Rudder 是一个给重度 agent 用户使用的 Agent Team 协作平台。
项目地址:
如果你已经在高频使用 Codex、Claude Code、Cursor,或者已经开始维护自己的 Agent Skill,Rudder 解决的是下一阶段的问题:
Agent 不只是完成任务,还能在真实任务、review 和 feedback 里持续迭代自己的能力。
Rudder 把 goals、issues、agent runs、reviews、feedback、skills 和 learning 串成一个 work loop。一次 agent run 结束后,不只留下 transcript,还会留下可追踪、可 review、可沉淀、可回滚的学习记录。
我自己现在高频用 Codex、Claude Code,也开始大量使用 Agent Skill。单次执行已经很强。改代码、查 API、写说明、修 CI,这些都能做。很多 know-how 也确实可以沉淀下来。
但用久了以后,真正麻烦的不是"agent 没有记忆",也不是"没有 skill"。
麻烦的是这些问题:
- 什么应该变成 memory?
- 什么应该变成 skill?
- 什么只是这次任务的一次性约束?
- 什么应该留在当前 issue 里?
- 什么根本不该沉淀?
一条 review feedback,可能是团队长期原则,也可能只是这次任务的临时要求。
一个成功经验,可能值得沉淀成 skill,也可能只适合留在这次任务里。
一个 skill 被启用以后,也不代表它真的让 agent 做得更好。它可能误触发,可能拿错 source of truth,可能增加上下文成本,也可能把旧判断带回新任务。
所以 Rudder 不是另一个"让 agent 记住更多"的工具。
它更像是一个让 agent team 在实践中成长的运行层:一边推进真实工作,一边把团队的流程、偏好、判断标准和 skill usage 变成可复用的能力资产。
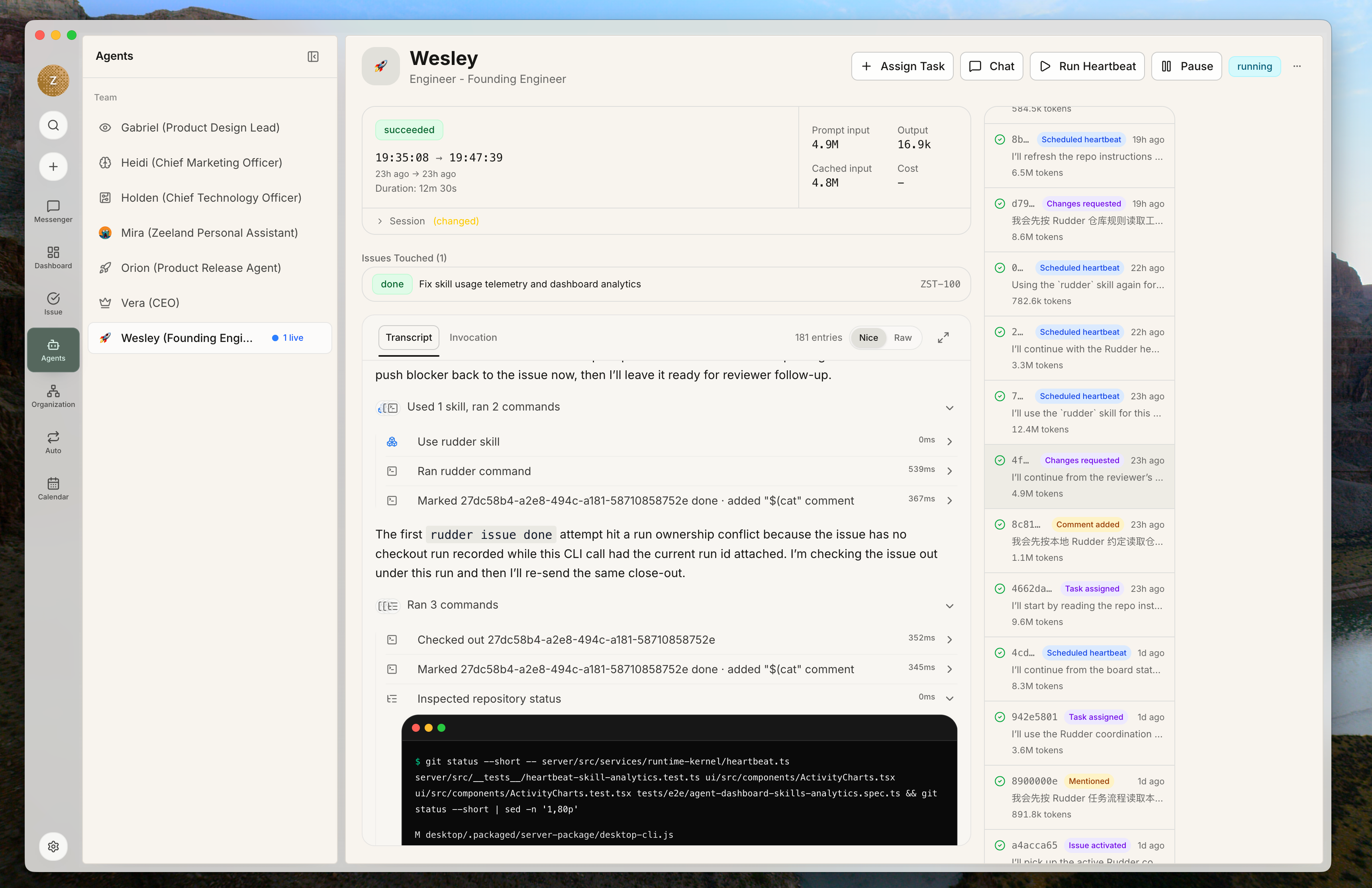
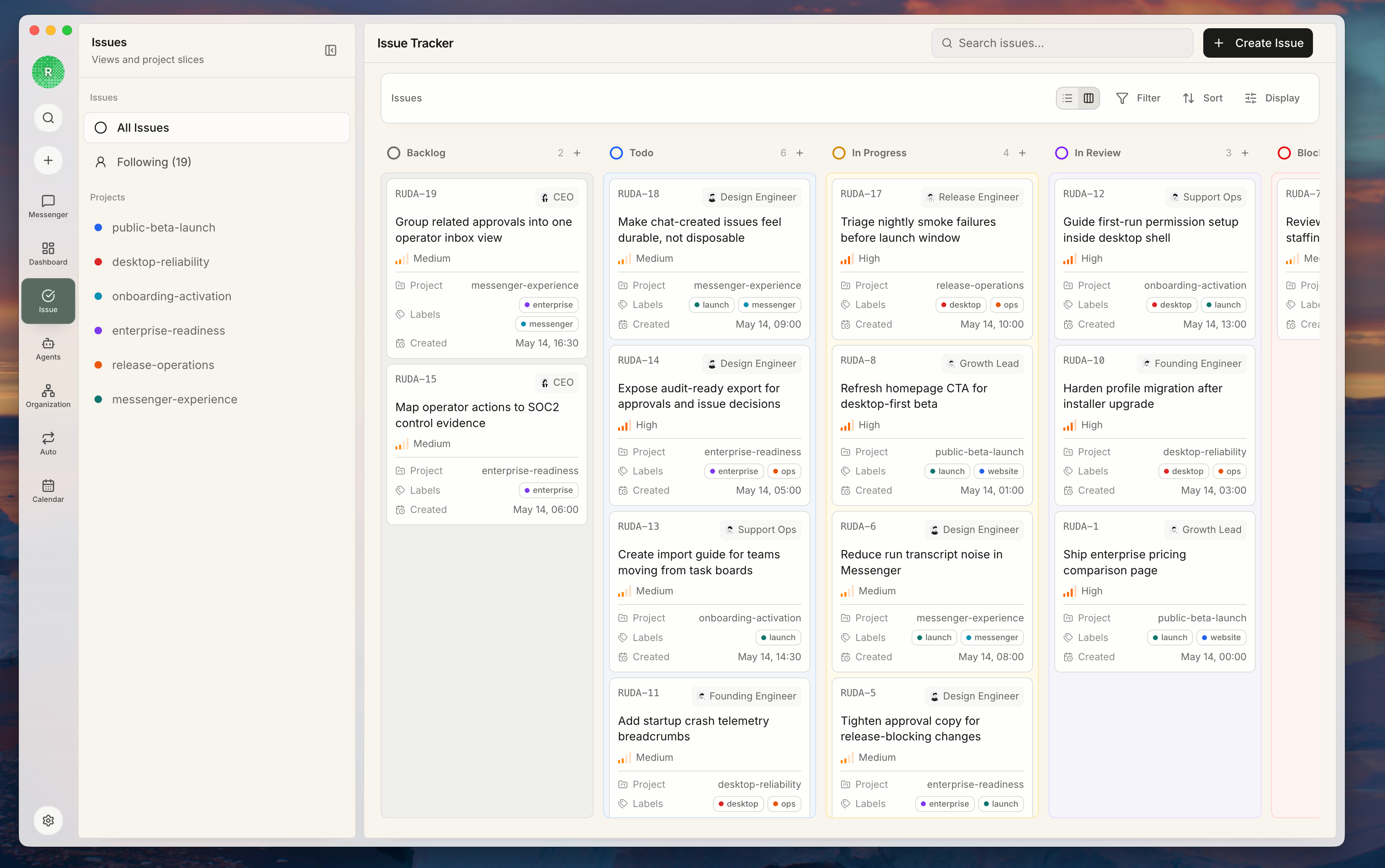
Rudder 设计理念
Rudder 把 agent work 拆成几个更稳定的对象:
- Goal:为什么做这件事。
- Issue:这次具体做什么,谁负责,验收标准是什么。
- Context:agent 这次可以依赖哪些资料、决策、workflow 和 skill。
- Run:agent 实际怎么执行,读了什么,调用了什么工具,产出了什么。
- Output:PR、文档、报告、截图、测试结果、发布说明这些真实产出。
- Review:人或 reviewer agent 怎么评价结果,是 approve、request changes,还是 blocked。
- Learning Proposal:这次 feedback 是否应该沉淀为 memory、skill、decision、workflow,还是 no-op。
- Skill Trace:某个 skill 被哪些 run 用过,在什么任务里用过,结果有没有改善。
这些对象串起来以后,agent work 就不只是一次性执行。
一个典型循环是:
text
chat 里澄清需求
-> 变成 issue
-> attach 本次相关 context / skill
-> agent 执行
-> 产出 PR / 文档 / 报告 / 截图
-> 人或 reviewer 给反馈
-> 生成 learning proposal
-> 决定进入 memory / skill / decision / workflow / no-op
-> eval、批准或回滚
-> 下一次真实任务继续验证Rudder 要做的事很直接:让 agent 从真实工作中学习,而不是靠越写越长的 prompt 成长。
举个例子
比如一次 release 任务失败了。
普通 agent 工具可能最后留下 transcript、错误日志和一句总结:"下次发布前要更小心。"
这句话没什么用。
Rudder 会更关心这些东西:
- 这次 issue 的目标是什么。
- agent 执行时加载了哪个 release skill。
- 它查了哪些 source of truth,比如 tag、registry、CI run。
- reviewer 为什么退回。
- 这次失败暴露的是 skill 的触发问题、流程问题,还是 source 读取问题。
- 这条经验是否值得变成 skill update。
- 更新后,下次类似 release 是否减少返工。
- 如果没有改善,能不能回滚这次 skill update。
这样一次失败就不是"又失败了一次",而是 agent team 的一次训练样本。
和 GitHub Issues + Claude Code + 一堆 Skill 有什么区别?
这个问题很关键。因为我自己也在用这些东西。
GitHub Issues / Linear 能管理任务,但它们不太关心 agent 在这次任务里学到了什么。
Codex / Claude Code 很适合执行任务,但 run 结束后,feedback、review、失败模式和 skill 更新很难自然进入下一次工作。
Agent Skill 能沉淀经验,但 skill 本身也会变成问题:
- 什么时候应该触发这个 skill?
- 这次触发是不是误触发?
- 它有没有先拿对 source of truth?
- 它有没有真的降低返工?
- 它是不是只是把一次性偏好写成了长期规则?
- 它变差以后能不能回滚?
Rudder 补的是这部分:agent work 的 learning governance。
它不是替代 Codex / Claude Code,而是把这些 agent 的执行过程放进一个可追踪、可 review、可沉淀、可回滚的工作循环里。
不做 AI 公司模拟器
我不太相信"PM agent 写 PRD,架构师 agent 写设计,开发 agent 写代码,QA agent 接着测"这种默认结构。
它看起来像公司,但经常只是把原始意图转述好几遍。一个 agent 总结需求,另一个 agent 基于总结继续做,reviewer 再基于二手材料挑问题。信息越传越薄。
Rudder 更接近另一种方式:一个 issue owner 持有完整意图。需要查资料,就叫 researcher。需要实现,就叫 builder。需要挑问题,就叫 reviewer。
Reviewer 不是流水线里的下一棒。它应该读同一份 issue、context、output、diff 和测试结果,专门找问题。最后是否接受,还是回到 owner 或人类。
Rudder 不是让 agent 看起来像一个公司。
它是让 agent work 真的有组织性。
适合谁用
Rudder 更适合这几类人:
- 高频使用 Codex / Claude Code / Cursor 的 builder。
- 已经开始写 Agent Skill,但发现 skill 越写越多、越写越乱的人。
- 想把 agent 放进真实开发、运营、研究或发布流程的人。
- 希望 agent 不只是执行任务,而是能从 review 和 feedback 里持续进步的人。
- 想搭一个小型 Agent Team。
如果你现在只是偶尔让 agent 写一段代码,可能暂时不需要 Rudder。
但如果你已经开始把 agent 当长期队友用,Rudder 解决的就是这个阶段的问题。
欢迎试用、star 和提 issue
Rudder 还在快速迭代。
GitHub 在这里:
https://github.com/Undertone0809/rudder
如果你也在重度使用 agent,欢迎试用、star,或者直接拿自己的 agent workflow 来挑战这个设计。
我尤其想听这些反馈:
- Agent Skill 多了以后,你们会不会遇到 skill 越写越长、越写越乱?
- 你们现在怎么判断一条 feedback 应该进 memory、skill、workflow,还是只留在当前 issue?
- 你们会不会想知道某个 skill 到底有没有让任务成功率变高?
- 如果一个工具能记录 run、review、learning proposal、skill update、eval 和 rollback,你会觉得这是刚需,还是过度设计?
- 如果你已经用 GitHub Issues、Linear、Notion、Obsidian、Claude Code 搭出自己的流程,Rudder 还缺什么理由让你愿意试?