写在前面
企业数字化走到今天,一个越来越普遍的诉求是:把散落在各个 SaaS/ERP/OA 中的业务数据汇聚起来,用一个统一的视图做经营分析。
传统做法是搭建一套完整的数据中台------Kafka + Flink + Hive + Spark + Superset,十几个组件,运维复杂度爆炸,动辄投入百万级预算和专职大数据团队。对于大多数中小企业甚至是大企业的业务部门,这套方案"杀鸡用牛刀"。
有没有一套轻量、低成本、业务人员也能上手的方案?
答案是:数环通 iPaaS(数据采集层)+ Apache Doris(实时分析层)+ DataEase(可视化决策层)。三个组件各司其职,组合起来形成一个完整的"数据采集 → 实时入仓 → 可视化分析"链路,且整体运维复杂度远低于传统大数据方案。
这篇文章完整介绍这套三件套方案的架构设计、组件能力、数据流转链路、部署方案和典型场景。
一、整体架构设计
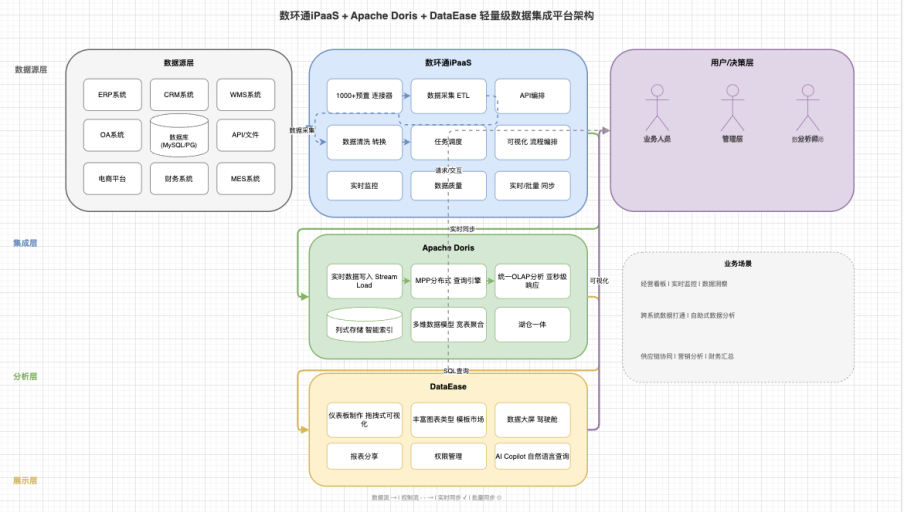
三层职责清晰:
| 层级 | 组件 | 职责 | 交付物 |
|---|---|---|---|
| 采集层 | 数环通 iPaaS | 连接源系统、数据清洗、增量同步 | 干净的结构化数据写入 Doris |
| 分析层 | Apache Doris | 存储、建模、实时计算 | 亚秒级 SQL 查询能力 |
| 展示层 | DataEase | 可视化报表、数据大屏、AI 问答 | 业务人员可操作的分析界面 |
二、三大核心组件详解
2.1 数环通 iPaaS:数据采集与集成层
数环通 iPaaS 是一站式企业级应用集成平台,以**「无代码、5 分钟跑通第一个场景」**为核心理念,帮助企业解决数据孤岛和应用协同问题。
核心能力
| 能力模块 | 说明 |
|---|---|
| 应用集成 | 1000+ 预置连接器,覆盖 ERP(SAP、金蝶、用友)、OA(钉钉、企微、飞书)、CRM、电商等主流应用 |
| 数据管道 | 支持多源异构数据的实时采集、清洗与同步,具备数据预览和可视化映射能力 |
| API 治理 | 统一 API 管理,支持接口生命周期管理和流量控制 |
| 企业自动化 | 可视化流程编排,实现业务流程的超自动化 |
在本方案中的角色
数环通 iPaaS 在这套架构中承担数据入口的角色------把企业散落在各个系统中的业务数据,通过预置连接器采集、经过数据清洗和格式标准化后,写入 Apache Doris。
关键能力点:
-
增量同步:基于时间戳或变更事件,只同步有变化的数据,避免全量拉取
-
数据清洗:在写入 Doris 之前完成字段映射、类型转换、空值处理、去重
-
调度策略:支持定时(cron)、事件触发(Webhook)、手动三种模式
-
写入 Doris:通过 Doris 的 Stream Load API 高效批量写入
典型数据链路:
金蝶 ERP (销售订单) → 数环通连接器采集 → 字段映射/清洗 → Stream Load → Doris ODS 表
钉钉 (考勤记录) → 数环通连接器采集 → 格式转换/补全 → Stream Load → Doris ODS 表
电商平台 (交易数据) → 数环通连接器采集 → 去重/标准化 → Stream Load → Doris ODS 表
典型应用场景
- 跨系统数据打通:订单自动同步、物流状态实时推送、财务数据自动归集
- 供应链协同:采购自动化下单、供应商交付进度实时同步
- 营销自动化:线索自动分发、转化漏斗实时监控
定价模式
| 版本 | 年费 | 适用场景 |
|---|---|---|
| 标准版 | 14,980 元/年 | 中小企业基础集成需求 |
| 企业版 | 49,800 元/年 | 中大型企业多系统深度集成 |
| 免费试用 | 0 元 | 功能体验与场景验证 |
支持免费试用体验,用户可按需选择,灵活扩展。
2.2 Apache Doris:实时数据仓库与分析层
Apache Doris 是全球领先的 MPP 架构实时分析型数据库,能够在亚秒级时间内返回海量数据的查询结果。作为 Apache 顶级项目,全球已有 5000+ 中大型企业生产部署,中国市值前 50 互联网公司 80% 以上使用 Doris。
架构特点
| 特性 | 说明 | 业务价值 |
|---|---|---|
| MPP 大规模并行处理 | 节点间和节点内并行执行,支持多表分布式 Shuffle Join | 大表 Join 不怕慢 |
| 向量化执行引擎 | 所有内存结构按列式布局,宽表聚合场景性能是非向量化 5-10 倍 | 复杂聚合秒出结果 |
| 列式存储与智能索引 | Sorted Compound Key、Min/Max、BloomFilter、Inverted 等多种索引 | 精确查询不扫全表 |
| 存算分离(3.0) | 计算节点无状态,秒级弹性伸缩,共享对象存储 | 按需扩缩降低成本 |
核心优势
- 实时性强:秒级数据入库,亚秒级查询响应,支持实时报表与多维分析
- 高兼容:兼容 MySQL 协议,标准 SQL,支持与主流 BI 工具无缝集成
- 高可用:多副本存储,支持同城和异地容灾,集群自动隔离故障节点
- 运维简单:仅两类核心进程(FE/BE),不依赖第三方系统(无需 ZooKeeper/HDFS)
在本方案中的角色
Doris 在这套架构中是数据的"心脏"------存储所有从数环通采集来的业务数据,通过分层建模(ODS → DWD → DWS → ADS)提供不同粒度的分析能力,对外通过 MySQL 协议暴露查询接口给 DataEase。
Doris 数仓分层设计:
ODS(操作数据层)
- ods_erp_sales_order ← 数环通同步的 ERP 销售订单原始数据
- ods_crm_customer ← 数环通同步的 CRM 客户原始数据
- ods_ecommerce_trade ← 数环通同步的电商交易原始数据
DWD(明细数据层)
- dwd_sales_order_detail ← 清洗后的订单明细(去重、状态标准化)
- dwd_customer_profile ← 客户画像明细(多源合并)
DWS(汇总数据层)
- dws_daily_sales_summary ← 日维度销售汇总
- dws_monthly_customer_ltv ← 月维度客户 LTV
ADS(应用数据层)
- ads_realtime_dashboard ← 实时看板数据
- ads_weekly_report ← 周报数据性能表现
- TPC-DS 1TB 测试中性能领先 ClickHouse
- ClickBench 测试 2022 年与 2024 年进入榜单前三
- 小米湖仓一体实践中,Doris 查询性能达到 Trino 的 5 倍
2.3 DataEase:数据可视化与决策层
DataEase 是**「人人可用的开源 BI 工具」**,以 GPLv3 开源许可协议发布,多次登顶 GitHub Trending 榜单,累计下载超过 30 万次。
核心能力
| 能力 | 说明 |
|---|---|
| 多源数据连接 | 支持近 20 种常见数据源(MySQL、PostgreSQL、Excel、CSV 等),可直连 Apache Doris |
| 拖拽式可视化 | 通过拖拽快速制作图表------折线图、柱状图、饼图、漏斗图、地图、仪表盘等 |
| 数据大屏 | 支持图层管理、大屏尺寸设置、动态数据刷新,实现「所见即所得」的驾驶舱 |
| AI 辅助(2.0) | DataEase Copilot 通过自然语言交互实现数据即问即答 |
| 模板市场 | 提供零售、证券、制造、电商等多种行业模板,开箱即用 |
在本方案中的角色
DataEase 直连 Doris(MySQL 协议兼容),为业务人员提供零代码的数据分析和可视化能力。
关键对接点:
- DataEase 添加数据源时选择 MySQL 类型,填入 Doris FE 的地址和端口即可直连
- 直接查询 Doris 的 ADS 层表,无需数据导出
- 支持实时刷新------Doris 中数据更新后,DataEase 看板自动体现
易用性优势
- 零门槛上手:业务人员无需编写 SQL,通过鼠标点击和拖拽即可完成数据分析全流程
- 一键部署:支持 Docker 容器化部署,分钟级完成安装
- 开箱即用:行业模板市场,选中即可基于自己的数据快速出图
三、数据流转全链路
把三个组件串起来,看完整的数据流转链路:
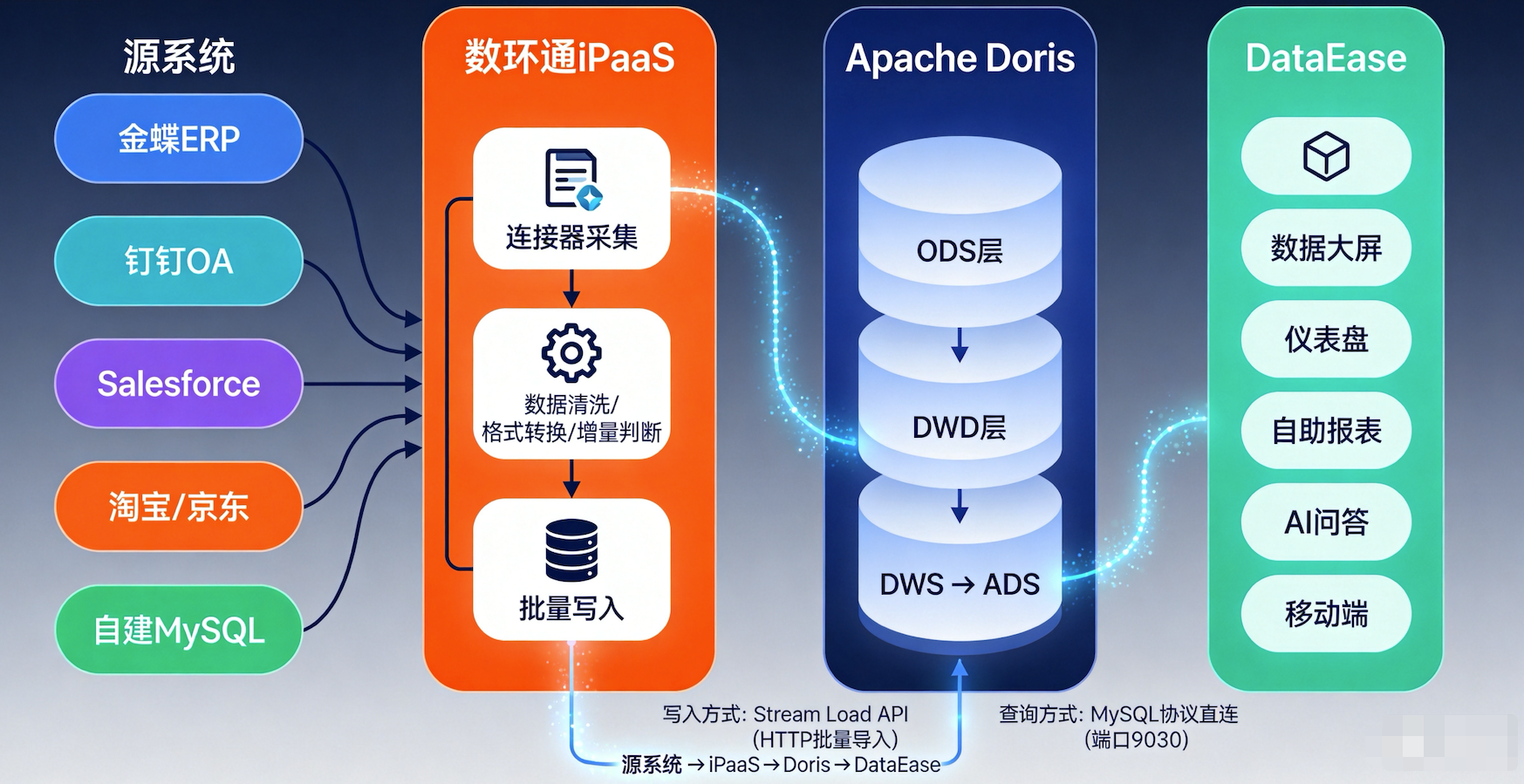
各环节技术细节
环节 1:数环通 → Doris(数据写入)
写入方式:Doris Stream Load
协议:HTTP PUT
地址:http://{doris_fe_host}:8030/api/{db}/{table}/_stream_load
格式:JSON 或 CSV
频率:每 5 分钟一次增量同步(可配置)
示例请求:
PUT /api/analytics_db/ods_erp_sales_order/_stream_load HTTP/1.1
Authorization: Basic {base64(user:password)}
Content-Type: application/json
Label: sync_20240101_001
[
{"order_id": "SO20240101001", "customer_name": "某科技公司", "amount": 15800.00, ...},
{"order_id": "SO20240101002", "customer_name": "某制造企业", "amount": 32500.00, ...}
]数环通 iPaaS 的数据管道节点原生支持 HTTP 输出,可以直接配置 Stream Load 的 URL 和认证信息,无需开发代码。
环节 2:Doris 内部(数仓分层计算)
sql
-- DWD 层:清洗标准化(Doris 物化视图或定时 INSERT INTO SELECT)
INSERT INTO dwd_sales_order_detail
SELECT
order_id,
customer_name,
CASE status WHEN '1' THEN '已下单' WHEN '2' THEN '已发货' ELSE '未知' END AS status_name,
amount,
DATE(create_time) AS order_date
FROM ods_erp_sales_order
WHERE create_time > '${last_sync_time}';
-- DWS 层:日汇总
INSERT INTO dws_daily_sales_summary
SELECT
order_date,
COUNT(*) AS order_count,
SUM(amount) AS total_amount,
COUNT(DISTINCT customer_name) AS customer_count
FROM dwd_sales_order_detail
GROUP BY order_date;
-- ADS 层:看板直接查询的宽表
CREATE TABLE ads_realtime_dashboard AS
SELECT
CURDATE() AS report_date,
(SELECT SUM(amount) FROM dws_daily_sales_summary WHERE order_date = CURDATE()) AS today_sales,
(SELECT COUNT(*) FROM dwd_sales_order_detail WHERE order_date = CURDATE()) AS today_orders,
...环节 3:Doris → DataEase(可视化展示)
DataEase 通过 MySQL 协议直连 Doris:
数据源类型:MySQL
主机地址:{doris_fe_host}
端口:9030
数据库:analytics_db
用户名:dataease_reader
密码:****
直接查询 ADS 层表,无需额外 ETL。四、部署方案
4.1 最小化部署(适合验证和小规模使用)
| 组件 | 部署方式 | 资源需求 | 说明 |
|---|---|---|---|
| 数环通 iPaaS | SaaS 版 | 无需自建 | 开通账号即用,通过公网采集数据写入 Doris |
| Apache Doris | 单机(1FE + 1BE) | 4C16G + 200G SSD | 支撑 TB 级数据量 |
| DataEase | Docker 单机 | 2C4G | 一行命令启动 |
bash
# DataEase 一键部署
docker run -d --name dataease \
-p 8100:8100 \
-v /opt/dataease/data:/opt/dataease/data \
registry.cn-qingdao.aliyuncs.com/dataease/dataease:latest
# Doris 单机部署(开发/验证用)
# 1. 启动 FE
sh fe/bin/start_fe.sh --daemon
# 2. 启动 BE
sh be/bin/start_be.sh --daemon
# 3. 添加 BE 到集群
mysql -h 127.0.0.1 -P 9030 -u root
> ALTER SYSTEM ADD BACKEND "127.0.0.1:9050";4.2 生产级部署(适合正式使用)
| 组件 | 部署方式 | 资源需求 | 说明 |
|---|---|---|---|
| 数环通 iPaaS | SaaS 版或私有化 | 私有化需 8C32G × 2 | 企业版支持私有化部署 |
| Apache Doris | 集群(3FE + 3BE) | BE: 16C64G × 3 + SSD | 高可用 + 高性能 |
| DataEase | Docker(高可用) | 4C8G × 2 | 前置 Nginx 做负载均衡 |
生产架构拓扑:
┌────────────────────────────────────┐
│ 负载均衡 (Nginx) │
└─────────┬──────────┬───────────────┘
│ │
┌─────────┴──┐ ┌────┴─────────┐
│ DataEase-1 │ │ DataEase-2 │
└─────────┬──┘ └────┬─────────┘
│ │
┌─────────┴──────────┴───────────────┐
│ Doris 集群 │
│ FE×3 (元数据 + 查询路由) │
│ BE×3 (存储 + 计算) │
└─────────┬──────────────────────────┘
│ Stream Load
┌─────────┴──────────────────────────┐
│ 数环通 iPaaS (SaaS/私有化) │
└────────────────────────────────────┘4.3 资源与成本估算
| 方案 | 年度总成本估算 | 适用规模 |
|---|---|---|
| 最小化(SaaS + 单机) | ~2-3 万/年 | 日均 10 万条数据,10 个报表 |
| 标准版 | ~8-12 万/年 | 日均 100 万条数据,50+ 报表 |
| 生产高可用 | ~20-30 万/年 | 日均千万级数据,100+ 报表 |
对比传统大数据方案(Kafka + Flink + Hive + Superset)动辄 50-100 万/年的综合投入,这套三件套方案的 TCO 降低 60-80%。
五、典型行业场景
5.1 零售电商:全渠道经营分析
数据源 分析目标
────── ────────
淘宝/京东/抖音店铺 ──┐ ┌── 全渠道 GMV 日报
线下 POS 系统 ──┤ iPaaS │── 各渠道 ROI 对比
金蝶财务系统 ──┼───→ Doris ───→├── 库存周转分析
WMS 仓储系统 ──┤ DataEase │── 爆品销量排行
CRM 会员系统 ──┘ └── 客户复购率热力图业务价值:
- 过去每天花 2 小时在各平台手动导出数据做 Excel,现在实时看板自动刷新
- 各渠道数据口径不一致(淘宝用"实付金额"、京东用"结算金额"),在数环通清洗层统一标准化
- 缺货预警从"人工巡检"变成"自动告警"
5.2 制造业:供应链可视化
数据源 分析目标
────── ────────
SAP ERP (采购/库存) ──┐ ┌── 原料库存预警大屏
MES 生产系统 ──┤ iPaaS │── 生产进度实时看板
SRM 供应商平台 ──┼──→ Doris ──→├── 供应商交付率排名
WMS 仓储系统 ──┤ DataEase │── 成品出库趋势
质检系统 ──┘ └── 质量合格率月报业务价值:
- 采购部门实时看到原料库存水位,提前 3 天预警避免停产
- 供应商交付率数据自动汇总,季度考核有数据支撑
- 生产排程依据从"经验"变成"数据"
5.3 SaaS 企业:客户成功分析
数据源 分析目标
────── ────────
自有业务系统 (用量) ──┐ ┌── 客户健康度评分
Salesforce (客户) ──┤ iPaaS │── 用量趋势与流失预警
企微 (沟通记录) ──┼──→ Doris ──→├── 续费率预测
工单系统 (支持) ──┤ DataEase │── 功能使用热力图
支付系统 (ARR) ──┘ └── MRR/ARR 实时看板业务价值:
- 客户成功团队从"被动响应工单"变成"主动发现风险客户"
- 用量下降的客户自动触发预警,CSM 提前介入挽留
- 续费率从 75% 提升到 85%(基于真实案例)
5.4 金融/证券:合规与风控报表
数据源 分析目标
────── ────────
核心交易系统 ──┐ ┌── 实时交易监控大屏
风控系统 ──┤ iPaaS │── 异常交易自动标记
客户信息系统 ──┼───→ Doris ──→├── 客户分级报表
外部数据 (征信) ──┤ DataEase │── 合规审计追溯
监管报送系统 ──┘ └── 日/月/年监管报表注意 :金融场景对数据安全要求高,建议采用数环通企业版(私有化部署)+ Doris 集群 + DataEase 内网部署,数据全链路不出企业网络。
六、与传统方案的对比
6.1 与重量级大数据方案对比
| 维度 | 传统大数据方案 | 三件套轻量方案 |
|---|---|---|
| 组件数量 | 8-12 个(Kafka/Flink/Hive/Spark/Airflow/Superset...) | 3 个 |
| 运维复杂度 | 需要专职大数据团队(3-5 人) | 1 人即可维护 |
| 部署周期 | 1-3 个月 | 1-3 天 |
| 年度成本 | 50-100 万+ | 8-30 万 |
| 实时性 | 分钟级(Flink)到小时级(Hive) | 秒级(Doris Stream Load) |
| 学习曲线 | 陡峭(需要 Java/Scala/SQL 多技能) | 平缓(SQL + 可视化) |
| 适用规模 | 日均亿级数据 | 日均百万到千万级数据 |
6.2 与 Excel + 手动报表对比
| 维度 | Excel 人工方式 | 三件套方案 |
|---|---|---|
| 数据时效 | T+1(次日才能看到昨天数据) | 实时(秒级延迟) |
| 人力投入 | 每天 2-3 小时做报表 | 一次配置,自动运行 |
| 数据准确性 | 人工操作易出错 | 系统自动,一致性有保障 |
| 可追溯性 | Excel 版本混乱 | 全链路日志可审计 |
| 扩展性 | 数据量大了 Excel 卡死 | Doris 支持 PB 级 |
6.3 与 ETL 工具 + BI 工具组合对比
| 维度 | Informatica + Tableau | 三件套方案 |
|---|---|---|
| License 成本 | 极高(Tableau 单用户万级) | DataEase 开源免费 |
| 数据存储 | 需要额外购买数据库 | Doris 开源免费 |
| 集成连接器 | 需要开发 | 数环通 1000+ 预置 |
| 国产化适配 | 弱 | 全栈国产化 |
| 本地化支持 | 海外厂商,响应慢 | 国内团队,响应快 |
七、落地实施步骤
第一阶段:验证期(1-2 周)
目标:跑通一个完整链路,验证可行性
Step 1: 注册数环通 iPaaS 免费试用账号
→ www.solinkup.com
Step 2: 部署 Doris 单机版(开发环境)
→ 4C16G 服务器一台
Step 3: 部署 DataEase(Docker 一键启动)
→ 2C4G 服务器一台
Step 4: 选一个数据源跑通全链路
→ 例:钉钉考勤数据 → Doris → DataEase 看板
Step 5: 验证数据准确性和时效性
→ 对比源系统数据,确认无误第二阶段:扩展期(2-4 周)
目标:接入核心业务数据源,搭建分析体系
Step 1: 梳理需要接入的数据源清单(按优先级排序)
Step 2: 在数环通中配置各数据源连接器 + 同步策略
Step 3: 在 Doris 中设计数仓分层模型(ODS/DWD/DWS/ADS)
Step 4: 在 DataEase 中搭建核心业务看板(3-5 个)
Step 5: 配置监控告警(同步失败告警、数据延迟告警)第三阶段:治理期(持续)
目标:精细化运营,持续优化
- 数据质量监控:空值率、重复率、延迟指标
- 报表权限管控:按部门/角色分配看板权限
- 成本优化:Doris 冷热分离,历史数据归档到对象存储
- 能力开放:DataEase 嵌入业务系统,数据能力下沉到一线八、常见问题(FAQ)
Q:数环通写入 Doris 的性能如何?会不会成为瓶颈?
A:Doris 的 Stream Load 写入性能可达单节点 100MB/s+。数环通通过批量聚合后一次性写入(而非逐条),日均百万条数据的写入场景下完全没有压力。如果数据量更大,可以增加 Doris BE 节点水平扩展。
Q:DataEase 能直连 Doris 吗?需要中间层吗?
A:可以直连,无需中间层。Doris 兼容 MySQL 协议,DataEase 在添加数据源时选择 MySQL 类型,填入 Doris FE 的 IP 和 9030 端口即可。查询走 Doris 的向量化引擎,亚秒级返回。
Q:这套方案能支撑多大的数据量?
A:取决于 Doris 集群规模。单机版支撑 TB 级;3 节点集群支撑 10TB+ 级;生产级大集群可支撑 PB 级。对于大多数中小企业的数据分析场景(日均百万到千万级增量),3 节点集群绰绰有余。
Q:已有 MySQL/PostgreSQL 做分析库,还需要换 Doris 吗?
A:如果当前分析查询在 MySQL 上已经够快(秒级返回),不需要换。但当数据量超过千万行、分析查询涉及多表 Join + 聚合时,MySQL 会明显变慢(分钟级)。Doris 的 MPP + 列存架构在 OLAP 场景下性能是 MySQL 的 10-100 倍。
Q:数据安全怎么保障?
A:三个层面:① 数环通传输层使用 TLS 加密 + OAuth2 鉴权;② Doris 支持 RBAC 权限控制 + 数据脱敏;③ DataEase 支持行级/列级权限和数据集权限。如果对数据驻留有要求,三个组件均支持私有化部署,数据不出企业网络。
Q:业务人员真的能自己用 DataEase 做分析吗?
A:DataEase 的设计理念就是"人人可用"。实际使用中,业务人员负责拖拽制图 (选维度、选指标、选图表类型),技术人员负责数据建模(设计 ADS 层宽表,确保业务人员看到的是干净的数据集)。分工明确后,业务人员无需写 SQL。
Q:这套方案和数环通自身的数据分析能力有什么关系?
A:数环通本身专注于数据采集和流程自动化,不做重度 BI 分析。在需要深度数据分析的场景下,用 Doris 做存储计算、DataEase 做可视化是最佳实践------各组件做各自最擅长的事。
九、写在最后
这套「数环通 iPaaS + Apache Doris + DataEase」的三件套方案,核心逻辑只有一句话:
用最少的组件、最低的运维成本,覆盖"数据采集 → 存储分析 → 可视化决策"的完整链路。
它不是要取代 Hadoop/Flink 这类重量级方案------那些方案在日均亿级数据、复杂流计算场景下依然不可替代。但对于 80% 的中小企业和大企业的业务部门来说,这套方案的 ROI 明显更优:
- 1-3 天完成全链路部署和验证
- 1 人即可完成日常运维
- 8-30 万/年覆盖从采集到可视化的全部成本
- 业务人员可自助完成 80% 的分析需求
如果你的企业正处于"数据散落各系统、分析还靠 Excel"的阶段,不妨从一个小场景开始验证------注册数环通免费试用,部署一个单机版 Doris + DataEase,选一个业务数据源跑通全链路。当第一个实时看板自动刷新出数据的那一刻,你就知道这条路走不走得通。
标签:#iPaaS #ApacheDoris #DataEase #数据集成 #数据仓库 #BI #可视化 #实时分析 #ETL #数据中台替代 #轻量级方案 #企业数字化 #数据管道 #低代码 #数环通