一、实验背景与目的
在这次数据分析实训中,我需要处理一批典型的互联网用户行为日志数据。这些数据都是半结构化的 TXT 文本,不能直接拿来分析,所以我要完整走一遍数据加工流程:从日志解析、结构化转换,到数据清洗、字段衍生、多维度聚合,最终产出可以用来做用户行为分析、浏览器市场格局研究,甚至后续流失预测建模的标准数据集。通过这次实操,我也能真正掌握企业里常用的 ETL 数据处理思路和平台操作方法。
实验目的
- 熟悉半结构化用户行为日志的格式、字段与数据特点,掌握日志解析方法。
- 完成从零散 TXT 日志到标准结构化数据表的转换,实现数据规整与入库。
- 掌握数据清洗、字段衍生、分组聚合、多分支加工等 ETL 核心操作。
- 输出可直接用于可视化与建模的浏览器用户行为统计数据表。
二、实验环境与数据
2.1 实验环境
- 实验平台:助睿在线实验平台
- 数据处理:助睿 ETL 数据集成平台
- 数据存储:团队私有数据库
- 数据规模:1000 名用户、800 万 + 条行为记录、约 825MB(本次实操使用 20 个样本文件)
2.2 实验数据
-
用户基本信息 :
demographic.csv,包含 user_id、性别、年龄、职业、教育、收入等。 -
行为日志 :
behavior/目录下大量 TXT 文件,记录浏览器访问与软件使用行为。 -
日志命名规则 :
用户ID_日期_开机时间.txt -
日志内部格式 : 第 1 行:Last<=> 数字(最后一条记录距开机秒数) 第 2 行:L_Start<=> 时间(开机时间) 第 3 行起:行为记录,以
[=]分隔字段,<=>分隔键值
2.3 核心字段
- T:行为发生距开机秒数
- P:进程名
- I:进程 ID
- U:访问 URL
- W:窗口句柄
- N:程序名
- C:开发公司
三、详细实验步骤
步骤 1:创建实验项目
- 登录助睿平台,进入数据集成页面。
- 点击新建项目 ,输入名称:
互联网用户行为日志数据加工,点击确定。 - 项目创建完成,进入项目内部进行资源管理。
步骤 2:导入实验数据
-
在项目内打开文件库 ,右键根目录→新建目录 ,命名为:
互联网用户行为日志数据集。
-
切换到公共空间 →数据资源 ,找到本次实验日志数据。
-
点击数据卡片更多→导出 ,选择目标目录为刚创建的文件夹。

-
重复操作,将 20 个日志 TXT 文件全部导入个人目录。
步骤 3:建立数据库连接与创建原始行为表
-
确认已配置团队私有数据库连接(未配置则按平台指引新建)。
-
新建转换:
创建原始行为日志数据表。
-
拖拽执行一个 SQL 脚本 组件,配置数据库连接。
-
执行建表 SQL,创建
behavior_events表:
sql
CREATE TABLE behavior_events (
id BIGINT AUTO_INCREMENT PRIMARY KEY COMMENT '自增主键',
session_id VARCHAR(255) COMMENT '会话唯一ID',
user_id VARCHAR(100) COMMENT '用户ID',
session_start_time VARCHAR(50) COMMENT '会话开始时间',
event_seconds INT COMMENT '事件发生秒数',
process_name VARCHAR(255) COMMENT '进程名称',
process_id VARCHAR(100) COMMENT '进程ID',
url TEXT COMMENT '访问网址',
addr_handle VARCHAR(255) COMMENT '地址栏句柄',
tab_handle VARCHAR(255) COMMENT '标签页句柄',
browser_version VARCHAR(100) COMMENT '浏览器版本',
window_handle VARCHAR(255) COMMENT '窗口句柄',
app_name VARCHAR(255) COMMENT '程序名称',
company_name VARCHAR(255) COMMENT '开发公司',
source_file VARCHAR(255) COMMENT '原始日志文件名',
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '入库时间',
INDEX idx_session_id (session_id),
INDEX idx_user_id (user_id)
) COMMENT '用户行为事件明细表';- 运行转换,完成建表。
步骤 4:日志结构化转换(半结构化→结构化)
新建转换:行为日志数据转为结构化数据

-
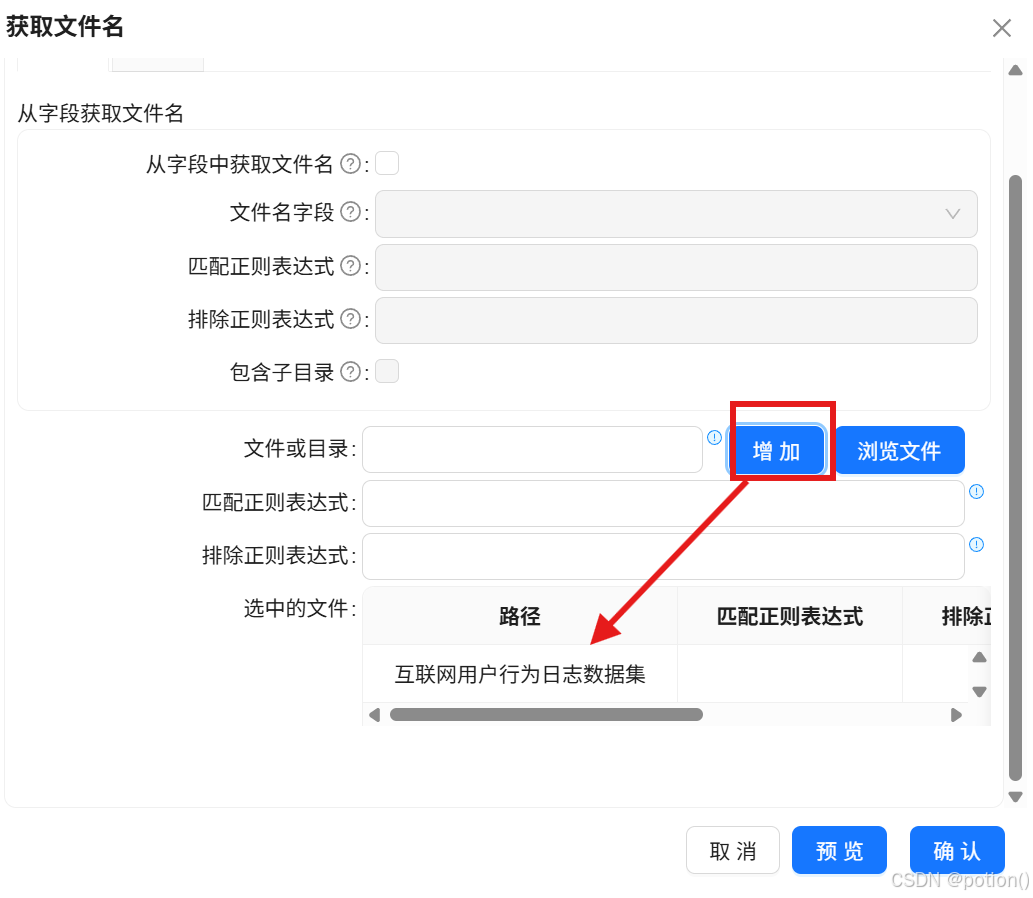
获取文件名
-
拖拽获取文件名组件,双击配置。
-
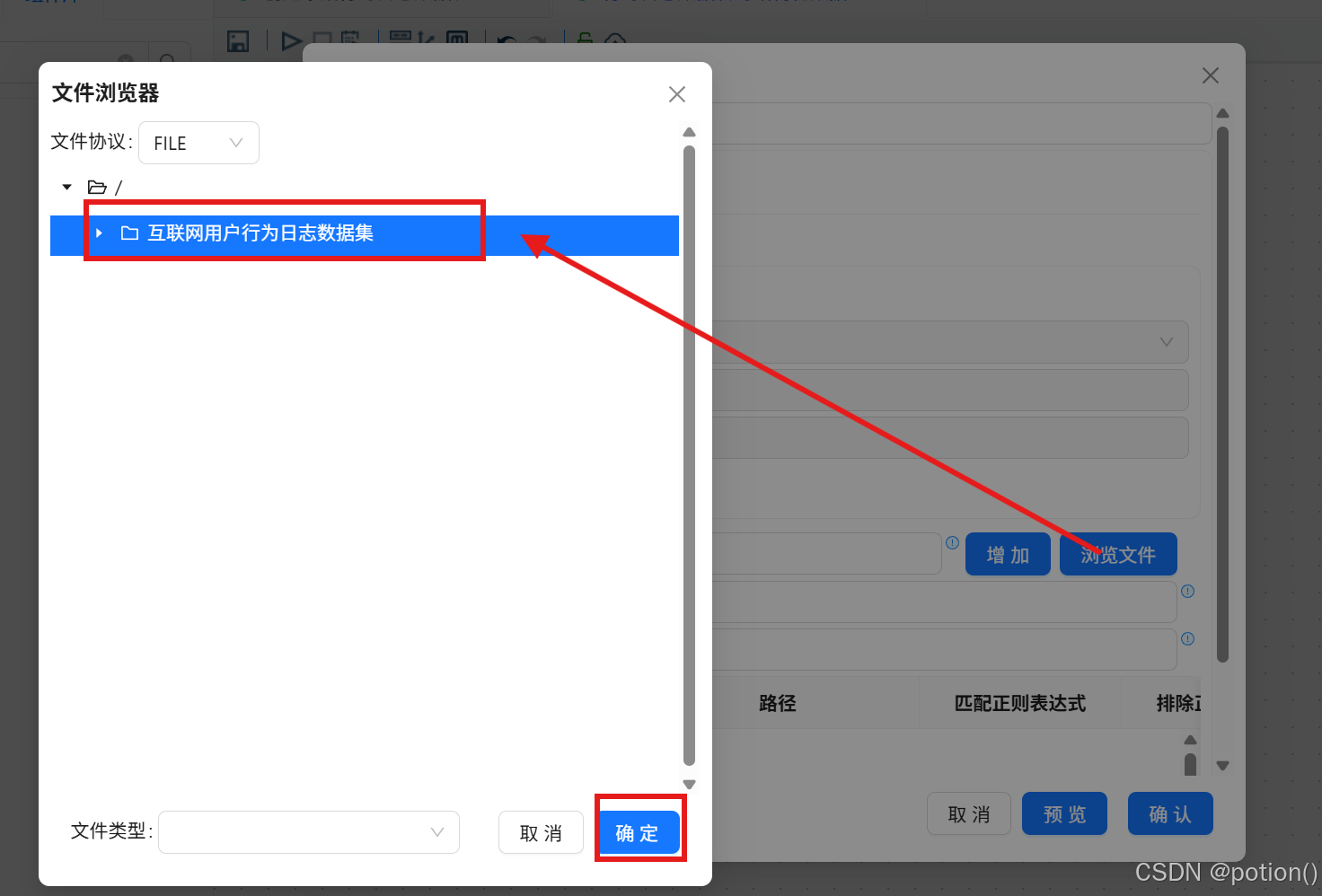
点击浏览文件 ,选择
互联网用户行为日志数据集目录。
-
点击增加→确认 ,批量读取所有 TXT 文件路径。
-
-
Java 代码解析日志
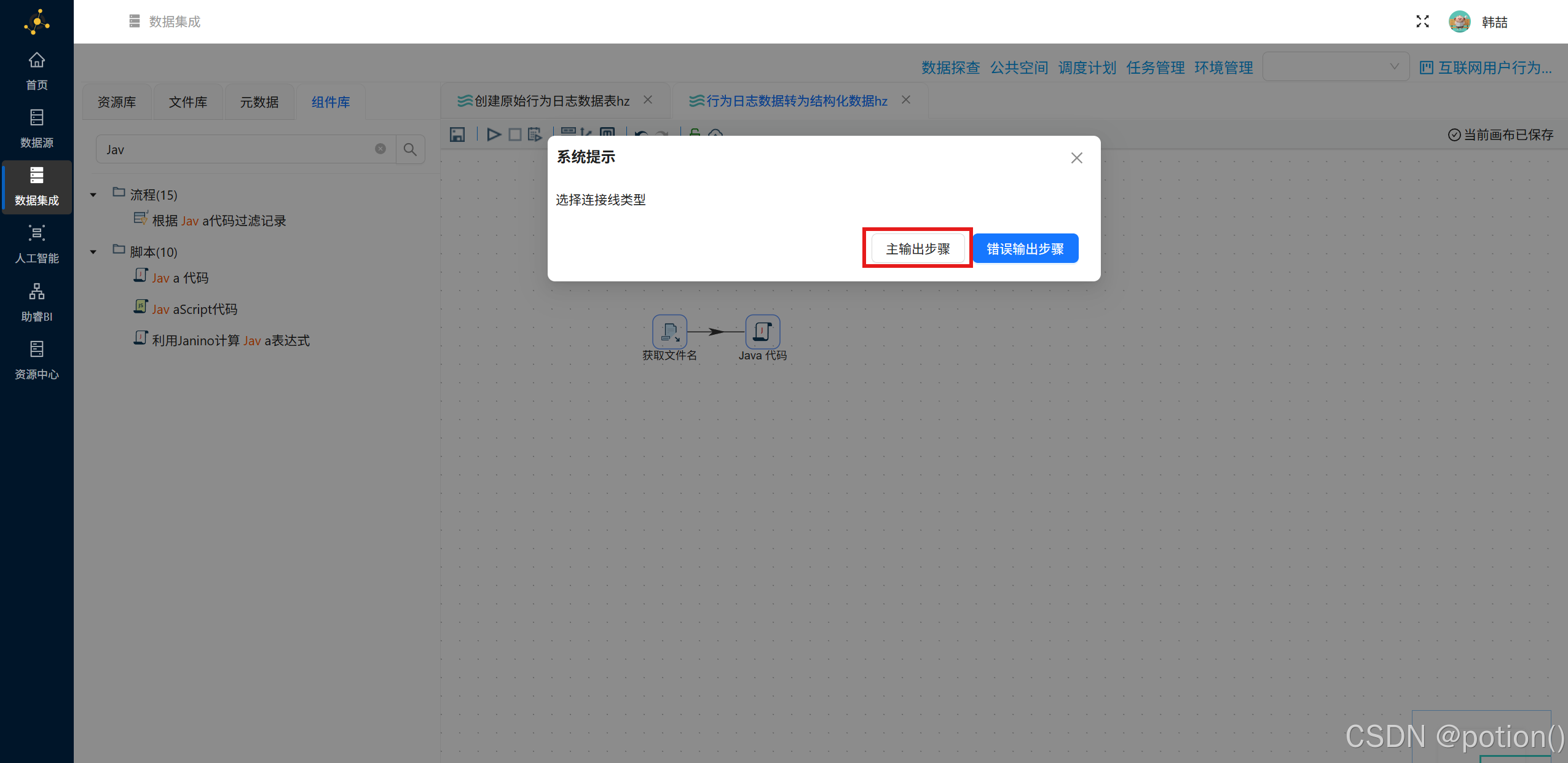
- 拖拽Java 代码 组件,连接到 "获取文件名"(主输出步骤)。
双击该组件,输入以下代码:
// 全局变量定义
String pathField;
String shortFilenameField;public boolean processRow() throws HopException {
if (first) {
pathField = "filename";
shortFilenameField = "short_filename";
first = false;
}Object[] r = getRow(); if (r == null) { setOutputDone(); return false; } String path = get(Fields.In, pathField).getString(r); String short_filename = get(Fields.In, shortFilenameField).getString(r); String user_id = ""; String l_start = ""; if (short_filename != null) { String name = short_filename.replace(".txt", ""); String[] parts = name.split("_"); if (parts.length >= 3) { user_id = parts[0]; l_start = parts[1] + " " + parts[2].replace("-", ":"); } } String session_id = user_id + "_" + l_start; java.io.BufferedReader br = null; try { br = new java.io.BufferedReader(new java.io.FileReader(path)); String line = ""; // 跳过前两行(Last和L_Start) br.readLine(); br.readLine(); while ((line = br.readLine()) != null) { if (line.trim().isEmpty()) { continue; } // 解析键值对 String[] kvPairs = line.split("\\[=\\]"); String t = ""; String p = ""; String i = ""; String u = ""; String a = ""; String b = ""; String v = ""; String w = ""; String n = ""; String c = ""; for (String kv : kvPairs) { int sepIdx = kv.indexOf("<=>"); if (sepIdx == -1) { continue; } String key = kv.substring(0, sepIdx).trim(); String val = kv.substring(sepIdx + 3); if ("T".equals(key)) { t = val; } else if ("P".equals(key)) { p = val; } else if ("I".equals(key)) { i = val; } else if ("U".equals(key)) { u = val; } else if ("A".equals(key)) { a = val; } else if ("B".equals(key)) { b = val; } else if ("V".equals(key)) { v = val; } else if ("W".equals(key)) { w = val; } else if ("N".equals(key)) { n = val; } else if ("C".equals(key)) { c = val; } } // 创建输出行 Object[] outRow = createOutputRow(r, data.outputRowMeta.size()); get(Fields.Out, "session_id").setValue(outRow, session_id); get(Fields.Out, "user_id").setValue(outRow, user_id); get(Fields.Out, "l_start").setValue(outRow, l_start); get(Fields.Out, "t").setValue(outRow, t); get(Fields.Out, "p").setValue(outRow, p); get(Fields.Out, "i").setValue(outRow, i); get(Fields.Out, "u").setValue(outRow, u); get(Fields.Out, "a").setValue(outRow, a); get(Fields.Out, "b").setValue(outRow, b); get(Fields.Out, "v").setValue(outRow, v); get(Fields.Out, "w").setValue(outRow, w); get(Fields.Out, "n").setValue(outRow, n); get(Fields.Out, "c").setValue(outRow, c); get(Fields.Out, "source_file").setValue(outRow, short_filename); putRow(data.outputRowMeta, outRow); } } catch (Exception e) { logError(e.getMessage(), e); } finally { try { if (br != null) { br.close(); } } catch (Exception e) { // ignore } } return true;}
- 拖拽Java 代码 组件,连接到 "获取文件名"(主输出步骤)。
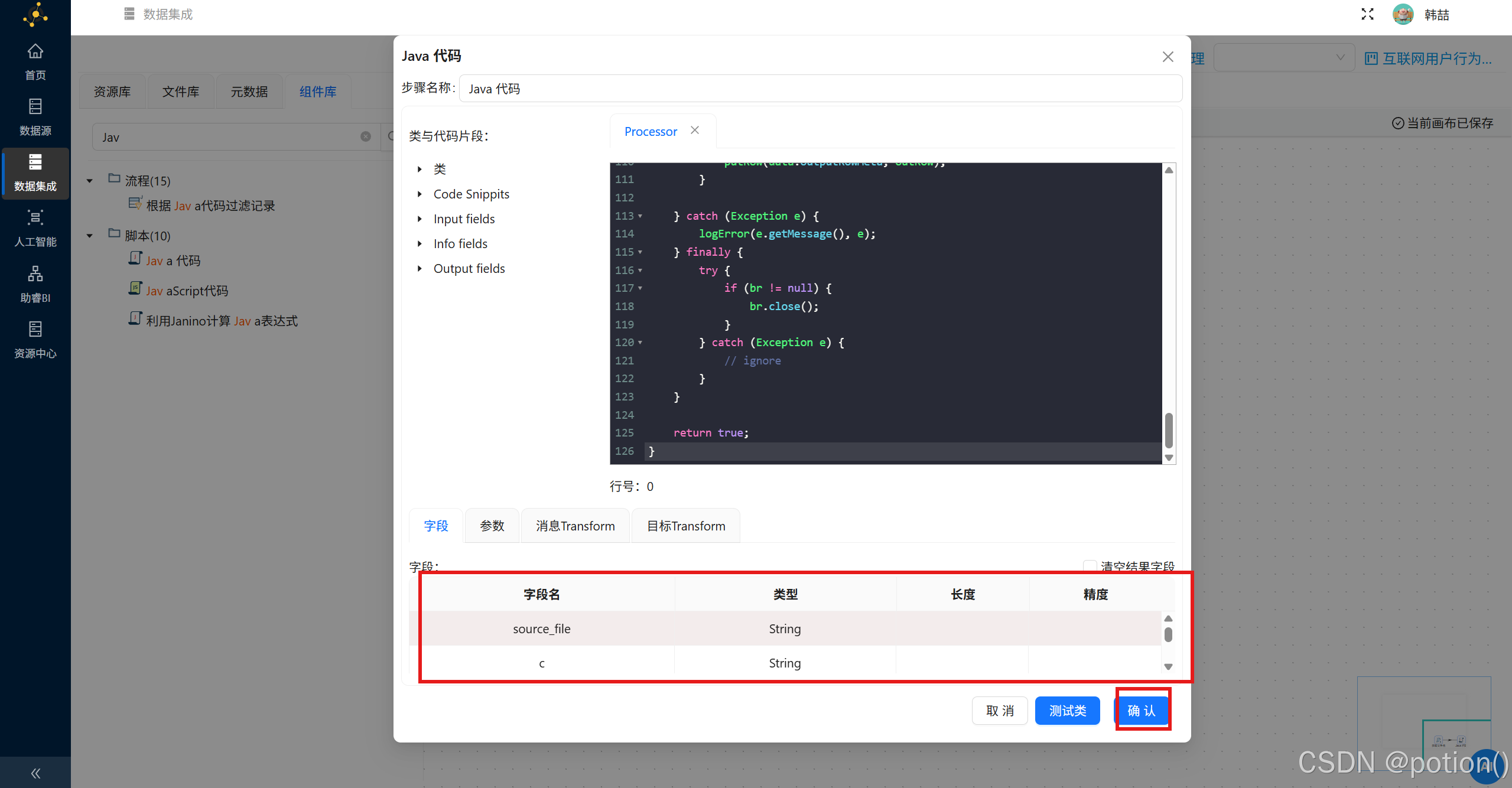
双击插入的行,,字段名输入"session_id",类型选择"String",继续插入行,依次将java代码中输出的字段进行配置,参考如下:
| 字段名 | 类型 |
|---|---|
| session_id | String |
| user_id | String |
| l_start | String |
| t | String |
| p | String |
| i | String |
| u | String |
| a | String |
| b | String |
| v | String |
| w | String |
| n | String |
| c | String |
| source_file | String |
 |
-
字段选择(清理冗余)
-
拖拽字段选择组件,连接 Java 代码输出。
-
切换到移除 tab,右键获取字段 。
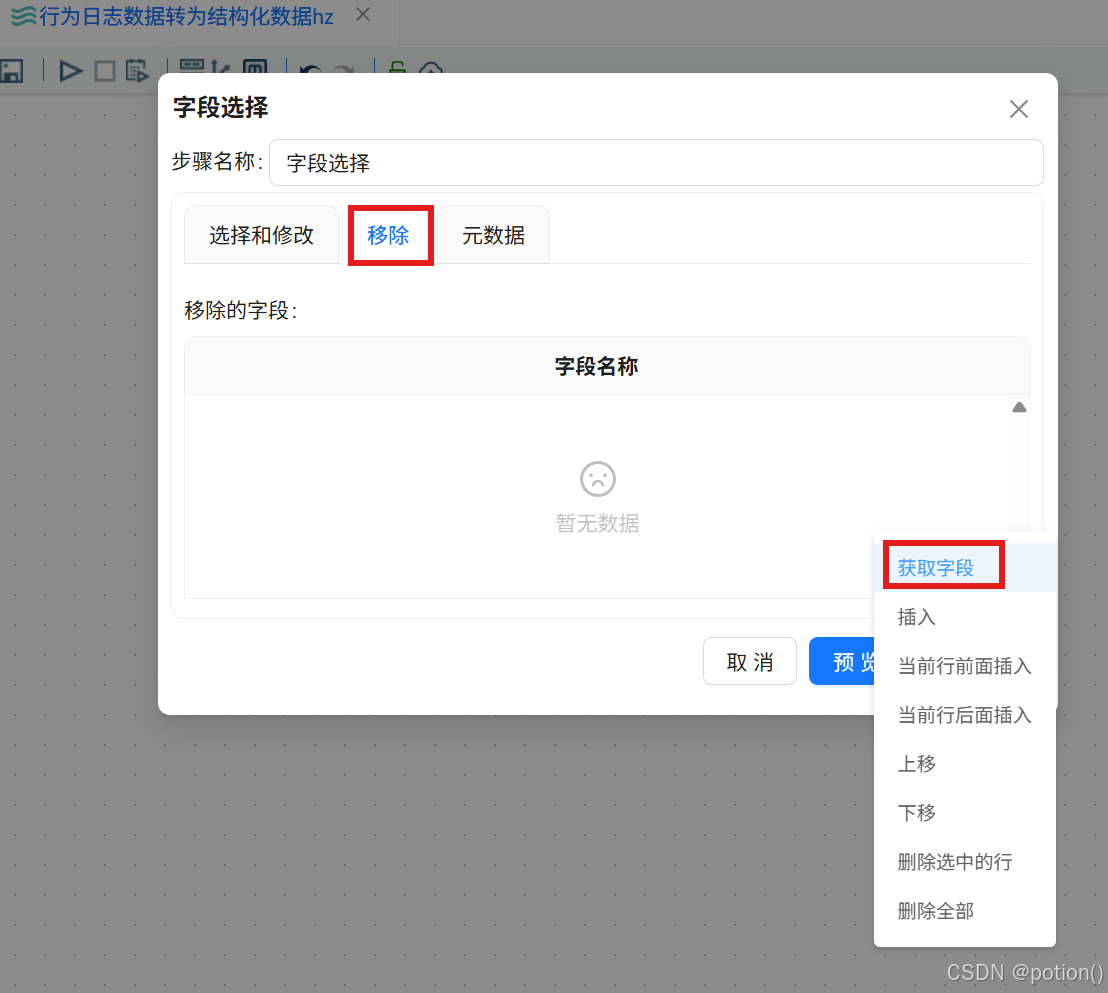
-
删除 Java 代码输出的有效字段,保留冗余字段并移除。
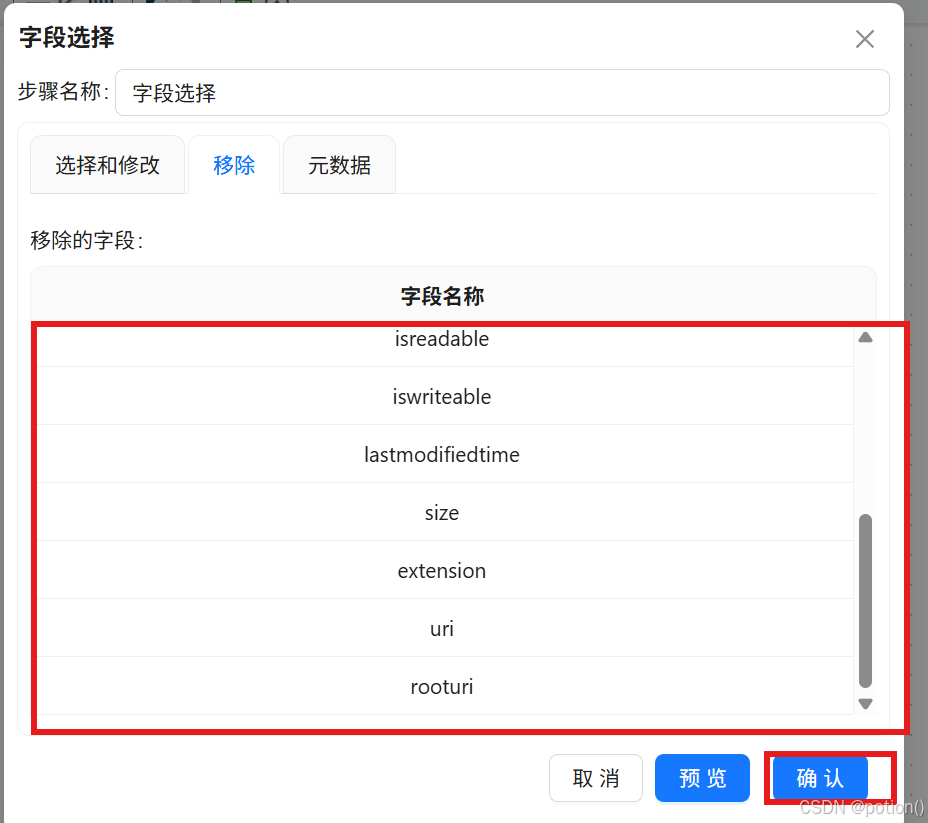
-
确认,只保留核心字段。
-
-
表输出(入库)
-
拖拽表输出组件,连接字段选择。
-
选择团队私有数据库 ,目标表:
behavior_events。
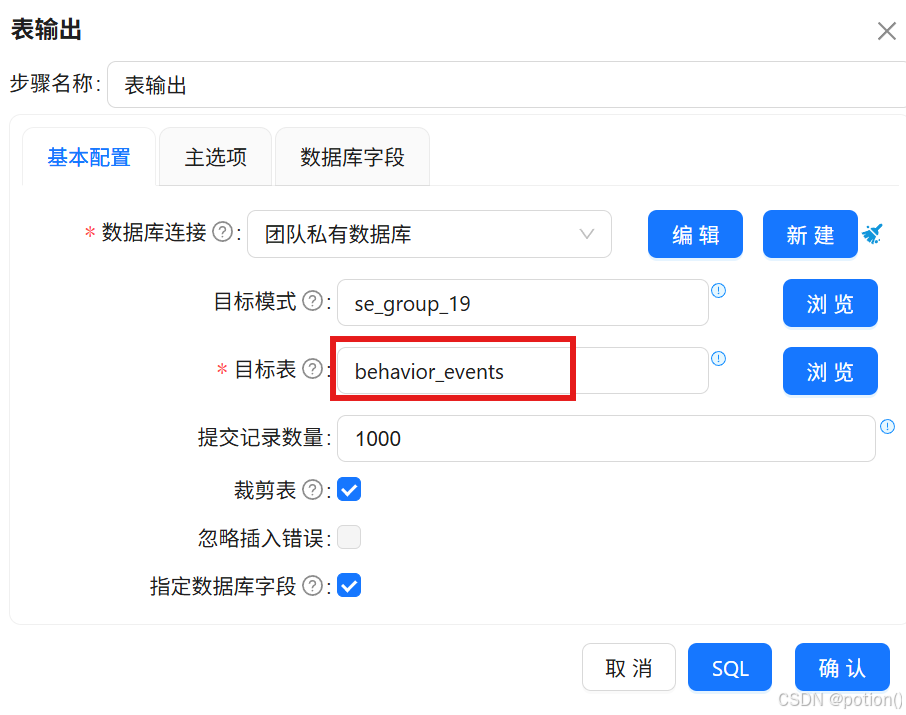
-
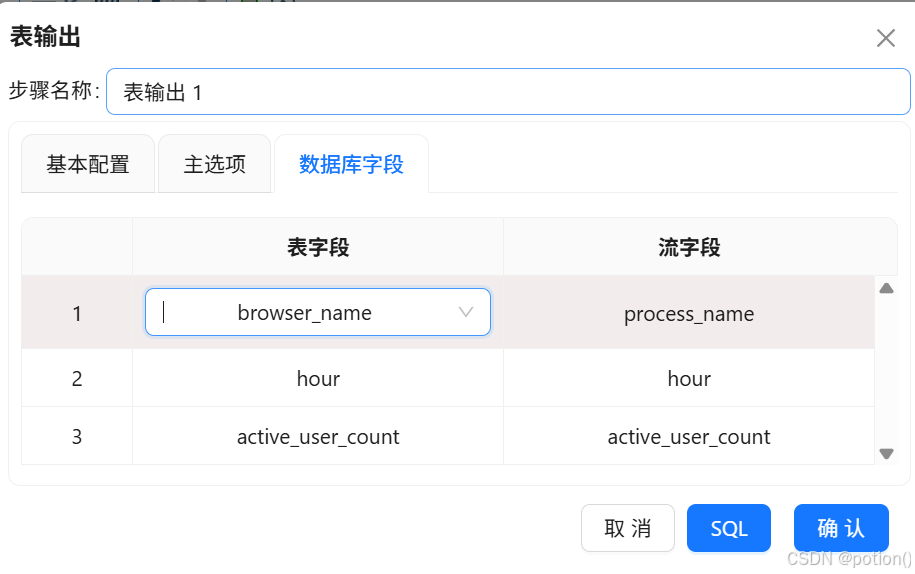
勾选裁剪表 、指定数据库字段 。
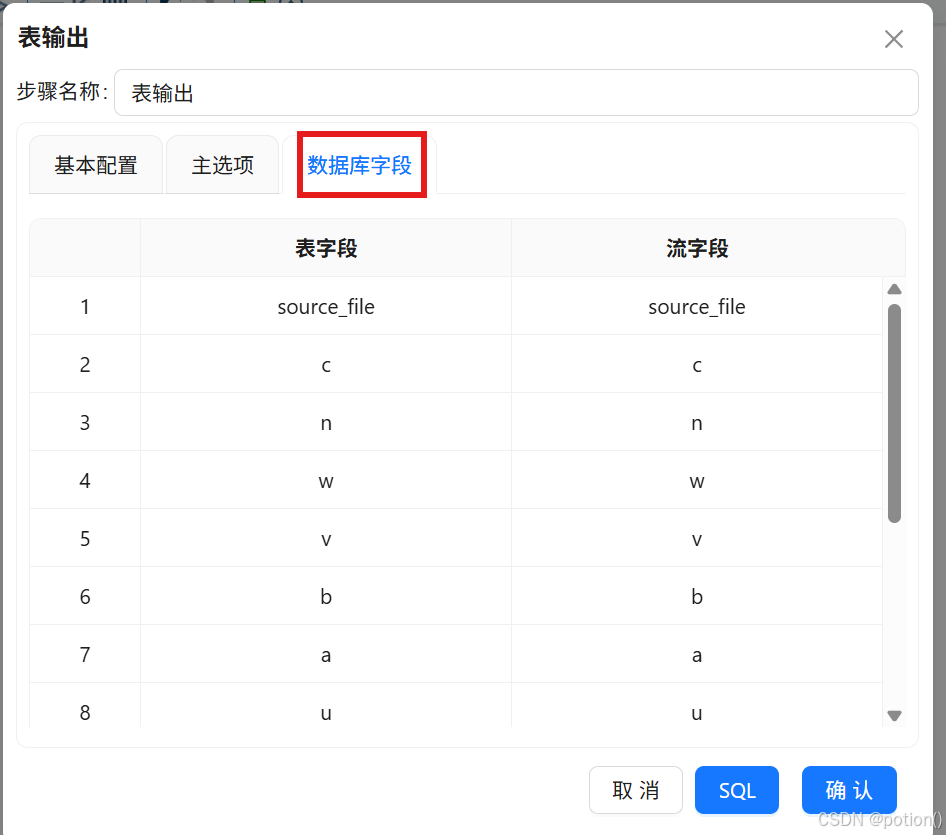
-
右键获取字段 ,手动匹配流字段与表字段。
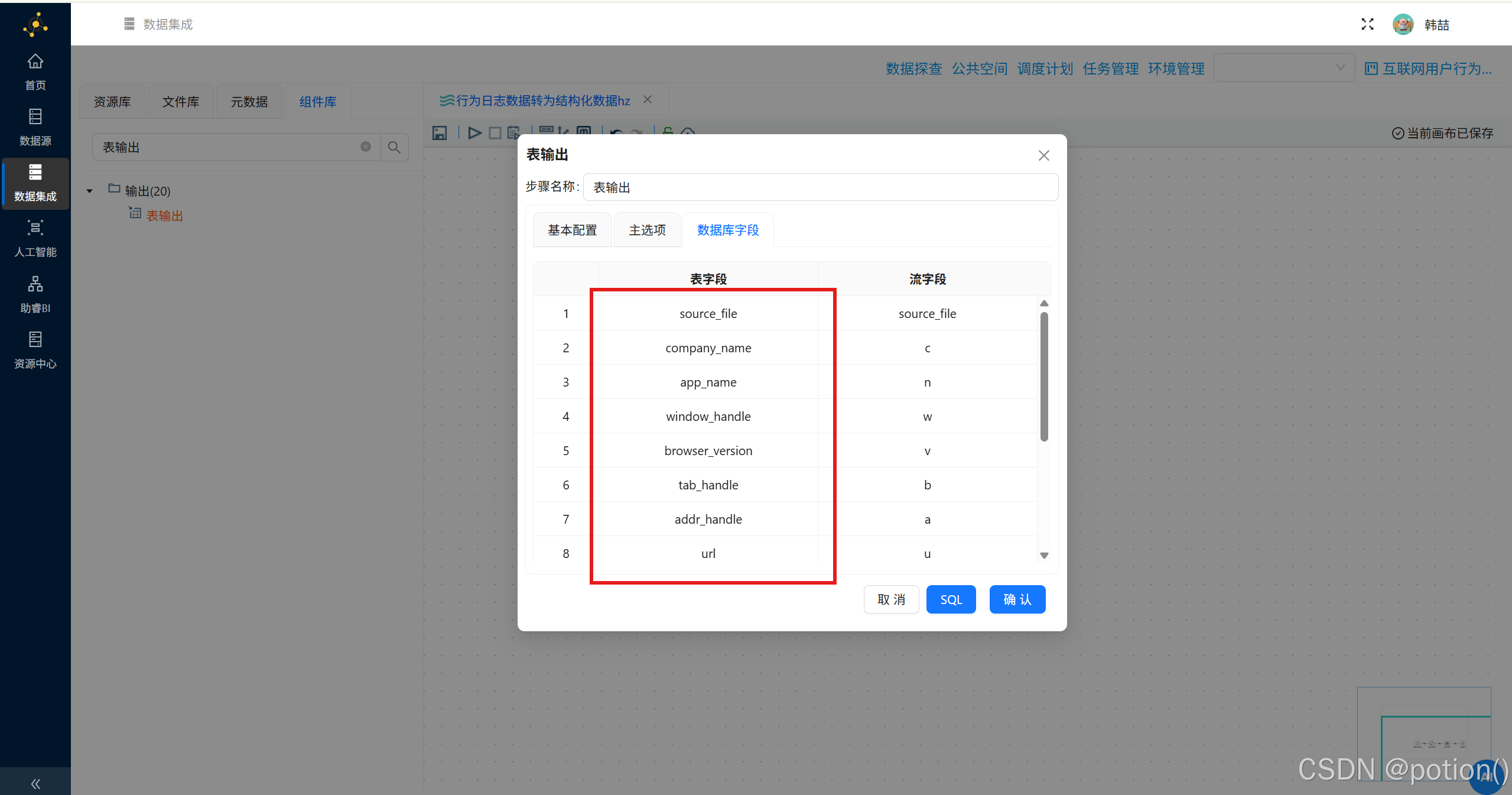
-
确认保存。
-
-
运行转换并验证
-
点击工具栏执行,使用默认配置启动。
-
查看执行日志,确认无报错。
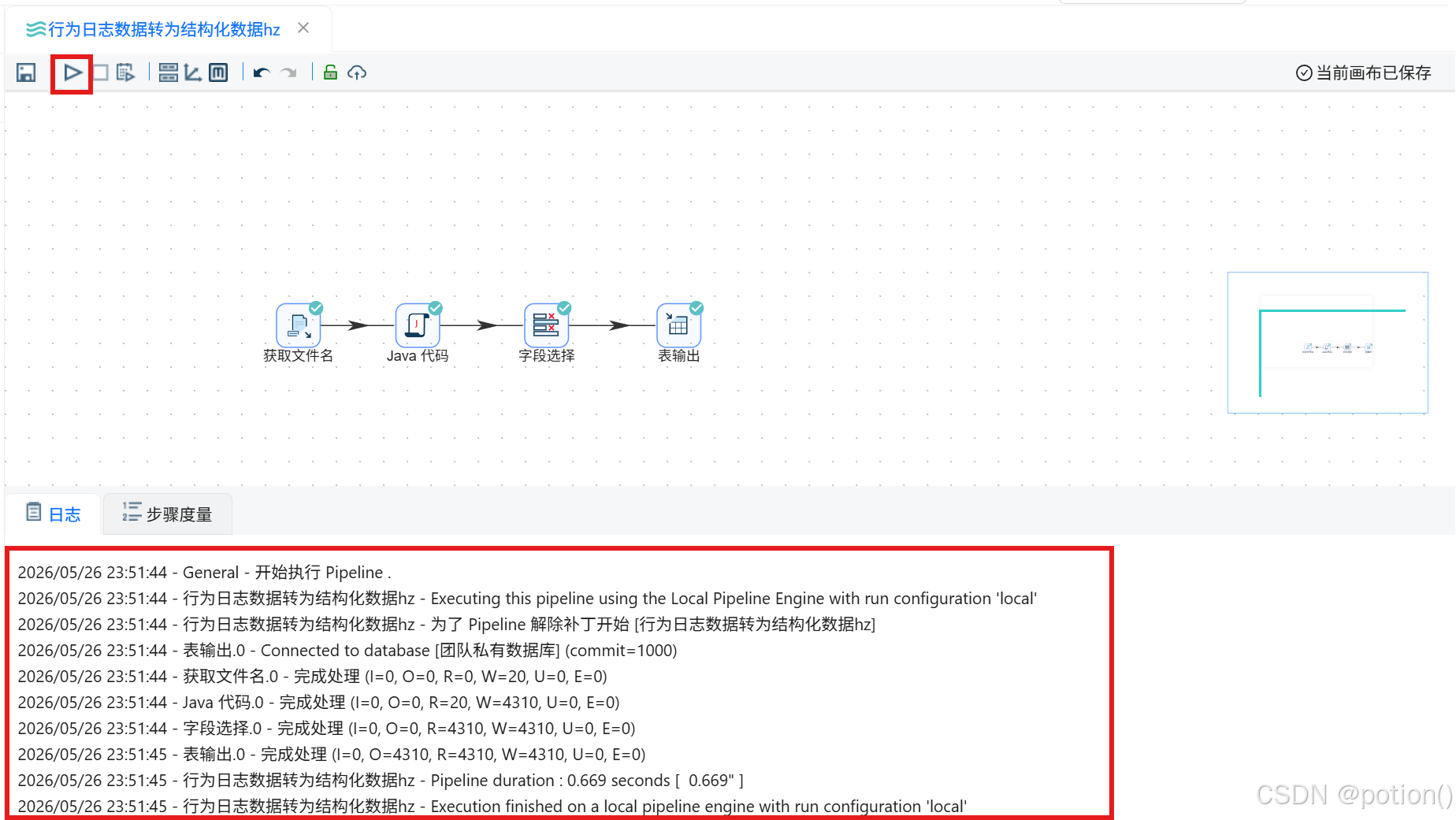
-
进入元数据 ,右键数据库加载元数据 ,打开
behavior_events查询数据,验证结构化结果。
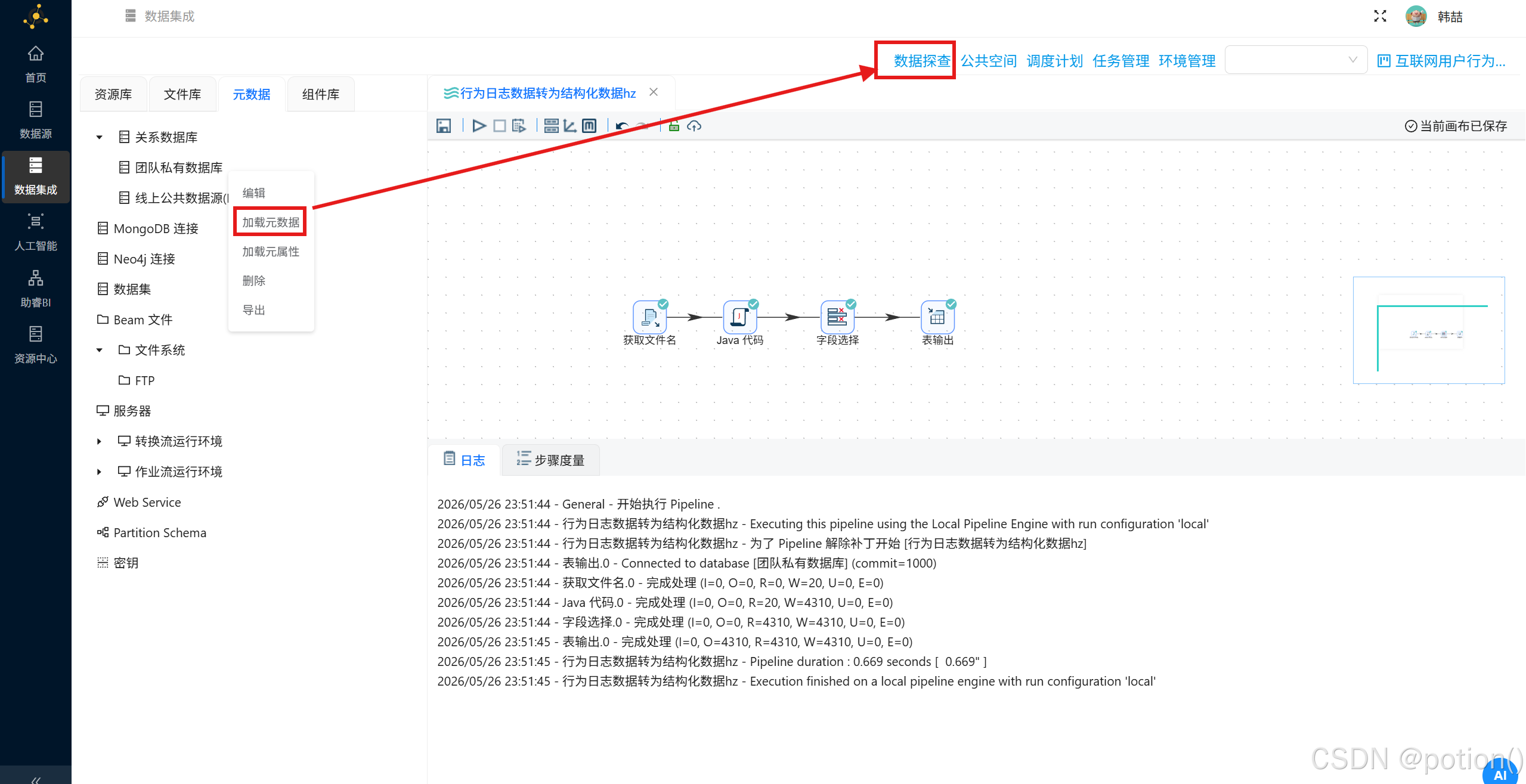
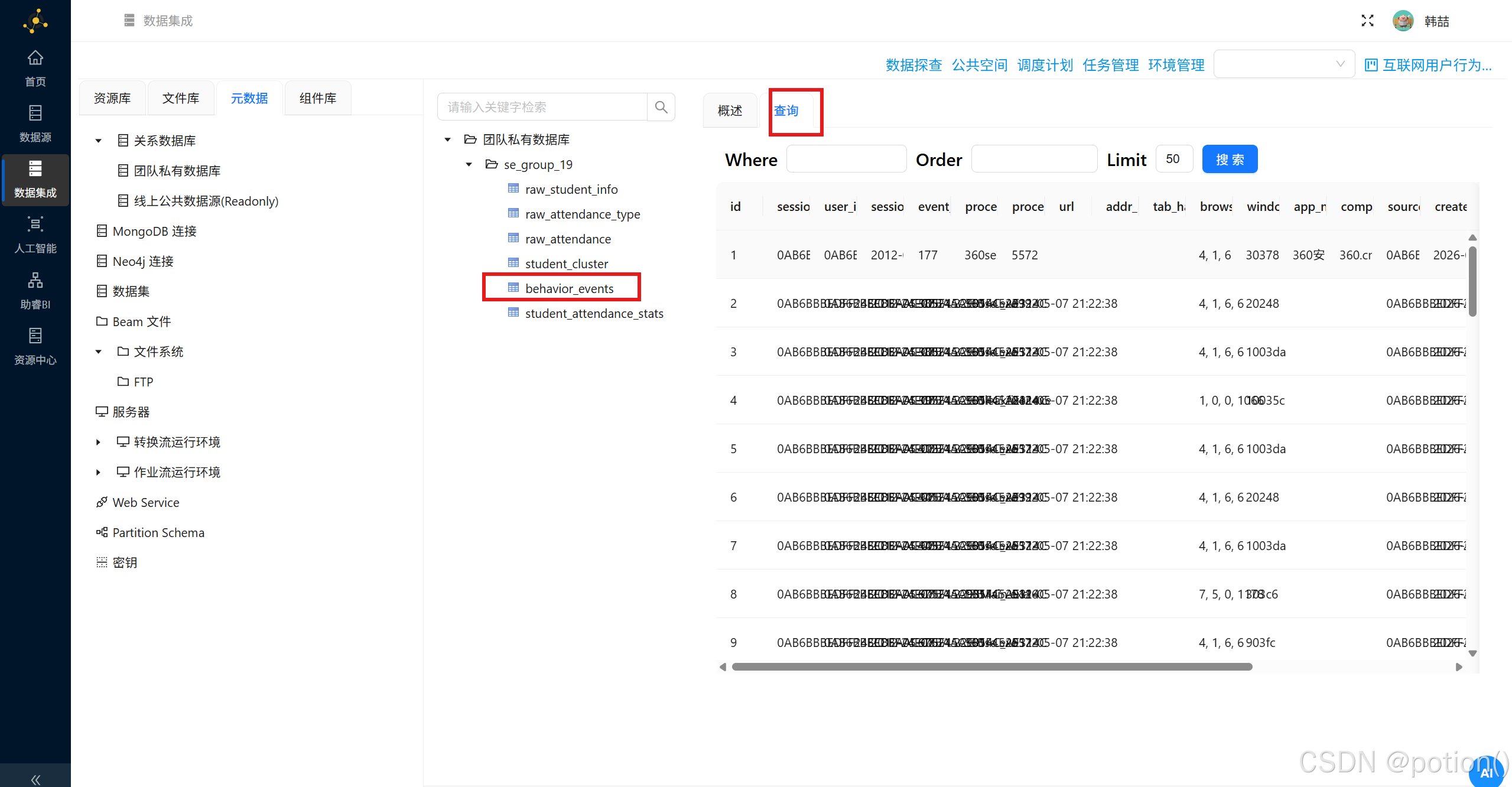
-
步骤 5:确定分析方向(统计进程用户规模)
5.1 创建进程统计表
-
新建转换:
创建进程统计表。
-
拖拽执行 SQL 脚本 ,执行建表语句:
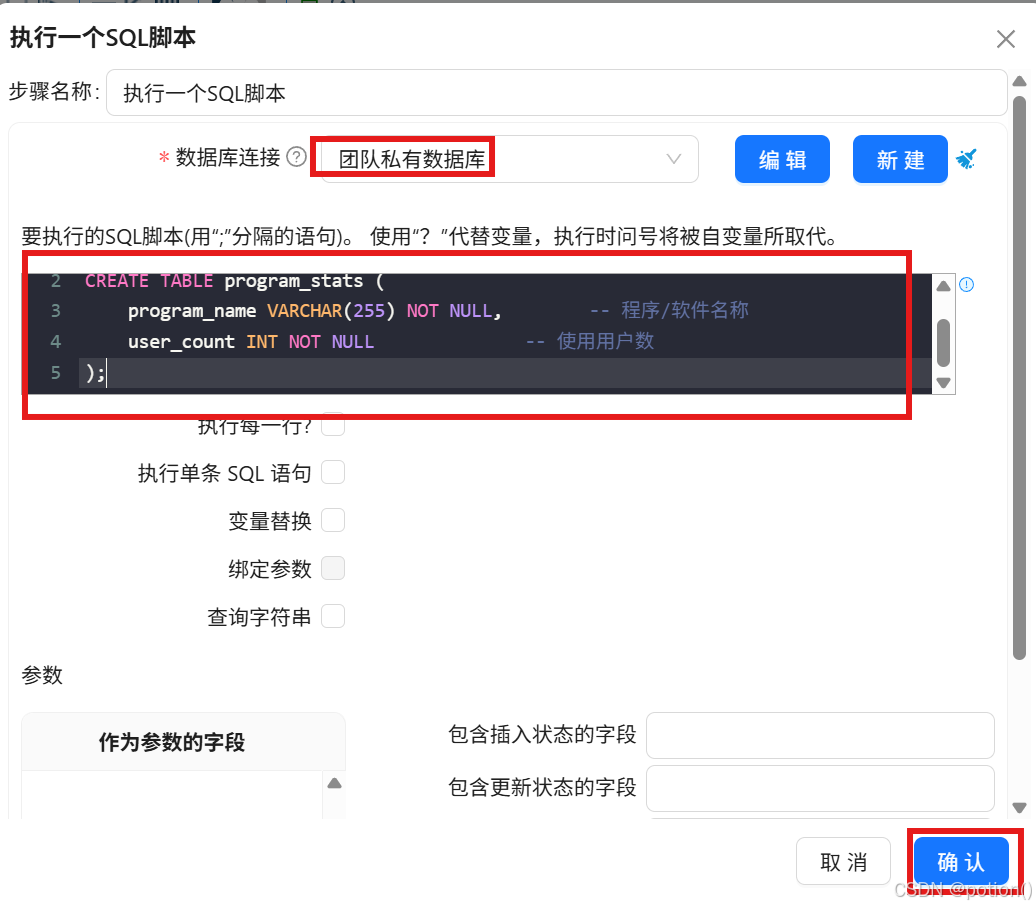
sql
CREATE TABLE program_stats (
program_name VARCHAR(255) NOT NULL,
user_count INT NOT NULL
);- 运行转换完成建表。
5.2 统计各进程用户数
新建转换:统计进程用户规模
-
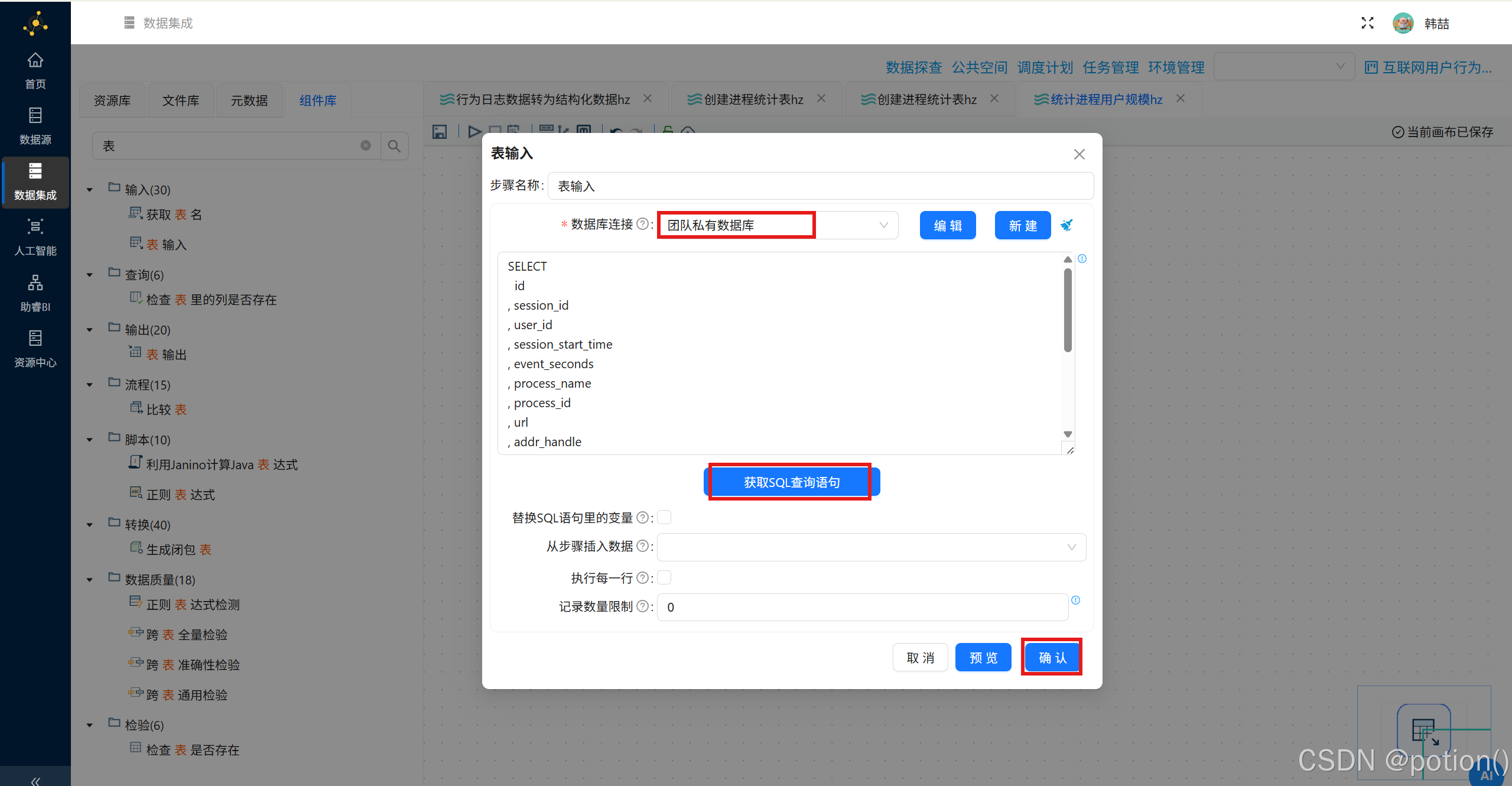
表输入 :读取
behavior_events全量数据。
-
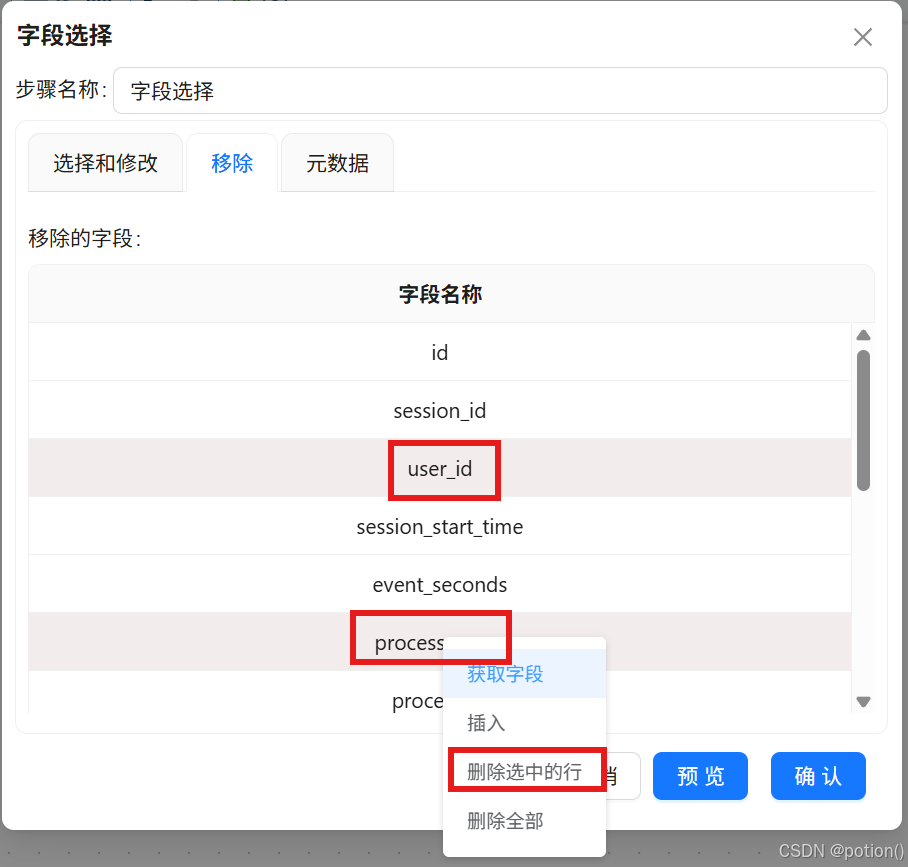
字段选择 :只保留
user_id、process_name,其余移除。统计每个进程得用户数量只需用到 user_id、process_name 两个字段,所以需要移除其他字段选中user_id、process_name 两个字段,右键点击"删除选中的行",删除后点击"确认"
-
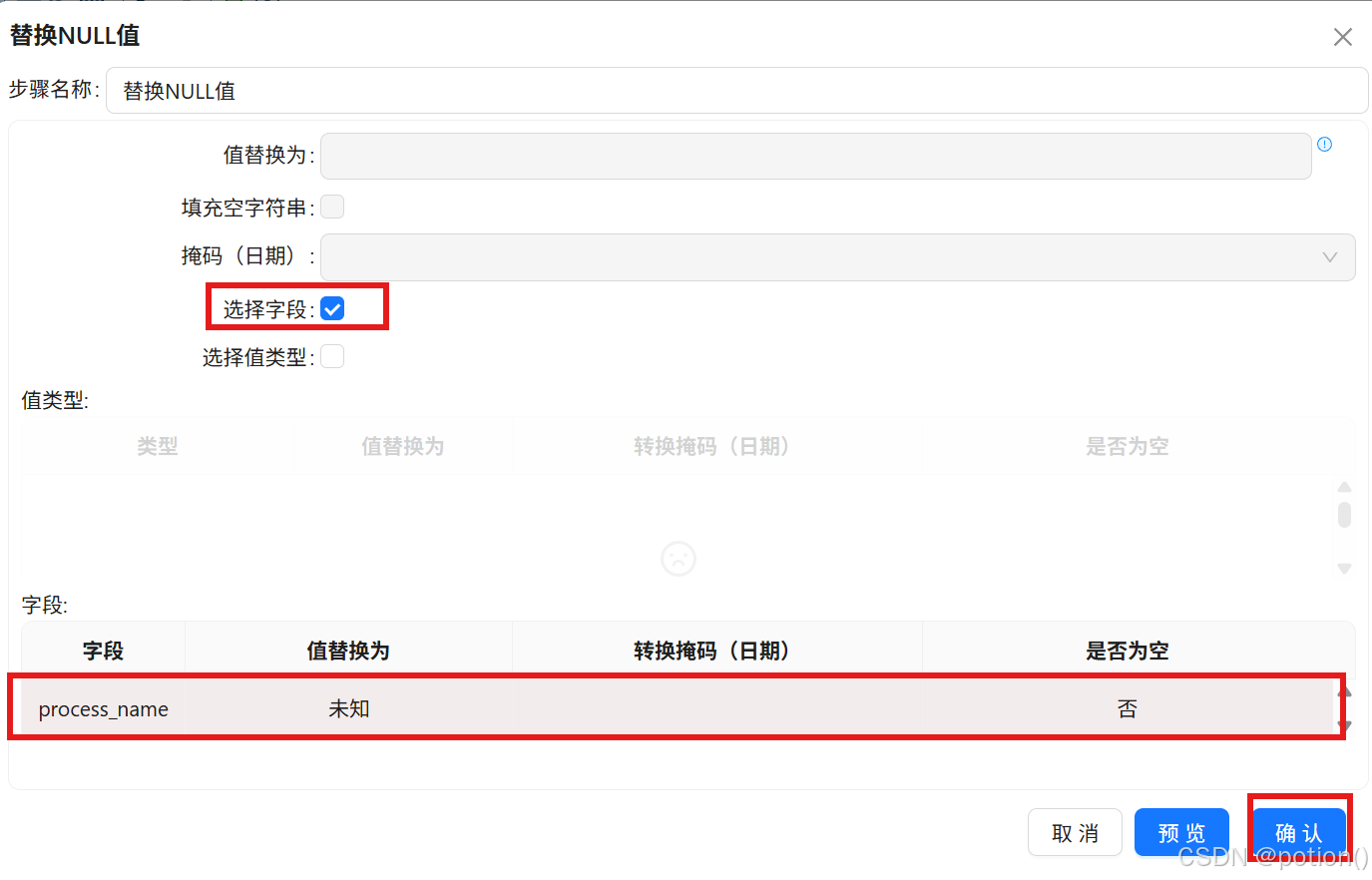
替换 NULL 值 :将
process_name空值替换为 "未知"。
-
排序记录 :按
process_name升序排序。
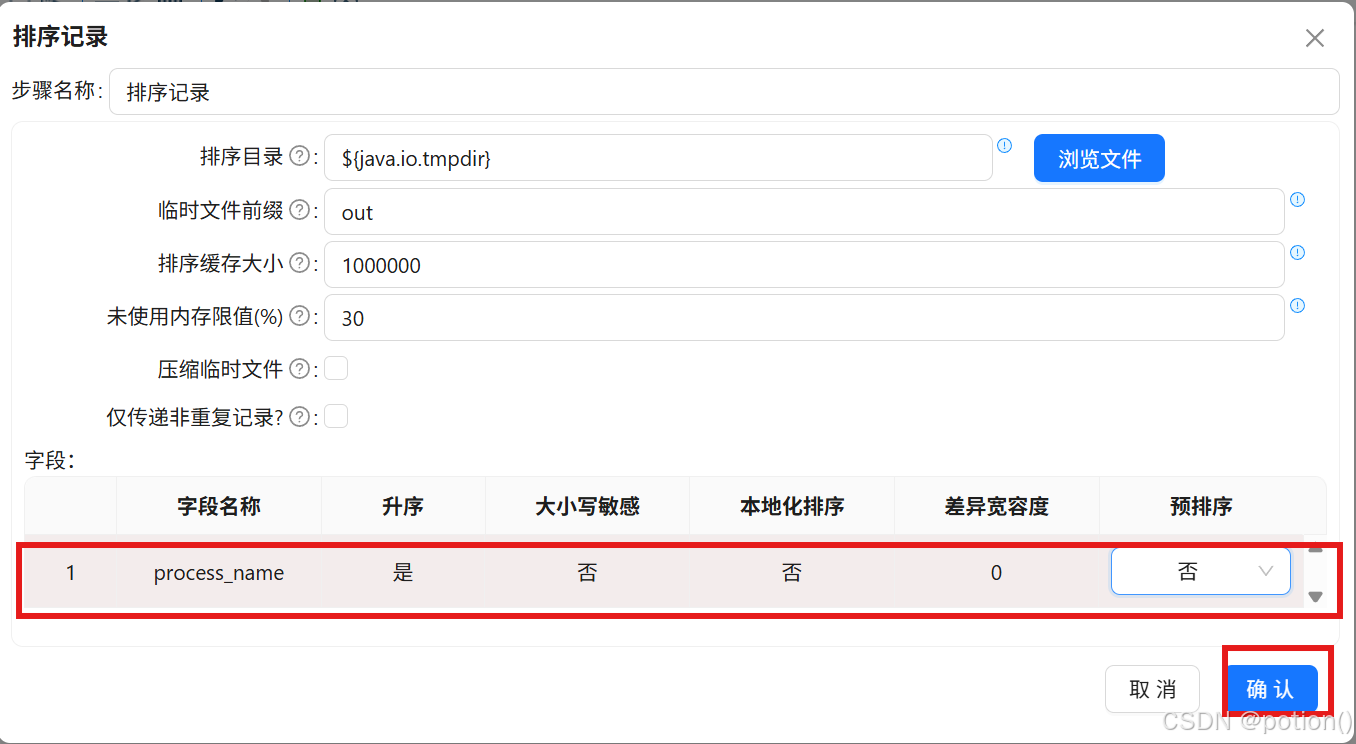
-
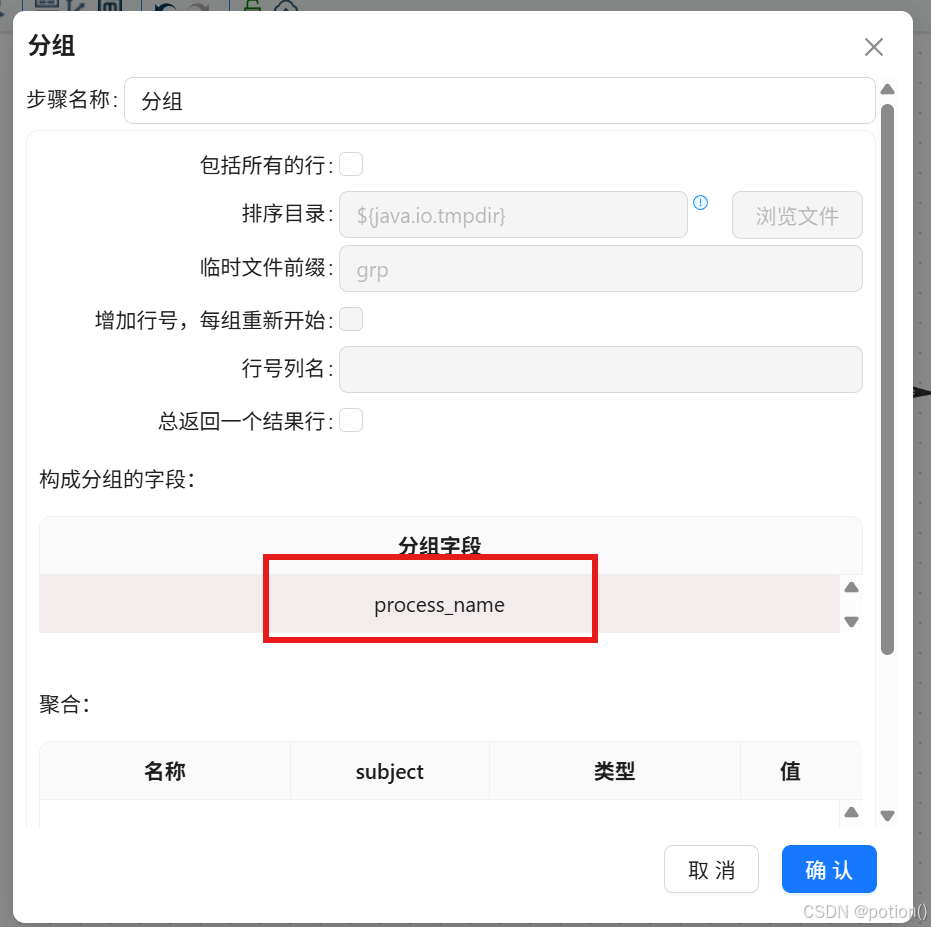
分组:
-
分组字段:
process_name
-
聚合:
user_count=user_id个数
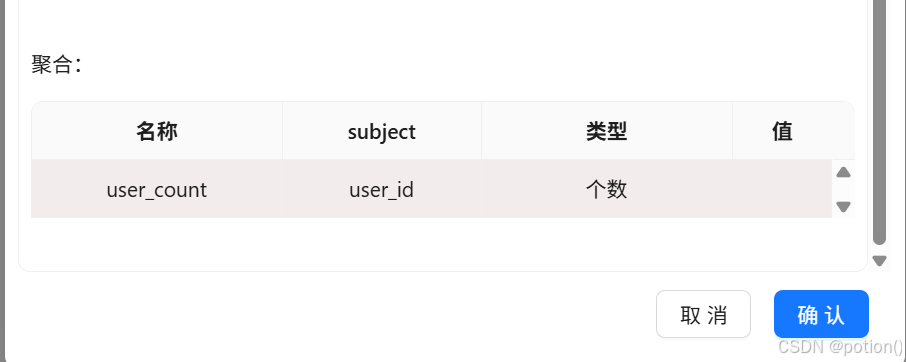
-
-
表输出 :输出到
program_stats,勾选裁剪表。
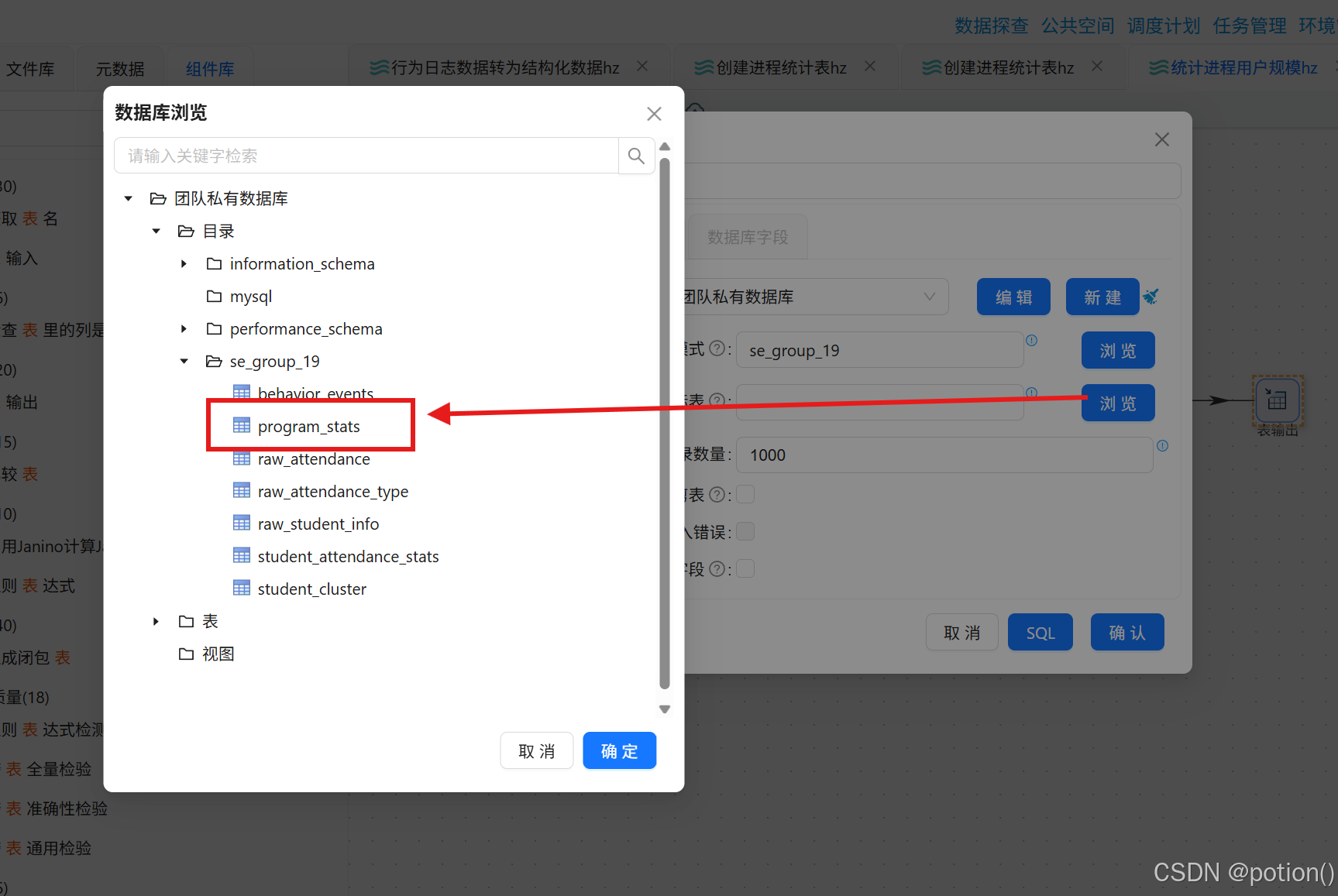
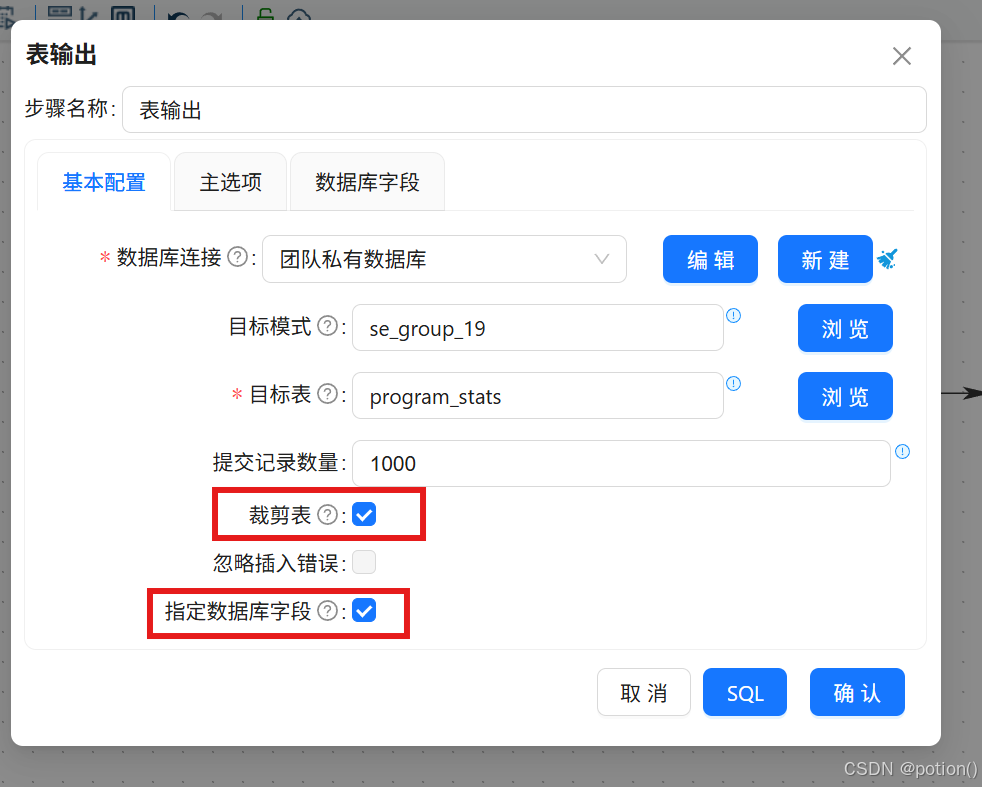
勾选后会激活"数据库字段"tab页,在数据库字段tab页,右键选择"获取字段"
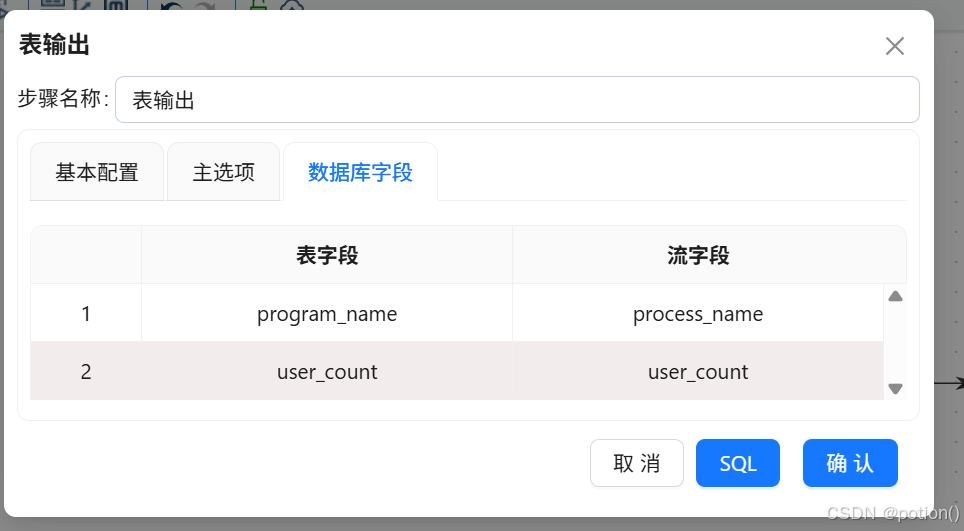
-
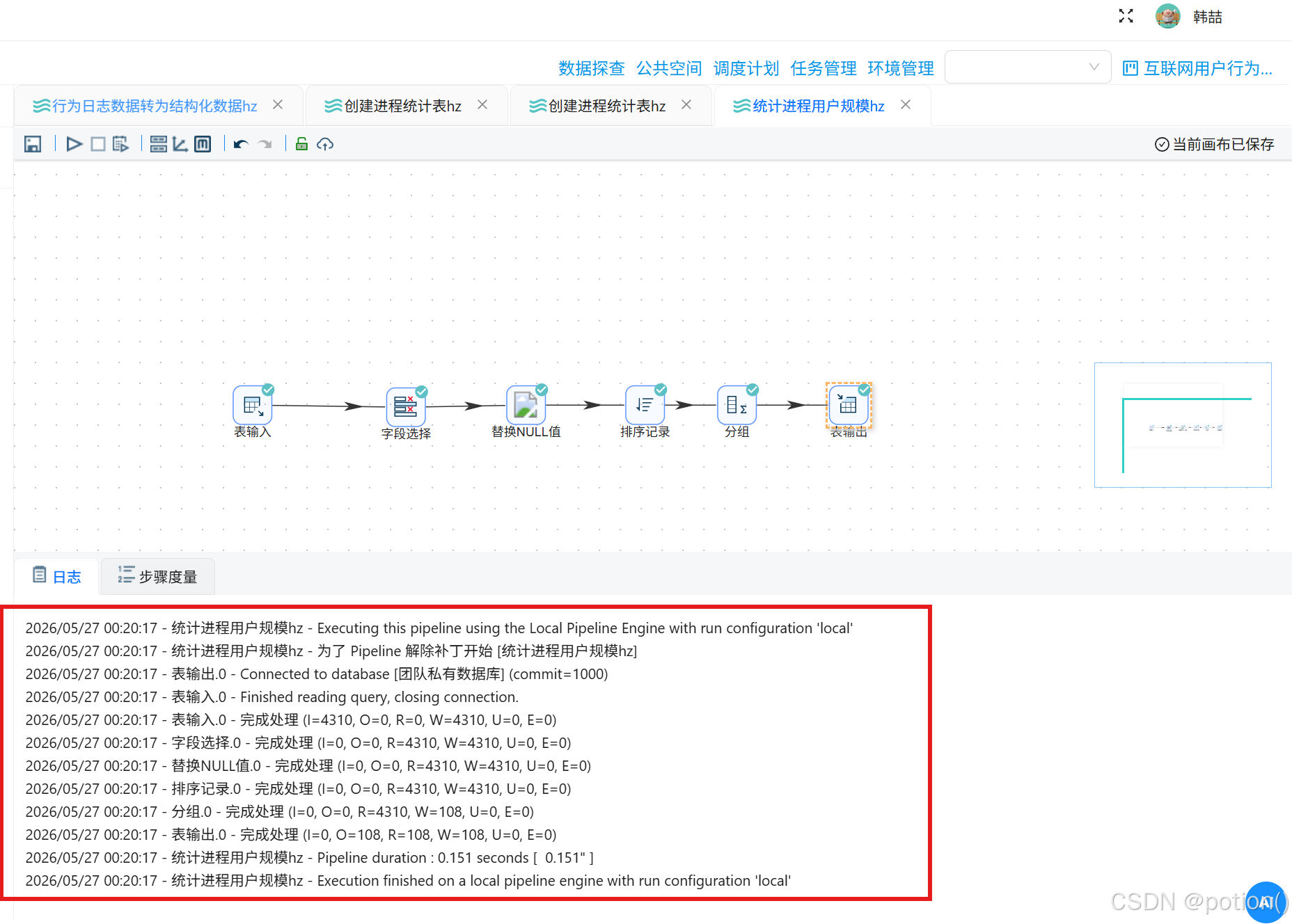
运行转换,完成统计。
5.3 BI 可视化确定分析对象
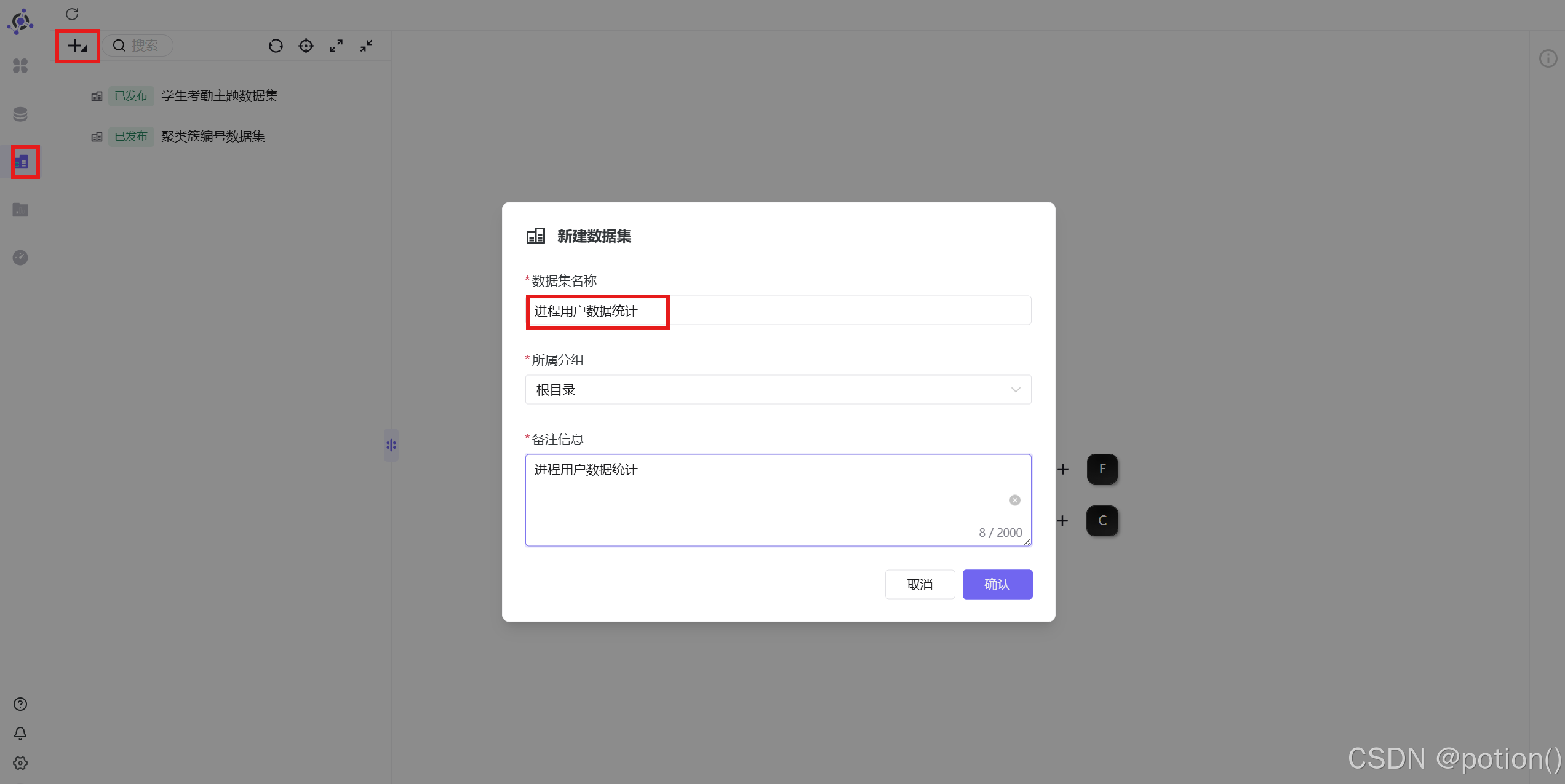
-
进入助睿 BI →数据集 →新建数据集 ,命名:
进程用户数据统计。
-
右上角数据源选择进程统计表 program_stats 所在的"商业数据分析"-"se_group_19",
选择
program_stats表,将 program_stats 拖拽至画布中,将字段备注修改为中文,保存并发布。
-
新建工作表,命名为"进程用户数量分析"
-
-
用水平条图展示:Y 轴程序名,X 轴用户数,降序排列。
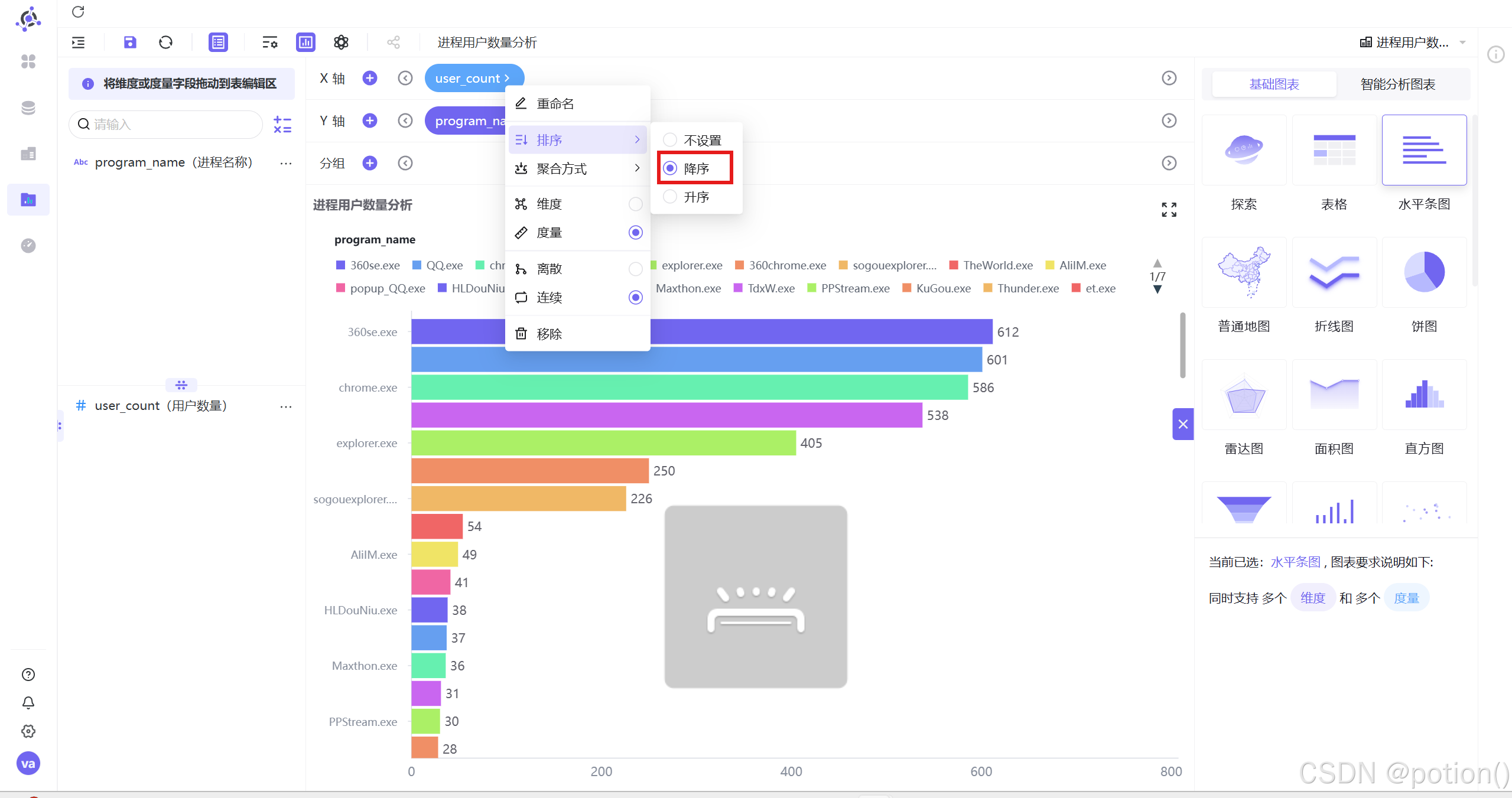
-
观察结果:浏览器类进程用户覆盖最广,确定以浏览器为核心分析对象。
步骤 6:创建分析目标表
新建两个转换,分别执行建表 SQL:
- 创建浏览器的用户数总使用时长统计表的"执行一个SQL脚本"组件配置如下:
sql
CREATE TABLE browser_coverage (
browser_name VARCHAR(50) NOT NULL COMMENT '浏览器进程名',
user_count INT NOT NULL COMMENT '使用用户数(去重)',
total_duration_sec BIGINT NOT NULL COMMENT '总使用时长(秒)'
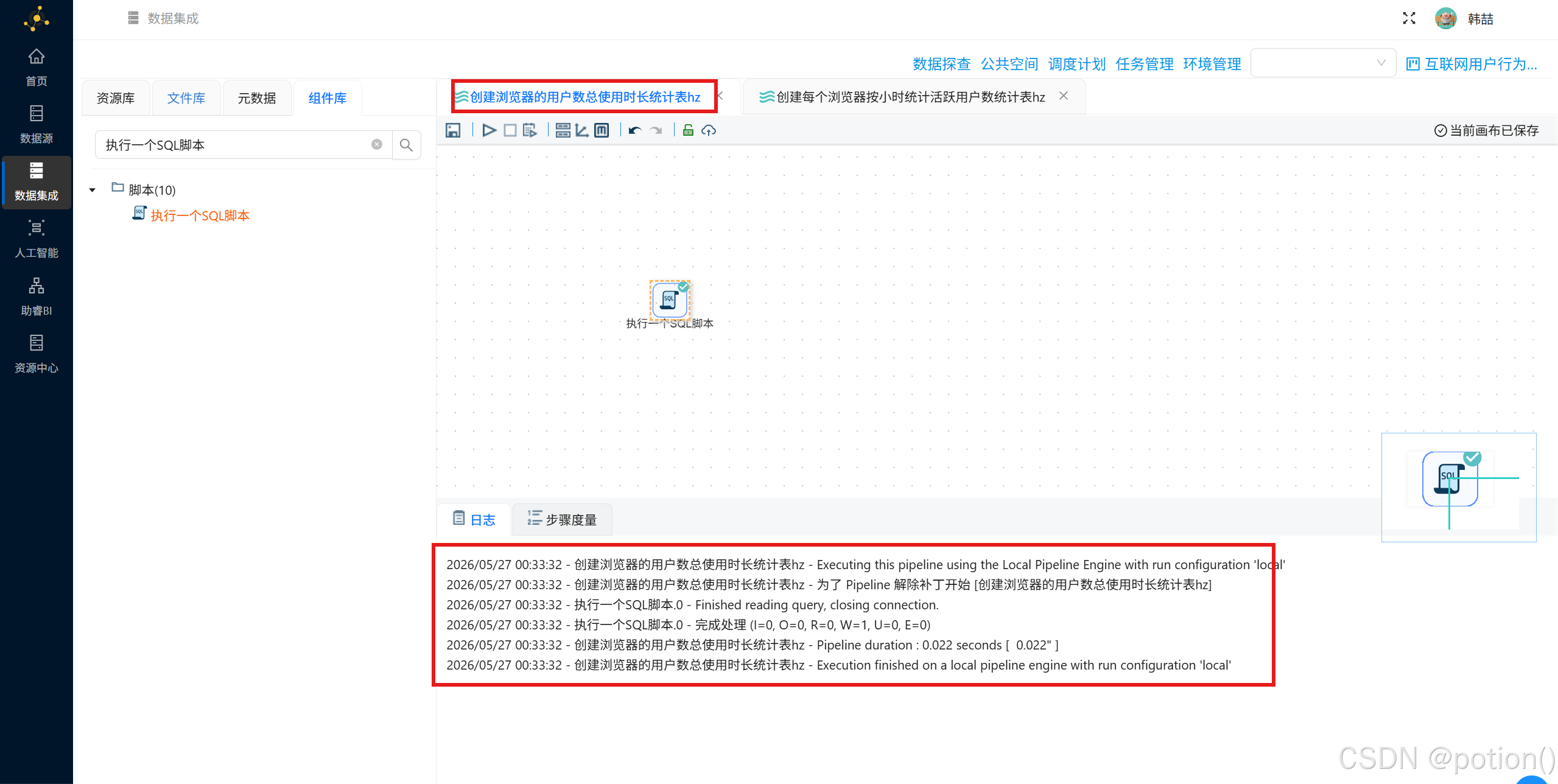
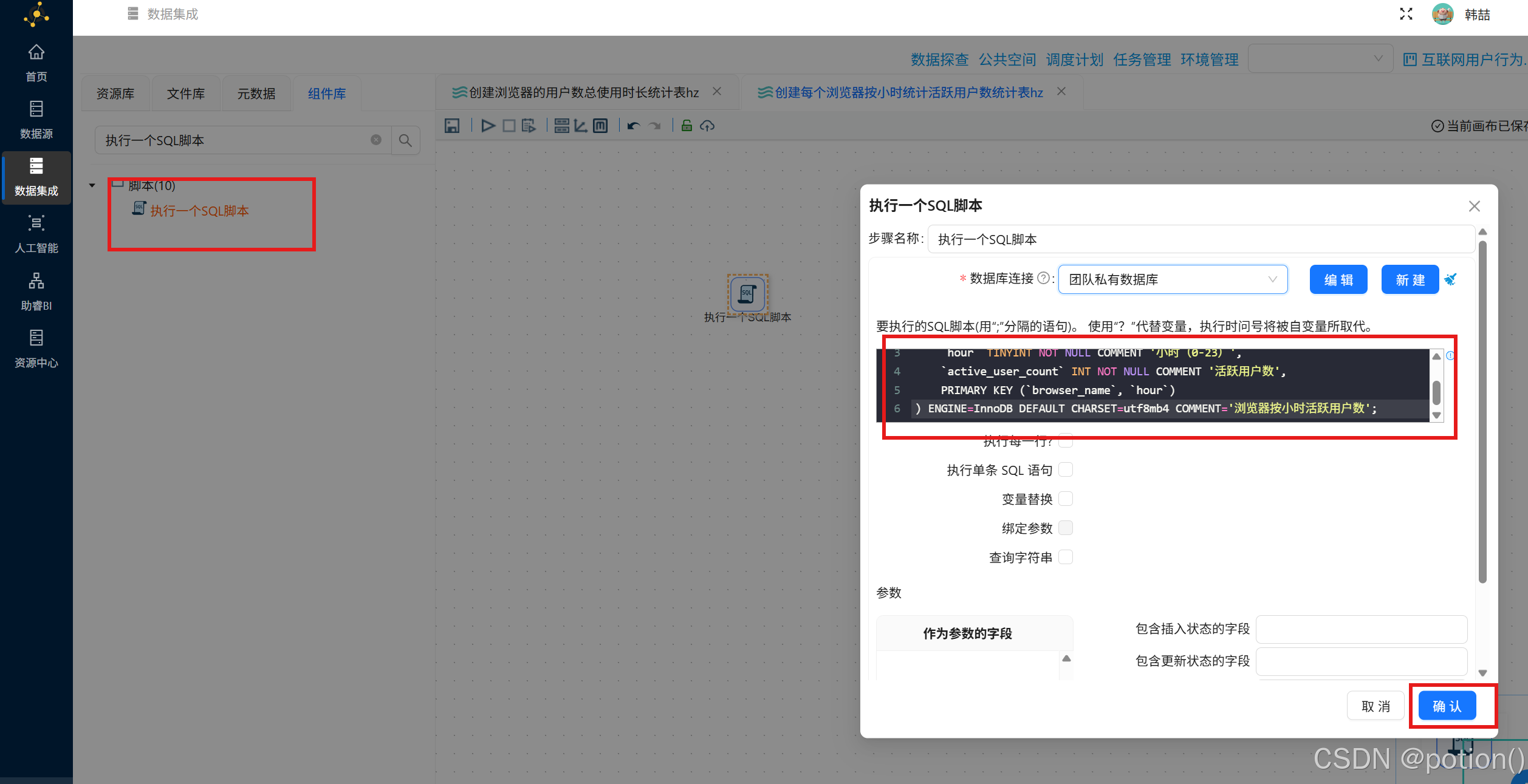
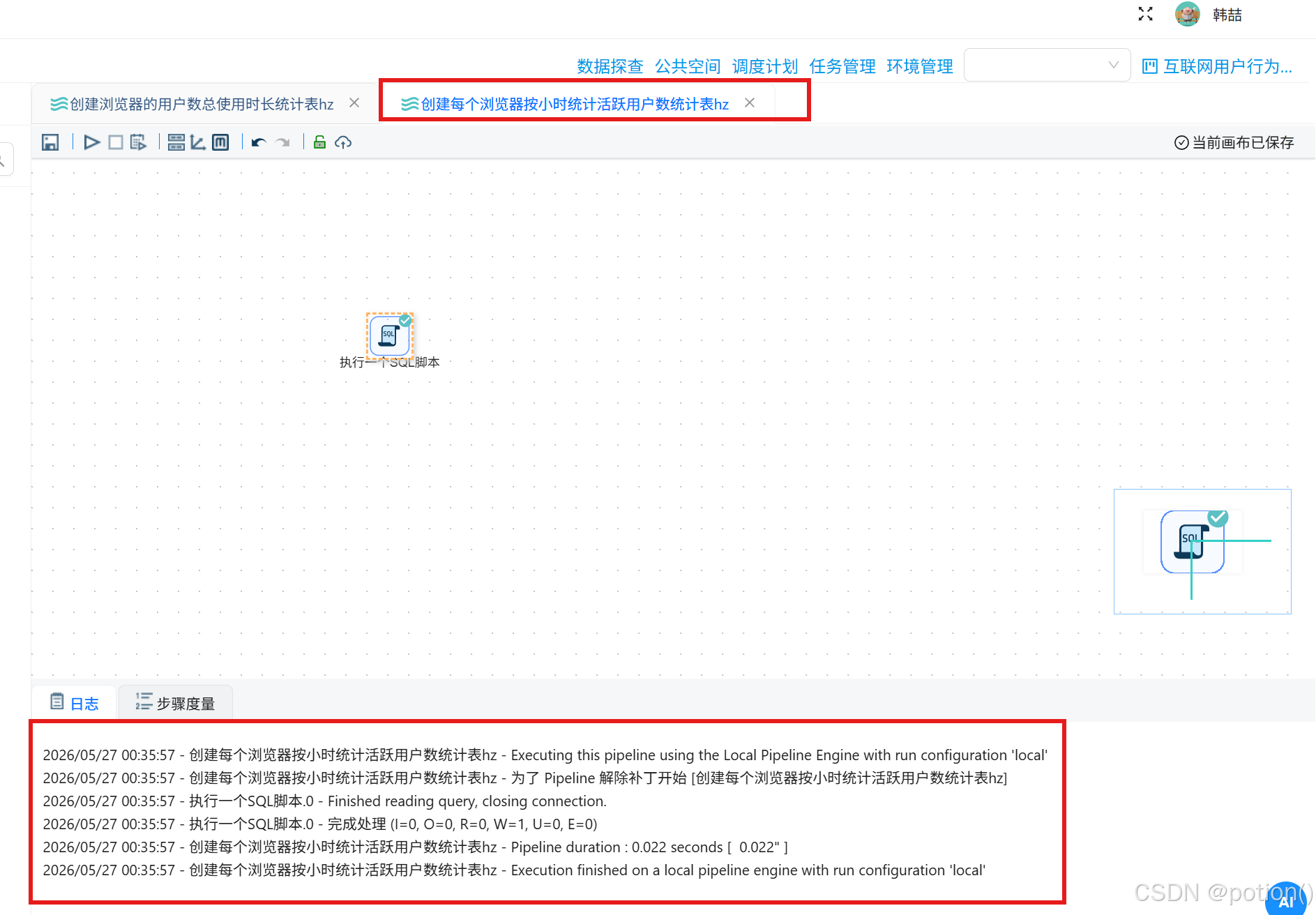
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='浏览器用户覆盖率与总时长';- 创建每个浏览器按小时统计活跃用户数统计表的"执行一个SQL脚本"组件配置如下:
sql
CREATE TABLE browser_hourly (
browser_name VARCHAR(50) NOT NULL COMMENT '浏览器进程名',
hour TINYINT NOT NULL COMMENT '小时(0-23)',
active_user_count INT NOT NULL COMMENT '活跃用户数',
PRIMARY KEY (browser_name, hour)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='浏览器按小时活跃用户数';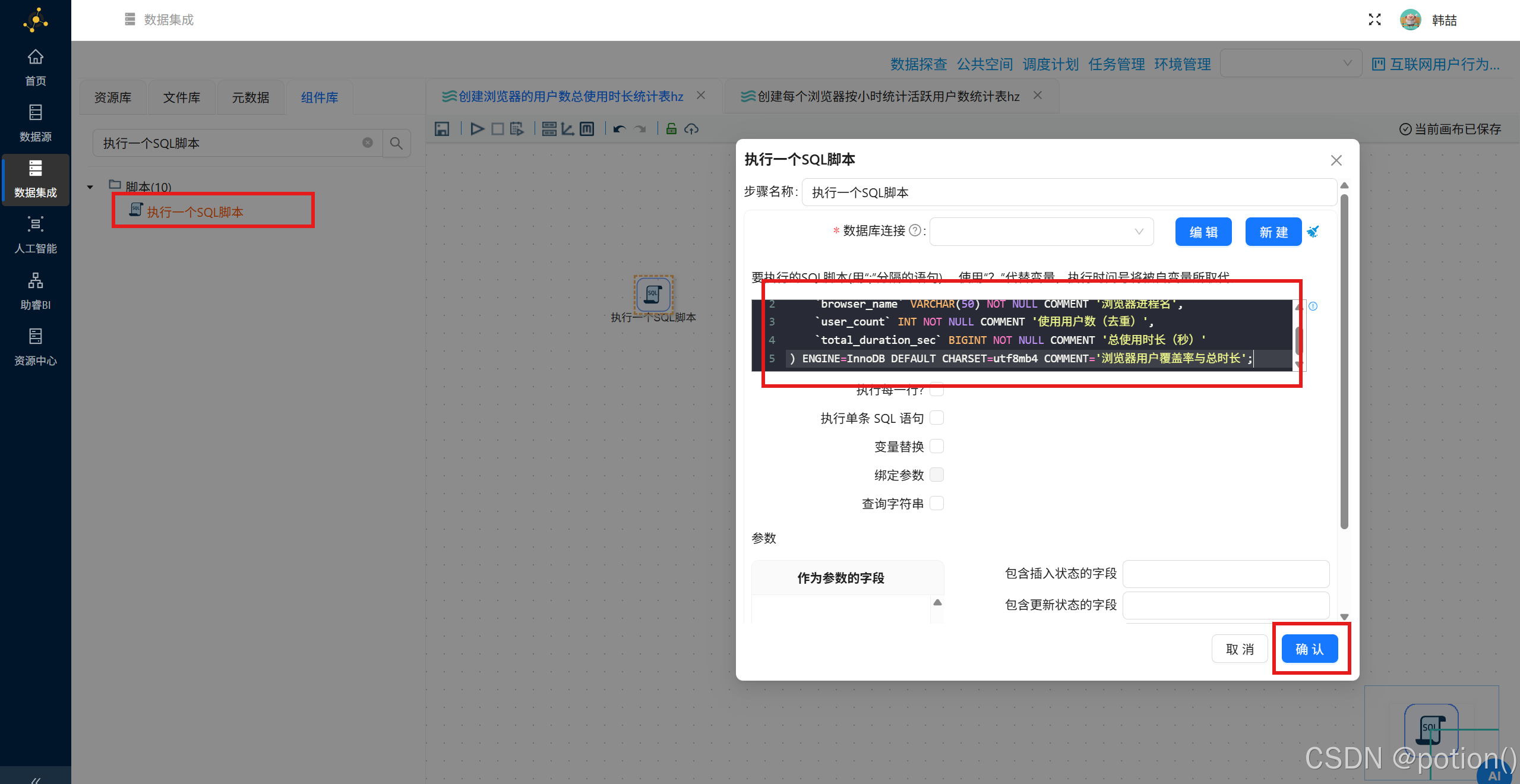
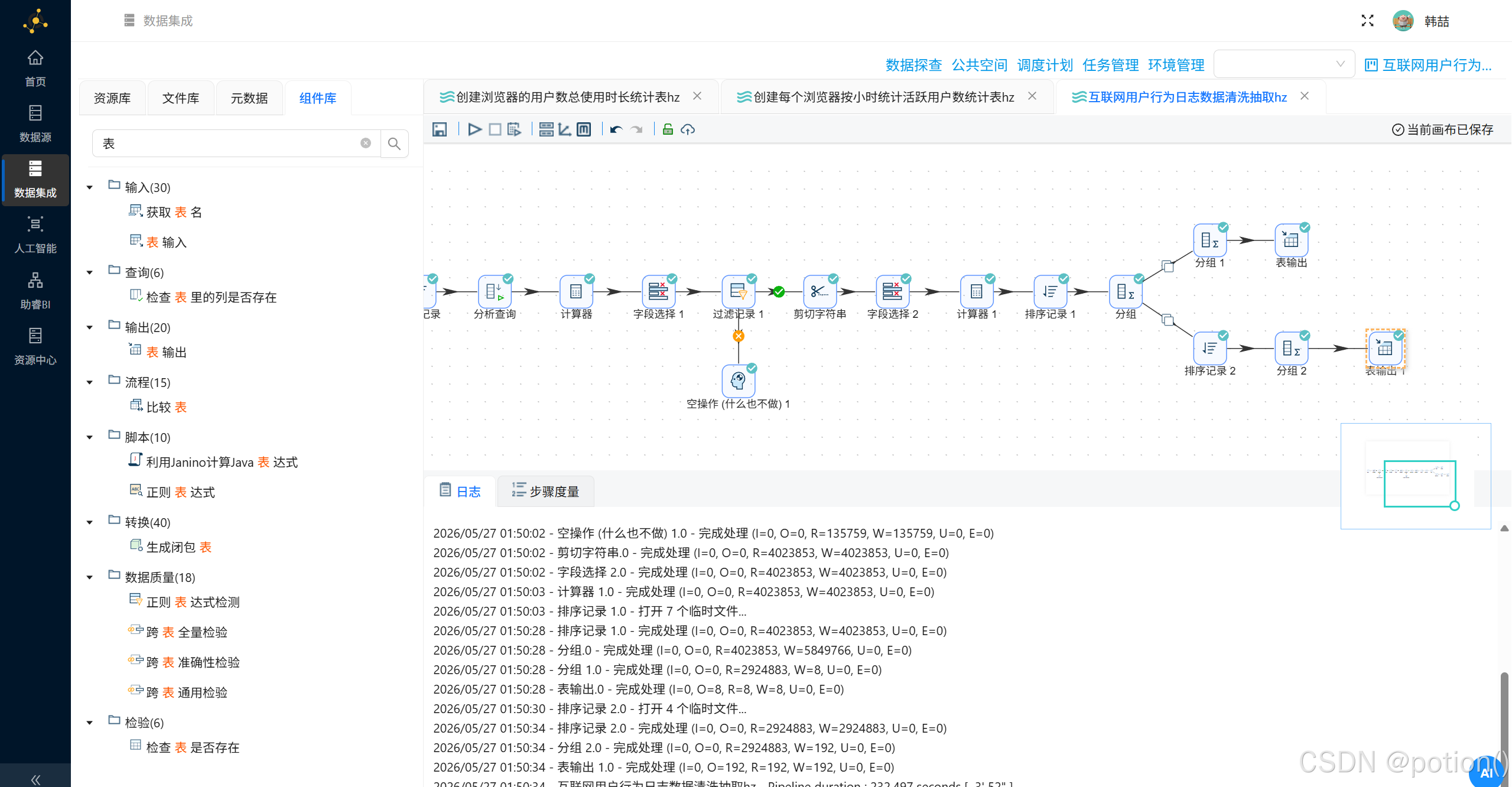
步骤 7:数据清洗、聚合与多分支加工(核心)
新建转换:互联网用户行为日志数据清洗抽取
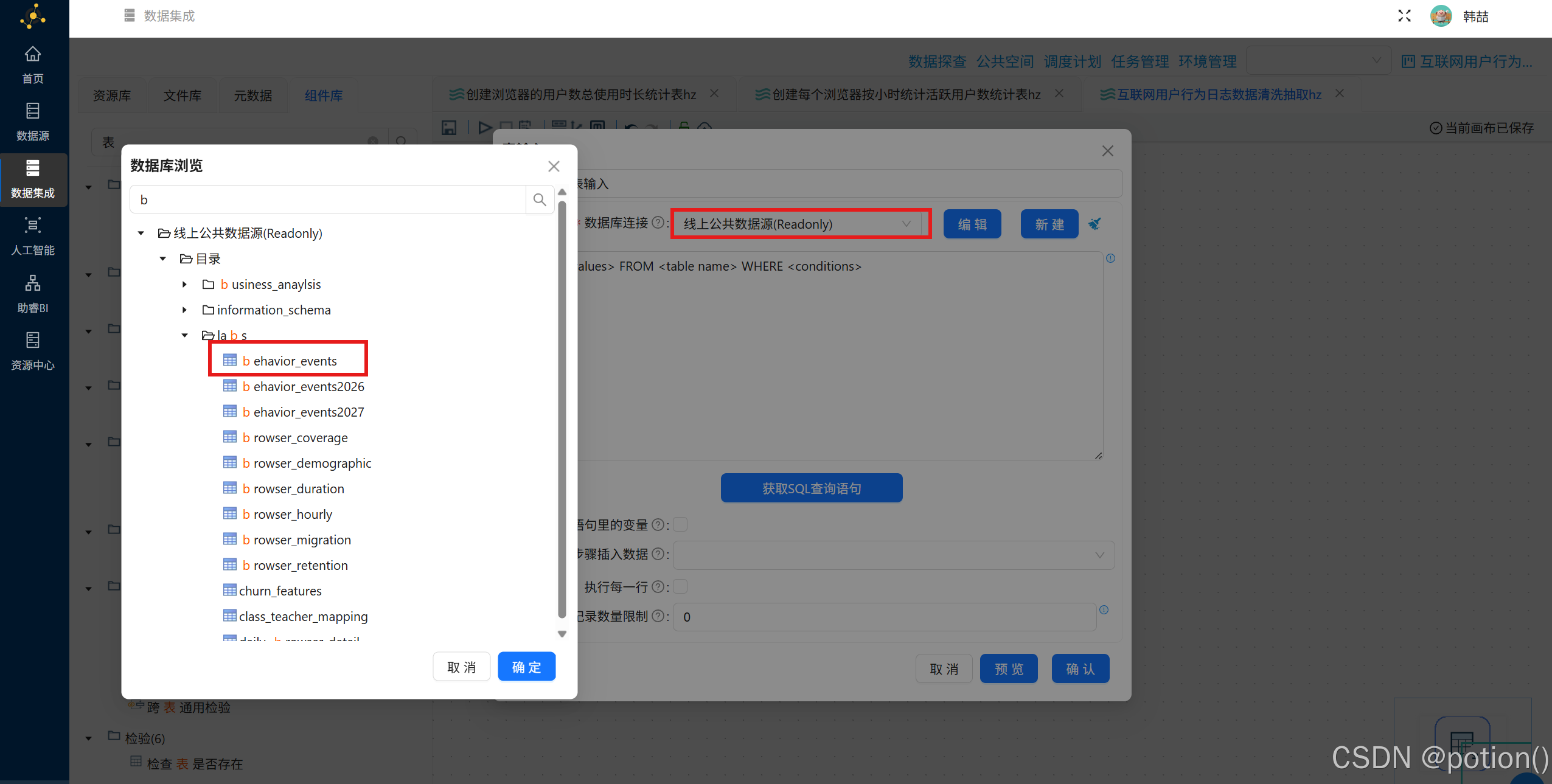
-
表输入
-
选择线上公共数据源 (全量 behavior_events)。
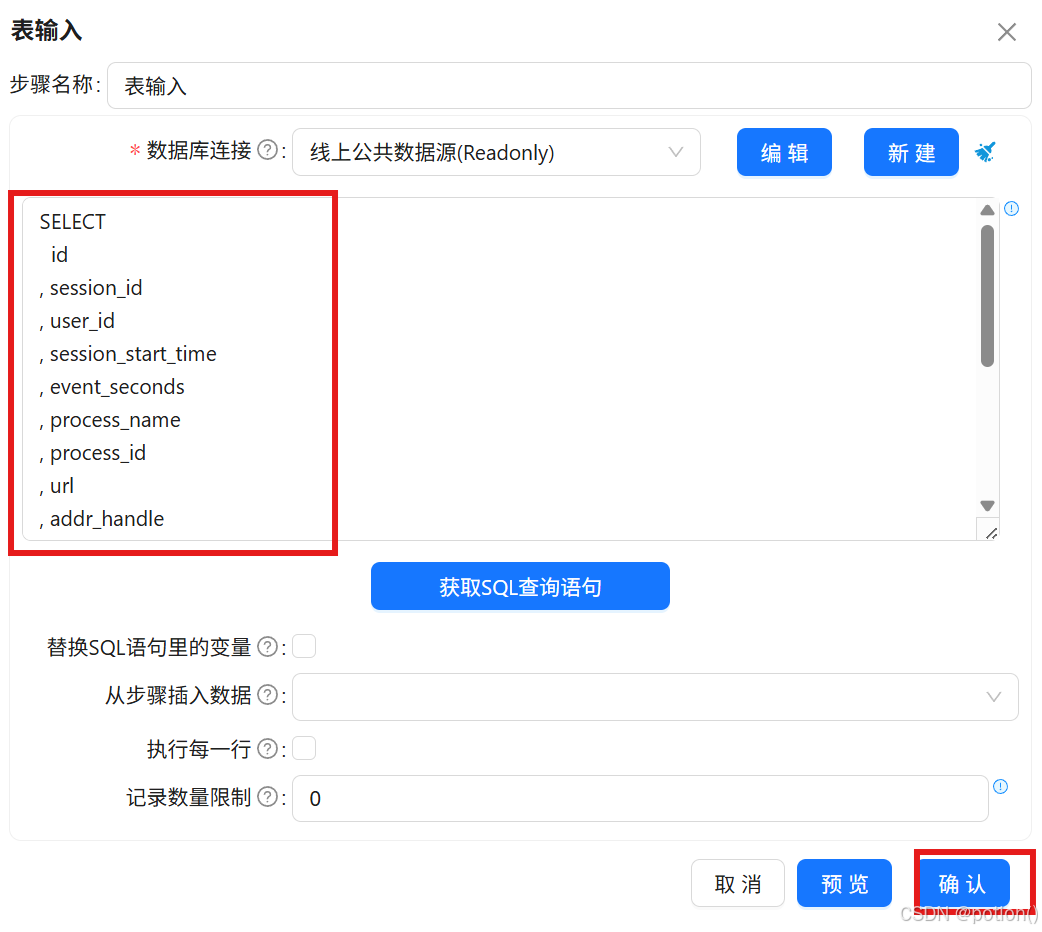
-
输入 SQL 读取全量行为数据。
-
-
字段选择
- 移除冗余字段,保留 :session_id、user_id、session_start_time、process_name、url、event_seconds。选中 session_id, user_id, session_start_time, process_name, url, event_seconds 后删除选中的行,保留下来的字段就是要移除的字段,点击"确认"
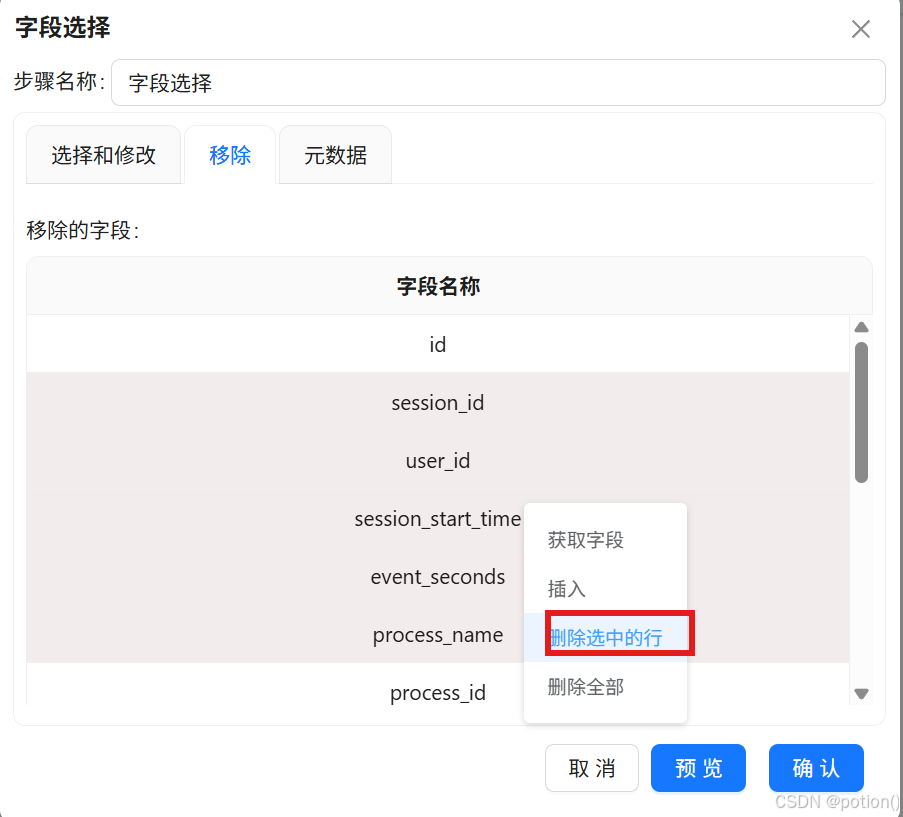
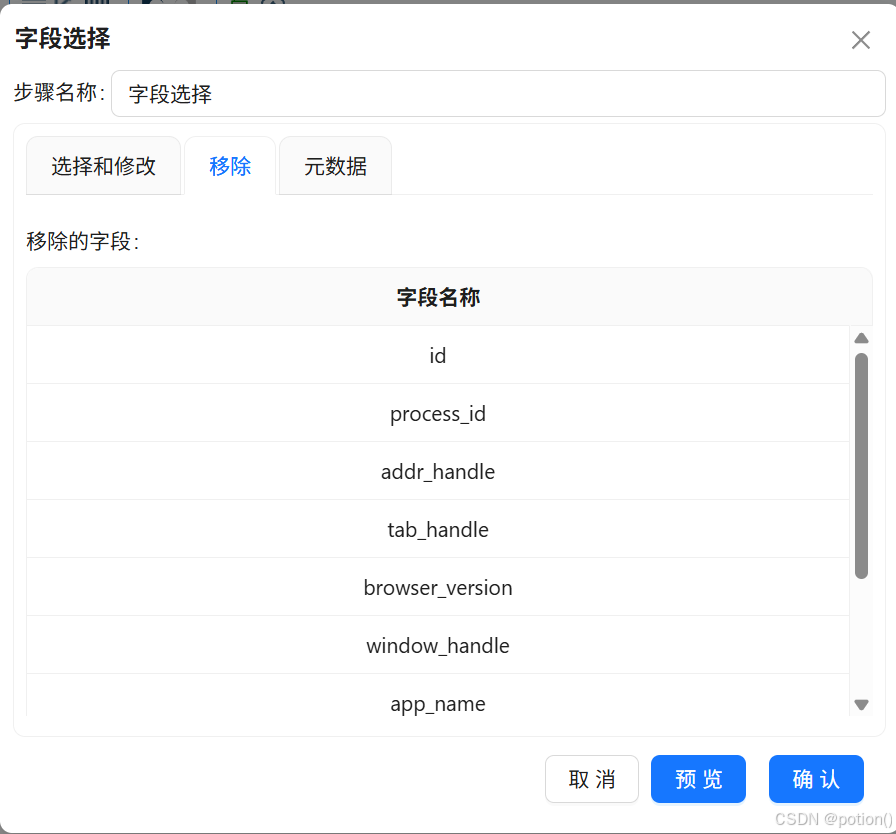
- 移除冗余字段,保留 :session_id、user_id、session_start_time、process_name、url、event_seconds。选中 session_id, user_id, session_start_time, process_name, url, event_seconds 后删除选中的行,保留下来的字段就是要移除的字段,点击"确认"
-
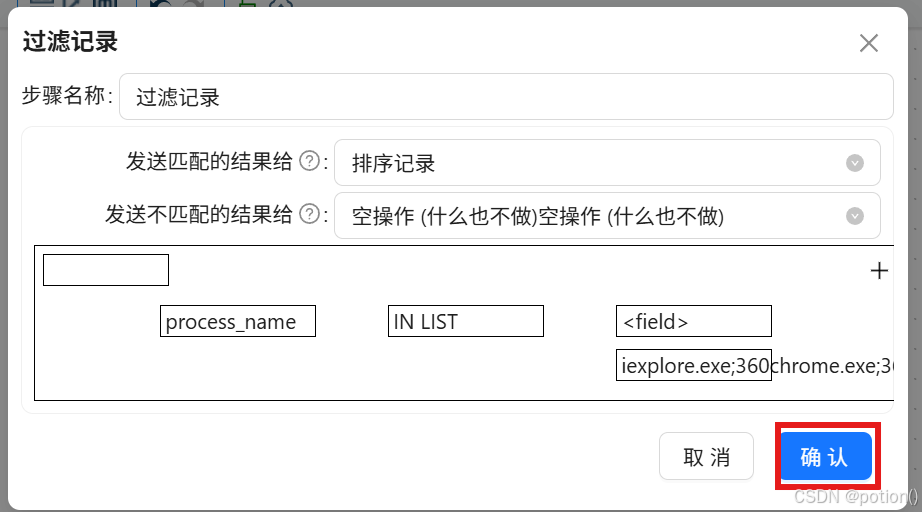
过滤记录(只保留主流浏览器)
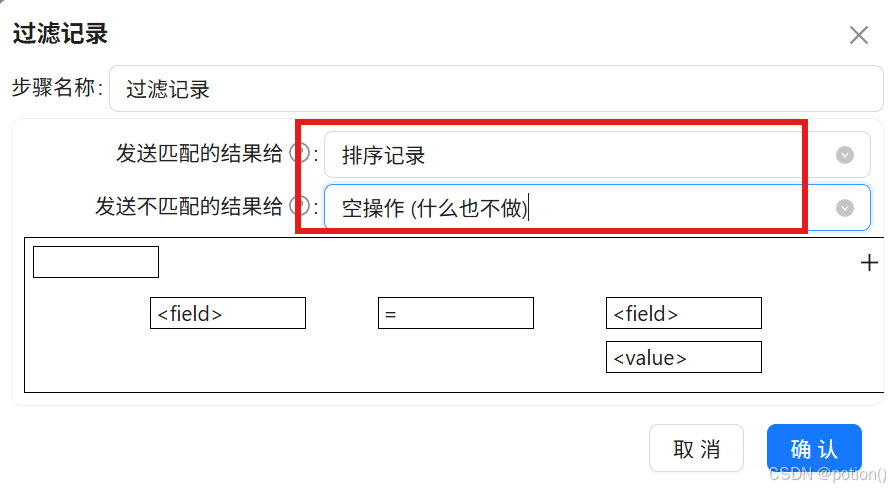
-
配置条件:
process_name IN LIST
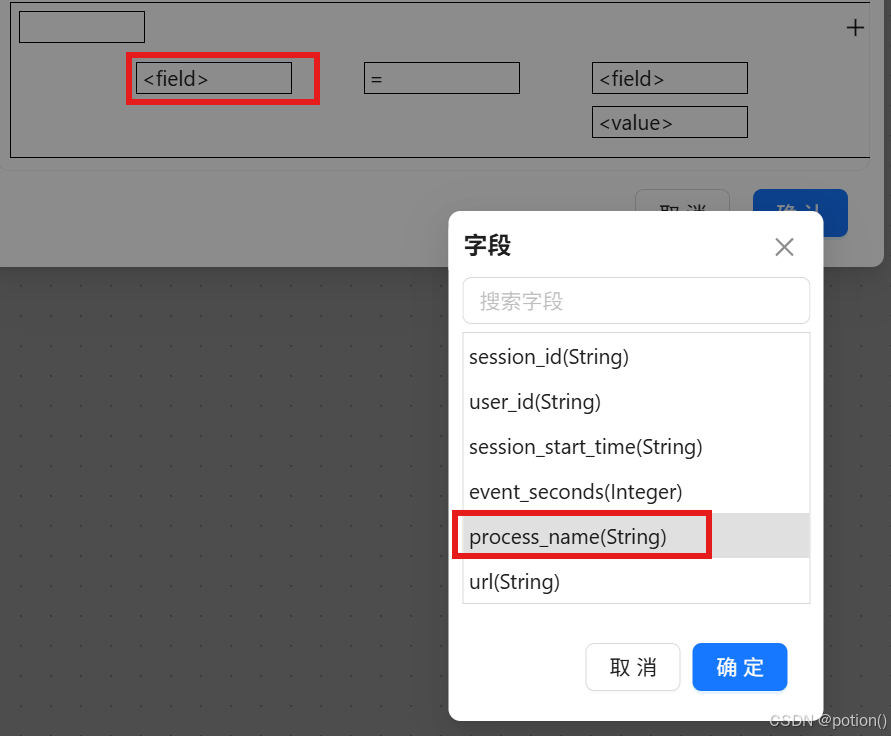
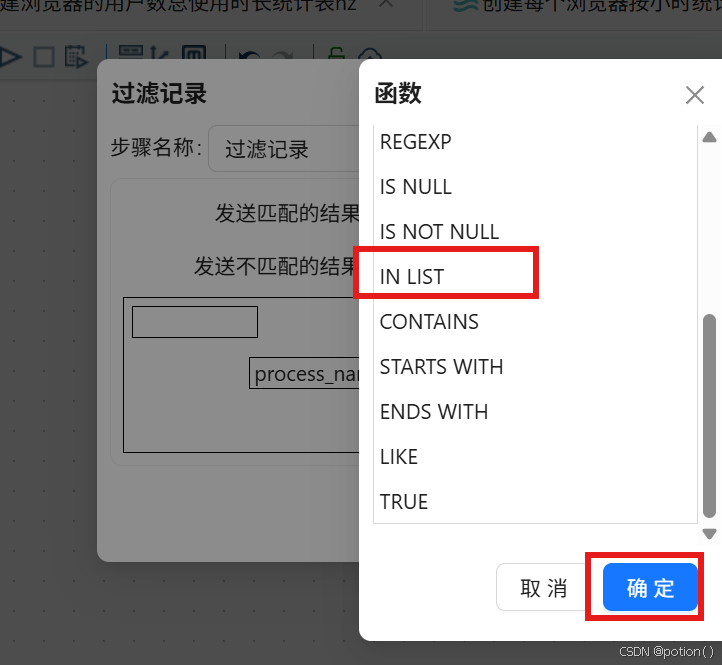
-
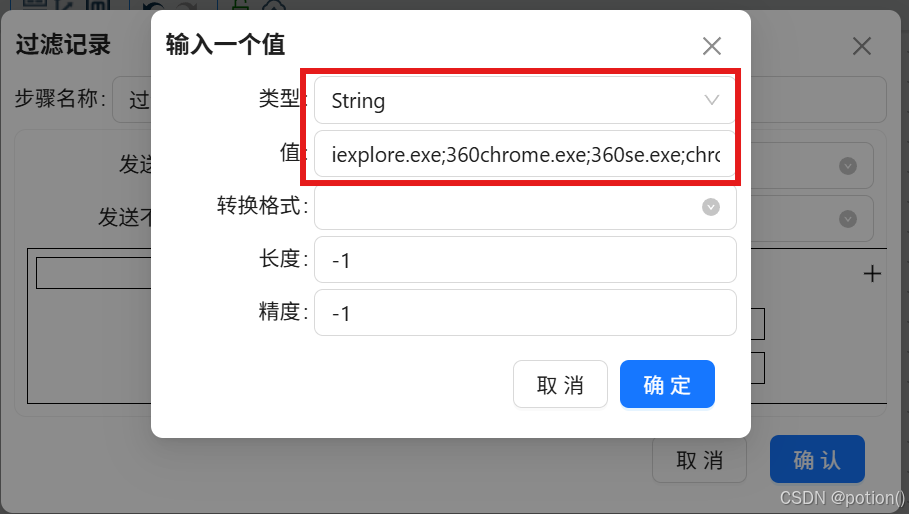
列表值:
iexplore.exe;360chrome.exe;360se.exe;chrome.exe;sogouexplorer.exe;QQBrowser.exe -
匹配输出到后续步骤,不匹配输出到空操作。
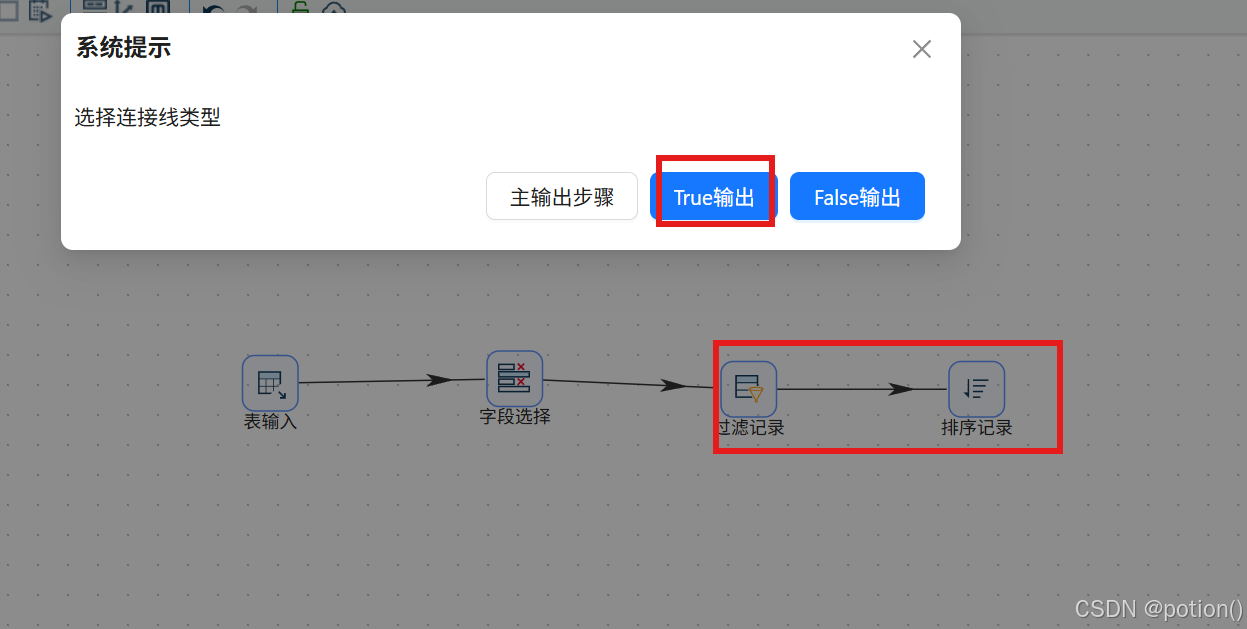
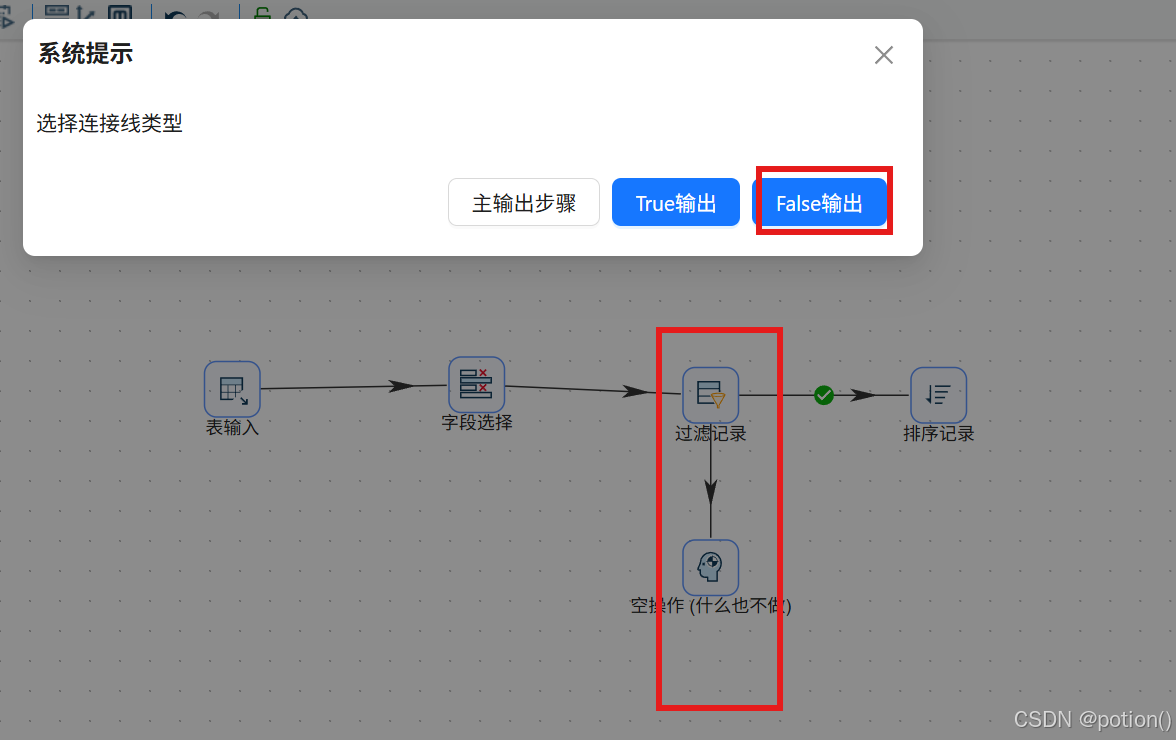
-
-
计算停留时长
先对过滤记录的真假输出选择连线类型
-
排序记录 :按
session_id、event_seconds升序。
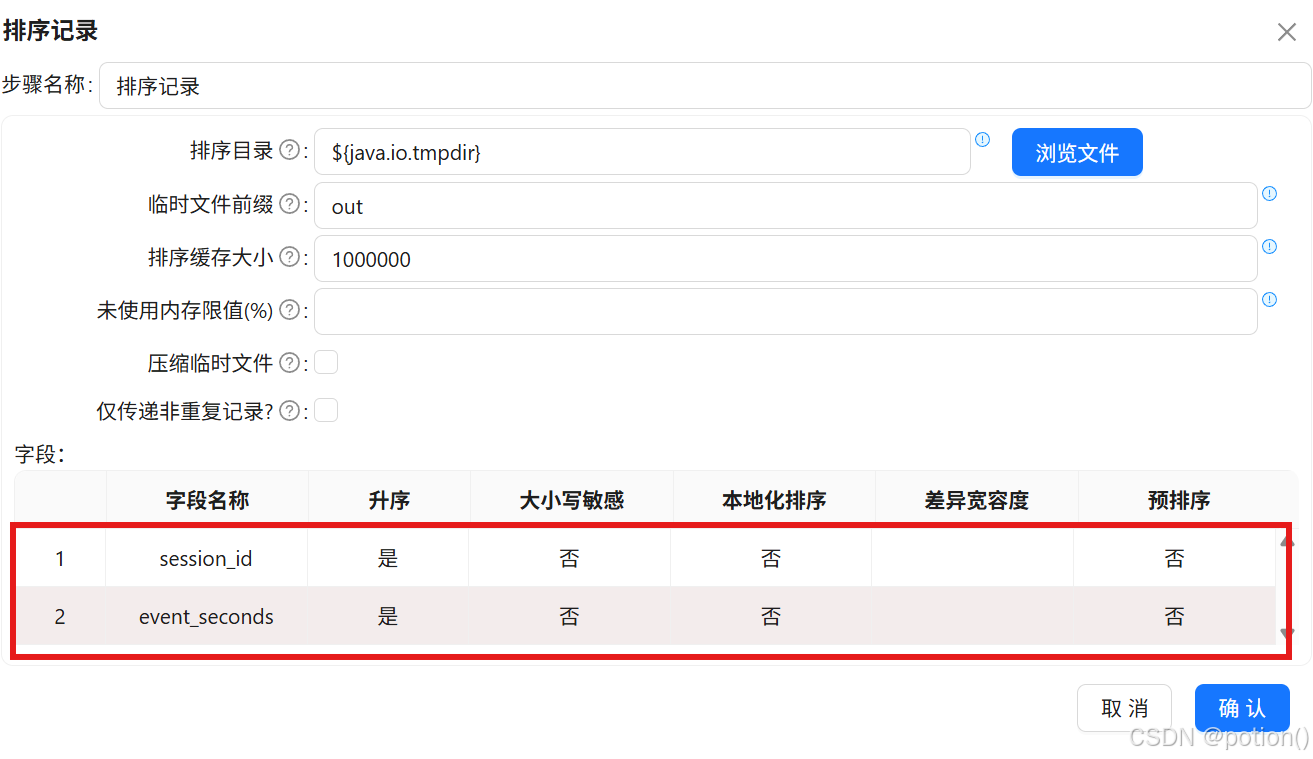
-
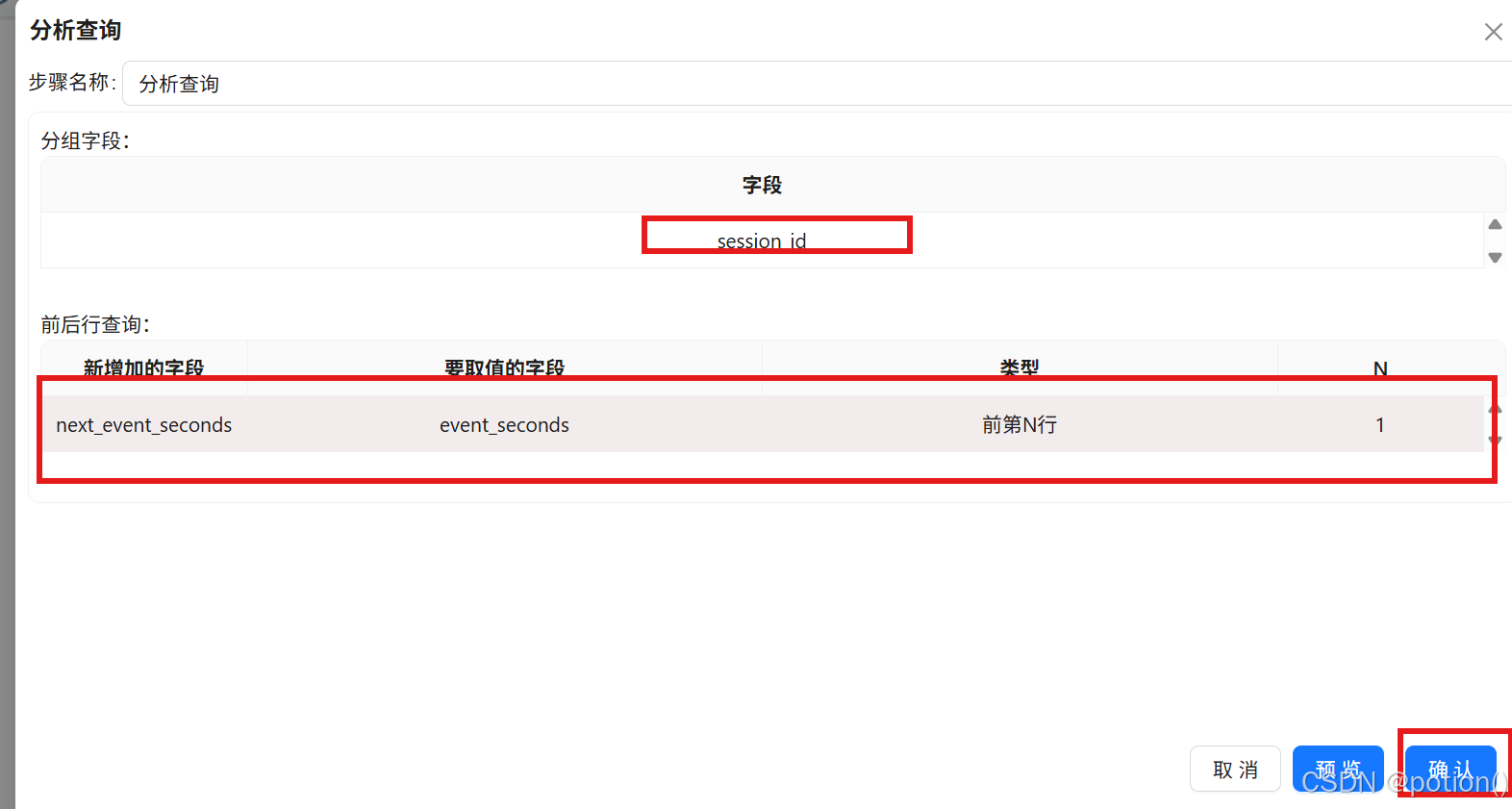
分析查询 :
分组字段为"session_id",新增加的字段"next_event_seconds",要取值的字段为"event_seconds",类型"前第N行",N为"1",获取同一会话内下一行的 event_seconds 值,存入新字段 next_event_seconds。
-
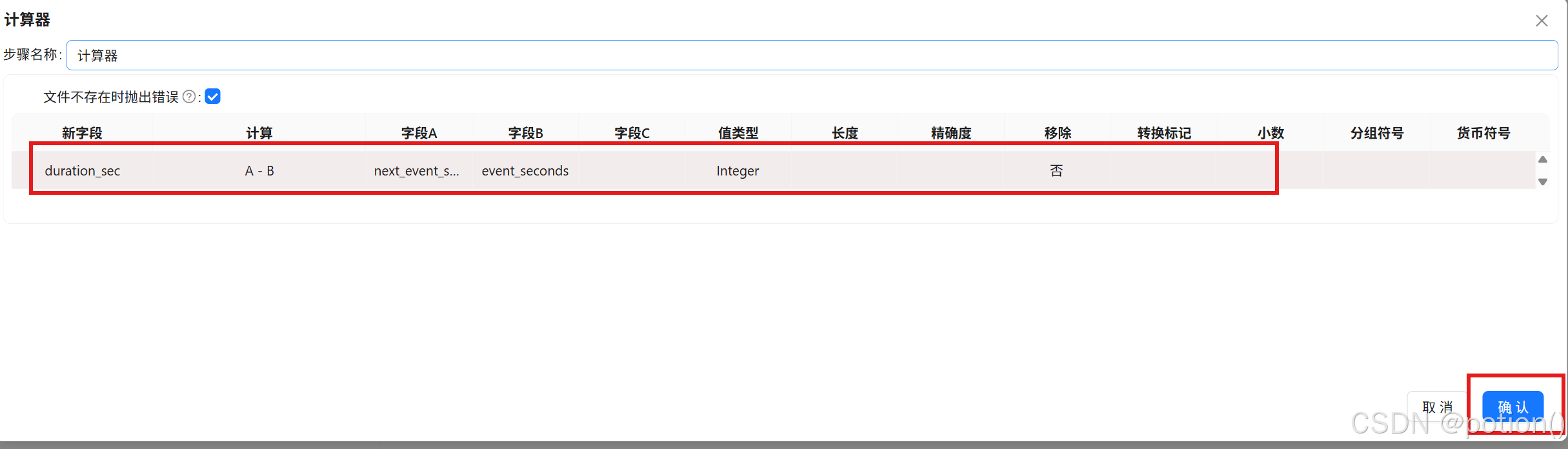
计算器 :
duration_sec = next_event_seconds - event_seconds。插入新字段行,新字段输入"duration_sec",计算公式选择"A - B",字段A选择"next_event_seconds",字段B选择"event_seconds",值类型为"Integer"
-
-
二次字段选择
- 只保留:user_id、process_name、session_start_time、url、duration_sec。
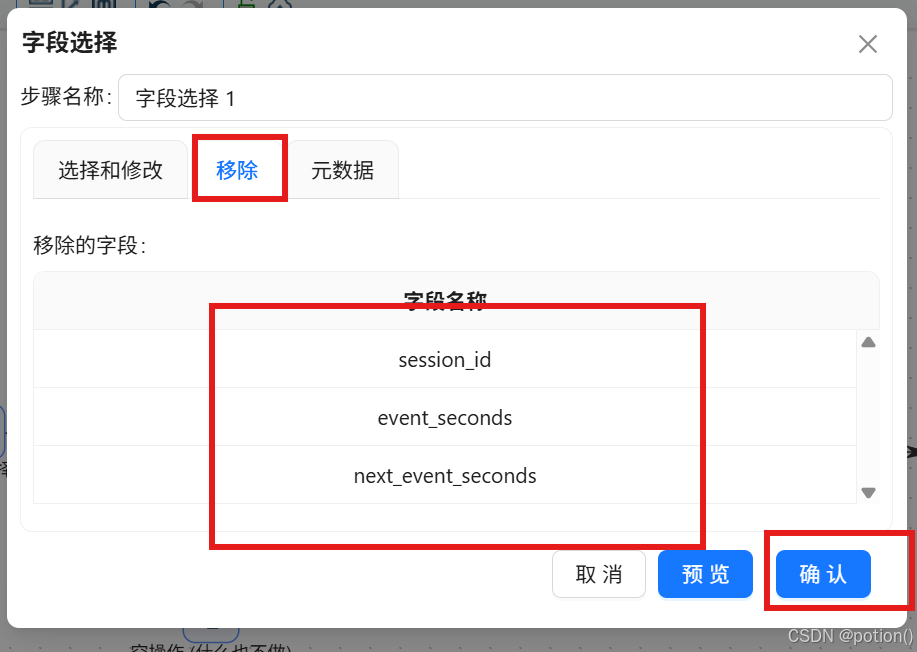
- 只保留:user_id、process_name、session_start_time、url、duration_sec。
-
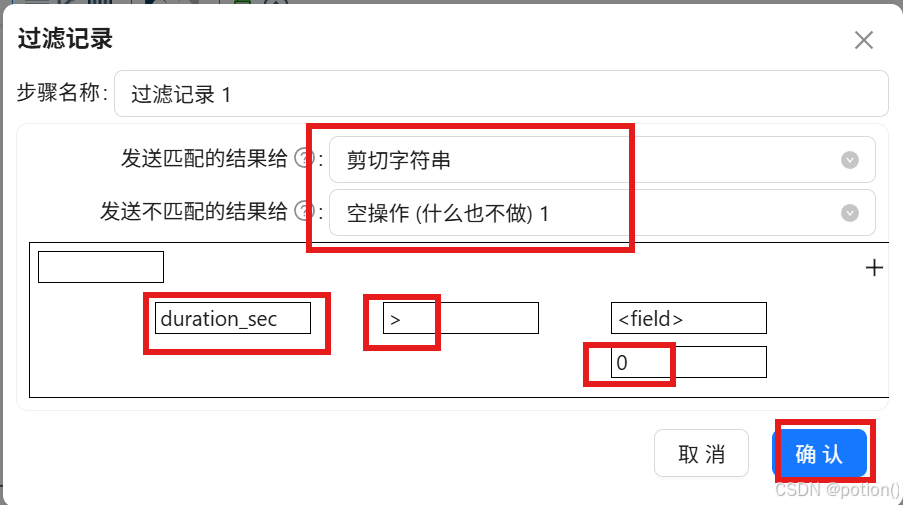
过滤无效时长
- 保留
duration_sec > 0的记录,剔除异常与末尾无效数据。
- 保留
-
提取日期与小时
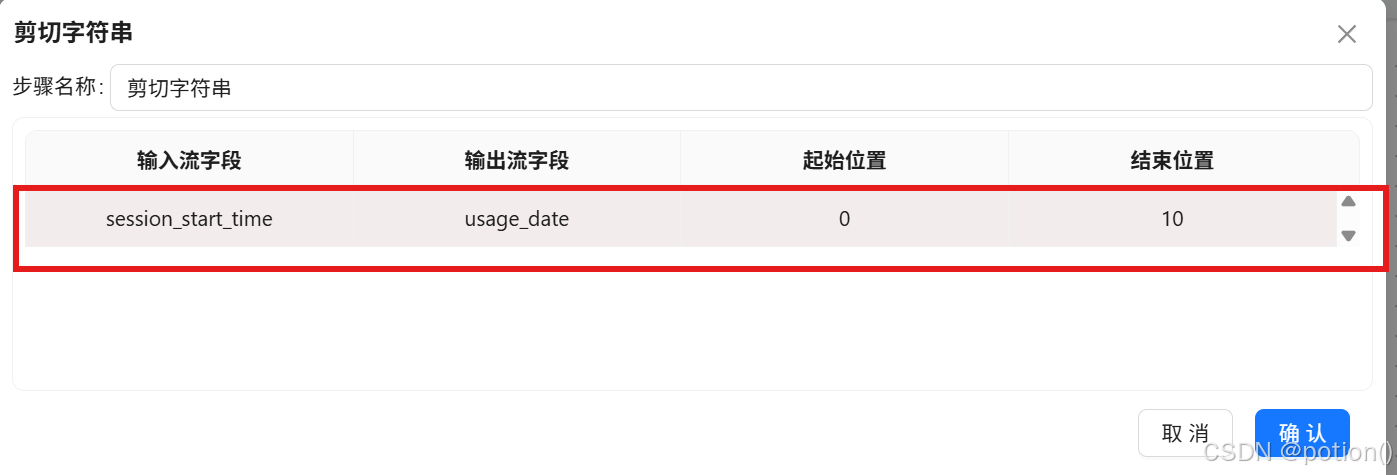
-
剪切字符串 :从
session_start_time截取日期(yyyy-MM-dd)。
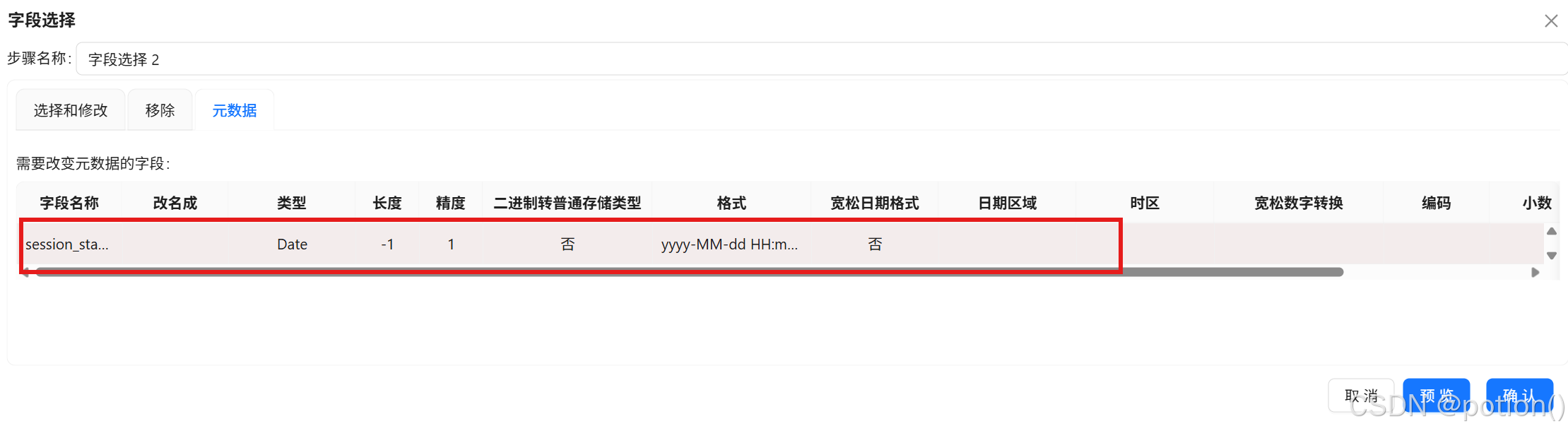
-
字段选择 :将
session_start_time转为 Date 类型。
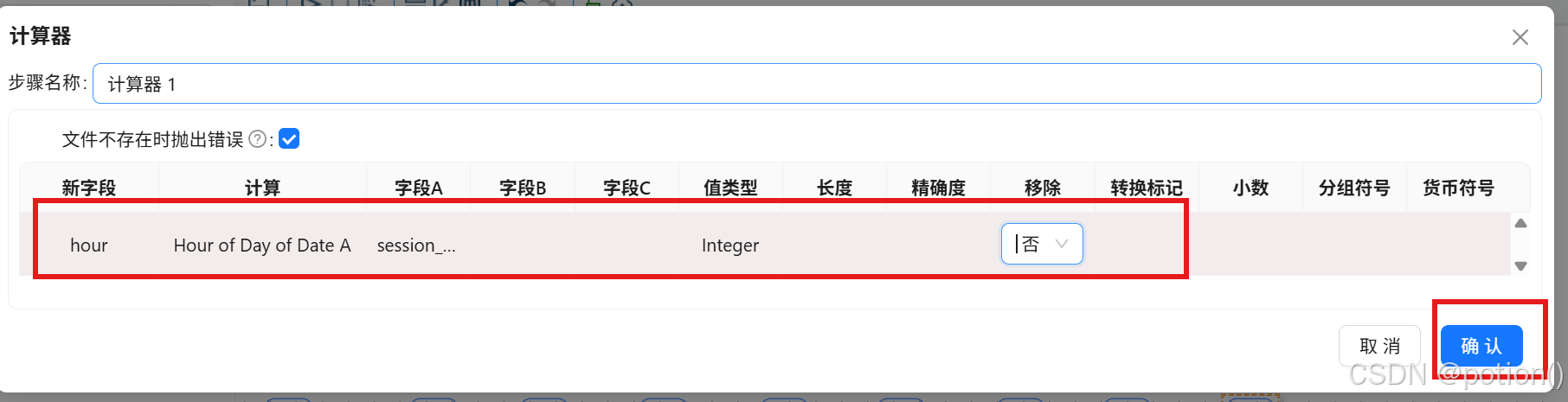
-
计算器 :提取小时(0-23),提取 yyyy-MM-dd HH:mm:ss 中的HH,生成
hour字段。
-
-
生成用户 - 日 - 浏览器 - 小时明细
-
排序记录 :按process_name排序。
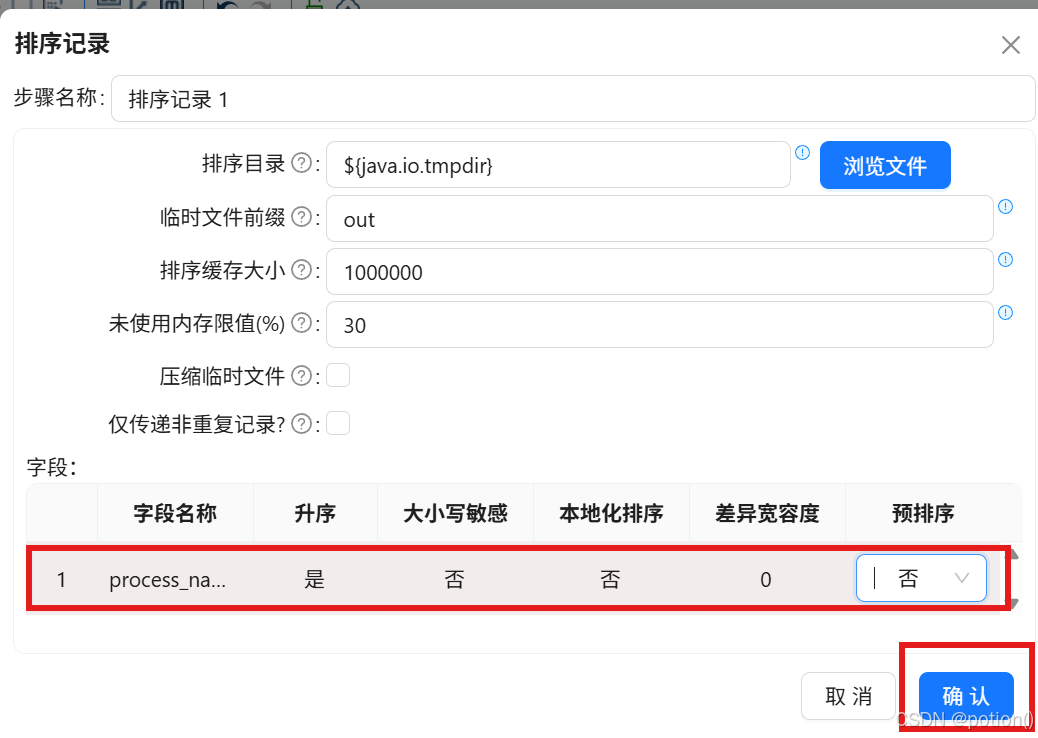
-
分组 :按 user_id、process_name、日期、hour 分组。
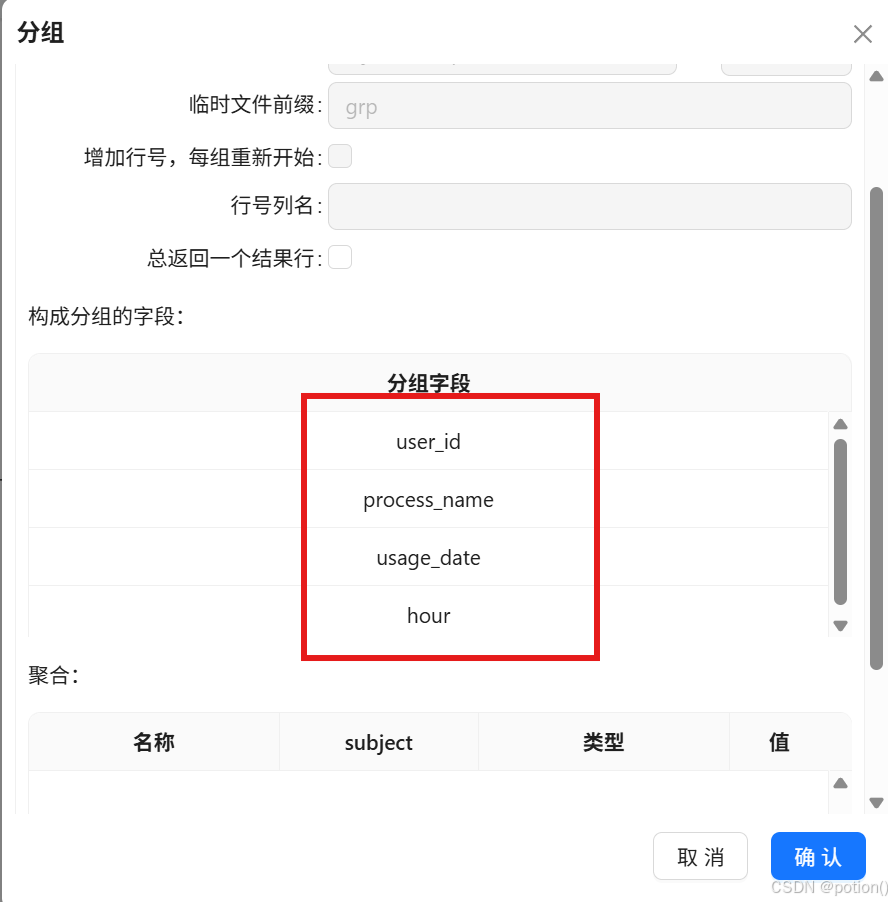
-
聚合:总时长求和、访问次数统计。
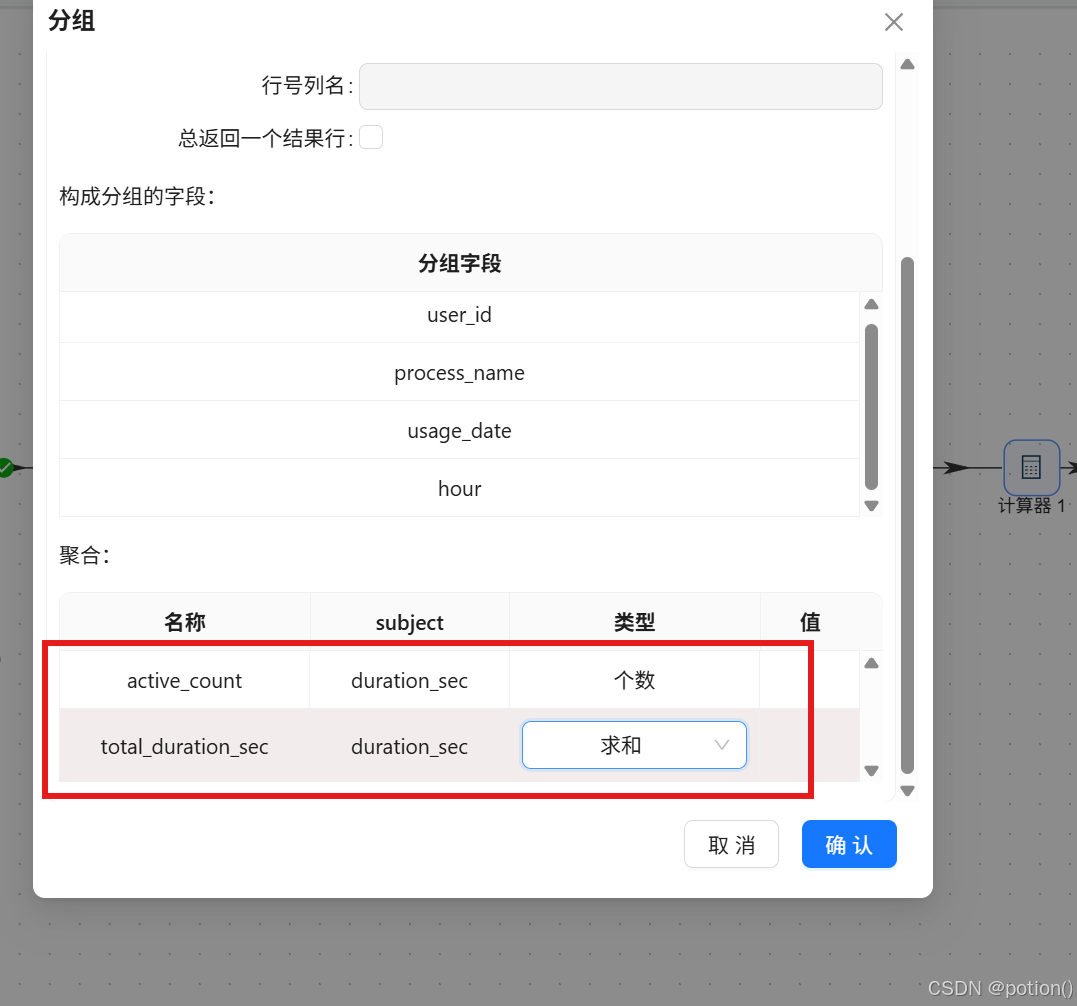
-
-
分支 A:生成市场格局表 browser_coverage
-
从上述明细分组 :只按
process_name分组。 -
聚合:
user_count:user_id 去重计数total_duration_sec:时长求和
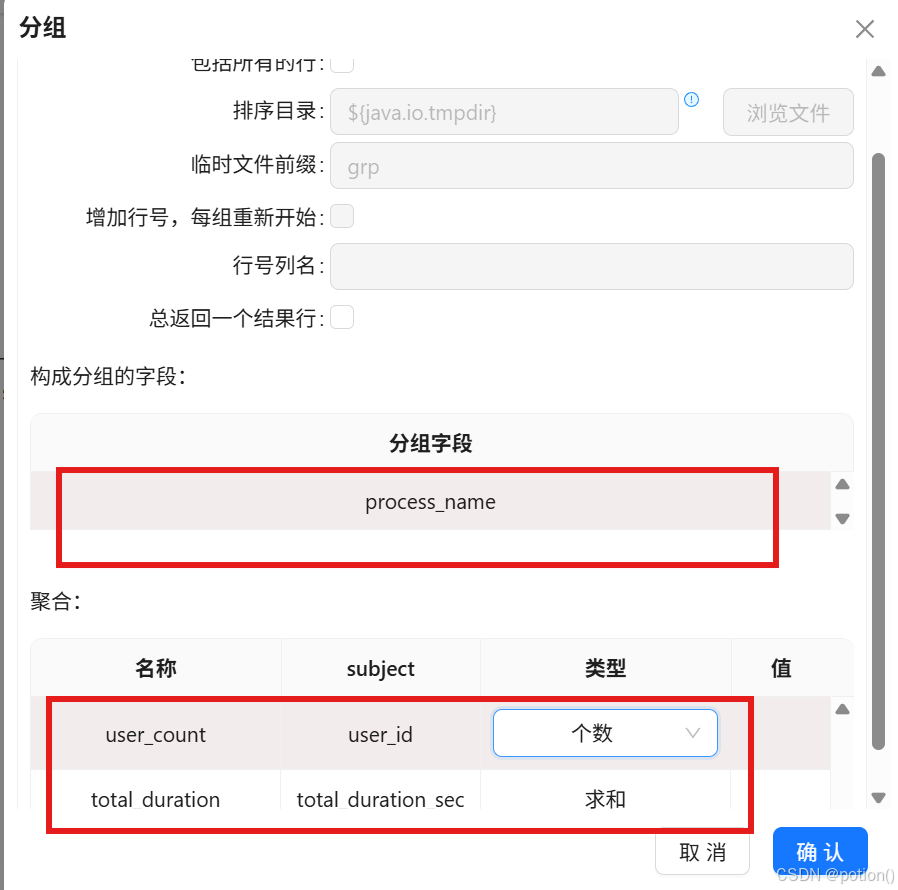
-
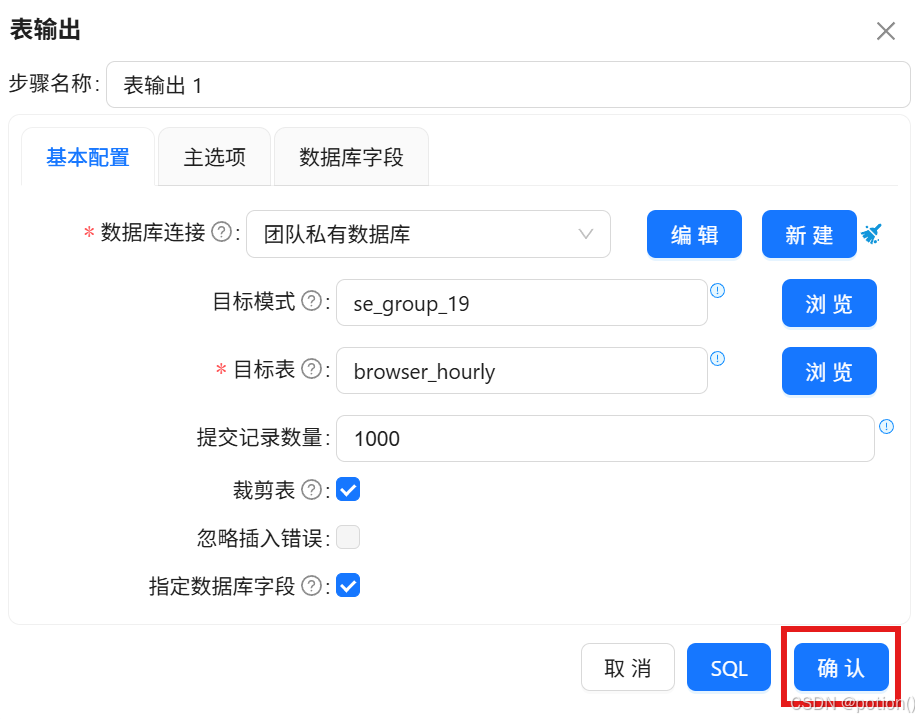
表输出 :写入
browser_coverage,勾选裁剪表。
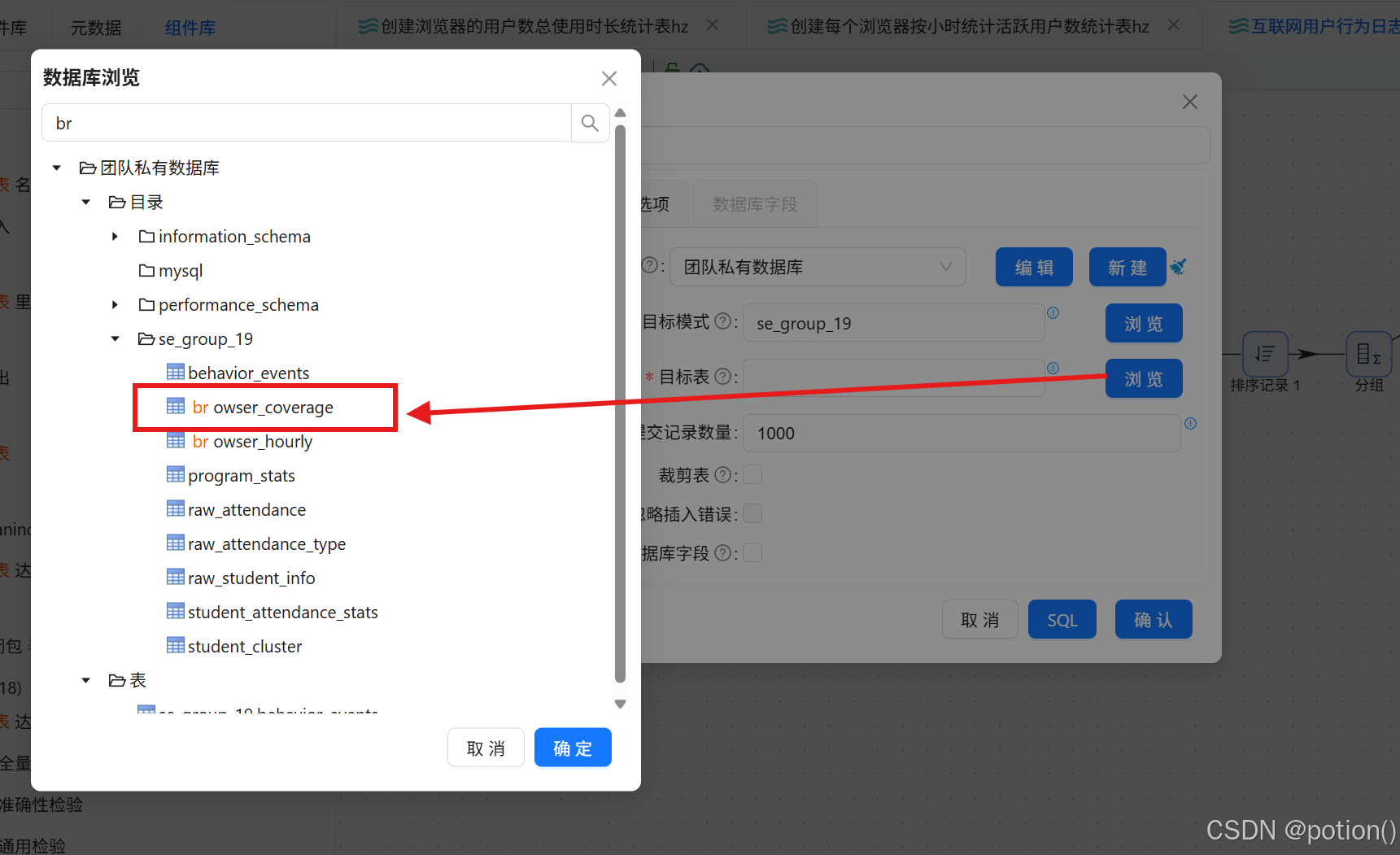
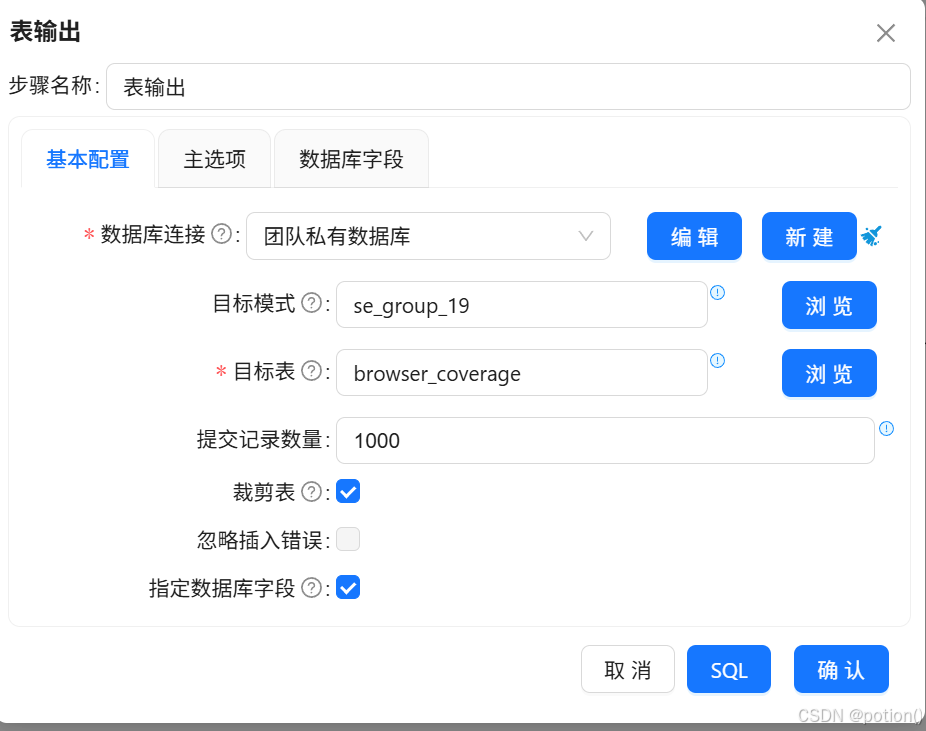
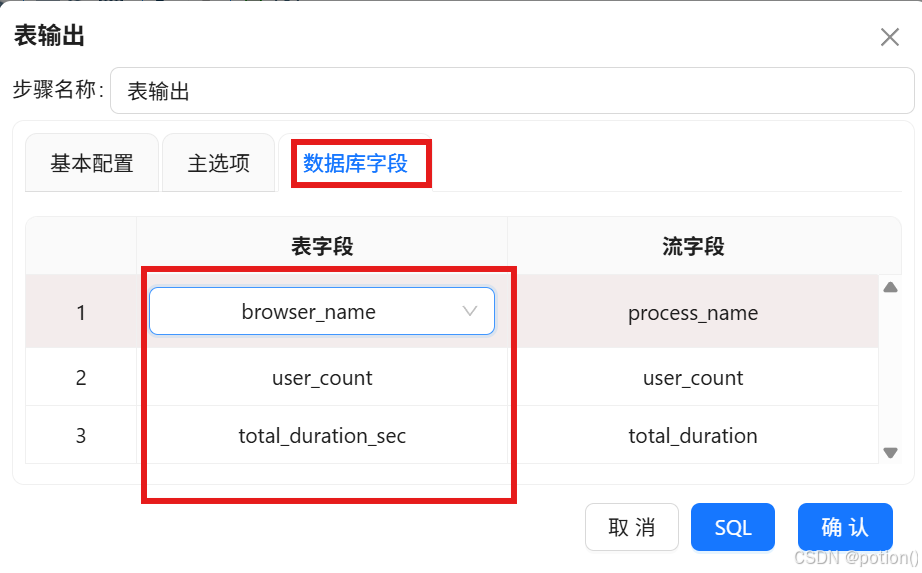
- 分支 B:生成时段统计表 browser_hourly
-
数据复制发送 ,按
process_name、hour排序。
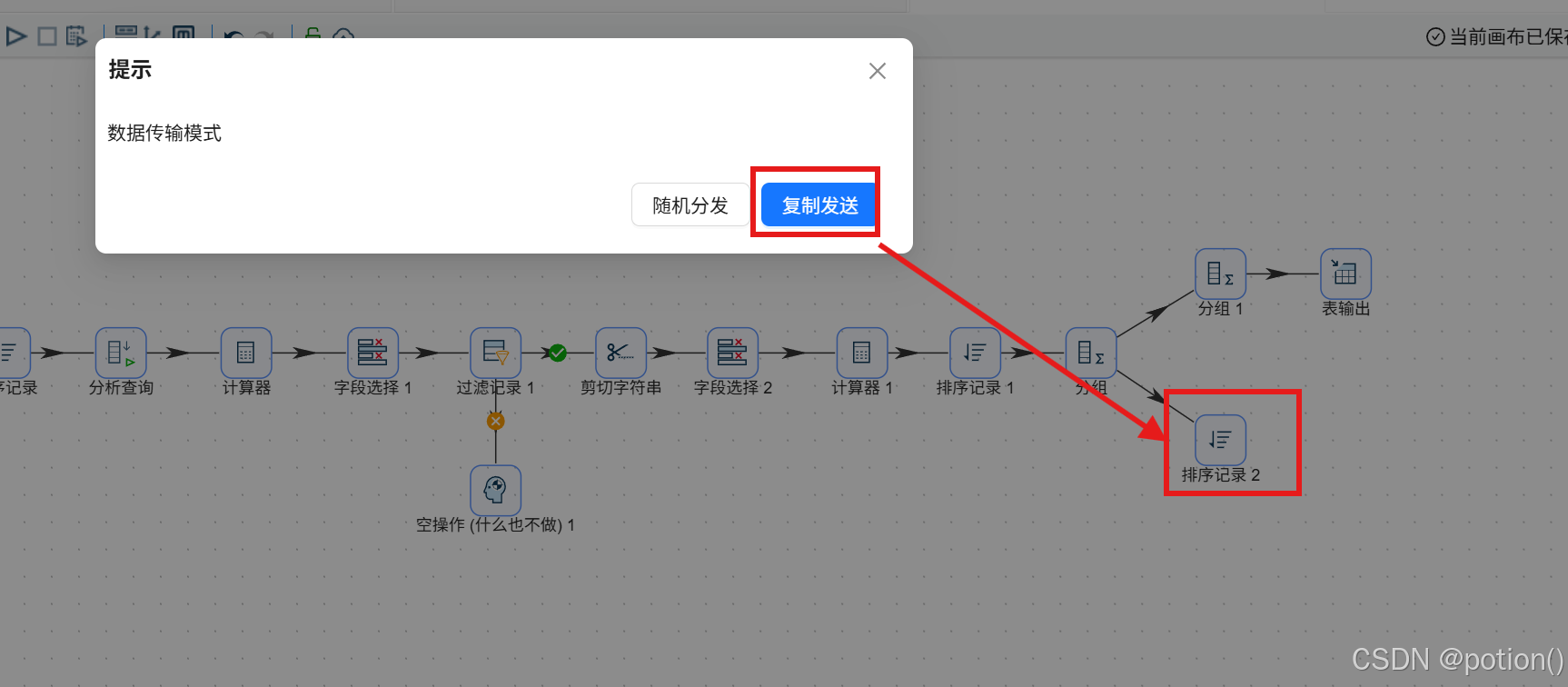
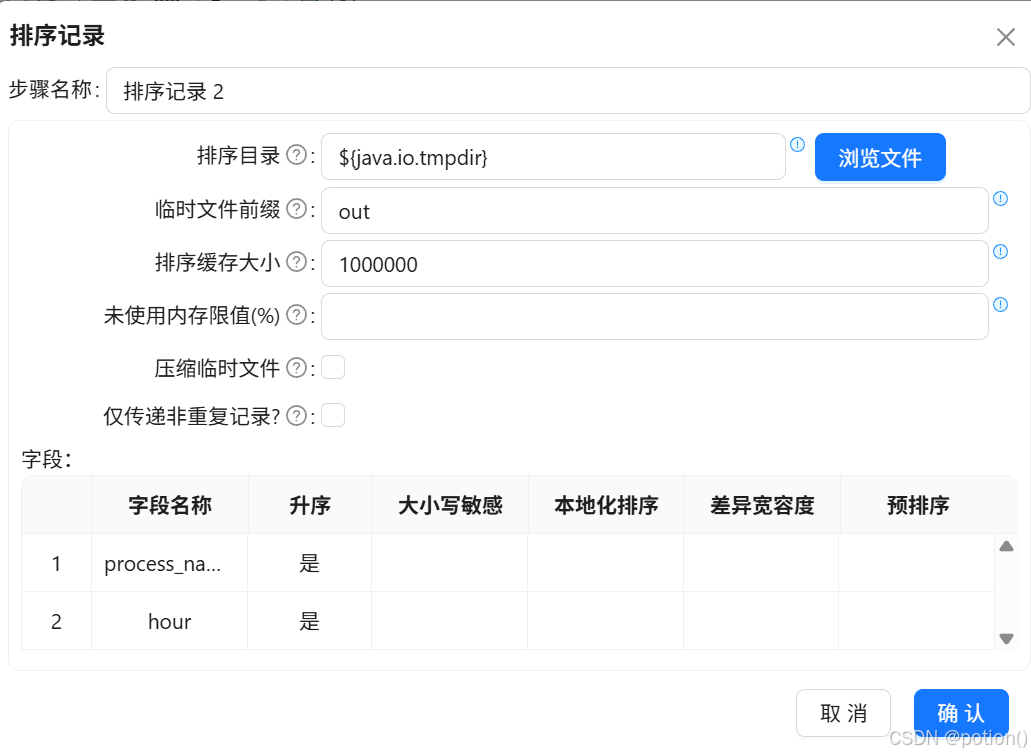
-
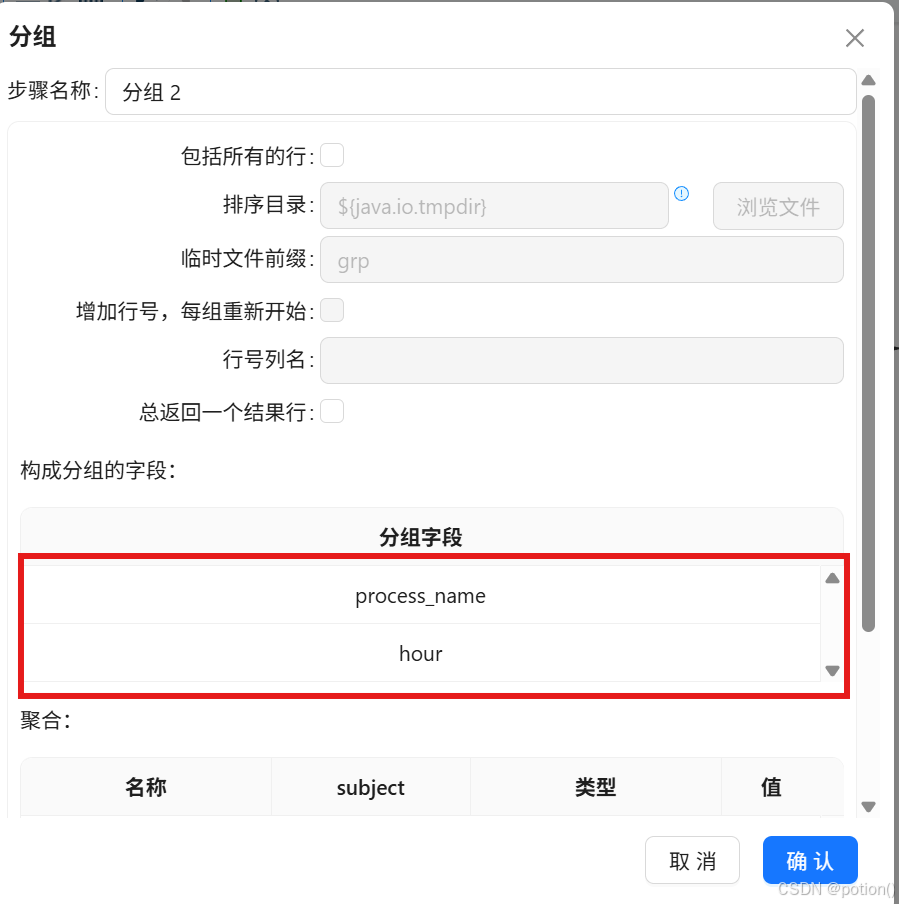
分组:
-
按
process_name、hour分组。
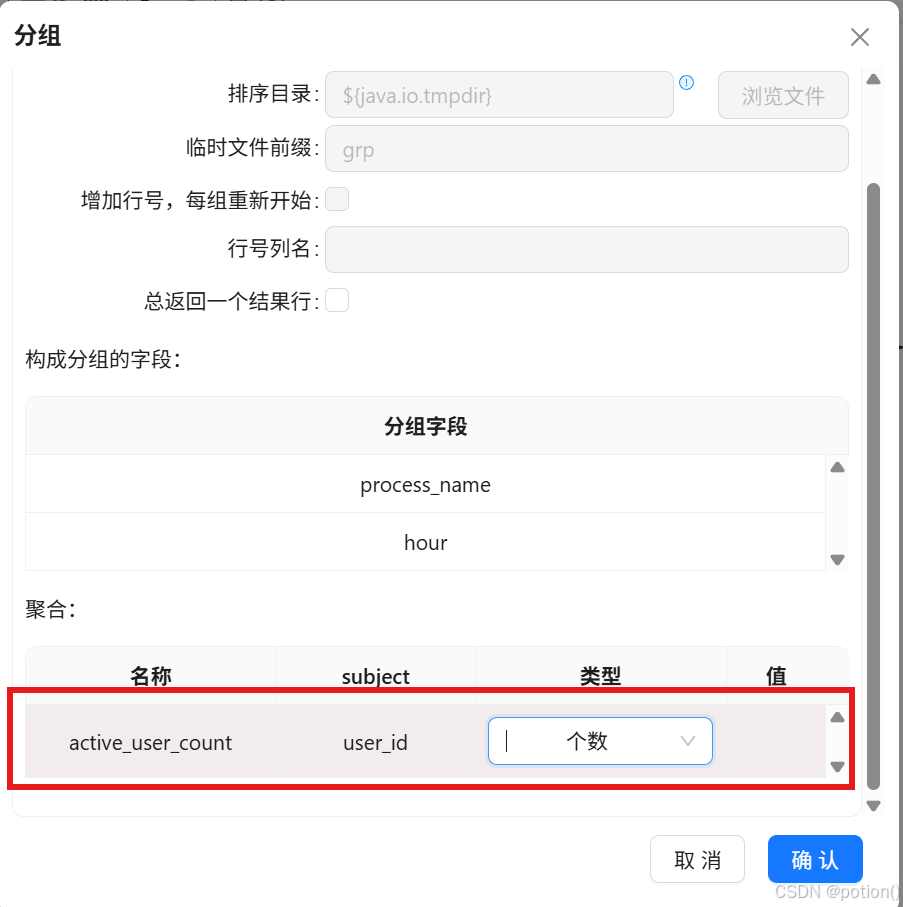
-
聚合:
active_user_count= user_id 个数。
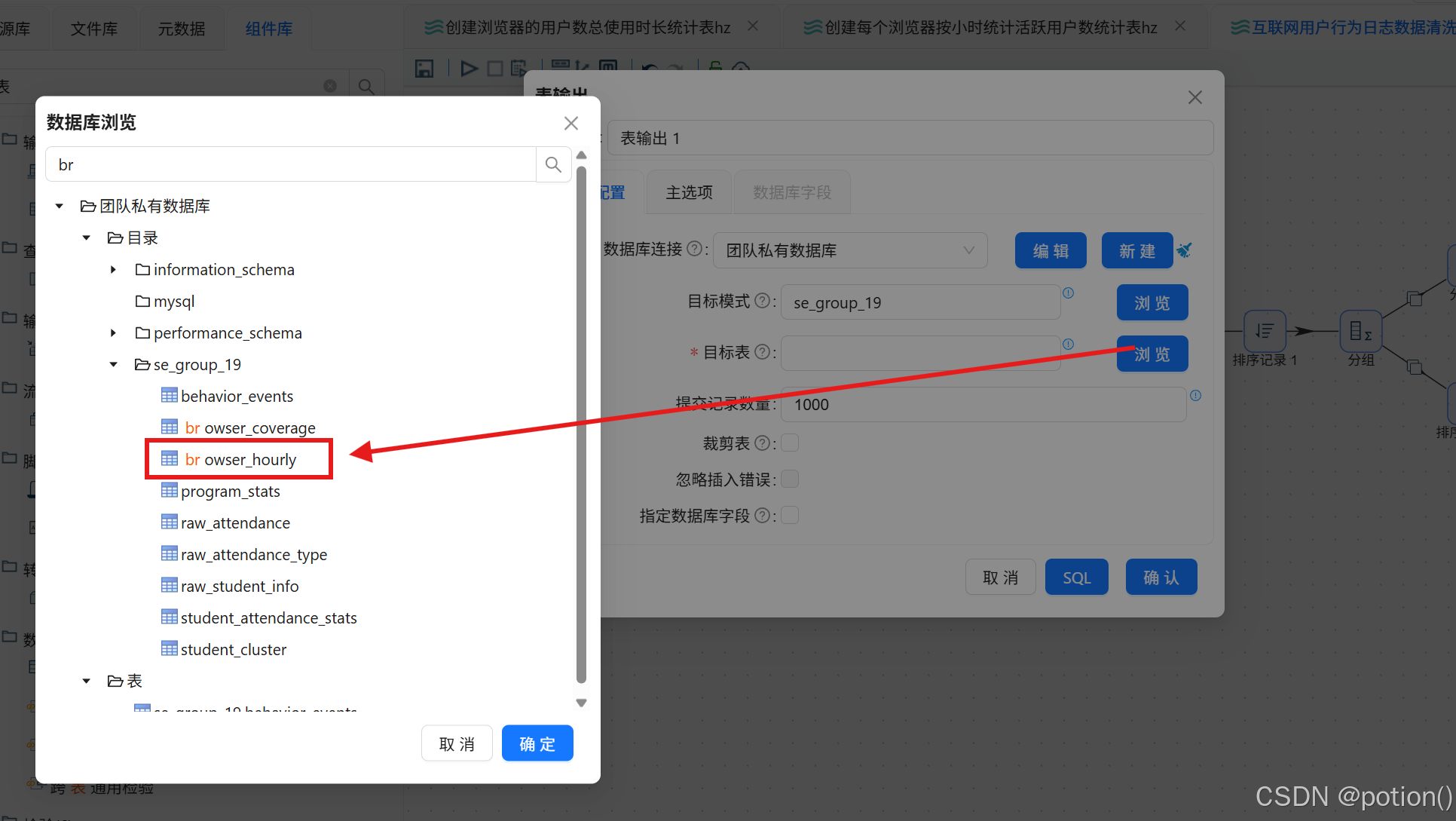
-
表输出 :写入
browser_hourly。
- 运行全转换流
-
点击执行,等待完成。
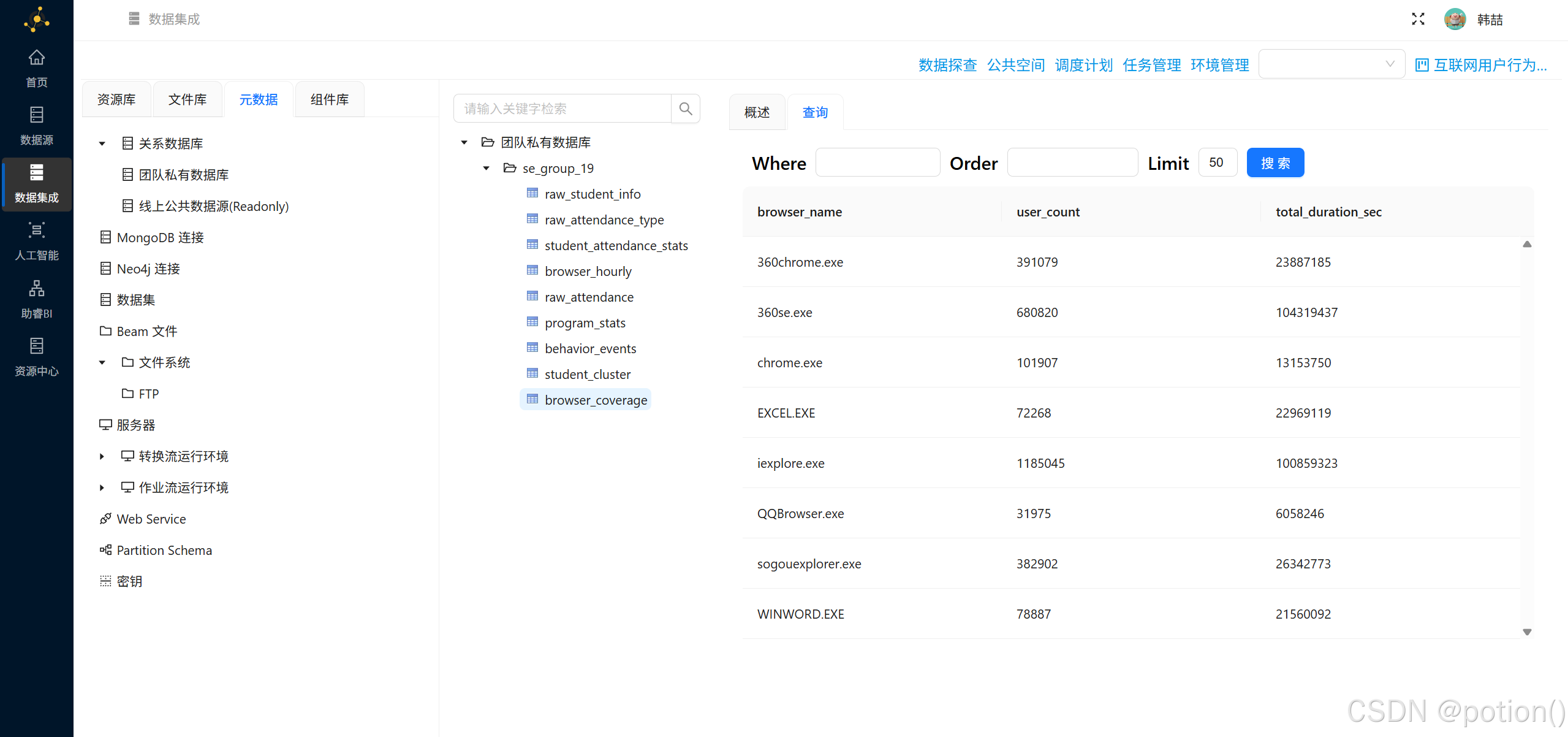
-
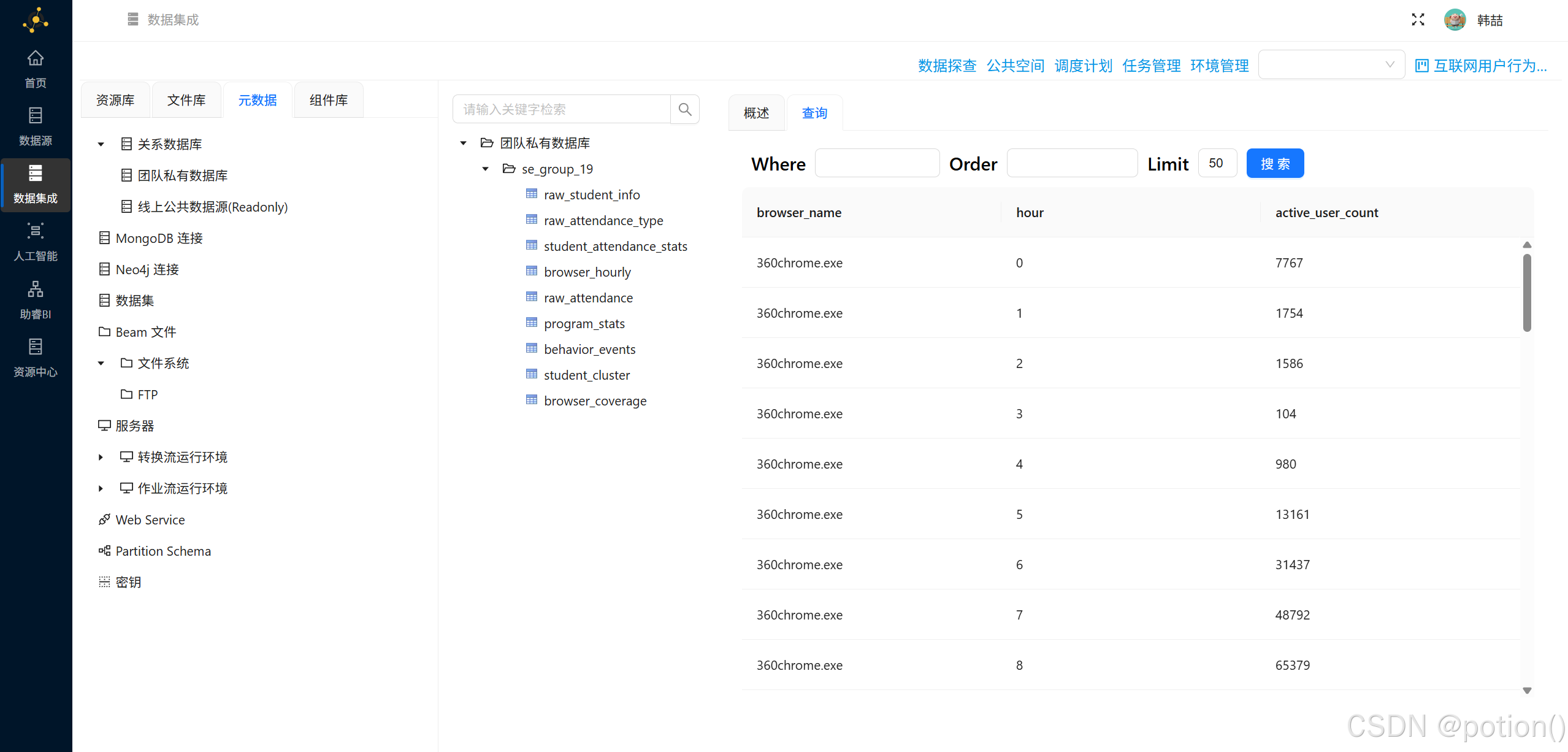
进入元数据→数据探查,分别查看
browser_coverage和browser_hourly数据是否正确。
四、实验结果与总结
实验结果
- 完成半结构化日志→结构化标准表
behavior_events。 - 统计得到
program_stats,确定浏览器为核心分析对象。 - 完成数据清洗、停留时长计算、日期 / 小时提取、多维度聚合。
- 输出两张核心表:
browser_coverage:各浏览器用户数与总使用时长。browser_hourly:各浏览器每小时活跃用户数。
实验总结
- 掌握半结构化日志解析的完整流程,能独立完成 TXT 文本到结构化表的转换。
- 熟练使用助睿 ETL 核心组件:获取文件名、Java 代码、字段选择、过滤、排序、分组、表输出。
- 理解数据加工逻辑:先结构化→再探索→再清洗聚合→输出分析宽表。
- 本次加工的数据可直接用于浏览器行为分析、用户画像、流失特征构建与可视化展示。