4. 文本语料的数据分析
4.1 标签数量分布
4.2 句子长度分布
4.3 词频统计与关键词词云
5. 文本特征处理
5.1 添加n-gram特征
5.2 文本长度规范
6. 文本数据增强
6.1 回译数据增强法
1️⃣ 概念 :一般基于google/百度/获取其他翻译接口,将句子先翻译成另外 一种或者几种语言,再翻译回原语言,实现样本句子增多的方法
2️⃣ 优势:操作简便 ;
3️⃣ 存在问题:短文本回译 语料易重复;多次翻译语料易失真;
4️⃣ 高重复率解决办法:连续的多语言翻译:
中文→韩文→日语→英文→中文,一般不超过3次;
更 多的翻译次数将 产生效率低下, 语义失真等问题;
6.2 使用 qwen-plus 实现回译数据增强法:
① 操作:百炼:API 参考(上) ---》OpenAI兼容-Chat(左):可看到 Python、Java (右) ---》将内容拷贝到本地代码;
② API Key获取:模型(上) ---》API Key(左):复制到 代码的环境配置文件.env 中;
代码实现:
1️⃣ 先导包:从 dotenv中导入 load_dotenv包from dotenv import load_dotenv,使用 load_dotenv()加载 .env环境变量;
2️⃣ 获取客户端代理 :client = OpenAI(api_key=xx, base_url=xx);
3️⃣ 导入提示词:with open('./prompt.txt', 'r', encoding='utf-8') as f: system_content = f.read();
4️⃣ 调用接口,获取翻译结果:
bash
completion = client.chat.completions.create(
model="qwen-plus",
messages=[# 列表中多个元素,每个元素有两个键值对组成:role、content
{"role": "system", "content": system_content}, # 提示词
{"role": "user", "content": sent}, # 要翻译的文本
])6.2.1 代码:
python
'''
homework: 使用 ds 实现回译数据增强法
todo 1 api-key;2 model 指定模型
'''
# 1 导包
import os
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv() # 加载.env环境变量
# 2 获取代理 客户端
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx"
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
# 3 导入提示词
with open('./prompt.txt', 'r', encoding='utf-8') as f:
system_content = f.read()
sent = "我爱上海陆家嘴,陆家嘴是真繁华。"
# 4 调用接口,获取翻译结果
completion = client.chat.completions.create(
# 模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
model="qwen-plus", # 自动帮忙指定了"qwen-plus"模型('qwen-plus'是一个文本模型)
messages=[
{"role": "system", "content": system_content}, # 提示词
{"role": "user", "content": sent}, # 要翻译的文本
]
)
# 5 打印结果
# print(completion)
# print("=" * 100)
# print(completion.model_dump_json())
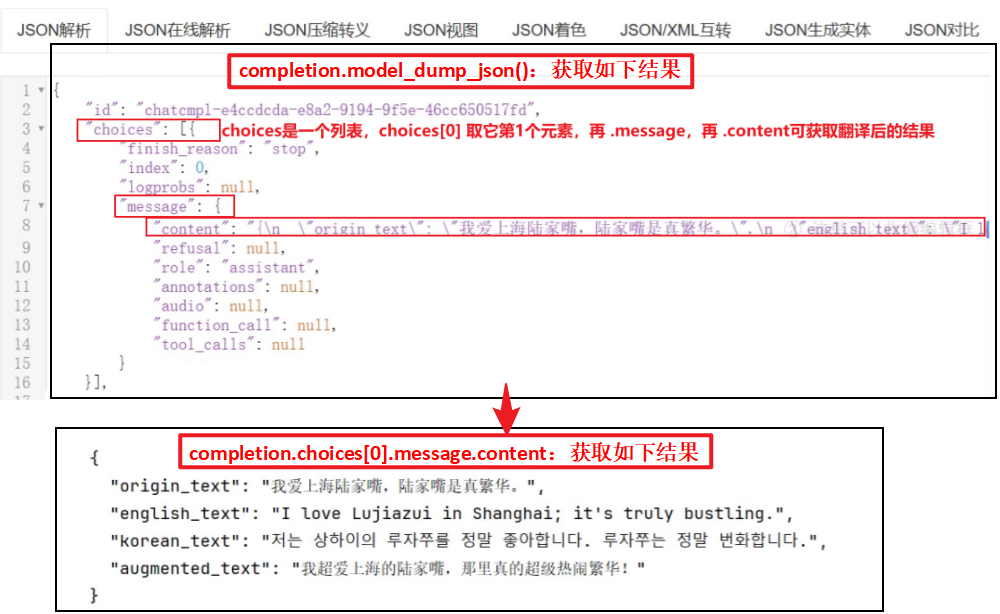
print(completion.choices[0].message.content)6.2.2 运行结果:
7. 迭代器&生成器&可迭代对象

可迭代对象(iter) < 选代器(iter next) < 生成器(iter next yield);
Iterator 和 Generator都可通过next()获取下一个元素;
python
from collections.abc import Iterable, Iterator, Generator
# 可选代对象(iter)<选代器(iter next)<生成器(iter next yield)
# Iterator 和 Generator都可通过next()获取下一个元素
# 1.可迭代对象
data = [1, 2, 3] # list列表
print(f'data是否是 可迭代对象:{isinstance(data, Iterable)}') # True
print(f'data是否是 迭代器:{isinstance(data, Iterator)}') # False
# 2.迭代器
it = iter(data)
print(f'it是否是 可迭代对象:{isinstance(it, Iterable)}') # True
print(f'it是否是 迭代器:{isinstance(it, Iterator)}') # True
print(f'it是否是 生成器:{isinstance(it, Generator)}') # False
# 3.生成器
def my_generator():
yield 1
yield 2
yield 3
gen = my_generator()
print(f'gen是否是 可迭代对象:{isinstance(gen, Iterable)}') # True
print(f'gen是否是 迭代器:{isinstance(gen, Iterator)}') # True
print(f'gen是否是 生成器:{isinstance(gen, Generator)}') # True
print(next(gen)) # 1
print(next(gen)) # 2
print(next(gen)) # 3
print(next(gen)) # 此行会报错(因为gen元素已经读完了)