前言
上篇文章《大模型训练全流程实战指南工具篇(十二)------ 大模型评测方法及典型评测集介绍》中,笔者系统梳理了大模型评测的完整体系。文章首先回答了"为什么需要评测"这一根本问题,随后介绍了三种主流评测方法------人工评测、数据集评测和大模型自动化评测,并分析了各自的适用场景。最后,详细列举了通用知识、数学推理、代码生成、综合考试等多个维度的代表性数据集,为大家建立起了对评测领域的整体认知。
了解了这些基本概念,本期内容将面向实战,聚焦如何在具体的生产与工作场景中开展数据集评测 与大模型自动化评测两种评测方式,帮助大家掌握可操作的评测流程与实战技巧。
一、EvalScope:数据集评测实战工具
前面讲了那么多评测方法和数据集,大家一定会问:"有没有一个工具能把这些东西都整合起来,让我一键完成评测?" 答案是肯定的------笔者这里推荐自己在工作中最常用的,由阿里魔搭社区(ModelScope)推出的 EvalScope 平台。
EvalScope不仅仅是一个评测工具,更是一个贯穿模型从训练到部署全链路的评估平台。它具备如下核心特性:
- 全面覆盖:内置MMLU、CMMLU、C-Eval、GSM8K、HumanEval等业界主流评测基准,支持大语言模型、多模态模型、Embedding模型、Reranker模型、CLIP模型乃至AIGC模型等多种模型类型。
- 简单易用:支持命令行和Python代码两种调用方式,一行命令即可启动标准数据集评测。(笔者一般使用Python代码调用的方式)
- 功能丰富:除了模型精度评测,还支持推理性能压测(吞吐量、延迟等指标)、评测结果可视化等高级能力
下面笔者就为大家介绍EvalScope工具,以及它在不同场景中的详细使用~
1.1 EvalScope核心架构
了解一个工具,先从架构入手是最清晰的方式。EvalScope的整体架构分为以下几个核心组件:

1.1.1 输入端
用户在输入端可以配置要评测的模型和要使用的评测数据集,模型可以通过API载入,也可以通过transformers加载本地模型。数据集可以用EvalScope自带的数据集,也可以自定义评测数据集。
1.1.2 组件端
EvalScope包含如下核心组件:
-
Model Adapter(模型适配器) :负责将不同模型(本地模型、API服务)的输出统一转换为框架所需的标准格式,屏蔽底层模型差异。
-
Data Adapter(数据适配器) :负责转换和处理输入数据,适配不同的评测数据集和格式需求。
-
Evaluation Backend(评测后端) :这是EvalScope的核心引擎,支持多种评测模式:
- Native:EvalScope自身的默认评测框架,支持单模型评测、竞技场模式、Baseline对比模式等。
- OpenCompass(另一种评测框架):集成了OpenCompass作为评测后端,简化了任务提交流程。
- VLMEvalKit(多模态模型的评测框架):支持多模态模型评测,轻松发起图文理解等评测任务。
- ThirdParty:支持ToolBench、RAGEval等第三方评测任务。
这个分层架构的设计使得EvalScope既有强大的内置能力,又能灵活集成外部评测框架,满足各种复杂场景的需求。
1.1.3 输出端
EvalScope的输出包括可评测的报告,记录了准确率等评价指标。同时还包括了数据可视化功能,将评价指标通过图表形式展示出来。
1.2 EvalScope环境搭建
-
首先安装EvalScope的环境,笔者这里同样使用Lab4AI 大模型实验室 的环境进行演示,新建一个VS Code运行实例。
-
实例已经为预置了conda环境,安装EvalScope非常简单,执行如下命令即可:
bash
# 创建conda环境
conda create -n evalscope python=3.12
conda activate evalscope
# 安装全部功能(含压测、可视化等,推荐)
pip install evalscope[all]- 安装完成后通过如下命令验证安装是否成功:
bash
evalscope --help-
开启大模型服务,为了快速测试演示,本期内容使用
vllm部署本地下载的Qwen2.5-0.5B-Instruct模型,按照笔者 《大模型训练全流程实战指南基础篇(三)------大模型本地部署实战(Vllm与Ollama)》 文章的内容,使用如下命令开启大模型服务:pythonvllm serve ./Qwen2_5_0_5/ --served-model-name Qwen2.5-0.5B --max-model-len 8048 --gpu-memory-utilization 0.9 --port 6666
1.3 EvalScope项目实战
为了更清晰地展示 EvalScope 的用法,笔者基于日常工作场景,将其分为三种典型情况: (1) 使用单一数据集评测大模型的单项能力 (2) 使用多个数据集综合评测大模型的各种通用能力; (3)使用自定义数据集评测模型在专业领域的效果。
下面就按照这三个场景逐一展开:
1.3.1 单一数据集单项能力的评测
如果想评测 Qwen2.5-0.5B-Instruct 模型的数学性能,可以采用 gsm8k 等数据集。这类数据集基本是计算题,有明确的答案,评测指标通常是准确率(答对题目数 ÷ 总测试数)。EvalScope 集成了大量公开数据集,只需编写如下脚本即可快速测试:
python
from evalscope.run import run_task
from evalscope.config import TaskConfig
task_cfg = TaskConfig(
model='Qwen2.5-0.5B', # 模型ID或本地路径
api_url='http://127.0.0.1:6666/v1',
api_key='EMPTY', # 没有设置这里可以随便填一个
datasets=['gsm8k'], # 指定评测数据集是gsm8k
limit=50 # 用来测试的评测集的数目,默认会全部评测,这里为了快速演示,随机在数据集中选取50条测试
)
run_task(task_cfg=task_cfg)可以看到评测脚本非常直观,这就是 EvalScope 的魅力------通过配置化方式,仅需数行代码就能轻松获得评测结果。执行该文件后,EvalScope 会自动将 gsm8k 数据集下载到 /用户目录/.cache/modelscope/hub/datasets 中,评测完成后在命令行输出结果。本次测试的准确率为 50%。
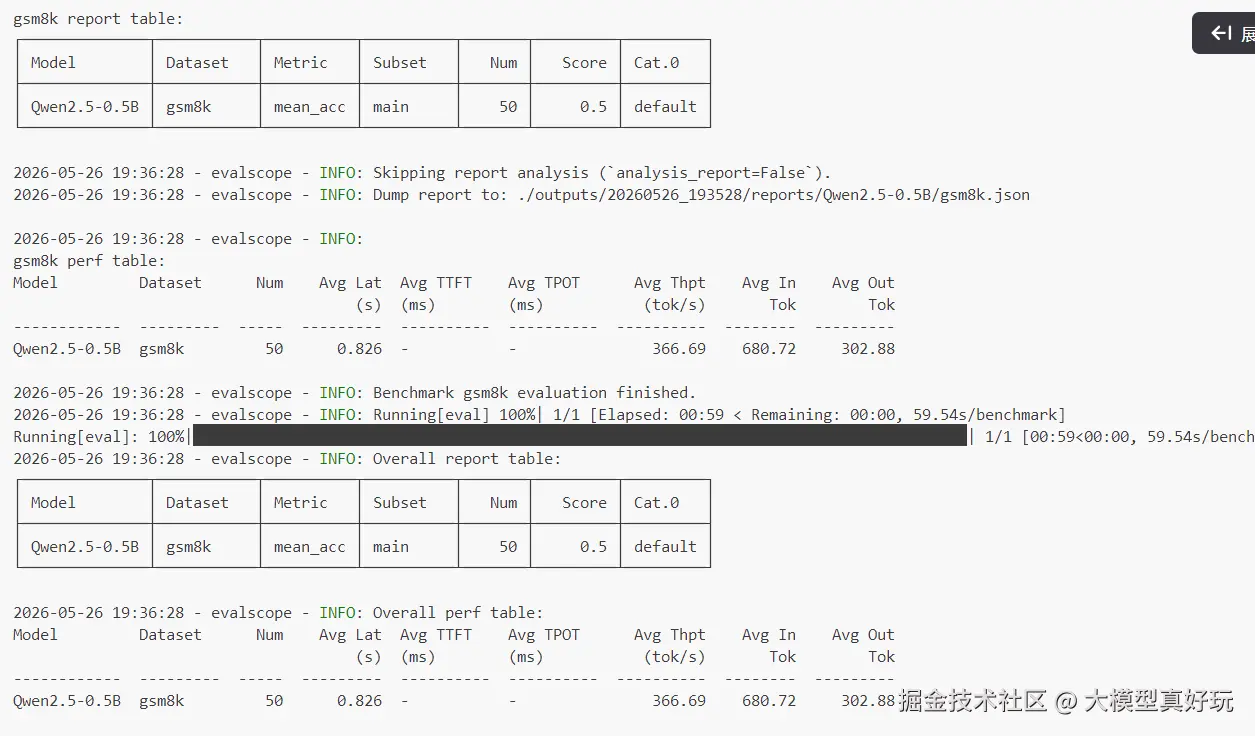
同时,EvalScope 还会将预测结果和评测报告保存到执行脚本目录下的 outputs 文件夹中。其中 predictions 文件夹存放模型的输出结果,reports 文件夹存放评测报告,report.html 是可视化的 HTML 文件。
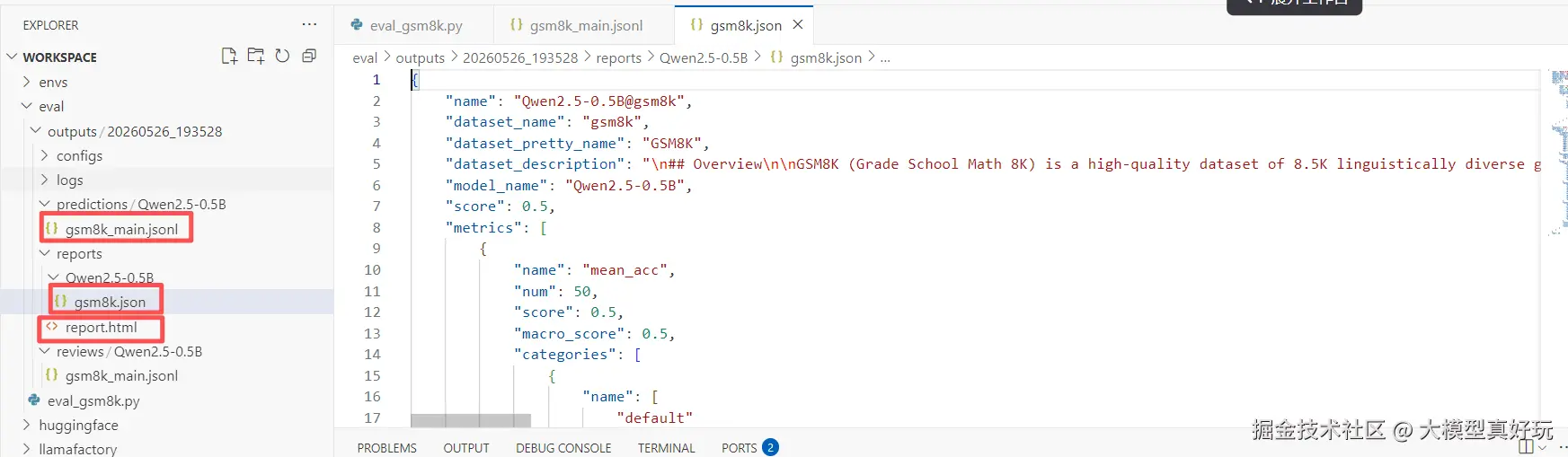
补充说明:如何评测数据集的子类别?
有时候大家遇到的数据集(如 ceval)包含多个子类别(下图展示了 Modelscope 上 ceval 数据集的预览,可以看到非常多类别),但只想评测其中某几个类别,该怎么做呢?
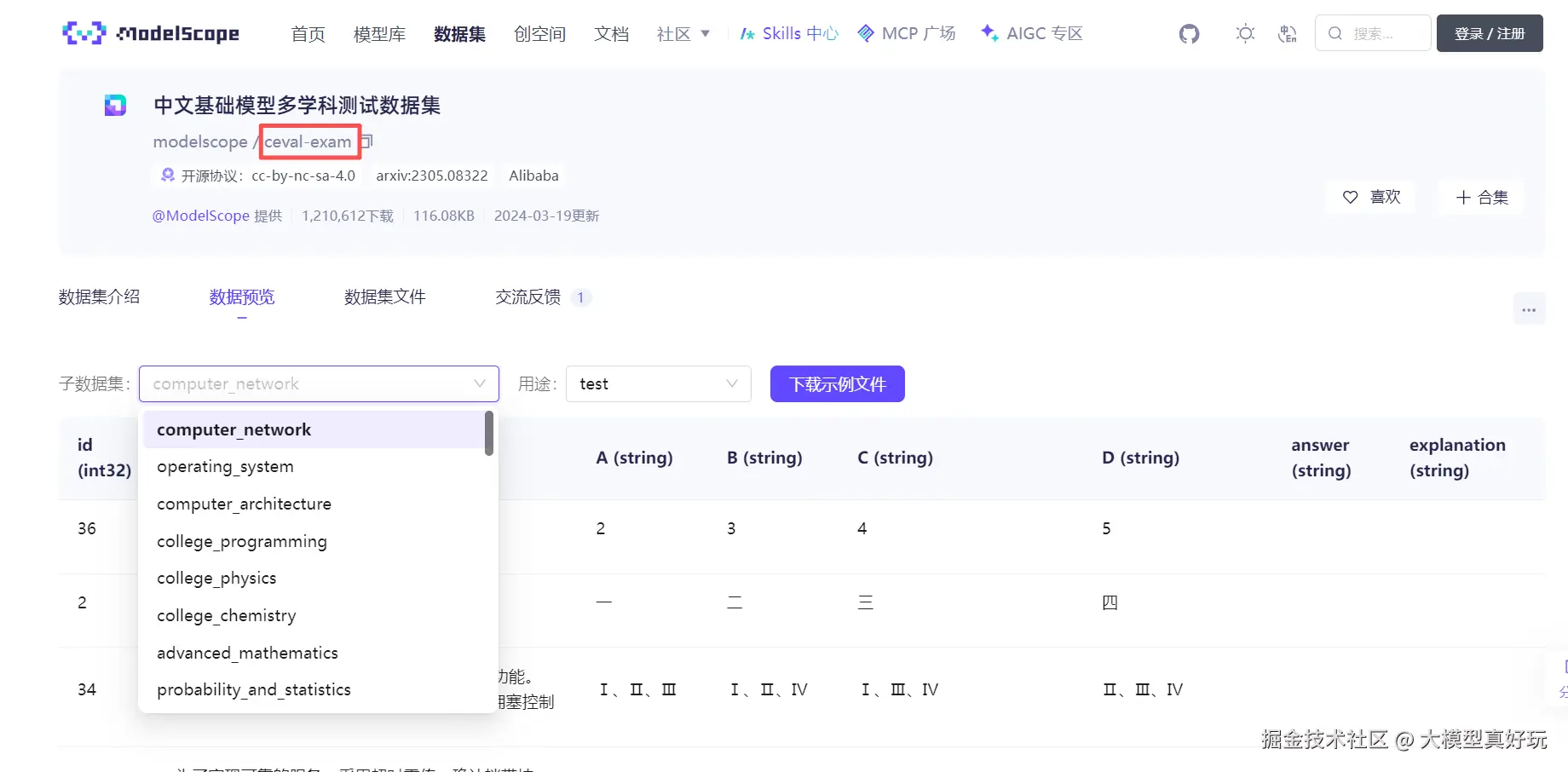
其实也非常简单,EvalScope 提供了 dataset_args 参数,可以对数据集进行精细化配置。例如,如果只想评测 ceval 中的 computer_network 和 operating_system 两个子类别,可以这样写:
python
from evalscope.config import TaskConfig
from evalscope.run import run_task
# 配置评测任务
task_cfg = TaskConfig(
model='Qwen2.5-0.5B', # 模型ID或本地路径
api_url='http://127.0.0.1:6666/v1',
api_key='EMPTY', # 没有设置这里可以随便填一个
datasets=['ceval'], # 评测数据集列表
limit=10, # 样本数限制(调试用,这里从ceval中每个子类中随机抽取10条样本)
eval_batch_size=4, # 批处理大小, 4条数据同时请求vllm模型服务
dataset_args={
'ceval': {
'subset_list': ['computer_network', 'operating_system'] # 精细化调整评测集的参数,ceval是由多个子数据集组成的,只评测其中的computer_network和operating_system参数。
}
},
generation_config={
'max_tokens': 2048,
'temperature': 0.0, # 大模型服务的参数设置
'top_p': 1.0,
'do_sample': False,
}
)
# 启动评测
run_task(task_cfg=task_cfg)评测结果如下。可以看到 EvalScope 完整列出了数据集及其子数据集的准确率,Qwen2.5-0.5B 在计算机网络上的表现似乎不太理想:
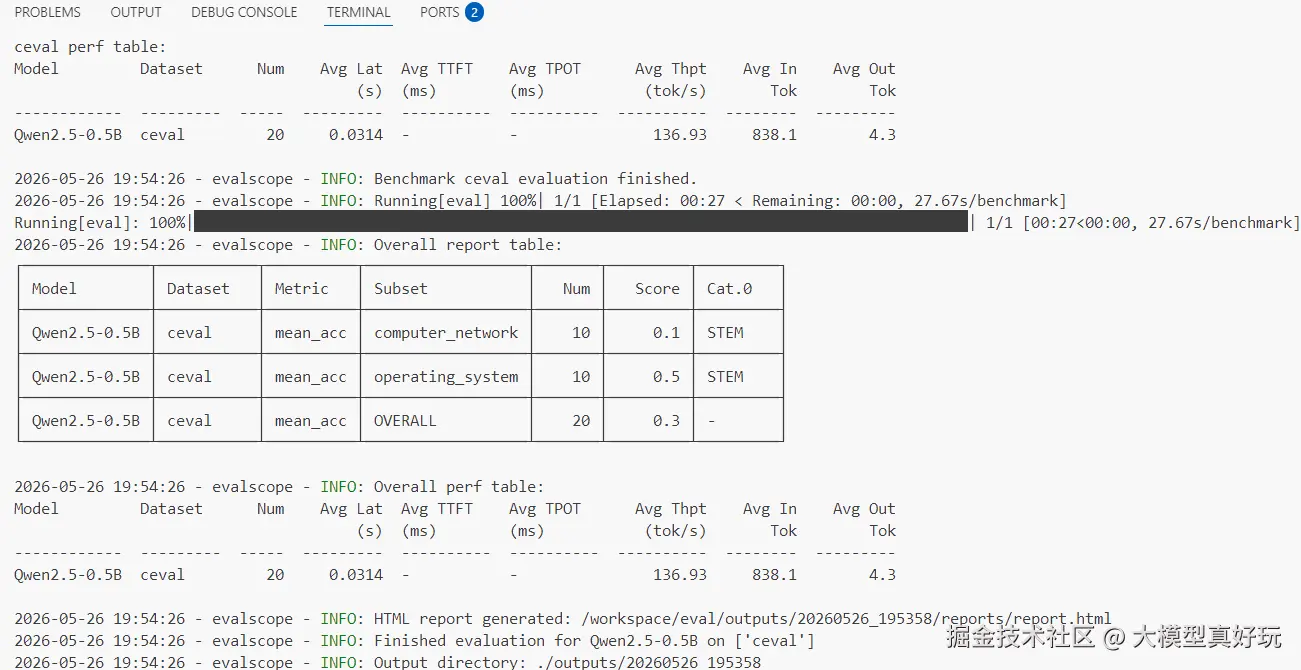
1.3.2 多数据集集合
有时候并不只是评测模型的单项能力。一个典型场景是:训练了一个专业模型,但又不希望它在其他领域的性能下降太多(否则模型就像被"训傻了",只会专业领域知识,出现明显的过拟合)。这时就需要使用多个数据集对模型进行综合评测。在 EvalScope 中,多数据集组合非常简单:
python
from evalscope.config import TaskConfig
from evalscope.run import run_task
# 配置评测任务
task_cfg = TaskConfig(
model='Qwen2.5-0.5B',
api_url='http://127.0.0.1:6666/v1',
api_key='EMPTY',
datasets=['ceval', 'gsm8k'], #多个数据集都列在评测集列表中
limit=10,
eval_batch_size=4,
# 针对每个数据集都可以设定明确的评测参数
dataset_args={
'ceval': {
'subset_list': ['computer_network', 'operating_system']
},
'gsm8k': {
"few_shot_num": 0
}
},
generation_config={ # 大模型服务的参数设置
'max_tokens': 2048,
'temperature': 0.0,
'top_p': 1.0,
'do_sample': False,
}
)
# 启动评测
run_task(task_cfg=task_cfg)评测结果如下:
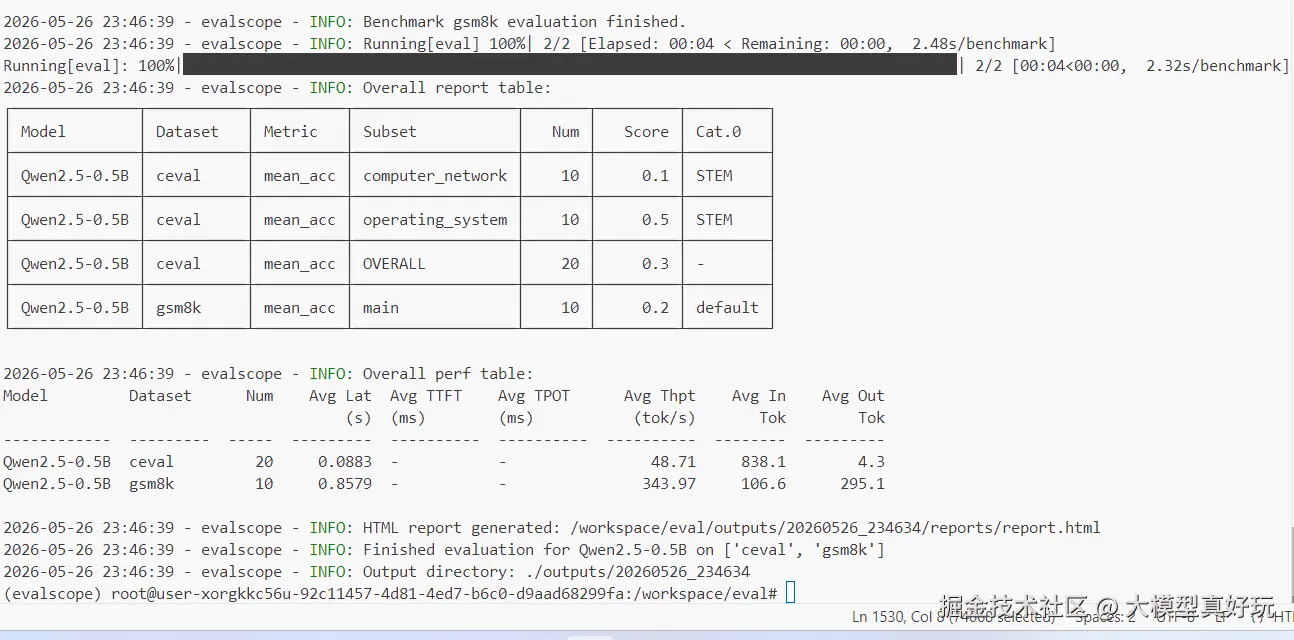
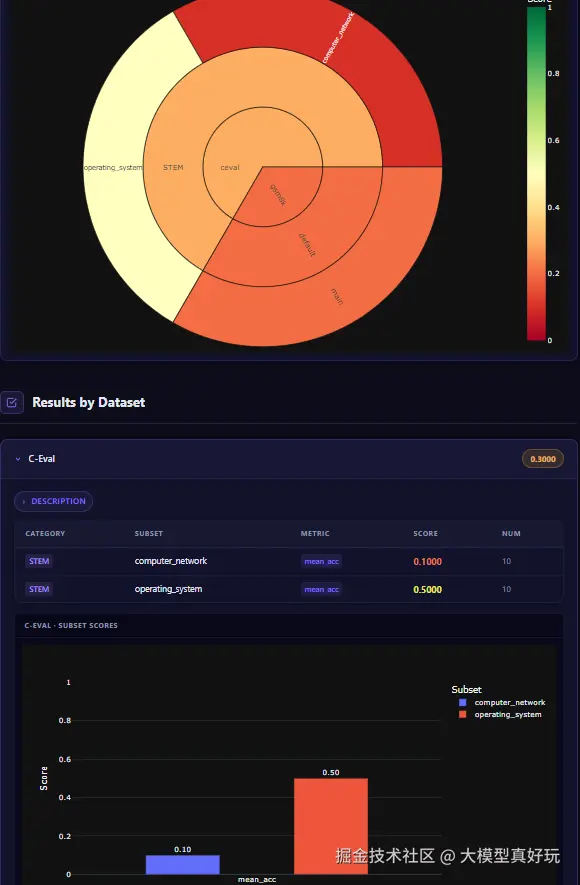
同时这里大家还可以看一下evalscope生成的可视化的报告,在输出目录outputs/20260526_234634下有一个report.html文件,将其在浏览器打开,可以看到该网页既通过饼图、柱状图合理的展现了评估形式,还详细记录了评估的列表和细节,非常方便对比不同数据集的结果:
1.3.3 自定义数据集评测
除了使用现成的选择题等带有标准答案的数据集,很多时候需要评估的是文本生成大模型。评测标准通常是回答与标准答案的相似度,或者是否包含了标准答案的核心思想。例如,当构建并微调一个中医药大模型时,就需要用中医药的问答对来评测模型,看模型的回答是否与医生诊断的标准答案一致、是否包含了核心思想。EvalScope 同样能很好地支持这种需求。
自定义选择题数据集(有明确答案)
首先来看有明确答案的选择题数据集,大家可以按照如下的格式编写一个jsonl文件,question是问题,A,B,C,D等是选项,answer是答案。
jsonl
{"id": "1", "question": "通常来说,组成动物蛋白质的氨基酸有____", "A": "4种", "B": "22种", "C": "20种", "D": "19种", "answer": "C"}
{"id": "2", "question": "血液内存在的下列物质中,不属于代谢终产物的是____。", "A": "尿素", "B": "尿酸", "C": "丙酮酸", "D": "二氧化碳", "answer": "C"}将数据集命名为 数据集名称_val.jsonl 的格式。笔者将其放在 mcq/example_val.jsonl 文件中,然后创建脚本 eval_custom_mcq.py:
python
from evalscope import TaskConfig, run_task
task_cfg = TaskConfig(
model='Qwen2.5-0.5B', # 模型ID或本地路径
api_url='http://127.0.0.1:6666/v1',
datasets=['general_mcq'], # 数据格式,选择题格式固定为 'general_mcq'
dataset_args={
'general_mcq': {
"local_path": "./mcq", # 自定义数据集路径
"subset_list": [
"example" # 自定义的评测数据集名称, 这里是example
]
}
},
)
run_task(task_cfg=task_cfg)
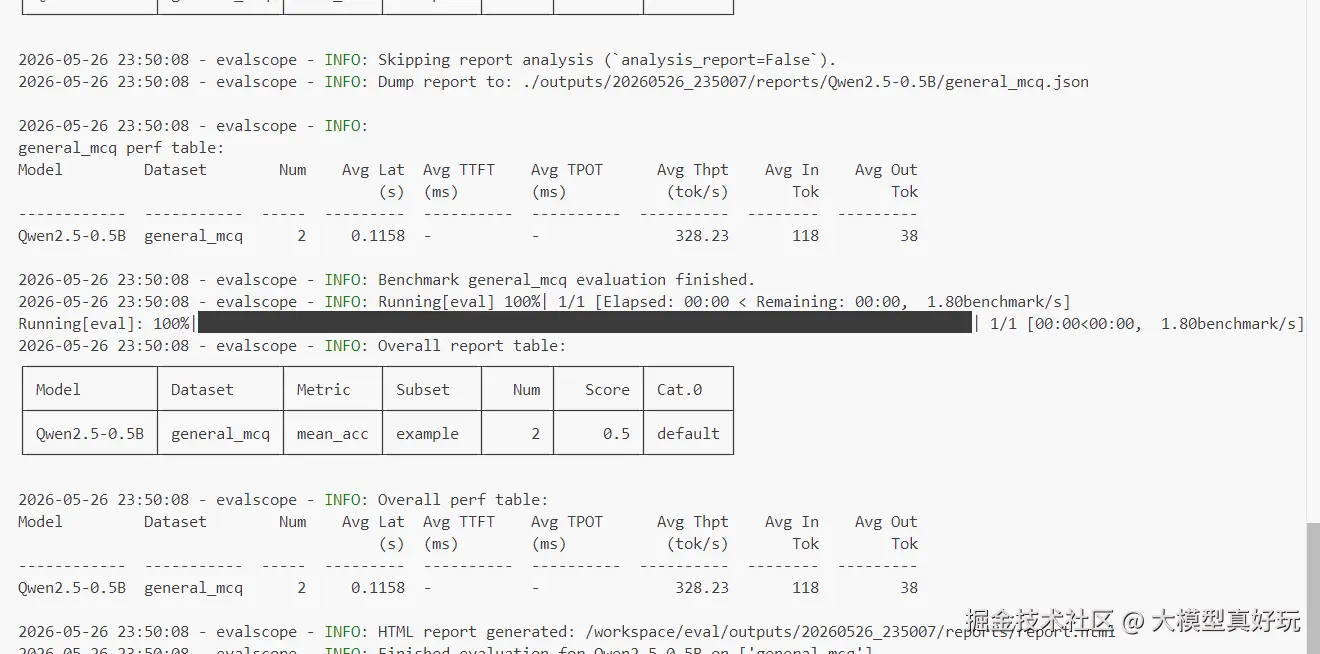
评测结果如下:
自定义问答数据集(无标准选项)
除了这种有准确答案的选择题之外,因为很多的大模型还是用于日常的问答任务,所以问答数据集的设定也非常有必要。同样的EvalScope 也支持对于问答数据集的自定义。大家按照如下格式组织成jsonl文件, 其中question是问题, response是预期回复.
jsonl
{"query": "世界上最高的山是哪座山?", "response": "是珠穆朗玛峰"}
{"query": "中国的首都是哪里?", "response": "中国的首都是北京"}然后大家同样将数据集重命名为数据集名称.jsonl的格式,笔者这里将它放在qa/example.jsonl文件中(注意这里文件名不需要加_val下标),然后创建脚本eval_custom_qa.py,编写代码如下:
python
from evalscope import TaskConfig, run_task
task_cfg = TaskConfig(
model='Qwen2.5-0.5B', # 模型ID或本地路径
api_url='http://127.0.0.1:6666/v1',
datasets=['general_qa'], # 数据格式,选择题格式固定为 'general_qa'
dataset_args={
'general_qa': {
"local_path": "./qa", # 自定义数据集路径
"subset_list": [
"example" # 自定义的评测数据集名称, 这里是example
]
}
},
)
run_task(task_cfg=task_cfg)评测结果如下:
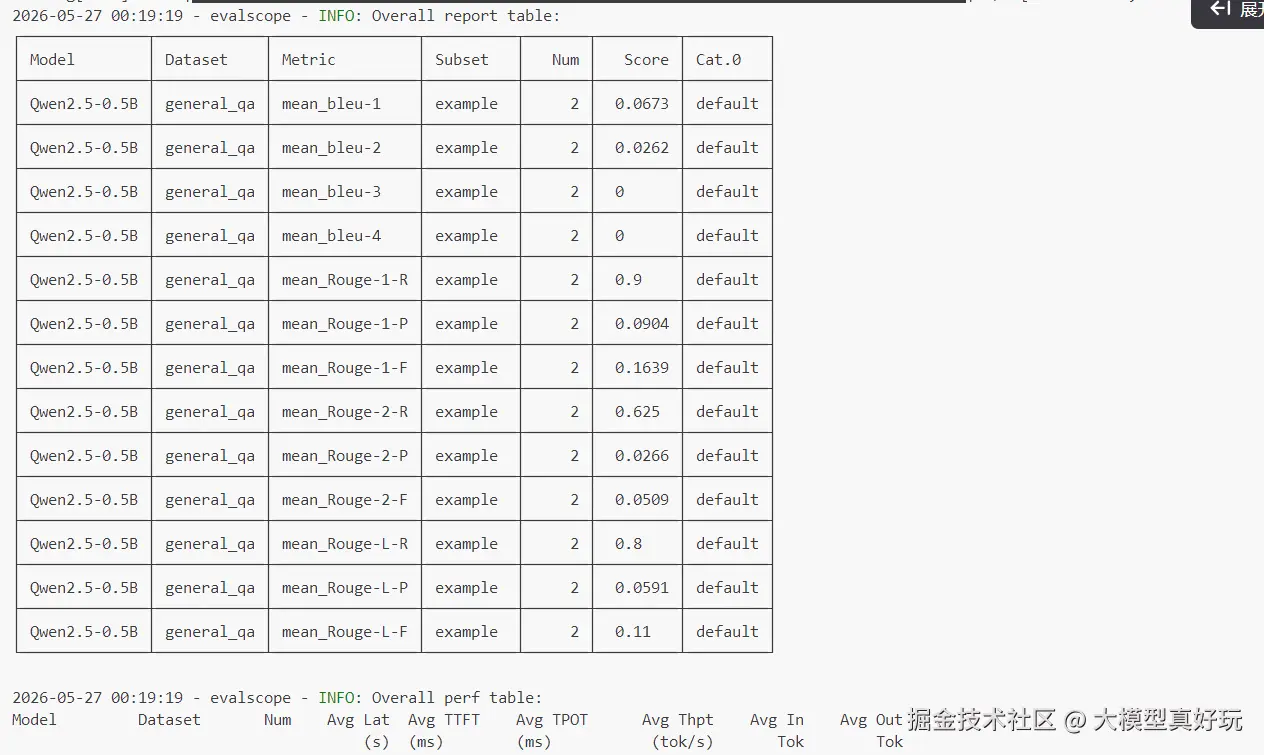
关于评测指标:看到这里大家可能会有疑问------准确率我很好理解,就是答对题目的比例,但问答对评测中 BLEU、ROUGE 这些指标代表什么?别急,下一节笔者会详细解释。
以上就是EvalScope日常工作生产中的常见用法与典型场景,当然EvalScope的功能还有很多,限于篇幅原因就不一一列举,大家可以看EvalScope官方文档 了解更多用法!
二、BLEU 与 ROUGE:自动评价生成文本的"考官"
在上一节自定义问答数据集的评测结果中,大家看到了 BLEU 和 ROUGE 这两个指标。它们代表什么含义?为什么能用来评估生成文本的好坏?其实,这两个指标最早来自机器翻译和文本摘要领域,用于自动判断生成文本的质量。对于需要自动评估生成内容的任务,BLEU 和 ROUGE 是最常用的两位"考官"------它们分别侧重于精确率 和召回率。
2.1 什么是n-gram?
在深入介绍这两个指标之前,先要了解一个基础概念:n-gram 。n-gram 是指文本中连续的 n 个词(或字符)。例如,对于句子 cat sits on mat:
- 1-gram(一元组):
cat,sits,on,mat - 2-gram(二元组):
cat sits,sits on,on mat - 3-gram:
cat sits on,sits on mat
n-gram 的长度越短,匹配条件越宽松;长度越长,对词序和短语结构的要求就越严格。
2.2 Bleu指标:精确率考官
BLEU 检查生成文本中的 n-gram 有多少出现在参考文本中。它偏向精确率:我生成的词里面,有多少是正确的?
但这里有一个问题:如果模型只生成一个词,而这个词恰好出现在参考文本中,那么精确率就是 100%------这显然不合理。因此,BLEU 在计算精确率的同时,还引入了长度惩罚因子,避免模型通过输出过短的内容来刷高分。
用数学公式精确的表示:
BLEU=BP×exp(N1∑n=1Nlogpn)
- pn = 生成文本中匹配上的 n-gram 数量 ÷ 生成文本中 n-gram 总数量
- BP 为长度惩罚因子(生成太短会降分)
为了更方便大家理解,笔者这里举一个小例子:
- 预期结果:
the cat is on the mat - 大模型预测:
the the the the the
计算 1-gram:参考中 the 出现 2 次,生成文本中有 5 个 the,匹配计数取 min(5,2)=2,准确率 p1=2/5=0.4。机器长度 5 < 参考长度 6,BP≈0.82,BLEU≈0.33。重复输出导致低分。
2.3 ROUGE指标:召回率考官
ROUGE 检查参考文本中的 n-gram 有多少被生成文本覆盖。它偏向召回率:正确答案里的词,模型生成结果覆盖了多少?
公式(ROUGE-N):
ROUGE-N=∑参考译文∑n-gram∈参考Count(n-gram)∑参考译文∑n-gram∈参考Countmatch(n-gram)
其中 Countmatch(n-gram) 取生成文本与当前参考译文中该 n-gram 出现次数的最小值。简单说:分子是 生成与参考共有的 n-gram 总数 ,分母是 参考中全部的 n-gram 总数。
小例子(文本摘要)
- 参考:
cat sits on mat - 生成:
mat cat sits
计算 ROUGE-1:参考的 1-gram 有 {cat, sits, on, mat},生成文本匹配了 {mat, cat, sits},共 3 个,得分 3/4 = 0.75。
计算 ROUGE-2:参考的 2-gram 有 {cat sits, sits on, on mat},生成文本的 2-gram 有 {mat cat, cat sits},只有 cat sits 匹配,得分 1/3 ≈ 0.33。
2.4 一句话总结
如果不想深究公式,可以记住这个精炼的对比:
- BLEU:生成内容里,正确的东西占比高不高(怕废话、怕重复)
- ROUGE:正确答案里,被覆盖的内容多不多(怕遗漏)
实际评价中,两者常常结合使用。n-gram 的阶数 n 可以调节:低阶(如 1-gram、2-gram)关注词汇覆盖,高阶(如 3-gram、4-gram)关注短语流畅度。BLEU 值越高、ROUGE 值越高,表示生成的内容越准确。
理解了这两个指标,再回头看看上一节自定义数据集的评测结果,是不是豁然开朗了?
三、如何使用裁判大模型进行自动化评测
评测大模型生成答案的质量,除了使用标准数据集,还有一种常用方式------用另一个大模型来当"裁判" 。
3.1 自动化评分流程
让大模型充当裁判,去评判模型生成的答案是否与预期答案吻合,不能仅凭一句"请判断这两句话是否一致"。要建立科学的评分体系,至少需要以下四个步骤:
- 定义维度和标准:确定评分维度(如相关性、准确性、完整性),每个维度设定 1~5 分的评分规则,并明确各分数对应的含义。
- 构造评估提示词:将用户问题、预期答案、待评估的生成答案以及评分规则,打包成一个结构化的提示词。
- 调用评估模型:例如调用 DeepSeek API,要求模型返回 JSON 格式的分数及评分理由。
- 汇总分析:计算平均分、分数分布等统计指标,形成评估报告。
3.2 提示词设计要点
自动化评测的关键在于构造高质量的评估提示词。设计时需要注意以下几点:
- 明确任务:说明需要将预期答案与生成答案进行对比,并按维度打分。
- 具体评分规则:避免模糊的"好/坏"描述,应使用可操作的细则。例如,"准确性 5 分:完全没有事实错误;1 分:关键信息全部错误"。
- 可选 Few-shot:附上 1~2 个示例,帮助裁判模型理解评分尺度。
实战案例(中医药领域)
笔者曾训练一个中医药大模型,需要针对专业领域设计评分提示词。具体做法如下:
-
定义专业评分维度(以中医问答为例):
- 辨证准确性(0~4 分) :是否准确判断证型(如肝郁脾虚、肾阳虚等)。
- 术语规范性(0~3 分) :中医术语(如"舌苔白腻""脉弦滑")使用是否标准。
- 用药安全性(0~3 分) :是否存在配伍禁忌、剂量超常或违背"十八反十九畏"。
-
加入 Few-shot 示例:提供几个按照上述维度人工评分的案例,让大模型更贴近人的评分标准。
-
设置较低的温度值 (如 temperature=0.1),并强制 JSON 输出 (设置
response_format={"type": "json_object"}),便于后续解析分数。
下面是利用 DeepSeek 作为裁判模型的示例代码:
python
import json, os, pandas as pd
from openai import OpenAI
client = OpenAI(api_key=os.environ["DEEPSEEK_API_KEY"],
base_url="https://api.deepseek.com")
PROMPT = """
你是一位资深中医专家,负责评估另一个模型在中医问答任务上的表现。
【评估任务】
比较"预期金标准答案"与"待评估模型答案",从以下三个维度打分:
1. 辨证准确性(0-4分)
- 4分:证型判断完全正确,包括病位、病性、病机
- 3分:主证正确,兼证有轻微偏差
- 2分:主证部分正确,但有明显遗漏
- 1分:证型判断错误
- 0分:完全无关或未作答
2. 中医术语规范性(0-3分)
- 3分:全部使用标准术语(如"舌红少苔""脉细数")
- 2分:有1处非标准或口语化表达
- 1分:多处不规范,但可理解
- 0分:术语错误或西医化严重
3. 用药安全性(0-3分)
- 3分:方药合理,无禁忌,剂量安全
- 2分:存在轻微不适宜(如未考虑患者体质)
- 1分:有违反"十八反""十九畏"或毒性药物超量风险
- 0分:明显危及安全的建议
【示例1(高质量)】
问题:"患者咳嗽痰白、怕冷、无汗,舌淡苔白,脉浮紧。宜用何方?"
金标准:"麻黄汤加减,组成:麻黄9g、桂枝6g、杏仁9g、炙甘草3g。"
待评估:"麻黄汤加减,麻黄8g、桂枝6g、杏仁9g、甘草3g。"
评分:辨证4分(风寒束表正确),术语3分(全部标准),安全3分(剂量合理)→ 总分10分
【示例2(低质量)】
待评估:"用银翘散,加板蓝根。"
评分:辨证1分(银翘散治风热,此证为风寒),术语2分,安全2分 → 总分5分
【输出格式】严格输出以下JSON,不附加任何解释:
{
"syndrome_score": 整数,
"term_score": 整数,
"safety_score": 整数,
"total_score": 整数,
"brief_reason": "一句话总结扣分点"
}
=== 开始评估 ===
用户问题:{question}
金标准答案:{expected}
待评估答案:{generated}
问题:{question}
预期:{expected}
模型答案:{generated}
"""
def score(question, expected, generated):
resp = client.chat.completions.create(
model="deepseek-chat",
messages=[{"role": "user", "content": PROMPT.format(
question=question, expected=expected, generated=generated)}],
temperature=0.1,
response_format={"type": "json_object"}
)
return json.loads(resp.choices[0].message.content)
# 批量评测示例
df = pd.read_json("test.json")
scores = [score(row["q"], row["exp"], row["gen"]) for _, row in df.iterrows()]
print(f"平均整体分: {sum(s['overall'] for s in scores)/len(scores):.2f}")通过以上方式,即可利用裁判大模型对模型生成结果进行自动化、多维度、可量化的评估。
以上就是笔者今天分享的全部内容啦!本教程示例代码可以关注笔者同名公众号:大模型真好玩 ,并私信大模型训练免费获得。
四、总结
本期内容聚焦大模型评测的实战落地,介绍了 EvalScope 工具,演示了单一数据集评测、多数据集综合评测及自定义数据集评测三种典型场景。随后,深入讲解了 BLEU(侧重精确率)和 ROUGE(侧重召回率)两大评估指标。最后,分享了如何用另一个大模型作为"裁判",通过专业化提示词实现自动化、可量化的生成质量评估。
通过本期内容,相信大家已经掌握了数据集评测与自动化评测的全套实战技能。下期笔者将进入实战篇,笔者将带大家从0到1完整跑通一个网络安全领域大模型的经典案例。大家敬请期待!大家读完感兴趣可以关注笔者的同名微信公众号:大模型真好玩,获取本系列分享以及其他系列分享的全部内容。
除大模型训练外,笔者也在同步更新《深入浅出LangChain&LangGraph AI Agent 智能体开发》免费专栏,要说明该专栏适合所有对 LangChain 感兴趣的学习者,无论之前是否接触过 LangChain。该专栏基于笔者在实际项目中的深度使用经验,系统讲解了使用LangChain/LangGraph如何开发智能体,目前已更新 45 讲,并持续补充实战与拓展内容。欢迎感兴趣的同学关注笔者的掘金账号与专栏,也可关注笔者的同名微信公众号大模型真好玩 ,每期分享涉及的代码均可在公众号私信: LangChain智能体开发免费获取。