同样要对抗长程任务的误差累积,RoboEnvision 给出了一剂和 VLP 不同的药方:彻底放弃自回归式逐段续写,改用"VLM 分解子任务 → 一次性生成各子任务关键帧 → 在关键帧之间插值合成长视频"的非自回归流水线,并配上专门保几何一致的注意力模块。
前两篇里,UniPi 教会了机器人"想象执行视频",VLP 又教会它"在想象上做树搜索来抗误差累积"。但 VLP 抗误差的方式是"分步短生成 + 反复搜索",代价是慢(一段计划要半小时)。有没有办法既保住长程的连贯,又不靠这种昂贵的逐步推演?
RoboEnvision(发表于 IROS 2025)给出的答案是:问题不在'要不要搜索',而在'生成范式'本身 。它一针见血地指出------自回归(autoregressive)地"画完一段、再接着往下画一段",本身就是误差累积的温床 。于是它干脆换一套 非自回归(non-autoregressive) 的生成流水线,从根上绕开这个陷阱。
一、要解决什么问题:自回归长视频的"接龙诅咒"
先把"自回归"这件事讲透。
很多长视频生成方法是这么干的:先生成头几秒的视频片段,然后把最后一帧(或最后几帧)当作新的起点,再生成下一段 ,如此一段段"接龙"下去,拼成长视频。这就是自回归------后面的内容依赖前面已生成的内容。
问题出在哪?打个比方:你玩"传话游戏",第一个人说的话传到第十个人,早就面目全非了。自回归长视频也一样:每一段生成都带着一点点误差,而下一段又是基于这段有瑕疵的结果继续画的,误差就这样一棒接一棒地传递、放大 。生成到后面,机器人可能手脚都对不上、物体也变了形。论文用实验把这一点钉死了:同样的模型,用自回归方式推理,长程任务成功率只有 27.0% ;而换成它的非自回归方式,飙到 67.4%。
RoboEnvision 还点出第二个被忽视的现实痛点:根本没有合适的数据来训练这种长程视频模型 。现有的长程操作数据集,要么太短、要么缺少"关键帧"标注,短视频和长视频之间还存在分布差异。为此作者专门构建了一个长程数据集 LHMM(Long-Horizon Manipulation MuJoCo),约 9 万段合成视频,并用抓取检测自动标出关键帧。
二、核心思想与直觉:先画"分镜头",再补"过渡帧"
RoboEnvision 的核心 idea,可以用拍电影来类比:
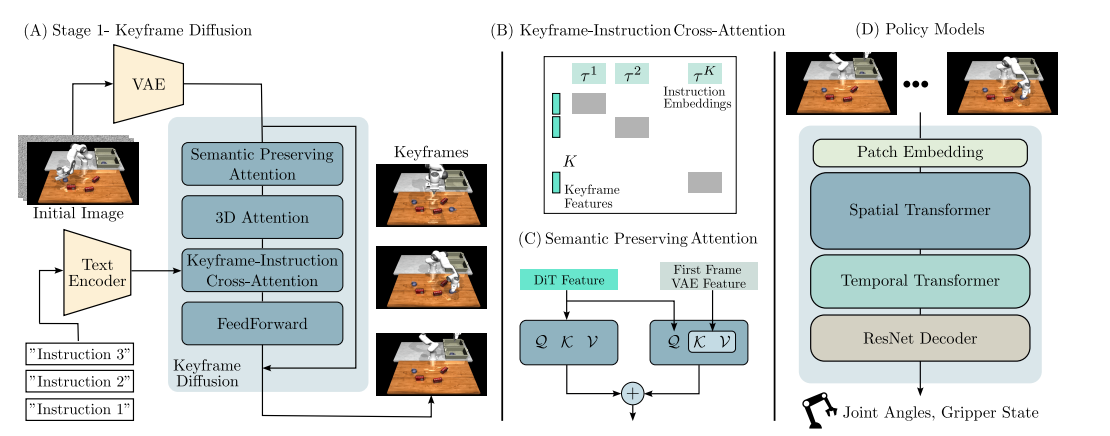
拍长片不会从第一秒一镜到底地拍到最后一秒。导演先定好几个关键的"分镜头"(每个镜头对应剧情的一个节点),再去补拍镜头之间的过渡。RoboEnvision 就是这么生成长视频的------先一次性生成一串关键帧(每帧代表一个子任务完成时的状态),再在相邻关键帧之间插值补出连贯的中间帧。
这就是非自回归 的精髓:所有关键帧是"同时"生成的,彼此之间能互相看到、保持全局一致,而不是一段段顺序接龙 。这样一来,整段长视频从一开始就握着"全局蓝图",自然不会越画越偏。它依然是级联式 WAM(先生成视频规划、再由策略模型解码动作),但在"怎么生成长视频"这一环做了范式级的革新。
整条流水线分三段,像一条精密的装配线:
- VLM 分解子任务:一个视觉语言模型(用 GPT-4o 或 DeepSeek)把"清理桌面"这种长指令,拆成 K 个原子级子任务("拿起杯子""放进水槽"......)。
- 粗模型生成关键帧(Stage 1) :一个"粗粒度"视频扩散模型,一次性生成 K 张关键帧,每张关键帧就是对应子任务完成那一刻的画面。
- 细模型插值补帧(Stage 2):一个"细粒度"视频扩散模型,在相邻关键帧之间插值,补出平滑过渡的中间帧,最终拼成完整长视频。
- 策略模型解码动作:一个 Transformer 策略模型,从生成的关键帧和部分中间帧里,回归出机器人各关节的目标状态。
三、方法详解:三段流水线 + 两个保一致的注意力绝活
3.1 第一段:VLM 把长任务拆成"关键帧清单"
输入一句高层指令(如"clean the table"),VLM 借助带空间推理的提示模板,把它分解成 K 个简单子指令 τ¹...τᴷ。每个子指令对应一张要生成的关键帧。这一步相当于电影开拍前先把"分镜脚本"写好。
3.2 第二段:粗模型一次性"画出所有分镜"
这是全篇技术含量最高的部分。粗模型基于 OpenSora (一个约 8 亿参数的 DiT,即 Diffusion Transformer------用 Transformer 当主干的扩散模型 )改造,输入初始观测 x₀ 和 K 条子指令,一次性输出 K 张关键帧 xₖ ∈ ℝ^(K×3×H×W)(比如 360×640 分辨率)。注意它在压缩时不做时间维度的压缩,以保住每张关键帧的独立性。
但"同时画 K 张关键帧"会带来两个新麻烦,作者用两个巧妙设计分别破解:
麻烦一:每张关键帧得各管各的子指令,别串台。
解法是一个关键帧-指令交叉注意力掩码(cross-attention mask) :构造一个对角块矩阵,让第 i 张关键帧只能"看见"第 i 条指令(矩阵非对角的位置填 −∞,等于把跨指令的注意力彻底掐断)。这样每张关键帧都严格对齐自己的子任务,不会把"拿杯子"画成"开抽屉"。
麻烦二:相邻关键帧之间物体动得很大,容易画飞、画变形。
因为关键帧之间隔着整整一个子任务,物体位置可能挪了一大截,几何上很难对上。这里上了两个"保一致"的注意力绝活,是本文最核心的创新:
- 3D 全时空注意力(替换分离式时空注意力) :常规视频模型为省算力,会把"空间注意力"和"时间注意力"分开算。RoboEnvision 反其道而行,在所有时空 token 之间整体算注意力 (形状 B×KHzWz×C),让模型能跨越关键帧之间的大跨度,追踪同一个物体在不同关键帧里跑到了哪,从而稳住物体位置、避免它在某帧凭空消失。
- 语义保持注意力(Semantics Preserving Attention,靠 VAE 特征注入) :小物体最容易在生成中糊掉、变形。解法是把首帧的 VAE 特征 (VAE 即变分自编码器,这里负责把图像压成隐特征,它保留了更细的空间细节)重新注入到空间注意力里------在原本的注意力结果上,额外加一项"对首帧 VAE 特征的注意力"。由于 VAE 特征和 DiT 特征处在同一空间,这相当于不断提醒模型"这个黄色小方块原本长这样",从而保住小物体的形状。消融显示,去掉这个模块,黄色小方块就会被画得扭曲变形。
3.3 第三段:细模型在关键帧之间"补过渡"
细模型(插值/填充扩散模型)的活儿相对单纯:给定相邻的两张关键帧 xₖᵢ₋₁、xₖᵢ 和该段子指令 lⁱ,在它们之间插值生成 Fᵢ 张中间帧。妙处在于------不同子任务段的插值是可以并行算的 (各段互不依赖),这正是非自回归带来的额外红利,大幅加速推理。最终长视频长度就是各段中间帧之和 Σ Fᵢ。
3.4 第四段:策略模型把视频翻译成关节指令
最后,一个时空 Transformer 策略模型 (带空间/时间注意力块 + 一个 ResNet 解码器)从生成的关键帧和挑选出的部分中间帧里,回归出机器人的关节角度 + 夹爪状态。推理时采用开环控制:一口气生成长视频、估出全程关节轨迹,然后照着执行。
这里有个反直觉但很重要的训练发现:必须拿"长程视频"来训练策略模型,而不能只用短程片段 。只用短程帧训练,成功率只有 49.4%;用上长程关键帧训练,才能到 67.4%。作者的解释是------长程视频的状态分布比短程视频丰富得多,只见过短程的策略,到了长程就水土不服。
3.5 流水线一览
| 阶段 | 组件 | 输入 → 输出 | 关键设计 |
|---|---|---|---|
| 子任务分解 | VLM(GPT-4o/DeepSeek) | 长指令 → K 条子指令 | 带空间推理的提示模板 |
| 关键帧生成 | 粗 DiT(OpenSora, 0.8B) | 首帧+K 指令 → K 张关键帧 | 交叉注意力掩码 + 3D 时空注意力 + 语义保持注意力 |
| 插值补帧 | 细 DiT | 相邻关键帧+子指令 → 中间帧 | 各段可并行加速 |
| 动作解码 | 时空 Transformer 策略 | 关键帧+中间帧 → 关节状态 | 须用长程视频训练 |
核心公式与逻辑梳理
RoboEnvision 的非自回归流水线可以拆成 5 步:
- 子任务分解 :VLM 把长指令拆成 KKK 条原子指令,相当于先写好"分镜脚本"。
- 粗模型同时生成 K 张关键帧 :以首帧和 KKK 条指令为条件,一次性 输出 KKK 张关键帧------所有分镜同时画完。
- 交叉注意力掩码 + 3D 时空注意力:前者保证每张关键帧只看自己那条指令,后者让所有关键帧共享全局上下文以稳住物体位置。
- 语义保持注意力:把首帧的 VAE 特征再注入回去,提醒模型"小物体原本长什么样",防止生成中变形。
- 细模型并行插值 + 策略解码:相邻关键帧之间各自独立插值(可并行加速),最后由 Transformer 策略把长视频翻译成关节指令。
公式 1:三段流水线的形式化
xk=KeyframeDiff (x0, (l1,...,lK)),xki−1:ki=FillingDiff (xki−1, xki, li)x_k=\mathrm{KeyframeDiff}\!\left(x^{0},\ (l^{1},\ldots,l^{K})\right),\qquad x^{k_{i-1}:k_i}=\mathrm{FillingDiff}\!\left(x^{k_{i-1}},\ x^{k_i},\ l^{i}\right)xk=KeyframeDiff(x0, (l1,...,lK)),xki−1:ki=FillingDiff(xki−1, xki, li)
- 符号说明 :x0x^{0}x0 是首帧观测,lil^{i}li 是第 iii 条子任务的文本指令,xkx_kxk 是被一次性生成出来的 KKK 张关键帧张量;xki−1:kix^{k_{i-1}:k_i}xki−1:ki 是第 i−1i-1i−1 张到第 iii 张关键帧之间被填充出的中间帧序列。
- 这条式子在做什么 :把"先定分镜、再补过渡"这件事写成两个独立的扩散调用。关键之处在于两步互相解耦:所有关键帧由同一次粗扩散同时生成(全局一致),各段中间帧由独立的细扩散并行生成(推理加速),这就是"非自回归"的数学体现。
公式 2:粗模型的去噪训练目标
minθ Et, (z,τ)∼pdata, ϵ∼N(0,I) ∥ ϵ−ϵθ (zt, t, ⨁i=1Kτi) ∥22\min_{\theta}\ \mathbb{E}{t,\,(z,\tau)\sim p{\mathrm{data}},\,\epsilon\sim\mathcal{N}(0,\mathbb{I})}\ \left\|\,\epsilon-\epsilon_{\theta}\!\Big(z_t,\,t,\,\bigoplus_{i=1}^{K}\tau^{i}\Big)\,\right\|_{2}^{2}θmin Et,(z,τ)∼pdata,ϵ∼N(0,I) ϵ−ϵθ(zt,t,i=1⨁Kτi) 22
其中 zt=αt z+1−αt ϵz_t=\sqrt{\alpha_t}\,z+\sqrt{1-\alpha_t}\,\epsilonzt=αt z+1−αt ϵ。
- 符号说明 :zzz 是干净的关键帧隐编码、ztz_tzt 是被加到第 ttt 步噪声的版本,αt\alpha_tαt 是噪声调度;ϵ\epsilonϵ 是真实加入的高斯噪声、ϵθ\epsilon_\thetaϵθ 是模型预测的噪声;τi\tau^{i}τi 是第 iii 条子任务的文本嵌入,⨁\bigoplus⨁ 是序列拼接;E(⋅)∼pdata\mathbb{E}{(\cdot)\sim p\mathrm{data}}E(⋅)∼pdata 表示在训练数据上取期望。
- 这条式子在做什么 :让网络学会"已知带噪关键帧 + KKK 条指令,预测当前是哪种噪声"。它和标准扩散损失一样,但关键区别在条件项 ------一次性吃下 KKK 条指令的拼接,从而能在一次前向里画完所有分镜。
公式 3:关键帧-指令交叉注意力掩码
A=softmax (QK⊤+M)V\mathcal{A}=\mathrm{softmax}\!\big(\mathcal{Q}\mathcal{K}^{\top}+\mathcal{M}\big)\mathcal{V}A=softmax(QK⊤+M)V
- 符号说明 :Q\mathcal{Q}Q 来自关键帧 token、K,V\mathcal{K},\mathcal{V}K,V 来自所有 KKK 条指令拼接出的文本 token;M\mathcal{M}M 是一个分块对角掩码矩阵------第 iii 张关键帧能"看见"第 iii 条指令的位置填 0,其余位置填 −∞-\infty−∞;softmax(−∞)=0\mathrm{softmax}(-\infty)=0softmax(−∞)=0 意味着跨指令的注意力被完全切断。
- 这条式子在做什么 :把"每个分镜只对应自己那条剧情"写成硬约束。如果不加 M\mathcal{M}M,第 1 张关键帧可能去"偷看"第 5 条指令,画面就会串台。这是"同时画多张关键帧"的安全锁。
公式 4:语义保持注意力
feature=Attention(QS, KS, VS) + Attention(QS′, Kz0, Vz0)\mathrm{feature}=\mathrm{Attention}(\mathcal{Q}_S,\,\mathcal{K}_S,\,\mathcal{V}S)\;+\;\mathrm{Attention}(\mathcal{Q}'S,\,\mathcal{K}{z^0},\,\mathcal{V}{z^0})feature=Attention(QS,KS,VS)+Attention(QS′,Kz0,Vz0)
- 符号说明 :左项是常规的空间自注意力(关键帧自己看自己);右项中 Kz0,Vz0\mathcal{K}{z^0},\mathcal{V}{z^0}Kz0,Vz0 来自首帧的 VAE 特征 z0z^0z0 ------也就是把首帧再编码一遍、作为额外的键值;QS′\mathcal{Q}'_SQS′ 是从同样的关键帧特征里出来的查询,去"问"首帧"这个物体长什么样"。
- 这条式子在做什么 :在每一层注意力里强制让生成过程对照首帧的细节。直觉是:黄色小方块在关键帧里只占几个像素,模型很容易把它糊掉或扭曲;但首帧 VAE 里它的形状是清晰的,把这条"参考线"持续注入回去,小物体就能在多张关键帧之间保持身份。这是 RoboEnvision 解决"小物体变形"问题的核心招式。
四、实验怎么做·结果说明了什么
4.1 两个基准 + 两类指标
- 数据集 :LanguageTable(约 5 万段视频,靠光流一致性把短片拼成长视频)和作者自建的 LHMM(约 9 万段合成长程视频,带关键帧标注)。
- 看两件事 :一是生成的视频质量与一致性 (用 LPIPS、FVD、SSIM、PSNR 等指标,前两个越低越好、后两个越高越好);二是下游长程任务成功率。
4.2 视频质量:在多数指标上拿下最佳
| 指标 | RoboEnvision | OpenSora(分层) | OpenSora(自回归) | AVDC |
|---|---|---|---|---|
| LPIPS↓(LanguageTable) | 0.1324 | 0.1445 | 0.1795 | 0.1857 |
| FVD↓(LanguageTable) | 136.75 | 147.37 | 176.61 | 189.64 |
| SSIM↑(LHMM) | 0.5820 | 0.5257 | 0.5232 | 0.4729 |
| PSNR↑(LHMM) | 17.27 | 16.61 | 16.46 | 15.33 |
横向对比里,自回归方式(OpenSora 自回归、AVDC)在 FVD/LPIPS 上明显垫底------这正是"接龙诅咒"在画质上的体现:误差累积让生成视频越来越不像真的。而 RoboEnvision 在 LHMM 上五项指标全胜、在 LanguageTable 上拿下四项,印证了非自回归对长视频一致性的根本优势。
4.3 长程任务成功率:对前作的大幅领先
在 LHMM 的 45 个长程任务上(成功率 %):
| 方法 | 成功率 |
|---|---|
| RoboEnvision | 67.4 |
| RoboEnvision(仅用短程训练策略) | 49.4 |
| RoboEnvision(改用自回归推理) | 27.0 |
| RDT-1B(强策略基线) | 34.1 |
| UniPi(复现) | 23.5 |
读懂这几行:相比强策略模型 RDT-1B 提升约 1.97 倍 ,相比开山的 UniPi 提升约 2.85 倍。更耐人寻味的是两条内部对照------把推理换成自回归会暴跌到 27.0%,把策略训练换成短程会掉到 49.4%。这两个数字,等于把 RoboEnvision 的两大主张("非自回归生成"+"用长程视频训策略")各自的贡献量化得明明白白。
4.4 消融:两个注意力模块各保了什么
| 配置 | LPIPS↓ | FVD↓ | SSIM↑ |
|---|---|---|---|
| 基线(纯 OpenSora) | 0.1498 | 184.71 | 0.6924 |
| 去掉语义保持注意力 | 0.1415 | 169.50 | 0.7032 |
| 去掉 3D 时空注意力 | 0.1430 | 168.83 | 0.7102 |
| 完整 RoboEnvision | 0.1305 | 167.57 | 0.7178 |
定性观察更直白:去掉 3D 时空注意力 ,物体会在关键帧之间消失、位置对不上;去掉语义保持注意力,小物体(如黄色方块)会被画得扭曲变形。两者合力,相比纯基线把 FVD 降了约 17 个点。这说明"同时画多张关键帧"并非免费午餐------必须有这两个模块兜底,全局一致性才立得住。
五、亮点与为什么重要
- 范式上的明确切换 :它把"长程视频生成"从主流的自回归续写,旗帜鲜明地推向非自回归的"关键帧→插值",并用数据证明这能从根上压制误差累积。这是对 UniPi/VLP 长程短板的一次正面强攻。
- 两个针对性注意力创新:"交叉注意力掩码 + 3D 时空注意力 + 语义保持注意力"这套组合拳,专门解决"同时生成多关键帧"带来的"对不上、画变形"难题,是可迁移的技术点。
- 并行可加速:非自回归让各插值段能并行生成,相比逐段接龙在效率上也更友好。
- 补上了数据缺口:自建 LHMM 长程数据集并自动标注关键帧,为后续长程视频-动作研究提供了基础设施。
六、局限与未解
- 开环执行不够鲁棒 :策略一口气估出全程轨迹后照着执行,没有视觉反馈闭环,一旦生成的视频有偏差,执行端很难临场纠正。
- 算力开销大:3D 全时空注意力比分离式注意力贵得多;任务分解还依赖 GPT-4o 这类付费大模型。
- 物理与几何信息仍有限 :作者自陈未来可引入深度和语义信息作为额外条件,进一步增强一致性和物理对齐------这也暗示当前纯 RGB 关键帧对真实物理的刻画仍不够。
- 依赖关键帧标注的数据:方法的有效性很大程度上建立在"有好的关键帧划分"之上,迁移到缺乏此类标注的真实长程数据仍有挑战。
七、在 WAM 谱系中的位置
RoboEnvision 牢牢站在级联式 → 像素空间显式规划 → 学习式动作提取这一支,是直接面向 UniPi、VLP 长程痛点的"第三代解法":
- 与 UniPi(本系列 01):UniPi 一次性生成单段执行视频,长程必崩;RoboEnvision 把它扩展为"分解子任务 + 多关键帧 + 插值"的长程版本,成功率提升近 2.85 倍。
- 与 VLP(本系列 02)的"路线之争" :二者都治"误差累积",但药方迥异。VLP 靠自回归式分步生成 + 树搜索剪枝 反复推演纠错(准但慢);RoboEnvision 靠非自回归一次性铺开关键帧从生成范式上避免误差(快且并行)。这恰好印证了 WAM 综述所说"长程规划"是当前最活跃的开放战场之一------同一痛点,社区正用截然不同的思路同时进攻。
- 与 This&That(本系列 04):RoboEnvision 攻"长程一致性",This&That 攻"指令歧义",二者补的是级联式视频规划的不同侧面。
如果说 UniPi 是"会想象",VLP 是"会审视想象",那 RoboEnvision 就是换了一种更聪明的方式去"组织想象"------先勾勒全局蓝图,再填充细节,让长程的连贯成为生成范式自带的属性,而非事后补救的结果。
八、参考
- 论文:《RoboEnvision: A Long-Horizon Video Generation Model for Multi-Task Robot Manipulation》
- 会议:IROS 2025(IEEE/RSJ International Conference on Intelligent Robots and Systems),DOI: 10.1109/IROS60139.2025.11246352
- arXiv:https://arxiv.org/abs/2506.22007
注:本文为基于该论文公开信息的学习性解读,方法名、基准与数字均取自论文以便检索与复核;解读、类比与组织为作者原创。