AI 应用微服务架构设计:从单体到分布式的演进
前言
随着 AI 应用的复杂度不断提升,单体架构难以满足需求。微服务架构为 AI 应用提供了更好的可扩展性、可维护性。
我在多个项目中设计过 AI 应用的微服务架构,今天分享一些实践经验。
微服务架构设计
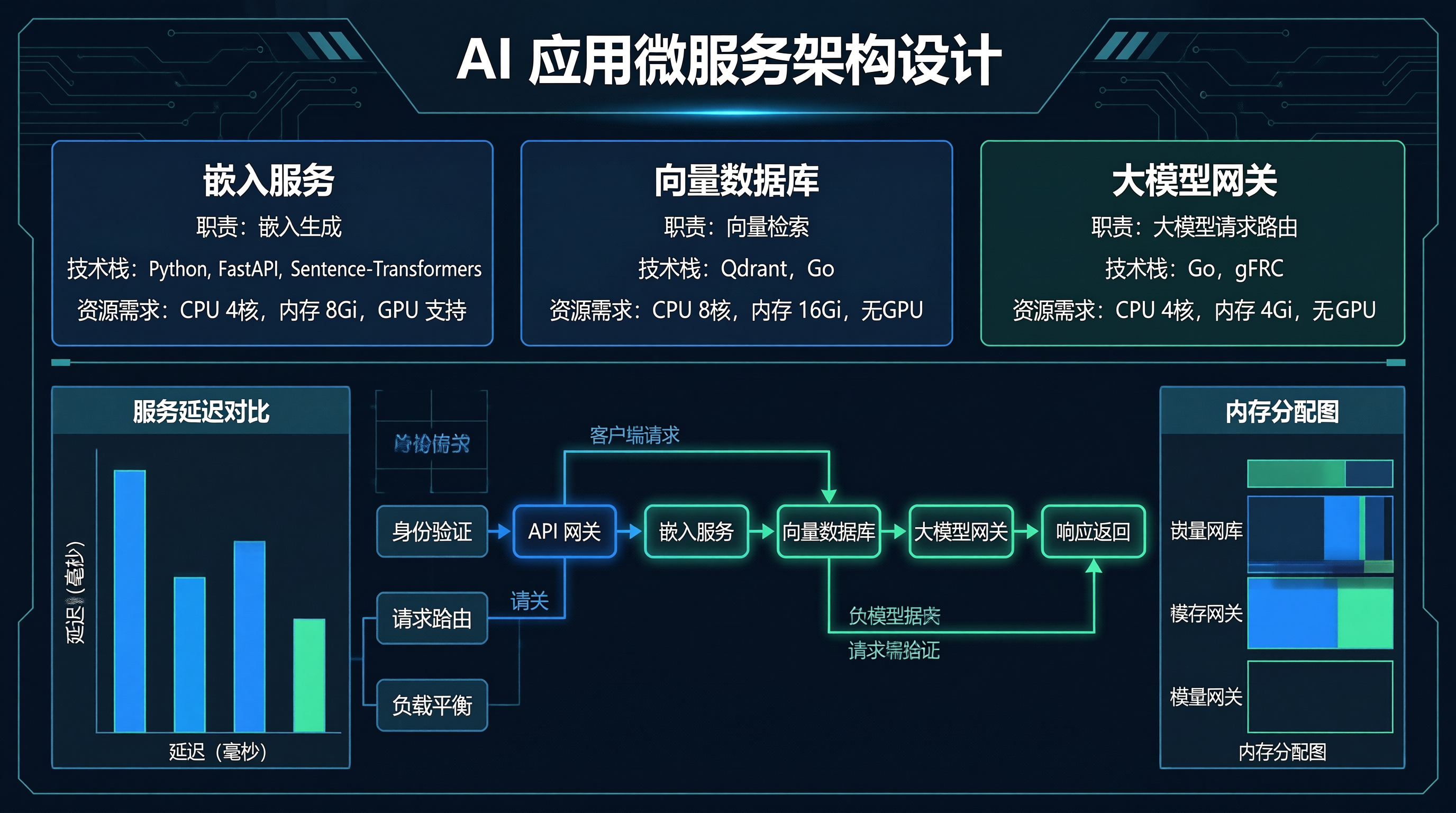
服务拆分原则
python
class ServiceArchitecture:
"""服务架构设计"""
def __init__(self):
self.services = {}
def define_service(self, name, responsibility, tech_stack, scale_requirements):
"""定义服务"""
self.services[name] = {
"name": name,
"responsibility": responsibility,
"tech_stack": tech_stack,
"scale_requirements": scale_requirements,
"dependencies": []
}
def add_dependency(self, service_name, dependency):
"""添加依赖"""
self.services[service_name]["dependencies"].append(dependency)
# 示例架构
arch = ServiceArchitecture()
arch.define_service(
"embedding-service",
"Embedding 生成",
["Python", "FastAPI", "Sentence-Transformers"],
{"cpu": "4c", "memory": "8Gi", "gpu": True}
)
arch.define_service(
"vector-db",
"向量检索",
["Qdrant", "Go"],
{"cpu": "8c", "memory": "16Gi", "gpu": False}
)
arch.define_service(
"llm-gateway",
"大模型网关",
["Go", "gRPC"],
{"cpu": "4c", "memory": "4Gi", "gpu": False}
)
arch.add_dependency("llm-gateway", "vector-db")API 网关设计
python
from fastapi import FastAPI, HTTPException, Depends
from fastapi.security import APIKeyHeader
import httpx
import asyncio
from concurrent.futures import ThreadPoolExecutor
app = FastAPI(title="AI Service Gateway")
api_key_header = APIKeyHeader(name="X-API-Key", auto_error=False)
async def verify_api_key(api_key: str = Depends(api_key_header)):
"""验证 API Key"""
valid_keys = {"key123", "key456"}
if not api_key or api_key not in valid_keys:
raise HTTPException(status_code=401, detail="Invalid API Key")
return api_key
class ServiceGateway:
"""服务网关"""
def __init__(self):
self.service_urls = {
"embedding": "http://embedding-service:8000",
"vector": "http://vector-db:6333",
"llm": "http://llm-gateway:8001"
}
self.client = httpx.AsyncClient(timeout=30.0)
async def route_request(self, service: str, path: str, data: dict = None):
"""路由请求"""
url = f"{self.service_urls[service]}{path}"
try:
if data:
response = await self.client.post(url, json=data)
else:
response = await self.client.get(url)
response.raise_for_status()
return response.json()
except Exception as e:
raise HTTPException(status_code=503, detail=f"Service unavailable: {str(e)}")
# API 路由
gateway = ServiceGateway()
@app.post("/api/v1/embeddings")
async def create_embeddings(texts: list, api_key: str = Depends(verify_api_key)):
return await gateway.route_request("embedding", "/embed", {"texts": texts})
@app.post("/api/v1/search")
async def search(query: str, top_k: int = 10, api_key: str = Depends(verify_api_key)):
return await gateway.route_request("vector", "/search", {"query": query, "top_k": top_k})服务间通信
异步消息队列
python
import asyncio
import json
from aiokafka import AIOKafkaProducer, AIOKafkaConsumer
class MessageBroker:
"""消息代理"""
def __init__(self, brokers):
self.brokers = brokers
self.producer = None
self.consumers = {}
async def start_producer(self):
"""启动生产者"""
self.producer = AIOKafkaProducer(
bootstrap_servers=self.brokers
)
await self.producer.start()
async def send_message(self, topic: str, message: dict):
"""发送消息"""
value = json.dumps(message).encode()
await self.producer.send_and_wait(topic, value)
async def start_consumer(self, topic: str, handler, group_id: str):
"""启动消费者"""
consumer = AIOKafkaConsumer(
topic,
bootstrap_servers=self.brokers,
group_id=group_id,
auto_offset_reset="earliest"
)
await consumer.start()
self.consumers[topic] = (consumer, handler)
# 消费消息
async for msg in consumer:
data = json.loads(msg.value.decode())
await handler(data)
# 示例使用
async def process_embedding_task(data):
"""处理 Embedding 任务"""
print(f"Processing: {data['task_id']}")
# 实际处理逻辑
broker = MessageBroker(["kafka:9092"])gRPC 服务定义
python
from grpc import aio, RpcError
from abc import ABC, abstractmethod
# Protocol Buffers 定义
'''
syntax = "proto3";
service EmbeddingService {
rpc GenerateEmbedding(EmbeddingRequest) returns (EmbeddingResponse);
rpc BatchGenerateEmbeddings(BatchEmbeddingRequest) returns (BatchEmbeddingResponse);
}
message EmbeddingRequest {
string text = 1;
}
message EmbeddingResponse {
repeated float vector = 1;
}
'''
class BaseGRPCService(ABC):
"""gRPC 服务基类"""
@abstractmethod
async def serve(self, port: int):
pass
@abstractmethod
async def stop(self):
pass容错与降级
熔断模式
python
from tenacity import retry, stop_after_attempt, wait_exponential, retry_if_exception_type
import time
from enum import Enum
class CircuitState(Enum):
CLOSED = "closed"
OPEN = "open"
HALF_OPEN = "half_open"
class CircuitBreaker:
"""熔断器"""
def __init__(self, max_failures=5, recovery_timeout=30):
self.state = CircuitState.CLOSED
self.failure_count = 0
self.max_failures = max_failures
self.recovery_timeout = recovery_timeout
self.last_failure_time = None
def call(self, func, *args, **kwargs):
"""带熔断的调用"""
if self.state == CircuitState.OPEN:
if self._can_recover():
self.state = CircuitState.HALF_OPEN
else:
raise Exception("Circuit breaker is open")
try:
result = func(*args, **kwargs)
self._on_success()
return result
except Exception as e:
self._on_failure()
raise
def _on_success(self):
"""成功"""
if self.state == CircuitState.HALF_OPEN:
self.state = CircuitState.CLOSED
self.failure_count = 0
def _on_failure(self):
"""失败"""
self.failure_count += 1
self.last_failure_time = time.time()
if self.state == CircuitState.HALF_OPEN:
self.state = CircuitState.OPEN
elif self.failure_count >= self.max_failures:
self.state = CircuitState.OPEN
def _can_recover(self):
"""是否可以恢复"""
if self.last_failure_time is None:
return True
return (time.time() - self.last_failure_time) > self.recovery_timeout降级策略
python
class FallbackService:
"""降级服务"""
def __init__(self):
self.fallback_cache = {}
def get_fallback(self, service: str):
"""获取降级响应"""
fallbacks = {
"embedding": self._embedding_fallback,
"search": self._search_fallback
}
return fallbacks.get(service, self._default_fallback)
def _embedding_fallback(self, text: str):
"""Embedding 降级"""
return {"vector": [0.0] * 1536, "source": "fallback"}
def _search_fallback(self, query: str):
"""搜索降级"""
return {"results": [], "source": "fallback"}
def _default_fallback(self, *args):
"""默认降级"""
return {"status": "service_unavailable", "retry_later": True}部署配置
yaml
# kubernetes/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: embedding-service
spec:
replicas: 3
selector:
matchLabels:
app: embedding-service
template:
metadata:
labels:
app: embedding-service
spec:
containers:
- name: embedding-service
image: ai-embedding-service:latest
ports:
- containerPort: 8000
resources:
requests:
cpu: "2"
memory: "4Gi"
limits:
cpu: "4"
memory: "8Gi"
livenessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 30
periodSeconds: 10
---
apiVersion: v1
kind: Service
metadata:
name: embedding-service
spec:
selector:
app: embedding-service
ports:
- port: 8000
targetPort: 8000
type: LoadBalancer总结
AI 应用微服务架构关键点:
- 服务拆分:按功能领域拆分,单一职责
- API 网关:统一入口,流量控制
- 异步通信:消息队列解耦服务
- 熔断降级:保障系统稳定性
- 容器编排:Kubernetes 高效管理
实践原则:
- 从单体开始,逐步拆分为微服务
- 优先拆分独立功能模块
- 使用容器简化部署
- 监控和日志是必要保障