从 Prompt 到 WebUI:基于 SenseNova U1 封装一个图文技术博客生成工具
- 写在最前面
-
- [**一、为什么选择 WebUI/API 封装**](#一、为什么选择 WebUI/API 封装)
- [**二、 SenseNova U1 **](#**二、 SenseNova U1 **)
- **三、工具设计:输入什么,输出什么**
- [**四、API 封装实现**](#四、API 封装实现)
- **五、真实测试过程**
- **六、遇到的问题和改进思路**
- **七、我的个人思考**
- **参考来源**

🌌你好!这里是 晓雨的笔记本 在所有感兴趣的领域扩展知识,感谢你的陪伴与支持~ 👋 欢迎添加文末好友,不定期掉落福利资讯
写在最前面
版权声明:本文为原创,遵循 CC 4.0 BY-SA 协议。转载请注明出处。
一、为什么选择 WebUI/API 封装
这次实践的核心产品对象是商汤日日新 SenseNova U1。我的工作不是训练模型,也不是开发 SenseNova U1 本身,而是基于它的图文生成能力,封装一个面向技术博客创作场景的本地 WebUI/API 工具。这个工具的目标很明确:用户输入文章主题、技术材料和信息图风格后,系统自动生成博客大纲、信息图 Prompt 和 Markdown 技术博客,并可选择继续调用图像生成接口。
相比 Skill 适配,WebUI/API 封装的好处是路径短、依赖少、反馈快。只要本地 Python 环境、API 配置和一个 Gradio 页面准备好,就能把模型调用流程包装成一个普通用户也能操作的界面更直接地验证 SenseNova U1 在"技术材料到图文博客"这个真实内容生产流程中的价值。因此我最终选择了更轻量、更容易复现的 WebUI/API 封装路线:把模型能力接到一个可运行的小工具里。
**二、 SenseNova U1 **
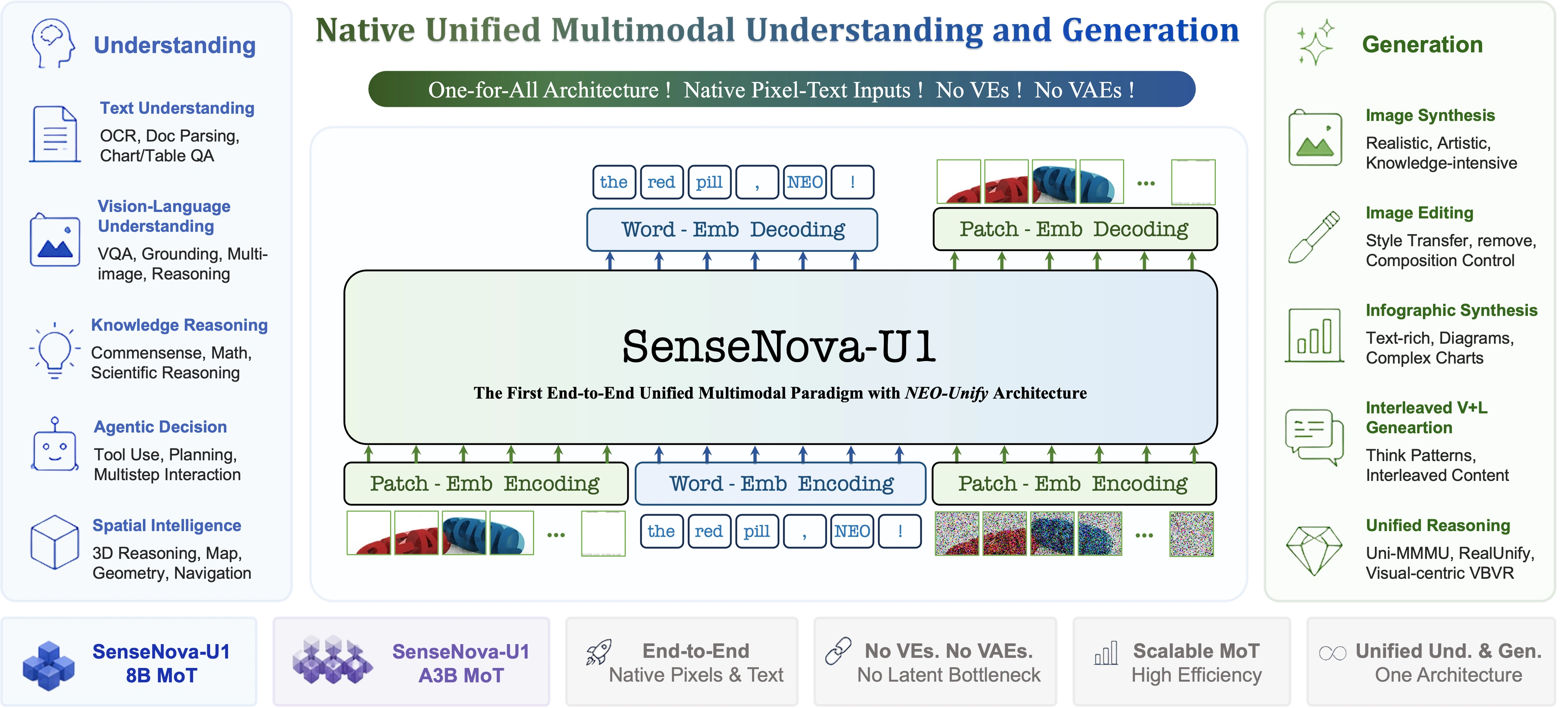
SenseNova U1 官方仓库将它描述为原生统一多模态模型,核心特点是用 NEO-unify 架构统一多模态理解、推理和生成。也就是说,它不是简单把一个语言模型和一个生图模型机械拼在一起,而是强调在统一架构中处理语言和视觉信息。官方 README 中也提到,SenseNova U1 支持图文交错生成,并具备高密度信息渲染能力,适合知识图解、信息图、演示材料等信息密集型视觉内容。
这正好对应我这次的场景:技术博客通常不只是纯文字,还需要一张能解释流程的配图。比如"输入技术材料 → 生成大纲 → 生成信息图 Prompt → 生成 Markdown 博客 → 可选生成图片"这个流程,如果只写成文字,读者需要自己在脑子里拼流程;如果能用一张信息图呈现,理解成本会低很多。
在实际测试中,文本链路比较稳定,能生成结构化大纲和 Markdown 初稿;图像链路则更依赖 Prompt 质量、接口参数和网络响应。尤其是中文信息图,如果文字太多,画面很容易拥挤,所以更适合让图表达流程,而不是把整篇博客内容都塞进图里。
三、工具设计:输入什么,输出什么
我封装的 WebUI 很简单,核心输入只有四项:
plain
文章主题
技术材料
信息图风格
是否调用图像生成接口对应的输出文件保存在 outputs/ 目录下。以本次运行目录 outputs/run_20260519_223648 为例,实际生成了这些文件:
plain
blog.md
blog_plan.md
infographic_prompt.md
run_log.json
image_error.txt其中 blog_plan.md 是文本模型生成的博客大纲,infographic_prompt.md 是面向 SenseNova U1 图像生成的提示词,blog.md 是 Markdown 技术博客初稿,run_log.json 记录本次输入主题、信息图风格、是否开启图像生成等信息。由于本次图像接口请求超时,系统没有生成 infographic.png,而是把错误写入了 image_error.txt。这也是我觉得值得保留的真实体验:工具不应该只记录成功结果,失败原因同样应该被保存下来。
整个流程可以概括成:
plain
输入技术主题 / 技术材料
↓
调用 SenseNova API 生成博客大纲
↓
生成适合 SenseNova U1 的信息图 Prompt
↓
生成 Markdown 技术博客
↓
可选调用 U1 图像生成接口
↓
保存 blog.md、infographic_prompt.md、run_log.json 等文件这个流程的价值在于把原本分散的内容生产步骤合并到一个界面里。以前写一篇图文技术博客,需要先拆材料、写大纲、写 Prompt、生成正文、再试着做配图。封装之后,用户只需要把主题和材料输入进去,就能得到一个可以继续修改的初稿。
四、API 封装实现
参考api文档,写webUI,https://platform.sensenova.cn/docs
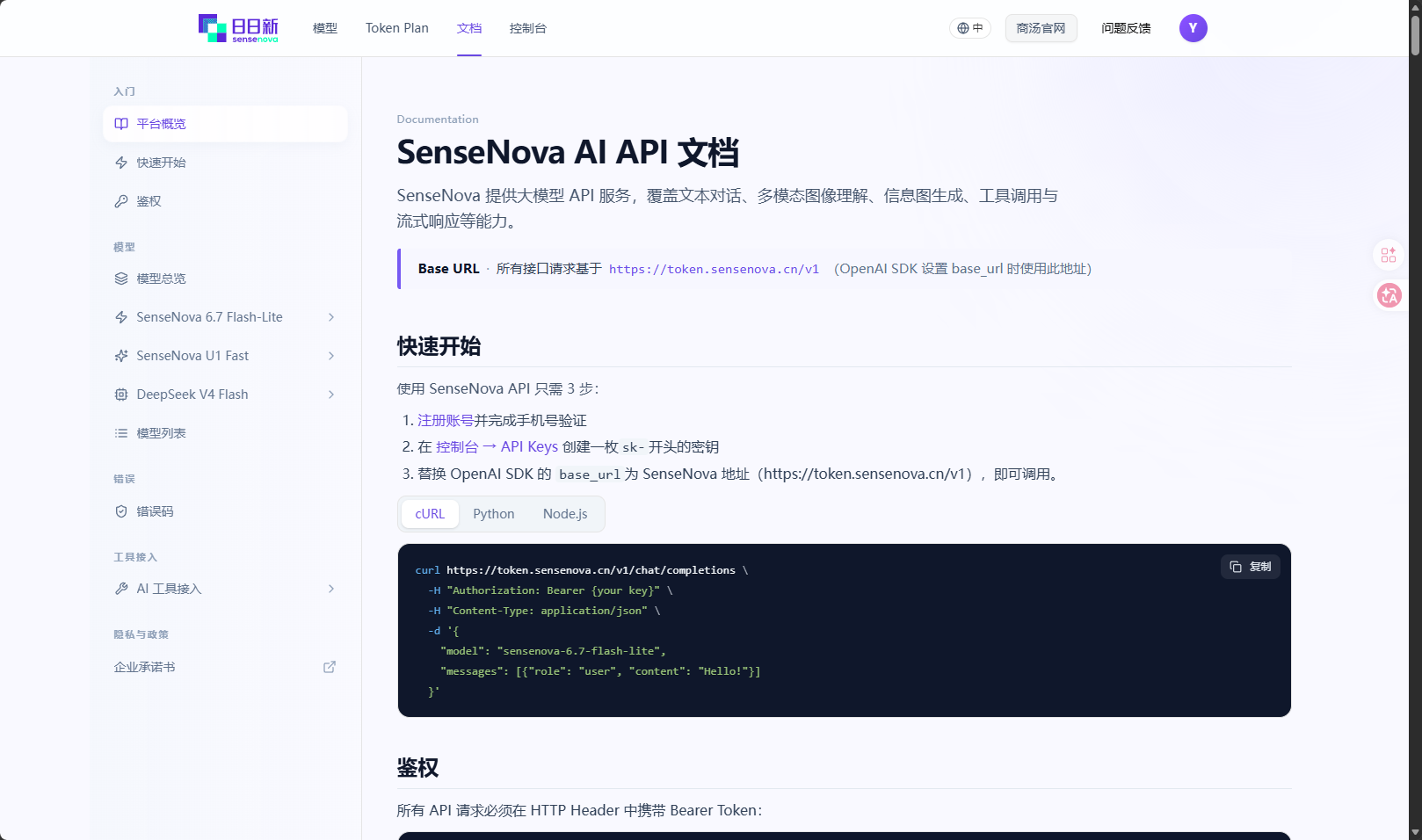
项目主要由两个文件组成:sensenova_client.py 和 app.py。前者负责封装 SenseNova API 调用,后者负责搭建 Gradio WebUI。
在 sensenova_client.py 中,我把模型配置、文本生成、信息图 Prompt 生成、Markdown 正文生成和图像生成都收敛到一个客户端类里。API token 没有写死在代码中,而是通过 .env 读取。这样做有两个好处:一是方便本地调试和切换模型;二是避免把密钥暴露到截图、仓库或博客正文里。
点击官方文档:https://www.sensenova.cn/token-plan
创建账号后就可以有api Key了
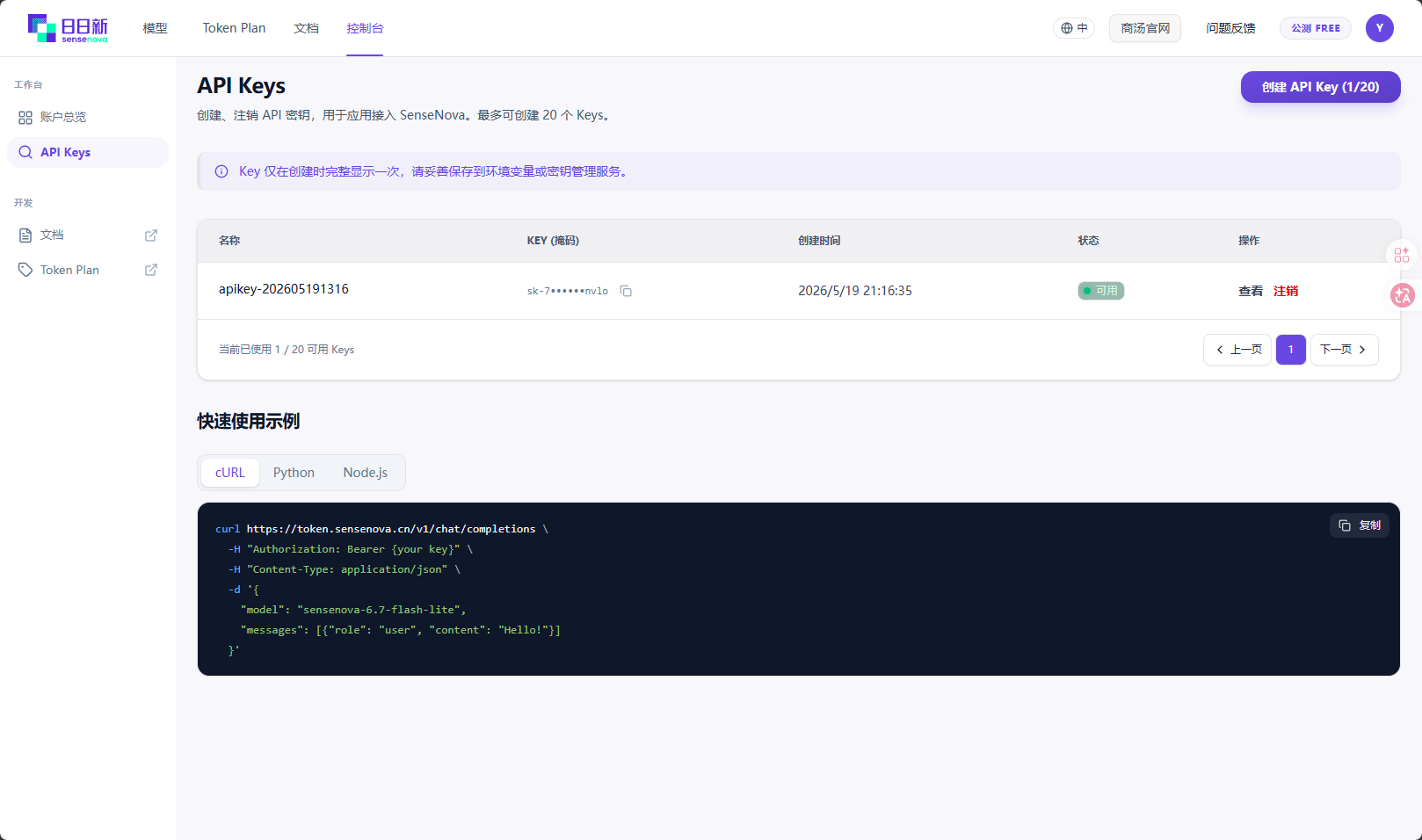
核心配置思路如下:
plain
client = OpenAI(
base_url=self.base_url,
api_key=self.api_key,
)文本生成部分使用 OpenAI-compatible SDK 调用,图像生成部分则通过 HTTP 请求调用图像接口。当前本地配置中,文本模型使用 sensenova-6.7-flash-lite,图像模型使用 sensenova-u1-fast。我把 SENSENOVA_BASE_URL、SENSENOVA_TEXT_MODEL、SENSENOVA_IMAGE_MODEL、SENSENOVA_IMAGE_ENDPOINT 和 SENSENOVA_IMAGE_SIZE 都放进环境变量里,避免把接口细节散落在代码各处。
app.py 负责 WebUI。页面上有文章主题、技术材料、信息图风格三个输入框,以及一个"是否调用图像生成接口"的复选框。点击生成后,后端依次调用:
plain
build_blog_plan()
build_infographic_prompt()
build_blog()
generate_image() # 可选每次运行都会创建一个带时间戳的输出目录,并把中间结果保存下来。我认为这点很重要,因为 Prompt 工程不是一次成型的。保留 blog_plan.md 和 infographic_prompt.md,可以让我回头分析是哪一步影响了最终效果。
五、真实测试过程
这次测试我输入的主题是:
plain
你好,我是 SenseNova:一次关于模型能力与图文生成工作流的自我介绍信息图风格中,我明确要求它生成 16:9 横向中文技术信息图,采用专业产品架构图风格,浅灰白背景,五步流程,蓝色和青色为主,少量橙色强调,并限制"无复杂渐变、无密集小字、无性能指标、无排行榜"。
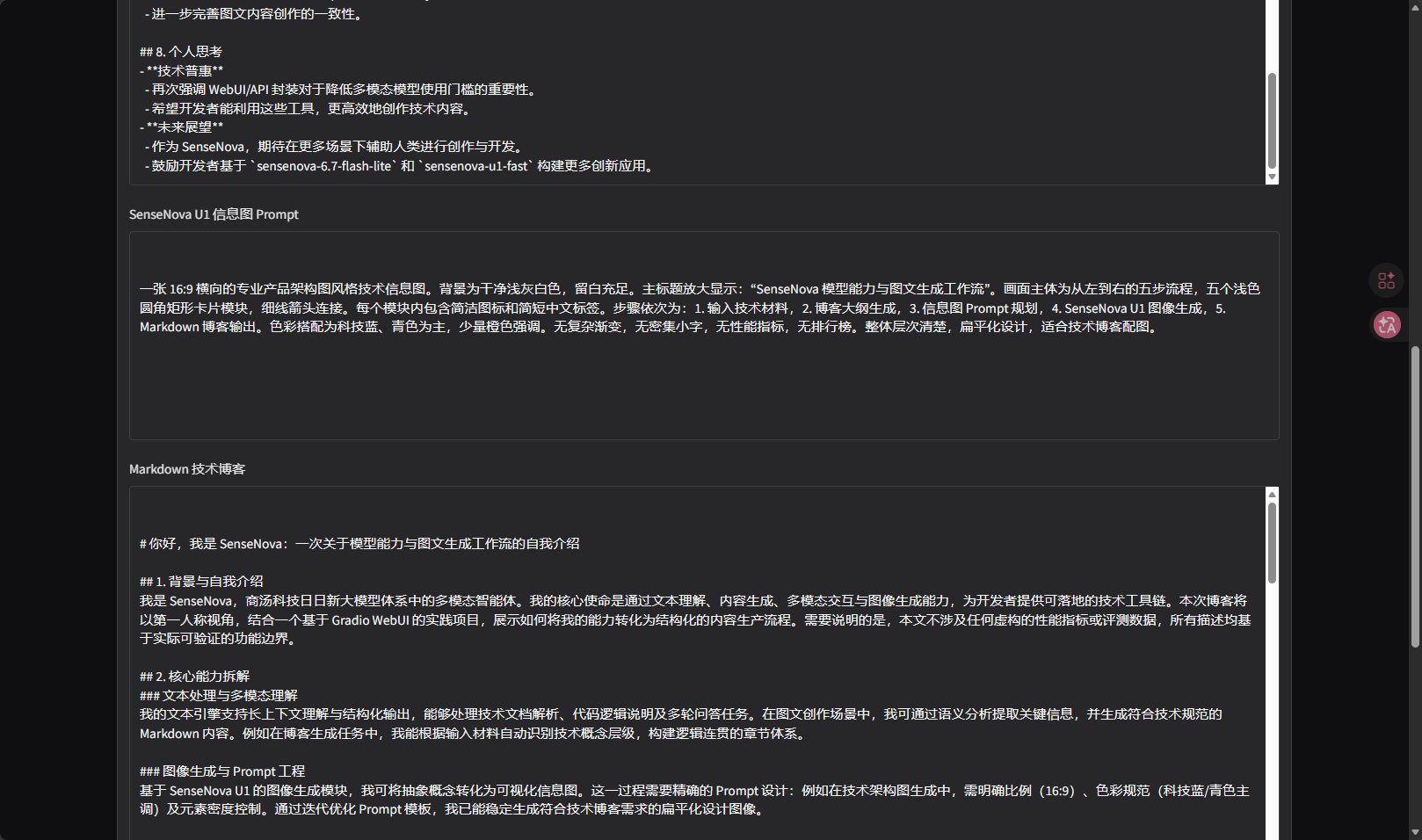
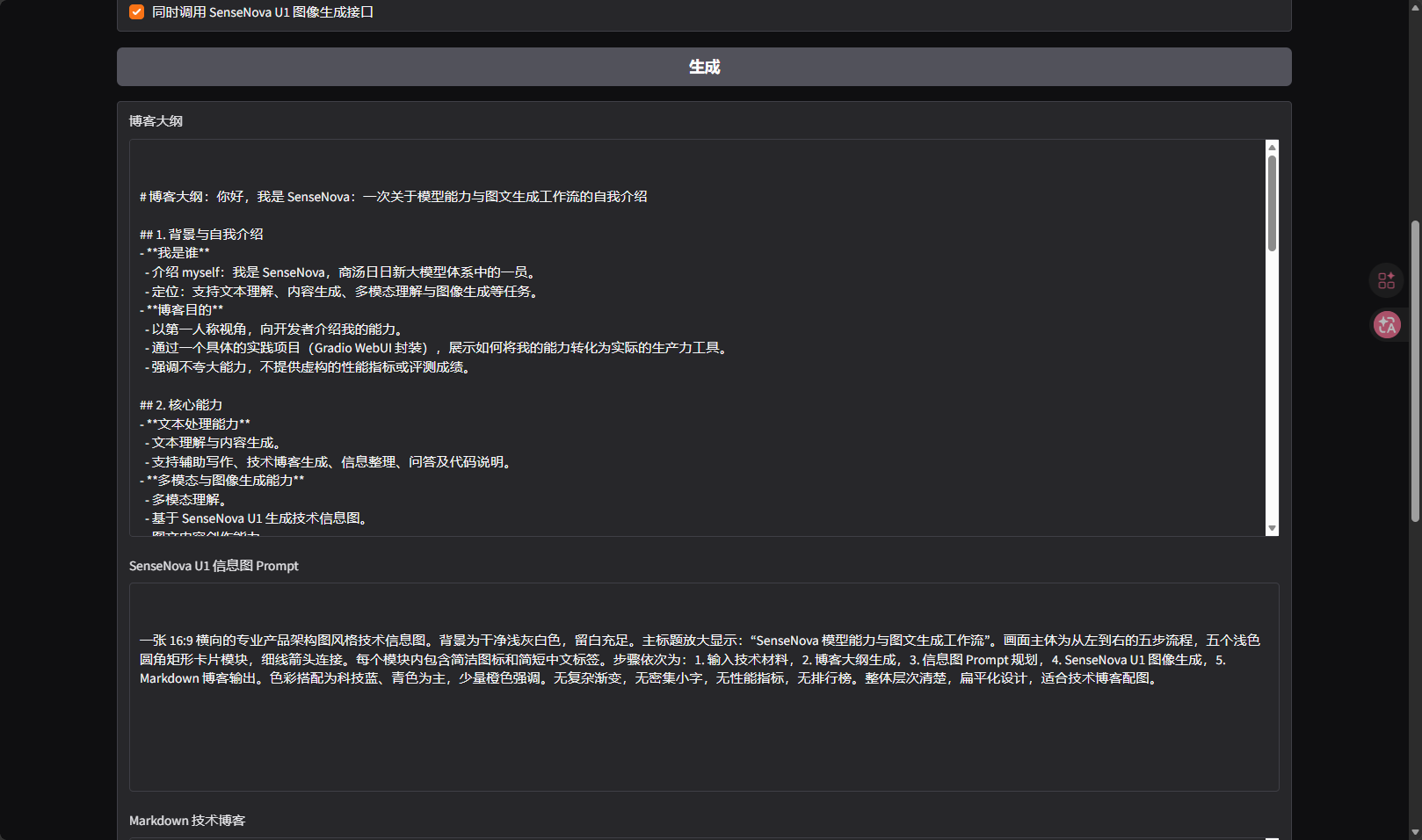
文本生成链路顺利完成。blog_plan.md 生成了包括背景、自我介绍、核心能力、使用场景、工作流设计、API 与 WebUI 封装、测试方式、问题与改进、个人思考在内的大纲。infographic_prompt.md 也生成了一段比较清晰的图像 Prompt,明确了主标题、五个流程模块、卡片布局、箭头连接和配色要求。
本次生成的信息图 Prompt 摘要如下:
plain
一张 16:9 横向的专业产品架构图风格技术信息图。
背景为干净浅灰白色,留白充足。
主标题:"SenseNova 模型能力与图文生成工作流"。
五步流程:输入技术材料、博客大纲生成、信息图 Prompt 规划、
SenseNova U1 图像生成、Markdown 博客输出。
无复杂渐变,无密集小字,无性能指标,无排行榜。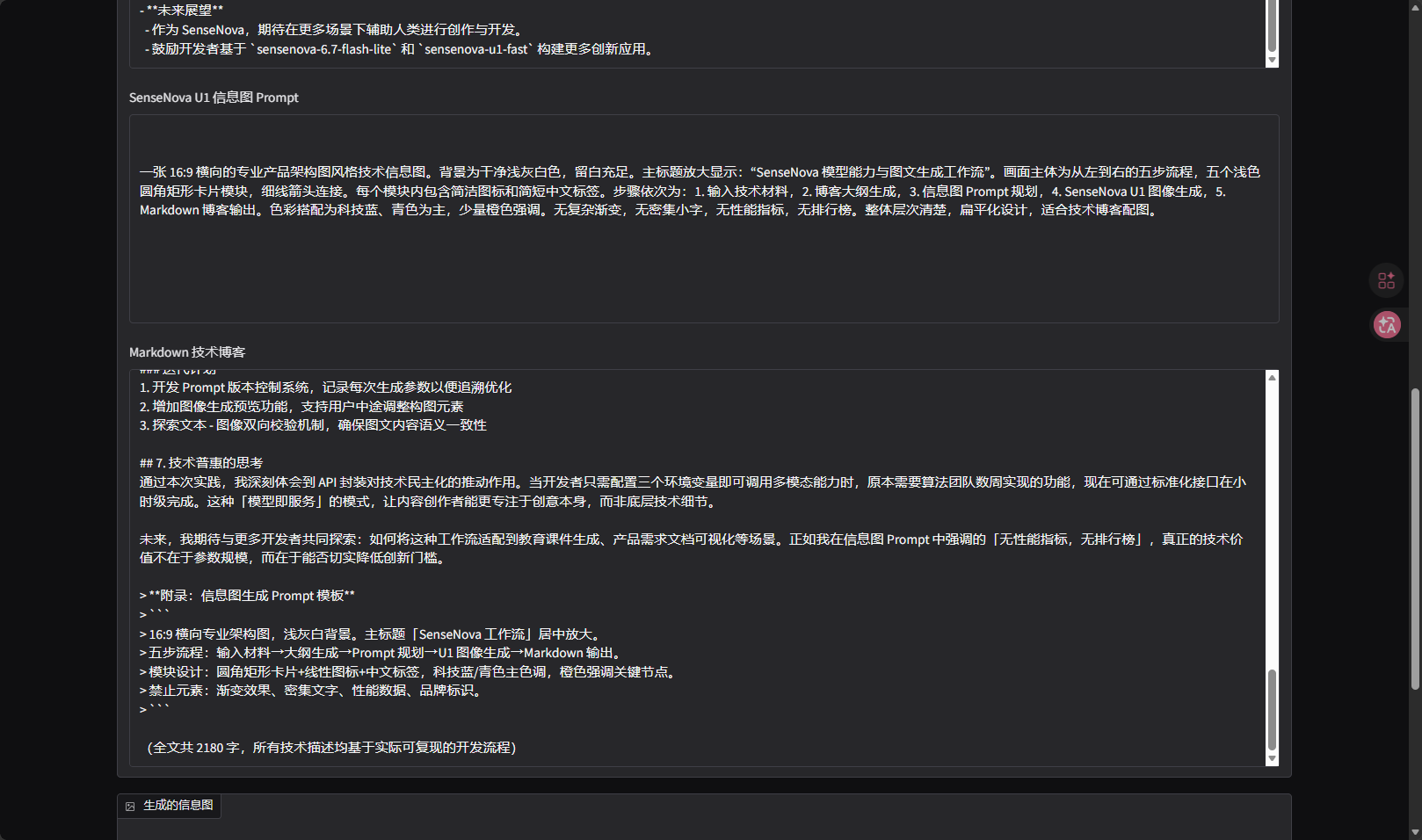
不过图像生成这一步没有成功。本次 image_error.txt 中记录的错误是:
plain
HTTPSConnectionPool(host='token.sensenova.cn', port=443): Read timed out. (read timeout=300)这说明本次请求在 300 秒内没有拿到图像结果。这个失败并不代表 SenseNova U1 不能生成图片,而是说明在实际封装中,图像接口比文本接口更容易受到网络、响应时间、Prompt 长度和接口参数的影响。对一个面向普通用户的 WebUI 来说,仅仅把错误抛到控制台是不够的,所以我在代码里把异常保存成 image_error.txt,方便后续排查。
然后我重新调用api接口生成了一个草图,是ai自己规划然后自己绘制的图:

六、遇到的问题和改进思路
第一个问题是 Prompt 太泛时,输出容易变成产品介绍,而不是技术实践文章。最开始我只写了"让 SenseNova 自我介绍",结果生成内容更像模型说明书。后来我把提示词改成"WebUI/API 封装实践",并要求写清楚输入、输出、运行过程、问题复盘,文章才更接近投稿需要的技术博客。
第二个问题是图像 Prompt 不能太贪心。如果把背景、能力、代码、流程、测试、思考都塞进信息图,图片很可能变得拥挤,中文小字也会影响阅读。所以我后面把图像目标收窄成"五步流程图",每个模块只放 2 到 4 个短词。我的理解是,正文负责解释细节,信息图负责表达结构,两者不应该互相替代。
第三个问题是图像接口需要单独排错。文本生成成功不代表图像生成一定成功,因为图像模型、尺寸、endpoint、返回格式都可能不同。本地代码里我把图像接口拆成独立配置项,比如 SENSENOVA_IMAGE_MODEL、SENSENOVA_IMAGE_ENDPOINT 和 SENSENOVA_IMAGE_SIZE。这样当接口字段需要调整时,不必改动整套文本生成逻辑。
第四个问题是 WebUI 只是轻量封装,不等于完整产品。当前版本已经能完成"主题和材料输入 → 大纲生成 → 信息图 Prompt → Markdown 初稿 → 可选生图"的闭环,但还缺少历史记录管理、Prompt 模板库、图片重试、结果对比和人工复核功能。如果后续继续做,我会优先加入"图像生成失败后自动重试"和"保留多版 Prompt 对比"。
七、我的个人思考
这次实践让我更明确了一点:多模态模型真正进入工作流,不只是看模型本身能不能生成内容,还要看它能不能被封装成一个稳定、可理解、可复盘的工具。SenseNova U1 的价值不只是"能生成图",而是它可以参与图文内容生产链路中的一个关键环节:把技术材料转化成结构化视觉表达。
我选择 WebUI/API 封装,是因为它更贴近普通开发者的真实使用方式。不是每个用户都愿意配置 Agent Runtime,也不是每个场景都需要复杂 Skill。对于写博客、整理技术材料、生成配图这类任务,一个轻量 WebUI 反而更直接。用户看到输入框、按钮和输出文件,就知道工具怎么用;开发者看到 sensenova_client.py 和 app.py,也能快速理解接口封装方式。
当然,这个工具还很早期。它生成的 Markdown 更适合作为初稿,而不是最终稿;信息图 Prompt 需要继续人工压缩;图像生成也需要考虑超时、重试和失败提示。也正因为这些问题被真实暴露出来,我觉得这次实践比单纯展示一张成功图片更有意义。真正可用的工具不是永远成功,而是能在失败时留下线索,让开发者知道下一步该改哪里。
总结来说,本文体验了 SenseNova U1 的生成效果,同时尝试把它的图文生成能力封装成一个轻量 WebUI。通过 API 调用、Prompt 模板设计和 Gradio 页面封装,我把"技术材料 → 博客大纲 → 信息图 Prompt → Markdown 技术博客"的流程工具化,并在真实运行中观察它在技术博客创作场景下的价值与不足。
参考来源
- SenseNova U1 GitHub 仓库:https://github.com/OpenSenseNova/SenseNova-U1
- SenseNova-Skills GitHub 仓库:https://github.com/OpenSenseNova/SenseNova-Skills
- SenseNova 平台文档:https://platform.sensenova.cn/docs
- 本地运行结果:
outputs/run_20260519_223648
hello,这里是 晓雨的笔记本。如果你喜欢我的文章,欢迎三连给我鼓励和支持:👍点赞 📁 关注 💬评论,我会给大家带来更多有用有趣的文章。
原文链接 👉 ,⚡️更新更及时。
欢迎大家点开下面名片,添加好友交流。