文章目录
什么是分包黏包
为什么会发生分包黏包
TCP是面向流, 没有边界 ,
一次请求发送的数据量较小,且发送处于同一个TCP等待时间段内, 就会导致黏包.
一次请求过大, 超出了缓存区大小, 就会发生分包, 分几次发送
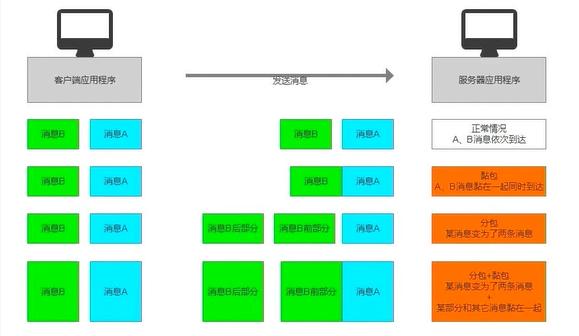
分包和黏包
- 正常的理想情况 , 分别发送两个包;
- 黏包:合并成一个包发送;
- 分包:拆分成两个或多个包发送;
- 分包和粘包:消息B进行了分包处理,分包一部分与消息A进行黏包处理。
如何处理分包黏包
这里提供一个简单思路
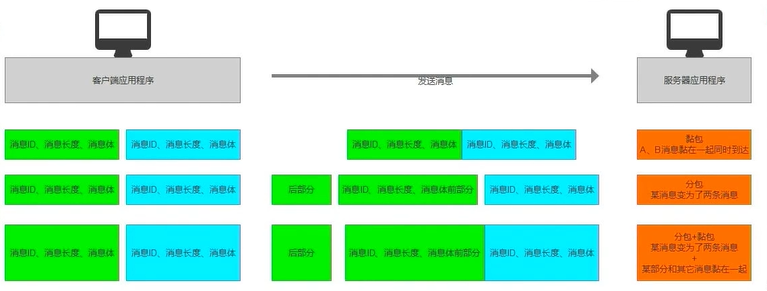
给所有消息加上一个ID头和信息长度头 . 这里起作用的是信息长度头
信息就会变成intint字节数组 , 长度为 4+4+字节数组长度.
- 收到消息后, 直接拼接到,处理分包时缓存的字节数组最后边.
- 如果此时分包缓存长度 >= 8 则有完整的头信息, 解析ID ,解析长度
- 如果 剩下的字节长度>=信息体长度 解析信息体
- 如果已经到了信息末尾, 则重置缓存的字节数组, 结束解读
- 如果没有到信息末尾, 继续循环判断, 直到读取所有信息
下面我举个例子, 例如
信息A : 你好世界 ID 为 1001 长度为 12
信息B : 世界你好 ID 为 1001 长度为 12
此时发生了 B分包A黏B包前半部分的情况 ;
1.第一段传来消息为 28个字节
2.第二段传来消息为 12个字节
1.拼接第一个28字节到字节数组后, cacheNum(字节数组长度) = 28 ,nowindex(当前索引位置) = 0
-
28字节有足够的头文件长度, 则解析头文件, 并且nowindex(当前索引位置) = 8
-
28字节减去当前索引位置 > 12字节消息体长度, 解读消息体, nowindex(当前索引位置) = 20 , 不等于 28
-
再次循环 , nowIndex(当前索引位置) = 20; cacheNum(字节数组长度) = 28
-
判断依旧有足够的头文件 , 解析头文件,nowindex(当前索引位置) = 28
-
28字节减去当前索引位置 = 0 <12
-
剩下的信息, 加上头信息, 重新粘贴到分包缓存的第0 位置
-
等待下次接收消息, 直接拼接到当前数组, 继续循环.
下面是具体的代码, 和相应注释
其中PlayerMsg 是一个自定义,继承了序列化的类, 1001 代表了这个类 , 我会贴上相关代码 , 序列化类的知识在我另一篇文章可以看到
csharp
//分包黏包处理的相关代码
byte[] cacheBytes = new byte[1024 * 1024];//处理分包时缓存的字节数组
int cacheNum = 0;// 字节数组长度
private void ReceiveMsg(object obj) {
byte[] receiveBytes = new byte[1024*1024];
int receiveNum = socket.Receive(receiveBytes);
HandleReceiveMsg(receiveBytes,receiveNum);
}
/// <summary>
/// 处理接受消息分包黏包问题的方法
/// </summary>
/// <param name="receiveBytes">接收到的字节数组</param>
/// <param name="receiveNum">字节数组长度</param>
private void HandleReceiveMsg(byte[] receiveBytes, int receiveNum) {
int msgID = 0; //信息ID头
int msgLength = 0; //信息长度头
int nowIndex = 0; //当前index
//收到消息后, 应该看看之前有没有缓存的 如果有的话直接拼接到后边
receiveBytes.CopyTo(cacheBytes , cacheNum);
cacheNum += receiveNum;
while (true) {
//每次将长度设为-1 避免上一次解析的数据, 影响这一次的判断
msgLength = -1;
//处理一条消息 , 如果字节数组包含完整的信息头
if (cacheNum - nowIndex >= 8) {
//解析ID
msgID = BitConverter.ToInt32(cacheBytes,nowIndex);
nowIndex += 4;
//解析长度
msgLength = BitConverter.ToInt32(cacheBytes,nowIndex);
nowIndex += 4;
}
//如果字节数组长度 - 当前index位置 剩下的信息 大于等于 信息体长度
if (cacheNum - nowIndex >= msgLength && msgLength != -1)
{
//解析消息体
BaseMsg baseMsg = null;
switch (msgID)
{
case 1001:
PlayerMsg msg = new PlayerMsg();
msg.Reading(cacheBytes, nowIndex);
baseMsg = msg;
break;
}
if (baseMsg != null) receiveQueue.Enqueue(baseMsg); //将接受到的放到接受消息队列
nowIndex += msgLength; //当前index位置 向后移动信息长度
if (nowIndex == cacheNum)
{ //如果当前index位置已经到了信息末尾 , 则重置字节数组长度,结束循环
cacheNum = 0;
break;
}
}
else { //如果剩下的信息, 比信息体长度短, 则证明分包
if (msgLength != -1) nowIndex -= 8; //如果进行了 id和长度的解析 但是 没有成功解析消息体 那么我们需要减去nowIndex移动的位置
//拷贝 到分包缓存 ,从当前位置 到分包缓存 的第0位置 要复制多少
Array.Copy(cacheBytes , nowIndex ,cacheBytes ,0 , cacheNum - nowIndex);
cacheNum -= nowIndex; //更改分包字节数组长度
break;
}
}
}PlayerMsg 相关代码 (相应知识可以看另一篇文章 :序列化基类)
csharp
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class PlayerMsg : BaseMsg
{
public int playerID;
public PlayerData playerData;
public override byte[] Writing()
{
int index = 0;
byte[] bytes = new byte[GetBytesNum()];
WriteInt(bytes,GetID(), ref index);
WriteInt(bytes, GetBytesNum() - 8, ref index);//设置消息体长度去掉识别头和长度头
WriteInt(bytes, playerID, ref index);
WriteData(bytes,playerData,ref index);
return bytes;
}
public override int Reading(byte[] bytes, int beginIndex = 0)
{
//反序列化不需要解析ID 因为收到消息的那一方收到就已经解析出来 , 才能判断用哪一个类的反序列化
int index = beginIndex;
playerID = ReadInt(bytes, ref index);
playerData = ReadData<PlayerData>(bytes, ref index);
return index - beginIndex;
}
public override int GetBytesNum()
{
//识别ID长度+ 信息长度 + ID长度 + 数据长度
return 4 + 4 + 4 + playerData.GetBytesNum();
}
public override int GetID()
{
return 1001;
}
}BaseMsg相关代码 (相应知识可以看另一篇文章 :序列化基类)
csharp
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class BaseMsg : BaseData
{
public override int GetBytesNum()
{
throw new System.NotImplementedException();
}
public override int Reading(byte[] bytes, int beginIndex = 0)
{
throw new System.NotImplementedException();
}
public override byte[] Writing()
{
throw new System.NotImplementedException();
}
public virtual int GetID() { return 0; }
}结语
分包黏包逻辑不复杂, 这里提供了一个简单的思路, 可以在工作学习中, 进一步优化方法