文章目录
- [1. 先说结论](#1. 先说结论)
- [2. 三种索引方式](#2. 三种索引方式)
- [3. 基础索引](#3. 基础索引)
-
- [维度索引工具: ellipsis ... 和 None/newaxis](#维度索引工具: ellipsis ... 和 None/newaxis)
- [4. 纯高级索引](#4. 纯高级索引)
- [5. 混合索引](#5. 混合索引)
-
- [5.1 对结果数组执行的 2 步操作](#5.1 对结果数组执行的 2 步操作)
- [5.2 高级索引对象被隔开,如 xind_1, :, ind_2](#5.2 高级索引对象被隔开,如 x[ind_1, :, ind_2])
- [5.3 只有一个高级索引对象](#5.3 只有一个高级索引对象)
-
- [5.3.1 高级索引对象不在第 0 维度时,如 x..., ind_1](#5.3.1 高级索引对象不在第 0 维度时,如 x[..., ind_1])
- [5.3.2 高级索引对象在第 0 维度时,如 xind_1, ...](#5.3.2 高级索引对象在第 0 维度时,如 x[ind_1, ...])
- [5.4 高级索引紧挨着,如 x..., ind_1, ind_2, :](#5.4 高级索引紧挨着,如 x[..., ind_1, ind_2, :])
- [6. 布尔索引 boolean array indexing](#6. 布尔索引 boolean array indexing)
-
- [6.1 对形状的影响和要求](#6.1 对形状的影响和要求)
- [6.2 用布尔数组修改原数组的 4 个常见用法](#6.2 用布尔数组修改原数组的 4 个常见用法)
- [7. 重复赋值问题和内存布局](#7. 重复赋值问题和内存布局)
-
- [7.1 重复赋值问题](#7.1 重复赋值问题)
- [7.2 内存布局 memory layout](#7.2 内存布局 memory layout)
- [8. take 和 take_along_axis 函数](#8. take 和 take_along_axis 函数)
-
- [8.1 take 函数](#8.1 take 函数)
- [8.2 take_along_axis 函数](#8.2 take_along_axis 函数)
- [9. 字段访问 field access](#9. 字段访问 field access)
从 Numpy 数组中提取数据时,可以使用基础索引、高级索引、take 函数和 take_along_axis 函数等。需要根据不同的目标使用不同的索引方式。
1. 先说结论
下面以 2D 数组为例进行说明,可以类推到更高维度。
-
需要以简单的整行或整列的形式提取数据,使用基础索引、混合索引或 take 函数。
-
需要每行提取不同位置的数据,使用纯高级索引或 take_along_axis 函数。
例如需要从第 0 行提取第 6 列的数据,第 1 行提取第 8 列的数据时。
-
需要提取孤立的数据,或者说提取的位置不规则时,使用纯高级索引。
例如需要从第 0 行提取 3 个数据,而第 1 行提取 2 个数据的情况。
3.1 如果要提取孤立的数据形成"矩形"数组,除了使用纯高级索引,还可以使用 ix_ 函数。
从提取数据的灵活程度来说,纯高级索引的灵活程度最高,因为它可以从数组中提取孤立的数据。
提取数据的灵活程度排序如下:
纯高级索引 > 混合索引 > 基础索引 。
2. 三种索引方式
-
基础索引方式 basic indexing 的 2 种情况:
1.1 使用整数或切片 slice 作为索引对象。例如
a[2]或者 a1:2 。1.2 使用元祖进行索引,且元祖内只有整数或切片。例如 a:, 2 或者 a1, 2 。
注意,x(exp1, exp2, ..., expN) 等效于 xexp1, exp2, ..., expN ,且后者实际是前者的 syntactic sugar 语法糖,因为后者省去了小括号,使用更方便。
后面将把 exp1、exp2 等叫做索引对象,exp1、exp2 可以是列表、整数和数组等。
-
纯高级索引方式 pure advanced indexing 的 2 种情况:
2.1 使用列表或数组作为索引对象时。例如 a\[1, 2] 。
2.2 使用元祖进行索引,但是元祖中的元素只有列表、元祖或数组。例如 a(1, 2), 。
-
混合索引方式 mixed indexing 。
当使用元祖进行索引,元祖内既有纯高级索引对象(列表,数组等),又有基础索引对象(整数和切片)时,就是混合索引,例如:
a:, \[0, 6] 。
Numpy 官方把纯高级索引和混合索引,都统一叫成高级索引 advanced indexing ,没有进行区分。官网对索引方式的介绍:https://numpy.org/doc/stable/user/basics.indexing.html
高级索引也叫花式索引 fancy indexing ,在官方术语表 glossary 中可查到:
https://numpy.org/doc/stable/glossary.html#term-fancy-indexing高级索引中的值可以是整数,也可以是布尔值,即布尔数组。使用布尔数组进行索引时,叫做 boolean array indexing 。
高级索引将生成拷贝 copy ,基础索引则生成视图 view 。原因是:变换数组时,如果更改 strides 属性,可以表达变换后的数组,则 Numpy 会优先生成视图。但是高级索引不能通过改 strides 属性来表达新的数组,所以只能生成 copy 。
但是为了便于理解和使用,建议区分纯高级索引和混合索引,因为它们产生的结果数组有很大区别,下面基于区分的方式进行详细讨论。
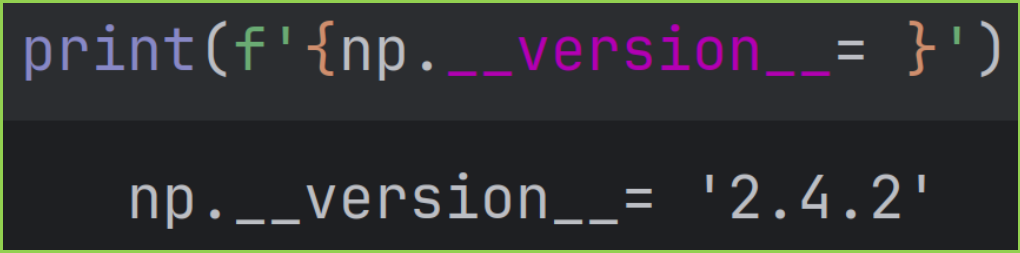
本篇的讨论,基于Numpy的 2.4.2 版本。
3. 基础索引
基础索引的 3 个特点如下:
- 使用整数会去掉对应维度,切片则保留该维度。如下图。
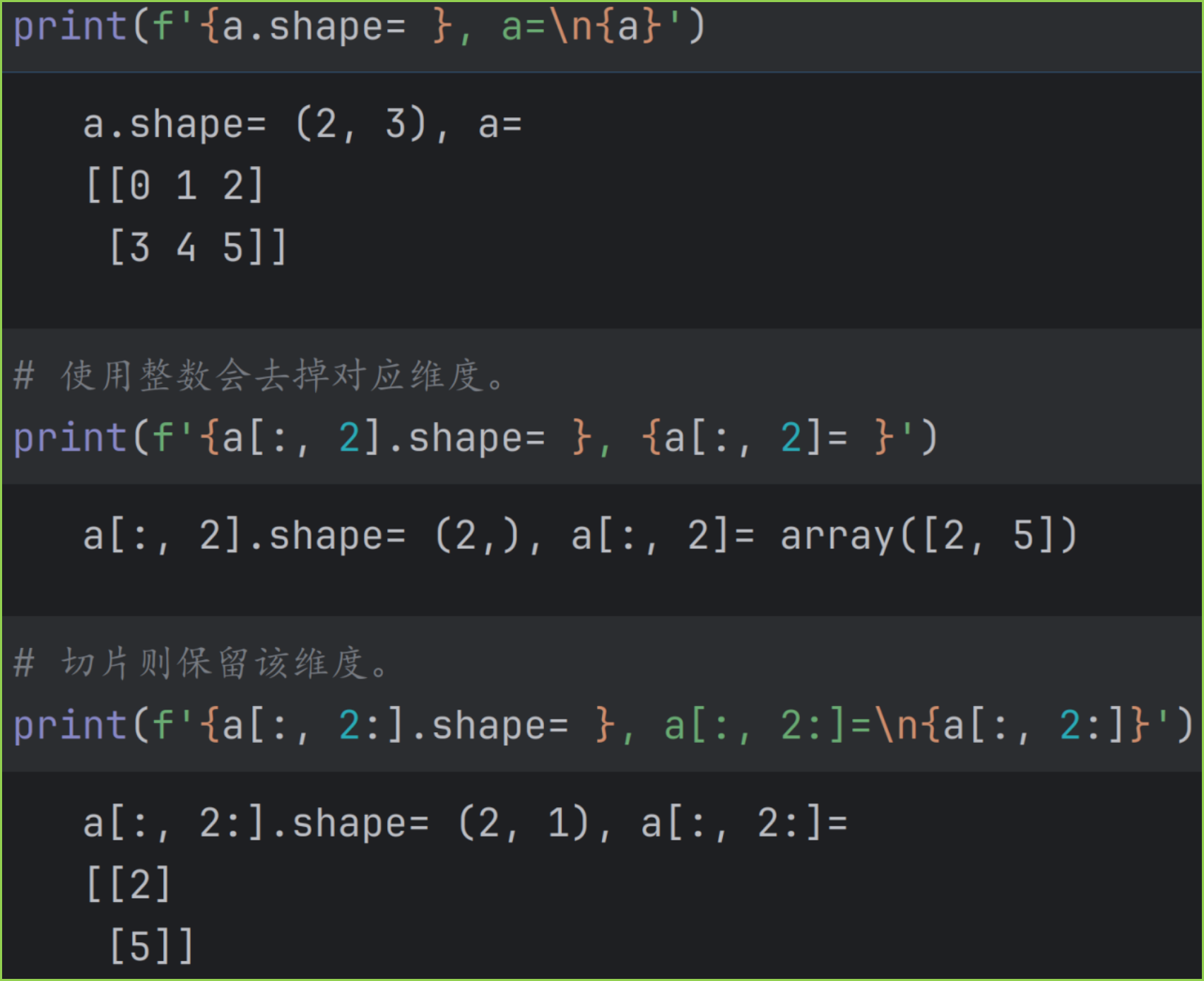
基础索引生成原数组的视图,用 shares_memory 可以查看。如下图。

用到的源码为:
python
# 1. 基础索引。
a = np.arange(6).reshape(2, 3)
print(f'{a.shape= }, a=\n{a}')
print(f'{a[:, 2].shape= }, {a[:, 2]= }')
print(f'{a[:, 2:].shape= }, a[:, 2:]=\n{a[:, 2:]}')
# 基础索引生成原数组的视图。
print(f'{np.shares_memory(a, a[:, 2])= }')为了直接显示结果,且代码也比较简单,后续将主要展示图片。
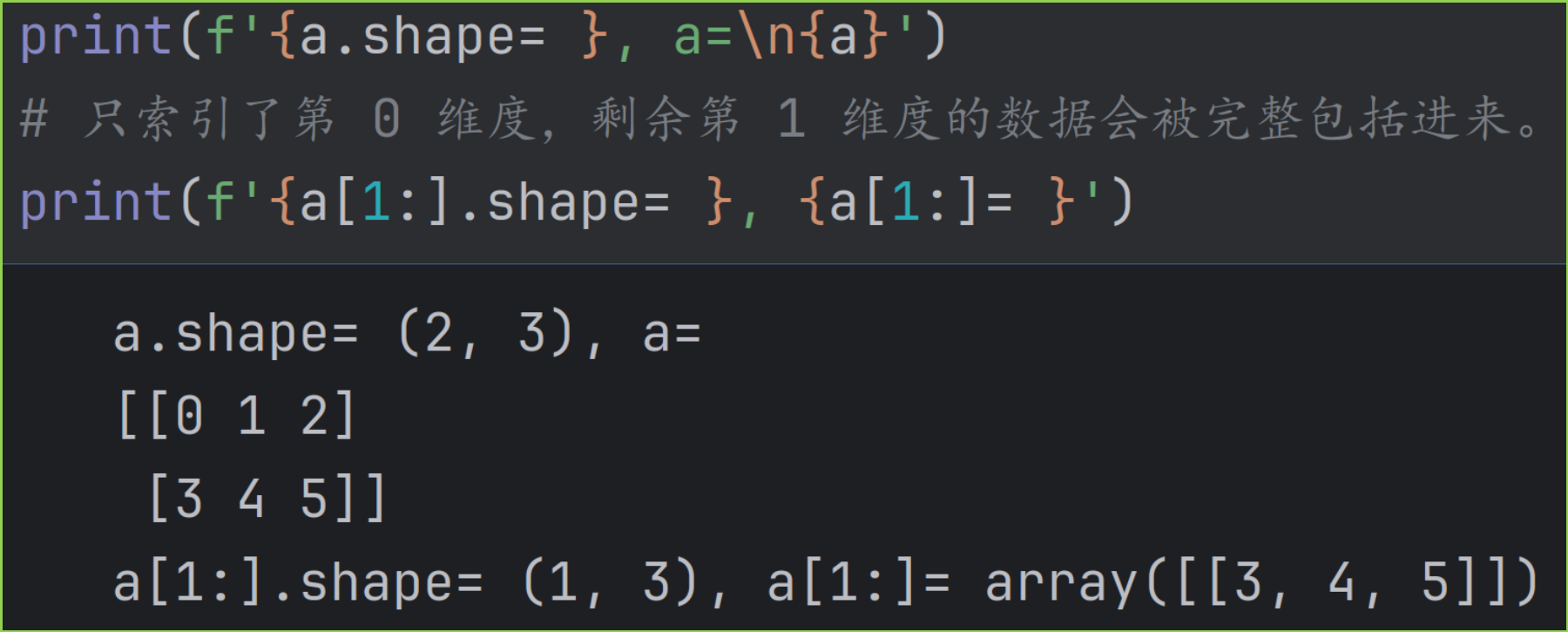
- 如果索引对象的数量少于数组的维度数量 ndim ,则会只索引前面几个维度。剩余维度的对应数据,会被完整包括进来。
假设 a 为 3D 数组,如果使用a[2],即只索引了第 0 维度,后面第 1, 2 维度对应的数据会被全部选上,等效于 a2, :, :
下图是一个 2D 数组的示例。
- 基础索引会生成原数组的 view 。此时原数组的引用数量会增加。原数组的所有 view 被回收 garbage-collected 之后,原数组的内存才能够被释放。
虽然两种方式等效,即 x[0, 2] == x[0][2] ,但是前者 x[0, 2] 更为高效。因为后者使用第一个索引 x[0] 时,需要创建一个临时数组。
维度索引工具: ellipsis ... 和 None/newaxis
有 2 个常用的维度索引工具 dimensional indexing tools ,它们既可以用于基础索引,也可以用于高级索引。
- 省略号 ellipsis ... 可以代表连续的多个维度。如果 a 的形状为 (6, 7, 8) , 则 a..., 0 返回形状 (6, 7) 的数组。
- None 和 newaxis 用于增加一个维度,例如 a..., None 和 a..., np.newaxis 作用相同,都得到形状为 (6, 7, 8, 1) 的数组。
4. 纯高级索引
纯高级索引和混合索引都生成原数组的拷贝 copy 。
使用纯高级索引时,注意 4 点:
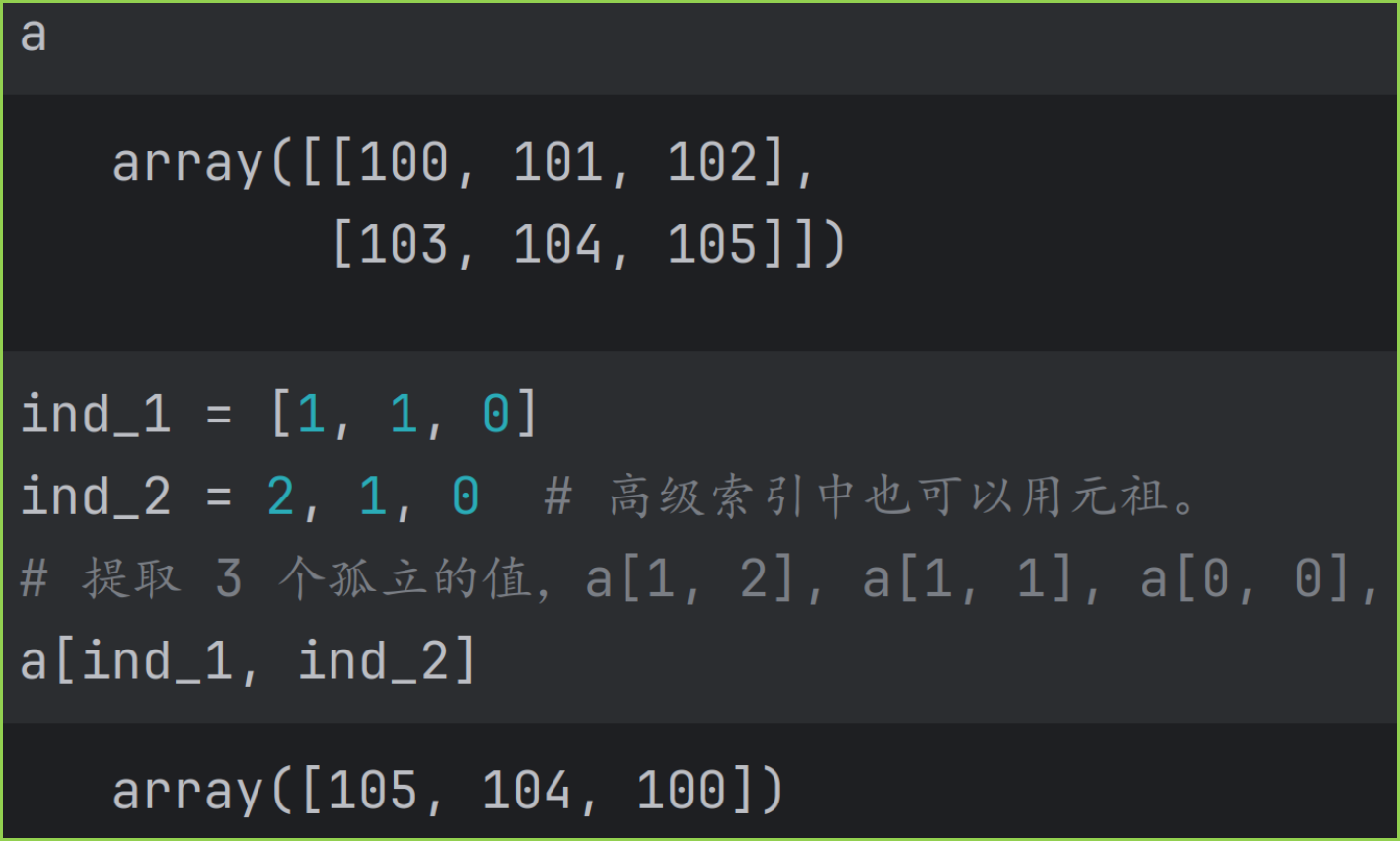
下面例子假设 a 为二维数组,使用 2 个索引对象进行索引 aind_1, ind_2 。
-
索引对象 ind_1, ind_2 的形状必须相同,或是可以相互扩展。
例如两个索引对象形状可以为 (3,) ,也可以为 (5, 6) 。或者是进行扩展,一个形状为 (2,),另一个为 (1,) 。
-
结果数组 resultant array 是若干个孤立的值,每个数值由 ind_1, ind_2 一一配对得到。结果数组的形状等于 ind_1, ind_2 扩展之后的形状。可以理解为下面 2 行代码:
python
for i, j in zip(ind_1, ind_2):
result[k] = a[i, j]一个示例如下。
下图是 ind_1, ind_2 进行扩展的示例。
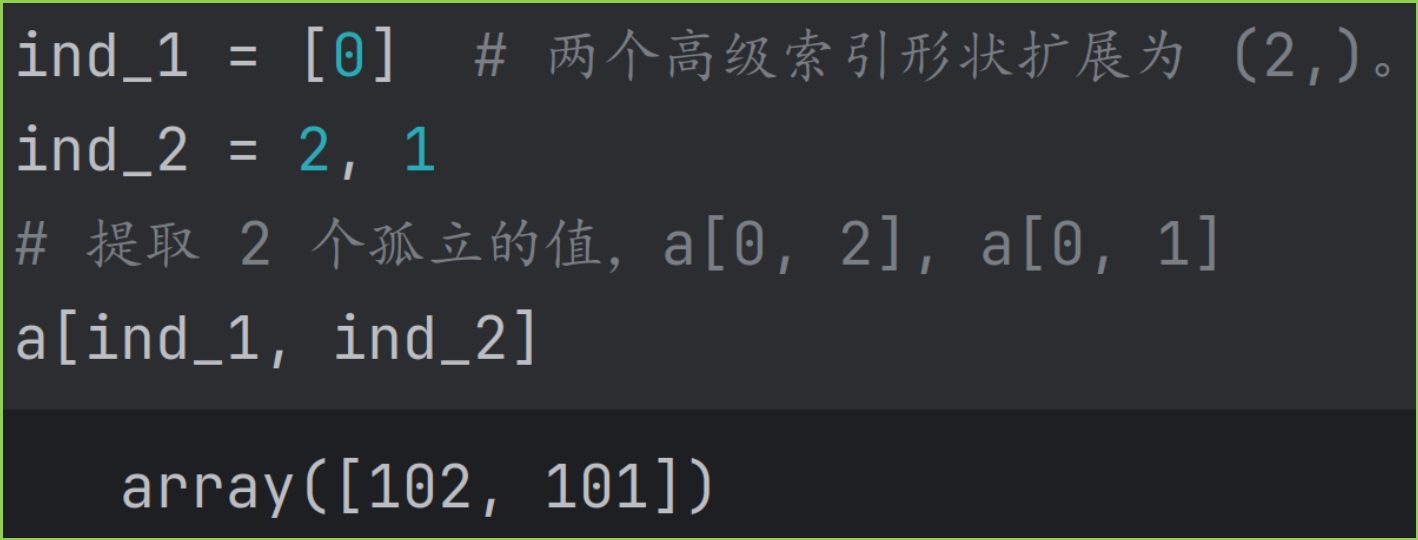
-
如果只索引了前面几个维度,则结果数组 resultant array 的形状等于: ind_1, ind_2 扩展得到的形状,加上后面几个没有被索引维度的形状。后续剩余维度的数据会全部包括进来。
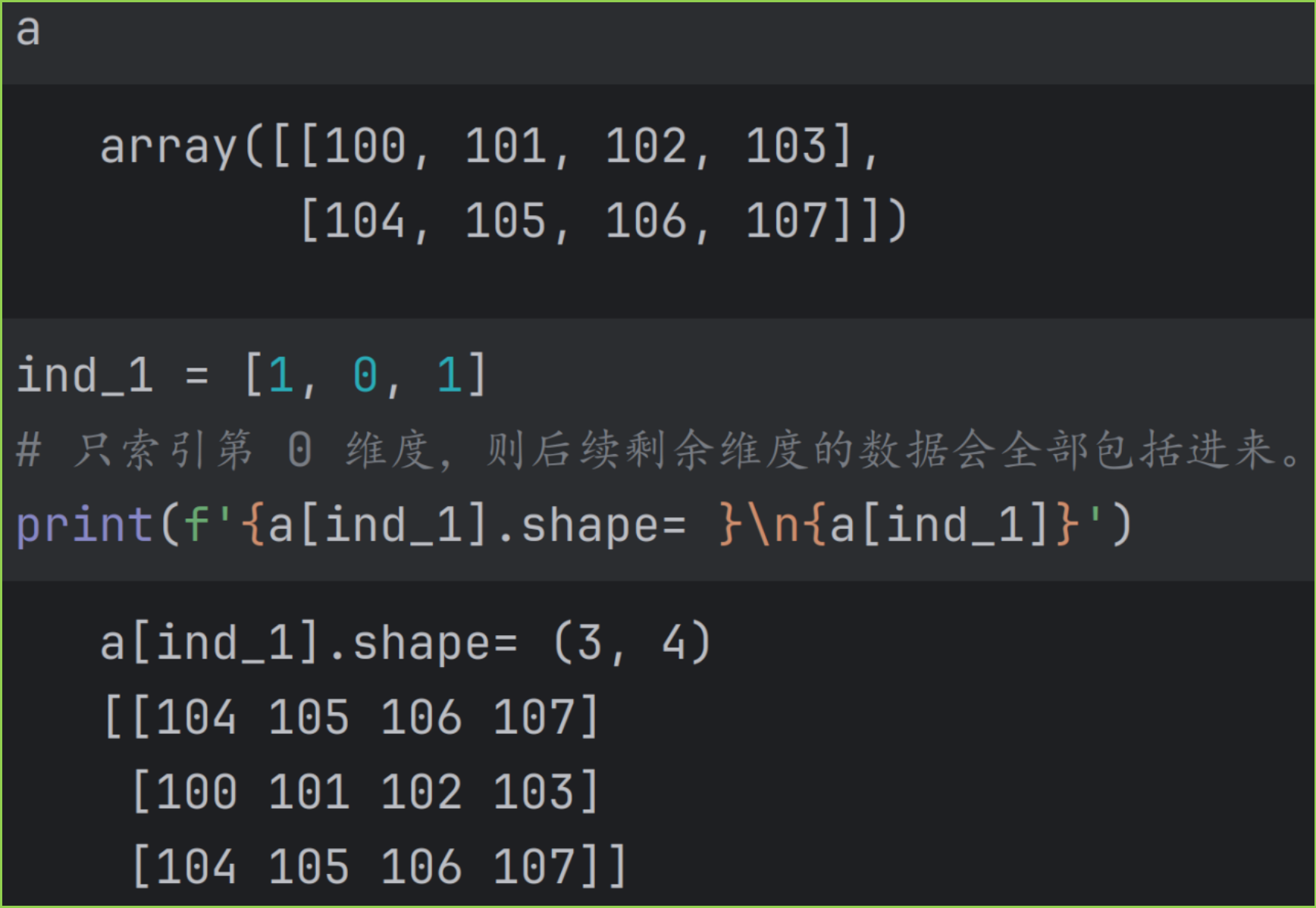
-
纯高级索引时,要从数组中提取一个"矩形"数组,或者说要生成一个多维度数组时,高级索引本身必须是多维的。
例如第一个索引数组形状为 (m, 1) ,第二个索引数组形状为 (1, n) ,两个索引数组进行扩展,就可以得到形状为 (m, n) 的结果数组。如果两个索引对象的形状都是 (m, n, k) ,则结果数组形状也为 (m, n, k) 。
下图是提取数组的 4 个角点,得到形状为 (2, 2) 数组的示例。
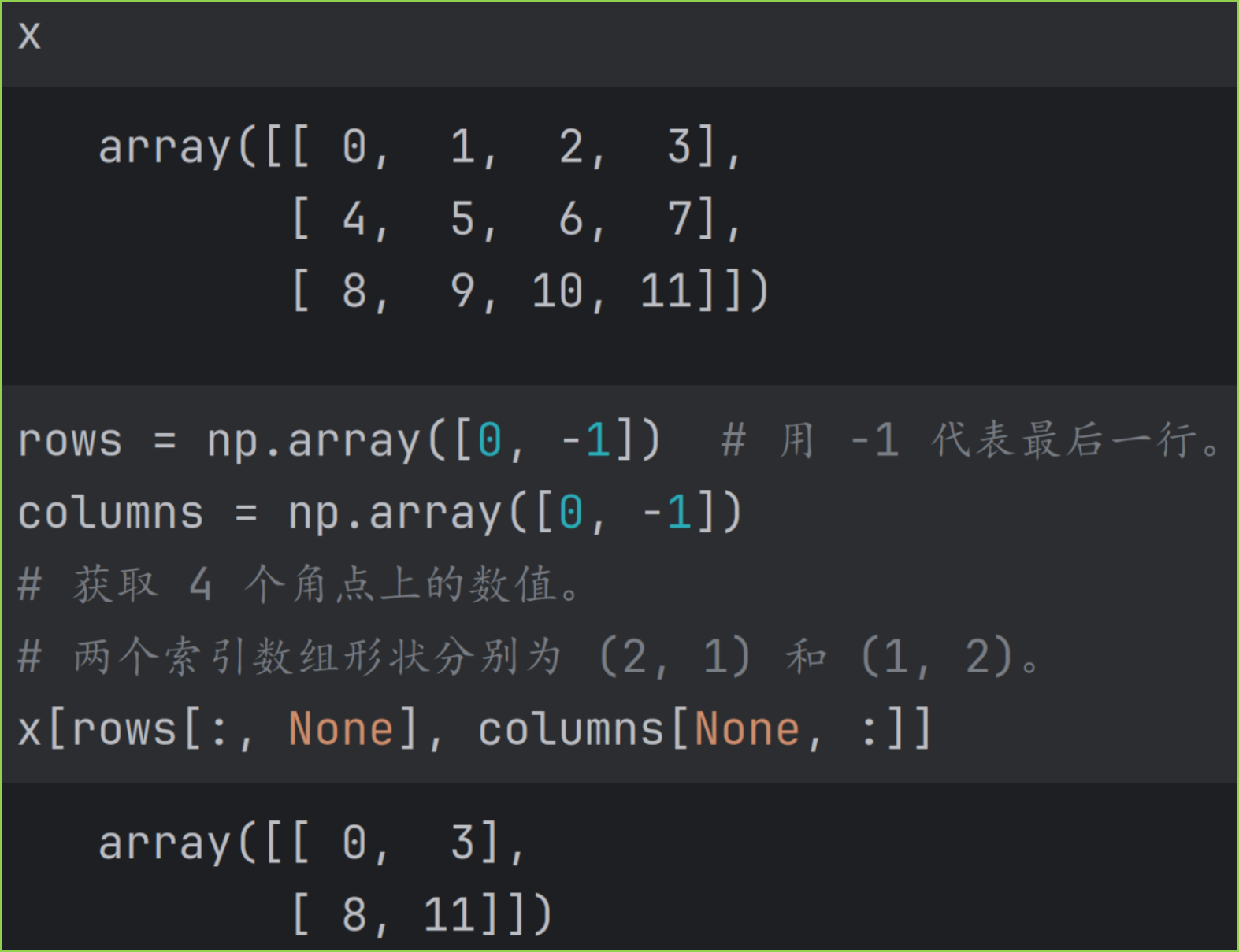
此时还可以使用 ix_ 函数构建索引数组,提取"矩形"数组,得到相同结果,示例如图。
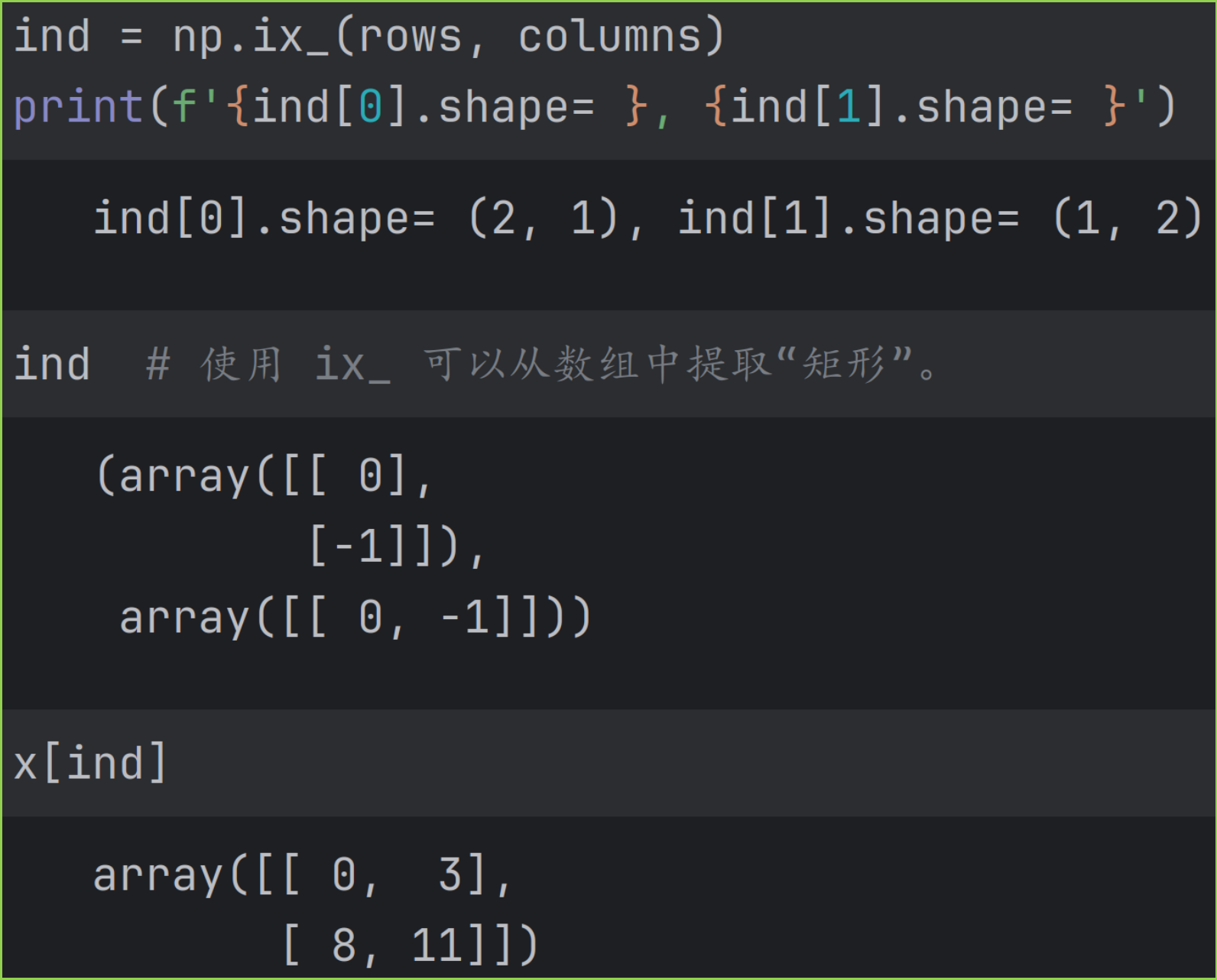
5. 混合索引
使用混合索引时,类似基础索引的结果,返回结果也是一个"矩形"。但是在提取数据方面,它比基础索引更为灵活。
混合索引分下面 3 种情况,其中 ind_1, ind_2 都是高级索引对象:
- 多个高级索引对象被隔开,如 xind_1, :, ind_2 。
- 只有一个高级索引对象,如 x..., ind_1 。
- 多个高级索引对象紧挨着的情况,如 x..., ind_1, ind_2, : 。
5.1 对结果数组执行的 2 步操作
使用混合索引时,从形状方面来说,对于结果数组会执行下面 2 步操作:
1. 把高级索引对象 ind_1, ind_2 合并得到新的维度,并放在结果数组的最前面第 0 维度。
2. 如果原数组中高级索引对象 ind_1, ind_2 位置唯一,则对结果数组进行转置,把合并后的新维度转置到原数组中高级索引的位置。
混合索引中两个高级索引对象 ind_1, ind_2 合并形成新维度的规律,和前面纯高级索引的规律相同,即:ind_1, ind_2 的形状必须相同,或是可以相互扩展。
为了简单起见,下面的讨论假设 ind_1, ind_2 都是 1D ,因此后面例子中 2 个维度会被合并成一个维度。而 ind_1, ind_2 是多维数组的情况同理可以类推。
5.2 高级索引对象被隔开,如 xind_1, :, ind_2
对于 xind_1, :, ind_2 高级索引对象被隔开的情况,合成的维度会放在最前面。一个示例如下。
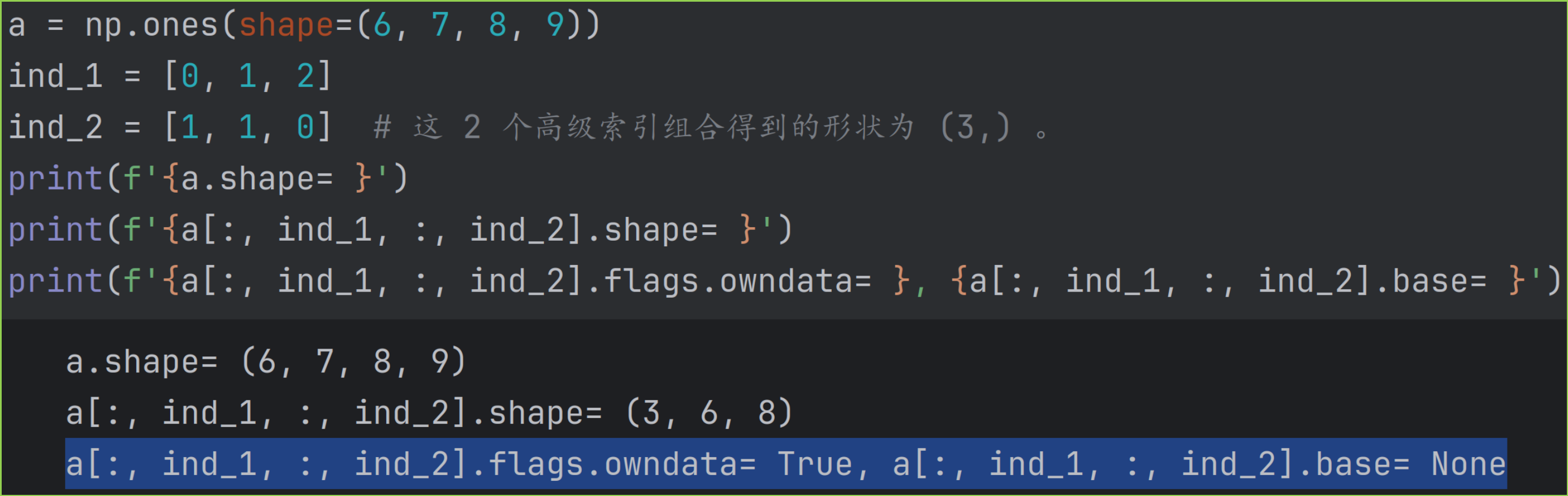
对形状的 2 个操作如下:
-
a 的第 1 维度和第 3 维度使用高级索引,合并成一个维度,形状为 (3,) 。结果数组第 0 维度大小为 3 。
-
原数组 a 中高级索引在第 1 维度和第 3 维度,位置不唯一,合并后的新维度无法转置回去,于是保持不变。a 的剩余维度会被添加到结果数组的后面,则最终结果数组形状为 (3, 6, 8) 。
属性 flags.owndata= True 表示该数组直接拥有底层数据,属性base= None则表示它不是 view ,没有基础数组。
5.3 只有一个高级索引对象
5.3.1 高级索引对象不在第 0 维度时,如 x..., ind_1
一个示例如下。
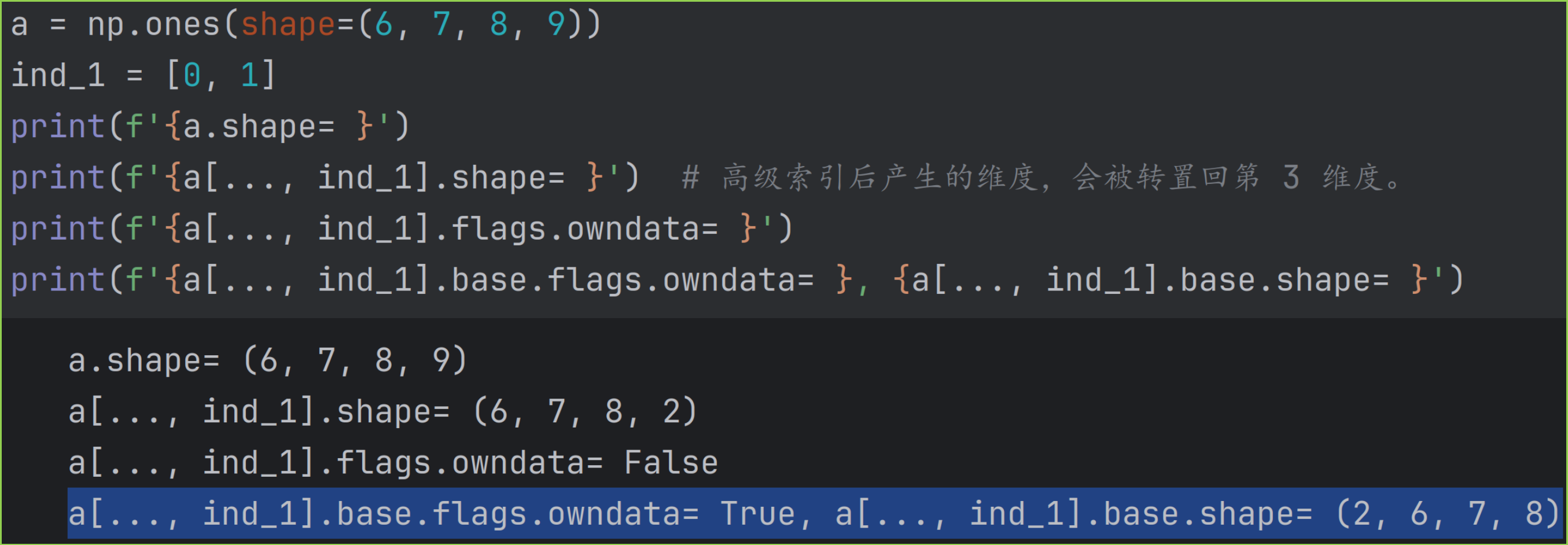
示例中混合索引对结果数组的形状操作是:
- 高级索引后得到的维度大小为 2,并被放在第 0 维度。
- 因为原数组高级索引位置确定,所以会被转置回高级索引的原始位置,即转置回第 3 维度。最终结果数组的形状为 (6, 7, 8, 2) 。
因为进行了一次转置操作,所以结果数组是有base数组的,即上面第一步的结果,形状为 (2, 6, 7, 8) 。并且结果数组并不拥有底层数据,flags.owndata 属性为 False ,其base数组才拥有底层数据,
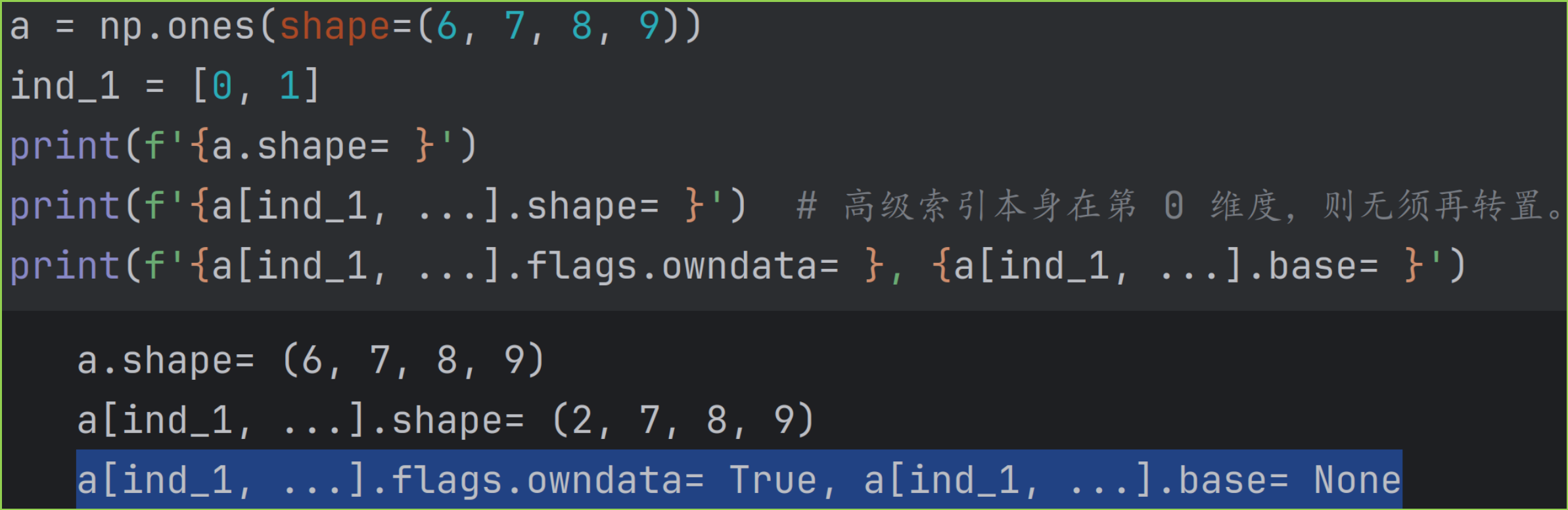
5.3.2 高级索引对象在第 0 维度时,如 xind_1, ...
此时索引之后,无须再转置。
因为没有进行第二步转置操作,所以结果数组直接拥有底层数据,flags.owndata 属性为 True 。也没有base数组。
只有一个高级索引时,它的一个使用场景是修改图片的颜色通道,例如从 OpenCV 图片的 bgr 格式修改为 rgb 格式,方法为:
python
rgb = bgr[..., (2, 1, 0)] 这里 bgr 形状为 (h, w, 3) ,最后一个通道为颜色通道。
5.4 高级索引紧挨着,如 x..., ind_1, ind_2, :
多个高级索引对象 multiple advanced indices 紧挨着时,如 x..., ind_1, ind_2, : ,示例如下:
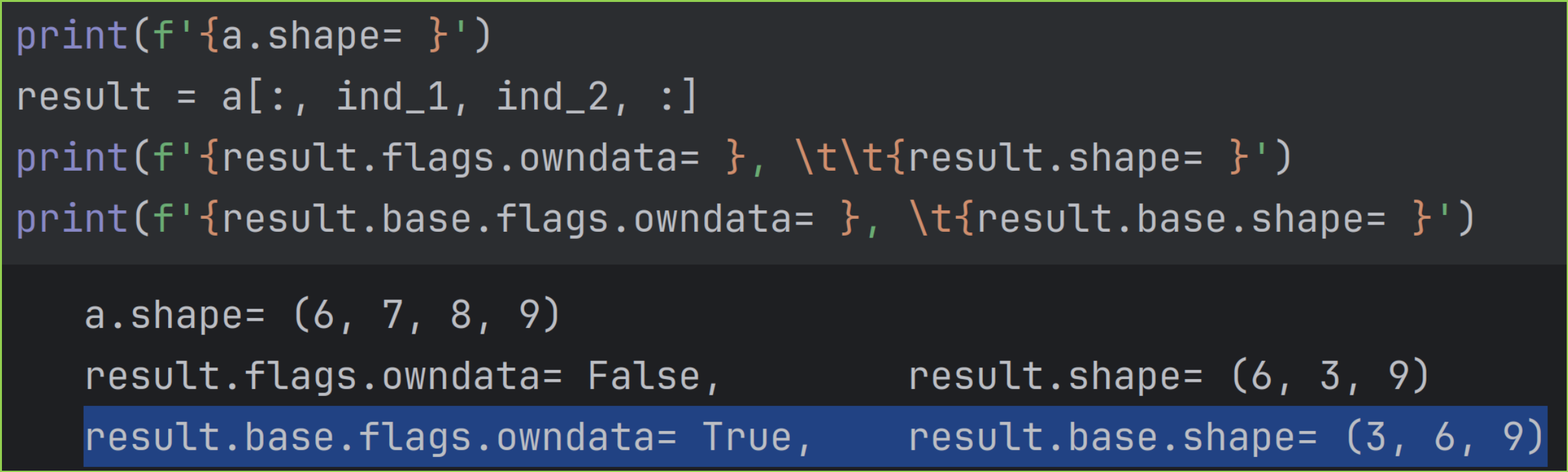
对结果数组执行 2 个操作如下:
- 紧挨着的高级索引会被合并成一个维度,并放在最前面,得到中间数组,形状为 (3, 6, 9) 。
- 因为原数组中高级索引位置唯一,则进行转置,把新维度转置到原数组 a 中高级索引的位置,即 a 数组第 1, 2 维度的位置,最终结果数组形状为 (6, 3, 9) 。
上面第一步得到形状为 (3, 6, 9) 的中间数组,会被当成base数组,并且base数组才直接拥有底层数据,所以 base.flags.owndata= True 。
而结果数组是base数组的视图 view ,所以结果数组不拥有底层数据,其属性 flags.owndata= False 。
6. 布尔索引 boolean array indexing
混合索引和纯高级索引中的数据可以是布尔值,此时叫做布尔数组索引 boolean array indexing 。
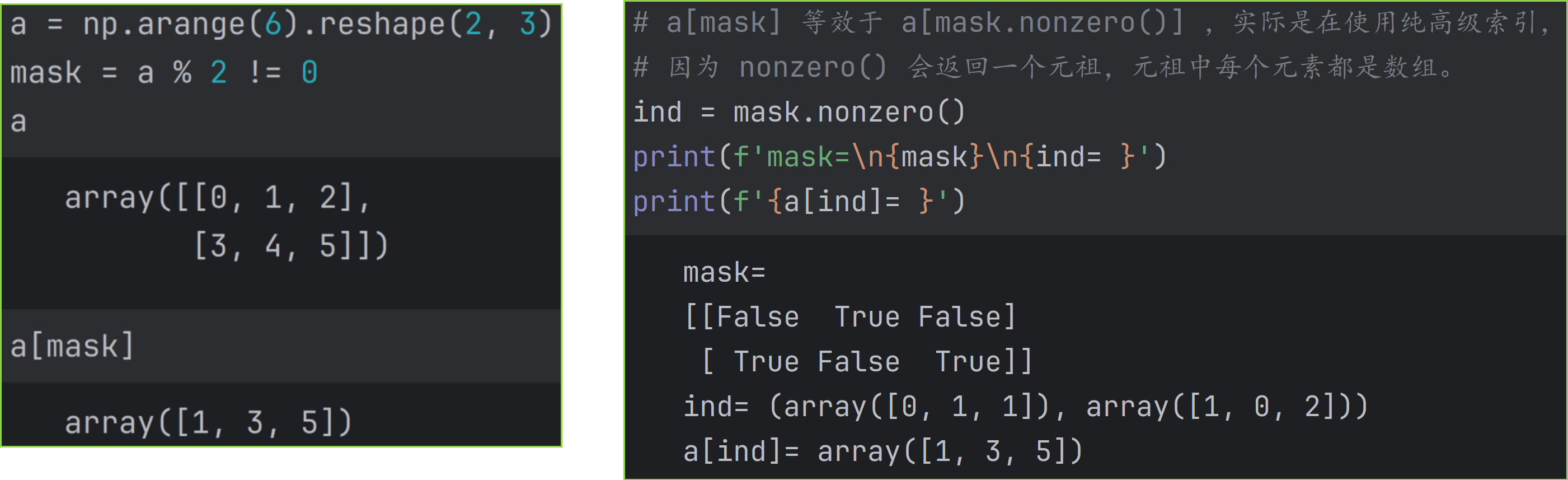
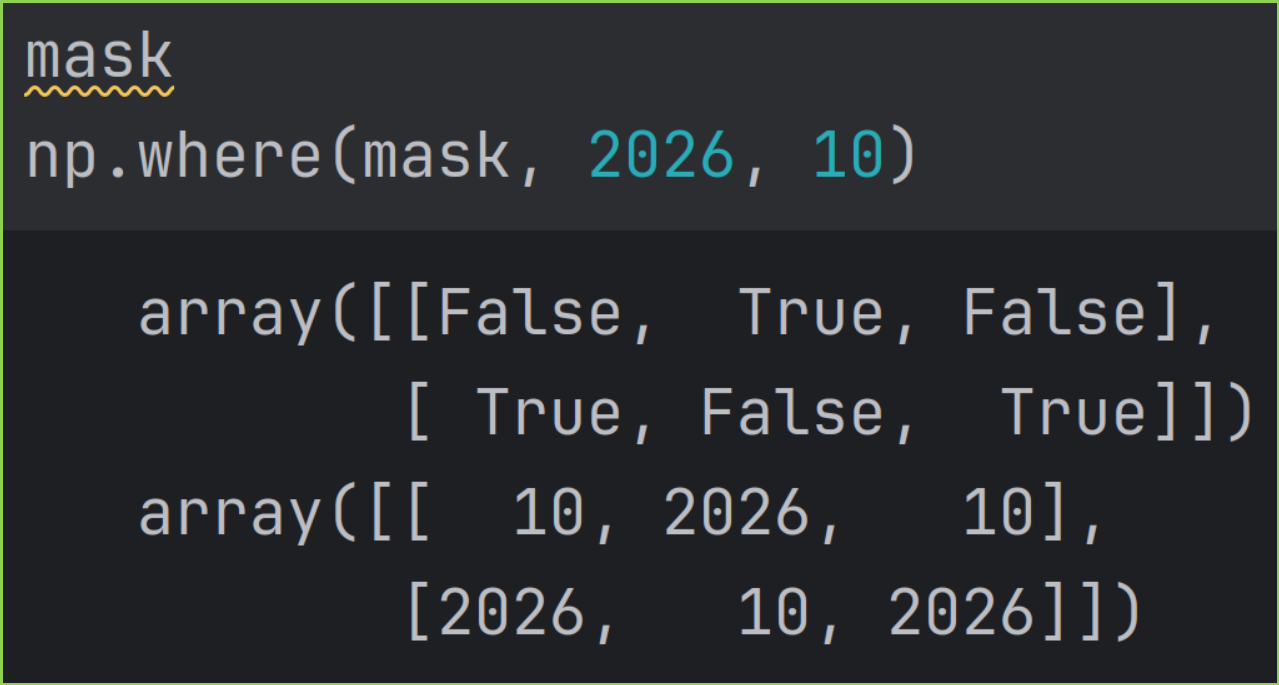
使用布尔数组 mask 作为索引时,实际是在使用纯高级索引。这是因为对于 a[mask] ,Numpy 会自动调用a[mask.nonzero()]。而mask.nonzero()则返回一个元祖,元祖中包含 n 个数组,指示了 n 个 True 的位置。示例如下图。
而且mask和 a 的形状相同时,a[mask] 的速度比后者a[mask.nonzero()]更快。
6.1 对形状的影响和要求
-
布尔数组会把被索引的维度缩减到 1 。例如形状为 (5, 6, 7) 的数组,被形状为 (5, 6, 7) 的布尔数组索引后变为 (n, ) ,得到 n 个位置为 True 的值。
-
布尔数组 mask 的维度数量少于 a 的维度数量时,形状必须严格匹配前面几个维度。例如形状为 (5, 6, 7) 的数组,对其使用布尔数组索引时,布尔数组的形状不可以为 (6, 7) ,只可以为 (5, 6) 或者 (5, ) 。
6.2 用布尔数组修改原数组的 4 个常见用法
用布尔数组 mask 作为索引修改原数组时,4 个常见用法是:
-
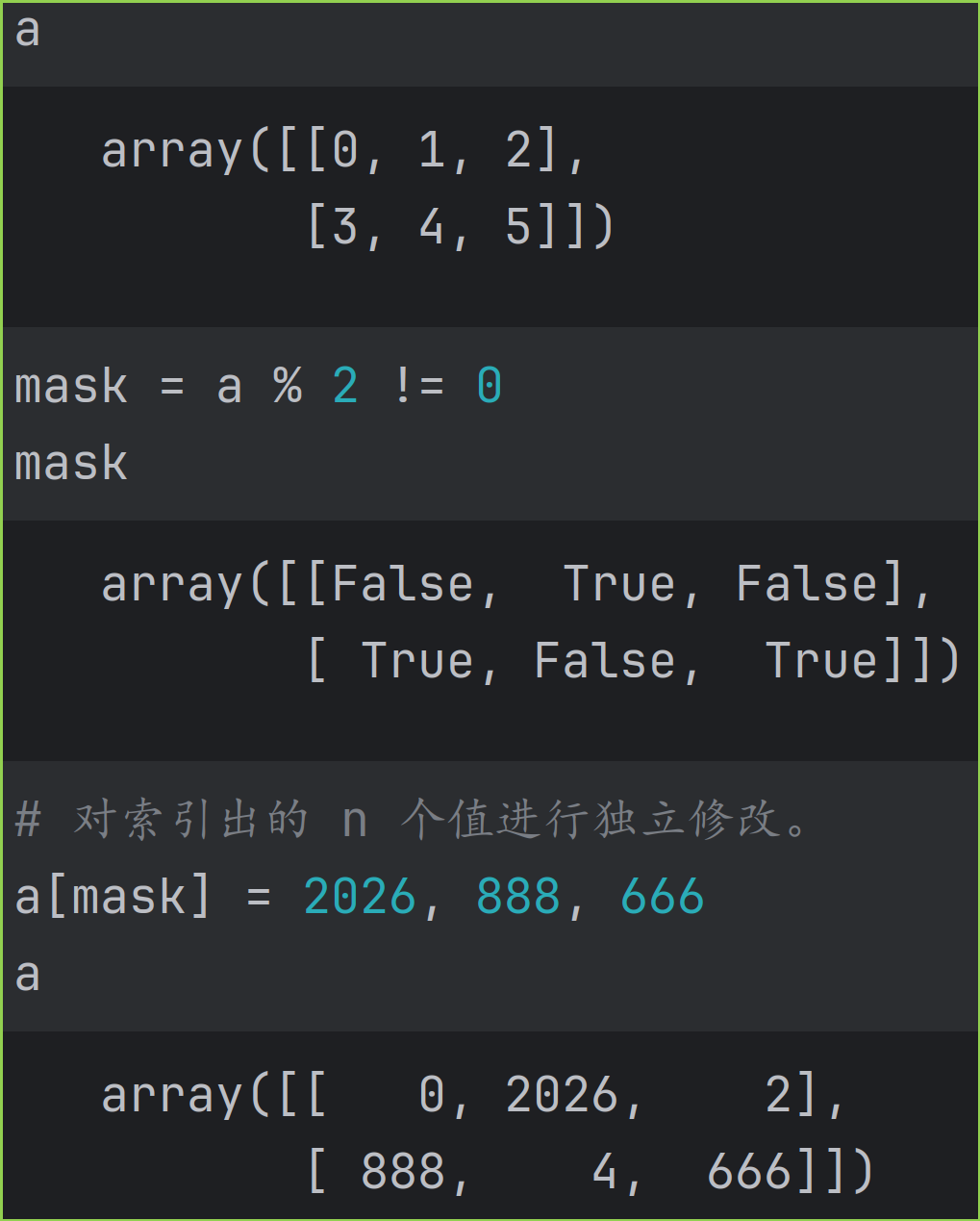
修改 True 位置对应的值,不改变 False 位置对应的值,直接用布尔数组作为索引。例如 amask = b 。
如果要把索引出的 n 个值独立修改,则可以把 b 作为一个长度为 n 的元祖,此时将一一对应,独立修改,如下图。
-
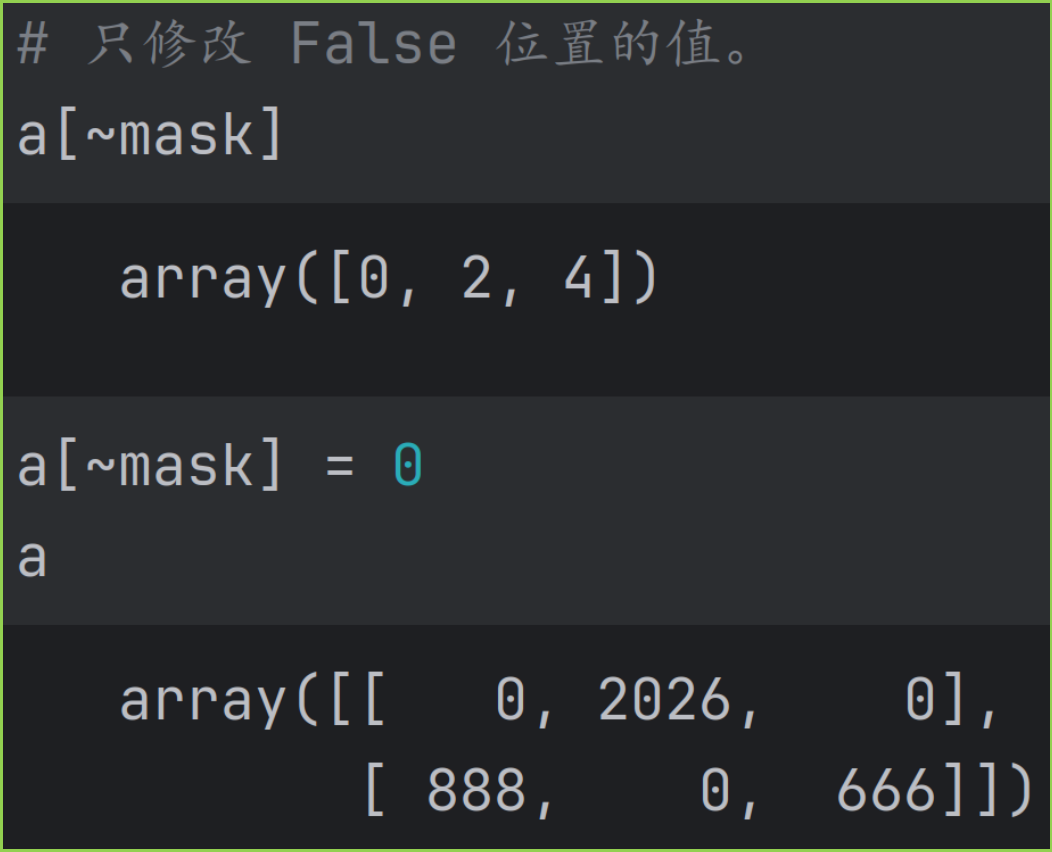
只修改 False 位置的值,使用 a\~mask = b 。如下图。
-
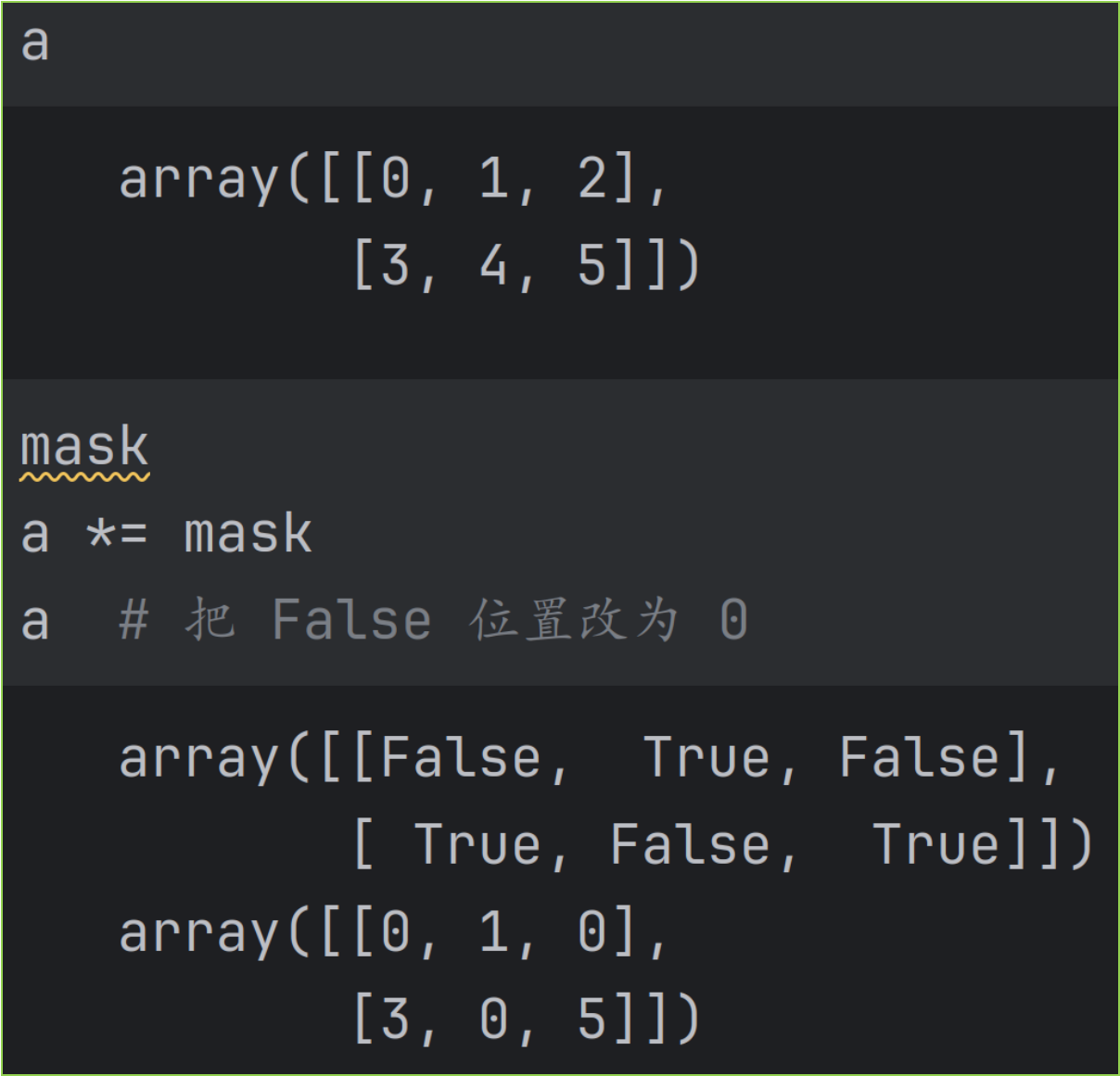
如果是把 False 位置改为 0 ,也可以用乘法,即 a *= mask 。
-
True 和 False 位置都需要输入某个不等于 0 的值,则用 where , 例如 a = np.where(mask, foo, bar) 。
7. 重复赋值问题和内存布局
使用高级索引时,还需要注意两点:重复赋值问题和内存布局。
7.1 重复赋值问题
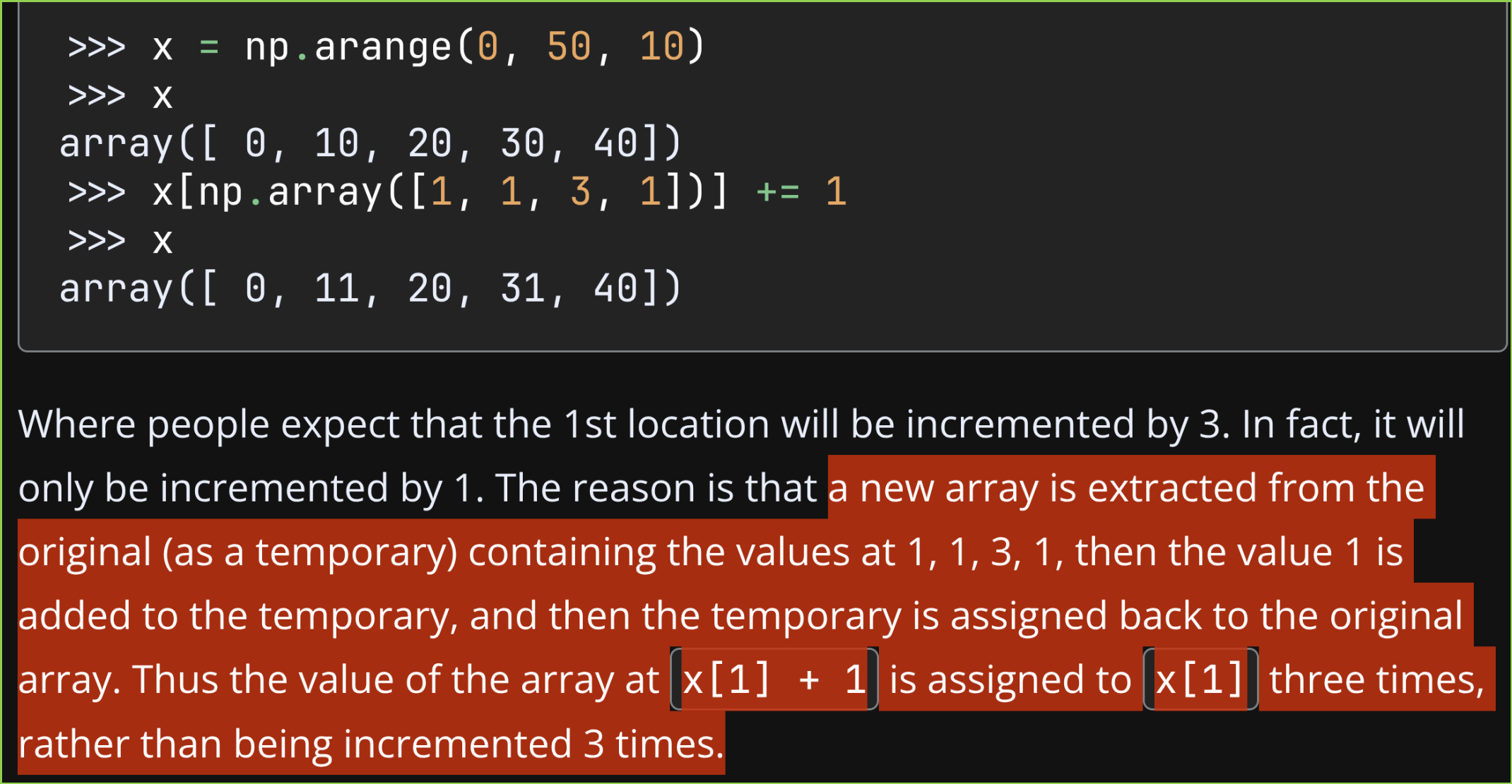
使用高级索引进行赋值时,单次赋值操作不要对同一个位置进行多次修改。否则可能出现意外结果。
下面 2 图是官网的示例和提示。位置 1 进行 +1 操作 3 次,但是最终只从 10 变成 11 。这是因为高级索引生成了一个临时数组,对临时数组进行 +1 操作,最后把临时数组的值赋值给了数组 a ,即有 3 个 11 被赋值到 a 的位置 1 上。

7.2 内存布局 memory layout
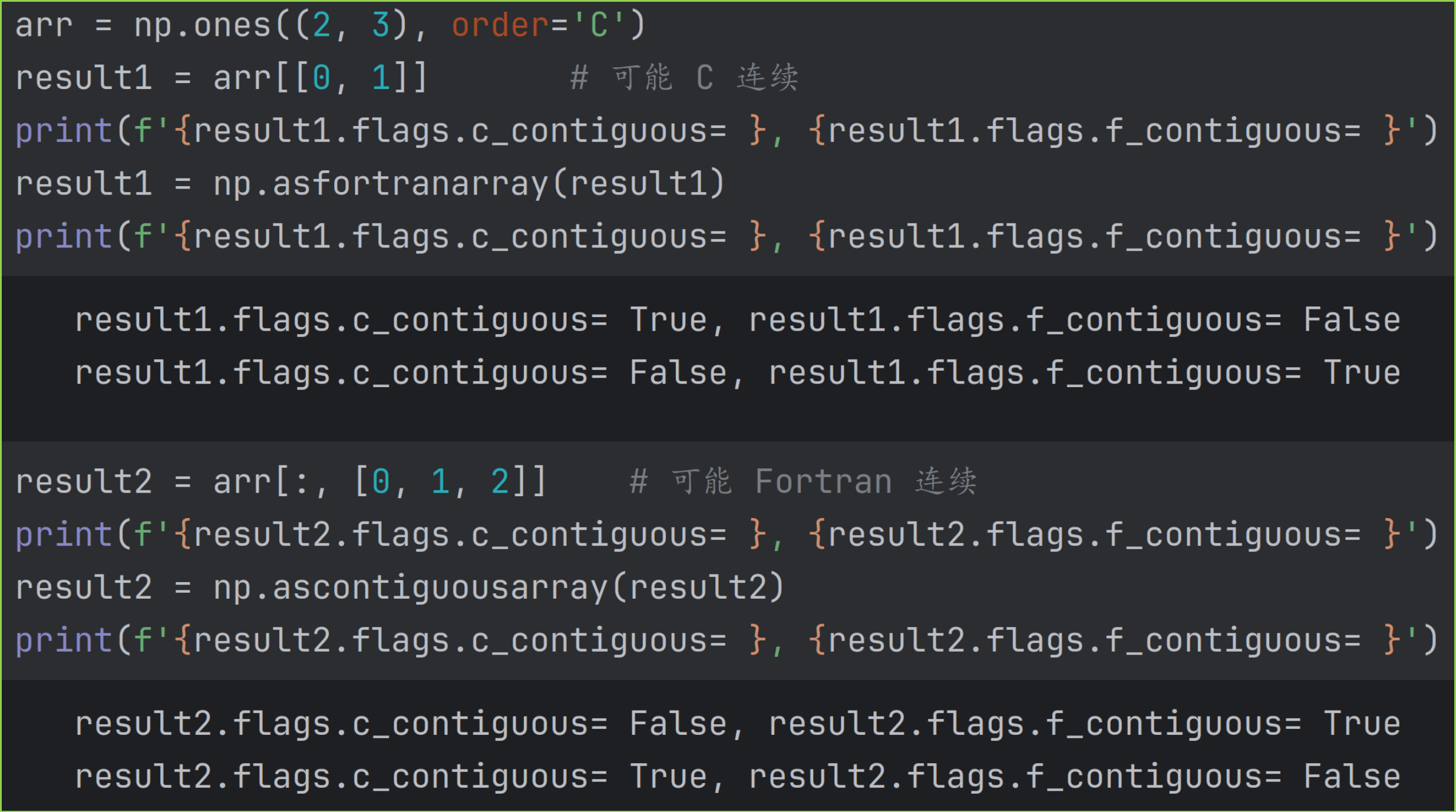
高级索引之后,内存布局 memory layout 可能发生变化,可能是 C 连续,也可能是Fortran连续。
可以用 flags.c_contiguous 查看是否为 C 连续,flags.f_contiguous 查看是否为Fortran连续。
asfortranarray 可以把数组改为Fortran连续,对应的 ascontiguousarray 改为 C 连续。示例如下。
8. take 和 take_along_axis 函数
8.1 take 函数
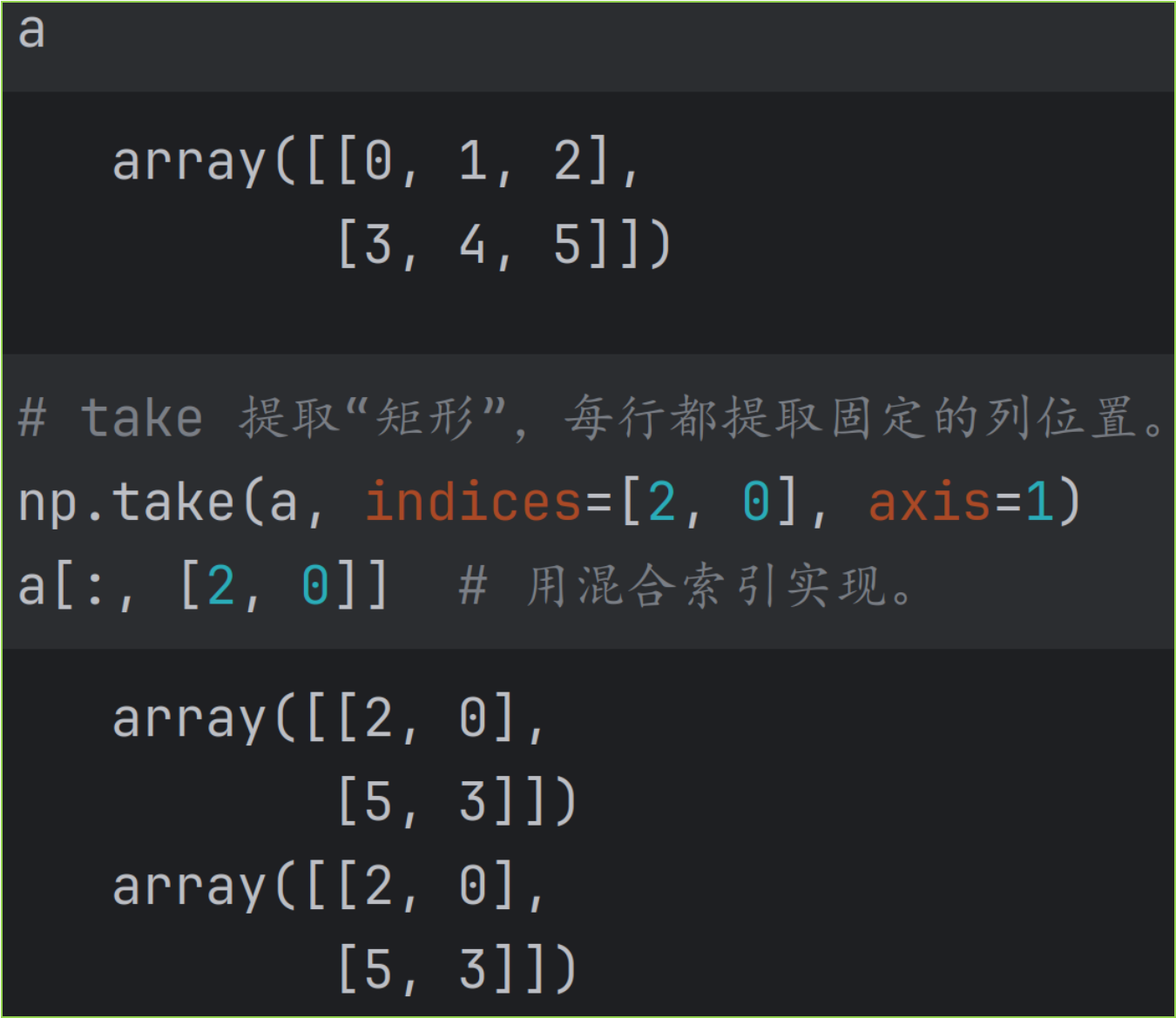
take 用于提取整行或整列,也可以从一维数组生成多维数组。作用相当于混合索引。
即 np.take(arr, indices, axis=1) 等效于 arr:, indices, ... 。
https://numpy.org/doc/stable/reference/generated/numpy.take.html
indices 是一维列表示例如图。
indices 是多维数组,a 是一维数组的示例如下图。
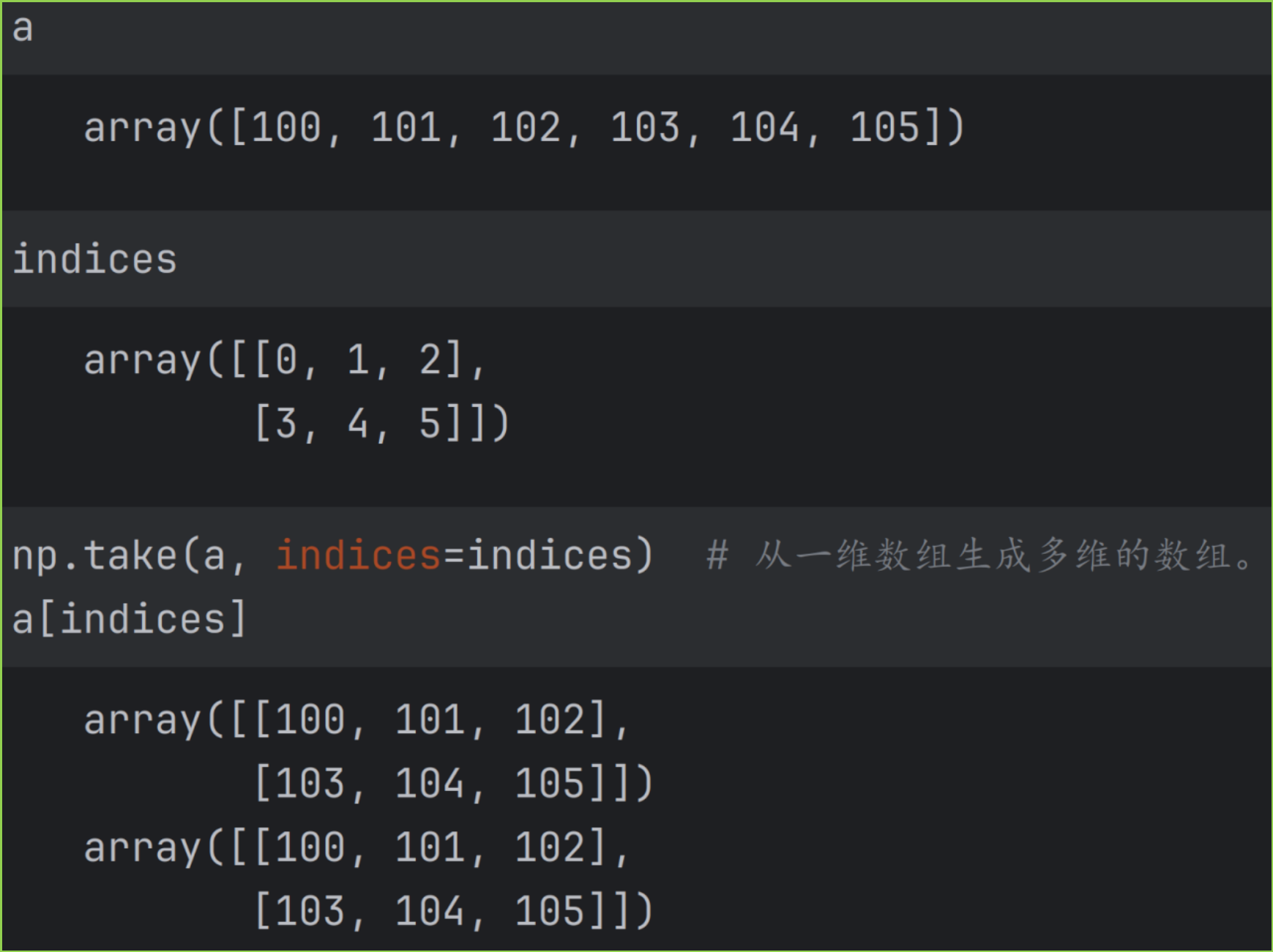
indices 是多维数组,a 是多维数组,axis = 1 的示例如下图。
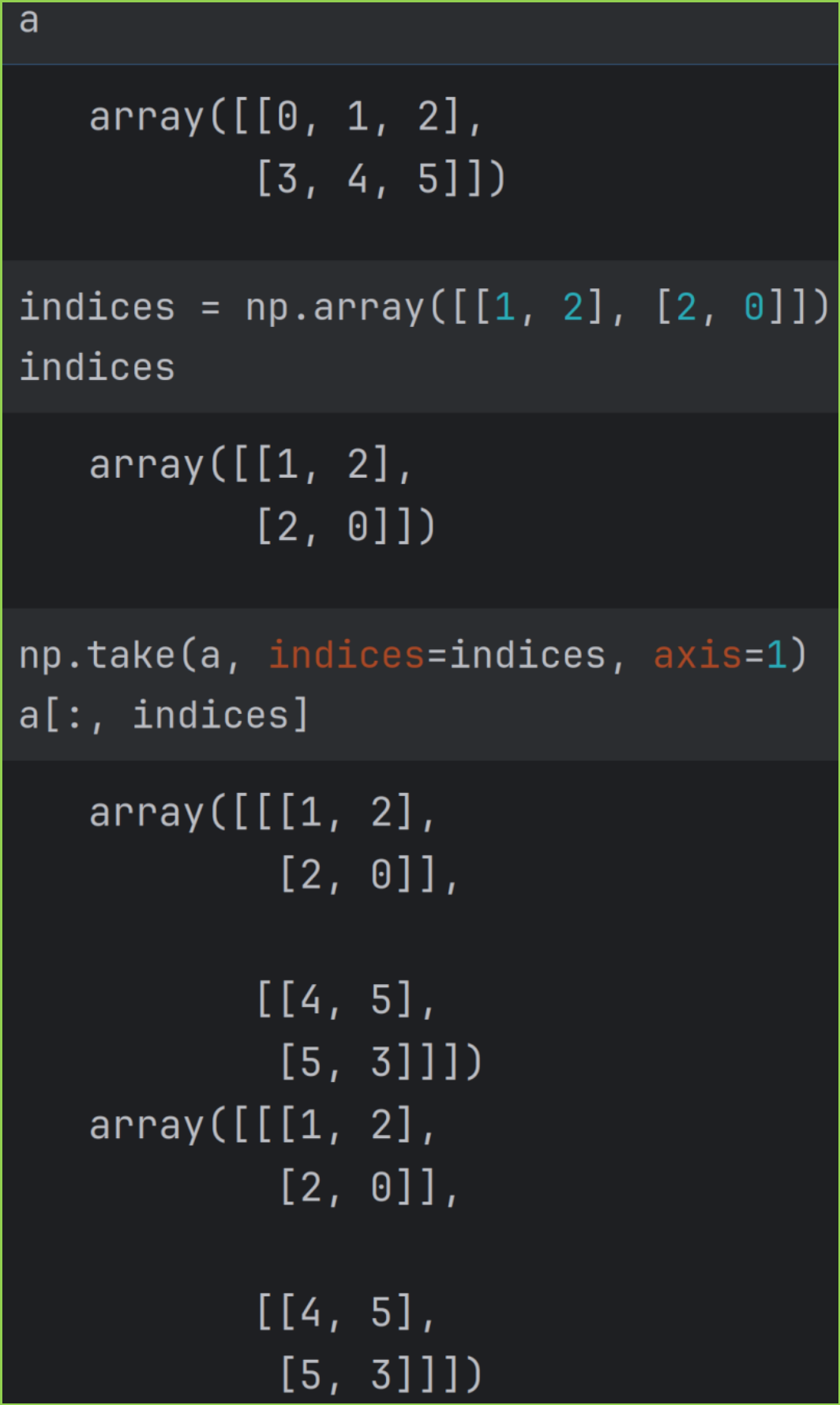
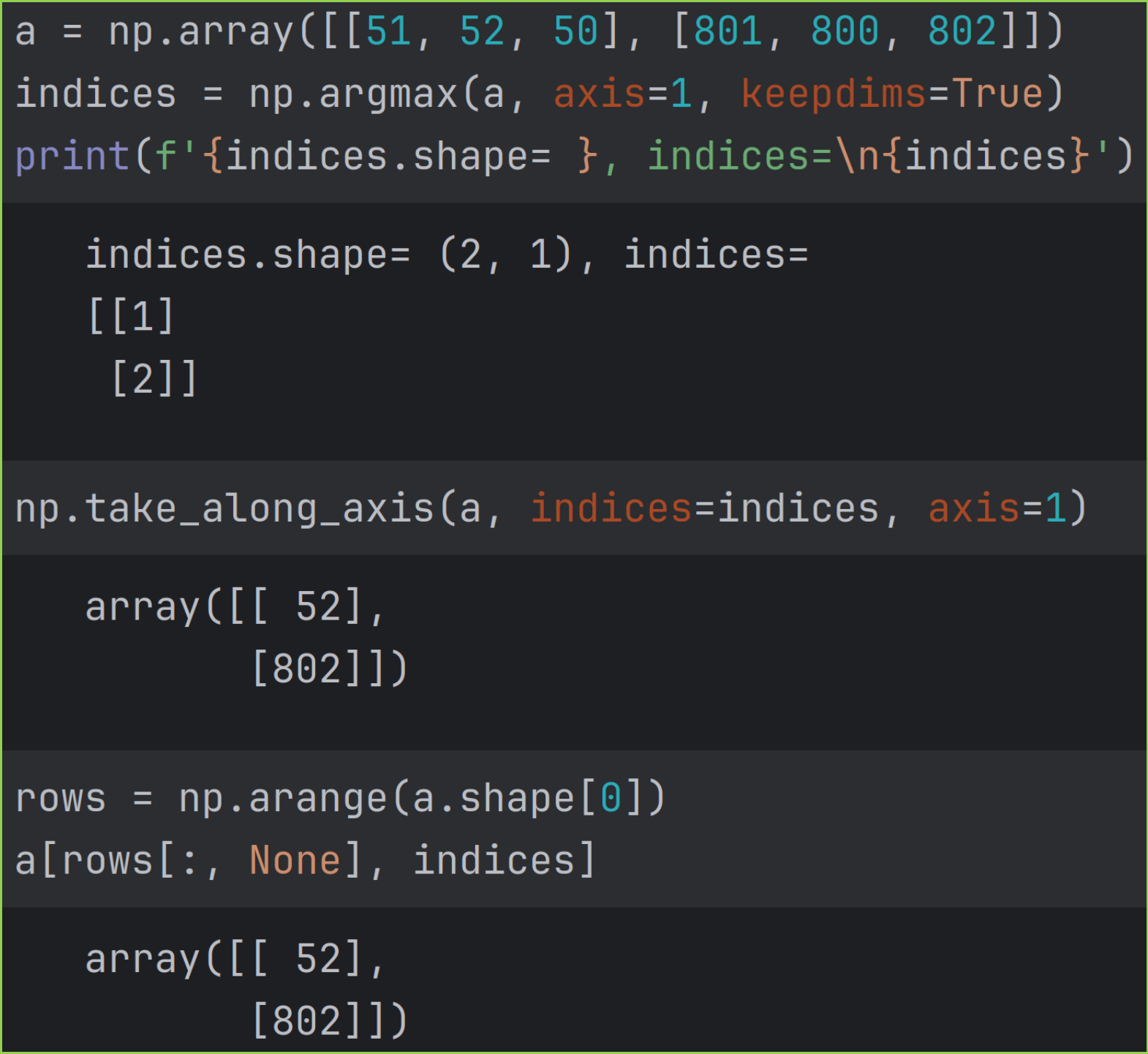
8.2 take_along_axis 函数
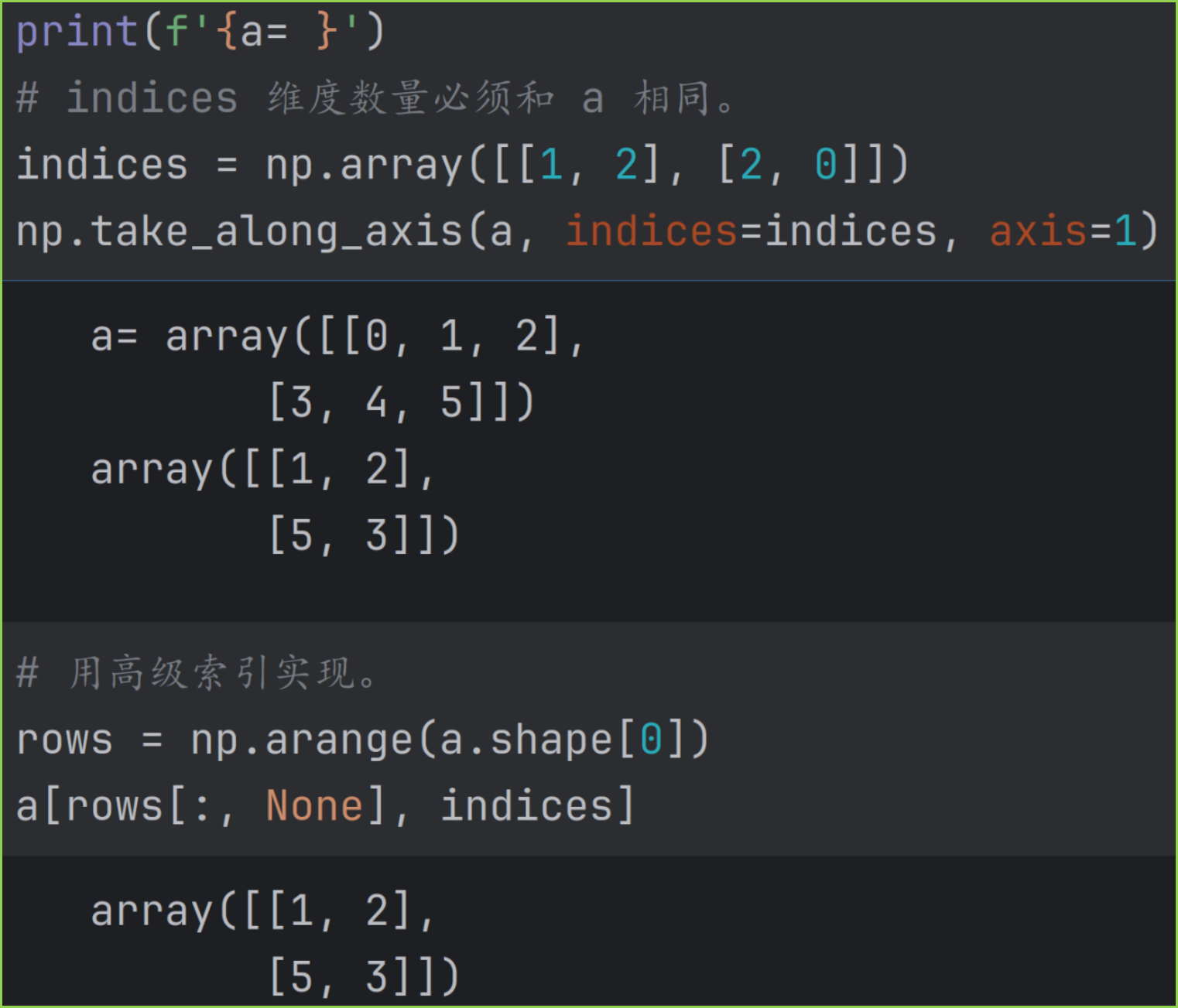
take_along_axis(arr, indices, axis=-1) 用于提取"矩形",但比 take 更为灵活,每行可以提取不同的列位置。例如从第 0 行提取第 6 列的数据,第 1 行提取第 8 列的数据。
https://numpy.org/doc/stable/reference/generated/numpy.take_along_axis.html
该函数维度数量始终不变,即 arr, indices 和结果数组的 ndim 相同。
take_along_axis 的功能可以用高级索引来实现。
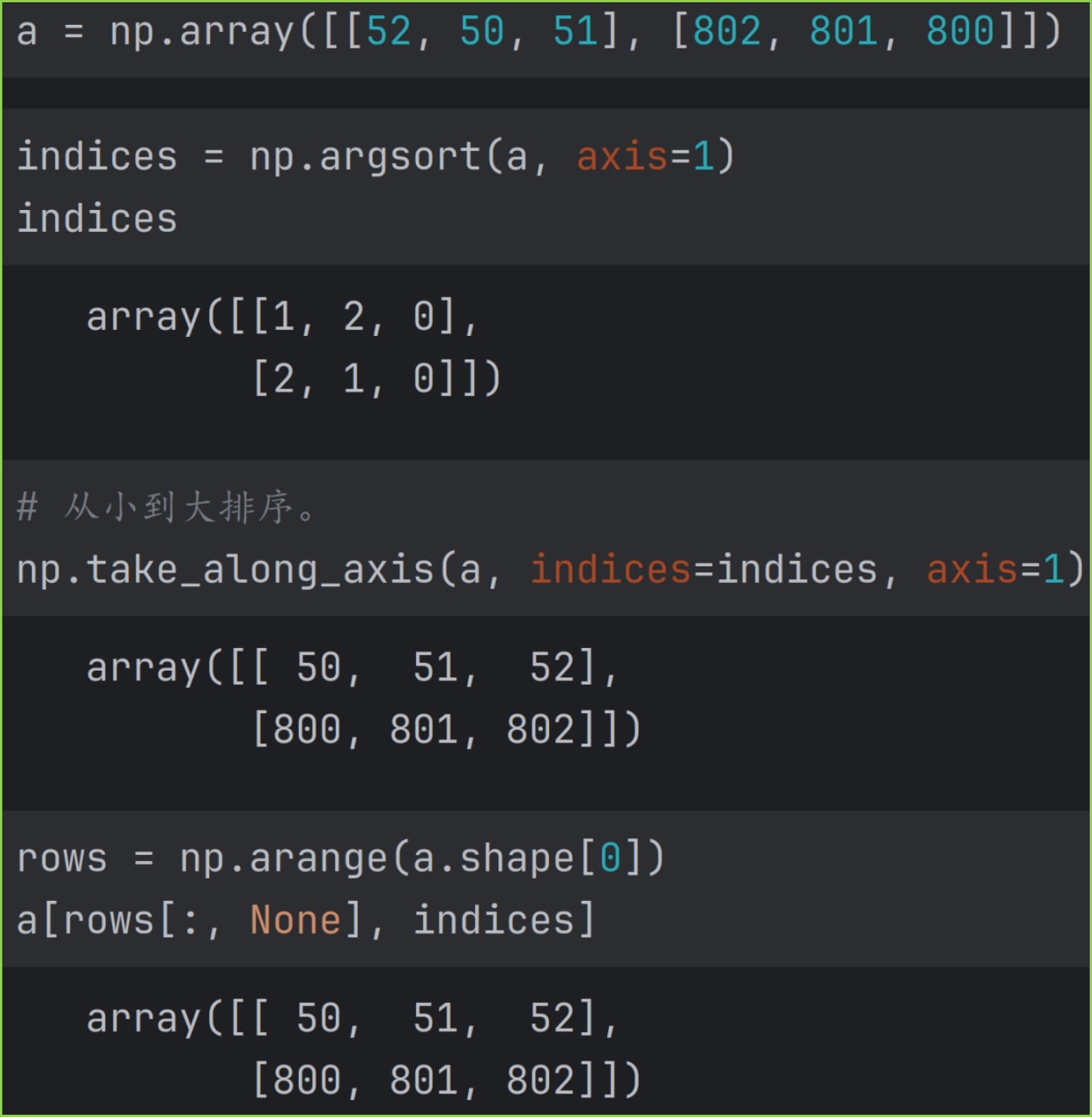
和 argsor 结合使用,对数组进行排序的例子如图。
和 argmax 结合使用,找出最值的示例如图。
9. 字段访问 field access
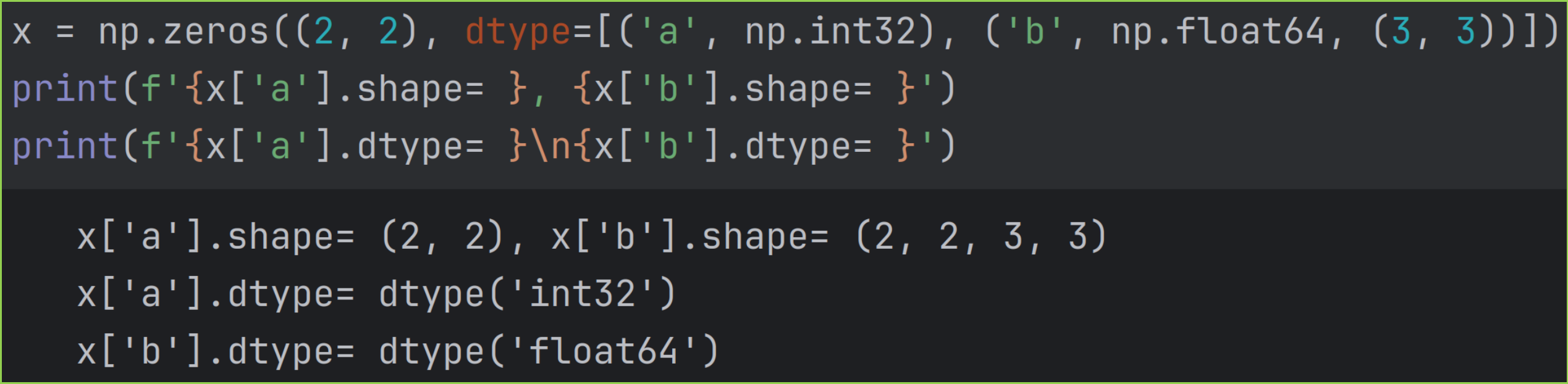
Numpy 官方还提供了另一种索引方式:字段访问 field access 。
对于结构数组 structured array ,可以用字典形式进行字段访问 field access 。因为字段访问使用较少,这里不做讨论。下面只展示一个官方的示例。
------------------------------ 本文结束 ------------------------------