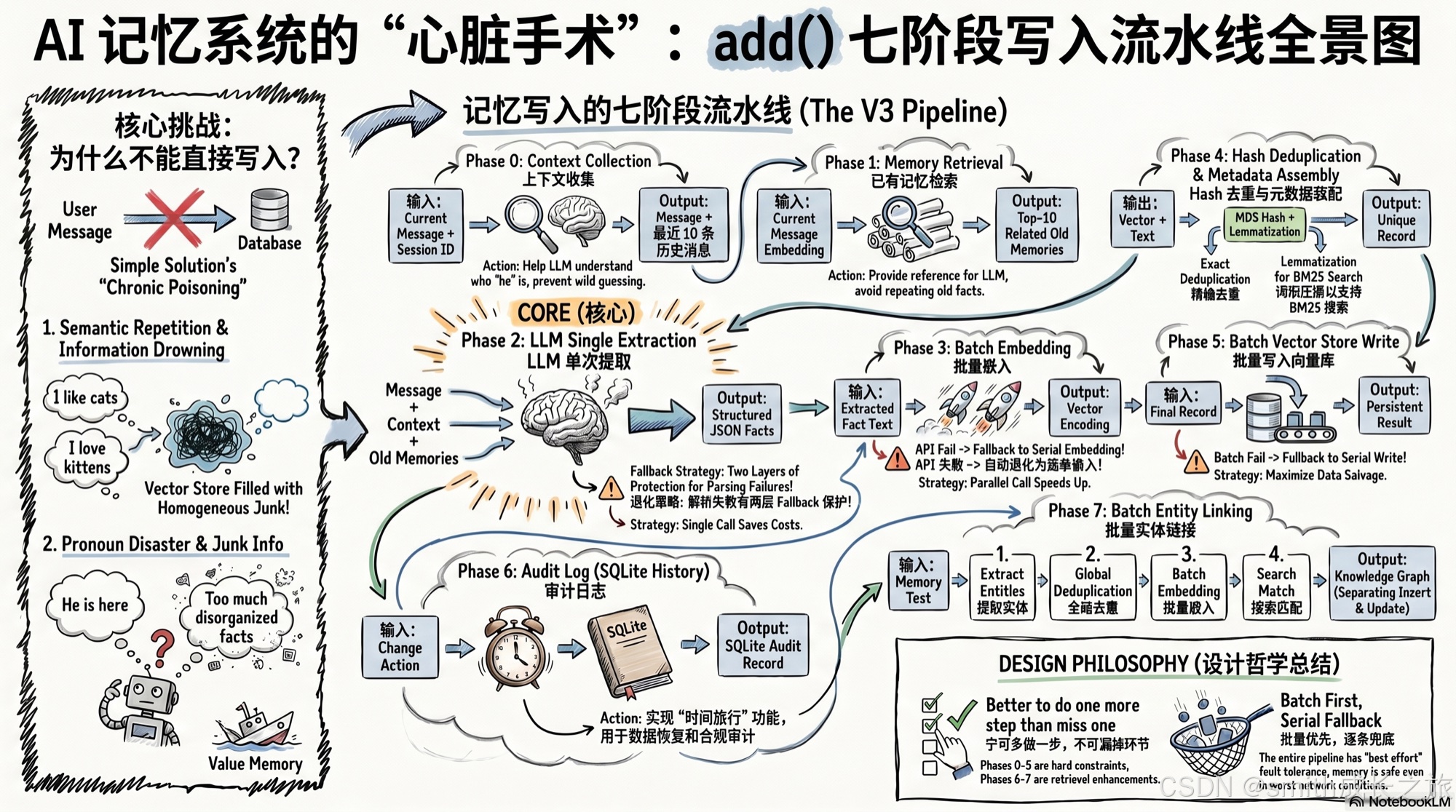
05 | Mem0 框架分析:记忆写入的七阶段流水线------从消息到持久化的完整数据流
一次 add() 调用到底做了什么?
当你在代码中写下 memory.add("我喜欢猫") 时,你以为只是存了一句话。但实际上,这条消息经历了一条七阶段的流水线,每个阶段都有独立的容错逻辑和 fallback 路径。
为什么需要七个阶段?能不能更简单?
答案是不能。因为每个阶段解决的是完全不同的问题:上下文补齐、语义去重、LLM 提取、向量编码、精确去重、持久化、实体关联。跳过任何一个,下游就会出问题------要么重复提取,要么丢失上下文,要么检索时找不到。
让我们逐阶段拆开看。
如果只有一个阶段:朴素方案的灾难
在拆解七阶段之前,先想一下:最简单的记忆写入长什么样?
python
def add(self, text, user_id):
embedding = self.embedding_model.embed(text)
self.vector_store.insert(vectors=[embedding], ids=[str(uuid.uuid4())], payloads=[{"data": text}])三行代码,一气呵成。有什么问题?
重复记忆------最痛的,因为它的伤害是累积的。 用户说"我喜欢猫",系统存了。下一轮用户又说"我真的很喜欢猫",又存了。再说"我最喜欢的动物是猫",又存了。三条记忆,语义完全相同,但向量不同(措辞差异导致嵌入漂移),hash 也不同------去重机制全部失效。然后呢?搜索"猫"返回的前三条全是同一个意思,真正有价值的记忆被挤出 top-k。更糟的是用户感知:你说"我不是说过了吗?"------信任当场坍塌。最隐蔽的一刀在嵌入空间:同义变体不断灌入,把有限向量库的容量一点点吃掉,其他主题的记忆被物理性地挤出去。这不是"偶尔重复"的小问题,是每天都在发生的慢性中毒。
代词灾难------偶尔致命。 用户说"他还是来了",系统忠实地存下这条记忆。未来检索命中时返回"他还是来了"------"他"是谁?没有上下文,这条记忆当场报废。问题不在于它经常发生,而在于一旦发生,那条记忆就是彻底的死信,没有任何补救手段。
剩下的两个问题篇幅短但同样真实:信息淹没 ------用户一口气说了五件事,朴素方案把"领养小狗、升职、感到压力"全塞进一条记忆,检索时这条记忆什么都沾边但什么都不精准;实体缺失------"Poppy 去了宠物医院"里的 Poppy 是个实体,没有实体提取,搜"Poppy"时语义向量反而离"宠物"更近,精确召回不可能。
这些问题不是边缘场景------它们是真实使用中每天都会遇到的问题。七阶段流水线就是为了逐个解决这些问题而设计的。
入口:两条路径的分叉
_add_to_vector_store 方法的一开始就有一个条件分支:if not infer。
当 infer=False 时,走的是直写路径:每条消息不做任何 LLM 处理,直接嵌入、直接存入向量库。这是一条快速通道,适用于你明确知道要存什么、不需要 LLM 帮你提取的场景。
直写路径的逻辑很直接:遍历消息列表,跳过 system 角色的消息(system 消息是指令不是内容),为每条消息生成嵌入,调用 _create_memory 写入。值得注意的是,直写路径会为每条消息设置 role 和 actor_id(如果消息中有 name 字段)。这意味着即使不走 LLM 提取,消息的元数据仍然被保留。
当 infer=True(默认值)时,走的是 V3 七阶段流水线。这是核心路径,也是本文的主角。
但在进入七阶段之前,add() 方法本身还做了一些重要的预处理:
- 参数校验 :
_build_filters_and_metadata校验 user_id / agent_id / run_id 至少提供一个,并且会 trim 空白字符、拒绝含内部空格的 ID。 - 消息格式标准化 :如果 messages 是字符串,自动包装为
[{"role": "user", "content": ...}];如果是 dict,包装为列表。这保证了下游代码始终处理 listdict 格式。 - 视觉消息处理 :如果 LLM 配置了
enable_vision,parse_vision_messages会把图片 URL 转换为文本描述(通过 LLM 的视觉能力),否则只保留文本内容。
Phase 0:上下文收集------LLM 不能只看当前消息
python
session_scope = _build_session_scope(filters)
last_messages = self.db.get_last_messages(session_scope, limit=10)
parsed_messages = parse_messages(messages)LLM 提取记忆时需要上下文。为什么?
想象用户说"他上周来找我"。如果 LLM 只看到这句话,"他"是谁?根本不知道。所以 Phase 0 从 SQLite 历史库中取出当前 session 的最近 10 条消息(last_messages),作为 Last k Messages 注入 prompt,让 LLM 能消解代词和指代。
_build_session_scope 根据 filters 中的 user_id / agent_id / run_id 构建一个确定性的 scope 字符串(如 user_id=alice&agent_id=bot),用来隔离不同 session 的历史消息。这个 scope 的构建方式是确定性的------对同一组 filters,总是产生相同的字符串。这意味着同一用户的历史消息总是被正确地关联在一起。
parse_messages 则把消息列表序列化为纯文本,供后续的 embedding 和 prompt 使用。它的逻辑是遍历消息列表,把每条消息的 role: content 拼接成文本。
如果跳过 Phase 0 会怎样?代词无法消解,LLM 只能把"他"原样保留在记忆中。未来检索时,"他还是来了"这条记忆几乎无法被正确理解------因为检索系统不知道"他"是谁。更严重的是,LLM 可能会猜测"他"是谁------从上下文的蛛丝马迹中推断一个名字,然后把这个推断当作事实记录。这就是 Integrity Rules 中"No Fabrication"要防止的行为。
Phase 1:已有记忆检索------给 LLM 提供去重参考
python
query_embedding = self.embedding_model.embed(parsed_messages, "search")
existing_results = self.vector_store.search(
query=parsed_messages,
vectors=query_embedding,
top_k=10,
filters=search_filters,
)为什么在写入之前要先做一次搜索?
因为 LLM 需要知道"系统已经记住了什么",才能避免重复提取。Phase 1 用当前消息的嵌入去向量库中搜索 top_k=10 的最相关已有记忆,然后把它们作为 Existing Memories 注入 prompt。
但这里有一个关键的追问:为什么用当前消息的嵌入去搜索,而不是用提取后的记忆文本去搜索?
因为提取发生在 Phase 2,而 Phase 1 必须在 Phase 2 之前完成。这是一个鸡生蛋的问题------你要知道"系统已经记住了什么"才能判断新信息是否值得提取,但你只有在提取完新信息后才能拿新信息去搜索。mem0 的解决方案是用原始消息作为搜索查询,而不是提取后的记忆。原始消息包含了新信息的全部语义,虽然不如提取后的记忆精炼,但作为去重参考已经足够了。
搜索的 filters 参数也很重要------它只保留 user_id、agent_id、run_id 三个字段。这意味着 Phase 1 的搜索是用户隔离的:你只能看到自己的已有记忆,不会看到其他用户的。这是记忆系统的基本安全约束。
这里有一个精巧的反幻觉设计:
python
uuid_mapping = {}
for idx, mem in enumerate(existing_results):
uuid_mapping[str(idx)] = mem.id
existing_memories.append({"id": str(idx), "text": mem.payload.get("data", "")})UUID 被映射为整数(0, 1, 2...)后传给 LLM。为什么不直接传 UUID?因为 UUID 是类似 a1b2c3d4-5678-9abc-def0-111111111111 的长字符串,LLM 在输出 linked_memory_ids 时极易编造或混淆。整数 ID 简单可靠,LLM 几乎不会搞错"0"和"1"。
但注意:从 prompt 的 few-shot 示例来看,实际上 LLM 在输出中直接使用 UUID。这意味着 mem0 团队经过测试发现,在 few-shot 示例的引导下,LLM 正确使用 UUID 的概率足够高。uuid_mapping 的代码可能是一个早期的防护措施,目前在内部流程中保持一致性,但 LLM 端已经不需要这个映射了。
Phase 2:LLM 单次提取------整个管线的核心
python
system_prompt = ADDITIVE_EXTRACTION_PROMPT
if is_agent_scoped:
system_prompt += AGENT_CONTEXT_SUFFIX
user_prompt = generate_additive_extraction_prompt(
existing_memories=existing_memories,
new_messages=parsed_messages,
last_k_messages=last_messages,
custom_instructions=custom_instr,
)
response = self.llm.generate_response(
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
],
response_format={"type": "json_object"},
)这是整个七阶段管线中唯一一次 LLM 调用。V3 的核心设计就是"单次调用、只做 ADD"------只调用一次 LLM,只让它提取事实,不让它管理状态。
为什么只调用一次?因为 LLM 调用是整个管线中最慢、最贵的一步。一次 gpt-4o 调用可能需要 1-3 秒,成本 0.01-0.05 美元。如果让 LLM 在提取后再做一次判断("这条记忆是 ADD 还是 UPDATE?"),延迟翻倍,成本翻倍,而准确性提升有限------因为 ADD-only 的 hash 去重已经能在下游处理大部分重复。
Agent 场景的特殊处理:如果 agent_id 存在且没有 user_id,system prompt 会追加 AGENT_CONTEXT_SUFFIX,把提取视角从"用户中心"切换到"Agent 中心"。
response_format={"type": "json_object"} 强制 LLM 输出合法 JSON,避免自由格式文本的解析困难。但这个参数只在 OpenAI 兼容的 API 中有效------其他 provider(如 Ollama)可能不支持,这时 LLM 的输出格式就不那么可靠了。
LLM 调用失败的容错哲学
LLM 调用的容错设计很关键:如果调用失败,整个方法直接返回空列表。宁可丢掉这一轮的提取,也不能让异常传播到上层。因为记忆提取是"尽力而为"的操作------这次没提取到,下次用户再提到时还有机会。
为什么不重试?三个原因:
- LLM 失败通常是持续性的------如果是 API key 过期或 rate limit,重试也不会成功
- 延迟敏感------用户在聊天界面等的是响应,不是记忆提取。重试会让用户等更久
- 幂等性------下一次 add 调用会重新走一遍 Phase 0-1,获取新的上下文和已有记忆,提取效果不会因为这次跳过而永久损失
LLM 返回的解析:两层 fallback
LLM 返回后的解析也有两层 fallback:
- 先用
remove_code_blocks去掉可能包裹在 markdown 代码块中的标记 - 先尝试
json.loads,如果失败则用extract_json从文本里提取 JSON
extract_json 是实战中不可或缺的------LLM 经常在 JSON 前后加上 ```````json```` 标记,甚至在 JSON 中间插入注释。extract_json 用正则或括号匹配的方式从文本中定位 JSON 结构,容忍各种格式噪声。
如果解析后 extracted_memories 为空,方法仍然会把当前消息保存到历史库(self.db.save_messages(messages, session_scope)),然后返回空列表。这个设计很重要:即使这一轮没有提取到记忆,对话历史仍然要保存,为下一轮的 Phase 0 提供上下文。如果因为没提取到记忆就不保存历史,下一轮的 LLM 就会缺少上下文,导致代词无法消解,形成恶性循环。
Phase 3:批量嵌入------并行提速的关键
python
mem_texts = [m.get("text", "") for m in extracted_memories if m.get("text")]
try:
mem_embeddings_list = self.embedding_model.embed_batch(mem_texts, "add")
embed_map = dict(zip(mem_texts, mem_embeddings_list))
except Exception:
# Fallback: embed individually
embed_map = {}
for text in mem_texts:
try:
embed_map[text] = self.embedding_model.embed(text, "add")
except Exception as e:
logger.warning(f"Failed to embed memory text: {e}")为什么是批量嵌入而不是逐条?
因为嵌入模型(如 OpenAI 的 text-embedding-3-small)通常支持批量 API------一次请求嵌入多条文本,比逐条调用快得多。假设一次 API 请求需要 200ms 的网络往返,10 条记忆逐条嵌入需要 2 秒,而批量嵌入只需要 200ms。对于用户体验来说,这可能是"可接受"和"不可接受"的区别。
但批量 API 可能失败(比如请求体过大、某条文本包含特殊字符),所以有 fallback 到逐条嵌入。每条嵌入失败只影响该条记忆(通过 text not in embed_map 在 Phase 4 中被跳过),不影响其他记忆的写入。
注意:这里用文本内容作为 dict 的 key。这意味着如果 LLM 提取了两条完全相同的文本,后面的会覆盖前面的。这是 Phase 3 层面的隐式去重,但不是主要去重机制------主要去重在 Phase 4。
这个隐式去重有一个微妙的问题:如果 LLM 提取了两条语义相同但措辞不同的记忆(如"User likes cats"和"User is fond of felines"),它们不会被 Phase 3 去重,因为文本不同。这种语义级去重由 Phase 4 的 hash 去重(只捕获完全相同的文本)和 Phase 1 的 Existing Memories(让 LLM 判断是否重复)共同完成。hash 去重是精确的确定性机制,LLM 判断是近似的概率性机制------两者互补。
Phase 4:Hash 去重 + 元数据装配------双层去重
python
existing_hashes = set()
for mem in existing_results:
h = mem.payload.get("hash")
if h:
existing_hashes.add(h)
records = []
seen_hashes = set() # 批次内去重
for mem in extracted_memories:
text = mem.get("text")
if not text or text not in embed_map:
continue
mem_hash = hashlib.md5(text.encode()).hexdigest()
if mem_hash in existing_hashes or mem_hash in seen_hashes:
continue
seen_hashes.add(mem_hash)
text_lemmatized = lemmatize_for_bm25(text)
memory_id = str(uuid.uuid4())
mem_metadata = deepcopy(metadata)
mem_metadata["data"] = text
mem_metadata["text_lemmatized"] = text_lemmatized
mem_metadata["hash"] = mem_hash
mem_metadata["created_at"] = datetime.now(timezone.utc).isoformat()
mem_metadata["updated_at"] = mem_metadata["created_at"]
...
records.append((memory_id, text, embed_map[text], mem_metadata))这一阶段做两件事:去重和装配。
双层去重
existing_hashes:从 Phase 1 检索到的已有记忆中提取 hash 集合。如果新提取的记忆 hash 与已有记忆重复,跳过。这是跨批次去重------防止多次 add 同一条记忆。seen_hashes:当前批次内的 hash 集合。如果同一批次中 LLM 提取了两条文本相同的记忆,只保留第一条。这是批内去重。
为什么用 MD5 hash 而不是语义相似度?
这是一个关键的设计决策。语义去重(如 cosine similarity > 0.95 就算重复)看起来更"智能",但有三个致命问题:
-
阈值不可靠:cosine similarity 0.95 是"几乎相同",但 0.90 呢?"User likes cats"和"User loves cats"的相似度可能在 0.88-0.92 之间------到底算不算重复?语义相似度在边界案例上极不稳定。
-
计算成本:要判断新记忆是否与已有记忆重复,你需要把新记忆和所有已有记忆做一次 cosine similarity 计算。如果用户有 10000 条记忆,这就是 10000 次计算。hash 去重只需要 O(1) 的查找。
-
确定性:相同的文本一定产生相同的 hash,不同的文本几乎不可能产生相同的 hash。语义去重依赖模型判断,不可靠且不可复现------同一个模型在不同时间可能给出不同的相似度分数。
hash 去重只捕获"完全相同的文本",但这是最安全、最确定的去重方式。语义层面的去重已经由 Phase 1 的 Existing Memories + Phase 2 的 prompt 引导 LLM 不重复提取来实现了。三层去重机制------LLM 的 prompt 级去重、hash 的精确级去重、embed_map 的隐式去重------共同构成了一个漏斗,从粗到细地过滤重复。
元数据装配
每条记忆的 payload 包含:
data:记忆文本text_lemmatized:用于 BM25 检索的词形还原版本hash:MD5 哈希值created_at/updated_at:时间戳attributed_to:归属(user 或 assistant)- 以及从 filters 传入的 user_id / agent_id / run_id
text_lemmatized 是这一阶段的重要产物。通过 lemmatize_for_bm25 函数,记忆文本被还原为词干形式(如 "running" → "run"),为后续的 BM25 关键词检索做准备。这个预处理在写入时做一次,检索时就不需要重复计算。
为什么不在检索时做词形还原?因为 BM25 的稀疏向量是在写入时生成的(Qdrant 的 _encode_bm25 方法),词形还原则是 BM25 编码的输入。如果在检索时才做词形还原,你需要对查询文本做一次还原,但对存储的文本却无法追溯还原------因为 BM25 的稀疏向量已经在写入时固化了。所以词形还原必须在写入时做,写入和检索使用同一套词形还原逻辑,才能保证 BM25 的匹配一致性。
Phase 5:批量写入 VectorStore------带 fallback 的持久化
python
try:
self.vector_store.insert(
vectors=all_vectors,
ids=all_ids,
payloads=all_payloads,
)
except Exception:
# Fallback: insert one by one
for mid, vec, pay in zip(all_ids, all_vectors, all_payloads):
try:
self.vector_store.insert(vectors=[vec], ids=[mid], payloads=[pay])
except Exception as e:
logger.error(f"Failed to insert memory {mid}: {e}")先尝试批量插入,失败则逐条插入。批量插入可能因为向量库的请求体限制、网络超时等原因失败,但其中大部分记录是合法的。逐条 fallback 最大限度地挽救了可写入的记录。
为什么不在逐条 fallback 时也重试?因为向量库的失败通常是瞬态的(网络超时、请求体过大)或持久性的(schema 不匹配)。瞬态失败在逐条模式下通常不会复现(因为单条请求体更小),持久性失败则重试也没用。所以逐条插入本身就是一种"重试"------用更小的请求体重试。
这个 fallback 模式在 mem0 的代码中反复出现------embed_batch → 逐条 embed,batch insert → 逐条 insert,batch_add_history → 逐条 add_history。这是一个统一的工程模式:批量优先,逐条兜底。它最大化了正常情况下的性能,同时最小化了异常情况下的损失。
Phase 6:批量历史记录------SQLite 中的审计日志
python
history_records = [
{"memory_id": r[0], "old_memory": None, "new_memory": r[1],
"event": "ADD", "created_at": r[3].get("created_at"), "is_deleted": 0}
for r in records
]
try:
self.db.batch_add_history(history_records)
except Exception:
for hr in history_records:
try:
self.db.add_history(...)
except Exception as e:
logger.error(...)每条记忆的写入都会记录到 SQLite 的 history 表中。这不是主数据存储(主数据在向量库),而是一条审计日志------记录了"什么时候、对哪条记忆、做了什么操作"。
审计日志有什么用?三个场景:
- 时间旅行 :通过
get_history(memory_id),你可以看到一条记忆的完整生命周期------何时创建、何时更新、何时删除。这对调试和用户支持很有价值。 - 数据恢复:如果向量库的数据丢失了(如 Qdrant 的 RocksDB 损坏),审计日志可以帮助你重建记忆数据------虽然你需要重新嵌入,但至少知道有哪些记忆曾经存在过。
- 合规审计:在某些行业(如医疗、金融),系统需要记录所有数据变更的历史。审计日志提供了这个能力。
同样的批量→逐条 fallback 模式。即使历史记录写入失败,也不影响主数据的完整性------记忆已经在 Phase 5 中写入了向量库。
Phase 7:批量实体链接------跨记忆的关联图谱
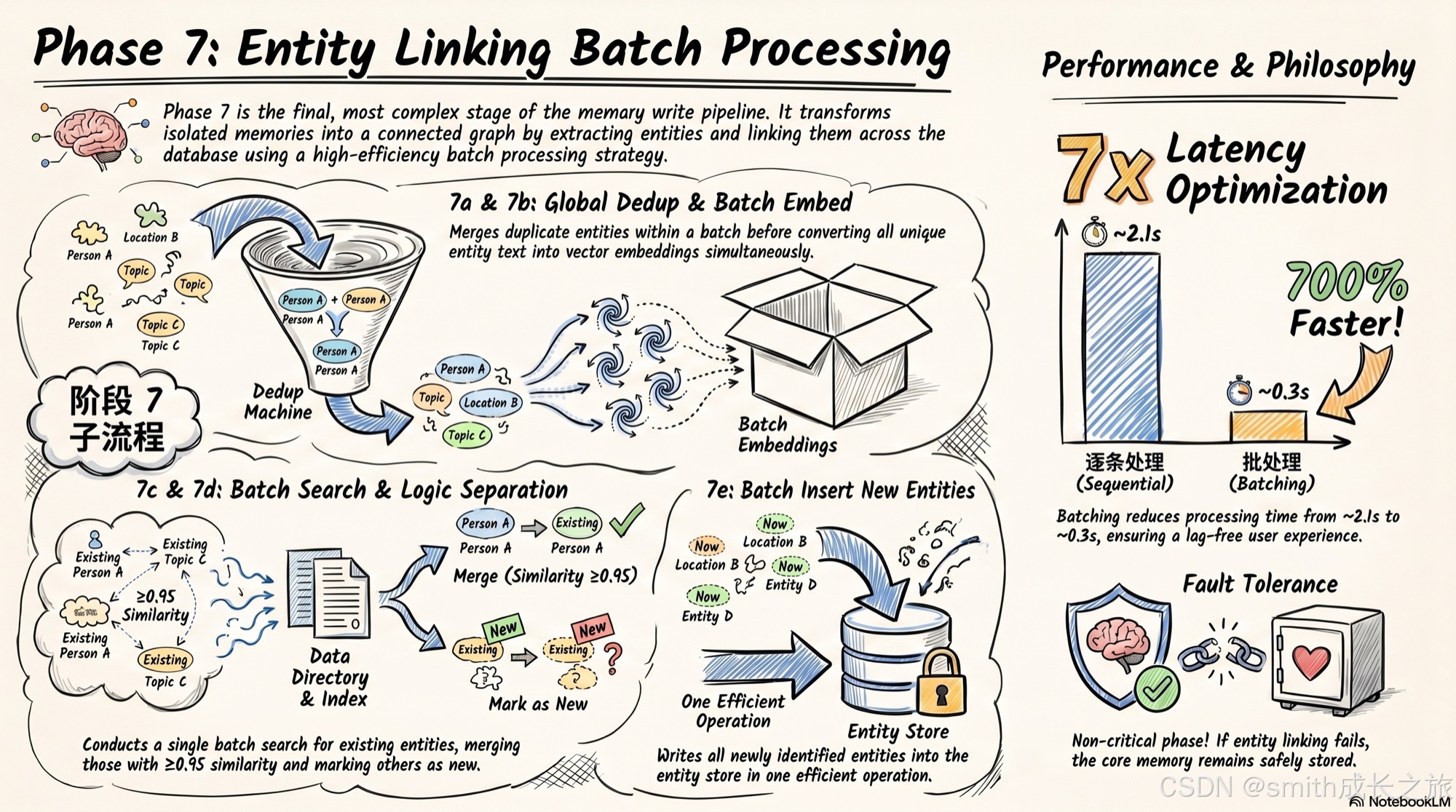
这是最复杂的阶段,也体现了最多的工程优化。
python
all_texts = [r[1] for r in records]
all_entities = extract_entities_batch(all_texts)首先,对所有记忆文本批量提取实体(spaCy NLP)。
7a:全局去重------同一批次中,不同记忆可能提到同一个实体(如 "Poppy" 同时出现在两条记忆中)。全局去重把相同实体的 memory_ids 合并:
python
global_entities = {} # normalized_key -> (entity_type, entity_text, set of memory_ids)
for idx, (memory_id, text, embedding, payload) in enumerate(records):
entities = all_entities[idx]
for entity_type, entity_text in entities:
key = entity_text.strip().lower()
if key in global_entities:
global_entities[key][2].add(memory_id)
else:
global_entities[key] = [entity_type, entity_text, {memory_id}]为什么要全局去重?因为如果不做,同一个实体"Poppy"会创建两条独立的 entity 记录,每条链接到一条记忆。当用户搜索"Poppy"时,entity boost 只会增强其中一条记忆的排名,而不是同时增强两条。全局去重确保同一个实体只有一条记录,但链接到所有相关的记忆。
7b:批量嵌入------所有去重后的实体文本一次性嵌入,避免逐条调用的开销。
7c:批量搜索 ------所有实体嵌入一次性在 entity_store 中搜索,找到已存在的匹配实体。search_batch 是 entity_store 的批量搜索接口,一次调用处理所有实体,而不是逐个搜索。
7d:分离插入和更新------搜索结果中相似度 >= 0.95 的,合并 linked_memory_ids 后更新;< 0.95 的,作为新实体收集起来。
7e:批量插入新实体------所有新实体一次性写入 entity_store。
这五步(7a-7e)形成了一个高效的批处理流程:提取 → 去重 → 嵌入 → 搜索 → 写入,每一步都是批量的。如果不做批量优化,每个实体单独处理,一次 add 调用可能触发几十次嵌入和搜索,延迟会急剧增加。
具体算一笔账:假设一次 add 提取了 5 条记忆,每条记忆有 2 个实体,共 10 个实体。全局去重后可能剩 7 个独立实体。
- 不批量的延迟:7 次嵌入(7 × 200ms = 1.4s)+ 7 次搜索(7 × 50ms = 0.35s)+ 7 次写入(7 × 50ms = 0.35s)= 约 2.1 秒
- 批量的延迟:1 次批量嵌入(200ms)+ 1 次批量搜索(50ms)+ 1 次批量写入(50ms)= 约 0.3 秒
7 倍的延迟差距。在实时对话场景中,这是"用户感知到卡顿"和"用户无感知"的区别。
整个 Phase 7 被一个大的 try/except 包裹,任何异常都只记录 warning,不影响主流程。实体链接是锦上添花,不是雪中送炭------即使实体链接全部失败,记忆本身已经安全地写入了向量库。
Phase 8:保存消息 + 返回
python
self.db.save_messages(messages, session_scope)
returned_memories = [
{"id": r[0], "memory": r[1], "event": "ADD"}
for r in records
]最后,把当前轮次的消息保存到历史库(为下一轮的 Phase 0 服务),然后返回所有写入的记忆。
save_messages 内部有一个值得注意的设计:保存后,它会删除该 session_scope 下超过最近 10 条的旧消息。这意味着 SQLite 中始终只保留每个 session 的最近 10 条消息------这是一个滑动窗口,防止历史库无限增长。
为什么是 10 条而不是 20 条或 50 条?因为 Phase 0 的 get_last_messages(session_scope, limit=10) 只取 10 条。保存更多也不会被用到,只是浪费存储。10 条消息通常足够消解最近对话中的代词和指代------更早的上下文由 Summary 提供。
为什么是七阶段?能不能合并?
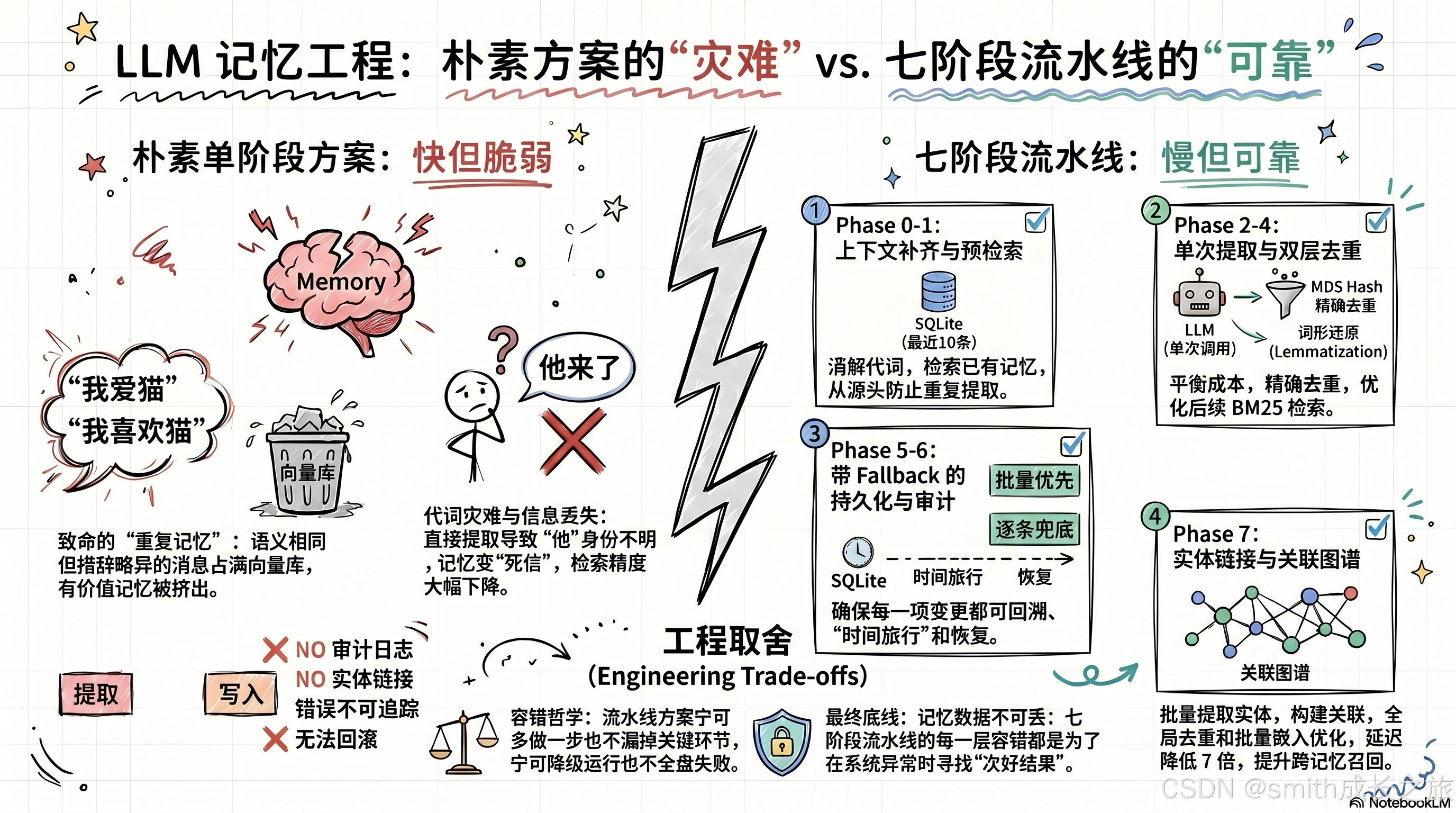
图:朴素单阶段方案 vs 七阶段流水线的容错对比
让我们审视每个阶段是否可以被合并或跳过:
| 阶段 | 能否跳过 | 后果 |
|---|---|---|
| Phase 0 | 否 | LLM 缺少上下文,代词无法消解,记忆中残留"他""那个" |
| Phase 1 | 否 | LLM 不知道已有记忆,无法去重和链接,重复记忆泛滥 |
| Phase 2 | 否 | 没有 LLM 提取,就没有结构化记忆,只有原始消息 |
| Phase 3 | 否 | 没有嵌入,无法写入向量库 |
| Phase 4 | 否 | 没有去重,重复记忆;没有词形还原,BM25 检索效果差 |
| Phase 5 | 否 | 没有持久化,记忆丢失 |
| Phase 6 | 可选 | 跳过则无审计日志,不影响功能 |
| Phase 7 | 可选 | 跳过则无实体链接,检索时少一路信号 |
Phase 6 和 7 可以跳过而不影响核心功能,但 Phase 0-5 每一个都是不可替代的。这七个阶段(实际是八个,如果算上最后的保存消息)形成了一条严密的流水线,每个阶段的输出是下一个阶段的输入。
能不能合并某些阶段?比如 Phase 3(嵌入)和 Phase 4(去重)能否合并?不能,因为嵌入必须在去重之前完成------你需要在嵌入成功后才能确定哪些记忆可以写入。而嵌入可能失败,失败的记忆在 Phase 4 中被 text not in embed_map 过滤掉。如果合并,你就需要在一个循环中同时处理嵌入和去重,逻辑更复杂,也更难做批量优化。
复杂度 vs. 容错
七阶段的优势:
- 每个阶段职责单一,逻辑清晰
- 每个阶段都有独立的容错和 fallback,不会因为一个阶段的失败导致整条管线崩溃
- 批量优化(embed_batch / batch_add_history / extract_entities_batch)在每个阶段内独立实现
七阶段的代价:
- 代码复杂度高------
_add_to_vector_store方法本身就有 300+ 行 - 阶段间的数据传递依赖约定(如 records 列表的四元组结构
(memory_id, text, embedding, payload)),而不是类型化的数据结构。如果某个阶段的开发者改变了元组的字段顺序,下游所有阶段都会出错------而且 Python 不会给你任何编译期警告。 - 调试困难------一次 add 调用涉及多次外部服务调用(LLM、嵌入模型、向量库、SQLite),任何一环都可能失败,且失败后的行为(降级、跳过、重试)各不相同
缓解措施:
- 每个 fallback 路径都确保了"尽力而为"的语义------能救多少救多少,不影响全局
- 大量的 try/except 和日志记录使得问题可追踪
- Phase 7 的"非致命"设计------实体链接失败不影响核心写入路径
- Phase 2 失败后仍然保存消息,避免下一轮缺少上下文
七阶段流水线的设计哲学可以总结为一句话:宁可多做一步也不漏掉一个关键环节,宁可降级运行也不全盘失败。这不是过度工程,而是在"记忆不可丢失"这一刚性约束下的工程必然。
每个阶段的 fallback 路径------从批量到逐条、从 LLM 提取到返回空、从实体链接到静默跳过------都是在回答同一个问题:当最好的结果不可得时,次好的结果是什么? 七阶段流水线的每一层容错,都是对这个问题的一次回答。而所有回答的底线是一样的:记忆数据本身不能丢。
但这里有一个我们一直绕过去的黑盒。Phase 7 的实体链接,整条流水线里它是唯一一个"失败也不影响写入"的阶段------设计上就允许跳过。可如果它真的不重要,为什么还要放在流水线的终点?实体提取到底解决了什么问题,让 mem0 宁可多加一个阶段、多一次 LLM 调用、多一层图数据库写入,也要把它留下?下一篇,我们拆开这个黑盒。