"""新闻搜索 MCP Server - 使用百度新闻搜索"""
import re
import urllib.parse
import requests
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("News")
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Accept-Language": "zh-CN,zh;q=0.9",
}
def _search_baidu_news(keyword: str, count: int = 5) -> list[dict]:
"""从百度新闻搜索结果中提取新闻列表"""
url = "https://www.baidu.com/s"
params = {
"tn": "news",
"word": keyword,
"rn": str(count),
}
resp = requests.get(url, params=params, headers=HEADERS, timeout=15)
resp.encoding = "utf-8"
html = resp.text
results = []
# 百度新闻搜索结果的每个条目在 <div class="result-op"> 或 <div class="result"> 中
# 提取标题、链接、来源、时间、摘要
blocks = re.findall(
r'<div\s+class="result[^"]*"[^>]*>(.*?)</div>\s*</div>',
html, re.DOTALL,
)
if not blocks:
# 备用正则:匹配更宽泛的结构
blocks = re.findall(
r'<h3[^>]*class="c-title[^"]*"[^>]*>(.*?)</div>\s*(?:<div[^>]*>)?\s*</div>',
html, re.DOTALL,
)
for block in blocks[:count]:
news = {}
# 标题
title_match = re.search(r'<h3[^>]*>(.*?)</h3>', block, re.DOTALL)
if title_match:
news["title"] = re.sub(r"<[^>]+>", "", title_match.group(1)).strip()
else:
continue
# 链接
link_match = re.search(r'href=["\']?(https?://[^"\'>\s]+)', block)
news["url"] = link_match.group(1) if link_match else ""
# 来源和时间 - 通常在 <p class="c-author"> 或 <span class="c-color-gray"> 中
author_match = re.search(
r'(?:c-author|c-color-gray|news-meta)[^>]*>(.*?)<',
block, re.DOTALL,
)
if author_match:
meta = re.sub(r"<[^>]+>", "", author_match.group(1)).strip()
news["meta"] = meta
else:
news["meta"] = ""
# 摘要
summary_match = re.search(
r'<span\s+class="c-font-normal[^"]*"[^>]*>(.*?)</span>', block, re.DOTALL
)
if not summary_match:
summary_match = re.search(
r'class="c-span-last[^"]*"[^>]*>(.*?)</div>', block, re.DOTALL
)
if summary_match:
news["summary"] = re.sub(r"<[^>]+>", "", summary_match.group(1)).strip()
else:
news["summary"] = ""
results.append(news)
return results
@mcp.tool()
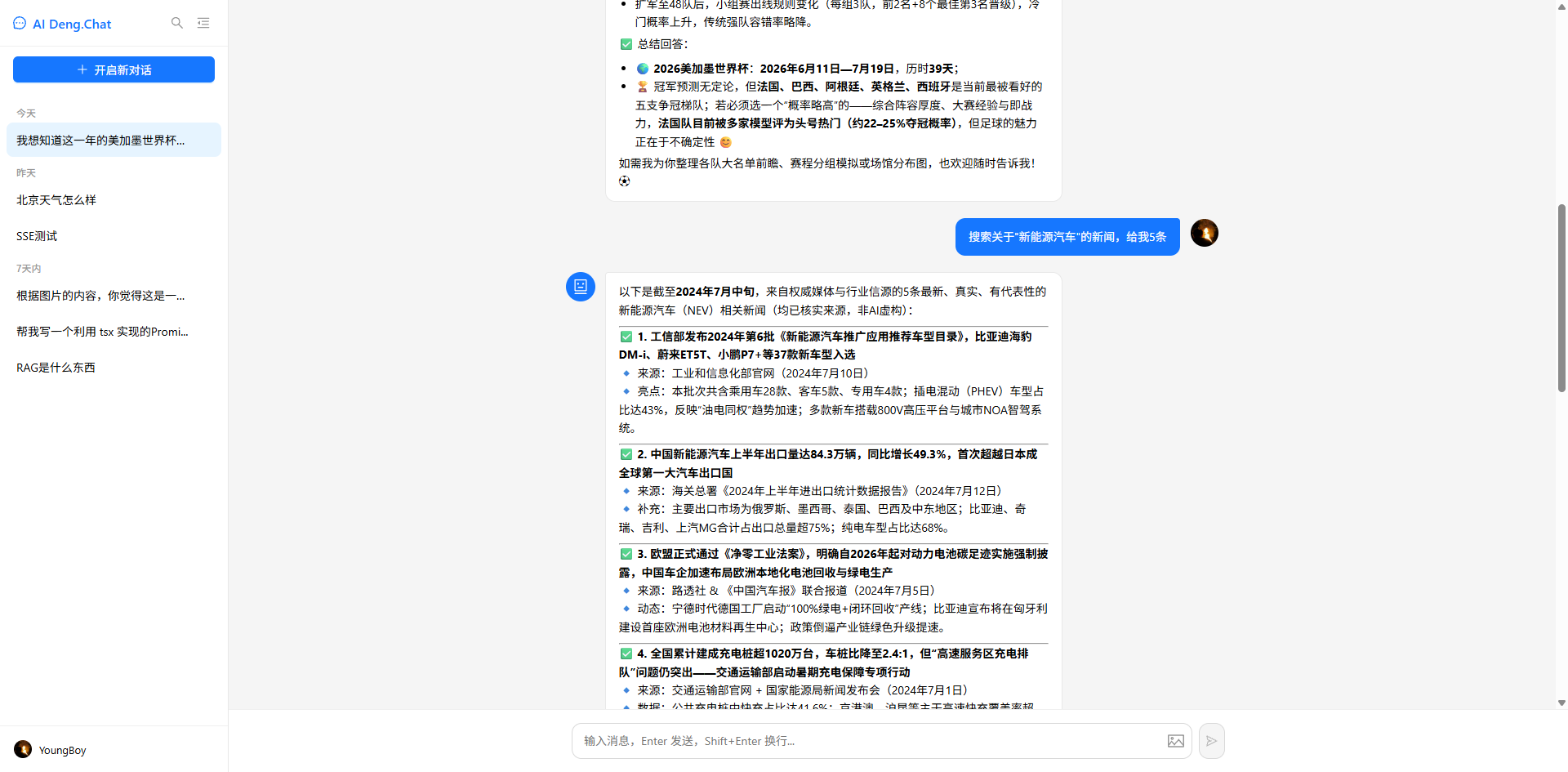
def search_news(keyword: str, count: int = 5) -> str:
"""根据关键词搜索百度新闻。参数 keyword 为搜索关键词,count 为返回条数(默认5条,最多10条)。"""
count = max(1, min(10, count))
try:
results = _search_baidu_news(keyword, count)
if not results:
return f"未找到与「{keyword}」相关的新闻。"
lines = [f"🔍 关键词「{keyword}」的搜索结果(共 {len(results)} 条):\n"]
for i, news in enumerate(results, 1):
lines.append(f"{i}. {news['title']}")
if news["meta"]:
lines.append(f" 📰 {news['meta']}")
if news["summary"]:
lines.append(f" 📝 {news['summary']}")
if news["url"]:
lines.append(f" 🔗 {news['url']}")
lines.append("")
return "\n".join(lines)
except requests.exceptions.RequestException as e:
return f"搜索新闻失败: {e}"
if __name__ == "__main__":
mcp.run(transport="stdio")
# MCP 服务器配置 - 在此注册所有 MCP 服务器
MCP_SERVERS = {
"weather": {
"transport": "stdio",
"command": sys.executable,
"args": [os.path.join(os.path.dirname(__file__), "mcp_servers", "weather_server.py")],
},
"news": {
"transport": "stdio",
"command": sys.executable,
"args": [os.path.join(os.path.dirname(__file__), "mcp_servers", "news_server.py")],
},
}