前言
上一篇博文讲过了,进程状态是进程的属性之一,只要是属性就在task_struct这个结构体里被描述,就是一个变量,以我们现在的认知,理解成一个int变量,叫做state就可以了,所有的状态都归结于每一个状态变量设置成几的问题。
运行
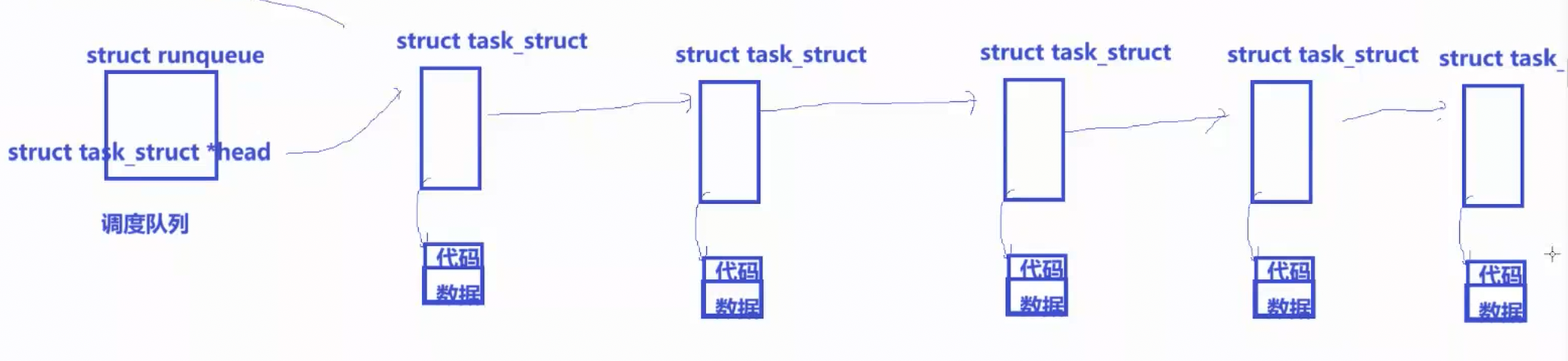
CPU会调度我们正在运行的进程,在调度算法里有一种常见的算法叫先进先出(FIFO),就是队列,一个CPU,一个调度队列。现在系统里有很多的进程,每一个进程都有自己的PCB,根据FIFO,每一个PCB都会被调度队列组织起来,CPU选择队头的进程先执行,有新的进程启动就插入到队尾,真正排队的是进程的PCB,通过PCB内部的指针找到对应的代码和数据,凡是在这个队列中的进程的状态就是运行状态。
阻塞
1.现象入手
我们一定写过下边的代码,当程序运行起来让我们输入的时候,我们不去输入,程序就会一直定在那里,这种状态就叫进程阻塞。
2.OS角度理解阻塞
上边的代码运行之后程序在等待什么?等待键盘上有数据,键盘是硬件,键盘上有数据叫就绪,所以在等待硬件就绪,操作系统最先知道硬件就绪这件事,因为操作系统是硬件的管理者,怎么管理?先描述再组织,也就是说我现在每一个硬件都对应在系统里有一个struct结构体,里边描述的是硬件的属性,额外的,在结构体里还会有一个叫wait_queue的指针,然后各个结构体之间再用链表组织起来。
请看下边那个调度队列的图,假设队头那个进程1里的代码就是上文写的scanf的代码,此时我运行了,但是我没有输入,没有输入OS就一直在等待硬件就绪,这叫事件不就绪,CPU会发现这件事,程序要想运行下去就必须要硬件就绪,但现在没有,CPU就会把当前的进程从调度队列里剥离出来,并且将当前进程的状态假设由R变成Block(上边不是说了嘛,就一个int变量,值由1变成2,就这样理解),之后,把当前进程的PCB列入到这个进程所等待的硬件的wait_queue当中,这个进程如今就不在调度队列里了,就永远不会被CPU调度了,就卡住了,就不会被执行了。后来用户输入了数据之后,OS就知道了相关硬件对应的属性的状态变了,就会去对应硬件的等待队列里去看看有没有进程在等待,如果有就将该进程状态改成运行,并且重新将这个进程列入到调度队列里,该进程被重新调度,就继续加载到内存,继续往后运行。综上,阻塞和运行的本质就是看你的进程的task_struct在谁提供的队列中。
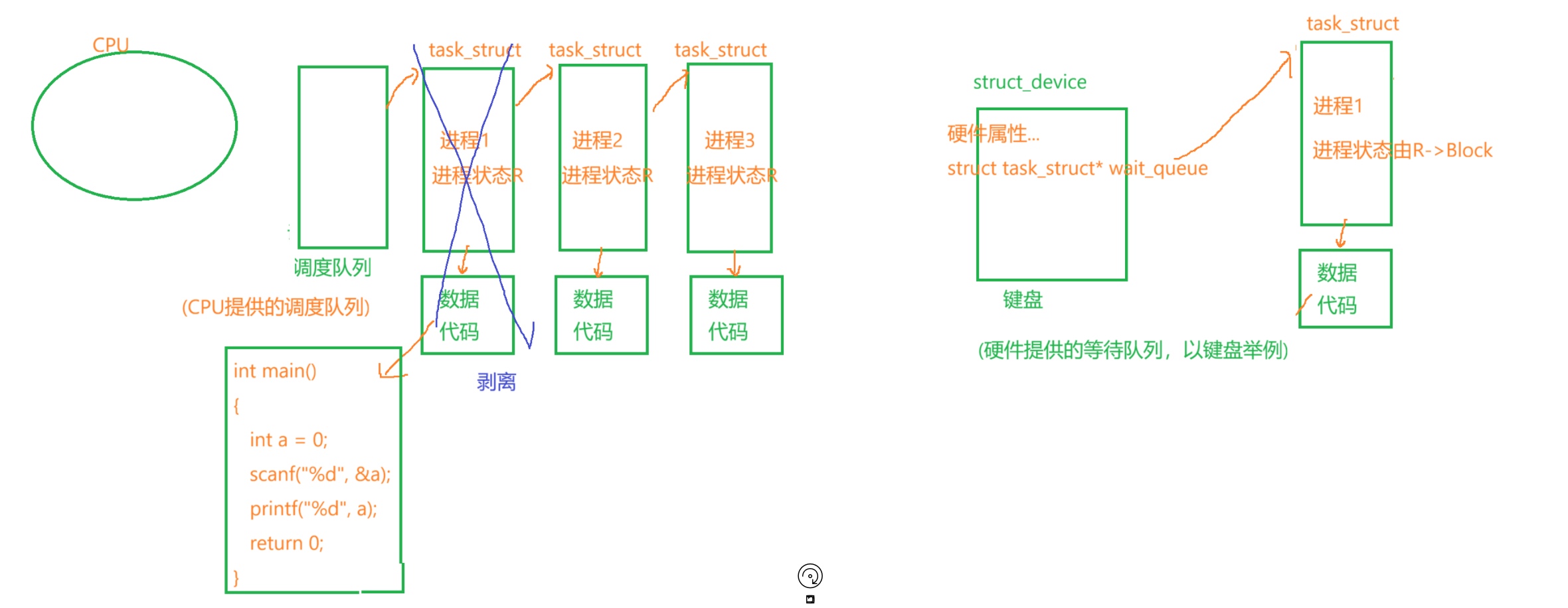
挂起
当OS里内存资源不足但是又有新的进程想启动,此时为了满足新的进程有内存资源,比如说,OS会将在等待队列里阻塞的进程的PCB指向的代码和数据换出(swap out)到磁盘的swap分区里,这叫挂起,等到硬件就绪,进程的PCB被重新唤起加入到调度队列里的时候,如果此时内存资源又充足,被交换到swap分区的代码数据再重新换入(swap in)到内存。但注意不是说只有阻塞的进程才会被挂起,其他状态下的进程都有可能被挂起。
一个进程的代码和数据可能本身也节省不出多少内存空间,但是OS里有成百上千个进程,被阻塞的进程也不会少,它们总共能节省出来的内存空间就多了。
那什么叫swap分区呢?一般在笔记本电脑里都会只有一个磁盘,为了方便管理与使用都会给磁盘分很多区,就比如电脑里有什么C盘D盘,而在安装OS的时候都默认会给磁盘分一个swap分区,它的大小一般跟内存差不多,或者是内存的1.5倍/2倍,这就变相动态的扩展了物理内存的大小。但是,不建议swap分区太大,太大就会导致内存过度依赖swap分区,就会进一步导致过度swap之后让系统变慢。swap分区存在的本质就是时间换空间。
如果一个被挂起的进程恰好又是阻塞的,就叫阻塞挂起。如果一个被挂起的进程是运行状态,就叫运行挂起,这种情况主要发生于所有阻塞的进程都被挂起了但是内存还是不够,OS就不得不将一些在调度队列中间的是运行状态但还没有被CPU调度的进程挂起。那如果运行挂起之后内存还是不够的话,LinuxOS就只能选择性的杀掉特定的进程。
注意区分阻塞和挂起,阻塞是硬件没有就绪,进程从调度队列里剥离到硬件结构体的等待队列,挂起是当内存资源不足时又有新的进程需要占用内存,为了腾出空间而将一些进程的PCB指向的代码和数据swap out到swap分区里。
上边说的三种状态是教材里笼统的OS状态,具体怎么在Linux下表示请看下文。
具体操作系统的状态(Linux)
RSDTt
R:running,(就绪+运行):并不意味着进程一定在运行中,它表明进程要么是在运行中要么在调度队列中。
S:sleeping,休眠状态(可被中断休眠)(浅度睡眠):等同于教材里的阻塞状态。
一些关于R和S的坑:请看下边的代码
cpp
1 #include<stdio.h>
2 #include<sys/types.h>
3 #include<unistd.h>
4
5 int main()
6 {
7 while(1)
8 {
9 printf("我是一个进程: %d\n", getpid());
10 }
11
12 return 0;
13 } 上述代码运行之后查看进程状态会发现它居然是S(后边那个+先不管),然后我们把上边代码的printf注释掉再看会发现进程状态就变成R了。
没注释:

注释了:

为什么一个是R一个是S?明明两个程序都在运行,怎么还会有S?很明显问题出在printf上,printf的本质是往显示器上打印,就是将数据从内存打印到显示器上,它是需要刷新缓冲区的,意思就是缓冲区在内存里,printf先打印到缓冲区里,然后再一刷新,就从内存到显示器上了,这本身其实没什么问题,但是现在的代码是死循环,缓冲区一下子就被打满了,但printf还一直要打,缓冲区就来不及刷新,显示器这个硬件没有就绪不就意味着程序阻塞了嘛,那就为S状态了,极少数的机会可以看到R状态,只不过这个阻塞的时间很短,肉眼根本就看不出来,所以看着运行结果一直还在打印,而将printf注释掉之后就只有一个while循环了,那此时的程序就是正常被调度处于运行状态。结论:有没有IO对程序的影响其实是很大的。
杀掉一个进程除了ctrl+c,也可以用指令kill -9 进程PID(-9是一个信号)。所以S状态的进程可以被kill发送信号直接杀掉,所以才说S又可以叫可被中断休眠和浅度睡眠。区别就是kill既可以杀掉前台进程也可以杀掉后台进程,ctrl+c只能杀掉前台进程。
现在来解释一下那个+和前后台进程的问题,就是假设我现在启动一个进程,然后再去输入指令没有用了,这个进程就称为前台进程,状态后边就会带个+号。

如果在启动进程的时候后边再加个取地址&,那么此时这个进程就叫做后台进程,状态显示的时候就没有+号。

手机里其实早就支持前后台进程了,你当前打开一个APP,手机屏上显示就是前台进程,你划掉再开一个APP,被划掉但是没有退出的叫后台进程。
D:(disk sleep):Linux特有的状态,休眠状态(不可被中断休眠)(深度睡眠),跟S一样,D也是对应教材上的阻塞,需跟S对比理解。D不可被信号或者OS杀掉,大多出现在进程往磁盘里写数据的时候(跟磁盘进行IO的时候),进程需要等待磁盘发出写完的信号,进程在等待的这个过程中其实相当于就是在白白占用内存资源,因为它几乎啥都不在干,但又不得不这样,不能让OS为了腾出内存空间给别的进程使用而杀掉这个进程,如果说这个进程被杀掉了,磁盘写数据可能就中断了,此时磁盘发出信号又没有进程去回应它,最后的结果就是磁盘直接将刚才写入的数据全部删掉,这会造成巨大损失,就比如银行一天的转账记录没了,D状态就是为了避免这样类似的情况,只有当磁盘写完了,进程才会从D状态唤醒。D状态很少见,基本上见到的话,你的Linux机器离挂掉也不远了。
T:stop,暂停状态。那休眠和暂停有什么区别呢?演示一下,myprocess里的代码是一个死循环代码,kill -l指令是显示所有的信号,19号是暂停,18号是继续。
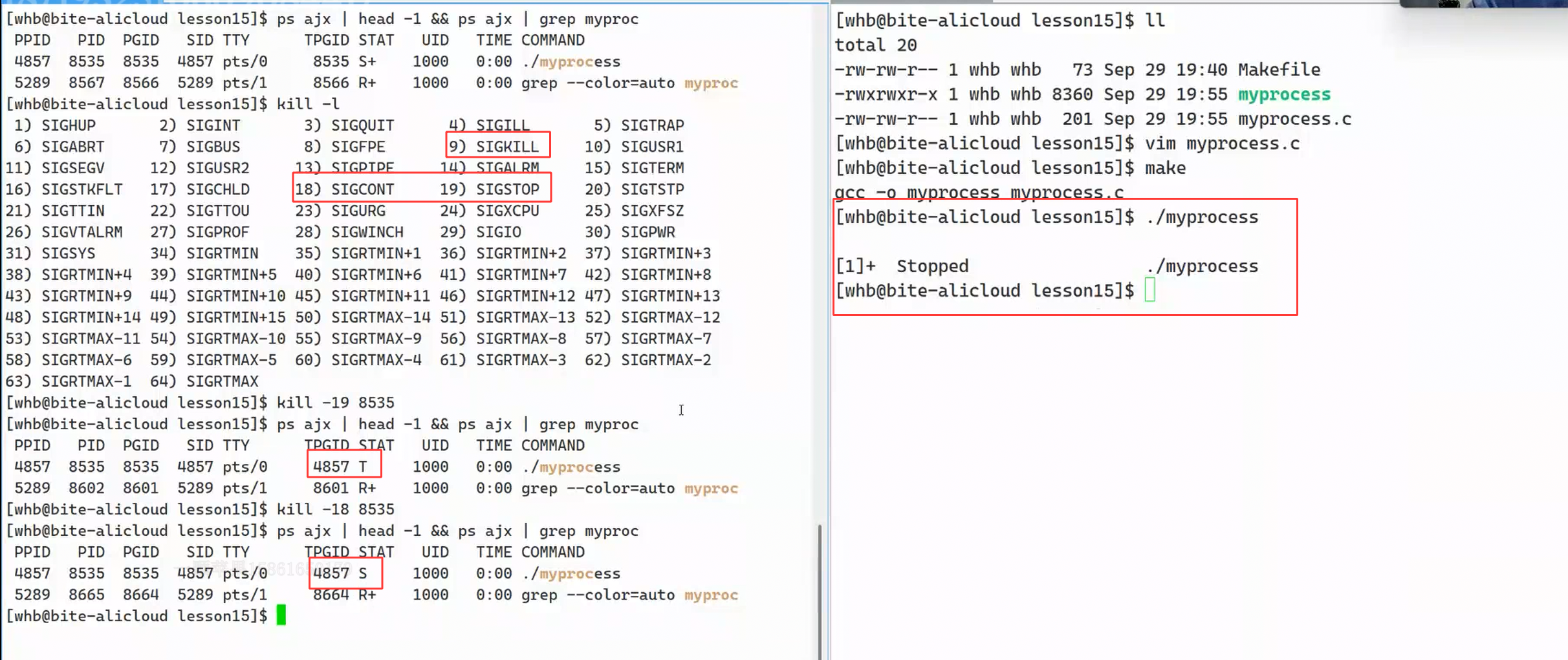
那T状态的场景是什么呢?先说一个结论,前台进程可以从键盘上获取输入,后台进程不可以。一旦后台进程里涉及到从键盘里获取输入,OS就会把后台进程的状态设置成T(暂停),不让它执行了。做对的事情(前台进程可以获取输入)就叫休眠,做错的事情(后台进程不可以获取输入)就叫暂停。
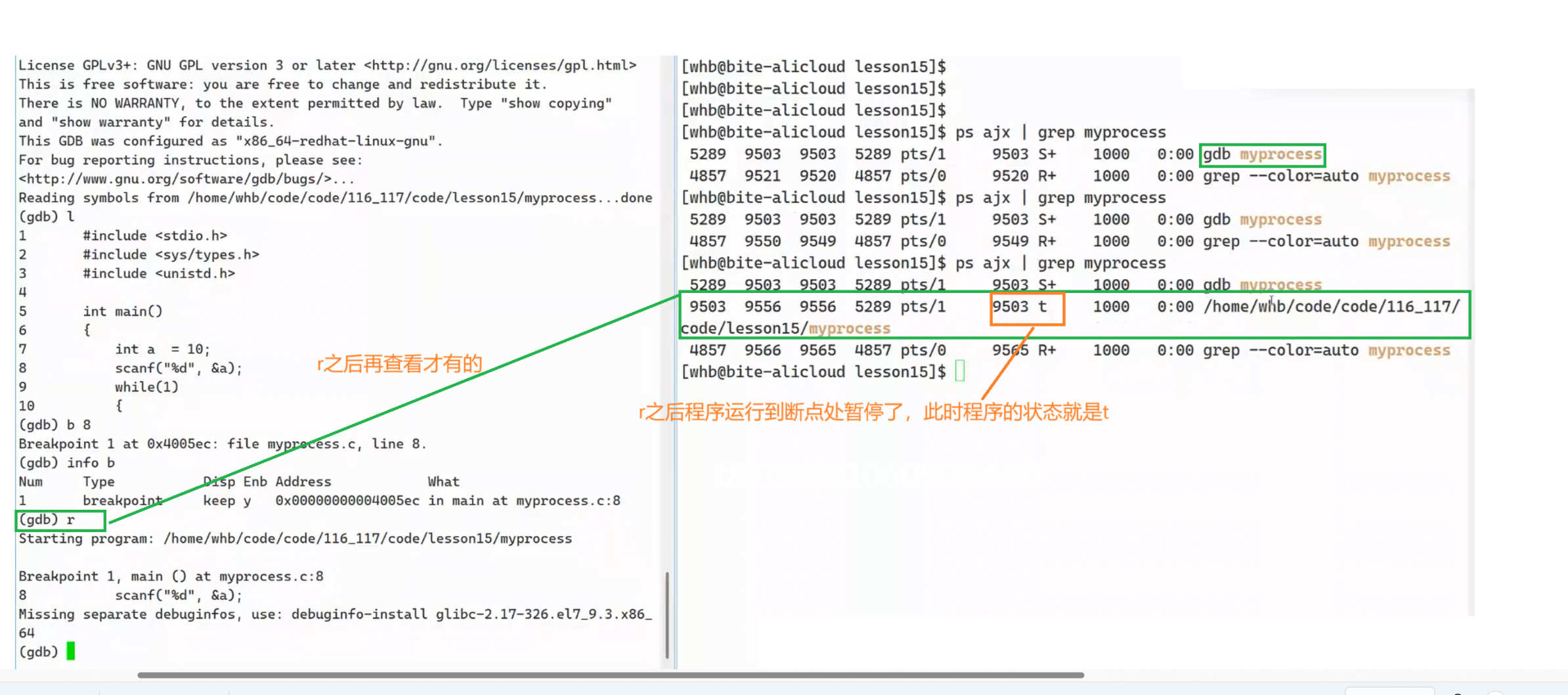
t:tracing stop,追踪暂停,追踪一个进程,在gdb调试的时候进程的状态。如下是一个gdb调试代码,设置了一个断点,还没有r,查看进程的时候发现gdb process是一个进程,也就是说gdb命令启动起来了之后自己是一个进程,r之后让process跑起来了(r的本质就是让gdb启动一个子进程),运行到断点处停下,此时process这个进程的状态就为t。可以理解成在子进程遇到断点时,gdb父进程向子进程发送19号(暂停)信号,把子进程暂停了,继续逐过程或者逐语句那一下之后又暂停,所以调试过程本质上就是gdb这个父进程一直在给子进程process发送18(继续),19(暂停)信号。
综上:T和t没有区别。
僵尸状态
X:死亡状态。意思就是进程将要或者马上被OS释放掉,但是一个进程创建出来就是为了完成任务的,但是现在进程已经没了,我怎么知道它是否完成任务了呢?所以进程结束后不能直接彻底销毁(X),必须先进入僵尸状态Z ------ (只保留进程的PCB(本质是为了保留退出信息)给父进程或者OS读取),父进程或者OS确认收到结果后,内核才彻底释放 PCB,进程进入真正的死亡 X 状态。
1.进程退出了,退出信息是什么?
写C/C++代码的时候,main函数结束都会有一个返回值0,表示程序正常结束,一个程序运行起来就是一个进程,因此,main函数的返回值是返回给OS的,同理,如果一个进程被kill发出的信号给杀掉了或者是其他的一些什么状况,反正就是没有正常运行完中途就退出了,返回值就不是0,综上,退出信息就是main函数的返回值或者收到的信号值。
2.进程退出了,退出信息保存在哪里?
进程=PCB+进程的代码和数据,代码和数据很显然无法用来保存数据,因此,退出信息就保存在task_struct里。
3.检测Z状态进程,回收Z状态进程,本质是在做什么?
本质是在获取并检查退出信息,获取完就让Z状态进程变为X状态并且释放掉它。
4.具体怎么回收?谁来回收?(暂时先了解一下)
一般都是父进程通过系统调用回收,系统调用底层还是OS,说白了就是OS来回收。
总结:如果我就是不回收子进程呢?进程就会永远处于Z状态,处于Z状态,就必须要保存进程的task_struct,则task_struct就不会被释放,其就要占据内存,这叫内存泄露了。所以子进程必须回收。那额外问一句,(与上文无关),如果对应的进程结束了,内存泄露问题还在吗?不在了,因为进程退出了之后,OS会自动帮你回收掉所开辟的内存空间,就像你自己写的C程序代码,你malloc之后没有free,等你程序跑完了,其实malloc开辟的空间就由OS自动帮你回收掉了,但是我们遇到过的APP基本都是常驻进程,就是不会自己退出的,说白了就是死循环,这样的进程才可能会有内存泄露问题。
孤儿进程
什么时候会处于僵尸状态?父进程不退出,子进程退出,子进程退出的时候父进程啥也不干,子进程的退出信号没有被检查确认,就处于僵尸状态。
那我现在如果是父进程先退出,子进程不退出呢?父进程肯定不会处于Z状态,因为父进程它的父进程是bash,等父进程退出了bash肯定会回收它的,所有的你在终端敲的命令的父进程都是bash,等命令执行完,该进程退出都会被bash回收,因此就也不会出现Z状态。再说回子进程,由于父进程退出了,子进程没有父进程了,就称这个进程为孤儿进程,每一个孤儿进程都会被1号进程所领养,1号进程的名字在不同版本的内核里可能不一样,大家可以用top指令查一查,我这里的1号进程就叫系统进程systemd。
为什么要被领养?子进程也是进程,它将来万一也要退出呢?那如果没有进程去回收它,它不就会一直处于Z状态,就有内存泄露问题呀,这样的僵尸进程越来越多,内存泄露也就越来越多,所以被系统进程领养的目的就是给孤儿进程退出进行善后,当孤儿进程退出的时候了,系统会自动回收孤儿进程,为什么要被系统领养?系统是进程的管理者,为了防止内存泄露,而进程又是孤儿,那只能由系统领养。OS会自动把孤儿进程变成后台进程。
补充:总结前后台进程:谁能从键盘获取数据输入,谁就是前台进程,键盘只有一个,所以在获取输入的时候只能有一个进程在键盘获取数据,因此前台进程在任何时刻都只能有一个,后台进程可以有多个。
进程优先级
1.什么是优先级?
之前学过一个叫权限的概念,权限是能不能的问题,而优先级是已经能了,先后的问题,进程在已经能得到某种资源的前提下,得到某种资源的先后顺序。
2.为什么要有优先级?
资源不足,僧多粥少,分配资源,通过设置优先级来决定进程获取某种资源的先后顺序。
3.Linux系统下是怎么设计优先级的?
之前说过一个ps指令可以查看进程状态,其有个-l选项可以查看进程更详细的状态。如下图,UID表示我这个人,表示这个进程是谁启动的,学文件权限的时候是通过用户名来表示文件的拥有者,所属组之类的信息,而UID则相当于是用一个编号来表示我这个人。

还有两个PRI(priority)和NI(nice),它们来表示进程的优先级,早就说过,进程属性都在task_struct这个结构体里,因此PRI和NI这两个优先级属性就是结构体里的两个整型变量而已。PRI很好理解,表示进程被执行的时候的优先级,数字越小表明进程的优先级越高,就跟考试的排名一样,默认值为80,NI就是nice,跟进程调度有关,进程调度下文会说,现在就先知道NI表示进程可被执行的优先级的修正数值,PRI(new)=PRI(old)+NI,根据这个"公式"也能知道NI为负值时,PRI的优先级会变高,因此在Linux下不是直接改PRI,而是通过调整NI值去调整进程的优先级,常见的有四五种调整NI的方式,这里我们用top。
调整NI
初始时:

1.top打开
2.r+输入你想调整进程的PID
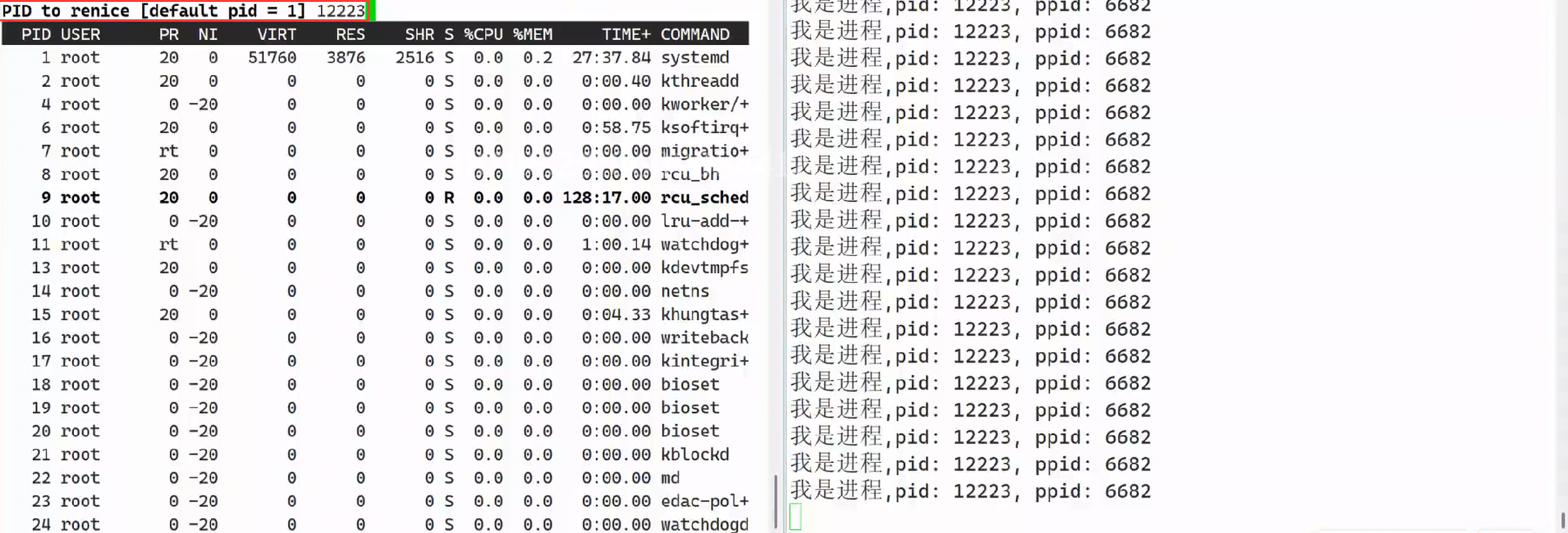
3.输入你想修改的NI,(我自己输入了10)
4.结果

关于NI的几个问题
1.能高频更改优先级吗?
不能(root除外),因为改多次OS会认为你是恶意在影响我进程的优先级,这里顺便再解释一下上边那个PRI(new)=PRI(old)+NI,这里的PRI(old)指的是什么,是我当前进程的PRI吗?不是,是上文说的PRI的默认值80,其实这样反而变方便了,不用让我们每次去修改PRI还要先查看一下当前进程的PRI。
2.进程优先级的变化范围是多少?
进程优先级的变化范围等价于nice的变化范围,nice的变化范围是-20,19,总共40个梯度(意思就是区间里总共40个数字),那进程优先级的变化范围就是60,99,也是40个梯度。注意这个NI的变化范围没必要去记,上文不是说了top可以修改NI的值嘛,你就故意将NI修改成100和-100,这样得到的最终结果由于NI有范围,最小哪个值最大哪个值就都知道了。结论:优先级的变化范围是有限的。
3.为什么NI是这个范围(优先级的变化范围为什么有限)?为什么不能随便改NI的值?
当今的OS大部分都是分时操作系统,给进程分配时间片,这是一个相对公平公正的调度策略,较为均衡的让不同的进程都能在一段时间之内,都能得到CPU资源。这样的模式是人和互联网共同的需求,我们使用手机,比如说现在既想用杀毒软件杀毒,也想刷刷抖音,这就是分时的好处,让多个进程共同干活,对于互联网来说也是这样,我今天想买火车票,我在买,别人也在买,这个过程也是分时的体现。分时OS的好处就是同时启动多个任务,一起跑,这也就说明了为什么优先级的变化范围是有限的,更改优先级不能改变的太狠,我们需要多线程工作,就必须各个进程的优先级差不多才行,所以NI的值也是需要限定的,不能随便改,限定NI的范围就是在限定PRI的范围,即限定优先级的范围。
补充:与分时OS相对的就是实时OS,这个OS就是一个进程结束了才能进入下一个,而且支持插队。