一、那个脱口而出的错误答案
你问 AI 这个问题:
小明爸爸有三个儿子,老大叫大明,老二叫二明,老三叫什么?
AI 回答:"老三叫三明。"
你忍住笑:"错了,是小明。"
AI 立刻改口:"你说得对,我刚才答错了。"
这幕很有喜感------AI 答错了,但不是因为不知道。它其实知道,只是太急着给答案,话先出口,脑子才跟上。

二、普通模式:一条路走到黑
大模型做的事很简单:猜下一个词。
你把问题输进去,模型把整段话看一遍,给所有可能的词打分,选最高的输出。然后把这个词拼回去,再猜下一个------一路走到结束,只走一遍。
没有回头。没有检查。没有草稿。
"三明"的答案就是这样出来的:序列里前几个词是"大明""二明",下一个最顺嘴的词就是"三明"。模型根本没停下来想------"小明爸爸"本身就是第三个儿子的名字。
这不是 AI 笨。它同时知道正确答案,只是被"大明""二明"这个pattern带跑了,第一时间输出了统计意义上最流畅的答案。
普通模式的特点:
- • 一次生成,不回头------写完就交卷,中途错了不会自我修正
- • 中间过程不可见------从问题到答案,中间全在模型内部的几十层计算里,外部看不到
- • 快------延迟低,适合简单任务
三、思考模式:几种不同的"想"法
思考模式的核心只有一个:不让模型直接给答案,让它先把推理过程展开。具体怎么做,有四种主要思路。
3.1 思维链:多说一句,就多想一层
最简单的方式,不需要任何额外技术------只在提示词里加一句话:"请一步步思考。"
模型接到这个指令后,不再直接输出答案,而是先把推理过程写出来,再给出最终答案。
用"三明"这道题举例。普通模式下它脱口"三明",而开启思维链后,它可能这样回应:
让我分析一下:题目说"小明爸爸有三个儿子",这意味着小明本人就是这三个儿子之一。老大是大明,老二是二明,所以老三就是小明自己。答案不是"三明",而是"小明"。
推理过程本身并没有使用新算法。它还是一次生成,只是生成的序列更长了------里面多了一段"自言自语"。
为什么这样就能提高准确率?
推理过程中的每一个词,都会进入模型的上下文,作为后续预测的参考。当模型写下"小明本人就是这三个儿子之一"这句话,它作为一个token又回到了上下文里,直接影响了下一个词的预测。
就像人类拿到一道题,在草稿纸上写下已知条件,解题思路瞬间清晰了。大模型的"草稿纸",就是这段被写进上下文的思考过程。
思维链的局限:它仍然是一条路径推理。如果走进死胡同,模型不会折返,只能硬着头皮走完。
3.2 自洽性:问十个人,取多数意见
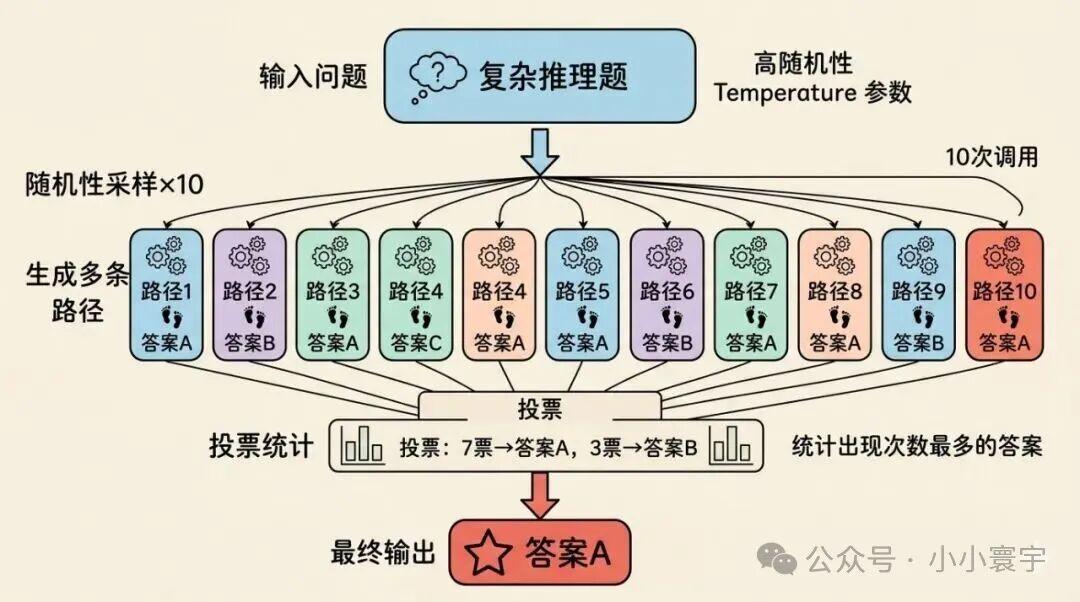
思维链只生成一条推理路径,自洽性(Self-Consistency)完全不同:生成多条路径,然后投票。
具体做法:用较高的随机性参数,针对同一个问题生成多个完整答案,统计哪个答案出现次数最多,作为最终输出。
就像把同一道选择题拿给 10 个人做,选 C 的有 7 人,你就相信答案是 C。
自洽性在数学、逻辑推理这类有明确正确答案的任务上效果显著。不过有个问题:你最终只看到一个答案,中间的思考过程通常不会展示给你看------只返回了汇总结果。
这是有代价的:生成 10 个答案意味着调用 10 次模型,成本成倍增加。对于医疗、法律、金融等高风险场景,这笔钱值得花。
3.3 自我纠正:先答,再批,再改
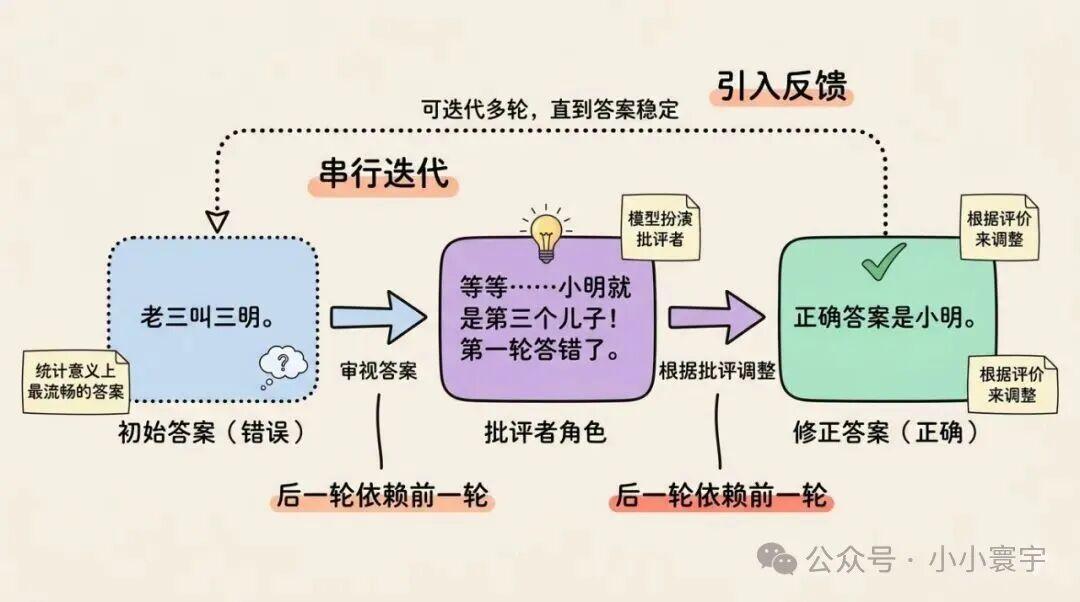
自洽性是"多条独立路径,互不干扰",自我纠正(Self-Correct / Reflexion)则是另一条路:串行迭代,后一轮依赖前一轮。
流程分三轮:
第一轮:给出初始答案。
老大是大明,老二是二明,所以老三叫三明。
第二轮:让模型扮演"批评者",审视刚才的答案。
检查一下:题目说"小明爸爸有三个儿子",小明爸爸就是小明本人......等等,小明就是第三个儿子!所以老三应该是"小明",不是"三明"。第一轮答错了。
第三轮:根据批评,修正答案。
正确答案是"小明"。因为题目里的"小明"就是爸爸的第三个儿子,名字在题目里已经给出了。
自我纠正的核心是引入反馈。模型不只生成答案,还生成对答案的评价,然后根据评价调整------类似人类写草稿、复核、修改、再复核的过程,可以迭代多轮,直到答案稳定。
3.4 思维树:同时探索多条岔路
自我纠正每次只走一条路径,思维树(Tree-of-Thoughts,ToT)更进一步:允许模型在推理过程中同时探索多个分支。
每一步生成几个可能的选项,然后评估哪个分支更有希望,差的分支直接放弃,继续往前走更有希望的那条。
用一道应用题来类比:你面对一道数学题,脑子里同时闪过两种解法------列方程和直接推算。你不会硬选一条走到黑,而是快速评估:方程法步骤清晰,可以推进;推算法这步有点绕,先放一放。然后选更有希望的那条继续。
思维树在代码生成、复杂规划类任务中效果显著。代价也最大------每一步都在生成多个分支,计算量成倍增加。
四、四种方式对比
| 思考方式 | 多次生成 | 路径关系 | 评估反馈 |
|---|---|---|---|
| 思维链 | 否 | 单条路径 | 无 |
| 自洽性 | 是 | 平行独立 | 无(仅最后投票) |
| 自我纠正 | 是 | 串行依赖 | 有(批评→修正) |
| 思维树 | 是 | 分叉搜索 | 有(启发式评估) |
思维链最轻量,自洽性和自我纠正适合不同场景,思维树最强但成本最高。
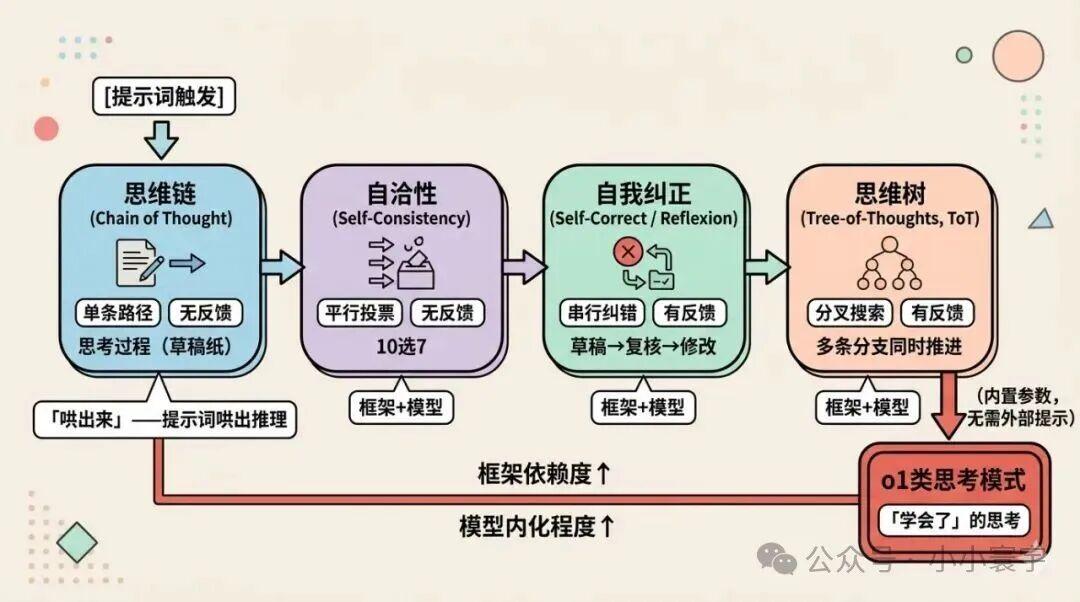
还有一个视角:如果把"谁来主导思考"和"对外部框架的依赖程度"放在一起看,这几种方式的差异本质上是一条演进线------
- • 思维链几乎完全靠模型自己的能力。模型推理能力强,提示词一给,它自己就写出推理链。这是"哄出来"的思考。
- • o1类思考模式更进一步:思考已经内置进模型参数,不需要外部提示,也不需要框架,模型自己就知道"先想再答"。这是"学会了"的思考。
中间的自洽性、自我纠正、思维树则介于两者之间------框架负责编排和调度,模型负责生成内容,各司其职。
演进的方向是:模型自己决定要不要想、想多久------不是靠人类告诉它,而是它学会了判断。
五、为什么"自言自语"能提高准确率
每多生成一个token,模型就多做一次完整的前向传播。
大模型的计算流程是:输入一段文字,经过N层Transformer(比如32层),输出下一个token。然后把这个token拼回去,再经过同样的32层,输出下一个......
在普通模式下,你问一个问题,模型走32层计算,直接出答案。中间过程全在黑盒子里,只走一遍。
在思考模式下,模型在给出最终答案前,先多生成了几十个甚至上百个思考token。这意味着它走了32层×几十次,而不是32层×1次。每一步都能看到前一步写下的内容,相当于在模型内部反复查阅同一张草稿纸,准确率自然就上去了。
这解释了为什么思考模式的token要收费:那些额外的"思考",本质上是在占用更多的GPU计算资源。
这还指向另一个趋势:过去 Scaling Law 说的是训练阶段------模型越大、训练数据越多、训练算力越强,模型越好。而思考模式代表另一个维度------推理阶段花更多算力,同一个模型就能给出更好的回答。
六、什么时候该用思考模式
思考模式让答案更准,但也更慢、更贵。
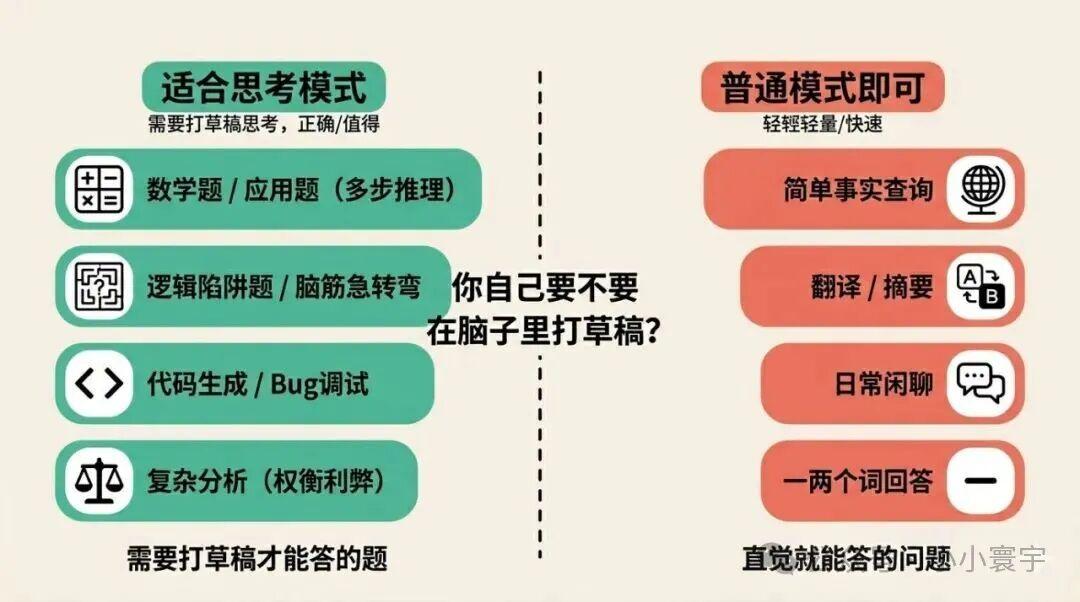
适合用的场景:
- • 需要多步推理的数学题和应用题
- • 有陷阱的逻辑题或脑筋急转弯
- • 代码生成和Bug调试(需要考虑边界情况)
- • 需要权衡利弊的复杂分析
不太适合的场景:
- • 简单的事实查询,比如"法国的首都是哪里"
- • 翻译、摘要这类不需要推理的任务
- • 日常闲聊
- • 只需要一两个词的回答
一个简单的判断原则:遇到这道题,你自己要不要在脑子里打草稿?
需要想才能答的,思考模式有帮助;直觉就能答的,开思考模式不仅浪费时间,还要多花钱。
现在主流 AI 产品越来越自动化------同一个模型,面对简单问题走普通模式快速返回,面对复杂问题自动开启思考模式,由模型自己判断。未来,这可能成为默认行为。
七、结语
那道"三明"题,AI 答错,不是因为不知道答案。在普通模式下,它根本没有停下来想一想的机会。
思考模式给了它这个机会------通过生成一段"自言自语",把推理过程写进上下文,等于给自己创造了一张草稿纸。草稿纸不能让不会做题的人突然变得会做,但它能帮助一个本来就会的人,把答案做对。
大模型并没有真正像人类一样"思考"。它只是在预测下一个词的时候,让自己多预测几次,多看几眼自己之前说过的话。
但就是这一点差别,让准确率有了质的飞跃。
文章首发于 「小小寰宇」
、
