在深度学习(尤其是 Transformer 架构)中,层标准化 (Layer Normalization) 是确保模型训练稳定的关键。
与其名字相对应的 Batch Normalization (批标准化) 不同,LayerNorm 的核心特征是:它针对单个样本的单个层级进行计算,不依赖于 Batch 中的其他样本。
以下是该公式的详细拆解:
1. 公式构成
y=x−ExVar(x)+ϵ∗w+by = \frac{x - Ex}{\sqrt{Var(x) + \epsilon}} * w + by=Var(x)+ϵ x−Ex∗w+b
-
ExExEx (均值):输入向量的平均值。
-
Var(x)Var(x)Var(x) (方差):输入向量的离散程度。
-
ϵ\epsilonϵ (Epsilon) :极小值(通常为 10−510^{-5}10−5),防止分母为 0 导致计算崩溃。
-
www (权重) 与 bbb (偏置) :可学习的仿射变换参数,允许模型在需要时"恢复"被归一化掉的特征表达能力。www 和 bbb 的维度通常都是
[Hidden Dimension (D)]。也就是说,它们的形状是一个长度为 DDD 的一维向量。
2. 均值和方差是怎么算出来的?
假设你的输入数据 xxx 是一个维度为 Batch Size, Sequence Length, Hidden Dimension 的张量。在 NLP 或 Transformer 中,LayerNorm 通常作用在最后一个维度 (即 Hidden Dimension,记为 ddd)。
对于某一个具体的样本中的某一个 Token(即一个长度为 ddd 的向量):
均值 ExExEx 的计算:
它是该向量所有元素的算术平均值:
Ex=1d∑i=1dxiEx = \frac{1}{d} \sum_{i=1}^{d} x_iEx=d1i=1∑dxi
方差 Var(x)Var(x)Var(x) 的计算:
它是该向量中每个元素偏离均值的程度:
Var(x)=1d∑i=1d(xi−Ex)2Var(x) = \frac{1}{d} \sum_{i=1}^{d} (x_i - Ex)^2Var(x)=d1i=1∑d(xi−Ex)2
前向
python
import torch
import triton
import triton.language as tl
@triton.jit
def _layer_norm_fwd_fused(
X, # 输入指针
Y, # 输出指针
W, # 权重指针
B, # 偏差指针
Mean, # 均值指针
Rstd, # 1/std 指针
stride, # 指针移动一行应该增加多少
N, # X 的列数
eps, # 用于避免除以 0 的 epsilon
BLOCK_SIZE: tl.constexpr,
):
row=tl.program_id(0)
X+=row*stride
Y+=row*stride
#计算均值
mean=0
_mean=tl.zeros([BLOCK_SIZE],dtype=tl.float32)
for off in range(0,N,BLOCK_SIZE):
cols=off+tl.arange(0,BLOCK_SIZE)
a=tl.load(X+cols,mask=cols<N,other=0.0).to(tl.float32)
_mean+=a
mean=tl.sum(_mean,axis=0)/N
#计算方差
_var=tl.zeros([BLOCK_SIZE],dtype=tl.float32)
for off in range(0, N, BLOCK_SIZE):
cols = off + tl.arange(0, BLOCK_SIZE)
x = tl.load(X + cols, mask=cols < N, other=0.).to(tl.float32)
x = tl.where(cols < N, x - mean, 0.)
_var += x * x
var = tl.sum(_var, axis=0) / N
rstd=1/tl.sqrt(var+eps)
tl.store(Mean+row,mean)
tl.store(Rstd+row,rstd)
#归一化并应用线性变换
for off in range(0,N,BLOCK_SIZE):
cols=off+tl.arange(0,BLOCK_SIZE)
mask=cols<N
w=tl.load(W+cols,mask=mask)
b=tl.load(B+cols,mask=mask)
x=tl.load(X+cols,mask=mask,other=0.0).to(tl.float32)
x_hat=(x-mean)*rstd
y=x_hat*w+b
tl.store(Y+cols,y,mask=mask)这段 Triton 代码实现了一个高性能的 Fused LayerNorm Forward Kernel。
它的核心思想是:在一个 GPU 程序(Kernel)中完成"算均值、算方差、归一化、仿射变换"全过程。这样做最大的好处是减少了对显存(HBM)的读写次数。
下面按照计算流程详细拆解:
1. 编程模型:一行一个 Program
python
row = tl.program_id(0)
Y += row * stride
X += row * stride在 Triton 的并行维度上,这个实现选择 program_id(0) 对应输入矩阵的一行。
-
每个实例(Program)独立负责处理一行数据。
-
通过 stride(步长)定位到该行在内存中的起始位置。
2. 计算均值 ExExEx (分块累加)
为了处理可能超过 BLOCK_SIZE 的超长向量,代码使用了循环:
python
_mean = tl.zeros([BLOCK_SIZE], dtype=tl.float32)
for off in range(0, N, BLOCK_SIZE):
cols = off + tl.arange(0, BLOCK_SIZE)
a = tl.load(X + cols, mask=cols < N, other=0.).to(tl.float32)
_mean += a # 将这一个 block 的值加到累加器里
mean = tl.sum(_mean, axis=0) / N # 最后做一次全量求和并除以 N-
并行规约:tl.sum 在 GPU 寄存器级别对当前 block 的元素求和。
-
数值精度:强制转换为 float32 计算,防止在累加过程中出现溢出或精度损失。
3. 计算方差 Var(x)Var(x)Var(x)
有了均值后,再跑一遍循环计算平方差:
python
x = tl.where(cols < N, x - mean, 0.)
_var += x * x
...
var = tl.sum(_var, axis=0) / N
rstd = 1 / tl.sqrt(var + eps) # 计算标准差的倒数(Root Standard Deviation)- Rstd :计算 1/Var+ϵ1/\sqrt{Var + \epsilon}1/Var+ϵ 。使用倒数是为了后续归一化时,可以直接用乘法 (x - mean) * rstd,乘法在硬件上比除法快得多。
4. 归一化与线性变换 (写入结果)
这是最后一步,将公式 y=x−ExVar+ϵ⋅w+by = \frac{x-Ex}{\sqrt{Var+\epsilon}} \cdot w + by=Var+ϵ x−Ex⋅w+b 付诸实现:
python
x_hat = (x - mean) * rstd # 归一化到 (0, 1) 分布
y = x_hat * w + b # 应用可学习的权重 w 和偏置 b
tl.store(Y + cols, y, mask=mask) # 写回显存LayerNorm 反向传播优化与实现
1. 数学推导 (VJP 公式)
反向传播的目标是计算梯度(Vector-Jacobian Product)。
1.1 输入梯度 ∇x\nabla x∇x
对于输入向量 xxx,其梯度计算最为复杂,涉及均值和方差的链式求导。为了简化,引入中间变量 x^=x−Exσ\hat{x} = \frac{x - Ex}{\sigma}x^=σx−Ex(即归一化后的值):
∇x=1σ(∇y⊙w−(1Nx^⋅(∇y⊙w))⏟c1⊙x^−1N∇y⋅w⏟c2)\nabla x = \frac{1}{\sigma} \left( \nabla y \odot w - \underbrace{\left( \frac{1}{N} \hat{x} \cdot (\nabla y \odot w) \right)}{c_1} \odot \hat{x} - \underbrace{\frac{1}{N} \nabla y \cdot w}{c_2} \right)∇x=σ1 ∇y⊙w−c1 (N1x^⋅(∇y⊙w))⊙x^−c2 N1∇y⋅w
-
c1c_1c1 和 c2c_2c2 :行内的标量常数。计算它们需要对整行特征进行 点积 (Dot Product)。
-
σ\sigmaσ :前向传播计算出的标准差(代码中通常存为其倒数
rstd)。
1.2 参数梯度 ∇w\nabla w∇w 与 ∇b\nabla b∇b
权重和偏置的梯度计算相对直接:
-
∇w=∇y⊙x^\nabla w = \nabla y \odot \hat{x}∇w=∇y⊙x^
-
∇b=∇y\nabla b = \nabla y∇b=∇y
2. 核心挑战:并行归约 (Parallel Reduction)
LayerNorm 的参数 www 和 bbb 是全行共享 的。这意味着如果输入有 MMM 行,每一行都会产生一组 ∇w\nabla w∇w 和 ∇b\nabla b∇b。我们需要将这 MMM 组结果累加起来得到最终梯度。
为什么不能直接加?
-
内存竞争:如果成千上万个线程同时向同一个显存地址写数据(Atomic Add),会造成严重的硬件阻塞。
-
L2 缓存优化:直接写回全局显存(HBM)太慢。
3. Triton 优化策略:两阶段归约
为了平衡并行度和内存带宽,教程采用了 分组累加 方案。
第一阶段:局部累加 (_layer_norm_bwd_dx_fused)
-
逻辑 :将所有行分成若干组(由
GROUP_SIZE_M定义)。 -
操作:
-
每个内核实例计算一行的 ∇w\nabla w∇w 和 ∇b\nabla b∇b。
-
利用 锁 (Lock) 机制,将结果累加到所属组的 中继缓冲区 (Intermediate Buffer) 中。
-
-
收益 :这些缓冲区较小,可以常驻在 L2 缓存 中,大幅提升读写速度。
第二阶段:全局聚合 (_layer_norm_bwd_dwdb)
-
逻辑:由另一个 Kernel 启动。
-
操作 :收集所有组的临时缓冲区结果,进行最后的求和,输出最终的 ∇w\nabla w∇w 和 ∇b\nabla b∇b 到全局显存。
第一阶段:_layer_norm_bwd_dx_fused
这一阶段的主要任务是:算出输入梯度 dxdxdx 并写回显存;同时把当前行的 dwdwdw 和 dbdbdb 粗略累加到 L2 缓存对应的组(Buffer)中。
python
@triton.jit
def _layer_norm_bwd_dx_fused(DX, DY, DW, DB, X, W, Mean, Rstd, Lock, stride, N,
GROUP_SIZE_M: tl.constexpr, BLOCK_SIZE_N: tl.constexpr):
# 1. 确定当前线程块(Program)负责处理输入矩阵的哪一行
row = tl.program_id(0)
cols = tl.arange(0, BLOCK_SIZE_N) # 针对这一行,生成列索引
mask = cols < N # 防止列索引越界的掩码
# 2. 将输入/输出指针移动到当前行对应的内存起始位置
X += row * stride
DY += row * stride
DX += row * stride
# 3. 分组与锁机制:根据行号模除组大小,决定该行属于哪一个 L2 缓冲区
lock_id = row % GROUP_SIZE_M
Lock += lock_id # 定位到该组对应的锁地址
Count = Lock + GROUP_SIZE_M # Count 紧跟在 Lock 后面,用来标记该组是否是第一次写入
# 4. 定位到当前组在临时缓冲区 DW/DB 中的写入起始位置(形状为 GROUP_SIZE_M x N)
DW = DW + lock_id * N + cols
DB = DB + lock_id * N + cols
# 5. 从显存(HBM)中读取计算所需的基础数据到 GPU 的寄存器/SRAM
x = tl.load(X + cols, mask=mask, other=0).to(tl.float32)
dy = tl.load(DY + cols, mask=mask, other=0).to(tl.float32)
w = tl.load(W + cols, mask=mask).to(tl.float32)
mean = tl.load(Mean + row) # 读取前向传播存好的均值
rstd = tl.load(Rstd + row) # 读取前向传播存好的标准差倒数
# 6. 【数学公式实现】计算 dx
xhat = (x - mean) * rstd # 核心公式中的 x_hat (归一化后的 x)
wdy = w * dy # 核心公式中的 ∇y ⊙ w
xhat = tl.where(mask, xhat, 0.) # 越界位置清零,防止干扰求和
wdy = tl.where(mask, wdy, 0.) # 同上
# 计算公式中的中间常数 c1 和 c2 (行内点积与求和)
c1 = tl.sum(xhat * wdy, axis=0) / N # c1 = 1/N * ∑(x_hat ⊙ ∇y ⊙ w)
c2 = tl.sum(wdy, axis=0) / N # c2 = 1/N * ∑(∇y ⊙ w)
# 结合 c1, c2 最终算出 dx = 1/σ * (∇y⊙w - c1⊙x_hat - c2)
dx = (wdy - (xhat * c1 + c2)) * rstd
# 7. 将计算好的 dx 独立写回显存(不需要加锁,因为每行只有一个线程块在写)
tl.store(DX + cols, dx, mask=mask)
# 8. 【第一阶段归约】准备累加当前行产生的偏导数 dw 和 db
partial_dw = (dy * xhat).to(w.dtype) # 当前行对 w 的梯度贡献:∇y ⊙ x_hat
partial_db = (dy).to(w.dtype) # 当前行对 b 的梯度贡献:∇y
# 自旋锁(Spinlock):尝试将 Lock 从 0 改为 1。如果返回 1 说明锁被别人占了,死循环等待
while tl.atomic_cas(Lock, 0, 1) == 1:
pass
# 成功拿到锁,读取计数器
count = tl.load(Count)
# 如果 count == 0,说明当前内核实例是这个组里的第一个到访者
if count == 0:
tl.atomic_xchg(Count, 1) # 将计数器安全地设为 1,代表缓冲区已被占领
# 注意:此时不需要读取 DW/DB 里的历史旧数据,因为里面全是上一次迭代的残余垃圾
else:
# 如果不是第一个,说明前面已经有同组的行把梯度写进去了,先读取出来叠加到当前梯度上
partial_dw += tl.load(DW, mask=mask)
partial_db += tl.load(DB, mask=mask)
# 将累加好的最新部分和写回 L2 缓存中的临时缓冲区
tl.store(DW, partial_dw, mask=mask)
tl.store(DB, partial_db, mask=mask)
# 释放锁:把 Lock 重新变回 0,让其他同组的行可以进来写
tl.atomic_xchg(Lock, 0)内存布局:Lock 与 Count 在显存中的真实结构
python
lock_id = row % GROUP_SIZE_M
Lock += lock_id # 定位到该组对应的锁地址
Count = Lock + GROUP_SIZE_M # Count 紧跟在 Lock 后面,用来标记该组是否是第一次写入在 Triton 的外部调用中,其实预先分配了两块连续的全局内存(Global Memory):一条用来做互斥锁(Lock),一条用来做计数器(Count)。
但在具体实现时,为了省去传入两个指针的开销,作者把它们合在了一起。Lock 指针指向的内存实际上是一个长度为 2 * GROUP_SIZE_M 的整型数组:
Text
内存地址偏移: [ 0, 1, 2, ... GROUP_SIZE_M-1 | GROUP_SIZE_M, ... 2*GROUP_SIZE_M-1 ] 对应功能: [ ----- 互斥锁 (Lock) ----- ] [ ------- 状态计数器 (Count) ------- ]Lock += lock_id:让当前线程(Program)定位到属于自己的那一个锁的内存地址。Count = Lock + GROUP_SIZE_M:根据上面的内存布局,指针向后移动GROUP_SIZE_M个位置,正好落在了对应组的Count(状态计数器)的内存地址上。
核心逻辑:解决多个 Thread Block 并发写入同一个显存地址的冲突
在 Triton 中,前向传播一行对应一个 Program(即一个 Thread Block)。反向传播时,我们需要计算权重梯度 dw,它的形状是 (N,)。
假设输入有 M=1024M=1024M=1024 行,意味着有 1024 个 Thread Block 会并行计算出 1024 个形状为 (N,) 的局部 dw。但最终输出的 FINAL_DW 只有一个 (N,)。
如果让 1024 个 Block 同时用 tl.store 往同一个地址写数据,后写的会覆盖先写的。为了解决这个写冲突,引入了分组锁机制:
-
第 0 行、第 16 行、第 32 行......它们算出来的
lock_id都是 0。 -
这意味着,这几十个行实例,必须把它们算出来的梯度,写进同一个临时缓冲区(0号缓冲区)里去累加。
python
# 自旋锁:使用硬件级原子操作 CAS (Compare-And-Swap)
# 尝试将 Lock 地址的值从 0 改为 1。如果该地址已经是 1,说明别的 Block 正在写入,CAS 会返回 1
# 此时当前 Block 会进入 while 死循环(自旋等待),直到占有的 Block 把值改回 0
while tl.atomic_cas(Lock, 0, 1) == 1:
pass一旦 atomic_cas 返回 0,代表当前 Block 成功抢到了该组的互斥权,可以安全地操作对应组的临时缓冲区 DW(形状为 GROUP_SIZE_M * N):
-
如果
count == 0:说明当前 Block 是第一个 访问该临时缓冲区的线程。此时不需要读取里面的历史值(因为里面是上一个 Batch 残留的脏数据),直接把当前算出的梯度写进去(store),并用tl.atomic_xchg(Count, 1)将计数器设为 1。 -
如果
count == 1:说明之前已经有同组的 Block 进去写过数据了。此时必须先执行tl.load(DW)把里面的累加值读出来,加上自己当前的梯度,再tl.store(DW)写回去。 -
最后 :用
tl.atomic_xchg(Lock, 0)把锁位置释放(改回 0),允许排队等待的下一个 Block 进来。
关于 L2 缓存控制的硬核真相
L2 缓存是硬件控制的,程序员无法通过软件指令指定某个变量"写入 L2"。
但是,GPU 的 L2 缓存硬件是用 LRU(最近最少使用) 或其变体算法来管理的。硬件的核心逻辑是:监测物理内存地址的访问频率。
这就是为什么代码不直接开辟一个 (M, N) 形状的巨型缓冲区(为每行分配一个空间),而是开辟一个 (GROUP_SIZE_M, N) 的小型临时缓冲区(例如 GROUP_SIZE_M = 16):
-
如果开辟
(M, N)缓冲区(假设 M=1024,N=4096M=1024, N=4096M=1024,N=4096),整个缓冲区大小为 1024×4096×4字节=16MB1024 \times 4096 \times 4 \text{字节} = 16\text{MB}1024×4096×4字节=16MB。随着线程交替写入,每个地址只会被访问一次。这超过了 L2 的缓存行置换极限,数据会频繁地掉进 HBM(显存),产生巨大的内存带宽开销。 -
如果限制缓冲区为
(16, N),大小仅为 16×4096×4字节=256KB16 \times 4096 \times 4 \text{字节} = 256\text{KB}16×4096×4字节=256KB。1024 个 Block 会分成 16 组,高频、反复、密集地抢占并读写这固定的 256KB 内存空间。
GPU 的存储管理单元(MMU)在硬件层面上检测到这 256KB 的地址空间正处于极高密度的"读-改-写"状态,就会自动将其标记为热点,常驻在 L2 缓存中不进行换出。
这就是算子优化中所谓的 "Hardware-friendly"(硬件友好) 编程。代码不指挥 L2 缓存,而是通过控制内存边界和访问频率,强迫硬件做出最有利于性能的缓存置换选择。
第二阶段:_layer_norm_bwd_dwdb
这一阶段由一个新的 Kernel 启动。它的任务是:把第一阶段留在临时缓冲区(L2 Cache)中的几组 GROUP_SIZE_M 局部梯度彻底加在一起,输出最终的 ∇w\nabla w∇w 和 ∇b\nabla b∇b。
python
@triton.jit
def _layer_norm_bwd_dwdb(DW, DB, FINAL_DW, FINAL_DB, M, N,
BLOCK_SIZE_M: tl.constexpr, BLOCK_SIZE_N: tl.constexpr):
# 1. 确定当前线程块负责最终 $w$ 和 $b$ 向量的哪一段列区间 (Cols)
pid = tl.program_id(0)
cols = pid * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)
# 2. 在寄存器中初始化用于累加最终梯度的二维全零矩阵
dw = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)
db = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)
# 3. 纵向循环遍历:把第一阶段产出的所有组(共 M 组,即第一阶段的 GROUP_SIZE_M)的数据拉出来
for i in range(0, M, BLOCK_SIZE_M):
rows = i + tl.arange(0, BLOCK_SIZE_M) # 当前迭代要处理的"组"索引
# 构建二维掩码,保证组索引不越界(rows < M)且列索引不越界(cols < N)
mask = (rows[:, None] < M) & (cols[None, :] < N)
# 计算在二维临时缓冲区中的偏移量
offs = rows[:, None] * N + cols[None, :]
# 将局部缓冲区中的值加载并累加到寄存器 dw 和 db 中
dw += tl.load(DW + offs, mask=mask, other=0.)
db += tl.load(DB + offs, mask=mask, other=0.)
# 4. 沿行方向(axis=0)进行最后的求和,把二维的块压扁成一维的一段特征
sum_dw = tl.sum(dw, axis=0)
sum_db = tl.sum(db, axis=0)
# 5. 将这群策群力、最终汇聚而成的全局梯度写回到最后的显存中(FINAL_DW / FINAL_DB)
tl.store(FINAL_DW + cols, sum_dw, mask=cols < N)
tl.store(FINAL_DB + cols, sum_db, mask=cols < N)性能测试
LayerNorm(torch.autograd.Function)
这个类负责将 Python 端的张量操作映射到 Triton 内核上。
python
class LayerNorm(torch.autograd.Function):
@staticmethod
def forward(ctx, x, normalized_shape, weight, bias, eps):
# allocate output
# 分配输出
y = torch.empty_like(x)
# reshape input data into 2D tensor
# 将输入数据的形状改为 2D 张量
x_arg = x.reshape(-1, x.shape[-1])
M, N = x_arg.shape
mean = torch.empty((M, ), dtype=torch.float32, device=x.device)
rstd = torch.empty((M, ), dtype=torch.float32, device=x.device)
# Less than 64KB per feature: enqueue fused kernel
# 少于 64KB 每个特征:入队融合内核
MAX_FUSED_SIZE = 65536 // x.element_size()
BLOCK_SIZE = min(MAX_FUSED_SIZE, triton.next_power_of_2(N))
if N > BLOCK_SIZE:
raise RuntimeError("This layer norm doesn't support feature dim >= 64KB.")
# heuristics for number of warps
# 对 warp 数量的启发算法
num_warps = min(max(BLOCK_SIZE // 256, 1), 8)
# enqueue kernel
# 入队内核
_layer_norm_fwd_fused[(M, )]( #
x_arg, y, weight, bias, mean, rstd, #
x_arg.stride(0), N, eps, #
BLOCK_SIZE=BLOCK_SIZE, num_warps=num_warps, num_ctas=1)
ctx.save_for_backward(x, weight, bias, mean, rstd)
ctx.BLOCK_SIZE = BLOCK_SIZE
ctx.num_warps = num_warps
ctx.eps = eps
return y
@staticmethod
def backward(ctx, dy):
x, w, b, m, v = ctx.saved_tensors
# heuristics for amount of parallel reduction stream for DW/DB
# 计算对 DW/DB 并行规约流数量的启发算法
N = w.shape[0]
GROUP_SIZE_M = 64
if N <= 8192: GROUP_SIZE_M = 96
if N <= 4096: GROUP_SIZE_M = 128
if N <= 1024: GROUP_SIZE_M = 256
# allocate output
# 分配输出
locks = torch.zeros(2 * GROUP_SIZE_M, dtype=torch.int32, device=w.device)
_dw = torch.zeros((GROUP_SIZE_M, N), dtype=x.dtype, device=w.device)
_db = torch.zeros((GROUP_SIZE_M, N), dtype=x.dtype, device=w.device)
dw = torch.empty((N, ), dtype=w.dtype, device=w.device)
db = torch.empty((N, ), dtype=w.dtype, device=w.device)
dx = torch.empty_like(dy)
# enqueue kernel using forward pass heuristics
# 使用前向传播启发算法入队内核
# also compute partial sums for DW and DB
# 同样用于计算 DW 和 DB 的部分和
x_arg = x.reshape(-1, x.shape[-1])
M, N = x_arg.shape
_layer_norm_bwd_dx_fused[(M, )]( #
dx, dy, _dw, _db, x, w, m, v, locks, #
x_arg.stride(0), N, #
BLOCK_SIZE_N=ctx.BLOCK_SIZE, #
GROUP_SIZE_M=GROUP_SIZE_M, #
num_warps=ctx.num_warps)
grid = lambda meta: [triton.cdiv(N, meta['BLOCK_SIZE_N'])]
# accumulate partial sums in separate kernel
# 在单独的内核中累加部分和
_layer_norm_bwd_dwdb[grid](
_dw, _db, dw, db, min(GROUP_SIZE_M, M), N, #
BLOCK_SIZE_M=32, #
BLOCK_SIZE_N=128, num_ctas=1)
return dx, None, dw, db, Noneforward 核心逻辑:
-
多维变二维 :
x.reshape(-1, x.shape[-1])。因为 LayerNorm 只在最后一个维度归一化,通过reshape(-1, N)可以把任何形状(如[B, L, D])压扁成[M, N]二维矩阵。每一行是一个独立的特征向量。 -
内存分配 :
mean和rstd被提前分配空间(大小为M),用于存储前向传播每行的均值和标准差倒数。 -
保存上下文 :
ctx.save_for_backward(...)极为关键!它把反向传播需要的x, weight, bias, mean, rstd缓存起来。正如前面所说,如果不存mean和rstd,反向传播就得重算一遍,拖慢速度。
backward 核心逻辑:
GROUP_SIZE_M 到底是怎么确定的,以及临时缓冲区在哪里分配。
python
N = w.shape[0]
GROUP_SIZE_M = 64
if N <= 8192: GROUP_SIZE_M = 96
if N <= 4096: GROUP_SIZE_M = 128
if N <= 1024: GROUP_SIZE_M = 256-
启发式调优(Heuristics) :根据特征维度 NNN 的大小,动态调整第一阶段归约的组数
GROUP_SIZE_M。-
NNN 越小(比如 1024),意味着每行的计算量越小,硬件冲突的概率更高,因此开辟更多分组 (256组) 来分散排队压力。
-
NNN 越大(比如 8192),每行计算时间长,且占用临时空间大,因此缩减为 96组。
-
-
分配第二阶段缓冲区:
-
locks = torch.zeros(2 * GROUP_SIZE_M, ...):分配我们在上一轮分析过的、连在一起的Lock和Count数组。 -
_dw, _db:大小为(GROUP_SIZE_M, N),就是那个会常驻在 L2 缓存中的临时梯度缓冲区。
-
-
两阶段调用:
-
第一步:启动
_layer_norm_bwd_dx_fused网格,大小为(M, )。 -
第二步:启动
_layer_norm_bwd_dwdb,利用grid = lambda meta: ...动态计算需要多少个 Block 来纵向收割合并这GROUP_SIZE_M组临时数据。
-
正确性校验:test_layer_norm
python
y_tri = layer_norm(x, w_shape, weight, bias, eps)
y_ref = torch.nn.functional.layer_norm(x, w_shape, weight, bias, eps).to(dtype)-
它使用 PyTorch 原生的标准 LayerNorm 作为黄金标准(Reference,即
y_ref)。 -
让它们使用相同的随机输入 x,w,bx, w, bx,w,b 跑前向和反向。
-
最后使用
torch.allclose(..., atol=1e-2)检查 Triton 算出的结果(y,dx,dw,db)与官方标准库的误差是否在 10−210^{-2}10−2 以内。如果通过,说明你的底层硬件算子写对了。
跑分与性能评估:bench_layer_norm
带宽计算公式 (GB/s):
GPU 的 LayerNorm 是典型的内存受限(Memory-Bound)任务,因此衡量它性能的指标不是 TFLOPs(算力),而是 GB/s(显存吞吐带宽)。
-
前向传播带宽 :
2 * x.numel() * x.element_size() / ms * 1e-6- 乘 2 是因为:读一次 xxx,写一次 yyy。
-
反向传播带宽 :
3 * x.numel() * x.element_size() / ms * 1e-6- 乘 3 是因为:读一次 xxx、读一次 dydydy、写一次 dxdxdx(这里简化了 www 和 bbb 的读写,因为 xxx 才是大头)。
带宽比拼 (provider):
测试代码会同时对以下三者进行压力测试,并画出吞吐量曲线:
-
triton:你手写的这个两阶段归约优化内核。 -
torch:PyTorch 自带的官方实现。 -
apex:NVIDIA 官方早期推出的针对 CUDA 极致优化的混合精度加速库(NVIDIA Apex FusedLayerNorm)。
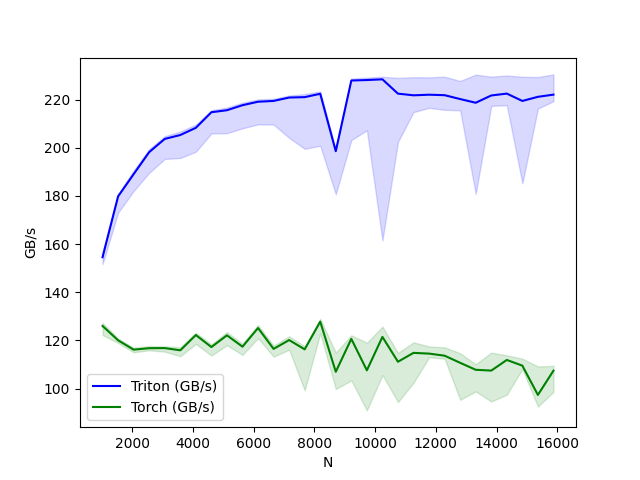
运行最后的 bench_layer_norm.run() 后,你会看到一张图表。
不过由于个人环境没下Apex,只有两个结果
原子操作
tl.atomic_cas (Compare-And-Swap / 比较并交换)
python
def atomic_cas(
pointer: Any,
cmp: Any,
val: Any,
sem: Any | None = None,
scope: Any | None = None,
_semantic: Any | None = None
) -> Any这是实现并发锁(Lock)最核心的原子操作。它的核心逻辑是:"如果当前内存的值是我预期的值,就把它改成新值;无论改没改成功,都把旧值还给我。"
参数含义
-
pointer: 目标内存地址的指针(在代码中就是Lock的地址)。 -
cmp: 预期值/比较值(Compare)。即你认为现在内存里应该是什么值(代码中是0,代表锁空闲)。 -
val: 新值(Value)。如果匹配成功,想要写入的新值(代码中是1,代表加锁)。 -
sem/scope(可选): 控制 GPU 缓存一致性的内存屏障范围(通常内部默认处理,高阶优化时调整)。
返回值(最关键)
- 返回的是该内存地址在执行此操作"之前"的旧值(Old Value)。
结合代码看死循环逻辑
python
while tl.atomic_cas(Lock, 0, 1) == 1:
pass-
场景 A:锁当前是空闲的(内存里的真实值是
0)atomic_cas看到内存是0,与我们的cmp=0匹配成功。- 硬件自动将内存的值改为
val=1(成功加锁)。 - 函数返回旧值
0。 while 0 == 1为 False,循环结束,当前线程成功进入临界区。
-
场景 B:锁正在被别人占用(内存里的真实值是
1)atomic_cas看到内存是1,与我们的cmp=0不匹配。- 硬件拒绝修改,内存依然保持
1。 - 函数返回旧值
1。 while 1 == 1为 True,触发pass,线程继续循环,直到占有锁的线程释放它。
tl.atomic_xchg (Atomic Exchange / 原子交换)
python
def atomic_xchg(
pointer: Any,
val: Any,
mask: Any | None = None,
sem: Any | None = None,
scope: Any | None = None,
_semantic: Any | None = None
) -> Any它的核心功能是:"无条件地将新值写入内存,强行霸占,并把被你踢出来的旧值还给你。"
参数含义
pointer: 目标内存地址的指针(代码中是Count或Lock)。val: 强行写入的新值(代码中释放锁时写0,独占计数器时写1)。mask(可选): 掩码。哪些通道需要执行此操作。
返回值
- 同样返回该内存地址在写入之前的旧值。