PyTorch强化学习实战------使用高级组件复现DQN
-
- [0. 前言](#0. 前言)
- [1. 通用函数](#1. 通用函数)
- [2. 实现 DQN](#2. 实现 DQN)
- [3. 超参数调优](#3. 超参数调优)
- [4. 训练结果](#4. 训练结果)
-
- [4.1 使用通用参数的训练结果](#4.1 使用通用参数的训练结果)
- [4.2 调优后的经典 DQN](#4.2 调优后的经典 DQN)
- 相关链接
0. 前言
本节,我们将使用在《强化学习高级组件》一节介绍的高级组件复现经典深度Q网络 (Deep Q-Network, DQN)方法。这将大幅精简代码,使核心逻辑更加突出。需要强调的是,本专栏的目标是培养对强化学习 (Reinforcement Learning, RL)方法的本质理解,这种能力远比掌握特定库更有价值,因为工具库会迭代更新,而对领域的深刻认知能快速理解相关原理和代码并根据实际应用选择合适的算法。
基础 DQN 实现包含三个核心文件:
dqn_model.py:DQN神经网络 (Neural Network,NN) 结构common.py:共享的通用函数与声明dqn_basic.py:基于Ignite库实现的完整DQN算法
1. 通用函数
首先从 common.py 内容开始。该文件使用 Python 的 dataclass 存储 Pong 环境的超参数,这是存储数据字段及其类型注解的标准方式。这使得我们可以很容易地为更复杂的 Atari 游戏添加不同配置集,并能够测试不同的超参数:
python
@dataclasses.dataclass
class Hyperparams:
env_name: str
stop_reward: float
run_name: str
replay_size: int
replay_initial: int
target_net_sync: int
epsilon_frames: int
learning_rate: float = 0.0001
batch_size: int = 32
gamma: float = 0.99
epsilon_start: float = 1.0
epsilon_final: float = 0.1
tuner_mode: bool = False
episodes_to_solve: int = 500
GAME_PARAMS = {
'pong': Hyperparams(
env_name="PongNoFrameskip-v4",
stop_reward=18.0,
run_name="pong",
replay_size=100_000,
replay_initial=10_000,
target_net_sync=1000,
epsilon_frames=100_000,
epsilon_final=0.02,
),
'breakout-small': Hyperparams(
env_name="BreakoutNoFrameskip-v4",
stop_reward=500.0,
run_name="breakout-small",
replay_size=300_000,
replay_initial=20_000,
target_net_sync=1000,
epsilon_frames=1_000_000,
batch_size=64,
),
'breakout': Hyperparams(
env_name="BreakoutNoFrameskip-v4",
stop_reward=500.0,
run_name='breakout',
replay_size=1_000_000,
replay_initial=50_000,
target_net_sync=10_000,
epsilon_frames=10_000_000,
learning_rate=0.00025,
),
'invaders': Hyperparams(
env_name="SpaceInvadersNoFrameskip-v4",
stop_reward=500.0,
run_name='invaders',
replay_size=10_000_000,
replay_initial=50_000,
target_net_sync=10_000,
epsilon_frames=10_000_000,
learning_rate=0.00025,
),
}common.py的unpack_batch,接收状态转移 (transitions) 批数据并将其转换为适合训练的一组 NumPy 数组。ExperienceSourceFirstLast 生成的每个状态转移都属于 ExperienceFirstLast 类型,这是一个包含以下字段的数据类:
state:来自环境的观测值action:智能体采取的整型动作reward:若创建ExperienceSourceFirstLast时设置steps_count=1属性,该字段为即时奖励;若步数较大,则包含该步数范围内折扣后的奖励总和last_state:若状态转移对应环境中的最终步骤,该字段为None;否则包含经验链中的最后观测值
unpack_batch代码如下:
python
def unpack_batch(batch: tt.List[ExperienceFirstLast]):
states, actions, rewards, dones, last_states = [],[],[],[],[]
for exp in batch:
states.append(exp.state)
actions.append(exp.action)
rewards.append(exp.reward)
dones.append(exp.last_state is None)
if exp.last_state is None:
lstate = exp.state # the result will be masked anyway
else:
lstate = exp.last_state
last_states.append(lstate)
return np.asarray(states), np.array(actions), np.array(rewards, dtype=np.float32), \
np.array(dones, dtype=bool), np.asarray(last_states)查看我们如何处理批次中的最终状态转移样本。为了避免对这些特殊情况单独处理,对于终止状态的转移样本,我们将初始状态存储在 last_states 数组中。为了确保贝尔曼更新计算的正确性,在损失计算时需要使用 dones 数组对这些批次条目进行掩码处理。另一种解决方案是仅针对非终止转移计算最后状态的值,但这会使损失函数逻辑稍显复杂。
DQN 损失函数的计算由 calc_loss_dqn 函数实现,添加 torch.no_grad(),用于阻止 PyTorch 对目标网络的计算图进行记录:
python
def calc_loss_dqn(
batch: tt.List[ExperienceFirstLast], net: nn.Module, tgt_net: nn.Module,
gamma: float, device: torch.device) -> torch.Tensor:
states, actions, rewards, dones, next_states = unpack_batch(batch)
states_v = torch.as_tensor(states).to(device)
next_states_v = torch.as_tensor(next_states).to(device)
actions_v = torch.LongTensor(actions).to(device)
rewards_v = torch.FloatTensor(rewards).to(device)
done_mask = torch.BoolTensor(dones).to(device)
actions_v = actions_v.unsqueeze(-1)
state_action_vals = net(states_v).gather(1, actions_v)
state_action_vals = state_action_vals.squeeze(-1)
with torch.no_grad():
next_state_vals = tgt_net(next_states_v).max(1)[0]
next_state_vals[done_mask] = 0.0
bellman_vals = next_state_vals.detach() * gamma + rewards_v
return nn.MSELoss()(state_action_vals, bellman_vals)除了这些核心 DQN 功能外,common.py 还提供了与训练循环、数据生成及 TensorBoard 跟踪相关的多个实用工具。首个实用工具是一个实现训练过程中 ε ε ε 值衰减的类。 ε ε ε 值定义了智能体采取随机动作的概率,其初始值应从 1.0 (完全随机行为)逐渐衰减至较小数值(如 0.02 或 0.01):
python
class EpsilonTracker:
def __init__(self, selector: EpsilonGreedyActionSelector, params: Hyperparams):
self.selector = selector
self.params = params
self.frame(0)
def frame(self, frame_idx: int):
eps = self.params.epsilon_start - frame_idx / self.params.epsilon_frames
self.selector.epsilon = max(self.params.epsilon_final, eps)函数 batch_generator 接收 ExperienceReplayBuffer,并从缓冲区无限地生成训练批次。该函数首先会确保缓冲区包含足够数量的样本:
python
def batch_generator(buffer: ExperienceReplayBuffer, initial: int, batch_size: int) -> \
tt.Generator[tt.List[ExperienceFirstLast], None, None]:
buffer.populate(initial)
while True:
buffer.populate(1)
yield buffer.sample(batch_size)最后,一个实用函数setup_ignite,它会挂载必要的 Ignite 处理器,用于显示训练进度并将指标写入 TensorBoard:
python
def setup_ignite(
engine: Engine, params: Hyperparams, exp_source: ExperienceSourceFirstLast,
run_name: str, extra_metrics: tt.Iterable[str] = (),
tuner_reward_episode: int = 100, tuner_reward_min: float = -19,
):
handler = lib.ignite.EndOfEpisodeHandler(
exp_source, bound_avg_reward=params.stop_reward)
handler.attach(engine)
lib.ignite.EpisodeFPSHandler().attach(engine)首先,setup_ignite 挂载了两个 Ignite 处理器:
EndOfEpisodeHandler:每当游戏回合结束时触发Ignite事件。当回合平均奖励超过某个阈值时也会触发事件,我们借此判断游戏是否最终解决EpisodeFPSHandler:追踪回合耗时及与环境的交互次数,由此计算每秒帧数 (FPS)------这是需要监控的重要性能指标
接下来,实现两个事件处理程序:
python
@engine.on(lib.ignite.EpisodeEvents.EPISODE_COMPLETED)
def episode_completed(trainer: Engine):
passed = trainer.state.metrics.get('time_passed', 0)
print("Episode %d: reward=%.0f, steps=%s, speed=%.1f f/s, elapsed=%s" % (
trainer.state.episode, trainer.state.episode_reward,
trainer.state.episode_steps, trainer.state.metrics.get('avg_fps', 0),
timedelta(seconds=int(passed))))
@engine.on(lib.ignite.EpisodeEvents.BOUND_REWARD_REACHED)
def game_solved(trainer: Engine):
passed = trainer.state.metrics['time_passed']
print("Game solved in %s, after %d episodes and %d iterations!" % (
timedelta(seconds=int(passed)), trainer.state.episode,
trainer.state.iteration))
trainer.should_terminate = True
trainer.state.solved = True其中一个事件处理器会在每个回合 (episode) 结束时触发,用于在控制台显示已完成的回合信息。另一个函数则会在平均奖励超过超参数设定的阈值(例如 Pong 游戏中设为 18.0 )时被调用,该函数会显示关于解决游戏的消息,并终止训练。
函数的其余部分与需要追踪的 TensorBoard 数据相关。首先,创建 TensorboardLogger:
python
now = datetime.now().isoformat(timespec='minutes').replace(':', '')
logdir = f"runs/{now}-{params.run_name}-{run_name}"
tb = tb_logger.TensorboardLogger(log_dir=logdir)
run_avg = RunningAverage(output_transform=lambda v: v['loss'])
run_avg.attach(engine, "avg_loss")这是 Ignite 提供的专用类,用于向 TensorBoard 写入数据。由于我们的处理函数会返回损失值,因此我们附加了 Ignite 自带的 RunningAverage 转换器,以获取随时间平滑处理的损失值曲线。
接下来,将需要监控的指标绑定到 Ignite 事件:
python
metrics = ['reward', 'steps', 'avg_reward']
handler = tb_logger.OutputHandler(tag="episodes", metric_names=metrics)
event = lib.ignite.EpisodeEvents.EPISODE_COMPLETED
tb.attach(engine, log_handler=handler, event_name=event)TensorboardLogger 可以跟踪 Ignite 的两组值:outputs (转换函数返回的值)和 metrics (训练过程中计算并保存在引擎状态中的指标)。EndOfEpisodeHandler 与 EpisodeFPSHandler 会提供每局游戏结束时更新的指标。因此我们挂载 OutputHandler,使其在每局游戏结束时将相关数据写入 TensorBoard。
接下来,我们跟踪另一组值------来自训练过程的指标:损失、FPS,以及可能与特定扩展逻辑相关的自定义指标:
python
lib.ignite.PeriodicEvents().attach(engine)
metrics = ['avg_loss', 'avg_fps']
metrics.extend(extra_metrics)
handler = tb_logger.OutputHandler(tag="train", metric_names=metrics,
output_transform=lambda a: a)
event = lib.ignite.PeriodEvents.ITERS_100_COMPLETED
tb.attach(engine, log_handler=handler, event_name=event)接下来我们追踪训练过程中的另一组数值:损失值、帧率以及可能涉及特定扩展逻辑的自定义指标。这些数值在每次训练迭代时都会更新,但由于迭代次数可能达数百万次,我们将每 100 次训练迭代才向 TensorBoard 存储一次数据,以避免生成过大的数据文件。整套机制为我们提供了从训练过程中收集标准化指标的统一方案。
2. 实现 DQN
接下来,实现dqn_basic.py,该文件负责创建必要类并启动训练流程。
(1) 首先创建环境:
python
def train(params: common.Hyperparams,
device: torch.device, _: dict) -> tt.Optional[int]:
env = gym.make(params.env_name)
env = lib.common.wrappers.wrap_dqn(env)
net = dqn_model.DQN(env.observation_space.shape, env.action_space.n).to(device)
tgt_net = lib.agent.TargetNet(net)以上代码中,应用了一组标准包装器 (wrapper)。接下来,创建 DQN 模型和目标网络。
(2) 构建智能体时,传入了一个ε-贪婪 (epsilon-greedy) 动作选择器:
python
selector = lib.actions.EpsilonGreedyActionSelector(epsilon=params.epsilon_start)
epsilon_tracker = common.EpsilonTracker(selector, params)
agent = lib.agent.DQNAgent(net, selector, device=device) 训练过程中, ε ε ε 值将通过 EpsilonTracker 类逐步衰减。这会减少随机动作的选择比例,让神经网络掌握更多控制权。
(3) 接下来,两个关键对象是 ExperienceSourceFirstLast 和 ExperienceReplayBuffer:
python
exp_source = lib.experience.ExperienceSourceFirstLast(
env, agent, gamma=params.gamma)
buffer = lib.experience.ExperienceReplayBuffer(
exp_source, buffer_size=params.replay_size)ExperienceSourceFirstLast 接收智能体和环境,生成游戏回合间的状态转移数据。这些转移数据将存储在经验回放缓冲区中。
(4) 创建优化器并定义处理函数:
python
optimizer = optim.Adam(net.parameters(), lr=params.learning_rate)
def process_batch(engine, batch):
optimizer.zero_grad()
loss_v = common.calc_loss_dqn(batch, net, tgt_net.target_model,
gamma=params.gamma, device=device)
loss_v.backward()
optimizer.step()
epsilon_tracker.frame(engine.state.iteration)
if engine.state.iteration % params.target_net_sync == 0:
tgt_net.sync()
return {
"loss": loss_v.item(),
"epsilon": selector.epsilon,
}该处理函数会对每批状态转移数据进行模型训练。通过调用 common.calc_loss_dqn 函数计算损失值后执行反向传播。此函数还负责让 EpsilonTracker 衰减 ε ε ε 值,并定期同步目标网络参数。
(5) 最后,创建 Ignite 的引擎 (Engine) 对象:
python
engine = Engine(process_batch)
common.setup_ignite(engine, params, exp_source, NAME)
r = engine.run(common.batch_generator(buffer, params.replay_initial, params.batch_size))
if r.solved:
return r.episode通过调用 common.py 中的函数进行配置,并启动训练流程。
3. 超参数调优
为确保对DQN 扩展算法的对比公平性,必须进行超参数调优。这是因为即使在相同游戏(如 Pong )中,当方法细节变更时,固定训练参数集可能导致次优结果。
理论上,代码中每个显式或隐式常量都可调整,例如:
- 网络配置 :层的数量和大小,激活函数,
dropout等 - 优化参数 :优化方法(如标准
SGD,Adam,AdaGrad等),学习率以及其他优化器参数 - 探索参数 : ε ε ε 衰减率、最终 ε ε ε 值
- 贝尔曼方程中的折扣因子 γ γ γ
但每新增一个调优参数都会使所需训练次数呈倍数增长,过多超参数可能需数百甚至上千次训练。本节将展示常规超参数调优方法,但仅针对以下参数进行搜索:
- 学习率
- 折扣因子 γ γ γ
- 特定
DQN扩展的专属参数
有多个库可以用于帮助超参数调优。本节,使用的是 Ray Tune,它是 Ray 项目的一部分,一个面向机器学习和深度学习的分布式计算框架。概括来说,需要定义:
- 待探索的超参数空间(采样的数值边界或明确数值列表)
- 使用特定超参数值执行训练的函数,该函数需返回希望通过调优优化的指标
这与机器学习问题非常相似,事实上确实如此------这同样是个优化问题。但存在本质区别:这种优化函数不可微分(因此无法通过梯度下降推动超参数朝着指标期望方向变化),且优化空间可能是离散的(例如,无法用 2.435 层神经网络进行训练,因为不可对非平滑函数求导)。
在本节中,我们将采用最简单的方法------超参数随机搜索。这种情况下,ray.tune 库会多次随机采样具体参数,并调用函数获取指标。最小(或最大)指标值对应本次运行中发现的最佳超参数组合。
本节中,我们的优化目标指标是智能体在解算游戏前需要进行的游戏局数(对于 Pong 游戏而言,指达到平均 18 分以上)。为展示调优效果,针对每个 DQN 扩展版本,我们既检查使用固定参数集的训练动态,也分析经过 20-30 轮调优后最佳超参数下的训练动态。我们也可以自行实验优化更多超参数,以找到更优的训练配置。
该过程的核心实现在 common.tune_params 函数中,首先从类型声明和超参数空间开始:
python
TrainFunc = tt.Callable[
[Hyperparams, torch.device, dict],
tt.Optional[int]
]
BASE_SPACE = {
"learning_rate": tune.loguniform(1e-5, 1e-4),
"gamma": tune.choice([0.9, 0.92, 0.95, 0.98, 0.99, 0.995]),
}首先定义训练函数,该函数接收一个 Hyperparams 数据类、要使用的 torch.device 设备对象,以及包含额外参数的字典(因为某些 DQN 扩展可能需要超出 Hyperparams 声明范围的额外参数)。
函数返回值可以是整数值(表示达到 18 分所需进行的游戏局数),若提前终止训练则返回 None。设置这一机制是因为某些超参数组合可能导致无法收敛或收敛速度过慢,为节省时间不会无限制等待训练完成。
这是一个以字符串为键(参数名)、以 tune 声明待探索取值范围为值的字典。取值可以是概率分布(均匀分布、对数均匀分布、正态分布等)或明确的待尝试值列表。也可以使用 tune.grid_search 声明一系列值列表,此时将穷举测试所有指定值。
在本节中,我们从对数均匀分布中采样学习率,从一个包含 6 个值(从 0.9 到 0.995 )的列表中采样 gamma 值。接下来,实现 tune_params 函数:
python
def tune_params(
base_params: Hyperparams, train_func: TrainFunc, device: torch.device,
samples: int = 10, extra_space: tt.Optional[tt.Dict[str, tt.Any]] = None,
):
search_space = dict(BASE_SPACE)
if extra_space is not None:
search_space.update(extra_space)
config = tune.TuneConfig(num_samples=samples)
def objective(config: dict, device: torch.device) -> dict:
keys = dataclasses.asdict(base_params).keys()
upd = {"tuner_mode": True}
for k, v in config.items():
if k in keys:
upd[k] = v
params = dataclasses.replace(base_params, **upd)
res = train_func(params, device, config)
return {"episodes": res if res is not None else 10**6}这个函数接收以下参数:
- 基础超参数集:用于训练的基础配置
- 训练函数:执行模型训练的函数
Torch设备:指定使用的计算设备- 采样次数:本轮调优中需要尝试的参数组合数量
- 附加搜索空间字典:扩展的超参数探索范围
在这个函数内部定义了一个目标函数,它根据采样的字典中创建 Hyperparameters 对象,调用训练函数执行实际训练,并返回 ray.tune 库要求的字典格式结果。
tune_params 函数的剩余逻辑较为简单:
python
obj = tune.with_parameters(objective, device=device)
if device.type == "cuda":
obj = tune.with_resources(obj, {"gpu": 1})
tuner = tune.Tuner(obj, param_space=search_space, tune_config=config)
results = tuner.fit()
best = results.get_best_result(metric="episodes", mode="min")
print(best.config)
print(best.metrics)此处我们对目标函数进行了封装,以便传递 torch 设备参数并合理分配 GPU 资源。这是为了让 Ray 能够正确并行化调优过程------若机器配备多块 GPU,系统将并行执行多个训练任务。随后,只需创建 Tuner 对象并启动超参数搜索即可。
与超参数调优相关的最后关键环节位于 setup_ignite 函数中。该函数会监测训练过程是否出现不收敛的情况,从而及时终止训练以避免无限等待。为了实现这一功能,我们在启用超参数调优模式时会使用 Ignite 事件处理器:
python
if params.tuner_mode:
@engine.on(lib.ignite.EpisodeEvents.EPISODE_COMPLETED)
def episode_completed(trainer: Engine):
avg_reward = trainer.state.metrics.get('avg_reward')
max_episodes = params.episodes_to_solve * 1.1
if trainer.state.episode > tuner_reward_episode and \
avg_reward < tuner_reward_min:
trainer.should_terminate = True
trainer.state.solved = False
elif trainer.state.episode > max_episodes:
trainer.should_terminate = True
trainer.state.solved = False
if trainer.should_terminate:
print(f"Episode {trainer.state.episode}, "
f"avg_reward {avg_reward:.2f}, terminating")此处我们设置了两个条件:
- 当平均奖励在完成
100局游戏后(通过tuner_reward_episode参数指定),平均奖励低于tuner_reward_min阈值(setup_ignite函数的一个参数,默认值为-19),这表明模型基本不可能收敛 - 当游戏局数超过
max_episodes上限(默认500局)仍未达成目标
若满足任一条件,系统将终止训练并将 solved 属性设为 False,这会使调优过程返回一个较大的常量指标值。
至此已完成超参数调优代码的说明。在正式运行查看结果前,我们先使用通用参数进行一次基准训练。
4. 训练结果
4.1 使用通用参数的训练结果
如果使用 --params common 参数启动训练,系统将调用 common.py 模块中的超参数来训练 Pong 游戏,我们也可以使用 --params best 命令行参数,采用针对 DQN 优化的最佳参数值进行训练。使用以下命令启动训练流程:
bash
python dqn_basic.py --dev cuda --params common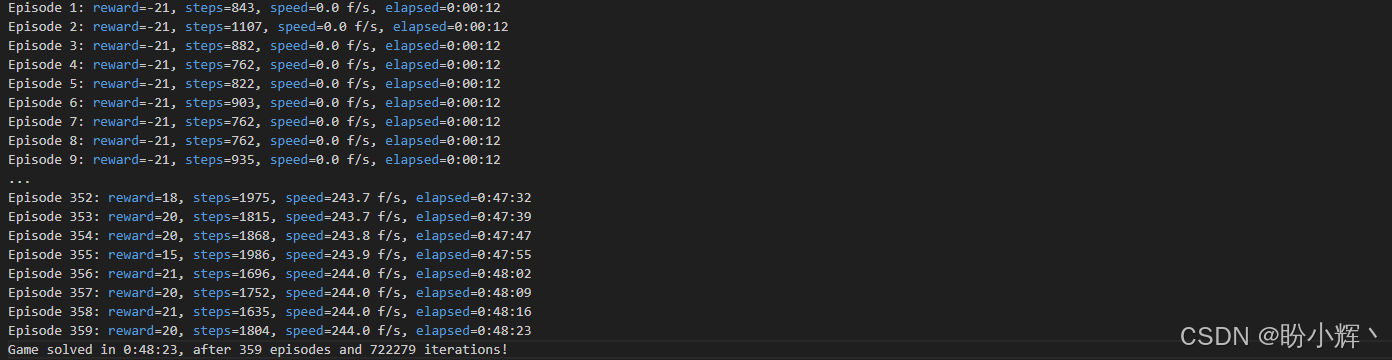
输出中的每一行都在游戏回合结束时写入,显示回合奖励、步数计数、速度以及总训练时间。对于经典 DQN 版本和常规超参数,通常需要约 70 万帧画面和 400 回合游戏才能达到平均奖励值 18 分。在训练过程中,我们可以通过 TensorBoard 查看训练过程的动态,其中展示了 ε ε ε 值、原始奖励值、平均奖励和速度等。下图呈现了各回合的奖励值与步数统计:
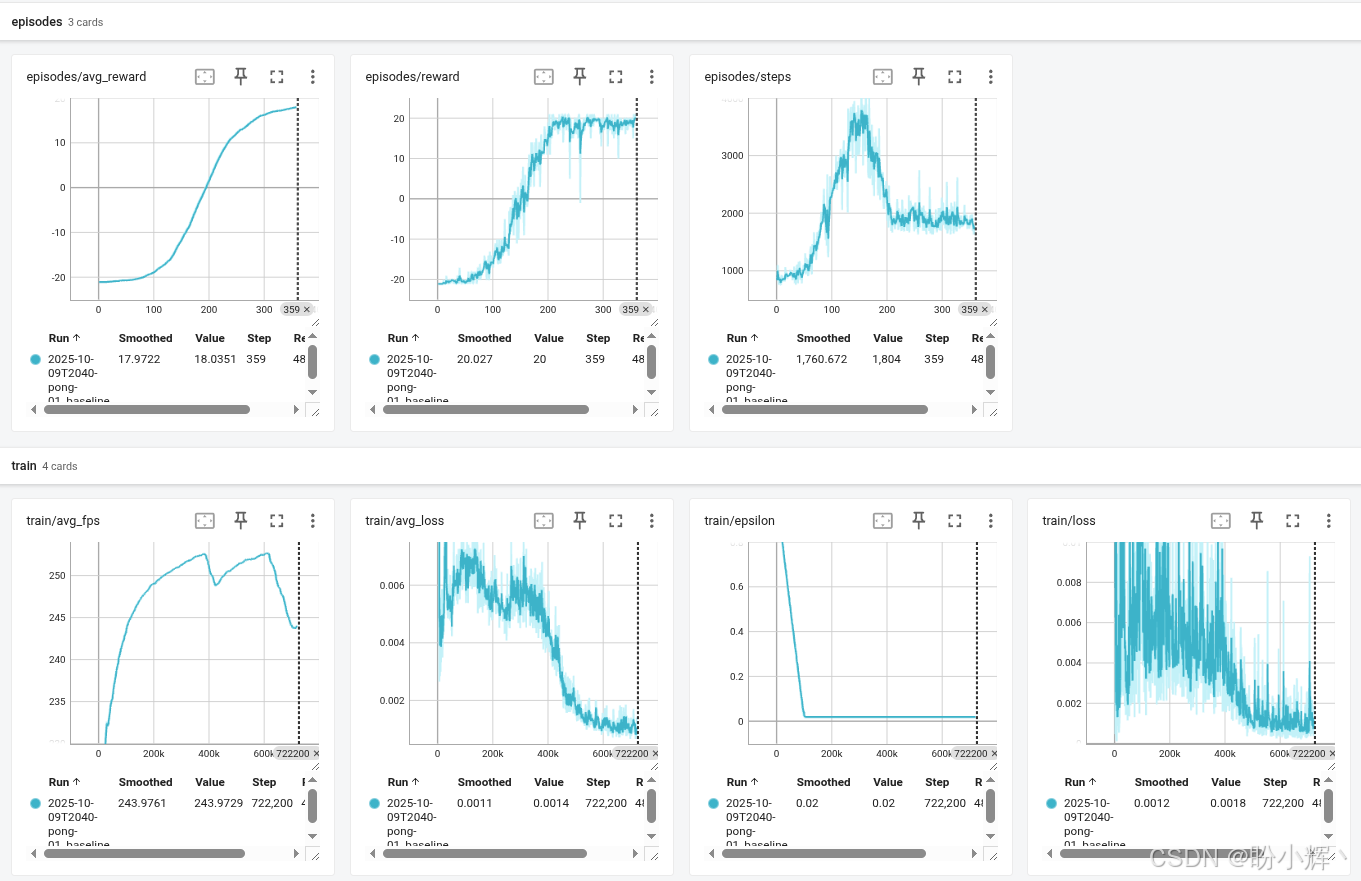
同样值得注意的是,训练过程中每回合游戏的步数变化规律。初期步数会随着神经网络胜率提升而增加,但当达到一定水平后,步数会减半并趋于稳定。这种现象源于 γ γ γ 参数的作用------该参数会随时间衰减智能体的奖励值,因此智能体不仅追求最大化累积奖励,还会优化奖励获取效率。
4.2 调优后的经典 DQN
当使用 --tune 30 命令行参数运行经典 DQN 后,可以得到以下参数组合,最终仅用 322 回合(原本需 360 回合)就解决了 Pong 游戏:
shell
{'learning_rate': 5.659919811395947e-05, 'gamma': 0.99}学习率基本保持不变(仍为 10 − 4 10^{-4} 10−4),但折扣因子 γ γ γ 有所降低( 0.98 vs 0.99)。这表明:在 Pong 游戏中,动作与奖励间因果关联的子轨迹相对较短,因此降低 γ γ γ 值能对训练过程产生稳定作用。
相关链接
PyTorch强化学习实战(1)------强化学习(Reinforcement Learning,RL)详解
PyTorch强化学习实战(2)------强化学习环境库Gymnasium
PyTorch强化学习实战(3)------Gymnasium API扩展功能
PyTorch强化学习实战(4)------PyTorch基础
PyTorch强化学习实战(5)------PyTorch Ignite 事件驱动机制与实践
PyTorch强化学习实战(6)------交叉熵方法详解与实现
PyTorch强化学习实战(7)------表格学习与贝尔曼方程
PyTorch强化学习实战(8)------Q学习详解与实现
PyTorch强化学习实战(9)------深度Q学习
PyTorch强化学习实战(10)------强化学习高级组件