HorizonVault 是中间件团队自研的一款高吞吐分布式存储引擎,主要面向 Kafka 远程存储、冷/温数据下沉和大容量低成本存储场景。随着 Kafka 集群数据规模持续增长,本地高性能磁盘很难无限扩张,HorizonVault 需要把大量历史数据稳定、可恢复、可治理地迁移到远端存储,同时维持足够高的写入吞吐和可控的读写延迟。
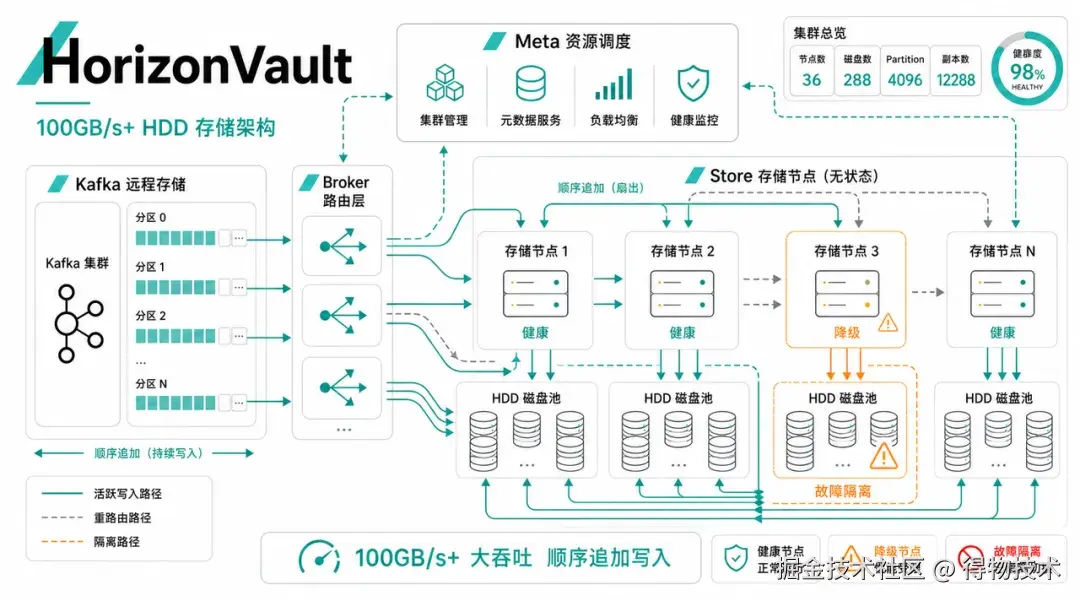
随着业务流量持续增长,Kafka 高性能本地磁盘会面临越来越高的容量和成本压力。远程存储可以缓解容量压力,但如果远端系统写入慢、抖动大、恢复弱,成本问题很快会变成稳定性问题。HorizonVault 的方向,是用通用大容量 HDD 承接冷/温数据,通过分布式并行写入摊薄单盘能力上限,再用顺序追加、磁盘隔离、状态感知调度和副本同步,把 HDD 的随机 I/O 短板控制在系统可以管理的范围内。
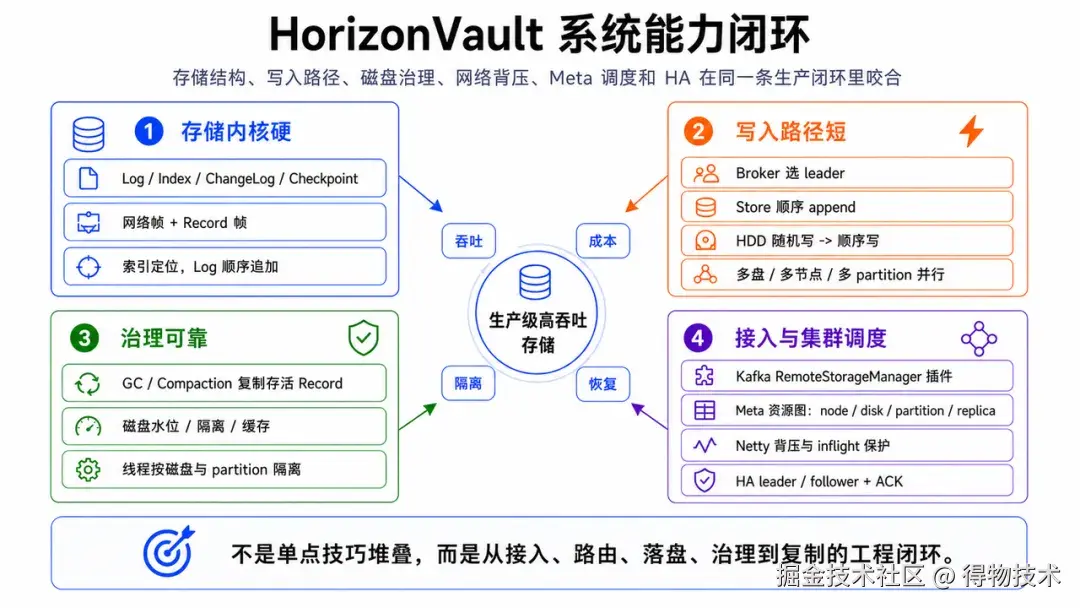
从系统形态看,HorizonVault 更像一套完整的数据基础设施。Broker 承接客户端读写,Meta 维护全局资源视图,Store 真正负责落盘,并按磁盘、分区、副本和日志段组织数据。HA 链路负责 leader/follower 复制,网络层负责高并发下的超时、背压和异步处理。这些机制共同构成了一条完整的写入和治理链路,也构成了 HorizonVault 最重要的系统价值。
如果用一句话概括:HorizonVault 把"写一个文件"变成了"基于集群资源状态、磁盘水位、线程隔离、网络背压和副本同步进度共同决策的一次分布式调度"。Kafka 自身非常擅长承接热数据读写,但当保留周期变长、topic 数量增多、分区副本规模扩大时,本地磁盘会成为成本和容量的双重压力点。Tiered Storage 的思路,是把热数据继续留在 Kafka 本地,把较冷的数据下沉到远端存储。这个方向看起来简单,真正落地时却会遇到三个硬问题。
- 第一个问题是吞吐。Kafka 下沉 segment 时,会持续产生一批批大对象。如果远端存储无法吃下持续写入,Kafka 本地磁盘释放就会跟不上,最终还是回到容量压力。
- 第二个问题是抖动。HDD 的平均顺序吞吐并不差,但它怕随机 I/O,怕队列堆积,怕某块盘突然变慢。一块慢盘如果没有被及时隔离,影响会从单盘扩散到 Broker 路由、Store 写线程、网络连接和上层请求延迟。
- 第三个问题是恢复。远端存储不能只是"写进去",还要能在节点重启、磁盘状态变化、leader/follower 切换之后恢复一致的状态。否则冷数据一旦成为事故现场,Kafka 降本反而会引入新的可靠性风险。
HorizonVault 的设计目标就是围绕这三个问题展开:把 Kafka 远程写入改造成适合 HDD 的大块顺序追加,把多节点多磁盘的并行度真正用起来,同时把慢盘、慢副本、慢请求都收敛在局部。这也是为什么 HorizonVault 没有把 HDD 当作普通挂载目录来用。它把磁盘提升成了系统的一等资源:有状态、有水位、有线程、有缓存、有隔离,也会被 Meta 纳入全局资源调度。只有这样,通用 HDD 才能从"容量介质"变成一套可承载高吞吐写入的资源池。
一、性能主线与整体架构:让流量打准、让数据写稳
讨论 HorizonVault 的性能,需要把 Netty、分区、副本这些组件放回完整的数据链路里看。单个组件只能解释局部能力,100GB/s+ 级别的集群吞吐来自顺序写、多盘并行和状态感知调度的组合。整体性能逻辑更接近下面这个公式:
ini
集群写入吞吐
= 单盘可持续顺序写吞吐
x 单节点可用磁盘数
x 可并行写入节点数
x 路由和隔离机制带来的有效利用率这几个因子里,最基础的是单盘顺序写。HDD 不适合大量随机小写,但持续顺序写仍然有不错的吞吐。HorizonVault 的 Store 写入路径尽量保持单调:真实数据进入 LogSegment,定位信息进入 IndexSegment,不在主写路径上做复杂原地更新,也不把数据和索引混在一起反复改写。
第二个因子是资源池并行。一个 Kafka 远程写入请求最终会落到某个 partition 的 leader replica,而这个 replica 又落在某个 Store 节点的一块磁盘上。Broker 负责选择合适的 partition 和 leader,Meta 负责让 replica 尽量均匀分布到节点和磁盘,Store 负责在单盘内部把写入顺序推进。上层看到的是一个远端存储端点,底层实际是一组节点、一组磁盘和一批 partition 在并行工作。
第三个因子是有效利用率。高吞吐系统在局部慢点出现后,很容易演变成全局排队:某块盘响应变慢、某个 follower 同步落后、某个网络连接积压,如果系统还继续把流量压上去,平均吞吐和 P99 延迟会一起恶化。HorizonVault 在 Broker、Store、Netty、HA 这些层面都做了状态反馈:慢盘会被隔离,慢副本会影响写入选择,入口连接会触发背压,强 ACK 请求会被挂起并由后续事件唤醒,写线程可以继续处理后续追加。所以 HorizonVault 的高吞吐更像一套持续筛选的流水线:能顺序写、能并行写、状态健康的请求尽快推进;会扩大尾延迟或故障半径的请求尽早换路、降级或失败。对 HDD 资源池来说,这种克制本身就是性能的一部分。
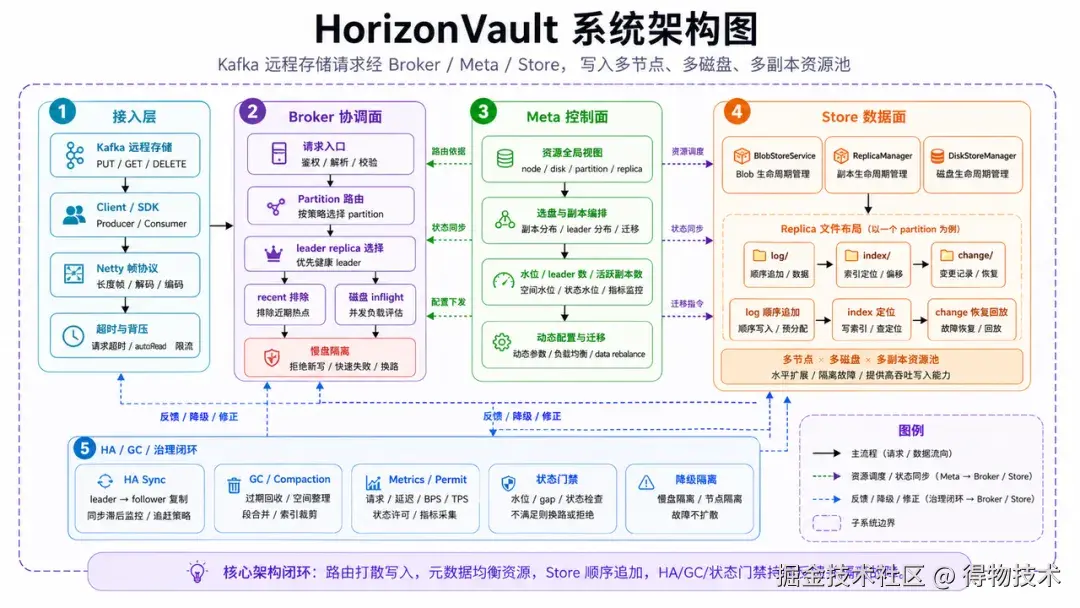
HorizonVault 的模块边界很清楚。Meta 是控制面,管理节点、磁盘、分区、副本、动态配置和迁移;Broker 是协调面,承接外部请求并选择可写 partition 或可读 replica;Store 是数据面,负责本地文件、索引、副本状态和 HA 同步;Network 是公共通信层,处理协议、连接、超时和背压;Common 则沉淀 BlobId、Record、PartitionState、ReplicaState、DiskState 等基础模型。
这种分层的目的,是让每一类问题在正确的位置被解决。Meta 不参与主写入路径落盘,它关心的是资源放得是否均匀、磁盘是否可用、副本角色是否合理。Broker 不直接写文件,它关心的是请求应该发到哪个 leader replica、目标磁盘是否还能接流量、读请求是否可以在 follower 上回退。Store 不做全局调度,它关心的是本地副本是否可写、磁盘水位是否安全、数据如何顺序追加、索引如何维护。
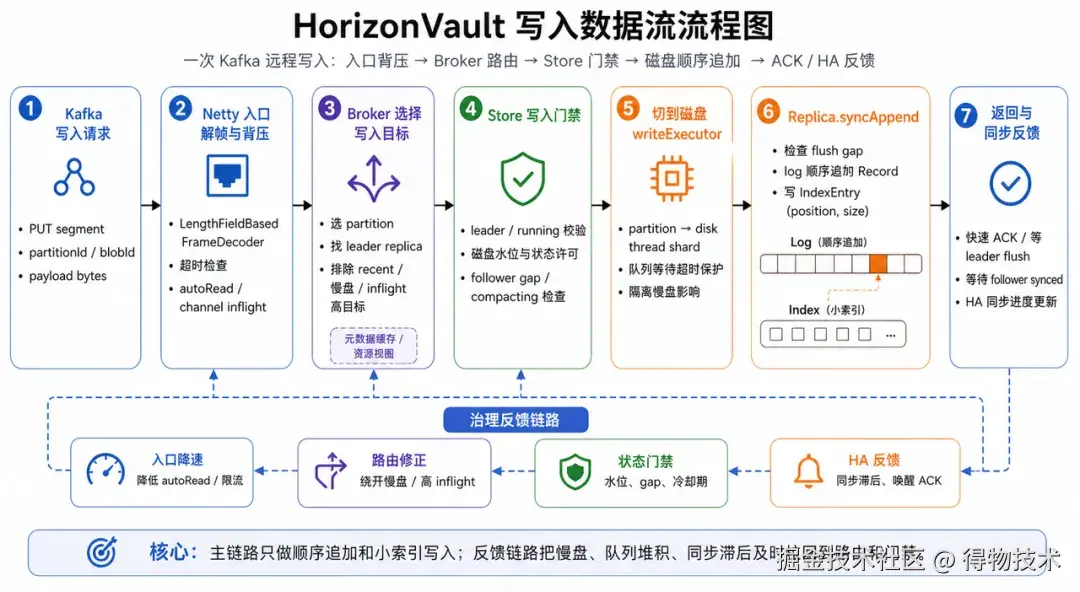
一条写入请求进来后,会先经过 Netty 长度帧、超时和背压处理;Broker 选择 partition 和 leader replica,并检查目标磁盘的 inflight 和隔离状态;Store 收到请求后继续做 leader、running、磁盘水位、状态许可、follower gap 等门禁;真正落盘时,Replica 把任务切到磁盘级 write executor,再执行 log append 和 index 更新。
这条链路里有一个很重要的设计取舍:Meta 的全局视图不在每次写入时成为同步瓶颈,但它提前把资源布局、状态和动态配置准备好;Broker 基于这些信息做路由;Store 基于本地状态做最终门禁。这样主路径足够短,控制路径又能持续影响主路径。对于 Kafka 远程存储这种持续大流量写入场景,这个边界非常关键。
二、存储结构:DiskStore、Replica、Log/Index 各司其职
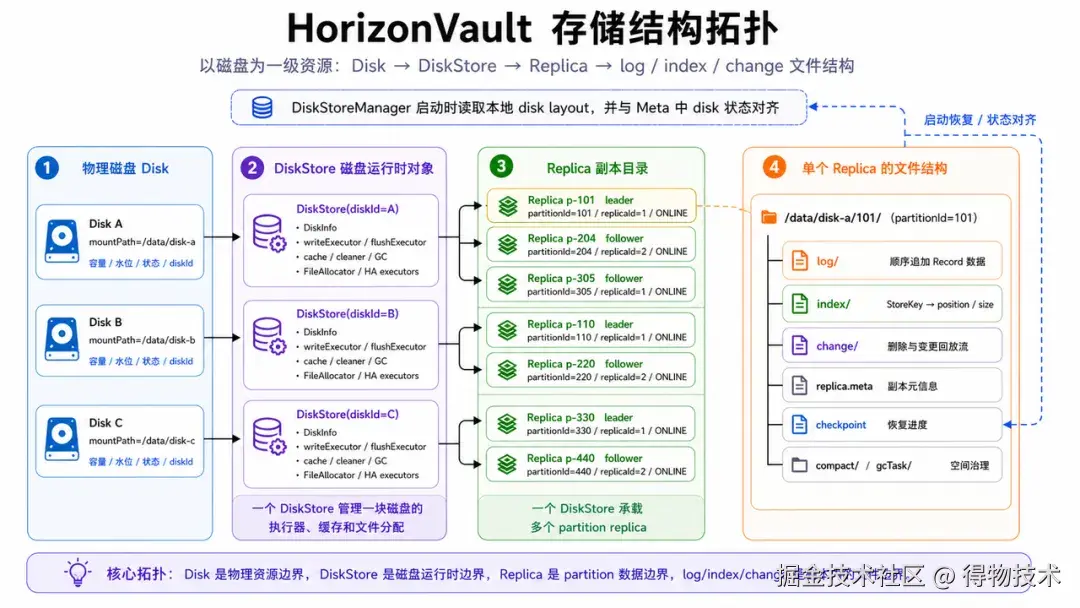
HorizonVault 的本地存储以磁盘为单位组织资源,避免把所有数据都放进一个大目录。每块磁盘进入运行态后,会被抽象成 DiskStore,里面挂着磁盘信息、执行器、缓存、限速器和文件分配器。也就是说,磁盘在系统里有自己的执行域和治理能力,可以主动参与资源调度和状态控制。Replica 则是一个分区副本在本地磁盘上的执行单元。一个 replica 目录下会有 log、index、change、replica.meta 等结构:
perl
mountPath/
<partitionId>/
log/ # 真实数据,顺序追加
index/ # key -> segment/position/size
change/ # 删除、变更回放
replica.meta这几个目录各有分工。LogSegment 承载真实 record,是吞吐主路径;IndexSegment 保存 StoreKey 到 log segment 位置的映射,是读路径定位的基础;ChangeLog 记录删除和变更,辅助恢复和回放;replica.meta 持久化副本本地状态。
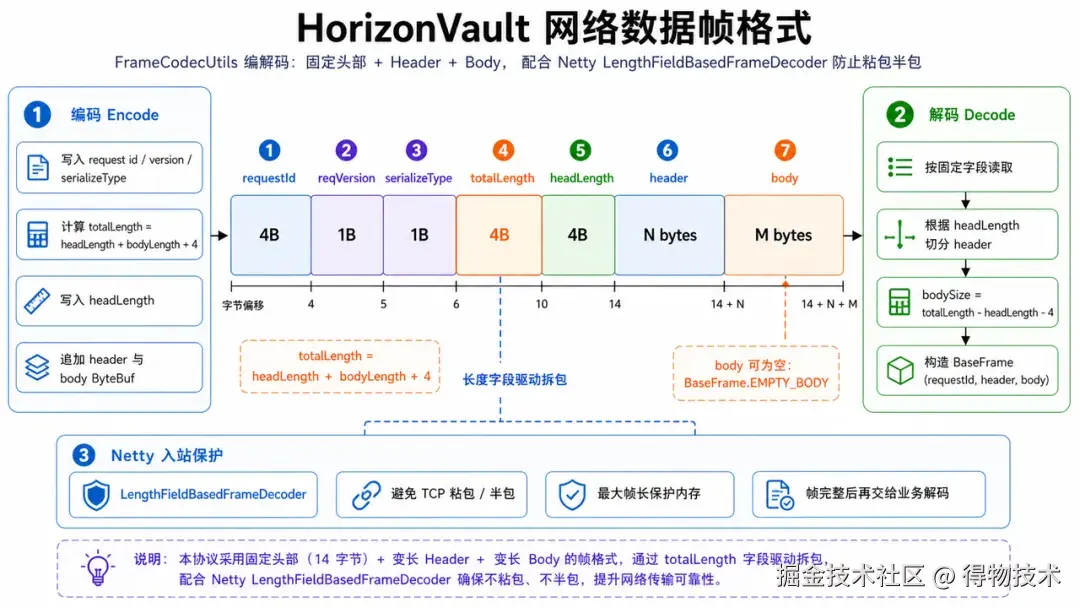
网络帧和落盘 record 也被分开设计。网络帧关心传输边界:requestId、版本、序列化类型、totalLength、headerLength、header 和 body。服务端和客户端都用长度帧处理 TCP 粘包/半包问题,并用最大帧长限制保护内存。
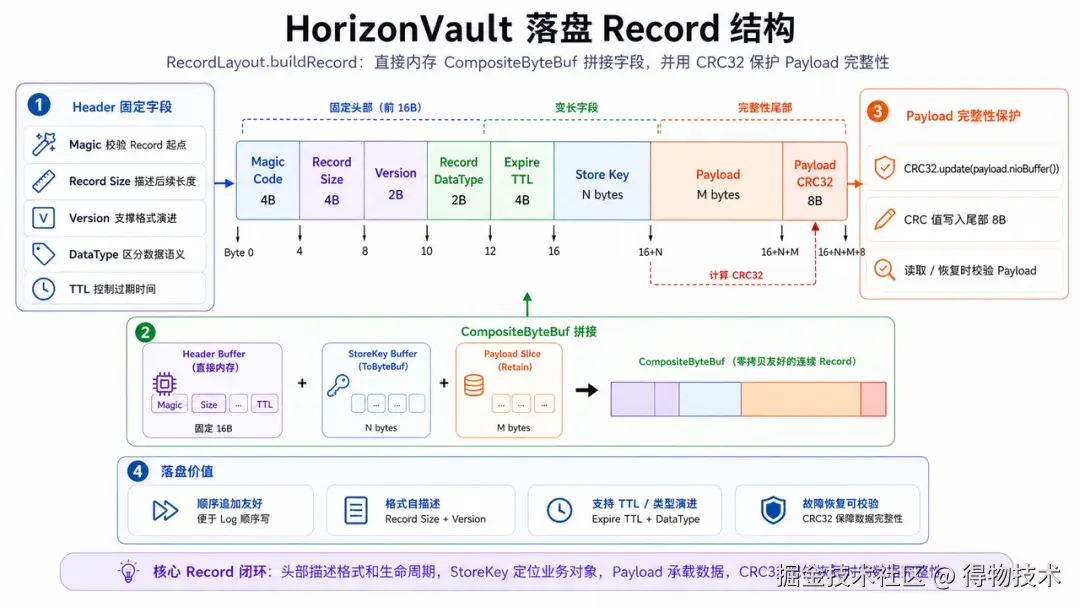
落盘 Record 关心的是恢复和完整性。Magic Code 用来识别记录边界,Record Size 让恢复扫描可以跳过完整记录,Version 和 RecordDataType 表达格式和语义,TTL 和 StoreKey 让生命周期与对象身份绑定在一起,Payload CRC32 则用于发现数据损坏。这个分层很朴素,但非常实用。网络层不要背负存储恢复语义,落盘层也不要依赖外部数据库告诉它"写到哪里"。重启后,Store 可以通过 magic、size、crc 和 index 重新确认文件边界;读请求可以通过 index 直接定位 log。
三、写入与读取:Log 顺序追加,Index 承接随机性
HorizonVault 的写入路径有一个非常明确的目标:不要把 HDD 拖进随机写模式。请求进入 Store 后,BlobStoreService 会先做一批防御性检查,包括节点是否允许写、blob 大小是否合规、本地 replica 是否存在、replica 是否 running、当前副本是否 leader、磁盘是否存在、磁盘水位和状态是否允许写。
这些检查对应的是高吞吐系统里常见的时间差问题:状态已经变化,但请求还在排队。写入真正进入 Replica.append 后,还会在线程内再次确认 replica 状态、leader size、请求超时和队列等待时间,避免一个过期请求或状态不再匹配的请求继续落盘。
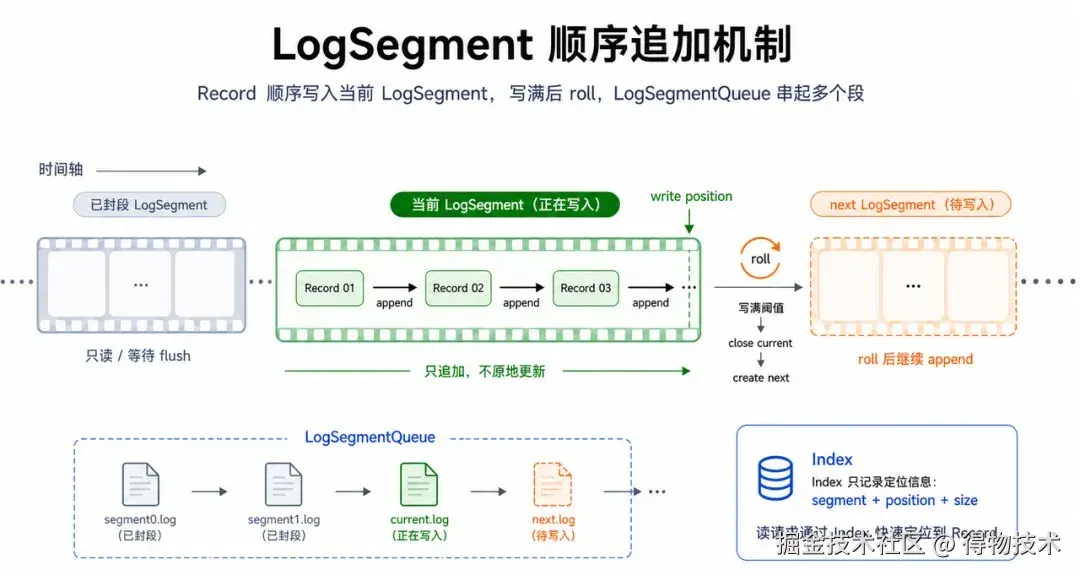
真正的落盘动作保持很短:
- record 追加到 LogSegment,返回 segment、position 和 size。
- 构造 IndexValue,把 flag、ttl、position、size 等定位信息写入 IndexSegment。
- 根据 ACK 等级决定请求是否可以立即返回,或者进入 PutReqHolder 等待 flush/follower synced。
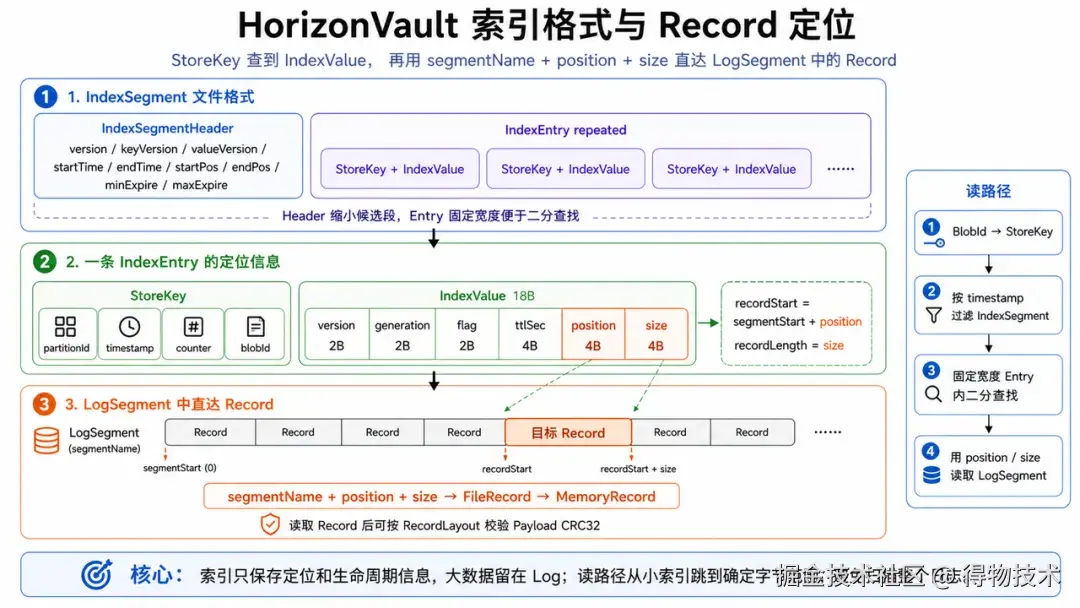
LogSegment 是主数据路径,IndexSegment 是定位路径。HorizonVault 没有把完整 record 元数据塞进索引,而是只保存定位和生命周期所必需的信息。这样索引 entry 足够小、格式固定,段内可以通过二分查找和按 offset 读取快速定位。读取路径正好反过来。BlobStoreService.get 找到本地 replica 后,Replica 先通过 IndexSegmentQueue 查 StoreKey 对应的 IndexEntry;IndexSegmentQueue 会先看缓存,缓存未命中再按 segment 从新到旧查找,并用 timestamp 边界过滤候选段。命中 IndexEntry 后,再根据 segmentName、position、size 从 LogSegment 读取对应 record。
这个结构把随机性压缩到了小索引上,把真正的大 payload 留在 log 里顺序组织。对 HDD 来说,这一点很关键:系统不要求磁盘承担大量小块随机读写,而是让小索引负责定位,让主数据保持连续追加和确定范围读取。索引还分内存态和文件态。活跃 IndexSegment 先在 direct memory 中追加固定宽度 entry,封段后再 dump 成文件态索引。文件态索引打开时只需要读取 header,并根据文件大小计算 entry 数量;后续查找通过 offset 读取 key/value。这个设计兼顾了写入阶段的低开销和读取阶段的确定性。
四、磁盘治理、线程隔离与网络背压
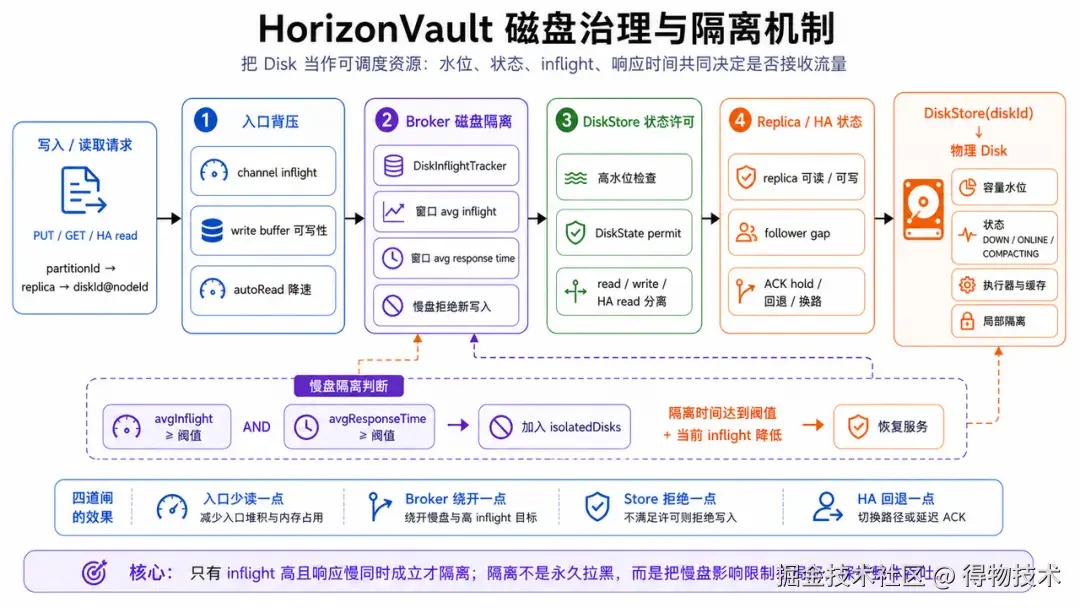
HorizonVault 把磁盘当作可调度、可隔离、可降级的资源。DiskStore 的写入许可会先检查高水位,再看当前 DiskState 是否允许 store write;读、写、HA read 也有各自的许可规则。这样一个磁盘可以处在"允许读但不允许写""允许 HA read 但不适合前台写"等更细的状态里。
Broker 侧还会做磁盘级 inflight 跟踪。发送 PUT 请求前,Broker 会用 diskId@nodeId 构造磁盘 key,并尝试增加 inflight。如果这块盘已经被隔离,请求会在发送前失败或换路,避免继续把流量打到问题盘上。
隔离判断会同时参考负载和响应时间。DiskMetricsCollector 会按窗口统计每块盘的 inflight 和响应时间。只有平均 inflight 高且平均响应时间也高,系统才认为这块盘正在拖慢整体链路。单独 inflight 高可能只是流量大,单独响应慢也可能只是瞬时抖动;两个条件同时成立,才更像一个需要路由避让的慢盘。
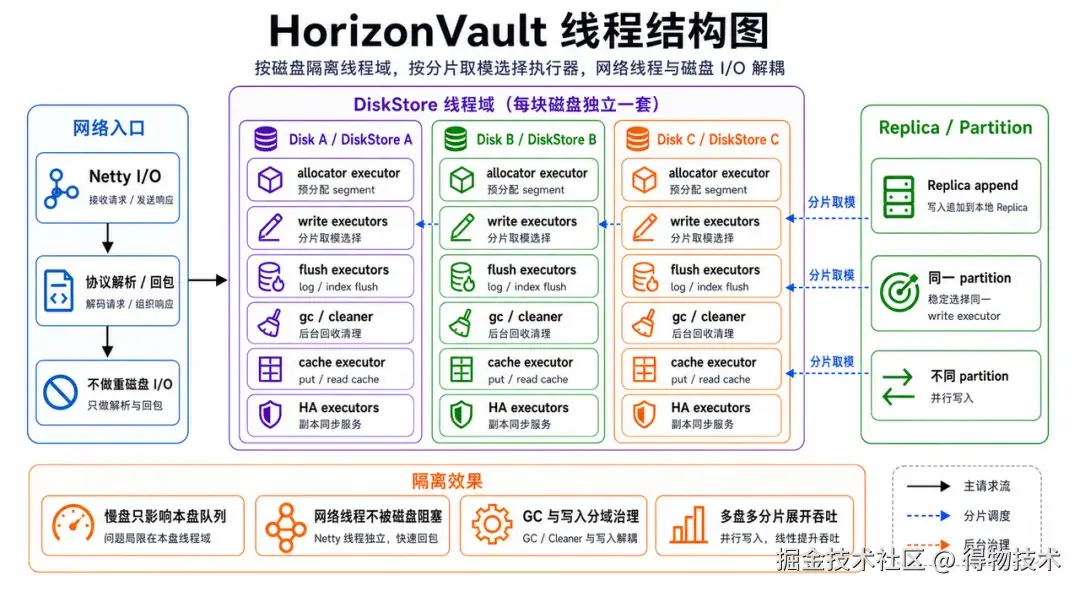
线程模型同样围绕磁盘展开。每个 DiskStore 都有自己的 allocator、cleaner、write、flush、cache、HA client/server 和 put request hold executor。写线程和刷盘线程还会按 partitionId 做稳定分片:同一个 partition 持续落到同一组执行器上,不同 partition 可以在同一块盘内并行推进,不同磁盘之间天然隔离。
这种设计比一个全局大线程池更适合 HDD。全局线程池短期看起来吞吐高,但慢盘出现后,很多无关任务会被拖进同一个队列。磁盘级线程边界让问题更容易局部化:一块盘慢,主要影响它自己的队列和 replica,其他磁盘仍然可以继续推进。
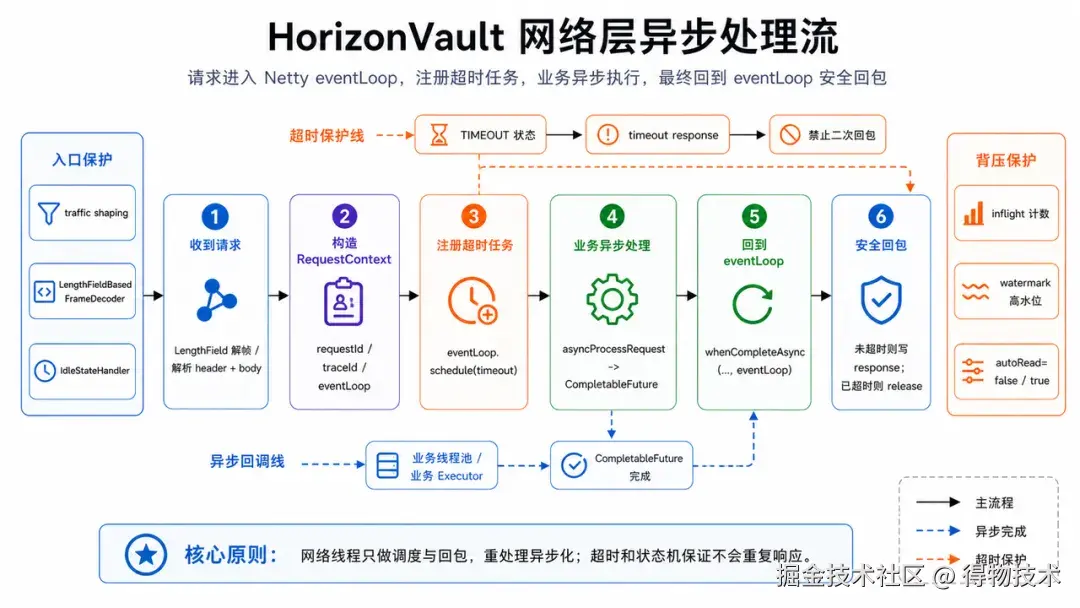
网络层负责把入口压力控制住。服务端基于 Netty NIO,pipeline 中有 traffic shaping、长度帧解码、idle handler、背压 handler 和业务 inbound handler。每个请求会记录 request id、trace id、client send time、server receive time 和当前 NIO event loop,并注册服务端超时任务。
背压通过 channel 级 inflight 和 write buffer 水位实现。请求读入时 inflight 加一,超过阈值就关闭 autoRead;响应写出后 inflight 减一,低于阈值再恢复读取。如果 channel 本身不可写,即使业务背压开关没有触发,也会关闭 autoRead。这个机制的意义是:当 Store 侧或网络写出变慢时,不让请求无限堆进内存和执行队列。
这几层连起来,就是 HorizonVault 的抗压方式:入口连接少读一点,Broker 路由绕开一点,Store 状态拒绝一点,副本同步慢了就换路或等待。高吞吐依赖可控队列里的健康请求持续向前,而非无条件接收更多请求。
五、Broker 和 Meta:状态感知的资源调度
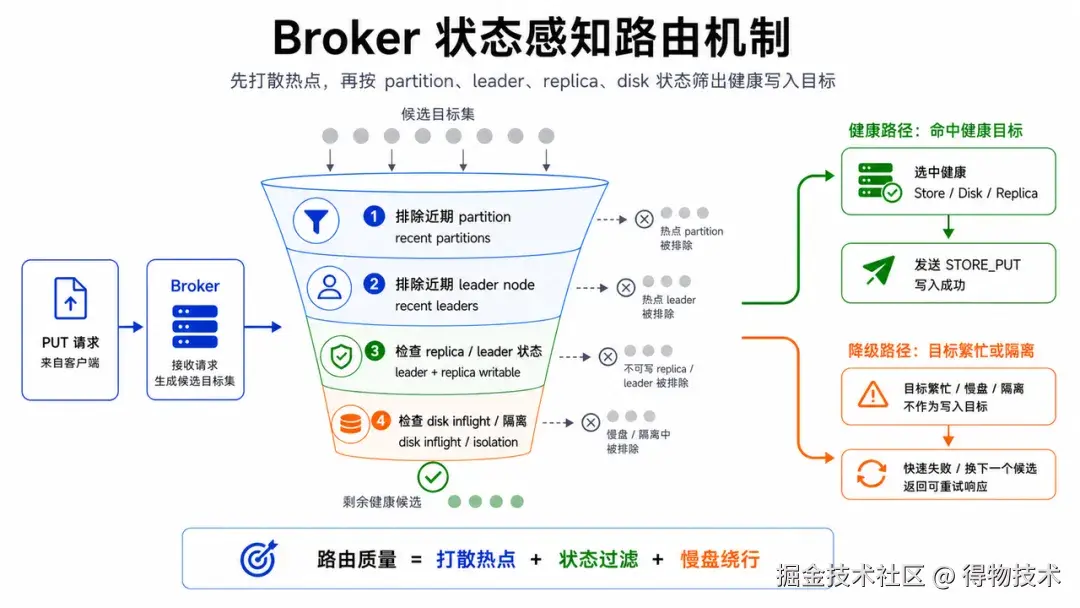
Broker PUT 的核心是状态感知的目标选择。它会排除近期使用过的 partition 和 leader node,减少连续命中热点;再从 PartitionManager 里选择候选 partition,根据 leader node 找到对应 ReplicaInfo 和 NodeInfo,最后拿到 Store client 发送 STORE_PUT。
这个过程看起来像路由,实际也是性能策略。HorizonVault 需要把写入摊到足够多的 partition、节点和磁盘上,同时避开已经表现出压力的目标。近期使用过的 partition 会被排除,目标磁盘 inflight 会被检查,隔离盘会被拒绝,发送失败后还可以通过排除集合继续找下一个目标。
GET 路径也会做状态筛选。Broker 会优先读 leader,以保证数据新鲜度;如果 leader 不可读,则按 replica 状态、节点状态、磁盘状态和 broker read choose 许可做回退。这样读路径天然支持 follower fallback,不会把一次读失败简单暴露给上层。
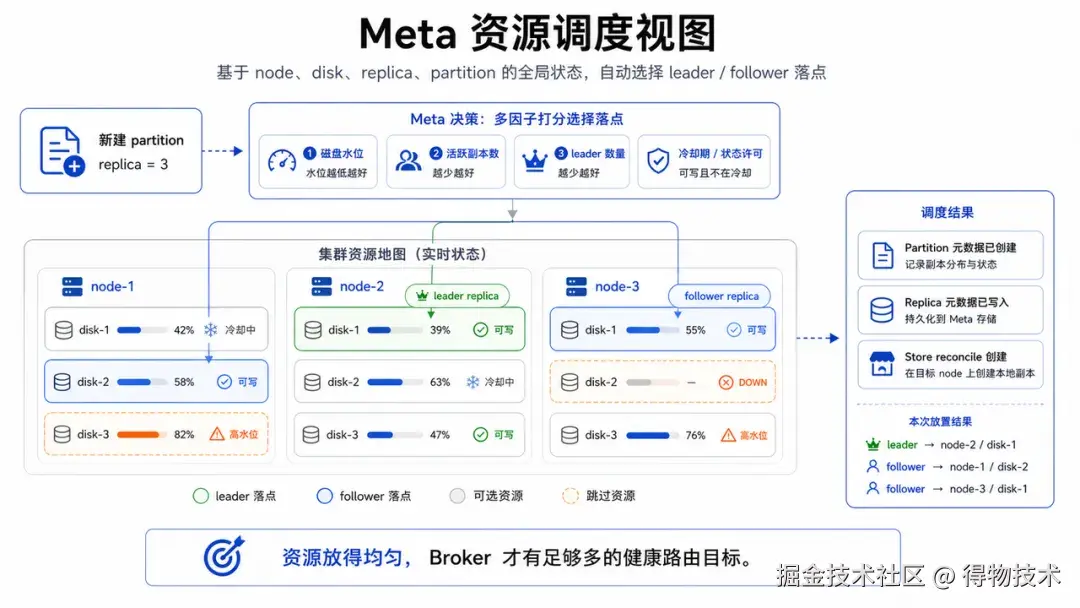
Meta 解决的是更长期的问题:资源一开始应该怎么放。Meta 管理的不只是一张 partition 表,而是 node、disk、replica、partition、迁移和动态配置组成的资源系统。创建 partition 时,PartitionResourceOperator 会拿到节点磁盘信息,过滤不可创建 replica 的磁盘,再排除冷却期磁盘,最后根据活跃副本数、leader 数、磁盘可用空间和水位策略挑选 leader/follower 目标盘。
这个过程决定了后续吞吐的天花板。如果 leader 都集中在少数节点,或者 replica 都落在少数磁盘,Broker 再怎么随机也很难打散热点。Meta 的价值,是在创建和迁移阶段就尽量把资源放匀,让 Broker 有足够多健康候选目标,让 Store 的多盘并行真正展开。也可以说,Broker 负责"当下这一次请求打到哪里",Meta 负责"长期看,系统有没有足够均匀的可选资源"。两者配合起来,HorizonVault 才能把通用 HDD 从单盘能力扩展成集群吞吐。
六、HA 复制:leader/follower 同步与写入 ACK 解耦
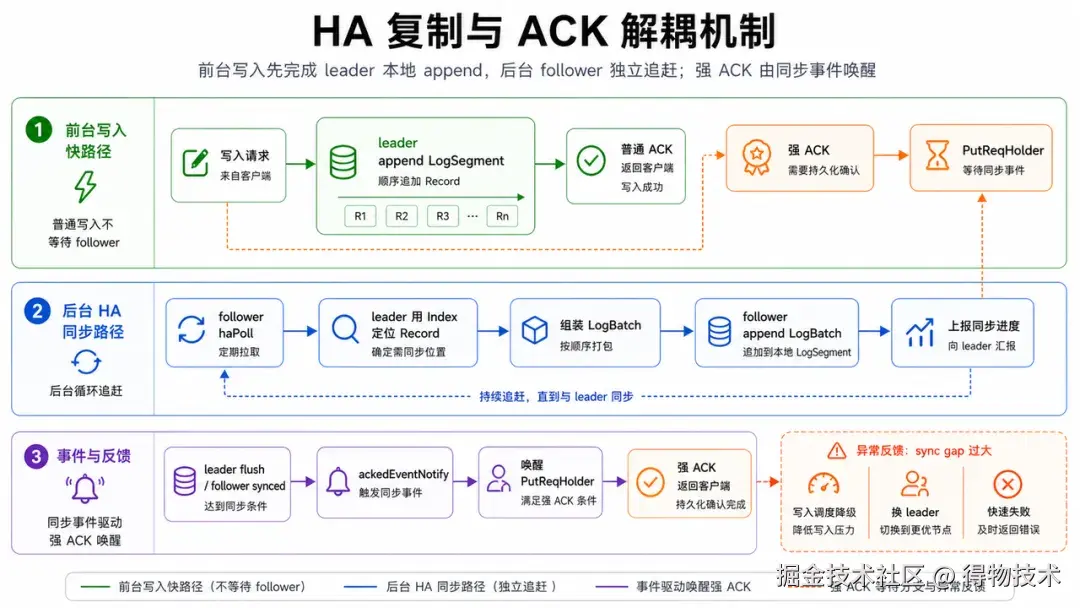
HorizonVault 的 HA 围绕 leader 本地追加和 follower 主动追赶展开。它的核心取舍是:前台写入先保证 leader 本地顺序追加足够快,follower 通过独立 HA 链路主动追赶;如果请求需要更强确认语义,再通过 ACK 等级把写入返回和 flush/follower synced 事件绑定起来。
Follower 采用主动 pull 模型。它会根据本地最后一条 index entry 推导自己的最大 blobId 和 log offset,然后向 leader 发起 haPoll,告诉 leader:我已经同步到这里,请从这里之后继续给我数据。Leader 收到后不会从 log 头开始扫,而是复用 IndexSegmentQueue 找到 fromBlobId 之后的 entry,再按 cache -> log 的顺序构造 LogBatch。
LogBatch 的 meta 很关键。每个 LogBatchSpan 记录原始 segment、原始 offset、record size、batch buffer 内偏移、blobId 和 flag。Follower 拿到 batch 后,就能按 span 顺序从 buffer 里切出 record,构造 MemoryRecord,再调用本地 Replica.append 写入自己的 log/index。HA 复制的实际过程,是先按 index 精确定位 record,再在 follower 本地顺序回放。
ACK 语义由 PutReqHolder 承接。普通写入可以在 leader append 后较快返回;如果请求要求 wait leader flush 或 follower synced,append 结果会按 log end offset 放进 pending map。后续 leader flush 到某个 offset,或者 follower 上报自己同步到某个 offset,PutReqHolder 再批量唤醒满足条件的请求。
这种设计避免了写线程直接阻塞等待 follower。强确认请求可以得到更严格语义,等待发生在事件驱动的 holder 里,磁盘写线程可以继续处理后续追加。对 HDD 后端来说,这一点很重要,因为 follower 的瞬时抖动不应该直接拖慢所有 leader append。同步健康度也会反过来影响写入。Leader 会维护 follower 的最大 blobId、最大 offset 和更新时间;当 follower 不存在,或者 leader log end offset 与 follower max offset 的 gap 超过阈值时,写路径可以尝试切到其它在线、可写、未高水位的 leader replica,避免继续把写入压到复制已经明显落后的分区上。
七、Kafka 插件接入:把 segment 生命周期映射成 HV Blob
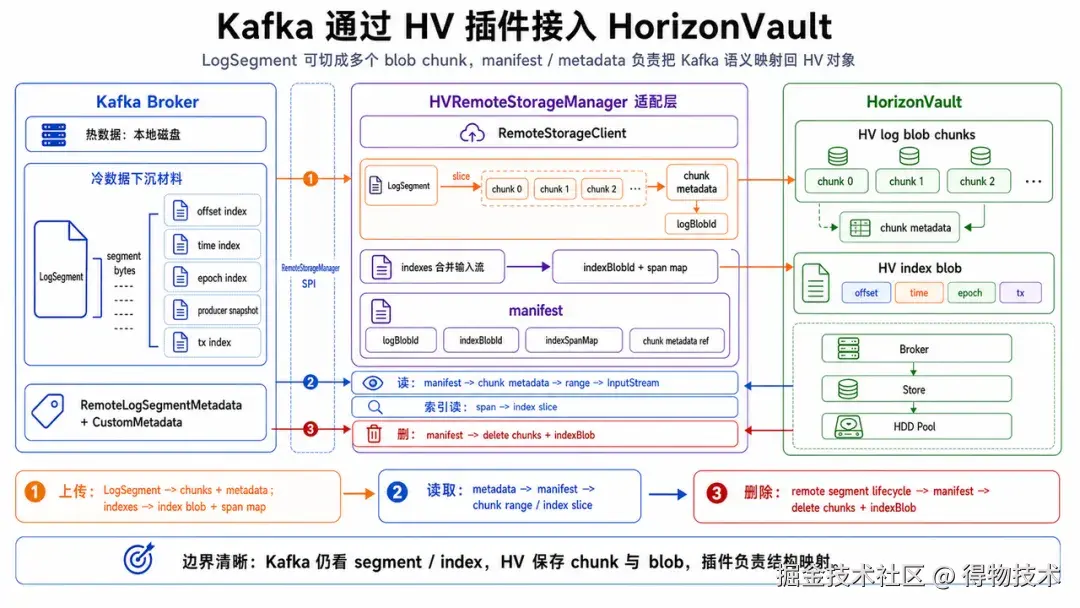
Kafka 接入 HorizonVault 走的是 Kafka Tiered Storage 的 RemoteStorageManager 扩展点。Kafka 下沉一个 segment 时,插件把 log segment 上传成 HV log blob,把 offset index、time index、leader epoch index、transaction index 等多个 Kafka index 合并成一个 HV index blob,并在 manifest 里记录每种 IndexType 对应的 offset 和 size。manifest 会写回 Kafka 的 remote log metadata,成为后续读取和删除的定位依据。
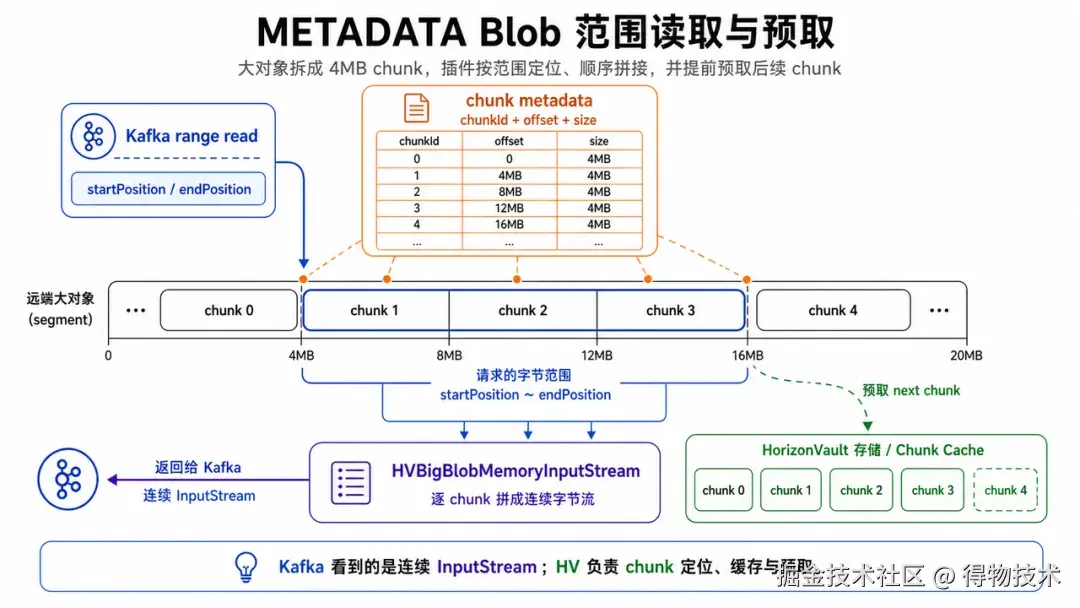
读取时,Kafka 仍然拿到普通 InputStream。底层如果是简单 blob,可以从 cache/HV 拉取后按范围 slice;如果是大对象 metadata blob,则根据 chunk metadata 按范围逐 chunk 读取,并配合预取。
删除时,Kafka 表达 remote segment 生命周期,插件解析 manifest 后删除对应的 log blob 和 index blob。这样 Kafka 不需要理解 HV 内部的 log/index/change 文件结构,HV 也不需要侵入 Kafka 的 remote metadata store,二者通过插件和 manifest 解耦。
八、系统价值:把性能、成本和稳定性放在一起解决
回到系统价值,HorizonVault 的强点来自一组互相接住的机制:
- Broker 把请求打到状态健康的 partition 和 leader replica。
- Meta 让节点、磁盘、replica 和 leader 分布尽量均匀。
- Store 把真实数据顺序追加到 log,把随机定位压缩到小索引。
- DiskStore 用状态、水位、线程、缓存、限速和隔离管理单盘。
- Network 用异步处理、超时和背压保护入口。
- HA 用 follower pull、LogBatch 回放和 ACK holder 解耦吞吐与确认语义。
- Kafka 插件把 segment/index 生命周期映射成 HV blob 和 manifest,让 Kafka 能以原生 Tiered Storage 方式接入。
这些机制串起来以后,HorizonVault 呈现出一套围绕资源池运行的闭环:Meta 负责把资源放匀,Broker 负责把流量打准,Store 负责把数据顺序写稳,DiskStore 负责把单盘状态管住,Network 负责把入口压力控住,HA 负责把副本追平,Kafka 插件负责把上层 segment 生命周期接进来。
这套闭环最终服务的是同一个目标:把性能、成本和稳定性放在一起解决。正常情况下,写入沿着顺序追加、多盘并行和异步处理一路推进,通用 HDD 的容量优势可以被转化成集群级吞吐;出现慢盘、慢副本、连接积压或同步 gap 时,系统又能把问题尽量限制在某块磁盘、某个副本、某条连接或某一次路由选择上。
对 Kafka 远程存储来说,这一点比单纯追求某个 benchmark 数字更重要。远程存储承接的是长期存在、持续增长、需要随时读回的数据,它既要帮助 Kafka 降低本地磁盘压力,也不能把冷数据变成新的稳定性风险。HorizonVault 的设计价值就在这里:用清晰的资源模型和分层隔离,把一组通用 HDD 组织成可调度、可恢复、可扩展的远程存储资源池,让 Kafka 的数据生命周期从本地磁盘自然延伸到远端存储。
往期回顾
1.Claude Code Harness 工程:数仓侧落地方案|得物技术
2.BP Claw 破解 AI 编码输入难题 ------FlinkSpec 需求智能化实践|得物技术
3.基于 Harness + SDD + 多仓管理模式的 AI 全栈开发实践|得物技术
4.通用 AI Agent 驱动网关路由安全审计实践|得物技术
文 /英杰
关注得物技术,每周更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。