AI 应用架构设计模式:从原型到生产级系统
前言
构建一个 AI 应用原型很容易,但将其打造成生产级别的系统却需要深思熟虑的架构设计。我之前经历过多个 AI 项目,从简单的问答机器人到复杂的 Agent 系统,对 AI 应用架构有了一些经验总结。
今天分享一些常见的 AI 应用架构模式,以及如何根据场景选择合适的架构。
常见的 AI 应用架构
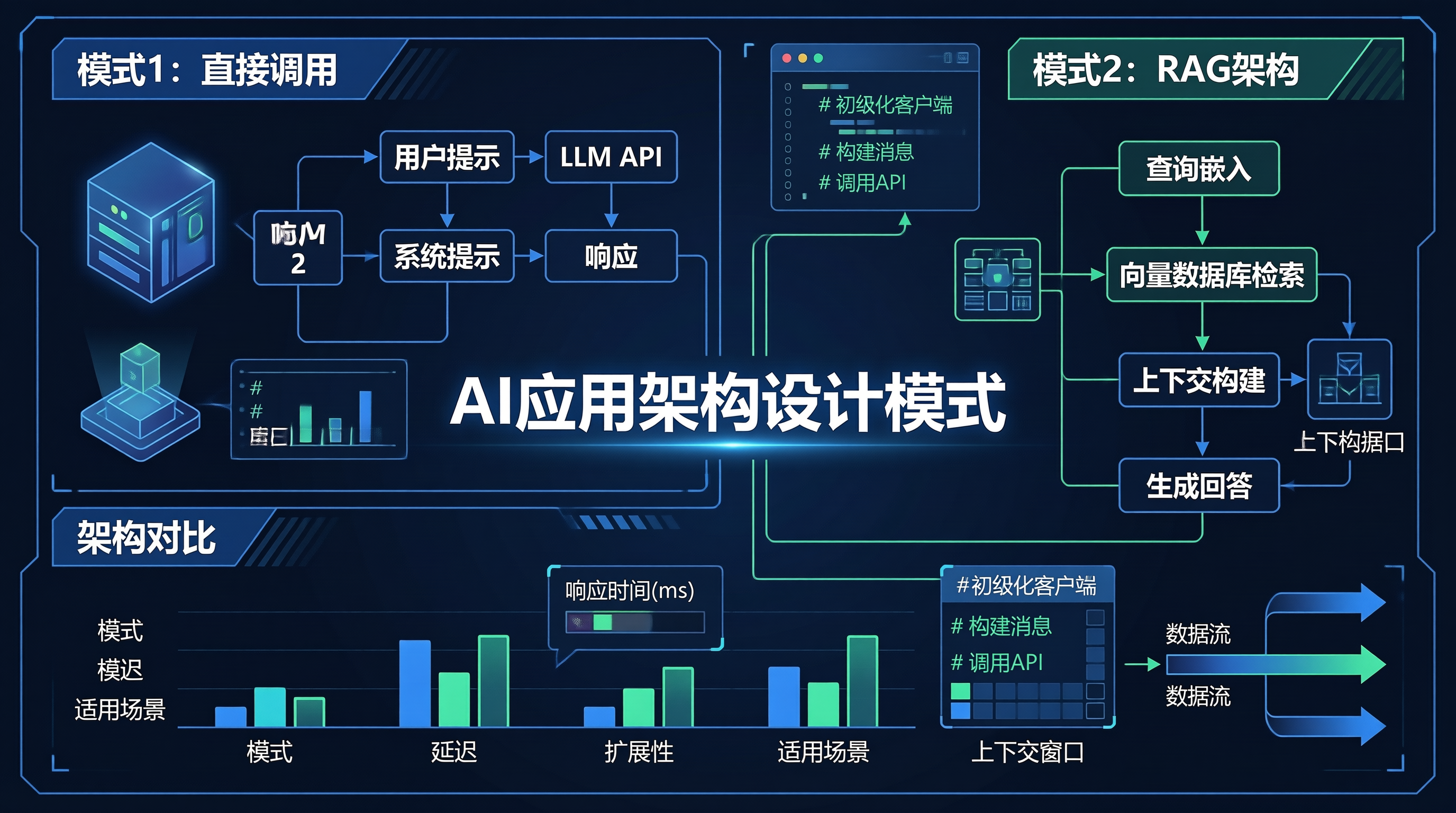
模式 1:直接调用(Direct Call)
最简单的架构,直接调用 LLM API:
python
class DirectLLMService:
"""直接调用模式"""
def __init__(self, api_key: str):
self.client = OpenAI(api_key=api_key)
def chat(self, prompt: str, system_prompt: str = None) -> str:
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
response = self.client.chat.completions.create(
model="gpt-4",
messages=messages,
temperature=0.7
)
return response.choices[0].message.content适用场景:
- 简单问答
- 一次性任务
- 快速原型
优点 :简单、快速
缺点:无法使用外部工具、上下文有限
模式 2:RAG 架构
Retrieval-Augmented Generation,结合知识库:
python
class RAGApplication:
"""RAG 架构"""
def __init__(self, llm, vector_store, embedding_model):
self.llm = llm
self.vector_store = vector_store
self.embedding_model = embedding_model
def query(self, question: str) -> str:
# 1. 检索相关文档
query_embedding = self.embedding_model.encode(question)
docs = self.vector_store.search(query_embedding, top_k=5)
# 2. 构建上下文
context = "\n\n".join([doc.content for doc in docs])
prompt = f"基于以下内容回答问题:\n\n{context}\n\n问题:{question}"
# 3. 生成回答
return self.llm.chat(prompt)适用场景:
- 知识库问答
- 文档理解
- 需要最新信息
优点 :利用外部知识、减少幻觉
缺点:依赖检索质量、延迟增加
模式 3:Agent 架构
带有工具调用能力的自主 Agent:
python
class ToolUsingAgent:
"""Agent 架构"""
def __init__(self, llm, tools: list):
self.llm = llm
self.tools = {t.name: t for t in tools}
self.max_iterations = 10
def run(self, task: str) -> str:
messages = [{"role": "user", "content": task}]
for _ in range(self.max_iterations):
# 1. LLM 决定行动
response = self.llm.chat(
messages=messages,
tools=self._get_tools_schema()
)
# 2. 检查是否需要工具调用
if not response.tool_calls:
return response.content
# 3. 执行工具
for call in response.tool_calls:
result = self.tools[call.name].execute(**call.arguments)
messages.append({
"role": "tool",
"tool_call_id": call.id,
"content": str(result)
})
return "任务超时"适用场景:
- 复杂多步骤任务
- 需要外部系统交互
- 自主决策
优点 :能力强大、可处理复杂任务
缺点:不确定性强、调试困难
生产级架构组件
缓存层
python
from functools import wraps
import hashlib
import json
import redis
class SemanticCache:
"""语义缓存"""
def __init__(self, redis_client, embedding_model, threshold=0.95):
self.redis = redis_client
self.embedding_model = embedding_model
self.threshold = threshold
def get(self, query: str) -> Optional[str]:
"""尝试从缓存获取"""
query_hash = self._hash(query)
cached = self.redis.get(f"cache:{query_hash}")
if cached:
return cached
return None
def set(self, query: str, response: str):
"""缓存响应"""
query_hash = self._hash(query)
self.redis.setex(f"cache:{query_hash}", 3600, response)
def _hash(self, text: str) -> str:
return hashlib.md5(text.encode()).hexdigest()
class LLMCache:
"""LLM 响应缓存"""
def __init__(self, cache: SemanticCache):
self.cache = cache
def cached_completion(self, prompt: str, **kwargs) -> str:
"""带缓存的 completion"""
# 检查缓存
cached = self.cache.get(prompt)
if cached:
return cached
# 调用 LLM
response = openai.ChatCompletion.create(prompt=prompt, **kwargs)
result = response.choices[0].message.content
# 缓存结果
self.cache.set(prompt, result)
return result限流与回退
python
import time
from collections import defaultdict
class RateLimiter:
"""限流器"""
def __init__(self, max_requests: int, window_seconds: int):
self.max_requests = max_requests
self.window_seconds = window_seconds
self.requests = defaultdict(list)
def is_allowed(self, user_id: str) -> bool:
now = time.time()
window_start = now - self.window_seconds
# 清理过期请求
self.requests[user_id] = [
t for t in self.requests[user_id]
if t > window_start
]
# 检查限制
if len(self.requests[user_id]) >= self.max_requests:
return False
self.requests[user_id].append(now)
return True
class ModelFallback:
"""模型回退"""
def __init__(self):
self.models = [
"gpt-4",
"gpt-4-turbo",
"gpt-3.5-turbo"
]
def chat_with_fallback(self, prompt: str) -> str:
for model in self.models:
try:
response = openai.ChatCompletion.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
except Exception as e:
print(f"Model {model} failed: {e}")
continue
raise Exception("All models failed")异步处理
python
import asyncio
from typing import List
class AsyncLLMWrapper:
"""异步 LLM 包装器"""
def __init__(self):
self.semaphore = asyncio.Semaphore(10) # 最大并发 10
async def achat(self, prompt: str, system: str = None) -> str:
"""异步聊天"""
async with self.semaphore:
loop = asyncio.get_event_loop()
return await loop.run_in_executor(
None,
lambda: self._sync_chat(prompt, system)
)
async def achat_batch(self, prompts: List[str]) -> List[str]:
"""批量异步聊天"""
tasks = [self.achat(p) for p in prompts]
return await asyncio.gather(*tasks)
def _sync_chat(self, prompt: str, system: str = None) -> str:
messages = []
if system:
messages.append({"role": "system", "content": system})
messages.append({"role": "user", "content": prompt})
response = openai.ChatCompletion.create(
model="gpt-4",
messages=messages
)
return response.choices[0].message.content完整生产架构
┌─────────────────────────────────────────────────────────────┐
│ API Gateway │
│ (认证、限流、日志) │
├─────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ 缓存层 │ │ 限流层 │ │ 监控层 │ │
│ │ Redis │ │ Rate Limit │ │ Metrics │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
│ │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ Application Layer │ │
│ │ ┌────────┐ ┌────────┐ ┌────────┐ ┌────────┐ │ │
│ │ │ QA │ │ RAG │ │ Agent │ │ 其他 │ │ │
│ │ └────────┘ └────────┘ └────────┘ └────────┘ │ │
│ └──────────────────────────────────────────────────────┘ │
│ │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ LLM Layer │ │
│ │ ┌────────┐ ┌────────┐ ┌────────┐ │ │
│ │ │ OpenAI │ │ Claude │ │ 本地 │ │ │
│ │ └────────┘ └────────┘ └────────┘ │ │
│ └──────────────────────────────────────────────────────┘ │
│ │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ External Services │ │
│ │ ┌────────┐ ┌────────┐ ┌────────┐ │ │
│ │ │Vector │ │ API │ │ Database│ │ │
│ │ │Store │ │服务 │ │ │ │ │
│ │ └────────┘ └────────┘ └────────┘ │ │
│ └──────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘实际应用代码
python
class AIApplication:
"""完整的 AI 应用"""
def __init__(self, config: dict):
# 初始化各组件
self.llm = self._init_llm(config["llm"])
self.vector_store = self._init_vector_store(config["vector_store"])
self.cache = self._init_cache(config["cache"])
self.rate_limiter = RateLimiter(**config["rate_limit"])
# 初始化应用层
self.qa_service = QAService(self.llm)
self.rag_service = RAGService(self.llm, self.vector_store)
self.agent_service = AgentService(self.llm, self._init_tools())
async def handle_request(self, request: dict) -> dict:
"""处理请求"""
user_id = request["user_id"]
# 1. 限流检查
if not self.rate_limiter.is_allowed(user_id):
return {"error": "Rate limit exceeded", "code": 429}
# 2. 路由
request_type = request["type"]
if request_type == "qa":
result = await self.qa_service.answer(request["question"])
elif request_type == "rag":
result = await self.rag_service.query(request["query"])
elif request_type == "agent":
result = await self.agent_service.run(request["task"])
else:
result = {"error": "Unknown request type"}
# 3. 记录日志
await self._log_request(request, result)
return result
def _init_llm(self, config: dict) -> LLM:
"""初始化 LLM"""
if config["provider"] == "openai":
return OpenAILLM(api_key=config["api_key"])
elif config["provider"] == "anthropic":
return AnthropicLLM(api_key=config["api_key"])
else:
return LocalLLM(config["model_path"])监控与可观测性
python
from prometheus_client import Counter, Histogram, Gauge
import time
# 指标定义
request_count = Counter('llm_requests_total', 'Total LLM requests', ['model', 'status'])
request_duration = Histogram('llm_request_duration_seconds', 'Request duration')
active_requests = Gauge('llm_active_requests', 'Active requests')
cache_hit_rate = Gauge('llm_cache_hit_rate', 'Cache hit rate')
class MonitoredLLM:
"""带监控的 LLM"""
def __init__(self, llm):
self.llm = llm
def chat(self, prompt: str) -> str:
model = self.llm.model_name
active_requests.inc()
start = time.time()
try:
result = self.llm.chat(prompt)
request_count.labels(model=model, status="success").inc()
return result
except Exception as e:
request_count.labels(model=model, status="error").inc()
raise
finally:
request_duration.observe(time.time() - start)
active_requests.dec()部署架构
Docker 部署
dockerfile
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY . .
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]Docker Compose
yaml
version: '3.8'
services:
api:
build: .
ports:
- "8000:8000"
environment:
- OPENAI_API_KEY=${OPENAI_API_KEY}
- REDIS_URL=redis://redis:6379
depends_on:
- redis
- qdrant
redis:
image: redis:7-alpine
ports:
- "6379:6379"
qdrant:
image: qdrant/qdrant
ports:
- "6333:6333"
volumes:
- qdrant_data:/qdrant/storage
volumes:
qdrant_data:总结
构建生产级 AI 应用需要考虑:
- 架构选择:简单问答用 Direct Call,RAG 用于知识库,Agent 用于复杂任务
- 可靠性:缓存、限流、回退机制
- 可观测性:完善的日志、监控、追踪
- 扩展性:异步处理、批量优化
关键要点:
- 从简单架构开始,根据需求演进
- 生产环境必须有监控和限流
- 缓存可以显著降低成本和延迟
- 异步处理提升吞吐量