
🏆 本文收录于 《滚雪球学 Spring Boot 3.x》 专栏,专注 Spring Boot 3.x 系统学习与实战进阶,内容持续更新中。
本专栏致力于打造高质量、体系化的 Spring Boot 3.x 学习路线,从零基础入门到进阶实战,帮助你快速掌握核心知识与企业级开发经验。 📌 想快速定位学习内容,可查看:【Spring Boot 3 教程导航帖】
🎉 当前专栏限时优惠中:一次订阅,终身阅读,后续更新章节全部免费解锁 👉 立即订阅 👈️ 🎁 想系统打通 Spring Boot 各主流版本?还可以查看: 👉 《Spring Boot 2.x 实战》 👉 《Spring Boot 3.x 实战》 👉 《Spring Boot 4.x 实战》
🚀 推荐合集:《Spring Boot 全栈实战合集》,一站式覆盖 Spring Boot 2.x、3.x、4.x 核心特性、项目实战与架构进阶内容。
演示环境说明:
- 开发工具:IDEA 2021.3
- JDK版本: JDK 17(推荐使用 JDK 17 或更高版本,因为 Spring Boot 3.x 系列要求 Java 17,Spring Boot 3.5.4 基于 Spring Framework 6.x 和 Jakarta EE 9,它们都要求至少 JDK 17。)
- Spring Boot版本:3.5.4(于25年7月24日发布)
- Maven版本:3.8.2 (或更高)
- Gradle:(如果使用 Gradle 构建工具的话):推荐使用 Gradle 7.5 或更高版本,确保与 JDK 17 兼容。
- 操作系统:Windows 11
1. 为什么数据库访问性能会成为系统瓶颈?
在大多数业务系统中,数据库访问几乎一定会出现在性能链路的中心位置。很多初学者在写 Spring Boot 应用时,往往把注意力集中在 Controller 是否能正常返回、Service 是否能完成业务逻辑,却忽视了最容易被放大的问题:数据库访问次数过多、单次 SQL 过慢、索引不合理、连接池配置不当、ORM 自动生成了低效 SQL。
数据库性能问题有一个典型特征:它不一定在功能上线当天就暴露出来,而是在数据量增长、并发升高、业务链路变长之后,逐步演化为"偶发卡顿""接口超时""线程堆积""数据库 CPU 飙高"等症状。此时,系统表面看起来像是"Java 代码慢",实际上往往是数据库访问策略出了问题。
在 Spring Boot 3.x 中,数据库访问方式非常灵活。你可以使用 JDBC、JdbcTemplate、Spring Data JPA、MyBatis,甚至是 R2DBC。不同方案有不同的抽象层级,但本质都绕不开同一个问题:如何让数据访问更高效、更稳定、更可观测。
如果把数据库访问优化比作一条链路,那么链路上至少有四个关键节点:
- 数据结构设计:索引、字段类型、范式与反范式
- SQL 设计:查询条件、排序、分页、聚合、更新方式
- 连接与并发:连接池、事务、锁、线程调度
- 应用层组织:ORM 生成 SQL、缓存、批处理、异步化
任何一个节点失衡,都可能拖垮整体性能。
2. Spring Boot 3.x 视角下的数据库访问栈
Spring Boot 3.x 带来的变化,不只是版本号升级,更重要的是基础生态的现代化:JDK 17 起步、Jakarta 命名空间迁移、对现代 observability 的更好支持,以及与 Hibernate 6、Spring Data 3 的适配。
从数据库访问的角度看,一个典型的 Spring Boot 3.x 应用通常会经过如下链路:
示意图绘制如下,仅供参考:
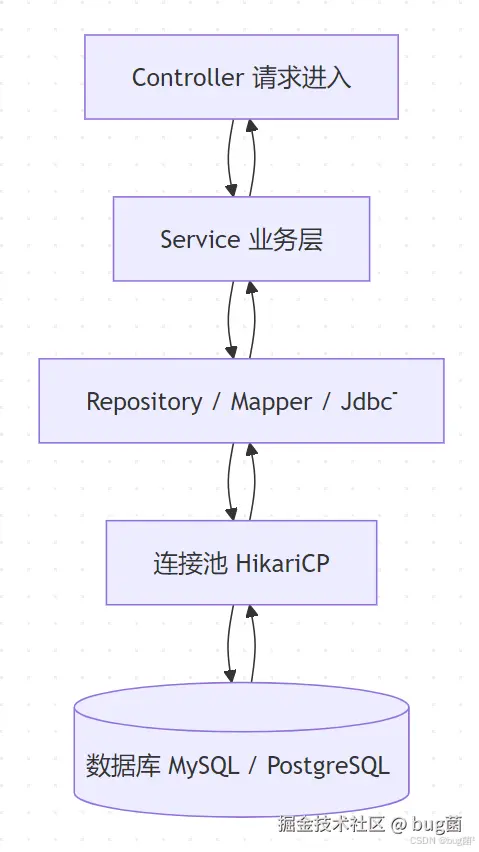
这里面最容易出问题的地方有三个:
- Repository 层隐藏了 SQL 复杂度,开发者容易忽略真实执行语句。
- 连接池把"连接创建成本"隐藏起来,开发者容易误以为连接是免费的。
- ORM 将对象世界映射到关系世界时,可能产生额外查询、N+1、隐式 join、分页偏差等问题。
在 Spring Boot 3.x 中,推荐你建立一种思维:不要只看"代码写得简洁不简洁",更要看"最终执行的 SQL 是否合理"。
3. 性能优化的总原则:先定位,再改造,再验证
数据库访问优化不是"经验主义艺术",而是一个可重复的工程过程。最佳实践通常遵循下面这条主线:
示意图绘制如下,仅供参考:

这条链路强调两个关键事实:
- 你不能凭感觉改 SQL,必须看执行计划、扫描行数、实际耗时。
- 你不能只优化数据库,还要回到 Java 代码,确认是不是 ORM 或调用方式导致的低效访问。
很多优化失败,都是因为直接跳到了"加索引"这一步。事实上,索引只是优化手段之一,不是万能钥匙。
4. 索引优化:从"能查到"到"查得快"
4.1 索引是什么
索引本质上是一种加速查找的数据结构。对于关系型数据库来说,常见的是 B+ 树索引。你可以把索引理解为一本书的目录:没有目录,想找某一页内容只能从头翻;有目录,就能快速定位。
但索引不是免费午餐。索引会占用存储空间,也会降低写入性能,因为每次插入、更新、删除,数据库都要维护索引结构。
因此,索引优化的第一原则不是"多建几个",而是"建对、用对、少而精"。
4.2 适合建立索引的字段
通常来说,以下字段很适合建索引:
- 经常出现在 WHERE 条件中的字段
- 经常出现在 JOIN 条件中的字段
- 经常出现在 ORDER BY 中的字段
- 经常出现在 GROUP BY 中且基数较高的字段
- 业务上需要唯一性的字段,例如手机号、订单号、用户名
4.3 不适合滥用索引的场景
以下场景通常不建议盲目加索引:
- 字段区分度太低,例如性别、状态位
- 查询数据量本身很小
- 写入非常频繁而查询较少
- 条件上大量使用函数、模糊前缀、隐式类型转换
例如下面这条 SQL 看起来没问题,但其实可能无法有效使用索引:
sql
SELECT *
FROM user_account
WHERE DATE(create_time) = '2026-04-15';原因是对字段做了函数运算,数据库很可能无法直接利用 create_time 上的索引。
更好的写法是:
sql
SELECT *
FROM user_account
WHERE create_time >= '2026-04-15 00:00:00'
AND create_time < '2026-04-16 00:00:00';4.4 联合索引的使用顺序
联合索引不是多个单列索引的简单叠加。它遵循最左前缀原则。比如有这样一个索引:
sql
CREATE INDEX idx_order_user_status_time ON t_order(user_id, status, create_time);那么下面这些查询通常更容易利用索引:
sql
SELECT * FROM t_order WHERE user_id = ?;
SELECT * FROM t_order WHERE user_id = ? AND status = ?;
SELECT * FROM t_order WHERE user_id = ? AND status = ? AND create_time >= ?;但如果你只写:
sql
SELECT * FROM t_order WHERE status = ?;就可能无法充分利用这个联合索引。
4.5 覆盖索引与回表
如果查询所需字段都包含在索引里,数据库可能只扫描索引,不必再回表读取整行数据,这就是覆盖索引。覆盖索引在高并发读场景下非常重要。
例如:
sql
SELECT user_id, status, create_time
FROM t_order
WHERE user_id = ?
AND status = ?;如果联合索引恰好包含这些列,那么数据库可能直接通过索引返回结果,减少一次回表访问。
4.6 索引优化的 Java 侧案例
下面这个 Repository 代码看似简单,但背后决定了是否能吃到索引红利。
java
package com.example.demo.repository;
import com.example.demo.entity.OrderEntity;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import java.time.LocalDateTime;
import java.util.List;
public interface OrderRepository extends JpaRepository<OrderEntity, Long> {
// 通过用户ID、状态和时间范围查询订单
// 该查询更容易命中 (user_id, status, create_time) 联合索引
@Query("select o from OrderEntity o where o.userId = :userId and o.status = :status and o.createTime between :startTime and :endTime")
List<OrderEntity> findByUserIdAndStatusAndCreateTimeBetween(
@Param("userId") Long userId,
@Param("status") Integer status,
@Param("startTime") LocalDateTime startTime,
@Param("endTime") LocalDateTime endTime);
}这段代码表面上是 JPA 查询,实际上是否高效,取决于底层表结构和索引设计。你必须在表层做配合,而不是指望 ORM 自动解决一切。
4.7 索引设计的实战建议
你可以按以下顺序思考:
-
先看查询模式,再看表结构。
-
按高频过滤条件设计联合索引。
-
把区分度高的字段尽量放在索引前部。
-
避免在索引列上进行函数、计算、隐式转换。
-
关注是否能形成覆盖索引。
-
用 EXPLAIN 验证,不要凭感觉。
5. 批量操作:从单条写入到吞吐提升
5.1 单条写入为什么慢
很多新手会写出这样的代码:
java
for (OrderEntity order : orders) {
orderRepository.save(order);
}这段代码的问题在于:每次 save 都可能触发一次数据库交互。如果数据量稍大,就会出现明显的性能瓶颈。
单条写入的成本主要包括:
- Java 方法调用成本
- ORM 状态管理成本
- SQL 发送成本
- 网络往返成本
- 数据库解析与执行成本
- 事务提交成本
当这些成本乘以成百上千条数据时,整体耗时会非常可观。
5.2 批量写入的核心价值
批量写入的价值不只是"少发几条 SQL",更重要的是减少网络往返、减少事务提交次数、降低数据库解析压力。
批量操作通常有两类:
- 批量插入
- 批量更新
5.3 JPA 批量插入示例
JPA 并不是天然高性能批量工具。若使用不当,saveAll 也未必真的批量。
下面给出一个适合批量插入的 Service 示例:
java
package com.example.demo.service;
import com.example.demo.entity.OrderEntity;
import com.example.demo.repository.OrderRepository;
import jakarta.persistence.EntityManager;
import jakarta.persistence.PersistenceContext;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
@Service
public class OrderBatchService {
private final OrderRepository orderRepository;
@PersistenceContext
private EntityManager entityManager;
public OrderBatchService(OrderRepository orderRepository) {
this.orderRepository = orderRepository;
}
@Transactional
public void batchInsert(List<OrderEntity> orders) {
// 分批处理,避免一次性持有过多持久化上下文对象
int batchSize = 50;
for (int i = 0; i < orders.size(); i++) {
orderRepository.save(orders.get(i));
// 每批提交前刷新并清空,释放一部分内存压力
if (i > 0 && i % batchSize == 0) {
entityManager.flush();
entityManager.clear();
}
}
// 处理剩余数据
entityManager.flush();
entityManager.clear();
}
}5.4 为什么要 flush 和 clear
JPA 在持久化时会把实体放入一级缓存,也就是持久化上下文。如果你一次性插入大量数据,不及时 flush 和 clear,就会导致内存占用不断上升,同时脏检查成本也会增加。
因此,批量处理常见的写法是:
- 每 50 条 flush 一次
- 每 50 条 clear 一次
这个数字不是绝对值,需要结合业务和数据库压力测试调整。
5.5 原生 JDBC 批处理示例
在强吞吐场景下,JDBC 批处理往往比 JPA 更直接、更可控。
java
package com.example.demo.service;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
@Service
public class OrderJdbcBatchService {
private final JdbcTemplate jdbcTemplate;
public OrderJdbcBatchService(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Transactional
public void batchInsert(List<OrderInput> inputs) {
String sql = "INSERT INTO t_order(user_id, order_no, status, create_time) VALUES (?, ?, ?, ?)";
// 使用 JDBC 的 batchUpdate 进行批量插入
jdbcTemplate.batchUpdate(sql, inputs, 100, (ps, item) -> {
ps.setLong(1, item.getUserId());
ps.setString(2, item.getOrderNo());
ps.setInt(3, item.getStatus());
ps.setTimestamp(4, java.sql.Timestamp.valueOf(item.getCreateTime()));
});
}
}这类写法的优点是明确、可控,缺点是业务代码和 SQL 耦合更高。
5.6 批量更新的注意点
批量更新比批量插入更容易出问题,因为更新通常伴随着条件、锁、版本号控制和业务状态流转。
建议注意以下几点:
-
避免逐条 update
-
尽量合并同类条件
-
注意事务范围不要过大
-
在高并发下考虑乐观锁
-
必要时拆批,防止长事务
6. 连接池:HikariCP 的核心参数与调优思路
6.1 为什么需要连接池
数据库连接不是轻量对象。每次创建连接都要经过认证、握手、初始化等流程,开销很高。连接池的作用就是复用连接,减少频繁创建和销毁的成本。
Spring Boot 3.x 默认使用 HikariCP,这是一款性能和稳定性都很出色的连接池。
6.2 连接池优化的基本思维
连接池调优不是"把最大连接数调到很大"这么简单。连接池参数要和数据库最大连接数、CPU 核数、应用并发、SQL 耗时共同决定。
连接池太小:
- 请求拿不到连接
- 应用线程阻塞
- 接口响应时间变长
连接池太大:
- 数据库压力增大
- 争抢严重
- 上下文切换增多
- 可能出现"连接很多但吞吐没上去"
6.3 Spring Boot 3.x 中的 Hikari 配置
下面是一个典型配置示例:
yaml
spring:
datasource:
url: jdbc:mysql://localhost:3306/demo?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8&rewriteBatchedStatements=true
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
hikari:
maximum-pool-size: 20
minimum-idle: 5
connection-timeout: 30000
idle-timeout: 600000
max-lifetime: 1800000
leak-detection-threshold: 20006.4 参数解读
maximum-pool-size:最大连接数,决定峰值时最多多少连接并发访问数据库。minimum-idle:最小空闲连接数,保证预热和快速响应。connection-timeout:拿连接的超时时间,太短会导致正常高峰也失败,太长会掩盖问题。idle-timeout:空闲连接回收时间。max-lifetime:连接最大生命周期,避免连接长期存在导致数据库侧断开。leak-detection-threshold:连接泄漏检测阈值,排查忘记关闭连接非常有帮助。
6.5 如何判断连接池是否合理
你不能只看"连接池跑起来了",还要看是否出现以下信号:
- 等待连接时间偏高
- 活跃连接长期接近上限
- 数据库 CPU 高但 TPS 没上去
- 业务线程被卡在获取连接阶段
在生产环境里,连接池问题常常不是根因,而是结果。真正根因往往是 SQL 太慢、事务太长、索引不合理。
7. SQL 优化联动:索引、执行计划、分页、排序、回表
7.1 SQL 优化的基本原则
SQL 优化不是"改几个关键字"就能解决,它通常与索引策略深度绑定。最有效的原则有以下几个:
- 让条件尽量可索引化
- 减少全表扫描
- 减少返回列数
- 避免无意义排序
- 控制分页偏移
- 减少回表次数
7.2 SELECT * 的问题
SELECT * 在开发阶段很方便,但在生产系统中经常带来副作用:
- 传输冗余字段,浪费网络带宽
- 取回不必要的大字段,例如 JSON、TEXT、BLOB
- 破坏覆盖索引的可能性
- 增加对象映射成本
建议只查询需要的字段。
7.3 大分页问题
下面这个分页查询在数据量很大时会越来越慢:
sql
SELECT id, user_id, order_no, status, create_time
FROM t_order
ORDER BY create_time DESC
LIMIT 100000, 20;原因是数据库需要先跳过前 100000 条,再返回 20 条。偏移越大,成本越高。
更好的方案是基于游标或时间、ID 做"游标翻页":
sql
SELECT id, user_id, order_no, status, create_time
FROM t_order
WHERE create_time < ?
ORDER BY create_time DESC
LIMIT 20;7.4 排序问题
排序会消耗 CPU 和内存。如果排序字段上没有索引,数据库可能需要额外的 filesort。高频排序字段,特别是和过滤条件一起使用的字段,应该认真设计索引。
7.5 回表问题
当查询列不在索引中时,数据库需要先通过索引找到主键,再回到主表读取完整数据,这就是回表。回表并不总是坏事,但在高频场景下,如果回表次数太多,性能会明显下降。
7.6 使用 EXPLAIN 观察执行计划
以下信息通常很有价值:
- type:访问类型,是否走索引
- key:实际使用的索引
- rows:预估扫描行数
- Extra:是否 Using filesort、Using temporary、Using index
你不需要死记硬背所有字段,但至少要会判断:
-
有没有走到你想要的索引
-
扫描行数是不是过大
-
有没有排序临时表
-
有没有覆盖索引
8. ORM 生成 SQL 的风险点:JPA 为什么会"写出慢 SQL"
8.1 ORM 的价值与代价
ORM 的价值非常明显:
- 提高开发效率
- 降低样板代码
- 便于领域建模
- 统一事务和对象管理
但代价同样真实:
- SQL 透明度下降
- 性能问题更隐蔽
- 复杂查询表达困难
- 容易产生 N+1 问题
Spring Data JPA 尤其适合简单 CRUD 和中等复杂度查询,但并不意味着它天然适合所有场景。
8.2 N+1 问题
N+1 是 ORM 世界最经典的性能陷阱之一。它的本质是:查询主对象一次,然后为了拿关联对象,逐条发起额外查询。
比如查询 100 个订单,再逐个查订单详情,就会变成 101 次查询。
示意图绘制如下,仅供参考:
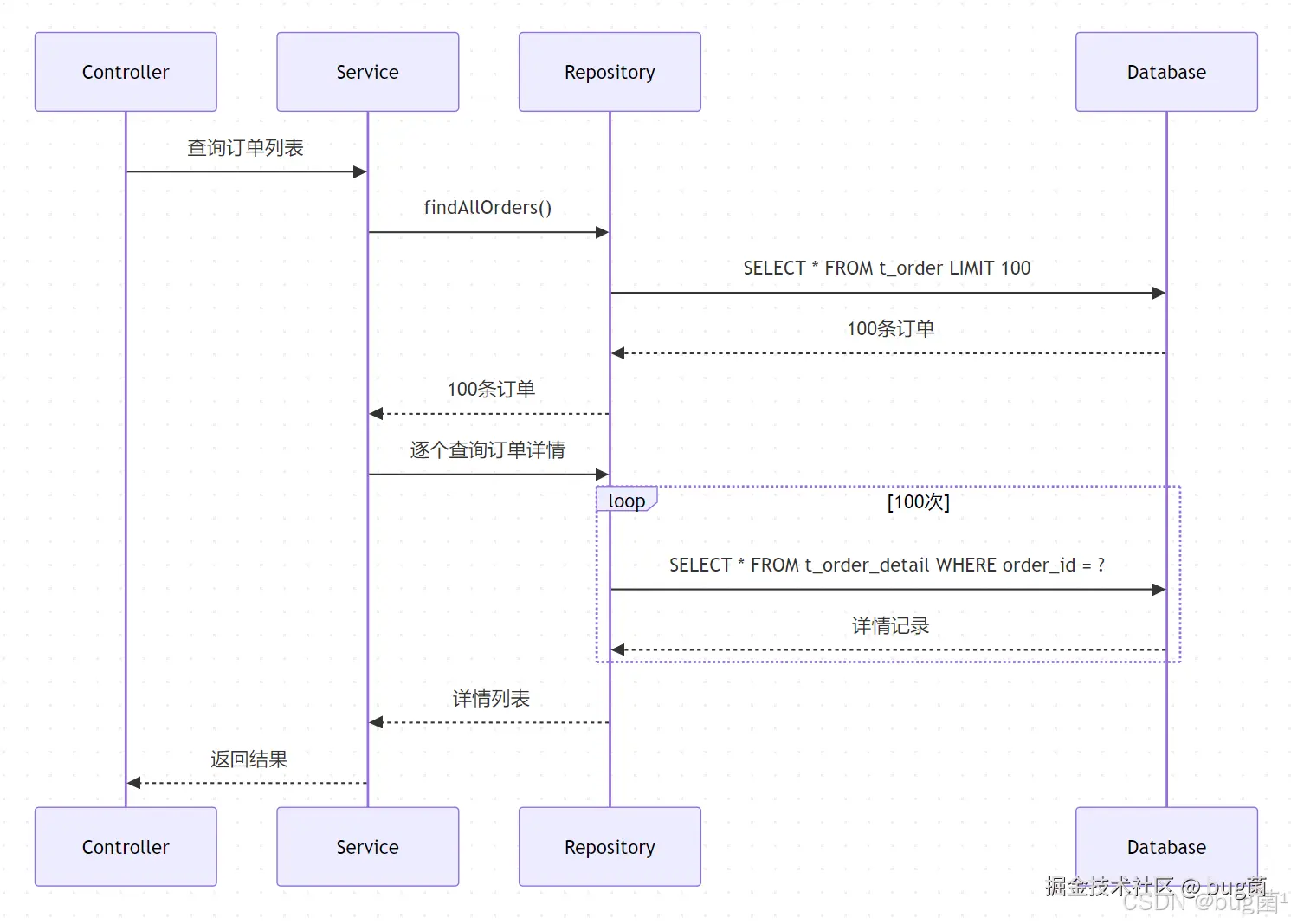
这个问题很典型,表面上是代码写得"面向对象",实际上却在数据库层制造了很多小查询。
8.3 懒加载与关联查询
JPA 的懒加载机制可以减少一些不必要的关联查询,但如果使用场景不当,反而会在循环中触发隐式查询。最好的做法是:
- 明确查询边界
- 需要什么就一次性查出来
- 在高频接口里避免不受控的关联展开
8.4 JPA 生成 SQL 的风险点
常见风险包括:
- 复杂方法名派生查询可读性下降
- 难以精确控制 join 方式
- 分页和排序组合后 SQL 变重
- 批量更新、批量删除能力有限
- 对数据库特性利用不足
8.5 一个看似优雅、实则危险的查询
java
List<OrderEntity> findByUserNameContainingAndStatusOrderByCreateTimeDesc(String userName, Integer status);这个方法名本身没有错,但它背后的 SQL 可能会出现:
- 模糊查询导致索引失效
- 排序字段未命中索引
- 返回列过多
- 在高并发下产生大量扫描
所以,ORM 的"优雅"必须服从性能与可维护性。
9. 慢查询如何回溯到代码层:从数据库日志到 Java 方法
9.1 慢查询分析的核心目标
慢查询分析不是单纯看数据库里哪条 SQL 慢,而是要回答一个更关键的问题:这条 SQL 是从哪一段代码发出来的,为什么会这样发?
只有回到代码层,你才能真正修复问题,而不是在数据库侧做一次临时补丁。
9.2 从数据库日志出发
首先你可以借助数据库慢查询日志、执行计划、监控平台,找到耗时较高的 SQL。
慢查询日志里通常会包含:
- SQL 执行时间
- 扫描行数
- 具体 SQL 文本
- 执行时间窗口
拿到 SQL 后,下一步是建立"SQL 到代码"的映射。
9.3 在 Spring Boot 中记录 SQL
对于开发和测试环境,开启 SQL 日志非常有帮助。
yaml
spring:
jpa:
show-sql: true
properties:
hibernate:
format_sql: true
highlight_sql: true
logging:
level:
org.hibernate.SQL: debug
org.hibernate.orm.jdbc.bind: trace不过要注意,生产环境不建议无脑开启过详细日志,因为会带来额外性能开销和日志噪音。
9.4 通过请求链路标识定位
更推荐的方式是给请求打上 traceId 或 requestId,把接口请求、业务日志、SQL 日志串起来。
例如,Controller 接到请求后记录一次关键日志:
java
package com.example.demo.web;
import jakarta.servlet.http.HttpServletRequest;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/orders")
public class OrderController {
private static final Logger log = LoggerFactory.getLogger(OrderController.class);
@GetMapping("/slow")
public String slowQuery(HttpServletRequest request) {
// 记录请求来源,便于排查慢请求对应的入口
log.info("收到请求:uri={}, remoteAddr={}", request.getRequestURI(), request.getRemoteAddr());
return "ok";
}
}如果你把日志格式统一成包含 traceId,就能在日志平台里按请求串联出整条链路。
9.5 使用 AOP 记录 Repository 或 Service 耗时
你可以在 Service 层加一个简单的耗时统计,快速定位是业务慢还是数据库慢。
java
package com.example.demo.aspect;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
@Aspect
@Component
public class CostTimeAspect {
private static final Logger log = LoggerFactory.getLogger(CostTimeAspect.class);
@Around("execution(* com.example.demo.service..*(..))")
public Object recordCostTime(ProceedingJoinPoint joinPoint) throws Throwable {
long start = System.currentTimeMillis();
try {
return joinPoint.proceed();
} finally {
long cost = System.currentTimeMillis() - start;
// 输出方法耗时,帮助判断是否为慢调用入口
log.info("方法耗时:{}#{},{}ms",
joinPoint.getSignature().getDeclaringTypeName(),
joinPoint.getSignature().getName(),
cost);
}
}
}9.6 把慢 SQL 反查回 Repository 方法
如果你使用 JPA,可以通过以下方式反查:
- 看 SQL 文本是否与某个
@Query对应 - 看 Repository 方法名是否生成了该 SQL
- 搜索项目中涉及该表名的所有 Repository
- 在业务日志里加入方法级别埋点
- 使用性能分析工具定位调用栈
9.7 一个实用建议:为复杂查询手写明确的方法名
与其让 ORM 自动拼 SQL,不如为高频关键查询写明确的方法接口,例如:
java
@Query("select new com.example.demo.dto.OrderSummaryDTO(o.id, o.orderNo, o.status, o.createTime) " +
"from OrderEntity o where o.userId = :userId and o.status = :status order by o.createTime desc")
List<OrderSummaryDTO> findOrderSummary(Long userId, Integer status);这样做的好处是:
-
业务含义清晰
-
SQL 边界明确
-
DTO 返回更轻量
-
便于优化索引和执行计划
10. Spring Data JPA 与原生 SQL 的选择边界
10.1 不要把选择变成信仰之争
很多团队会陷入"JPA 好还是 MyBatis 好"的争论。实际上,真正应该讨论的是:这个场景下哪种方式更适合当前性能目标、团队能力和维护成本。
Spring Data JPA 的优势:
- 开发效率高
- 对简单 CRUD 非常友好
- 领域对象表达自然
- 事务与实体状态管理方便
原生 SQL 的优势:
- 对执行计划和语法控制更强
- 复杂查询更容易精确表达
- 更容易做性能极限优化
- 适合报表、统计、复杂联表和批量任务
10.2 适合用 JPA 的场景
- 单表 CRUD
- 简单条件查询
- 中等复杂度分页列表
- 以业务建模为中心的领域服务
- 不追求极限性能的普通后台系统
10.3 适合用原生 SQL 的场景
- 高并发核心接口
- 复杂联表查询
- 大数据量统计和聚合
- 批量写入、批量更新
- 需要精确控制索引、Hint、排序、分页方式的场景
10.4 选择边界的判断标准
你可以用以下四个问题来判断:
- 这条查询是否处在核心链路上?
- 是否对性能、延迟非常敏感?
- SQL 是否明显复杂到 ORM 表达困难?
- 团队是否有能力维护手写 SQL?
如果这四个问题里有两个以上答案偏向"是",那么原生 SQL 往往更合适。
10.5 JPA 与原生 SQL 的组合策略
更现实的做法不是二选一,而是组合使用:
- 主流程、简单 CRUD 用 JPA
- 核心性能链路用原生 SQL
- 批量处理用 JdbcTemplate 或原生批量能力
- 报表统计用原生 SQL 或专门的数据访问层
这才是大多数中大型项目更健康的实践。
11. 一个完整的性能优化案例:订单查询与批处理改造
下面我们用一个贴近业务的案例,把前面讲的索引、SQL、批量、连接池、ORM 风险串起来。
11.1 场景背景
某电商后台有一个"订单查询"和"订单导入"功能:
- 订单查询接口经常超时
- 导入接口在批量导入 5 万条数据时非常慢
- 数据库 CPU 偶尔飙高
- 业务同学感觉"JPA 写起来很方便,但一上线就卡"
11.2 初始版本的问题
订单表结构大致如下:
sql
CREATE TABLE t_order (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
user_id BIGINT NOT NULL,
order_no VARCHAR(64) NOT NULL,
status INT NOT NULL,
total_amount DECIMAL(18,2) NOT NULL,
create_time DATETIME NOT NULL,
update_time DATETIME NOT NULL
);初始查询代码:
java
package com.example.demo.service;
import com.example.demo.entity.OrderEntity;
import com.example.demo.repository.OrderRepository;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class OrderQueryService {
private final OrderRepository orderRepository;
public OrderQueryService(OrderRepository orderRepository) {
this.orderRepository = orderRepository;
}
public List<OrderEntity> queryByUserId(Long userId) {
// 直接按用户ID查询订单列表
return orderRepository.findByUserIdOrderByCreateTimeDesc(userId);
}
}Repository:
java
package com.example.demo.repository;
import com.example.demo.entity.OrderEntity;
import org.springframework.data.jpa.repository.JpaRepository;
import java.util.List;
public interface OrderRepository extends JpaRepository<OrderEntity, Long> {
// 根据用户ID查询订单并按时间倒序排列
List<OrderEntity> findByUserIdOrderByCreateTimeDesc(Long userId);
}11.3 问题分析
表面上看,这段代码很简单,但问题可能有:
create_time没有合适索引,排序慢- 返回实体过多,包含不必要字段
- 订单列表分页不合理
- 查询条件缺少状态过滤,返回数据太多
- JPA 加载关联对象导致额外查询
11.4 优化方案一:补充合理索引
sql
CREATE INDEX idx_order_user_time ON t_order(user_id, create_time DESC);
CREATE INDEX idx_order_user_status_time ON t_order(user_id, status, create_time DESC);这样,用户维度的时间倒序列表更容易命中索引。
11.5 优化方案二:使用 DTO 投影减少数据量
java
package com.example.demo.dto;
import java.math.BigDecimal;
import java.time.LocalDateTime;
public class OrderSummaryDTO {
private Long id;
private String orderNo;
private Integer status;
private BigDecimal totalAmount;
private LocalDateTime createTime;
public OrderSummaryDTO(Long id, String orderNo, Integer status, BigDecimal totalAmount, LocalDateTime createTime) {
this.id = id;
this.orderNo = orderNo;
this.status = status;
this.totalAmount = totalAmount;
this.createTime = createTime;
}
public Long getId() {
return id;
}
public String getOrderNo() {
return orderNo;
}
public Integer getStatus() {
return status;
}
public BigDecimal getTotalAmount() {
return totalAmount;
}
public LocalDateTime getCreateTime() {
return createTime;
}
}Repository 改造:
java
package com.example.demo.repository;
import com.example.demo.dto.OrderSummaryDTO;
import com.example.demo.entity.OrderEntity;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import java.util.List;
public interface OrderRepository extends JpaRepository<OrderEntity, Long> {
@Query("select new com.example.demo.dto.OrderSummaryDTO(o.id, o.orderNo, o.status, o.totalAmount, o.createTime) " +
"from OrderEntity o where o.userId = :userId order by o.createTime desc")
List<OrderSummaryDTO> findOrderSummaryByUserId(@Param("userId") Long userId);
}11.6 优化方案三:分页改成游标翻页
java
package com.example.demo.repository;
import com.example.demo.dto.OrderSummaryDTO;
import com.example.demo.entity.OrderEntity;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import java.time.LocalDateTime;
import java.util.List;
public interface OrderRepository extends JpaRepository<OrderEntity, Long> {
@Query("select new com.example.demo.dto.OrderSummaryDTO(o.id, o.orderNo, o.status, o.totalAmount, o.createTime) " +
"from OrderEntity o where o.userId = :userId and o.createTime < :beforeTime order by o.createTime desc")
List<OrderSummaryDTO> findOrderSummaryByUserIdAndBeforeTime(
@Param("userId") Long userId,
@Param("beforeTime") LocalDateTime beforeTime,
org.springframework.data.domain.Pageable pageable);
}11.7 批量导入改造
初始导入逻辑:
java
for (OrderEntity order : orders) {
orderRepository.save(order);
}改造成批处理:
java
package com.example.demo.service;
import com.example.demo.entity.OrderEntity;
import jakarta.persistence.EntityManager;
import jakarta.persistence.PersistenceContext;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
@Service
public class OrderImportService {
@PersistenceContext
private EntityManager entityManager;
@Transactional
public void importOrders(List<OrderEntity> orders) {
// 每批处理的数量,具体值需要压测后确定
int batchSize = 100;
for (int i = 0; i < orders.size(); i++) {
entityManager.persist(orders.get(i));
if (i > 0 && i % batchSize == 0) {
// 刷新到数据库并清理持久化上下文
entityManager.flush();
entityManager.clear();
}
}
entityManager.flush();
entityManager.clear();
}
}11.8 优化前后的效果预期
经过这些改造后,通常可以看到:
- 查询耗时下降
- 数据库扫描行数减少
- 导入吞吐提升
- 连接池等待时间下降
- CPU 峰值降低
关键不在于"代码看起来更短",而在于"数据访问路径更合理"。
12. 常见误区与排查清单
12.1 误区一:加索引一定更快
不是。索引会提升读性能,但也会增加写成本。是否加索引,取决于查询与写入的平衡。
12.2 误区二:JPA 一定比手写 SQL 好维护
对简单 CRUD 来说,JPA 的确方便;但对复杂查询、高并发链路,手写 SQL 往往更清晰、更高效。
12.3 误区三:连接池越大越好
不是。连接池应该和数据库能力、SQL 耗时、并发模型一起设计。
12.4 误区四:慢查询只需要改数据库
不是。很多慢查询根源是代码层的查询方式不合理,例如循环查询、N+1、DTO 设计不合理、分页方式不当。
12.5 排查清单
你可以按这个顺序排查:
-
是否有慢 SQL 日志
-
SQL 是否命中预期索引
-
扫描行数是否过大
-
是否存在 N+1
-
是否存在
SELECT * -
是否存在大偏移分页
-
是否存在长事务
-
连接池是否耗尽
-
ORM 是否生成了意外 SQL
-
是否能用 DTO、原生 SQL 或批量操作改善
13. 总结:把性能优化做成工程能力
数据库访问优化,不是某一个工具的专属能力,而是贯穿模型设计、SQL 编写、ORM 使用、事务控制、连接池配置、监控排查的系统工程。
在 Spring Boot 3.x 时代,开发者更应该建立下面这套方法论:
- 用 JPA 提升开发效率,但不要被 ORM 绑架
- 用索引提升查询效率,但不要迷信索引
- 用批量处理提升写入吞吐,但要注意事务和内存
- 用连接池复用昂贵资源,但要和数据库能力匹配
- 用日志、监控、执行计划把慢查询精准定位到代码层
- 对核心链路,敢于选择原生 SQL 与 DTO 投影
真正高质量的数据库访问优化,不是"把 SQL 调快一点"这么简单,而是把数据访问从"能跑"提升到"稳定、可观测、可扩展"。
如果你能把本文的思路真正落到项目里,你会发现性能优化并不是玄学,而是一种可以不断复用、持续沉淀的工程能力。
...
ok,同学们,本节课就上到这儿,下课~
🧧 学习福利 · 限时开放 🧧
当然,无论你是计算机专业在读学生 ,还是对编程充满兴趣的入门者,都强烈建议系统学习SpringBoot全体系专栏:👉 「滚雪球学 Spring Boot」;涵盖SpringBoot所有教学内容。
该专栏以"循序渐进 + 实战驱动"为核心理念,从基础到进阶到就业到架构师逐层展开,帮助你快速建立完整的 Spring Boot 技术体系,带你玩转SpringBoot框架。
📌 学习承诺: 通过该专栏,你将能够:
- 快速掌握 Spring Boot 核心开发能力
- 构建完整的后端项目认知体系
- 实现从"入门"到"独立开发"的跃迁
就像"滚雪球"一样,知识不断积累、能力持续放大,实现指数级成长 🚀
最后,如果这篇文章对你有所帮助,帮忙给作者来个一键三连,关注、点赞、收藏,您的支持就是我坚持写作最大的动力。
同时欢迎大家关注技术号:「猿圈奇妙屋」 ,以便学习更多同类型的技术文章,免费白嫖最新BAT互联网公司面试题、4000G PDF编程电子书、简历模板、技术文章Markdown文档等海量资料。
ps:本文涉及所有源代码,均已上传至Gitee开源,供同学们直接对照学习 Gitee传送门,同时,原创开源不易,欢迎给个star🌟,想体验下被🌟的感jio,非常感谢❗
🫵 Who am I?
我是 bug菌,一名深耕 Java 后端领域数十年的一线研发老兵,曾担任独角兽企业后端技术经理、研发架构师等职位,长期专注于 Java 后端、分布式架构、微服务治理、高并发系统、工程效能与研发管理等方向。
目前活跃于多个主流技术社区,包括:
CSDN|** 稀土掘金| InfoQ| 51CTO| 华为云开发者社区| 阿里云开发者社区| 腾讯云开发者社区| 开源中国| 博客园| 墨天轮** 等平台。
曾获得:
- CSDN 博客之星 Top30
- 华为云多年度十佳博主 & 卓越贡献奖
- 掘金多年度人气作者 Top40
- CSDN、掘金、InfoQ、51CTO 等平台签约作者 / 优质作者
截至目前,全网技术内容累计影响读者众多,全网粉丝已超过 30w+。
如果你也关注 Java 后端、架构设计、技术成长、职场进阶与研发管理,欢迎关注我的技术内容合集入口:👉 点击查看 👈️
硬核技术号 「猿圈奇妙屋」 期待你的加入。
这里不仅分享技术干货,也记录一线研发人的成长、踩坑、思考与进阶路径。
愿我们一起打怪升级,在技术路上持续进阶。

- End -