引子
这个系列前文讲了好几篇,全是纯文本大模型------输入是文字,输出也是文字,一切都是 token。
但你有没有好奇过:为什么 ChatGPT 能回答"这张图里有什么"?为什么你发给它一张手绘数学题,它能帮你解题?
图片不是 token,LLM 不直接认像素。那它是怎么"看懂"图片的?
反过来问:你让它"画一幅日落图",它是怎么"生成"一张图片的?它输出的 token 怎么变成像素的?
这两个问题分别对应多模态大模型的两面:输入端 (理解多模态)和输出端(生成多模态)。
一、先说结论
多模态大模型并不是另一套架构,而是在文本大模型的两端各接了几根管道:
bash
输入侧:图片/音频/视频 → 各模态编码器 → 向量序列 → 拼入 LLM
输出侧:LLM 生成文本;扩散模型 DiT 生成图片/视频;声码器生成音频
LLM 核心本身------Attention + FFN 的堆叠------完全不变。前文讲的所有东西:Attention 公式、残差连接、LayerNorm、KV Cache、预测下一个 token,在多模态模型里照用不误。
二、核心思路:把一切都变成向量
前文第三篇讲过,文本进入 LLM 核心(堆叠 Attention + FFN)之前要走两步:
bash
文字 → Token → 向量 → 进入多层 Attention + FFN 堆叠LLM 核心只操作向量。它不关心这些向量是从文字来的还是从图片来的。只要是向量,它就能处理。
多模态的核心思路就这么简单:给每种模态各配一个编码器,把图片、音频都翻译成向量,然后交给同一个 LLM 核心处理。
bash
文本大模型:
文字 → Tokenizer → Embedding → [向量₁, 向量₂, 向量₃] → 多层 Attention + FFN
多模态大模型:
文字 → Tokenizer → Embedding → [向量₁, 向量₂, 向量₃] ─┐
├→ 拼在一起 → 多层 Attention + FFN
图片 → 图像编码器 → 投影层 → [向量ₐ, 向量ᵦ, 向量ᵧ, ...] ─┘对 LLM 核心来说,它看到的就是一个向量序列------前几个来自图片,后面几个来自文字。它用同样的 Attention 机制处理所有向量,根本不区分来源。
三、图片是怎么变成向量的
文本变向量,前文讲透了:文字 → BPE 分词 → Token ID → 查 Embedding 表。
图片的路径不同,但目标一样------变成一组向量。
3.1 把图片切成"碎片":ViT
最常用的方法叫 ViT(Vision Transformer),思路非常直接:
bash
一张 224×224 的图片
│
▼ 切成 14×14 = 196 个小方块(每个 16×16 像素)
│
▼ 每个小方块通过线性层,变成一个向量(比如 768 维)
│
▼ 加上位置编码(告诉模型"这个方块在左上角还是右下角")
│
▼ 得到 196 个向量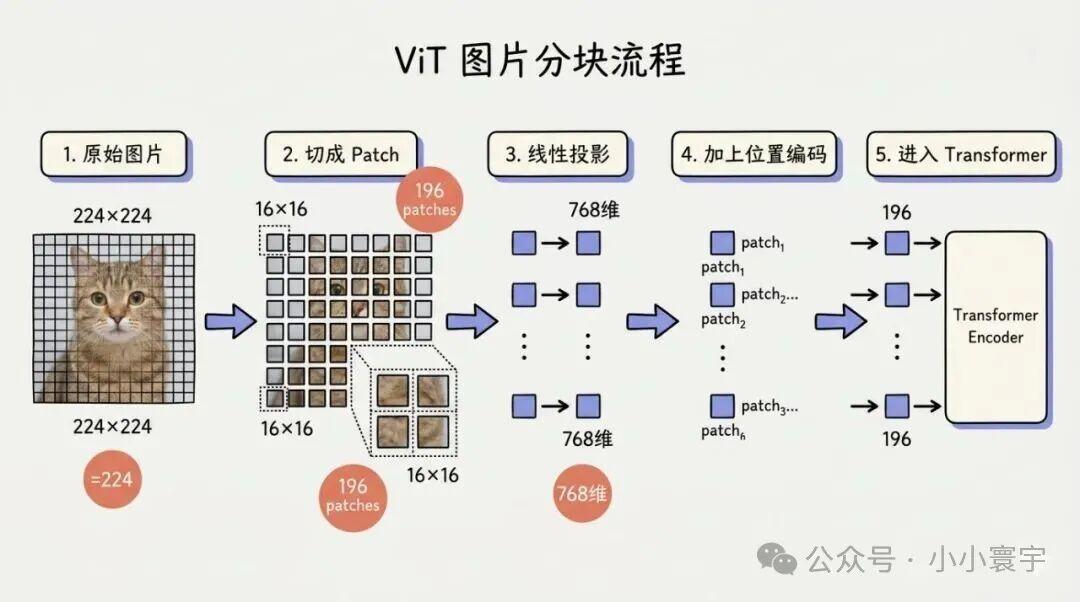
这 196 个向量就是图片的"token"。每个向量代表图片的一个局部区域------就像文本的一个 token 代表一个词或子词。
为什么要切成 patch,而不是把整张图压成一个向量? 如果把整张 224×224 图直接压成一个向量,会丢失空间细节。切成 196 个 patch 后,每个 patch 保留局部信息,后续 Attention 让这些 patch 互相"交流",模型就能同时看到整体和局部。
和文本 token 的对比:
| 文本 | 图片 | |
|---|---|---|
| 原始输入 | 字符串 | 像素矩阵 |
| "分词"方式 | BPE 切成子词 | 切成 16×16 方块(patch) |
| 每个"token" | 一个子词 | 一个图片方块 |
| 变成向量 | 查 Embedding 表 | 线性投影(矩阵乘法) |
| 向量维度 | 768 | 768(对齐到同一维度) |
| 典型数量 | 几十到几千 | 196~1024 个 |
3.2 投影层:对齐到同一个空间
图像编码器(如 ViT)输出的向量和文本 Embedding 的向量,通常不在同一个空间里------维度不同,语义含义也不同。
需要一个投影层(通常一两层线性网络),把图像向量"翻译"到文本模型的向量空间:
bash
图像编码器输出(1024维) → 投影层(1024 → 4096) → 和文本向量同维度(4096维)投影层的权重是训练时学出来的。训练目标是让投影后的图像向量,和对应文本描述的向量尽量接近------"一只猫"的图像向量应该靠近"cat"的文本向量。
3.3 以 LLaVA 为例
LLaVA(Large Language and Vision Assistant)是最经典的多模态架构之一,结构清晰,看一张图就够了:
bash
输入:"请描述这张图片" + [一张猫的照片]
┌──────────────────────────────────────────────┐
│ 文本部分 │
│ "请描述这张图片" → Tokenizer → Embedding │
│ → [向量₁, 向量₂, 向量₃, 向量₄, 向量₅] │
└──────────────────────┬───────────────────────┘
│ 拼接
▼
┌──────────────────────┴───────────────────────┐
│ 图片部分 │
│ 猫的照片 → ViT 编码器 → 196 个图像向量 │
│ → 投影层 → [向量ₐ, 向量ᵦ, ..., 向量₁₉₆] │
└──────────────────────┬───────────────────────┘
▼
[向量₁, ..., 向量₅, 向量ₐ, ..., 向量₁₉₆]
│
▼
多层 Attention + FFN(和前文一模一样)
│
▼
逐 token 生成回答:
"这张图片中有一只橘色的猫..."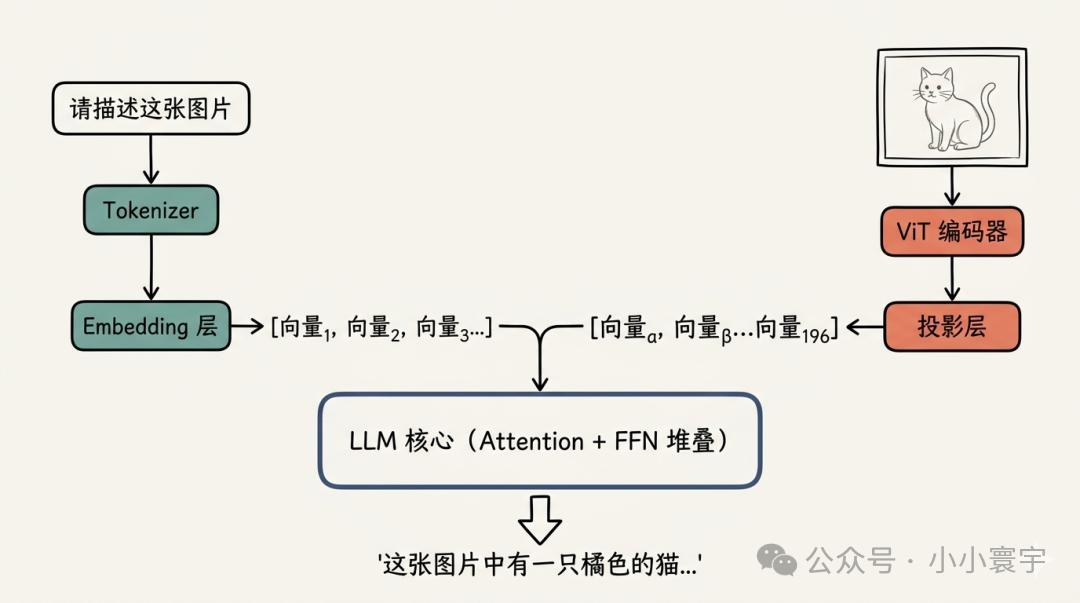
LLM 核心和前文完全一样,唯一的改动是在前面加了一条图像处理的管线:模型的"大脑"没变,只是"眼睛"是新装的。
四、Attention 是怎么工作的
看上面的 LLaVA 流程图,有个细节还没展开:文本向量和图像向量混在一起,Attention 怎么知道哪些是文字、哪些是图片?
答案是:它不需要知道,序列顺序已经解决了这个问题。
输入的向量序列是这样的:
bash
输入序列:[patch₁, patch₂, ..., patch₁₉₆, 请, 描述, 这张, 图片, ...]
↑ 图片部分 ↑ 文本部分因果掩码决定了每个位置能看到谁:
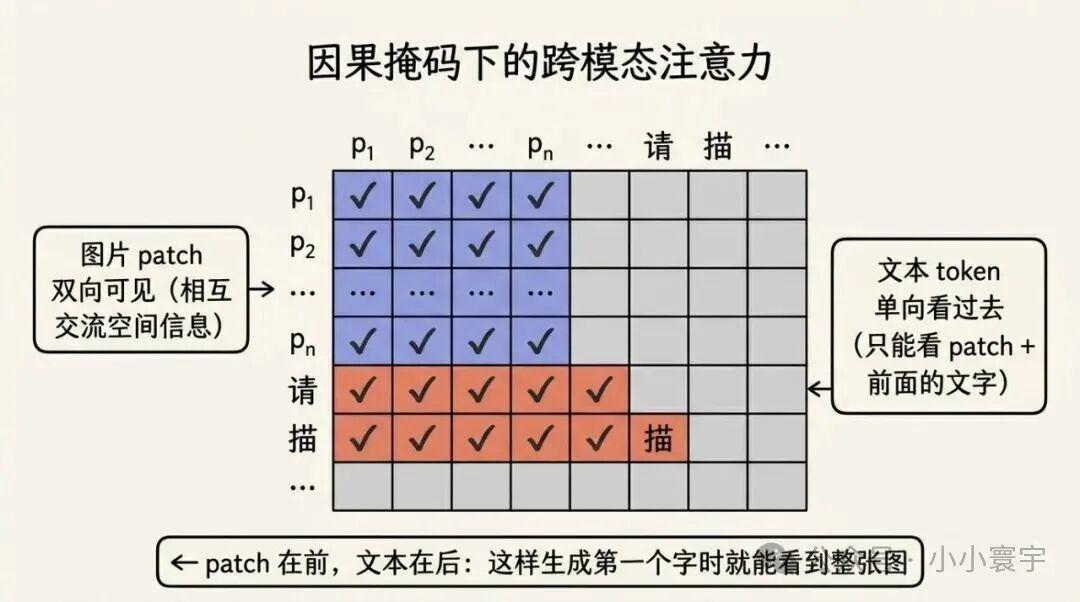
所以 patch 为什么要在文字前面?因为生成是自左向右的------生成"描述"这个词时还不知道自己要说什么,必须先看到整张图。把 patch 放在前面,标准因果掩码自然让每个文本 token 可以回看所有 patch,不需要任何特殊设计。
五、音频和视频:同一套思路
图片讲完了,但多模态的世界远不止图片。音频、视频,都可以走同样的路子:编码成向量序列 → 投影到文本空间 → 交给 LLM 核心处理。
音频、视频、图片的编码思路其实是一回事:
bash
图片: 像素矩阵 → 切 patch → 向量序列
音频: 频谱图 → 切 patch → 向量序列
视频: 帧序列 → 每帧切 patch → 向量序列
文本: 字符串 → BPE 分词 → 向量序列区别只在于"切分方式"和"用什么编码器"。
5.1 音频:让模型"听懂"声音
一段语音进入模型之前,需要先做一层预处理:
bash
原始波形(PCM)→ 短时傅里叶变换(STFT)→ 梅尔频谱图(Mel Spectrogram)→ 编码器 → 向量序列为什么要转成频谱图? 原始音频波形每秒包含上万个采样点(16kHz 采样率 = 每秒 16000 个数字),直接处理太贵,而且不直观。
转成梅尔频谱图之后,相当于把声音"翻译"成了一张图:横轴是时间,纵轴是频率,颜色深浅代表能量大小。这张图再交给类似 ViT 的编码器去处理------音频的"图片化",思路和把图片切成 patch 一模一样。
bash
[一段5秒的语音,16kHz采样]
│
▼ STFT + 梅尔滤波器
[频谱图: 约 500帧 × 80频带]
│
▼ 切成 16×16 的 patch(时间×频率)
[约 2000 个音频 patch]
│
▼ 线性投影 → 每个 patch 一个向量
[约 2000 个音频向量]每帧约 2040ms,相邻帧重叠 50%,所以 1 秒音频大约产生 50100 个向量。一段 30 秒的语音就能产生几千个音频向量,直接塞进 LLM 核心。
OpenAI 的 Whisper 是目前最常用的音频编码器之一------它的编码器部分基于 Transformer Encoder 架构,输入梅尔频谱图,输出向量序列,再通过跨注意力机制接入 LLM。GPT-4o 的音频理解、Gemini 的语音理解,大多是这个路子。
5.2 视频:时间维度的挑战
视频比图片多了一个维度:时间。
图片的信息是静态的,一张图切 196 个 patch 就够了。但视频是一连串图片(帧)的序列,模型不仅要理解"每一帧里有什么",还要理解"帧和帧之间发生了什么"------物体的运动、场景的切换、动作的先后顺序。
视频的处理思路是先从时间轴上采样帧,再对每帧分别做图片的处理:
bash
[一段30帧/秒的30秒视频 = 900帧]
│
▼ 均匀采样(比如每隔15帧取1帧)
[30帧]
│
▼ 每帧 resize 到 224×224,通过 ViT 切 patch
[每帧 196 个 patch × 30帧 = 5880 个 patch]
│
▼ 每个 patch 投影成一个向量
[5880 个视频向量]1 秒视频如果采样 2~3 帧,一段 1 分钟的视频就可能产生几千到上万个视频向量。随之而来的有三个实际问题:上下文窗口很快被填满;Attention 计算量随 token 数量平方增长,1 万个 token 的 Attention 矩阵就是 1 亿个元素;推理成本比处理图片贵上几十到上百倍。
这也是为什么目前的视频理解模型大多只处理短视频(几十秒),或者对视频先做"描述压缩"------用另一个模型先把视频转成一段文字描述,再让 LLM 处理。
视频还有一个图片没有的问题:帧的顺序很重要 。图片的 patch 可以加位置编码,视频除了每帧内部的空间位置编码,还需要全局时间位置编码,让模型知道哪帧在前、哪帧在后。
主流做法是给每个帧分配一个时间戳 embedding,和帧内 patch 的空间位置编码加在一起:
bash
patch_final_vector = patch_vector + 空间位置编码 + 时间戳编码这样,Attention 机制就能同时学到帧内关系(猫的各个部位在一帧内的空间关系)和帧间关系(猫从左跳到右的运动轨迹)。
六、输出端:模型怎么"生成"图片和音频
前面讲的都是输入------把图片、音频、视频变成向量,让模型"看懂"。但多模态还有另一半:输出。
当模型能看图之后,它是怎么把"一只猫"的意图,变成一张真正的猫的图片的?当你让 ChatGPT 画一幅日落,它是怎么一步步生成像素的?
6.1 两种生成范式,两个 Transformer
多模态大模型的输出有两种完全不同的生成范式,共用同一套骨架------Attention + FFN 堆叠,但各有各的玩法:
| 范式 | 代表 | 注意力掩码 | 训练目标 | 生成方式 |
|---|---|---|---|---|
| 自回归 Transformer(GPT) | LLM 文本生成 | 因果掩码(只能看过去) | 预测下一个 Token | 逐个 token 前向生成 |
| 扩散 Transformer(DiT) | 图像/视频生成 | 无掩码(双向可见) | 预测噪声 ε | 从噪声迭代去噪(T 步) |
两种模型的"大脑"是一样的(堆叠 Attention + FFN),差别只在于:掩码方式不同、输出不同、训练目标不同。
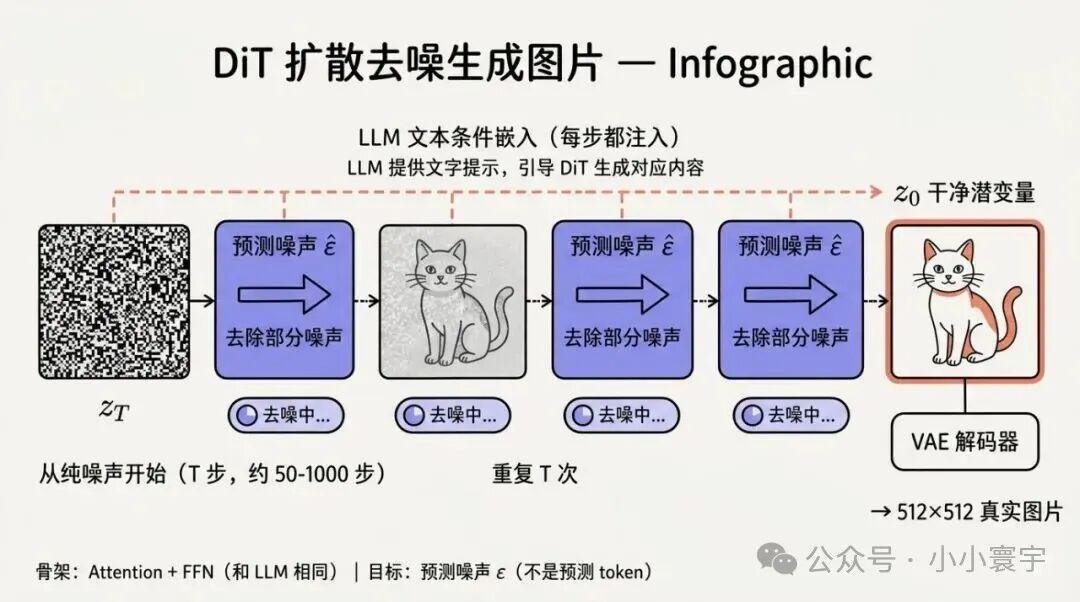
6.2 图片生成:扩散 Transformer(DiT)
自回归 LLM 生成图片直接输出像素很难,主流方案是扩散 Transformer(DiT)------它也是一个 Transformer,骨架和 LLM 完全一样(Attention + FFN 堆叠),但有三处不同:
区别一:注意力无掩码GPT 有因果掩码,每个 token 只能看到之前的 token。DiT 没有掩码,所有位置两两可见------就像一个"双向"的 Transformer。
区别二:输入是噪声 + 条件 DiT 输入的不是 token 序列,而是:带噪潜变量 z_t + 时间步 t + 文本条件。LLM 输出的向量通过交叉注意力或 AdaLN 调制注入进去。
区别三:训练目标和生成方式
- • 训练目标:
MSE(ε, ε̂)--- 预测噪声,不是预测 token - • 生成方式:从纯噪声
z_T开始,迭代 T 步去噪,每步预测并去掉一部分噪声,最终得到干净图像
bash
用户输入:"画一只在草地上奔跑的狗"
▼ LLM 理解用户意图,输出文本条件嵌入
▼ DiT 主干(Attention + FFN 堆叠,无因果掩码)
输入:噪声 z_T + 文本条件
迭代 T 步:预测噪声 → 去除部分噪声 → 降噪到 z_{T-1} → ...
最终输出:干净潜变量 z_0
▼ VAE 解码器
把潜变量映射回像素空间 → 512×512 图片具体代表:GPT-4o 用 DALL·E 3(DiT),Gemini 用 ImageFX(DiT)。LLaVA 这类理解型模型本身只理解图片,生成靠调用外部 DiT(如 Stable Diffusion)。
DiT 和 GPT 骨架相同(都是 Attention + FFN),差别只在三点:DiT 没有因果掩码、输入是噪声而非 token、目标是预测噪声而非下一个 token。
6.3 音频生成:声学 Token 的路子
图片生成靠扩散模型,音频生成靠另一套:声学 Token。
流程是:
bash
用户输入:"用温柔的声音朗读这段文字"
▼ LLM 理解内容 + 情感意图
▼ LLM 输出两类 token:
- 文本 token(说话内容)
- 声学 token(音高、语速、停顿)
▼ 声学解码器(基于 Transformer 架构的声码器)
把声学 token 还原成波形
输出真实的人声音频这里的核心思想是:把声学特征也 token 化------像文本 token 一样,让 LLM 预测声学 token,再把 token 变回波形。
GPT-4o 的语音对话就是这个路子:输入音频 → Whisper 编码器 → LLM → 声学 token → 声码器 → 输出语音。全程 token 流,打通了文本和语音的边界。
6.4 视频生成:最难的那块
视频生成是当前最前沿、也最困难的方向。
为什么难? 因为视频 = 图片 × 时间。生成一张图已经很难了,还要保证几十帧、上百帧之间的连贯性------人物不能跳变,动作要流畅,光影要一致。
目前主流的视频生成模型(如 Sora、Runway、Pika)走的是扩散模型 + 时序建模的路子:
bash
用户输入:"一只猫从左向右奔跑"
▼ LLM 解析意图,输出文本条件嵌入
▼ 时序 DiT 主干(Attention + FFN 堆叠,无掩码)
从噪声开始,在时间轴上逐步去噪
保证帧间连贯性(通过时序 Attention 机制)
▼ VAE 解码器 → 输出 16~60fps,时长 5~60 秒视频时序 DiT 和图片 DiT 的区别在于:在每帧内部切 patch 的基础上,还要在时间轴上加时序位置编码,让模型区分"第 1 秒的猫"和"第 3 秒的猫"。
目前多模态大模型大多还不具备高质量视频生成能力 ,原因是:视频 token 数量太大(几分钟视频可能有数十万 token),超出 LLM 核心处理能力;时序一致性难以保证;计算成本极高。所以现在常见的产品形态是:LLM 做理解+规划,时序 DiT(如 Sora)做生成,两者配合工作,而不是一个模型搞定一切。
6.5 完整的双向多模态架构
讲到这里,可以画一张完整的架构图了。从用户视角看,这就是一个整体------你给它文字+图片,它给你文字+图片,只是内部用了两套不同的生成机制。
以用户输入"把图中的狗给删除" + 一张狗的照片 为例:
bash
用户输入: 文字 "把图中的狗给删除" + 图片
│ │
┌─────────▼──────────┐ ┌─────────────▼─────────────┐
│ 文本 Tokenizer │ │ 图片编码器 (ViT) │
│ → Embedding 层 │ │ → 切成 patch → 投影层 │
└─────────┬──────────┘ └─────────────┬─────────────┘
│ │
▼ ▼
┌──────────────────┐ ┌──────────────────────────┐
│ 文字向量序列 │ │ 图片向量序列 [patch₁..] │
└────────┬─────────┘ └────────────┬─────────────┘
│ │
└──────────────┬───────────────────────────┘
│ 拼接 → [patch₁..,文字向量序列]
▼
┌──────────────────────────────────────┐
│ LLM 核心(同一个 Transformer) │
│ 堆叠 Attention + FFN × N │
│ 输入: 向量序列(图片 patch + 文本) │
│ 输出: 文本 token(自回归因果掩码) │
└──────────┬───────────────┬────────────┘
│ │
┌──────────┘ └──────────────────┐
▼ ▼
自回归生成文本 LLM 输出的文本条件嵌入(Text Embedding)
│ │
▼ ▼
直接输出文字 注入 DiT(扩散 Transformer)
│
从噪声 z_T 迭代去噪 T 步
│
▼
潜变量 z_0 → VAE 解码 → 像素(编辑后的图片)总结一下:输入侧,文字和图片各走各的管线,最后拼在一起进同一个 LLM 核心;输出侧,LLM 自回归生成文字,同时把文本条件注入给 DiT,由 DiT 生成图片。两套机制骨架相同(都是 Attention + FFN 堆叠),但输入、掩码和训练目标都不同。
最后要纠正一个常见误解:扩散模型不是 LLM 的"解码器",它是一个独立的 Transformer,只是靠 LLM 提供文字条件来控制生成内容。
七、多模态带来的新问题
7.1 上下文窗口压力更大
前文第八篇讲过上下文窗口的限制。多模态让这个问题更严重:
bash
一段文本: "请描述这张图片" → 约 5 个 token
一张图片: 224×224, 16×16 patch → 196 个 token
一张高清图: 448×448, 16×16 patch → 784 个 token一张图片就吃掉了几百个 token 的窗口空间。如果对话中包含多张图片,窗口会被快速占满。
这也是为什么很多多模态模型会对图像做压缩------比如只保留最重要的几十个 patch 向量,而不是全部 196 个。
7.2 推理成本更高
更多的 token 意味着更大的 KV Cache 和更多的 Attention 计算(n²)。处理一张图片的推理成本远高于处理一句话。
7.3 对齐的难度
让图像向量和文本向量在同一个空间里"说同一种语言",这件事比字面上听起来要难得多。投影层的训练如果不到位,模型很可能"看到了"图片但还是"看不懂"------图片的向量和文字的向量虽然在数学上碰巧维度相同,但在语义上各说各话。
八、总结
读完前文再看多模态,你会发现核心其实没变多少。
LLM 那部分完全照旧:Attention 公式、残差连接、LayerNorm、KV Cache,一个都没改。
真正新加的只有两件事:入口处,给图片、音频、视频各配一个编码器 + 投影层,把它们变成向量序列,拼进 LLM 的输入里;出口处,图片和视频不走 LLM 的自回归管线,而是交给扩散 DiT,音频走声学 Token 加声码器。
两套生成机制(自回归 LLM 生成文字,扩散 DiT 生成图片/视频)骨架相同------都是 Attention + FFN 的堆叠------只是输入、掩码和训练目标不同。
说白了,多模态就是给同一个大脑接了两组新的感官和手脚。
文章首发于 「小小寰宇」
