这篇文章也是将单目深度估计融合到立体匹配中,没有foundation stereo复杂的结构,使用了单目和双目两个分支互补,思想直观很简单,但是网络略显粗糙。
MonSter: Marry Monodepth to Stereo Unleashes Power 论文总结
文章目录
- [MonSter: Marry Monodepth to Stereo Unleashes Power 论文总结](#MonSter: Marry Monodepth to Stereo Unleashes Power 论文总结)
-
- 一句话总结
- [0. 论文概述(Executive Summary)](#0. 论文概述(Executive Summary))
- [1. 问题背景与动机](#1. 问题背景与动机)
- [2. 相关工作与创新关联](#2. 相关工作与创新关联)
-
- [2.1 前人工作综述](#2.1 前人工作综述)
- [2.2 存在的问题与不足](#2.2 存在的问题与不足)
- [2.3 本论文与前人工作的关系](#2.3 本论文与前人工作的关系)
- [3. 贡献与核心创新点](#3. 贡献与核心创新点)
-
- [3.1 创新点一:Stereo Guided Alignment(SGA)](#3.1 创新点一:Stereo Guided Alignment(SGA))
- [3.2 创新点二:Mono Guided Refinement(MGR)](#3.2 创新点二:Mono Guided Refinement(MGR))
- [3.3 创新点三:双分支互迭代架构](#3.3 创新点三:双分支互迭代架构)
- [4. 方法与网络设计](#4. 方法与网络设计)
-
- [4.1 整体网络架构概览](#4.1 整体网络架构概览)
-
- [4.1.1 网络三大部分](#4.1.1 网络三大部分)
- [4.1.2 信息流向图示(文字描述)](#4.1.2 信息流向图示(文字描述))
- [4.1.3 各模块功能概述](#4.1.3 各模块功能概述)
- [4.2 网络详细分析](#4.2 网络详细分析)
-
- [4.2.1 全局尺度‑偏移对齐(Global Scale‑Shift Alignment)](#4.2.1 全局尺度‑偏移对齐(Global Scale‑Shift Alignment))
- [4.2.2 Stereo Guided Alignment(SGA)详解](#4.2.2 Stereo Guided Alignment(SGA)详解)
- [4.2.3 Mono Guided Refinement(MGR)详解](#4.2.3 Mono Guided Refinement(MGR)详解)
- [4.2.4 损失函数与训练策略](#4.2.4 损失函数与训练策略)
- [5. 实验结果](#5. 实验结果)
-
- [5.1 数据集与评估指标](#5.1 数据集与评估指标)
- [5.2 消融研究](#5.2 消融研究)
- [5.3 性能对比](#5.3 性能对比)
- [5.4 零样本泛化性能](#5.4 零样本泛化性能)
- [6. 不足之处与未来工作](#6. 不足之处与未来工作)
- [7. 总体评价](#7. 总体评价)
文章基本信息
- 标题:MonSter: Marry Monodepth to Stereo Unleashes Power
- 作者:Junda Cheng, Longliang Liu, Gangwei Xu, Xianqi Wang, Zhaoxing Zhang, Xin Yang (华中科技大学), 等 (Autel Robotics, Intel Labs)
- 年份:2025
- 会议/期刊: CVPR
一句话总结
MonSter 提出了一种双分支迭代互增强 框架,将单目深度估计(Monocular Depth Estimation)和立体匹配(Stereo Matching)深度融合,通过 SGA(Stereo Guided Alignment) 和 MGR(Mono Guided Refinement) 模块,用立体匹配恢复单目深度的像素级尺度和偏移,再用精细化的单目深度引导立体匹配处理病态区域(反光、无纹理、细结构、远距离),在五大公开榜单上均取得第一名,零样本泛化能力显著超越现有方法。
0. 论文概述(Executive Summary)
立体匹配通过左右图像对应关系恢复深度,但在遮挡(occlusion)、无纹理区域(textureless areas)、重复/细薄结构(repetitive/thin structures)、远距离物体(distant objects) 等缺乏匹配线索的区域表现不佳。现有方法主要通过增强特征表示或注意力机制来改进匹配代价,但无法从根本上解决误匹配(mismatching) 问题。
与此相对,单目深度估计直接从单张图像恢复三维结构,不涉及匹配问题,但其输出是相对深度(relative depth) ,存在全局尺度和偏移歧义(scale and shift ambiguities),且即使经过全局对齐,仍存在显著的像素级误差(见图3)。
MonSter 的核心洞察是:将立体匹配任务解耦为"从相对深度恢复像素级尺度和偏移"的简化问题。为此,MonSter 设计了:
- 单目分支:使用预训练的 DepthAnythingV2(冻结参数)提供丰富结构先验。
- 立体分支:基于 IGEv 架构,共享 ViT 编码器特征。
- 互优化模块:交替执行 SGA(用可靠立体视差校正单目视差的逐像素偏移)和 MGR(用精细化单目视差引导立体视差在病态区域的优化)。
通过多次迭代,单目深度从粗粒度的物体级结构演化为像素级几何,完全释放了立体匹配的潜力。
实验表明:MonSter 在 SceneFlow、KITTI 2012、KITTI 2015、Middlebury、ETH3D 五个榜单上均排名第一,在 ETH3D 的 Bad 1.0 指标上提升达 49.5%;零样本泛化性能全面领先(见表5);在反光区域、边缘/非边缘区域、远距离背景上均显著优于 SOTA。
1. 问题背景与动机
立体匹配的核心任务:给定一对已校正的立体图像 ( I L , I R ) (I_L, I_R) (IL,IR),估计视差图 D D D,进而转换为度量深度。深度学习方法主要分为两类:
- 代价滤波法(cost filtering‑based):构建 3D/4D 代价体积,用 CNN 正则化。
- 迭代优化法(iterative optimization‑based):构建全对相关体积,用 ConvGRU 迭代更新视差。
共同局限 :都依赖于左右图像间的显式对应关系。在以下病态区域(ill‑posed regions) 中,匹配线索不足:
- 遮挡(occlusions)
- 无纹理/低纹理区域(textureless / low‑texture areas)
- 重复或细薄结构(repetitive / thin structures)
- 远距离物体(distant objects,像素占比小)
单目深度估计则完全不受匹配问题困扰,但其输出是相对深度,存在尺度和偏移歧义。如图3所示,即使经过全局最小二乘对齐,单目深度与真实视差之间仍有巨大残差,无法直接像素级融合。
动机 :如何利用单目深度先验的结构性优势 ,同时克服其尺度/偏移歧义 ,并将其与立体匹配的精确几何有机结合,从而彻底解决病态区域的深度感知问题?
2. 相关工作与创新关联
2.1 前人工作综述
| 类别 | 代表方法 | 核心思想 | 不足 |
|---|---|---|---|
| 匹配增强 | GwcNet, ACVNet, IGEV | 改进代价体积表达力 / 几何编码 | 仍依赖匹配,病态区域无效 |
| 迭代优化 | RAFT‑Stereo, CREStereo | ConvGRU 相关体索引 | 同上 |
| 结构先验 | EdgeStereo, SegStereo | 边缘/语义线索 | 仅物体级先验,缺乏像素级几何 |
| 单目+立体 | CLStereo, LoS | 单目深度作为局部结构先验 | 未解决尺度/偏移歧义,可能引入噪声 |
2.2 存在的问题与不足
- 现有方法本质上是匹配驱动,无法跳出"寻找对应点"的框架。
- 单目深度先验的使用往往是单向且粗粒度(全局对齐后直接融合),导致在复杂曲面(斜平面、弯曲表面)上引入噪声。
- 缺乏自适应、像素级的校正机制来消除单目深度的尺度和偏移歧义。
2.3 本论文与前人工作的关系
- 继承:立体分支基于 IGEV 37 的几何编码体积和 ConvGRU 迭代结构。
- 改进 :
- 引入冻结的 ViT 编码器(DINOv2)作为共享特征提取器,提供丰富上下文。
- 提出双向互优化:SGA 用立体视差校正单目视差的逐像素偏移;MGR 用校正后的单目视差引导立体视差。
- 实现从物体级粗结构到像素级精细几何的演化。
- 本质差异 :不再将单目深度视为"额外线索",而是将立体匹配任务重新定义为"从相对深度恢复尺度和偏移",从而绕过匹配困难。
3. 贡献与核心创新点
3.1 创新点一:Stereo Guided Alignment(SGA)
- 目标 :解决单目深度的逐像素尺度/偏移歧义。
- 方法 :利用立体分支中高置信度的匹配区域 ,通过条件引导的 ConvGRU 更新单目视差的残差偏移 Δ t \Delta t Δt。
- 关键 :避免将不可靠的立体匹配噪声引入单目分支,通过流残差图(flow residual map) 计算置信度,自适应选择可靠立体线索。
3.2 创新点二:Mono Guided Refinement(MGR)
- 目标:用精细化后的单目视差引导立体匹配,改善病态区域。
- 方法 :对称于 SGA,将单目视差作为条件输入另一个 ConvGRU,同时融合立体分支自身的几何特征,输出残差视差 Δ d \Delta d Δd 更新立体视差。
- 关键:单目视差在远距离、反光、无纹理区域仍然可靠,可有效补充立体匹配的不足。
3.3 创新点三:双分支互迭代架构
- 流程 :全局尺度‑偏移对齐 → 交替执行 SGA 和 MGR 共 N 2 N_2 N2 轮。
- 效果:单目深度从粗到精,立体匹配从易到难,两者相互促进,最终输出高精度立体视差。
- 共享特征:ViT 编码器同时服务于单目和立体分支,冻结参数以保留泛化能力。
4. 方法与网络设计
4.1 整体网络架构概览
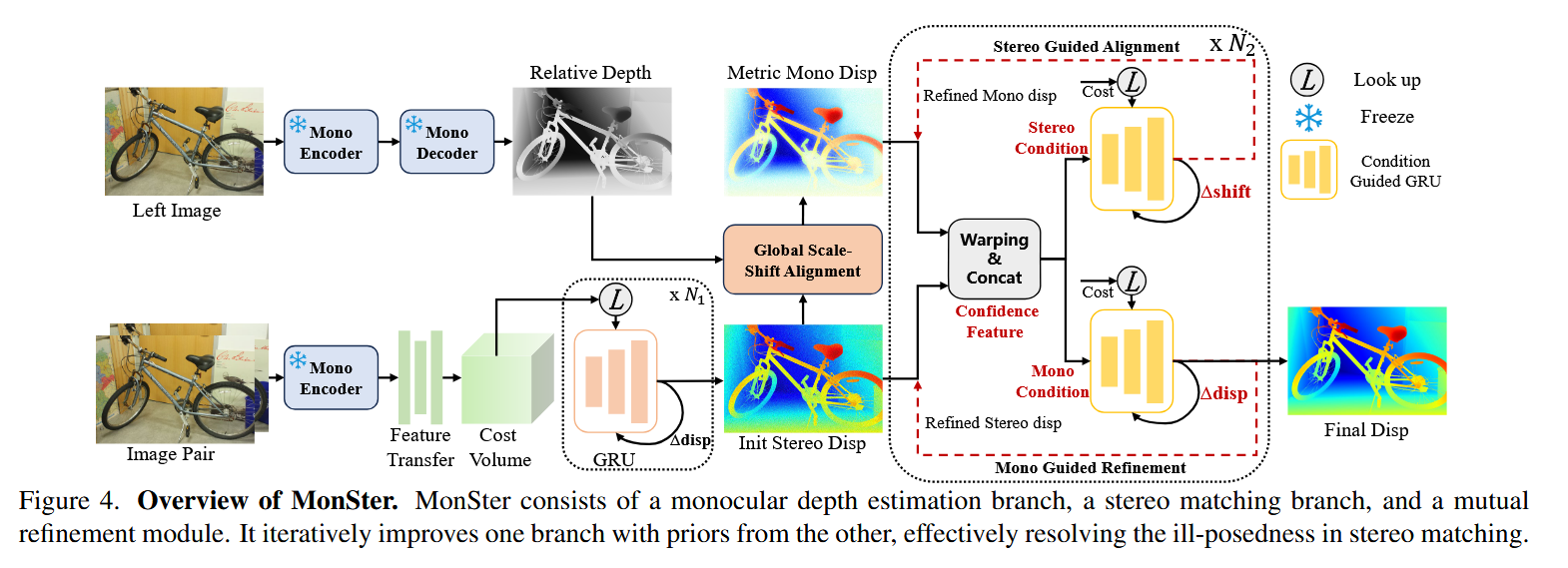
4.1.1 网络三大部分
- 单目深度分支(Monocular Depth Branch)
- 使用 DepthAnythingV2 45(ViT‑large + DPT 解码器),输出相对深度 D M \mathcal{D}_M DM。
- 参数冻结,不参与训练,保证泛化能力。
- 立体匹配分支(Stereo Matching Branch)
- 基于 IGEv 37,但特征提取器改为共享的 ViT 编码器 + 特征转移网络(2D 卷积金字塔)。
- 生成多尺度特征 F = { F 0 , F 1 , F 2 , F 3 } \mathcal{F} = \{F_0, F_1, F_2, F_3\} F={F0,F1,F2,F3},构建几何编码体积(Geometry Encoding Volume),ConvGRU 迭代 N 1 N_1 N1 次得到初始视差 D S 0 \mathcal{D}_S^0 DS0。
- 互优化模块(Mutual Refinement Module)
- 包含 SGA 和 MGR ,交替执行 N 2 N_2 N2 轮,每轮更新一次单目视差和立体视差。
4.1.2 信息流向图示(文字描述)
左图 I_L + 右图 I_R
│
├──→ 共享 ViT 编码器 (DINOv2,冻结)
│ │
│ ├──→ 单目分支:DPT 解码器 → 相对深度 D_M
│ │
│ └──→ 特征转移网络 → 金字塔特征 F
│ │
│ └──→ 立体分支:几何编码体积 + ConvGRU (N1 次)
│ │
│ ↓
│ 初始视差 D_S^0
│
└──→ 全局尺度‑偏移对齐 (公式1) → 单目视差 D_M^0
│
↓
┌─────────────────────────────┐
│ 迭代 j = 0..N2-1: │
│ SGA: D_M^{j} → D_M^{j+1} │
│ MGR: D_S^{j} → D_S^{j+1} │
└─────────────────────────────┘
│
↓
最终立体视差 D_S^{N2} (输出)4.1.3 各模块功能概述
| 模块 | 输入 | 输出 | 功能 |
|---|---|---|---|
| 全局对齐 | 相对深度 D M D_M DM,初始视差 D S 0 D_S^0 DS0 | 单目视差 D M 0 D_M^0 DM0 | 最小二乘求全局尺度 s G s_G sG 和偏移 t G t_G tG |
| SGA | D M j , D S j D_M^j, D_S^j DMj,DSj,几何特征 G S j G_S^j GSj,流残差 F S j F_S^j FSj | 更新的 D M j + 1 D_M^{j+1} DMj+1 | 用可靠立体线索校正单目视差的逐像素偏移 |
| MGR | D M j , D S j D_M^{j}, D_S^{j} DMj,DSj,双边的几何和流特征 | 更新的 D S j + 1 D_S^{j+1} DSj+1 | 用精细单目视差引导立体视差在病态区域的优化 |
4.2 网络详细分析
4.2.1 全局尺度‑偏移对齐(Global Scale‑Shift Alignment)
目的 :将单目相对深度 D M \mathcal{D}_M DM 转化为与立体视差 D S 0 D_S^0 DS0 粗略对齐的单目视差 D M 0 D_M^0 DM0。
方法 :在筛选后的像素集合 Ω \Omega Ω 上求解最小二乘问题:
s G , t G = arg min s G , t G ∑ i ∈ Ω ( s G D M ( i ) + t G − D S 0 ( i ) ) 2 D M 0 = s G D M + t G ( 1 ) \begin{aligned} s_G, t_G &= \arg\min_{s_G, t_G} \sum_{i \in \Omega} \left( s_G \mathcal{D}_M(i) + t_G - \mathcal{D}_S^0(i) \right)^2 \\ D_M^0 &= s_G \mathcal{D}_M + t_G \end{aligned} \quad (1) sG,tGDM0=argsG,tGmini∈Ω∑(sGDM(i)+tG−DS0(i))2=sGDM+tG(1)
其中 Ω \Omega Ω 定义为视差值从小到大排序后 20% 到 90% 之间的像素区域,用于排除天空、极远距离和近处异常值。
4.2.2 Stereo Guided Alignment(SGA)详解
目标 :在每一轮互优化中,利用高置信度的立体匹配线索 ,为单目视差预测一个逐像素残差偏移 Δ t \Delta t Δt,从而校正局部尺度/偏移误差。
步骤:
- 计算立体流残差图(置信度指标):
F S j ( x , y ) = ∥ F S L ( x , y ) − F S R ( x − D S j , y ) ∥ 1 ( 2 ) \mathbf{F}_S^j(x,y) = \left\| F_S^L(x,y) - F_S^R(x - D_S^j, y) \right\|_1 \quad (2) FSj(x,y)= FSL(x,y)−FSR(x−DSj,y) 1(2)
- F S L , F S R F_S^L, F_S^R FSL,FSR:左右图像在 1/4 分辨率下的特征。
- 残差越小,表示该像素的立体匹配越可靠。
- 构建立体条件特征:
x S j = E n g ( \[ G S j , F S j , D S j ) , E n d ( D M j ) , D M j ] ( 3 ) x_S^j = \left \\mathrm{En}_g(\[G_S\^j, F_S\^j, D_S\^j),\; \mathrm{En}_d(D_M^j),\; D_M^j \right] \quad (3) xSj=Eng(\[GSj,FSj,DSj),End(DMj),DMj](3)
- G S j G_S^j GSj:用当前立体视差从几何编码体积索引得到的几何特征。
- E n g , E n d \mathrm{En}_g, \mathrm{En}_d Eng,End:两个卷积层,用于特征编码。
- 条件引导的 ConvGRU 更新(公式 4):
z j = σ ( C o n v ( h M j − 1 , x S j , W z ) + c z ) r j = σ ( C o n v ( h M j − 1 , x S j , W r ) + c r ) h ~ M j = tanh ( C o n v ( r j ⊙ h M j − 1 , x S j , W h ) + c h ) h M j = ( 1 − z j ) ⊙ h M j − 1 + z j ⊙ h ~ M j ( 4 ) \begin{aligned} z^j &= \sigma\left( \mathrm{Conv}(h_M\^{j-1}, x_S\^j, W_z) + c_z \right) \\ r^j &= \sigma\left( \mathrm{Conv}(h_M\^{j-1}, x_S\^j, W_r) + c_r \right) \\ \tilde{h}_M^j &= \tanh\left( \mathrm{Conv}(r\^j \\odot h_M\^{j-1}, x_S\^j, W_h) + c_h \right) \\ h_M^j &= (1 - z^j) \odot h_M^{j-1} + z^j \odot \tilde{h}_M^j \end{aligned} \quad (4) zjrjh~MjhMj=σ(Conv(hMj−1,xSj,Wz)+cz)=σ(Conv(hMj−1,xSj,Wr)+cr)=tanh(Conv(rj⊙hMj−1,xSj,Wh)+ch)=(1−zj)⊙hMj−1+zj⊙h~Mj(4)
- 与标准 ConvGRU 一致,但输入条件 x S j x_S^j xSj 中融入了立体匹配的可靠信息。
- c z , c r , c h c_z, c_r, c_h cz,cr,ch 为可学习的上下文特征。
- 解码残差偏移并更新单目视差:
D M j + 1 = D M j + Δ t , Δ t = C o n v ( h M j ) ( 5 ) D_M^{j+1} = D_M^j + \Delta t, \quad \Delta t = \mathrm{Conv}(h_M^j) \quad (5) DMj+1=DMj+Δt,Δt=Conv(hMj)(5)
4.2.3 Mono Guided Refinement(MGR)详解
目标:利用 SGA 细化后的单目视差,改善立体视差在病态区域的精度。
步骤:
- 计算单目流残差图(用单目视差做 warp):
F M j ( x , y ) = ∥ F S L ( x , y ) − F S R ( x − D M j , y ) ∥ 1 ( 6 ) \mathbf{F}_M^j(x,y) = \left\| F_S^L(x,y) - F_S^R(x - D_M^j, y) \right\|_1 \quad (6) FMj(x,y)= FSL(x,y)−FSR(x−DMj,y) 1(6)
- 构建双路条件特征(同时包含单目和立体信息):
x M j = E n g ( \[ G M j , F M j , D M j ) , E n d ( D M j ) , D M j , E n g ( G S j , F S j , D S j ) , E n d ( D S j ) , D S j ] ( 6 ) \begin{aligned} x_M^j = \&\\mathrm{En}_g(\[G_M\^j, \\mathbf{F}_M\^j, D_M\^j),\; \mathrm{En}_d(D_M^j),\; D_M^j,\\ &\mathrm{En}_g(G_S\^j, \\mathbf{F}_S\^j, D_S\^j),\; \mathrm{En}_d(D_S^j),\; D_S^j] \end{aligned} \quad (6) xMj=Eng(\[GMj,FMj,DMj),End(DMj),DMj,Eng(GSj,FSj,DSj),End(DSj),DSj](6)
- G M j G_M^j GMj:用单目视差从几何编码体积索引得到的几何特征。
-
同样使用公式 (4) 的 ConvGRU ,但将条件替换为 x M j x_M^j xMj,更新立体分支的隐藏状态 h S j h_S^j hSj。
-
解码残差视差并更新立体视差:
D S j + 1 = D S j + Δ d ( 5 相同形式 ) D_S^{j+1} = D_S^j + \Delta d \quad (5\ \text{相同形式}) DSj+1=DSj+Δd(5 相同形式)
4.2.4 损失函数与训练策略
总体损失 :
L = L S t e r e o + L M o n o \mathcal{L} = \mathcal{L}{Stereo} + \mathcal{L}{Mono} L=LStereo+LMono
- 立体分支损失 L S t e r e o \mathcal{L}_{Stereo} LStereo:
L S t e r e o = ∑ i = 0 N 1 − 1 γ N 1 + N 2 − i ∥ d i − d g t ∥ 1 + ∑ i = N 1 N 1 + N 2 − 1 γ N 1 + N 2 − i ∥ D S i − N 1 − d g t ∥ 1 ( 7 ) \begin{aligned} \mathcal{L}{Stereo} = &\sum{i=0}^{N_1-1} \gamma^{\,N_1+N_2-i} \| \mathbf{d}i - \mathbf{d}{gt} \|1 \\ &+ \sum{i=N_1}^{N_1+N_2-1} \gamma^{\,N_1+N_2-i} \| \mathbf{D}S^{\,i-N_1} - \mathbf{d}{gt} \|_1 \end{aligned} \quad (7) LStereo=i=0∑N1−1γN1+N2−i∥di−dgt∥1+i=N1∑N1+N2−1γN1+N2−i∥DSi−N1−dgt∥1(7)
- 单目分支损失 L M o n o \mathcal{L}_{Mono} LMono:
L M o n o = ∑ i = N 1 N 1 + N 2 − 1 γ N 1 + N 2 − i ∥ D M i − N 1 − d g t ∥ 1 ( 7 ) \mathcal{L}{Mono} = \sum{i=N_1}^{N_1+N_2-1} \gamma^{\,N_1+N_2-i} \| \mathbf{D}M^{\,i-N_1} - \mathbf{d}{gt} \|_1 \quad (7) LMono=i=N1∑N1+N2−1γN1+N2−i∥DMi−N1−dgt∥1(7)
其中:
- γ = 0.9 \gamma = 0.9 γ=0.9:指数权重,越靠后的迭代权重越高。
- N 1 N_1 N1:初始立体迭代次数(默认 2)。
- N 2 N_2 N2:互优化迭代次数(默认 2)。
- d g t \mathbf{d}_{gt} dgt:视差真值。
训练策略:
- 优化器:AdamW,学习率 2e-4,one‑cycle 调度。
- 批大小:8。
- 预训练:先在 Scene Flow 上训练 200k 步。
- 微调:在 ETH3D / Middlebury 上使用 BTS(Basic Training Set,包含多个数据集)进一步训练。
- 单目分支完全冻结,仅训练立体分支、特征转移网络、SGA/MGR 模块。
5. 实验结果
5.1 数据集与评估指标
| 数据集 | 类型 | 主要指标 |
|---|---|---|
| Scene Flow | 合成 | EPE (End Point Error, px) |
| KITTI 2012/2015 | 真实驾驶场景 | D1‑all, Out‑N, 等 |
| ETH3D | 室内/室外多视角 | Bad 1.0, Bad 2.0, RMSE |
| Middlebury | 高分辨率立体 | Bad 2.0, RMSE |
5.2 消融研究
表6 (Scene Flow 测试集):逐步验证各模块有效性
| 模型 | 单目深度 | 融合方式 | 尺度/偏移校正 | 特征共享 | EPE (px) | >1px (%) |
|---|---|---|---|---|---|---|
| Baseline (IGEv) | ✗ | -- | -- | -- | 0.47 | 5.21 |
| Mono+Conv | ✓ | Conv | ✗ | ✗ | 0.46 | 5.12 |
| Mono+MGR | ✓ | MGR | ✗ | ✗ | 0.43 | 4.96 |
| Mono+MGR+Conv | ✓ | MGR+Conv | ✗ | ✗ | 0.42 | 4.82 |
| Mono+MGR+SGA | ✓ | MGR | ✓ (SGA) | ✗ | 0.39 | 4.43 |
| Full (MonSter) | ✓ | MGR | ✓ (SGA) | ✓ | 0.37 | 4.25 |
- MGR vs Conv:MGR 比简单卷积融合提升 6.52% EPE。
- SGA:在 MGR 基础上加入 SGA 再提升 9.30% EPE 和 10.69% 1px 误差。
- 特征共享:再提升 5.13% EPE。
表7 :MonSter 对多种单目深度模型的兼容性(DepthAnythingV2, V1, MiDaS 均优于基线),且仅需 4 次迭代(基线 IGEv 需 32 次)即可达到更高精度。
5.3 性能对比
五大榜单排名第一(截至论文提交时):
| 数据集 | 指标 | MonSter | 之前 SOTA | 提升幅度 |
|---|---|---|---|---|
| Scene Flow | EPE | 0.37 | 0.44 (Selective‑IGEV) | 15.91% |
| ETH3D | Bad 1.0 (NoC) | 0.46 | 0.91 (LoS) | 49.45% |
| Middlebury | RMSE | 6.71 | 7.26 (Selective‑IGEV) | 7.58% |
| KITTI 2015 | D1‑all (All) | 1.33 | 1.59 (CREStereo) | 16.57% |
| KITTI 2012 | Out‑3 (All) | 1.36 | 1.69 (NMRF‑Stereo) | 19.26% |
病态区域专项提升:
- 反光区域(KITTI 2012) :Out‑4(All) 从 4.38 (Selective‑IGEV) 降至 3.38(提升 30.16%)。
- 边缘区域(Scene Flow) :EPE 从 2.23 (IGEv) 降至 1.91(提升 14.35%)。
- 非边缘区域 :EPE 从 0.41 降至 0.31(提升 24.39%)。
- 远距离背景(KITTI 2015 D1‑bg) :从 1.27 (IGEv) 降至 1.05(提升 18.12%)。
5.4 零样本泛化性能
仅 Scene Flow 训练,直接测试真实数据集:
| 方法 | KITTI‑12 (>3px) | KITTI‑15 (>3px) | Middlebury (>2px) | ETH3D (>1px) |
|---|---|---|---|---|
| IGEv | 4.84 | 5.51 | 6.23 | 3.62 |
| MonSter | 3.62 | 3.97 | 5.17 | 2.03 |
混合 3 个合成数据集训练后,泛化能力进一步提升(Middlebury 2.94 vs IGEv 3.95,ETH3D 1.21 vs 2.38)。
6. 不足之处与未来工作
- 计算开销 :MonSter 总参数量 356.1M(其中单目分支 335.3M),推理时间 0.64s 比基线 IGEv (0.37s) 长。作者认为精度提升可接受,但未来可通过编码器量化或蒸馏减少开销。
- 单目分支限制:目前使用固定的 DepthAnythingV2,虽然展示了兼容性,但未探索联合微调的可能性(冻结是为了保留泛化能力)。
- 未来方向 :
- 扩大仿真数据的规模和多样性,训练一个 立体基础模型(stereo foundation model)。
- 将 MonSter 应用于更多下游任务(自动驾驶、机器人导航、3D 重建)。
7. 总体评价
| 维度 | 评价 |
|---|---|
| 创新性 | ★★★★★ 首次将立体匹配解耦为"单目深度 + 像素级尺度和偏移恢复",双向迭代互增强,思路新颖。 |
| 性能 | ★★★★★ 五大榜单第一,提升幅度显著(最高 49.5%),零样本泛化能力极强。 |
| 实用性 | ★★★★☆ 参数量较大,推理速度中等,但对精度要求高的场景(如自动驾驶)极具价值。 |
| 理论贡献 | ★★★★☆ 揭示了单目深度与立体匹配的互补本质,为融合几何与先验提供了新范式。 |
| 可复现性 | ★★★★★ 代码已开源,详细说明训练细节和超参数。 |
核心启示 :通过将立体匹配的任务重新定义为从相对深度恢复精确尺度和偏移,可以彻底绕过匹配歧义问题,充分发挥大规模预训练单目模型的潜力。MonSter 为后续"几何+先验"融合研究开辟了明确方向。