1. 摘要中文翻译
最近的研究越来越多地探索将大语言模型(LLM)作为推荐系统的新范式,这得益于其强大的可扩展性和丰富的世界知识。然而,现有的工作存在三个关键局限性:
- 大多数努力集中在召回(retrieval)和排序(ranking)上,而对提炼最终推荐结果至关重要的**重排(reranking)**阶段在很大程度上被忽视了;
- LLM 通常仅在零样本或监督微调设置下使用,其推理能力(特别是通过强化学习和高质量推理数据增强的能力)未能得到充分挖掘;
- 物品通常由无语义的 ID 表示,这在拥有数十亿标识符的工业系统中造成了巨大的可扩展性挑战。
为了填补这些空白,我们提出了 GR2 ,这是一个具有专为重排定制的三阶段训练流水线的端到端框架。首先,预训练的 LLM 在语义 ID 上进行中期训练,这些语义 ID 是通过一个唯一性 ≥99% 的分词器将无语义 ID 编码而成的。接下来,利用更强大的大规模 LLM,通过精心设计的提示和拒绝采样 生成高质量的推理轨迹(reasoning traces),并用于监督微调(SFT)以赋予模型基础推理技能。最后,我们应用了解耦剪切与动态采样策略优化(DAPO),利用专为重排设计的可验证奖励实现可扩展的强化学习(RL)监督。
在两个真实数据集上的实验证明了 GR2 的有效性:它在 Recall@5 指标上超过了目前最先进的 OneRec-Think 模型 2.4%,在 NDCG@5 上超过了 1.3%。消融实验证实,高级推理轨迹带来了显著的性能提升。我们还发现强化学习的奖励设计在重排中至关重要:LLM 倾向于通过保持原始物品顺序来"骗取奖励"(reward hacking),这促使我们设计了条件可验证奖励来减轻这种行为,从而优化重排性能。
1. 解决了什么问题?(背景与动机)
传统的推荐系统通常分为召回(从海量中捞出几百个)、排序(定个粗略顺序)和重排(最终精挑细选)。作者发现:
- 重排被忽视了:大家都去研究前两个阶段,但重排直接决定了用户最后看到什么。
- 模型"不爱思考":以前的模型只是生硬地输出结果,没有利用 LLM 的逻辑推理能力(即"思维链")。
- ID 没意义:如果只给物品编个数字号(如"物品 12345"),模型很难理解它的属性。
2. GR2 是如何工作的?(三阶段方案)
- 第一步:赋予物品"语义"
- 通过分词技术,把枯燥的数字 ID 转换成包含语义信息的 ID,让模型能通过 ID 就"读懂"物品的大致类别或特征。
- 第二步:教模型"学会思考"
- 用一个更强的大模型(老师)来写出推荐的理由(推理轨迹),然后教给小模型(学生)。这让模型在推荐时不仅给出排名,还能根据逻辑进行判断。
- 第三步:用强化学习"精益求精"
- 使用一种叫 DAPO 的强化学习算法。作者发现,如果奖励设计得不好,模型会投机取巧(比如为了不出错直接照抄输入顺序)。因此,他们设计了专门的"可验证奖励",强迫模型真正去优化排名。
3. 结果如何?
- 性能更强:在 Recall(召回率)和 NDCG(排名质量)这两个核心指标上,GR2 都打破了之前的纪录(超过了 OneRec-Think)。
- 推理有用:实验证明,让模型写出"推理过程"确实能显著提高它推荐的准确性。
总结: GR2 是一个让推荐模型通过"理解语义"、"学会推理"和"强化学习"来变得更精准的系统,特别是在决定最终展示顺序的"重排"环节表现优异。
1.介绍 中文翻译
推荐系统已成为各类在线平台中不可或缺的组成部分。它们通过智能地识别并展示符合用户兴趣和需求的物品,发挥着缓解信息过载的作用 (Ramanujam et al., 2025; Behdin et al., 2025; Deng et al., 2025)。在过去的十年中,深度神经网络被广泛用于建模用户反馈与海量物品及用户特征之间的复杂关系,这些特征通常通过大规模嵌入表(embedding tables)进行编码 (Liang et al., 2025; Luo et al., 2025; Zhang et al., 2024, 2022; Wang et al., 2021; Zhou et al., 2019)。最近,大语言模型(LLMs)凭借其通过模型缩放(scaling)实现性能持续提升的卓越能力、丰富的世界知识以及细腻的上下文理解能力,已成为推荐系统的一种变革性范式(transformative paradigm) (Zhou et al., 2025c; Zhang et al., 2025b; Zhao et al., 2024; Wu et al., 2024)。显著的例子包括:P5 (Geng et al., 2022),它在一个单一的 LLM 模型中统一了多种推荐任务;OneRec-Think (Liu et al., 2025),它通过微调 LLM 整合了召回和排序阶段;以及 PLUM (He et al., 2025),它通过适配预训练大语言模型,为 YouTube 提供可扩展且高效的推荐,提升了召回质量和系统性能。
提到的代表性模型简述
- P5: 它是首个尝试用"Prompt(提示词)"统一所有推荐任务的模型。无论是预测用户下一笔买什么,还是给物品写评论,都用同一个模型处理。
- OneRec-Think: 这是 Meta 这篇论文主要对比的对象。它的特点是在推荐过程中加入了一些"思考过程"(In-text reasoning),让模型在输出推荐结果前先生成一段分析文字。
- PLUM: 这是 Google 针对 YouTube 开发的模型,证明了大模型在处理超大规模(工业级)推荐任务时的可行性和效率。
这一段文字是论文的背景介绍,主要可以总结为以下三个核心要点:
推荐系统的初衷: 由于互联网信息极度丰富(信息过载),推荐系统通过智能识别用户兴趣,将最相关的物品精准展示给用户,已成为各类在线平台不可或缺的工具。
过去十年的主流技术(深度学习) : 在过去十年中,行业主要依靠深度神经网络 来处理海量数据。其技术核心是使用大规模嵌入表(Embedding Tables),将用户和物品的各种特征转化为数学向量,从而建模它们之间复杂的交互关系。
当前的行业变革(大模型时代): 随着技术发展,**大语言模型(LLM)**正在成为一种颠覆性的新模式。LLM 的优势在于:
- 可扩展性:模型规模越大,性能越强(Scaling Law)。
- 知识储备:拥有丰富的"世界知识"。
- 上下文理解:能更细腻地捕捉用户的意图。
- 全能性 :文中列举了 P5 、OneRec-Think 和 PLUM 等前沿工作,证明了 LLM 可以统一多种推荐任务、整合召回与排序阶段,并在 YouTube 这种工业级规模上实现落地。
一句话总结: 推荐系统正经历从"基于嵌入表的深度学习"向"基于大语言模型(LLM)的智能理解"的重大范式转移。
重排(Re-ranking)直接负责精炼和增强推荐结果,因此是现代推荐系统中至关重要的组成部分。尽管重排具有重要意义,但在最近基于 LLM 的研究方法中,这一阶段经常被忽视。此外,这些研究通常将 LLM 应用于 零样本(Zero-shot)场景,或在没有 推理轨迹(Reasoning Trace)的情况下对推荐数据集进行微调,从而未能充分利用模型的推理能力------特别是那些可以通过 强化学习(RL)和整合高质量推理数据来增强的能力。另一个普遍存在的局限性是依赖无语义物品标识符,这在工业环境中带来了巨大的可扩展性和适应性挑战,因为海量的物品 ID 会导致 LLM **词表(Vocabulary)**的不可控扩张。
这段话主要总结了当前 LLM 推荐系统的"三大遗憾",也就是本文 GR2 想要解决的痛点:
- 重排阶段被冷落:大家都在卷前面的召回和排序,却没人在重排这个关键点上发挥 LLM 的长处。
- 推理能力没被激发:现有的模型要么直接用(零样本),要么死记硬背(不带推理轨迹的微调),没有通过强化学习(RL)去教模型如何逻辑严密地思考。
- 物品 ID 太累赘:继续使用那种没意义的数字 ID(无语义标识符),导致系统在面对海量数据时效率极低。
总结一句话: 作者认为现在的 LLM 推荐系统"没用对地方"、 "脑子没转起来"且"命名太乱",这就是他们要推出 GR2 框架的原因。
为了解决上述局限性,我们推出了生成式推理重排器 (GR2) ,这是一个先进的基于 LLM 的推荐框架,它将物品的语义表示 与世界知识 及复杂推理相结合,以有效地对候选列表进行重排。GR2 围绕一个三阶段训练流水线构建,如附图 1 所示,该流水线专为大规模推荐系统中的重排需求而量身定制。
在第一阶段 ,预训练的学生 LLM (例如 Qwen3-8B)在受 OneRec-Think 启发的语义物品标识符 上进行中期训练(mid-training)。这些语义 ID 是使用专为实现至少 99% 唯一性而设计的分词器从无语义的原始物品 ID 转换而来的,使模型能够更好地捕捉物品语义,在不同物品空间中稳健地泛化,并确保可靠的物品可辨识度。
第二阶段 利用一个模型规模更大、功能更强大的教师 LLM (例如 Qwen3-32B)来生成高质量、层级化的推理轨迹 。这是通过针对重排问题精心设计的提示词(Prompts)和严耕的**拒绝采样(rejection sampling)实现的,以确保生成的轨迹既相关又富有信息量。这些推理轨迹作为监督微调(SFT)**的基础,赋予模型基础推理技能,并使其能够解释物品语义与用户偏好之间的联系。
在最终阶段 ,GR2 通过重新设计专为重排任务定制的奖励函数来适配 DAPO 算法。适配后的 DAPO 通过符合重排目标的自定义奖励函数提供可扩展的监督,进一步精炼学生 LLM 的推理能力,并增强其交付高度相关和个性化重排候选列表的能力。
① 学生/教师模型 (Student/Teacher LLM)
- 解释 :这是一种"知识蒸馏"技术。教师模型 通常很大、很聪明但运行慢(如 32B 参数);学生模型较小、运行快(如 8B 参数)。
- 目的:我们让聪明的老师先写出完美的推理步骤,然后让学生去模仿。最终我们只需要在系统中使用快速的学生模型。
② 中期训练 (Mid-training)
- 解释:这介于"预训练"(让模型学通用知识)和"微调"(让模型学具体任务)之间。
- 目的:模型虽然懂中文英文,但它不认识你公司的物品 ID。中期训练就是为了让模型在开始做推荐任务前,先花点时间熟悉一下这些"语义 ID"长什么样。
③ 拒绝采样 (Rejection Sampling) ------ "优中选优"
- 解释:教师模型虽然聪明,但偶尔也会胡言乱语。
- 操作:模型会生成很多条推理逻辑,我们只保留那些逻辑正确、能推导出正确结果的,把剩下的"拒绝"掉。这样微调数据才干净。
④ 监督微调 (SFT)
- 解释:这就是"手把手教学"。给模型看几万个"问题 + 教师给出的完美推理过程 + 正确答案",让模型学会这个套路。
⑤ DAPO 与 奖励函数 (Reward Function)
- DAPO:一种先进的强化学习算法。它的作用是让模型在没有标准答案的情况下,通过"不断尝试并获取奖励"来变得更聪明。
- 奖励函数:就像是考试的打分标准。在重排任务中,如果模型把用户真正喜欢的物品排到了最前面,我们就给它高分(正奖励),逼迫它向这个目标进化。
这段话主要介绍了 GR2 框架的**"三步走"进化路线图**:
- 第一步(换脑):把原来没意义的数字 ID 换成模型能读懂的"语义 ID",并让小模型(学生)先认认这些词。
- 第二步(开窍):请一个聪明的大模型(教师)写出为什么这么推荐的"逻辑过程",并让小模型反复练习这些逻辑,学会如何分析用户心理。
- 第三步(精进):通过强化学习(RL)和专门的重排评分标准,让模型在实战练习中不断磨练,直到它能给出一份完美的最终推荐清单。
1. 核心贡献中文翻译
- 与以往主要将 LLM 用于召回和后期排序的工作不同,我们研究并建立了专门为推荐系统重排阶段定制的 LLM 设计原则。
- 我们引入了一种将无语义物品标识符转换为语义 ID 的鲁棒方法,实现了 \\geq 99\\% 的唯一性。通过在语义 ID 与世界知识的混合数据上进行中期训练,我们使 LLM 能够识别这些丰富的表示并对其进行推理,有效地将物品语义与外部知识连接起来。
- 意识到推理在重排中的核心地位,我们开发了专门针对重排语境定制的提示词,以引导出高质量、层级化的推理轨迹 。我们采用拒绝采样来过滤噪声轨迹,随后在这些精选轨迹上对模型进行微调,以赋予其基础推理能力。
- 为了进一步增强模型的推理精通度,我们将 DAPO 算法与专门为重排场景设计的自定义奖励函数相结合。这一阶段提供了可扩展的、奖励驱动的监督,使 LLM 能够优化其推理过程并提供卓越的重排性能。
- 我们在两个真实数据集上对 GR2 进行了全面评估,结果证明了其卓越的性能:GR2 在 Recall@K 和 NDCG@K 指标上始终优于领先的基准模型 OneRec-Think。此外,消融实验证实了推理和强化学习的关键贡献,揭示了我们设计的更多见解。
① 定位明确:主攻"重排"
- 背景:之前的研究大多在想办法让 LLM 帮我们从 1 亿个商品里选出 1000 个(召回)。
- 创新:GR2 认为 LLM 这么聪明,更适合做"精挑细选"的工作。因此,他们专门为重排阶段总结了一套设计规则。
② 身份转换:语义 ID (Semantic ID)
- 技术细节:作者提到唯一性 \\geq 99\\%。这意味着几乎每一个不同的物品都有一个独一无二的"名字",不会搞混。
- 桥梁作用:通过中期训练,模型把物品的 ID(内部代号)和它读过的书、看过的百科(外部世界知识)联系在了一起。比如,模型看到 ID 知道这是"iPhone",同时它脑子里关于"苹果公司"、"智能手机"的知识也会被激活。Contributions
③ 逻辑训练:高质量推理轨迹
- 拒绝采样(Rejection Sampling):这就像是批改作业。大模型(老师)写了很多解题步骤,作者只挑出那些逻辑通顺、答案正确的步骤给小模型看。
- 层级化(Hierarchical):推理不是乱写的,而是分层次的(例如:先看用户大类偏好,再看具体属性匹配,最后定结论)。
④ 强化学习:DAPO 算法
- 奖励驱动:这是 GR2 变强的关键。作者设计了一个特殊的"计分器",专门看重排的结果好不好。如果模型通过思考把用户最想要的排到了第一名,计分器就给高分,模型就会朝着这个方向进化。
③ 战绩显赫:Recall@K 与 NDCG@K
- Recall@K(召回率):用户真正喜欢的那个东西,有没有出现在你排的前 K 个位置里?
- NDCG@K(排名质量):不仅要出现,位置越靠前得分越高。
- OneRec-Think:这是当时最强的竞争对手,而 GR2 全面超越了它。
- 消融实验(Ablation Studies):这是一种"拆零件"实验。作者把"推理"拆掉看看效果,再把"强化学习"拆掉看看效果,结果发现这两个零件都至关重要。
2 符号化 中期训练Tokenized Mid-Training
在本节中,我们将介绍构建基于 LLM 的生成式推荐模型的关键组件:分词(Tokenization)与中期训练(Mid-Training) 。为了提高**码本(Codebook,原文误写为 Cookbook)**的利用率,我们引入了针对 SID(语义 ID) 生成的增强方案。为了获得生成式召回器(Generative Retriever),我们借鉴了目前最先进的生成式召回器的中期训练工作流,即在 LLM 上进行多任务后训练。
这一节中,作者介绍了构建一个 基于 LLM 的生成式推荐模型 所需要的两个关键组成部分:
第一,Tokenization,也就是把商品转成 token / 语义 ID。
第二,Mid-Training,也就是在预训练 LLM 和最终任务微调之间,再做一次推荐领域的中间训练。为了提升 codebook 的使用效率,作者提出了对 SID 生成方法 的改进。
为了得到一个生成式检索器,作者借鉴了已有最先进的 LLM 生成式推荐模型的 mid-training 流程,也就是在 LLM 上进行多任务后训练。
③ Generative Recommendation Model (生成式推荐模型)
- 背景:传统的推荐系统是给物品"打分"。
- 解释:生成式模型是像写字一样,"写"出它推荐的物品 ID。这种方式更符合大模型的工作直觉。
④ Codebook utilization,码本利用率 !
- 背景知识:在生成语义 ID 时,会用到一个"码本"(Codebook,可以理解为一本字典,里面存了很多语义向量)。
- 术语解释 :如果在生成 ID 时,这本"字典"里只有前 10 页被用到,后 990 页都没人用,这叫利用率低。Codebook utilization 就是指如何让这本字典里的每一个词都被充分利用,从而让生成的 ID 更精准。
⑤ Generative Retriever (生成式召回器)
- 解释:在推荐的第一步,需要从海量库里"捞"出候选物品。用生成 ID 的方式来捞物品的模型,就叫生成式召回器。
⑦ Multi-task post-training (多任务后训练)
- 解释:指在模型预训练结束之后,同时给它安排好几项"作业"(比如:预测下一个买什么、预测商品的描述、预测商品分类等),让模型在多种任务中全面理解推荐领域的知识。
这一段话是第二章的"预告"。作者告诉我们,为了让 LLM 变成一个合格的推荐专家,他们做了两件大事:
- 改进了 ID 生成方式:通过优化"码本"的利用率,让生成的语义 ID(SID)质量更高,能更准确地代表每一个商品。
- 设定了训练流程:他们参考了目前业界最强的做法,通过让模型同时学习多种不同的推荐相关任务(多任务训练),来完成"中期训练",从而让模型真正"入行"。
总结一句话: 这一段是为第一阶段(语义 ID 与中期训练)定调子,强调了他们如何改进 ID 的质量以及如何训练模型。
2.1 分词器与语义 ID (SID)
被称为语义 ID (SID) 的技术在推荐系统中已被广泛采用,用以缓解由于海量物品和用户词表导致的大规模嵌入表(Embedding Tables)的可扩展性问题。开创性工作 TIGER (Rajput et al., 2023) 是首个将该技术应用于序列推荐的研究。从高层面上看,给定一个物品的文本特征 x(如标题、类别),分词器将其映射为一个离散整数序列,即一种紧凑的符号表示,定义为:
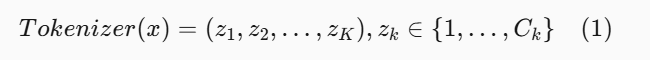
其中 C_i 是第 i 个码本(Codebook)的大小。该分词器的核心是一个 残差量化变分自编码器 (RQ-VAE) Residual-Quantized Variational Autoencoder。由于 SID 本身不是本文的主要贡献,我们将详细的公式表达放在附录 A 中。
在传统的推荐系统里,如果你有 1 亿个商品,你就要在内存里开一个 1 亿行的超级大表。每新加一个商品,表就变大一点。
- 问题:内存装不下,而且新商品和旧商品之间没有任何逻辑联系。
- 解决思路 :能不能像邮政编码 一样给商品起名字?
- 第一位 z_1 代表省份(大类)
- 第二位 z_2 代表城市(子类)
- ...
- 结果 :这就是 SID。这样大模型只需要记住"省份、城市"这些基本词汇(码本),就能通过排列组合认出几十亿个商品。
3. 结合附录 A:详解 RQ-VAE 的工作原理
很多同学看到 RQ-VAE(残差量化变分自编码器)就头大。我们用**"雕刻艺术"**来打比方,结合附录 A 的公式来拆解它:
第一步:特征提取 (Embedding) ------ 准备石料
首先,把物品的文字描述 x(比如"欧莱雅补水洗面奶")通过一个编码器变成一个高维向量 h(一串反映特征的小数)。这在附录 A 中定义为:h = f_{enc}(x)
第二步:层级量化 (Residual Quantization) ------ 逐级雕刻
我们要把这个向量 h 变成 K 个整数 (z_1, z_2,..., z_K)。
粗雕 (z_1): 我们手里有一本字典(码本 ),里面存了几百个基本的形状。我们找一个最像 h 的形状,记为 z_1。
算残差 (Residual) : 第一步不可能刻得百分百完美,剩下的误差就是"残差" r_2:
r_2 = h - {第一步刻出的形状}
精雕 (z_2, z_3): 拿着剩下的这点误差 r_2,再去第二本字典里找最像的形状,记为 z_2。以此类推,直到刻完 K 步。
第三步:还原 (Reconstruction) ------ 拼装成品
最后,把这 K 块拼在一起,就得到了一个和原始向量 h 非常接近的还原向量 。
h ≈ q1 + q2 + q3 + q4
4. 总结:这样做的好处
- 层级关系:z_1 通常代表大类别,z_K 代表微小的细节。
- 节省空间:大模型不需要存 1 亿个独立 ID,只需要存 K 本小字典(码本)即可。
- 语义理解:因为 SID 是从文字描述里"雕"出来的,所以相似的商品(比如两款不同的洗面奶)它们的 SID 前几位会非常相似。大模型一看开头,就知道它们是一类东西。
RQ-VAE 的作用是把商品变成一种 语义化、离散化、可组合的 token 表示。它的好处是:
第一,离散化。
LLM 可以像处理词一样处理这些 SID token。
第二,可组合。
少量 code token 可以组合出大量商品 SID。
第三,保留语义。
因为 SID 是从商品文本向量量化来的,所以它不是完全随机 ID,而是和商品语义有关。
在 2.1 节中,作者介绍了 Semantic ID 的基本定义。给定商品文本特征 xxx,tokenizer 将其映射为一个长度为 KKK 的离散整数序列 (z1,z2,...,zK)(z_1, z_2, ..., z_K)(z1,z2,...,zK),其中每个 zkz_kzk 来自对应层级的 codebook。该 tokenizer 的核心是 RQ-VAE,它通过残差量化将连续商品语义向量转换为离散 token 表示,从而缓解海量 item ID 带来的 embedding table 扩展问题,并使 LLM 能够以生成 token 的方式处理推荐任务。
2.2 对比损失 (Contrastive Loss)
编码物品共同参与历史(co-engagement history,即哪些物品常被同一个用户点击或购买)的一种有效方法是应用对比损失。对于第 i 个锚点物品(anchor item)x_i,其对比损失表示为:
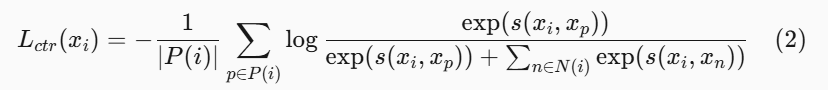
其中,P(i) 表示共同参与(正样本)的索引集合,N(i) 表示随机抽样的非共同参与(负样本)的集合。两个物品 x_i 和 x_j 之间的相似度定义为经温度参数 (T > 0)缩放后的余弦相似度:

一种有效地编码 item co-engagement history 的方法,是使用 contrastive loss,对比损失。
这里有两个关键词:
item co-engagement history :商品共同交互历史。
contrastive loss:对比学习损失。什么是 item co-engagement?
在推荐系统里,商品之间的关系不只来自文本。
比如从文本上看:护发素 A 和 护发素 B 很像,这是文本语义相似。
但推荐系统还关心用户行为:
很多买了护发素 A 的用户,也买了发膜 C
很多买了洗发水 D 的用户,也买了护发精油 E
这种"被同一批用户共同点击、购买、收藏、观看"的关系,就叫 co-engagement。
在电商推荐里,co-engagement 可以理解为:
两个商品经常被同一个用户或相似用户共同交互,那么它们在推荐意义上是相关的。
为什么 SID 需要 co-engagement?
前面 2.1 讲的 SID 主要来自商品文本特征,比如 title、category、description。
但只看文本会有局限。
例如:
商品 A:洗发水 商品 B:护发素 商品 C:吹风机 商品 D:面霜从文本语义上看,洗发水和护发素最接近。
但从用户购买序列看,买完洗发水和护发素后,用户可能下一步更容易买吹风机、发膜、护发精油。
也就是说:文本相似 ≠ 推荐相关
所以作者希望 tokenizer 生成的 SID 不仅保留文本语义,还能反映用户交互行为中的推荐关系。
对比损失在这里做什么?
对比学习的核心思想很简单:
让"相关的商品"在向量空间中更近,让"不相关的商品"更远。
在这篇论文中:
正样本 positive items :和当前商品有共同交互关系的商品。
例如很多用户同时买过 A 和 B,那么 B 就可以作为 A 的正样本。
负样本 negative items :随机采样的、没有共同交互关系的商品。
例如 A 是护发素,随机采到一个篮球鞋或车载杯架,它可能就是负样本。
训练目标就是:
举一个推荐系统例子
假设 anchor item 是:A:L'Oreal 洗发水
从用户行为日志中发现,经常和它共同购买的商品有:
B:L'Oreal 护发素
C:发膜
D:护发精油
这些就是正样本。
随机负样本可能是:
E:篮球鞋 F:汽车脚垫 G:手机壳对比损失希望模型学到:
A 和 B/C/D 的向量距离更近 A 和 E/F/G 的向量距离更远这样训练出来的商品表示
h更符合推荐需求。
这一小段的核心
这一小节开头的意思是:
仅靠商品文本生成 SID 还不够,因为推荐系统真正关心的是用户行为中的商品相关性。作者因此引入 contrastive loss,把共同交互过的商品拉近,把无关商品推远,使商品表示和最终 SID 更适合推荐任务。
你汇报时可以这样说:
在 2.2 节中,作者进一步引入对比学习来编码商品之间的共同交互关系。具体来说,对于一个 anchor item,它把用户行为中共同交互过的商品作为正样本,把随机采样的非共同交互商品作为负样本,通过 contrastive loss 拉近正样本、推远负样本,从而使 tokenizer 学到的商品表示不仅具有文本语义,也包含推荐行为语义。
公式2:
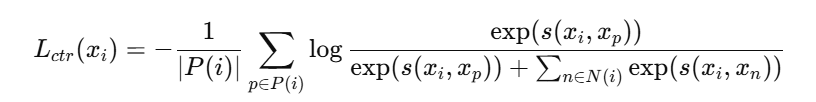
-
xi:表示第 i个商品,也就是当前的 anchor item。
-
P(i):表示和 xi 有共同交互关系的 正样本集合。P(i) 表示 co-engaged positive samples,也就是共同交互过的正样本商品。
-
N(i):表示负样本集合,也就是随机采样的一些非共同交互商品。N(i) 是 randomly sampled non-co-engaged negative samples。
-
s(xi,xp):表示 anchor 商品 xi 和正样本 xp 的相似度。
s(xi,xn):表示 anchor 商品 xi 和负样本 xn 的相似度。
相似度公式后面公式 3 会讲,简单说就是 temperature-scaled cosine similarity,也就是带温度系数的余弦相似度。
这个公式在做什么?它的核心可以理解成一个分类问题:
给定 anchor 商品 xix_ixi,模型要从"一堆候选商品"里认出哪个是它的正样本。
公式 2 本质上就是:
对每个 anchor 商品,把 co-engaged 商品当成正样本,把随机非 co-engaged 商品当成负样本。模型通过 softmax 形式的对比损失,让 anchor 更接近正样本,更远离负样本。
汇报:公式 2 定义了商品级别的 contrastive loss。对于每个 anchor item xix_ixi,作者将与其有共同交互关系的商品集合 P(i)P(i)P(i) 作为正样本,将随机采样的非共同交互商品集合 N(i)N(i)N(i) 作为负样本。损失函数鼓励 anchor item 与正样本之间的相似度高于与负样本之间的相似度,从而将用户行为中的 co-engagement 信息编码进商品表示中。这样生成的 SID 不仅反映文本语义,也更符合推荐任务中的行为相关性。这一小节 2.2 的整体含义
2.2 小节其实是在给 tokenizer 的训练加入用户行为信号。
前面的 SID 主要来自商品文本语义,但推荐任务不只需要文本相似,还需要行为相关。
所以作者引入 contrastive loss,让共同交互商品更近,非共同交互商品更远。
也就是说,商品向量 hhh 不只是学成:文本上像不像。
还要学成:推荐行为上相不相关。
这样后面用 RQ-VAE 量化得到的 SID,也会更适合推荐任务。
做完对比损失训练后,我们的商品向量 h 就进化了:
- 它包含了文字语义 (知道自己是洗发水)。
- 它包含了行为语义 (知道自己经常和护发素出现在一起)。
这样生成的语义 ID(SID)就会更懂用户的真实需求。
2.3 Techniques for Balanced Codebook Utilization
翻译:2.3 平衡码本利用率的技巧
训练 RQ-VAE 的一个关键挑战是codebook collapse码本崩溃,即只有一小部分码本条目被活跃使用,而其余条目则处于"死亡"状态。这会导致重建质量差,并且生成的语义 ID 碰撞率(即不同物品共享相同 ID)很高。我们采用了五种互补技术来确保码本的平衡利用。
这会导致两个问题:
- 重构质量变差
因为可用 code 太少,模型很难准确表示不同商品的语义向量。- 生成的 SID 碰撞率变高
很多不同商品会被分配到相同或非常相似的 SID。(不同商品被编码得太像,甚至完全一样,模型无法区分它们。)所以这篇论文特别强调 SID uniqueness ,也就是 SID 唯一率。作者希望不同商品尽可能拥有不同 SID,并且后面实验中目标是达到 ≥99% uniqueness 。
一个好的 SID 至少要满足两个要求:
**第一,语义上有用。**相似或相关商品的 SID 应该体现某种语义关系。
**第二,区分度足够高。**不同商品不能大量撞 SID,否则无法做精确推荐。
3. 五大招数详细拆解
① RQ-K-means 初始化(面向残差量化结构的 k-means 初始化)
- 做法:不要随机乱填字典里的初始值。先用 K-means 聚类算法给现有的商品数据分个类,根据类别的中心点来填字典的初始内容。
- 目的:让字典从第一天起就贴合数据的实际分布。
② 指数移动平均 (EMA) 更新
- 做法:更新字典内容时,不要用剧烈的"梯度下降"算法,而是用温和的"移动平均"方式。
- 公式理解:新字典 = 0.99 \\times 旧字典 + 0.01 \\times 本次新学到的内容。
- 目的:让学习过程更平稳,防止某个条目突然被改得面目全非,导致大家都不认它了。Techniques for Balanced Codebook Utilization
③ 多样性损失 (Diversity Loss)
- 做法:在算分的时候,加一个惩罚项。如果模型把所有物品都挤在一个条目里,就扣分。
- 目的:强迫模型把物品均匀地分配到字典的各个条目中,雨露均沾。
④ 死码重置 (Dead Code Reset) ------ 非常重要
- 做法 :模型会盯着字典。如果发现某个条目(比如数字"7")已经连续好几千次没被翻过牌子了(这就是死码),模型会强制把这个条目重置。
- 怎么重置?:找到目前最难区分、分得最烂的一批物品,强行把这个死码分配给它们。
- 目的:变废为宝,让不干活的条目重新上岗,解决最难的问题。Techniques for Balanced Codebook Utilization
⑤ 随机最后层级 (Random Last Levels)
- 做法:语义 ID 通常有 4 层。前 3 层严格按照语义来(保证大方向是对的),最后一层在训练时随机给一个。
- 目的 :这是为了暴力提升唯一性。即便两个东西非常像,前 3 层都一样,最后一层的随机化也能强行把它们分开,确保每个商品都有一个全球唯一的 ID。
(1)RQ-K-means Initialization
前面我们说过,codebook 里面存的是很多个可学习的原型向量。
比如一个 codebook 有 256 个 code:那训练开始时,这些 code 向量要先有一个初始值。
最简单的方式是:随机初始化。也就是随便生成一些向量作为初始 code。
但问题是:随机初始化可能很差。
为什么随机初始化不好?
如果 codebook 随机初始化,有些 code 可能离所有商品都很远:
训练时,商品会倾向于选择距离自己最近的 code。
如果某些 code 一开始就离所有商品很远,它们很可能从一开始就没人选,后面也很难被训练到,于是变成 dead code。
这就容易导致前面讲的:codebook collapse
也就是少数 code 被大量使用,大量 code 死掉。
k-means++ 初始化在做什么?
k-means++ 是一种更聪明的聚类中心初始化方法。
它的大意是:不要随机乱放 code,而是根据真实商品向量的分布,把 code 初始化到数据比较集中的地方,并尽量让不同 code 分散开。
为什么叫 RQ-K-Means?
因为这里不是普通的单层 k-means,而是和 Residual Quantization,残差量化 结合。
我们之前说过,RQ-VAE 是多层 codebook:
第 1 层 codebook:近似原始向量 h
第 2 层 codebook:近似第 1 层剩下的残差
第 3 层 codebook:继续近似残差
所以初始化时也要逐层进行:
第一层,对原始商品向量聚类:
第二层,对第一层没表示好的残差聚类:
第三层,对第二层之后剩下的残差聚类:
所以叫 RQ-K-Means:它是面向残差量化结构的 k-means 初始化。
用推荐系统例子理解
假设我们有 100 万个商品,如果随机初始化 codebook,可能很多 code 没有落在这些商品语义区域附近。但 RQ-K-Means 会先看这些商品向量的真实分布,然后把 code 初始化到比较合理的位置。这样每个 code 一开始就有机会被商品选中,训练更稳定,codebook 使用更均衡。
RQ-K-means Initialization 是为了给 codebook 一个好的起点。它不是随机初始化 code,而是根据商品向量和残差的真实分布,用 k-means++ 初始化每一层 codebook,从而减少 dead code 和 codebook collapse。
汇报:第一种技术是 RQ-K-means initialization。作者没有随机初始化 codebook,而是使用 k-means++ 对商品向量及其逐层残差进行聚类,用聚类中心初始化各层 codebook。这样可以让 code 向量在训练初期就覆盖真实商品语义空间,降低 dead code 出现的概率,并提升 codebook utilization。
(2)EMA Codebook Updates 指数移动平均 (EMA) 更新
② 指数移动平均 (EMA) 更新
- 做法:更新字典内容时,不要用剧烈的"梯度下降"算法,而是用温和的"移动平均"方式。
- 公式理解:新字典 = 0.99 旧字典 + 0.01 本次新学到的内容。
- 目的:让学习过程更平稳,防止某个条目突然被改得面目全非,导致大家都不认它了。Techniques for Balanced Codebook Utilization
他们不是直接用梯度下降来更新 codebook entries,而是使用 指数移动平均 EMA,Exponential Moving Average 来更新第 kkk 个 codebook。
具体来说,先通过优化器得到一个临时更新后的 codebook:e~(k)
然后再用 EMA 方式,把旧 codebook 和新 codebook 平滑融合:e(k)←γe(k)+(1−γ)e~(k)
其中 γ是衰减系数,取值通常在 0.95 到 0.99 之间。
e(k):表示第 k 层 codebook 里的 code 向量。
e~(k):表示通过优化器计算出来的"临时新版 codebook"。也就是说 如果直接按梯度更新,codebook 会变成这个样子。
γ:是 EMA 的平滑系数。比如:γ=0.99,enew=0.99eold+0.01e~
也就是说,新 codebook 大部分保留旧值,只吸收一点点新变化。
EMA 的核心思想是:
不要让 codebook 一下子剧烈变化,而是慢慢、平滑地更新。
为什么 codebook 不能更新太剧烈?
因为 RQ-VAE 里商品和 codebook 的关系是"最近邻选择"。
一个商品会选择距离自己最近的 code。
如果 codebook 每一步变化太大,就会出现:
这一步商品 A 选择 code 7
下一步 code 7 跑远了,商品 A 改选 code 33
再下一步 code 33 又跑远了,商品 A 又改选 code 2
这样分配会非常不稳定。
不稳定会进一步导致:少数 code 被越来越多商品选中
其他 code 慢慢没人选
codebook collapse 加重
所以作者用 EMA 让 codebook 更新更平滑,避免某些 code 突然失效。
公式解释:
第一步,先按普通优化器算一个"候选更新":
e~(k)←Optimizer(e(k),∇e(k)L)意思是:
根据当前损失 LLL 对 codebook 的梯度,算出一个临时更新结果。
第二步,不直接采用它,而是做平滑:
e(k)←γe(k)+(1−γ)e~(k)意思是:
新 codebook = 大部分旧 codebook + 小部分临时新 codebook。
为什么 EMA 在这篇论文里重要?
因为作者后面在 Table 2 里做了 ablation。
他们发现:
EMA Update 是防止 codebook collapse 最关键的技术。
论文在 5.2.1 中总结说,开启 EMA 后,平均 SID uniqueness 从 31.32% 提升到 97.50% ,提升约 66.2%,是最有影响的技术。
也就是说,没有 EMA 的时候,很多 codebook 配置会严重坍塌,SID 唯一性很差;有 EMA 后,codebook 使用明显更稳定。
这一段你可以怎么记?
EMA Codebook Updates 的作用是让 codebook 更新更稳定。它先通过梯度得到一个临时更新结果,再用指数移动平均将旧 codebook 和新结果平滑融合,避免 code 向量剧烈移动,从而减少 dead code 和 codebook collapse。
汇报时可以这样说
第二种技术是 EMA codebook update。与直接用梯度下降更新 codebook 不同,作者先计算一个临时更新后的 codebook,再使用指数移动平均将旧 codebook 与临时更新结果平滑融合。这样可以避免 code 向量在训练过程中剧烈震荡,使商品到 code 的分配更加稳定。实验表明,EMA 是提升 SID 唯一性和防止 codebook collapse 的关键技术。
③ 多样性损失 (Diversity Loss)、均匀使用损失
- 做法:在算分的时候,加一个惩罚项。如果模型把所有物品都挤在一个条目里,就扣分。
- 目的:强迫模型把物品均匀地分配到字典的各个条目中,雨露均沾。鼓励每个 codebook 里的 code 尽量都被使用,而不是只用少数几个 code。
公式 6:每个 code 被使用的比例
论文先定义:
pk,j:第 jjj 个 code 在当前 batch 里的使用比例。
公式 7:Diversity Loss
论文定义:
对每个 codebook,计算所有 code 使用比例的平方和,然后乘上一个权重 λdiv
均匀是平方和小,不均匀时平方和更大。而训练时是要 最小化 loss,所以模型会被鼓励让 p更均匀。
这和推荐系统有什么关系?
如果 codebook 使用不均匀,大量商品会挤到少数几个 code 上。
加入 diversity loss 后,模型会受到额外约束:不要总是用那几个热门 code,要尽量把商品分散到更多 code 上。这样可以提高 SID 的区分能力,减少 collision。
但这里有一个细节:它不是越强越好
Diversity Loss 的目标是让 code 使用更均匀,但它也可能带来副作用。
如果强行让所有 code 都均匀使用,可能会破坏真实语义分布。
比如电商平台上,护肤和服装商品本来就很多,某些冷门类目商品本来就少。
如果强行要求所有 code 使用一样多,可能会让语义相近的商品被硬拆开,或者让不相似的商品被挤到一起。
所以 diversity loss 一般只是一个正则项,用 λdiv 控制强度。
论文后面的实验也发现,Diversity Loss 的效果并不是最关键的。作者在 5.2.1 总结说,Diversity Loss 影响很小,平均只带来约 +0.6% 的 uniqueness 提升,说明 EMA 已经提供了比较充分的 codebook utilization。
这一段的核心
你可以这样理解:
Diversity Loss 是一个显式鼓励 codebook 使用均匀的正则项。它统计当前 batch 中每个 code 的使用比例,如果少数 code 被过度使用,平方和就会变大;训练最小化这个损失,就会推动模型更均匀地使用 codebook,从而缓解 codebook collapse 和 SID collision。
汇报时可以这样说
第三种技术是 diversity loss。作者统计每个 codebook 中各个 code 在 mini-batch 内的使用比例 pk,j,并最小化这些比例的平方和。由于平方和在分布均匀时最小,该正则项可以鼓励 codebook entries 被更均匀地使用,从而减少 dead code 和 SID 碰撞。不过实验表明,它的贡献相对有限,说明在该设置下 EMA update 已经是更核心的稳定因素。
④ 死码重置 (Dead Code Reset) ------ 非常重要
- 做法 :模型会盯着字典。如果发现某个条目(比如数字"7")已经连续好几千次没被翻过牌子了(这就是死码),模型会强制把这个条目重置。
- 怎么重置?:找到目前最难区分、分得最烂的一批物品,强行把这个死码分配给它们。
- 目的:变废为宝,让不干活的条目重新上岗,解决最难的问题。Techniques for Balanced Codebook Utilization
作者会记录每个 codebook entry 连续多少个 batch 没有被使用。
如果某个 code 连续超过 τ 个 batch 都没有被用到,就用一个 hard sample 来重新初始化它。这里的 hard sample 指的是:在当前 codebook 下重构误差最大的样本。
Dead Code Reset 怎么做?
论文里的公式是:
ek←ri∗其中:i∗=argmaxi∥ri−ezi∥22
我们先不急着看公式,先说白话。
它做的是:
- 检查哪个 code 长时间没被使用;
- 找到当前 batch 中 最难被表示好的商品样本;
- 把这个 dead code 重新初始化到这个难样本的残差位置;
- 让这个 code 以后有机会被类似样本使用。
举个推荐系统例子
假设平台里大多数商品是:护肤品、服装、鞋子、日用品
但也有一些比较特殊的商品:汽车脚垫、车载香薰、宠物饮水机、户外帐篷
如果 codebook 训练不充分,模型可能主要用 code 去表示热门大类,而特殊商品表示得很差。
比如某个汽车用品商品的重构误差很大:汽车脚垫的原始语义向量 h,和当前 code 组合重构出来的向量 h_hat,差距很大。这说明当前 codebook 不太会表示这类商品。
这时如果有一个 code 已经死掉了,长期没人用,Dead Code Reset 就会把它重新放到这个难样本附近。
也就是说:dead code 233,原来没人用,现在被重新初始化到"汽车脚垫"残差附近。这样以后类似汽车用品的商品,就可能开始使用 code 233
为什么选择"重构误差最大的样本"?
因为重构误差大说明:当前 codebook 对这个样本表示得不好。
既然某个 code 已经没人用,那就让它去服务当前最需要帮助的样本。
这比随机重置更合理。
随机重置可能又把 code 放到一个没用的位置;
而用 hard sample 重置,可以更快提升 codebook 覆盖能力。
公式怎么理解?
论文写:ek←ri∗ 意思是:如果第 k 个 code 是 dead code,就把它重新设置为某个 hard sample 的残差向量。
这里 ri 是样本 i的残差,ezi是它当前选择的 code 向量。
∥ri−ezi∥22 表示当前 code 对这个残差的重构误差。然后:i∗=argmaxi∥ri−ezi∥22 就是找出误差最大的那个样本。
所以整件事就是:找出当前表示最差的样本,把死掉的 code 移过去,让它帮助表示这个样本。
这个方法一定好吗?
不一定。直觉上它很合理,因为它能复活 dead code。
但论文后面的实验发现,Dead Code Reset 的效果并不总是正向的。
在 5.2.1 的总结里,作者说 Dead Code Reset 反而有轻微负面影响,平均约 -4.0%。他们推测原因是:重置 unused codes 可能会扰乱已经学到的表示。
为什么会扰乱?
因为某个 code 虽然暂时没人用,但它的位置可能仍然有潜在意义。
突然把它移动到 hard sample 附近,可能会让局部表示空间发生变化,导致已有商品分配不稳定。
这一段的核心
你可以这样理解:
Dead Code Reset 是一种"复活死 code"的机制。模型会追踪每个 code 连续未被使用的 batch 数,如果超过阈值 τ\tauτ,就将该 code 重新初始化为当前重构误差最大的 hard sample 的残差向量。这样可以提升 codebook 覆盖能力,但也可能扰乱已学到的表示,因此实验中效果并不稳定。
汇报时可以这样说
第四种技术是 dead code reset。作者记录每个 code 连续未被使用的次数,当某个 code 超过阈值 τ 仍未被使用时,就将其重置为当前重构误差最大的样本残差。该方法的目标是复活 dead codes,使它们重新参与表示难以重构的商品。不过实验结果显示,该机制可能对 SID 唯一性有轻微负面影响,说明频繁重置可能会破坏已有的 codebook 结构。
⑤ 随机最后层级 (Random Last Levels)随机化最后几层 code / 随机最后层
- 做法:语义 ID 通常有 4 层。前 3 层严格按照语义来(保证大方向是对的),最后一层在训练时随机给一个。
- 目的 :这是为了暴力提升唯一性。即便两个东西非常像,前 3 层都一样,最后一层的随机化也能强行把它们分开,确保每个商品都有一个全球唯一的 ID。
这个技术在这篇论文里非常关键,因为作者后面实验发现:
所有达到 ≥99% SID 唯一率的配置,都用了 Random Last Level。对于前面的层:正常选择距离残差最近的 code
对于最后几层:不再选最近的 code,而是随机选一个 code
为什么这样能提高唯一性?
因为前几层主要保留语义,最后几层用来增加区分度。
假设两个商品很相似:L'Oreal 洗发水、Pantene 洗发水
正常情况下,它们可能前几层都一样:这就发生 SID collision。
如果最后一层随机分配,这样它们前面语义相同,但最后一层不同,从而避免撞 SID。
这会不会破坏语义?
会有一点风险,所以作者只随机 最后几层,不随机前面层。
论文里的直觉是:
前面层捕捉粗粒度语义,比如商品类型;后面层编码更细的细节。随机化最后 M 层,用一些重构精度换取更高的 SID 唯一性。
也就是说:前面层:负责语义。后面层:负责区分
这样既保留相似商品的语义接近性,又提高了唯一性。
和前面几种方法有什么区别?
前面几种方法主要是训练 codebook:
RQ-K-means:让初始化更合理 EMA:让 codebook 更新更稳定 Diversity Loss:鼓励 code 使用均匀 Dead Code Reset:复活长期不用的 code而 Random Last Levels 更像是在 SID 生成阶段增加随机区分度。
它不是让 codebook 自己学得更好,而是直接通过随机最后几层减少 collision。
为什么它特别适合大规模推荐?
在工业推荐系统里,商品数量可能非常巨大,很多商品文本和语义高度相似。
比如:
同品牌不同容量的洗发水 同款不同颜色的衣服 同系列不同尺码的鞋子 同型号不同包装数量的商品这些商品在语义向量上非常近,很容易被 RQ-VAE 分到相同 SID。
如果 SID 相同,生成式推荐模型就无法区分它们。
Random Last Levels 可以给这些高度相似的商品额外分配不同尾部 token,从而提升唯一性。
但它的代价是什么?
代价是:
最后几层不再完全由语义最近邻决定,所以重构质量可能下降。
论文也说,这是在:reconstruction fidelity 和:SID uniqueness 之间做权衡。
也就是:语义重构更准确 vs 商品 ID 更唯一
推荐系统中,尤其是生成式推荐中,唯一性非常重要。
因为如果两个商品 SID 一样,模型生成 SID 后无法唯一映射到具体商品。
这一段的核心
你可以这样理解:
Random Last Levels 是在生成 SID 时,对最后 MMM 层 code 进行随机分配。前面层仍通过最近邻量化保留主要语义,最后层通过随机 code 增加区分度,从而显著降低 SID collision,提高 SID uniqueness。它牺牲了一部分重构精度,但换来了更高的商品唯一可识别性。
汇报时可以这样说
第五种技术是 Random Last Levels。作者认为 SID 的前几层主要承载粗粒度语义,而后几层更多表示细粒度差异。因此,在推理阶段,前 L−M层仍按照最近邻残差量化选择 code,而最后 M 层则随机选择 code。这样可以在基本保留商品语义的同时,为相似商品引入额外区分度,从而显著提高 SID 唯一率。实验表明,所有达到 99% 以上唯一率的配置都使用了该技术。
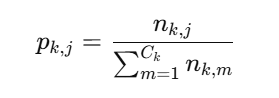
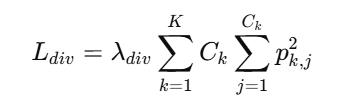
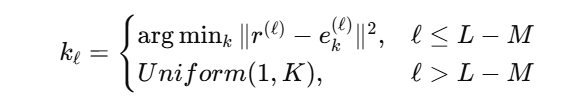
生成好 SID 之后,怎么让 LLM 学会理解这些 SID。
这一小节要解决的问题是:
SID 已经生成好了,但 LLM 一开始并不认识这些 SID token。那怎么让 LLM 理解这些 SID,并把它们和自然语言、商品语义、用户行为联系起来?
这就是 Mid-Training 要做的事。
翻译:TIGER 这类方法是在 Semantic ID 序列 上训练一个自回归模型。
也就是说,它主要让模型学习:用户历史 SID 序列 → 下一个商品 SID
但是,在大语言模型时代,利用预训练语言模型中已经包含的 世界知识,变成了一个重要方向。
为此,快手提出的 OneRec-Think 为预训练 LLM 引入了一个 mid-training 阶段。
这个阶段被称为:item alignment,商品对齐阶段
这是一个关键设计,它使 LLM 能够把推荐系统中的知识和语言,也就是 Semantic IDs,与 LLM 原本的语言空间和世界知识对齐起来。
mid-training 阶段的核心思想是:
把 Semantic IDs,也就是 SID,和自然语言 token 交织在同一个序列中。
然后通过 next-token prediction,下一个 token 预测目标,来优化 SID 的 embedding table。
这段在对比什么?
作者在对比两种思路。
第一种:传统生成式推荐,比如 TIGER
TIGER 的核心是把推荐做成生成任务。
例如用户买过:
商品 A → <s_a_57><s_b_12><s_c_203> 商品 B → <s_a_57><s_b_15><s_c_88> 商品 C → <s_a_57><s_b_19><s_c_55>模型学习预测下一个商品 SID:
<s_a_57><s_b_23><s_c_61>这种方式主要在 SID 序列本身 上训练。
它的优点是:推荐任务形式很清楚,直接预测下一个 item 的 SID。
但缺点是:它没有充分利用 LLM 已经学到的自然语言知识和常识。
什么叫 LLM 的 world knowledge?
LLM 在大规模文本上预训练过,所以它可能已经知道很多常识,比如:
洗发水和护发素经常搭配使用; 买了相机之后可能买镜头、存储卡、三脚架; 买了手机之后可能买手机壳、贴膜、充电器; 护肤流程中洁面、爽肤水、精华、面霜、防晒有一定顺序。这些知识对于推荐非常有用。这就是传统纯 SID 模型不容易显式利用的东西。
动机:所以作者想做的不是只训练一个"SID 序列预测器",而是:
让预训练 LLM 既理解 SID,又保留和利用它原本的自然语言世界知识。
这就需要 Mid-Training。
Mid-Training 可以理解为:
在通用预训练 LLM 和最终推荐任务训练之间,加一个中间训练阶段,让 LLM 适应推荐领域和 SID 表示。
它的位置大概是:
通用预训练 LLM ↓ Mid-Training:学习 SID、商品文本、用户行为 ↓ 后续 reasoning SFT / RL ↓ 最终 GR2 re-ranker为什么叫 "mid"?因为它不是最早的通用预训练,也不是最后的任务微调,而是中间的领域适配训练。
一个简单例子
假设 LLM 原本只认识自然语言:
L'Oreal shampoo hair conditioner beauty product但它不认识:
<s_a_57><s_b_12><s_c_203><s_d_8>Mid-Training 要让它学会:
<s_a_57><s_b_12><s_c_203><s_d_8> ≈ 某个洗发水/护发相关商品同时还要让它学会:
用户买过 SID1、SID2、SID3 下一个可能是 SID4以及:
某个 SID 可以对应商品标题、描述、类别
这一小段你可以怎么理解?
这段的意思是:
早期生成式推荐方法主要在 SID 序列上训练模型,让模型预测下一个 SID。但在 LLM 推荐中,我们希望利用预训练 LLM 的语言理解和世界知识。因此,需要一个 mid-training 阶段,把 SID 这种推荐系统中的离散商品表示对齐到 LLM 的语言空间中。
汇报时可以这样说
在 2.4 节中,作者从 TIGER 的纯 SID 序列建模出发,指出在 LLM 时代,仅仅训练 SID 序列预测器是不够的。预训练 LLM 已经包含大量自然语言知识和商品常识,因此需要通过 mid-training 将推荐系统中的 SID 表示与 LLM 的语言空间和世界知识进行对齐,使模型既能处理离散商品 token,又能利用自然语言语义进行推荐。
什么是 item alignment?
它不是简单地让模型背 SID,而是让模型学会:
SID ↔ 商品文本 ↔ 用户行为 ↔ LLM 原有知识也就是说,LLM 原本认识自然语言,但它不认识sid
item alignment 的目标就是让模型知道:
这个 SID 对应某个商品;
这个商品有标题、类别、描述;
这个商品可能和哪些用户行为序列相关;
这个商品与其他商品有什么推荐关系。为什么叫 alignment?
因为 LLM 原本有一个语言语义空间。
比如它知道:
shampoo 和 conditioner 相关
conditioner 和 hair mask 相关
phone 和 phone case 相关但是推荐系统里的 SID 是新加入的特殊 token。如果不训练,LLM 看到 SID 就像看到乱码。所以 mid-training 要把 SID 拉进 LLM 的语义空间:
<s_a_57><s_b_7><s_c_213><s_d_26>
↓ 对齐
"One'n Only Argan Oil Leave-In Treatment"
↓ 对齐
Beauty > Hair Care > Hair & Scalp Treatments
↓ 对齐
用户买了 cleanser and conditioner 后可能买 styling cream这就是 item alignment 的意思。
结合推荐系统举个例子
假设有一个商品:
Title: One'n Only Argan Oil Leave-In Treatment
Category: Beauty > Hair Care > Hair & Scalp Treatments
SID: <s_a_57><s_b_7><s_c_213><s_d_26>mid-training 可能设计任务让 LLM 学:
任务 1:看到 SID,生成商品描述
输入:
<|sid_begin|><s_a_57><s_b_7><s_c_213><s_d_26><|sid_end|>
输出:
Title: One'n Only Argan Oil Leave-In Treatment
Category: Beauty > Hair Care > Hair & Scalp Treatments任务 2:看到用户历史 SID,预测下一个 SID
输入:
用户买过:
<s_a_57>... argan oil leave-in treatment
<s_a_7>... cleanser and conditioner
输出:
下一个可能购买:
<s_a_...>...任务 3:看到商品文本,理解它对应的 SID 或推荐语义
这样训练之后,LLM 才能在后面的 re-ranking 阶段真的使用 SID,而不是只把它当作乱码。
这篇 GR2 和 OneRec-Think 的关系
这篇论文不是完全从零发明 mid-training。
它说自己 follow the setup of item alignment from OneRec-Think。
也就是说:
GR2 借鉴了 OneRec-Think 的 item alignment 思路,把 SID 和自然语言商品信息混合到同一个训练序列里,通过 next-token prediction 让 LLM 学会理解 SID。
这个设计是后面 GR2 推理重排序的基础。
这一段你需要记住什么?
这段的核心是:
Mid-training / item alignment 的目的,是让预训练 LLM 认识推荐系统里的 SID,并把 SID 与商品文本、类别信息、用户行为和 LLM 原有世界知识对齐。
如果没有这个阶段,后面直接让 LLM 看:
<|sid_begin|><s_a_57><s_b_7><s_c_213><s_d_26><|sid_end|>它很可能不知道这些 token 表示什么商品,也不能有效推理用户偏好。
汇报时可以这样说
OneRec-Think 引入了 item alignment 作为 mid-training 阶段,其目标是将推荐系统中的 Semantic ID 与预训练 LLM 的语言空间和世界知识进行对齐。GR2 继承了这一思路,通过将 SID、商品标题、类别、用户行为序列等信息混合到训练样本中,使 LLM 在 next-token prediction 目标下学习 SID 的语义和推荐关系。这样,模型后续才能基于 SID 进行推理和重排序。
llm原本的训练方式:给定前面的 token,预测下一个 token现在 interleave SIDs with natural language tokens,也就是把 SID 和自然语言混在同一个 LLM 输入/输出序列里。
但如果训练时反复让它看到:
<这个 SID> 对应 Title: One'n Only Argan Oil Leave-In Treatment <这个 SID> 对应 Category: Beauty > Hair Care模型就会逐渐把这个 SID 和商品语义联系起来。
这一段的核心
你可以这样记:
Mid-training 的核心是把 SID token 和自然语言商品信息放在同一个序列中,用 LLM 原本的 next-token prediction 目标训练。这样可以优化 SID embedding,使 SID 与商品标题、类别、用户行为和 LLM 原有世界知识对齐。
汇报时可以这样说
Mid-training 的关键思想是将 Semantic IDs 和自然语言 token 交织在同一训练序列中,并通过 next-token prediction 目标优化 SID token 的 embedding。由于 SID 是新增的推荐系统专用 token,预训练 LLM 一开始并不了解其含义。通过将 SID 与商品标题、类别、描述和用户行为序列共同建模,模型可以逐渐把 SID 对齐到原有语言语义空间中,从而为后续基于 SID 的推理和重排序奠定基础。
第 2 节整体总结
现在第 2 节 Tokenized Mid-Training 就讲完了。它整体可以分成两大块:
第一块:生成 SID
包括:
2.1 Tokenizer and Semantic ID 2.2 Contrastive Loss 2.3 Balanced Codebook Utilization目标是把商品从原始 item ID 转成高质量的语义 ID。
这里的关键点是:
商品文本先被编码成连续向量,再通过 RQ-VAE tokenizer 离散化为 SID;为了让 SID 更适合推荐任务,作者加入 co-engagement contrastive loss;为了避免 SID 碰撞,作者又使用多种技术提升 codebook 利用率。
第二块:让 LLM 学会 SID
也就是:
2.4 Mid-Training目标是通过 item alignment,让 LLM 把 SID 和商品文本、类别、用户行为、世界知识对齐起来。
汇报时可以这样总结第 2 节
第 2 节主要解决 GR2 的商品表示和 LLM 对齐问题。首先,作者使用 RQ-VAE tokenizer 将商品文本特征编码为离散 Semantic ID,以替代原始非语义 item ID。为了使 SID 更适合推荐任务,作者加入基于 co-engagement 的 contrastive loss,让共同交互商品在语义空间中更接近。随后,作者针对 codebook collapse 问题提出多种 codebook utilization 技术,包括 RQ-K-means 初始化、EMA 更新、diversity loss、dead code reset 和 random last levels,以提升 SID 唯一性。最后,作者通过 mid-training / item alignment 将 SID 与自然语言商品信息和用户行为序列混合训练,使预训练 LLM 能够理解并使用这些 SID,为后续 reasoning-based re-ranking 打基础。
好,我们进入 第 3 章 Reasoning Data Generation。
这一章要解决的问题是:
已经有 SID,也让 LLM 认识 SID 了;接下来,怎么让 LLM 学会"有逻辑地解释为什么要这样重排序"?
也就是说,第 3 章开始从"商品表示"进入"推理数据构造"。
第 3 章开头:整体目标
论文第 3 章开头说:
In this section, we elucidate the design of reasoning data generation for the re-ranking task.
翻译:
在这一节中,作者介绍了面向 re-ranking 任务的 reasoning data generation,也就是推理数据生成方法。
这里的 reasoning data 指的是训练 LLM 用的"带推理过程的数据"。
为什么需要 reasoning data?
前面第 2 章做完之后,模型已经具备一些推荐能力:
用户历史 SID → 预测下一个商品 SID但是这还不够。
GR2 的目标不是只让模型给出一个排序结果,而是希望模型能像推荐专家一样:
先分析用户历史购买行为;
再总结用户偏好;
再比较候选商品;
最后给出重排序列表。比如用户买过:
Argan Oil Leave-In Treatment
Hair Cleanser and Conditioner with Argan Oil模型不应该只是输出:
Candidate 1而应该能解释:
用户近期购买的商品都与 argan oil 和 hair care 有关;
其中一个是 cleanser and conditioner,另一个是 leave-in treatment;
因此接下来更可能购买 styling cream 或 hair treatment;
Candidate 1 与这些历史商品在品牌、成分和使用场景上更匹配。这种解释过程就是 reasoning trace推理轨迹 。
第 3 章分成两部分
论文说,第 3 章主要有两个部分:
3.1 Chat-formatted Template of Reasoning Training Data
也就是:怎么把一个训练样本组织成 LLM 能理解的聊天格式。
它会包含:
system message:告诉模型它是推荐专家;
user message:给出用户历史和候选商品;
assistant message:给出推理过程和最终排序。3.2 Reasoning Trace Generation
也就是:怎么生成高质量 reasoning traces。
作者主要用了两类方法:
Targeted Sampling
Rejection Sampling这两个后面我们会重点讲。
这一章和第 2 章的关系
你可以把前后关系理解成:
第 2 章:让 LLM 认识商品 SID
第 3 章:构造带推理过程的训练数据
第 4 章:用 SFT 和 RL 让模型真正学会 reasoning re-ranking也就是说,第 3 章不是直接训练模型,而是准备训练数据。
第 3 章开头的核心意思是:
为了让 LLM 在 re-ranking 中具备推理能力,作者需要构造带有 reasoning trace 的训练样本。这些样本不仅包含用户历史和候选商品,还包含模型应该学习的逐步分析过程以及最终排序结果。
汇报时可以这样说
第 3 章主要介绍 GR2 如何生成用于重排序任务的推理训练数据。作者认为,仅让 LLM 预测排序结果是不够的,还需要让模型学习如何基于用户历史、商品 SID、标题和类别信息进行逐步推理。因此,本章首先设计了 chat-format 的训练样本结构,然后提出 targeted sampling 和 rejection sampling 两种 reasoning trace 生成策略,用于构造高质量的监督微调数据。
3.1 Chat-formatted Template of Reasoning Training Data
这一小节要回答的问题是:
一条用于训练 re-ranker 的 reasoning 数据,具体长什么样?
你提到的"chat format"(聊天格式)是训练和微调大语言模型(LLM)时非常核心的一种数据组织方式。它的核心思想是将模型与用户的每一次交互都模拟成一场"对话",通过三种不同角色的消息来构建完整的上下文。
这种格式之所以成为主流,是因为它能最自然、最有效地教会模型如何在真实场景中与人互动。
三种核心消息角色
这三种消息各自扮演着不同的角色,共同构成了一个完整的对话单元:
系统消息 (System Message)
这是对话的"总导演"或"角色设定"。它由开发者预先设定,用于告诉 AI 模型它应该扮演什么角色、遵循什么规则以及以何种风格进行回复。
- 作用:为整个对话设定背景和基调。
- 举例:"你是一个乐于助人的资深程序员,请用简洁幽默的风格回答问题。"
用户消息 (User Message)
这代表了真实用户的输入,也就是我们向 AI 提出的问题、指令或任何信息。它是触发 AI 思考和回复的直接原因。
- 作用:提供具体的任务请求或对话内容。
- 举例:"请帮我写一个快速排序的 Python 代码。"
助手消息 (Assistant Message)
这是 AI 模型根据"系统消息"的设定和"用户消息"的请求,所生成的回复内容。在训练数据中,这相当于"标准答案"。
- 作用:记录模型给出的理想回应,作为学习的目标。
- 举例:模型生成的一段完整、正确的快速排序代码。
为什么这种格式如此重要?
这种
chat format已经成为 LLM 微调数据的事实标准,主要原因有以下几点:
- 结构清晰:它明确区分了"指令"(system)、"问题"(user)和"答案"(assistant),让模型能够清晰地学习到在不同情境下应该如何回应。
- 模拟真实场景:绝大多数 LLM 的应用都是以聊天机器人的形式出现的,使用对话格式进行训练,能让模型更好地适应其最终的工作环境。
- 支持多轮对话:通过将多组"用户消息"和"助手消息"按顺序排列,可以轻松地构建出包含上下文记忆的复杂对话,让模型学会"记住"之前的聊天内容。