1.作者介绍
王浩宇,男,西安工程大学电子信息学院,2025级研究生
研究方向:古建筑数字化保护
电子邮件:why1904791793@163.com
2 . MLP 神经网络的红酒品质回归预测(PyTorch-free 的 sklearn 全流程实现)知识介绍
2.1 多层感知机(MLP)
MLP 是前馈神经网络,由输入层、隐藏层、输出层组成,层间全连接且通过非线性激活函数引入非线性表达能力:
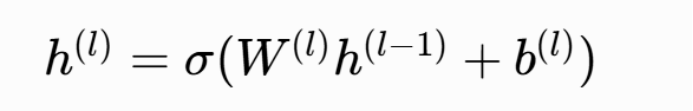
其中,ReLU 激活函数,Wl为权重、bl 偏置
2.2 回归评估指标
平均绝对误差MAE(又称L1范数损失),即误差绝对值的平均值。MAE可以准确反映实际预测误差的大小。MAE用于评价真实值与拟合值的偏离程度,MAE值越接近于0,说明模型拟合越好,模型预测准确率越高(但是RMSE值还是使用最多的)。
MAE计算公式:
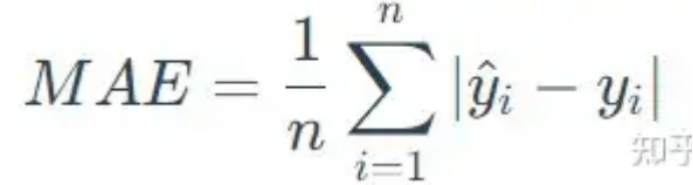
均方误差MSE(又称L2范数损失),即误差平方和的平均值,MSE是衡量模型预测误差的一种常用指标。MSE值越接近于0,说明模型拟合越好。
MSE计算公式:
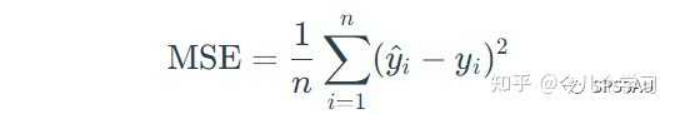
均方误差根RMSE,是均方误差MSE的算术平方根,回归模型中最常用的评价模型指标。相比于均方误差MSE,均方误差根RMSE更常用。RMSE值越接近0,说明模型拟合越好。
RMSE值计算公式:
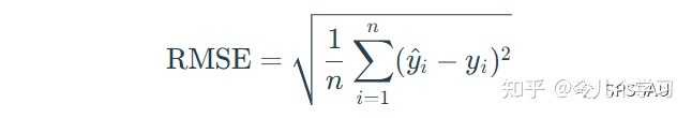
R方值是衡量回归模型拟合优度的统计量,它表示回归模型对观测值的拟合程度,代表了模型中因变量可由自变量解释的百分比。R方值的取值范围在0到1之间,R方值越大,说明回归模型对观测值的拟合程度越好。比如R方为0.5,说明所有自变量可以解释因变量50%的变化原因。
R方计算公式如下
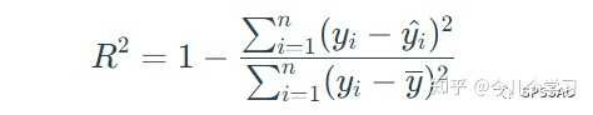
2.3 数据标准化
神经网络对输入尺度敏感,采用两阶段标准化:
- 特征标准化:StandardScaler将11个特征转为零均值、单位方差;
- 目标值标准化:TransformedTargetRegressor包裹 MLP,自动标准化 quality并在预测时还原(提升训练稳定性)。
- 实验设计与实现
3.1 数据集准备
3.1.1 数据来源
UCI Machine Learning Repository:
下载地址:https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv
3.1.2 数据集概览
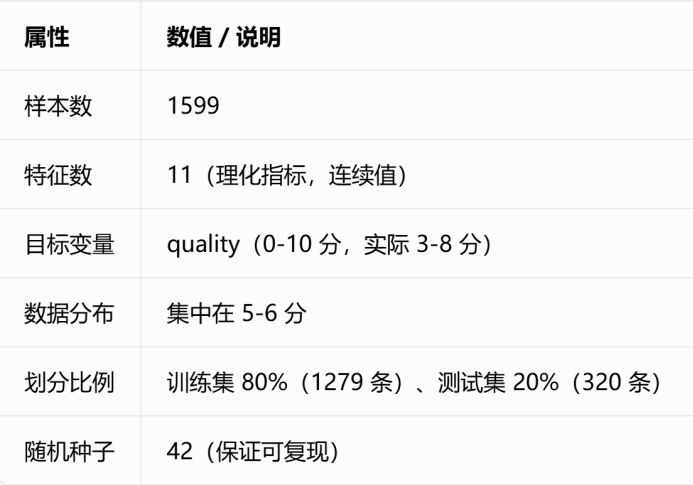
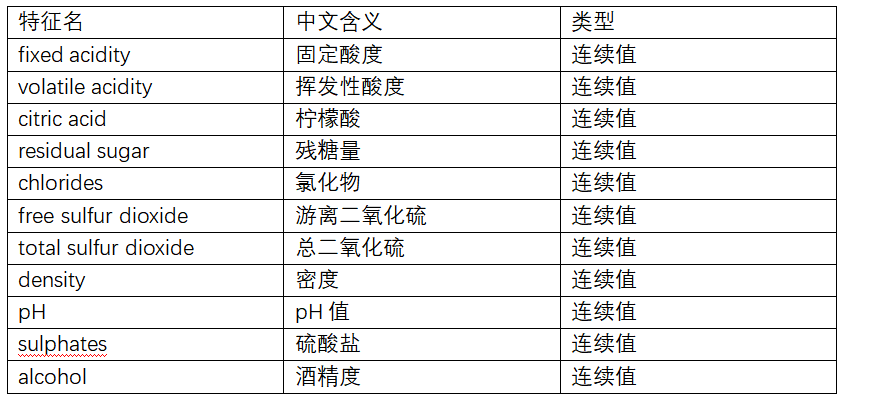
3.1.3 特征说明
3.1.4 数据预处理
- 自动兼容分号/逗号分隔的 CSV 格式;
- 固定随机种子划分训练/测试集;
- 特征+目标值双标准化。
3.2 模型架构与超参数
3.2.1 模型结构

3.2.2 核心超参数
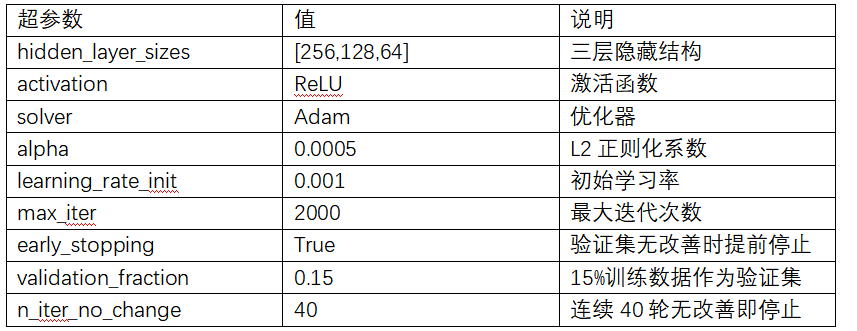
3.2.3 Pipeline 管道
Pipeline( ("feature_scaler", StandardScaler()), # 特征标准化 ("model", TransformedTargetRegressor( # 目标值标准化+MLP regressor=MLPRegressor(...), transformer=StandardScaler() )) )
3.3 核心代码片段
3.3.1 数据加载
python
def load_dataset(path: Path) -> tuple[pd.DataFrame, pd.Series]:
# 自动兼容分号/逗号分隔的 CSV 格式
data = pd.read_csv(path, sep=None, engine="python")
if data.shape[1] == 1 and ";" in str(data.columns[0]):
data = pd.read_csv(path, sep=";", quotechar='"')
x = data[FEATURE_COLUMNS]
y = data[TARGET_COLUMN]
return x, y3.3.2 模型构建
python
def build_model(hidden_layers, max_iter, random_state) -> Pipeline:
mlp = MLPRegressor(
hidden_layer_sizes=tuple(hidden_layers),
activation="relu",
solver="adam",
alpha=0.0005,
max_iter=max_iter,
early_stopping=True,
validation_fraction=0.15,
n_iter_no_change=40,
)
return Pipeline([
("feature_scaler", StandardScaler()),
("model", TransformedTargetRegressor(regressor=mlp, transformer=StandardScaler())),
])3.3.3 模型评估
python
def evaluate(y_true, y_pred) -> dict:
mse = mean_squared_error(y_true, y_pred)
return {
"mae": float(mean_absolute_error(y_true, y_pred)),
"mse": float(mse),
"rmse": float(np.sqrt(mse)),
"r2": float(r2_score(y_true, y_pred)),
}3.4 运行方式
3.4.1 环境安装
python -m venv .venv
...venv\Scripts\Activate.ps1
pip install -r requirements.txt
3.4.2 训练模型
#默认参数训练
python train_mlp_wine_quality.py
#自定义参数
python train_mlp_wine_quality.py --hidden-layers 256 128 64 --max-iter 3000
#使用自定义数据
python train_mlp_wine_quality.py --data .\data\my_red_wine.csv
3.4.3 预测新样本
python predict.py --input .\data\new_wines.csv
- 实验结果与分析
4.1 性能指标
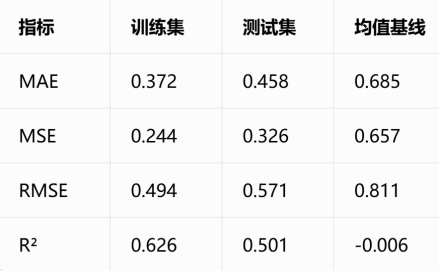
关键结论:
- 测试集 MAE=0.458,相比基线提升约33%;
- R²=0.501,模型可解释50%的品质方差;
- 训练/测试集指标差距合理,无严重过拟合。
4.2 可视化结果
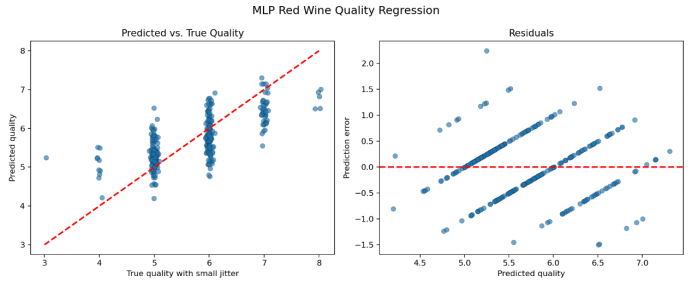
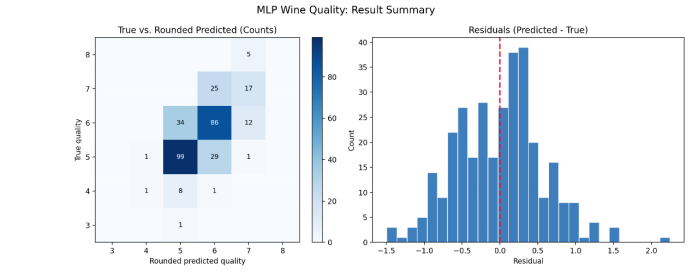
4.3 误差分析 - 残差以0为中心呈正态分布,无系统性偏差;
- 边缘评分(3/8分)样本少,预测误差较大(数据不平衡);
- 中间评分(5/6分)预测最准(训练样本多)。
- 项目文件结构
基于mlp的神经网络的红酒品质回归预测/
├── train_mlp_wine_quality.py # 训练主脚本
├── predict.py # 预测脚本
├── render_code_card.py # 代码卡片渲染
├── requirements.txt # 依赖清单
├── README.md # 项目说明
├── data/
│ ├── winequality-red.csv # 原始数据集
│ └── new_wines.csv # 待预测样本
└── outputs/
├── mlp_wine_quality_model.joblib # 训练好的模型
├── metrics.json # 评估指标
├── test_predictions.csv # 测试集预测结果
├── new_predictions.csv # 新样本预测结果
├── prediction_scatter.png # 散点图
├── true_vs_rounded_pred_heatmap.png # 热力图
├── residual_hist.png # 残差直方图
└── result_summary.png # 结果汇总图 - 总结与改进方向
6.1 总结
本文基于 sklearn 实现了 MLP 红酒品质回归预测,模型轻量化(数MB)、性能优于基线,适合教学和轻量部署。
6.2 改进方向
1 .类别不平衡:对边缘评分样本过采样/调整损失权重;
2 . 模型升级:对比 XGBoost/随机森林,或升级为 TabNet/PyTorch 模型;
3 .特征工程:构造交互项(如 pH×酸度、酒精度×残糖);
4 .任务转换:将回归改为分类(低/中/高档次),评估准确率。
参考文献
1 Cortez, P., et al. (2009). Wine Quality Data Set. UCI Machine Learning Repository.
2 scikit-learn MLPRegressor 官方文档:https://scikit-learn.org/stable/modules/generated/sklearn.neural_network.MLPRegressor.html
3 scikit-learn TransformedTargetRegressor:https://scikit-learn.org/stable/modules/generated/sklearn.compose.TransformedTargetRegressor.html
4 https://www.zhihu.com/question/595477316/answer/3288447234