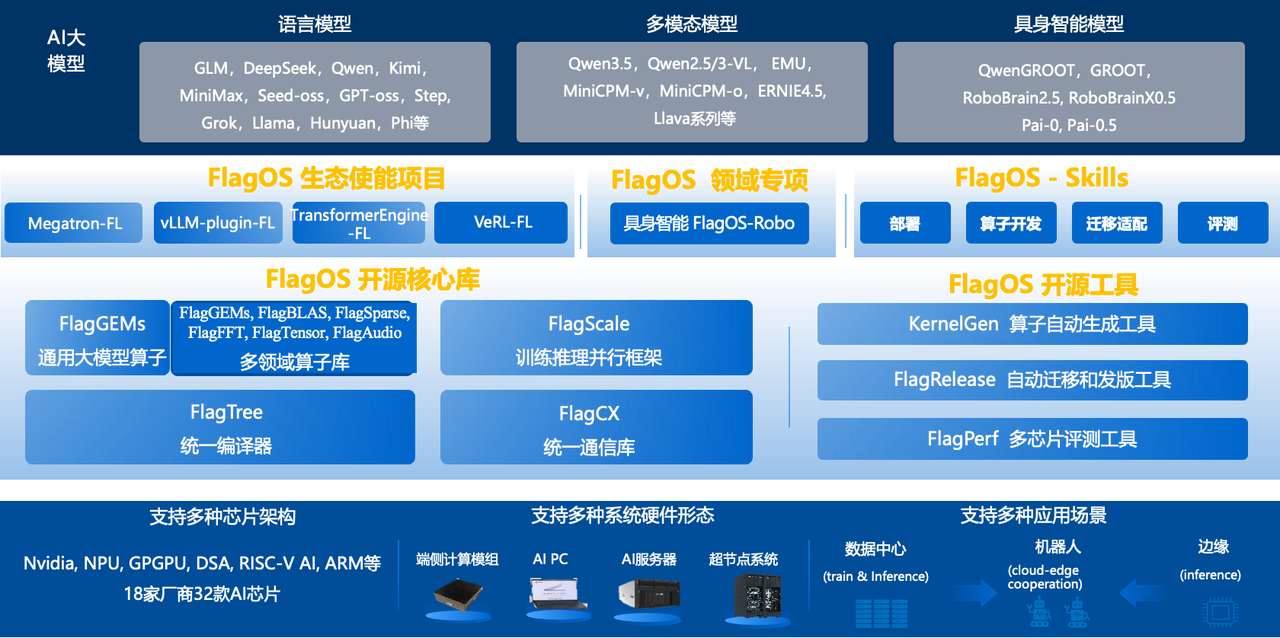
1. 高性能算子库 FlagGems:核心算子深度适配,释放硬件算力
FlagGems 作为 FlagOS 核心的高性能通用大模型算子库,基于 Triton 语言实现,已拥有超过500个大模型常用算子,覆盖 Attention 计算、RMSNorm 等 MiniCPM5-1B 推理链路上的关键计算模块,同时原生支持 NVIDIA、摩尔线程、沐曦、清微智能、天数等接近 20 家 AI 芯片。本次测试中,仅部分启用 13 个 FlagGems 算子即在 NVIDIA H20 上实现吞吐量反超 CUDA 原生 2.0%。
2. 统一 AI 编译器 FlagTree:一次编写,多芯编译
FlagTree 是 FlagOS 面向多 AI 芯片后端的统一编译器,基于 Triton 深度定制,可将大模型核心算子编译为英伟达、华为昇腾、平头哥、海光、摩尔线程等十多种不同 AI 芯片后端可识别的指令,彻底解决不同芯片编译器生态割裂的问题,大幅降低算子跨芯片适配的开发成本。
3. 模型跨芯迁移发布工具 FlagRelease:半自动实现模型跨芯迁移与版本发布
依托 FlagOS 全栈技术能力,FlagRelease 已完成包括 MiniCPM5-1B 在内的多款模型在多种芯片上的模型迁移、精度对齐与版本发布,覆盖 HuggingFace、魔搭等开源社区平台。开发者可直接下载使用,无需自行迁移。截至本文发布,FlagRelease 已发布覆盖 10+ 家芯片厂商、12+ 款硬件、70+ 个开源模型实例的跨芯适配版本。
4. 统一多芯片接入插件 vLLM-plugin-FL:兼容原生使用习惯
vLLM-plugin-FL 是 FlagOS 为 vLLM 推理服务框架打造的专属插件,基于 FlagOS 统一多芯片后端开发,在完全不改变 vLLM 原生接口与用户使用习惯的前提下,实现多芯片推理部署。目前 vLLM-plugin-FL 已经支持了清微、摩尔线程、海光、沐曦、平头哥、天数智芯、昆仑芯、华为、英伟达等多家芯片。
六、开源共建:FlagOS 持续做开发者的"跨芯适配后盾"
当下,"异构算力协同、大模型普惠落地"已成为全球开源开发者社区的核心热点,打破硬件生态隔离、让大模型在不同算力平台高效低成本运行,是无数开发者的核心诉求。FlagOS 从诞生之初就将开源开放、众智共建刻入技术基因,始终以开发者为中心,通过全栈开源的统一系统软件栈,把复杂的"M×N"硬件适配问题降维为"M+N",做每一位开发者最可靠的跨芯适配后盾。
全栈开源无保留,把技术主动权交给开发者
目前,FlagOS 已形成完整的开源技术体系,所有核心组件均已开源在 GitHub,同时开放了数十款最新的主流基础大模型、十多款 AI 芯片的适配方案与最佳实践,开发者可自由获取、深度定制:
-
四大核心技术库: FlagGems 通用大模型算子库、FlagTree 统一 AI 编译器、FlagScale 训练推理并行框架、FlagCX 统一通信库,覆盖算子开发、编译优化、并行计算、跨芯片通信全链路;
-
三大开源工具平台: FlagRelease 大模型自动迁移发版平台、KernelGen 算子自动生成工具、FlagPerf 多芯片评测工具,提供从模型适配、性能评测到工程落地的一站式工具链;
-
全场景扩展生态: vLLM-plugin-FL、Megatron-LM-FL、TransformerEngine-FL 等框架增强组件,以及 FlagOS-Robo 具身智能工具包,覆盖大模型训练、推理、应用全场景。
多路径参与共建,全层级开发者均可入局
我们为不同技术方向、不同经验层级的开发者,设计了低门槛、多路径的共建方式,无论你是 AI 开发新手,还是深耕系统软件的资深专家,都能在 FlagOS 社区找到自己的位置。
-
新手友好型参与: 可在对应仓库提交 Issue 反馈 bug、优化建议,或是补充完善文档、撰写入门教程与最佳实践,也可参与社区技术交流、分享使用经验,零门槛开启开源之旅;(社区文档参考https://docs.flagos.io/en/latest/)
-
深度技术共建: 开发者可直接参与 FlagGems 算子开发与优化(新增算子 / 性能调优 / 新芯片后端支持)、KernelGen 算子生成流程增强、FlagTree 编译器后端扩展等核心模块,与社区核心开发者一起推动技术演进。
-
生态工具贡献: 开发者可基于 FlagOS Skills 开发面向国产芯片的 AI Agent 专业技能,帮助更多开发者通过自然语言完成芯片适配、模型部署等操作。
关于众智 FlagOS 社区
为解决不同AI芯片大规模落地应用,北京智源研究院联合众多科研机构、芯片企业、系统厂商、算法和软件相关单位等国内外机构共同发起并创立了众智FlagOS社区,目前已经有78家成员单位。FlagOS是一款专为异构AI芯片打造的开源、统一系统软件栈,支持 AI 模型一次开发即可无缝移植至各类硬件平台,大幅降低迁移与适配成本。它包括大型算子库、统一AI编译器、并行训推框架、统一通信库等核心开源项目,致力于构建「模型-系统-芯片」三层贯通的开放技术生态,通过"一次开发跨芯迁移"释放硬件计算潜力,打破不同芯片软件栈之间生态隔离。
-
社区官网:https://flagos.io
-
GitHub:https://github.com/flagos-ai
-
GitCode:https://gitcode.com/flagos-ai
-
SkillHub:https://skillhub.flagos.io