记得刚学习数据库时,老师讲到事务就提到了 ACID 这个字眼。那时候比较懵逼,考试时记不住这4个单词所有的含义,反正写个 ACID 的话,2分也能拿一分。一直到工作了好几年之后,准确来说到我学习这个之前,其实一直持续懵逼的状态就是:你问事务,我就说 ACID,主打一个不深究放过自己。
就像当年面试人家问什么是 MVC,我就说就是那个3个圈圈,模型视图控制器,具体不太好描述。不过目前为止真正的行家遇到比较少,几乎都能糊弄过去。我猜大概率可能是人家不好揭穿我,也有可能是跟我一样在不求甚解的阶段。至于哪一种也不重要,目前来说有AI学东西还是很快的,虽然无法决定我的上限,但它能显著提升我能力的下限。
下面复习一遍数据库事务。数据库管理系统在写入或者更新数据的过程中,为了保证数据是正确可靠的,需要满足四个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability) ,简称 ACID 。这次学习的步骤是先学习原子性 和持久性 ,至于隔离性后续再分享。https://www.modelscope.cn/learn/434140
https://www.modelscope.cn/learn/434139
📊 ACID 核心特性
| 特性 | 英文 | 核心定义 | 关键说明 |
|---|---|---|---|
| 原子性 | Atomicity | 不可分割 | 事务中的操作要么全部完成,要么全部不完成。若发生错误,系统会回滚(Rollback)到事务开始前的状态。 |
| 一致性 | Consistency | 数据完整性 | 事务执行前后,数据库的完整性约束没有被破坏。写入的数据必须完全符合所有的预设规则。 |
| 隔离性 | Isolation | 并发互不干扰 | 多个并发事务之间相互隔离,防止交叉执行导致数据不一致。(如读未提交、可重复读等) |
| 持久性 | Durability | 永久生效 | 事务一旦提交,对数据的修改就是永久的。即使后续发生系统故障或断电,数据也不会丢失。 |
1.为什么说 ACID 的提法不太严谨?
在学习《凤凰架构》后,原文中总结的一点让我豁然开朗:https://www.modelscope.cn/learn/434140
https://www.modelscope.cn/learn/434139
"对这四种特性是不太严谨的,因为这四种特性并不正交。A、I、D 是手段,C 是目的,为了拼凑个单词缩写才弄到一块去。其实误导的弊端已经超过了易于传播的好处。"
当一个服务只操作一个数据源的时候,通过 A、I、D 来获得一致性是相对容易的。但当一个服务涉及到多个不同的数据源,甚至多个不同服务同时涉及到多个不同的数据源时,就变得非常困难。
举个经典的购物例子,成功售出后,需要确保以下三步被正确地处理:
1.减去用户账号中的钱,修改用户余额。https://www.modelscope.cn/learn/434140
https://www.modelscope.cn/learn/434139
UPDATE user_money SET balance = balance - 100 WHERE user_id = 123 AND balance >= 100;2.修改库存的数量,然后把商品状态标为待配送。https://www.modelscope.cn/learn/434140
https://www.modelscope.cn/learn/434139
UPDATE goods_info SET stock = stock - 1, status = '待配送' WHERE id = 4;3.商家的账号增加钱。
UPDATE user_wallet SET balance = balance + 100 WHERE user_id = 2;这里我们要区分两种场景:
场景一:
本地事务。如果这三个表恰好都在同一个数据库实例里,那事情就很简单,使用本地事务包裹这三条 SQL 即可。
场景二:https://www.modelscope.cn/learn/434140
https://www.modelscope.cn/learn/434139
分布式事务。如果是微服务架构,用户库、商品库https://www.modelscope.cn/learn/434140
https://www.modelscope.cn/learn/434139和商家钱包库通常是物理隔离的。此时简单的本地事务就无能为力了,需要引入 TCC、Saga 等方案。
这一次我们主要聚焦在第一种场景------本地事务,看看数据库是如何在底层实现它的。
2.数据库是如何实现原子性和持久性的?
原子性和持久性在事务里是密切相关的两个属性:
- 原子性保证了事务的多个操作要么都生效,要么都不生效,不会存在中间状态。
- 持久性保证了一旦事务生效,就不会再因为任何原因而导致其修改的内容被撤销或丢失。也就是说,数据必须要成功写入磁盘后才能拥有持久性。
但是实现它们也有困难,因为写入磁盘这个操作不是原子的 ,不仅有写入与未写入,还存在着"正在写"的中间状态。接下来我们结合代码代入使用场景进一步体会:https://www.modelscope.cn/learn/434140
https://www.modelscope.cn/learn/434139
using (var scope = new TransactionScope())
{
using (var conn = new SqlConnection(ConnectionString))
{
conn.Open();
string sql1 = "UPDATE user_money SET balance = balance - 100 WHERE user_id = 123 AND balance >= 100"; // 1. 减去用户账号中的钱
ExecuteNonQuery(conn, sql1);
string sql2 = "UPDATE goods_info SET stock = stock - 1, status = '待配送' WHERE id = 4"; // 2. 修改库存数量,并把商品状态标为待配送
ExecuteNonQuery(conn, sql2);
string sql3 = "UPDATE user_wallet SET balance = balance + 100 WHERE user_id = 2"; // 3. 商家的账号增加钱
ExecuteNonQuery(conn, sql3);
}
scope.Complete(); //关键分水岭
}💥 崩溃场景推演
- 未提交事务崩溃 :如果程序还没走到
scope.Complete(),数据库已经将其中一个数据的变动写入了磁盘,此时服务器崩溃。重启之后,数据库必须想办法得知崩溃前发生过一次不完整的操作,将已经修改过的数据恢复成原来的样子,以保证原子性 。https://www.modelscope.cn/learn/434140
https://www.modelscope.cn/learn/434139 - 已提交事务崩溃 :如果已经执行了
scope.Complete(),程序日志记录了成功,但数据库还未将全部三个数据的变动都写入到磁盘,此时服务器崩溃。重启之后,数据库也必须要有办法得知崩溃前发生过一次完整的操作,将还没来得及写入磁盘的那部分数据重新写入,以保证持久性。
为了解决这些问题,数据库界探索出了不同的策略。
📜 策略一:Commit Logging(追加日志)https://www.modelscope.cn/learn/434140
https://www.modelscope.cn/learn/434139
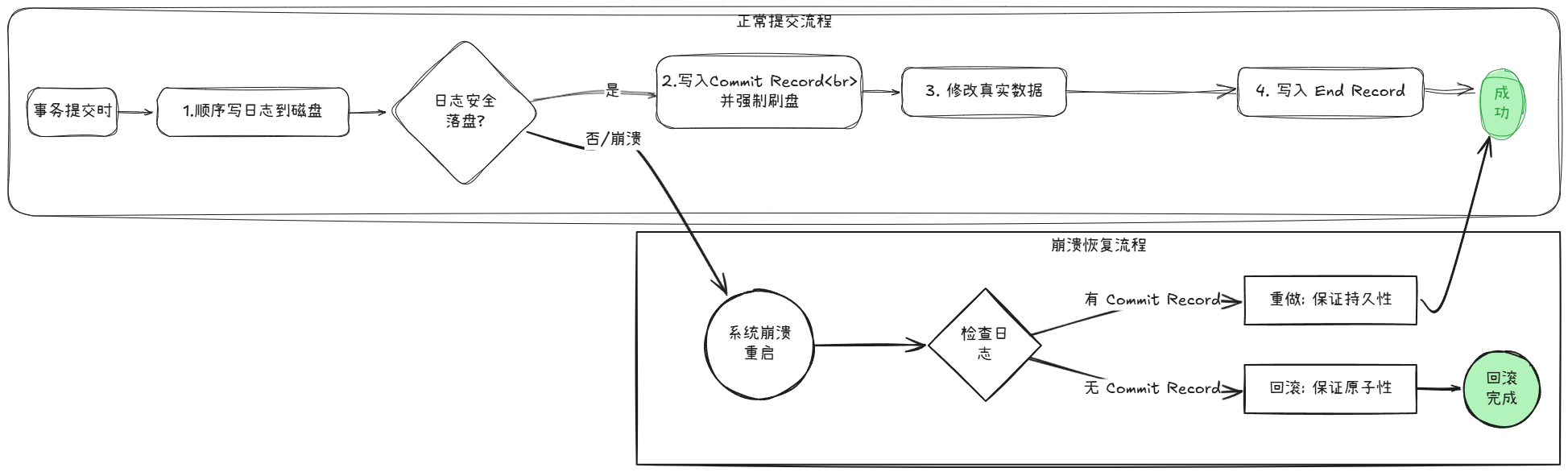
这种思路比较简单:先把我要做的事情记录到磁盘中(比如修改什么数据、从什么值改成什么值),写完了日志用一个特殊状态来标记下,然后再修改数据。
流程大致如下:
修改xxxx放到第15页 (Update Log)
修改xxx放到第39页 (Update Log)
Commit Record
开始在后台真实改第15页的那个数据
开始在后台改第39页的那个数据
改完了写一条
End record当 Complete 命令执行时,数据库首先将 Commit Record 写入日志文件并强制刷盘。此时真实数据文件尚未被修改,仅日志中记录了事务已准备好提交的状态。https://www.modelscope.cn/learn/434140
https://www.modelscope.cn/learn/434139
- 保证持久性:如果在修改真实数据时崩溃,重启后根据已经写入磁盘的日志信息恢复现场、继续修改数据即可。
- 保证原子性 :如果
End record日志没有写入成功就发生崩溃,系统重启后会看到一部分没有Commit Record的日志,那将这部分日志标记为回滚状态即可。
⚡️ 策略二:WAL 机制(Write-Ahead Logging)
Commit Logging 存在一个巨大的缺陷:性能瓶颈。所有对数据的真实修改都必须发生在事务提交、日志写入了 Commit Record 之后。假设一个大型事务执行了 10 秒钟,这 10 秒内产生的大量数据修改只能堆积在内存里。直到第 10 秒末提交时,数据库才必须手忙脚乱地把积攒的数据一股脑地往磁盘上写。这就导致了平时磁盘闲得发慌,提交时磁盘忙到卡死。有没有办法解决呢?我们先看两个专业定义:
FORCE:当事务提交后,要求变动数据必须同时完成写入。
NO-FORCE:不强制变动数据必须同时完成写入。
STEAL :在事务提交前,允许变动数据提前写入。https://www.modelscope.cn/learn/434140
https://www.modelscope.cn/learn/434139
NO-STEAL :不允许在事务提交前提前写入。https://www.modelscope.cn/learn/434140
https://www.modelscope.cn/learn/434139
大白话理解就是:立马写磁盘叫 FORCE,反之 NO-FORCE;偷偷写点叫 STEAL,不准偷偷写叫 NO-STEAL。
Commit Logging 允许 NO-FORCE,但不允许 STEAL。因为假如事务提交前就有部分变动数据写入磁盘,那一旦事务要回滚,这些提前写入的变动数据就都成了错误。
现代数据库(如 MySQL InnoDB)采用了 WAL 机制 ,它既允许 NO-FORCE,也允许 STEAL。为了实现这一点,它引入了两种关键日志:https://www.modelscope.cn/learn/434140
https://www.modelscope.cn/learn/434139
- 1.Undo Log(回滚日志) :为了支持 STEAL。在数据提前写入磁盘前,先记录修改前的旧值。一旦事务回滚或崩溃,就利用它来擦除那些提前写入的"脏数据",保证原子性。
- 2.Redo Log(重做日志) :为了支持 NO-FORCE。在数据被修改前,先强制将物理修改记录刷入磁盘。一旦提交后发生崩溃,就利用它来重放那些还没来得及写入磁盘的数据,保证持久性。

组合角度分析:https://www.modelscope.cn/learn/434140
https://www.modelscope.cn/learn/434139
- STEAL + NO-FORCE:允许偷偷写(需 Undo Log 当后悔药),允许提交后不实时写(需 Redo Log 当记事本)。这是现代数据库的主流选择。
- NO-FORCE + NO-STEAL:不允许偷写,允许提交后不实时写,所以只需要 Redo Log。
- FORCE + NO-STEAL:没偷写,而且强制写磁盘,所以不需要日志(性能最差)。
3.总结
我们可以得出以下结论:
1. 为什么需要 NO-FORCE 与 Redo Log?https://www.modelscope.cn/learn/434140
https://www.modelscope.cn/learn/434139
绝大多数数据库都采用 NO-FORCE 策略来优化 I/O 性能。为了实现它,就需要引入 Redo Log。即使修改数据时系统崩溃了,重启后数据库可以根据 Redo Log 恢复现场。
通俗理解:我先把要改的东西记录在日志里,再根据日志统一写到磁盘中。万一我在写入磁盘的过程中"晕倒"(宕机)了,等我"醒来"(重启)的时候,照着日志重新做一遍,也能成功。
2. 为什么需要 STEAL 与 Undo Log?
为了进一步提升性能,允许在事务提交前"偷偷地"先写一点数据到磁盘(STEAL)。但这带来了新问题:万一事务回滚,这些提前写入的数据就变成了"脏数据"。这就需要引入 Undo Log,在偷摸写入数据之前记录旧值,以便随时恢复。
3. Binlog 与 SQL Server 的事务日志https://www.modelscope.cn/learn/434140
https://www.modelscope.cn/learn/434139
最后额外说一下,在 MySQL 中还有一个 Binlog 的概念。它和 Redo Log 所处的层面不一样:
- Redo Log:处于 InnoDB 存储引擎层,主要负责底层的崩溃恢复。
- Binlog:处于 MySQL Server 层,主要负责主从复制和数据恢复。
为了保证 Binlog 与 InnoDB 引擎层的 Redo Log 之间的数据一致,MySQL 引入了 2PC(两阶段提交) 机制。而在 SQL Server 中,也有差不多的概念,叫做事务日志(Transaction Log),它的功能更广,同时承担了类似 Redo Log 和 Undo Log 的职责。https://www.modelscope.cn/learn/434140