声明:本篇博客是以吴恩达的【Agent智能体】教程为基础,并对其中的内容做了笔记整理以及个人收获的总结。

这篇文章主要是简单介绍一些常用的智能体设计模式,后面会详细介绍每一个智能体的设计模式,这些模式可以帮助思考如何将构建模块组合成更复杂的工作流
智能体设计模式概览

- 反思
- 工具使用
- 规划
- 多智能体协作
反思(Reflection)
单个LLM的反思
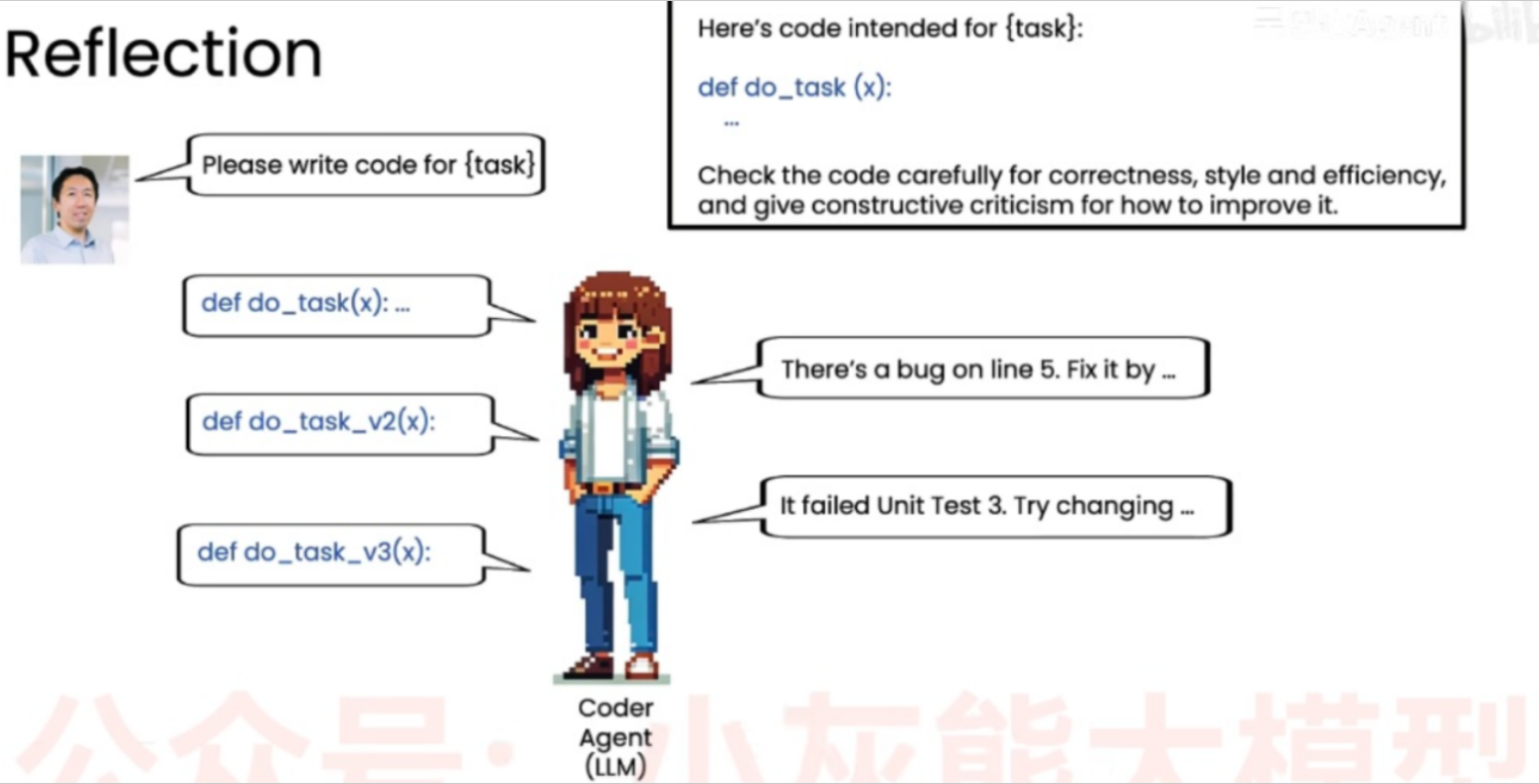
这个图展示了同一个 LLM 承担"编写"和"审查"两个工作。
人类提出需求:"Please write code for {task}"(请为某任务编写代码)。
- 初始生成: Coder Agent 生成了第一版初始代码
def do_task(x)。 - 反思: 系统将生成的第一版代码放入一个特定的提示词模板中(右上角黑框),要求 LLM 仔细检查代码的正确性、风格和效率,并给出建设性的改进意见。
- 自我纠错: Coder Agent 审视自己刚才写的代码,发现了问题(例如:"第5行有个bug,通过...修复"或"未通过单元测试3")。
- 迭代输出: 基于自己的反思,Coder Agent 重新编写代码,迭代出
v2甚至v3版本,直到代码完善。
总结:让智能体自己检查,用反馈不断的迭代,生成更好的输出版本
多个智能体的反思
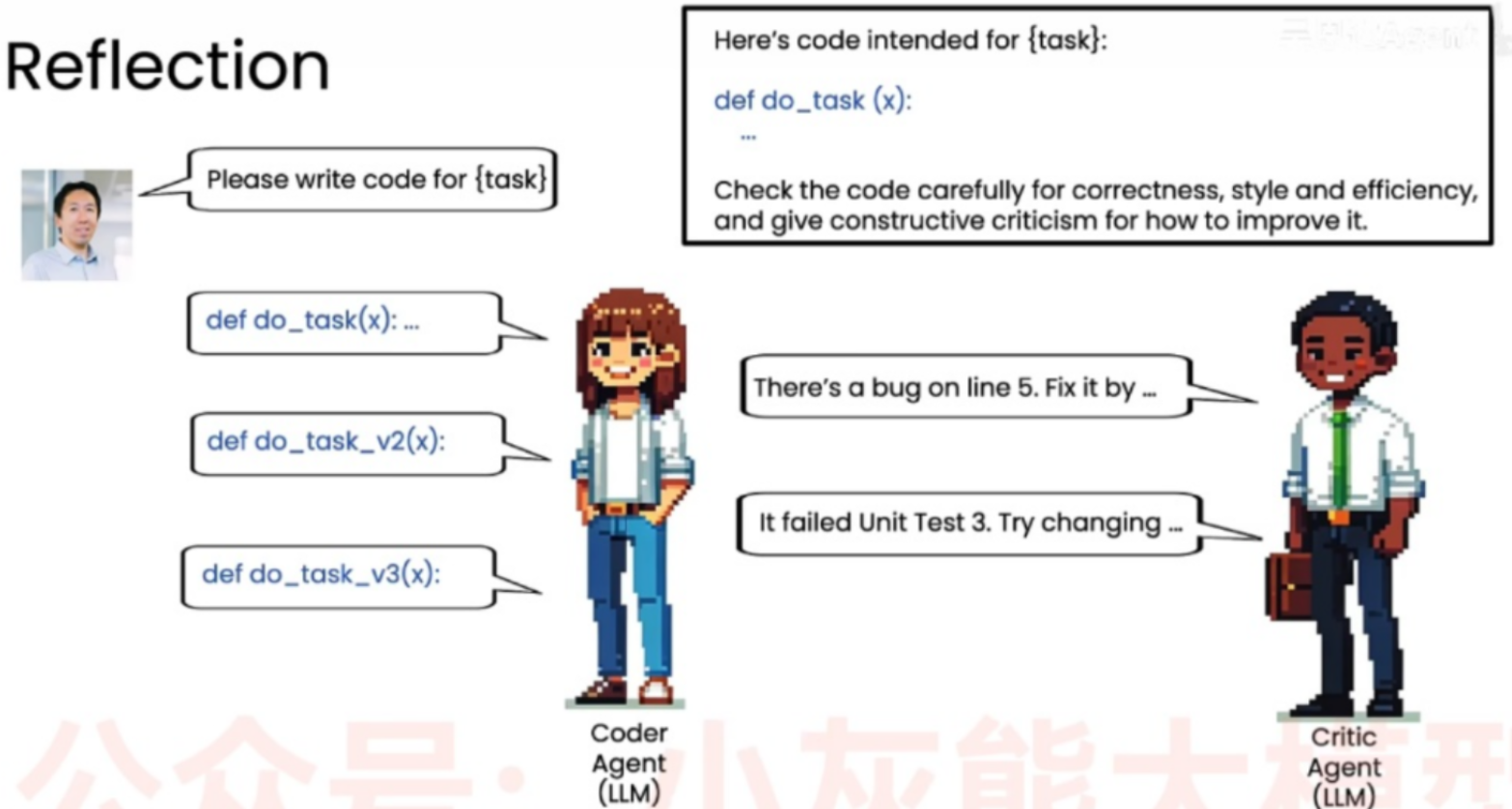
还是同样的需求,不过这次同一个任务由两个不同的智能体来协作完成!
- 分工 : 左边的 Coder Agent 专职负责写代码,右边新增了一个 Critic Agent(审查员智能体) 负责代码审查(Code Review)。
- 审查:Coder Agent 写出第一版代码后,交由 Critic Agent 进行审阅。Critic Agent 按照右上角的审查标准,给出具体的修改建议(指出bug和未通过的测试)。
- 根据反馈迭代: Coder Agent 接收到 Critic Agent 的批评和建议后,进行针对性的修改,生成改进后的
v2和v3版本。
工具使用(ToolUse)
"工具使用"是给 AI 装上了"手和脚",让它能够与外部世界互动,并弥补自身的先天缺陷。

- 网络搜索工具 (Web search tool)
- AI 没有直接凭记忆瞎编,而是调用了搜索引擎去查找最新的评论信息。这让 AI 能够获取实时的、外部的客观事实。
- 代码执行工具 (Code execution tool)
- AI 知道自己算术不准,于是它选择编写一段 Python 代码 (
value = principal*(1 + interest_rate)years)并将其发送给后端的代码解释器去运行。这样就能得到 100% 准确的数学结果,避免了幻觉。
- AI 知道自己算术不准,于是它选择编写一段 Python 代码 (
开发者为LLM提供了各种工具:

- 分析 (Analysis): 用于精准计算和数据处理。例如:代码执行环境、Wolfram Alpha(专业计算引擎)。
- 信息收集 (Information gathering): 用于突破知识盲区。例如:网络搜索、查阅维基百科、直接读取企业的内部数据库(Database access)。
- 生产力 (Productivity): 用于执行现实世界的动作。例如:帮用户发邮件 (Email)、在日历上安排会议 (Calendar)、发送消息 (Messaging)。
- 图像处理 (Images): 扩展多模态能力。例如:生成图片、识别图片内容 (Image captioning)、提取图片中的文字 (OCR)。
规划(Planning)
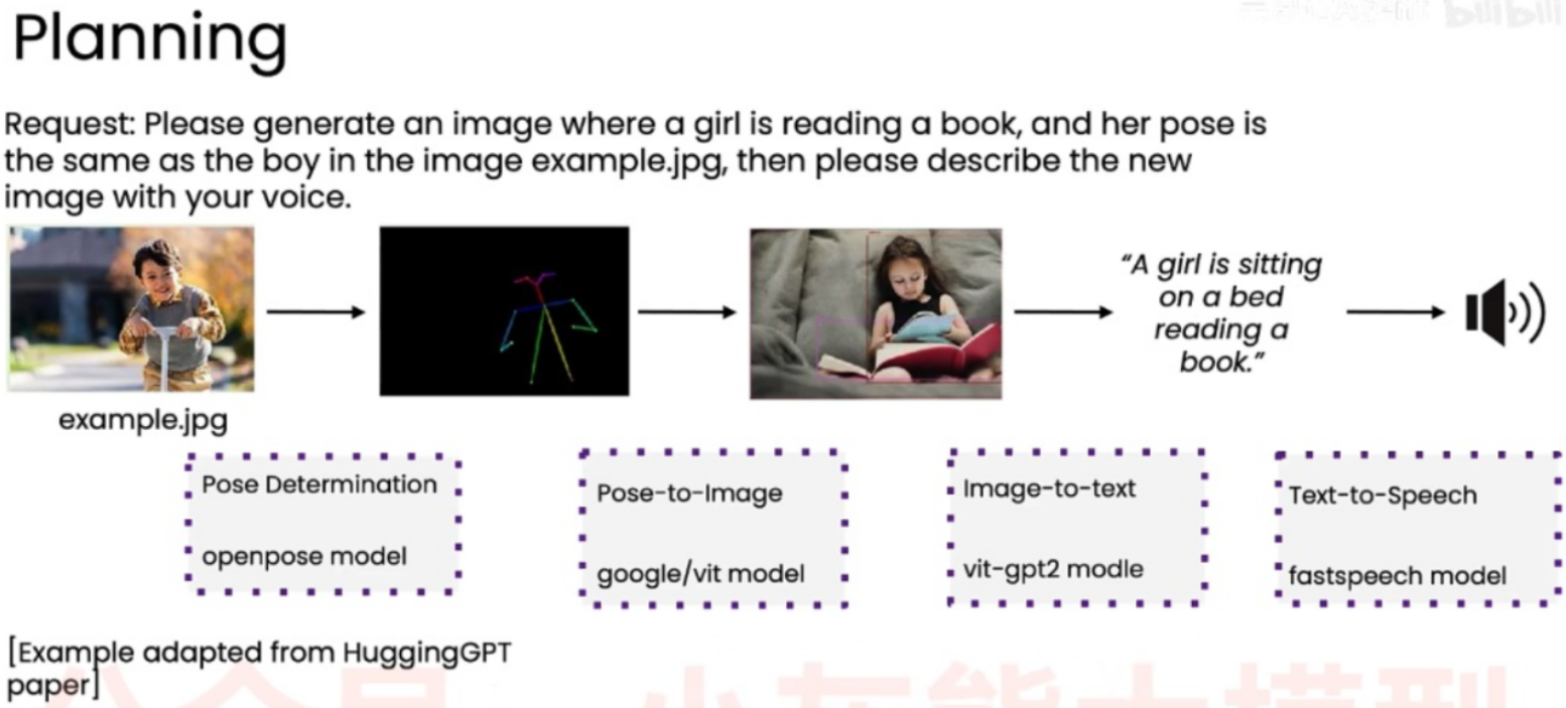
户提出的 "Request" (请求),它包含两个部分:
- 任务 A:生成图像。 条件是:一个女孩正在读书,且她的姿势必须与提供的
example.jpg中的男孩相同。 - 任务 B:语音描述。 条件是:对新生成的图像用语音进行描述。
这是一个非常具有挑战性的请求,因为它要求系统:
- 理解文本语义 (女孩在读书)。
- 进行条件图像生成,并保持特定的、非自然姿势(骑滑板车的姿势应用到读书上)。
- 从图像生成文本。
- 从文本生成语音。
AI会对复杂的任务进行规划,然后按照步骤执行:
- 第一步:姿势提取 (Pose Determination)
- 输入: 用户的示例图片
example.jpg(男孩骑滑板车)。 - 动作: 调用 "openpose model"。
- 输出: 提取出一个彩色的、简化的姿势骨架图(skeleton)。
- 输入: 用户的示例图片
- 第二步:姿势到图像生成 (Pose-to-Image)
- 输入: 第一步得到的骨架图 + 用户的文本请求("一个女孩读书")。
- 动作: 调用 "google/vit model"这些工具
- 输出: 生成一张新的图片:一个女孩在床(或沙发)上读书,且她的姿势(腿部的弯曲、身体的倾斜)与滑板车男孩的骨架姿势非常相似,尽管场景和人物完全变了。这是核心的条件生成步骤。
- 第三步:图像转文本 (Image-to-text)
- 输入: 上一步新生成的女孩读书图。
- 动作: 调用 "vit-gpt2 model"
- 输出: 生成一句文字描述:"A girl is sitting on a bed reading a book."
- 第四步:文本转语音 (Text-to-Speech)
- 输入: 上一步生成的文字描述。
- 动作: 调用 "fastspeech model"。
- 输出: 一个扬声器图标,代表最终输出一段对该描述的语音播报。
总结:规划中,LLM会决定需要采取哪些行动顺序,这个例子中就是一系列Api的调用,这样模型就能正确的执行每一步,开发者无需提前硬编码,而是由LLM自主决定执行哪些步骤
多智能体协作(Multi-agent collaboration)
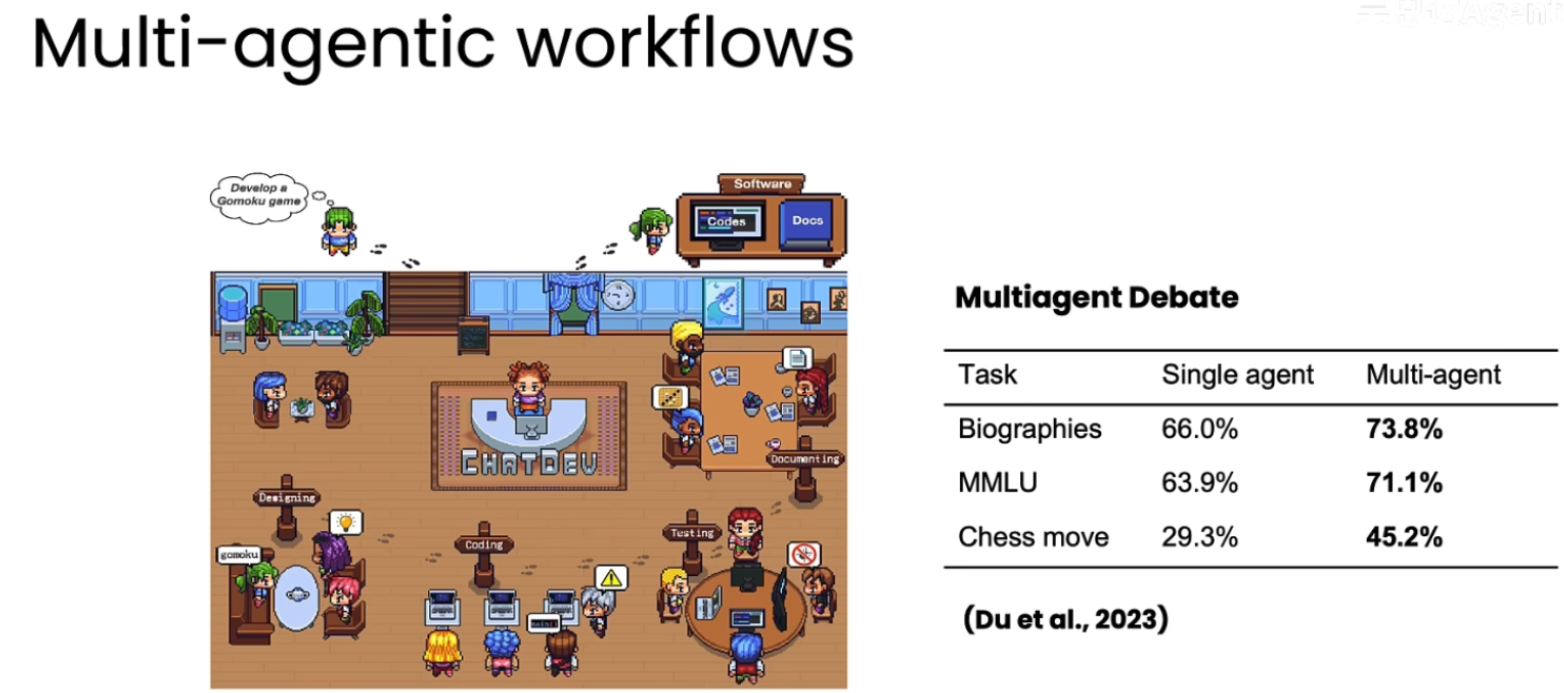
这张图展示了多智能体工作流这种设计模式。
核心思想:将一个复杂的任务拆解,分配给多个扮演不同角色的 AI 智能体,让它们通过协作、沟通甚至辩论来共同完成任务,这比依赖单一 AI 效果更好。
如果这篇文章对你有帮助,欢迎点赞、评论、关注、收藏。你们的支持是我前进的动力!