前置知识
- 一:项目背景
- 二:项目最终理想运行形态
-
- [1. 第一步:数据清洗,也就是网页去标签](#1. 第一步:数据清洗,也就是网页去标签)
- [2. 第二步:启动 HTTP 搜索服务](#2. 第二步:启动 HTTP 搜索服务)
- 3.浏览器访问后的效果
- 三:搜索结果页面展示要素
-
- [1. 第一部分:网页标题 Title](#1. 第一部分:网页标题 Title)
- [2. 第二部分:网页摘要 Description](#2. 第二部分:网页摘要 Description)
- [3. 第三部分:目标网址 URL](#3. 第三部分:目标网址 URL)
- 四:搜索引擎宏观原理
-
- [1. 客户端是什么?](#1. 客户端是什么?)
- 2.服务器是什么?
- 3.搜索之前,服务器提前做了什么?
- 4.数据清理和简历索引
- 5.用户发起搜索请求
- 6.服务器如何处理关键词?
- 五:正排索引
- 六:倒排索引
- 七:获取测试数据源
一:项目背景
1.为什么不做"全网搜索",而做"站内搜索"?
全网搜索不是一个小项目,而是一个系统级工程,我们自己实现一个完整搜索引擎是不可能的。
2.什么是站内搜索?
既然全网搜索太大,那我们可以退一步,做一个简单的搜索引擎,也就是 站内搜索。
站内搜索的特点是:
只搜索某一个网站或某一批固定文档里的内容。
比如 C++ 学习中常用的 cplusplus.com 或者类似标准文档网站,它们内部就支持搜索。你搜索 string,它会返回和 C++ STL、容器、字符串相关的结果。
它和全网搜索最大的区别是:
| 对比项 | 全网搜索 | 站内搜索 |
|---|---|---|
| 搜索范围 | 整个互联网 | 某个网站 / 某批文档 |
| 数据量 | 极大 | 相对较小 |
| 内容相关性 | 很杂 | 更垂直 |
| 技术难度 | 极高 | 适合学习和项目实践 |
| 示例 | 百度、搜狗、360 | C++ 文档搜索、Boost 文档搜索 |
二:项目最终理想运行形态
1. 第一步:数据清洗,也就是网页去标签
原始网页里面会有大量 HTML 标签。
但是搜索引擎真正展示给用户的内容,通常不会把这些标签暴露出来。比如你搜索一个关键词,返回结果里不会出现一堆
html
<html>、<body>、<div>
这样的标签。
所以在真正搜索之前,需要先对网页信息做一次处理。
bash
原始 Boost HTML 文档
↓
读取网页文件
↓
去掉 HTML 标签
↓
提取标题、正文、URL 等核心信息
↓
生成后续搜索可以使用的干净数据2. 第二步:启动 HTTP 搜索服务
数据清洗完成以后,就要启动真正的搜索服务。
启动服务以后,服务器会做一件比较耗时的事情:构建索引
因为搜索引擎必须先有一批可搜索的数据,也就是 Boost 文档资源。服务启动时会根据这些网页资源建立索引。
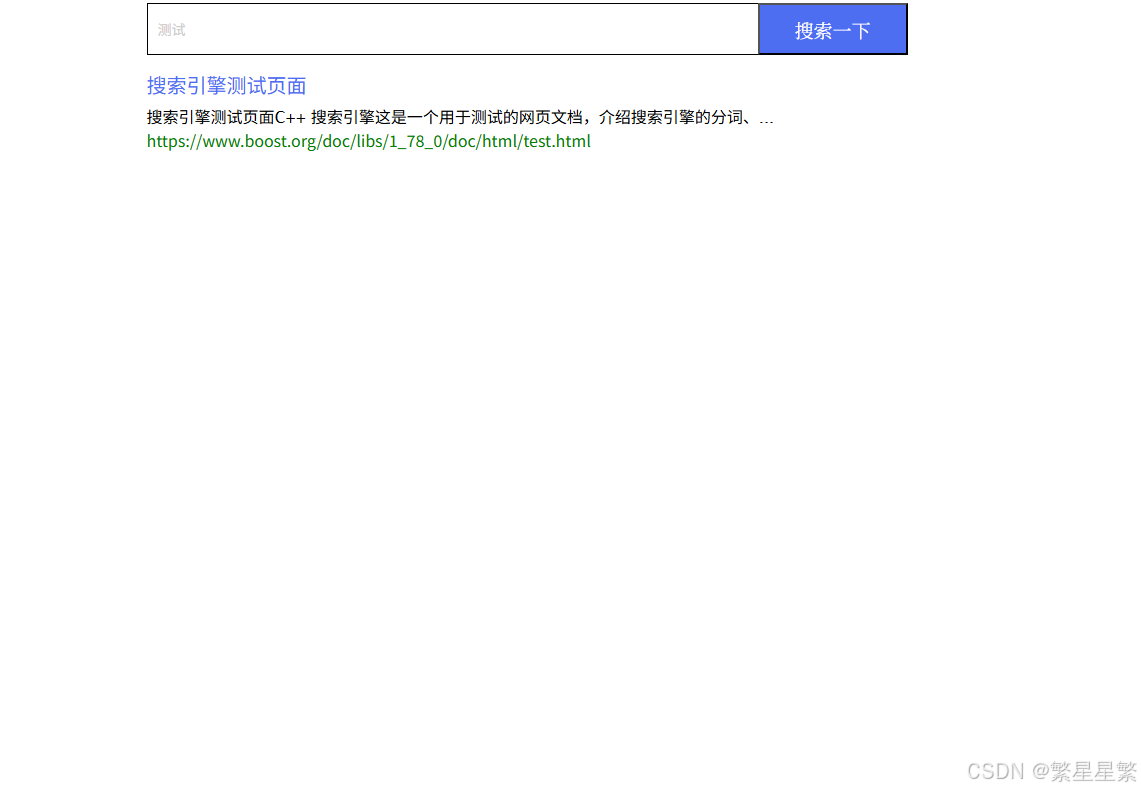
3.浏览器访问后的效果
当浏览器访问服务器 IP 和 8081 端口后,会看到一个搜索框。
用户输入关键词,比如 filesystem,点击搜索后,服务端会在 Boost 文档中检索对应内容。
最终返回的搜索结果不是乱七八糟的 HTML 文件,而是整理过的结果
三:搜索结果页面展示要素
1. 第一部分:网页标题 Title
标题一般是搜索结果中最显眼的那一行。
它有两个作用:
第一,告诉用户这个网页大概是干什么的。
用户看到标题,就能快速判断这个结果是否值得点进去。
第二,标题通常是可以点击的。
点击标题后,浏览器会跳转到目标网页。
所以标题既是展示信息,也是跳转入口。
在网页中,这个标题通常来自 HTML 页面中的 title 信息,或者搜索引擎提取出来的页面主标题。
2. 第二部分:网页摘要 Description
摘要也可以理解为网页内容的简短描述。
它的作用是帮助用户进一步判断这个页面是否符合自己的搜索意图。
比如你搜一个关键词,标题可能很短,光看标题不一定知道内容是否相关。
这时候摘要就会展示网页中的一小段相关文本。
有些搜索引擎可能会在摘要区域显示图片、时间等额外信息。但我们这个项目暂时不考虑这么复杂。
我们只关注核心摘要。
3. 第三部分:目标网址 URL
搜索结果中还会显示目标网页对应的网址。
这个 URL 表示用户点击标题之后要跳转到哪里。
在我们这个项目中,搜索 Boost 文档时,最终点击标题应该能跳转到 Boost 官网对应的文档页面。
所以 URL 是必须保留的信息。
四:搜索引擎宏观原理
1. 客户端是什么?
对我们这个项目来说,客户端主要就是浏览器 。
用户在浏览器页面输入搜索关键词,然后点击搜索按钮。
2.服务器是什么?
服务器可以理解成运行在云服务器上的一个服务程序。
这个服务程序就是我们的搜索引擎服务,也可以称为 searcher。
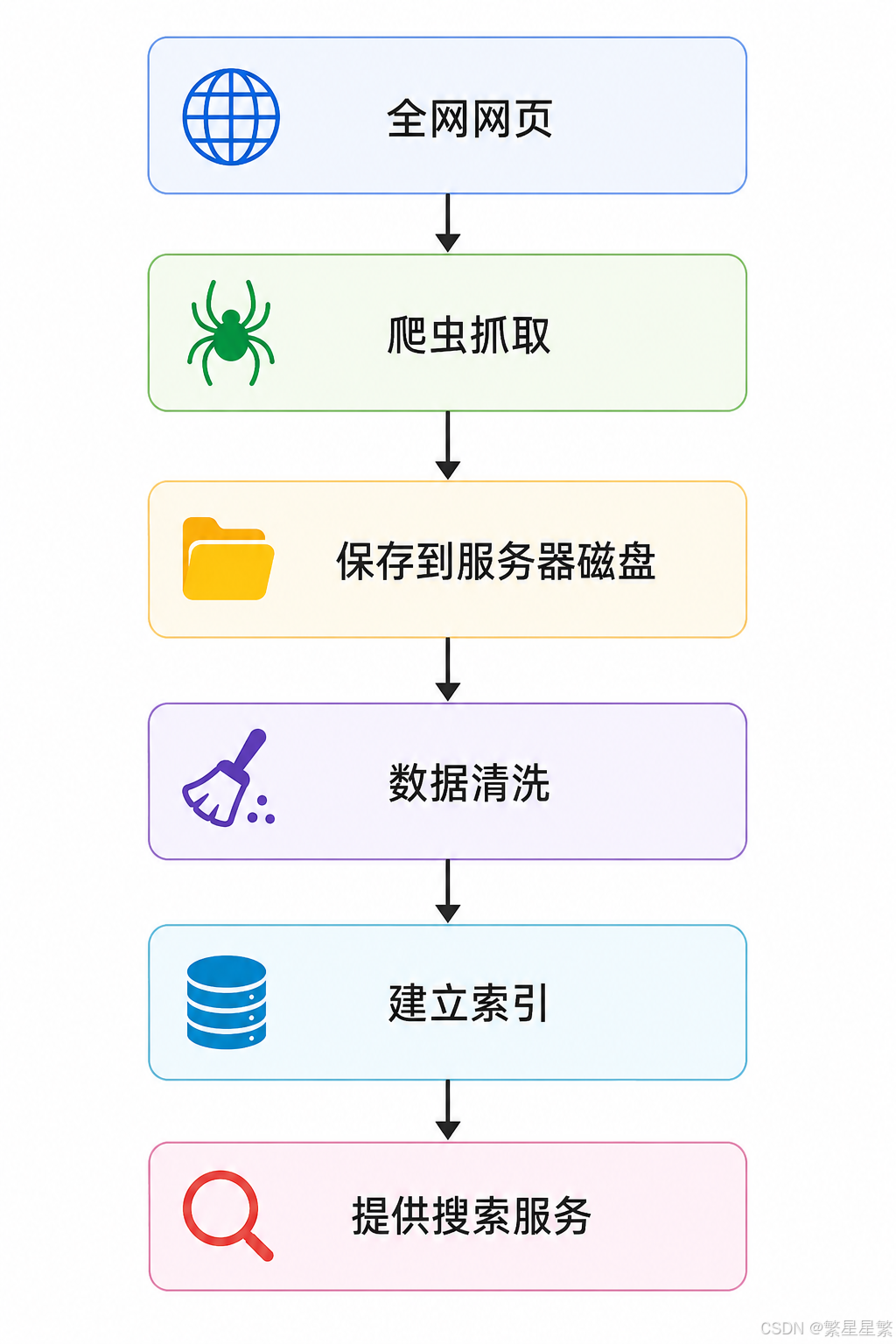
3.搜索之前,服务器提前做了什么?
搜索服务运行在内存中。
但是网页数据通常存放在磁盘中。
真实搜索引擎公司会有爬虫程序,不断从全网抓取网页,把网页保存下来。
不过我们这个项目不会做全网爬虫。
原因有两个:
bash
第一,全网爬虫难度很高。
第二,爬虫可能涉及一定法律和合规风险。4.数据清理和简历索引
数据清洗之后,搜索服务要做第二件事:建立索引。
搜索引擎如果没有索引,每次用户输入关键词,都要把所有网页从头扫一遍。
数据量小的时候还能忍,数据量一大就完全不现实。
所以搜索引擎一定要提前建立索引。
5.用户发起搜索请求
当服务器准备好数据和索引之后,用户就可以搜索了。
用户在浏览器输入关键词,然后浏览器向服务器发起 HTTP 请求。
6.服务器如何处理关键词?
bash
接收 HTTP 请求
↓
解析搜索关键词
↓
根据关键词检索索引
↓
找到相关文档
↓
整理每个文档的标题、摘要、URL
↓
拼接成新的 HTML 页面
↓
返回给浏览器这里有一个很重要的点:
返回给用户的网页,不是原始 Boost 文档页面。
而是我们根据搜索结果重新拼接出来的一个结果页。
这个结果页里面包含多条结果,每条结果又包含:
bash
title + desc + url用户看到的是搜索结果页,而不是某个单独的原始网页
五:正排索引
1.正排索引是什么
只要我知道某个文档的编号,就可以直接找到这个文档里面的内容。
比如现在有两个文档:
| 文档 ID | 文档内容 |
|---|---|
| 1 | 雷军买了四斤小米 |
| 2 | 雷军发布了小米手机 |
你现在告诉我:我要看 1 号文档
那我就可以根据文档 ID 直接找到:雷军买了四斤小米
这就是正排索引的作用。
2.正排索引在搜索引擎中的作用
正排索引不是用来直接查关键字的。
它主要用于:根据文档 ID 找回完整文档信息
比如用户搜索"小米"之后,搜索引擎可能先找到:
bash
文档 1
文档 2正排索引的本质是 文档 ID → 文档内容。它不是用来直接根据关键字搜索的,而是在搜索结果已经找到相关文档 ID 之后,用来取回文档标题、正文、描述、URL 等完整信息。
六:倒排索引
1.为什么要分词?
搜索引擎最终是根据关键字搜索的。
但一篇文档通常不是天然按关键字存储的,而是一整段文本。
比如:雷军发布了小米手机
如果不处理,这就是一整句话。
但用户搜索的时候,可能搜的是:
bash
雷军
小米
小米手机
手机所以我们必须先把一句话拆成一个个有意义的词。
这个过程就叫:分词
分词的目的主要有两个:
bash
1. 方便建立倒排索引
2. 方便后续查找如果不分词,就没法知道哪些关键词对应哪些文档。
2.停止词:分词后需要忽略的一类词
比如中文里的:
bash
了
的
在
是
啊
呢英文里的:
bash
a
the
is
of
in这些词几乎每篇文章都会出现。
如果我们把这些词也加入索引,会带来两个问题。
第一个问题是:区分度太低。
比如用户搜索"的",几乎所有文档都有"的",那这个词对判断文档是否相关没有太大意义。
第二个问题是:增加索引成本和搜索成本。
如果"的"这个词出现在几乎所有文档中,那么倒排索引中这个词后面会挂非常多文档 ID。
这样不仅占空间,还会拖慢查找。
所以一般分词之后,会把停止词过滤掉。
总之:分词是为了把文档拆成关键词,方便后面建立倒排索引。停止词是那些出现频率很高、区分度很低的词,一般会在分词后被过滤掉,避免浪费索引空间和搜索时间。
3.倒排索引是什么?
倒排索引是搜索引擎中非常核心的结构。
它的关系和正排索引刚好反过来:关键字 → 文档 ID
也就是说,我不是先问"某个文档里有什么",而是先问:某个关键字出现在哪些文档里?
比如有两个文档:
bash
文档 1:雷军买了四斤小米
文档 2:雷军发布了小米手机经过分词之后:
bash
文档 1:雷军 / 买 / 四斤 / 小米
文档 2:雷军 / 发布 / 小米 / 手机 / 小米手机那么倒排索引大概可以建立成这样:
| 关键字 | 文档 ID |
|---|---|
| 雷军 | 1, 2 |
| 买 | 1 |
| 四斤 | 1 |
| 小米 | 1, 2 |
| 发布 | 2 |
| 手机 | 2 |
| 小米手机 | 2 |
倒排索引的本质是 关键字 → 文档 ID。它是搜索引擎快速查找的核心结构。用户输入关键字后,搜索引擎不是逐个扫描文档,而是直接根据关键字查倒排索引,快速找到相关文档 ID。
七:获取测试数据源
本次项目我们选择 Boost 文档作为搜索数据源
bash
进入 Boost 官网
↓
找到 Documentation
↓
选择某个 Boost 版本
↓
下载 Boost 压缩包
↓
上传到 Linux 服务器
↓
解压
↓
找到 doc/html 目录
↓
把里面的 HTML 文档拷贝到项目数据目录