数据分析岗位招聘数据可视化分析系统 --- 技术文档
1. 项目概述
1.1 项目简介
本系统是一个面向数据分析岗位招聘市场的可视化分析平台,基于 Flask 框架构建,集成了数据概览、多维分析、高级统计、机器学习预测、报告导出等功能模块。系统通过对招聘数据的深度挖掘,帮助用户了解行业薪资分布、学历/经验要求、地域差异、企业特征等关键维度的信息。
1.2 技术栈
| 层级 | 技术 | 版本/说明 |
|---|---|---|
| 后端框架 | Flask | Python Web 框架 |
| 模板引擎 | Jinja2 | Flask 内置 |
| 前端框架 | Bootstrap 5 | 响应式 UI |
| 图表库 | Apache ECharts | 交互式可视化 |
| 图标库 | Bootstrap Icons + Boxicons | 矢量图标 |
| 数据库 | MySQL 8.x | 关系型数据库 |
| ORM/驱动 | PyMySQL | MySQL 连接器(DictCursor) |
| 数据处理 | Pandas + NumPy | 数据清洗与分析 |
| 机器学习 | scikit-learn, XGBoost | 回归/分类/聚类 |
| 统计分析 | SciPy | 假设检验、正态性检验 |
| 关联规则 | mlxtend | Apriori 算法 |
| 报告生成 | openpyxl, reportlab | Excel / PDF 导出 |
| 配置管理 | PyYAML | config.yaml |
1.3 运行环境
- Python: 3.8+
- MySQL: 5.7+ / 8.x
- 端口: 5002(config.yaml 中配置)
- 数据库名 :
design_149_job_analysis
1.4 启动方式
bash
# 安装依赖
pip install -r requirements.txt
# 启动(自动建表、导入数据)
python run.pyrun.py 启动流程:
- 检查 Python 依赖是否安装
- 检查数据文件
data/data_analyst_jobs.xlsx是否存在 - 创建必要目录(
reports/,model/) - 加载
config.yaml配置 - 初始化数据库连接,自动建表并导入 CSV 数据
- 启动 Flask 开发服务器
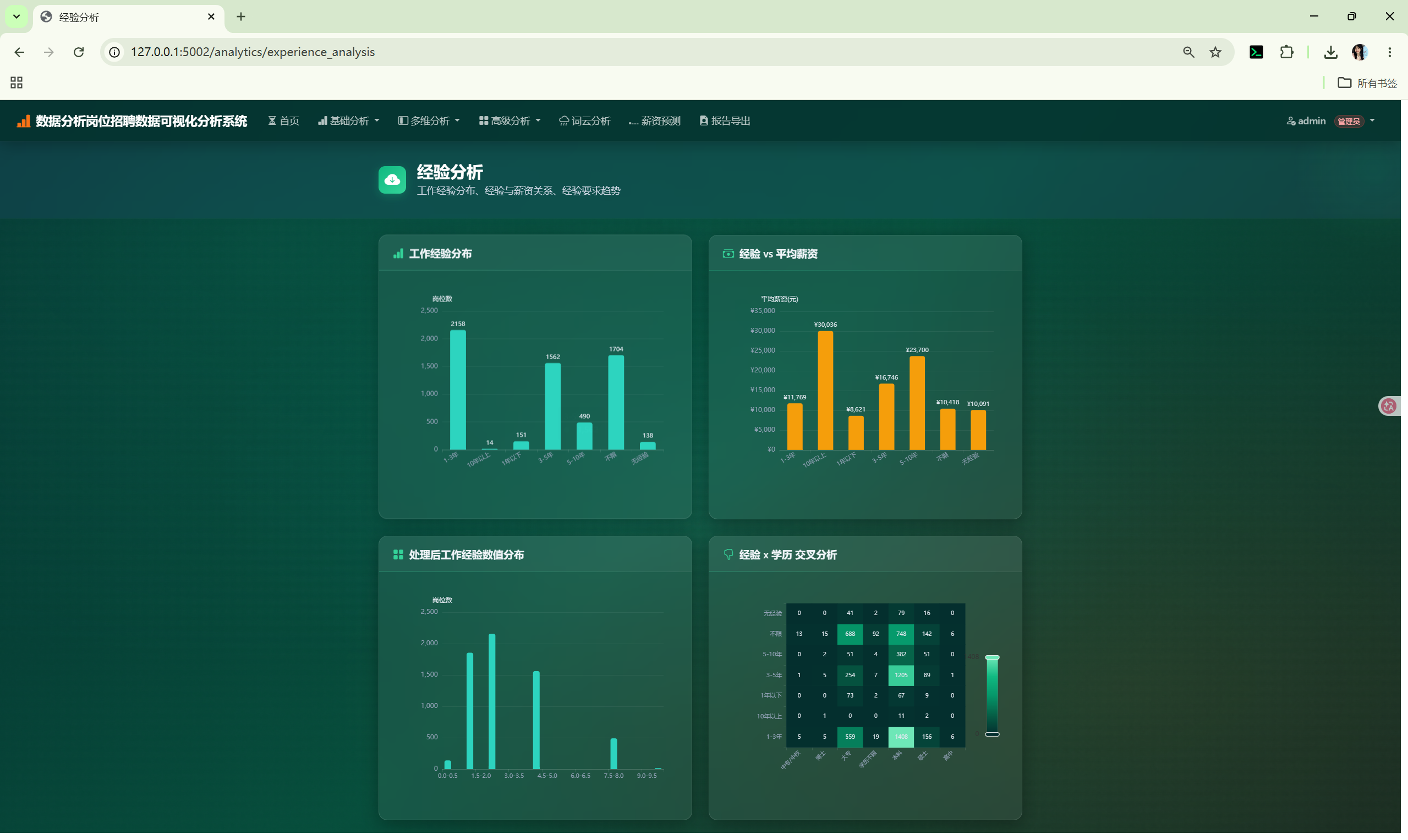
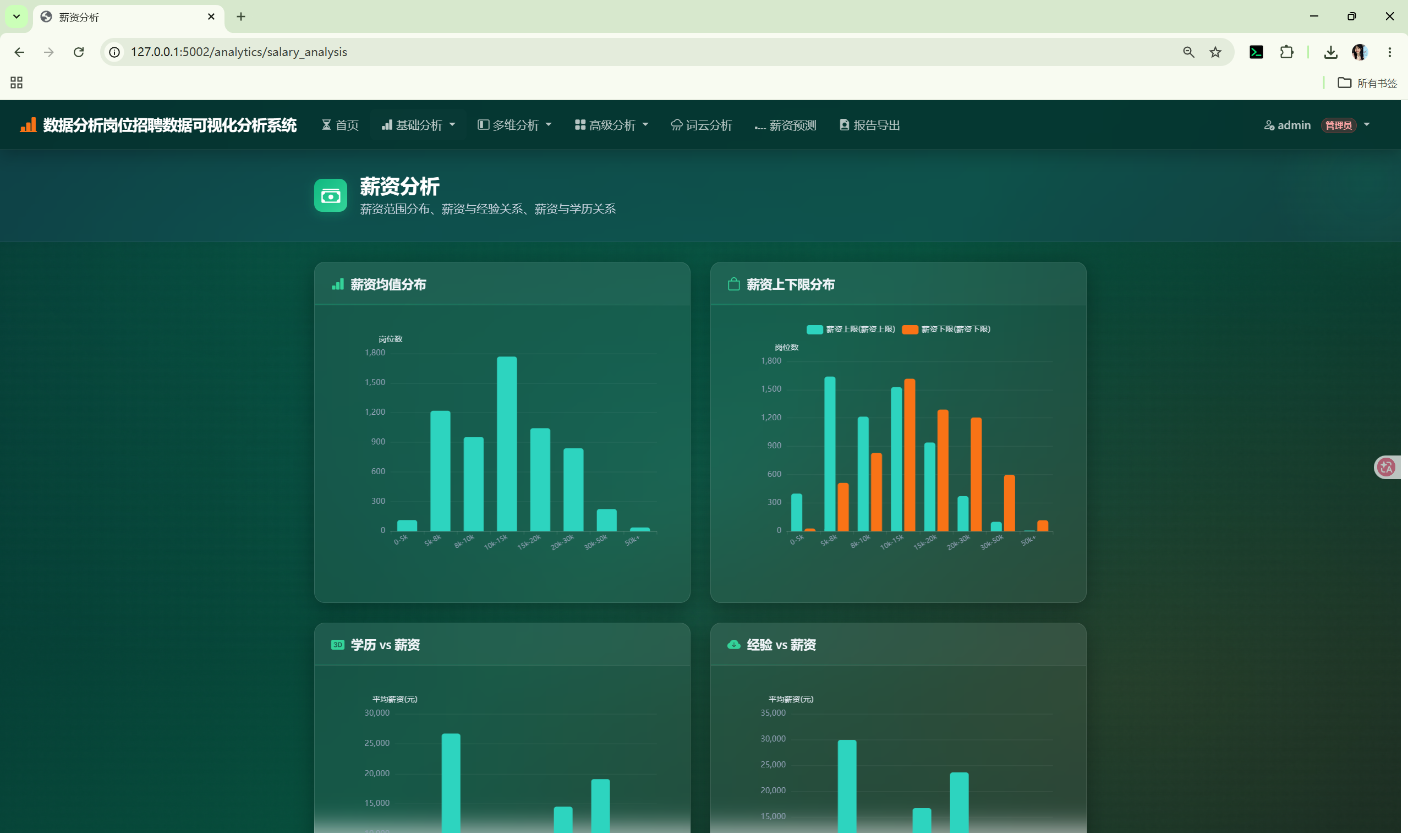
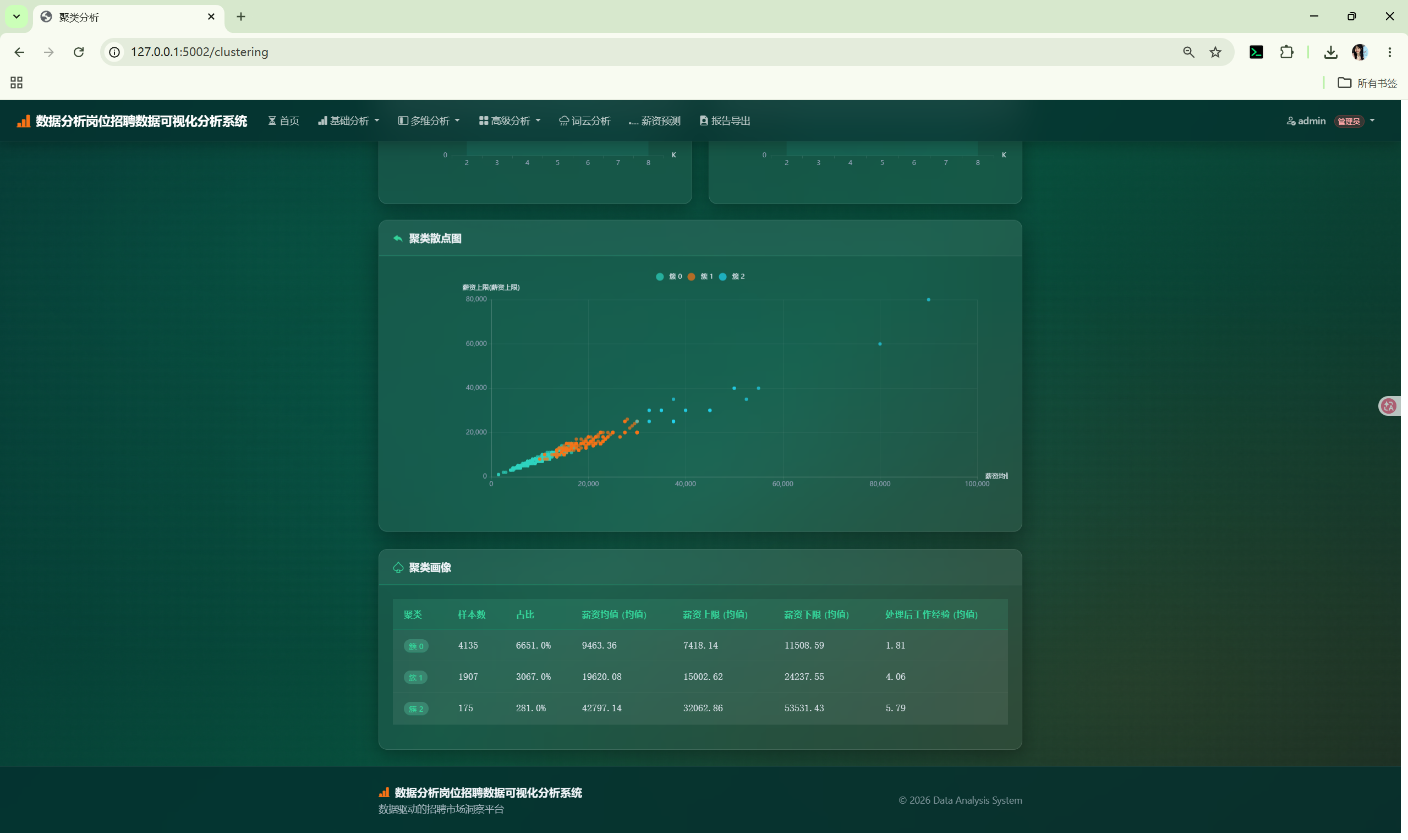
2. 系统架构
2.1 整体架构
┌─────────────────────────────────────────────────────┐
│ 浏览器 (前端) │
│ Bootstrap 5 + ECharts + Bootstrap Icons │
└──────────────────────┬──────────────────────────────┘
│ HTTP
┌──────────────────────▼──────────────────────────────┐
│ Flask (app.py) │
│ 路由层:请求处理、权限校验、模板渲染 │
│ 35 个路由,覆盖认证/分析/管理/预测/报告 │
└──────┬───────────────────────────────────┬──────────┘
│ │
┌──────▼──────────┐ ┌─────────▼──────────┐
│ shared/ 核心模块 │ │ database.py │
│ 纯数据分析逻辑 │ │ MySQL 数据层 │
│ 无 Web 依赖 │ │ PyMySQL DictCursor│
└─────────────────┘ └────────────────────┘
│
┌──────▼──────────┐
│ data/*.xlsx │
│ 原始数据集 │
└─────────────────┘2.2 分层设计
| 层级 | 文件 | 职责 |
|---|---|---|
| 路由层 | app.py |
HTTP 请求处理、权限校验、数据转换、模板渲染 |
| 核心业务层 | shared/*.py |
纯数据分析逻辑,不依赖 Web 框架,返回 dict/list |
| 数据访问层 | database.py |
MySQL CRUD、表结构管理、CSV 导入 |
| 配置层 | config.yaml |
数据库连接、特征定义、模块开关、分析参数 |
| 展示层 | templates/*.html |
Jinja2 模板 + ECharts 图表渲染 |
2.3 设计原则
- 核心模块与 Web 层解耦 :
shared/中的模块只接收数据路径和参数,返回纯 dict/list,可独立测试 - 配置驱动 :特征列、分析页面、模块开关均通过
config.yaml声明,新增分析页面只需添加配置 - 动态表结构 :数据库表列根据
config.yaml的features自动生成 - 单一主题色 :使用
#10b981(绿色系)同色系调色板,不做跨色相渐变
3. 目录结构
code/
├── app.py # Flask 主应用(1150 行)
├── database.py # MySQL 数据库层(751 行)
├── run.py # 启动入口(97 行)
├── predictor.py # ML 训练包装器(79 行)
├── knowledge_crawler.py # 知识爬虫包装器(78 行)
├── config.yaml # 项目配置文件(245 行)
├── requirements.txt # Python 依赖
├── CLAUDE.md # AI 辅助开发规范
│
├── shared/ # 核心分析模块(纯逻辑,无 Web 依赖)
│ ├── __init__.py
│ ├── analysis_core.py # 数据分析(246 行)
│ ├── anomaly_core.py # 异常检测(228 行)
│ ├── association_core.py # 关联规则(195 行)
│ ├── clustering_core.py # 聚类分析(245 行)
│ ├── predictor_core.py # ML 预测(175 行)
│ ├── regression_core.py # 回归分析(247 行)
│ ├── report_core.py # 报告生成(304 行)
│ └── stats_core.py # 统计检验(249 行)
│
├── templates/ # Jinja2 模板(28 个文件)
│ ├── base.html # 基础布局(导航栏、页脚、ECharts 主题)
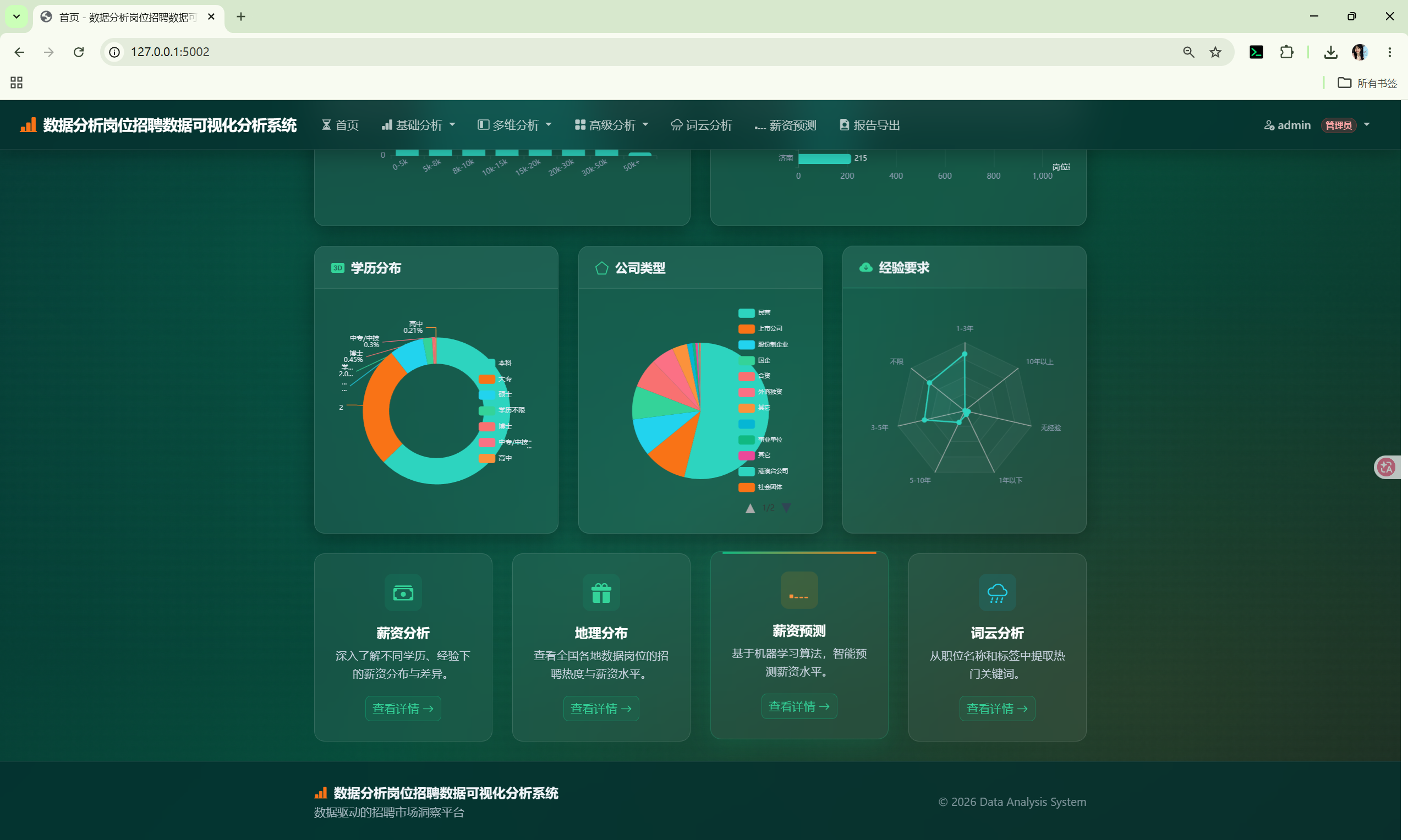
│ ├── index.html # 首页仪表盘
│ ├── login.html / register.html
│ ├── profile.html # 个人中心
│ ├── overview.html # 数据概览
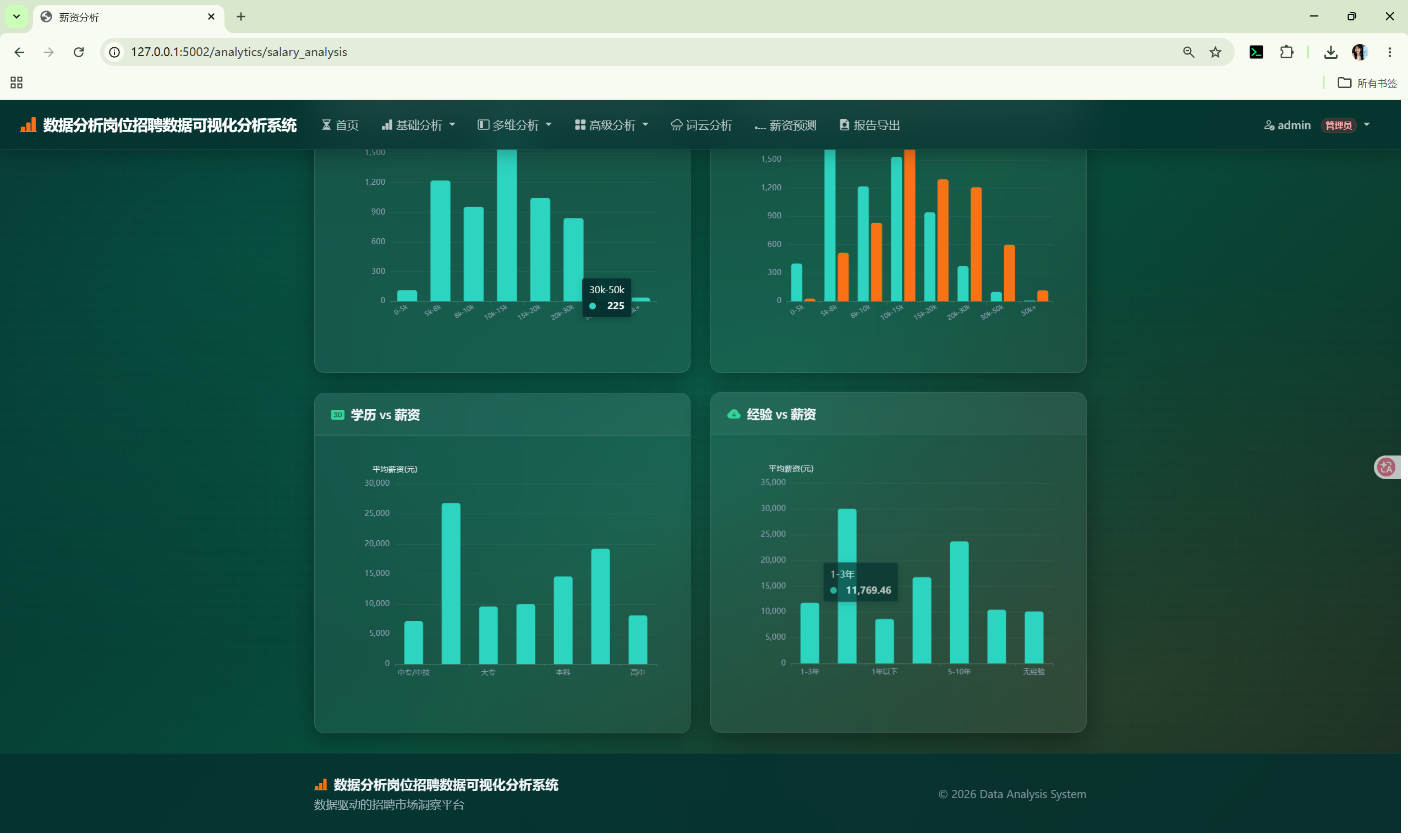
│ ├── salary_analysis.html # 薪资分析
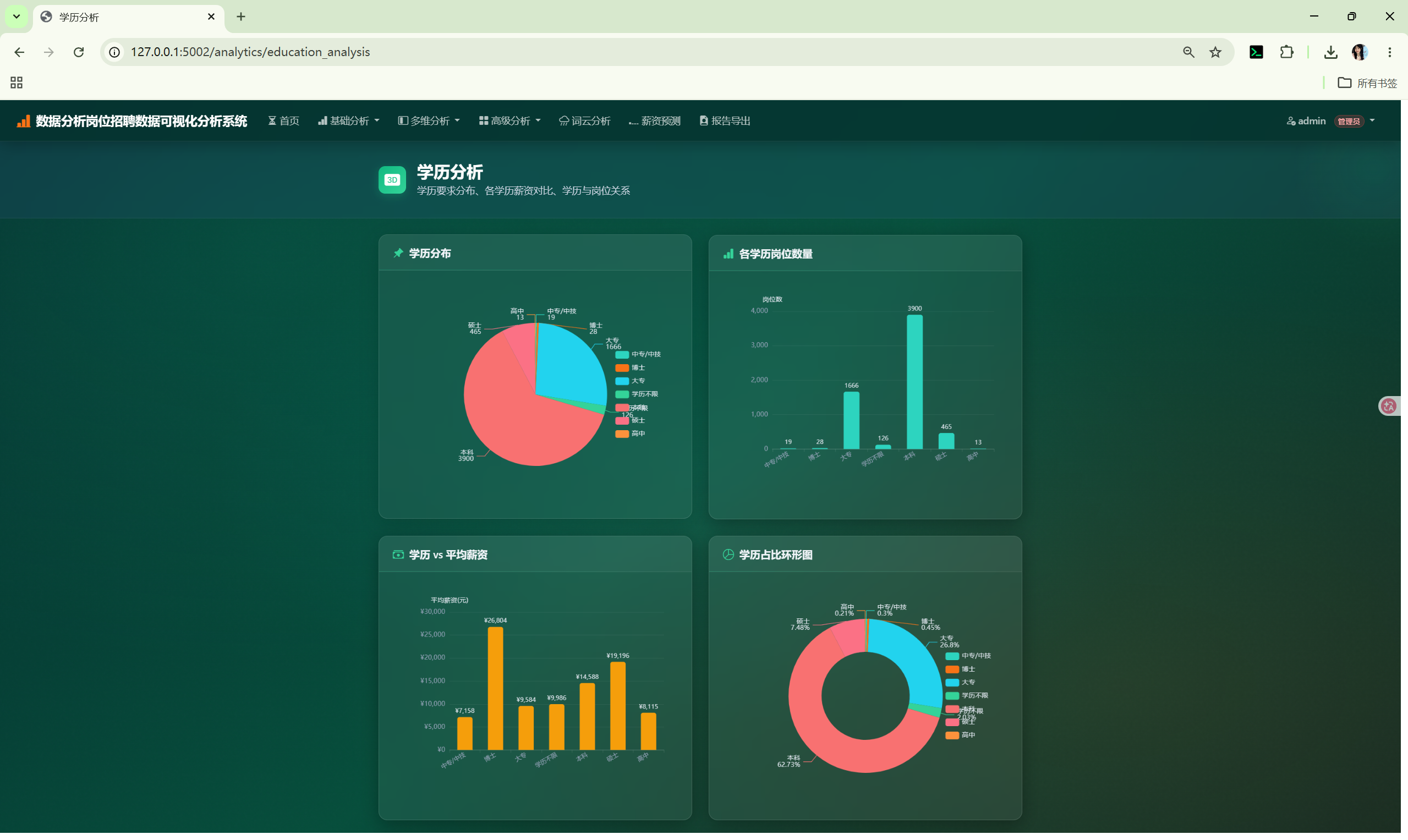
│ ├── education_analysis.html # 学历分析
│ ├── experience_analysis.html# 经验分析
│ ├── company_analysis.html # 公司分析
│ ├── geo_distribution.html # 地理分布
│ ├── geo_map.html # 地图可视化
│ ├── salary_stats.html # 统计检验
│ ├── regression_analysis.html# 回归分析
│ ├── anomaly_detection.html # 异常检测
│ ├── correlations.html # 相关性分析
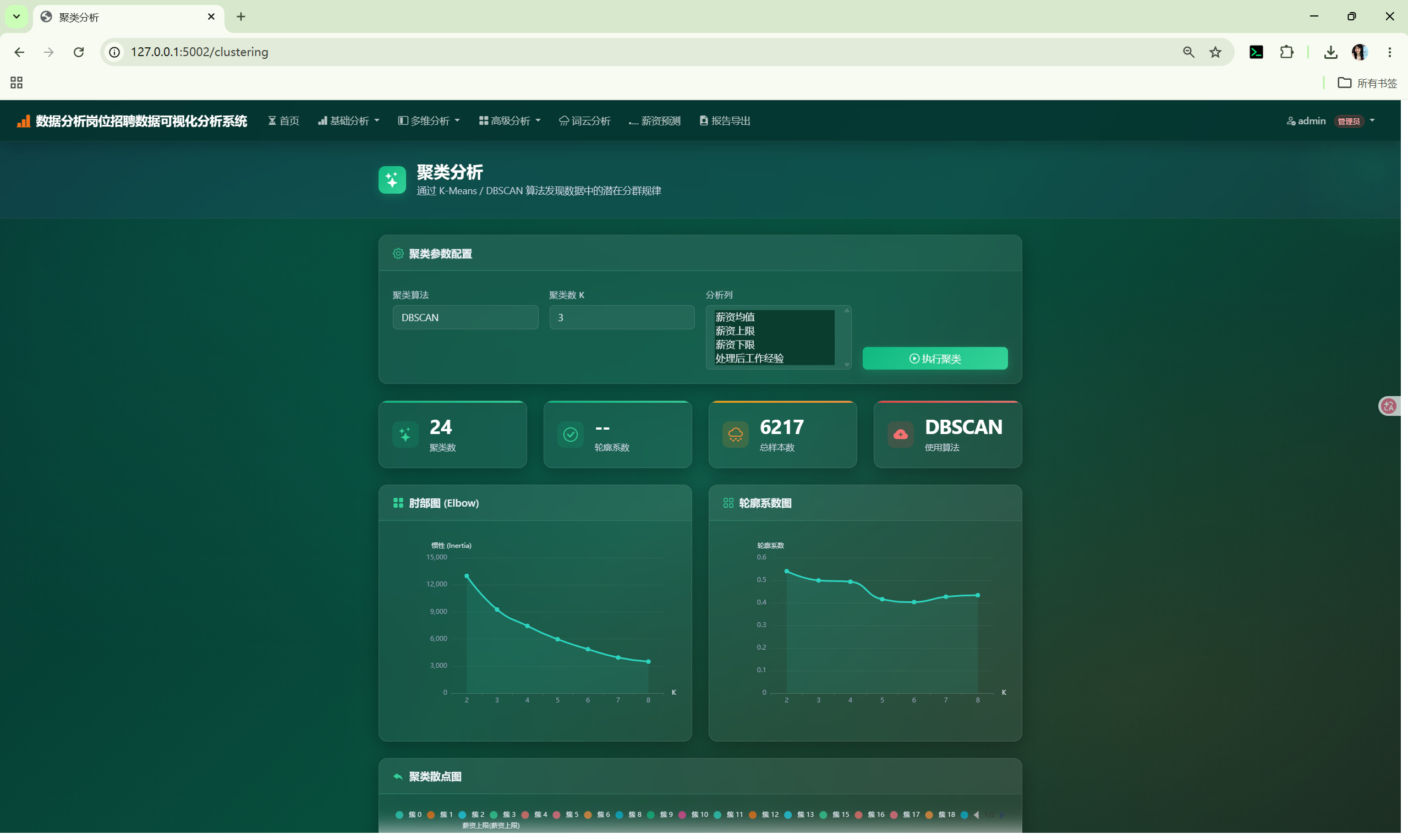
│ ├── clustering.html # 聚类分析
│ ├── association.html # 关联规则
│ ├── word_cloud.html # 词云分析
│ ├── salary_predict.html # 薪资预测
│ ├── reports.html # 报告导出
│ ├── data_manage.html # 数据管理(列表)
│ ├── data_manage_edit.html # 数据管理(编辑)
│ └── admin/
│ ├── dashboard.html # 管理后台
│ └── users.html # 用户管理
│
├── static/
│ ├── css/
│ │ ├── style.css # 自定义样式(1074 行,glassmorphism 设计系统)
│ │ ├── bootstrap.min.css # Bootstrap 5
│ │ ├── bootstrap-icons.css
│ │ └── boxicons.min.css
│ ├── js/
│ │ ├── echarts.min.js # Apache ECharts
│ │ └── bootstrap.bundle.min.js
│ └── fonts/
│ ├── bootstrap-icons.woff2
│ └── boxicons.woff2
│
├── data/
│ ├── data_analyst_jobs.xlsx # 主数据集(884 KB)
│ └── data_analyst_jobs.csv # 自动转换的 CSV(1.4 MB)
│
├── reports/ # 生成的报告文件
├── model/ # ML 模型存储(运行时生成)
└── docs/ # 项目文档4. 配置文件 (config.yaml)
4.1 项目配置
yaml
project:
id: '149'
name: 数据分析岗位招聘数据可视化分析系统
name_en: data_analyst_job_analysis
stack: flask_bootstrap
db_name: design_149_job_analysis
db_host: localhost
db_port: 3306
db_user: root
db_password: '123456'
port: 5002
theme_color: '#10b981'4.2 数据集特征定义
yaml
dataset:
file: data_analyst_jobs.xlsx
target_column: '' # 无分类目标列
features:
- key: 职位名称
label: 职位名称
type: text # 文本类型
- key: 薪资均值
label: 薪资均值
type: numeric # 数值类型
range: [1500, 160000]
- key: 工作经验
label: 工作经验
type: categorical # 分类类型
options: [不限, 1-3年, 5-10年, 3-5年, 1年以下, 无经验, 10年以上]
- key: 本科
label: 本科
type: binary # 二值类型 (0/1)特征类型说明:
| type | 用途 | 数据库列类型 | 表单控件 |
|---|---|---|---|
text |
文本字段 | VARCHAR(200) | <input type="text"> |
numeric |
数值字段 | DOUBLE | <input type="number"> |
categorical |
分类字段 | VARCHAR(100) | <select> |
binary |
二值标记 | INT | <select> (0/1) |
4.3 模块开关
yaml
modules:
auth: true # 用户认证
prediction: true # ML 预测
analytics: true # 基础分析
data_manage: true # 数据管理
dashboard: true # 仪表盘
statistical_analysis: true # 统计检验
regression: true # 回归分析
anomaly_detection: true # 异常检测
clustering: true # 聚类分析
association_rules: true # 关联规则
report_export: true # 报告导出
geo_map: true # 地图可视化
word_cloud: true # 词云分析
salary_predict: true # 薪资预测4.4 分析页面配置
每个分析页面在 analysis_pages 中声明路由、标题、描述和使用的列:
yaml
analysis_pages:
- route: salary_analysis
title: 薪资分析
description: 薪资范围分布、薪资与经验关系、薪资与学历关系
columns: [薪资均值, 薪资上限, 薪资下限]
- route: salary_stats
title: 薪资统计检验
type: statistical # 特殊类型,使用 StatsCore
columns: [薪资均值, 薪资上限, 薪资下限, 处理后工作经验]
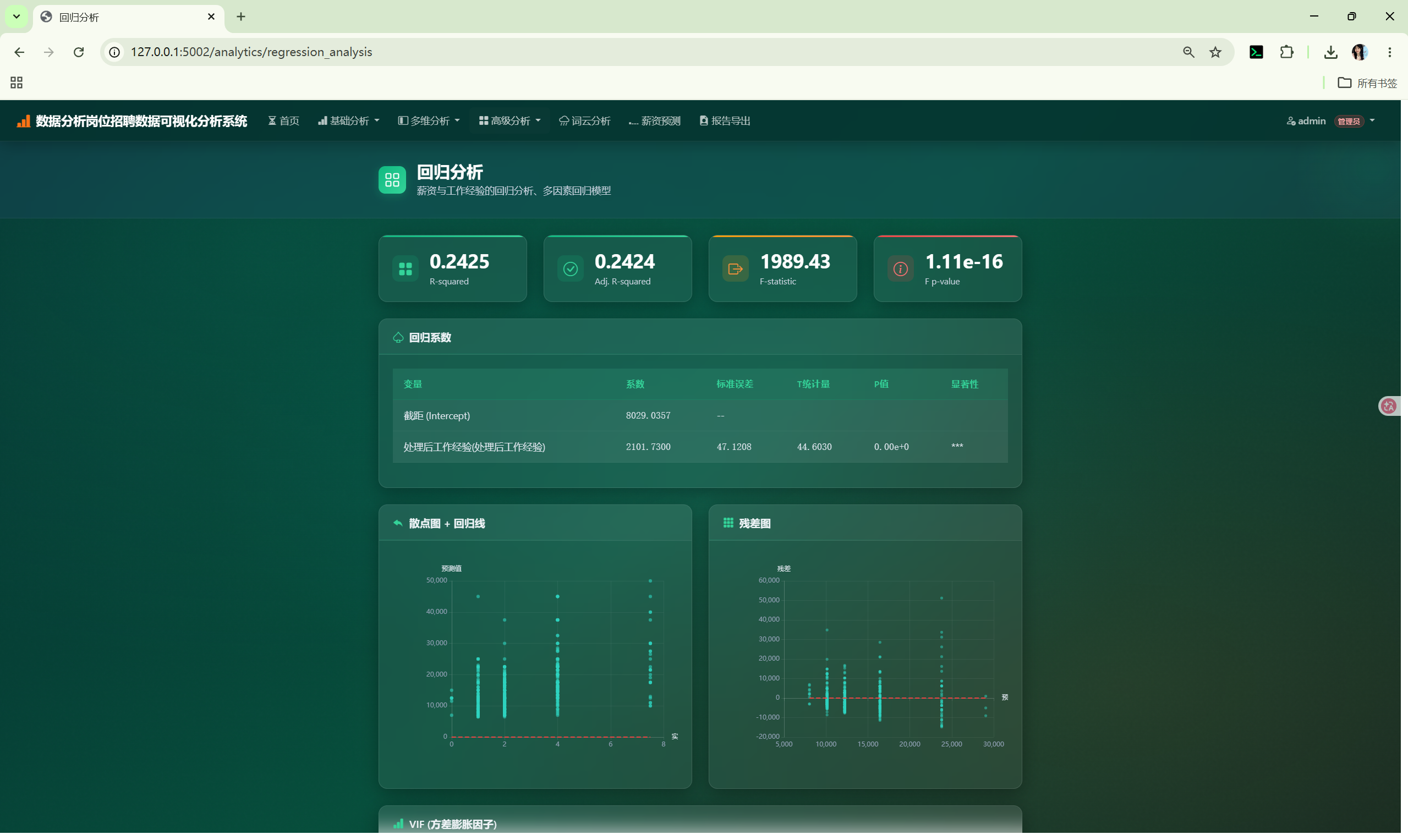
- route: regression_analysis
title: 回归分析
type: regression # 特殊类型,使用 RegressionCore
target: 薪资均值
predictors: [处理后工作经验]5. 数据库设计
5.1 连接配置
python
DB_CONFIG = {
'host': 'localhost',
'port': 3306,
'user': 'root',
'password': '123456',
'database': 'design_149_job_analysis',
'charset': 'utf8mb4',
'cursorclass': pymysql.cursors.DictCursor # 返回字典格式
}5.2 数据表
users --- 用户表
| 字段 | 类型 | 说明 |
|---|---|---|
| id | INT PK AUTO_INCREMENT | 用户 ID |
| username | VARCHAR(50) UNIQUE | 用户名 |
| VARCHAR(100) UNIQUE | 邮箱 | |
| password_hash | VARCHAR(255) | bcrypt 哈希密码 |
| role | VARCHAR(20) | 角色:user / admin |
| status | VARCHAR(20) | 状态:active / disabled |
| full_name | VARCHAR(50) | 姓名 |
| phone | VARCHAR(20) | 手机 |
| gender | VARCHAR(10) | 性别 |
| age | INT | 年龄 |
| bio | TEXT | 个人简介 |
| last_login_at | DATETIME | 最后登录时间 |
| created_at | TIMESTAMP | 注册时间 |
默认管理员:admin / admin123
dataset_data --- 招聘数据表
列由 config.yaml 的 features 动态生成:
sql
CREATE TABLE dataset_data (
id INT PRIMARY KEY AUTO_INCREMENT,
`职位名称` VARCHAR(200),
`薪资范围` VARCHAR(200),
`薪资均值` DOUBLE,
`工作经验` VARCHAR(100),
`学历要求` VARCHAR(100),
`公司类型` VARCHAR(100),
... -- 所有 features 中的列
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);列名使用中文原名(feat["key"].lower() 对中文无效),用反引号包裹。
predictions --- 预测历史表
| 字段 | 类型 | 说明 |
|---|---|---|
| id | INT PK | 记录 ID |
| user_id | INT FK → users | 用户 ID |
| 动态特征列 | 各类型 | 根据 config 动态生成 |
| prediction_result | DOUBLE | 预测结果 |
| risk_level | VARCHAR(50) | 风险等级 |
| algorithm | VARCHAR(50) | 使用的算法 |
| created_at | TIMESTAMP | 预测时间 |
5.3 数据导入
系统启动时自动检测 dataset_data 表是否为空,若为空则从 data/data_analyst_jobs.xlsx 导入数据:
- Pandas 读取 Excel 文件
- 根据
config.yaml的 features 匹配列名(大小写不敏感) - 逐行 INSERT 到
dataset_data表
6. 核心模块详解 (shared/)
6.1 AnalysisCore --- 数据分析
文件 : shared/analysis_core.py (246 行)
负责基础数据统计和分布分析,是大多数分析页面的数据源。
| 方法 | 返回值示例 | 用途 |
|---|---|---|
overview() |
{total_samples, feature_count, numeric_stats, missing_values} |
数据概览页 |
category_distribution(columns) |
{col: {labels: [], values: []}} |
学历/经验/公司类型分布 |
numeric_distribution(col, bins) |
{labels, counts, mean, median} |
薪资分布直方图 |
correlation_matrix(columns) |
{columns: [], matrix: [[]]} |
相关性热力图 |
aggregate(group_by, agg_col, func) |
{labels: [], values: []} |
分组聚合 |
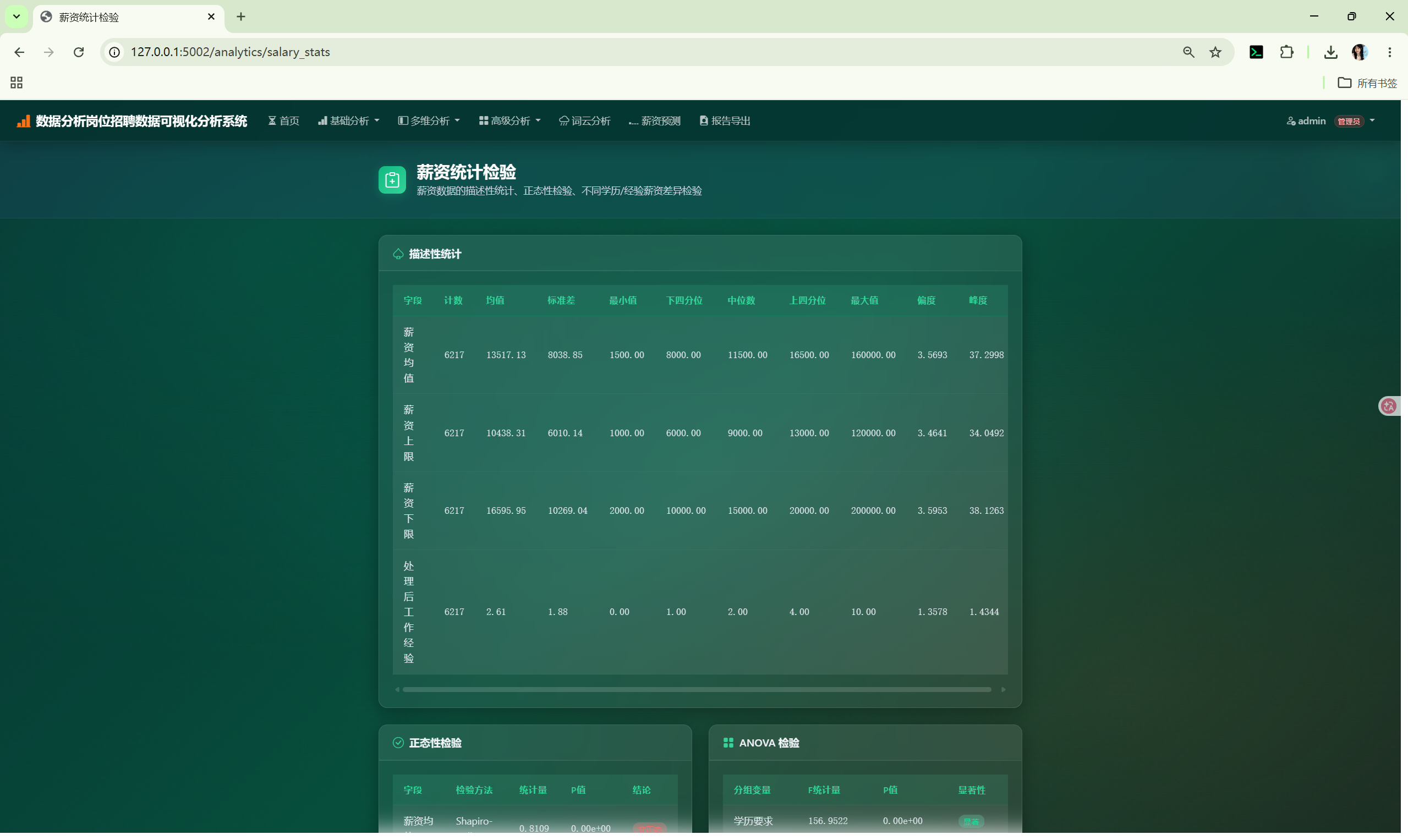
6.2 StatsCore --- 统计检验
文件 : shared/stats_core.py (249 行)
提供描述性统计和假设检验功能。
| 方法 | 算法 | 返回值 |
|---|---|---|
descriptive_stats(columns) |
均值/中位数/标准差/四分位 | {col: {count, mean, std, min, q1, median, q3, max}} |
normality_test(column) |
Shapiro-Wilk | {statistic, p_value, is_normal} |
ttest(column, group_column) |
独立样本 t 检验 | {statistic, p_value, significant, group_stats} |
anova(column, group_column) |
单因素 ANOVA | {f_statistic, p_value, significant, groups} |
chi_square(col1, col2) |
卡方检验 | {chi2, p_value, significant, dof, contingency_table} |
6.3 RegressionCore --- 回归分析
文件 : shared/regression_core.py (247 行)
| 方法 | 说明 |
|---|---|
linear_regression(x_col, y_col) |
简单线性回归,返回斜率/截距/R²/p 值/散点数据/拟合线 |
multiple_regression(target, predictors) |
多元线性回归,返回各系数/R²/调整 R²/F 统计量 |
diagnostics(target, predictors) |
VIF 多重共线性检验 + 残差分析 |
6.4 ClusteringCore --- 聚类分析
文件 : shared/clustering_core.py (245 行)
| 方法 | 算法 | 说明 |
|---|---|---|
find_optimal_k(columns, max_k) |
肘部法 + 轮廓系数 | 推荐最优 K 值 |
kmeans(columns, k) |
K-Means | 返回聚类标签/中心/画像/散点数据/轮廓系数 |
dbscan(columns, eps, min_samples) |
DBSCAN | 返回簇数/噪声点数/画像 |
数据流程:提取数值列 → 去缺失值 → StandardScaler 标准化 → 聚类 → 逆标准化中心
6.5 AnomalyCore --- 异常检测
文件 : shared/anomaly_core.py (228 行)
| 方法 | 算法 | 说明 |
|---|---|---|
iqr_detection(columns, multiplier) |
IQR 四分位距法 | 基于 Q1-1.5×IQR / Q3+1.5×IQR |
zscore_detection(columns, threshold) |
Z-Score 法 | 标准差阈值(默认 3.0) |
isolation_forest(columns, contamination) |
孤立森林 | 无监督异常检测 |
6.6 AssociationCore --- 关联规则
文件 : shared/association_core.py (195 行)
| 方法 | 说明 |
|---|---|
prepare_transactions(columns) |
将分类列转换为事务格式 |
mine_rules(columns, min_support, min_confidence) |
Apriori 挖掘频繁项集和关联规则 |
top_rules(columns, top_n, sort_by) |
按 lift/confidence/support 排序的 Top-N 规则 |
6.7 PredictorCore --- 机器学习预测
文件 : shared/predictor_core.py (175 行)
| 方法 | 说明 |
|---|---|
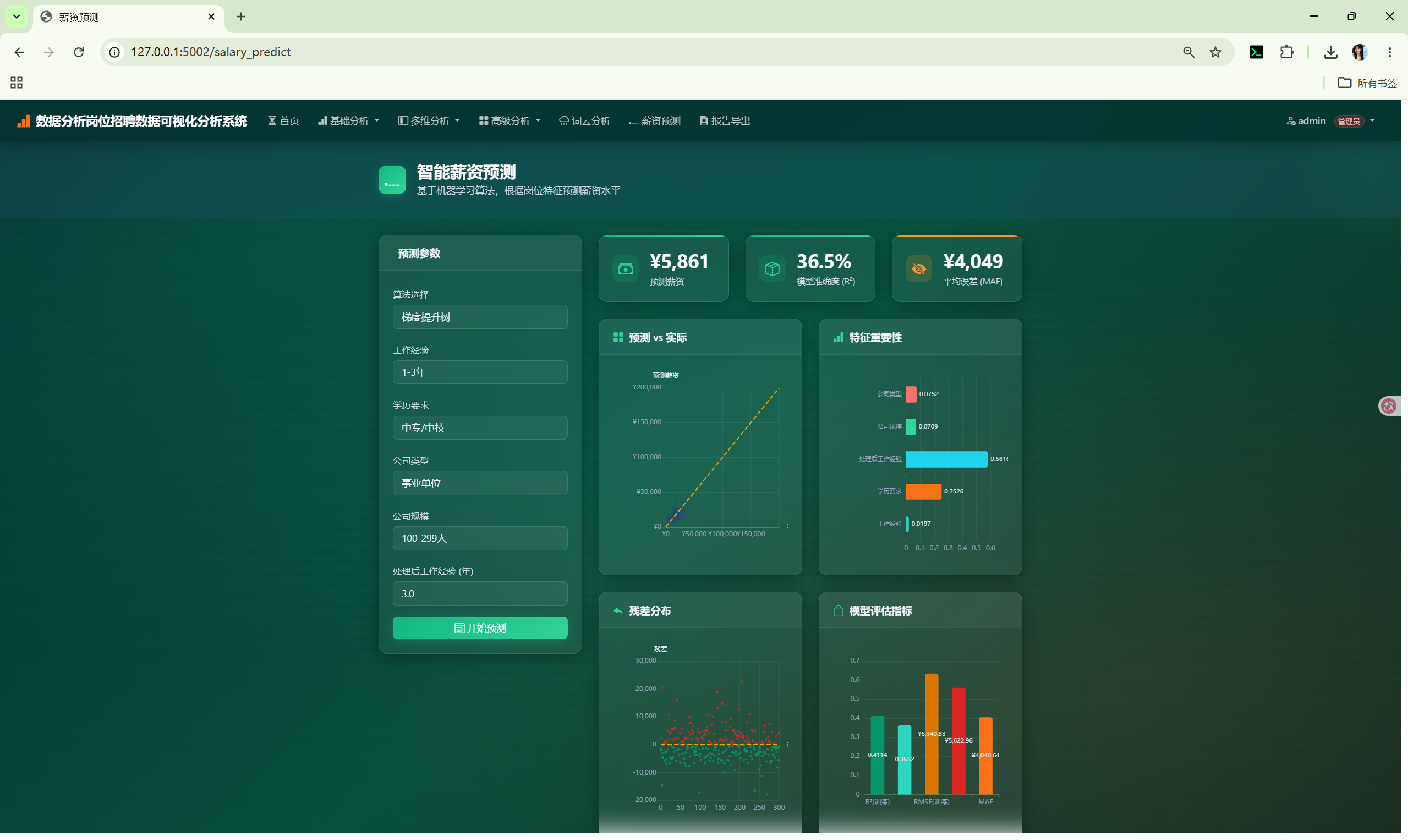
train_and_predict(target, features, algorithm) |
训练模型并返回评估指标(R²/RMSE/MAE)、特征重要性、散点数据、残差 |
compare_algorithms(target, features, algorithms) |
多算法对比,返回各算法的评估指标 |
predict_single(algorithm, input_data) |
单次预测,返回预测薪资 |
支持的算法:
| 算法 | 标识 | 类型 |
|---|---|---|
| 随机森林 | random_forest |
集成学习 |
| 梯度提升树 | gradient_boosting |
集成学习 |
| XGBoost | xgboost |
集成学习 |
| 线性回归 | linear_regression |
线性模型 |
| 岭回归 | ridge |
线性模型 + L2 正则 |
| K 近邻 | knn |
实例学习 |
6.8 ReportCore --- 报告生成
文件 : shared/report_core.py (304 行)
| 方法 | 说明 |
|---|---|
prepare_report_data(sections) |
汇总概览、描述性统计、相关性、分布数据 |
generate_excel(output_dir, title) |
生成多 Sheet 的 Excel 报告 |
generate_pdf(output_dir, title) |
生成 PDF 报告(reportlab) |
list_reports(output_dir) |
列出已生成的报告文件 |
7. 路由设计 (app.py)
7.1 路由总览
系统共 35 个路由,按功能分为 6 组:
| 分组 | 路由数 | 说明 |
|---|---|---|
| 认证 | 5 | 登录、注册、登出、个人资料、修改密码 |
| 基础分析 | 6 | 概览、薪资、学历、经验、公司、地理 |
| 高级分析 | 5 | 统计检验、回归、聚类、相关性、异常检测 |
| 专项功能 | 4 | 地图、词云、薪资预测、关联规则 |
| 报告 | 3 | 列表、生成、下载 |
| 管理 | 12 | 数据 CRUD、用户管理、管理后台 |
7.2 权限控制
python
def require_login():
"""未登录返回 None,路由中检查后 redirect"""
user = get_current_user()
if not user:
return None
return user
def require_admin():
"""非管理员返回 None"""
user = get_current_user()
if not user or user.get("role") != "admin":
return None
return user| 权限级别 | 可访问路由 |
|---|---|
| 未登录 | /, /login, /register |
| 普通用户 | 所有分析页面、预测、报告 |
| 管理员 | 全部 + /admin/*、/data_manage/* |
7.3 动态分析页面路由
/analytics/<page_route> 是一个通配路由,根据 config.yaml 的 analysis_pages 配置动态分发:
python
@app.route("/analytics/<page_route>")
def analytics_page(page_route):
# 1. 在 analysis_pages 中查找匹配的配置
# 2. 根据 type 字段选择核心模块:
# - "statistical" → StatsCore
# - "regression" → RegressionCore
# - "anomaly" → AnomalyCore
# - 默认 → AnalysisCore
# 3. 调用对应模块获取数据
# 4. 渲染对应的模板7.4 关键路由实现
首页 /
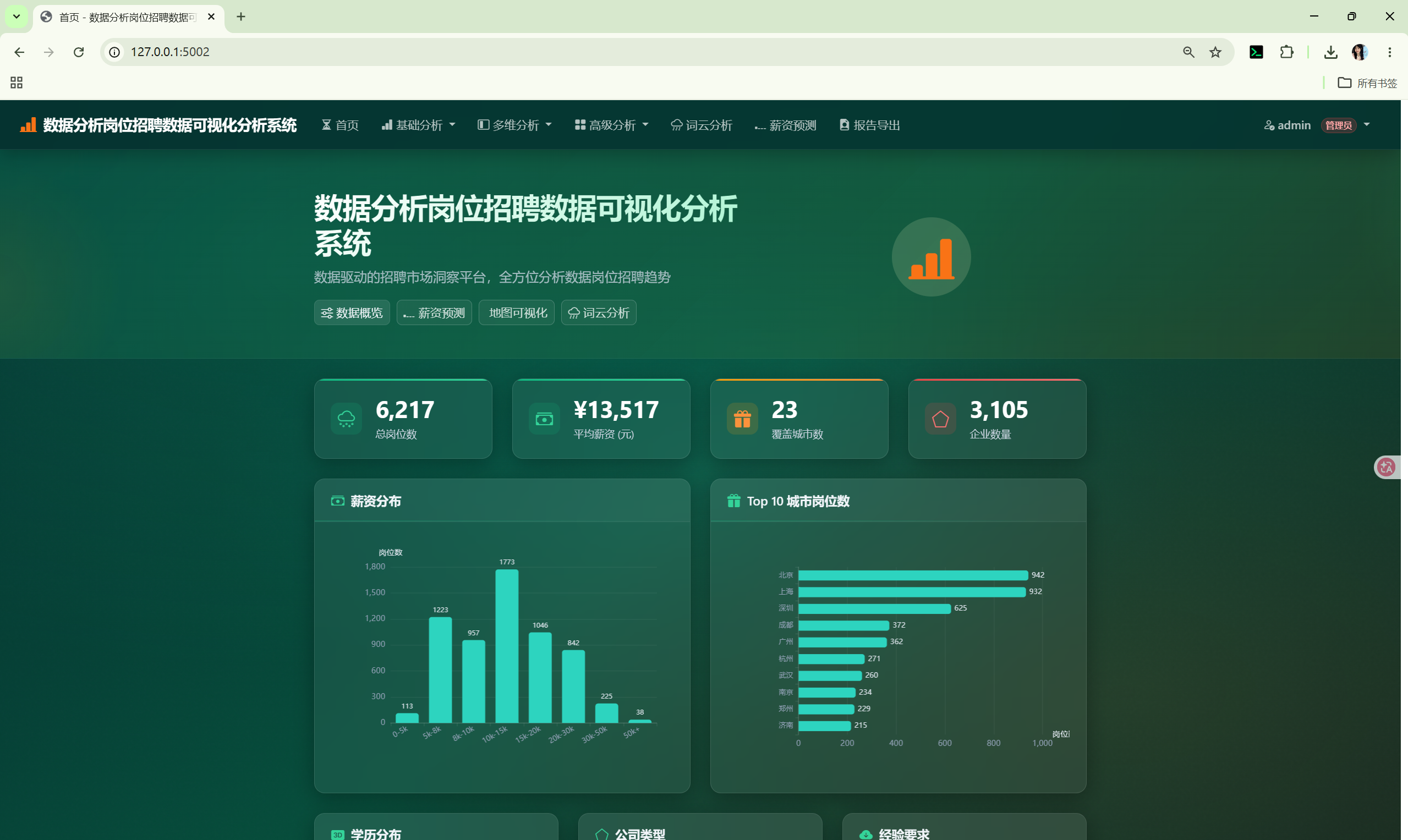
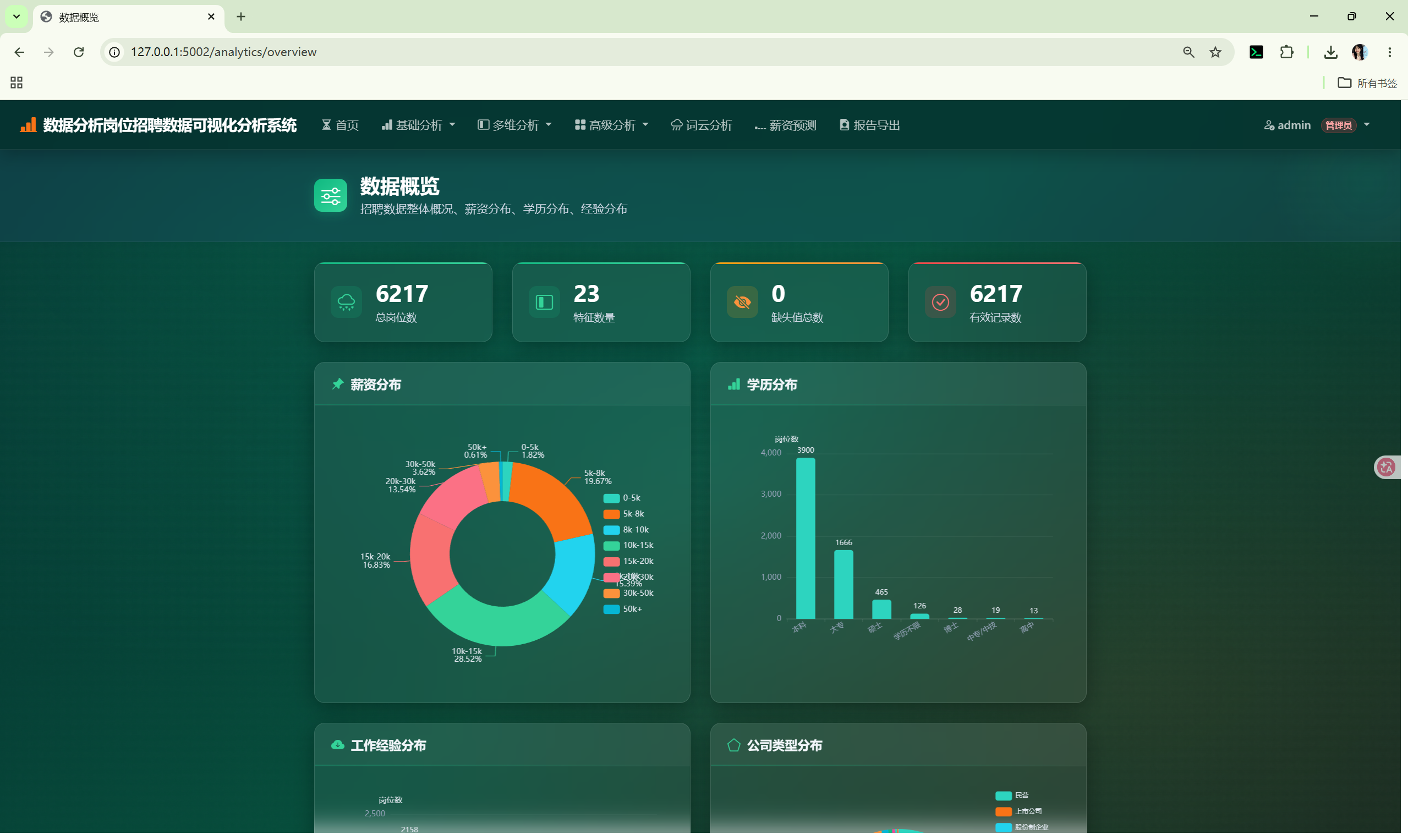
GET / → AnalysisCore.overview() + category_distribution() + aggregate()
→ 渲染 index.html
→ 前端 AJAX 加载 /api/overview 获取 KPI 数据薪资预测 /salary_predict
GET → 渲染空表单
POST → PredictorCore.train_and_predict() 或 predict_single()
→ 返回预测结果 + 散点图 + 特征重要性 + 残差图聚类分析 /clustering
GET → 渲染参数配置表单
POST → ClusteringCore.kmeans() 或 dbscan()
→ 字段映射:silhouette_score → silhouette, total_samples → labels
→ profile → cluster_stats
→ 渲染结果 + 肘部图 + 轮廓图 + 散点图8. 前端设计
8.1 设计系统
系统采用 Glassmorphism(毛玻璃) 设计风格:
css
/* 核心 CSS 变量 */
--primary: #10b981; /* 翡翠绿 */
--primary-dark: #059669;
--primary-light: #34d399;
--accent: #f97316; /* 橙色强调 */
--bg-gradient: linear-gradient(135deg, #042f2e 0%, #064e3b 50%, #0f2922 100%);
--text-primary: #f1f5f0; /* 主文字:近白 */
--text-secondary: #cbd5e1; /* 次文字:亮灰 */
--text-muted: #94a3b8; /* 辅助文字:中灰 */
/* 卡片毛玻璃效果 */
.card {
background: rgba(255, 255, 255, 0.05);
backdrop-filter: blur(10px);
border: 1px solid rgba(255, 255, 255, 0.08);
}8.2 ECharts 主题
全局注册 glass 主题,所有图表使用 echarts.init(dom, 'glass') 初始化:
javascript
echarts.registerTheme('glass', {
color: ['#2dd4bf','#f97316','#22d3ee','#34d399','#f87171',
'#fb7185','#fb923c','#06b6d4','#10b981','#ec4899'],
textStyle: { color: '#e2e8f0', textBorderColor: 'transparent', textBorderWidth: 0 },
tooltip: { backgroundColor: 'rgba(4,47,46,0.95)' },
categoryAxis: { axisLabel: { color: '#94a3b8' }, splitLine: { lineStyle: { color: 'rgba(255,255,255,0.06)' } } },
valueAxis: { axisLabel: { color: '#94a3b8' }, splitLine: { lineStyle: { color: 'rgba(255,255,255,0.06)' } } },
legend: { textStyle: { color: '#e2e8f0' } },
});重要注意 :ECharts 的 registerTheme 不会合并嵌套对象。如果图表配置中指定了 legend: {textStyle: {fontSize: 10}},主题中的 legend.textStyle.color 会被完全覆盖。因此每个图表的 legend.textStyle 和 label 都需要显式设置 color: '#e2e8f0'。
8.3 图表配色方案
javascript
var chartColors = [
'#2dd4bf', // 青绿
'#f97316', // 橙色
'#22d3ee', // 天蓝
'#34d399', // 翠绿
'#f87171', // 珊瑚红
'#fb7185', // 玫红
'#fb923c', // 浅橙
'#06b6d4', // 深青
'#10b981', // 翡翠绿
'#ec4899' // 粉红
];8.4 页面结构
每个页面遵循统一结构:
html
{% extends "base.html" %}
{% block title %}页面标题{% endblock %}
{% block content %}
<!-- 页头 -->
<div class="page-header">
<div class="header-icon"><i class="bi bi-xxx"></i></div>
<div class="header-title">页面标题</div>
</div>
<!-- 内容区 -->
<div class="container py-4">
<!-- 统计卡片 -->
<div class="row g-4 mb-4">
<div class="col-lg-3 col-md-6">
<div class="stat-card stat-card-primary">...</div>
</div>
</div>
<!-- 图表 -->
<div class="card chart-card">
<div class="card-body"><div id="chartId" style="height:400px;"></div></div>
</div>
</div>
{% endblock %}
{% block extra_js %}
<script>
var data = {{ data | tojson }};
var chart = echarts.init(document.getElementById('chartId'), 'glass');
chart.setOption({ /* ECharts 配置 */ });
</script>
{% endblock %}9. 数据分析页面说明
9.1 基础分析
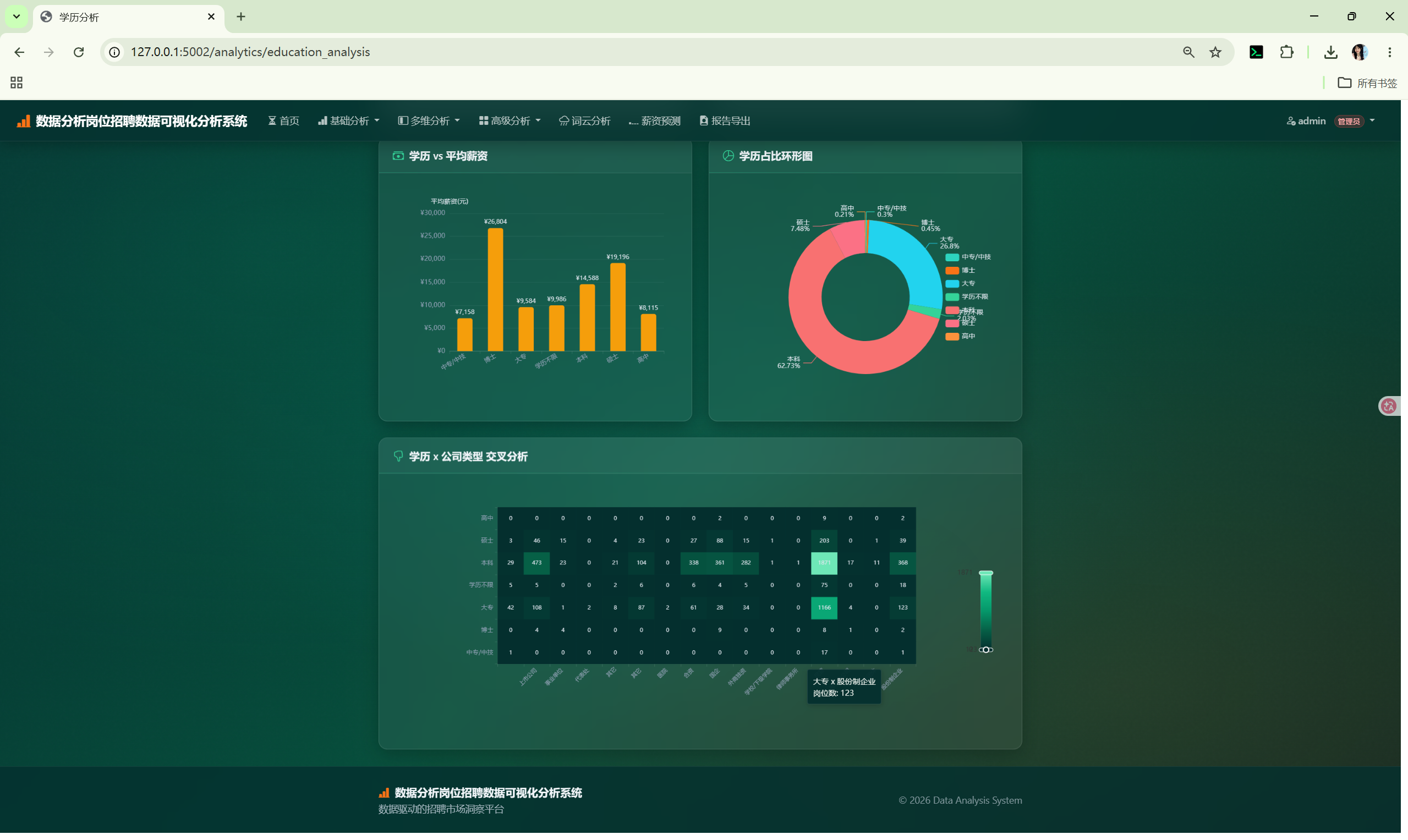
| 页面 | 路由 | 图表类型 | 数据来源 |
|---|---|---|---|
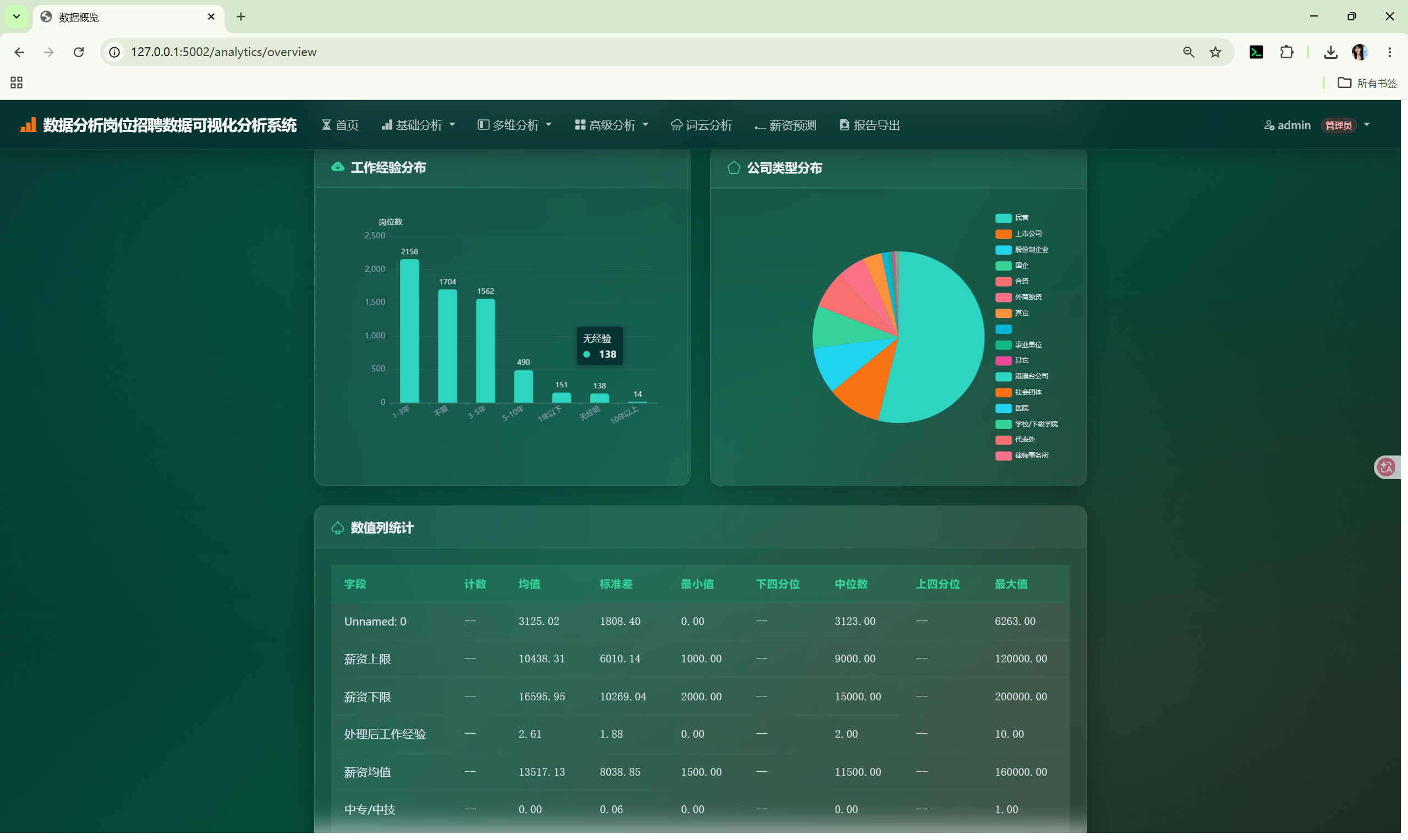
| 数据概览 | /analytics/overview |
柱状图、环形图、表格 | overview() + category_distribution() |
| 薪资分析 | /analytics/salary_analysis |
柱状图、散点图、箱线图 | numeric_distribution() + aggregate() |
| 学历分析 | /analytics/education_analysis |
环形图、柱状图 | category_distribution() + aggregate() |
| 经验分析 | /analytics/experience_analysis |
柱状图、折线图 | category_distribution() + aggregate() |
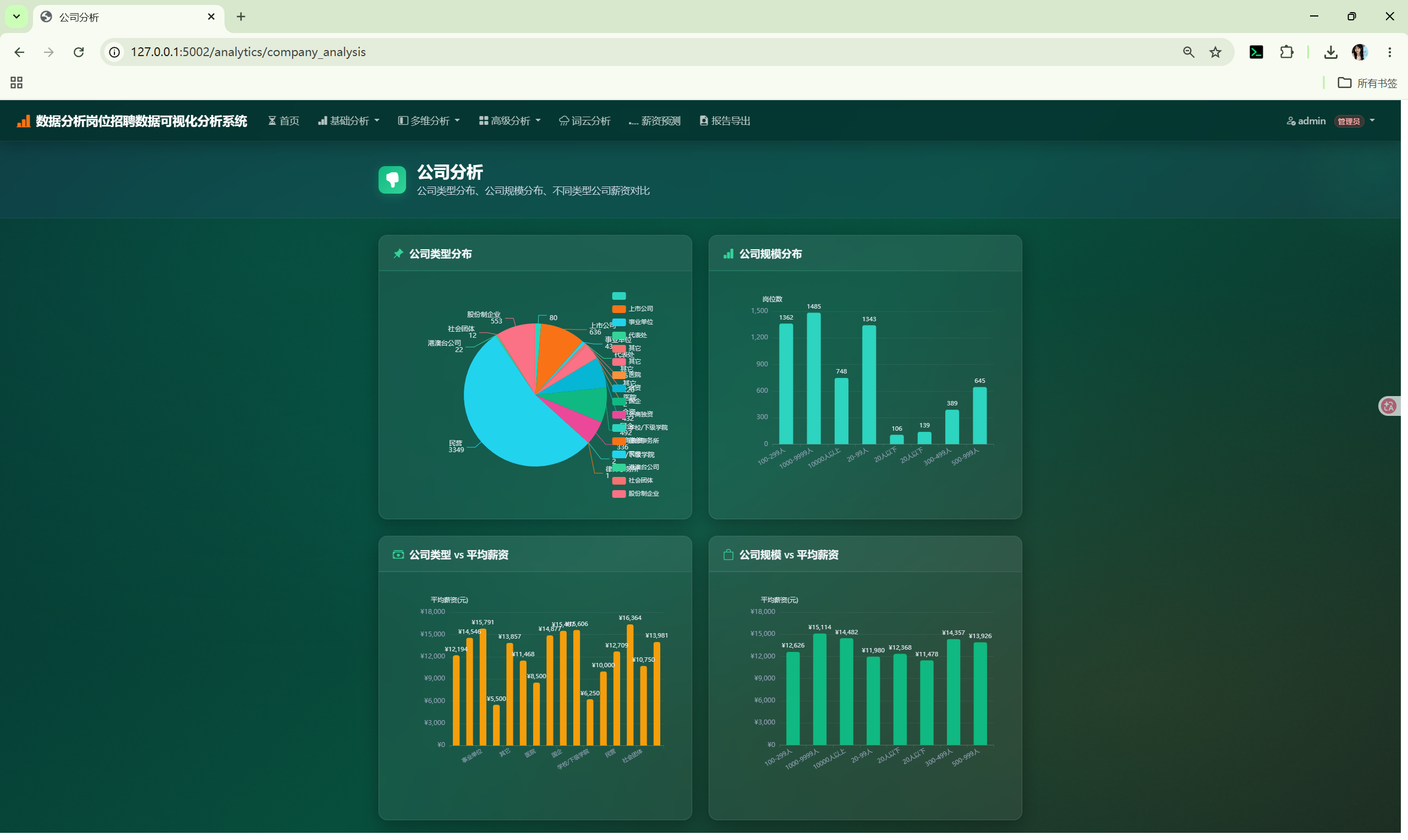
| 公司分析 | /analytics/company_analysis |
饼图、柱状图 | category_distribution() + aggregate() |
| 地理分布 | /analytics/geo_distribution |
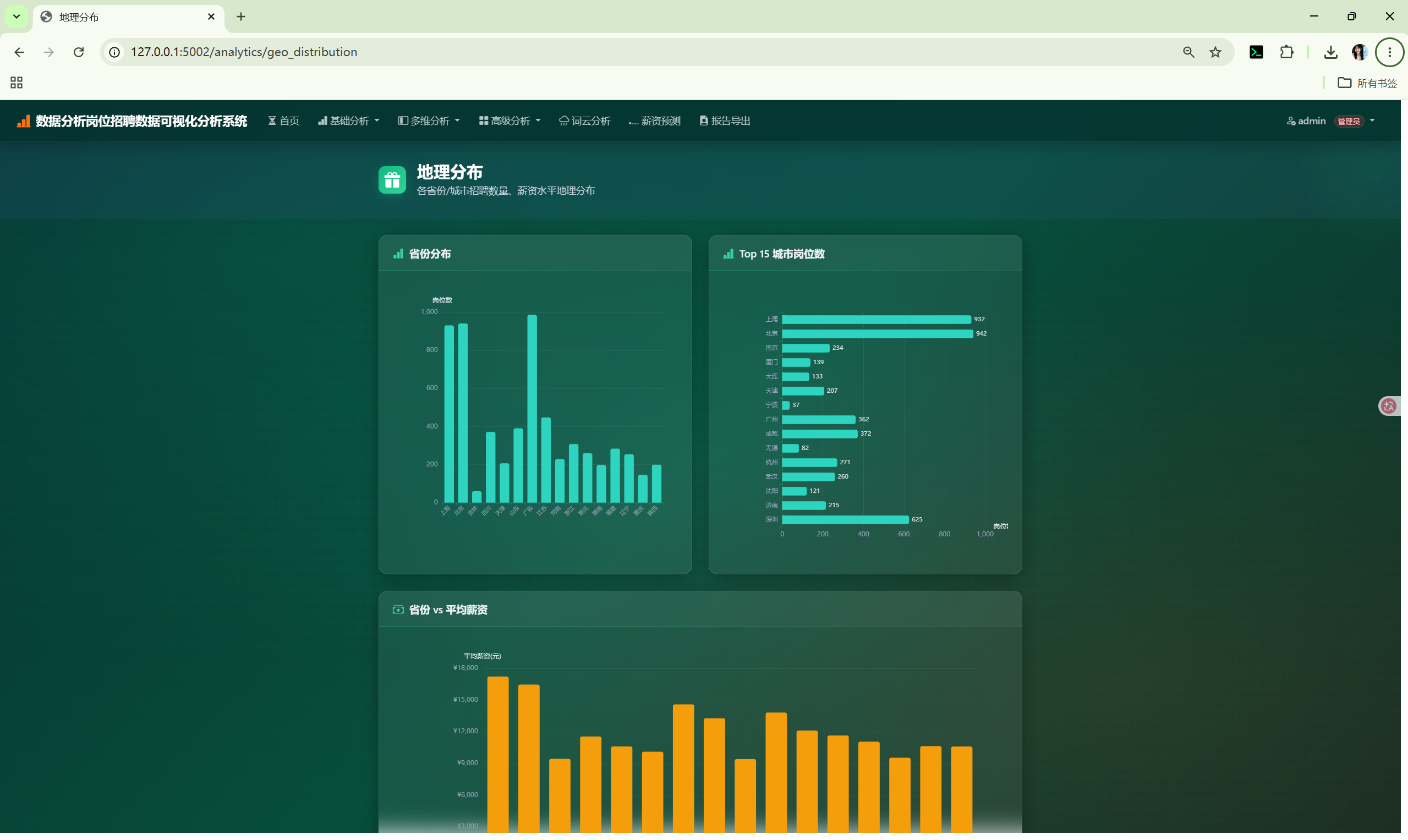
柱状图 | aggregate(group_by=城市) |
9.2 高级分析
| 页面 | 路由 | 核心模块 | 分析内容 |
|---|---|---|---|
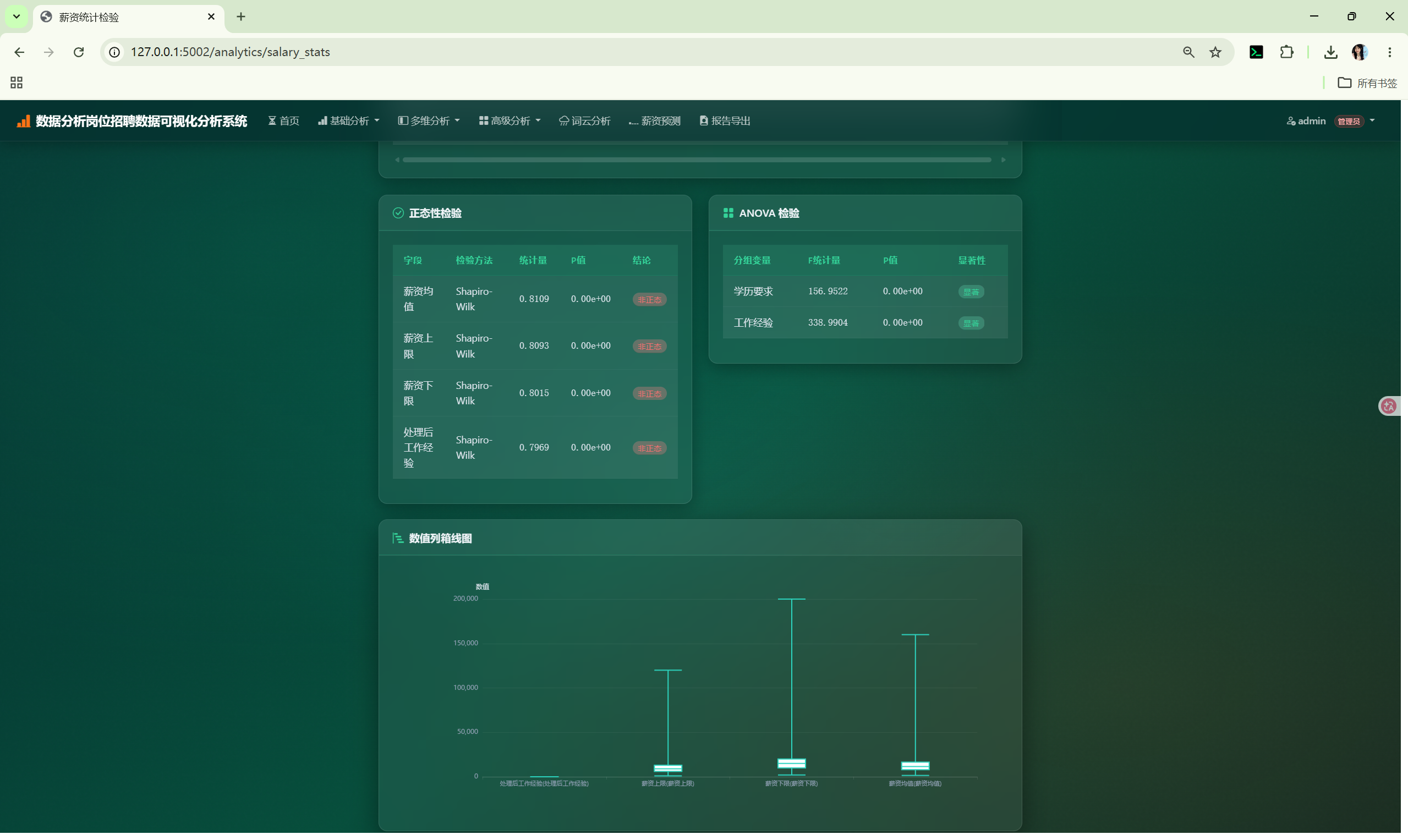
| 统计检验 | /analytics/salary_stats |
StatsCore | 描述性统计、正态性检验、ANOVA |
| 回归分析 | /analytics/regression_analysis |
RegressionCore | 线性回归、多元回归、VIF 诊断 |
| 相关性分析 | /analytics/correlations |
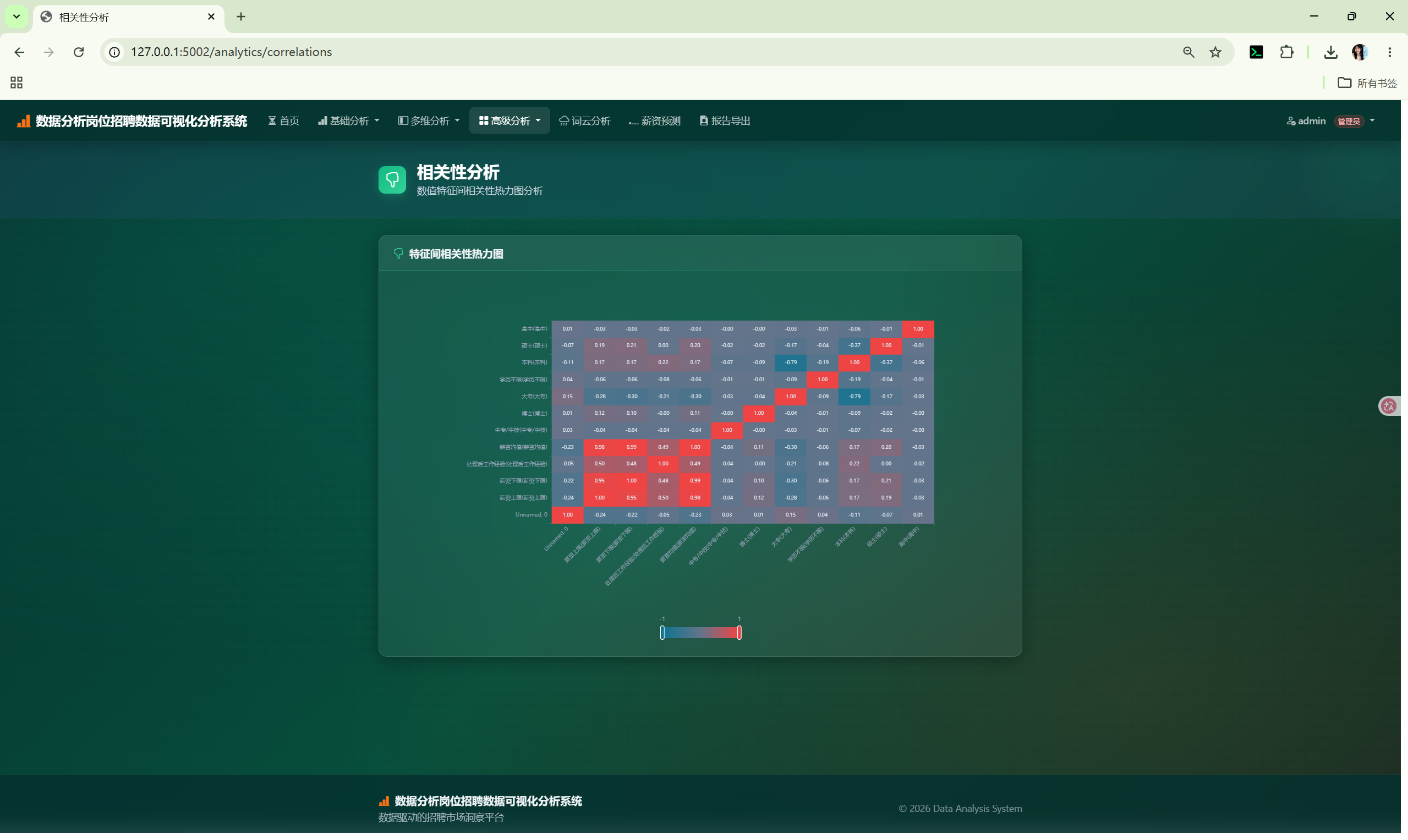
AnalysisCore | Pearson 相关系数热力图 |
| 异常检测 | /analytics/anomaly_detection |
AnomalyCore | IQR / Z-Score / 孤立森林 |
| 聚类分析 | /clustering |
ClusteringCore | K-Means / DBSCAN |
| 关联规则 | /association |
AssociationCore | Apriori 频繁项集 |
9.3 专项功能
| 页面 | 路由 | 说明 |
|---|---|---|
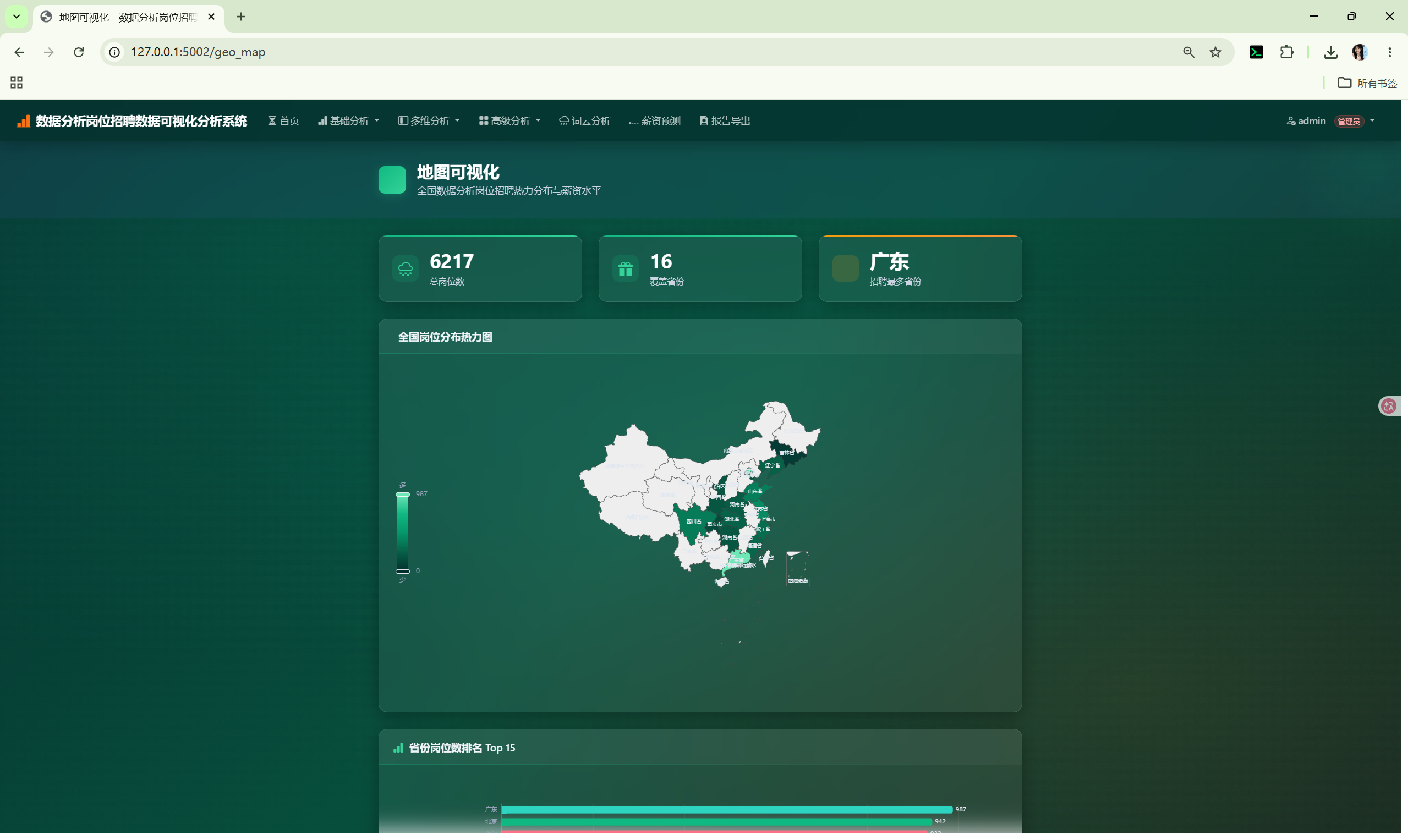
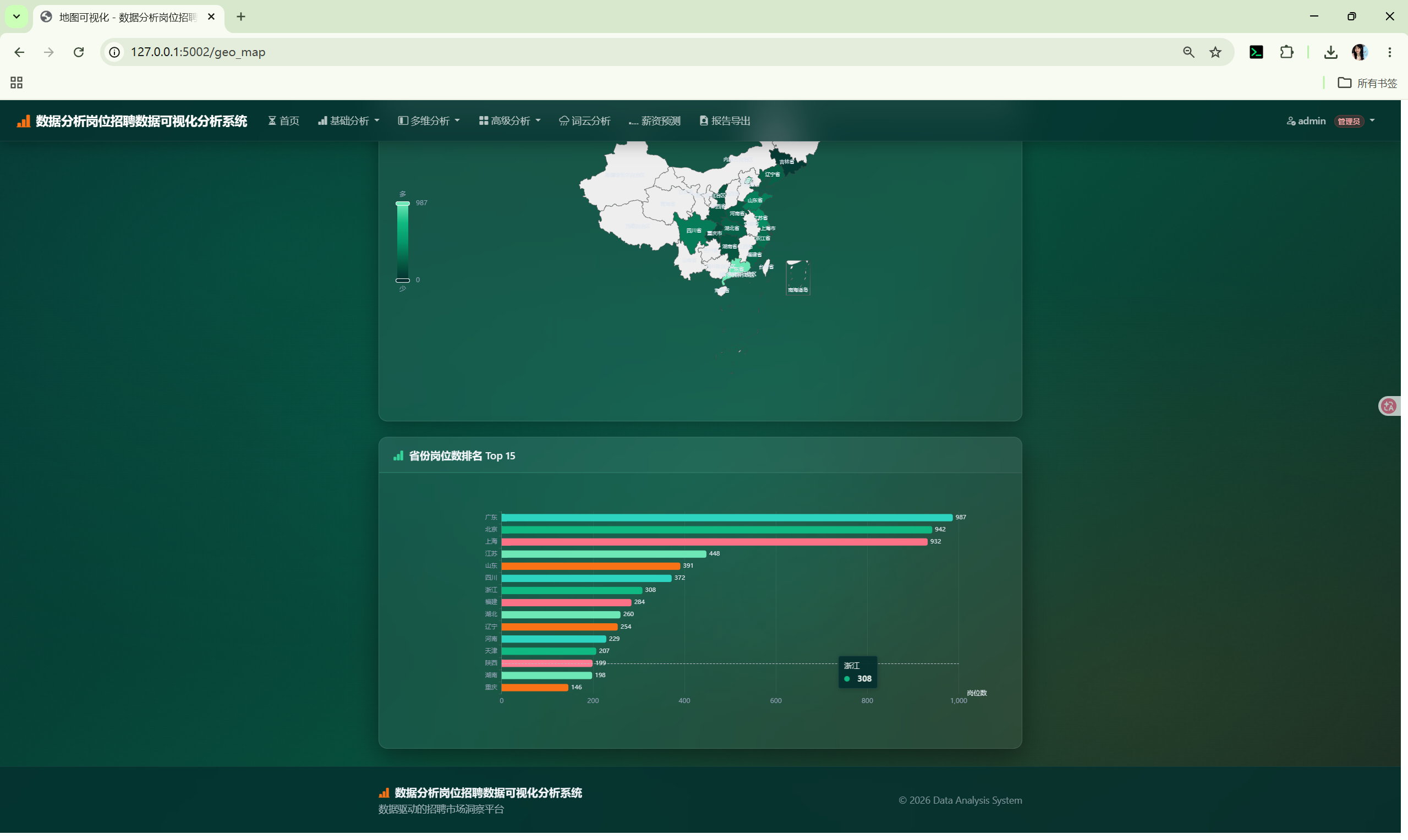
| 地图可视化 | /geo_map |
省级招聘数量和平均薪资的中国地图 |
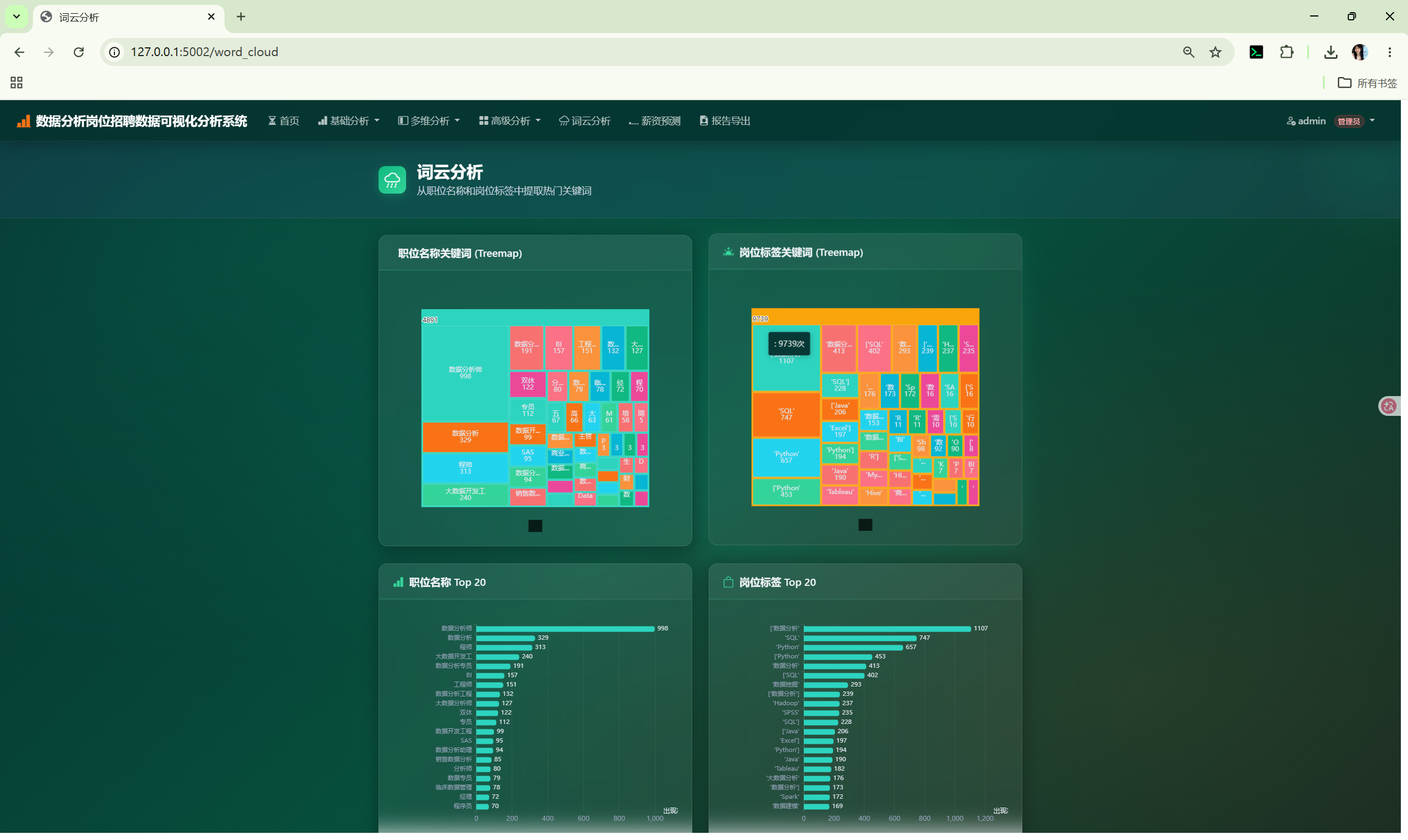
| 词云分析 | /word_cloud |
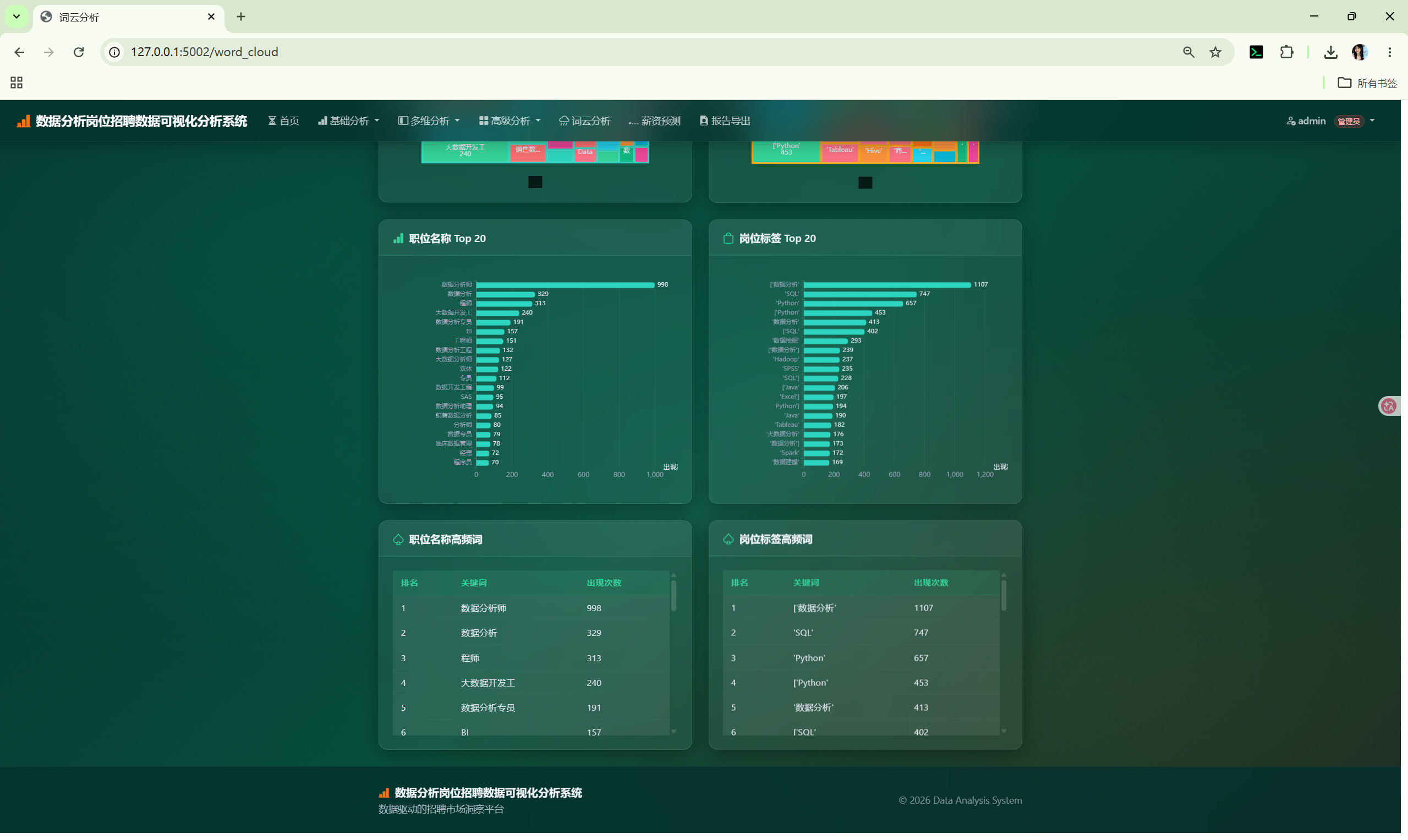
从职位名称和岗位标签提取关键词 |
| 薪资预测 | /salary_predict |
选择算法和特征,预测薪资水平 |
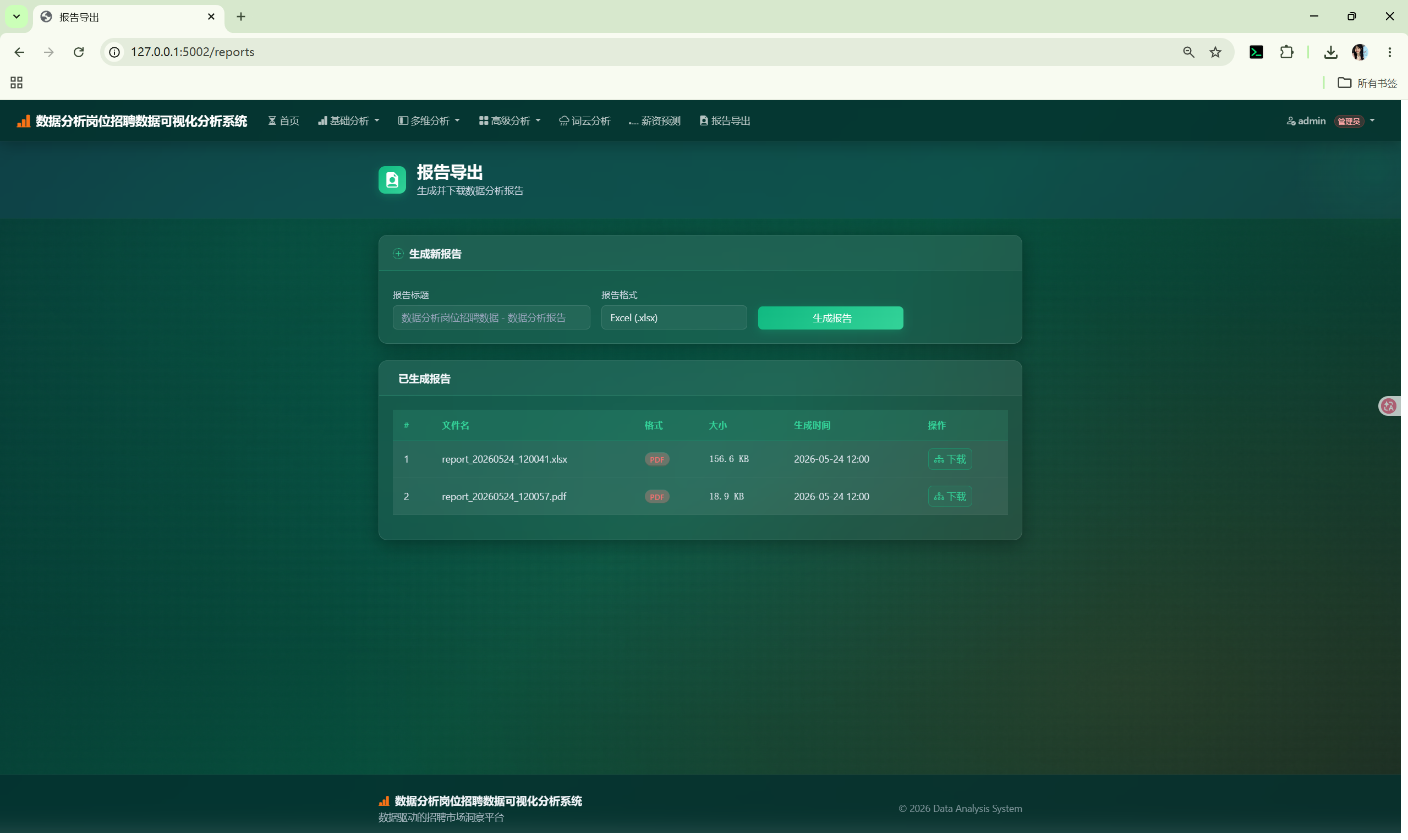
| 报告导出 | /reports |
生成 Excel / PDF 报告 |
10. 用户与权限系统
10.1 角色
| 角色 | 权限 |
|---|---|
user |
浏览分析页面、使用薪资预测、生成报告 |
admin |
全部用户权限 + 数据管理 + 用户管理 + 管理后台 |
10.2 认证流程
用户提交用户名/密码
↓
db.authenticate_user()
↓
bcrypt 验证密码哈希
↓
写入 Flask session: session["user_id"] = user["id"]
↓
后续请求通过 get_current_user() 从 session 读取用户信息10.3 密码安全
- 使用
bcrypt算法哈希存储 - 默认管理员密码:
admin123 - 管理员可重置任意用户密码为
123456
11. API 接口
11.1 JSON API
| 端点 | 方法 | 说明 | 返回 |
|---|---|---|---|
/api/overview |
GET | 数据集概览 | {total_records, avg_salary, city_count, company_count, salary_dist, top_cities, ...} |
11.2 报告下载
| 端点 | 方法 | 说明 |
|---|---|---|
/reports/download/<filename> |
GET | 下载已生成的 Excel/PDF 报告 |
12. 数据集说明
12.1 数据来源
- 文件 :
data/data_analyst_jobs.xlsx(884 KB) - 记录数: 约 3000+ 条招聘记录
- 字段数: 22 个特征列
12.2 字段说明
| 字段名 | 类型 | 说明 | 示例 |
|---|---|---|---|
| 职位名称 | text | 招聘岗位名称 | 数据分析师、BI 分析师 |
| 薪资范围 | text | 原始薪资字符串 | 15-25K·13薪 |
| 地点 | text | 工作地点 | 北京朝阳区 |
| 工作经验 | categorical | 经验要求 | 1-3年、3-5年、不限 |
| 学历要求 | categorical | 学历门槛 | 本科、硕士、大专 |
| 岗位标签 | text | 技能标签 | Python,SQL,数据挖掘 |
| 公司名称 | text | 招聘企业 | 字节跳动、阿里巴巴 |
| 公司类型 | categorical | 企业性质 | 民营、上市公司、国企 |
| 公司规模 | categorical | 员工人数 | 100-299人、1000人以上 |
| 省份 | categorical | 所在省份 | 北京、上海、广东 |
| 城市 | categorical | 所在城市 | 北京、上海、深圳 |
| 薪资上限 | numeric | 最高月薪(元) | 25000 |
| 薪资下限 | numeric | 最低月薪(元) | 15000 |
| 薪资均值 | numeric | 平均月薪(元) | 20000 |
| 处理后工作经验 | numeric | 经验年限(年) | 3 |
| 本科/硕士/大专/... | binary | 学历标记 (0/1) | 1 |
13. 部署与运维
13.1 环境准备
bash
# 1. 安装 Python 依赖
pip install -r requirements.txt
# 2. 确保 MySQL 服务运行
# 3. 创建数据库(或由系统自动创建)
mysql -u root -p -e "CREATE DATABASE IF NOT EXISTS design_149_job_analysis CHARACTER SET utf8mb4;"
# 4. 启动
python run.py13.2 依赖列表
PyYAML>=6.0
pandas>=1.5.0
numpy>=1.21.0
pymysql>=1.0.0
Flask>=2.0.0
scipy>=1.9.0
scikit-learn>=1.1.0
mlxtend>=0.21.0
openpyxl>=3.0.0
reportlab>=3.6.013.3 配置修改
修改 config.yaml 后重启服务即可生效:
- 数据库连接 : 修改
project.db_*字段 - 端口 : 修改
project.port - 主题色 : 修改
project.theme_color - 启用/禁用模块 : 修改
modules.*布尔值 - 新增特征 : 在
dataset.features中添加定义
13.4 生产环境建议
- 使用 Gunicorn / uWSGI 替代 Flask 开发服务器
- 配置 Nginx 反向代理
- 设置
app.secret_key为强随机值 - 关闭
debug=True - 定期备份 MySQL 数据库
14. 扩展指南
14.1 新增分析页面
- 在
config.yaml的analysis_pages中添加配置:
yaml
- route: new_analysis
title: 新分析页面
description: 描述
columns: [薪资均值, 工作经验]-
创建模板
templates/new_analysis.html(继承base.html) -
如需特殊处理,在
app.py的analytics_page()中添加条件分支
14.2 新增 ML 算法
- 在
shared/predictor_core.py的train_and_predict()中添加算法分支:
python
elif algorithm == "new_algo":
from sklearn.xxx import NewModel
model = NewModel(param1=value1)-
在
config.yaml的algorithms中添加标识 -
在
templates/salary_predict.html的算法选择框中添加选项
14.3 新增特征列
- 在
config.yaml的dataset.features中添加定义 - 重新导入数据(清空
dataset_data表后重启) - 相关分析页面会自动识别新列
15. 已知问题与注意事项
-
ECharts 主题不合并嵌套对象 :图表中任何
legend.textStyle或label配置会覆盖主题的同名属性,需显式设置color: '#e2e8f0' -
Bootstrap Icons 版本限制 :项目打包的
bootstrap-icons.css不包含所有图标。已知缺失:bi-building、bi-arrow-down-up、bi-pin-map-fill。可用替代:bi-people-fill、bi-exclamation-triangle、bi-geo-alt -
数据库列名 :中文列名使用原样存储(
.lower()对中文无效),SQL 中需用反引号包裹 -
遗留代码 :
database.py中包含医疗系统遗留的consultations、health_contents表及方法,当前业务未使用 -
缺失模块 :
shared/crawler_core.py和shared/comparative_core.py在代码中被引用但不存在,相关功能不可用