
我读完 DeepSeek-Reasonix 之后,最大的感受是:这个项目真正厉害的地方,不是"用了 DeepSeek 的 KV Cache",而是把整个 Agent Loop 都设计成了 DeepSeek prefix cache 最喜欢的形状。
很多人一看到 99%+ cache hit,会下意识以为项目里用了什么隐藏的缓存 API。其实不是。DeepSeek 本身就有自动 prefix cache;Reasonix 做的是另一件事:让每一轮请求的前缀尽可能字节级稳定。
所以它的高命中率不是一个单点技巧,而是一套工程纪律:系统提示词不乱动,工具列表不乱动,历史消息不重排,临时推理不污染上下文,工具结果按确定顺序追加,长上下文只在受控边界折叠。
换句话说:
DeepSeek 给了你可缓存的能力,Reasonix 负责让输入真的长得像"可以被缓存"的输入。
先说清楚:这里的 KV Cache 指的是什么
这里说的"KV cache 命中 99.5%+",更准确地讲,是 DeepSeek API usage 里的 prompt cache hit token ratio,不是模型内部 GPU 显存里的 KV cache 压缩率。
DeepSeek 的上下文缓存默认开启。后续请求如果和之前请求有重叠前缀,重叠部分会被视为 cache hit,并在 usage 里返回:
prompt_cache_hit_tokensprompt_cache_miss_tokens
这意味着 cache hit 的关键不是"语义相似",而是请求前缀能不能被复用。
DeepSeek 官方文档给出的模式很像这样:
text
第一次请求:A + B
第二次请求:A + B + C第二次请求里的 A + B 就有机会命中缓存。
但如果你每一轮都让 A 发生一点点变化,后面的 B + C + D 再长也没用,因为前缀已经断了。
这就是普通 Agent 很难吃满 DeepSeek cache 的原因。
真实数据:为什么这个项目让人眼前一亮
Reasonix 仓库里有一个真实用户单日数据:
| 类型 | Tokens |
|---|---|
| Input --- cache hit | 435,033,856 |
| Input --- cache miss | 767,616 |
| Output | 179,763 |
| Day total | 435,981,235 |
输入侧 cache hit ratio 是:
text
435,033,856 / (435,033,856 + 767,616) = 99.82%这个数字非常夸张。
如果按项目里的 v4-flash 价格估算,这一天总成本约 1.38∗∗;如果完全没有缓存,同等输入会约∗∗61.06。
也就是说,真正节省成本的不是"模型便宜"这一个因素,而是 长会话里绝大部分输入都变成了 cache hit。
这也是 Reasonix 这个项目值得学习的地方:它不是简单接了一个便宜模型,而是围绕模型的计费结构重新设计了 Agent 运行时。
Reasonix 的哲学:DeepSeek 原生,而不是通用 LLM SDK
Reasonix 的架构文档开头写得很直白:
Reasonix is opinionated, not general.
它不是一个通用 Agent 框架,不追求"所有模型都能接"。它的每个抽象都必须服务于 DeepSeek 的行为或经济属性。项目北极星也很明确:
coding agent that stays cheap enough to leave on.
也就是:一个便宜到可以一直开着的 coding agent。
这句话很重要。
很多 Agent 框架追求的是"多模型兼容":OpenAI、Claude、DeepSeek、Gemini 都能接。但通用抽象通常会带来一个问题:框架内部会把消息、工具、历史记录、系统提示词抽象成一种"通用形状",然后每次请求前再序列化成目标模型需要的格式。
这个过程很容易产生微小但致命的漂移:
- 工具顺序变了
- schema 序列化变了
- 系统提示词里插了新时间戳
- 历史消息被压缩重写
- 工具结果按完成时间写入,而不是按模型声明顺序写入
- 临时 plan state 被塞回上下文
对普通调用来说,这些变化可能无所谓。
但对 DeepSeek prefix cache 来说,这些变化就是灾难。
Reasonix 的哲学不是"我也支持 DeepSeek",而是:
我先承认 DeepSeek 的缓存机制、工具调用习惯、计费结构都很特殊,然后围绕这些特殊性设计运行时。
为什么普通 Agent 命中率低?

一个普通 coding agent 的 prompt 往往是这样拼出来的:
text
系统提示词
工具定义
用户目标
历史对话
工具调用
工具结果
临时计划
模型思考摘要
时间戳
当前状态如果每一轮都把这些内容重新拼一遍,那么其中任何一段发生变化,DeepSeek 都很难把旧前缀识别成同一个前缀。
尤其 coding agent 的上下文很长:工具 schema 大、历史工具结果多、文件内容多、错误重试多。只要前面一点点字节漂移,后面几十万 token 都可能从 hit 变成 miss。
很多框架会做这些看似合理、但对 prefix cache 很不友好的操作:
text
每轮重新生成系统提示词
每轮重新排序工具列表
把工具结果按返回时间写入历史
把旧消息 summarize 后替换中间历史
把隐藏 plan state 插回消息列表
把失败工具调用改写成更干净的消息这些动作都会破坏一个关键性质:
text
第 N+1 轮请求 = 第 N 轮请求 + 新增内容Reasonix 的核心就是要尽可能守住这个性质。
第一根柱子:Cache-First Loop

Reasonix 把上下文分成三个区域:
text
IMMUTABLE PREFIX
system + tool_specs + few_shots
APPEND-ONLY LOG
assistant₁ / tool₁ / assistant₂ / tool₂ ...
VOLATILE SCRATCH
R1 thought / transient plan state这三个区域分别解决三个问题:
- 最前面的系统提示词、工具定义、few-shot 示例必须固定
- 中间的历史消息只能追加,不能重排、不能随便改写
- 临时推理和计划状态不能污染下一轮上下文
这就是它的 Cache-First Loop。
1. ImmutablePrefix:把最贵、最容易漂移的部分钉死
ImmutablePrefix 持有三类内容:
- system prompt
- tool specs
- few shots
源码里有一个很关键的注释:每次 addTool 都会带来一次 cache miss,因为 DeepSeek 的 prefix cache 和完整工具列表有关。
这说明作者很清楚一件事:tools 也是 prompt 前缀的一部分。
很多人只关注 messages,却忽略 tools 参数。如果工具 schema 每轮重新生成、顺序不稳定、MCP 工具热插拔不受控,那么 DeepSeek 看到的就不是同一个前缀。
Reasonix 做了几件很工程化的事:
第一,ImmutablePrefix 只允许通过受控方法替换 system 或增删工具。
第二,每次 system 或 tools 变化,都会让 fingerprint 失效。
第三,它会基于 system、tools、few shots 计算 SHA-256 指纹,并提供 verifyFingerprint() 检查漂移。
第四,取工具列表时返回 clone,而不是原对象引用,降低外部代码误改工具定义的概率。
这不是代码洁癖,而是为了一个目标:
让 session 里最前面的那一大块字节长期不变。
2. AppendOnlyLog:历史只增长,不重排,不就地编辑
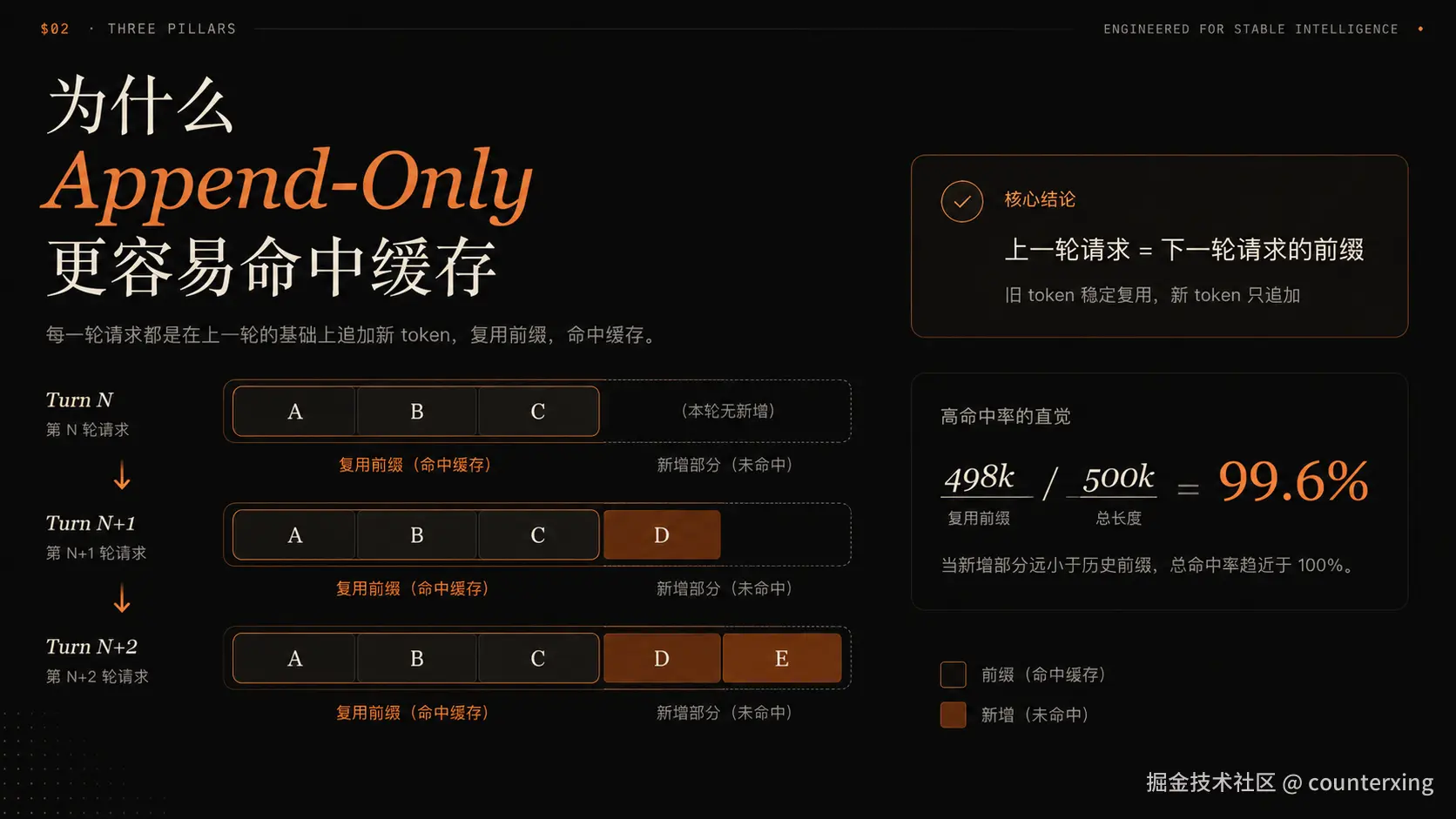
第二个关键类是 AppendOnlyLog。
它的核心规则很简单:日常情况下只允许 append。
这对 prefix cache 极其重要。DeepSeek 最喜欢的请求形态是:
text
第 N 轮请求:A + B + C
第 N+1 轮请求:A + B + C + D
第 N+2 轮请求:A + B + C + D + E这样从第二轮开始,绝大部分旧 token 都可以命中。
普通 Agent 很容易把历史变成这样:
text
第 N 轮请求:A + B + C
第 N+1 轮请求:A + B' + D
第 N+2 轮请求:A' + B'' + D + E看起来内容差不多,但对 cache 来说已经不是同一个前缀了。
Reasonix 的 log 设计就是让历史尽量保持"上一轮是下一轮前缀"的形状。
它不是完全不改历史,而是把改历史变成少数、显式、可控的事件。日常 loop 里,坚持 append-only。
3. VolatileScratch:临时推理不要污染下一轮缓存
第三个区域是 VolatileScratch。
这里放的是:
- R1 thought
- transient plan state
- 临时 notes
这些东西每轮 reset,而且不会直接发给上游。
这背后的思想是:模型每轮的隐藏推理、临时计划、修复状态,很多只是当轮有用。如果把它们作为普通消息塞回历史,会产生两个问题:
第一,内容巨大,会扩大未来 prompt。
第二,内容不稳定,会让前缀不断变化。
所以 Reasonix 把"需要保留的事实"和"当轮临时思考"分开。
临时思考进入 scratch;真正需要进入历史的内容,要经过工具调用、repair、summary 等机制,变成稳定、可复用的 log 内容。
这也是它所谓 R1 Thought Harvest 的含义:不是把思维链全部塞进上下文,而是从 DeepSeek/R1 可能乱放的位置里,把有用的结构化意图捞出来,再以稳定形式进入工具调用流程。
第二根柱子:Tool-Call Repair 不是附属功能,而是缓存稳定性的保护层

表面看,Tool-Call Repair 是为了解决 DeepSeek 工具调用不稳的问题。
但我读源码后的感受是,它还有一个更深的作用:
减少 Agent 因工具调用失败而产生的上下文抖动。
Reasonix 的 repair pipeline 是:
text
schema flatten → scavenge → truncation repair → storm breaker1. Flatten:复杂工具 schema 先摊平,调用后再还原
DeepSeek 在复杂 schema 下可能丢参数。Reasonix 的处理方式是:
- schema 超过 2 层
- 或者 leaf 参数超过 10 个
就把 schema 展平成 dot path。
例如原来可能是:
json
{
"user": {
"profile": {
"name": "..."
}
}
}展平后变成:
json
{
"user.profile.name": "..."
}模型按扁平字段填参数,dispatch 前再 re-nest 回原来的嵌套对象。
这件事对缓存有什么关系?关系很大。
工具调用如果老失败,模型就会反复重试、解释、修正,日志里会塞入大量失败消息;这些消息既增加 token,也制造不稳定尾部。
Flatten 提高一次成功率,间接让 append-only log 更干净。
2. Scavenge:从 reasoning/content 里捞回模型本来想调用的工具
DeepSeek/R1 有时会把 tool-call JSON 放进 reasoning_content,但没有放到标准 tool_calls 字段。
Reasonix 不会直接放弃这次工具调用,而是扫描 reasoning 和 content 两个通道,把里面的 DSML invoke blocks 或 raw JSON 对象转成真正的 ToolCall。
这很有 DeepSeek 原生味道。
它不是假装所有模型都完美遵守 OpenAI tool call 格式,而是承认 DeepSeek/R1 的输出习惯,然后在 loop 里吸收这些偏差。
这也是为什么它能稳定运行:模型偏了,运行时把它拉回来;而不是让偏差扩散成更多重试和更多上下文污染。
3. Truncation 与 Storm:让错误不要扩散成上下文污染
Repair pipeline 还会尝试修复被截断的 JSON 参数。
如果修不了,它不会默默用 {} 执行,而是保留原始参数,让工具层返回明确的 invalid JSON。
这是一种"宁可失败得清楚,也不要成功得错误"的选择。
Storm breaker 则会过滤重复工具调用,避免相同 (tool, args) 在滑动窗口里反复出现。
对 coding agent 来说,这能防止一种很常见的循环:
text
读同一个文件
没理解
再读同一个文件
还是没理解
继续读同一个文件这种循环不仅浪费时间,也会把上下文撑爆。
所以 Tool-Call Repair 的价值不只是"工具更准",也是"日志更稳定"。一个稳定的 Agent 才可能有稳定的缓存命中。
第三根柱子:并行工具调用也要保持确定性

很多 Agent 为了快,会把多个工具并发执行。
问题是,如果并发结果按完成时间写回历史,那么每轮日志顺序就会变成不确定的:网络快慢、文件大小、机器负载都会改变消息顺序。
对 prefix cache 来说,这也是前缀漂移。
Reasonix 的 dispatch 做得很克制:
- 每个工具可以声明
parallelSafe - 默认不是 parallel safe
- 只把连续的 parallel-safe 调用组成 chunk
- 非 parallel-safe 调用成为串行 barrier
- chunk 内可以并行执行
- 但工具结果写回历史时,仍然按模型声明顺序 append
这点很漂亮:
运行可以并发,历史必须确定。
这就是 Reasonix 工程哲学的一种缩影:不是为了缓存牺牲所有体验,而是在速度和确定性之间做边界清晰的设计。
长上下文怎么办?Auto-compact 不是反缓存,而是"受控破坏"
你可能会问:如果 append-only log 一直增长,迟早会爆上下文。那它怎么兼顾长 session 和 cache?
答案是:Reasonix 会 compact,但 compact 是受控的。
它不是每轮都压缩,而是在上下文压力到一定程度之后才 fold。
fold 的过程大概是:
- 估算当前上下文 token
- 判断是否超过阈值
- 按 token 预算保留最近 tail
- 尽量在 user message 边界切开
- 把旧 head 总结成一个 synthetic assistant message
- 接上 tail
- 之后继续保持稳定
这看起来违反 append-only,但它是"少数、显式、可解释"的违反。
普通框架的问题是:
text
每轮都轻微漂移 → 持续 missReasonix 的策略是:
text
平时完全稳定 → 偶尔明确 fold → fold 后重新稳定长期看,第二种更容易出现极高累计命中率。
而且它的 summary instruction 很保守:要求保留用户原始目标、负面约束、决策、看过或改过的文件、仍相关的工具结果和 open todos,不要做逐轮流水账。
这说明它不是为了省 token 粗暴摘要,而是为了把"未来仍需要命中的语义状态"压成稳定文本。
为什么能到 99%+?核心是"大部分 token 都是旧前缀"
高命中率的数学原因其实很简单。
假设一个 coding session 已经很长,当前请求里有 500,000 input tokens。
其中:
- 498,000 tokens 来自稳定的 system、tools、few shots、历史 log 和折叠摘要
- 2,000 tokens 是当前用户新输入或新工具结果
只要前 498,000 tokens 和上一轮完全一致,那么本轮输入侧命中率就是:
text
498,000 / 500,000 = 99.6%所以 Reasonix 的工作不是"让新 token 命中"。新 token 本来就不可能命中。
它的工作是:
让旧 token 不要因为工程抖动变成 miss。
这也解释了为什么真实案例能到 99.82%。当一天里累计输入达到 4.35 亿 hit tokens,而 miss 只有 76.8 万 tokens 时,说明大部分请求都在重复利用极长、稳定的旧前缀。
仓库里的 τ-bench-lite 也提供了一个较小规模的对照:
| metric | baseline | reasonix | delta |
|---|---|---|---|
| pass rate | 100% | 100% | +0pp |
| cache hit | 32.8% | 90.2% | +57.4pp |
| mean cost / task | $0.000992 | $0.000593 | ×0.60 |
这个 benchmark 的意义不是证明所有场景都 99%,而是说明:
同样的任务,同样的 DeepSeek cache,client loop 的形状会显著影响命中率。
它到底"原生"在哪里?
我会把 Reasonix 的 DeepSeek 原生性总结成四层。
第一层:经济原生
它不是把 DeepSeek 当成便宜 OpenAI 替代品,而是把 DeepSeek 的缓存计费差异当作产品基础。
项目自己的 benchmark 说得很直接:
cache 是 DeepSeek 的,但 hit rate 是 client 的。
同一个 API,不同 client 的命中率可能完全不同。
第二层:协议原生
它显式读取 DeepSeek usage 里的 cache hit/miss tokens,并围绕这个指标做 UI 和成本统计。
成本函数也直接用:
text
cache hit tokens × hit price
cache miss tokens × miss price
completion tokens × output price这不是一个附属统计,而是产品体验的一部分。
第三层:行为原生
它承认 DeepSeek/R1 的工具调用可能有自己的偏差:
- tool call 出现在 reasoning/content
- 复杂 schema 可能掉参数
- JSON 可能截断
- 相同工具可能重复调用
所以它做了 flatten、scavenge、truncation repair、storm breaker。
这不是通用 SDK 思路,而是模型行为适配思路。
第四层:上下文原生
它知道 DeepSeek prefix cache 要的是稳定前缀,所以把 prefix、log、scratch、dispatch、compaction 都设计成服务于稳定字节序列。
这四层合起来,才是"DeepSeek 原生"。
对我们做 Agent 产品有什么启发?
我觉得最值得借鉴的不是代码,而是下面五条设计原则。
1. 把 prompt 构造从"函数"升级成"状态机"
普通做法是每轮调用:
text
buildPrompt(state)Reasonix 的做法更像:
text
session start: 固定 prefix
每一轮: append log
必要时: 受控 foldprompt 不再是每次重新生成的字符串,而是一个有不变量的运行时结构。
2. 工具定义要有稳定身份
工具 schema 的顺序、内容、序列化都应该稳定。
MCP 工具热插拔、动态工具注册、权限变化,都要被视为会导致 cache miss 的重大事件,而不是普通小改动。
3. 并发结果不能按完成时间写历史
并发执行可以,但 history append 必须按模型声明顺序。
否则你以为自己只是优化 latency,实际上是在制造 prefix nondeterminism。
4. 隐藏状态不要随便进入消息历史
模型思考、临时计划、repair notes、debug 信息,都要分清楚:
- 哪些只是当轮 scratch
- 哪些是未来需要保留的事实
把所有东西都塞进上下文,是低命中率和高成本的共同来源。
5. Compaction 要少做、晚做、可解释地做
摘要不是简单"压缩聊天记录",而是一次 prefix rewrite。
既然它会破坏缓存连续性,就必须在阈值、边界、保留内容上很谨慎。
Reasonix 的 fold 之所以可接受,是因为它平时不乱写,到了上下文压力点才写,并且写完后继续稳定。
也要看清边界
Reasonix 的 99.82% 是一个真实单日案例,但不是任何情况下都保证。
DeepSeek 的 cache 是 best-effort,不保证 100%,缓存也可能被自动清理。
这些情况都会带来 miss:
- 新 session
- 刚启动的前几轮
- system prompt 变化
- tool list 变化
- MCP 工具热插拔
- compact 发生的那一轮
- 服务端缓存被清理
另外,99%+ 通常发生在 长 session、长前缀、少漂移 的条件下。
短对话里本来就没有多少旧 token 可复用,命中率不可能神奇地很高。
τ-bench-lite 里 Reasonix 是 90.2%,而真实长会话是 99.82%,这两个数字并不矛盾:越长、越稳定,旧前缀占比越大,命中率越接近 100%。
结论
Reasonix 的设计哲学可以用一句话概括:
它不是在 Agent 上"加了缓存",而是把 Agent 改造成 DeepSeek prefix cache 最喜欢的形状。
这个形状有几个硬约束:
text
system / tools / few-shots 固定
历史只追加
临时思考不污染上下文
工具调用失败被本地修复
并发执行但按声明顺序落盘
长上下文只在阈值处受控折叠
cache hit/miss 被持续计量所以它能做到 99.5% 甚至 99.82%,不是因为某个神秘 KV cache 技巧,而是因为它把"字节稳定性"提升成了架构原则。
DeepSeek 提供缓存能力,Reasonix 负责让输入长得像可以被缓存的输入。
这才是这个项目最值得学习的地方。
参考
- DeepSeek-Reasonix 仓库:github.com/esengine/De...
- Reasonix Architecture:github.com/esengine/De...
- Real-world cache benchmark:github.com/esengine/De...
- τ-bench-lite report:github.com/esengine/De...
- DeepSeek Context Caching 文档:api-docs.deepseek.com/guides/kv_c...