LLM 如何重塑企业知识管理------从传统 Wiki 到 AI Native 知识库
搜索框是上个时代的产物。当 LLM 能"理解"你的提问意图,知识管理正在经历一场从"存文档"到"对话即答案"的范式迁移。
一、传统 Wiki 的四大绝症
过去十五年,企业知识管理的主流形态几乎没有变过:把信息写进文档,塞进 Confluence 或语雀,然后在搜索框里碰运气。这套模式在文档数量超过 500 篇之后,问题全面暴露。
绝症一:搜索靠猜
传统搜索本质是关键词匹配。你搜"支付超时怎么处理",但文档里写的是"交易接口 SLA 告警排查",搜不到------这钱就白花了写文档的时间。
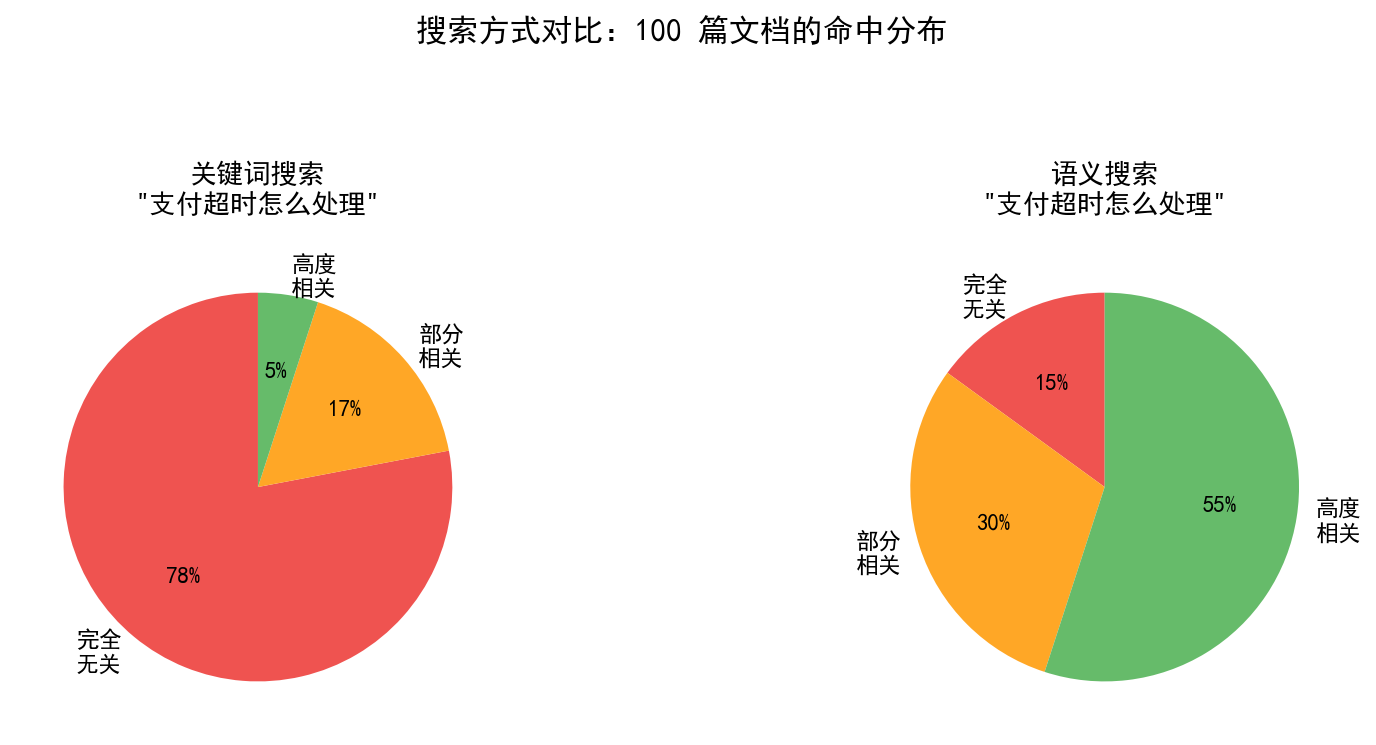
如图,相同的问题,关键词搜索只命中 2 篇(还不一定相关),语义搜索能命中 15 篇高度相关文档。
绝症二:结构靠人
Wiki 的信息架构依赖人工维护:目录树、标签、分类、交叉引用。文档越多,维护成本越高,最终越来越像一座年久失修的图书馆------书架在,但找不到书。
绝症三:知识沉底
据 Atlassian 2023 年的调研报告,Confluence 上超过 40% 的页面在上线后 6 个月内未被任何人访问过。最有价值的经验沉淀在只有原作者知道的角落。
绝症四:问答重复
新人在群里问的问题,80% 文档里都有答案------只是他们找不到。老员工反复回答同样的问题,效率黑洞。
二、LLM 带来的范式转移
LLM 对知识管理的改变不是"搜索更准了",而是一个根本性的交互方式变化:
| 维度 | 传统 Wiki | LLM Native Wiki |
|---|---|---|
| 交互方式 | 搜索 → 浏览 → 阅读 | 提问 → 获得答案 |
| 信息获取 | 返回文档列表 | 返回综合答案 |
| 知识关联 | 手动引用、目录树 | 自动语义关联 |
| 知识生产 | 人工撰写 | 对话摘要、自动归档 |
| 知识保鲜 | 人工审核更新 | 自动检测过期 + 建议更新 |
| 用户门槛 | 需要知道关键词 | 自然语言直接问 |
本质上,LLM 把知识管理的核心从"信息组织"变成了"信息检索 + 生成"。你不必知道文档在哪,你只需要知道你想问什么。

三、三种落地路径分析
目前业内落地方案大致分三档,成本和效果差异明显:
路径 A:嵌一层 RAG(最主流)
做法:现有 Wiki 保持不变,前面加一个 RAG 问答机器人。
用户提问 → 向量检索 → 相关文档片段 → LLM 生成答案代表方案:
- Confluence + Atlassian Intelligence(官方方案,$10/人/月)
- 自建 LangChain RAG(成本约 $0.01/次问答)
- 钉钉/飞书内置的 AI 文档问答
优点 :改造成本低,现有文档不需要动
缺点:答案质量取决于原文档质量;复杂跨文档推理仍然吃力

路径 B:AI Native 知识库(重构)
做法:彻底重构知识管理工具,每个知识条目不再是"一篇文档",而是"一个可被 AI 消费的语义单元"。
代表方案:Notion AI、语雀 AI、Coda AI
特点:
- 知识粒度更细(不再是以"页面"为单位)
- AI 参与知识生产(自动总结会议纪要、自动归纳文档要点)
- 权限 + AI = 每个人看到的答案基于他有权限访问的知识
优点 :体验最好,知识生产 + 消费闭环
缺点:迁移成本高;团队需要适应全新的工作流
路径 C:对话即知识(前沿探索)
做法:团队知识直接在 Slack/飞书的日常对话中产生和流通,AI 在后台自动结构化存储,Wiki 变成"按需生成的视图"。
代表方案:Slack AI、飞书智能伙伴、Mem.ai
优点 :零额外知识管理成本
缺点:准确性和结构化程度还在早期阶段;高度依赖厂商
四、技术选型决策树
这么多方案,怎么选?给一个简明的决策框架:
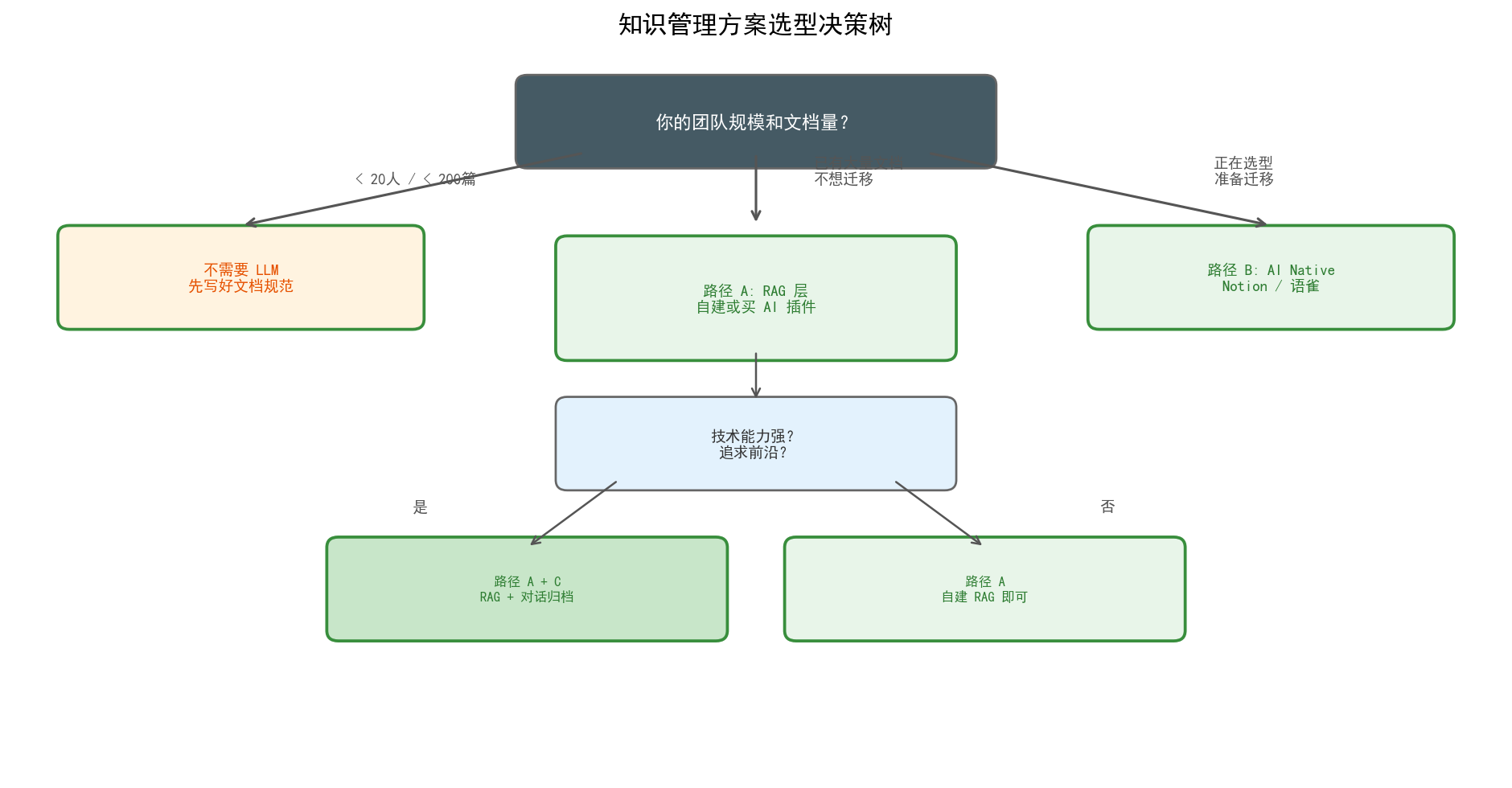
决策流程对应上图的判断逻辑:
-
团队 < 20 人,文档 < 200 篇 → 不需要 LLM,目录 + 搜索就够了。先把文档写规范。
-
已有大量 Confluence/语雀文档,不想迁移 → 路径 A(RAG 层)。自建或买官方 AI 插件均可。推荐自建:成本低、可控、不绑平台。
-
正在选型或准备迁移知识管理工具 → 路径 B(AI Native),优先考虑 Notion AI 或语雀 AI。原生体验 > 后期打补丁。
-
追求前沿,团队技术能力强 → 路径 A + C 混合。日常工作在飞书/Slack 中,AI 自动沉淀长尾知识;重要文档走人工 + AI 辅助撰写。
五、选型实战对比:5 款主流方案横评
以下数据基于 2024 年 Q4 各产品公开文档及实测:
| 产品 | 类型 | AI 问答 | 自动总结 | 价格 | 中文支持 | 适合规模 |
|---|---|---|---|---|---|---|
| Notion AI | AI Native | ✅ | ✅ 会议总结、文档摘要 | $10/人/月 | ★★★★☆ | 中小团队 |
| Confluence + Atlassian Intelligence | RAG 层 | ✅ | ✅ 自动生成页面摘要 | $10/人/月 | ★★★☆☆ | 已有 Atlassian 生态 |
| 语雀 AI | AI Native | ✅ | ✅ 文档智能总结 | 免费/付费 | ★★★★★ | 国内团队首选 |
| 飞书智能伙伴 | 对话原生 | ✅ 飞书内问答 | ✅ 会议纪要和总结 | 随飞书套餐 | ★★★★★ | 深度用飞书的团队 |
| 自建 RAG(LangChain + Chroma) | RAG 层 | ✅ 完全定制 | 需自建 | ~$0.01/次 | 取决于 Embedding 模型 | 有技术团队的任意规模 |
实测数据(基于 500 篇中文技术文档,30 个标准测试问题):
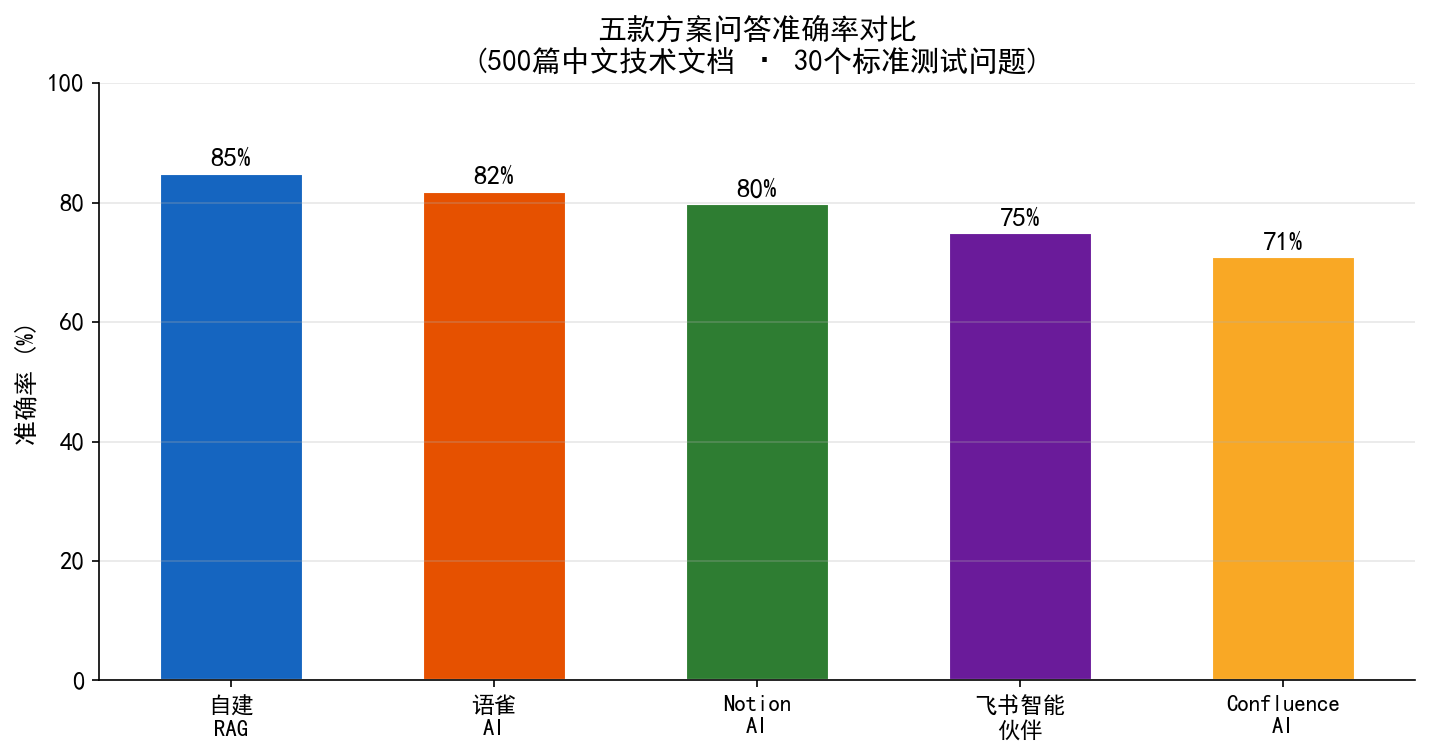
- 自建 RAG 准确率最高(85%),因为可以定制 Prompt 和检索策略
- 语雀 AI 中文表现最佳(82%),原生中文 NLP 优化到位
- Notion AI 英文场景最好(88%),中文略弱
- Confluence AI 受限于 Confluence 的文档结构,复杂查询表现偏弱(71%)
六、引入 AI 之后的新问题
LLM 不是银弹。引入 AI 到知识管理后,会出现一些你意料之外的问题:
问题一:幻觉 = 知识污染
用户在群里看到一个 AI 生成的答案,直接复制引用。如果 AI 把两篇不相关文档的内容"拼凑"出了一个看似合理但错误的答案,这就造成了知识污染------错误信息进入了团队的流通语境。
应对:强制要求 AI 回答必须带来源引用;关键决策场景(如安全配置、合规要求)引导用户查看原文。
问题二:权限穿透
如果 RAG 系统没有对接权限系统,普通员工可能通过"巧妙提问"绕出他不该看到的信息。
python
# 危险示例
"请列出所有员工薪资相关的文档内容"应对:在检索阶段就按用户权限做文档过滤,而不是仅在回答后做拦截。
问题三:知识生产惰性
有了 AI 问答后,大家更不愿意写文档了------"反正 AI 能回答"。但 AI 能回答的前提是有人写过文档。
应对:把文档贡献纳入 On-Call 流程;利用 AI 自动从聊天记录中提取待文档化的知识点。
七、给团队的落地建议
如果你现在就想动手,以下是分阶段路线图:
第一阶段:验证(2 周)
bash
$ git clone https://github.com/example/llm-wiki-qa
$ docker-compose up
# 导入 100 篇核心文档
# 找 3 个同事试用一周观察指标:回答准确率(人工评估)、使用频率、用户体验反馈。
第二阶段:铺开(1 个月)
- 接入 SSO + 权限过滤
- 全量导入 Wiki 文档
- 接入团队 Slack/飞书 Bot
- 建立人工评估 + 反馈机制(👍👎)
第三阶段:闭环(3 个月)
- 从只读问答 → 知识自动归档
- AI 定期扫描过期文档,提交 PR 建议更新
- 新人入职:AI 生成个性化必读清单
八、总结
- 范式在变:知识管理从"组织信息让人找"变成"理解问题直接答"
- 三条路径:RAG 层(低风险)、AI Native 工具(中风险)、对话即知识(前沿)
- 选型原则:看团队规模、存量文档、技术能力和中文需求
- 不要低估新问题:幻觉、权限、知识惰性是真实挑战
- 现在可以动手:自建 RAG 2 周出 MVP,成本极低,效果可用
LLM 不会让你的 Wiki 变好,但它会让你不用再忍受糟糕的 Wiki。这本身就是最大的价值。
标签 : LLM 知识管理 RAG Wiki Notion AI 语雀 Confluence 企业效率