前言
看这篇博客之前请先看:
本篇博客是本人学习完之后的理解笔记
💓 个人主页:普通young man-CSDN博客
⏩ 文章专栏:C++_普通young man的博客-CSDN博客
⏩ 本人giee: 普通小青年 (pu-tong-young-man) - Gitee.com
若有问题 评论区见📝
🎉欢迎大家点赞👍收藏⭐文章

目录
[1. 模式切换](#1. 模式切换)
[2. 移动光标](#2. 移动光标)
[3. 删除文字](#3. 删除文字)
[4. 复制与粘贴](#4. 复制与粘贴)
[5. 替换与更改](#5. 替换与更改)
[6. 撤销与恢复](#6. 撤销与恢复)
[7. 其他操作](#7. 其他操作)
[1 进入方式](#1 进入方式)
[2 基础操作类](#2 基础操作类)
[3 查找类](#3 查找类)
[4 文件保存与退出类](#4 文件保存与退出类)
[为什么进度条代码必须 fflush(stdout)](#为什么进度条代码必须 fflush(stdout))
软件管理包yum
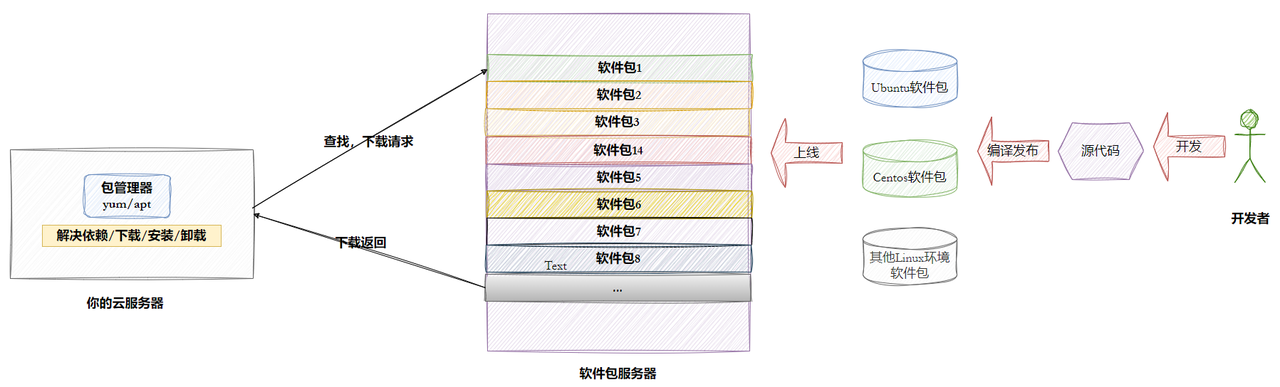
什么是软件包
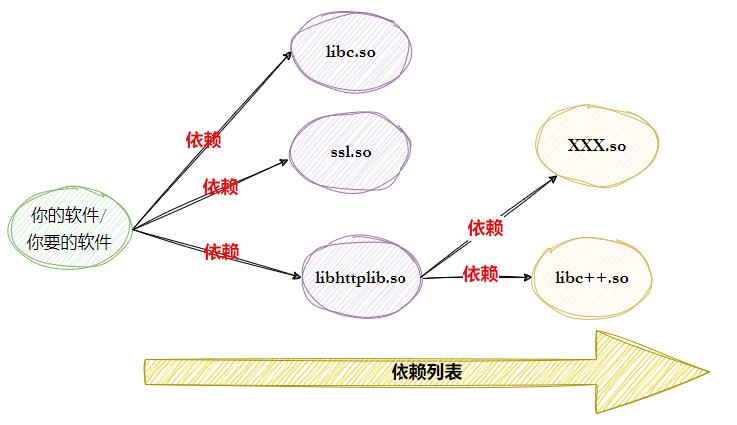
在 Linux 里装软件,最原始的办法是下载源码自己编译,特别麻烦。后来大家就把常用软件提前编译好,做成 "软件包",放到服务器上,再通过 "包管理器" 这个工具,就能像手机应用商店装 App 一样,一键下载安装,还能自动处理软件之间的依赖关系,省事很多。不同的 Linux 系统用的包管理器不一样:比如 CentOS、RedHat 这些系统用 yum,Ubuntu 则用 apt,它们的作用都差不多,都是帮你轻松管理软件的 "应用商店"
linux的软件生态
这里直接简单易懂的用三个点概括:
开发者写软件,社区打包好程序员把软件写好后,Linux 社区会把它提前做成 "安装包",放到专门的服务器上,就像 App Store 里的 App
包管理器 = 你的专属应用商店比如
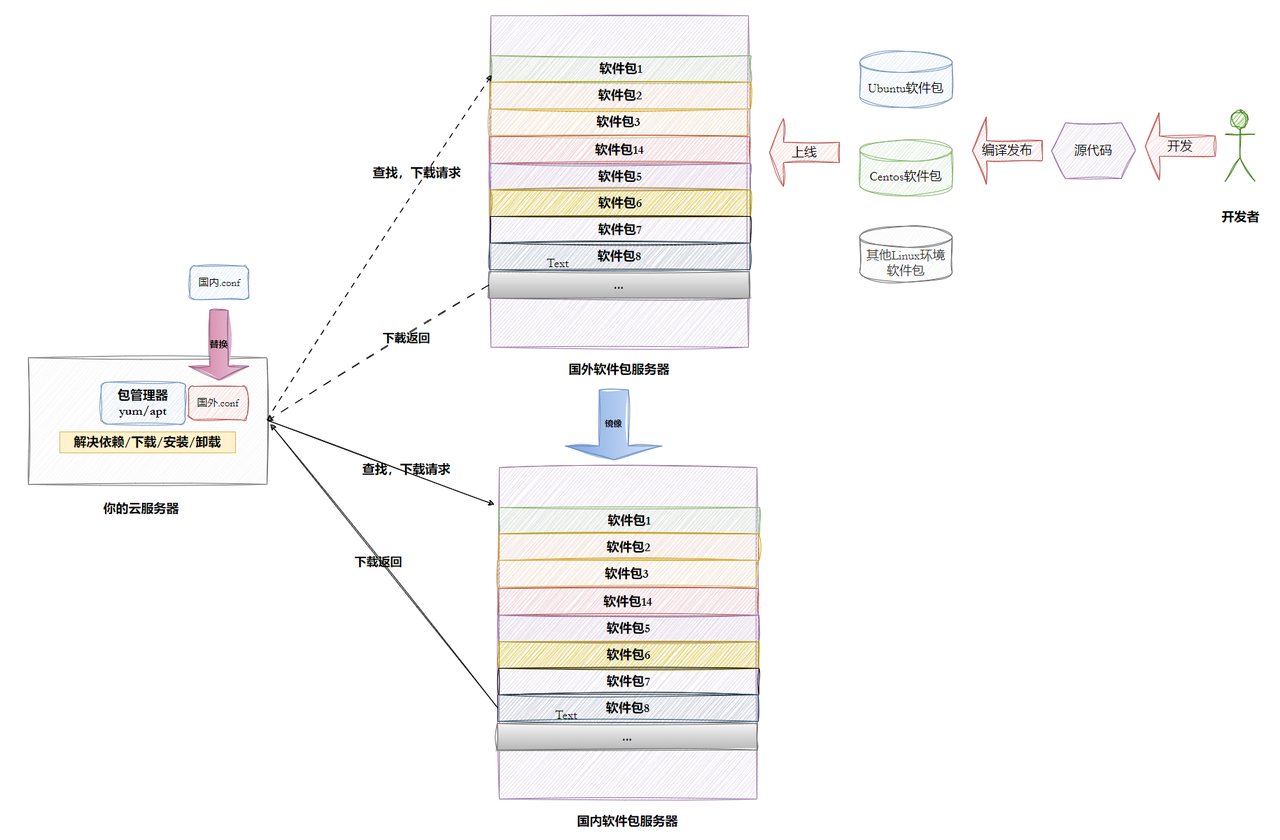
yum(CentOS 用)和apt(Ubuntu 用),就是你 Linux 里的 "应用商店 App"。你只要敲一条命令,它就会自动去服务器上下载软件,还顺便把软件需要的所有配套工具(依赖)一起装好,不用你自己瞎找镜像源 = 国内加速通道官方服务器在国外,下载慢。阿里云、清华这些国内机构,把软件包复制到了国内服务器上,你把 "应用商店" 的地址改成这些国内镜像源,下载速度就快很多
通过生态插入题外话(建议看):
为什么华为鸿蒙一直都起不来,我看很多平台的网友只知道胡乱喷,根本不懂,不懂华为要去维护一个生态有多难:
技术 vs 生态,到底差在哪?
- 技术,就像你开了一家餐厅,菜做得再好吃、厨房设备再顶级,这只是 "硬件实力"。
- 生态,则是餐厅的完整商业闭环:有没有稳定的食材供应链?有没有人愿意来吃饭?有没有人愿意加盟你的品牌?有没有配套的外卖、团购、供应链支持?
在这个mac,windows...遍地的时代,华为只能通过先散布给一小部分的用户来维护生态,华为手机确实昂贵这个是没得说的,但是大家也不要去无脑乱喷,中国这么多的企业为什么只有华为敢做自己的系统,因为想要维护一个生态真的很难
yum的各种操作
- 查看软件包
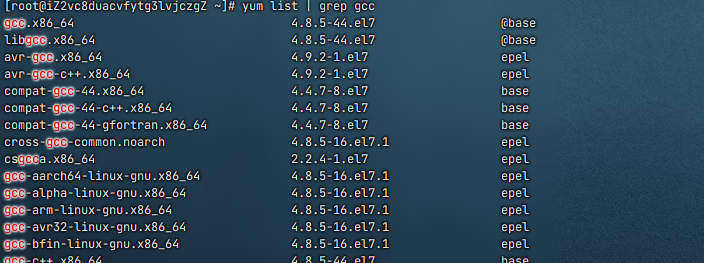
yum list
软件包命名格式为软件名 - 主版本号。次版本号。源程序发行号 - 软件包发行号。
系统版本.cpu 架构,x86_64 代表 64 位系统安装包,i686 代表 32 位系统安装包,选用时需和自身系统匹配
el7 对应 CentOS7、Redhat7 系统,el6 对应 CentOS6、Redhat6 系统,base 指代软件源名称,等同于手机专属应用商店,属于正规安全的软件来源。

也可以单独查某个软件包:
yum list | grep lrzsz
- 安装软件
yum install -y 软件名
- 卸载软件
yum remove -y 软件名
- yum源
这个我直接贴一个博主文章:
编辑器vim
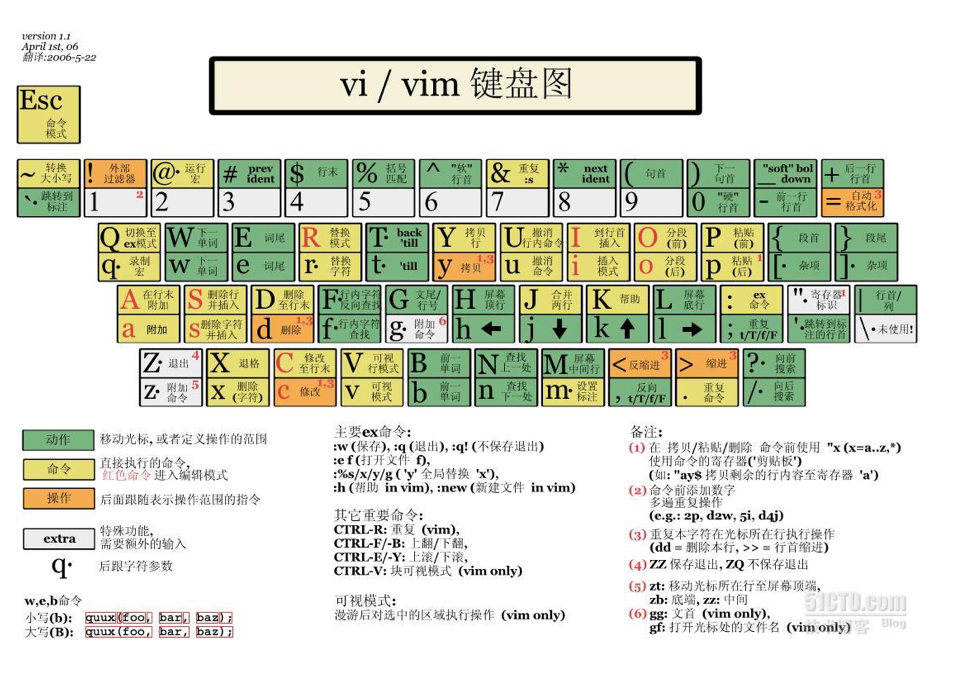
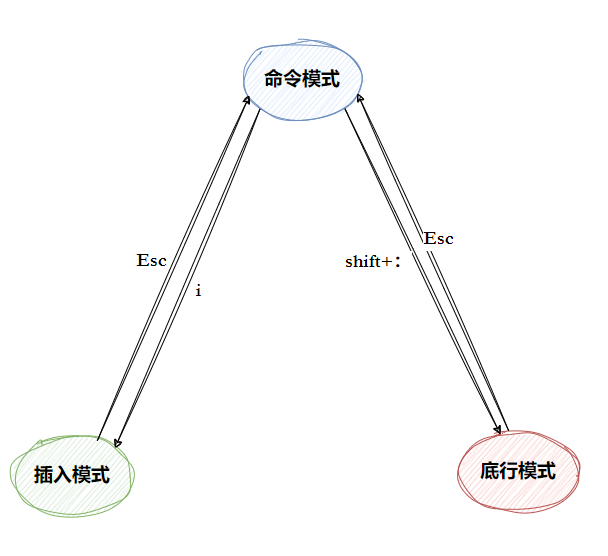
vim简单理解就是编辑器,有点像win中的记事本,但是他和win的区别就是他有更丰富的模式:
- 正常 / 普通 / 命令模式 (Normal mode):控制屏幕光标的移动,字符、字或行的删除,移动复制某区段及进入 Insert mode 下,或者到 last line mode
- 插入模式 (Insert mode):只有在 Insert mode 下,才可以做文字输入,按「ESC」键可回到命令行模式。该模式是我们后面用的最频繁的编辑模式。
- 末行模式 (last line mode):文件保存或退出,也可以进行文件替换,找字符串,列出行号等操作。
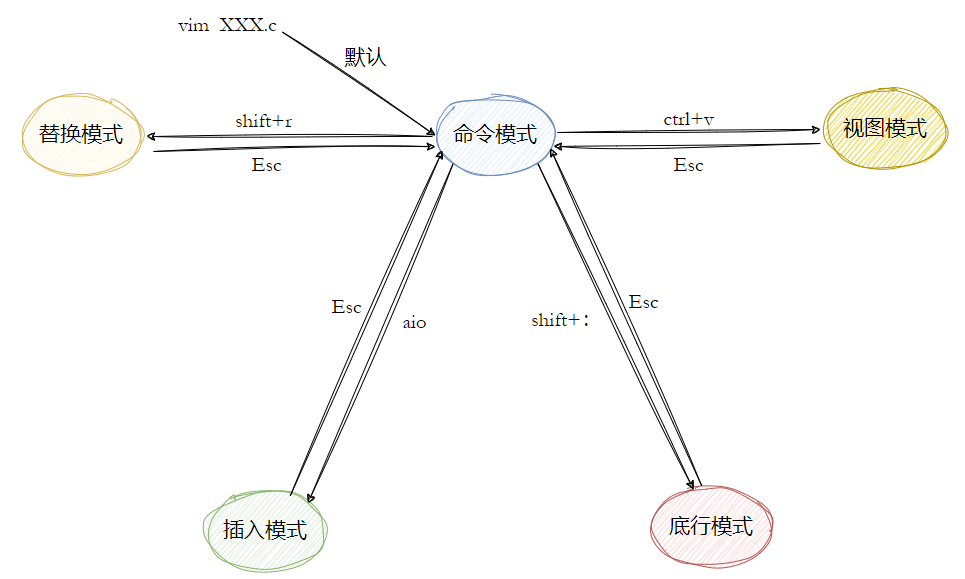
命令模式
1. 模式切换
- 从插入模式切换为命令模式:按
ESC键2. 移动光标
- 基础移动:
h(左)、j(下)、k(上)、l(右)- 行首尾:
^(行首)、$(行尾)- 单词跳转:
w(下一个单词开头)、e(下一个单词结尾)、b(上一个单词开头)- 全文跳转:
gg(文本开头)、G(文本末尾,或shift+g)- 行内定位:
#l(光标移到该行第 #个位置,如5l)、#G(移到第 #行开头,如15G)- 翻页操作:
ctrl+b(向后翻一页)、ctrl+f(向前翻一页)、ctrl+u(向后翻半页)、ctrl+d(向前翻半页)3. 删除文字
- 单个字符:
x(删除光标后一个字符)、X(删除光标前一个字符)- 批量字符:
#x(删除光标后 #个字符,如6x)、#X(删除光标前 #个字符,如20X)- 整行删除:
dd(删除光标所在行)、#dd(从光标行开始删除 #行)4. 复制与粘贴
- 复制:
yw(复制光标到单词结尾的字符)、#yw(复制 #个单词)、yy(复制光标所在行)、#yy(复制光标行往下 #行,如6yy)- 粘贴:
p(将缓冲区内容粘贴到光标位置)5. 替换与更改
- 替换字符:
r(替换光标所在位置的单个字符)、R(持续替换,按ESC退出)- 更改文本:
cw(更改光标所在单词到结尾)、c#w(更改 #个单词,如c3w)6. 撤销与恢复
- 撤销操作:
u(撤销上一次操作,多次按可撤销多次)- 恢复撤销:
ctrl+r(恢复被撤销的操作)7. 其他操作
- 显示行号:
ctrl+g(显示光标所在行的行号)- 退出编辑:ZZ
插入模式
i:从光标当前位置开始输入文字a:从光标当前位置的下一个字符位置开始输入文字o:在光标所在行的下方插入新行,从新行的行首开始输入文字
底行模式
1 进入方式
先按
ESC回到正常模式,再输入:进入末行模式2 基础操作类
set nu:在文件每行前显示行号#(如:15):直接跳转到指定行号(示例中跳转到第 15 行)3 查找类
/关键字:向下查找指定内容,按n跳转到下一个匹配项?关键字:向上查找指定内容,按n跳转到上一个匹配项4 文件保存与退出类
w:保存文件q:退出文件(未修改 / 修改已保存时可用)q!:强制退出文件(放弃修改,不保存)wq:保存文件并退出(最常用)
美化vim
这里先给一个我自己在用的美化git:
VimForCpp: 快速将vim打造成c++ IDE![]() https://gitee.com/HGtz2222/VimForCppGitHub - wsdjeg/vim-galore-zh_cn: Vim 从入门到精通 · GitHub
https://gitee.com/HGtz2222/VimForCppGitHub - wsdjeg/vim-galore-zh_cn: Vim 从入门到精通 · GitHub![]() https://github.com/wsdjeg/vim-galore-zh_cn这个就是在用户的家目录中创建一个.vimrc的文件,然后在里面添加我上面链接里的内容,这个文件事即刻生效的,这里需要注意的是不要在root中用这个美化目录,否者可能会导致文件编辑错误,只需要在普通用户中美化
https://github.com/wsdjeg/vim-galore-zh_cn这个就是在用户的家目录中创建一个.vimrc的文件,然后在里面添加我上面链接里的内容,这个文件事即刻生效的,这里需要注意的是不要在root中用这个美化目录,否者可能会导致文件编辑错误,只需要在普通用户中美化

编译器gcc/g++
使用
查看预处理结果:
gcc -E source.c生成汇编代码:
gcc -S source.c静态与动态链接
静态链接:
gcc -static source.cpp -o program动态链接(默认方式):
gcc source.cpp -o program动态链接(.so)/静态链接(.a)
Linux下,动态库XXX.so,静态库XXX.a
Windows下,动态库XXX.dll,静态库XXX.lib
首先一个说出区别:
采用动态链接生成的可执行程序体积通常较小(因为库代码未被打包进文件中)。
可执行程序对静态库的依赖较小,但动态库在运行时必须存在,缺失则无法启动。
程序运行时,静态链接的程序会在内存中产生大量重复的库代码(每个进程都拷贝一份)。
动态链接更节省内存和磁盘空间(多进程共享同一份动态库代码)。
一个小故事讲解动静态链接:
从前有一个小村庄,住着三位大厨:红烧肉大厨、糖醋鱼大厨和宫保鸡丁大厨。他们各自都有拿手菜,但很多步骤是相同的------比如切葱姜蒜、熬高汤、调糖醋汁。
静态链接的故事
最初,每位大厨都把自己的厨房塞得满满当当:红烧肉大厨有一套葱姜蒜罐、一锅高汤、一碗糖醋汁;糖醋鱼大厨也有一套完全一样的;宫保鸡丁大厨同样如此。
这样,每位大厨做菜时不用求人,出餐很快。但村庄的厨房空间被占去大半,而且每次熬高汤都要三人分别烧三锅,浪费柴火。
→ 这就是静态链接:每个程序(大厨)都把自己需要的库代码(调料和半成品)完整复制一份到自己内部,导致可执行文件(厨房)体积大,内存里也会出现大量重复的代码(多锅高汤)。
动态链接的故事
后来,村长建议建一个"公共调料站":里面常备葱姜蒜罐、一大锅高汤、一大碗糖醋汁。三位大厨的厨房里只留一张"取料单",上面写着"需要时去公共站取"。
做菜时,大厨们就凭单子去公共站舀一勺高汤、捏一把葱姜蒜。这样每个厨房空出了很多地方,柴火也只烧一锅就够了。但有个条件:公共站绝对不能关门或丢失调料,否则三位大厨谁也做不成菜。
→ 这就是动态链接:可执行程序(厨房)体积很小,因为不包含库代码;但运行时必须依赖动态库(公共站),缺失就会崩溃;多个程序共享同一份库,节省内存和磁盘空间。
后来有一天夜里,公共站的糖醋汁被老鼠偷喝了。第二天,糖醋鱼大厨急得团团转,而红烧肉大厨因为自己厨房里还藏着一份备份(静态链接),依然淡定开工------这就是两种方式的取舍故事。
自动化构建make/makefile
make 命令 + makefile 文件 = 项目自动化构建,在大型项目中,你只需写好makefile文件之后你就能极大的提高你的开发效率
makefile语法
cpp
# ==================================================
# 多文件编译 Makefile(支持自动识别所有 .c 文件)
# ==================================================
# 目标可执行文件名
BIN = test.exe
# 使用 wildcard 函数自动识别当前目录下所有 .c 源文件
SRC = $(wildcard *.c)
# 将源文件列表中的 .c 替换为 .o,得到目标文件列表
OBJ = $(SRC:.c=.o)
# 编译器
CC = gcc
# 链接选项(指定输出文件)
FLAGS = -o
# 编译选项(仅编译不链接)
O_FLAGS = -c
# 删除命令
RM = rm -f
# --------------------------------------------------
# 链接:将所有的 .o 文件链接成最终的可执行文件
# $@ 代表目标($(BIN))
# $^ 代表所有依赖文件($(OBJ))
# --------------------------------------------------
$(BIN): $(OBJ)
@$(CC) $(FLAGS) $@ $^
@echo "Linking ... $^ to $@"
# --------------------------------------------------
# 编译:将每个 .c 文件编译成对应的 .o 文件
# 模式规则 %.o:%.c 会自动匹配所有 .c 文件
# $< 代表规则中的第一个依赖文件(即当前要编译的那个 .c 文件)
# 注意:$< 并不是一次性读取所有 .c 文件,而是逐个处理每个匹配的 .c 文件
# --------------------------------------------------
%.o: %.c
@$(CC) $(O_FLAGS) $<
@echo "Completed ... $< to $@"
# --------------------------------------------------
# 伪目标(.PHONY)解释:
# .PHONY 用来声明一个目标不是真正的文件,而是一个命令标签。
# 如果不声明为伪目标,当当前目录下恰好有一个名为 clean 或 list_var 的文件时,
# make 会认为该文件已存在且没有依赖更新,从而跳过执行对应的命令。
# 使用 .PHONY 可以确保 make 总是执行这些目标对应的命令,无论是否存在同名文件。
# --------------------------------------------------
.PHONY: clean
clean:
@$(RM) $(OBJ) $(BIN)
@echo "remove ... $(OBJ) and $(BIN)"
.PHONY: list_var
list_var:
@echo "BIN = $(BIN)"
@echo "SRC = $(SRC)"
@echo "OBJ = $(OBJ)"
@echo "CC = $(CC)"
@echo "FLAGS = $(FLAGS)"
@echo "O_FLAGS = $(O_FLAGS)"
@echo "RM = $(RM)"make工作过程
找文件 → 当前目录查找 Makefile 或 makefile。
定目标 → 将文件中第一个目标(如 test.exe)作为终极目标。
判新旧 → 若目标不存在,或依赖文件比它新,则执行命令重新生成。
cppstat 文件名 # 详细显示三种时间 ls -l 文件名 # 显示 mtime(默认) ls -lu 文件名 # 显示 atime ls -lc 文件名 # 显示 ctime
时间戳 全称 含义 何时更新 mtime Modification time 文件内容最后修改的时间 编辑、写入文件内容时(make) ctime Change time 文件元数据(权限、所有者、链接数等)最后改变的时间 修改文件属性(如 chmod、chown、mv)或修改内容时也会更新atime Access time 文件最后被读取的时间 使用 cat、less、vi只读打开等操作时
递归依赖 → 若依赖文件(如 .o)不存在,则查找生成它的规则,一层层处理(类似堆栈)。
生成最终文件 → 从底层源文件开始,依次编译、链接,得到终极目标。
错误处理 → 依赖文件缺失或命令执行失败时,make 退出并报错。
严格依赖 → 若依赖关系中的文件始终无法生成,make 拒绝工作。
进度条程序
代码展示
cpp
// progress.h
// 作用:声明进度条刷新函数,以及需要的头文件和宏定义
#pragma once // 防止头文件重复包含
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#define MAX 101 // 进度条数组最大长度(100个符号 + '\0')
#define SYMBOL '#' // 进度条填充符号
// 声明刷新函数:参数为已下载量(D_Volume)和总大小(total)
void Refresh(double D_Volume, double total);
// progress.c
// 实现 Refresh 函数:动态打印进度条
#include "progress.h"
void Refresh(double D_Volume, double total)
{
static int cnt = 0; // 静态变量,记录旋转字符的索引,每次调用自增
const char* type = "/|-\\"; // 旋转动画字符序列
int len = strlen(type); // 字符序列长度(4个字符)
char arr[MAX] = {0}; // 存放进度条符号的数组,初始全0
// 计算当前已下载比例(0~100)
int ratio = (int)(D_Volume * 100 / total);
// 用 '#' 填充进度条数组前 ratio 个位置
for (int i = 0; i < ratio; i++) {
arr[i] = SYMBOL;
}
// 计算百分比(浮点数,保留一位小数)
double Percentage = (D_Volume / total) * 100;
// 格式化输出:\r 使光标回到行首,实现原地刷新
// 格式:[##########........][百分比%][旋转字符]
printf("[%-100s][%.1f%%][%c]\r", arr, Percentage, type[cnt % len]);
fflush(stdout); // 立即刷新输出缓冲区(虽然 Refresh 内没加,但调用者已加,此处也可以补上)
cnt++; // 下次调用时旋转到下一个字符
}
// main.c
// 模拟下载过程,调用 Refresh 实时显示进度
#define _POSIX_C_SOURCE 200809L // 启用 POSIX 2008.9 特性(usleep 等)
#include "progress.h"
#include <unistd.h> // usleep
// 定义函数指针类型 P_refresh:指向一个返回 void,参数为 (double total, double speed) 的函数
// 注意:参数顺序写反了?原代码中 Download 调用 p(D_Volume,total),实际第一个是已下载量,第二个是总大小
// 这里保持原样,但建议修正为 (double current, double total)
typedef void (*P_refresh)(double total, double speed); // 保留原定义,但实际调用参数不同
// 模拟下载函数
void Download(P_refresh p)
{
double total = 1024.0; // 下载总大小(单位任意)
double speed = 1.0; // 下载速度(每次循环增加的量)
double D_Volume = 0; // 当前已下载量
while (D_Volume <= total) {
// 调用传入的回调函数,刷新进度条
// 注意:原回调函数 Refresh 的第一个参数是已下载量,第二个是总量,这里传参正确
p(D_Volume, total); // p 实际指向 Refresh
D_Volume += speed; // 模拟下载:每次增加 speed
fflush(stdout); // 刷新标准输出(确保 \r 实时显示)
usleep(5000); // 休眠 5000 微秒 = 5ms,控制刷新速度
}
printf("\nDone !\n"); // 下载完成,换行输出结束语
}
int main()
{
Download(Refresh); // 将 Refresh 函数作为回调传给 Download
return 0;
}解释缓冲区
缓冲区是内存中的一段区域,用于临时存放数据。程序输出数据时,不一定立即显示到屏幕,而是先放入缓冲区,等满足条件后再统一输出。这样做可以提高效率(减少慢速 I/O 操作)
| 方式 | 刷新条件 | 示例 |
|---|---|---|
| 无缓冲 | 数据立即输出 | stderr(标准错误) |
| 行缓冲 | 遇到换行符 \n、程序正常结束、缓冲区满、调用 fflush |
stdout 当输出到终端时 |
| 全缓冲 | 缓冲区满、调用 fflush、程序正常结束 |
文件读写 |
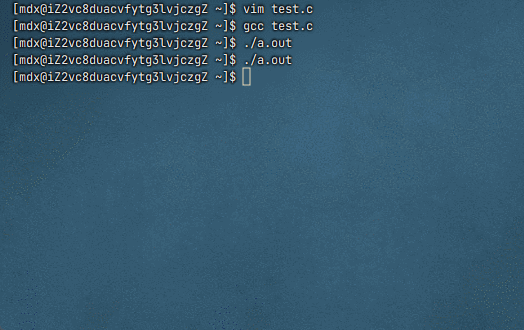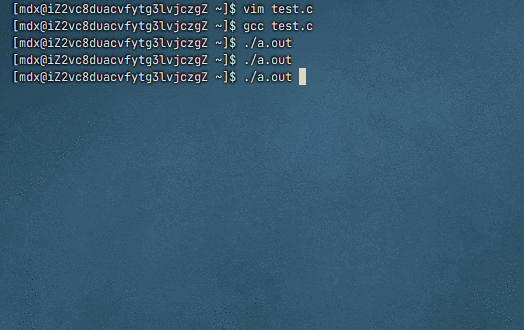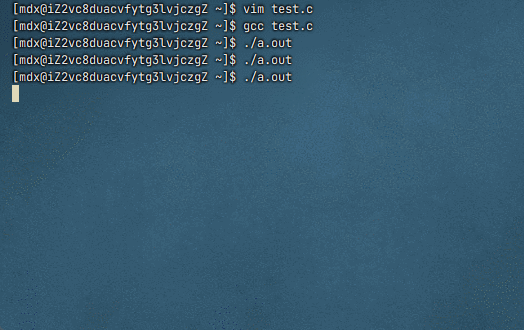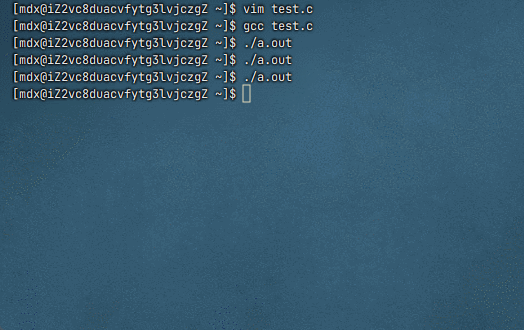
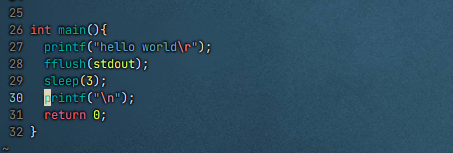
为什么进度条代码必须 fflush(stdout)
默认情况下,
stdout是行缓冲 :只有遇到\n或缓冲区满才会自动显示进度条使用了
\r(回车),不是换行符,所以不会触发行缓冲刷新如果不调用
fflush(stdout),数据会一直留在缓冲区中,直到程序结束或缓冲区满,导致屏幕上看不到动态变化(或者几秒后才突然出现一堆输出)
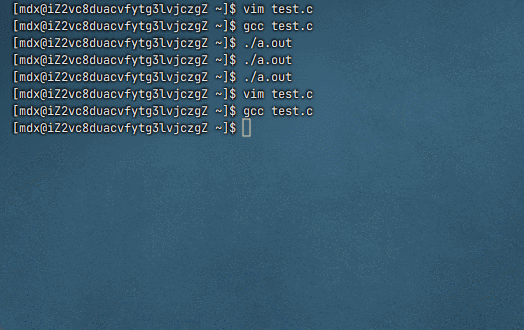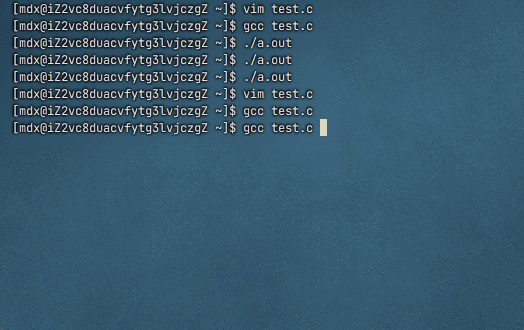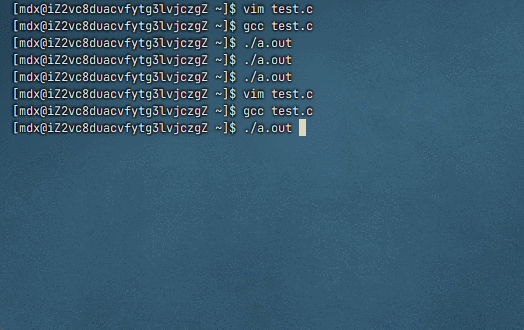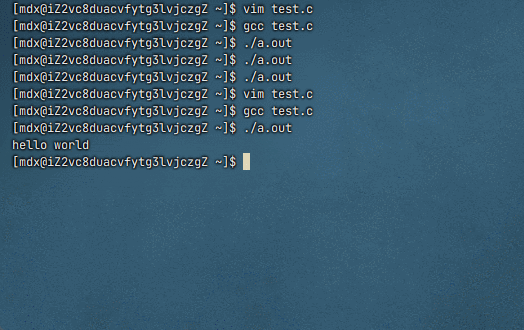
fflush(stdout)强制将缓冲区内容立即输出到显示器 ,配合\r实现原地刷新效果这里被缓冲区吞了,程序结束也没打印出来,因为程序结束就意味着被释放了
修改后

调试器gdb/cgdb
直接上表格
| 类别 | 命令/操作 | 作用 | 示例 |
|---|---|---|---|
| 源代码查看 | list / l |
显示源代码,默认从上次位置开始每次10行 | l 或 list/1 |
list/1 行号 |
显示指定行号附近的源代码 | list/1 10 |
|
list/1 函数名 |
列出指定函数的源代码 | list/1 main |
|
list/1 文件名:行号 |
列出指定文件的源代码 | list/1 mycmd.c:1 |
|
| 程序运行 | run / r |
从程序开始连续执行 | run |
continue / c |
从当前位置继续执行 | continue |
|
finish |
执行到当前函数返回,然后停止 | finish |
|
until 行号 |
执行到指定行号 | until 20 |
|
| 单步调试 | next / n |
单步执行,不进入函数内部(逐过程,F10) | next |
step / s |
单步执行,进入函数内部(逐语句,F11) | step |
|
| 断点管理 | break / b [文件名:]行号 |
在指定行设置断点 | break 10 或 break test.c:10 |
break 函数名 |
在函数开头设置断点 | break main |
|
info break / info b |
查看所有断点信息 | info break |
|
delete / d |
删除所有断点 | delete breakpoints |
|
delete 编号 |
删除指定编号的断点 | delete breakpoints 1 |
|
disable breakpoints |
禁用所有断点 | disable breakpoints |
|
enable breakpoints |
启用所有断点 | enable breakpoints |
|
| 条件断点 | 添加新条件断点 | b 行号/函数名 if 条件 |
b 10 if i == 30 |
| 为已有断点追加条件 | condition 断点编号 条件(注意无 if) |
condition 2 i==30 |
|
| 变量操作 | print / p 变量/表达式 |
打印变量或表达式的值 | p x 或 p start+end |
set var 变量=值 |
修改变量的值 | set var i=10 |
|
display 变量名 |
每次停止时自动显示该变量的值 | display x |
|
undisplay 编号 |
取消指定编号的变量显示 | undisplay 1 |
|
info locals |
查看当前栈帧的局部变量值 | info locals |
|
| 监视点 | watch 表达式 |
监视表达式(如变量),值变化时暂停程序 | watch i |
| 调用栈 | backtrace / bt |
查看当前函数调用栈及参数 | backtrace |
| 退出 | quit |
退出 GDB 调试器 | quit |
| 辅助信息 | Cgdb 分屏操作 | ESC 进入代码屏,i 回到 GDB 命令屏 |
--- |
| set var 用途 | 运行时修改变量,用于确定问题原因(如模拟条件) | set var i=30 |
说明:
条件断点新增与追加的语法区别:新增时命令中包含
if;对已有断点使用condition命令时不需要if。
watch在程序执行期间监视表达式,一旦值改变即中断,常用于定位变量意外修改。
