混沌工程为什么难落地?
Cloud Native
每个 SRE 团队都知道混沌工程的价值------在可控条件下主动注入故障,验证系统韧性,防患于未然。
但现实是,绝大多数团队的故障演练停留在"年度任务"而非"日常习惯"。原因很简单:
门槛太高,流程太碎。
一次完整演练五步:定位目标 → 拼装命令 → 确认安全 → 验证效果 → 善后清理。每一步都要查文档、写参数、跑命令。即使是经验丰富的工程师,单次演练也需要 20-30 分钟。而任何一步遗漏(忘了验证、忘了清理),后果都可能比不演练更糟。
Blade AI 要解决的只有一个问题:让故障演练的成本低到可以成为日常。
Blade AI 是什么
Cloud Native

Blade AI 是 ChaosBlade 生态的智能代理层。它不替代 ChaosBlade,而是接管"人 → ChaosBlade"之间的所有繁琐环节。
项目地址:github.com/chaosblade-io/chaosblade
你只需要用自然语言描述故障场景:"给 cms-demo 命名空间的 accounting 服务注入 CPU 压力 80%,持续 5 分钟",Blade AI 自动完成剩下的一切:定位 Pod → 匹配技能 → 安全校验 → 目标健康预检 → 请你确认 → 执行注入 → 验证效果 → 基线对比 → 生成摘要。

ChaosBlade 负责"如何注入",Blade AI 负责"如何安全、完整、可追溯地完成一次故障演练"。
七大核心特点
Cloud Native

▍1. 自然语言驱动 + 主动调研澄清
不需要记 blade create k8s pod-cpu fullload --cpu-percent 80 --names xxx --namespace yyy --timeout 300 这样的长命令。描述你想做的事情,Agent 自动映射到正确的 ChaosBlade 命令、填充参数、选择目标。
关键差异:意图不清晰时 Agent 不会瞎猜,也不会简单"反问"------而是主动调用工具去查。意图澄清阶段挂着三个工具:
-
kubectl(只读子集)--- "你说的 accounting 服务,是 namespace=cms-demo 还是 payments?"→ Agent 直接 kubectl get pods -A | grep accounting 自己看。
-
activate_skill --- 拉取技能完整说明书(参数语义、安全红线、验证步骤)。
-
read_skill_resource --- 读取技能附带的剧本/示例。
收敛到结构化意图后,Agent 调用一个特殊工具 submit_fault_intent(带完整 schema)作为意图阶段→执行阶段的正式握手,避免靠字符串解析做交接的脆弱。
▍2. 多层安全纵深,确定性大于聪明
安全不靠"小心点",靠工程约束:

关键设计:safety_check 是纯规则引擎,不依赖 LLM------因为 LLM 有幻觉,规则没有。"能不能注入"这个判断必须是确定性的。
确认门不是简单 yes/no:拒绝时可以同时输入自由文本反馈(例如"换成 50% 跑 30 秒"),这段反馈会被当作下一轮用户消息直接进入意图澄清------一次拒绝 = 一次有意义的对话推进,而不是从零重输。底层用 LangGraph 原生的 interrupt() / Command(resume=...) 实现真正的 human-in-the-loop(不是前端轮询装作 HIL),同一条 SSE 流横跨"暂停 → 用户决定 → 续跑"。
▍3. 两层效果验证 + 基线对比
注入成功 ≠ 故障生效。ChaosBlade 返回 Running 只说明命令被接受了,不代表 CPU 真的飙到了 80%。
Blade AI 在注入后执行两层独立验证:
-
Layer 1(确定性):blade status 程序化确认实验状态为 Running。
-
Layer 2(语义性):LLM 读取技能里的"注入验证"段,发起 kubectl top pod / 应用指标查询,与注入前基线做 before/after 对比。
Layer 2 最少轮询若干次(间隔 ~10 秒),给故障效果留渗透时间。
▍4. 故障恢复与注入同等重要
光注入不能恢复,不算一次完整的演练。
Blade AI 的恢复不是简单调个 blade destroy,而是一条与注入对等的完整链路:
-
智能路由:/recover latest 自动检测当前活跃实验------0 个则告知无需恢复,1 个则自动选择,多个则列出清单让你选。
-
路径匹配:自动识别注入方式(主机 blade / kubectl exec / kubectl 原生),用对应路径销毁。主机 blade destroy 清理不了 kubectl exec 创建的实验,Agent 不会犯这个错。
-
非 ChaosBlade 恢复:副本缩容用 kubectl scale --replicas=N 恢复、节点隔离用 kubectl uncordon、PVC 异常用 kubectl patch 回滚。
-
两层恢复验证:与注入验证对等------Layer 1 确认 blade destroy 返回 Destroyed 或 kubectl 回滚成功;Layer 2 语义性验证确认指标回到基线。
-
恢复状态分级:recovered / partial_recovered(部分 Pod 未回来)/ failed
。 -
--force兜底:CLI 提供强制清理标志供残留实验回收。
演练的闭环从注入开始,到恢复结束。Blade AI 保证闭环完整。
▍5. 目标健康预检 + FCAT 自适应
真实案例:某节点 DiskPressure=True 已持续 103 天,Agent 之前会毫不知情地尝试注入,白白浪费 5+ 分钟。
注入前自动检测 DiskPressure、Evicted、NotReady 等状态,提前暴露问题。更聪明的是 FCAT 规则引擎(Fault Context Adaptation Table):
-
目标 Pod 内存限制低于阈值时,自动缩减 burn 参数防止 OOMKill。
-
发现同一目标已有同类实验时,自动升级确认级别到 confirm_required 并附上活跃实验 UID。
-
FCAT 规则是声明式的,覆盖参数注入 / 冲突升级 / 基线补充 / 验证宽容度多类。
▍6. Replan 自适应 + 多轮尝试追踪
Phase 2 执行出错不等于任务失败。Agent 携带失败原因自动回退到规划阶段重新生成计划------但只对可重试错误(网络抖动、目标暂时不可达等模式匹配)触发,不可重试错误(鉴权失败、参数不合法)直接终止,避免无效循环。
每次尝试都被记录原因:INITIAL(首次)、GRAPH_REPLAN(图层回退重试)、LLM_TARGET_SWITCH(Agent 自主换目标)、USER_RERUN(用户重跑)。在 TUI 中你能看到 v1 FAIL → v2 FAIL → v3 SUCCESS 的收敛时间线------Agent 的自适应能力不再是黑盒。
最终失败时写入枚举化的 12 类失败原因:PLANNING_TIMEOUT / SAFETY_REJECTED / USER_REJECTED / PREREQUISITE_FAILED / EXECUTION_FAILED / EXECUTION_TIMEOUT / REPLAN_EXHAUSTED / VERIFICATION_FAILED / RECOVERY_FAILED / RECOVERY_VERIFICATION_TIMEOUT / WALL_CLOCK_TIMEOUT / INTERNAL_ERROR。每类原因都有 LLM 诊断增强------不是简单贴个标签,而是带上"为什么、怎么改"的可操作信息。
▍7. 三种运行模式,覆盖全场景

三种模式共享同一套安全校验、效果验证和恢复逻辑。安全是路径无关的。
架构概述
Cloud Native
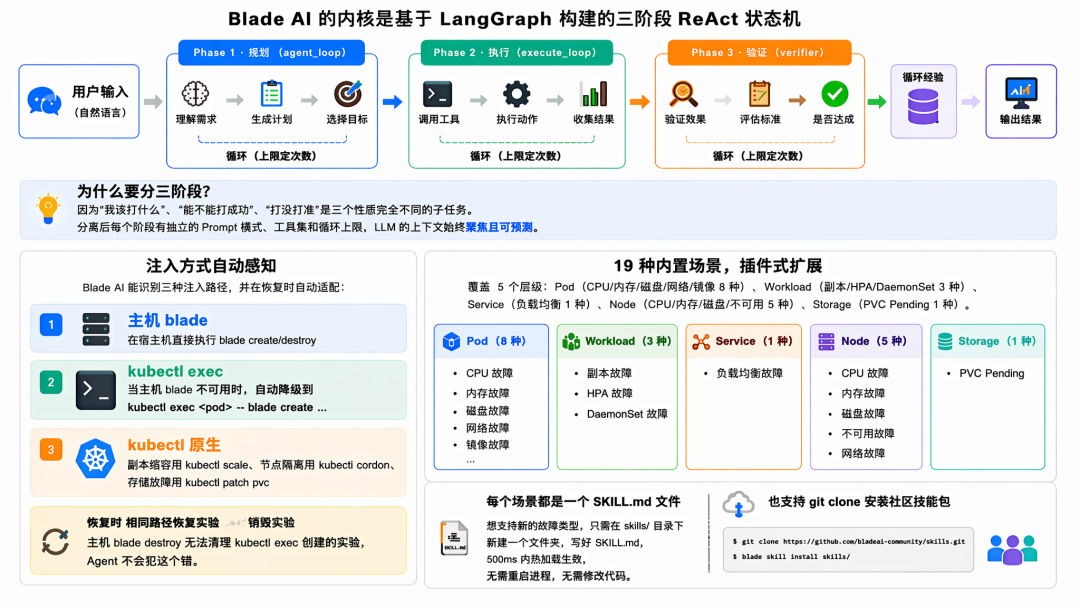
Blade AI 的内核是基于 LangGraph 构建的多阶段状态机,由 5 个独立的 ReAct loop 组成:intent_clarification(意图澄清)、agent_loop(计划生成)、safety_check(规则校验)、execute_loop(注入执行)、verifier_loop(效果验证)。
为什么分阶段?"我该打什么"、"能不能打成功"、"打没打准"是性质完全不同的子任务。分离后每个阶段有独立的 Prompt 模式、工具集和循环上限,LLM 的上下文始终聚焦且可预测。
▍注入方式自动感知
Agent 能识别三种注入路径并在恢复时自动匹配:
-
主机 blade --- 宿主机直接执行 blade create/destroy
。 -
kubectl exec --- 主机 blade 不可用时降级到 kubectl exec <pod> -- blade create ...
。 -
kubectl 原生 --- 副本缩容用 kubectl scale、节点隔离用 kubectl cordon、存储故障用 kubectl patch pvc
。
恢复时 Agent 自动使用相同路径销毁实验。
▍19 种内置场景,插件式扩展
覆盖 7 类 K8s 资源:Pod(CPU/内存/磁盘/网络/镜像)、Workload(副本、HPA、DaemonSet)、Service(负载均衡)、Node(CPU/内存/磁盘/不可用)、Storage(PVC Pending)等。
每个场景都是一个 SKILL.md 文件------想支持新故障类型,只需在 skills/ 目录下新建文件夹、写好 SKILL.md。配合 watchdog(可选依赖)500ms 内热加载生效,无需重启进程。技能元信息里声明的 required_tools(如 blade、kubectl)在激活前自动探测,缺工具直接失败而不是跑到一半才报错。也支持:
-
/skills install <url> --- 一键 git clone 社区技能包。
-
/skills enable/disable --- 临时屏蔽某个技能。
-
/skills reload --- 手动重扫目录。
▍TUI ↔ Server:零启动负担 + 跨进程稳定状态
TUI 启动时自动 spawn Python server 子进程,自动发现 .venv / venv / env、自动选可用端口、stderr 写到 ~/.blade-ai/logs/------用户什么都不用手动开。退出时自动 kill server。
每个 TUI session 一对一绑定一个稳定的 LangGraph thread(POST /sessions 分配,所有后续 /turn 共享)。这就是为什么 Agent 总能"记得你上一轮说了什么"------thread state 由 AsyncSqliteSaver 持久化到 checkpoints.db,重启后 /tasks active 能列出所有中断任务并引导恢复。
TUI 与 server 之间用 TUI Protocol Version 校验------版本不匹配时 TUI 直接硬失败提示升级,而不是"看似能用但事件解析错乱"的隐性 bug。
▍内存与记忆架构
LLM 推理前的统一管道 PreReasoningHook:工具输出截断 → 上下文测量 → 必要时压缩 → 异步持久化 → 合并回 LangGraph state。"长对话不失忆"的能力集中在这一处,不散落到各节点;附带 per-task 断路器(连续 3 次压缩失败自动熔断)。
三层记忆按生命周期分级:
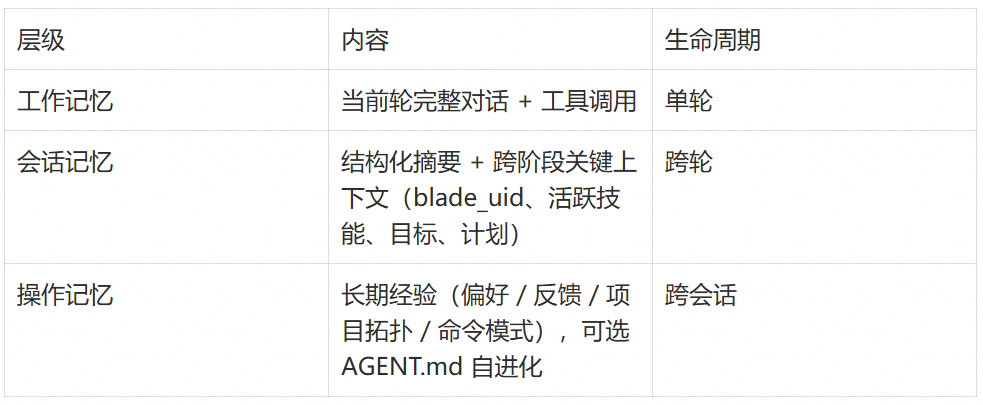
Token 管理路径:CJK 感知估算 → 最近 3 条工具输出各 16KB(更旧裁至 1KB)→ K8s 资源字段化精简(保留 name/phase/containerState 而非截字节)→ 空闲微压缩 → 增量摘要不二压。被裁原文完整落盘 ~/.blade-ai/memory/tool_cache/,/expand T# 取回。
反幻觉因果隔离:恢复阶段把注入阶段的具体指标数值替换为 已过期 --- 请重新执行------LLM 看得到旧输出但拿不到数字,必须重新采集,避免"看着旧数据当现状"。
▍模块化 Prompt 与知识
Prompt 是 50+ 独立 section 函数的组合,按四阶段装配:FULL(规划)/ MINIMAL(极简)/ VERIFICATION(验证)/ INTENT(澄清)。
-
U 形注意力------关键规则放开头和结尾(首因 + 近因),避开 Lost-in-the-Middle,从生产事故反推。
-
CACHE_BOUNDARY 切分稳定 / 动态 section,支持 LLM API 级缓存降本。
-
9 篇约 166KB 领域知识按需加载------摘要常驻 Prompt、全文按章节调取,系统 Prompt 始终精简。
▍持久化与审计
除前述 AsyncSqliteSaver checkpoints 外:per-task 对话 JSONL 原子追加、TUI 会话快照定期 + 增量、TaskStore(SQLite / PostgreSQL 双后端)------任何重启场景都能从断点恢复。会话级统计涵盖注入次数、成功 / 失败比、恢复次数、Token 消耗、USD 成本。
界面体验
Cloud Native
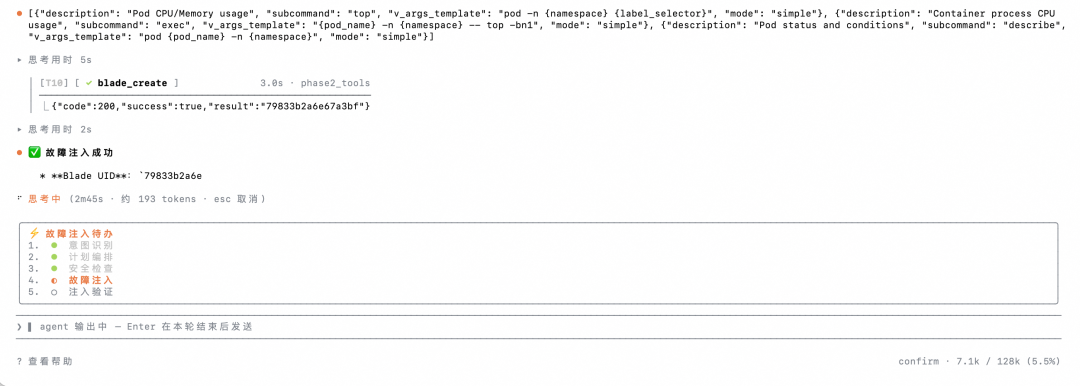
▍5 阶段实时进度条
输入框上方常驻进度指示:
go
✓ 意图识别 → ✓ 故障计划 → ◉ 安全检查 → ○ 故障注入 → ○ 注入验证当前阶段高亮,已完成打勾,失败标红。背后由 with_phase_events 装饰器把每个图节点的进入/退出实时推到 TUI,不需要轮询。
▍上下文窗口压力指示器
底部状态栏实时显示当前对话占用 / 窗口总量:
apache
confirm · 85.0k / 128k (66.4%)颜色随压力变化:灰(< 70%)→ 黄(70-99%)→ 红(≥ 100%)。这个数字就是触发自动压缩的同一指标,所见即所得,永远知道离压缩还多远。
▍实验卡片:每次注入都是正式实验
确认后渲染一张结构化的实验卡片:

每次故障注入不再是一行命令,而是一个有目标、有参数、有安全状态、有影响范围的混沌实验。
▍定位器系统:引用任意步骤
每个实验和工具调用都获得短标识符(E1、E2、T1、T3...),后续可随时:
bash
/show E1 # 重新查看实验卡片/copy T3 # 复制工具输出的原始文本/rerun E1 # 重放实验(打印原始描述供再发起)/expand T5 # 展开工具调用的完整输出(含截前完整文本)▍录像回放:复盘和培训
每次任务的所有事件自动写入 ~/.blade-ai/recordings/<task_id>.jsonl:
bash
/replay task-xxx # 逐步回放/replay task-xxx --speed 3 # 三倍速/recordings list # 列出所有录像/recordings export task-xxx # 导出文件▍手动 /compact 主动压缩
长对话累积之后可主动触发上下文压缩:
-
一边按 /compact、一边看实时 spinner 进度(⠙ 正在压缩当前会话上下文... (3s · esc 取消))。
-
与自动压缩走同一套 PreReasoningHook 逻辑(不存在双轨实现)。
-
esc 随时中断,前端用 SSE 流避免"压缩中静默"的体验问题。
▍中英双语 + 自适应主题
-
/permission auto | confirm--- 权限模式可中途切换,下一次/turn生效。CI 跑批用 auto,手动演练用 confirm。 -
中英双语自动检测 --- 根据 BLADE_AI_LANG / LC_ALL / LANG 决定,中文用户开箱即中文界面(~600 条 i18n key,错误信息、修复建议、卡片标题全覆盖)。
-
OSC 11 终端背景自适应 --- 探测终端背景色(明 / 暗 / 自动),用户消息气泡、卡片边框、Footer 灰度自动选对比度。明色终端不刺眼、暗色终端不发灰。
-
/retry --- 流式中断后一键重发最后一条 NL 输入,省得重打。
真实交互示例
Cloud Native
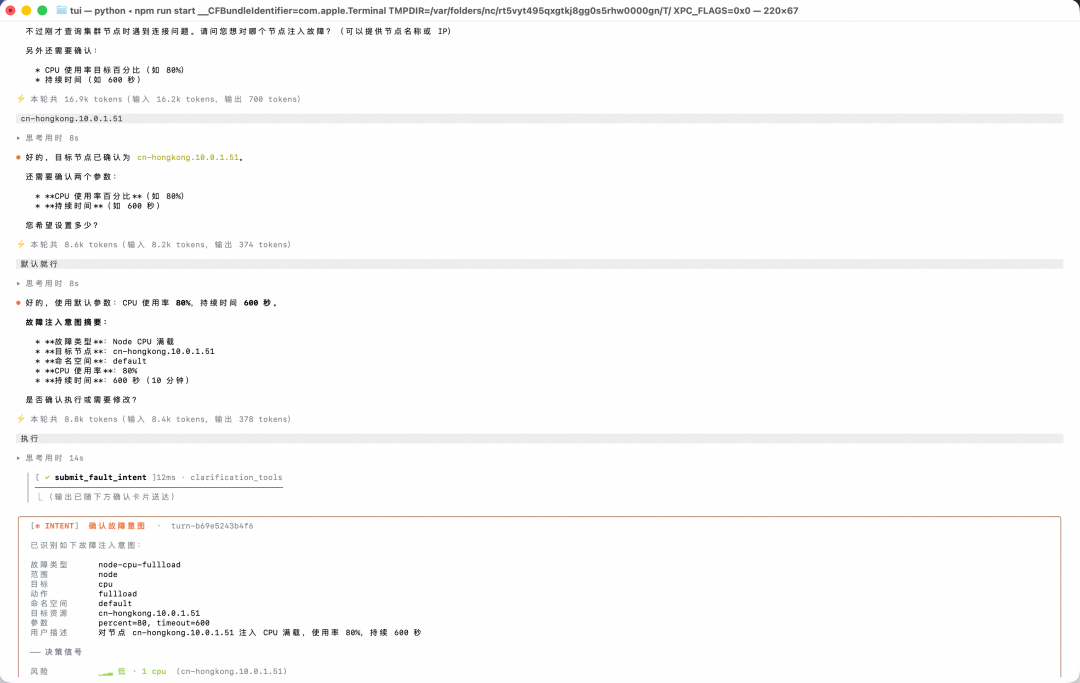
▍示例 1:TUI 对话模式
▍示例 2:CLI Direct 模式(CI/CD 集成)
shell
# 在 CI 流水线中嵌入故障演练blade-ai inject -i "对 cms-demo 命名空间中 accounting 服务注入 CPU 满载故障,负载 80%" \ --kubeconfig ~/.kube/starops_test_config# JSON 输出(便于脚本解析)# {# "task_id": "task-20260521-f7e2a8",# "status": "injected",# "blade_uid": "f7e2a8...",# "verification": {"layer1": "passed", "layer2": "passed"},# "baseline_delta": "+42567%"# }# 业务验证完成后恢复blade-ai recover --task-id task-20260521-f7e2a8
▍示例 3:Dry-Run 模式(只看计划不执行)
bash
> /plan 如果对 Node 注入内存压力 90%,会影响哪些 Pod?📋 Dry-Run 预览 --- 仅展示计划,不会真正执行。 • 技能: Node_内存使用率过高 • 目标: namespace=cms-demo node=cn-hz.10.0.1.5 • 故障类型: node-mem-burn • 参数: mem-percent=90, timeout=300s • 安全检查: safe • 影响范围: 该节点上运行 12 个 Pod(accounting×2, payment×3, ...)继续 /plan <修改建议> 调整计划,或 /run 落地执行。> /plan 改成 70%,只持续 1 分钟📋 Dry-Run 预览(已更新) • 参数: mem-percent=70, timeout=60s> /run[执行中]...快速开始
Cloud Native
▍安装
nginx
# 一键安装(自包含二进制,无需 Python)curl -fsSL https://chaosblade.io/install-agent.sh | bash▍首次配置

安装后直接运行 blade-ai,自动进入交互式配置向导:
-
LLM API Key --- 支持阿里云百炼、OpenAI 兼容接口,实时验证 Key 是否有效。
-
模型选择 --- 9 个候选模型可选,推荐 qwen3.6-max-preview(支持深度推理)。
-
集群配置 --- 自动扫描 ~/.kube/ 下的 kubeconfig,列出可用 Context。
-
权限模式 --- 确认模式(日常)或自动模式(CI/CD)。
-
环境自检 --- 并行检测 blade 二进制、K8s 连通性、ChaosBlade Operator。
向导支持编辑模式(/config wizard),修改时预填当前配置。
▍常用命令速查
bash
# TUI 斜杠命令/help # 查看所有命令/plan <描述> # Dry-Run 预览,不执行/run # 落地执行当前计划/recover latest # 恢复最近一次注入/review [task_id] # 查看任务详情/tasks [active|failed|all] # 查看任务列表(含可恢复的中断任务)/skills list/show/reload/install/enable/disable # 技能管理/doctor # 环境自检(7 项并行)/mode # 切换信息密度(calm/working/dense)/memory show/clear/path # 查看或清理会话记忆/compact # 主动压缩对话(可 esc 取消)/replay <task_id> # 回放任务录像# CLI 命令blade-ai inject --help # 注入参数(--direct 跳过 LLM)blade-ai recover --help # 恢复参数(--force 兜底清理)blade-ai metric --help # 指标查询blade-ai update # 自更新blade-ai uninstall # 干净卸载# Server APIblade-ai-server # 启动 HTTP API(0.0.0.0:8089)写在最后
Cloud Native
Blade AI 不是要取代 SRE 的判断力------它把"拼命令、查文档、验效果"这些重复劳动交给 Agent,让你把精力花在真正需要人类判断的事情上:这个故障场景有没有意义?系统的响应符不符合预期?接下来该演练什么?
混沌工程的真正瓶颈从来不是工具,是"值不值得花 30 分钟做一次演练"。当成本降到一句话 + 30 秒,答案就变了。
项目地址:github.com/chaosblade-io/chaosblade
Star 项目、提交 Issue、或者贡献一个故障场景的 SKILL.md------每个 PR 都让混沌工程离"日常习惯"更近一步。