这期分享的安全会议论文是来自安全顶级会议之一的usenix security 2025 ,题目是 Towards Label-Only Membership Inference Attack against Pre-trained Large Language Models(针对预训练大语言模型的仅标签成员推断攻击),官网链接为 https://www.usenix.org/system/files/usenixsecurity25-he-yu.pdf
一、论文背景
成员推断攻击(Membership Inference Attack,MIA)旨在预测某个数据样本是否属于模型的训练集。除了用于构建提取攻击和评估数据泄露之外,MIAs 还可以用于审核机器"遗忘"效果,以及检测 LLMs 是否在未经授权的情况下使用了某人的数据进行预训练。现有的 MIA 攻击通常是基于 logits,(logits 可以简单理解为模型在做选择前给每个候选答案打的**"原始分"**,这些分数可以是任意实数:可能很大、很小、为负都行。分数越大,模型越倾向选它,通过 softmax 操作,模型可以将 logits 变成概率)
然而许多公共商业 LLM API 仅向用户提供生成的 token,而非完整的 logits,这使得以前的攻击方法在很大程度上无法使用。于是本文提出了一种方法仅通过检查生成的 token 来推断成员身份,而无需访问完整的 logits。
二、论文工作概述
- 本文发现基于鲁棒性差距的仅标签 MIA 在 LLM 的预训练阶段大多无效,可能原因包括更好的泛化能力和扰动过于粗糙。
- 本文提出了 PETAL,一种针对 LLM 预训练阶段的简单而有效的仅标签 MIA 方法,利用词元级语义相似度来近似成员推断的输出概率。
三、label-only MIA 对于预训练 LLM 基本无效
论文先系统复现/对比了既有攻击路线,特别是"基于鲁棒性差异(robustness gap)"的 label-only 方法(例如对输入做词级扰动:random swapping / back translation / word substitution,然后看输出相似度变化),发现它们在预训练 LLM 上几乎等同随机猜测(AUC 约 0.5),具体结果如下表所示:
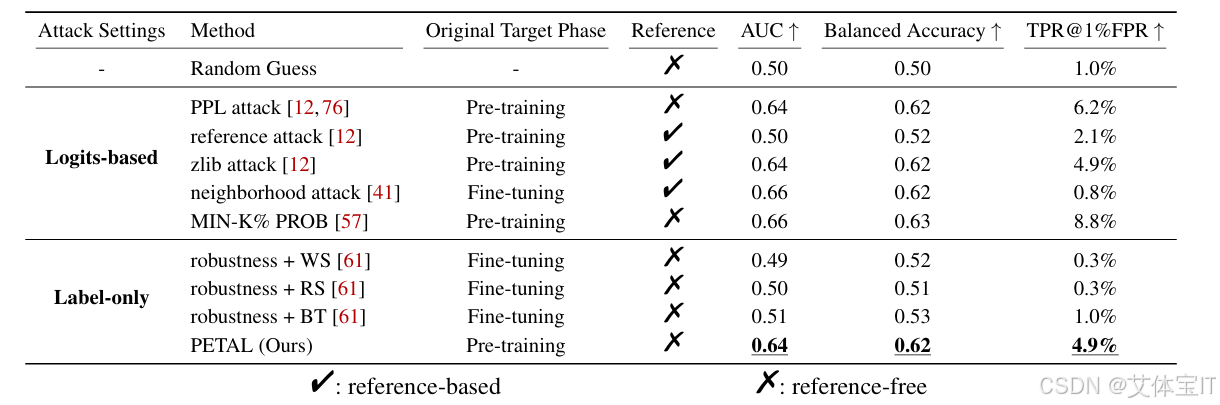
这说明在微调场景有效的 label-only MIA 直接搬到预训练阶段没有很好的效果,论文也给出了原因分析,
- 预训练 LLM 泛化更强:预训练语料巨大、每个样本暴露次数少(文中提到通常 ❤️ 次),导致成员与非成员在"离决策边界的距离/鲁棒性"差距非常小;
- token 级扰动太粗:只能在词/token 层面改动前缀,不够细粒度,捕捉不到这种"微小差异"。
四、PETAL 设计
论文提出新攻击 PETAL(PEr-Token semAntic simiLarity):不同于传统的 logits-based MIA 常用 perplexity/loss 做 membership score(成员通常 perplexity 更小),label-only 没 logits,无法算 perplexity,因此 PETAL 用 token-level 语义相似度 去"拟合/近似"模型对 token 的概率,从而得到"替代 perplexity",再阈值判断 membership。
整体的设计如下图所示:
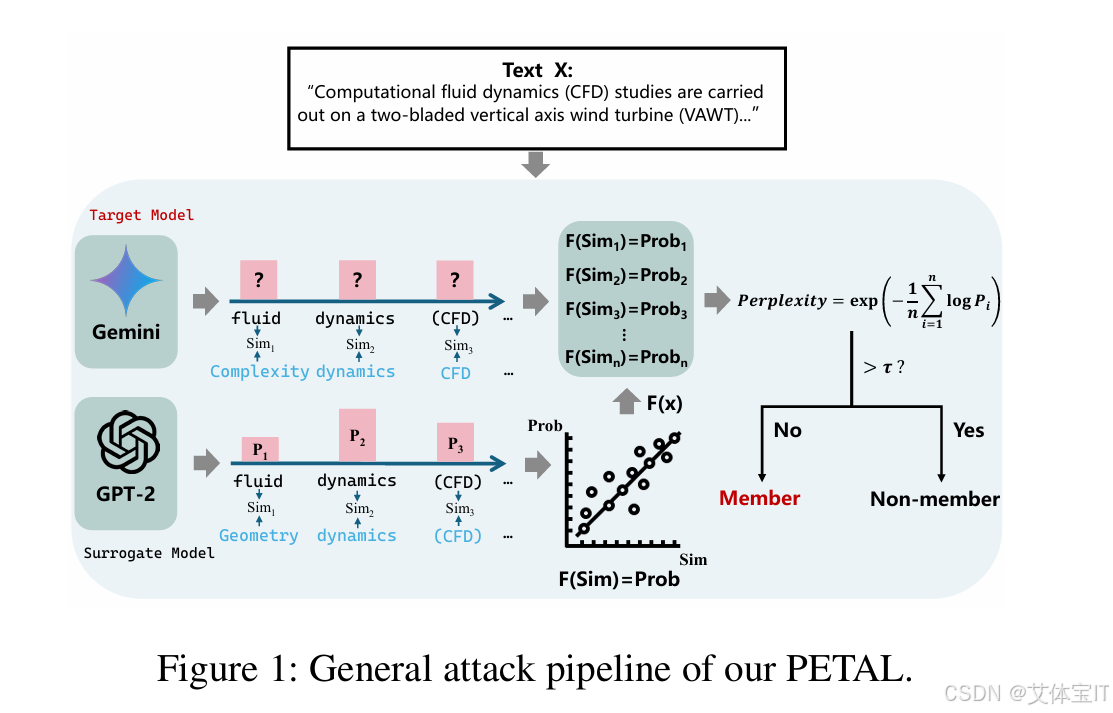
首先文章提出了一个代理模型(图中 GPT-2)的概念,用于捕获语义相似性与输出概率之间的映射,通过将语义相似度得分的分布与真实输出概率对齐,作为输出概率的良好替代。
具体而言,代理模型需要计算"每个位置的语义相似度"Sim,例如图里 "fluid" 和 "Complexity" 就会得到一个 Sim1;"dynamics"和"dynamics"会得到更高的 Sim2;"(CFD)"与"CFD"也会很高。同时代理模型已知真实概率的,因此通过回归学出一个函数(图里写 **F(x)**,散点 + 拟合线)
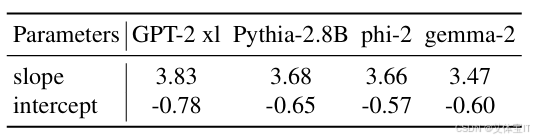
本文为了证明这种概率与模型本身的固有属性相关性较小,选取了 GPT-2 XL 、Pythia-2.8B 、phi-2 和 gemma-2 这四种预训练数据集、架构和发布时间上存在显著差异的模型,进行语义相似性概率对的回归计算,如下表所示。
在设计 PETAL 时还有一个要点,即要对文本 X(Computational fluid dynamics (CFD) studies are carried out on a two-bladed vertical axis wind turbine (VAWT)...)做"逐 token 查询",意思每次只预测下一个 token,论文论证在一系列的 token 序列中,只有第一个生成 token 最能反映成员/非成员差异;因为生成是迭代的,后续 token 会受到先前生成误差累积影响,使得成员信号被"稀释/污染"。因此 PETAL 的概率近似是基于"每一步只取 first generated token 的信号"。
最后把 F 用到目标模型:通过计算目标模型的每个位置 i 和 token 的相似度,估计每个 token 的概率(图右上角 F(Sim)=Prob),从而得到近似的 perplexity,并与阈值进行比较。
五、实验设置与主要结果
论文在实验中主要使用两个成员推断攻击常用基准:WikiMIA 和 MIMIR。WikiMIA 基于 Wikipedia 事件文本,根据文本时间与目标模型预训练数据截止时间来划分 member / non-member;MIMIR 则基于 The Pile 数据集,训练集样本作为 member,测试集样本作为 non-member。目标模型方面,WikiMIA 上测试了 Pythia-6.9B、OPT-6.7B、LLaMA2-13B 和 Falcon-7B;MIMIR 上测试了 Pythia 系列的 160M、1.4B、2.8B、6.9B 模型。对比方法包括五类 logits-based 攻击:PPL attack、reference attack、zlib attack、neighborhood attack、MIN-K% PROB,以及三类 label-only 的鲁棒性攻击:word substitution、random swapping、back translation。论文使用 Balanced Accuracy、AUC 和 TPR@1%FPR 作为主要评价指标。
实验结果表明,PETAL 显著优于已有 label-only 攻击,并且在很多场景下接近甚至持平于 logits-based 攻击。在 WikiMIA 上,PETAL 对 Pythia、OPT、LLaMA2、Falcon 的 AUC 分别为 0.64、0.62、0.58、0.60,而三种鲁棒性 label-only 攻击大多只有 0.47--0.51 左右,基本接近随机猜测。对应的 Balanced Accuracy 也达到 0.62、0.59、0.57、0.57,TPR@1%FPR 分别为 4.9%、3.1%、1.6%、2.1%。
在 MIMIR 上,PETAL 的优势同样明显。以平均 AUC 为例,PETAL 在 Pythia 160M、1.4B、2.8B、6.9B 上分别达到 0.65、0.67、0.67、0.67,而三种 label-only 鲁棒性攻击的平均 AUC 只在 0.52--0.55 附近。论文特别指出,除 arXiv 子集外,PETAL 基本都能达到与 logits-based 攻击相当的水平;arXiv 效果相对弱,可能是因为其中包含大量 LaTeX 源码和特殊字符,使 GPT-2 XL 代理模型更难学习"语义相似度---概率"的映射。
论文还强调了低误报率下的攻击效果。过去有研究认为,像 hard label 这样信息量有限的攻击设置很难在低 FPR 下取得较高 TPR。但 PETAL 在不访问输出概率的情况下,在 MIMIR 多个子集上仍取得了与 logits-based 方法相近的 TPR@1%FPR。例如在 DM Mathematics 子集上,鲁棒性 label-only 攻击几乎失效,而 PETAL 仍能达到较高 TPR。这说明即使 API 只返回生成文本,预训练 LLM 仍然存在可利用的成员隐私泄露信号。
六、从 AppSec 到 AI Security:如何保护 LLM 的训练数据隐私
这篇论文的价值不只是提出了一种新的 MIA 攻击方法,更重要的是它把 LLM 训练数据隐私风险推进到了一个更现实的威胁模型下:攻击者不需要 logits、不需要模型参数,也不需要白盒访问,只需要模型 API 返回的生成 token,就可能判断某段文本是否出现在训练数据中。PETAL 的核心思想是利用 token 级语义相似度近似输出概率,再计算近似 perplexity,最终基于"成员样本更容易被模型记住、perplexity 更小"这一假设进行成员推断。
这与 Mend.io 这类 AppSec / AI Security 平台有很强的结合空间。传统 Mend AppSec 关注的是代码、依赖、容器、开源组件、许可证和漏洞;而在 AI Native 应用中,风险边界已经从"代码和依赖"扩展到了"模型、训练数据、提示词、Agent、RAG 数据源和模型 API"。
如今 Mend 也已覆盖 code layer、AI layer 以及二者之间的攻击面,并强调对 AI models、agents、system prompts、SBOM / AI-BOM、AI red teaming、runtime guardrails 等能力的治理。企业再将 PETAL 类方法集成到 AI-BOM、AI red teaming、CI/CD policy gate 和 runtime guardrails 中,可以帮助企业把"训练数据隐私泄露风险"变成一个可扫描、可度量、可阻断、可审计的安全问题。