小剧场:一张桌子,两种焦虑
想象具身智能领域的四位大牛坐在同一张咖啡桌前。Johns Hopkins 的人先开口:"我们的机器人会用视频模型'想象'前方,画面漂亮得很,但它原地转了三圈找不到一只马克杯------因为它画的是像素,不是空间。" GigaAI 的工程师苦笑:"我们的问题更直接------连数据都没有。真机采一条轨迹几百美元,换个花瓶策略就崩了。" 做 3D 重建的人插话:"我能给你精确的几何,但我只看得见'去过的地方',拐角后面的世界我一无所知。" 做视频生成的人摇头:"我能想象拐角后面,但生成的门可能开着、墙可能穿模------你敢让机器人信吗?"
四个人的焦虑指向同一个死结:具身智能需要的不是更好看的画面,也不是更精确的点云,而是一个能在三维空间中"想清楚"世界状态、并用这种理解去"造出"训练数据的完整闭环。
这两篇论文放在一起,其实是在回答同一个问题:世界模型到底应该是机器人的"脑内沙盘"还是"数据工厂"?答案是------它必须同时是两者。
全局地图:两块拼图,一条暗线
| 维度 | 3D-Belief | GigaWorld-0 |
|---|---|---|
| 核心问题 | 机器人无法在三维空间中形成、更新和推理"信念" | 具身智能数据采集太贵、多样性太低 |
| 方法抓手 | 3DGS + 3D 空间扩散,直接在高斯体参数空间做信念推理 | 视频生成 + 3D 物理双流并行,批量制造合成训练数据 |
| 最强实验 | 具身导航 SR 59.17%(零 token 消耗),Chamfer 距离 4 倍优势 | 2B 参数超越 14B 模型,零真机交互完成人形机器人部署 |
| 总体判断 | 把世界模型从"生成像素"升级为"维护三维信念" | 把世界模型从"看客"变成"数据工厂" |
它们在解决同一层问题吗? 表面上不是------一个做推理,一个做数据。但暗线是一致的:都在试图让具身智能体摆脱对"真实世界实时交互"的依赖。3D-Belief 让机器人用更少的观测"想清楚"更多空间;GigaWorld-0 让机器人用零真机交互"学到"操作技能。一个压缩了感知成本,一个压缩了数据成本。
哪篇是关键转折点? 3D-Belief。因为如果机器人的三维信念不可靠,GigaWorld-0 生成的合成数据里那些"看起来对但物理上错"的画面就会被当作真知识学进去。信念推理是数据引擎的质检员。
共同卡点:具身智能的"感知-想象-数据"三角困境
│
├── 3D-Belief 解法:在三维空间里"想清楚" → 压缩感知成本
│ │
│ └── 代价:假设静态世界、内存线性增长
│
└── GigaWorld-0 解法:用世界模型"造数据" → 压缩数据成本
│
└── 代价:视频幻觉、物理辨识跨平台迁移
│
└── 交汇点:信念推理是数据引擎的质检员3D-Belief:给机器人一块"三维脑内沙盘"
它补上了哪块拼图?
现有世界模型在像素空间做扩散,生成的画面再逼真也无法回答"杯子在我左边还是右边?"3D 重建模型能给出显式几何,但只表示"看过的",对未见区域束手无策。3D-Belief 试图补上的缺口是:让机器人同时拥有"已知区域的精确记忆"和"未知区域的多假设想象",并以统一的三维结构持续更新。
核心假设:三维高斯体(3DGS primitives)可以作为"信念原子"------每颗高斯体携带位置、形状、颜色和语义标签,它们拼在一起就是机器人对整个世界的"信念快照"。扩散模型在这个参数空间里做想象,而不是在像素空间里画画。
与其他论文的切入差异:它不做视频预测(那是 DFoT、NWM 的路线),也不做纯几何重建(那是 VGGT 的路线),而是直接在三维空间里做"信念推理"------这是一条全新的路径。
它怎么做:信念更新的循环心脏
输入:第一人称图像 o^{t+1} + 噪声图 n^{t+1}
│
▼
┌─────────────────────────────────┐
│ 当前三维信念 z^t │
│ ├── 已观测高斯体 z_o^t (蓝色) │ ← 来自真实观察,被"追加"
│ └── 想象高斯体 z_i^t (绿色) │ ← 来自扩散模型,被"整块替换"
└─────────────────────────────────┘
│
▼ U-ViT 骨干网络
├── 上头:MVS 代价体 → 多视角深度 → 3D 高斯体
└── 下头:CLIP 蒸馏 → 逐像素语义图 → 语义嵌入
│
▼
更新后的三维信念 z^{t+1}
(已观测部分 expand,想象部分 replace)关键设计:已观测部分被"追加"(expand),想象部分被"整块替换"------新的观测证据可以推翻之前的猜测。这保证了每一步计算成本恒定,不会随轨迹变长膨胀。
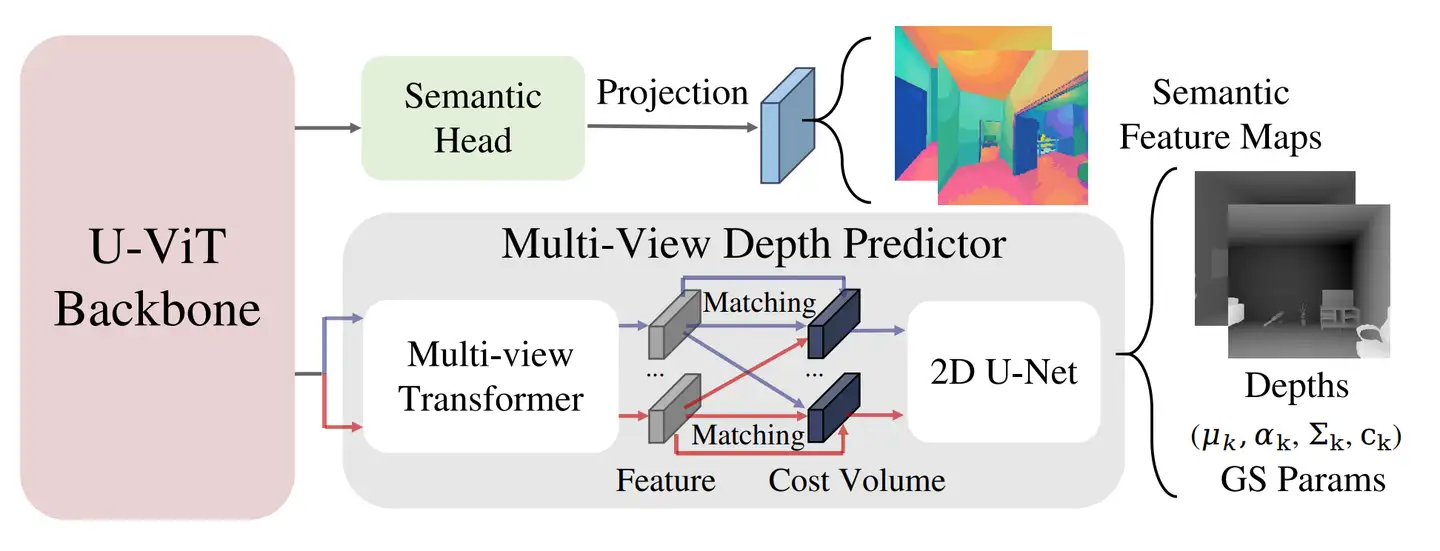
看图提示: 先看中间的 U-ViT 骨干,它分出两个头------上面的深度头和下面的语义头。
这张图揭示了 3D-Belief 的核心工程决策:用一个共享骨干同时处理几何和语义,而不是分两个独立模型。上面的 MVS 风格代价体把 2D 特征"抬"成 3D 高斯体参数(位置、协方差、颜色),下面的语义头通过 CLIP 蒸馏给每颗高斯体加上可被自然语言查询的语义嵌入。这个设计支撑了总论点:三维信念不是单纯的几何,而是"带语义的结构化认知"------机器人不仅能知道"那里有东西",还能知道"那是一只杯子"。风险在于:CLIP 语义嵌入的精度是否足以区分相似物体(红色马克杯 vs 红色蜡烛)?论文没有做细粒度语义的消融。
实验解剖:三维约束反哺二维生成
最有说服力的不是三维指标,而是这个反直觉发现:
| 方法 | LPIPS ↓ | PSNR ↑ | SSIM ↑ |
|---|---|---|---|
| NWM | 0.1876 | 18.75 | 0.702 |
| DFoT | 0.1206 | 23.35 | 0.841 |
| 3D-Belief | 0.0502 | 28.81 | 0.928 |
LPIPS 从 0.12 降到 0.05,PSNR 从 23.35 跳到 28.81------结构性优势,不是调参红利。原因:在三维空间里确定了一面墙的位置,从任意新视角渲染就只是投影问题,不存在像素空间方法中的"视角模糊"。
但必须指出:在 RealEstate10K(真实房产视频)上,3D-Belief 的 Observed 区域 PSNR/SSIM 反而低于 GEN3C(20.01 vs 22.90),只是在 FID/FVD 分布指标上大幅领先。这说明其优势更多在"想象未见区域的分布真实性",而非"已见区域的像素级保真"。
真正的试金石:3D-CORE 与具身导航
| 任务 | 指标 | DFoT-VGGT | 3D-Belief |
|---|---|---|---|
| 物体补全 | Chamfer ↓ | 0.830 | 0.216 |
| 房间补全 | Occ. Acc. ↑ | 0.252 | 0.900 |
| 物体恒常性 | LPIPS ↓ | 0.555 | 0.123 |
房间占用准确率从 0.252 到 0.900------DFoT-VGGT 几乎是瞎猜,3D-Belief 达到 90%。根本原因:"imagination-then-lift"在场景级空间推理上存在结构性瓶颈。
最核心的导航对比:
| 方法 | SR% ↑ | Token/step ↓ |
|---|---|---|
| Gemini 3.0 (纯 VLM) | 45.00 | 7513 |
| 3D-Belief | 59.17 | 0 |
VLM 用语言推理三维空间是"用一维符号系统思考三维问题",而 3D-Belief 直接在三维空间里做心智模拟。消融实验进一步证明:去掉几何后 SR 从 45.83 暴跌到 17.50,从多假设降为单假设掉了 10 个百分点。
疑点:静态世界的假设比论文暗示的更严重
论文坦承"假设静态世界",但当前信念更新公式没有任何机制区分"世界变了"和"我的猜测错了"。在长时程任务中,门会开关、椅子会被移动------这种歧义会被指数级放大。另一个模糊处理:RealEstate10K 上像素级指标落后,用分布指标弥补,论文将其定位为"补充基准"是策略性降级。
GigaWorld-0:把世界模型从"看客"改造成"数据工厂"
它补上了哪块拼图?
具身智能最大的瓶颈不是算法、不是算力,而是数据。真实数据采集慢、成本高、多样性极低;仿真数据便宜但 sim2real 鸿沟难跨。GigaWorld-0 的野心是:用一个足够逼真、足够可控、足够物理的世界模型,直接批量"印刷"训练数据,让 VLA 模型在从未见过真实机器人的情况下学会操作。
核心假设:视觉真实性和物理正确性是两个本质上冲突的目标,不应该试图用一个模型同时解决------就像拍电影,美术组负责布景打光,物理特效组负责让它合理。
与其他论文的差异:不做推理(那是 3D-Belief 的路线),不做单点视频生成(那是 Wan2.2、Cosmos 的路线),而是把视频生成和 3D 物理仿真统一成一个"数据工厂"。
它怎么做:双流并行的数据生产线
输入:单张图片 + 文本描述
│
├── 视频流水线(管"皮相":视觉多样性)
│ ├── Video-Dreamer:MoE-DiT 基础视频生成
│ ├── AppearanceTransfer:纹理/材质/光照编辑
│ ├── ViewTransfer:任意视角视频合成
│ └── MimicTransfer:人手视频 → 机器人臂视频
│
└── 3D 流水线(管"骨相":几何与物理一致性)
├── 3D-FG:前景物体 3D 资产生成
├── 3D-BG:背景场景 3DGS 重建
├── 3D-Phys:物理属性推断 + 可微分系统辨识
└── 3D-Act:可执行操作轨迹生成
│
▼
合成训练数据 → VLA 模型训练 → 零真机交互部署关键插图:MoE-DiT 的视频生成架构
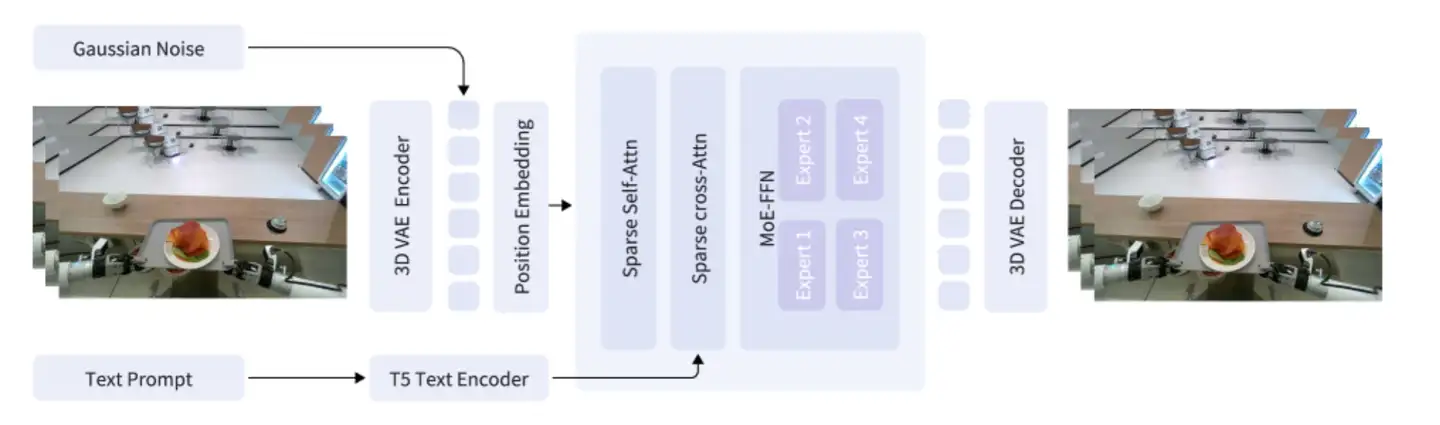
看图提示: 关注三条路径------左侧文本条件(T5 编码器)、中间图像条件(首帧输入)、底部 MoE-DiT 主干。
这张图揭示了 GigaWorld-0 的效率秘密:MoE 层被嵌入到 DiT 的 FFN 块中,每个 token 通过门控机制选择 Top-2 专家。4 个路由专家让不同语义区域(背景纹理 vs 机械臂运动)由不同专家专门处理,避免了参数冗余。这个设计支撑了"2B 参数超越 14B"的核心实验结果。风险在于:专家分化是自动发生的,论文没有展示每个专家到底学到了什么------如果分化不充分,MoE 就退化为普通稠密模型。
关键插图:MimicTransfer 的人机映射
看图提示: 观察人手抓取杯子把手位置与机械臂夹爪的空间对应关系。

MimicTransfer 把人手第一人称视频转成机器人臂操作视频。通过逆运动学(IK)将手部关键点映射到机械臂关节空间,再用视频模型渲染出"看起来像机器人自己在操作"的画面。这是 GigaWorld-0 解决数据成本问题的核心武器------如果可靠,YouTube 和 Bilibili 上的海量烹饪、手工视频就变成了免费训练数据。但风险也在这里:人手 27 个自由度 vs 机械臂 6-7 个自由度,在精细操作(拧瓶盖、穿针引线)中映射质量会急剧下降。
实验解剖:小模型大能量
| 模型 | 激活参数 | 总分 |
|---|---|---|
| Cosmos-Predict2 | 14B | 79.88 |
| Wan2.2 | 14B | 78.85 |
| GigaWorld-0-Dreamer | 2B | 82.07 |
2B 激活参数拿到最高总分,比 14B 模型高出 2.19 分。MoE 让模型用更少计算量覆盖更大参数空间,不同专家专精不同语义区域。差距主要在 subject consistency(12.6 vs 11.9-12.2)和 object consistency(91.9 vs 88.1-93.1),说明 GigaWorld-0 的优势不在"能不能动",而在"动的时候东西不变形"。
但最让人信服的不是基准分数,而是真实机器人部署:GigaBrain-0 在 G1 人形机器人和 PiPER 双臂上完成了叠衣服、榨果汁、搬箱子等任务------完全在合成数据上训练,部署前没有经过任何真实世界交互。这是对"世界模型作为数据引擎"最有力的验证。
疑点:三个未解之谜
视频幻觉的质检困境: 质量评估管线从几何一致性、多视角一致性、文本对齐、物理合理性四个维度打分,但评估模型本身也可能有盲区。"看起来对但物理上错"的视频会溜进训练集,VLA 模型学到错误的物理直觉。
MimicTransfer 的泛化边界: 论文只展示了抓取类任务的成功案例,没有讨论精细操作的失败场景。抓取、放置这类"粗放"操作可能没问题,涉及旋转、滑动、柔顺控制的任务映射质量可能急剧下降。
3D-Phys 的跨平台迁移: PINN 辨识出的物理参数是"仿真器里的最优参数"还是"真实世界的物理参数"?换一台同型号机器人,参数需要重新辨识吗?
横向对照:当"脑内沙盘"遇上"数据工厂"
方法差异:同一块硬币的两面
| 维度 | 3D-Belief | GigaWorld-0 |
|---|---|---|
| 核心目标 | 在线推理三维世界状态 | 离线批量制造训练数据 |
| 架构 | U-ViT + 3DGS 扩散 | MoE-DiT + 3D 物理管线 |
| 训练信号 | 自监督(多视角一致性 + CLIP 蒸馏) | 混合(视频重建 + 物理仿真 + RL) |
| 数据依赖 | 多视角图像序列 | 单张图片 + 文本描述 |
| 推理成本 | 实时信念更新(恒定步长) | 离线批量生成(GPU 密集) |
| 泛化方式 | 三维几何约束内建 | MoE 专家自动分化 |
| 部署难度 | 需要实时深度估计 | 需要完整 3D 物理管线 |
| 评估协议 | 3D-CORE + 具身导航 SR | PBench + 真机部署 |
证据强弱:哪些结论被钉牢了
| 共同主张 | 支持论文 | 证据类型 | 强度 | 为什么不能打满分 |
|---|---|---|---|---|
| 三维几何约束能提升生成质量 | 3D-Belief | LPIPS/PSNR/SSIM | 强 | RealEstate10K 上像素级指标反而落后 |
| MoE 架构比稠密模型更高效 | GigaWorld-0 | PBench/DreamGen | 中 | 只做了 2B vs 14B,缺少同参数量级的公平对比 |
| 信念推理提升导航成功率 | 3D-Belief | 3D-CORE + SR% | 强 | 仅在 AI2-THOR 仿真中验证 |
| 合成数据能替代真实数据 | GigaWorld-0 | 真机部署 | 中 | 只展示了抓取类任务,精细操作未验证 |
| 多假设优于单假设 | 3D-Belief | 消融实验 | 强 | 消融干净,SR 从 45.83 到 35.14 |
回到总论点:世界模型的下一个范式
总洞见
这两篇论文合起来最重要的启发是:世界模型正在从"感知工具"进化为"认知基础设施"。 3D-Belief 证明了世界模型可以维护可推理的三维信念,让机器人"想清楚"再去行动;GigaWorld-0 证明了世界模型可以批量制造训练数据,让机器人"不碰真机"就学会操作。两者共同指向一个趋势:具身智能的核心瓶颈正在从"算法"转向"认知架构"------不是缺少更好的策略网络,而是缺少能让策略网络可靠学习和推理的底层世界表示。
对这个方向的判断
趋势: 到 2027 年,主流世界模型基准将完全以具身任务表现(导航成功率、操作成功率、长时程一致性)为主要指标,视觉质量指标降为辅助。"三维信念"概念会从室内导航扩展到自动驾驶(遮挡区域推理)和手术机器人(术中结构推断)。
风险: 3D-Belief 的静态世界假设和 GigaWorld-0 的视频幻觉问题,都指向同一个深层挑战------世界模型的"可信度"还没有被系统性地评估。当前的基准只测"对的时候有多对",不测"错的时候有多错",更不测"模型知不知道自己错了"。在安全攸关的场景(手术、自动驾驶)中,这个问题会成为真正的拦路虎。
下一阶段瓶颈: 从"单次推理"到"持续认知"。3D-Belief 的信念更新是无状态的------每一步只看当前观测和上一步信念;GigaWorld-0 的数据生成是离线的------生成完就结束了。真正的具身智能需要的是一个能持续运行数小时甚至数天、在信念衰退和世界变化之间动态平衡的认知系统。这需要引入记忆衰减机制、变化检测模块和不确定性量化------这些都是当前两篇论文都没有解决的问题。
一句话结论
世界模型的终局不是"生成更好的画面",也不是"造更多的数据",而是让机器人拥有一个可推理、可更新、可信赖的三维心智------3D-Belief 和 GigaWorld-0 分别从"想"和"造"两个方向逼近了这个目标,但"可信"这一环仍是整个拼图中缺失最大的一块。